



あのサービスの監視・オブザーバビリティ アーキテクチャ選定【後編】
ユーザーや顧客へ信頼性を担保した価値提供をしていく中で、監視・オブザーバビリティの取り組みは非常に重要です。
前回の監視・オブザーバビリティ特集では、合同会社DMM.com、株式会社MIXI、株式会社マネーフォワード、パイオニア株式会社、Sansan株式会社、株式会社ZOZOの6社の各サービスを支える監視・オブザーバビリティをご紹介しました。
今回後編では、Chatwork株式会社、株式会社カカクコム、株式会社LayerX、株式会社リンクアンドモチベーション、株式会社タップルのアーキテクチャをご紹介します。
各社がどのようなアーキテクチャを組んでいるのか、またそのアーキテクチャにしている背景や意図についてぜひ参考にしてみてください。
株式会社kubell(旧Chatwork株式会社)
アーキテクチャ設計の背景・意図
書籍「オブザーバビリティ・エンジニアリング」で紹介されている「高いカーディナリティ、高いディメンション、探索可能性をサポートするツール」を実現することを方針としています。
Scala製アプリケーションを分散システムとして運用していることから、システムの可観測性を獲得することが重要であると考えています。また、エラーバジェットの消費状況から分散システムのどこに障害があるか、短いステップで探索することを目指しています。
トレーシングは、SLIに合わせた Sampling をするため、 Tail Sampling を実現しています。Tail Sampling を実現するためには、同一のTrace IDのSpanを同じ Open Telemetry Collector のインスタンスに送る必要があるため、Load Balancer の役割をする Open Telemetry Collector を配置し、 Honeycomb に送る内容を Sampling します。
Datadog Metrics は、JVMやインフラ部分のMetricsを扱っており、アプリケーションに関するMetricsは送っていません。Datadog Logs も同様にアプリケーションの起動や停止に関するログのみを送っており、ユーザー操作に起因するログに関しては全て Honeycomb Traces で収集しています。
株式会社カカクコム(食べログ)
アーキテクチャ設計の背景・意図
食べログでは、「監視データは一箇所に」「監視システムの運用コストを減らす」ことを目的に、Kubernetesやその上で稼働するアプリケーションの監視にNew Relicを利用しています。Kubernetesコアコンポーネントやノードの監視にはNew Relic Kubernetes Integrationを利用し、ミドルウェア以上の監視にはPrometheusとNew Relic Prometheus Remote Writeを利用しています。
これにより、New Relic一箇所からシステム全体を横断して監視できる一方、データ保管にはSaaSを使うことで監視システムの運用コストを下げています。アプリケーションの障害もその原因がKubernetesにある場合もあるため、監視データを一箇所へ集約してクエリできるようにしておくことはシステム全体把握に役立ちます。
◆執筆:株式会社カカクコム 食べログシステム本部 技術部 SREチーム
▼事例はこちらもご参照ください
Speaker Deck:食べログ on Kubernetes ~ 運用15年以上の大規模レガシーシステムを Kubernetesに乗せていく~
株式会社LayerX
アーキテクチャ設計の背景・意図
プロダクトの成長に伴い、内部のアーキテクチャも進化していきます。サービスの分割や機能追加に伴うプロセスの増加、外部サービスの連携など、1つのプロセスだけでは簡潔しないアーキテクチャとなり、ローカル開発の複雑化も進んでいきます。
バクラクでは、増え続けるサービスや外部連携を円滑に開発するため、 lxdev と呼ばれるローカル開発に特化したプロセスマネージャを使い、ローカル開発のプロセス起動やログの閲覧などを簡単にしています。(参考記事:https://tech.layerx.co.jp/entry/2022/12/12/131507)
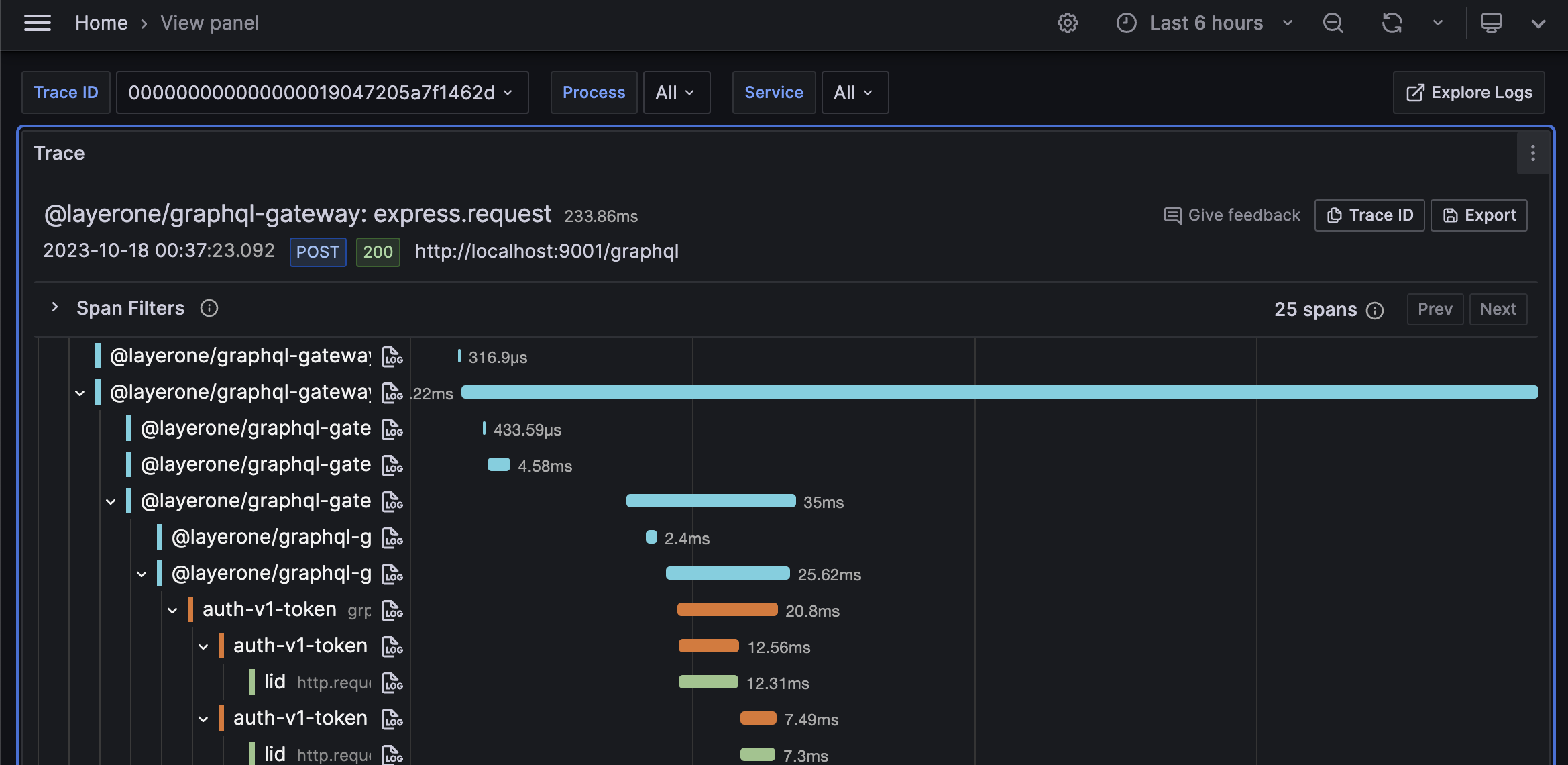 ローカル開発で複数のプロセスを横断するような機能を開発するとき、以下の問題が発生します。
ローカル開発で複数のプロセスを横断するような機能を開発するとき、以下の問題が発生します。
- 複数プロセスのログの確認が面倒
- どのサービスがどのサービスを呼んでいるのか、コールツリーがログだけでは判断が難しい
この問題を解決するために、Grafana が提供するオープンソースの Loki, Tempo を活用し、ローカル開発でもログとトレースの集約を行い、可視化することにしました。
これによって、ローカル上で複雑なコールスタックや、外部連携の発生などが可視化され、開発における複雑なシステム動作の認知負荷の低減に成功しています。
◆執筆:株式会社LayerX Enablingチーム
株式会社リンクアンドモチベーション
アーキテクチャ設計の背景・意図
当社ではモチベーションクラウドをはじめ複数のプロダクトを開発・運用しています。
アーキテクチャは全プロダクトで共通しており、以下のツールを利用しています。
- Logs
- Amazon CloudWatch Logs
- Amazon CloudWatch Logs
- Metrics
- Datadog (AWS連携)
- Datadog (AWS連携)
- Traces
- Sentry
- Datadog RUM / APM
- Sentry
開発者はDatadogおよびSentryのアラートを受けて障害の解析を開始します。
解析時にはDatadogのRUM、SentryのSession Replayなどの機能を用いて、障害発生時のユーザーの行動を分析できます。
Amazon Athenaを介してアプリケーション/インフラストラクチャなど複数の異なるログを組み合わせて解析することで事象の原因を特定します。
上記の仕組みを構築することでオブザーバビリティを向上し、特定の誰かではなく開発者全員でインシデント対応やそのプロセス改善に取り組んでいます。
株式会社タップル
アーキテクチャ設計の背景・意図
タップルではバックエンドで利用しているDatadogにモバイルチームが設計したアプリ内のログを送信し、システム全体で一貫性を保ったオブザーバビリティ設計を心がけ、クライアント、バックエンドの連携を強化しています。
特にアプリ内課金時のOS側のサービス起因のエラーや、SNSを利用した認証などの外部サービスによる障害は、ユーザーへの影響も大きく、バックエンドシステムのみでは原因特定が困難なため、クライアントエンジニアが中心にログ設計や監視設計を行い、障害時には調査対応をリードすることもあります。
また、パフォーマンス監視にもDatadogを利用し、バックエンドのメトリクスデータの他にモバイルアプリ内の起動速度や非応答時間といったログも管理しています。ログの件数に関しては、AppleのMetricKitなどを利用し、OS側が集計し分析したログをDatadogへと送ることで件数を削減しています。
◆執筆:タップル SREチーム + モバイルチーム








