



【アーキテクチャConference 2025】マルチプロダクトを支えるスケーラブルなデータパイプライン設計〜速度と品質を両立するチームと技術〜
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に登壇したのは、株式会社estie マーケットリサーチ事業本部 エンジニアリングマネージャーの丸島 晃明さん、データマネジメント事業本部 スタッフエンジニアの山本 亮介さん、マーケットリサーチ事業本部 QAエンジニアの粕谷 恭平さんです。
商業用不動産のデータプロダクトを複数展開するestieでは、プロダクト数の増加に伴い、データパイプライン開発における「速度」と「品質」のトレードオフという課題に直面。本セッションでは、この課題を解決するために実施した「社内オープンソース化」と「QAチームとのコラボレーション」という2つのアプローチについてご紹介いただきました。
■プロフィール
山本 亮介
株式会社estie
データマネジメント事業本部 ソフトウェアエンジニア・スタッフエンジニア
2018年に東京工業大学(現東京科学大学)大学院博士課程を中退し、Sound Hound AI日本法人でソフトウェアエンジニアとして音声アシスタントのバックエンド開発に従事。国内外問わず活躍し、スタッフソフトウェアエンジニアとして多言語対応・ビルドシステム更新などを行った。2023年4月にestieへ入社し、データパイプラインの開発に従事。プロダクトの枠を越えて活躍し、2024年10月よりスタッフエンジニアに就任。
丸島 晃明
株式会社estie
マーケットリサーチ事業本部 エンジニアリングマネージャー
1993年静岡生まれ。静岡大学大学院総合科学技術研究科情報学修了。その後、ヤフー株式会社(現LINEヤフー株式会社)へ入社。ヤフーではソフトウェアエンジニアとしてYahoo! JAPANのユーザーデータを扱う業務に従事。 2021年11月に正社員としてestieに入社し、estie オフィスリサーチおよびestie 物流リサーチを開発するチームのマネジメントを担当。
粕谷 恭平
株式会社estie
マーケットリサーチ事業本部
不動産業界で賃貸仲介・収益不動産売買の営業を約6年ほど経験。趣味ではじめたプログラミングをきっかけに不動産テックのestieを知りIT業界未経験で2021年に1人目のQAエンジニアとして入社。以来いくつかの開発ユニットでQAエンジニアとして従事。
estieと商業用不動産データ
丸島:株式会社estieは、2018年創業の不動産スタートアップです。商業用不動産のデータを扱ったプロダクトを提供しています。みなさんは「不動産」と聞くと、マンションや一戸建て、アパートといった住居を思い浮かべる方が多いかもしれません。しかし、私たちはもう少し領域を広げて、オフィスやホテル、商業施設、データセンターなども対象に入ります。商業用不動産とは、人間や物が経済活動をして、経済的・社会的な価値が生み出される場所としての不動産です。
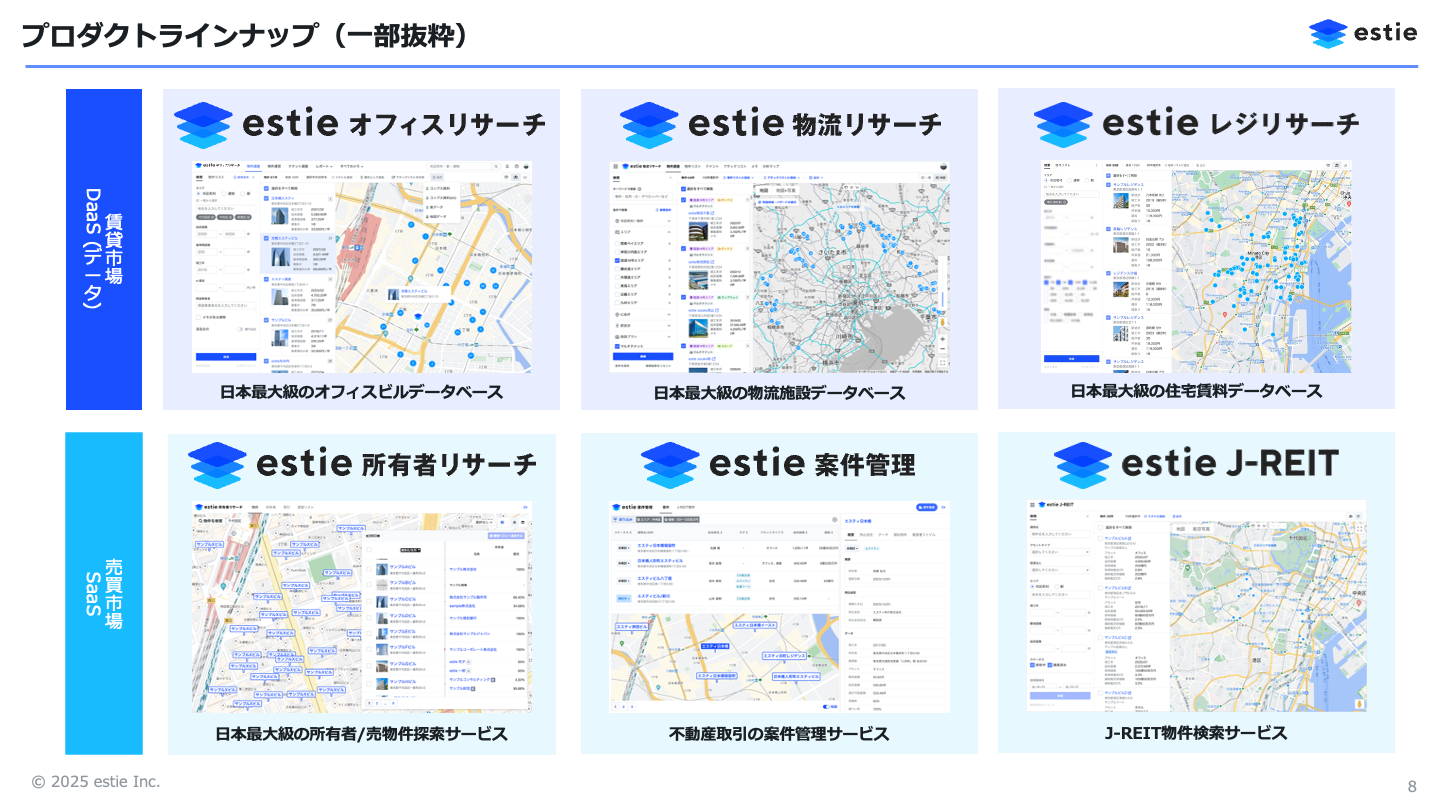
プロダクトとしては、オフィスのデータベースである「estie オフィスリサーチ」や、物流倉庫のデータベースである「estie 物流リサーチ」など、いくつかのプロダクトを提供しています。実際には未公開のものも含めて、10を超えるプロダクトを開発しています。
丸島:私たちが実現したいのは、ミクロな観点では「企業が最も生産的になれる立地選択を可能にすること」です。マクロな観点では「都市の未来をデータドリブンに導くこと」、つまり街づくりをデータドリブンに行えるようにしたいと考えています。例えば、ある土地に何を建てるべきかを判断する際に、オフィスを建てれば産業が根付く、物流施設を建てれば物流が活性化する、ホテルを建てれば観光客が増えるといったことを、データをもとに判断できるようになればと考えています。
世界規模で見ると、東京は商業不動産の資産価値として世界一位を誇る都市です。しかし、情報の透明性という点では11位程度にとどまっています。日本の市場は非常に魅力的に見られていますが、情報の透明性がないために投資しにくいという状況があります。私たちはデータベースを提供することで、日本にお金が循環し、活気づいていく世界を目指しています。
商業用不動産業界には、これまで中央集権的なデータベースが存在していませんでした。各社が独自に情報を収集してきたという歴史的背景があります。PDFをメーリングリストで回したり、紙をFAXで送ったり、関係会社同士の定例会議で情報交換してデータベース化していました。
その結果、各社のデータベースは非常に貴重なものとなり、情報を他社に出したくないという状況が生まれました。自分のビルの空室が出たときに、隣のビルがいくらで貸しているのか知ろうとしてもわからない。結果として「勘と経験と度胸」で決める世界になっていました。
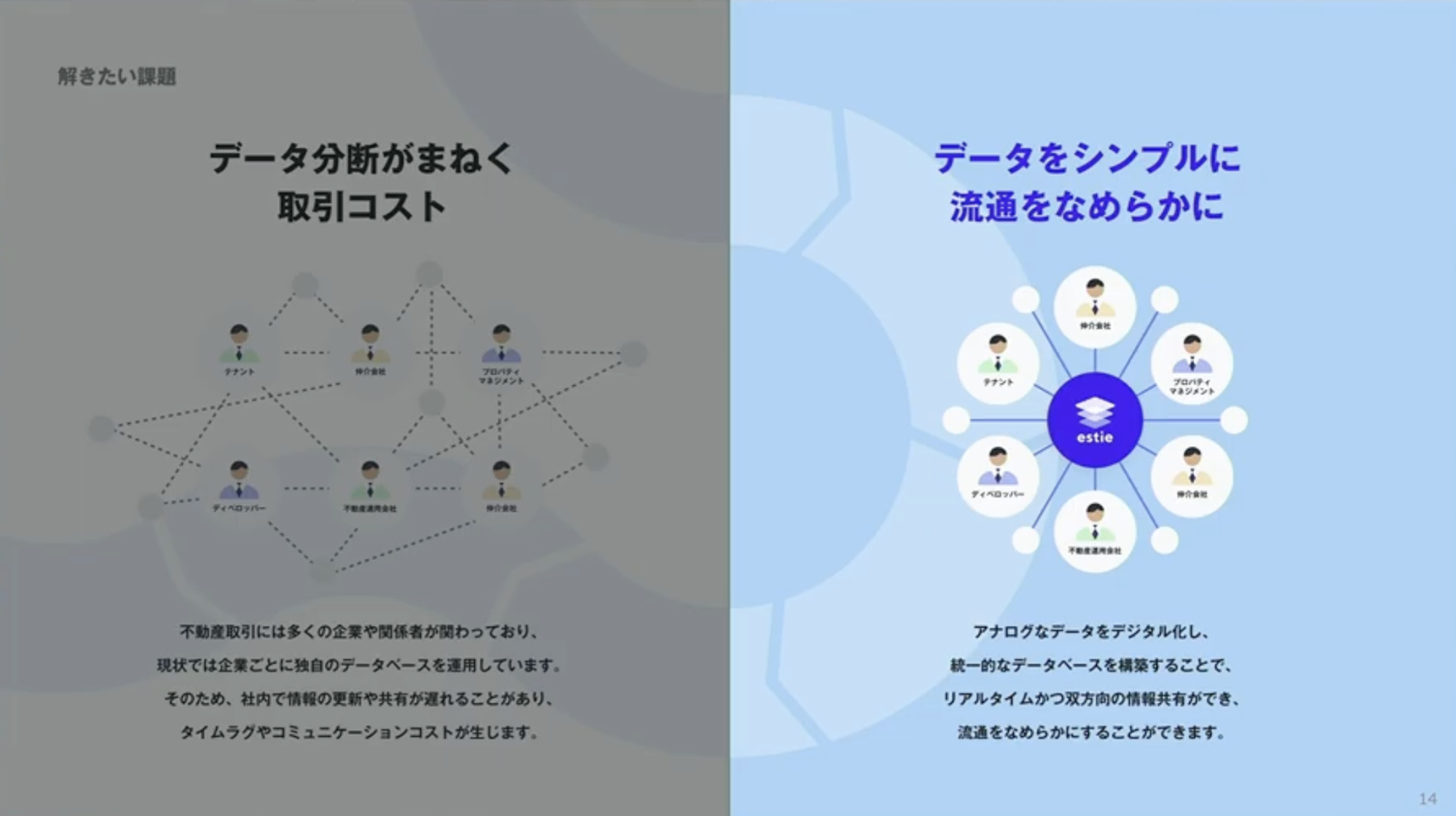
丸島:この課題を解決するために、私たちは各パートナー企業と連携しながらデータを集約し、統一的なデータベースを作っています。ただ、連携方法はAPIの場合もあれば、毎日CSVがアップロードされる場合もあれば、メールで届く場合もあります。さまざまな方法で連携されるデータと、さまざまなフォーマットのデータを束ねて、ユーザーに届けて価値にする。そのためのデータパイプラインシステムが必要になりました。
これまでのestie〜チーム変遷とマルチプロダクト化の課題〜
丸島:かつてのestieのシステムは、MySQLとPythonをベースにしたバッチ処理システムで、API連携やJSON、CSV、PDF、手書きメモ、テキストなど、さまざまなデータを収集・加工してプロダクトに届けていました。
私たちはドメインに根ざしたシステムを開発しているため、ユーザーからはデータに関するフィードバックもアプリケーションに関するフィードバックも両方届きます。「新しいデータが欲しい」「このデータをこう見せてほしい」といった要望が次々と来ます。そうなると、開発チームはアプリケーションだけでなくデータパイプラインもメンテナンスし、機能改修もするという状況になります。
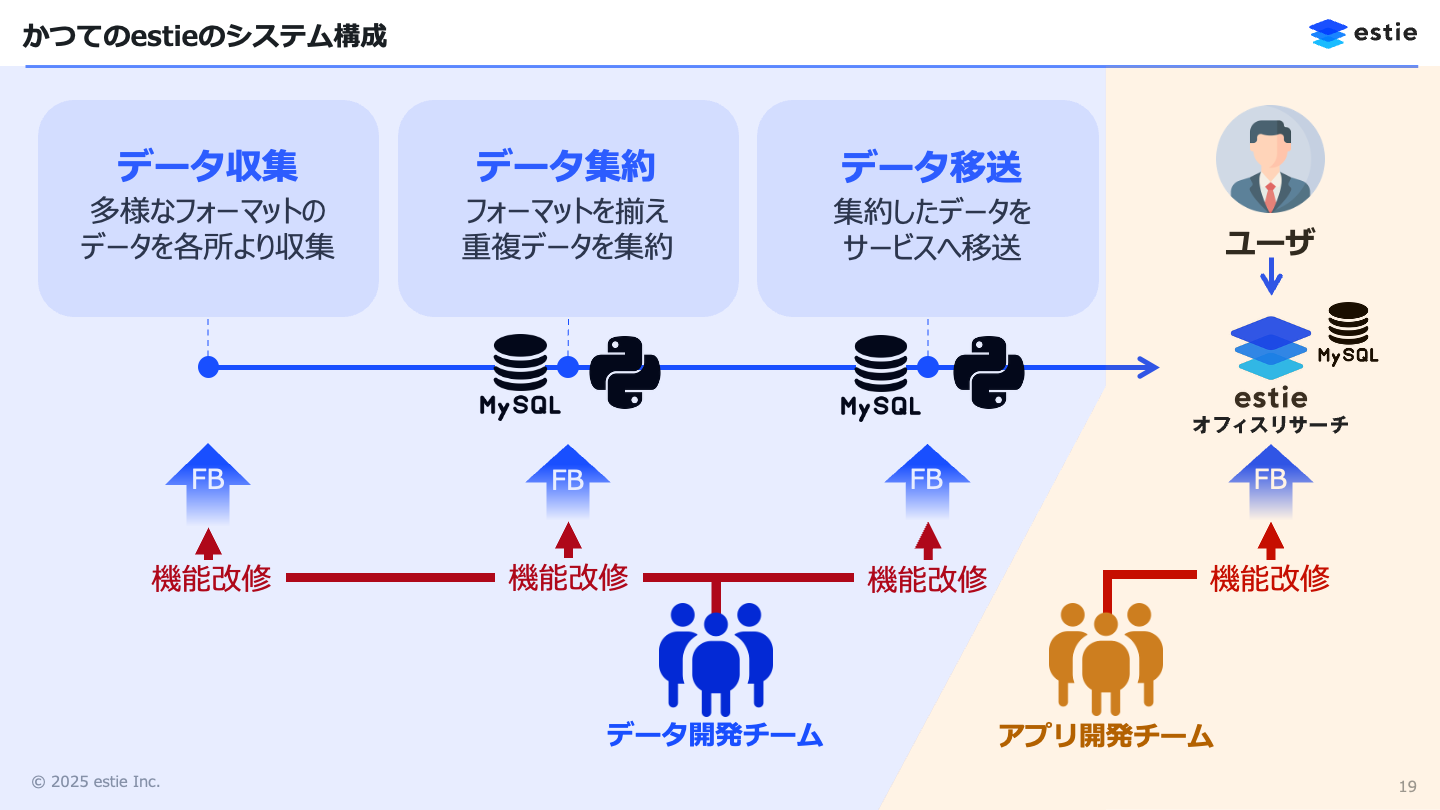
丸島:当然ながら、メンバーには得意領域の違いがあります。データ開発が得意な人とアプリケーション開発が得意な人が分かれてきて、スクラムセレモニーの最中に、片方のメンバーが内職をしているような状況が生まれました。その結果、「このチームは同じチームである必要があるのか?」という疑問が出てきました。
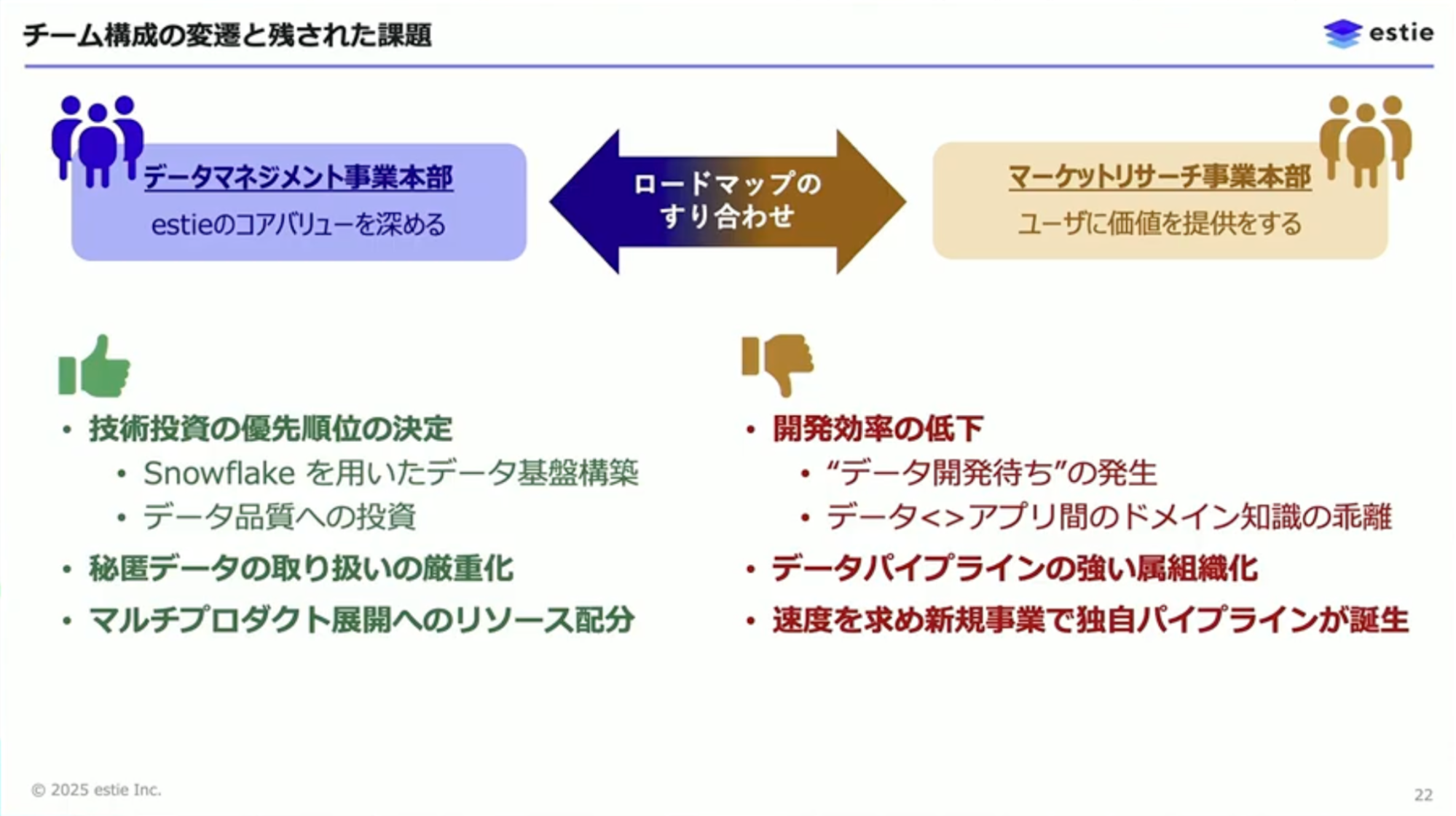
この疑問を解消するため、チームを分割しました。データマネジメント事業本部とマーケットリサーチ事業本部の2つに分かれ、ロードマップをすり合わせながら進めていく形になりました。
チームを分割して良かった点は、データの品質を高めるための投資ができるようになった点です。事業に近いところで開発していると、どうしても「売れるデータをつくろう」という方向に力学が働きがちです。コアバリューを深めるミッションを持つチームが分割されたことで、品質への投資が可能になりました。また、MySQLとPythonベースだった基盤をSnowflakeに乗せ替えるという意思決定もできるようになりました。
さらに、私たちはセンシティブなデータを扱うこともあります。以前は同じチームだと全員がデータを見てしまい、どこから漏れるかわからないという怖さがありました。チームを分割してデータを集約することで、知る必要がある人だけが知る体制を整備できました。加えて、以前はマーケット調査という1つのプロダクトだけで開発していましたが、物流施設のプロダクトなどマルチプロダクトへ展開していく上で、今どこに投資するべきかという資源配分の決定もしやすくなりました。
一方で、チームが分かれたことでコミュニケーションが増え、開発効率が低下するという問題が起きました。具体的には「データの開発待ち」が発生しました。データソースの開拓からデータモデルの定義、パイプラインシステムの構築、実行、テストという流れがあるため、アプリケーションチームは待っている間に他のタスクを始めてしまい、コンテキストスイッチが増えていきました。
丸島:また、アプリケーションチームの方がユーザーに近いため、ユーザーが求めているものを詳しく知っていますが、それをデータチームに伝えきれずに事故が起きることもありました。データパイプラインを扱える人がデータチームにしかいないという「属組織化」も進み、データの組織がスケールしないと事業がスケールしないという問題が生じました。
最終的には、新規事業を立ち上げる際に「データチームを待っていられない」と判断され、新規事業側で独自のパイプラインが立ち上がってしまいました。速度と品質がトレードオフになり、「あちらを立てればこちらが立たず」という状態になってしまったのが実情です。

最近のアーキテクチャの変遷と将来への取り組み
スケールするデータパイプライン開発
山本:先ほどのセクションでお話ししたように、チーム分割によってマルチプロダクト展開ができるようになった一方で、速度と品質がトレードオフになっていました。さらに深刻なのは、速度も品質も両方達成するのが難しくなってきたことです。
マルチプロダクト展開によって、まずオフィス、物流施設、住宅といったアセットタイプが増加しました。さらに、データの扱い方が異なるプロダクトも増加していきました。この2つの組み合わせで、アセットタイプごとに加工するデータが増え、プロダクトごとに提供するデータも増え、必要なドメイン知識が掛け算で増えていきました。
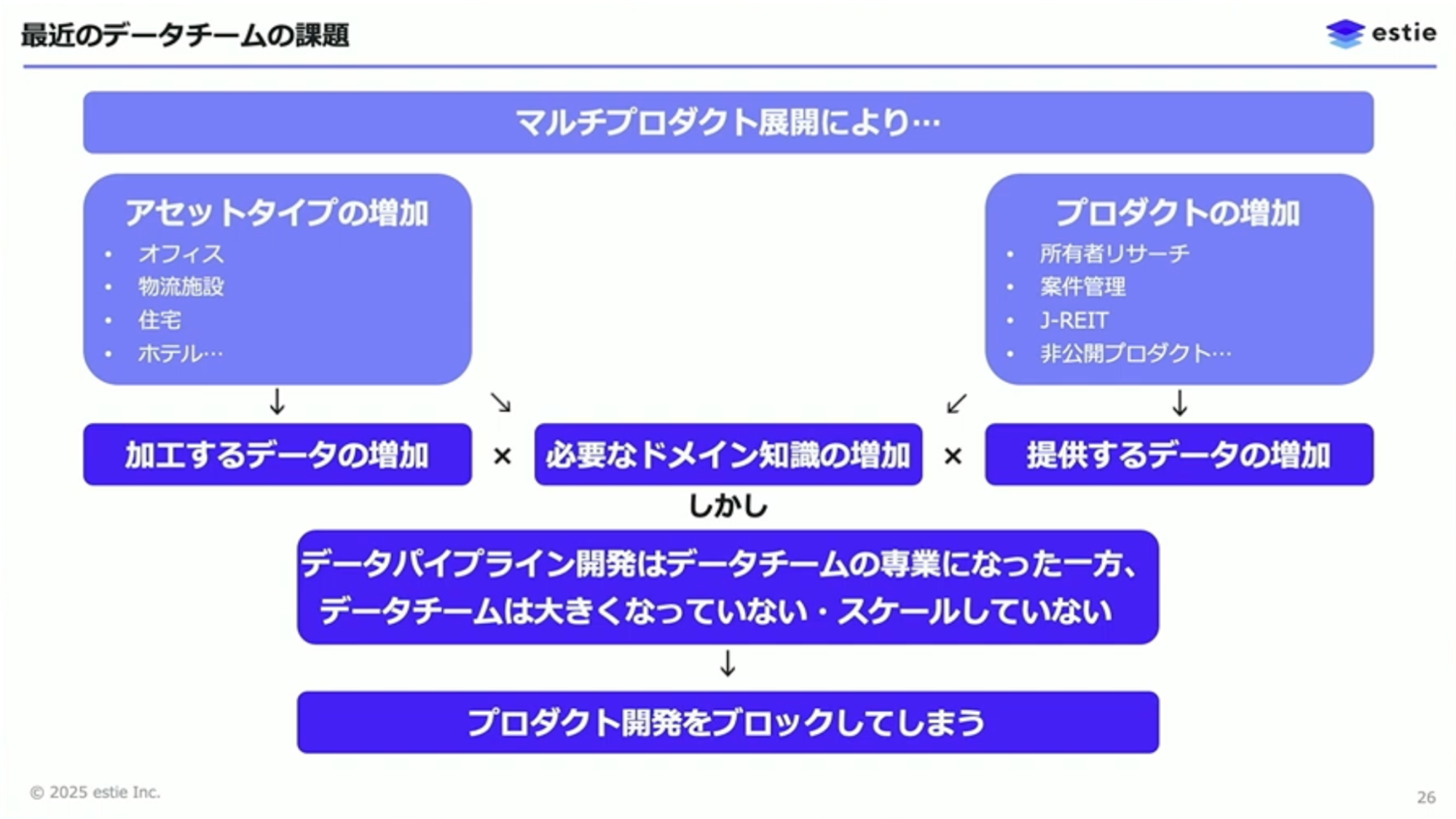
山本:データパイプライン開発がデータチームの専業となった一方で、需要に応じてデータチームの人員を細かく増減するわけにもいきません。10を超えるプロダクトに対して、5名から10名程度のデータチームで対応するという状況になりました。速度を保つことも品質を保つこともより難しくなり、マルチプロダクト展開に対してデータパイプライン開発をスケールさせる対策が必要になりました。
対策として、プロダクト開発者にもデータパイプラインの開発に関わっていただくことにしました。これはチーム分割を完全に否定するものではなく、プロダクトチームとデータチームで必要な部分の人員をシェアするという形です。
山本:この方法にはいくつかの利点があります。まず、プロダクトチーム側には、データパイプライン開発を進めてブロックを解消するインセンティブがあるため、積極的に人員を振ってもらいやすくなります。また、プロダクト開発者はデータチームよりもプロダクトに近い位置にいるため、より良い背景知識を持っています。プロダクトチームが欲しているデータを作る際に伝言ゲームが発生しなくなり、事故も減ります。
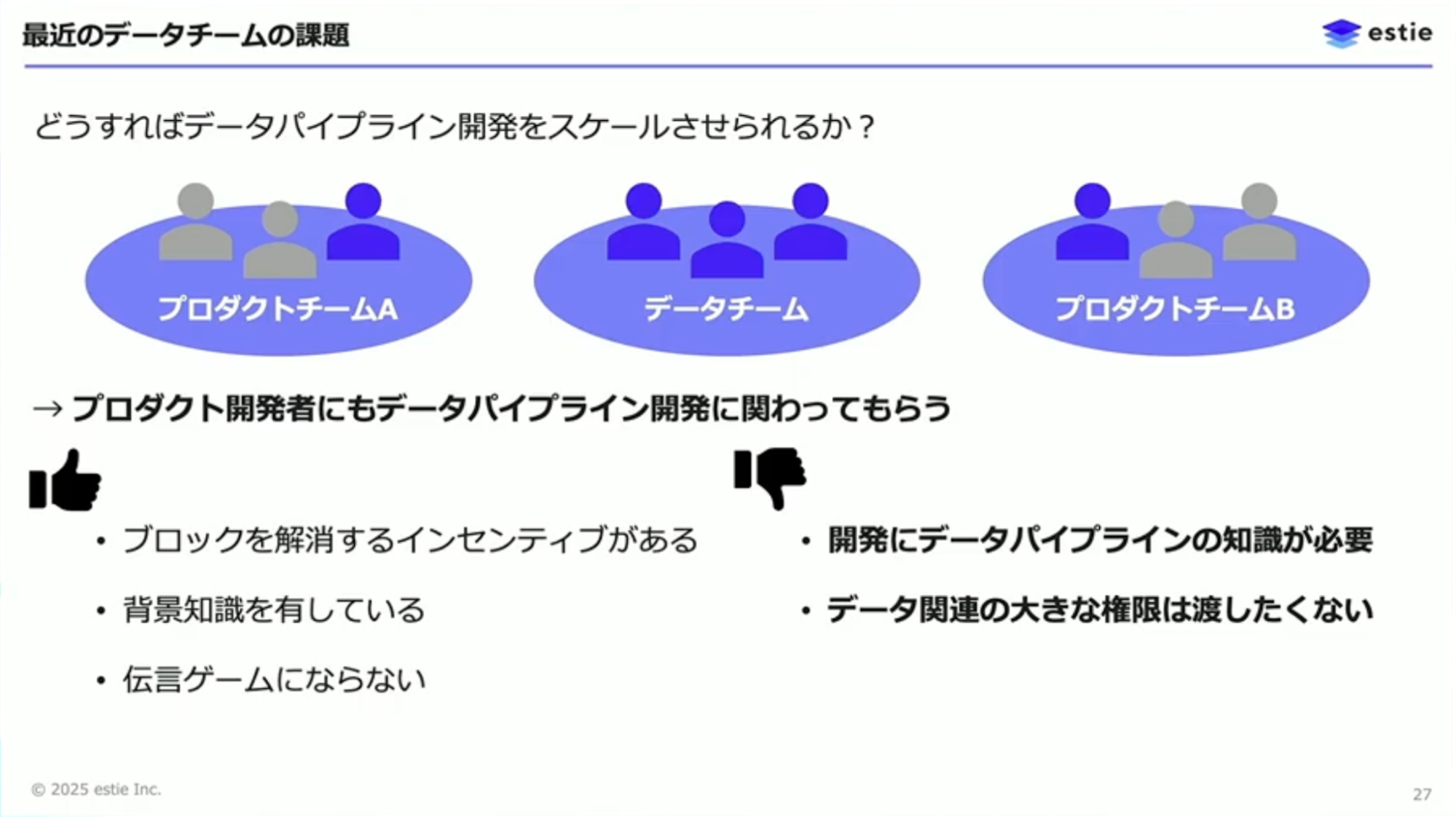
山本:ただし、この取り組みをうまく機能させるには2つの障害がありました。1つ目は、データチーム分割後に独自に技術開発を進めたため、データチームしか持っていない知識や実装ノウハウがあったことです。2つ目は、秘匿性のあるデータを含むパイプラインの大きな権限はプロダクトチームに渡したくないという事情です。
1つ目の障害に対しては、データチームとプロダクトチームの二人三脚で開発を行うことにしました。データチームの担当者が実装のお手伝いやコードレビューを行う、いわゆるイネーブリングを実施しています。データチーム側の関わりの大きさは、プロジェクトの規模や急ぎ具合によって変化させています。大きなプロジェクトでは、プロダクトチームからデータチームへの異動や出張という形で密に協力することもあります。
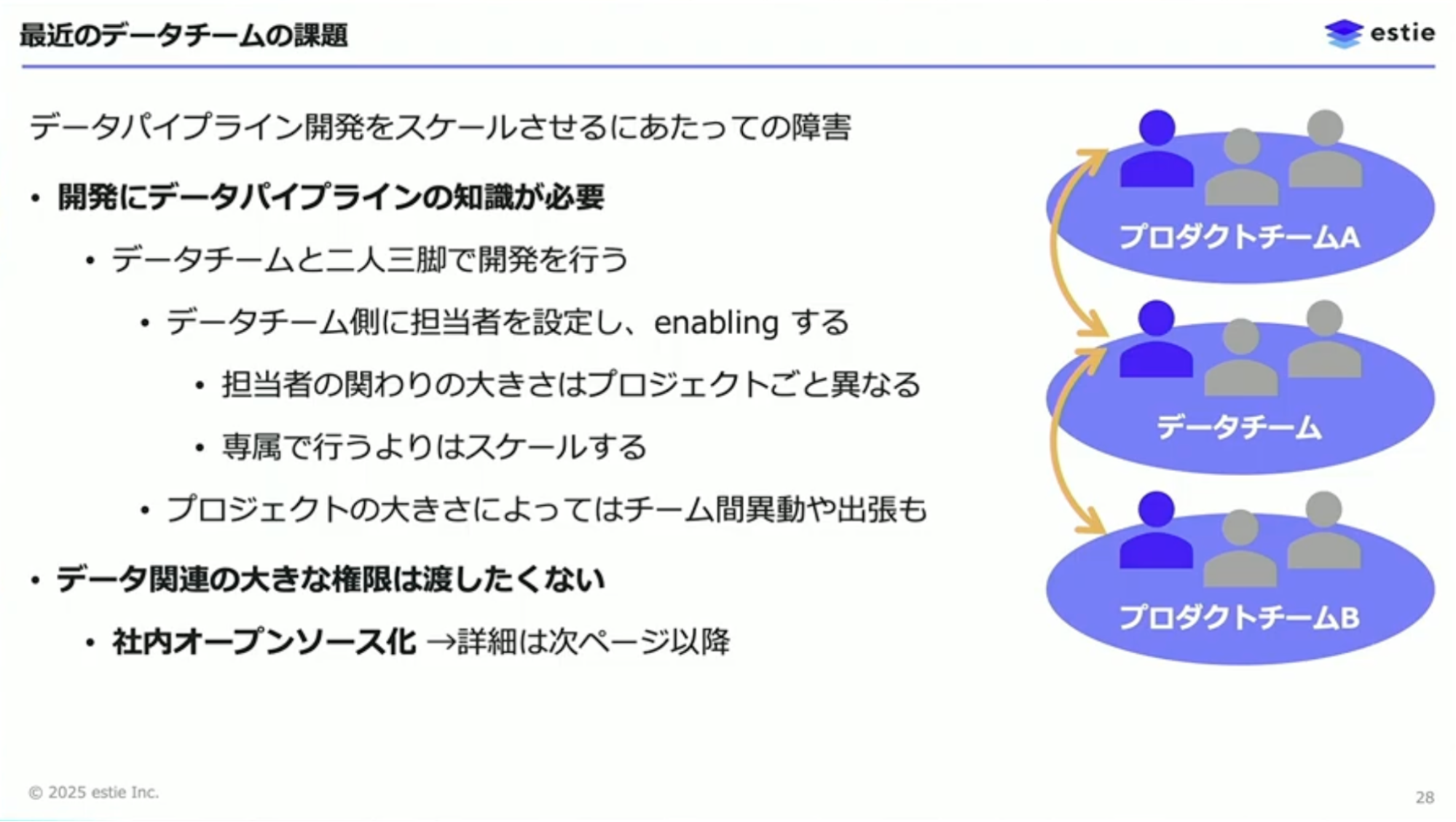
山本:2つ目の障害に対しては、社内オープンソース化という取り組みを行いました。estie独特の要件として、商業用不動産のデータの流通経路には大きな情報価値があり、どのパートナーと関係を持っているかということですら社内でも秘匿しておきたいという事情があります。
従来のアーキテクチャでは、流通経路が類推できてしまうデータやコードが、SnowflakeやGitHub上でデータパイプラインの他の部分と十分に分離されていませんでした。これは、もともとデータチームが流通経路を知っている人だけで構成されていたため、問題になっていなかったのです。プロダクトチームは秘匿済みの成果物だけにアクセスできる形でした。
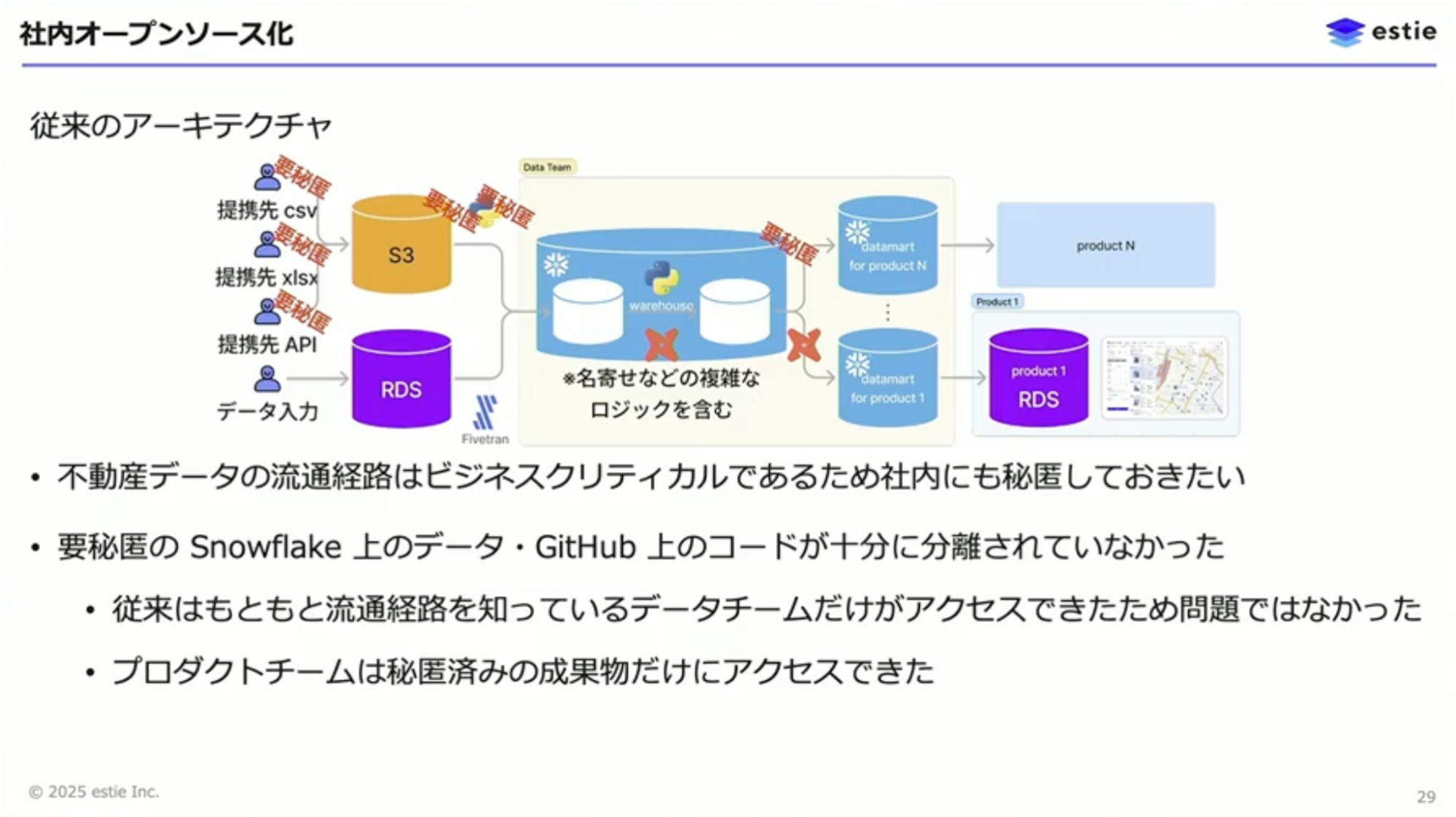
山本:データ加工ロジックの大部分をプロダクトチームと協力して開発できるようにするため、リアーキテクチャを実施しました。秘匿データとコードをデータベース・リポジトリ単位で分離し、要秘匿のデータやコードには新しく権限を設定しました。データチームとは独立した権限になったため、異動や出張も容易になりました。データパイプライン開発の核となるデータやコードは、開発に携わる全員に公開できる状態としました。
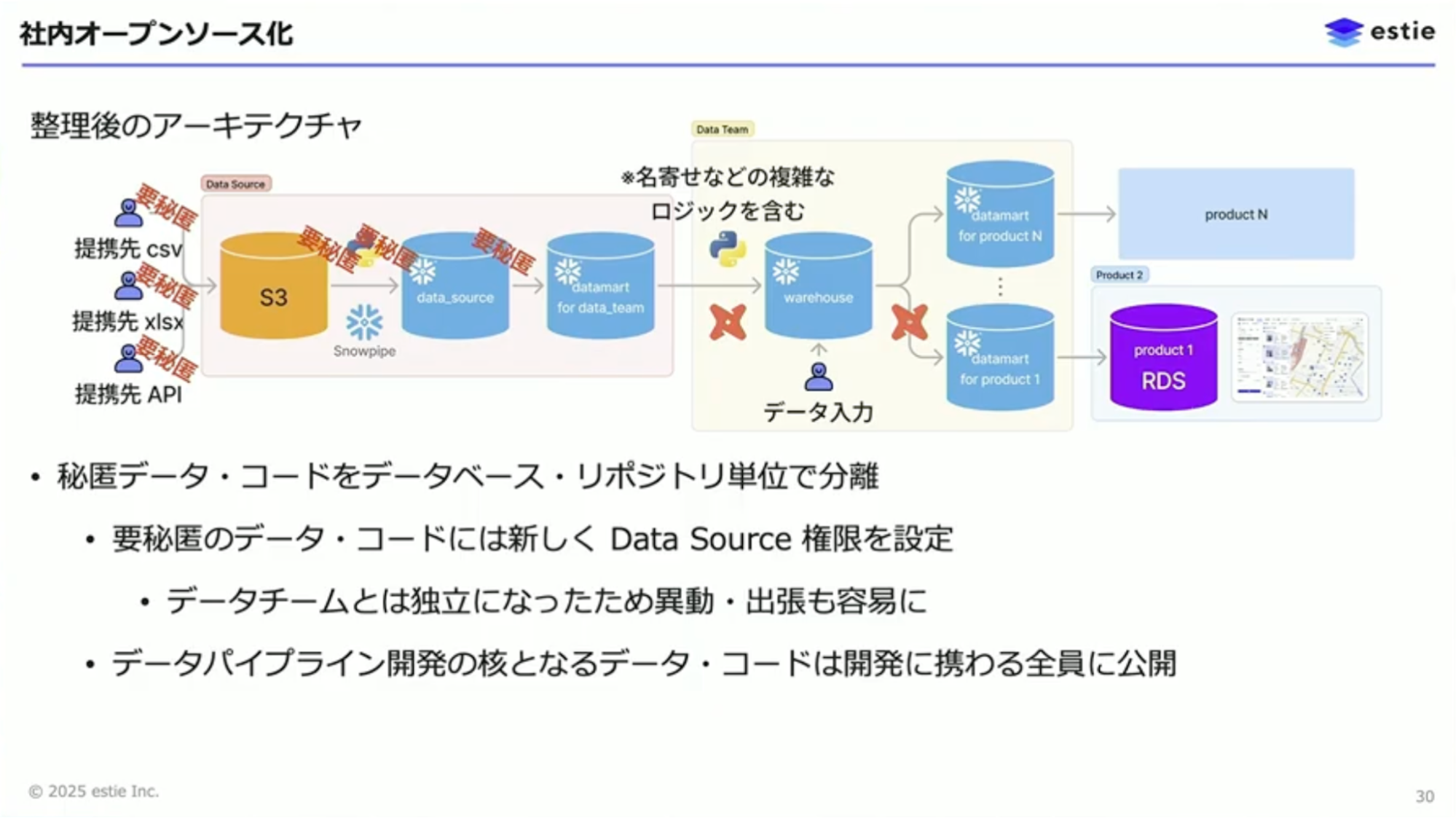
山本:追加の取り組みとして、データチーム外の人がより安全に開発に参加できるよう、Snowflakeのzero-copy clone機能を活用し、read-onlyの本番データベースから開発者が自由に読み書きできる開発データベースを作成するワークフローを整備しました。また、dbtをdry-runするCIやフォーマッターの強制、Elementaryを用いた異常検知と担当者への通知も導入しました。さらに、dbt docsやElementary ReportをGitHub Pagesにデプロイし、GitHubアカウントを持つ社員であれば誰でも現在のデータカタログや監視状況を確認できるようにしました。
社内オープンソース化の成果として、まずプロダクトチームの開発をブロックしなくなりました。プロダクト側から人を張ってもらうことで、高速開発も可能になりました。また、副次的な成果として、やる気のある人が自発的にパイプライン開発に参加してくれるようになりました。データチームに依頼するほどでもないロジックの微妙な改善や、すぐには必要ではないがあると便利なオープンデータの取り込み実装などを行っていただいています。これらの取り組みによってデータチームの手が空き、より基盤側の整備に取り組む余裕が生まれました。

山本:社内オープンソース化により開発はスケールするようになりました。しかし、一方で実行はまだスケールしていません。Snowflakeに限らずDWHは高価なので、チューニングをしていく必要があります。空いたデータチームの手で改善に取り組んでいく予定です。
また、データの種類は大幅に増えましたが、クオリティの担保が追いついていないという課題もあります。これまではデータチームがすべてを目で確認したり、異常データを経験則から弾いたりすることができていました。しかし、アセットタイプやプロダクトが増えたことでデータ量も種類も増加し、これまでの経験則が役に立たなくなってきました。必要な背景知識があまりにも多く、データチームだけでは限界というところまで来ていました。そこで、ちょうどデータの課題について模索していたQAチームとの協力が始まりました。

QAの品質向上に向けた取り組み
粕谷:はじめにQAエンジニアについて簡単にご説明しますと、Quality Assuranceの名前の通り、品質を軸にもつエンジニアです。弊社のQAチームは開発組織のサイズに対して少人数で構成されており、いくつかの開発ユニットに所属しながら横断的なタスクにも取り組んでいます。プロダクトの信頼性と、組織の生産性向上への貢献を職務としています。
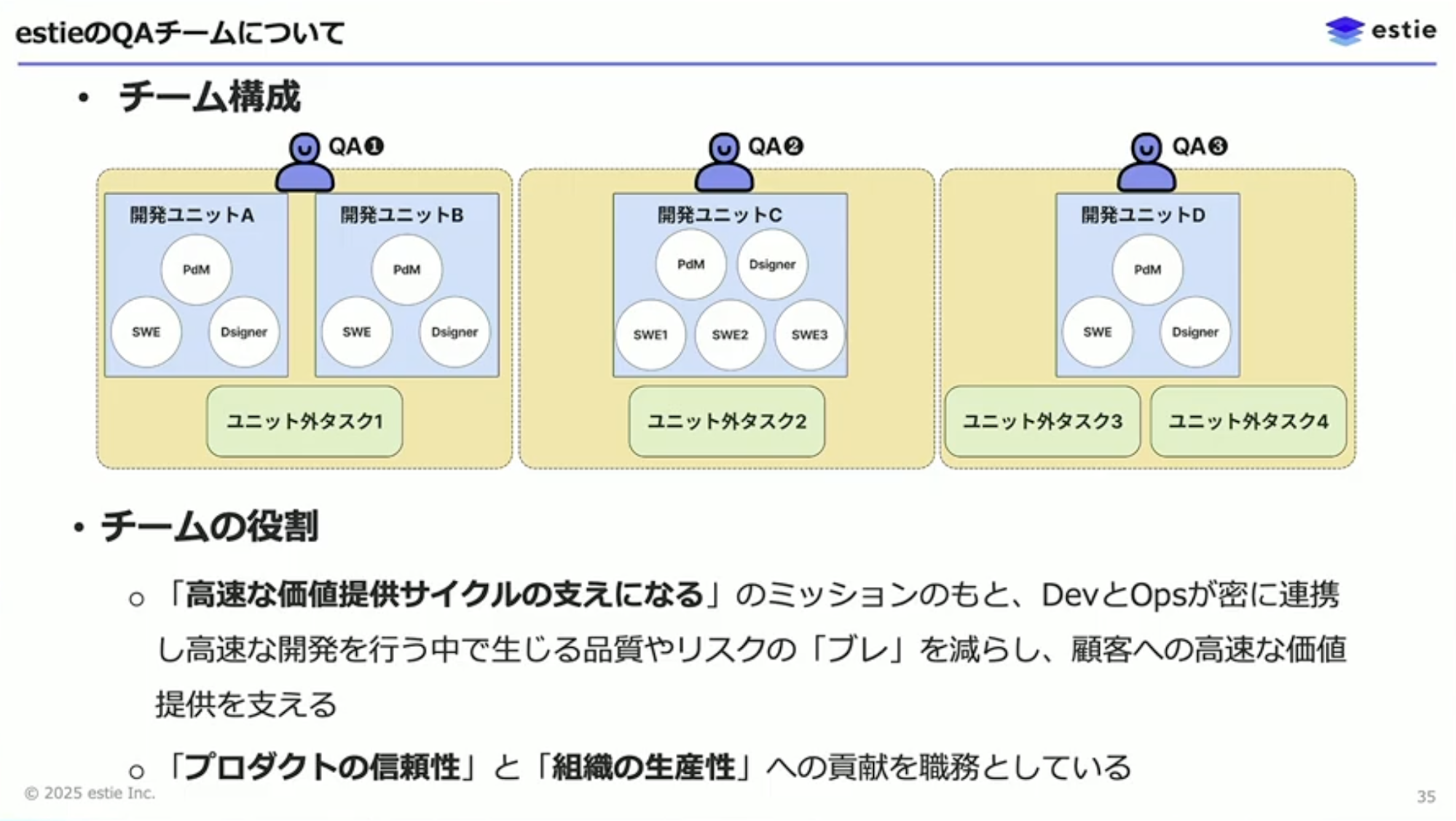
粕谷:データチームとのコラボレーション以前、私はUIを持つユーザー向けアプリケーション領域を主に担当していました。開発チームの特徴としてビジネスサイドと近い距離で開発をしていたため、ユーザーサイドへの染み出しはしやすい状態でしたが、データチームが管轄するデータパイプライン領域への染み出しはできていませんでした。
Vertical Dataプロダクトの特性上、データに価値があることは明白です。しかし、そのコアに対して貢献できていないことにもどかしさを感じていました。そもそもデータ品質とは何か、完全性・一意性・適時性・有効性・正確性・一貫性等データ品質指標の中でどこに課題があるのか意識できていませんでした。
過去にパイプライン開発のテスト業務を巻き取ろうとした際には、開発の前提となるコンテキストやデータエンジニアリング領域の知識不足でボトルネックになってしまいました。
そんな中で、データ品質に向き合う機運が高まりました。きっかけは、データ関連の不具合が少しずつ増えてきたことです。取り扱うデータの種類や量が増えたことでパイプラインが複雑化し、それが要因となっていました。
具体的な課題が見えたことで、やるべきことが明確になりました。「データ起因での不具合をプロダクトに伝播させない仕組みをつくろう」という方針のもとデータチームとの相談を重ね、コラボレーションが開始しました。

粕谷:さまざまな議論を経て、方針としてはデータパイプラインの後段にサーキットブレーカーを設け、生成されたデータが受け入れ基準を満たさない場合はデータを更新しないこととしました。サーキットブレーカーとは、特定の条件の場合にデータ処理を止めて、プロダクトへのデータ移送も強制遮断する仕組みです。

取り組み内容は大きく2つです。1つ目はデータコントラクトの作成です。データコントラクトはQAが主導で作成しています。まずプロダクトにとって重要なデータを定義し、それらに対してチームに蓄積しているドメイン知識を活用してデータコントラクトを作成します。特に重要なものは「Critical」として定義し、dbtやElementaryといったOSSを用いてテストを実装します。
具体例として、サービスの中で重要なデータである建物の募集データに対して追加したCriticalテストをご紹介します。「募集賃料のnull率が直近1か月の平均+3標準偏差の範囲内であること」「募集中判定フラグの真偽の分布が直近1か月の平均±3標準偏差の範囲内であること」といった基準を設けています。データソースの問題なのかパイプラインのロジックの問題なのかに関係なく、プロダクトにとって重要なデータに大きな変化があった場合は異常と判定しています。

2つ目の取り組みがサーキットブレーカーの導入です。技術的な部分や実装自体はデータチームにお願いしました。Criticalテストが失敗した場合には、プロダクトのデータが更新されないことで、データインシデントを未然に防ぐことができます。
運用の中で偽陽性による弊害が出る可能性はありますが、現在は誤検知によって一時的にデータ更新が止まるリスクよりも、不具合を見逃してデータ品質が低下するリスクを重視した運用をしています。
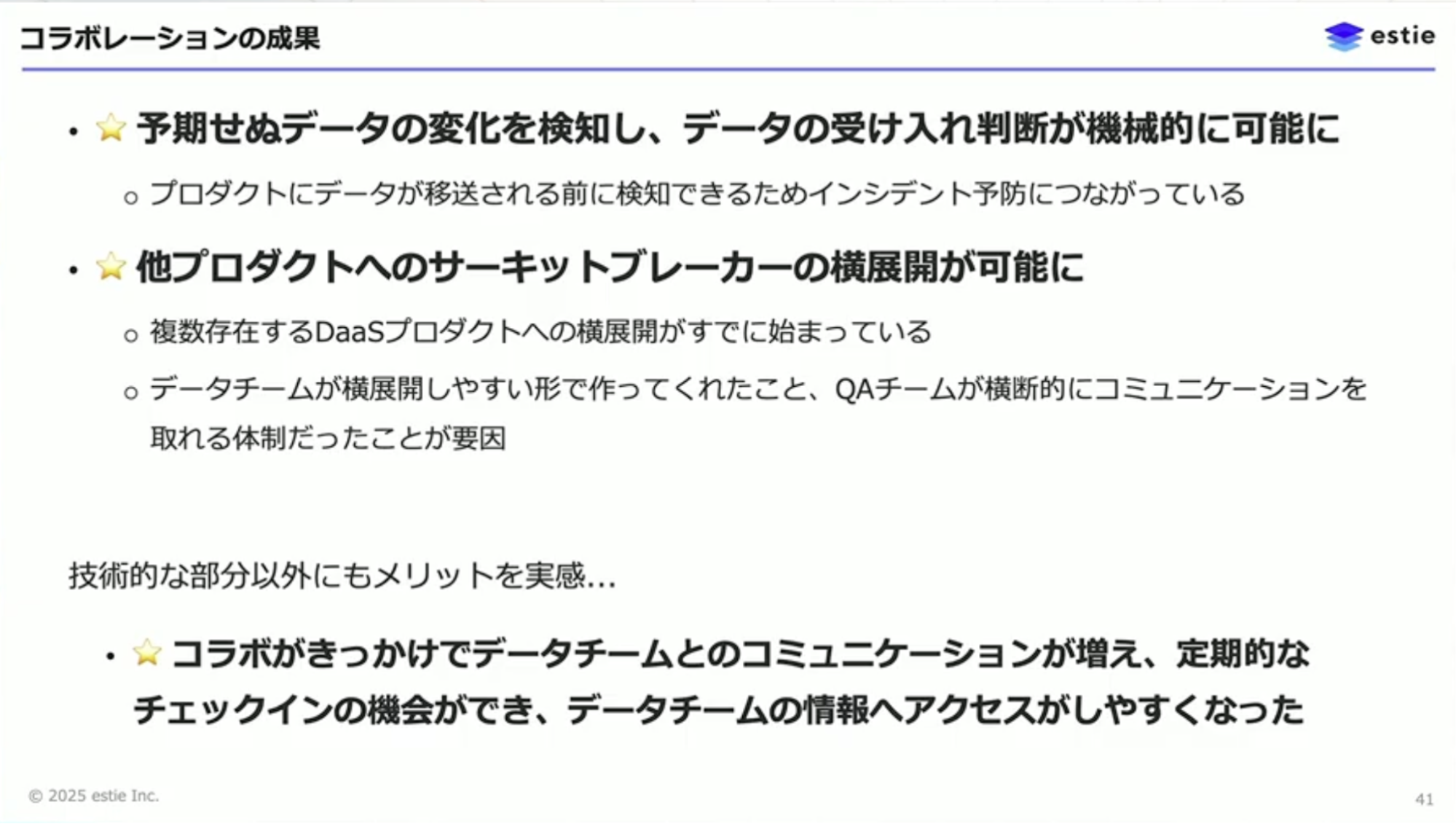
コラボレーションの成果として、予期せぬデータの変化を事前に検知できるようになりました。データコントラクトの作成によって、データの受け入れ基準を機械的に判断できるようになりました。また、サーキットブレーカーの横展開も可能になり、複数のプロダクトへの展開がすでに始まっています。
技術以外の部分でも、データチームとのコミュニケーションが増えたことでチーム間の距離感が近くなりました。これは個人的にはとても大きな成果だと感じています。
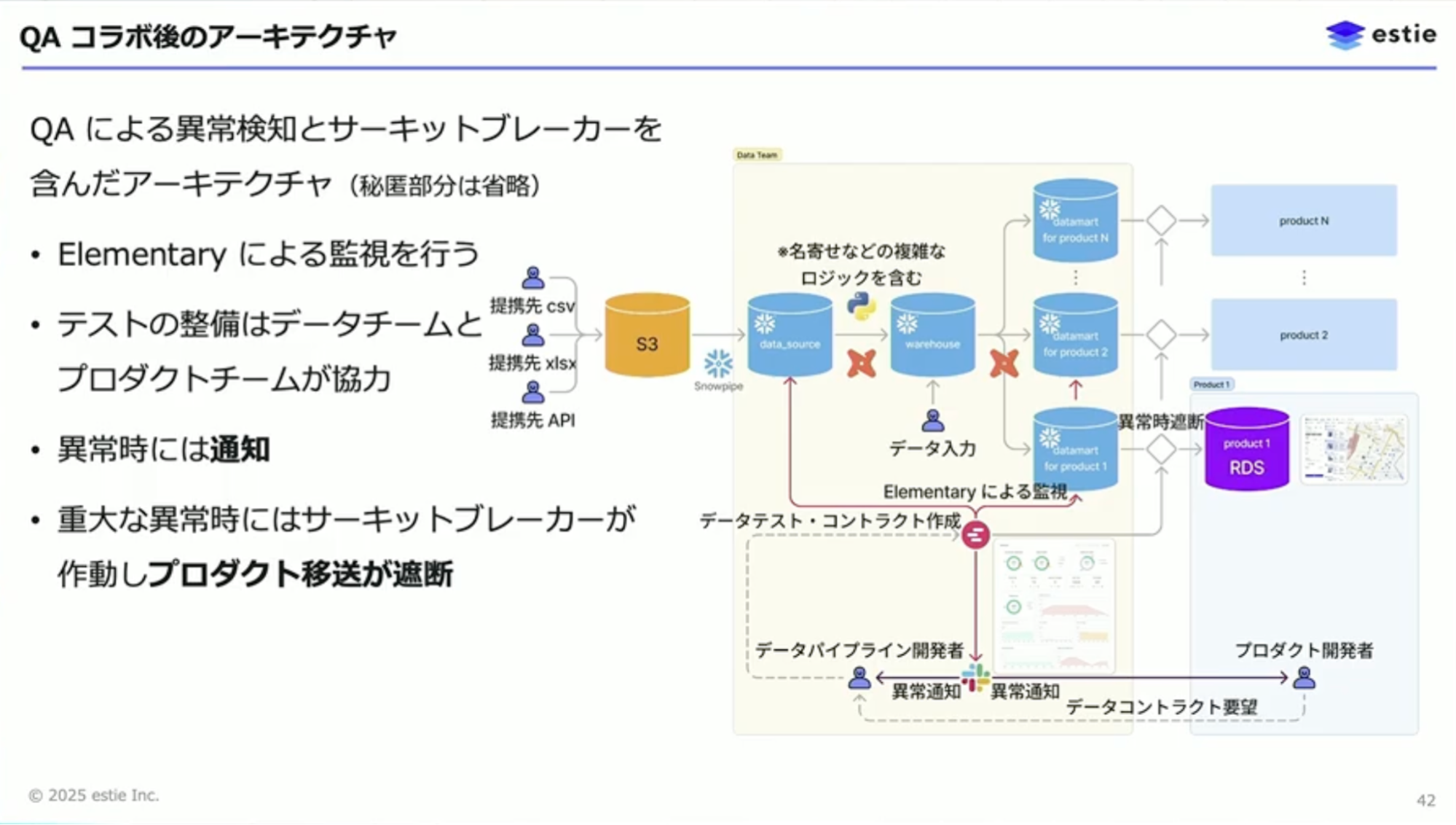
山本:QAチームとのコラボレーションによって新しくなったアーキテクチャでは、Elementaryによる監視が追加されています。監視対象のテストの整備は、データチームとQAチームを含むプロダクトチームが協力して行っています。
異常が検知されてテストが失敗した際には、あらかじめ登録しておいたテストのオーナーにSlackで通知が行われ、すぐに気づけるようになっています。重大と指定されたテストが失敗した際にはサーキットブレーカーが作動し、移送が中断されます。これによって、データの異常に気づくだけでなく、異常のあるデータを顧客に提供しないということが実現できるようになりました。
山本:社内オープンソース化とQAとのコラボレーションによって解決した課題をまとめます。まず、データパイプライン開発がスケールするようになり、新規プロダクトがいくら出てきても開発をブロックしなくなりました。
また、データクオリティの担保ができるようになりました。QAチームがもともと各プロダクトとのつながりが強く背景知識が豊富だったこと、そして社内オープンソース化で整備されたElementaryの異常検知を活用したこと、サーキットブレーカーを実装したことでデータインシデントが起きにくくなりました。
一方で、まだ解決していない課題もあります。データパイプライン開発はスケールしましたが、実行のスケールはまだ達成できていません。毎日のdbt buildに9時間ほどかかっており、チューニングが必要です。社内オープンソース化によって空いたデータチームの手で改善に取り組んでいく予定です。
データテストも完全ではありません。テストの偽陽性は運用の中で閾値を調整していく必要があります。異常発生時の原因調査はまだ難しく、調査に有用なメタデータの整備が必要です。また、テストによって今まで気づかれなかった汚いデータが発見されるようになりました。これはある意味で正解なのですが、随時修正していく必要があります。

山本:今後の取り組みとしては、先ほど挙げた2つの課題に加えて、データチームの手が空いてきたこともあり、パイプラインのアーキテクチャ統一を行いたいと考えています。もともと各プロダクトで独自にデータパイプライン開発をしてもらっていたという歴史的経緯がありますので、これを統一していきます。また、すべてのデータパイプラインが同一の基盤に乗ったことで、プロダクト間連携もできるようになってきたので、そちらも進めていきたいと考えています。
まとめ
山本:estieでは、アプリ開発チームとデータ開発チームが分離したことで、開発サイクルの違いや知識の差分がチーム間で生じる状態になっていました。最近の課題である「開発がスケールしない」に対しては、社内オープンソース化を行いました。これによってプロダクトチームをイネーブリングし、データ開発に入ってもらうことで、プロダクトチームの力によってデータ開発がスケールするようになりました。また、QAチームとのコラボレーションによってデータクオリティの担保も実現しました。今後の取り組みとしては、データチームはより基盤側にシフトしていく方針です。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。