



今日から始める「システム監視」。大量トラフィックのシステムを安定して運用する知見をアソビューのSREに学ぶ
はじめに
アソビュー株式会社では、アソビュー!という電子チケットを販売するサイトを運営しています。
システムを安定稼働させるためには、日常的にシステムの状態を監視して、問題があれば調整するというプロセスを繰り返すことが必要不可欠です。本記事では、アソビュー株式会社において、どのような体制でこの安定稼働を実現しているかということを書くことによって、同じようにシステムを安定稼働させたいと日々考えておられる方々を想定読者として、そのノウハウを共有しようと思います。
安定稼働をするために必要な要素
人間の健康管理のために必要なこと
システムを安定稼働するために必要なことというのは、人間が健康に生きていくためにやっておいたほうがいいことと共通点が多くあります。人間の場合には、健康診断を毎年実施したり、体調不良であれば通院したりします。健康を管理するために、人々は、体温計というものを利用して体温という指標を測り、病気なのか通院したほうがいいのかの一時切り分けをします。異常があれば病院に行き、お医者さんに適切な処置をしてもらうことにより、病気が軽減して楽になります。また、早いタイミングで病院に行くことにより大きな病気を防ぐことができます。
自覚症状がないケースにおいても検出するための仕組みが定期健診と言われるものです。これらも、定期的に検査して数値が規定値を超えるものがないかどうかをチェックしたり、検査観点に従って機器を利用して、異常がないかどうかをチェックしたりします。異常がある場合には、精密検査をします。どういう項目をチェックするかは、医療の専門家である方々によって決められており、これらを定期的に検査するということを国全体でやることで国民の健康が長く続くように制度が作られています。
システムの健康管理のために必要なこと
前節にて、人間の健康管理の中では、下記の観点があるということを記述しました。
- 「体温計」という計測器
- 「熱が37度を超えたら病院に行く」というような日常行動指針
- 「定期健診」のような定点確認
システムにおいても、このような観点と同じように
- 異常と正常のしきい値をきちんと定めて常に観測する視点
- 軽度の異常を素早く検知して、大きな異常になることを防止する視点
- 自覚症状はなくても異常が潜んでないかを定期的に点検することによって、大きな異常を未然に防ぐという視点
が必要となり、同じような形で運用する方法を定めていくことになります。
いくつかの例
計測器としては、監視ツールなどがあります。アソビューでは、Datadogを利用して、各種システムの観測を行っています。
「異常と正常のしきい値をきちんと定めて常に観測する視点」の例としては、常に、システムの状態が定められた速度で応答しているかどうかを監視することにより、きちんと想定された動作を継続的に行っているかをチェックします。これは、SLOの運用とも呼ばれています。
まだ、過去のデータがあまり蓄積されていなければ、いきなり数値で表現することが難しい場合もあるでしょう。そういう場合には、ダッシュボードなどを作成して、ダッシュボードとシステムの安定度をチェックしながら、その適切な値が定められるような状態を作って、定期的にチェックしていくことにより、そのような姿に近づいていくこともできます。
「軽度の異常を素早く検知」する例としては、システムが出力するエラーログなどを監視することです。エラーというのは、基本的には、想定外の事象が起こっているという自覚症状のようなものです。この自覚症状をうまく検知して、素早く適切な処置をすることにより、大きな障害につながることを防げます。エラーが不適切なものであれば、エラーの出力自体を調整することによって、今後より良いものになりますし、兆候を正しくキャッチできているのであれば、その兆候となっているもの自体に対して修正をかけることにより、将来のシステム安定へとつなげることができます。
システムを運用するうえでの計測項目
ここからは、システムを運用するうえで、どのようなものを計測して、それに対してどういうアクションを取るかということについて具体的に説明していきます。これらの計測項目は、Datadogによって収集されたものを利用しています。
CPU
当社ではDBのCPUは重要指標の一つとして運用しています。DBのCPU利用率は、ユーザーの訪問数と強い相関関係があることから、GWや長期休暇などの繁忙期に用意したCPUで足りるかというのをチェックするために利用しています。また、想定値以上のCPUの利用率を検出した場合には、通知します。詳細は、後述します。
エラー監視
エラーの監視は、HTTPレスポンスが500のものとログレベルがエラーのものを監視しています。HTTPレスポンスは、SLOにも利用しており、常にあるしきい値以内のエラー率に収まっていることを確認するのに利用しています。ログのエラーについては、Datadogのエラートラッキングの機能も、新規のエラーが発生した場合と、1時間に一定件数のエラーが出ているものについて、Slackへ通知をするなどして異常検知に利用しています。
レイテンシ監視
レイテンシも重要な指標として活用しています。SLOにも利用しており、日々リリースする機能に対してサービスレベルが一定のものをキープしているかどうかをチェックしています。
非同期処理においても、完了までにどのくらい時間がかかっているかを計測しておきます。遅延が一定程度以上発生した場合には、通知を行います。
スロークエリ発生件数
スロークエリは、そのクエリが呼ばれるリクエストが、少しでもスパイクすると、DBに多大な負荷をかけることがあります。これを防ぐために、1秒以上かかったクエリをスロークエリとみなし、5分間でスロークエリの検出が一定件数を超えた場合には、スロークエリの発生を通知して、開発側のバックログに登録してもらうようにしています。
メモリ不足エラー発生の監視
コンテナレベルのOutOfMemoryやJava VMレベルでのOutOfMemoryなども監視しています。アプリケーションの機能追加を重ねていくと、メモリの利用量がだんだん増えていく傾向にあります。メモリの枯渇状態を監視して、適切なメモリの値を常に調整しています。
アプリケーションごとの同時接続数の監視
現在のアソビューでは、アプリケーションごとのPod単位での同時接続数をオートスケールの基準にしています。アプリケーションごとに同時にいくつの接続までできるかを定めて、既定値を超えたら水平スケールをする設定を組んでいます。これにより、夜間などのアクセス数が少ない時間帯に自動縮退をしています。
基本的な監視に対する考え方
ここまでは、どういう項目を計測しているかという点を中心に記述しましたが、ここからは、安定稼働を継続維持するために、これらの項目をどのような考え方でどのように取り扱っているのかを記述していきます。
通知に対する基本的な考え方
基本的には、全ての通知に対してなんらかの反応が行われるようにしておくべきだと考えています。通知が来ていたけれど何もしないものがあるという状態が発生すると、その状態が正しい状態なのかどうかが不明な状態になり得ます。さらに、本来反応すべきだった通知に対して反応せずにいた結果、その通知はいずれノイズと化し、結果として障害が発生するということにもつながりかねません。
また、通知に反応した結果、何もしなくてよかったというケースも実際にはあると思います。それが繰り返される場合には、通知自体のチューニングをして、何もしなくてよいという率を減らすということが大切だと考えます。
日々発生する通知にきちんと対応していくことが、安定稼働のための第一歩であることは間違いないと考えます。
検査項目をどのように定めていくのかという考え方
まずは、安定稼働を維持していくために検査項目をどう定めるのがいいのかということについて書きます。当たり前の話なのですが、検査項目というのは、システムの異常を適切に検知することがとても大切になります。例えば、CPUの利用率を監視したいときに、どのような状態を検知すればいいでしょうか。
その場合には、CPU利用率がどうなったときに、このシステムはどう困るのかということを考えて定めていくことが大切です。
例えば、CPU利用率90%が数秒間程度続き、その後、30%程度に落ち着いた場合を想定してみましょう。その程度なら問題ないというシステムだったのに、数秒超えただけで通知が飛んでしまった場合には、通知に対応してから、この通知はいらなかったと気づくことができると思います。そういうときは、通知の設定をすぐにチューニングして「1分間CPU利用率の平均が90%を超えている場合に通知する」と変更しておくと、今後はより欲しいときに通知が受け取れるようになるはずです。
なので、日々、通知をチューニングしながら通知を受けて追ってくというのが運用上とても大事なことと考えます。通知を無視するという対応は、チューニングの機会を失うことになるという観点からも良くないと考えています。
通知先チャンネルとメンション先の考え方
当社では、基本的にSlackのチャンネルで通知を行っています。チャンネルとメンションの機能を使って通知を行います。チャンネル自体は、下記のような単位で分けています。
チャンネルの参加者とメンションの利用用途は、分けたほうがいいかと考えます。
チャンネル参加者:すぐに反応する必要はないが、1日に1度程度は、確認したほうが良い人が参加する
メンション先:すぐに反応して、対応の必要性を判断できる人へメンションする。通知のチューニングもメンション先の人が中心で実施する
アソビューでは、下記のような感じで通知用のチャンネルを運営しています。
- 緊急対応が必要なアラートを通知
- 参加者:経営陣、開発、QA、SRE
- 重要なエラーの発生を通知
- 参加者:開発、SRE
- インフラ系のアラート
- 参加者:SRE
- 全てのエラーの発生を通知
- 参加者:開発、SRE
- チケットの急激な販売増加を通知
- 参加者:開発、SRE、ビジネス部門
通知先が全員だと、責任の範囲があいまいになり、誰が対応すべきかあやふやになってしまいます。通知先は、すぐに反応をしてほしい人にするのがいいと考えます。自動振り分けの仕組みを利用して、チーム単位への振り分けを自動で実行するのが難しい場合には、@hereメンションで全員に通知を送ります。その場合でも可用性の責任を持つSREが、最後にはボールがこぼれていないかどうかチェックして、こぼれていれば、手動で問題を切り分けて適切な人やチームにメンションして、問題が必要以上に長引かないようにしていきます。
また、テスト中のアラートは精度が悪いこともあるので、上記とは別のテスト用のチャンネルを作って、そこで通知が思った通りになるようになるまでテストします。その後、ある程度、思った通知になってきた段階で、運用に使っているチャンネルで通知するという流れで運用しています。
通知例)
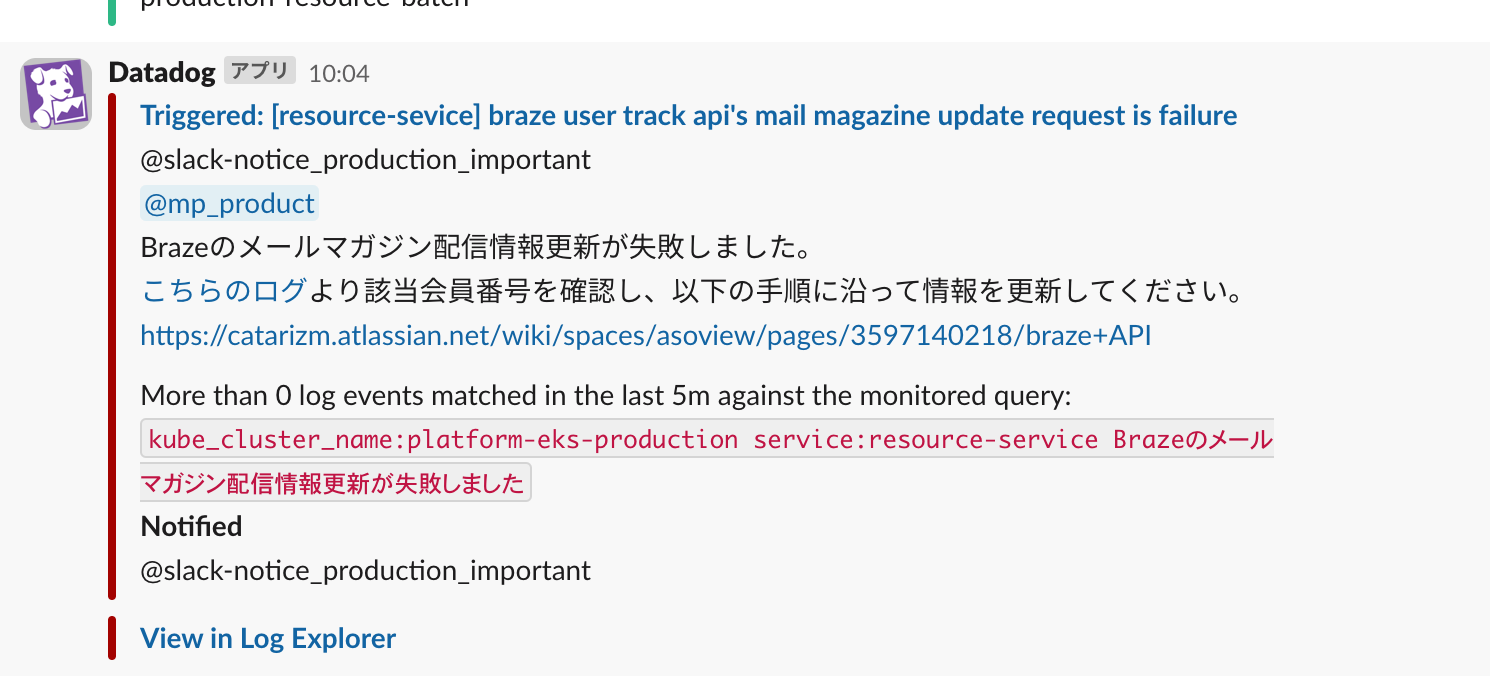
SLOの確認
レイテンシとエラー率について重要ないくつかのエンドポイントのSLOを定めて監視しています。SLOは、少なくとも基本的に週に1度以上枯渇状況を確認して、枯渇状態が確認できたら対応するような流れで進めています。また、枯渇した場合にはSlackで通知を行い、異常発生時に開発者が気づきやすいようにしています。
訪問者数のトレンドをチェックする
週に1度は、サービスの利用者数が前年と比べてどのような増加推移になっているかをチェックします。このシートは、Google Analyticsの情報から連携して、スプレッドシートの関数を使いながら管理しています。障害記録やイベントの情報も入力しておいて、翌年の同時期のイベントと比較しやすいように情報を残しておきます。
また、障害が発生したときもこのシートに記録に残しておくことによって、昨年の実績と比較して今年のインフラスペックについての妥当性の検討などにも利用します。
シート例)

システムを安定稼働させるために定期的に実施していること
本パートでは、アソビューにて、安定稼働させるために、日々定常的に行っていることをご紹介していきたいと思います。
繁忙期の負荷対策
ここでは、普段よりもリクエストが増える繁忙期も、安定稼働するために、SREがどのようなことを実施しているかを記述します。
繁忙期のリクエスト数の見積もり
アソビュー!では、GWや夏休みに多くの利用者がサービスを利用しにくるという特性があります。これらの時期が来る前に、想定の最大アクセス数を見積もり、インフラの設定がこの繁忙期に問題なく稼働できるかどうかというのをスプレッドシートの表を使って計測しています。アプリケーションについては、水平オートスケールを導入しているので、最大レプリカ数の値に問題がないかどうかをチェックし、データベースにおいては、Aurora Serverlessを利用しているので、ReaderDBのインスタンスの数をチェックします。
以下、具体的な例を示しながら説明していきます。
DBのスペックの見積もり
最初に、日付単位で、訪問者数の見積もりを行います。
また、直近でアクセスが比較的多かった日を基準日として、その日のインフラの状況を計算します。
例えば、
| 日付 | 訪問者数 |
|---|---|
| 6/25(実績) | 2,000,000人 |
| 8/13(予想) | 6,000,000人 |
というような予測があったとします。
DBの状況としては、下記だったとします。
| DB CPU利用率 (6/25実績) | 25% |
|---|
となっていた場合には、だいたいピークの8/13には6/25の3倍来る可能性があることから
25%×3=75%
さらに、予測のブレを吸収するために安全係数を一定かけます。ここでは、安全係数を2と設定することにより
75%×2=150%
となります。現在、Readerのインスタンスが2台の冗長構成だったと仮定すると、これでは足りないと判断されるために、ピーク時には、いつもより1台増やす運用をしようということになります。
こちらに記述した内容は、わかりやすさを優先して実際よりも少し単純化していますが、だいたいこのような流れでスペックを見積もって、負荷の増加に耐えられるインフラになっているかをチェックしています。
アプリケーションのスペックの見積もり
アプリケーションの負荷については、Kubernetes上のPodの数で調整します。前述した通り、同時接続数の数に応じてPodは自動的に増減する仕組みを導入していますが、ここでは、その最大値のみを調整します。同時接続数は、Datadogの下記のメトリックスを使って概算値である程度、単純化して算出しています。
- p99のレイテンシ
- 分間のアクセス数
最初に、直近で最高のアクセスのあった日付を選んで、その日の24時間でのピーク値を下記の値で算出します。
(想定同時接続数)=(1分間あたりのアクセス数)/ 60 * (p99のレイテンシ)
例として、単純化するためにわかりやすい数字を用いて説明します。
p99のレイテンシ:0.5s
分間アクセス数:12,000回
とすると、
(同時接続数)= 12000/60×0.5 = 100
となり、ここでは、同時接続数を100とみなします。p99の値を取っているので、実際には、これよりも少ない値にも多い値にもなる可能性はありますが、一旦、これで算出した値を見積もっています。
これらのリクエストを、1台で同時に25個リクエストを処理できるという性能のPodとして、最大4台のPodがあれば大丈夫という計算値になります。
これを訪問者の増加と比例するという前提で見積もり、3倍の訪問者が来ることが想定される場合には、これも安全係数2をかけて、
最大Pod数= 4×3×2 = 24
と見積もり、最大Pod数を調整していきます。
このようなオペレーションを繁忙期前に実施することによって、より安定的に稼働するように運用しています。
オートスケールの上限設定とDBの理論最大コネクション数の管理
一方でデータベースなどのリソースにおいては、最大コネクション数というのが定められているものもあり、システム全体でコネクションを取得できる数というのには上限があります。
上記のようにこの上限を超えてPodを増やし過ぎると、コネクションの取得時にエラーになることがあり得ます。なので、最大Pod数を見積もると同時にコネクションの上限の理論値も管理しておく必要があります。
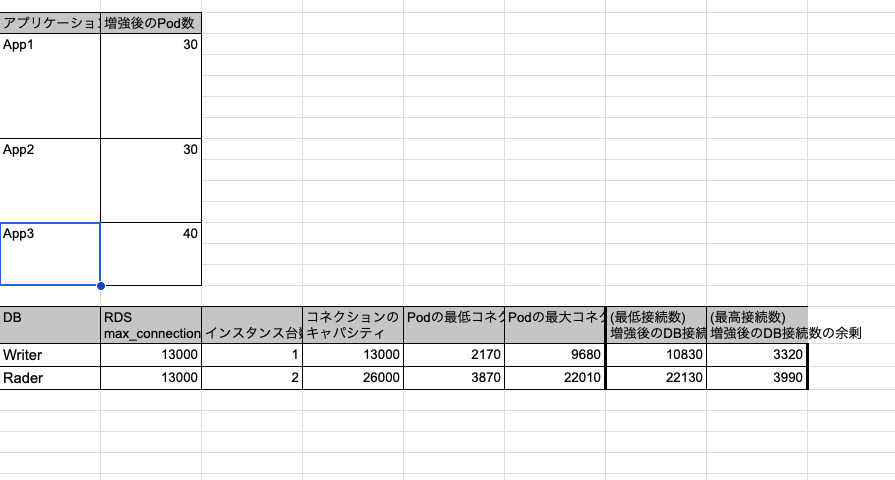
アソビューでは、スプレッドシートでPodごとのコネクション数を管理して、スプレッドシートの関数を利用しながら、最大Pod数を入力すると、合計の必要コネクション数の理論値を算出するようなスプレッドシートを作成しています。
マイクロサービス構成では、1Podあたりのコネクション数をきちんと割り当てておかないと、コネクション数が簡単に枯渇してしまうので、このあたりをうまく調整することはとても大事です。
シート管理例:
高負荷イベントの定期確認
通常、オートスケール機能などでほとんどの場合は安定的に稼働できるのですが、アソビューの場合には、超人気チケットの発売開始直後のスパイクやテレビ放送直後のスパイクのように、オートスケールの機能では間に合わないケースも存在しています。そのケースに対応するために、高負荷時のイベントの情報共有を行う仕組みがあります。
人気チケット販売開始などがある場合には、それをGoogleカレンダーに登録して、いつどういう人気チケットの販売があるかといったことを確認しています。発売前のチケットの見積もりは非常に難しいのですが、発売開始前のトラフィックなどを元に、どれくらいの人が殺到しそうかを監視して、必要であれば手動でウォームアップを行い、急なスパイクに備えて準備するといった対応をしています。発売直前のアクセス動向は、Google Analyticsのリアルタイムの状況を監視して判断に利用しています。こちらの値が一定のしきい値を超えた場合には、手動によるスケールの調整を行うことにより、安定的な稼働を実現しています。
パフォーマンス上影響のあるSQLをチェック
SQLというのは、リリース当初はパフォーマンス上問題なく動いていたとしても、経年劣化のように、日々のデータの積み重ねにより、徐々に悪化したり、突然悪化したり、また、ちょっとした負荷で顕著にインフラに大打撃を与えたりと、安定稼働を目指すことにおいて、大きな要素となります。 そこで、アソビューでは、主に、下記の観点を全て満たすものに対して優先度をつけて、その優先度が高いものについて重点的に監視して、安定稼働をするように運営しています。
- Indexが効率的に利用される実行計画になっていない
- 実行回数が、サイト訪問者数に比例して増減する
これらのクエリをDatadogの機能を利用しながら抽出しています。
もう一つの観点としては、スケール上限のあるWriterのリソースを無駄遣いしていないかどうかというのを確認するのも重要です。
Writer側に対して不要な負荷がかかっていないかの確認
RDBのWriterは、水平にスケールアウトができないので、極力無駄なリソースが流れてこないことを確認する必要があります。また、Writeで、重いSQLが流れていないかどうかというのも日々チェックして、余分な処理が動かない状態になっていることを確認します。
APMをうまく利用すると、DBホスト単位でSQLをリストアップすることができます。こちらのリストを、下記の単位で並べ替えることができるので
- 総実行時間が長い順
- リクエスト数
これらの大きいリクエストのトランザクションをチェックします。
例えば、実行回数も実行時間も長いSQLの一つをランダムでピックアップしてチェックして確認したトレースが下記のようなものだったとします。

こちらのSQLは、HTTPメソッドがGETのリクエストの際に発行されており、SQLも同一トランザクション内で、Select文のみであることはDatadogで確認可能です。こちらの一連のSQLは、Readerインスタンスで実行可能ではないかというものを開発側と確認して、修正依頼をしていくという感じの流れになります。これは、結構、手間がかかる作業になるために、現在は数カ月に1度くらいの割合で実施しています。
これらの作業によって、水平スケールアウトが可能なReaderインスタンスに負荷を逃がしていき、Writerは必要最小限な負荷になるようにしています。こういうチェックの自動化も進めていきたい部分ではありますが、現状は、手動のチェックで運用しています。Writeインスタンスは、スケール上限が存在するということを意識して、普段からその上限に達しにくくする仕組みを意識することが重要だと考えます。
Indexが適切に利用されていないクエリの確認
Database Monitoringを導入すると、実行計画ベースでの絞り込みが行えるようになります。こちらを使うと、1度のクエリでスキャンした行数の順に並べ替えることができるので、これはIndexであまり絞り込みができていないクエリとかなり近い結果になります。そちらを使って、Indexが適切に使われていないクエリを重点的にチェックするということを実施しています。

ここでも、実行回数が多いものほど、高負荷時に負荷をかける可能性が高いので、そこを中心に問題をなるべく多く事前に検出して、高負荷時にも問題が起こらないように日々チェックしています。
開発者やEmbedded SREとの定期的なミーティング
アソビューでの開発組織の中では、通常開発者と、SREに近いことが実施可能なEmbedded SREという役割があります。各開発チームで、インフラに近いことを実施したり、インフラ寄りの相談を気軽にしたりできるように、Embedded SREという役割が存在して、Embedded SREの方を通じながらSREとコミュニケーションを取って、日々のインフラの運用をしています。
安定的な運用のためには、開発者と日々の積極的なコミュニケーションを取っていくこともとても大事だと考えています。アソビューでは、週に1度の定例ミーティングを開き、下記のトピックスで情報を確認して、現在のインフラの状況を共有する場を設けています。
- SLOの状態の共有
- SLOの変化や動向を定点でチェックしてその結果を共有します。SLOの運用が正しく回っているかどうかを定期的に確認するとともにその結果をレポートとしてこの会議体で共有しています。
- 本番環境で発生した重大なアラートの共有
- 下記のような事象が本番環境で発生したら、それがなぜ起きたとか、どういう背景で起きたものなのかや、どうするのが良さそうかなどを開発全体に共有します。ここで共有することによって、他のチームで起こる可能性のある事象も未然に防ぐなどの効果を期待しています。また、それぞれの問題をこういう感じのPRで修正したなどの共有も実施します。
- OutOfMemoryの発生
- エラー件数が一定時間に一定以上発生
- スロークエリ
- DBのCPUの負荷急上昇
- 下記のような事象が本番環境で発生したら、それがなぜ起きたとか、どういう背景で起きたものなのかや、どうするのが良さそうかなどを開発全体に共有します。ここで共有することによって、他のチームで起こる可能性のある事象も未然に防ぐなどの効果を期待しています。また、それぞれの問題をこういう感じのPRで修正したなどの共有も実施します。
- セキュリティの動向
- アソビューでは、Contrast Securityというツールを使ってコードの脆弱性のチェックを実施しています。この結果を踏まえて、どういう脆弱性が新たに発生したかの情報を共有してセキュリティの啓蒙活動につなげています。
- 負荷トレンドについて
- 1週間の負荷トレンドについての共有と、今後の負荷の見込みを共有しています。また、インフラに過度な負荷がかかっていた場合については、どのような理由で負荷がかかったかなどの共有を行います。
- その他Tips型情報
- Datadogで新しくこういうことができるようになったとか、こういう使い方をしたらこういう問題を検出できるなど、可用性に間接的に関わるトピックスを紹介しています。例えば、DatadogのDatabase Monitoringを利用すると、インデックスが効いていないSQLを簡単に抽出できるようになるなどです。Datadogの通知機能をこのように利用すると、システムの異常に素早く気づくことができるなどの情報を発信しています。
- 社内のCI/CDなどのUpdate情報
負荷テストの実施
高負荷時の可用性を担保するためには、定期的な負荷テストを実施することが必要です。ここでは、アソビューにおける負荷テストの基本的な考え方を紹介していきます。
負荷テストの目的とゴール設計
アソビューでは、負荷テストを大きくは、下記の2つの目的で実施しています。
- 高負荷時に安定的に稼働することを目的としたもの
- システムの性能限界がどこにあるかを見つけることを目的にしたもの
前者では、一定の想定した負荷をかけ続けるテストを実施して、下記の部分に着目して問題ないことを確認します。
- 高負荷時もレイテンシが安定して稼働していること
- 高負荷時もエラー率が上昇することなく稼働していること
- 非同期の処理の遅延などが発生していないこと
後者のテストでは、想定負荷の5〜10倍程度の負荷をかけることによって、システムのどの部分がどの程度の負荷がかかったときに最初に異常な状態になるかというのを確認します。これにより、現在のシステムの将来的な性能限界がどの部分にあるかを事前に把握して対応し、将来の成長に備えることができるために、これを実施しています。
負荷テストの目標値の設定
アソビューでは、画面ごとやチケット種別ごとに負荷テストの目標値を定めています。チケットの販売などの負荷指標としては、1分間に何枚販売可能な性能があるかという軸で指標化しています。
基本的には、訪問者数の前年比をベースに実施する負荷テストの目標値を、下記の式で定めています。
(当年目標値)=(前年のピーク時の訪問者数)×(増加率)×(バッファ係数)
例えば、前年比の訪問者数が傾向上30%増加しているという状況の場合には、バッファを含めて
(当年目標値)=(前年のピーク時の訪問者数)×1.5
という感じで算出して、この値をベースに負荷テストを実施します。
さらに4〜10倍の負荷を少しずつ増やしながら、性能限界がどの点にあるのかというテストも実施します。
負荷テストの結果を振り返る
負荷テスト実施後の成果としては、
- 分間の販売数が何枚までは安定的に稼働可能かがわかる
- 分間の販売数が何枚を超えると、どのリソースが最初に問題になるか、そして、そのリソースが拡張する難易度はどうだったかを把握する
などがあります。
また、アプリケーションを改修すると、より負荷性能をこのくらい上げることができそうということもきちんと振り返ることが大事です。
インフラは、限りある資源と考え、少しでも有効活用して少ないインフラリソースでより多くの人のリクエストを受け付けられるように調整していくというのが何より大切です。
監視に利用しているツールについて
アソビューでは、監視にDatadogを利用しています。ツールは、デフォルトの設定でもそれなりに観測できますが、いろいろと設定をしていくことにより開発効率が格段に上がります。ここでは、アソビューでDatadogのどの機能をどのように利用しているかということと、監視ツールをどう活用していくべきかという点について記載していこうと思います。
利用している機能とそれをどう利用しているか
アソビューでは、主に下記の機能を利用しています。いろいろな機能を組み合わせてさまざまな角度からシステムを観測できるようにしています。
APM
Javaのエージェントを設置して、オンライン処理のトレース情報などを送信しています。こちらのデータを、SLOの策定やダッシュボードにも利用したり、トラブル時の状況確認やシステムの安定稼働などにも利用したりしています。
また、KubernetesのHPAを設定する際の元データは、こちらの情報を使い、KubernetesからDatadogの情報を取得して、リソース不足を検知してオートスケールするのにも利用しています。
ログ管理
ログ管理では、アプリケーションのログを取り込むのはもちろん、AuroraRDSのスロークエリなどのログもDatadog Fowarderを利用してDatadogに取り込んでいます。主な目的は、APMのデータとログを連動させて、APMのトレース情報に対応するログを結びつける設定をすることによって、調査時の効率を大幅に上げることです。
また、エラートラッキング機能というエラーの分析機能とAlertの仕組みを組み合わせて、エラー発生時に、エラーの重要度や発生具合によって適切な人に通知をするということを実現しています。これも主目的の一つです。
担当の割り振りなども、Datadogの設定上でタグやログの中身から適任者に割り振るという設定をAlertの中に組み込むことによって、より知らせたい人に通知するということを実現しています。
また、1週間で発生したエラーをサマライズするというのもエラートラッキング機能を利用することによって実施しています。
加えて、エラーの通知のノイズを発生させないためにも、エラーのトリアージなどを実施して、不要なエラーを取り除くなども実施する必要がありますが、それを支援する機能をうまく活用して、エラーをより精度高く通知するようにしています。
ContinuousProfiler
こちらの用途は主に下記となります。
- Java内部のパフォーマンスの悪い部分を効率的に探す
- OutOfMemoryなどが発生したときにどの処理に起因しているのかを特定する
- どの処理でCPUを利用しているのかなど、APMでは見られないより内部の情報のメトリックスを確認する
Database Monitoring
こちらの機能は、主に実行計画を確認するという目的で利用します。問題発生当時の実行計画が保存されているので、当時の実行計画を確認することによりSQLによるパフォーマンス劣化の原因を特定しやすくなります。
また、前述した通り、予防的な観点でも利用しています。1回のSQLあたりにどれくらいの行をスキャンしているかというのがSQLごとに平均値とともに表示できるため、適切にIndexで絞り込みができていないクエリを抽出するのに役に立っています。
Alert
各種機能とAlertを組み合わせると利用効果は抜群になります。Kubernetes上のイベントなどもDatadogに取り込むことができるので、例えば、Kubernetes上で、コンテナがOutOfMemoryでKillされたというような事象をSlackで通知するというのが簡単な設定で実現できます。
また、ログ機能とAlertを組み合わせると、ログの特定の文字列に反応して通知するということも簡単にできるため、再発防止などで監視を徹底するようなことを実施したいときにはとても役に立ちます。
Browser Testing
こちらは、外形監視をシナリオベースでしたいときに有用なものになります。アソビューのサービスがブラウザレベルできちんと動作できているかというのを主要なブラウザやモバイルなどの端末ごとにテストできるので、モバイル端末のみで表示が崩れるというような問題も簡単に検知することができるようになります。問題の発見の早期化にとても役立ちます。
監視ツールをどう活用すべきか
このような監視ツールは、いろいろな機能を使いこなしてこそ、価格に見合った効果が出るものだと思っています。おそらく、デフォルトの機能だけでは高価だと感じたとしても、いろいろな機能を目的に向かって設定して、それを使いこなすことによって、ツールにかかる投資対効果が高くなってくると思います。なので、ツールはベンダーとも相談しながら、深い機能まで使っていき、やりたいことをどう実現していくのかということを追求するのがいいと思います。
ツール選定の観点
また、やりたいことがきちんとできるかどうかというのがツール選定の観点となり、選定時
に、譲れない選定ポイントを細かく定めておかないと、結果的に使えなかったということはあり得ます。基本的に、どのベンダーも同じと思っていても、細かい部分でいろいろできないことがある場合もあります。例えば、「SLO作れます」と言っても、希望するSLO粒度によっては、できないということもあるかもしれません。なので、どういう粒度のSLOを作るのか、そのSLOはどうやって運用するから運用上どういう機能が必要そうかということは、事前にきちんと観点として持ったうえで、比較検討するのが良いと考えています。
最後に
本記事では、アソビューにおける運用の知見をいろいろと書いてみました。こちらを読んでいただき、少しでも皆様のお役に立てれば幸いです。






