


Amazon CloudWatchとGrafanaによるサービス監視の導入

参考になった
9

株式会社ACES / takaaki inada
| ツールの利用規模 | ツールの利用開始時期 |
|---|---|
| 10名以下 | 2022年4月 |
| ツールの利用規模 | 10名以下 |
|---|---|
| ツールの利用開始時期 | 2022年4月 |
アーキテクチャ
アーキテクチャの意図・工夫
監視ダッシュボードは、ログ 、メトリクス、トレースという別々のデータソースからデータを取得して表示しています。表示部分はGrafanaが担当しますが、Grafana自体はデータは保持せず表示するだけで、データソースとしてとして、ログはCloudWatch Logs、メトリクスはCloudwatch Metrics、トレースはX-Rayから取得します。
導入の背景・解決したかった問題
導入背景
弊社のプロダクトサービスの営業支援AIツール「ACES Meet」の正式リリースに向けて、商用に耐え得る、安心してお客様にご利用して頂けるサービスの提供を支えるサービス監視基盤の整備が急務となっておりました。
選定理由
サービス監視基盤構築にかけられる時間は必ずしも潤沢にあるとは言えない状況でした。
とはいうものの、時間や足りない人的リソースを外部サービスでお金で解決して補うというのも悩ましく、一度外部サービスを使うと構成が複雑になったり、あまり深い理由もなく安易に外部サービスを使ってベンダーロックインで高い料金を払い続けたり、結局そのままずるずる使ってしまい、後で外部サービスにひきずられて後悔するというのは避けたいと言う気持ちがありました。外部サービスを必要に応じて使う構成には、実際のプロダクトが成熟してSLOによる監視要件がシュアになった時にいつでも拡張できると判断しました。まずは手軽に、監視要件に対して全てを満たすシステム基盤をはじめから作ろうとせず、一旦AWSだけでスモールにやってみようと思いました。
AWSだけでスモールにとなると、監視基盤の技術選定としては、Cloud Watch (+ Prometheus)でメトリクス収集を行い、Xrayでアプリケーションモニタリングを行い、Grafanaを可視化ダッシュボードとして利用するぐらいです。AWSが標準で提供しているダッシュボードではなく、Grafanaを可視化ツールとして使うことを選定したのは、私自身がGrafanaを前職で使い慣れていて可視化ツールとして優れている点を理解しており、また、AWSが標準で提供しているCloudWatchダッシュボードは以前は使いにくい印象があったためです。Amazon Managed GrafanaをサーベイしてAWSマルチアカウントで使いやすいサービス設計になっていることがわかったのも、弊社はセキュリティ設計上の観点で、顧客/プロダクト毎にAWSアカウントを発行して運用しておりますので、新しいサービスを構築した時にAWSマルチアカウント環境で簡単に水平展開出来しやすいメリットがあり、Grafana選定を後押ししました。
導入の成果
現在、おかげさまで多くのお客さまにACES Meetをお使いいただいており、導入企業100社を超えるプロダクトにまで成長しました。

絶え間ないサービスアップデートを裏で支え続けていたのがサービス監視基盤です。
当たり前のことですが、安定したサービスの提供には、まずサービスの品質を計測して可視化する必要があります。とりあえず強い人がぱぱっとサービス動かしてみてうまく動いている、は最初はいいのですが、残念ながら永続的に続くものではないと思います。
サービスはアップデートしますし、担当は変わりますし、よくわからないエラーが出始めたりします。
毎日朝会で1分でも可視化ダッシュボードでSLOを満たせているかチーム内で確認しているか、当たり前のことが出来ている必要があります。
現時点ではさすがにアプリケーションモニタリングの面で機能不足を感じるところもありますが、導入時のサービス監視基盤が老朽化することもなく、負債化することもなく、色褪せることなく動いています。 というのはスモールにスタートしたとは言え、CloudWatch自体は大規模サービスに耐え得るもので、かつ、大規模サービスで使われているものなので、無駄のない上にスケールすることができる、シンプルソリューションです。
AWSは監視の部分でお金をとろうとしてないのか低コストで運用できており、X-Rayも、CloudWatch自体も全然お金がかかっていません。実際、 X-Rayが月に数ドルしか請求がきてないのをほんとかと二度見したことが何回もあります。(X-Rayは参照数で課金されるため、安定して動いていて全然X-Rayのトレースを見に行く必要がなければお金がほとんどかからないためです。)
導入に向けた社内への説明
上長・チームへの説明
ACES Meetの正式リリースに向けた時期というのは、正社員が20名程度でしたので、経営陣・上長への説明で苦労するということはなく、サービス監視要件をまとめて、SLOとしてリクエストエラーレートとリクエストレイテンシーを、システムのモニタリングとしてCPU、メモリ、DISKを監視してモニタリングするというのを、以下の通り普通にまとめたぐらいでした。 (そもそもお金のかかる外部サービスの導入という話ではないため、いわゆる経営陣への説明自体が不要でした。)
上長にはCloudWatchやX-Rayまわりは概算のコスト試算は軽くはして、Managed Grafanaは利用ユーザ数での課金となるため料金体系を説明して、開発メンバー数がこれだけだからまぁこんなものでしょ、ぐらいの会話をしてOKをもらった記憶があります。 基本的に将来を見据えた基盤の資産化、テンプレート化は会社としてとても大事にしており、話がスムーズでした。
活用方法
よく使う機能
監視ダッシュボード
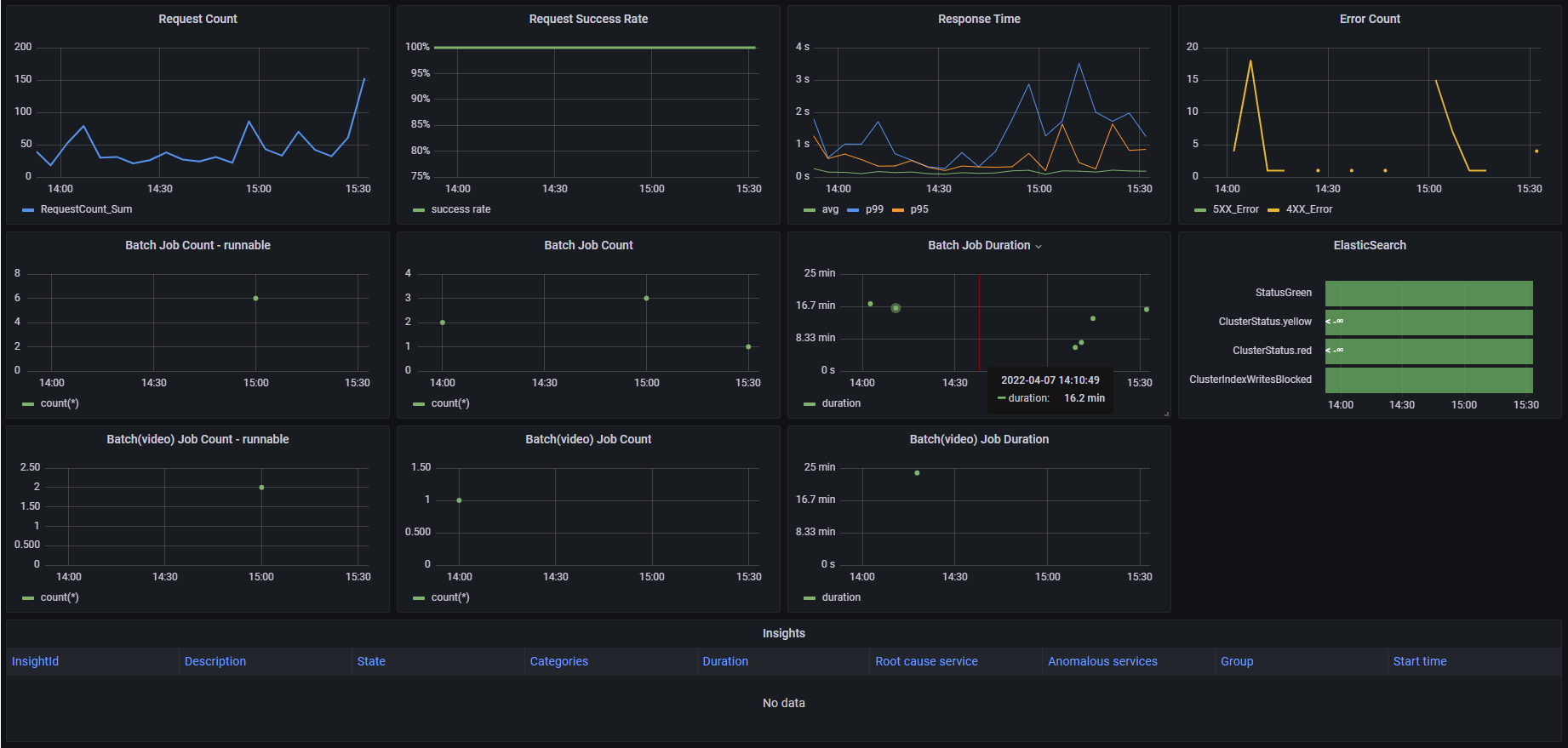
障害発生時にどこで何が起きたか確実に把握できるための必要最低限の全てのシステムメトリクスをワンサイトで提供するボードです。
監視ダッシュボードで最低限これだけは見る項目
一番大事で最低でも見ておかなければいけないのは、以下の2つ
- リクエストエラーレート
- リクエストレスポンス(リクエストレイテンシ)
BatchJobが存在する場合は上記2つに加えて、Batchのエラーが発生しているかとリクエスト完了までの処理時間の最大値(時間的に許容最大値があれば超えていないかどうか) を見ています。
また、以下も見ておくようにしています。
- そもそもリクエストがきているか
- リクエストのスパイクがないか
- 時系列的なリクエストの推移に変化がないか
InsightsはAWSが自動的に障害を検知してレポートをあげてくれる機能でそのまま表示しており、StateがActiveであればまさに「障害中」であるincidentの期間もレポートとしてまとめてくれるので、ここも必ず見ます。
(これらは、今回作成した監視ダッシュボードでは最上級の「Overview」に最低限これだけは見る項目としてまとめています。)
監視ダッシュボードを見るタイミング
弊社では、以下のタイミングで監視ダッシュボードを見ています。
- 障害発生時(言わずもがな)
- サーバチームの朝会で毎朝1分眺める(障害早期検知、未然検知という観点)
- 週次定例でタイムレンジを週や月に変えて長期傾向を観察(Diskやメモリの使用容量等短期では気付きにくい長期の傾向に気付く)
見るべきポイント
障害発生時
障害の原因は、単純なバグの他、リクエストの高負荷、DBの高負荷、接続外部システムのダウン、Zone障害(センターの災害、センターで掃除のおばちゃんがサーバラックの電源を足にひっかけて引っこ抜いた)等さまざまです。
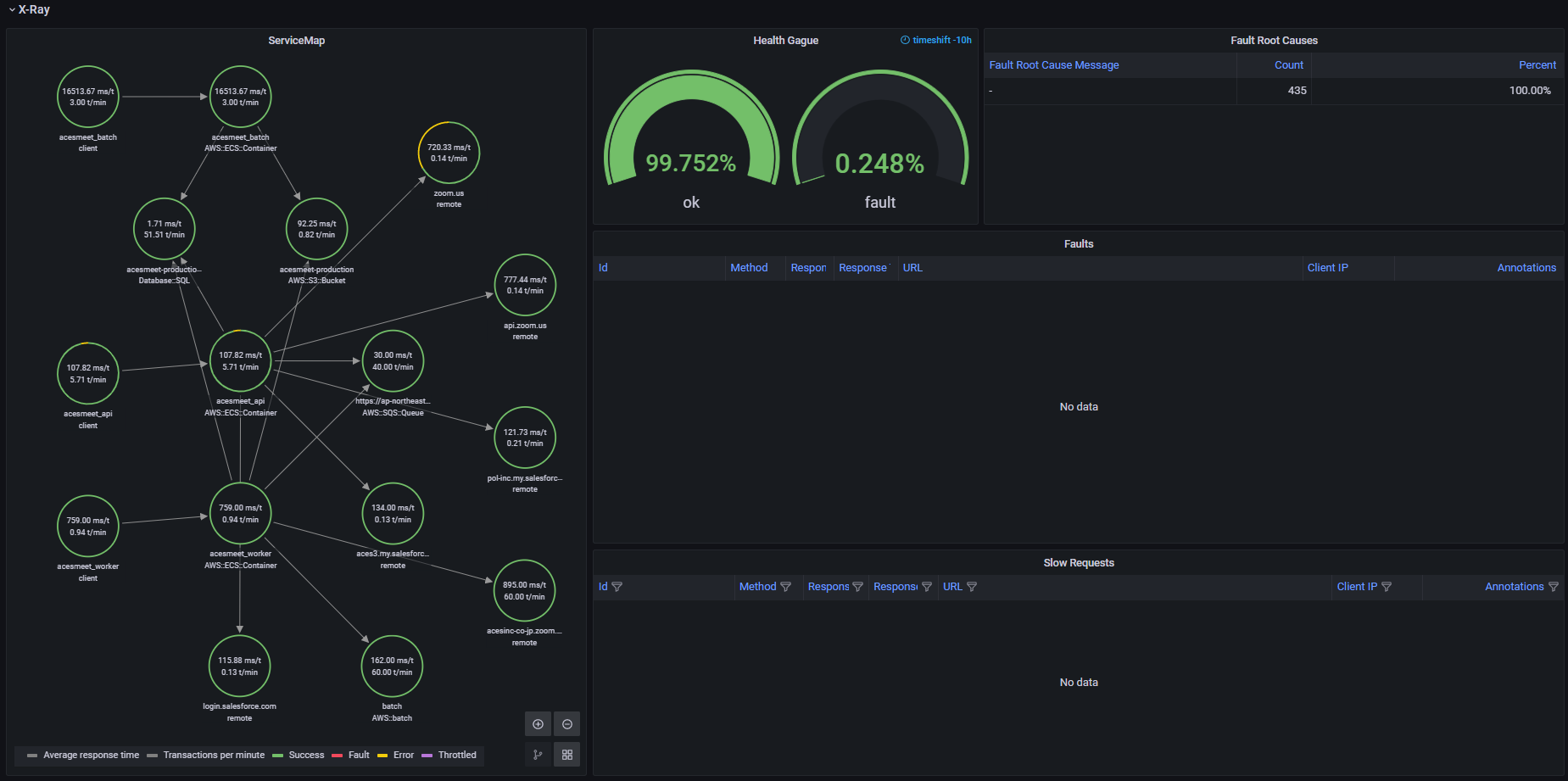
リクエストエラーレート、リクエストレイテンシで異常がみられる場合は、監視ダッシュボードのX-Rayでエラーリクエスト一覧と、スローリクエスト一覧で、個別のリクエストのトレースを行って原因を究明を行っています。
外部システムがダウンしている場合、X-Rayのサービスのノードマップ可視化でどのサービスがダウンしているか特定しています。Amazon Managed GrafanaはX-Rayの情報を可視化してGrafanaのパネルへ統合が出来るので便利です。
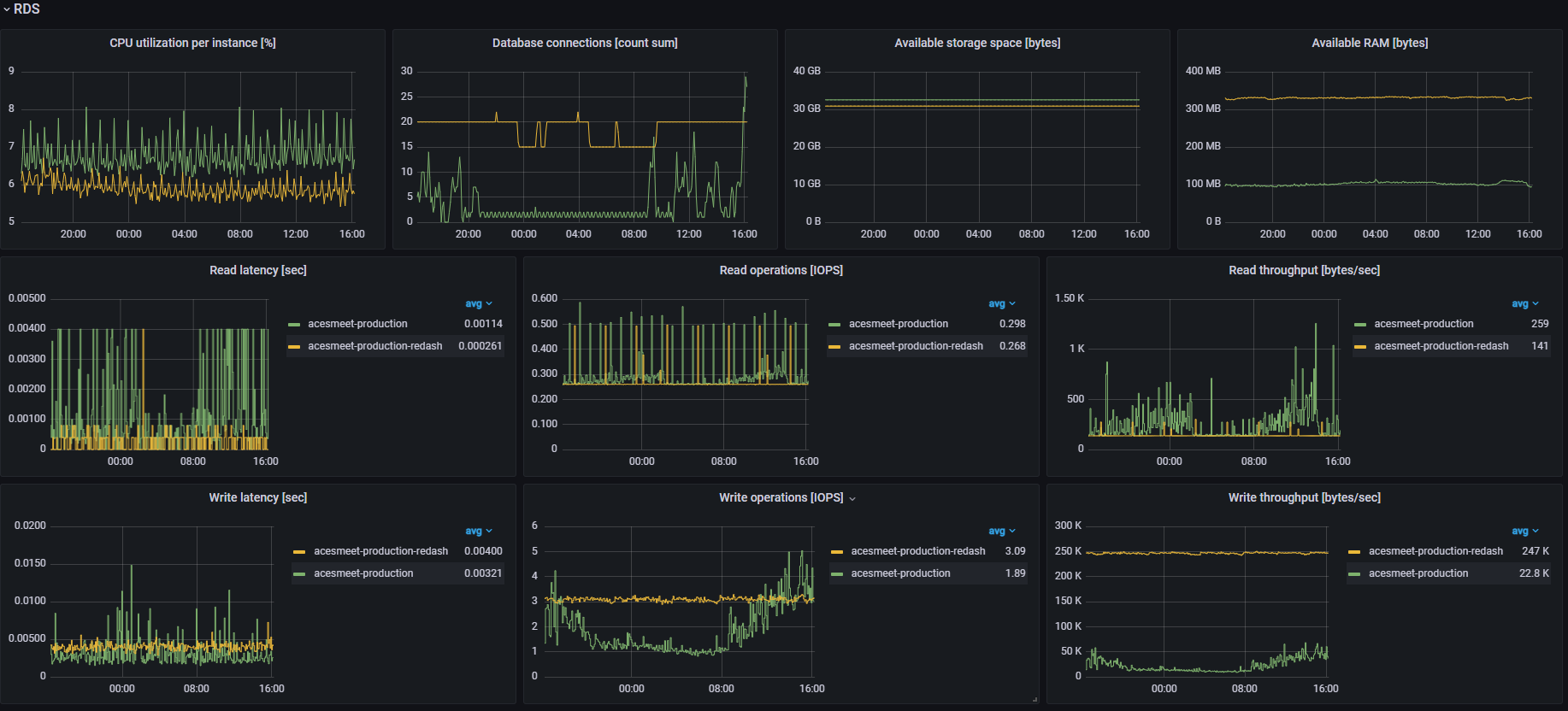
長期傾向の観察
経年の変化はCPU/Disk/MemoryやDBのConnection数等を通して徐々にあらわれてきますので、定期的に監視しています。
特にシステムダウンにつながる障害がおこりやすいのは、一番処理に時間がかかるDBで、DBの状態は特に気にしています。
スパイクアクセスがあった場合、一番処理に時間のかかるDBに処理が集中し、DBのconnection数がはねがあってconnection上限に達してconnectionがつなげられなくなり、システムダウンに至る場合もあります。
システムダウンに至らなくとも、システム全体としてリクエストレイテンシが大幅に悪化し、ユーザ影響を与えるので、事前に変化や負荷状態に気付けるようにして、DBレプリカやスケールの検討等、障害が起こる前に対策を講じています。
ツールの良い点
- スモールにスタート可能な点
- CloudWatch自体は大規模サービスに耐え得るもので、かつ、大規模サービスで使われているものなので、無駄がない上にスケールするシンプルソリューションであること
- 低コストであること
AWSは監視の部分でお金をとろうとしてないのか、X-Rayも、CloudWatch自体も全然お金がかかっていないです。
ツールの課題点
アプリケーションモニタリング(X-Ray)は、特にAPI毎のモニタリング(どのAPIがよくリクエストされているか、特定のAPIのエラーレートとレイテンシの把握)が弱いように思います。
認証APIだけエラーが発生している、特定のリソースにアクセスするAPIだけエラーが発生している、というのを監視するのにnginxのアクセスログをCloudWatch Logsに入れて、CloudWatch Logs InsightsでAPI毎に可視化しています。
ただ、ログベースのモニタリングになるため、可視化に時間がかかってしまうという問題や、ログ検索料金が別途発生してしまうのが課題です。nginxのアクセスログをelasitcsearchに入れてAPI毎に可視化する解決方法もありますが、こちらはさらに高コストになってしまいます。
その他
ここで書ききれていない監視設計の詳細はGrafana+CloudWatchを使ったAWSマルチアカウントでのプロダクト監視基盤構築のご紹介 - ACES エンジニアブログにもまとめていますので、あわせてご覧頂ければと思います。
ツールを検討されている方へ
HappyMonitoringなサービス監視で、レッツエンジョイ、エンジニアライフです!
株式会社ACES / takaaki inada
ソニーグループにてAWS Solution ArchitectおよびSREエンジニアとしてホームエレクトロニクス製品向けサービスのクラウドアーキテクチャ設計、クラウドインフラ構築などに従事。2021年より株式会社ACESにて、AIアルゴリズムサービスのクラウドアーキテクチャ設計、クラウドインフラ構築、MLOpsを担当。

よく見られているレビュー



株式会社ACES / takaaki inada
ソニーグループにてAWS Solutio...
レビューしているツール
目次
- アーキテクチャ
- 導入の背景・解決したかった問題
- 活用方法