



月間2,000万人が使うメルカリ検索機能のアーキテクチャ。ElasticsearchのTiered Index設計とGatlingによる負荷検証
メルカリはお客さま同士でモノを売買できる日本最大のフリマアプリで、サービス開始から累計40億品以上の商品が出品されています(2024年9月時点)。そんな膨大な商品の中から欲しいものを見つけるために欠かせないのが検索機能です。
この記事では、今の検索チームが運用しているシステムに設計段階から関わっているメンバーの私が、主に設計時に盛り込んだ工夫を紹介しようと思います。
メルカリの検索機能の紹介
検索機能は希望の商品を見つけやすくするために不可欠な機能です。例えば、“iPhone”と検索したら、“iPhone”に関連する商品がたくさん出てきます。検索機能は主に以下に説明する4つを提供しています。
全文検索
全文検索ではまず、与えられた文章を解析して単語を拾い、索引(インデックス)を作っておきます。ここでの文章とは、お客さまが出品する一つ一つの商品に書かれた商品説明文です。アプリの検索画面から、今度は検索したい文章(クエリ)が入力されると、同じ解析プロセスをたどって単語を抽出し、あらかじめ作っておいた索引と照合して、その単語を持つ文章(商品)を抽出します。抽出された商品を、関連度が高い順に並べ替えて、最も関連度が高いものから順に表示する、これが全文検索です。
並べ替え
抽出された商品を並べ替えるときに、関連度順以外にも、他の情報を指定できます。例えば、価格順に並べ替えたい場合などに利用されます。
絞り込み
抽出する対象となる商品群をあらかじめ別の情報で絞り込みます。例えば、初めから50,000円以上の商品には興味がない場合、絞り込み条件をそのように設定します。全文検索と併せて使われることがほとんどです。
ファセット
抽出された商品を別の情報を元にまとめることができます。例えば、その商品をカテゴリでまとめて、商品数が多いカテゴリに対して絞り込みを掛けることを促すときなどに使われます。
検索アーキテクチャ:負荷対策
メルカリは月間アクティブユーザー(MAU)2,000万人を抱えるサービスです。2,000万人を超えるお客さまがさまざまなクエリを投げています。また、検索の利用者は人間だけにとどまりません。メルカリアプリの中では、検索以外の機能も裏で検索クエリを投げている場合があります。例えば、最近の検索したキーワードからおすすめの商品を表示するコンポーネント(アプリの中の表示部分)がありますが、これは裏で検索機能を呼び出しています。しかも、1つの機能だけではなく、複数の機能が裏で検索機能を使用しているのです。これらを合わせると、相当な量のクエリが届きます。
検索対象となるインデックスには4億件を超える商品情報が含まれており、クエリが投げられるたびに索引が引かれ、関連度順に並べ替えられ、絞り込みやファセットの計算が行われます。これによって、実に多くの計算資源が消費されています。その規模は一時期にはメルカリのインフラコストの3分の1を占めるほどでした。大規模な検索サービスにおいて、検索アーキテクチャを決定する際に必須となるのは、この負荷をいかに効率的にさばくかです。検索機能はCPUもメモリも大量に必要となるため、これをうまくさばけるかどうかで、企業の支払うコストに大きな違いが生じます。
検索結果は、最も関連度が高い順に並べ替えられ、そのうちN件のみが表示されます。キーワードにヒットする検索結果が1,000件でも、1,000万件でも、返されるのはトップのN件のみです(これをTopNと呼びます)。例えば、価格順で表示する際に、キーワードを「Tシャツ」として検索してみてください。100%、300円の商品が表示されます(メルカリの最低出品価格は300円です)。このとき、あらゆる場合において、検索エンジンは4億件の中からTシャツにヒットするものをリストアップし、それを価格順に並べ替えて、TopNを表示します。
では、もっと効率的にTopNを返せないでしょうか。ここで、索引を2つに分割し、価格が低いものばかりの索引と、価格が高いものばかりの索引を用意しましょう。同じクエリを処理しようとするとどうなるでしょうか? もし300円の商品でTopNが埋まるのであれば、価格が低いものばかりで作られた索引のみを使用すればよさそうです。仮に半分に分割していたとしたら、探索範囲は4億件から2億件になり、より効率的に動作しそうです。
インデックスを階層的に構築することから、このような処理はTiered Indexと呼ばれます。1段目でTopNが埋まらなかった場合は次の段へ進み、そこで見つからなければさらに次の段へ、という流れです。
負荷軽減のアイデアが定まったとして、それをどう試すのでしょうか。本番環境に入れて試すのも悪くないですが、私たちは事前にベンチマークテストを行っています。ツールとしてはGatlingを使っています。使い始めてから数年経っており、最新版の機能は追えていないものの、いまでも心地よく使えています。出力がわかりやすいというのと、カスタマイズが容易という2点で気に入っています。私たちは、クエリログをGatlingに読ませてそこからgRPCリクエストを再現することで負荷を掛けています。いつでも誰でも負荷試験をやってもらえるように、Spinnakerから簡単に打てるようなちょっとした工夫はしています。以下は実行画面です。シナリオには、どんなベンチマークセットを打ちたいかが選択できます。結果はGCSに自動的に送られて、自分で眺めることができます。
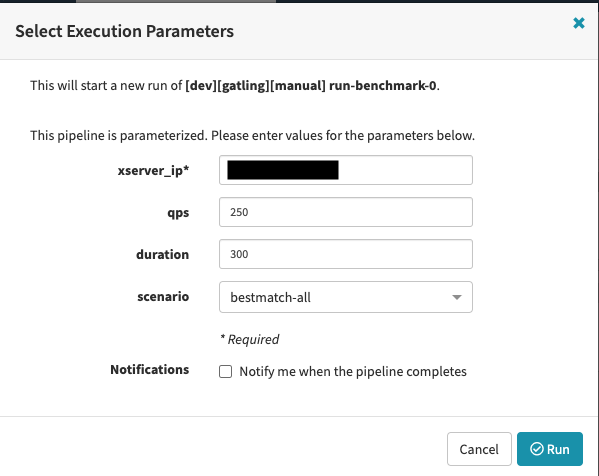
現在の我々のTiered indexで各Tierのサイズは、ベンチマークテストを経て決めたものを運用しています。クエリは時間が経つごとに改善が繰り返され、変化していきますので、本来は継続的に見直すべきなのですが、優先度的になかなか手を回すことができないのもまた現実です。
検索アーキテクチャ:カスタマイズ性
検索システムでは、いかに有用なTopNを返すかが重要です。TopNは我々にとって、商店の陳列棚に相当します。TopNに表示されない商品は、倉庫に積まれているのと同じ状態です。当然ながら、この陳列棚に何を入れるかを決めるアルゴリズムに対して、さまざまな努力が行われます。立ち上げ時のアーキテクチャを考える際に、まず検討されたのはこのアルゴリズムのカスタマイズ性をどう高めるかでした。
私が以前いた職場ではApache Solrを使用しており、カスタマイズはJavaプラグインで行われていました。メルカリはElasticsearchを使用していますが、同じようなプラグインの仕組みがあります。しかし、メルカリにはJavaエンジニアよりもGoエンジニアや機械学習のPythonエンジニアが多く在籍しています。議論の結果、自然言語処理の部分は別にアプリケーションを作成することになりました。こちらのほうがカスタマイズ時の開発効率が良く、さまざまなカスタマイズも容易になります。全体的な効率は低下するかもしれませんが、Elasticsearchから自然言語処理の負荷を外部にオフロードできるため、運用もしやすくなるという判断でした。
自然言語処理の部分は、索引を作成する際とクエリを処理する際で同じものを使用しないと、正確な結果が得られません。したがって、両方の処理はElasticsearchの外部で行っています。実際、この方法はメルカリにとって有効でした。結果として、チーム内外のGoやPythonエンジニアがPull Requestを作成でき、この選択をしなかった場合より多くの人が開発に関わったと思います。
一方で、個人的には、Elasticsearchで完結しない仕組みを構築したことが、後の再利用性を損ねる可能性があると懸念していましたし、実際その通りになりました。メルカリではElasticsearch部分は再利用可能に作られていますが、Elasticsearchから分離した自然言語処理部分はそうなっていないのです。この辺りは、後に他のサービスでも検索を作りたいとなったときに、メルカリの自然言語処理のノウハウを再活用できないなどで今まさに課題になっています。この点に関しては、SolrやElasticsearchのように、プラガブルな仕組みを最初からもっと作り込むべきだったと思っています。
検索アーキテクチャ:コストの見える化
個人的に特にこだわりがあるのはコストです。メルカリは、創業当時はデータセンターでSolrを運用していました。それがクラウド化するタイミングで、ElasticsearchをKubernetes上で運用するということになりました。データセンターはラックを借りるので、どれだけ使おうが同じ料金です。上下するのは電気代くらいでしょう。クラウドは違います。使った分だけの従量課金です。つまり、最適化で効率を上げれば、その分使用料金は下がり、成果が目に見えるわけです。逆もしかりです。なんらかの機能改善を行って、クエリの負荷を高めると、使用料金は上がります。その機能改善から得られる売り上げの増加分と、コストが割に合っているのか、すなわち機能のコストパフォーマンスが見えるようになります。また、先ほど少し述べましたが、検索クエリはお客さまが使用するいわゆる「検索ボックスから検索をする」だけではありません。おすすめの表示や、キャンペーンページの生成など、さまざまなサービスから実行されます。つまり、共有リソースになっています。誰がどのくらい使ったか(使われているか)がわかるようになれば、それぞれのサービスでのコストパフォーマンスもわかるようになります。
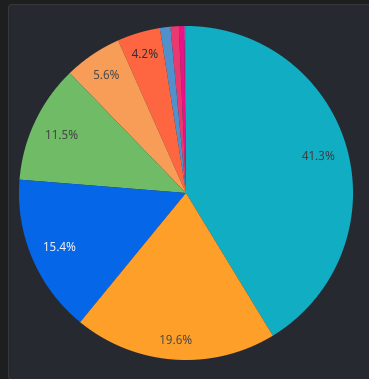
そこで、検索トラフィックに識別子を付けてもらうようにしました。以下は、その識別子ごとのパイチャートです。一番大きい部分がいわゆるお客さまが検索ボックスにキーワードを入れて商品を検索する部分のトラフィックです。残りの6割は他のさまざまなサービスからのトラフィックになります。これらは担当のチームが違いますし、それぞれで費用や説明責任を果たしてもらう必要があります。
検索システム側も、索引ごとに料金がわかるようになっています。これで、索引ごとにかかった値段を、その索引で受けた、識別子ごとのトラフィックで分割することで、トラフィックごとの料金が表示できます。クエリの負荷はそのクエリのレイテンシを掛けることで擬似的に出すことにしています。これで1リクエストあたりの料金が算出できます。検索サービスに関しては、この1リクエストあたりの料金を会社に報告することで、予算の調整や成果の報告が可能になりました。さらに、この料金を基準にして、ビジネスサイドと機能のコストパフォーマンスについて議論することができるようになりました。
売り上げに関する数値はどの企業でも、リクエストあたり、お客さまあたりなどで当たり前のように計算されています。コストの議論を同じ単位で測るようにすることは、利益率がちゃんと担保できるか、費用対効果が見積もれるか、を議論するための第一歩だと思います。
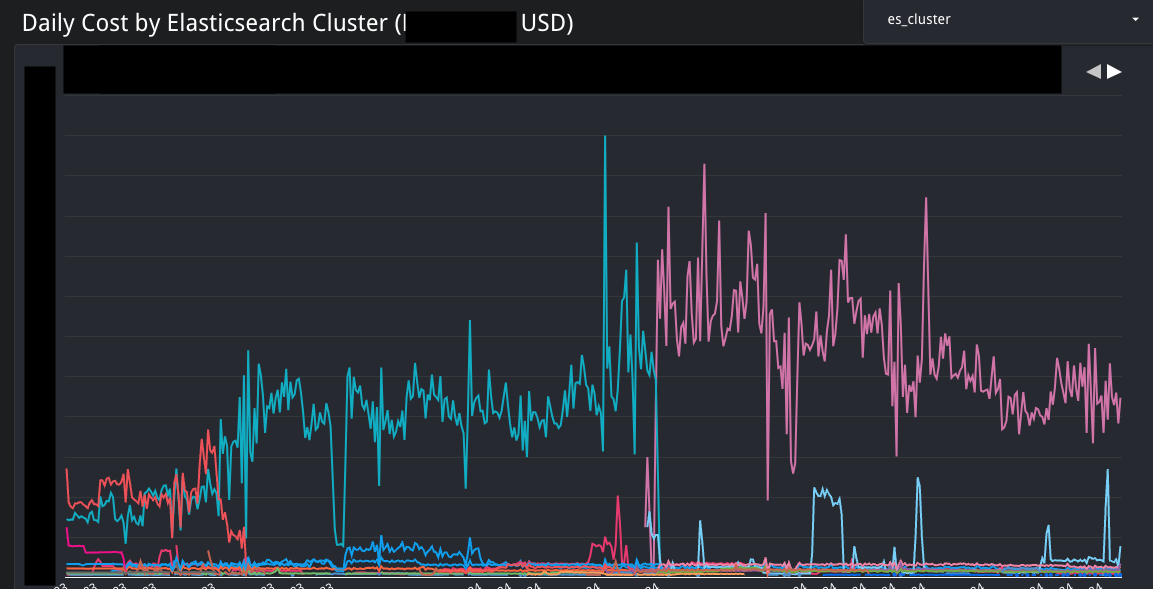
データの表示はData Studio(Looker Studio)で行っています。その理由は、コストの計算にはアクセスログと請求情報をBigQueryで集計したものを収めたテーブルがあり、それを表示するのに簡単だからです。誰でもアクセスできるため、経営層からの参照も容易です。グラフは何枚もありますが、なるべくわかりやすいものを表示するようにしています。以下は、Elasticsearchクラスタごとの料金を示したものです。料金がどのように変遷したのかが一目でわかります。
まとめ
検索アーキテクチャを決める場合、さまざまな要素があります。検索は金食い虫です。お金がかからない工夫は継続的にやりつつも、かかる部分にはかかります。ここに関しては、きちんと説明責任を果たせる仕組みを入れることで、みんなが納得するシステムを目指しています。また、企業文化やそのとき現場にいる人材の特性に応じた仕組みを考えることも、最終的にお客さまに良い機能を提供する近道になると思います。ただ、独自の判断をして、再利用性が低下してしまったことなどは振り返ると反省点として挙げることができます。SLOやエラーバジェットの議論を売り上げベースですることができていないなど、まだまだ改善の余地はありますが、あくまでメルカリの検索チームではこうだったよ、という一例をみなさまに共有させていただきました。





