



【開発生産性カンファレンス 2025】 AIエージェントが変える開発組織のEnabling
2025年7月3、4日に「開発生産性Conference 2025」がファインディ株式会社により開催されました。
生成AIの進化に伴い開発組織のあり方が変わりつつある中で、3日に登壇したバクラク事業部 CTOの中川 佳希さんは「組織のあり方や手法をアンラーニングするタイミングは、まさに“今”なのではないか」と語ります。AIを活用する上で開発組織、エンジニアに求められているものは何なのか? 開発ドキュメント管理の改善や新たな検索ツールの導入といった同社の取り組みについてもご紹介いただきました。
■プロフィール
中川 佳希/@yyoshiki41
株式会社LayerX
執行役員 バクラク事業 CTO
2020年6月にLayerXに入社。バクラク事業の立ち上げからエンジニアとして携わり、技術と事業の両面から開発に取り組む。その後、プロダクトチームのテックリードを経て、開発組織を支援するEnabling Teamを組成。2024年1月にバクラク事業部 CTOに就任し、現在はAIエージェントの活用を推進しつつ、開発組織のEnablingや技術戦略を通じて、事業成長に取り組んでいる。趣味は車とラジオを聴くこと。
「with AI」で開発生産性を上げられるのか?
中川:株式会社LayerXの執行役員バクラク事業CTOを務める中川が登壇させていただきます。私は2020年にLayerXに入社し、AI SaaS「バクラク」の前身プロダクトの開発から携わってまいりました。2021年にプロダクトのテックリードを務め、2022年からはプロダクト横断の開発組織であるイネーブリングチームに所属し、昨年1月にバクラク事業のCTOに就任して現在に至ります。
会社としては、今年の4月に行動指針を「Bet AI」に更新しました。AIを10年に一度のパラダイムシフトと捉え、この未来にBet(賭ける)していくことを掲げています。AI Coding Meetupなど、開発者のコミュニティおよび組織の運営も行っています。
それでは、本題に入ります。 2025年はエージェント元年と言われています。

AIコーディングは、人間のアシストとしてのコード補完から、より自律的にコードを書くエージェントへと変化してきました。人間がゼロからスクラッチでコードを書く時代は終わりを迎えていて、コーディングはエンジニアにとって全く別の仕事になったと言えるでしょう。しかし、それはエンジニアの仕事がなくなることを意味するものではありません。現行ツールの延長線上で、エンジニアがいなくなる世界とは、まだ大きな距離があります。
現在普及しているAIコーディングは、Chat-Oriented Programming(以下、CHOP)と一部で呼ばれていて、チャット形式でLLMと反復的なやり取りを行いながらコードやプログラムの完成を目指すプログラミングです。ChatGPTに端を発するLLMとの対話形式が、現在では主要なプログラミングスタイルとして普及していると思います。上図に載っているツールでも、チャット形式でLLMとやり取りをしながらプログラミングをする形をとっています。
CHOPは、コード検索・AIコーディングツールを開発するSourcegraph社で主に使われている言葉ではありますが、個人的にはVibe Codingよりも現実の業務をより反映しているものだと考えています。
プログラミングがチャット形式で行われるようになり、働き方は大きく変わりましたが、「vs AI」ではなく「with AI」が最も重要だと思います。この破壊的な技術に対し、拒否反応を示したり悲観したりするのではなく、組織のあり方や手法をアンラーニングする必要があると思います。そのタイミングは、まさに“今”です。
「The Future of Human vs AIーit’s human(junior) with AI.」
これは、ジュニアエンジニアがいなくなるのではないかと一時期騒がれた際に書かれたブログ「Mastering AI at FAANG: A Roadmap from Junior to Senior Engineer」の中で用いられた言葉です。ブログではジュニアに焦点が当てられていますが、より広義のエンジニアに当てはまるのではないかと考えています。
AIエージェントはデジタルな労働力として捉えられており、自律的にタスクを遂行し、目的を達成するシステムと定義されています。これは、人間が判断して行っている多様なユースケースを自動化できる可能性を示しています。
ここで「AIエージェントで開発生産性は上がっているのか?」という問いが浮かびます。
「Writing is easy,reading is hard」
これはサヒール・ラヴィンギア氏がXにポストした言葉です。
この言葉には余白がありますが、同じ感覚の人も多いのではないでしょうか。ボトルネックが単にコーディングだったのであれば、CHOPに代表されるような解消に向かっているはずです。ただし、生成されるコードの品質は依然として課題です。
開発生産性向上という点で、実装フェーズ、いわゆるインプリメンテーションにおいては部分的に肯定できます。しかし、全体パイプラインで見ると、実装のみでは価値がありません。デリバリーからカスタマーサクセスを達成し、最終的なアウトカムにつなげる必要があります。つまり、全体パイプライン上での出力を測る必要性、もしくは単純なプルリクエストによるコード変更やリリース回数では測れないことを意味しています。
SaaS企業では、従業員1人当たりARR(年間定期収益)が生産性指標や健全性の把握によく使われることがあります。一般的にマジックナンバーとして用いられるのは、従業員1人当たりARR1500万円、つまり1人当たり1500万円の売上が立っている状態です。AI活用で生産性がさらに向上すれば、この基準値もさらに上がることが予想されます。ただし、ARRは反映されるまでに時間がかかるため、リカーリングレベニュー(継続的な契約で発生する定期的な収益)自体が長期的な指標である点に注意が必要です。
全体最適の観点では「何をつくり、提供するか?」「成長可能な品質をどう保証するか?」といった、コーディング以外の問題でも生産性を上げなければ、ボトルネックが他に移っただけで別の課題が残ってしまうと思います。
バクラクが取り入れている「チームトポロジー」戦略
中川:バクラクにおけるイネーブリングと、これまでの取り組みをご紹介します。
バクラクの開発組織は、チームトポロジーに基づき、4つのチームに分かれて開発を進めています。

ストリームアラインドチームは、特定ビジネスドメインにおいて、一連のフローを担当します。このチームは基本的にプロダクト単位で、2~5人で構成されています。
私が所属していたイネーブリングチームでは、ストリームアラインドチームとコラボレートし、開発の障害を取り除き、システムや組織に必要な機能の発見とその技術の伝搬を担うと定義しています。
コンプリケイテッドサブシステムチームは、専門知識を要するAIやMLの開発・運用を担っています。バクラクではファイルの処理を多く扱っており、AI-OCRなど強みとなる機能は、このチームが開発しています。
プラットフォームチームは、デリバリーを加速するための社内サービス(X as a Service)を提供するチームで、SREや認証認可基盤を開発するメンバーなどが所属しています。
これらストリームアラインドチームと3つのチームが連携しながら開発を進めるのが、チームトポロジーにおける定義です。
ストリームアラインドチームがビジネスドメインに集中できる環境を構築するため、プラットフォームチームは共同でコラボレーションを進めます。コンプリケイテッドサブシステムチームは、XaaSとしてストリームアラインドチームが利用できるサービスを開発・提供。そして、イネーブリングチームが新しい仕組みを可能にし、それを伝搬する、という構造をとっています。
チームトポロジーの背景にある認知負荷理論についても触れてみたいと思います。認知負荷理論は、人間の認知能力には限界があるとした上で、情報処理の効率性を高めるために認知負荷を管理してデザインするための理論です。
基本的にチームトポロジーでは、ストリームアラインドチームの認知負荷をいかに下げられるか、そのために3チームがどのように協業していくか、が主体となります。
人間の認知モデルに関する3つの用語「長期記憶」「ワーキングメモリ」「認知不可」についても説明します。
「長期記憶」は、長期間にわたって情報を保存するスペースで、容量に制限はありません。定着すれば無意識的に利用できるものです。
「ワーキングメモリ」は、認知活動中に情報の保持と処理が同時に行われる一時的なスペースで、長期記憶の容量とは異なり、有限で貴重なリソースです。この限られた容量を効率的に使用することが、学習や生産性において重要とされています。
「認知負荷」は、情報を処理する際にワーキングメモリを消費する負荷で、下記の3種類に分類されます。
①課題“内”在性負荷
学習対象そのものの複雑さや困難度によって生じるもので、変化させることはできない
②課題“外”在性負荷
学習対象とは直接関係のない認知負荷で、ワーキングメモリの容量を消費する要因となるため、最小化すべき
③ 学習促進負荷
長期記憶の知識構築に役立つ認知負荷で、生産的な意味を持ってワーキングメモリのリソースをさくことが求められる。ワーキングメモリから課題外在性負荷と課題内在性負荷を引き、残された容量が割り当てられる最大値と仮定される
開発における3つの認知負荷の例として、ストリームアラインドチームが送金システムの構築を目指すケースをご紹介します。
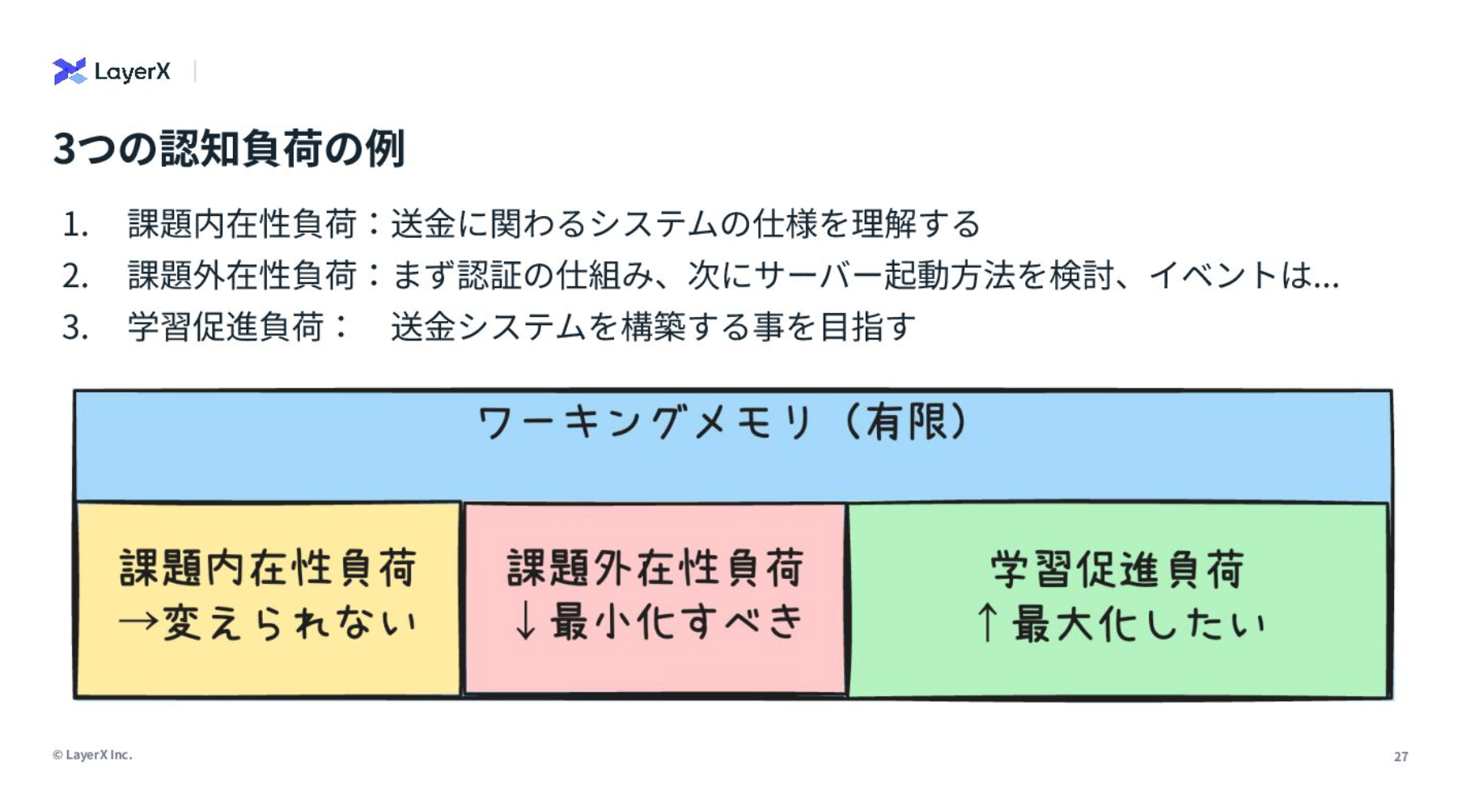
黄緑色の部分は学習促進負荷で、ストリームアラインドチームが学習を通して達成したいものです。
ピンク色の課題外在性負荷は、開発に必要な認証の仕組み、サーバーの起動方法の検討、イベントアーキテクチャの構築方法など、直接的な送金システムの構築には不要な認知負荷です。
黄色の課題内在性負荷は、送金システムにかかる仕様を理解する部分です。この複雑性は、変えることができません。
ストリームアラインドチームが開発に集中できる環境をつくるために、イネーブリングチームは課題外在性負荷を最小化して取り除き、開発者のワーキングメモリが、よりドメイン内での開発に最大限当てられることを目指します。具体的には、新たな仕組みや技術の導入、技術的な意思決定のサポート、複雑な技術課題への対処などを行います。
イネーブリングチームの具体的な取り組みは、昨年の「Developers Summit」で登壇した際の資料「ビジネスドメインの拡大を実現するバクラクシリーズでのモデル開発」にまとめております。要約は下図の通りです。
カット部分
AIコーディングにおいて考えるべき認知負荷とは
中川:チャットインターフェースから誰でもコーディングを始められる状態にはなりましたが、自然言語の指示から期待通りのコード出力を得て理解するには、まだまだ能力と技能が求められると思います。
AIは便利ですが、開発者が入力したプロンプトから期待しない値や認知できないコードを生み出すなど、簡単に課題外在性負荷を増幅させる可能性があります。開発者自身でステップや出力をデザインしないと、ワーキングメモリを簡単にオーバーしてしまうでしょう。
ワーキングメモリから溢れた状態では、学習対象にリソースをさけなくなってしまいます。その結果、複雑なことの理解が困難になったり、能動的に処理するための動機付けやモチベーションが失われることも起きたりします。
ここで必要になってくるのが、開発者によるAIのイネーブリングだと思います。課題外在性負荷を最小化する意識は、個人の開発者レベルにおいても重要度が増しているのではないでしょうか。
AIへのインプットとして、暗黙的な仕様が隠されていないか、データ表現に決められたスキーマが与えられているか、既存の振る舞いを壊すようなコードをAIが出力していないかなど、気をつける点は多岐にわたります。
AIコーディングでシェアされている「まずプランを立てさせる」「『振る舞いの変更』と『構造の変更』を分離して行う」「テストから始めてガードレールを敷く」といったナレッジは、課題外在性負荷の最小化の理に適ったものが多いです。
▼詳細
AI Coding Meetup #2 を開催しました #aicoding
https://tech.layerx.co.jp/entry/2025/06/16/114735
学習を妨げ、課題外在性負荷を上げるアンチパターンもあります。
課題外在性負荷は、目的に関係しない複雑性以外に、ストレスやマルチタスクといった状況も含まれます。人の脳は、コンピューターのように複数のCPUに情報を分散させて並列処理する機能は備わっておらず、実際は逐次でしか情報を処理できません。人間がマルチタスクをこなせていると感じていても、実際は複数のジョブを細分化して入れ子にして処理しているに過ぎず、これは並列処理ではありません。その状態では、常にコンテキストスイッチが頭の中で動いています。
AIコーディングは、自分の工程を話しながら開発を行えるため、簡単に実装並列数を上げることができるものの、開発者に深い思考(ディープシンキング)が求められるタスクや学習とは相性が悪いです。本質的に考えるべきタスク以外で、ワーキングメモリが溢れる可能性があります。
AIコーディングにおけるイネーブリングと取り組み事例
中川:CHOPに求められる能力や技能は大きく3つあると思います。

3番目のスキルは、CHOP以前から求められている重要なソフトウェアエンジニアのスキルだと考えています。
ここで、コンテキストエンジニアリングについて説明します。コンテキストエンジニアリングは、プロンプトエンジニアリングを包含する概念です。プロンプトという入力情報だけでなく、文脈や前提条件、その順序と量までも設計対象とするエンジニアリングです。ここも新たにイネーブリングが必要とされるエンジニア領域だと考えます。
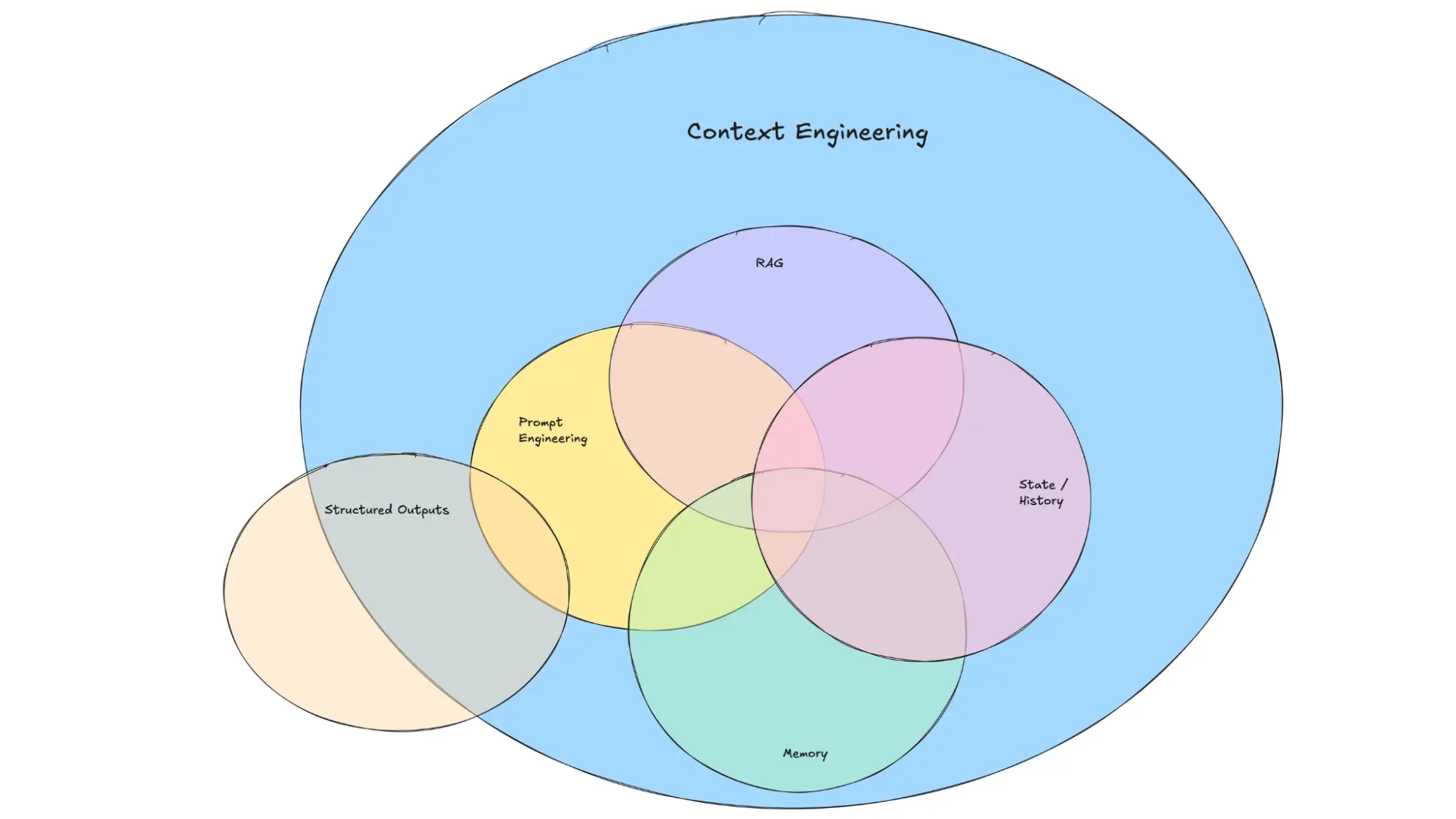
https://www.promptingguide.ai/guides/context-engineering-guide
また、AIコーディングを進める上で、AIが落とし穴にはまることがよくあります。複雑性の高いプロジェクトでは、プロンプトを繰り返し変更しても期待に応えてくれないこともあります。さらに、それを続けると、指示達成のために既存の振る舞いを壊したり、ハルシネーションを起こしたりすることもあるでしょう。
開発者がAIを落とし穴から救うためには、プロンプトに限らず文脈を補うコンテキストエンジニアリングが必要です。開発者とAIの双方が利用可能な背景情報や文脈を整えて提供することの重要性が、非常に高まっています。
そこでバクラク事業では、4月から開発ドキュメントとコードベースを同じ場所で管理する取り組みを開始しました。
具体的には、Design Docsなどの開発関連ドキュメントがNotionにあり、AIコーディングツールから参照しづらいという課題の解決策として、ドキュメントとコードベースをGitレポジトリで管理するようにしました。
Design Docsは、ある機能や仕組みを実装するための設計情報であり、チーム内外でのコンセンサス形成にも用いられています。誰のどのような問題を解決するのか、アーキテクチャ、サービスインターフェース、データモデルの定義などを、具体的な実装指針と共に示したものです。
Design Docs自体は、実装方式が変わるたびに可能な限り更新し、常に最新の状態を維持することが望ましいとされています。現在バクラクでは、300ファイル以上のドキュメントが、Gitリポジトリ内でコードベースと同じ場所に管理されています。
そこで、Notion to MarkdownというCLIを自社で開発しました。

※詳細は記事記事末尾のアーカイブ動画(25:10~25:45)をご覧ください
AIに渡すドキュメントを充実させるために、過去のプルリクエストを参考に定型化した開発手順やAIルールも作成しています。
このキャプチャは、新プロダクト追加時のユーザー権限、ロールの追加方法です。複数のプルリクエストをルール化することで、より精緻なFew-shotの例エグザンプルとしてLLMに渡し、今後の開発における定型化された手順として活用できます。
PRD(製品要求仕様書)を整形するためのMCPの利用についてもご紹介します。

PRDは議論の過程で二転三転するため、人間の手だけで都度修正することは非常に手間がかかります。そのため、Notion AIで会話ログや議論の過程をすべて書き起こします。ある程度、意思決定や仕様が固まった段階で、Notion AIで生成した情報を、指定したフォーマットのMarkdown形式でLLMにまとめさせます。その情報をGitにコミットし、以降の変更はGit内のAIコーディングツールなどを利用して更新します。実装時には、このMarkdownファイルを参照しながらAIコーディングを行います。
最後に紹介するのは、Chrome拡張の検索ツール「Bakuraku Dev Search」です。

これは、開発者自身の学習を支えるためのツールです。コード、お客様に公開している外部仕様、データベース、そして本番アプリケーションのログも検索できます。AI系ツールは非常に量が多く、流れも速いため、開発者以外も含めてマインドシェアを奪わず、日常的に使ってもらえるものを提供することが重要だと考えています。個人的にお気に入りの「Ask Devin」は、Devin searchに直接検索クエリを投げられます。コードベースとドキュメントを同じGitリポジトリで管理しているため、横断的な検索が可能です。
また、有志のメンバーが作成したアプリとして、Snowflakeに蓄積されたログデータをLLMに与えることで、「リクエストログを自然言語で説明してくれる」機能も提供しています。今では開発者だけでなく、PdM、QA、カスタマーサポートのメンバーも利用する機能になっています。
これまで説明してきた認知負荷の中で、インストラクションデザインという重要な概念があります。これは学習者の認知負荷を考慮し、効果的な学習を促すための設計であり、その必要性も提示されています。LLMも同様ですが、人間に対して一度に情報を与えすぎると、逆に認知負荷を高めてしまい、学習効率が落ちてしまいます。そのため、より日常的に必要な時にリーチできる情報をデザインしておくことが重要です。バクラク事業部では、開発者自身の最適な学習を支えるために、紹介したような日常的なツールも提供しています。
開発者とAIのイネーブリングが求められる時代
中川:まとめます。
CHOPを含め、AIコーディングの発展によって、イネーブリングの対象は非常に広がりました。開発者とAI、双方のイネーブリングが求められる時代になったと思います。ただしLLMやAIコーディングは日々進歩している一方で、人間の処理能力やワーキングメモリーには限界があり、その上限は変わりません。
イネーブリングとしては、課題外在性負荷を取り除くこと。また、課題外在性負荷をAIによって生み出さないという注意深さも求められてくると思います。
以上でセッションは終了です。ご清聴ありがとうございました。
※開発ツールやその裏側、サービスに関するAIについては、8/1に開催されたLayerXの自社カンファレンス「Bet AI Day」でも紹介されています

アーカイブ動画も公開しております。こちらも併せてご覧ください。
※ご視聴には登録が必要です






