



BigQueryの導入理由から新機能Analytics Hubによるコスト削減まで。プレイドのCore Platformチームが活用法を解説する
はじめに
株式会社プレイドのCore Platformチームに所属しているBrownです。このたびはプレイドでコアに使用しているBigQueryについて、なぜBigQueryをコアのアーキテクチャに置いているのかから、BigQueryの新しい機能であるAnalytics Hubを用いたストレージや管理コストの削減に関して記事を寄稿させていただきます。 本記事では、BigQueryを使う際に、近年よく耳にするようになった「データのサイロ化」をデータ分析の具体例として取り上げ、そのようなデータに対してどうやってBigQueryを活用するのかについて紹介します。
このブログの想定する読者の方
- データウェアハウスという言葉は知っていて、アプリケーションで使用するデータベースの管理や運用はしたことがあるものの、一般的なデータベースの特性などにはあまり知見がないので、今後BigQuery含め、データベースの特性を理解して使いこなしたい方
- すでにBigQueryを使っていて、BigQuery特有のいろいろな機能についてもっと知りたい・使いたい方
自己紹介
株式会社プレイドについて
株式会社プレイドは「データによって人の価値を最大化する」をミッションに、多彩なプロダクトやサービスを展開しています。企業や団体が保有する1st Party Customer Dataを中心に、あらゆる機会・環境・ニーズで生じるデータを、リアルタイム・マルチチャネル・ワンストップで最大限活用可能にし、優れた顧客体験を実現するプラットフォームとして「KARTE」シリーズを提供しています。
筆者について

Brown
2022年1月に株式会社プレイドに入社しました。プレイドでは、秒間10万リクエストを超えるような大規模なリアルタイム解析エンジンBlitzの開発や、インフラ・データ基盤周りを担当するCore Platformチームに所属しています。データベースと分散システムに興味があり、プレイドでは主にデータベース周りの開発を行っています。
Linkedin : https://www.linkedin.com/in/takaaki-kanetsuki/
サイロ化したデータを利活用できる形に集約する意義
まずは、いろいろなところに散らばったサイロ化したデータを集約し、そのデータを価値のあるものとして利活用することの意義をご紹介します。「データのサイロ化」「サイロ化したデータを集約する」という言葉を最近耳にしたものの、どういうものかをご存じでない方も多いのではないでしょうか。ここではそのデータのサイロ化について、概念からご紹介します。
「データのサイロ化」とは、異なる部門やシステム間でデータが分断され、共有や統合が困難になる状況を指します。この現象は、組織内でデータが各部門やプロジェクト固有のシステムやデータベースに閉じ込められ、他との相互運用性がない状態で保持されることによって発生します。例えば、オンラインストアと実店舗を持つ小売業者で、オンラインストアの売り上げデータはEC事業部が、実店舗の売り上げデータは店舗事業部がそれぞれ別に管理する状態を考えてみましょう。
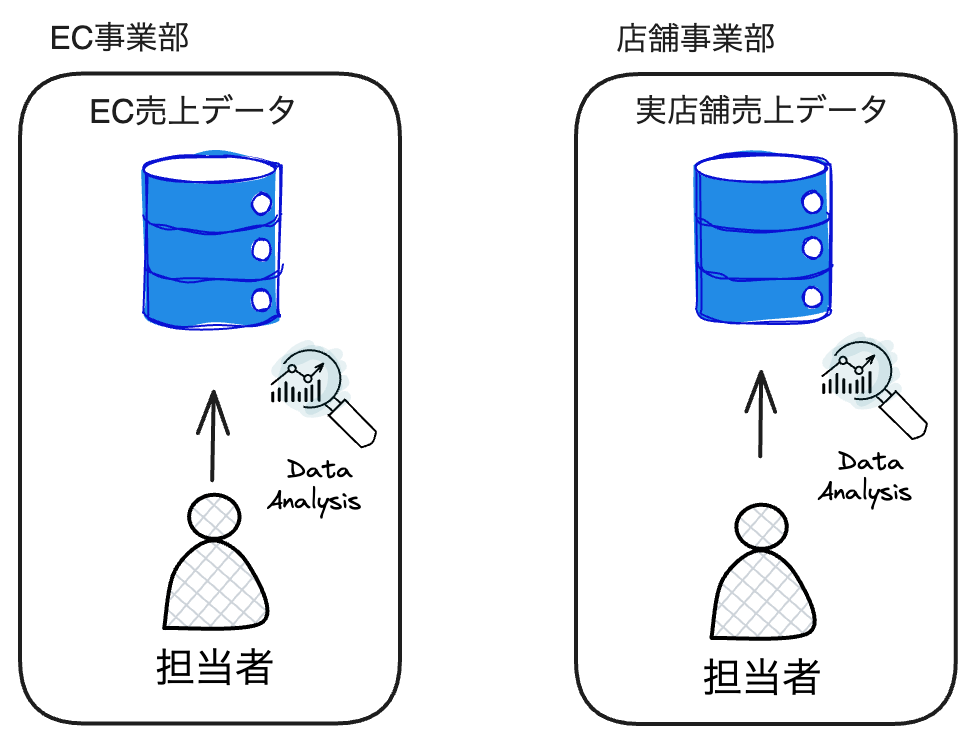
この図では、EC事業部・店舗事業部が別々のデータベースにそれぞれのデータを格納しており、そのデータを使う各事業部の担当者としては、そのデータを見るだけで十分という場合が多いと思います。一方で、EC事業部・店舗事業部を統括する責任者としては、それぞれの事業部で同じ商品を売っているため、オンラインと実店舗で売れる商品の違いや、実店舗に来店した後にオンラインストアで購入した会員顧客のデータなどを結合してデータ分析をしたいという場合もあると思います。ところが、それぞれのデータが独立しているため、データの結合ができません。
そこで、以下の図のように、それぞれの事業部のデータを1カ所のデータウェアハウスに集約することで、統括責任者はその集約されたデータを使用し、それぞれの事業部のデータを結合したり、組み合わせてデータ分析を行ったりすることで、より良い示唆を得ることができます。
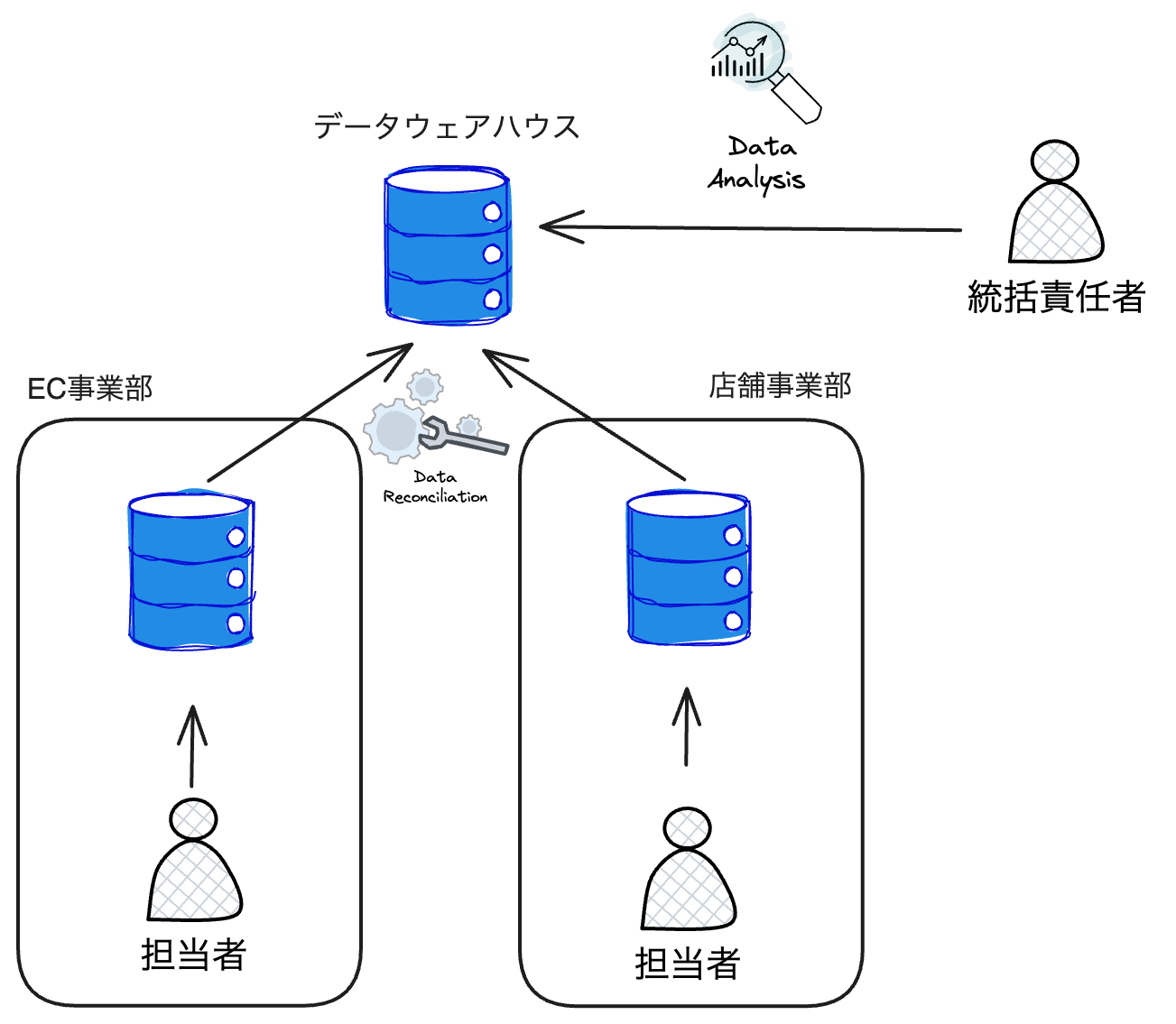
大規模な分析の処理を行うのに必要なデータベース
しかし前述のようなサイロ化したデータを1カ所に集め、重いクエリを用いて分析を行うというのは容易ではありません。例えば、MySQLなどの汎用データベースをサーバー上にセットアップして、各所から1TBのデータをインポートして分析をするために、複雑なJOINのようなコストの高い処理が必要なクエリを実行すると、おそらくクエリがなかなか返ってこないという事象に悩まされると思います。
そこで、大規模な分析の処理を行うためには、クエリを分散処理できる機構を持ったOLAPデータベースを使用するケースが多いです。この記事では、BigQueryのような分散処理を行うことができるデータベースがどのように作用するのかを後述します。
なぜプレイドではBigQueryを使うのか
プレイドでは日々大量のイベントデータを処理しており、BigQueryのテーブルの中には1つのテーブルに10TB/日の書き込み量のある巨大なものもあります。
例えば、一般的なPostgreSQLをオンプレミスのサーバーでセルフホストしているデータベースで、 2TB入っているeventsテーブルに対して、以下のようなクエリを実行するとどうでしょうか。おそらくなかなかクエリが返ってこないと思います。また、このクエリがスロークエリとなって、データベースのリソースを食いつぶし、他のクエリの実行をブロックしてしまうことも考えられます。
SELECT
e.event_id,
e.event_date,
e.event_type,
s.sale_amount,
s.sale_date
FROM `project.dataset.events` e
JOIN `project.dataset.sales` s
ON e.event_id = s.event_id
WHERE e.event_date BETWEEN '2020-01-01' AND '2024-12-31'
AND s.sale_amount > 100
ORDER BY e.event_date DESC;
そこで、上記のようなデータベースから、BigQueryを使うように変更をすると、どのような利点が得られるのかを考えてみましょう。
BigQueryでは、クエリを実行するコンピュート部分とストレージがそれぞれ別のコンポーネントになっており、そのコンポーネント間は高速なネットワークで通信するアーキテクチャを取っています。このような分離した構成によって、コンピュートとストレージそれぞれが独立してリソース管理を行うことができます。クエリを実行したときには、BigQueryのクエリ実行コンポーネントであるDremelがクエリを分割して、分割されたクエリそれぞれを別のノードやスレッドで分散処理するため、シングルノードでクエリを実行するのに比べ、より高速にクエリ結果を得ることができるようです。なぜ、より高速にクエリが実行できるのかや、どのような処理が行われているのかは、以前私が書いた別の記事をご参照ください。
BigQueryの分散処理の仕組みを深掘りする
また、ストレージのコンポーネントの中ではColossus Flash Cacheと呼ばれるストレージからの読み込みを高速化するファイルキャッシュに加え、カラムナフォーマットのCapacitorなどが組み合わさって1つのデータベースとして動いており、非常に高い性能を出すことができます。このパフォーマンスの良さは、弊社のシステムを提供する上で欠かせません。
BigQueryはデータベースそのものの強さだけではなく、後述するBigQuery Analytics HubやBigQuery Omniのような他のデータソースとデータをスムーズにデータ連携できる機能を備えていることから、データ分析ツールを提供している弊社としては、それらの機能をうまく使いこなして、KARTEのユーザーに価値を届けることに重きを置いています。
プレイドでのBigQueryのコスト削減
プレイドでの具体的な使用量や金額をここで書くことはできないものの、日々大量のBigQueryのスロットやストレージを使用しており、特に円安の現在においては、コスト削減が悩みの種になっています。今までにもいろいろなコスト削減にトライしており、以下の記事ではスロットやエディション関連での最適化を紹介しているので、ぜひご覧ください。
・6,000スロットを使うBigQueryのリソース配分最適化への挑戦
・BigQueryのコストの最適化への再挑戦〜BigQuery Editionsへの料金体系の移行について〜
前者の「6,000スロットを使うBigQueryのリソース配分最適化への挑戦」では、日々大量のスロットを使用している中で、そもそもスロットがどういうものなのか、どのようにスロットを利用するとうまく活用できるのかに関して実験や考察を記載しています。
そして後者の「BigQueryのコストの最適化への再挑戦〜BigQuery Editionsへの料金体系の移行について〜」では、2023年4月に適用されたBigQueryの料金体系の変更に伴い、スロットの単価の増加とストレージコストの減少の主に2つの影響を弊社は受けたため、それらへの対応について詳細に記述しています。特にスロットに関しては単価が $0.024/slothour から $0.048/slothourへ変更されたことでコストが2倍になりました。弊社のように大量のスロットを使っているとその影響が非常に大きいため、スロット使用のモニタリングなどを強化し、スロット使用のコスト最適化を行いました。
Analytics Hubの活用
さて、ここからはBigQueryを使用したデータ連携でのストレージコストと、管理コストの削減方法について紹介していきます。
例えば、グループ会社間で異なるGCPプロジェクトを使用してBigQueryをそれぞれの会社で使っている状態で、そのデータをグループ会社間で共有したいときには、以下のような手法がとられるのではないでしょうか。
1. グループ会社Aからグループ会社BのGCPプロジェクトのBigQueryに、共有したいデータのみコピーする
2. グループ会社Aのデータセットに、グループ会社Bの人がアクセスできるように、サービスアカウントに権限を付与する
それぞれよくあるケースではないかと思うのですが、両方ともにメリット・デメリットがあります。まず1では、グループ会社Bに属する人のサービスアカウントに、グループ会社Aのデータセットに直接アクセスできる権限を付与しなくてもよいので、アクセス管理・監視が簡単ではあるものの、データの実体ごとコピーしているため、コピーのコストがかかる上、同じデータに対してのストレージ料金が、A、B両方の会社で課金されます。一方、2ではストレージコストはかからないものの、会社Bに属する人が、GCPプロジェクトを越えて会社Aのデータセットに直接アクセスできる権限を得てしまうため、その権限を適切にグループ会社間で管理・監視する必要があり、煩雑です。
そこで、BigQueryのAnalytics Hubという機能を使うと、以下のように会社Aが持つデータセットのSymbolic LinkなどのLinked Datasetを会社BのGCPプロジェクトへ共有し、会社Bに属する人はそのデータセットにクエリをかけることで、会社Aのデータセットの中身を見ることができます。ここで特徴となるのは、Linked Datasetはデータ実体を持たないため、ストレージコストはそのデータの持ち主の会社Aにのみ課金され、会社Bはクエリにかかった費用のみを払えば済むということです。また、サービスアカウントへの権限付与も、一度Linked Datasetが作られると、会社Bに属する人は、通常通り自身の会社のGCPプロジェクト内にあるデータセットのみにアクセスするため、GCPプロジェクトをまたいだ権限付与が不要です。
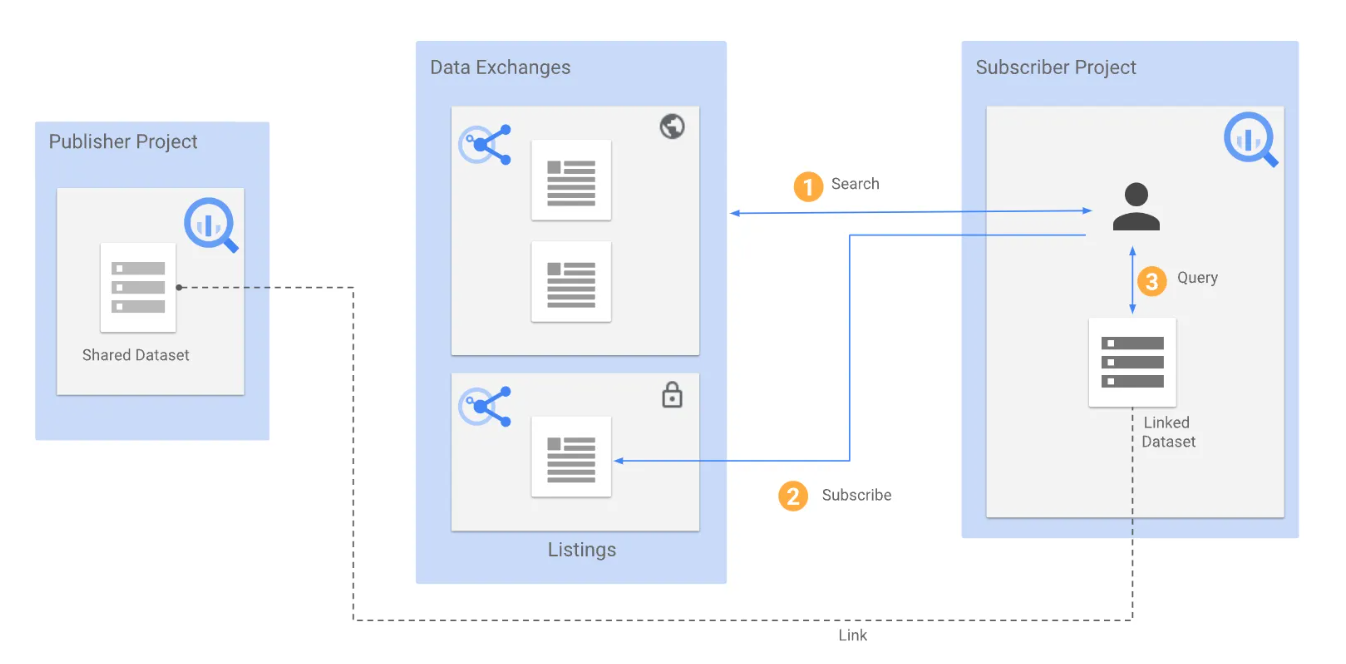
( Introduction to Analytics Hub より引用)
また、Analytics Hubを使うことで、直接GCPプロジェクトをまたいだサービスアカウントに権限付与を行う必要がないのに加え、どのデータセットがどこのプロジェクトに共有されているかや、なぜそれが共有されているかなどをAnalytics Hubの画面で一覧で見ることができるため、管理も非常にシンプルになります。さらに、もし何らかの事情ですぐに共有を停止する際にもAnalytics Hubの画面から共有停止を行うだけで済みます。
弊社の中での具体的なAnalytics Hubのユースケースや、機能の紹介はこちらの記事で解説しているので、ぜひご覧ください。
BigQuery Analytics Hubを使った透明性が高くセキュアなデータ共有
終わりに
今回の記事では、なぜプレイドではBigQueryを使うのかということから、BigQueryのAnalytics Hubという新しい機能を用いてストレージコストを削減する話をご紹介しました。BigQueryは2011年にGAになってからもう10年以上が経過しており、現在では多くの会社で使用されています。しかし、その特性を理解した上でBigQueryの進化にキャッチアップし続ける取り組みをしているところは、それほど多くないのではないかと思います。
プレイドではこの記事のように、日々BigQueryの進化をキャッチアップして、新しい知見や、その進化によって得られたメリットなどをみなさんにご紹介していきます。






