



【内製開発Summit 2026】AI時代の内製開発を加速させるデジタルレジリエンス戦略
2026年2月25日、ファインディ株式会社が主催するイベント「内製開発Summit 2026」が、浜松町コンベンションホールにて開催されました。
本記事では、Splunk Services Japan合同会社 ソリューションズアーキテクチャ本部 Observability Solutions Architectの中上 健太朗さんによるセッション「AI時代の内製開発を加速させるデジタルレジリエンス戦略」の内容をお届けします。
セッションでは、内製開発で作り上げたサービスを「作った後」にどう支え続けるかという観点から、推測や経験に頼らないオブザーバビリティ駆動のアプローチの重要性が語られました。OpenTelemetryによるテレメトリーデータの標準化やコンテキストの整備、Splunkを活用したデータ相関分析、さらにはAI AssistantやAI Troubleshooting Agent、MCP for Splunkといった機能による問題調査の効率化まで、デジタルレジリエンスを実現するための戦略が紹介されました。

■プロフィール
中上 健太朗
Splunk Services Japan合同会社
ソリューションズアーキテクチャ本部 Observability Solutions Architect
外資系SIerでインフラエンジニアとしてキャリアをスタートし、システム構築から運用まで、オンプレミスからクラウドネイティブまで幅広く経験。2023年にSplunkに入社し、現在はオブザーバビリティ専門のエンジニアとして、Splunk Observabilityの導入支援や活用提案に従事している。OpenTelemetry MeetupやObservability Conference Tokyo 2025のコアスタッフとしても活動し、オブザーバビリティの実践と普及に取り組んでいる。
内製開発の核は「作った後」の運用にある
中上:本日はご参加いただきましてありがとうございます。「AI時代の内製開発を加速させるデジタルレジリエンス戦略」と題しまして、セッションを始めさせていただきます。
このサミットには、これから内製開発に取り組む皆様、あるいはすでに本格的に取り組み始めていらっしゃる皆様が多く集まっていらっしゃるかと思います。皆様が開発する事業の核となるようなサービスを、責任を持って提供し続けていく上で、様々な判断の連続になっていくはずです。ユーザー体験に問題が起きているのかどうかを正しく判断する必要がありますし、それに基づいて本番サービスをリリースすべきかどうかという判断を迫られる場面もあるでしょう。そういった判断を自信を持って行うにはどうあるべきなのか、今日はその点についてお話しさせていただきます。
Splunkはより安全でレジリエント(高弾力、高回復力)なデジタル世界の構築を目指す会社です。2024年からCiscoファミリーとしてサービスを提供しています。セキュリティ侵害に伴うビジネスの停止や大規模なシステム障害によるサービス停止を事前に防ぐこと、そして発生してしまった場合にもいち早く原因をつかんで元の状態に回復できるようにすること。そうしたレジリエントな状態を実現するためのソリューションを提供しています。

このサミットではいろいろなセッションで、ビジネスに貢献するためにどう迅速に内製開発に取り組むべきか、ベンダー依存をどう低減するか、人材育成や組織コミュニケーションをどうするかといった実践が語られていると思います。他方で、皆様が作る内製開発のサービスは、一度作ったら終わりではないはずです。むしろ作った後、サービスを運用していく時間の方が長くなっていきます。品質を維持し、場合によっては改善していく中で、どんなアプローチを取るべきなのか。トラブルが起きたときにどう対応してきたのか。こうした「作った後」の話は、これまであまり語られてこなかったように感じています。
AIにお任せしても解決しない「想定外」のトラブル
少し内製開発という文脈からは外れるかもしれませんが、私自身の経験を例にお話しします。仕事の性質上、お客様にデモ用のアプリを作って体験してもらうことがあるのですが、昨今はAIに要件を伝えれば効率的に作ってくれます。エラーが出てもAIにお任せして修正してもらい、一応動くものができあがります。
ところが、デモシナリオ通りに動かしてみるとうまく動かない。AIにエラーを伝えて修正を依頼しても、問題が解消しない。何度もやりとりを繰り返しても直らず、時間だけがどんどん溶けていく。そうこうしているうちに、なぜか直ったりするのですが、エンジニアの感覚としては「何もしてないのに壊れた」よりも「何もしてないのに直った」方が怖いわけです。案の定、翌日にもう一度試すとやっぱり直っていない。デモの期日も迫る中、うまくいかないとお客様や一緒に働くメンバーにも迷惑をかけてしまいます。
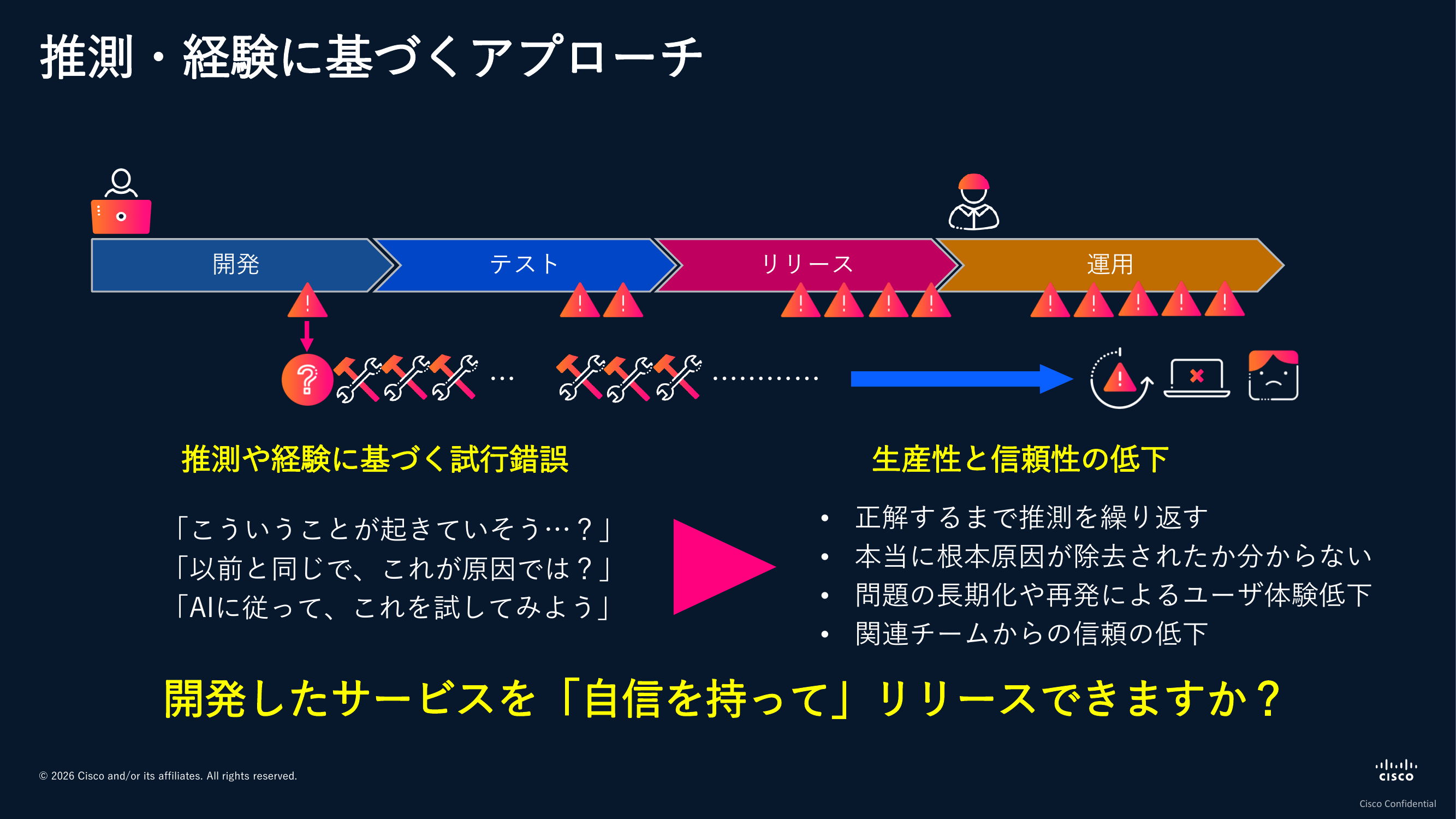
なぜこんなことが起きたかを考えてみると、結局のところ、発生した想定外の事象に対して推測と経験に基づいてただ試行錯誤を繰り返していただけだったからです。自分の経験や詳しい方の知見に基づいて対応する、過去のナレッジを参照してみる。もちろんこれで直るパターンもありますが、そのナレッジも外れることは往々にしてあります。正解するまで推測を繰り返すしかなくなり、根本原因が除去されたかどうかもわからないまま、別のタイミングで同じ問題が再発してしまう可能性も残ります。
問題解消までの時間が長くなれば、ユーザー体験は悪化しますし、チームや上司からの信頼も失います。本来開発したかった機能に手が回らなくなることもあるでしょう。こんな状態で、責任を持ってリリースしなければならないサービスを自信を持って提供できるかというと、なかなか難しいのではないでしょうか。
オブザーバビリティ駆動のアプローチへの転換
では本来やるべきアプローチはどうだったのかを考えてみると、システムがどんな状態になっていて、どこでトラブルが起きていて、その原因が何だったのかを正しく理解し、その理解に基づいてアクションや判断を取ることが重要だったはずです。これをオブザーバビリティ駆動のアプローチと呼んでいます。
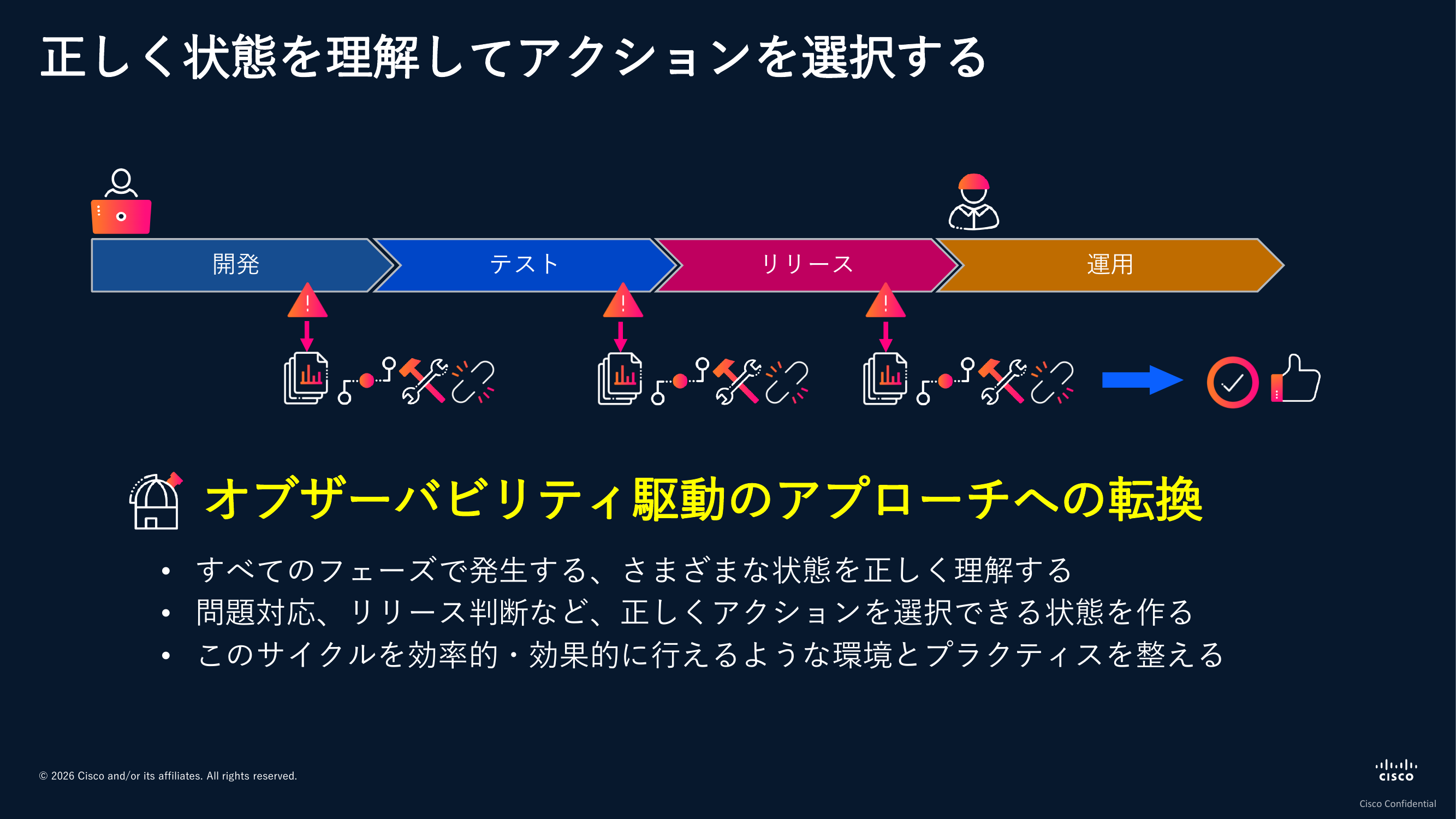
すぐ解消できる問題だからさっさと修正しよう、ユーザーにとってクリティカルだからリリースをやめよう、エラーが起きる可能性はあるが大きな影響は及ぼさないからゴーしよう。そんな判断が正確にできる方が望ましいわけです。
ただ、原因を分析しましょうと言うのは簡単ですが、じっくり時間をかけていられないのも現実です。こういったアプローチ自体をスムーズに実践できる状態を整えていくことが重要であり、それがひいては皆様のサービスがユーザーに信頼され続ける状態につながっていくと考えています。
オブザーバビリティという言葉は広く世の中に浸透してきました。オブザーバビリティは「システムがどのような状態になったとしても、どんなに斬新で奇妙なものであっても、どれだけ理解し説明できるかを示す尺度である」という定義で紹介されています。皆様のシステムが健全に動いているのか、どこかでトラブルを抱えているのかを知るためには、実際にアクセスしたユーザーの体感を知る必要がありますし、ネットワーク上で問題が起きていないか、アプリケーションやインフラ、データベースでエラーやパフォーマンスダウンの傾向がないかも把握しなければなりません。
テレメトリーデータの相関分析を支えるコンテキストの整備
こういったシステムの状態を理解するためのデータをシステムの外部に出力することや、そのデータ自体のことをテレメトリーデータと呼びます。こうしたテレメトリーデータを定期的に取得し、経時的に参照・分析できるようにすることで、システム全体に問題がないのか、あるならどこにあるのかを把握できるようになります。
データを集めて分析しましょう、という話をしているだけなのですが、実際に皆様はどこまで取り組まれているでしょうか。多くの方は何かしら実践しています。一番わかりやすいのは監視の仕組みです。データを集めて定期的に評価し、通知を飛ばすということを行っている。しかし、皆様のメールボックスには数万件の未読アラートメールが残っていたりしないでしょうか。アラート通知が飛んできても無視してしまっている。これは、監視という、データを集めて評価し異常を判断するという営みがうまくできておらず、信用に値しない通知を行っているということです。つまり、データを集めたけれども適切に扱えていないということです。
また、通知されたアラートを踏まえて、原因分析の際にデータを活用できていますかというと、やはり使い切れていないというお客様が多くいらっしゃいます。データはある、ダッシュボードもある、監視通知も設定している。でもデータは使えていない。なぜかというと、データを活用するための条件が整っていないケースがよく見られるからです。
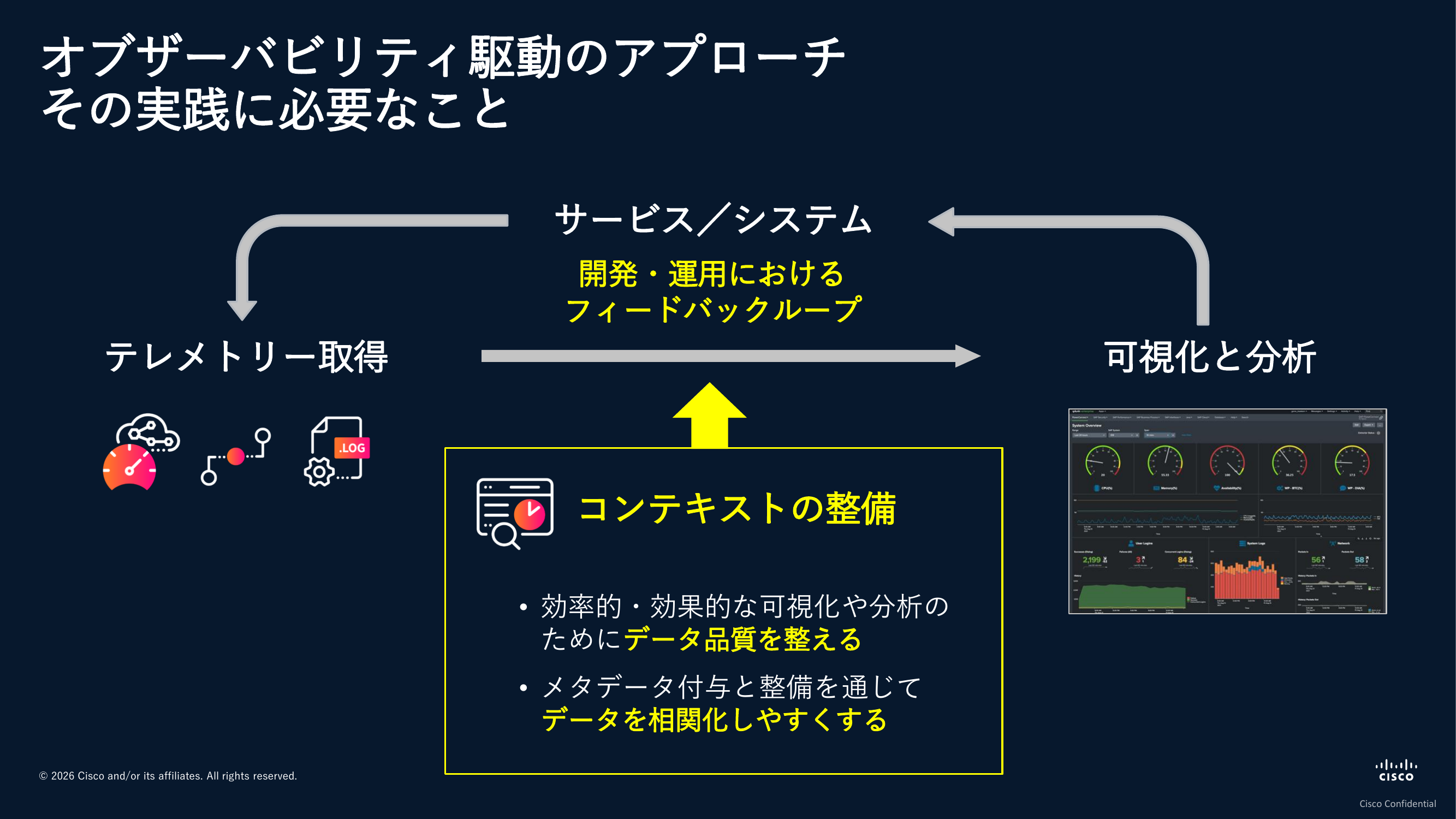
一つ一つのデータはあっても、それを関係づけて調査する手法がない。データに基づく状態の理解やアクションの選択を行っていく上では、コンテキスト、つまりデータを相関して分析できるようなメタデータを付与・整備することが重要になります。この部分に取り組みきれていないお客様はまだまだ多くいらっしゃいますし、これから内製開発に進まれる皆様におかれましては、プラクティスを変えるタイミングにぜひ意識を払っていただきたいと思います。
OpenTelemetryによるテレメトリーの標準化
こうした課題を克服することに取り組んでいるプロジェクトとして、OpenTelemetryがあります。Cloud Native Computing Foundationが推進しているプロジェクトで、テレメトリーデータを生成・収集・管理・送信するためのAPI、SDK、ツール群を提供しています。テレメトリーデータ自体を標準化することに取り組んでおり、OpenTelemetryのツール群に基づいてデータを扱えば、自然とメタデータが整い、分析しやすい状態になっていきます。

少し具体的な例をお見せします。それぞれOpenTelemetryに準拠したデータ形式の例ですが、左がメトリクスデータ(統計的な数値データ)、真ん中がアプリケーションの処理を記録したトレース、右側がログです。
一番上の部分を見ると、どのテレメトリーにも共通した内容が入っています。「プロダクション環境のapp-server-03で動いているorder-serviceというアプリケーションのバージョン2.1.4のデータ」というように共通化されているのです。メトリクスで/api/ordersの処理が滞留しているとわかれば、同じエンドポイントのトランザクション情報がトレースの中に埋め込まれています。同じキーとバリューが入っているので紐づけやすくなり、さらに同じIDで後続処理も追えます。そのIDをキーにしてログを拾ってくると、検証処理に30秒以上かかっていることが記録されている。
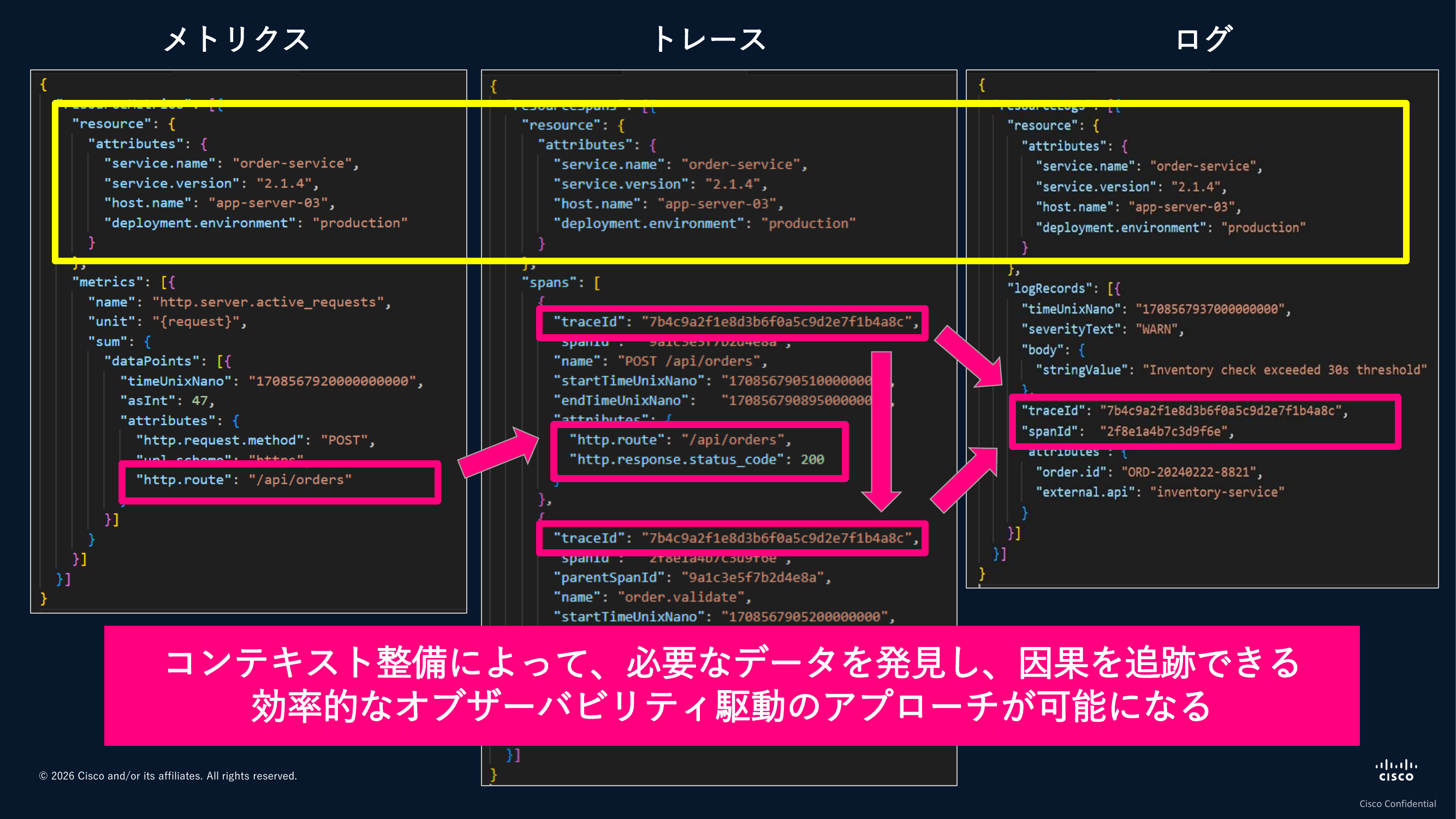
このように、データがそれぞれ独立したものではなく、データ間がきちんと分析で繋がっていく。因果を追跡しやすい状態を作れると、分析が格段にしやすくなります。OpenTelemetryというフレームワークに準拠しておくと、自然とこうした形のデータが整うということになります。
とはいえ、こうしたデータをそのまま人が目で追いかけるのは大変です。Splunkのような専用のオブザーバビリティプラットフォームを活用することで、データの相関分析がしやすくなり、システムを健全な状態に保ちやすくなります。
現実のシステム複雑性と非構造データへの対応
OpenTelemetryに準拠するサービスは広がりを見せていますが、必ずしもあらゆるすべてのシステムコンポーネントやサービスが対応しているわけではありません。皆様が運用管理されているシステムは、より複雑で、さまざまなコンポーネントから成り立っているはずです。CDNやWAF、ロードバランサー、物理的なネットワーク機器、本番サービスイン済みの関連システム、基幹システム、既存の運用ツール、外部のSaaSサービス。こうしたものが全部連携した形でシステムは動いており、全体が見えなければ健全性は判断できません。
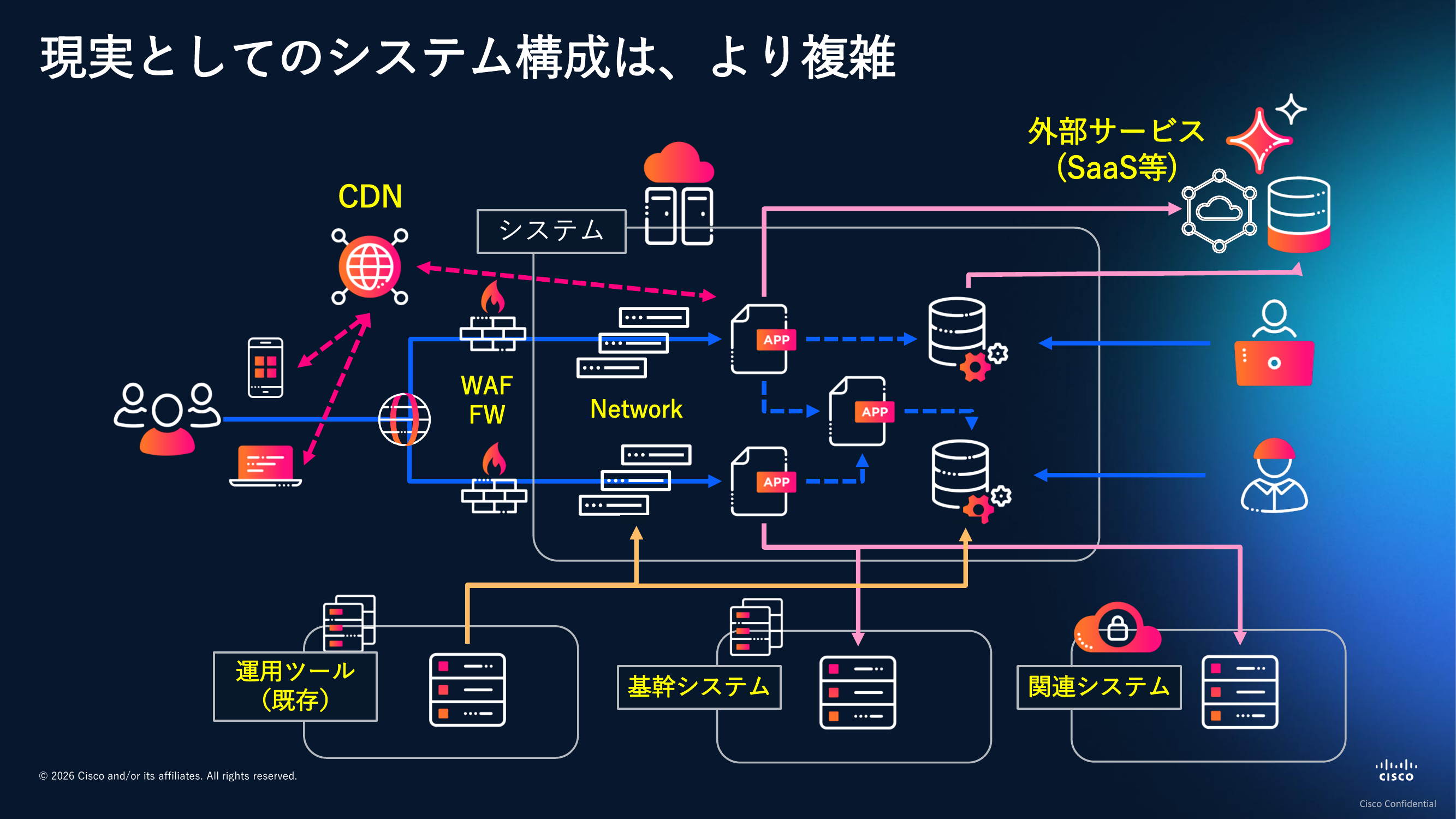
これを全部OpenTelemetryでカバーできるかというと、残念ながらいろいろな制約事項が出てきます。外部サービスや商用製品が出力するログは独自フォーマットになっていて、それぞれまったく異なる形式でデータが記録されています。
こうした標準化のフレームワークに乗り切れないデータを正規化できないという現実的な悩みがあります。加えて、既存システムの運用を変えたくない、変更を加えられないというケースもあるでしょう。現実に存在する「標準化が難しい世界」を扱うための工夫や仕組みが欠かせません。
一般的には、生成されるログを分析の際にどう使うかを事前に想定して加工処理を施し、分析基盤に取り込むことが必要になります。いわゆるETL処理ですが、データ量や種類が増えるほど都度ETLを組み込むのは負担が大きくなります。
Splunkの場合は、データを取り込んだ後に加工する機能を提供しています。任意のフィールドを設定したり、異なるツールが出力するログのメタデータを自動的に正規化したり、グルーピングしたりといった基盤機能を活用しながら、データが相関しやすい状態を作っていくことが可能です。
データ品質がAI分析の精度を左右する
コンテキストを整えておくことは、人が分析する上でも重要ですが、AIにデータを渡して分析させるという場合においても効いてきます。AIエージェントはユーザーのリクエストに対応したツールを呼び出し、データを参照して解釈を加え、回答を返すという処理をしています。データがいろいろなところに分散して置かれていれば、その都度ツールを呼び出してデータを取得することになり、トークンの消費量が増えて推論精度が落ちてしまいます。
同じプラットフォームにデータを置いたとしても、データが構造化されていなければ、必要以上のデータを参照してつなぎ合わせてしまい、構造化されている場合と比較して推論精度は下がります。つまり、データプラットフォーム上でデータを相関できる状態にしておくことで、エージェントの回答精度を高め、トークン消費も抑え、効率的にAI分析できるようになるということです。
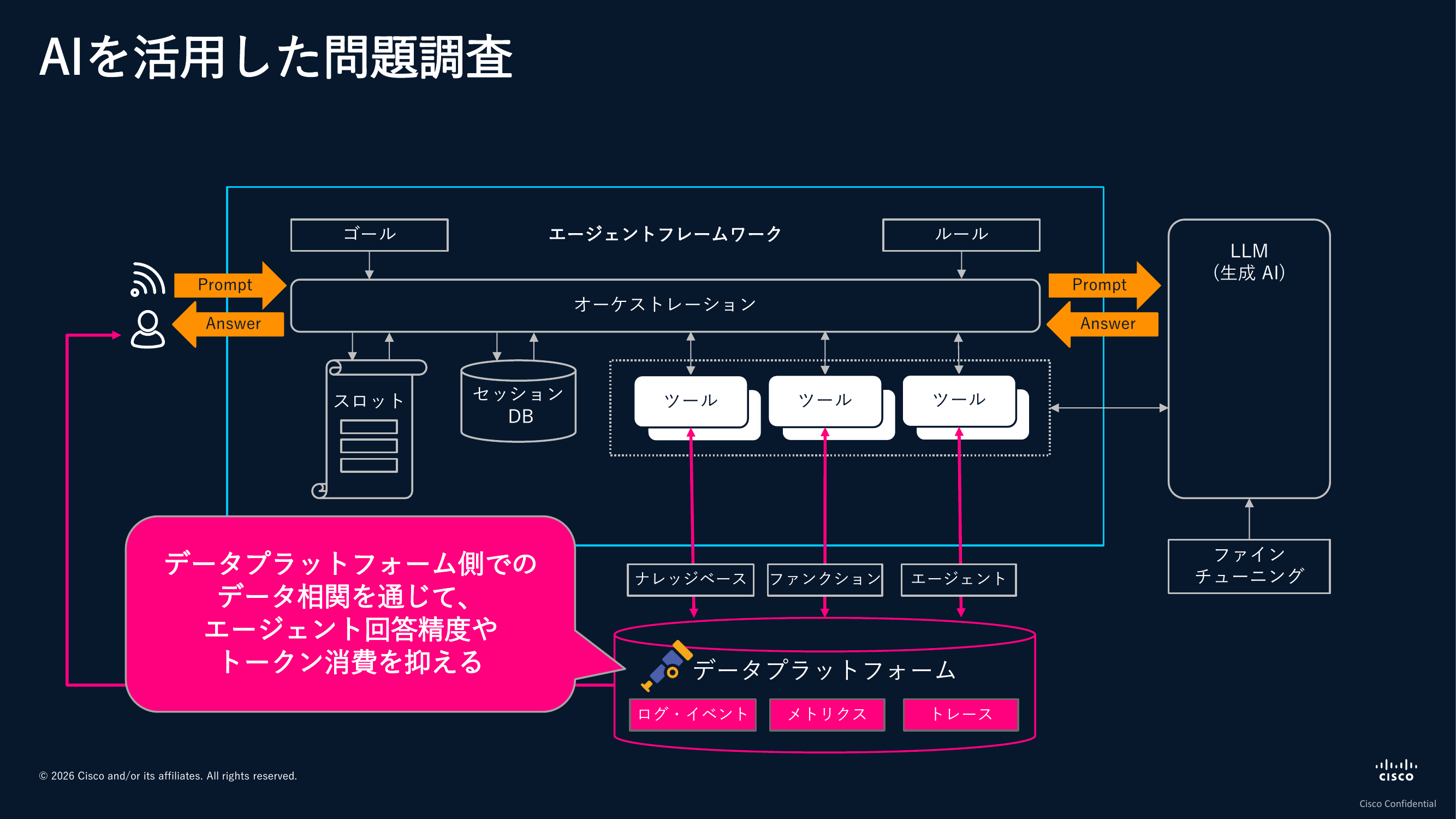
ここまでのまとめとして振り返ると、皆様が内製開発を通じて事業の核として作り上げていくサービスを、自信を持って維持・改善し、支え続けていくには、オブザーバビリティ駆動のアプローチが重要です。そして、このアプローチを効果的・効率的に実践するためには、計測と可視化・分析を支えるコンテキストの整備や、業界標準フレームワークであるOpenTelemetryへの準拠が鍵となります。こうした取り組みを通じてデジタルレジリエンスを実現していくこと、すなわち問題や想定外の事態にもすぐに健全な状態に回復できる能力を備えることが、皆様の運用業務や開発業務をスムーズにしていくことにつながります。

Splunkが提供するオブザーバビリティとAI機能
Splunkはオブザーバビリティとセキュリティの統合プラットフォームを提供しています。皆様のビジネスに大きな影響を及ぼすような事態は、システムの大規模障害か、セキュリティインシデントの発生によって引き起こされます。その両面にアプローチできる基盤を提供しているのが特徴です。
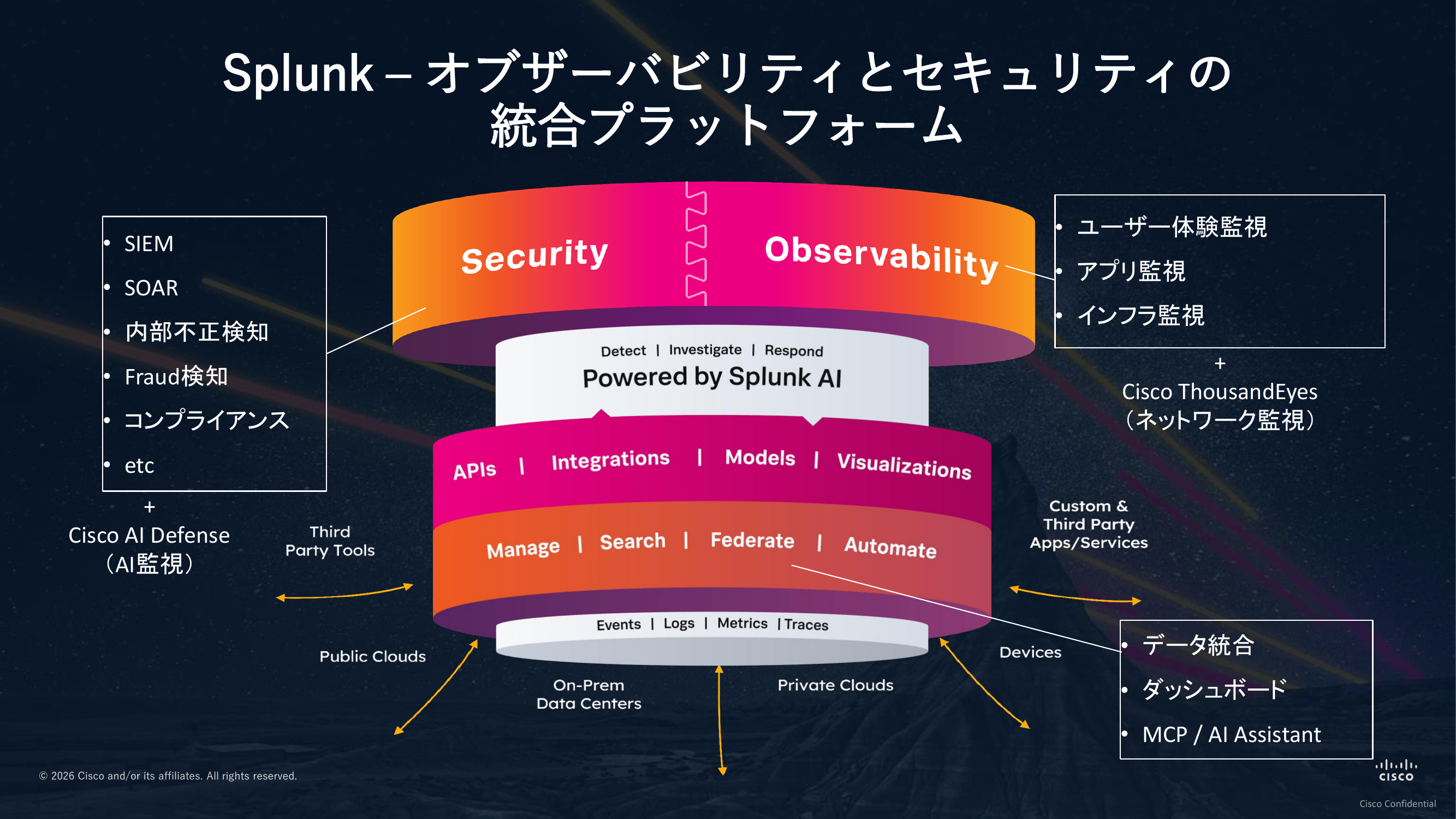
本セッションでOpenTelemetryに言及しましたが、SplunkはOpenTelemetryネイティブなオブザーバビリティプラットフォームを提供しています。長年にわたりOpenTelemetryプロジェクトに大きく貢献していることからも、この点をご理解いただけるかと思います。

データをSplunkに取り込んでいただければ、最初から使えるダッシュボードを用意していますし、分析用やモニター投影用のリッチなダッシュボードも構築可能です。もちろん可視化するだけではなく、そこを入口にして、データを効率的に分析できる仕組みも整えてあります。
アプリケーション間でどこからどこにリクエストが流れ、どこでエラーが起きているのかをサービスマップ上で視覚的に把握できるようになっています。エラー率が上がっているサービスが真っ赤にハイライトされるので、そこから調査を始めることができます。
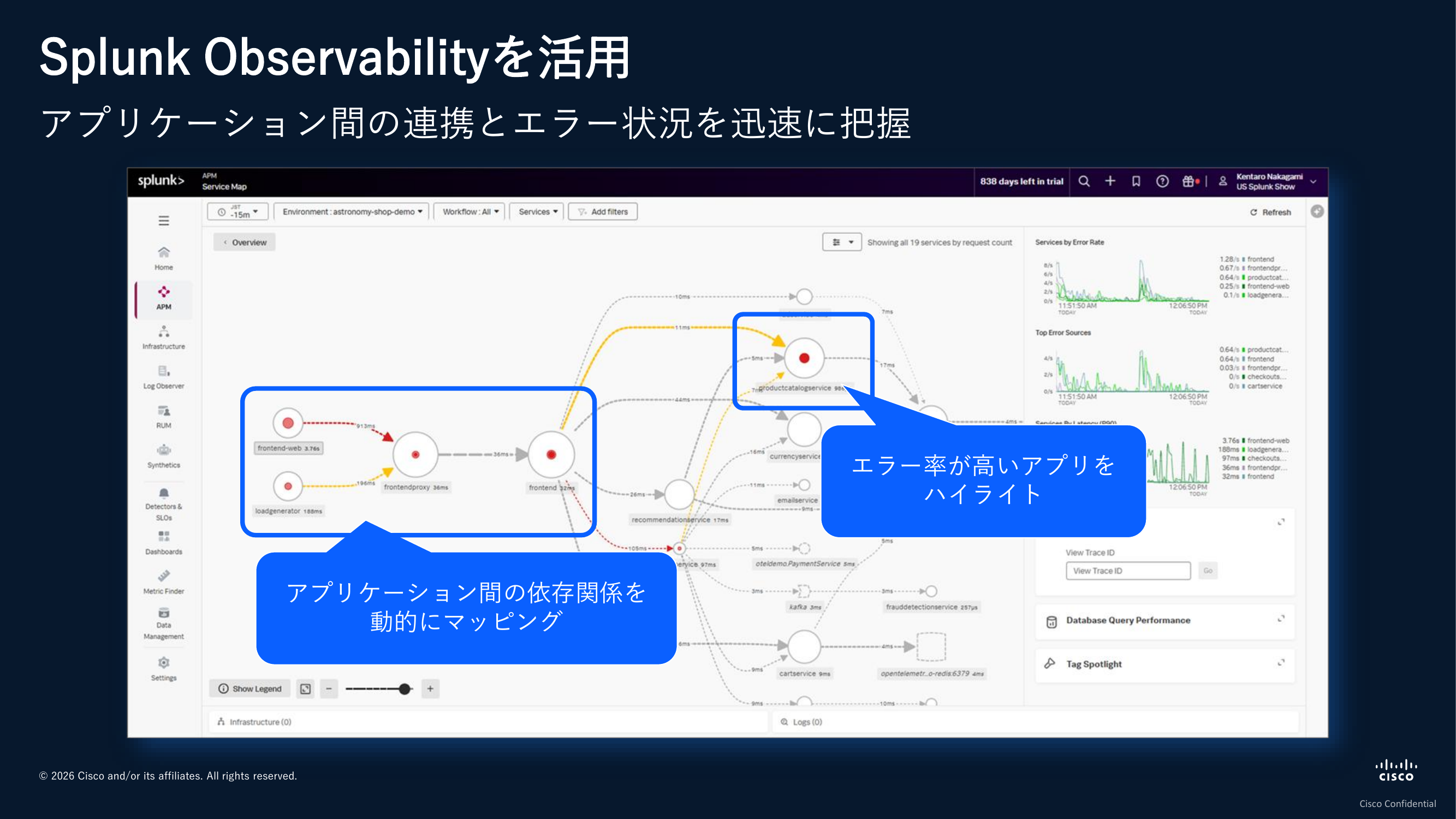
サービスマップの中でアプリケーションのバージョン別やリージョン別に動的に分解して、エラーの傾向を理解するといったこともできるようになっています。マップ上でエラーになっているものを見つけたら、そこからトレースの詳細を開き、ステータスコードやエラーメッセージの確認、関連するコンテナのリソース情報へのジャンプ、関連ログの抽出といった深い原因調査へと進んでいけます。

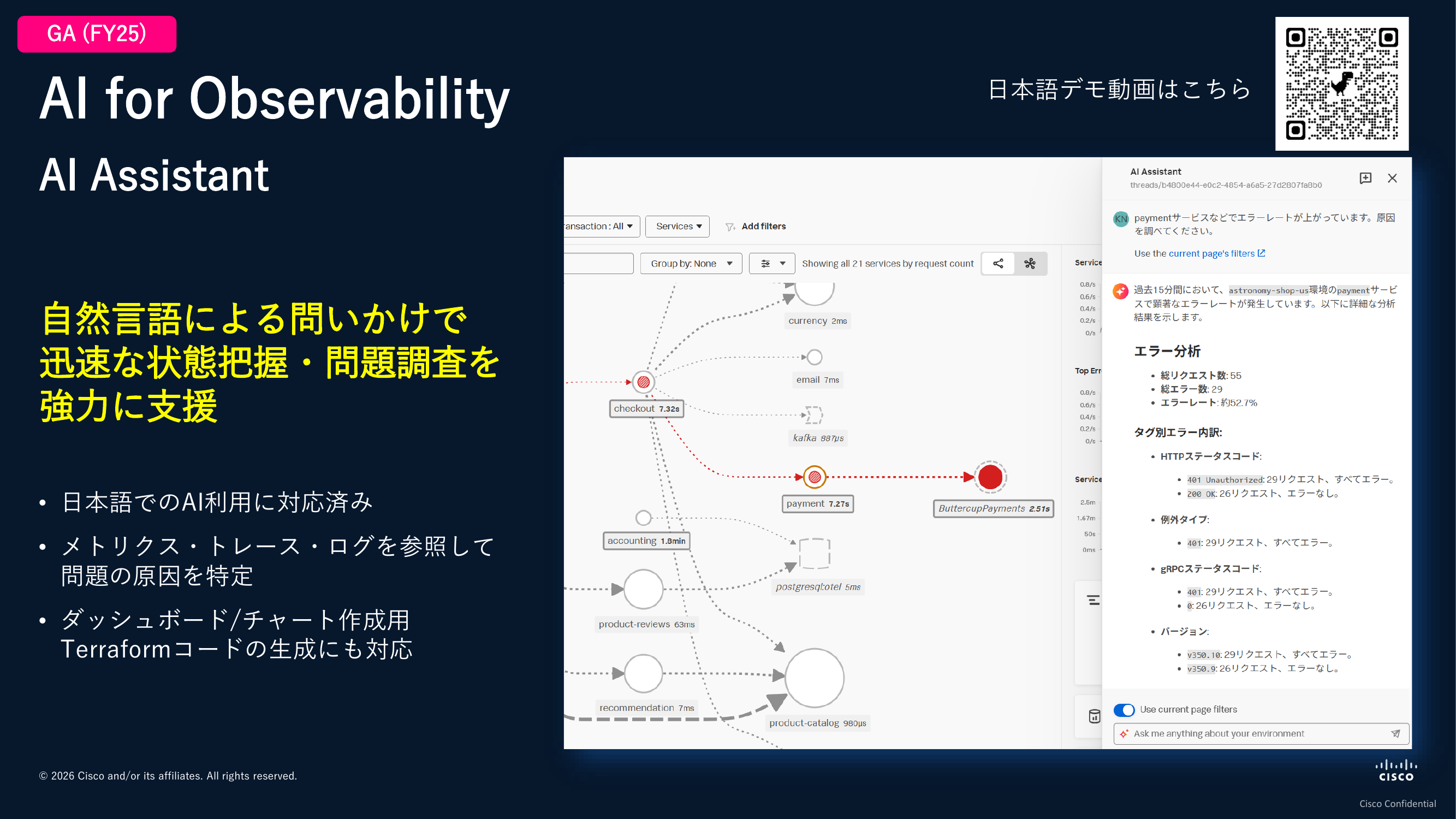
こうした分析をさらに簡単に実施できるようにするために、昨年リリースしたのがAI Assistantというサービスです。自然言語で問いかけをして、問題調査をAIに任せることができます。メトリクス・トレース・ログを参照して問題の原因を特定するほか、ダッシュボードやチャートの作成、Terraformコードの生成にも対応しています。日本語での問いかけにも対応しており、日本のお客様にも多く使っていただいています。
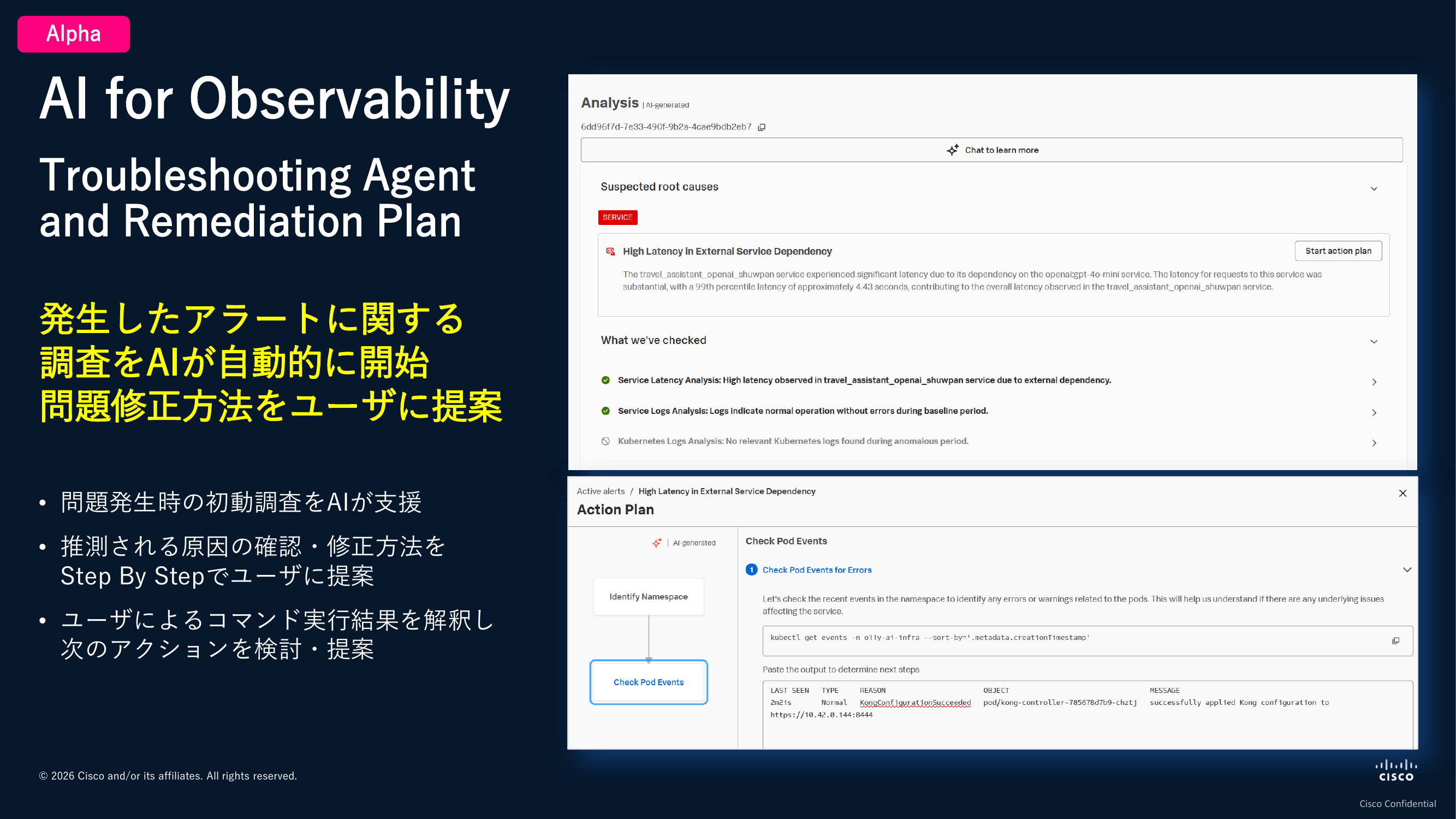
加えて、現在開発中でまもなくリリース予定のAI Troubleshooting Agentという機能では、通知されたアラートに含まれるリンクをクリックすると、Splunk ObservabilityのWebページが立ち上がり、その時点でAIが自動的に問題調査を開始して原因の推測結果を教えてくれるというものです。
AIが推測した原因が正しいかどうかを確認するために、コマンドを実行してその出力を貼り付けるよう指示してくれます。その結果を解釈して、次のアクションをステップバイステップで提案してくれる仕組みになっています。
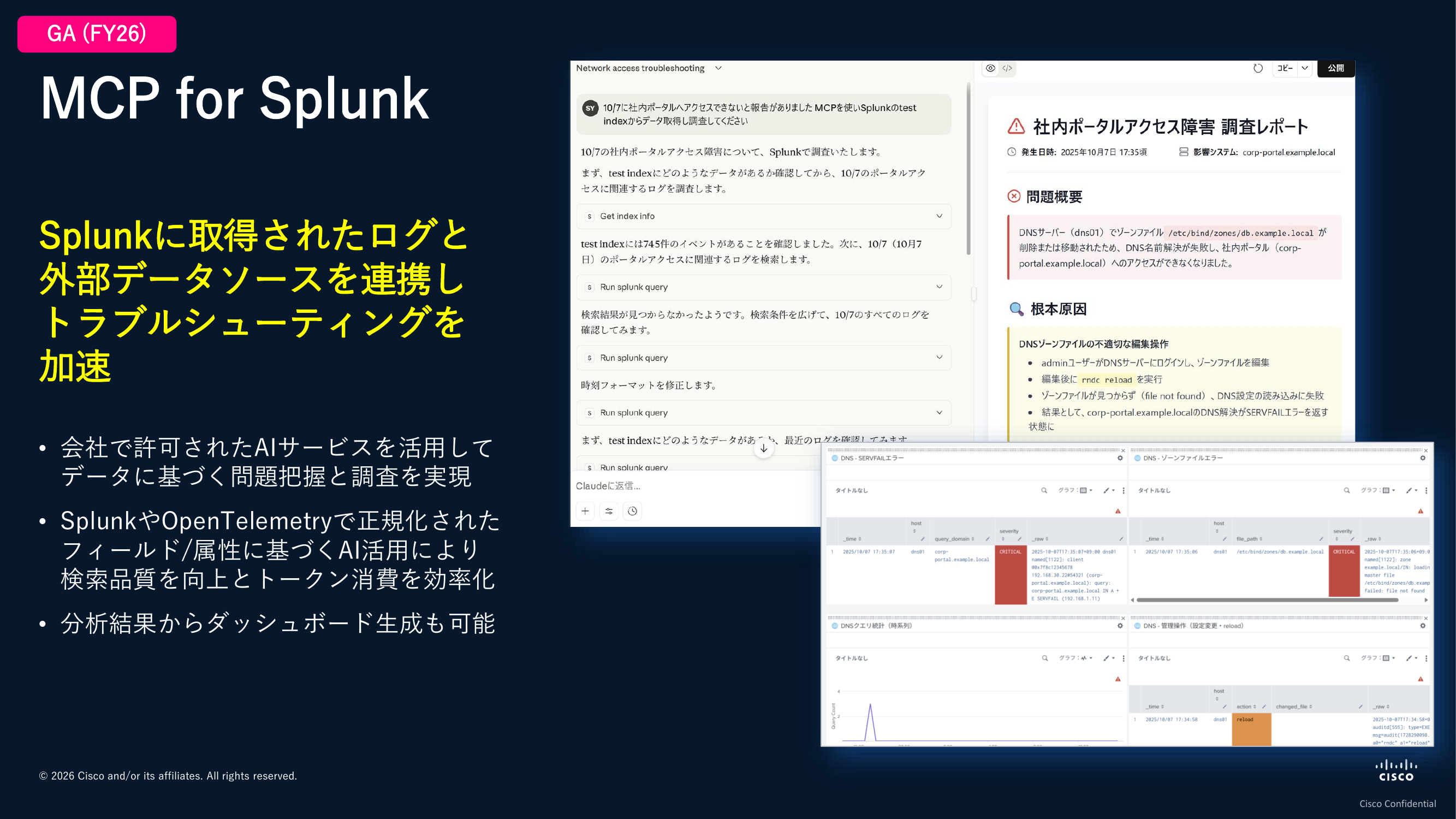
Splunkに蓄えたデータ以外のものも参照しながらAIに分析させるためのMCPの機能も提供を始めています。いろいろなコラボレーションツールや外部データソースを含めて、汎用的なAIサービスの頭脳と組み合わせて活用いただけます。ここで強調したいのは、AIがすごいという話をしたいのではなく、OpenTelemetryやSplunkといった基盤を通じてデータが整っている状態、コンテキストが整備されている状態であるからこそ、AIが分析しやすい状態になっているのだという点です。
AI Assistantでトリアージ時間を50%削減した導入事例
AI Assistantを実際にお使いいただいているお客様の事例をご紹介します。アメリカのRepayという企業は、年間250億ドル規模の決済をつかさどるプラットフォームを提供しています。本番アプリケーションで発生した問題に対してAI Assistantを活用し、対処すべき問題がどれかを判断するトリアージまでの時間を50%削減できたとのことです。AI Assistantが分析をしてくれるので、すべてのアプリケーションのエンドポイントを全部調査したり、すべてのアラートを全部チェックしたりする必要がなくなったというコメントをいただいています。

もう一つは国内大手企業のお客様です。Web/販売店向けサービスや契約管理など、自社事業の運営に関わるサービスを内製で開発・運用されています。
こちらのお客様では開発フェーズからSplunk Observabilityを活用し、OpenTelemetryベースの計装を採用しています。開発およびテストフェーズの段階からAI Assistantを適用いただいている事例です。

アプリケーション開発の中では、本番相当のリクエストを長時間流し続けるロングランテストを実施されるケースが多いと思います。夜間も含めて処理を流し続け、夜間に発生したエラーを翌朝にまとめてチェックする運用をされていたのですが、大量のアラートを一通りチェックするのに1時間ほどかかっていたそうです。
AI Assistantにサマリーをさせて、特に問題になりそうなものについては原因分析まで実行させる形にした結果、毎朝のエラー調査時間を15〜30分まで短縮し、50〜75%の削減を実現されました。データを整えてSplunkに蓄えていただければ、こうしたサービスを活用して皆様の内製開発を支えていくことができると考えています。
デジタルレジリエンスを高め、サービスを支え続ける

皆様がこれから開発していく、あるいは今開発されている事業の核となるサービス。これをユーザーから信頼を得られるものとして支え続けていくには、オブザーバビリティ駆動のアプローチが必要です。推測や経験ではなく、データに基づいて状態を理解し、アクションを選択する。様々な判断を要する場面において、正しく状態を理解して自信を持って対応できるようにしていくためのアプローチです。
このアプローチの効率性や効果を高めていくためには、データの品質が鍵を握ります。データを構造化して、データ間を相関づけられるような形でメタデータを整えていく。そのために業界標準フレームワークであるOpenTelemetryを採用したり、Splunkのようなデータ構造化に長けたプラットフォームを活用いただくことが重要です。それはAIを活用する文脈においても同様です。
こうした取り組みを通じてデジタルレジリエンスを高めて、問題や想定外に強いサービス、それを支えるプラクティスを定着させていくことが大切だと考えています。弊社は皆様のデジタルレジリエンスを高めていく内製開発のパートナーとして、サポートさせていただきたいと思っております。
本日はご清聴いただきまして、誠にありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
内製開発Summit 2026
※動画の視聴にはFindyへのログインが必要です。





