



【アーキテクチャConference 2025】 サービスカタログに基づくTerraform/K8sコードの自動生成
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に登壇した、株式会社enechain Platform Engineering Desk プリンシパルエンジニアの遠藤 雅彰さんは「プラットフォームチームの課題解決にはIDPが有効だった」と語ります。しかし同社は、IDP構築のデファクトスタンダードになりつつある「Backstage」ではなく、内製ツールとDatadogを併用する独自の戦略を採りました。本セッションでは、Backstageを選択しなかった理由から内製ツールの詳細、AIを活用した移行手法まで、具体的な取り組みをご紹介いただきました。
■プロフィール
遠藤 雅彰
株式会社enechain
Platform Engineering Desk プリンシパルエンジニア
新卒では組み込み系の企業でエンジニアとして働き、2社目からWEB系にスキルチェンジ、4社目となる株式会社メルカリではテックリードとして国内外の決済機能の開発及び後払いサービスの立ち上げや、メルペイの立ち上げなどに携わる。その後、株式会社freeeの課金基盤のテックリードを経て、2022年10月にenechain入社。現在はアプリケーション/インフラ両方の基盤の開発を行う。
プラットフォームチームが直面していた理想と現実のギャップ
enechainの遠藤です。本日は「サービスカタログに基づくTerraform/K8sコードの自動生成」というタイトルでお話しさせていただきたいと思います。

enechainという会社についてご存知ない方も多いかと思いますので、軽くご紹介させてください。enechainは「エネルギーマーケットの力で日本経済を豊かに。社会をサステイナブルに」をミッションとし、取引高年間1兆円規模の電力マーケットプレイスを運営している会社です。
2019年の創業以来、これまでに9つほどのサービスを展開してきました。なかなかのスピードで開発できているのではないかと思いますが、サービスが拡大していく中で、いくつかの大きな課題も発生していました。
プラットフォームチームにおける課題は、創業当初のスピード感で事業を拡大していった結果、マニフェストやTerraformが独自形式で作られてしまい、メンテナンスコストが増大していたことです。また、新しく推奨構成を作っても利用が進まず、開発と負債解消に伴うコスト発生も大きな問題となっていました。新しくプロジェクトを立ち上げる際には、古いコードや推奨設定以前のコードをコピペして参照されるケースも多く、問題が広がっていました。
そんな中で我々が描いていた理想の運用は「セルフサービス運用」「構成変更の適用」「チーム間連携」「依存関係の理解」という4つの点に集約されます。
具体的には、開発者自身が自分たちでサービスのメンテナンスを完結できるセルフサービス化を実現し、新しい設定が発生した瞬間に我々の方で即座にアップデートできる状態を目指しました。同時に、連絡先などの管理も自動化され、サービス間の依存関係を正確に把握した上でインフラ構築を行えている、という状況を目標に据えていました。
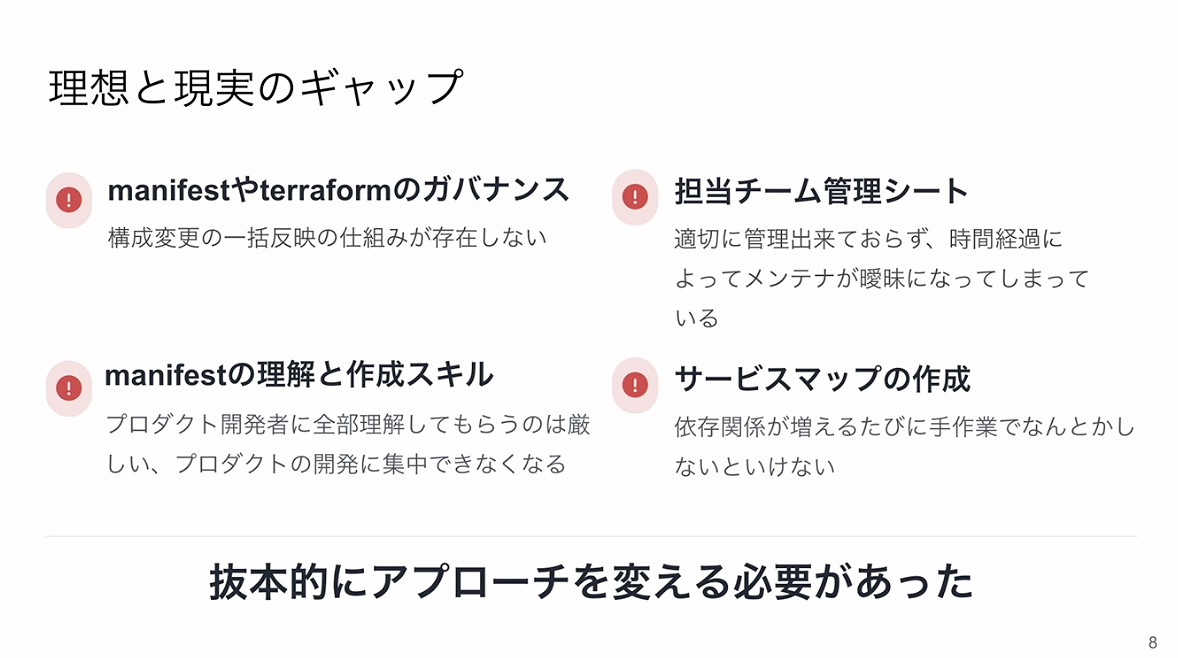
しかし、実際にはいくつかのギャップが発生していました。まず、マニフェストやTerraformのガバナンス面において、構成変更を一括で行う仕組みが整っていませんでした。また、プロダクト開発側が必ずしもマニフェストに精通しているわけではないため、修正コストが高くなってしまい、これらを一から学習してもらうと本来の開発業務に集中できなくなるという問題もありました。
さらに、担当チームを管理するシートなどは存在していたものの、時間の経過とともにメンテナンスが曖昧になり、情報の信頼性が失われていました。サービスマップについても、各々がNotionなどに作成はしていましたが、内容が陳腐化してしまうといった問題に直面していました。
課題解決のために発足したInstant Universeプロジェクト

これらの問題を解決するため、我々はインターナルデベロッパープラットフォーム(以下、IDP)の導入を検討しました。
IDPとは開発者が自発的に開発・デプロイできる環境を提供するプラットフォームで、テンプレートを用いて開発者がセルフサービスで環境構築やデプロイできるように設計するというものです。同時に、標準化によって開発標準を明確にし、サービスカタログを活用してオーナー情報やリポジトリ、ステータス、依存関係などを一元管理できる仕組みです。
検討の結果、IDPは今回の課題解決に有効だと判断しました。そこで「標準化の段階ではテンプレートで生成しやすいように可能な限り統一する」「自動生成するにあたって全プロジェクトへの反映を可能にしてガバナンスを効かせる」「サービスカタログの導入によって可視化と運用改善を目指す」を目標に掲げ、Instant Universeプロジェクトが発足しました。

Instant Universeプロジェクトは2つのフェーズに区切って進めることとなり、フェーズ1(Instant Universe V1)では「テンプレートの導入と標準化の実施」を目的にしていました。このタイミングでは新規プロダクトにターゲットを絞り、既存プロダクトにはタッチしないということを最初に決めました。
フェーズ2(Instant Universe V2)では「カタログモデルの導入と自動化の実装」を目指し、このタイミングで既存プロダクトを移行することにしました。
フェーズを分けた理由は、標準化が進んでいない中で導入しても問題が拡大するだけで、我々の理想からは遠のいてしまうからです。そのため、まずはフェーズ1で新規プロダクトが作られるたびに標準から外れた構成が生まれるのを防ぎたいと考えました。

なお、Instant Universe V1は、2024年5月にリリースしています。標準化の定義、スクリプトによるテンプレート生成、新規プロジェクトをこちらから生成するところはすでに実現しています。
計画見直し?内製ツールとDatadogを併用した移行戦略
Instant Universe V2を開発している途中で、実は計画の見直しが発生しました。背景にあるのは、Backstageの台頭です。Backstageは強力かつ良いツールであるため、独自開発を続けるべきか、Backstageの標準化に則った方がいいのか悩みました。そこで、一度立ち止まって検討することにしました。また、社内でDatadogも導入していたため、Datadogのサービスカタログを使う案も含めて、3つの選択肢を比較検討して再度プランを練り直しました。

DatadogとBackstageのそれぞれの強みを比較すると、前者は運用監視に特化したサービスカタログであり、開発者ポータルを提供しない代わりに、監視やアラートなどの周辺に強みを持っています。後者は開発者ポータルとしてのサービスカタログです。API連携によって情報の読み込みはできるものの、リアルタイム監視よりも表示機能に強みを持っています。Datadogはテンプレートやドキュメント、ワークフローを提供していないため、単純に比較するとBackstageが有利だと感じられます。
何が自分たちに適しているのか正確に判断するため、改めて自分たちが欲しかったものを整理しました。我々が求めていたものを整理すると、開発者のセルフサービス、アップデートの適用、メンテナンス状況や依存関係を把握できるようにする仕組みです。

検討の結果、内製ツールとDatadogの併用という方向で進めることにしました。
Datadogに決めた理由は、サービスカタログやプロダクト担当者はDatadogでも管理できますし、実際のAPIリクエストからサービスマップを表示してくれるため現実に即した情報が見られるからです。また、PagerDuty相当のアラート対応が可能になったのも大きな理由でした。ただ、DatadogにはScaffolderなどテンプレートに関する機能が備わっていないため、不足している部分は独自ツールで補完することにしました。
具体的には、上図の右側で示しているように、テンプレート機能を活用してサービスカタログなどのDatadog上の設定状態をTerraform経由で登録・管理する形です。マスターデータを独自ツールに集約し、そこからDatadogへ情報を連携させることができています。Datadogが持つ機能を最大限に活用できる構成をとりました。
ちなみに、Backstageを使わなかった理由は、プラットフォームチームの人数が少ないからです。フロントエンド、バックエンド、データベースという3層構成の維持管理を限られた人数で行うのは厳しいと判断しました。また、セキュリティアップデートに伴う定期的なビルド&デプロイが必要ですし、エラーが発生した際にメンテナンス工数がかかることも気になりました。
Reactを使えるメンバーが少なく、学習コストが高めであるというのもネックでした。さらに、我々は電力業界に直結する事業をしていることもあり、トークン管理をはじめとするセキュリティポリシーを厳格に運用する必要があります。加えて、プロダクト側で依存関係の定義などが放置されてしまうリスクもあります。諸々を考慮して、安定的な運用に不安が残るBackstageよりも、使い慣れたDatadogを活用する方がいいと判断しました。

開発者の負担を軽減する内製ツール「pedcli」

内製ツールとしては「pedcli」というものを作りました。Goで作ったCLIツールで、init、edit、generate、docsという4つのサブコマンドに区切っています。
git initのようにinitコマンドを行うと、最初のテンプレートが生成され、editコマンドで操作をし、generateでテンプレートから実データを書き出し、docsでGitHub上で見えるようなドキュメントを生成します。
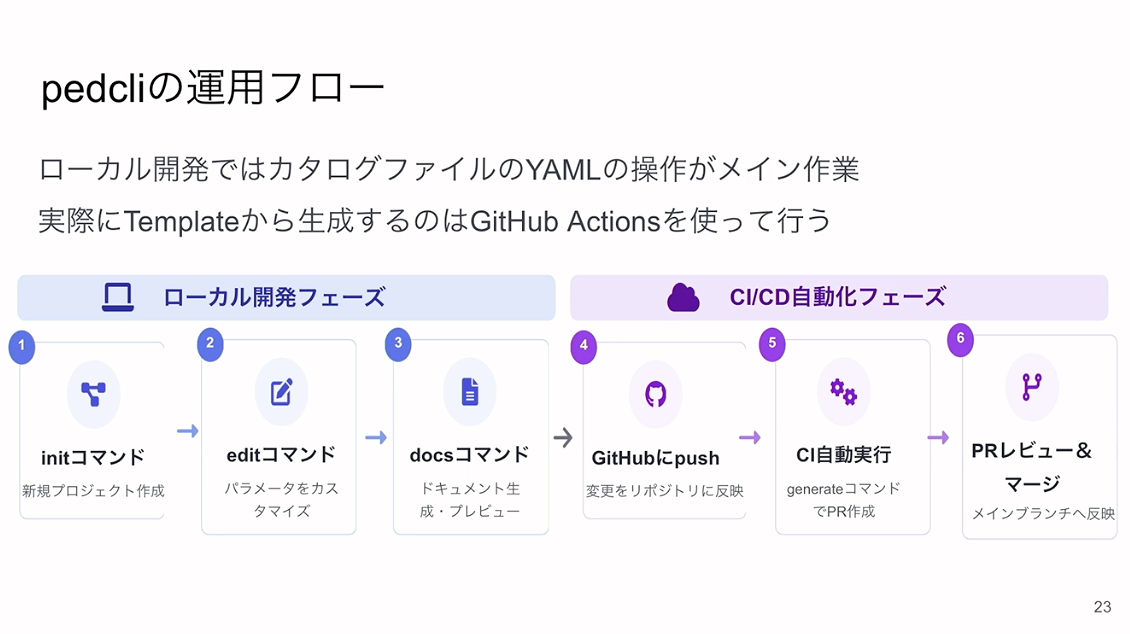
運用フローはシンプルで、ローカル開発フェーズではinit、edit、docsの3つのコマンドを使います。それに対し、CI/CDのフェーズでは、git pushした後にCIの自動実行によってgenerateを行い、自動でPRを作成して、それをレビューしてマージしてメインブランチへ反映するGitOpsのフローを採用しています。
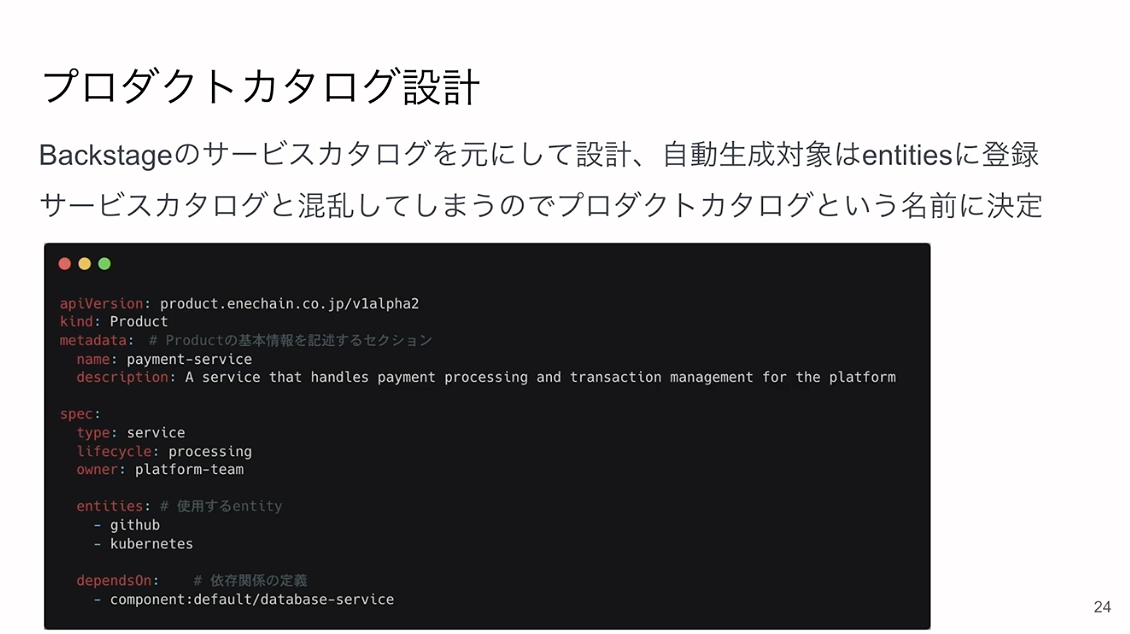
また「プロダクトカタログ」というものも設計しました。Backstageに「サービスカタログ」という名前があるため、混乱を防ぐために「プロダクトカタログ」という名前にしています。
中身はBackstageのサービスカタログを元に設計していますが、実際には「entities」を独自に拡張して運用しています。このエンティティは、サービス開発者が「どの機能を利用するか」を宣言するために登録するもので、GitHubやKubernetesのような単位で区切っています。
我々はエンティティを「プロダクトが必要とするリソースの種類を表す概念」と定義しており、自動生成されるテンプレートとも紐づいています。YAML上では、メタデータに加えて、PRの送信先設定やテンプレート実行時に渡すパラメーター、バリデーションに使われる正規表現なども管理できるようになっています。

プロダクトカタログからの生成物については、ファイル名にプレフィックスを付与することで運用方法を区別するルールを導入しています。
自動生成ファイルは「gen_」から始まっており、全て再生成の対象となるため、ユーザー側で更新しないルールを設けています。一方で、手動運用ファイルには「gen_」を付けません。自動生成の対象外であり、サービス開発者に操作してもらうことを前提にしています。
このように、ファイル名を確認するだけで「システムが管理するファイル」か「人間が管理するファイル」かを判別できる仕組みを整えました。
また、プロダクトカタログを使ってもらうためにYAMLファイルを自分たちで触ってみたところ、YAMLファイルの入力漏れなどレビューコストや修正コストがかかることが判明し、専用エディタを作成するとともにドキュメントを生成できるようにしました。

左側の図は、enumの値を解釈して何を入力できるのかを分かりやすくしたものです。右側の図で赤くなっている部分はエラー表示で、YAMLにエラーが発生した際に、我々に問い合わせせずとも開発者自身でエラー箇所がわかるようにしています。
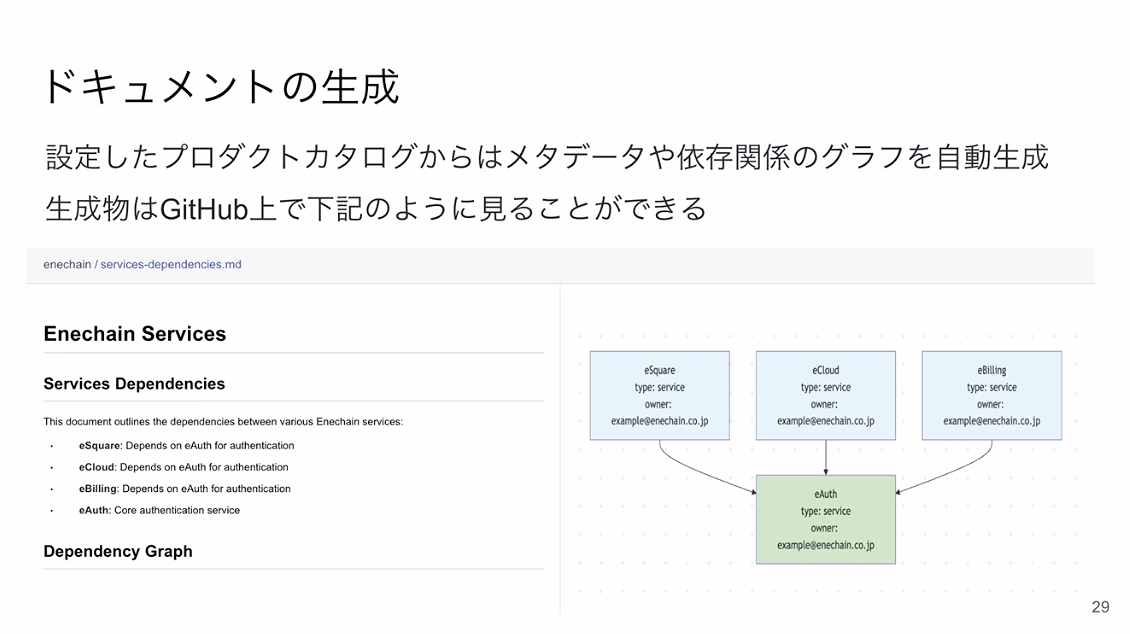
ドキュメントについては、GitHub上でメタデータや依存関係の設定から各種情報を自動生成するため、特定のウェブページを開かずともGitHub上で見られるようにしています。
スクリプトとAIを駆使した、既存プロダクトの移行
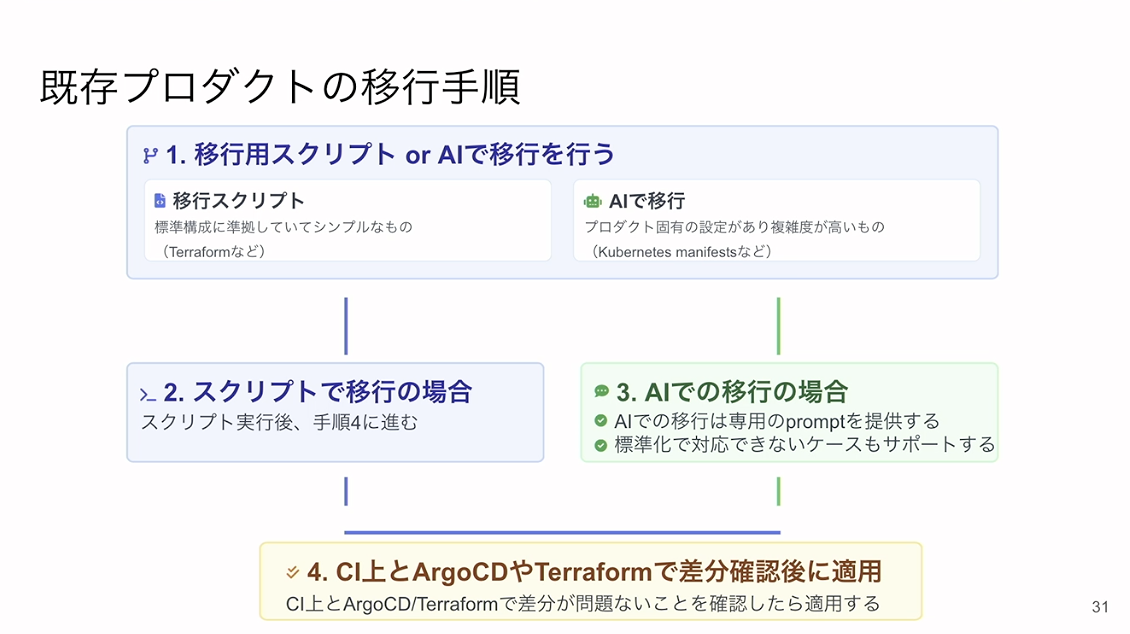
ここからはプロダクトの導入の話に移りたいと思います。
プロダクトカタログに手作業で移行するとかなり重いコストがかかるため、「移行スクリプト」と「AI」という2つの手法を提供することにしました。
移行スクリプトの方はそのまま実行するのみですが、AIでの移行には専用のプロンプトを用意しました。標準化で対応できないような複雑なパターン、例えばKubernetesのマニフェストなどは、AIを活用した移行を試みました。
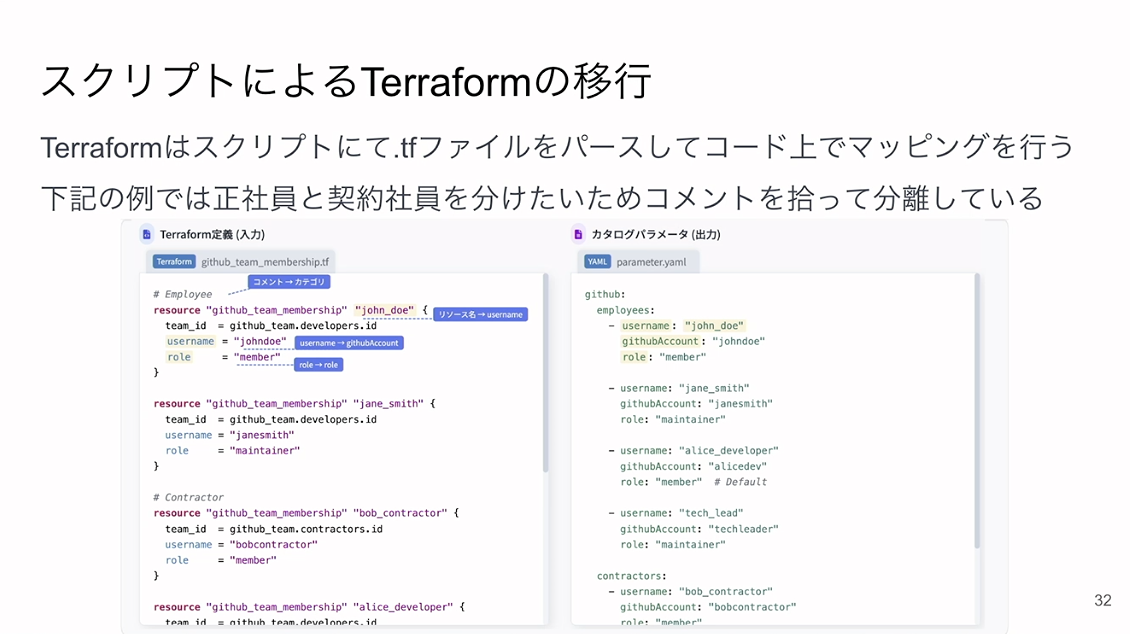
スクリプトの方はシンプルに取り込めるようになっていて、主にTerraformで使われています。

AIの方は、プロダクトカタログの生成から新しいマニフェストの生成、古いマニフェストと新しいマニフェストの差分レポートの作成、Kustomizeパッチの出力、ビルド結果の検証まで、5つのフェーズが自動で行われます。検証の結果が完全に一致したら、PRが作成されます。

プロンプトにはテンプレート情報を埋め込み、「Must」や「Required」を用いてAIに指示を出します。「Must match」では「こういうフォーマットでデータを出力する」「入力パラメーターをこのような感じに構築して」と指示しています。

同時にMarkdownでマッピングも用意しました。これは環境によって変わることもありますが、基本的には「既存のリソースがどのエンティティに対応するか」を列挙したものです。右側ではパラメーターの抽出ガイドとして「どのデータをどこから拾い、新しくどこへマッピングすべきか」という具体的な指示を出しています。
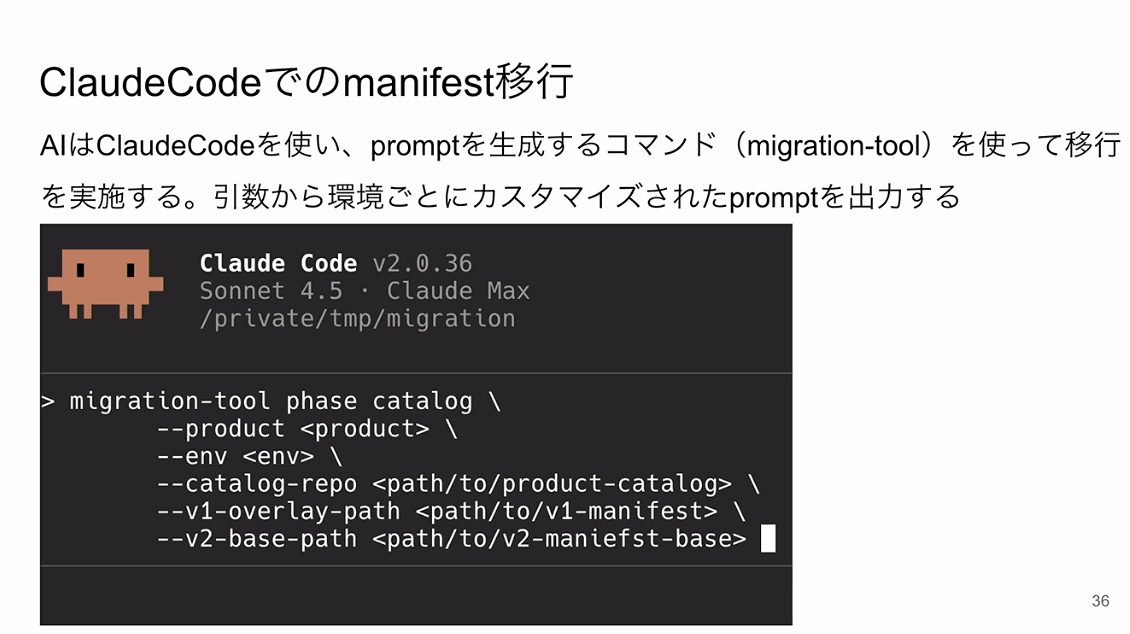
実際の移行にはClaude Codeを使用しました。プロンプトを生成するコマンドとしてマイグレーションツールを使い、プロンプトを環境に応じて生成します。

実行することで、自動的にYAMLファイルのマイグレーションが指示通りに実行されます。画面では指示通りにエンティティとリソースファイルのマッピングを生成し、その後にプロダクトカタログを生成するところを出力しています。
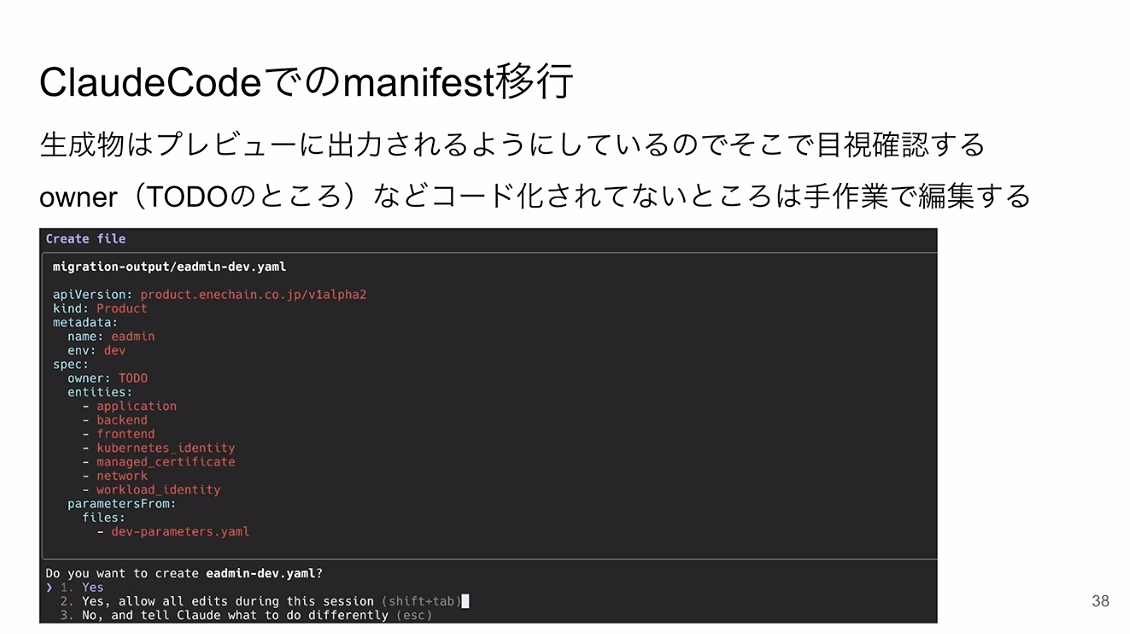
実際にClaude Codeで出力されたものがこちらです。我々が想定していた通りの結果が得られました。ownerがTODOになっていますが、ここはコード化されていない部分です。そういった部分は手動で編集し、それ以外は全部自動で対応するという形です。
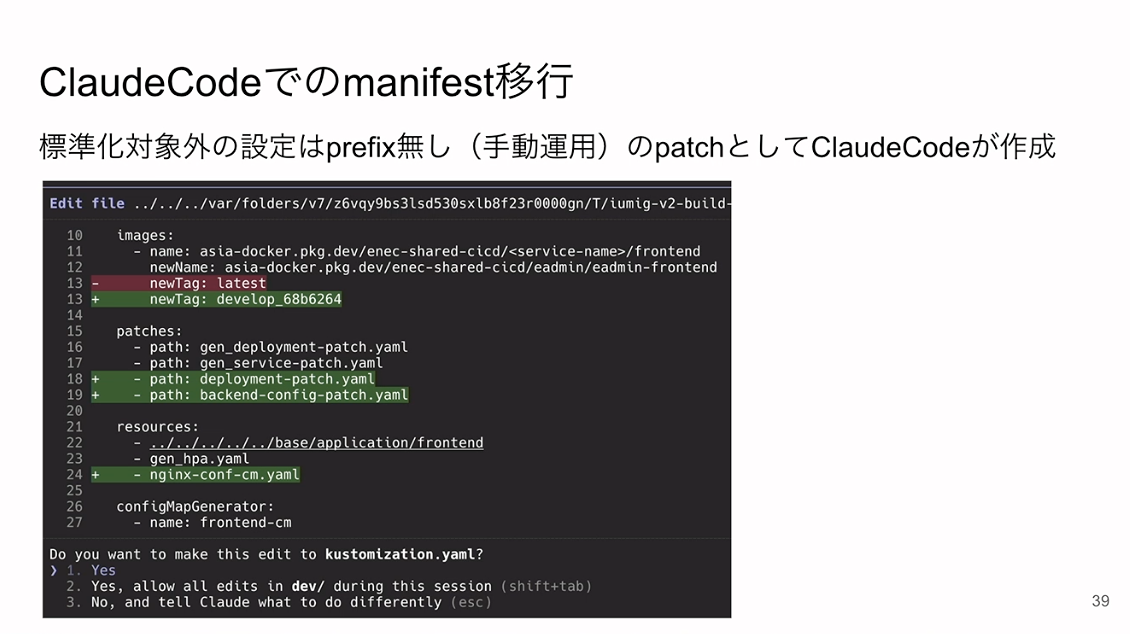
パッチは手動運用のファイルとしてClaude Codeに生成させ「gen_」がついていない状態で出力させています。

AIによる自動生成の結果については、想定通りのマニフェストが出力され、無事に移行作業を完了させることができました。kustomization.yamlはkustomizeの予約名で、本当は自動生成にしたかったのですが、プレフィックスを付与しない運用で妥協しました。
AIを使って移行してみた感想として、移行作業は目論見通りに完了しました。標準化されているものは30分程度でスムーズに移行できましたし、AIが強力になってきているのを実感しました。一方で、標準化対応されてないプロダクトの移行には約4時間ほどかかってしまい、原因を調べるのが大変でした。
IDP導入の鍵は「標準化」と「テンプレート化」
IDPを導入してみて、最初に標準化とテンプレート化を行うことが有効だと学びました。そのおかげでスムーズに新しいフォーマットに移行できましたし、事前にやっておいてよかったと実感しています。今の規模だとGitOpsの運用で十分ということが分かったのも大きかったです。Backstageの管理に時間を取られず移行に集中できたのも、結果的によかったところだと思います。
また、社内フィードバックで「Datadogのサービスカタログの方が我々に適してそうだね」という声もいただきました。自分たちで実際に軽く触ってみて、何が最適解なのかを考えるのが一番大事だなと思いました。
反面、テンプレートを用意するのには、想像以上にコストと時間がかかりました。約3ヶ月でInstant Universe V2をリリースして移行完了できたのですが、テンプレートの作成には約1.5ヶ月、移行準備には1ヶ月近くかかっています。移行作業自体は1日以内にさっと終わるところもありましたが、やはりKubernetesのマニフェストの移行が一番大変でした。AIを使わなかったとしたら、おそらく数日間がかりの規模の作業だったでしょう。
今後の展望としては、全プロダクトへの導入を進めつつ、AI連携によるカタログ操作の簡略化を目指します。また、Datadogとの連携を強化して、セキュリティ検知機能などもエンティティ化することで、設定漏れのないガバナンスが効いた状態を自動で実現したいと考えています。
内製化にこだわらず、我々に適しているツールが出てきた際には、今のツールを使って逆にマイグレーションをすることを視野に入れながら運用していくつもりです。
以上です。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。