


GitHubを使わずDatabricksだけでお手軽にライブラリ共有やCIができる環境を作ってみた

参考になった
12

株式会社カケハシ / hskksk
| ツールの利用規模 | ツールの利用開始時期 |
|---|---|
| 301名〜500名 | 2022年7月 |
| ツールの利用規模 | 301名〜500名 |
|---|---|
| ツールの利用開始時期 | 2022年7月 |
アーキテクチャ

アーキテクチャの意図・工夫
Databricksの機能のみを使って
- コード共有したい
- だれでも自由に処理を拡張したい
- テグレが起こらないようにしたい
を実現する環境になっています。
すごい基本的な機能を使って作っている環境ですが、分析用のNotebookがあり、そこから共有できそうな関数を切り出したモジュールを作っておいてインポートして使います。そのモジュールのテストコードを動かせるようなNotebookを作っておき、それを定期実行、スケジューラー登録されたJobsから実行することによってテストをするというような環境になります。
この環境でテストした結果、失敗すると、このJobsからSlackとかメールとかで通知を飛ばすことができるようになっています。通知を見て何かエラーが出ているとなったら、エラーが出た付近での修正変更履歴を確認して、この変更がいけなかったんだなということで、ロールバックすることができるような環境になっています。
実際に作ってみて使えそうであったため、いくつかの分析プロジェクトで導入をしている状況になります。
導入の背景・解決したかった問題
導入背景
詳しくはこちらのテックブログ『カケハシがDatabricksを導入した背景と技術選定のポイント』をご覧ください。
導入に向けた社内への説明
上長・チームへの説明
すでに導入されているツールだったため、割愛させていただきます。
活用方法
カケハシでのDatabricks利用
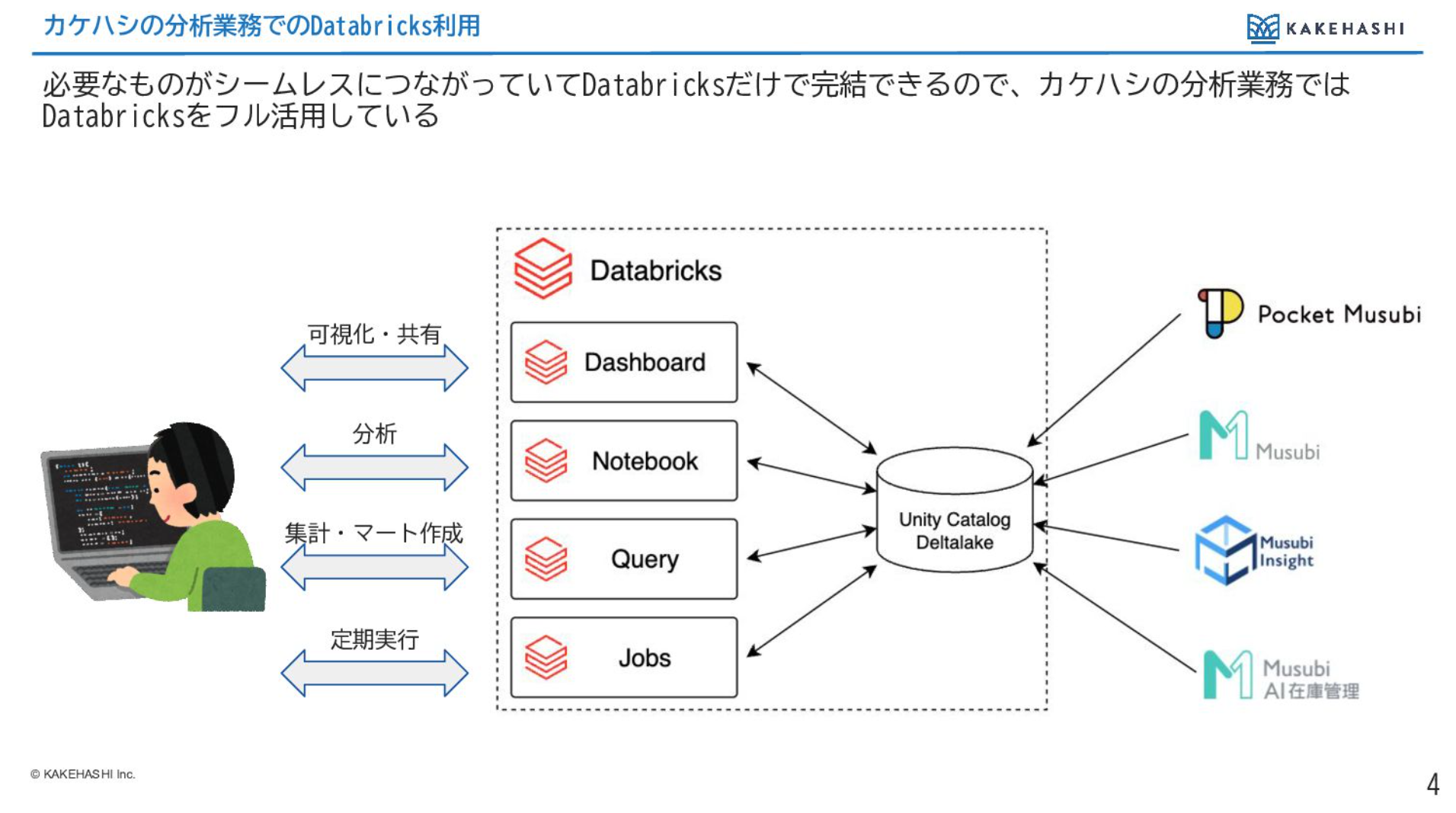
カケハシではデータ分析の業務はほとんどDatabricks上だけで完結して実施をしています。
これはDatabricksがデータ分析に必要になるような機能をオールインワンで備えているところが大きいと思っています。
また、カケハシでは全てのプロダクトのデータがDatabricksのUnity Catalog上に蓄えられており、そちらを使って分析していけば良いので、他のところにアクセスする必要がないという形になっているため、基本的にDatabricksをフル活用しています。
解決したかった課題
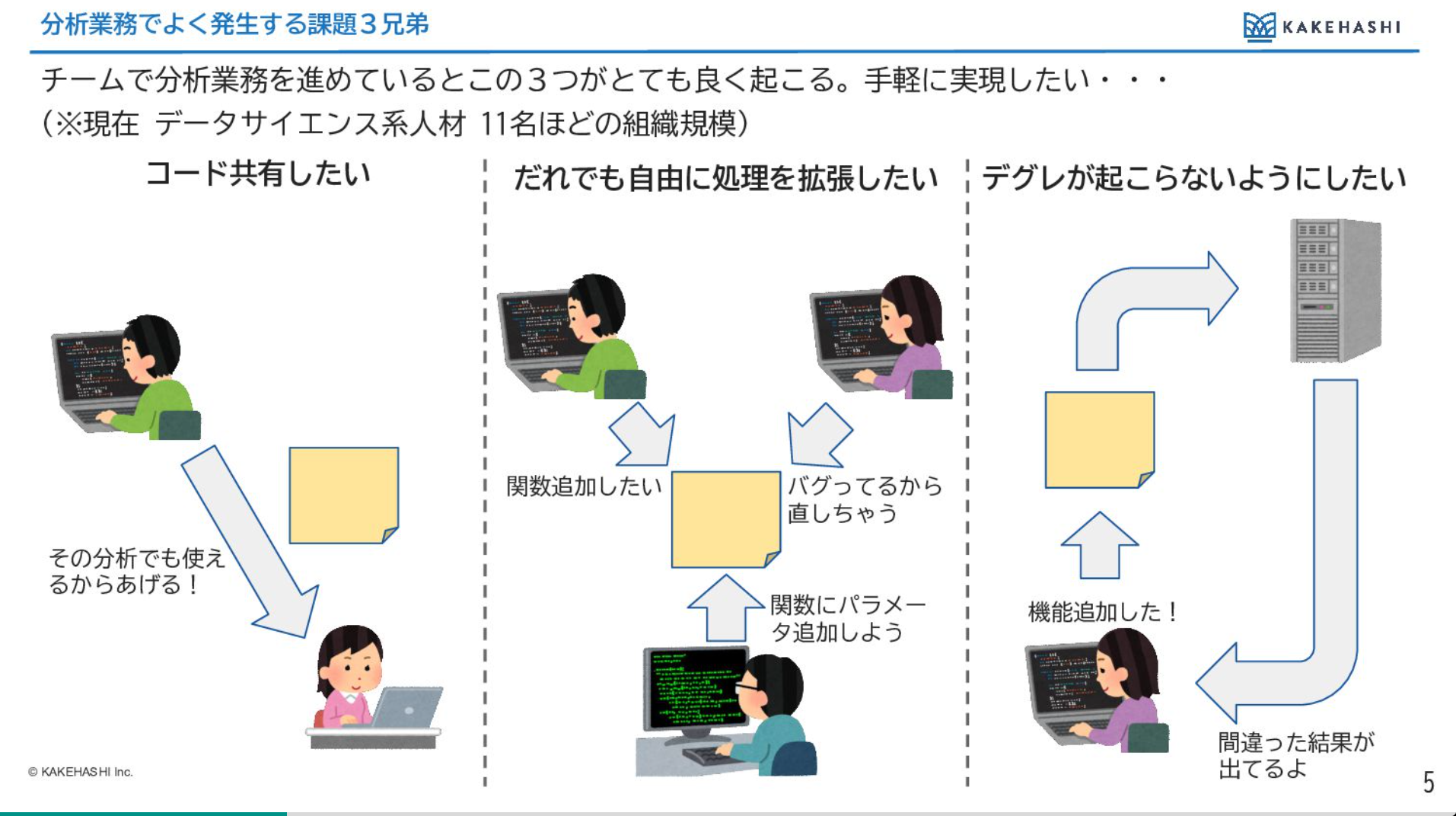
弊社のデータサイエンスチームが大きくなってきている中で、データサイエンティストと機械学習エンジニアという職種で合わせて11~12名ほどおり、その中でチームとして一緒に分析を進めていくこともよくある形になってきています。そうすると以下の三つの課題が、頻繁に発生するようになってきており、できるだけこうした課題を簡単にできるようにしていきたいと考えております。
- チーム間でコードを共有したい
- チームで共有して使っているものに誰でも自由に変更を加えて拡張したい
- チームで自由に変更を加えてもテグレが起こらないように自動的にチェックされるようにしたい
推奨されている解決方法
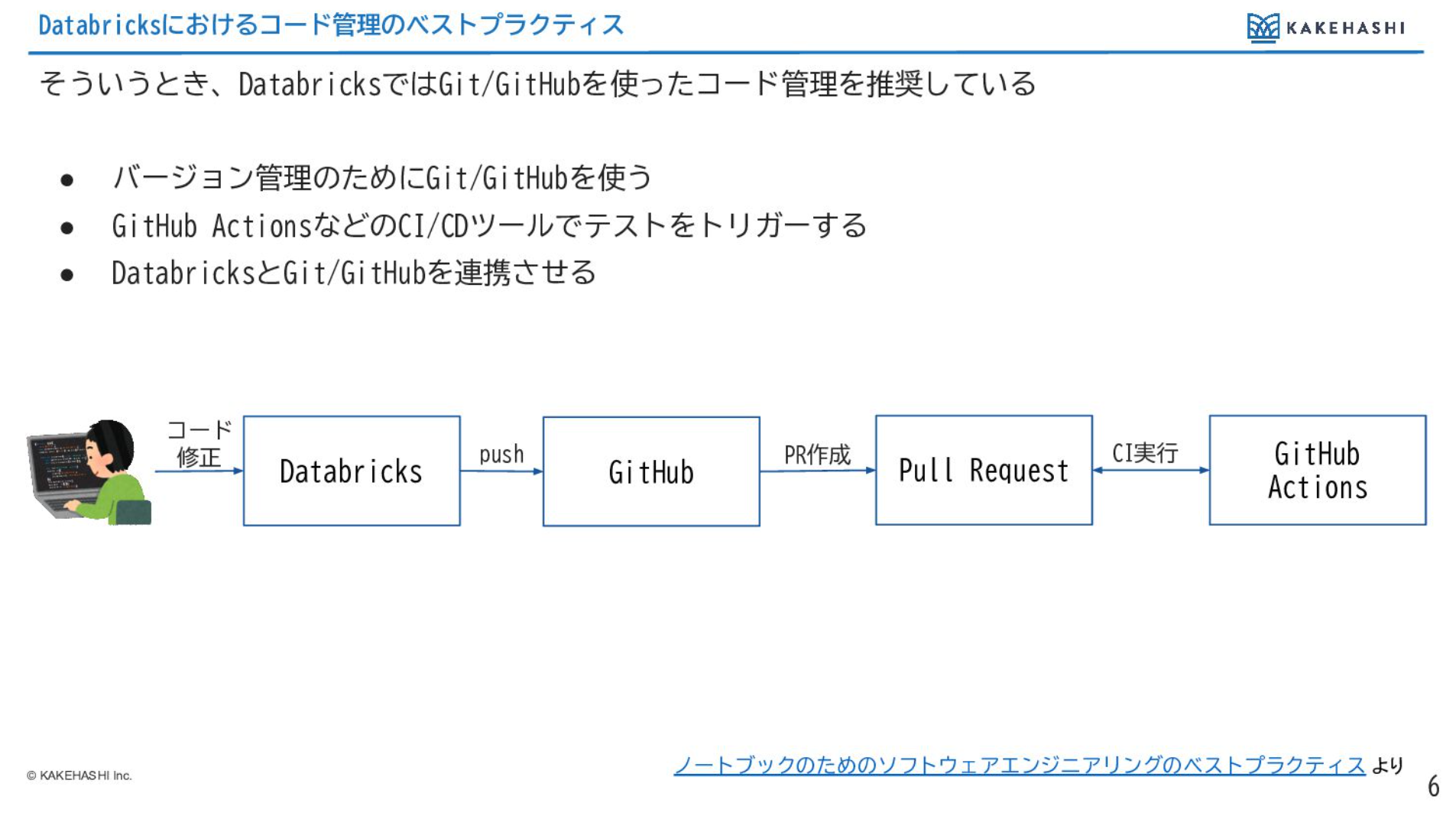
Databricksさんとしては、上述の課題に対してGitHubでコード管理をすることを推奨されている形になっていると思います。
バージョン管理のためにGitHub上にNotebookなどのコードを置いて管理し、GitHub Actions を使ってCIを回して自動テストをさせ、DatabricksとGitHubが連携できるようになっています。その後、連携してコードをDatabricksにシンクするような形が推奨されております。
実際に挑戦した時の苦労・悩み
実際に弊社ではGitHubでのコード管理をやってみたことがありますが、弊社の場合では結構大変でした。
大変だった理由は主に以下の4つです。
- 現在の当社のフェーズでは、高品質なプロダクションコードが要求されない、仮説検証の分析が多かったこと
・品質の高いコードを書くことはbetterではあるものの、スピード重視の分析が多く、後述のデータサイエンティストの性質を考慮すると、労力に見合いませんでした。 - ビジネスサイドに近い業務経験でGitHubに触れたことのないデータサイエンティストにとってGitHubはハードルが高い
・branch、commit、pushなど様々な独自の概念があってなかなか慣れず、エンジニアに質問しまくってしまう
・操作をミスしたときのリカバリが周りにエンジニアがいないと厳しい - CIのためにGitHub Actionsのymlファイルを書くのもかなり辛い
・書いてあること一つ一つが謎でどう書いたら良いかわからない
・マウスでポチポチするだけでCI作りたい - カケハシではGitHubリソースもlaC管理しているのでさらに敷居が高く、GitHubリポジトリ管理したくない
・弊社ではGitHubのリソースのリポジトリ・権限なども含めて全てTerraformで管理する形になっているため、Terraformもデータサイエンティストからすると、全く馴染みのないものになってしまっているのですごく敷居が高かった
Databricks活用の決め手
以上のような状況から、現在のフェーズにおいて、やりたいことを実現するために本当にGitHubで管理しなければならないのかなという疑問が生じてきました。
そんな中でDatabricks機能を調べてみるとGitHubで管理できることをいずれもカバーできるような機能がそろっていたため、Databricksの機能を使うことになりました。
ややGitHubと比べると制限はある形にはなっていますが、データサイエンティストからすると十分管理したいコードを管理できるため、Databricksでコード管理を始めました。
よく使う機能
- バージョン管理
- コードにコメントをつけてFB
- 過去バージョンへのロールバック
- スケジュールジョブでの定期自動テスト
ツールの良い点
- マウスでポチポチするだけでCI環境を作れる
- GitHubを使ったり、GitHub Actionsのymlを書く必要がないのでかなりハードルが下がる
- PRを出す必要なくコード修正が可能なのがとても楽
- ちょっとした変更にPR作って出したりレビューするのもデータサイエンティストにとっては結構負担だった
- リグレッションテスト程度ならすぐ作れるので負担が小さい
- 分析作業の中で、処理途中のデータをチェックしているのでそれをテストにするだけ
- おかしな修正があれば過去バージョンに戻せるので怖くない
ツールの課題点
手軽さを意識したため、代わりに難しさを感じる場面もありました。
- ブランチが使えず、差分の全revertはできても一部の差分のrevertはできないため、たくさん変更するときは不安が残る
- ノートブック以外のリソース(クエリなど)はこの仕組みでは管理できない
- 自動テストをさせることはできる
- 変更履歴を見られず、ロールバックができない
その他
今後やっていこうとしていること
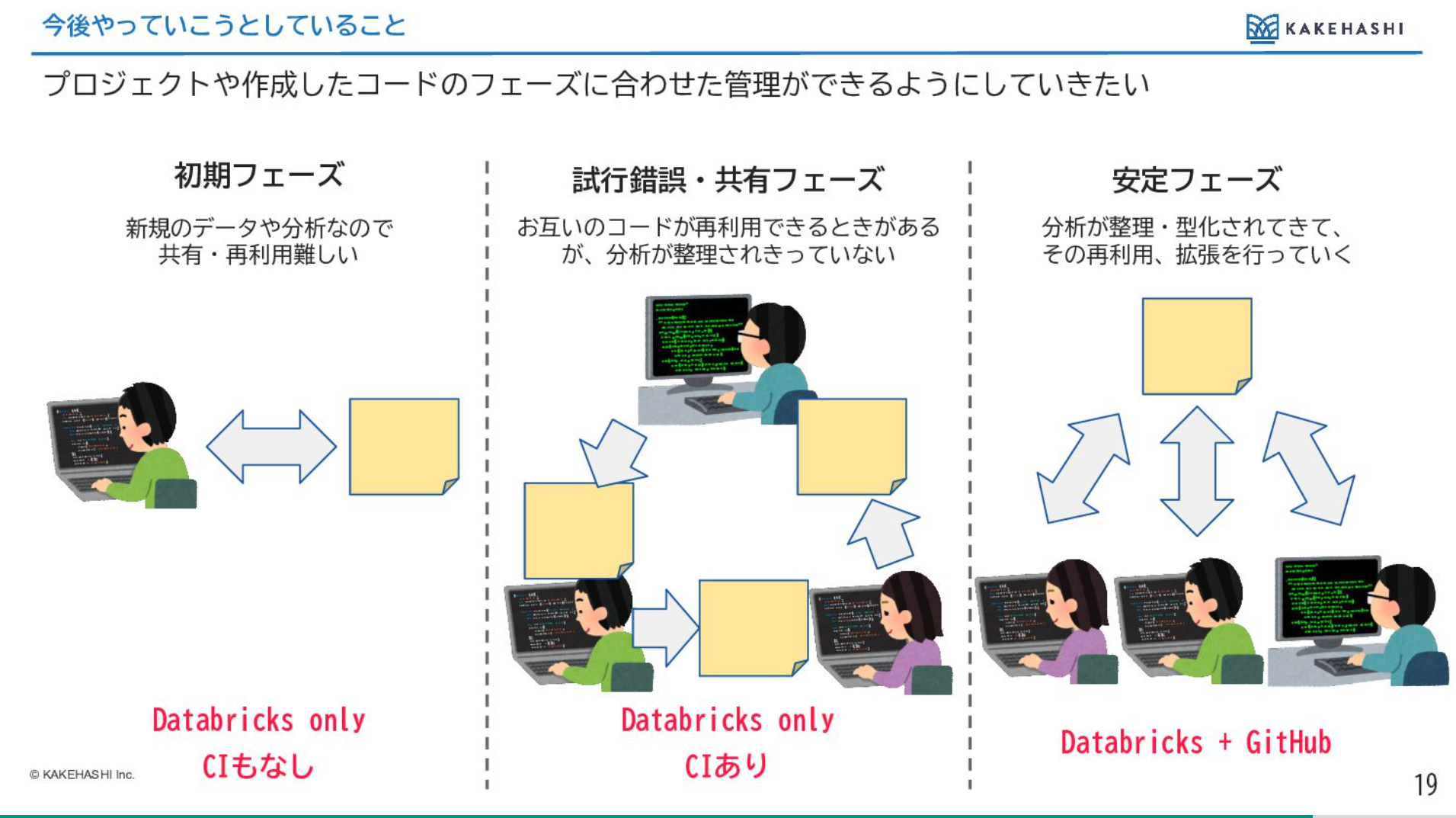
場合によってGitHubを使ったが良い場合と、DatabricksだけでこのCIが動かせるようにする方が良い場合と、CIもそもそも使わないような場合がありそうだなということで、コードやプロジェクトのフェーズに合わせてこの選択肢を柔軟にとっていけるといいなと今は考えております。
元々は下の図の左側と右側のやり方しかなかったところに、中間的な手間と管理の機能性を持つようなところを新しく作ることができたのは、かなり良かったなと思っています。
よりグラデーションがうまく作れるようになってきていると感じています。
ツールを検討されている方へ
GitHubに触れたことがないようなデータサイエンティストでも、そこまで品質をちゃんと管理する必要のないコードを共有するのに適した手軽さで使える環境をDatabricksで作ることができました。簡単にテストをしたり、簡単なデグレを防止するには十分使えるような環境だと思っています。
ただ、たくさん変更をしたり、Notebook以外のリソースを管理するような場合には、GitHubが不可欠になってるかなとは思います。
しかし、Databricksは、データ関連の機能がオールインワンで搭載されていて、非常に直感的に使える環境になっていますので、どんどん使ってみていただきたいなと思っています。
より詳しい話はこちらのテックブログに掲載しています。もしご興味がありましたら、ご一読をお願いします。
株式会社カケハシ / hskksk

よく見られているレビュー



株式会社カケハシ / hskksk
レビューしているツール
目次
- アーキテクチャ
- 導入の背景・解決したかった問題
- 活用方法