



Snowflake導入でどう変わった?身近なサービス4社の技術選定
データの利活用への重要性が年々高まっている昨今ですが、スケーラビリティやデータ活用までのリードタイム、価格面での懸念に応える製品としてSnowflakeに対する注目度も右肩上がりとなっています。
本記事では、Snowflakeを導入している企業・事業を対象に「なぜSnowflakeを導入したのか」「Snowflakeを導入して何が変わったか」さらには「データ基盤チームとして何を目指しているのか」を伺いました。
Snowflakeのメリットや活用方法はもちろん、Snowflakeという枠を飛び出してデータ基盤の設計思想やデータチームの取り組み方等でも参考にしていただける内容となっています。
株式会社kubell(旧Chatwork株式会社)
事業概要
国内最大級のビジネスチャット「Chatwork」を中心に、複数の周辺サービスを展開しています。Snowflakeは増大するデータを効率的に蓄積・利用可能な状態に整備するプロジェクトに導入しています。
データ基盤アーキテクチャ構築・改善の工夫ポイント
次世代データ基盤プロジェクトでは、データフローにモダンデータスタックと称されるエコシステム、開発・運用にはIaC、CI/CD、DevSecOpsなどを導入しました。これらにより限られた人員リソースで、ゼロから新しいアーキテクチャのデータ基盤を素早く立ち上げることに成功しています。
またdbtの導入によりデータフローの開発を定型化でき、データ処理の学習コスト削減に繋がりました。
さらに開発環境をコンテナ化することで、環境差分による問題を極小化でき、開発からデプロイまでスムーズに実施できています。
調査・検証・設計・仕様については、リモートかつ非同期な開発を目指し、docs整備を徹底しています。
cf. https://creators-note.chatwork.com/entry/2022/09/15/090509
会員限定コンテンツ無料登録してアーキテクチャを見る
Snowflake導入によって得られた成果、解決できた課題
従来のデータ基盤はリソース制約が大きなボトルネックでした。この制約により、オンデマンド処理に時間がかかる、重要指標の集計が度々落ちて業績分析に支障が出る等の問題が起きていました。
Snowflakeではコンピュートリソースとストレージの分離により、裏で重い処理が動いても影響なくオンデマンドクエリの実行が可能です。処理スピードも速く、旧データ基盤で数時間かかる処理が数分で終わるケースもあります。これにより大半のオンデマンドクエリは数秒〜1分以内で終わるようになりました。
また、データメンテナンスに費やす時間が最小限に抑えられているため、開発に集中できるようになりました。
cf. https://creators-note.chatwork.com/entry/2023/12/24/100550
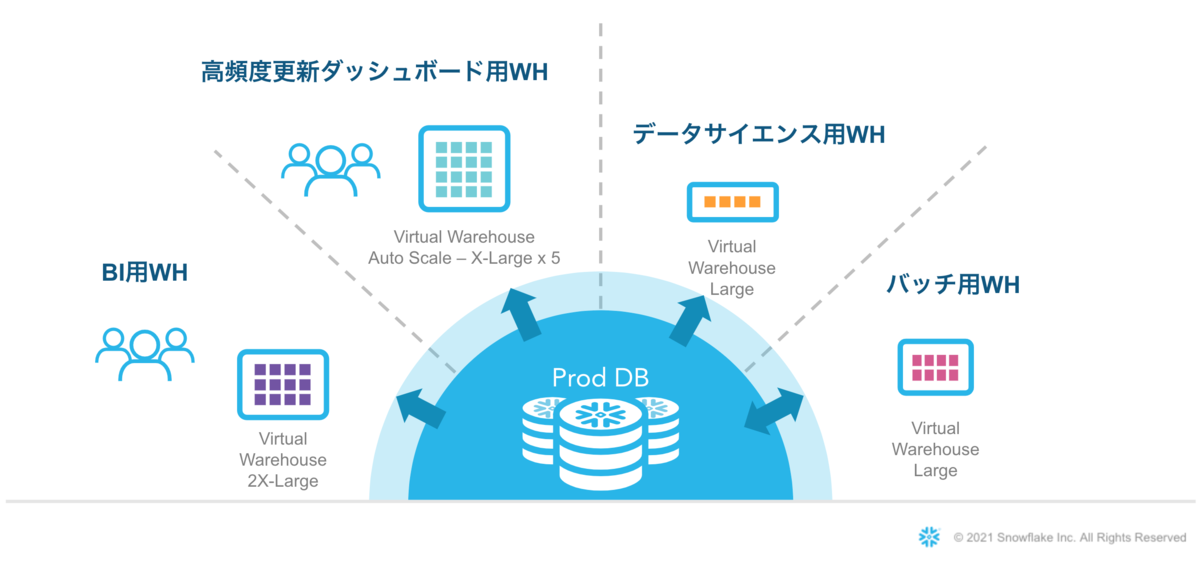
Chatworkのデータ基盤の今後の展望
Snowflakeを中心とした次世代データ基盤の立ち上げフェーズは、スムーズに通過しました。
今は、本格的なデータ利活用のニーズに応えられるよう、我々データエンジニアは分散型の開発・管理・運用体制の実現を目指しています。幸いにもデータエンジニアリングのテクノロジーは急速に進化しているため、ただ闇雲に追随するだけでなく、目的に合わせて機能するように導入していきたいと考えています。
現在データエンジニアの採用を強化しており、3月にはChatworkのSnowflakeに関わる取り組みについて発信するイベントを開催予定です。
cf.https://creators-note.chatwork.com/entry/2023/12/24/100550
執筆
技術基盤戦略室 次世代データ基盤構築プロジェクト、データエンジニアリングチーム 三ツ橋和宏(みっつ)(@kaz3284)
dely株式会社
事業概要
delyが運用するクラシルは国内No.1のレシピ動画プラットフォームです。 「80億人に1日3回の幸せを届ける」をサービスミッションに掲げ、レシピサービスのリーディングカンパニーとして、毎日使いやすい、人のあたたかさが伝わるサービスを目指しています。
データ基盤アーキテクチャ
データ基盤アーキテクチャ構築・改善の工夫ポイント
データ分析用途・ML用途でSnowflakeを活用しています。
Snowflake導入によって得られた成果、解決できた課題
クラシルでは、ユーザー投稿型のコンテンツのリリースや、コンテンツ配信やレコメンドのさらなる最適化を予定しています。
これらを実現するためには、データ基盤におけるデータ鮮度を高めること、アプリケーション利用に耐えられる性能が担保できるデータ基盤であることが重要になってきます。
そこで、スケールが叶う基盤かつ、データを利用可能にするまでのリードタイムを短縮することを目的として、Snowflakeを導入しました。
導入後は、データを利用するための時間がほぼリアルタイムになったことや、分析に対しての性能も既存のデータ基盤よりも高速な処理を実現しました。
クラシルのデータ基盤の今後の展望
クラシルのデータ基盤チームでは、行動ログをもとにクラシルユーザーへの価値提供のため意思決定をすることを目的としています。
これまでもある程度最適化されており、現状の基盤で比較的安定稼働ができている状態ではありました。
しかし、これからのクラシルのためには高速で信頼性の高いデータパイプラインの構築が必要になります。
クラシルのコンテンツ配信やレコメンド最適化はこれからが本番を迎えます。またコンテンツ量の増加により、データ基盤の重要性は更に高まる見込みです。
さらに全社の分析基盤の刷新も控えており、より安定かつ高速なデータ基盤をより少ない管理コストで運営していくことに挑戦しています。
執筆
データエンジニア・張替裕矢(@gappy50)
株式会社GENDA
事業概要
GENDAは2018年の創業以来、「世界一のエンタメ企業」を目指しています。アミューズメント、カラオケ、キャラクターMD、フード&ビバレッジ、コンテンツ&プロモーション(映画や体験型コンテンツ等)などエンターテイメントにおいて幅広く事業を展開しています。国内のみならず、米国や英国、中国大陸や台湾、中東、ベトナムなど海外にも進出しております。
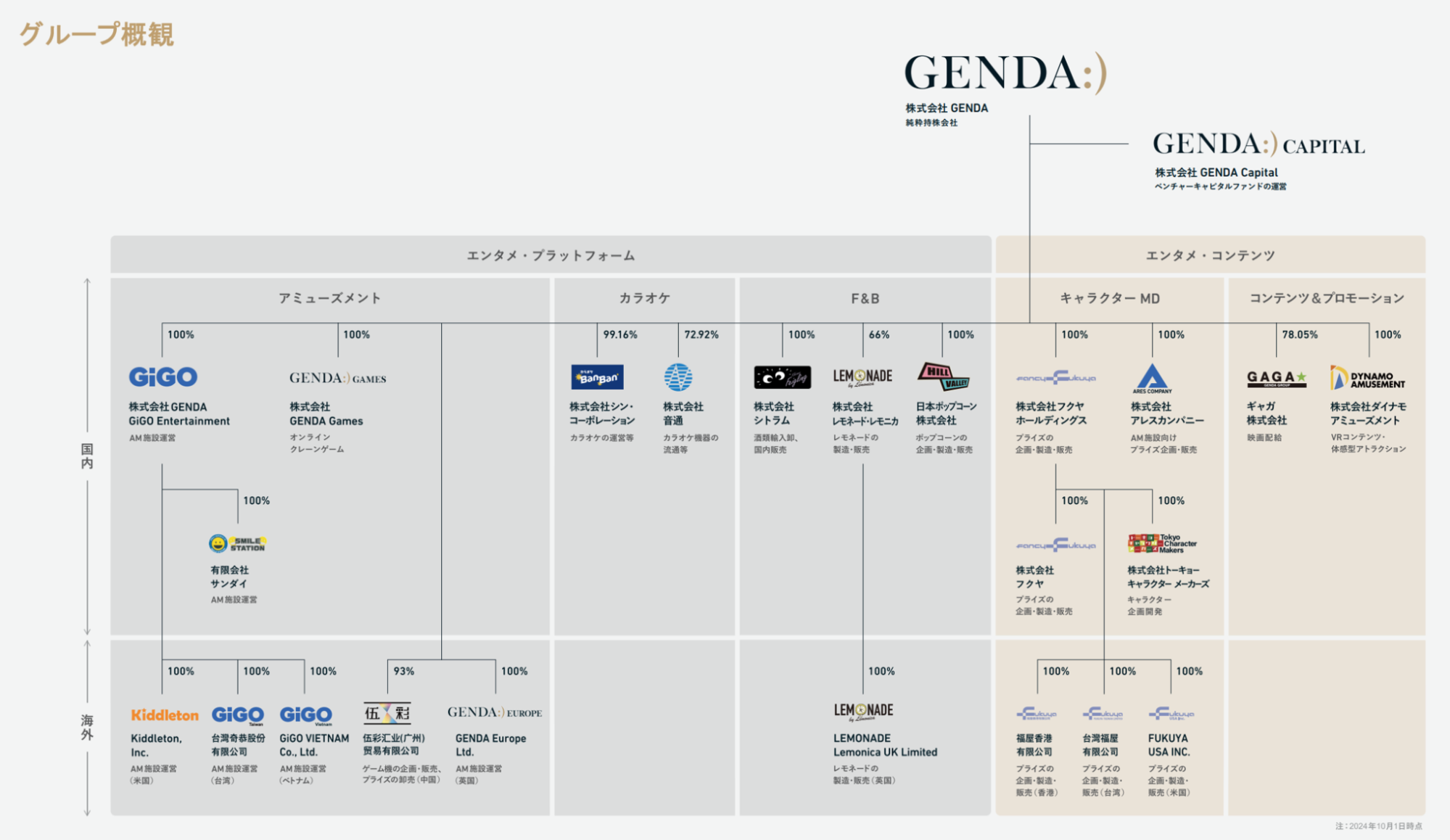
データ基盤アーキテクチャ
事業内での基盤
会員限定コンテンツ無料登録してアーキテクチャを見る
複数事業間でのデータ連携
会員限定コンテンツ無料登録してアーキテクチャを見る
データ基盤アーキテクチャ構築・改善の工夫ポイント
最近では事業間でのデータ連携も進んでいます。M&Aで迎え入れた企業が複数あり、複数の企業の事業それぞれでSnowflakeアカウントが異なっています。 それを純粋持株会社のGENDAのデータチームが主導で連携を取るシステムを構築しており、連携が小規模であればプライベートシェアリング、一定以上の規模であればMAツールなどを介する形で用途ごとに使い分けています。
Snowflake導入によって得られた成果、解決できた課題
サービス導入前は特定のデータウェアハウスを持たない、ややアナログなデータ基盤がある状態でした。 事業判断に必要なデータが各所に散っていたり(いわゆるデータのサイロ化)、社員それぞれがExcelで分析作業をする関係でツール自体やネットワークの重さが深刻になるなどのつらい状況が発生していました。 ですので、モダンなデータ基盤を作る必要性に迫られており、Snowflake導入の検討・決定に至りました。
導入後は、これはデータウェアハウスすべてに共通するお話なのですが、会社のデータを一元管理できることと、コンピュートリソースをデータウェアハウス側で持っていることは、弊社の従来のデータ基盤と比較して非常に画期的で、これにより全社でのデータ活用が大幅に進みました。 運用者の観点でいうと、Snowflakeはフルマネージドなサービスですので、定常的な管理にほとんど工数がかからない点が最大のポイントだと思います。
GENDAのデータ基盤の今後の展望
GENDAはエンターテイメント領域で多種多様かつオンライン・オフライン両方の事業を展開しており、今後もさらに広い領域に進出していく方針です。
データチームとしては多種多様な事業のデータを統合し、データの活用によってシナジーを創出できるようなデータ基盤の構築を目指しています。事業間でのデータの共有にSnowflakeが持つプライベートデータシェアリングなどの機能が有効であると期待していましたが、実際に段階が進んでその通りの感触を抱いています。
最近はSnowflakeの機能が機械学習やAIといった方面でも充実していっていますので、データウェアハウスとしての機能以外も活用して全社のデータ活用をバックアップしていきたいと考えております。
執筆
株式会社GENDA データチームマネージャー こみぃ(@kommy_jp)
スターフェスティバル株式会社
事業概要
お弁当やケータリングのデリバリーサービス「ごちクル」を含む、様々なサービスを展開しています。これらのサービスにおいて、企業全体のデータを集約し分析するための基盤としてSnowflakeを活用しています。
データ基盤アーキテクチャ
データ基盤アーキテクチャ構築・改善の工夫ポイント
具体的には、データ連携ツールやSnowflakeのリソース管理をTerraformやDockerfileでテンプレート化し、データ基盤チーム以外でもマニュアルを参考にして作業できるように取り組んでいます。新たなデータパイプラインを作成する際には、データ連携ツールEmbulkの設定やSnowflakeのテーブル定義などをデータ利用者に作成してもらい、GithubでPull Requestを上げてもらいます。このPull Requestをデータ基盤チームがレビュー、承認すると自動で環境が作成されます。このようにテンプレート、マニュアル化することで、少人数なデータ基盤チームでもパイプライン作成やテーブル作成などがボトルネックになるのを防ぐようにしています。
Snowflake導入によって得られた成果、解決できた課題
①弊社のサービスは多岐に渡り、使用しているデータソースもRDS、BigQuery、kintone、Salesforceなど多数あります。これらの異なるデータソースからのデータ活用が課題でしたが、Snowflakeを導入したことで、これらのデータを簡単に横断検索し活用することが可能になり、データ活用のハードルを下げることができました。
② データ基盤チームは少人数で運営しており、他の業務を兼務しながらデータに関する問い合わせ対応やデータパイプラインの構築、レポートの作成等に追われていました。そのため、データ基盤のメンテナンスやユーザー向けの検証環境の整備など、本来必要な運用作業に十分な時間を割くことが難しい状況でした。Snowflakeの導入により、データ基盤のメンテナンス作業の多くが不要になり検証環境の提供も効率的に行うことができるようになりました。
スターフェスティバルのデータ基盤の今後の展望
データ基盤チームは、全社がデータドリブンで意思決定を行える環境の構築を目指しています。初期段階では開発チームに焦点を当て、データを活用した開発プロセスの普及を目標にしています。将来的には、営業やCS部門を含む全社にこの文化を広げ、一貫したデータソースを基にした意思決定が可能な組織を実現することを目指しています。
執筆
データ基盤チーム 山﨑皓平(やまざきこうへい)(@koonagi3)







.png)