



メンテナンスコスト削減を実現したOpenTelemetryへの挑戦 ~NTTデータに学ぶ、オブザーバビリティの取り組み~
オブザーバビリティの重要性が高まっている現在、その実現に向けたオープンソースプロジェクトであるOpenTelemetryが注目を集めています。一方、OpenTelemetryの具体的な導入事例やOpenTelemetryを用いたオブザーバビリティの取り組みについては、発信されている情報はまだ多くありません。
そんななか、Findy Toolsでは株式会社NTTデータの取り組みに注目。NTTデータでは、クラウドネイティブ環境やマイクロサービスアーキテクチャの採用増加に伴い、システムが複雑に。この課題に対応するため、OpenTelemetry を軸としたオブザーバビリティの実現に積極的に取り組んでいるといいます。
今回、Splunkのソリューションアーキテクトであり、OpenTelemetry Meetup の主催者でもある大谷 和紀さんをインタビュアーに迎え、NTTデータにおけるOpenTelemetryの活用事例や導入過程で起こった問題についてお話を伺いました。
OpenTelemetryの導入を検討している企業や、オブザーバビリティの取り組みを強化したい方々は、ぜひ参考にしてください。
◆プロフィール
岡本隆史(おかもとたかし)
NTTデータグループ 技術革新統括本部
1997年度にNTTデータに入社。先進技術のスペシャリストとして,クラウド・OSSを中心とした雑多な技術検証、導入支援を実施している。o11y/OpenTelemetryに関しては、「Observability(オブザーバビリティ)」「可観測性」とは何か」や、
「マイクロサービスの障害で胃を痛めないための「シン・オブザーバビリティ基盤」をOpenTelemetryで作る」などの記事を執筆。
柏原由紀(かしわばらゆき)
NTTデータグループ 技術革新統括本部
2015年度にNTTデータに入社。アジャイル開発部門でPaaSの整備・運用支援、アジャイル開発支援、マイクロサービスアプリケーション開発支援など行う。現在は、クラウド担当としてSREの普及展開に携わっており、その一環でオブザーバビリティに関する支援を行っている。
青木琢也(あおきたくや)
NTTデータグループ 技術革新統括本部
2019年度にNTTデータに入社し、性能問題を解決するプロフェッショナルサービス「まかせいのう」チームに配属。性能や監視を軸にしたアーキテクチャ設計に従事。現在は自組織に新設した「Observability高度化支援サービス」の企画・デリバリーや、「まかせいのう」のノウハウを集約した性能監視・分析ツール「MacaseinouBOX®」の開発を行っている。
大谷和紀(おおたにかずのり)@katzchang
Splunk Services Japan合同会社
シニアソリューションアーキテクト・オブザーバビリティとして、オブザーバビリティ製品を専門に導入支援を担当。それまでは業務システム業界でSEとしての経験を積んだ後、VOYAGE GROUP(現CARTA HOLDINGS)子会社にて広告配信サービスを構築・運用リード/CTOを経て、New Relicでカスタマーサクセスマネージャーを担当し、現職に至る。DevOpsの推進、クラウドマイグレーション、アジャイルプラクティスの導入なども。好きなビルドツールはMake。
「メンテナンスと学習のコストを削減したい」OpenTelemetry導入の背景
大谷 NTTデータグループは、オブザーバビリティの導入・活用支援を通じて、顧客企業のビジネスの成功をサポートしている注目の企業です。本日は、OpenTelemetryを利用したプロジェクトについて、詳しいお話を伺っていきます。

柏原由紀さん
柏原 私たちのOpenTelemetry導入の取り組みは、社内ユーザー向けのアプリケーション開発プロジェクトから始まりました。このプロジェクトには2つの大きな目標がありました。1つは新しい技術を積極的に試すこと、もう1つはフルクラウドネイティブでクラウドポータビリティの高いシステムを構築することです。
2つの目標を達成するため、私たちはKubernetesのマネージドサービスであるAmazon EKSを採用しました。Kubernetesの中に閉じて環境を構築し、移植性を確保しながらオブザーバビリティに取り組もうという方針でした。
この方針に基づき、アプリケーション、データベース、監視ツールなど、システムのすべてをEKS内に配置。これにより、システム全体を簡単に別の環境に移動したり、同じ環境を再現したりできるようになりました。
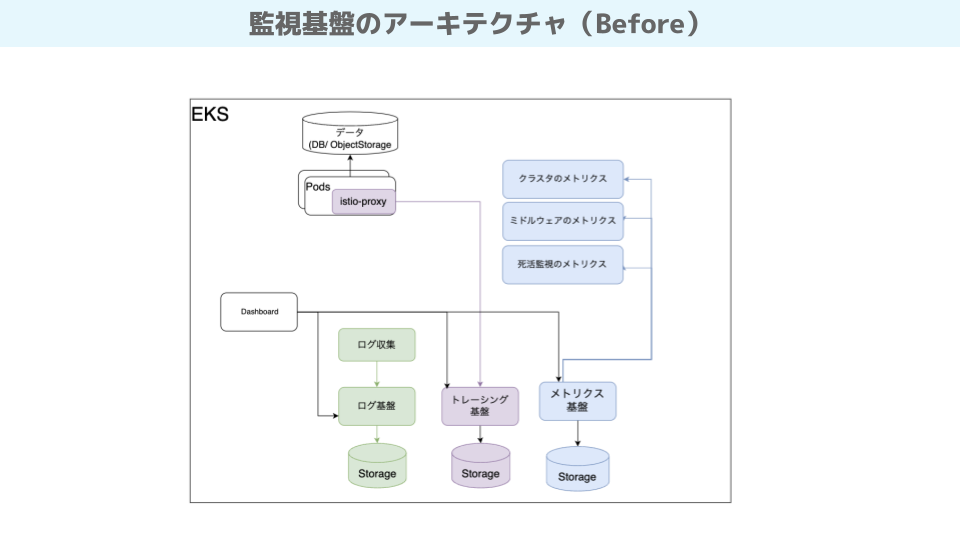
しかし、時間が経つにつれて、いくつかの課題が浮き彫りになってきました。最大の問題は、システムのメンテナンスが難しくなったことです。特に、チームメンバーが変わったり、使用している技術のバージョンアップに対応したりするのが、とても大変になってきました。
岡本 このプロジェクトは新しい技術をたくさん取り入れた実験的な性質を持っていました。最初は技術に詳しい人材がいて上手く回っていましたが、そういった人材がチームを離れると、急に管理が難しくなってきたのです。
大谷 つまり、データベースを含むすべてをEKSという一つの環境に集約したことで、柔軟性は高まったものの、システム全体の複雑さが増し、メンテナンス性が低下したということですね。
柏原 その通りです。そこで我々は、アーキテクチャの見直しを行うことにしました。
アーキテクチャの見直しにあたり、S3やRDSといったAWSのマネージドサービスをできるだけ活用することにしました。マネージドサービスを利用することで、メンテナンスコストを削減し、メンバーのキャッチアップも楽になると考えたからです。また、これまで使用してきた既存の監視ツールとの互換性を維持することも重要でした。
こういった課題を解決するために、OpenTelemetryの導入を決めたのです。
具体的な実装としては、収集したデータを外部に保存する部分だけをOpenTelemetry Collectorという仕組みを使って実現しました。この方法を採用したことで、開発者の負担を抑えつつ、監視データの管理や保持に関する問題を軽減することができましたね。
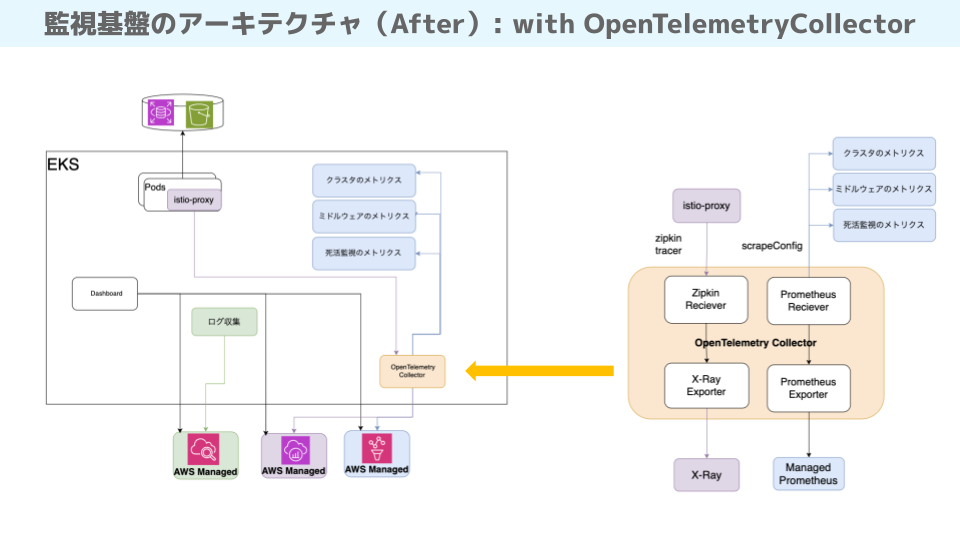
OpenTelemetry導入でぶつかった課題。マネージドサービスをうまく活用
大谷 OpenTelemetryの導入で苦労したことはありますか?
柏原 OpenTelemetry Collectorの設定、特にreceiversの設定を作成するのが大変でした。
大谷 OpenTelemetry Collectorのreceiversの設定は、基本的には以前使っていたPrometheusの設定と似た構造になっていますよね。
柏原 おっしゃる通りです。ただ、意外と簡単ではありませんでした。その理由は、私たちがkube-prometheus-stack(Kubernetesクラスター上でPrometheusモニタリングスタックをデプロイおよび管理するためのツールキット)を使っていたからです。kube-prometheus-stackは多くの設定を内包しているので、Prometheusの設定の書き方を知らなくても使えてしまう。つまり、書き方に慣れていなかったんです。
大谷 自動化されていた部分を手動で設定し直す必要があったわけですね。
柏原 はい。kube-prometheus-stackで実現していた監視機能を、OpenTelemetryを利用した新しいアーキテクチャに移行する必要がありました。これがかなり困難で……単純にコピー&ペーストで済むような簡単な作業ではありませんでした。既存の監視設定を新しいOpenTelemetryベースのアーキテクチャに適応させるのは、予想以上に難しかったです。
そこで、aws-observability-acceleratorを一部流用しました。
aws-observability-acceleratorは、AWSのベストプラクティスに基づいたモジュールのセットです。これを使うと、収集からダッシュボード表示までのデプロイを簡素化できます。我々はこれをベースに、必要な設定を加えていきました。
大谷 なるほど。OpenTelemetryの公式リポジトリにあるパッケージ(Helm chart)は使用しなかったのでしょうか?
柏原 検討はしましたが、最終的にはAWSのマネージドサービスを選択しました。収集する部分と表示する部分を自分たちでメンテナンスするのは避けたかったんです。マネージドサービスを活用することで、メンテナンスの負担を減らすことができました。
大谷 切り替える際に、収集した過去のデータはどうされたのでしょうか?
柏原 結論から言うと、過去のデータは捨てる選択をしました。もともと、テレメトリーデータの長期保存や過去データの活用までは考えていませんでした。クラウドコストの兼ね合いもあり、1週間から1か月程度で削除していたので、残す価値がそれほどありませんでした。
大谷 なるほど。では、新旧のシステムを同時に動かす移行期間中の並行稼働はどのように実装されたのでしょうか?
柏原 並行稼働は行いましたが、データを二重に送信したわけではありません。最初から2つの独立したデータ収集パスを設定しました。具体的には、既存のkube-prometheus-stackによる収集と、OpenTelemetry Collectorを使用した新しい収集方法を並行して実装しました。kube-prometheus-stackでは、すでにNode Exporterなどのエクスポーターがデプロイされており、メトリクスを公開していました。
一方、新しいアーキテクチャでは、OpenTelemetry CollectorのPrometheus receiverを設定し、同じエクスポーターからメトリクスをスクレイプするようにしました。
つまり、共通のデータソースを利用しつつ、2つの収集システムを並行運用したんです。これにより、既存のモニタリングを維持しながら新しいOpenTelemetryベースのアーキテクチャを段階的に導入し、検証することができました。
大谷 既存のエクスポーターを利用して、収集システムの方を二重化することで並行稼働を実現したわけですね。

大谷和紀さん
OpenTelemetryを活用したオブザーバビリティ運用の実践
大谷 監視基盤の構築について、具体的にはどのような技術や手法を用いたのですか?
柏原 このプロジェクトではユーザー数が少数で社内に限られていたため、専門の監視体制を組むよりは、開発者自身が監視も行う形を取りました。
大谷 つまり、監視専門チームは設けず、開発者が自ら調査や対応を行う形だったのですね。
柏原 その通りです。また、このプロジェクトではマイクロサービスアーキテクチャを採用しています。これは複数チームで大きなサービスを開発する際に、チームごとの開発をやりやすくするためです。同時に、サービス全体のリリースも簡単にできることを目指していました。
このような構成において、OpenTelemetryのトレース機能が非常に有用でした。パフォーマンスの問題を特定する際、例えば何かが遅いときに「どこで時間がかかっているのか」、トレースを使って簡単に特定できるようになったので。
具体的には、トレーシング情報を用いて、どのAPIが特に重たいかを分析しました。ただし、私たちの環境ではアプリケーション内部の処理レベルでのトレース分析はせず、コンテナ単位、APIアクセスレベルでどこが重たいかの分析に限定して使用しています。
青木 システムが複雑化、特にマイクロサービスが細分化されてくると、トレースの重要性が増します。問題が発生した際に、どこで起きているのかを特定するのが難しくなりますから。
大谷 なるほど。トレースを使うことで、システム全体の状況把握が格段に容易になるわけですね。
ところで、トレースの導入に際して何か課題はありましたか?
青木 はい、いくつかありました。例えば、設定が適切に行われず、トレースが途中で途切れてしまうケースもあります。また、トレースを導入はしたものの、実際には十分に活用されていないこともあります。これらの課題を克服するには、継続的な改善と教育が必要だと感じています。

青木琢也さん
OpenTelemetry導入で多くのメリットを得られた
大谷 OpenTelemetryを導入して、具体的にどのようなメリットがありましたか?
柏原 まず、システムのメンテナンス性が大幅に向上しました。マネージドサービスを活用することで、バージョンアップへの追従が格段に楽になりましたね。
また、OpenTelemetryを挟むことで、将来的に他のサービスやツールへの変更や拡張も選択肢に入れることが可能になります。
青木 クラウドポータビリティを保持したいケースだとGoogleCloudなどへの移行の選択肢を残すことができますね。
それだけではなく、コスト面でもメリットがあります。あるユースケースでは、単一のオブサバサービリティツールで全てのログを収集・保管するよりも、OpenTelemetry Collectorを経由してログを収集し、各種ログを利用用途に合わせてS3等のオブジェクトストレージや複数のオブザーバビリティツールに適切に振り分けることで、大幅なコスト削減に繋がったという結果が出ています。
大谷 トレーシングの導入による具体的なメリットはありましたか?
柏原 先ほども触れましたが、マイクロサービスアーキテクチャを採用している環境下で、問題の切り分けが非常に楽になったことです。
例えば、あるAPIのレスポンスが遅いという問題が発生したとき、トレーシング情報がない場合、ログを細かく確認しながら問題箇所を特定する必要があり、実際にこれをしようとすると多大な時間がかかります。
しかし、トレーシングを導入することで、どのサービスのどの処理で時間がかかっているのかが一目で分かるようになりました。これにより、問題解決をスピーディに行えるようになりました。
青木 また、ハイブリッドクラウドや複数のシステムをまたぐ通信の場合、どちら側、あるいはその間のネットワークに問題があるのかを特定するのにも役立っています。さらに、アプリケーション側の問題なのか、データベース側の問題なのかも、トレーシングがあると素早く問題を見つけられます。
大谷 ログと比べてトレーシングだと時間がかからない理由は何でしょうか?
岡本 トレーシングはコンテキスト情報を含んだ構造化されたデータだからですね。ログの場合、異なるシステム間でタイムスタンプなどの情報を使って突合せる必要がありますが、それには時間がかかります。トレースIDがあれば簡単ですが、ない場合は推測で近い時間のログを探すことになり、時間がかかってしまいます。
大谷 なるほど。トレーシング機能による問題のスピーディーな特定は、現代の複雑なシステム環境において非常に重要なメリットといえますね。OpenTelemetryの導入で多くのメリットが得られることが分かりました。
オブザーバビリティの重要性が高まるなか、OpenTelemetryの可能性に期待
大谷 オブザーバビリティ、そしてOpenTelemetryの今後の展望と課題について、御社ではどのように感じていますか?
青木 まず、オブザーバビリティの現状からお話しします。私が担当する「まかせいのう」というサービスでは、性能関連のサポートを上流工程からリリース後まで一貫して提供しています。最近では、クラウドのコスト改善なども行っていますが、特に注力しているのがオブザーバビリティ高度化のサービスです。
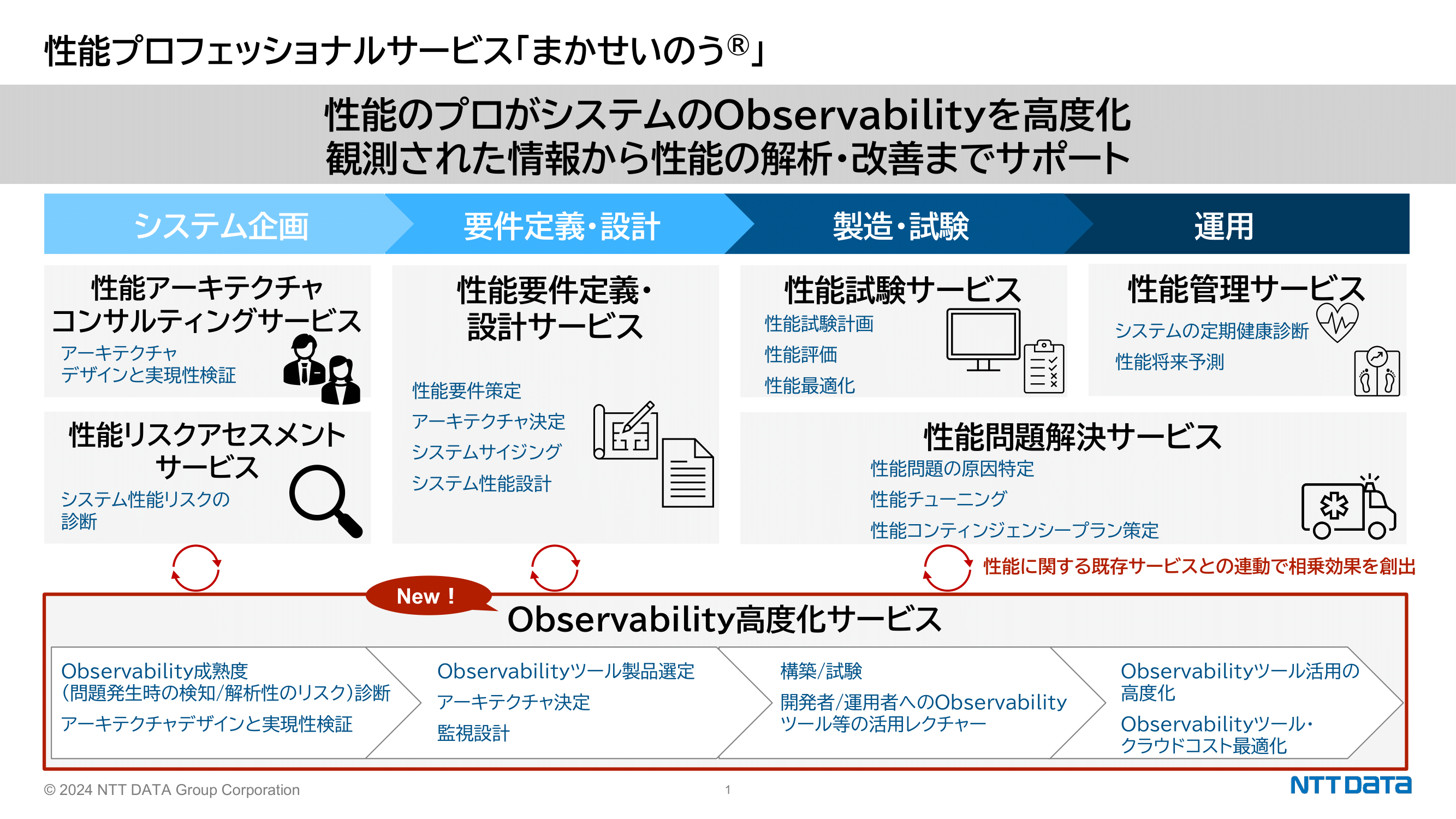
このサービスでは、お客様のオブザーバビリティの成熟度評価から始まり、検証や導入支援まで行っています。また、導入支援はツールの導入のみならず、既存の運用監視の仕組みを考慮してOpenTelemetryやオブザーバビリティツールを含む最適なソリューションの提案とインテグレーション、及び運用後の活用のサポートまで行っています。
しかし、課題もあります。最も大きい課題の1つは、オブザーバビリティ自体の認知度が低いこと。セキュリティ対策ほど当たり前の存在にはなっておらず、お客様が導入を躊躇する原因にもなっています。
大谷 たしかに認知度が高いとはいえませんね。他に導入を躊躇する理由として、オブザーバビリティはコストに対するリターンが分かりにくいという点もありそうです。
青木 おっしゃる通りです。ROIの計算が難しいのは大きな課題です。我々のサービスでは、オブザーバビリティツールの導入だけをゴールとせずに、 オブザーバビリティの高度化により得られた情報を活用し、システムのボトルネック改善やクラウドコスト最適化などの改善活動までセットで行うことで、初めてお客様に価値を感じていただけることが多いと感じています。
ただ、最近では良い兆しも見えています。例えば、障害対応で原因特定に長時間を要してしまったお客様から「再発防止のため」という文脈で声をかけていただくことが増えました。また、先進的なお客様の中には、自らその重要性を理解したうえで「APMツールを導入したい」とおっしゃる方も出てきています。
大谷 OpenTelemetryについては、どのような状況でしょうか?
青木 OpenTelemetryに関しては、まだメリットや実績が十分に認知されていないのが現状です。ただ、今回紹介したプロジェクトのように、いくつかのプロジェクトで利用されはじめています。
大谷 具体的に、どのような場合にOpenTelemetryが候補になるのでしょうか?
青木 主に2つのケースがあります。一つは、本番環境と開発環境で異なるツールを使いたい場合です。例えば、本番環境ではSaaSを、開発環境ではコスト削減のためOSS製品を使いたい。このとき、OpenTelemetryを使うことで、アプリケーション側の実装を統一できます。
もう一つは、将来的なツールの切り替えを見越したケースです。OpenTelemetryを採用しておくことで、将来の選択肢を広げられます。
岡本 OpenTelemetryと商用のオブザーバビリティツールを比較して、どちらが良いかと質問されることがありますが、これは少し的外れだと思います。重要なのは、SaaSのオブザーバビリティツールかOpenTelemetryかという二択ではないということです。
OpenTelemetryはデータ収集と転送のための仕様やコレクターツールであり、商用ツールとは異なる役割を果たします。例えば、OpenTelemetryを使ってデータを収集し、それをSaaSのオブザーバビリティツールに送信して分析や可視化を行うという使い方。これにより、OpenTelemetryの柔軟性とSaaSツールの高度な分析機能の両方を活用できるのです。
つまり、OpenTelemetryとSaaSのオブザーバビリティツールは対立するものではなく、むしろ組み合わせることで、より強力なオブザーバビリティ環境を構築できるといえるでしょう。

岡本隆史さん
大谷 最後に、今後の展望を聞かせてください。各ベンダーがOpenTelemetryに対応したエージェントを提供するようになれば、導入の障壁は低くなりそうでしょうか。
青木 そう思います。 ただ、 OpenTelemetryのメリットを活用するうえでの課題もあります。
オブザーバビリティベンダー固有の機能も多いので、完全な互換性を得るのは難しいのが現状です。
例えば、OpenTelemetryに対応したベンダーAのエージェントの実装でデータを収集し、バックエンドとしてベンダーAのSaaSを使用し可視化・分析していたとします。バックエンドを別のベンダーBのSaaSに切り替えたい場合、エージェントの実装を変えなくても簡単に切り替えられることがOpenTelemetryのよさではありますが、ベンダーBのエージェントを使用した場合に比べると取得できる情報が少なかったり、ベンダーBのSaaSの全ての機能をフル活用できない場合があります。
大谷 OpenTelemetryの標準化が進めば、ベンダー間の切り替えや連携がより簡単になりそうですが、完全な互換性の実現にはまだ時間がかかりそうですね。
本日は、OpenTelemetryの導入と活用について、NTTデータのみなさまから貴重なお話を伺うことができました。OpenTelemetryの導入により、システムのメンテナンス性向上、クラウドポータビリティの確保、そしてマイクロサービスにおける問題解決の迅速化など、多くのメリットが得られることが分かりました。
OpenTelemetryは単なるツールではなく、オブザーバビリティを実現するための重要な基盤技術。今後のクラウドネイティブな環境において、ますます重要になっていくでしょう。今後、より多くの企業がOpenTelemetryを活用し、オブザーバビリティを実現していくことを期待しています。

執筆:河原崎亜矢
編集:山口 紗英 @yamasa_fin