



【開発生産性カンファレンス 2025】監視・分析・拡張性を一手に:TiDBが支えるmixi2のデータ基盤
2025年7月3、4日に「開発生産性Conference 2025」がファインディ株式会社により開催されました。
4日に登壇したMIXIの開発本部 CTO室 SREグループ 松矢 晃太朗さんは、「mixi2」の開発当初から選定したTiDBについて、単なるNewSQLの選択肢にとどまらない開発生産性そのものを押し上げるインフラだと語ります。
本セッションでは、TiDBに標準で備わっているGrafanaやダッシュボードによるモニタリングの容易さが、運用コストを大きく下げた点、さらにTiCDCとKafkaを使ったリアルタイムデータ分析基盤の構築によって、プロダクト改善のフィードバックループが加速した点を中心にご紹介いただきました。
※【セッションスポンサー企業】PingCAP株式会社
■プロフィール
松矢 晃太朗
株式会社MIXI
開発本部 CTO室 SREグループ
2022年度に新卒としてミクシィ(現 MIXI)に入社し、ゲーム関連のプロジェクトで二度の新規リリース、運用に携わる。
2025年2月から「mixi2」に参画し、インフラを中心に機能開発も行っている。
mixi2のデータ基盤にTiDBを選んだ理由
松矢:こんにちは、株式会社MIXI開発本部CTO室SREグループの松矢晃太朗です。
私は2022年度に新卒として入社し、これまで3年間はゲーム関連のプロジェクトで二度の新規リリースと運用に携わってきました。今年2月からは「mixi2」に参画し、インフラを中心に機能開発も行っています。
今回は、TiDBが支えるmixi2のデータ基盤について、なぜTiDBを選択し、どのように活用してきたかを事例ベースでお話しします。
mixi2は招待制の短文テキスト型SNSです。「今を共有でき、すぐ集える」をコンセプトに、タイムライン機能のほか、スタンプ、コミュニティ、イベント機能を備えています。身近な人や同じ属性の人たちとつながりやすいのが特徴です。
現在、サーバーエンジニアは4名で運用しており、比較的少人数です。この少数精鋭体制だからこそ、効率的な開発と運用が求められています。
mixi2はInternal APIを中心としたマイクロサービスアーキテクチャを採用しています。データベース、キャッシュ、サーチエンジンなどの外部サービスと連携し、APIのレイテンシーを維持するために、ジョブキューやOutboxパターンを駆使した非同期ジョブを是とした設計となっています。
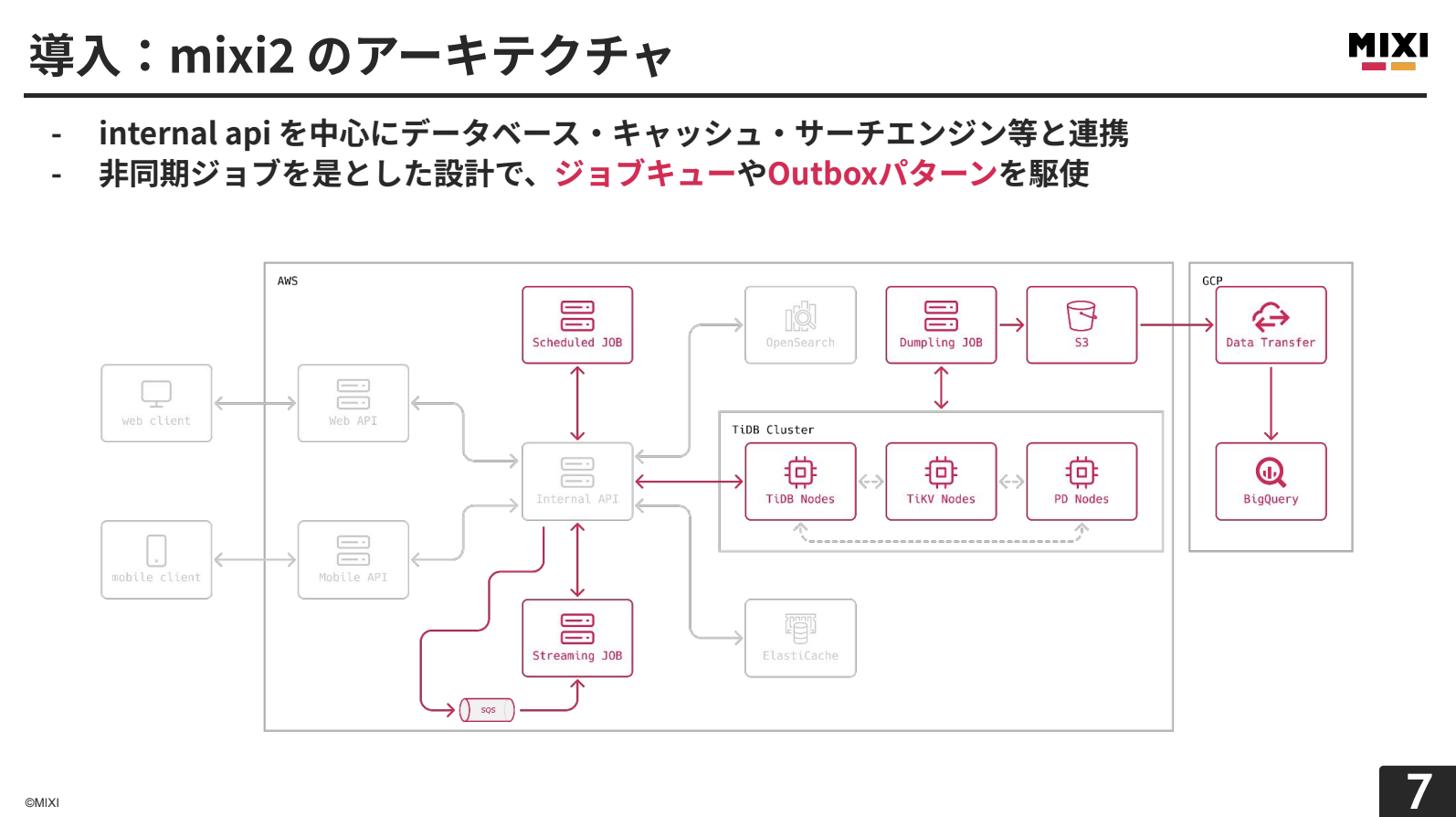
今日は特に、非同期処理部分、TiDBクラスター、そしてダンプリングから始まるデータ分析用の仕組みを中心にお話しします。
SNSを開発するにあたり、ユーザーやリクエストの増加に対応できるスケーラビリティ、特に水平スケール性能は必須でした。検討した選択肢を比較すると以下のようになります。
RDBシャーディングは、単一シャードでのクエリレイテンシーは良好ですが、シャードをまたがるクエリでは通信や結合処理のオーバーヘッドが高くなります。分散トランザクションではアプリケーション側での考慮事項が多く、運用コストが高くなります。
NoSQLは、スケーラビリティや耐障害性能は申し分ありませんが、トランザクションサポートが限定的で、複雑な一貫性のある更新処理には不向きです。
NewSQLは、レイテンシーは他の選択肢に劣る場合がありますが、サービス水準として許容できる程度を確保しつつ、ACID特性や耐障害性能を備えています。
以上の理由から、mixi2ではNewSQLの中からデータベースを選定することにしました。
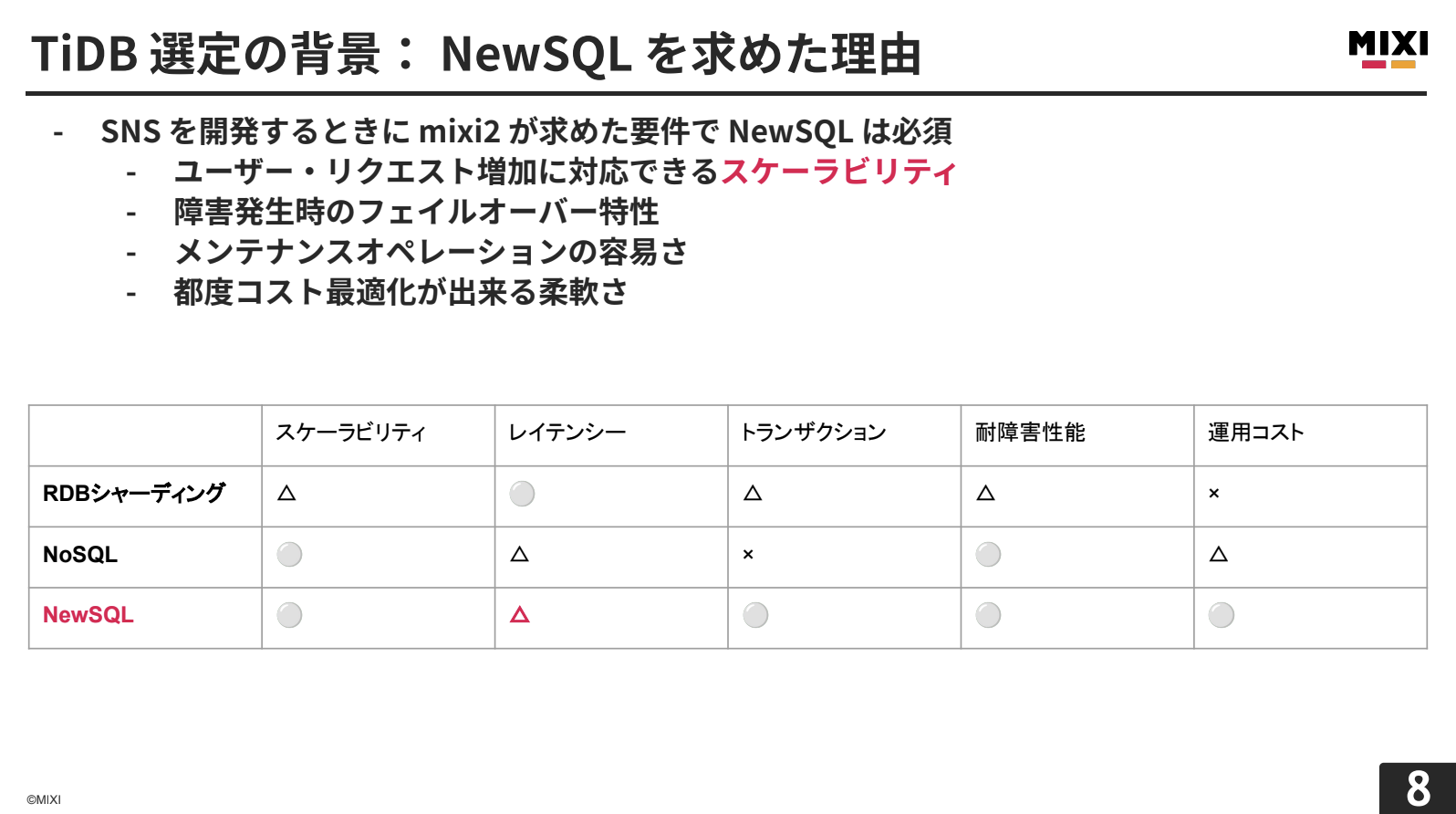
NewSQLの中でTiDBを選んだ理由は4つあります。
1つ目は、TiDBの公式ドキュメントが豊富で質が高いことです。検証段階から運用時のトラブル対応まで、公式ドキュメントに答えが載っていることが多く、エンジニアのオンボーディングにも優しいです。実際、私も途中参画でしたが、特に問題なくキャッチアップできました。
2つ目は、Go・Rustで書かれたOSSであることです。mixi2のサーバー言語がGoであることの一致に加え、TiDBのデータレイヤーであるTiKVがRustを採用しており、予期しないガベージコレクションが発生しない設計になっています。これによりレイテンシーの安定性が高まり、データレイヤーでのストップ・ザ・ワールドを言語レベルから回避できる安心感があります。
3つ目は、tiupコマンドが大変優秀であることです。TiDBクラスターを操作するCLIとして、非常に使いやすく設計されています。
最後は、TiDBクラスターを構成するコンポーネントの分割単位が意味的に単純明快で、拡張性に期待感が持てることです。
Spannerのスケーラビリティは群を抜いており、非常に良い選択肢でしたが、すでにAWSでの開発を進めていたこともあり、採用には至りませんでした。
こうした理由から、mixi2ではTiDBを採用することに決めました。

TiDBとは
松矢:それでは、TiDBについて開発目線と運用目線、両方の視点から紹介していきます。
TiDBは3つの基本コンポーネントで構成されています。SQL解析レイヤー(TiDB)、データレイヤー(TiKV)、メタデータ・リージョン管理(PD)です。コンポーネントが役割ごとに明確に分離されているため、使用状況に応じてコスト最適化が可能なアーキテクチャになっています。
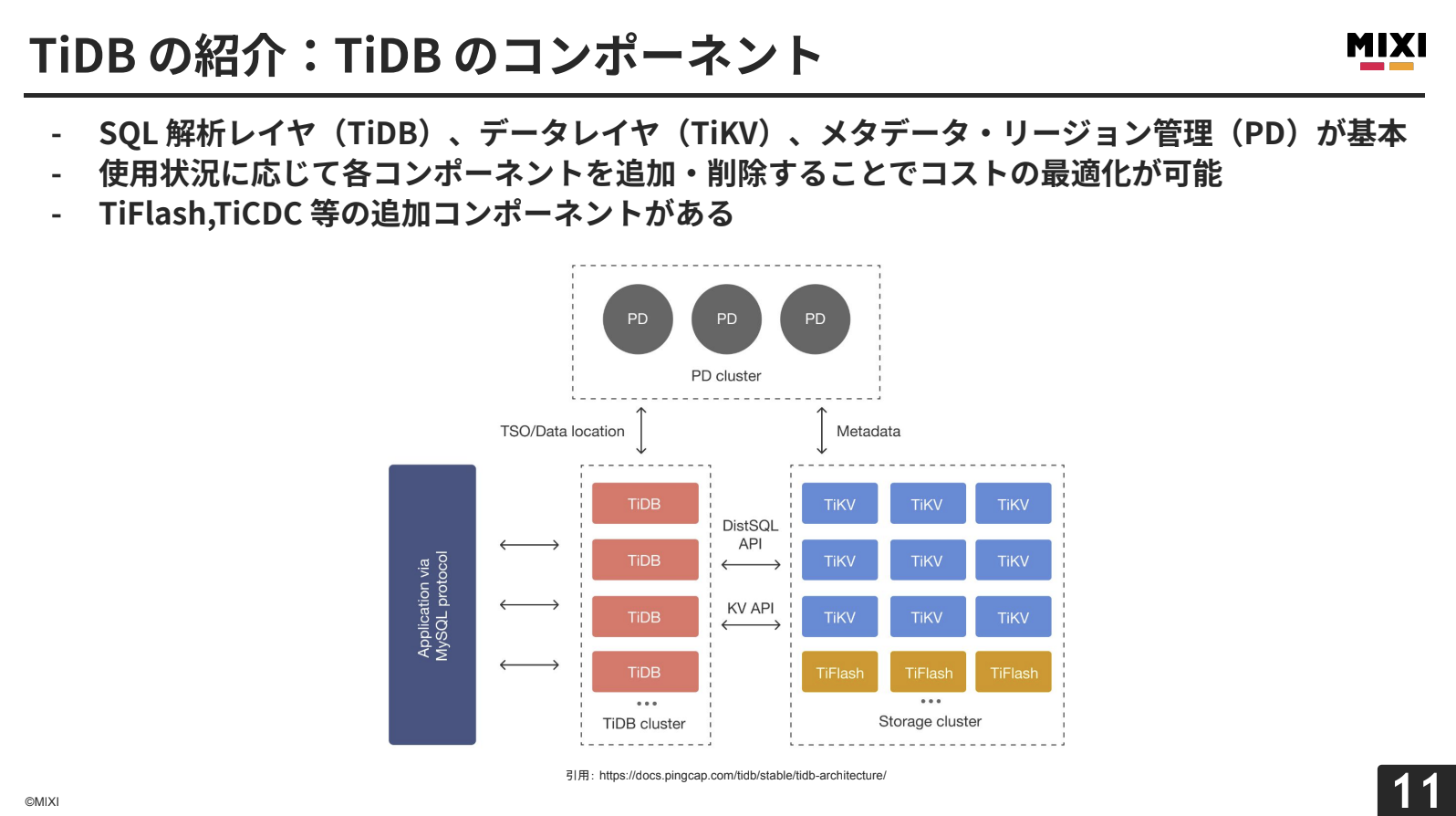
PD(Placement Driver)は、クラスターのメタ情報を管理し、データの配置やリーダーをスケジュールします。また、トランザクション時にタイムスタンプオラクルを発行し、分散トランザクションでもクラスター単位で一貫した順序保証を行います。
TiDBは、MySQL互換のステートレスなコンピューティング層として振る舞い、水平にリニアなスケーリングが可能です。クエリをアプリケーションから受け取り、実行計画を立ててPDとやり取りしながら、どのTiKVのデータを取得するかを決定します。
TiKVは、キーバリュー形式でデータを保持します。データはRegion単位で論理的に分割され、それぞれがRaftグループを形成し、通常3つの複製が異なるTiKVノードに配置されます。TiKVは、MVCCやTwo-Phase Commitの仕組みを採用し、内部的にRocksDBベースのオンディスクKey-Valueストアを持っています。
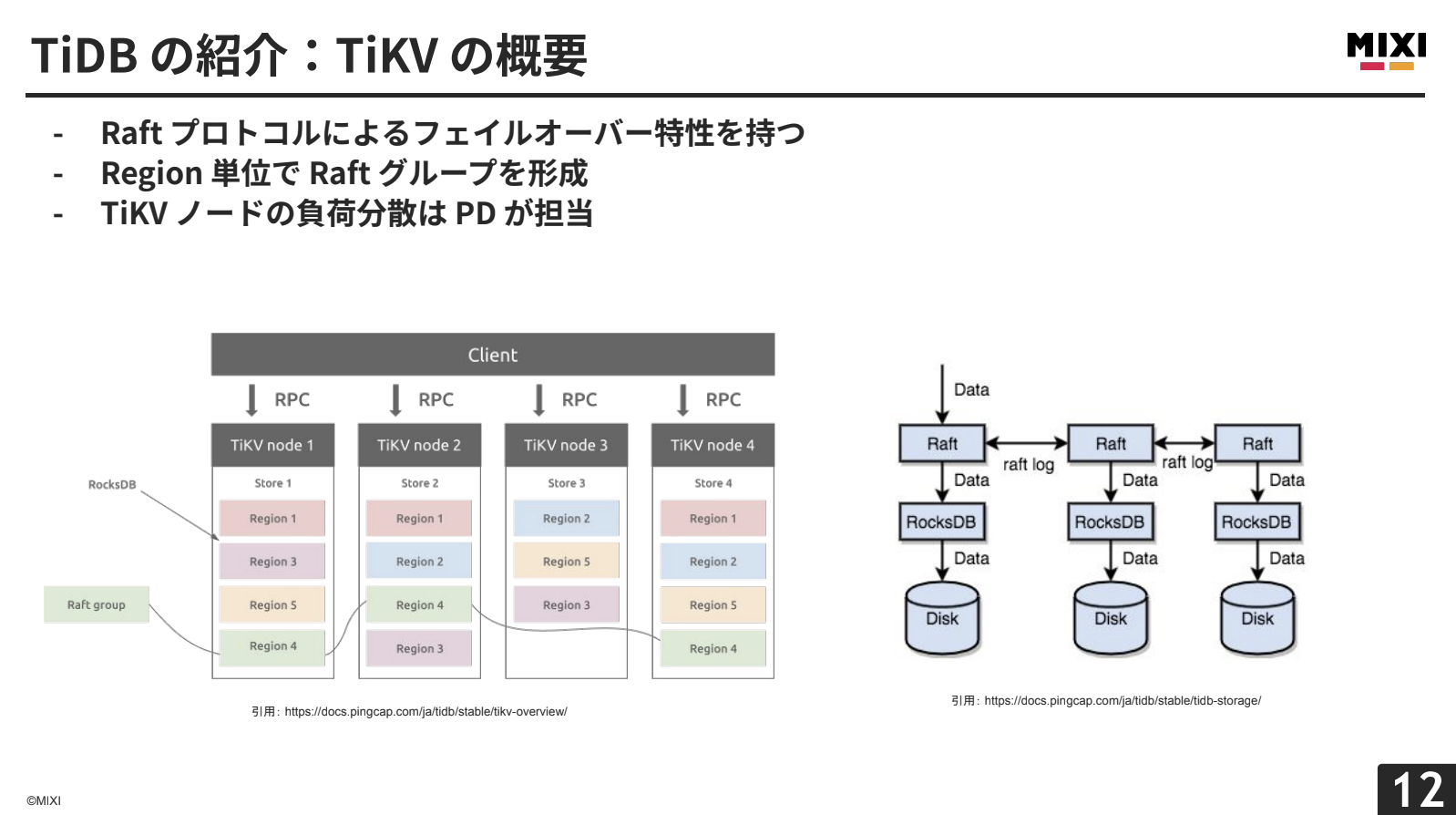
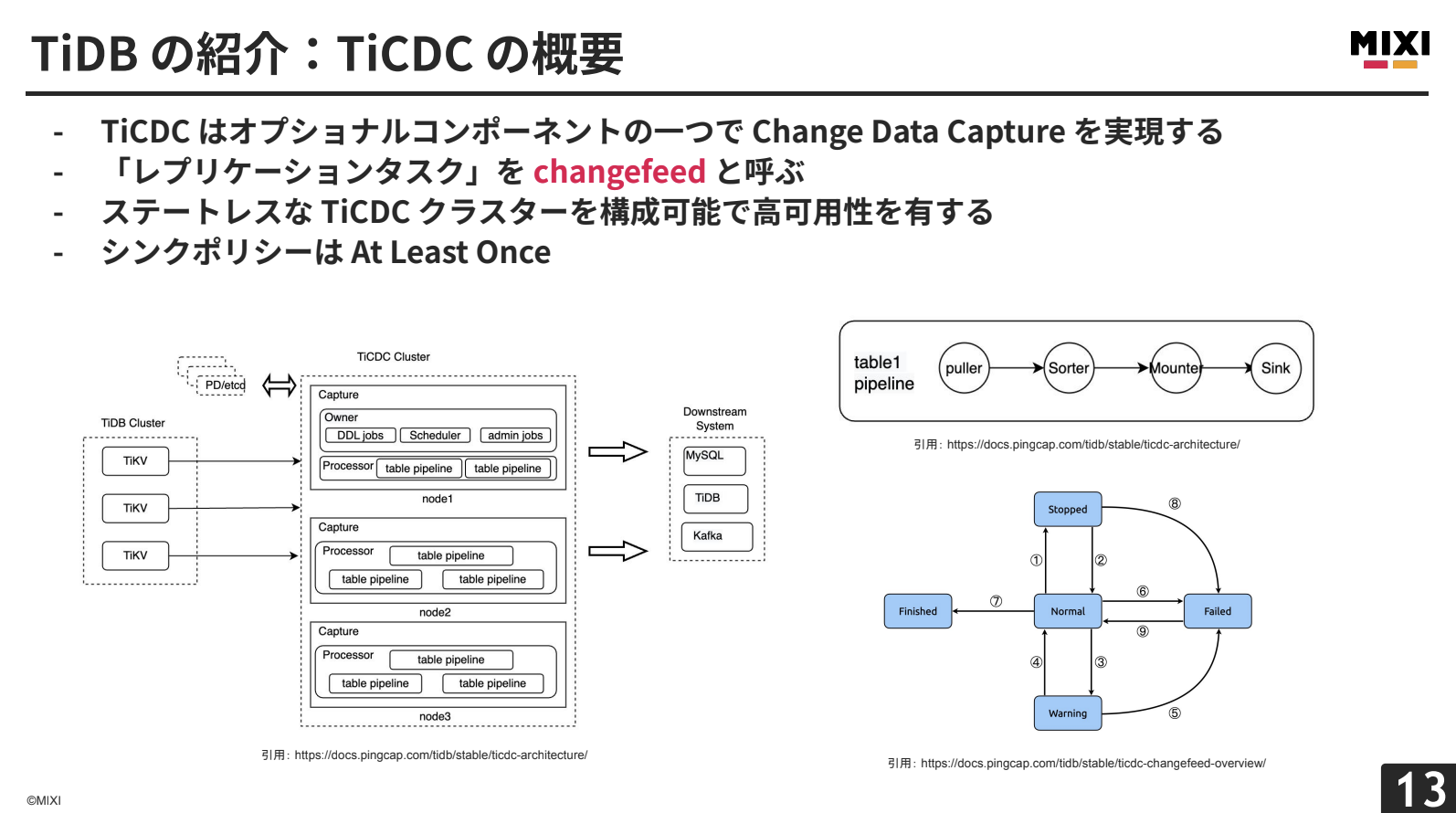
TiCDCは、Change Data Captureを実現するオプショナルコンポーネントです。データの変更を外部システムにリアルタイムに複製します。レプリケーションタスクを「changefeed」と呼び、PDに内包されたetcdで状態を管理しています。
処理パイプラインは、TiKVのRaftログからデータを取得するPuller→時系列順に並べ替えるSorter→下流システムに合わせて変換するMounter→実際に下流へリクエストを送信するSinkで構成されます。
changefeedは、Normal(レプリケーション実行中)→Warning(30分間の自動リトライ)→Failed(手動再開が必要)という状態遷移を持ちます。WarningやFailed状態では、TiKVの古いデータのGCをブロックするため、デフォルトで24時間以内の解決が必要です。
TiDBでは、スナップショットとログバックアップの両方を活用し、バックアップ保持期間内の任意のタイミングにデータを復元できます(Point In Time Recovery)。スナップショットは高速、ログバックアップはやや低速ですが細かい時点指定が可能です。
ダンプリングでは論理フルバックアップを生成でき、別のTiDBクラスターや異なるシステムにも復元可能です。mixi2では1日1回実行し、BigQueryへのデータ挿入に使用しています。
TiDBクラスターには標準でTiDBダッシュボードが備わっており、クラスター全体の実行ステータスを一覧できます。特にスロークエリの統計が見られ、実際にクエリのジッター原因特定に役立っています。mixi2では、障害発生時にまずTiDBダッシュボードを確認するフローが定着しています。
また、Prometheus、Grafana、AlertManagerも標準装備されています。Grafanaだけで31個のグループ、アラート設定も71個が事前に用意されているため、通知先設定のみでプロダクションレディな監視環境が実現します。
この監視機能の価値を、実際の運用事例で紹介します。
とある日の対応
22:21にアラートを受信し、約3分後にはTiDBダッシュボードでTiDBインスタンス1台の異常終了を把握できました。同時にサービスに影響がないことも確認できたため、落ち着いて対応を進め、約18分で復旧完了しました。
アラート設定や状態可視化は通常、リリース直前や障害後に追加することが多いのですが、そのコストがほぼゼロで達成できるのは大きなメリットです。

Slow Queriesの発見と解決
リリース初期に、TiDBダッシュボードで明らかに異常なクエリを発見しました。詳細を調査すると、delete_skipped_countが大きな値を示していました。これは、TiKVのRocksDBレイヤーで削除マーカーが付けられたキーの合計数を表しており、高頻度でUPDATE/DELETEを繰り返すテーブルで削除マーカー付きレコードが増え、スキャンコストが高くなっていたことが原因でした。SELECT条件を工夫することで改善できました。
TiDBダッシュボードでは、Slow Queriesの履歴だけでなく実行計画まで確認でき、調査から原因特定までのリードタイムが大幅に短縮されます。

mixi2が直面した課題
松矢:次に、mixi2が現在抱えている問題について、ビジネス的・技術的側面から赤裸々にお話しします。
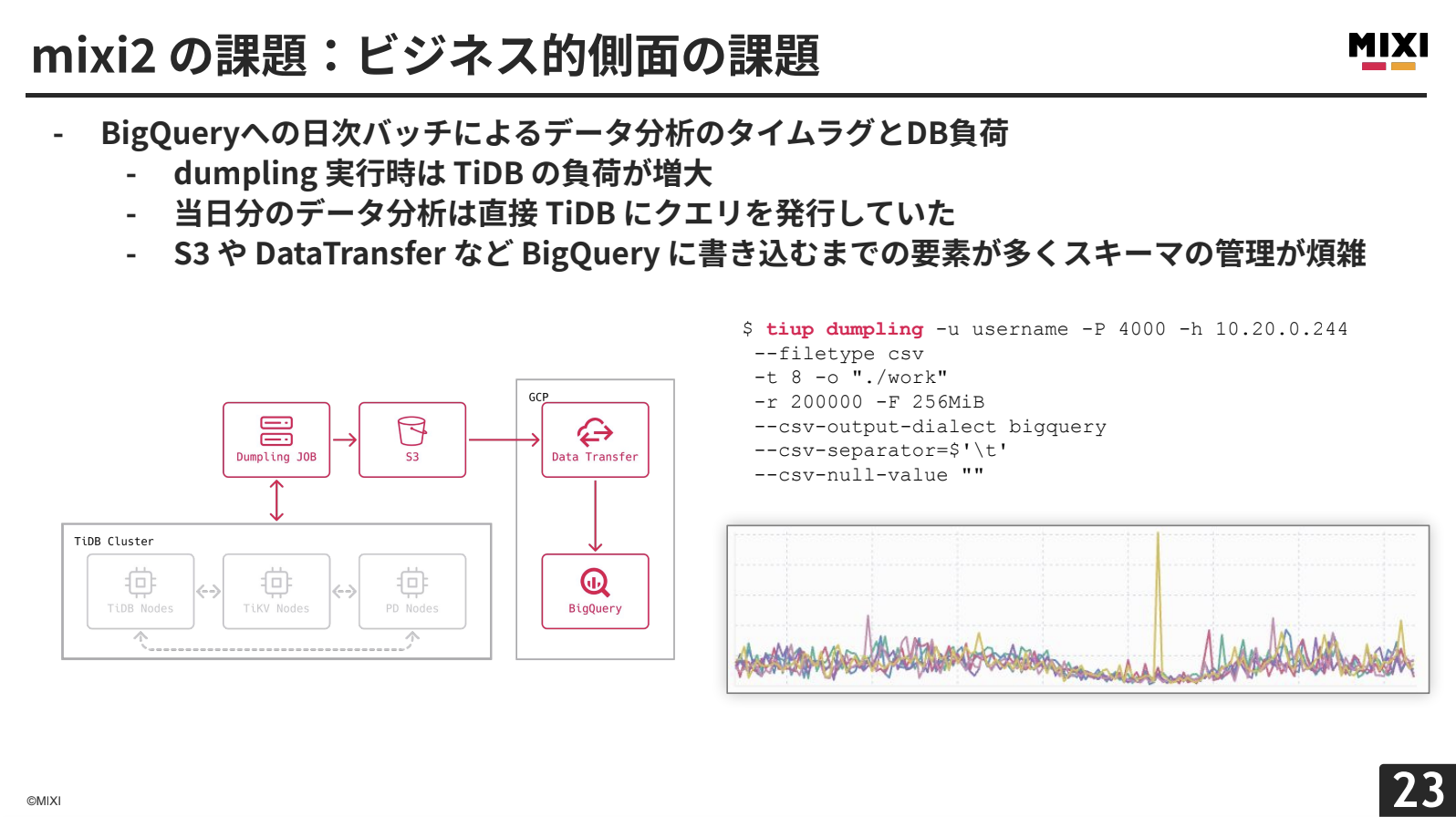
まずはビジネス的側面の課題です。mixi2では、データ分析にBigQueryを使用しています。現状のデータフローは、まずTiDBクラスターからtiupのダンプリングコマンドで論理フルバックアップを取得した後、データクレンジングを行ってからS3へと保存しています。その後、GCP側でData Transferを経由して、BigQueryにインサートするという構成です。
この構成では当然、BigQueryにあるデータはダンプリング時点でのデータになりますので、例えば新機能をリリースしたとしても、そのデータを分析できるのは翌日以降となってしまいます。結果的に、フィードバックループの反応も遅れてしまうという課題を感じています。
mixi2では当日分のデータについては、直接アプリケーションDBにクエリを発行していたりします。大変お恥ずかしい話なのですが、実際にリリース直後に分析クエリを同時多発的に発行してしまい、TiDBインスタンスの負荷がアラート水準まで上昇してしまったという経験もあります。
また、ダンプリングでは論理フルバックアップを取得するので、データの増加に伴い、ダンプリング時のTiDBの負荷が上昇し、いずれ無視できない領域に達してしまうと予想されます。実際、ある日のダンプリング時のTiDBの負荷を見ると、すでに無視できない領域に達していると言っても過言ではありません。
さらに、S3やData Transferなど、BigQueryに書き込むまでの要素が多く、スキーマの管理が煩雑になっているという問題もあります。
また、mixi2内の投稿の不正検知に関しても、現状、カスタマーサポートメンバーの力量に依存する部分が多く、全体把握のためにはユーザーからの通報ベースでの対応をしなくてはならない、というのも問題として抱えています。
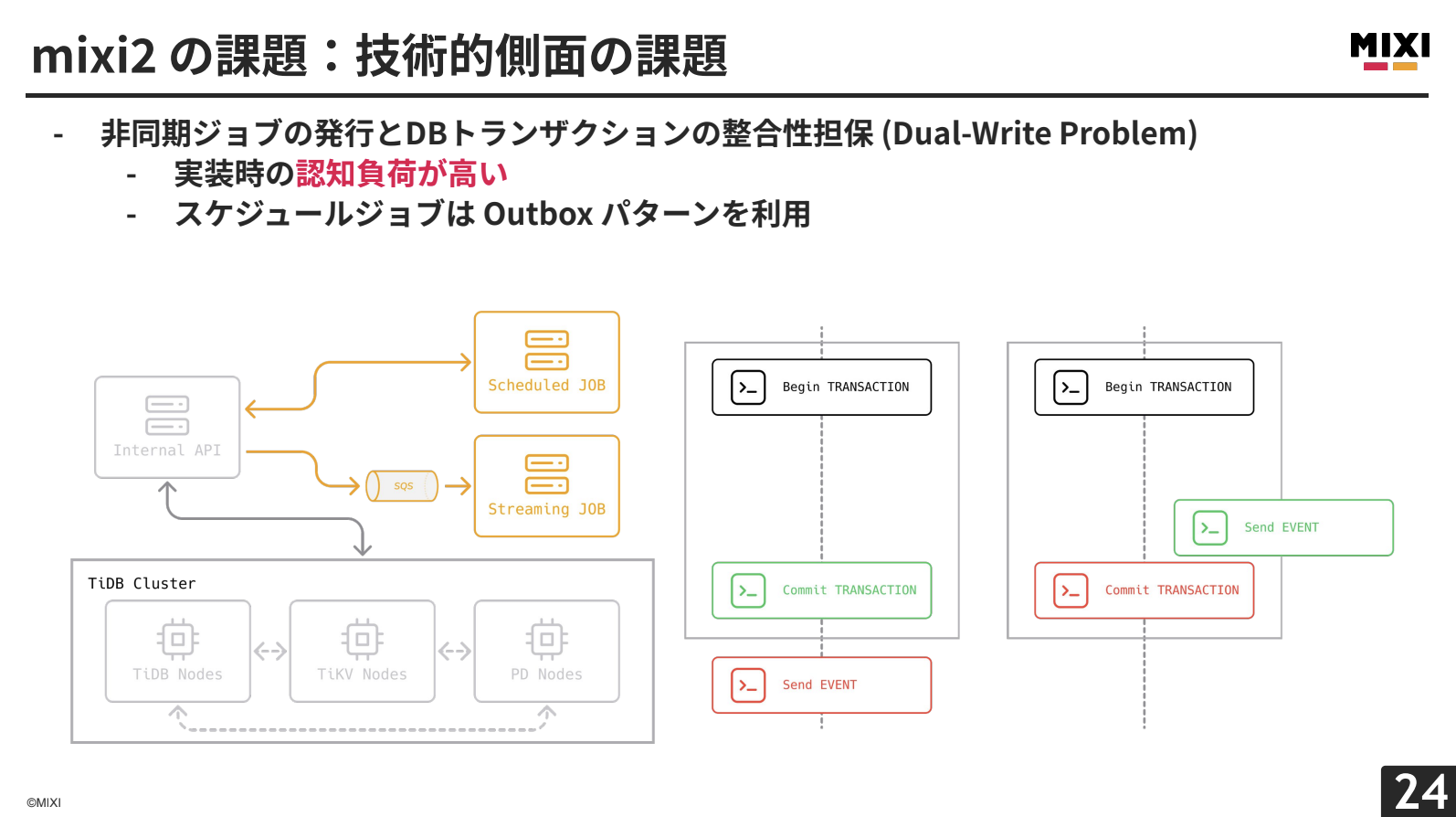
次に、技術的側面の課題です。mixi2では、非同期ジョブのキューイングシステムとして、AWS SQSのシンプルキューサービスを使用しています。したがって、非同期ジョブを発行する場合は、リクエストの処理中にデータベーストランザクションをコミットした直前か、直後にフックを挿入するような形で、SQSへメッセージを送信しています。
この場合、フックをどのタイミングで入れるかをはじめ、SQSのメッセージ送信に失敗した場合に、トランザクションをロールバックすべきかどうかを、実装時に考慮しなくてはなりません。実装時の認知負荷が高いという問題があります。
一部のスケジュール系の非同期ジョブは、事前にジョブテーブルに書き込んでおき、スケジュールジョブワーカーから定期的にジョブを取り出し、ジョブを実行するという、Outboxパターンと呼ばれる方法で、このDual-Write Problemを回避しているのですが、すべての非同期ジョブを、このOutboxパターンに移行するというのは、リアルタイム性を一部犠牲にすることになります。
例えば、自分がmixi2で投稿を行ったときに、フォロワーへの投稿配信といった処理などが遅れることになり、mixi2が提供したい価値の水準を落としてしまうことになります。
どうやって課題を解決したか
松矢:先ほどお話しした課題を一網打尽に解決する方法が、TiCDCとKafkaのコンビネーションを導入することです。
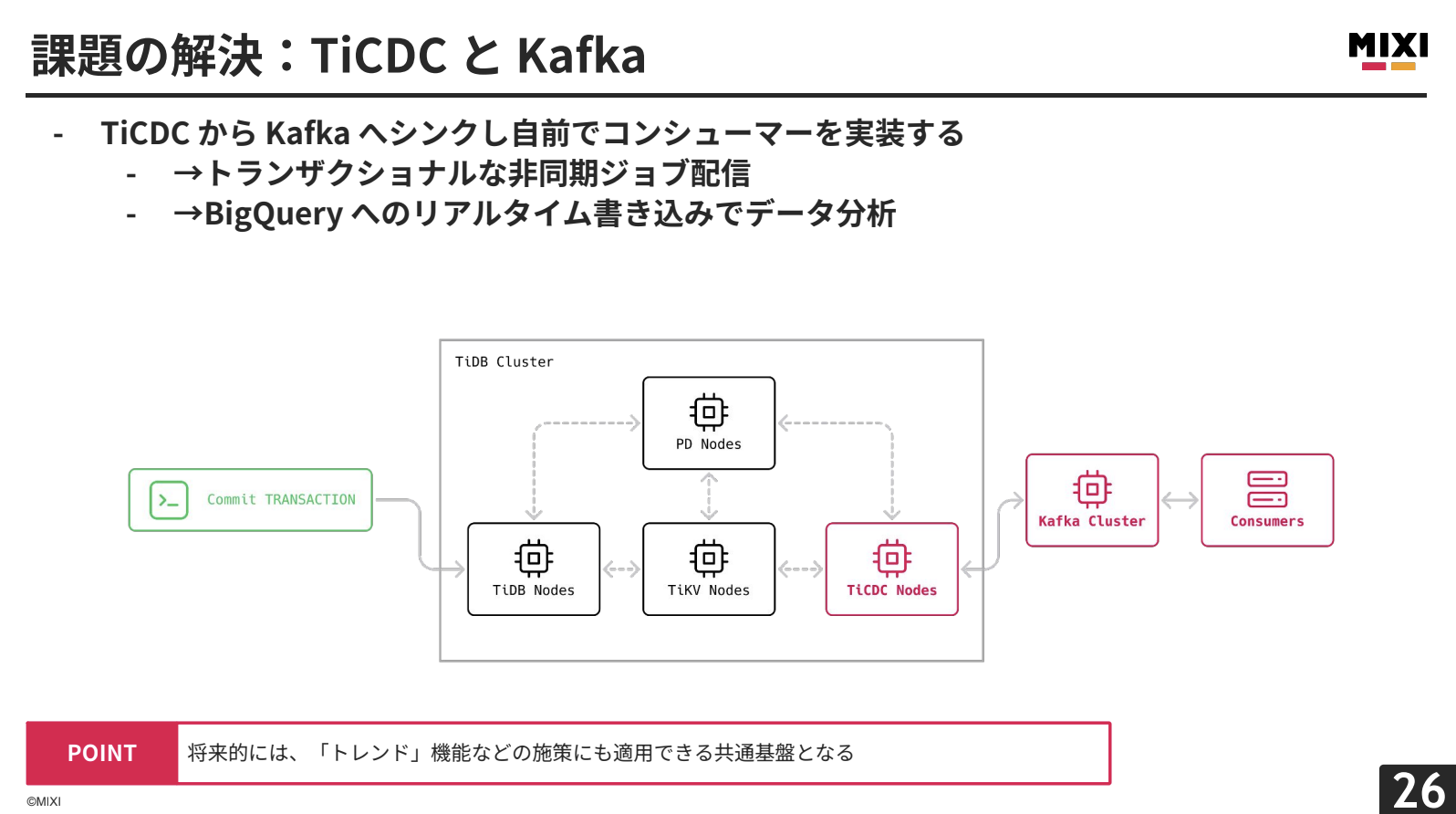
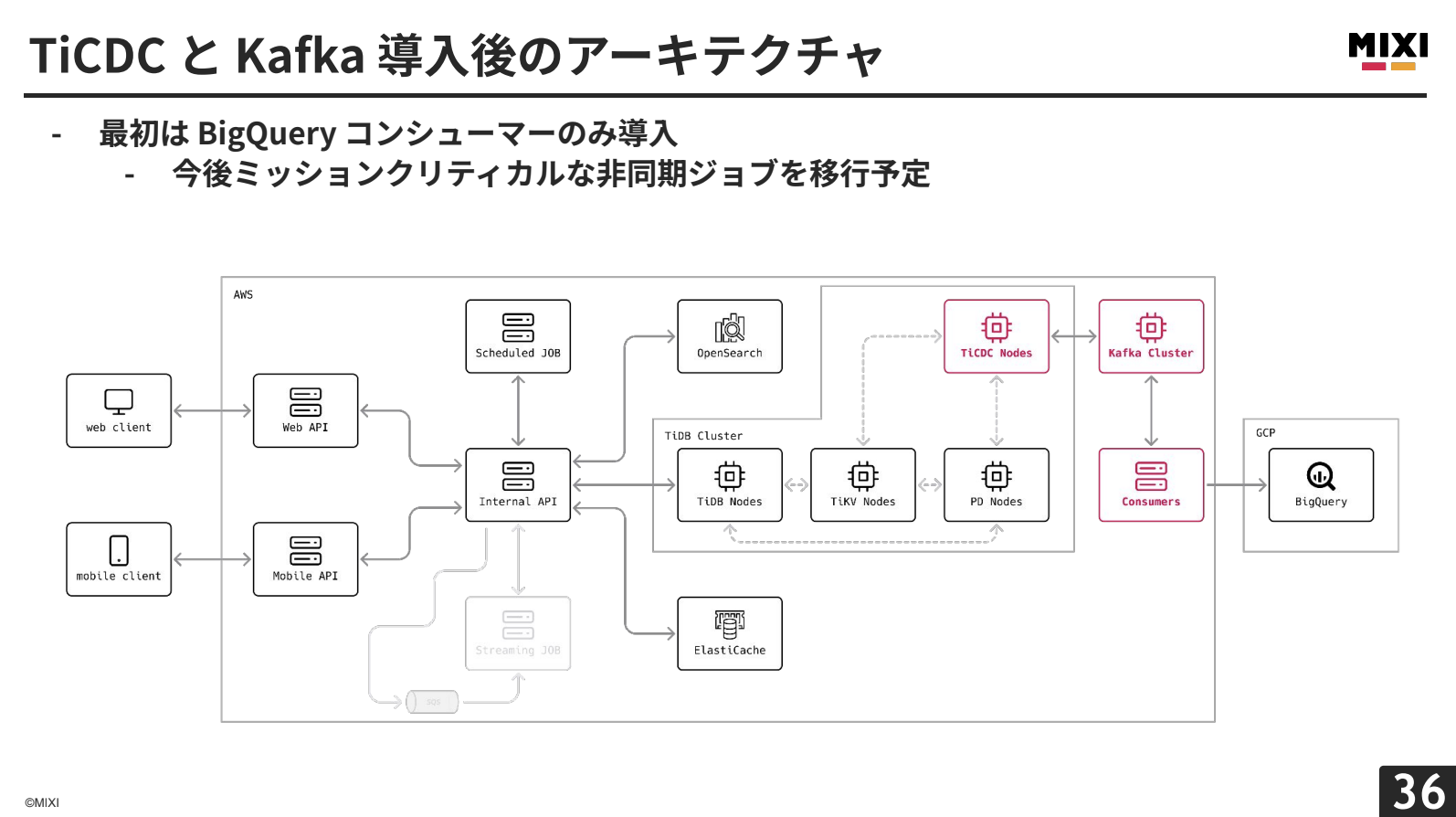
これまでのmixi2では、TiDBクラスターにPD、TiDB、TiKVという基本構成でしたが、そこに新しくTiCDCを導入することで、データの変更をリアルタイムに下流へ流すことができます。下流のシステムとしてKafkaを利用し、Kafkaのさらに下流のコンシューマーによって、データの使い方を決定できるようにしています。
この構成では、データベーストランザクションが成功したときに、一蓮托生の関係で、TiCDCにデータ変更をキャプチャーさせることができ、Dual-Write Problemを解決できます。また、Kafkaコンシューマーの実装によっては、BigQueryへのリアルタイムインサートや投稿の不正検知も実現できます。
Kafkaは分散型のイベントストリーミングプラットフォームで、高スループットかつ低レイテンシーが特徴です。TiCDCはレプリケーション先としてKafkaを公式対応しており、データ変更を直接Kafkaへ送信できます。mixi2では、Strimzi Kafka Operatorを使ってKubernetes上で比較的低運用コストで運用しています。
mixi2では、EKS上にKRaftモードでKafkaを構築し、Controller兼Brokerが3台、Brokerが3台の合計6台で構成しています。Schema Registryを併用してメッセージのスキーマ管理を行い、Avroプロトコルでメッセージサイズを最適化しています。PrometheusやKafbatなどの監視ツールも導入し、可観測性を向上させています。
各トピックで24パーティションを保持し、コンシューマーグループの並行性向上と将来的なスループット限界緩和を図っています。パーティションディスパッチャーはindex-valueに設定し、データのプライマリキーをもとにパーティションを分散させています。約1億メッセージのテストでは、最大と最小の差が0.16%前後に収まりました。
必要なテーブルのみレプリケーションするフィルタリングや、Kafkaのログリテーション設定により、保持データ量を計算可能にしています。
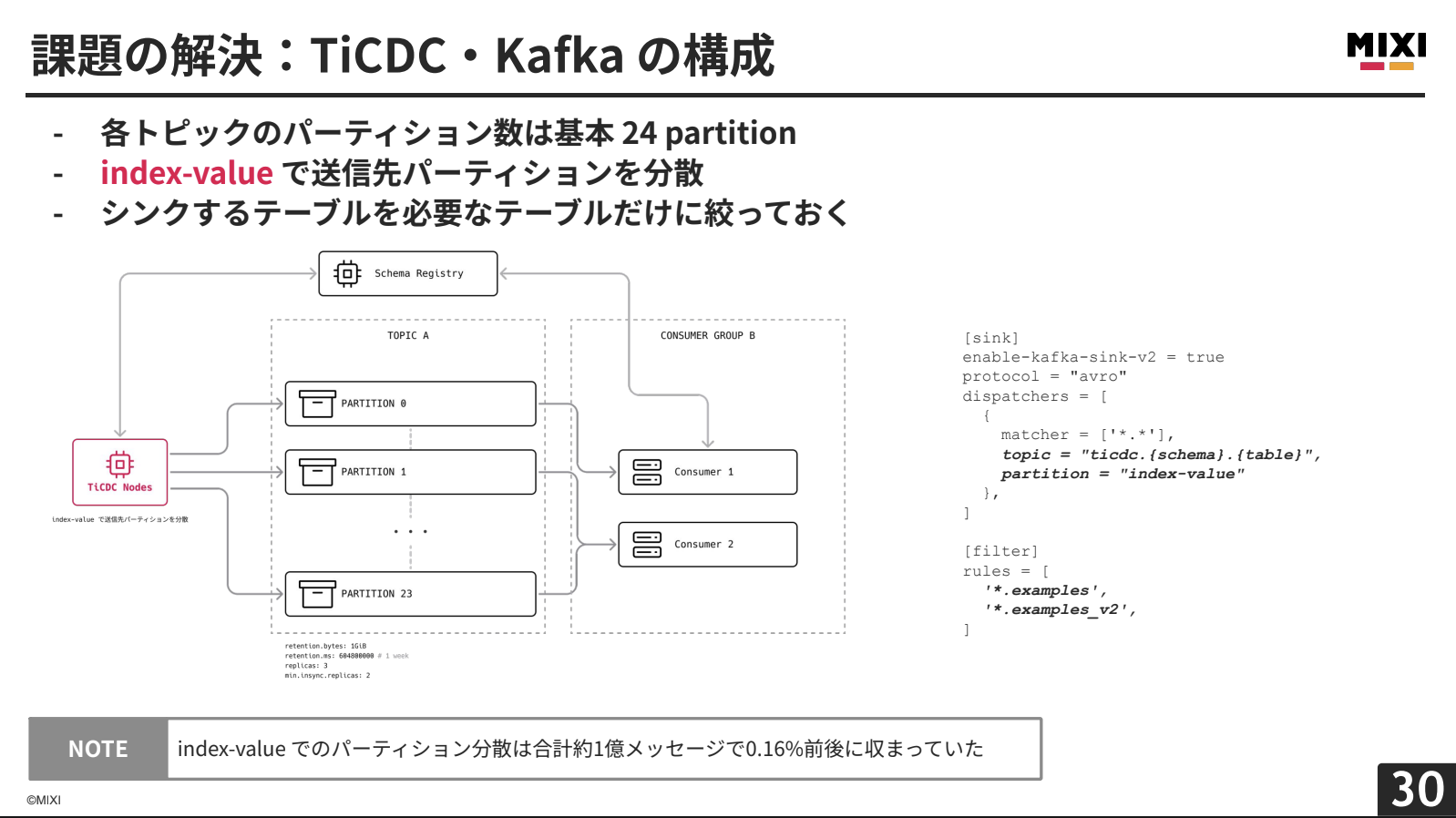
mixi2のサーバー言語がGoのため、コンシューマーもGoで実装し、TiCDCも使用しているkafka-goライブラリを採用しています。
Storage Writer APIを使用して直接BigQueryへデータをインサートします。JSONエンコードしたテーブルデータをデータカラムとし、メタデータを別カラムに追加することで、BigQueryのビュー側でスキーマ変更に対応しています。
不正検知用の学習済みモデルをEKS上のサーバーとして配置し、投稿があるたびにコンシューマーから検知サーバーにリクエストを送信してスコアリングを行います。不正と検知された投稿はデータベースに保存し、管理画面経由でカスタマーサポートメンバーが確認・判断します。
既存の非同期ジョブは、ミッションクリティカルな性質と移行戦略の違いを考慮し、SQSと併用しながら徐々にTiCDC・Kafka経由へ移行予定です。
メッセージ処理に失敗した場合は、指定リトライ回数分は同じトピック・パーティションに再送し、それでも失敗した場合はDLQトピックに送信します。DLQトピックは1つのみの構成とし、メッセージヘッダーにエラー情報とオリジナルトピック情報を格納しています。
DLQトピックへのメッセージ追加時にサーバーメンバーに通知し、原因調査・解決後はDLQ再送ツールでオリジナルトピックに再送します。

TiCDCの有無によるTiKV・TiDBへの影響調査、リリース前負荷試験同等RPSでのスペック選定、運用リハーサルを目的として負荷試験を実施しました。TiCDCのchangefeed有効時でも、TiKV・TiDBにはほとんど影響が見られませんでした。
Kafkaブローカーのストレージフル状態を検証したところ、changefeedがFailed状態に遷移し、再開後にTiCDCインスタンスでOut of Memoryが発生しました。この場合、TiCDCインスタンスを速やかに追加してサブタスクを分割する対応が必要です。一方、TiDB・TiKV・PDは問題なく動作していました。
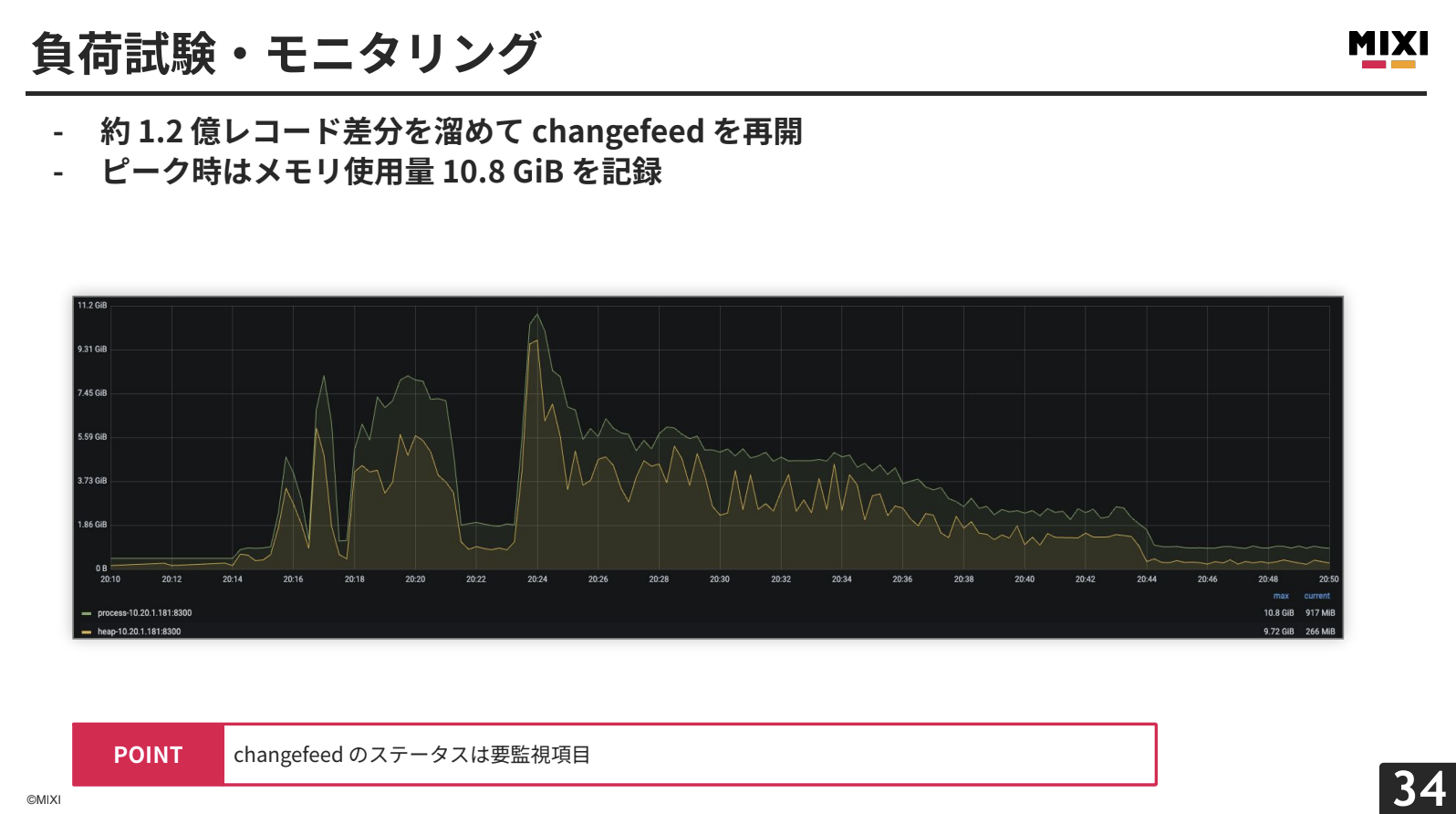
TiCDCインスタンスのスペックを上げ、約1.2億レコードの差分をためてからchangefeedを再開したところ、最大10.8GBのメモリー使用量でOut of Memoryを発生させずに30分足らずで完了しました。
changefeedのステータス監視、GCブロック時間内での対応、メッセージ量計算とTiCDCスペック選定が重要であることが分かりました。
導入後は、ダンプリングジョブからBigQueryまでのアーキテクチャがTiCDC・Kafkaに置き換わりました。開発生産性の面では、Dual-Write Problem解決、システムの疎結合化による実装時認知負荷軽減、リアルタイムデータ活用性の拡大、可観測性向上とDLQ運用の簡素化を実現しました。
この構成はリリース前から計画していましたが、少人数でのMVP開発のためリリース時はオミットされていました。今回の事例のように、運用中のシステムでも無理なく拡張できるのがTiDBの特徴だと感じています。
まとめ
松矢:最後にまとめです。
一つ目、データベースの観測性にコストをかける前にちゃんと“見える”のが TiDB の強みです。
二つ目、TiCDC をはじめとした周辺ツールはいずれも独立性が高く、TiDB クラスタに対してオンデマンドに拡張可能です。
三つ目、TiCDC によるトランザクショナルなイベント伝播により、整合性の確保とシステムの疎結合化を両立できます。
本日は最後までご清聴ありがとうございました。

アーカイブ動画も公開しております。こちらも併せてご覧ください。
※ご視聴には登録が必要です






