



【開発生産性カンファレンス 2025】AI時代の開発生産性を加速させるアーキテクチャ設計
2025年7月3、4日に「開発生産性Conference 2025」がファインディ株式会社により開催されました。
3日に登壇した株式会社プレイドの日鼻 旬さんは、同社のプラットフォームエンジニアリングのヘッドを務めています。本セッションでは、AIを用いて開発生産性を向上するためのシステムアーキテクチャを模索してきた中で辿り着いた現状の構成と、得られた学びについてお話しいただきました。
■プロフィール
日鼻 旬
株式会社プレイド
執行役員 VP of Core Platform
東京大学大学院修了後、日本IBMにて複数のシステム開発プロジェクトを経験した後、2019年プレイドに入社。KARTEのリアルタイム解析エンジンの刷新プロジェクトなどに従事し、現在はKARTEの基盤システムの開発・運用を統括している。2024年より執行役員 VP of Core Platformに就任。
GitHub Issue中心のコーディングエージェント開発環境
日鼻:株式会社プレイドの日鼻です。私は2019年にプレイドに入社し、コアサービスである「KARTE」のリアルタイム解析エンジンを開発していました。現在は、プラットフォームエンジニアリングのヘッドを務めています。
「KARTE」についてもご紹介させてください。プロダクトとしては、Googleアナリティクスをイメージしていただくとわかりやすいかもしれません。クライアントのWebサイト側にSDKを組み込み、Webサイトに訪問したユーザーの行動ログをイベントとして「KARTE」に送信し、ユーザーの属性をビジュアライズします。
それだけでなく、行動履歴に基づいて特定のユーザーにポップアップ表示やクーポンの提供といったインタラクションを画面上で設定できる解析エンジンと配信機能も内包しています。具体的には、ユーザーの行動ログがイベントとして送信されると、そのイベントログと過去履歴を照合・計算し、条件に合致した場合にポップアップなどを表示します。この点はGoogleアナリティクスとの大きな違いです。
それでは本題に入ります。本日は「AI向けの開発環境づくり」「AI時代のデータアーキテクチャ」「今後の取り組み(AIエージェント)」という3つのテーマでお話しします。
プレイドでは開発時にAIを使いたいのであれば使うという、各自が自由にできるスタイルです。例えば、デザインツールだとFigma AIやClaude Artifactを使っています。IDEやコーディングエージェントでは、VS Code、Cursor、Java開発をするためIntelliJ、話題のClaude Codeももちろん使っています。
AI向けの開発環境づくりとして、コーディングエージェントに自律的に開発してもらう環境をつくる方法は、主に2パターンあると思います。
1つ目はエンジニアが開発PCの中でコーディングエージェントやIDEを立ち上げてコーディングしてもらい、出来上がったものをGitHubのPull Request(以下、PR)として投げてマージする方法です。
2つ目は発展的に、例えばエンジニアがIssueを通じてタスク依頼をすると、Devinのようなエージェントが勝手にコーディングして、その中でIssueもPRも出してくれて、マージは人が判断するといった方法です。
1つ目については多くの情報が出回っており、解説してもあまり面白くないと思います。逆にリモートでどうやってもらうかというところについては、私たちが試行錯誤してきた結果が出ているため、本日はそれを紹介したいと思います。
リモートで対応させる時にどうすれば良いか考えた時に、我々はClaude Codeを使っているため「ローカルでコーディングエージェントを使ったワークフローをそのままリモートでやらせれば良い」という考えにいたりました。
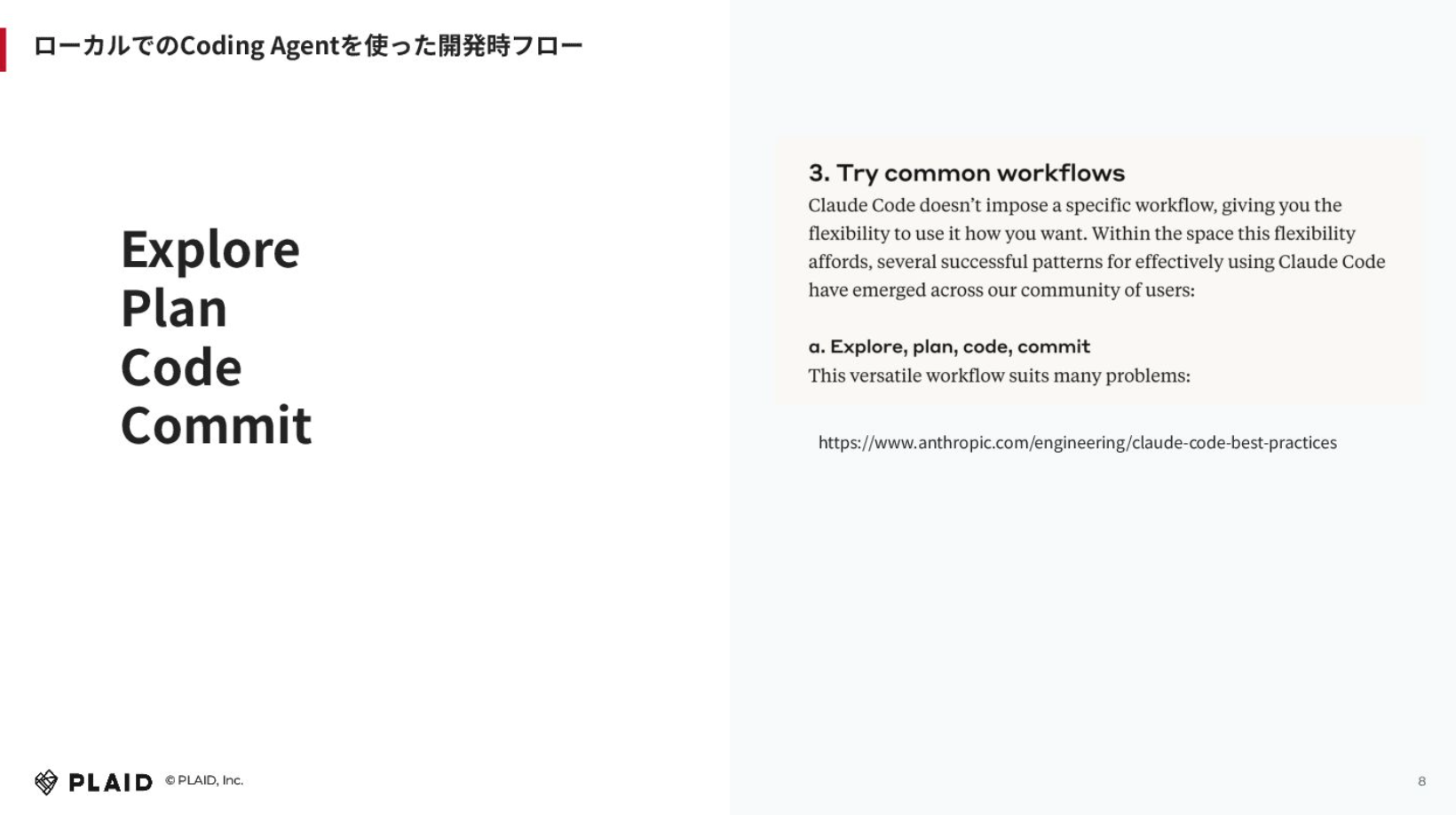
右側にあるのは、Anthropicが出しているClaude Codeのベストプラクティスの中から抜粋した文章で、Common Workflowで試してみた事例です。書いてあることとしては、例えばClaude Codeを使うときに、まずディレクトリコードなどをエクスプローリングしてもらいます。やりたいことを指示した時に、Claude Codeにプランしてもらい、その結果を見て良いか悪いかを人間が判断し、良ければコーディングしてもらいます。そして、人間がPRをあげる、もしくはClaude CodeにPRをあげてもらうと。主にこの4つのワークフローのステップに集約されると思います。
これをGitHub Issue上でどう実現するかを考えて、このようなワークフローを組んでみました。
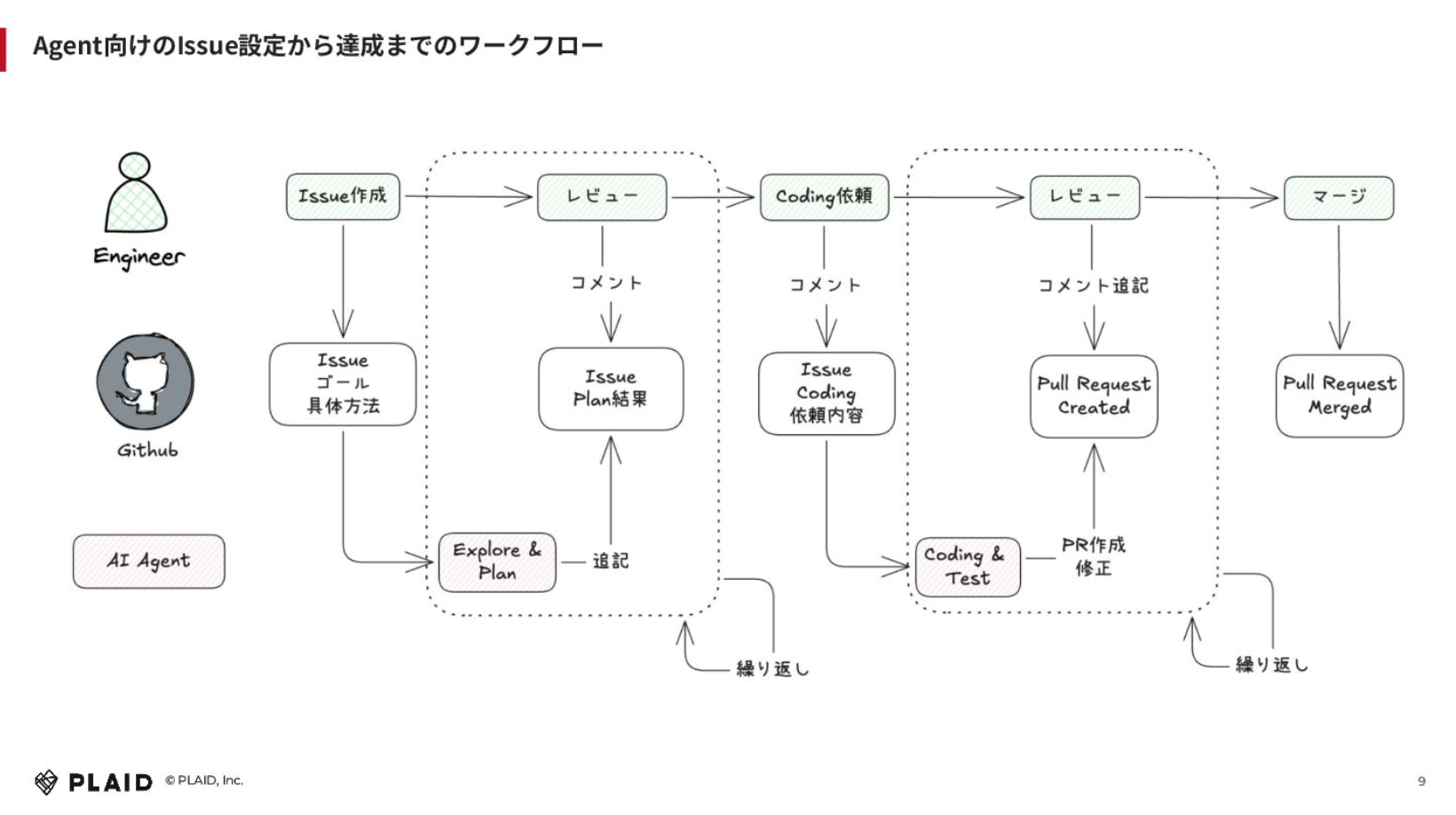
基本的にはエンジニアがIssueを作成します。GitHub IssueにIssueでやってほしいことやゴールを書き、GitHub Actionsの中でClaude Code Actionを動かして、エクスプローリングしてディレクトリ構造などを見てプランしてもらう。それをIssueのプラン結果としてClaude Code ActionがGitHub Issueにコメントを追記します。そこに対して、そのプランが合っているか、間違っているかというところをIssue上にコメントしていきます。それを何回か繰り返します。
結果的にそのプランで良くなったら、GitHub Issue上にコメントしてコーディングを依頼します。そうすると、Claude Code ActionがコーディングやテストをしてくれてPRをつくります。そこで終わりではなく、そこに対して「このコードはいらない」「ここはもっとこうしてください」などレビューコメントをします。これでPRの内容について繰り返しイテレーションをさせて、良ければマージする。あとはデプロイフローに乗っていくということを実際にやってみました。
ポイントとしては、Issueにコメントしていくことで履歴が残るため、どういう思考で何を修正させたかがログとして残るということです。レビューやPRについても残ります。
Claude Code Actionの場合は、GitHubのMCPを使ってGitHub IssueやPRのコメントを取ってきてくれるため、このフローはうまくいきました。
具体例を出すと、このような形です。内容は出せませんが、Claude Code ActionがTodoを書き出してくれます。下の方には実装プランが書かれています。
コーディングについても「最新のプランに基づいて実装してPRを作成して」とコメントすると、このように対応してくれます。この時はPRの権限を与えていなかったため、手動でチェックしてCreate PRのリンクを押さないとPRはつくれませんでしたが、権限を与えればつくってくれました。データモデルやビジネスロジック、APIなど、思ったよりも対応してくれました。
このフローを取り入れて感じたのは、一番最初のIssue作成時の情報が重要で、どれだけ丁寧に細かく書くかによって結果が左右されるということです。具体的には、画面UIのスクリーンショットを貼ったり、APIのスペックなどを丁寧に書いたりする必要があります。
社内でこのワークフローを運用して気づいた点としては、Issueを作成させるところも、ローカルのAIエージェントに任せると精度が高いということです。まず、Claude Codeを自分のPCで動かしながらIssueを作成してもらうと。Claude Codeはローカルのディレクトリの中の情報などを取ってきてくれて、人が書くよりもコンテキストが入った情報を出してくれます。そこからはGitHub ActionsのClaude Code Actionに処理させると、並列数が上がるということに気づきました。
2つ目は、エージェントの能力を最大限拡張するため、エクスプローリングとプランの部分をメインにMCPサーバーの活用にもトライしました。エージェントやLMMモデルが持っている情報は古かったり限りがあったりするため、エクスターナルもしくはインターナルなリソースを使って最大限エクスプローリングしてもらうことが重要になってきます。
MCPサーバーの活用にトライした際の課題と、解決法についてもお話しします。
MCPサーバーで対応することは、3つに分類されると思っています。1つ目は、エクスターナルでパブリックなリソースを取ってくる形。2つ目がインターナルで社内のプライベートなリソースを活用するパターンで、SlackやSentryというエラートラッキングツールのMCPを使う場合などです。3つ目は、思考を拡張させるために、リソースはないけれどExtended ThinkingのようなMCPを使うケースです。
これらに対するセキュリティ上の課題が何かというと、一番最初に情報漏洩リスクが挙げられると思います。Claude Code Actionの方でも、デフォルトではウェブサーチをしません。Claude Codeは人がチェックしてアローリストなどに追加すればスキップしますが、GitHub Actionsの中で都度チェックするというのは難しいでしょう。本気で取り組むなら、自由にさせないといけません。しかし、それをすると、例えばGitHub Actionsがアクセスできるシークレットな情報が漏洩する可能性が無きにしも非ずです。
もう1つが、インターナルなソースに対しての権限管理が難しいということ。例えば、GitHub IssueにアクセスできてもSlackのチャンネルにアクセスできない人が、MCPを介してエクスプローリングできるようになります。GitHub issueを通じて本来のアクセスコントロールの抜け穴になってしまう可能性があるのです。
情報漏洩リスクがありエクスプローリングが難しいという課題に対してどのようにアプローチしたのかというと、GitHubリポジトリを分けました。
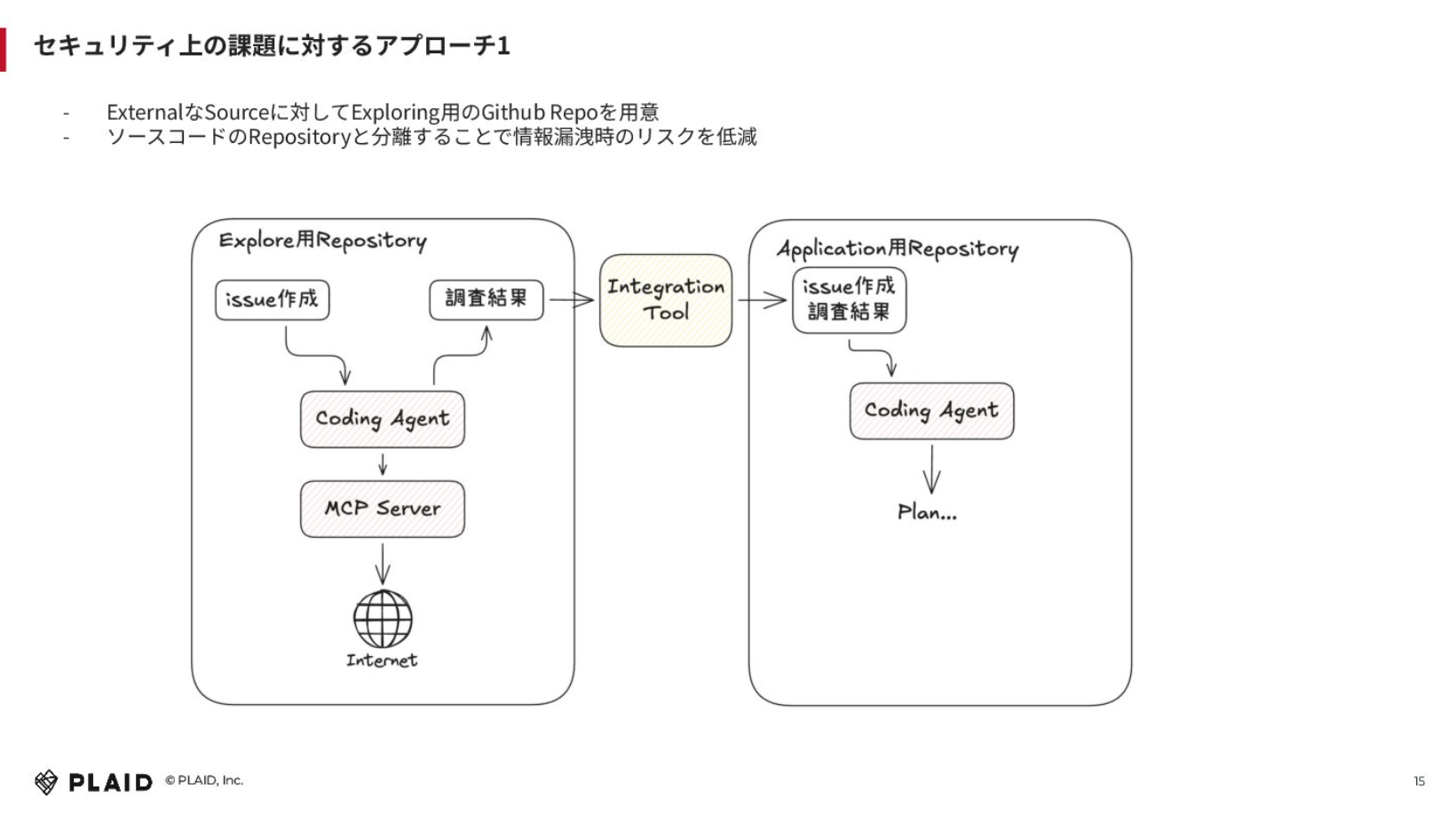
エクスターナルなソースに対して、エクスプローリング用のGitHub Repoを用意して、その中で調査させる形です。これの何が良いかというと、仮にGitHub Actionsの中でアプリケーションのデプロイをするシークレットを持っていても、別のリポジトリでエクスプローリングするため、情報漏洩時リスクが低減できています。
エクスプローリング用のリポジトリの中でIssueを作成して、MCPサーバーを通じてインターネット経由でコーディングエージェントにウェブサーチをしてもらうと。まだ試せていませんが、Gemini CLIなどを利用しても面白そうだなと思います。
調査結果はIssueのコメントに貼り付けて、Zapierなどのインテグレーションツールを通じてアプリケーションのリポジトリにIssueを作成し、実際のコーディングのストラクチャーをもとに、プランを立ててもらうという方法をとりました。
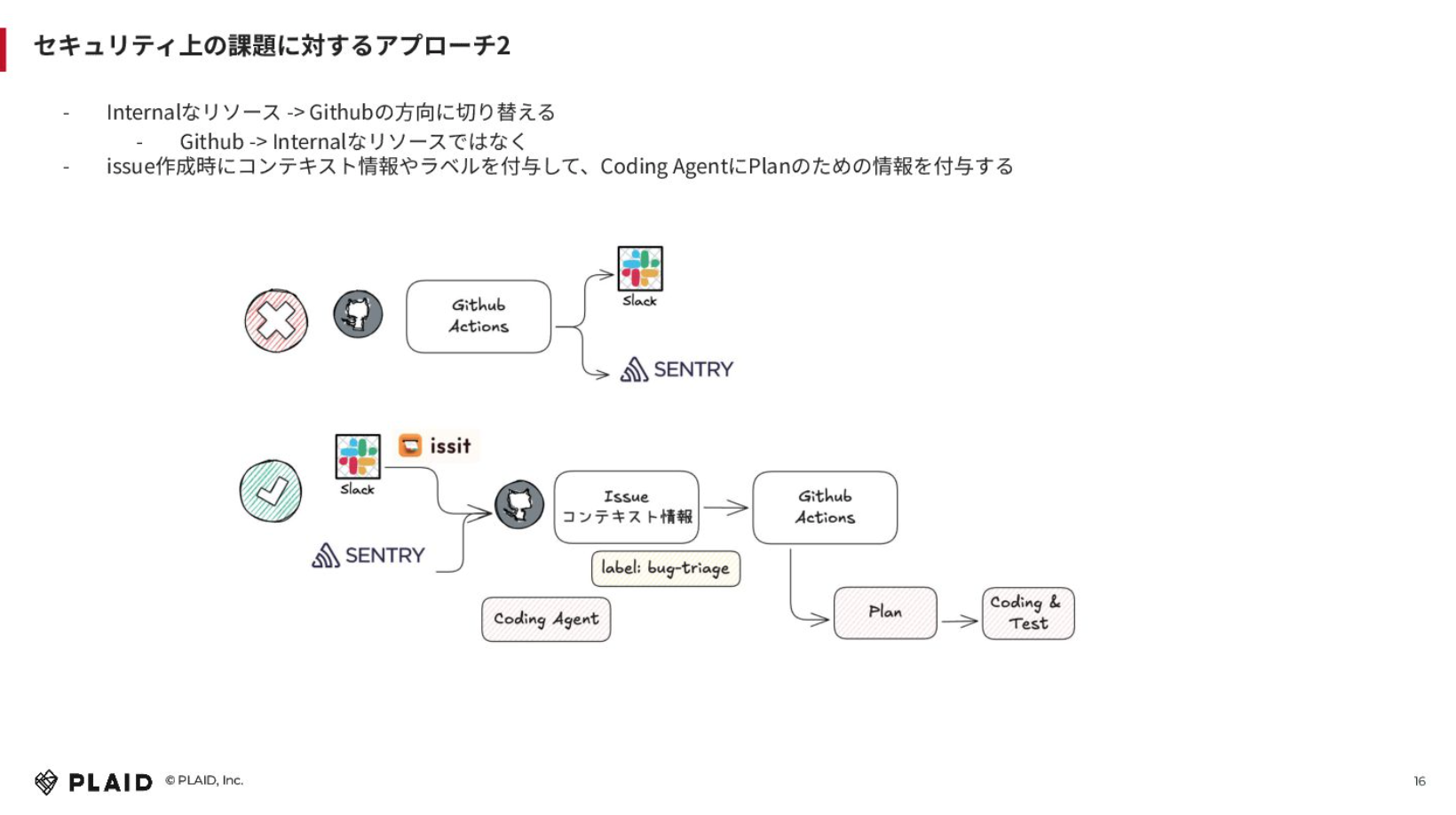
インターナルなリソースに対しては、向き先を切り替えました。GitHub Actionsの中からSlackやSentryなど他のツールを見るのではなく、SlackやSentryからGitHub Issueを作成する形に向きを変えるということです。issitというGitHub Issueを簡単に作成できるSlackのアプリケーションを自社開発しているため、それを使ってインターナルなリソースの方からIssueを作成し、Issueに対してコンテキスト情報を渡すようにしています。
例えば、Sentry経由だと「エラートラッキングのバグをトリアージしてください」というラベルをつけて、その中でGitHub Actionsを動かして、プランやコーディング、テストをしてもらうという感じです。
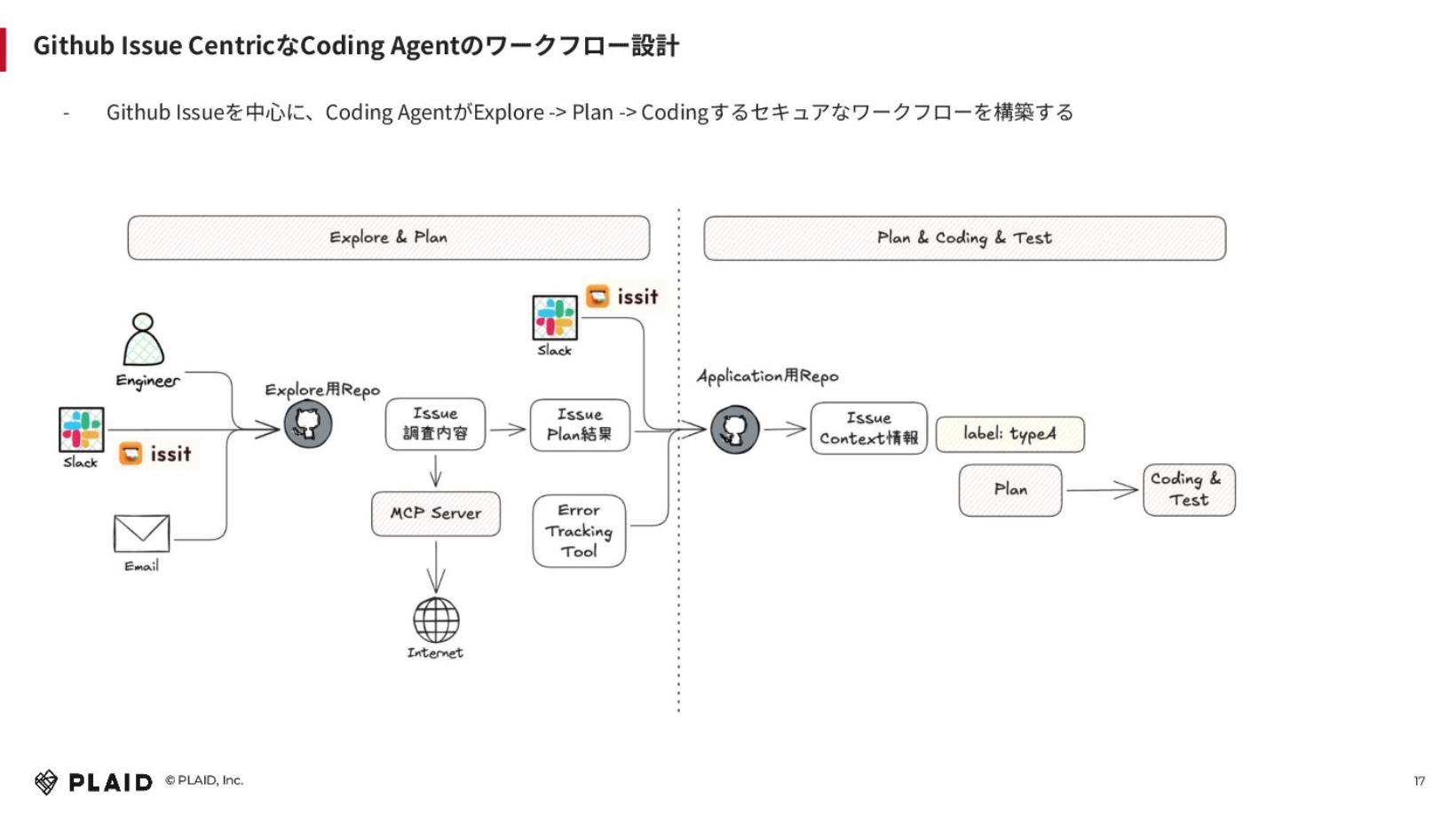
トータルで言うと、GitHub Issue Centricなコーディングエージェントのワークフローを設計しました。上図の左側がエクスプローリングやプランフェーズで、右側が実際のコーディングストラクチャーを見てプランしてコーディングしてテストするフローです。
事前のパブリックな情報をもとに、エクスプローリングが必要なものについてはエクスプローリングリポジトリでIssueをつくり、MCPサーバーを通じてインターネット経由でサーチしてもらい、Issue結果を貼り付けます。その結果をアプリケーションのリポジトリの方に連携して、そこからIssueコンテキストは十分にあるため、インターネットにアクセスしなくてもそのままプランしてコーディングできます。
エクスプローリングが必要なくても十分にコンテキストがあるケースに関しては、直接アプリケーションのリポジトリにSlack経由もしくはエラートラッキングツール経由でIssueを作成すれば、トリアージやプランを依頼するフローが実現できます。

「AI向けの開発環境づくり」についてまとめます。
コーディングエージェントが非同期で開発して人がレビューするヒューマンインザループのようなフローをつくれたものの、AIエージェントの進化次第で変わる可能性はあると思っています。例えば、GitHub Copilot Agentがセキュアにウェブサーチもしてくれるようになれば、このフローは必要なくなるでしょう。ただ、その未来が来るまでは使えるものだと考えています。
あとは、コーディングエージェントの自律性を拡張することとセキュリティの担保が難しいと感じました。私たちも試行錯誤している段階であり、このやり方が正しいのかどうかはわかりません。おそらく、これ以外にも方法はあると思います。
学びとして「GitHub Issue Centricなコーディングエージェントのワークフロー設計」はマルチエージェントに近いと考えています。先ほど見せた画像の左側がエクスプローリングするエージェント、右側がコーディングするエージェントだと捉えることもできると思います。
マルチエージェントで各エージェントの目的・責務ごとに権限やセキュリティを分けてオーケストレーションしていけば、パターンを拡張してさらなる自律性を拡張しつつ、セキュリティを担保できるのではないかと考えています。
AI時代の開発生産性を最大化するデータアーキテクチャの設計思想
日鼻:次に「AI時代のデータアーキテクチャ」と題してお話しします。
コーディングエージェントが開発しやすいシステムが何かというと、一般的でありふれていて、かつ独立しているアプリケーションです。Bolt.newなどで簡単につくれるものであることが鉄則であり、ありふれたものをつくれるかどうか、が重要だと思います。
KARTEの場合、訪問者の属性や行動をダッシュボードで見せる必要があるため、データの可視化が重要だと言えます。つまり、データアーキテクチャの話になっていくと。そのため本日は、データの可視化やアーキテクチャに特化した話をしようと思います。
AIとは関係ないのですが、学びになった例として、PdMがBIツールベースで「KARTE」の中にあるメールやアプリプッシュなどを大量に配信できる「KARTE Message」のレポート画面を開発した事例もお話しします。
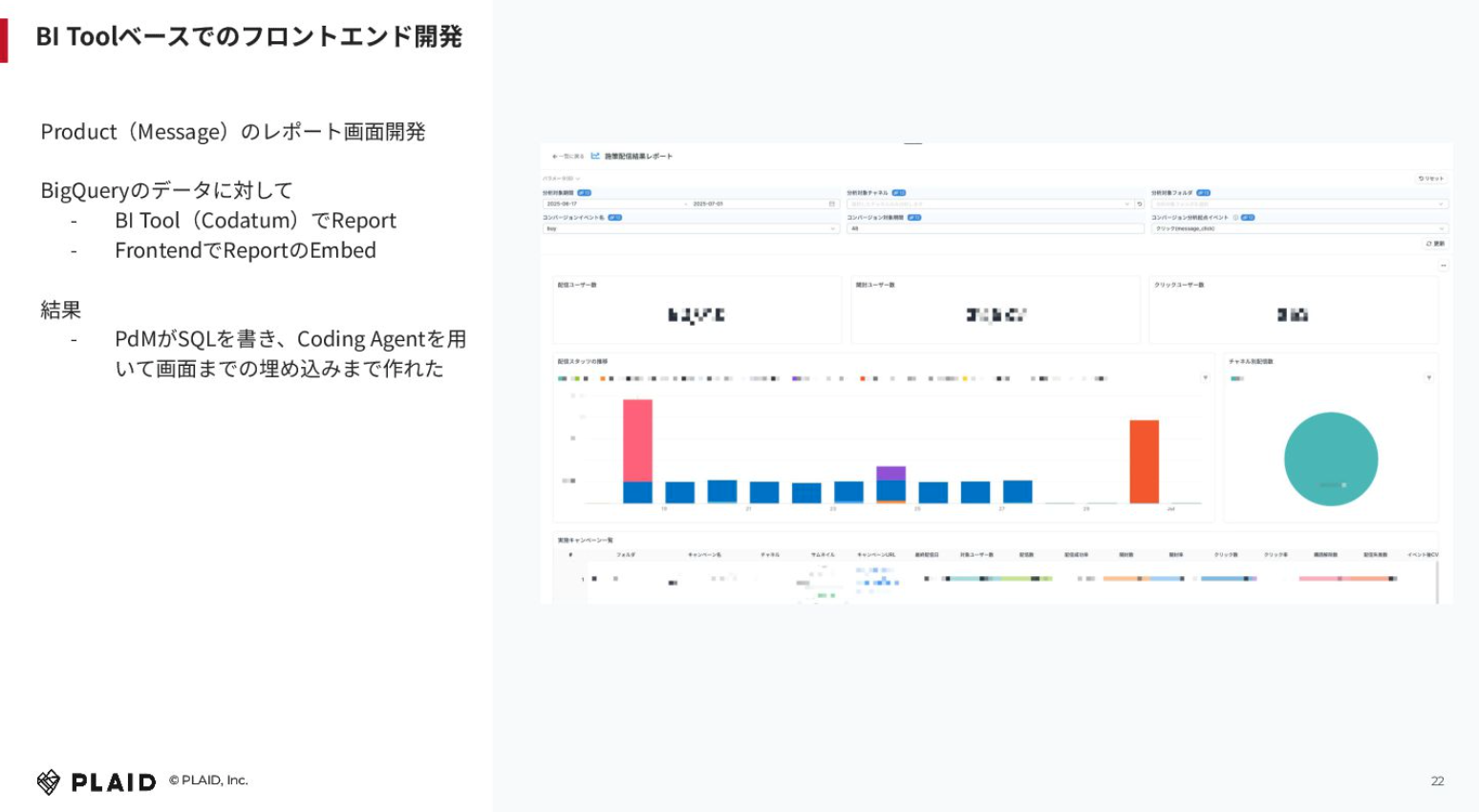
何をしたのかというと、BigQueryに溜まっていたデータに対して、BIツール「Codatum」を使ってNotebook的なレポートを作成しました。SQLを書けるのであれば誰でもできるものですね。そのレポートをフロントエンドの中でエンベッドしました。画像の右の方で出している各コンポーネントは、全てNotebook的なところから画面表示しています。
結果として、エンジニアではなくPdMがSQLをどんどん書いて、コーディングエージェントを用いて、画面の埋め込みまで簡単に作成できました。この事例から我々が学んだことは、データがあればフロントエンドのデータの可視化領域は簡単にできるのではないかということです。
ちなみに「Codatum」はグループ会社で開発しているもので、分析機能を簡単に自社アプリケーションへ統合してくれるBIツールです。
なぜうまくいったかというところで、現在のアーキテクチャを解説すると、基本的に我々はデータウェアハウスにデータを集約していて、BigQueryをメインで使っています。
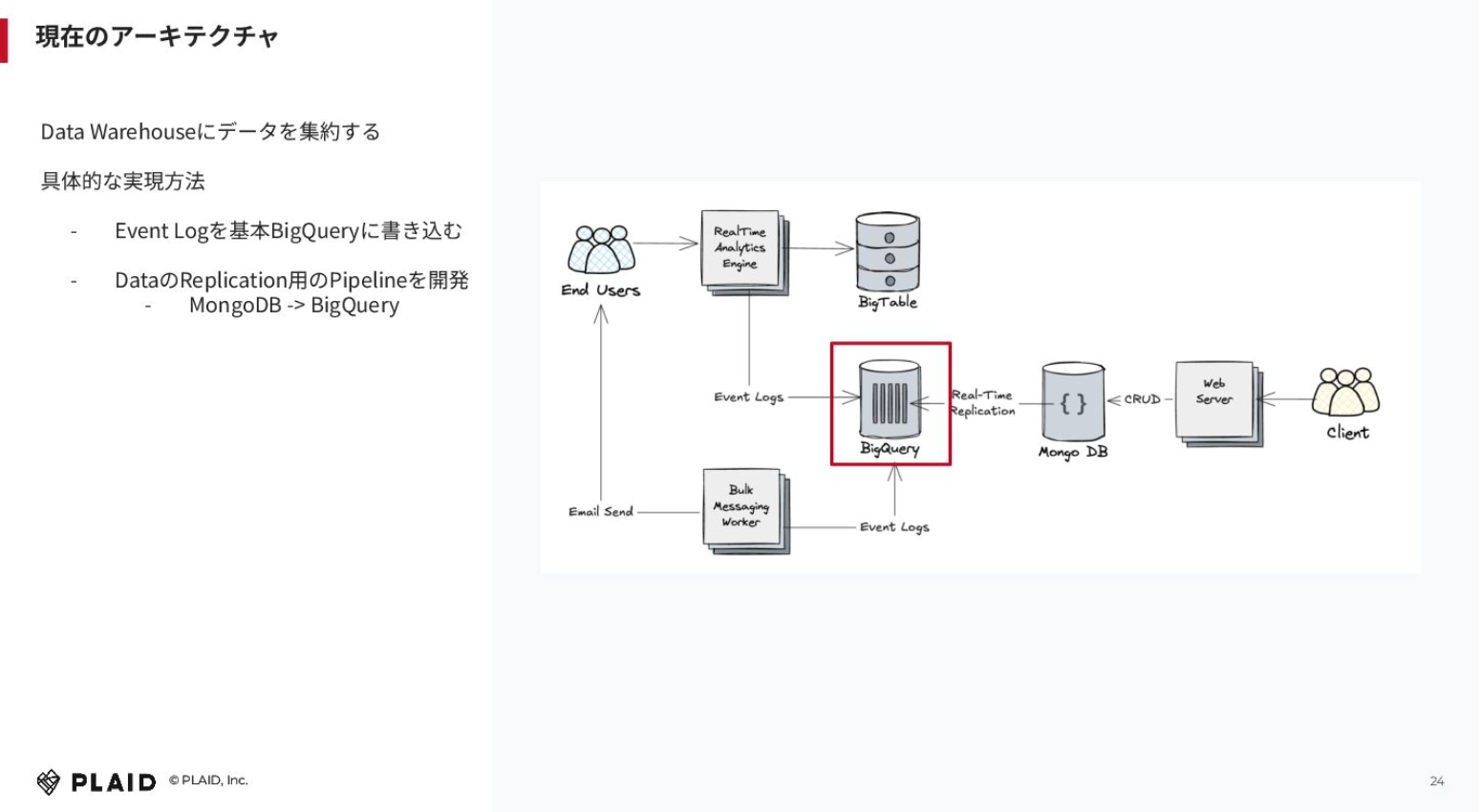
エンドユーザー(Webサイトに訪れてくれたクライアントのカスタマー)が送ってくれたイベントを解析するエンジンがあり、Bigtableをキーバリューストアとしてメインで使用しつつ、BigQueryにもイベントログを書き込んでいます。
画像下の方にあるBulk Messaging Workerでは、先ほどご紹介した「KARTE Message」のシステムをつくっていて、そこも同じようにイベントログをBigQueryに貯めています。
それだけではなく、クライアントがウェブのサーバー経由で「この人に何時に配信したい」「このようなセグメンテーションをする」という設定を、基本的にはMongoDBの方にコンフィグレーションとして入れていて、リアルタイムでBigQueryにレプリケーションしています。
MongoDBがトランザクション系かどうかは置いておいて、設定系のDBの情報もBigQueryに集約していくアプローチをとっています。そのため、BigQueryにデータがたまる構造になっています。その結果、SQLさえ書けばどんどんフロントに埋め込んで画面開発を進められる状況をつくれました。
ただ、課題がないわけではありません。今のデータアーキテクチャ上の課題は何かというと、インタラクティブにデータ探索したい時に遅いという問題があります。データウェアハウスでは特徴的だと思います。
我々の場合、生データだと月間で13ビリオンぐらいイベント数があり、1日当たりでも3~5テラぐらいあると思います。BigQueryは強力なのですが、これだけデータ量が多いと、どうしても遅くなってしまいます。ただ、柔軟なクエリをかけられると。
中間データを用意したら良いという考え方もありますが、分析軸が固定的であるため、パイプライン管理が面倒になってしまいます。
これを根本的に解決する取り組みとして、インタラクティブなデータ探索用のデータベースを開発しています。OLAPのDBという感じですね。
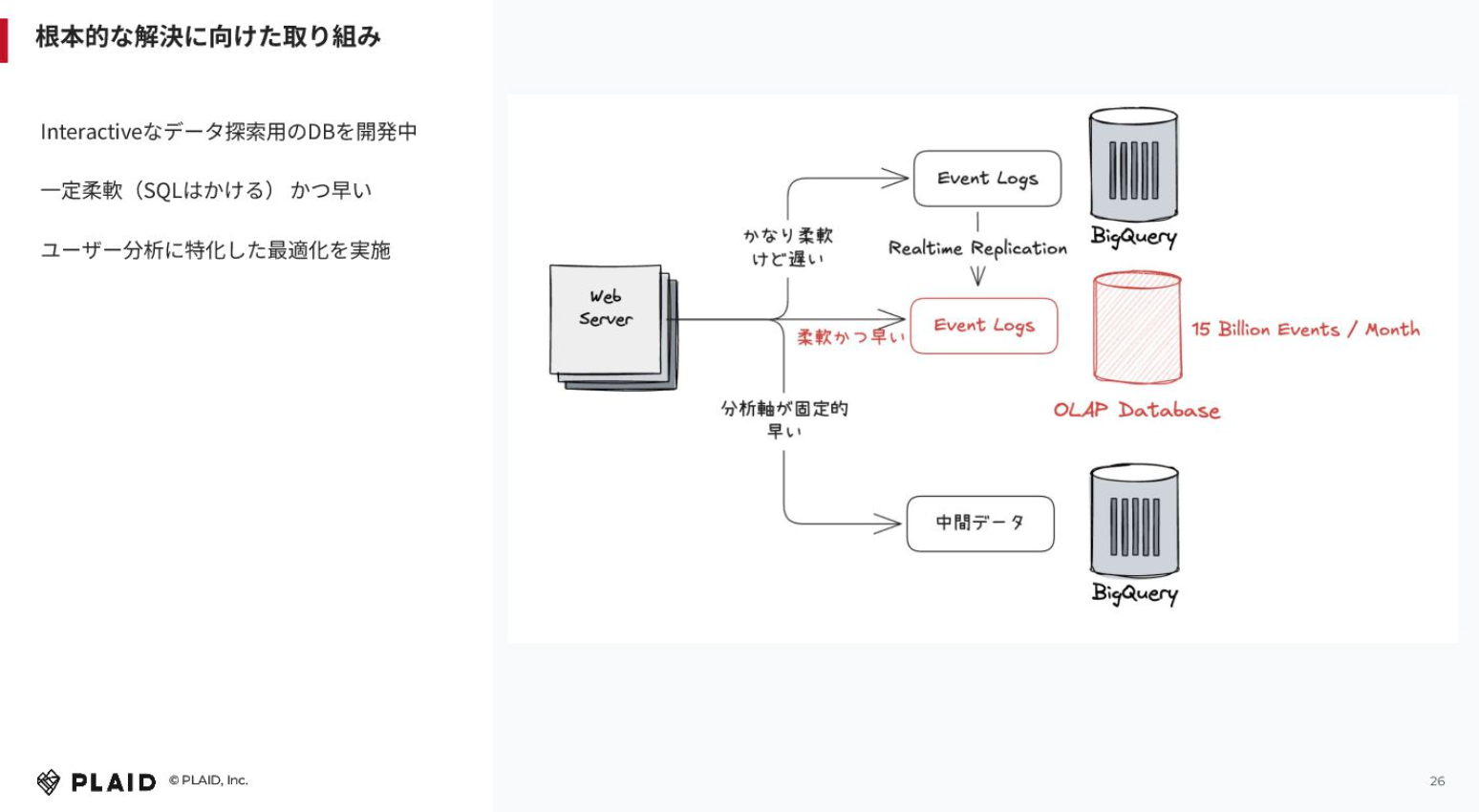
この特徴は、柔軟かつ速いという点です。我々の場合、先ほども言った通りデータ量が膨大です。ClickHouse等を使う手もあるかもしれませんが、コストが大きくなってしまいますし、本当に速いのか?という疑問もあります。
そのため、ユーザー分析に特化した最適化を実施したDBを内部で開発しています。それが出来上がりつつあるため、柔軟ではないけれども中間データを用意することなくSQLが書けて、かつ速い状況がつくれるのではないかと考えています。
「高速なデータ分析がもたらす世界」についてもお話しさせてください。
Looker Studioにはカンバセーショナルアナリティクスという機能があり、AIエージェントが会話の中で探索的にレポートをつくってくれます。Snowflakeでも似たような機能を見たことがあります。各プラットフォーマーがこのような機能を提供するようになると思いますし、そうなったときには速さが重要です。例えば、1~2分かかるとなると、会話にならないでしょう。高速なデータ分析ができると、ストレスなく会話しながらデータを可視化し、イテレーションを回せるようになるのではないかと考えています。

まとめます。AI時代には、サイロ化したデータを1箇所に集約するデータアーキテクチャが重要だと考えています。最初から保存場所を1箇所にまとめようとすると破綻するでしょうし、既存の資産をもう一度リビルドするのかという話になります。そこで我々は、リアルタイムなレプリケーションを増やしていって、BigQueryに貯めつつDB自体は集約しないというアプローチをとっています。それは上手くいったと考えています。
その上で、高速かつインタラクティブに分析できるデータ基盤がAI時代には不可欠だと考えています。逆説的ですが、AIがレポートしてくれるのであれば、画面を開発しなくても良いのではないか、という説もあります。そのため、AIがインタラクティブに分析できる世界をつくっていくことが重要なのではないかと、個人的には考えています。
Mastraを活用したAIエージェント開発の最前線
日鼻:今後の取り組みとして、我々がどういうふうにAIエージェントをつくっていくのかについてもご紹介したいと思います。
我々はプロダクトに組み込むAIエージェントを開発しており、フレームワークとしてはMastraを使っています。TypeScriptベースのエージェントフレームワークで、スター数も伸びているのでご存知の方も多いと思います。
我々がなぜMastraを採用しているのかというと、Node.jsベースのアプリケーションを書き続けてきて、TypeScriptとの相性が良かったところが大きいです。エージェントフレームワークはPython系が多いと思うのですが、TypeScriptのエージェントフレームワークとしては、Mastraが一番伸びていると思います。
これを我々がどう活用しているのかについても、ざっくりと解説します。
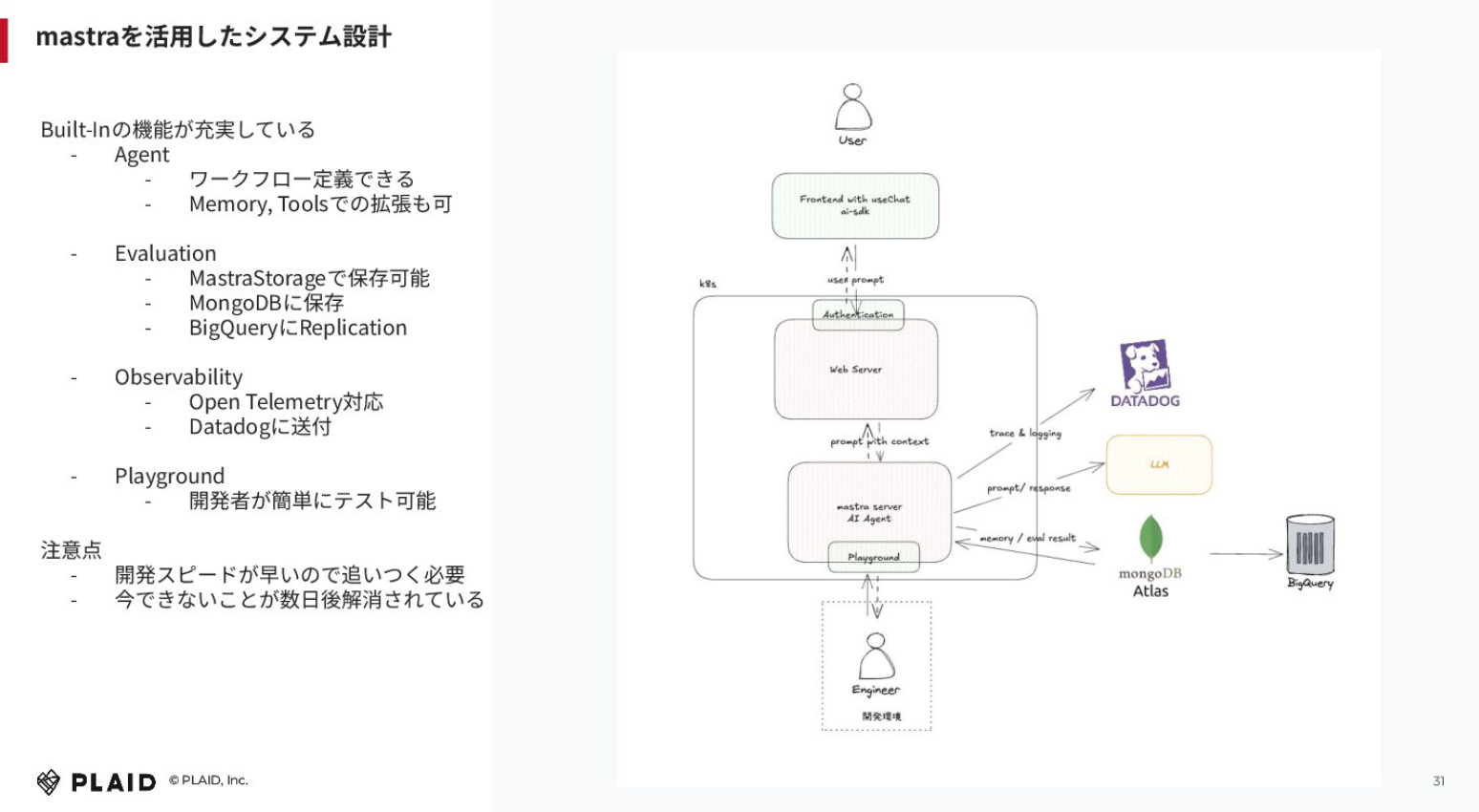
「KARTE」の管理画面を操作するユーザー(クライアント企業)がいたとして、そこにVercelのAI SDKを使ってUIを組み込みます。既存の認可基盤を使って、Webサーバー(Kubernetes)にプロンプトが流れてきて、その裏側にMastraのサーバーがあります。ここがAIエージェントのコアコンポーネントです。そこから右側のLLMにプロンプトを投げたり、ワークフロー的に重要なコンテキストを取ってきたりします。ツールという仕組みもあり、他のAPIを呼び出すことも可能で、そこら辺でエージェントのワークフロー定義を書きつつ、機能拡張していっています。
Mastraの良い点は、ビルトインの機能が充実していることです。エージェントで言うとワークフローの定義ができますし、重要な情報をメモリに載せて記憶させたり、ツールで他のサービスのインターナルAPIを呼び出したりと、自由に拡張できます。
エージェントを開発するときに重要になってくるのが、オブザーバビリティや評価が適切にできているかという点です。我々は、Mastra StorageというところでMongoDBに保存しつつ、BigQueryにレプリケーションをしています。オブザーバビリティについては、OpenTelemetryに対応しており、普段のアプリケーション開発でもDatadogを使っているため、そこに送付しています。Playground的にも開発者が簡単にテスト可能なモックを作成できますし、簡単にテストできます。
ただ、開発スピードが速いため、追いつくのが大変とまでは言いませんが注意は必要です。これを開発していたメインのエンジニアに聞いたところ、採用した当初は8個ほど改善点があったそうですが、今は解消されているそうです。フィードバックをあげてPRやIssueを作成すればすぐに解消されますので、現状できないことだけで判断するのはもったいないと思います。
AIが拓く開発生産性の未来
日鼻:本日の内容をまとめます。伝えたいことは3つあり、1つ目がコーディングエージェントが非同期的にタスクを実行できれば、開発の並列度はより上がるということです。最初は人間の方がマルチタスクに慣れておらずストレスが溜まるということもありましたが、トータルで見ると、並列度を上げていくアプローチの方が大きなスループットが出ます。AIコーディングエージェントやGitHub Actionsを通じたエージェントとのやり取りが遅くても、開発の並列度を上げていく方が、10Xや100Xの開発生産性を生み出すと考えています。
2つ目は、我々のようなデータ可視化が中心のサービスにおいて、開発生産性はデータアーキテクチャに大きく左右されるという点です。中間データの作成を不要にすることで、生産性はさらに向上するはず。最終的には、定常的に閲覧するレポート以外はAIが生成するというのが主流になってくるのではないかと考えています。
3つ目は宣言でもあるのですが、プレイドではプロダクト組み込み用のAIエージェントやMCPサーバーをこれから開発していくので、楽しみにしていてほしいです。
ご清聴ありがとうございました。

アーカイブ動画も公開しております。こちらも併せてご覧ください。
※ご視聴には登録が必要です






