


Langfuseを導入してLLMアプリケーション開発を劇的に進化させる

参考になった
45

KDDIアジャイル開発センター株式会社 / tubone24
メンバー / フルスタックエンジニア・プロダクトエンジニア / 従業員規模: 101名〜300名 / エンジニア組織: 101名〜300名
| 利用プラン | 利用機能 | ツールの利用規模 | ツールの利用開始時期 | 事業形態 |
|---|---|---|---|---|
OSS版(セルフホステッド) | Traces・Prompts management・Datasets | 10名以下 | 2024年4月 | B to B |
| 利用プラン | OSS版(セルフホステッド) |
|---|---|
| 利用機能 | Traces・Prompts management・Datasets |
| ツールの利用規模 | 10名以下 |
| ツールの利用開始時期 | 2024年4月 |
| 事業形態 | B to B |
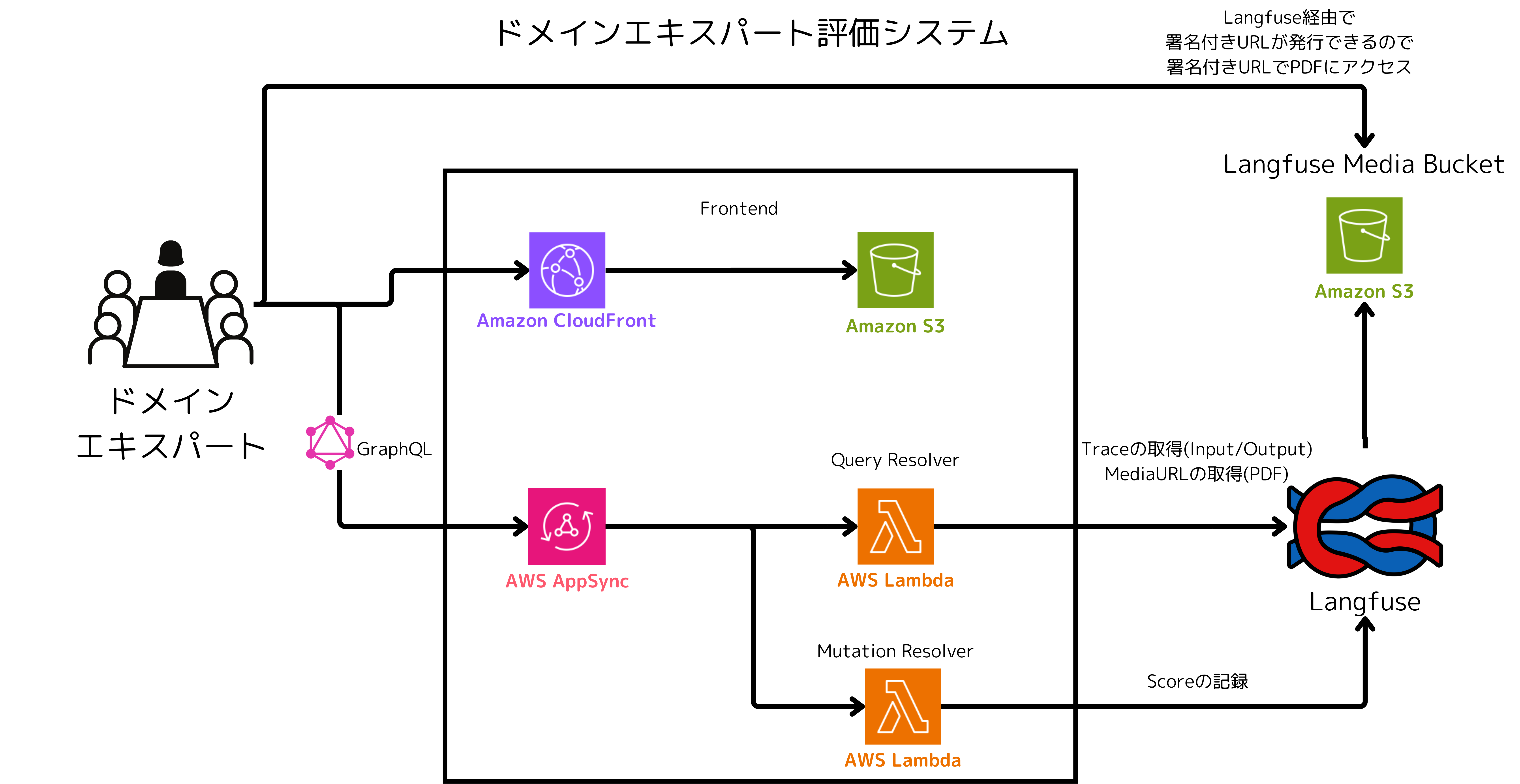
アーキテクチャ
アーキテクチャの意図・工夫
全体
Langfuse基盤を中心にLLMアプリケーションや、CI/CD(GitHub Actions)、ドメインエキスパートによる手動評価システムが連なってます。
LLMアプリケーション(アーキテクチャの前提)
LLMアプリケーションは平日日勤帯によく利用されるアプリケーションです。 このあと後述するコストカットのための工夫はこちらの要件によるものです。
また、基盤モデルとしてAmazon Bedrockを利用しており、LangChain(ChatBedrockConverse) + LangGraphと、Boto3経由でConvese APIをtool useで利用する2通りの実装が混在しているアプリケーションとなっております。
Langfuse基盤
Langfuse基盤は主に次のようなAWSサービスから構成されています。
Langfuse V3で必要になるコンポーネントについては、次のブログに詳細を記載しておりますので合わせてご確認いただければと思います。
Langfuse v3はv2からどのように変わったのかを噛み締めながらAWSマネージドサービスでLangfuse v3を作りきる
- AWS App Runner: Langfuse Webサーバー
- LangfuseのWebサーバーはLangfuseの画面とAPIを提供します。Dockerのイメージで提供され、中身はNext.jsで動いています。
- Next.jsはAWS App Runnerで動かすことができます。App RunnerはHTTPリクエストを同期的に処理するWebアプリケーションの実行に特化したサービスで、自動スケーリングやアイドル時の一時停止によるコスト削減(0インスタンスへのスケールダウン)が魅力のサービスです。
- 前提でも書いた通りLLMアプリケーションは平日日勤帯で主に利用されるものですので、Trace/Observationの記録は夜間や土日にほとんど発生しません。App Runnerを利用することで非稼働時間のvCPU利用料が発生しなくなるため、ECS Fargateで実装するよりもコストメリットがあります。
- Amazon ECS Fargate (Spot): Langfuse Worker
- LangfuseのバックエンドのWorker(Langfuse Workerコンテナ)実行基盤として使用しております。こちらもDockerのイメージで提供されます。(WorkerはLangfuse v3から追加されたコンポーネント)
- App Runnerはバッチ処理や非同期ジョブには対応していないため、代わりにECSのFargateを採用してWorkerコンテナを常駐実行します。
- スポットインスタンス(Fargate Spot)を用いることで最大70%のコスト削減が可能で、非同期処理を低コストでスケーラブルに実現します。
- Fargate Spotはスポットインスタンスと同様に、AWSの未使用リソースを利用しているため、リソースが不足している場合にはインスタンスが削除される可能性があります。WorkerコンテナはLangfuse webサーバーからのジョブをQueueを経由して受け取るため、万が一のインスタンス削除時でもジョブはQueueに残り、次のインスタンスが起動すると再開されるため、Trace/Observationの記録が途切れることはありません。
- Amazon ECS Fargate (Spot): Clickhouse(Langfuse OLAP)
- ClickhouseはLangfuseのOLAP(Online Analytical Processing)基盤として構築する必要があります。(Langfuse v3から追加されたコンポーネント)
- こちらもLangfuse workerと同様にFargate Spotを利用しており、コストメリットを享受しています。
- FargateおよびFargate Spotを利用すると、Clickhouseのテーブルデータが永続化されないため、データの永続化はAmazon EFSとAmazon S3を利用しています。
- Amazon EFSとAmazon S3をClickhouseのDiskとして利用する具体的な実装方法はLangfuse v3を安く運用する方法をご確認ください。
- Amazon Aurora Serveless v2: PostgreSQL(Langfuse OLTP)
- LangfuseのOLTP(Online Transaction Processing)基盤としてPostgreSQLを構築する必要があるため、Amazon Aurora Serverless v2を利用しています。
- Aurora Serverless v2は、データベースのリソースを自動的にスケーリングすることができるため、Langfuseの利用状況に合わせてリソースを自動的に調整することができます。
- Amazon ElastiCache: Valkey(Langfuse Queue)
- Langfuse WebサーバーとWorkerコンテナの間で非同期ジョブをやり取りするためのキューシステムとしてRedisを構築する必要がありますので、Amazon ElastiCacheを利用しています。
- エンジンはRedis準拠であれば動作するため、Valkeyを利用することでコストメリットを享受しています。
- Amazon S3: Langfuse Media
- Langfuseのメディアファイルを保存するためのストレージとしてAmazon S3を利用しています。
- 例えばマルチモーダルLLMを利用するとき、画像や音声のような非構造化データをLangfuseのTraceと紐づけて管理するAttachmentsという機能がありますが、こちらの機能を利用するためには専用のS3バケットが必要です。
- S3はLangfuseのMedia APIがあり、仕組みとしてはS3の署名付きURLを生成しています
- Amazon S3: Langfuse Event
- Langfuseのイベントを保存するためのストレージとしてAmazon S3を利用しています。
上記具体的な構築についてはIaC化(Terraform)したものを公開しておりますのでぜひご活用くださいませ。 tubone24/langfuse-v3-terraform
CI/CD(GitHub Actions)
Langfuse基盤とCI/CD(GitHub Actions)を連携させることで、Langfuse基盤単体で足りないところを補完しています。
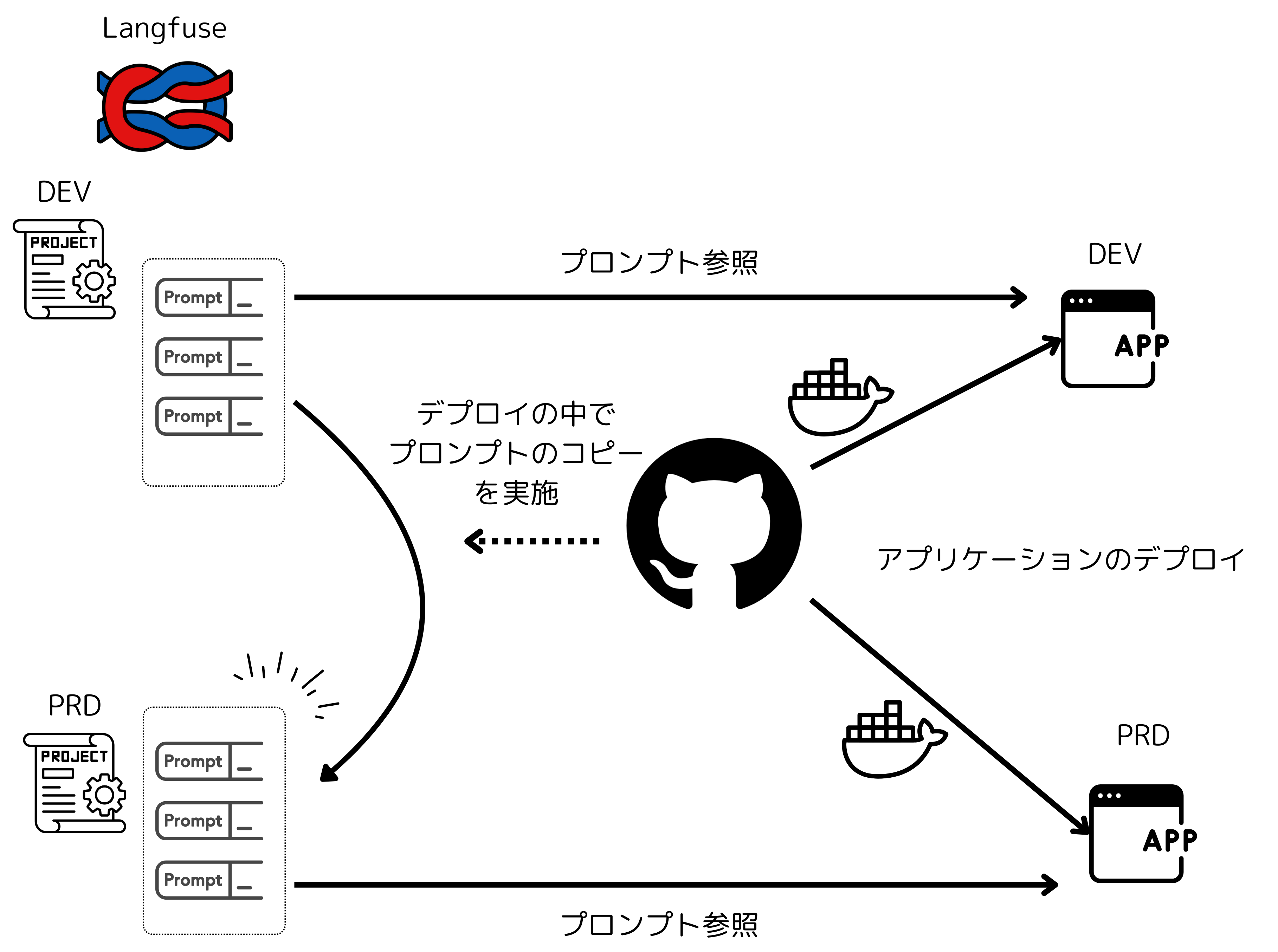
1. プロンプトの他環境デプロイ
弊プロジェクトでは、本番環境以外にも開発環境やステージング環境を用意しています。
開発環境で作成したプロンプトをLLMアプリケーションと合わせてステージング環境・本番環境にデプロイ必要があるのですが、Langfuseのプロンプトはプロジェクト単位で管理されます。
プロンプトを他環境で共有するには同一プロジェクトに全環境を紐づける必要がありますが、これではTrace/Observationの記録が混在してしまい、管理が難しくなる問題がありました。
そこでプロンプトをLangfuse SDKを利用し、コピーするスクリプトを作成し、アプリケーションのデプロイパイプラインに載せることで、他環境へのデプロイを自動化しました。
2. 自働評価(LLM as Judge)
LangfuseにはLLMによる自動評価機能がありますが、残念ながらセルフホステッドのLangfuseではPro版以上でしか利用できません。
そこで、CI/CDパイプラインとRagasを組み合わせることで、Langfuseのプロンプトを自動評価する機能を実現しております。

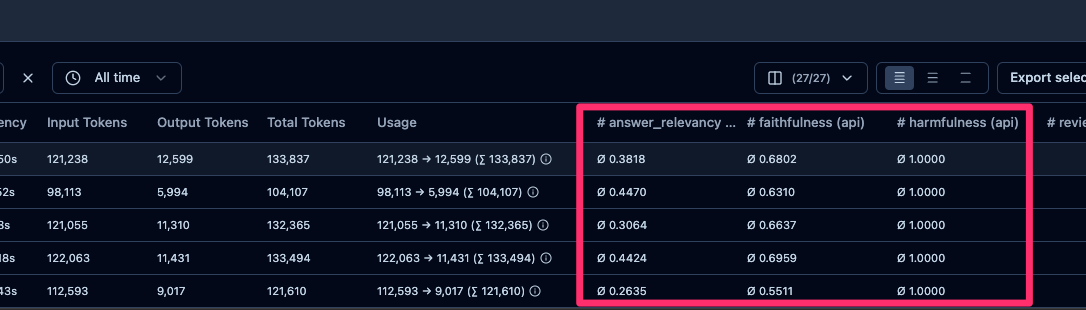
LangfuseにはScore APIがあり、Trace/Observationに対して0〜1のスコアを記録することができます。
こちらを応用してRagasで算出されたスコアをLangfuseのGeneration(LLMのINPUT/OUTPUTをまとめたObservation)に対して紐づけた形で記録することでTraces画面から簡単に確認することができます。
キャプチャのようにTraces一覧、詳細画面で各スコアを確認することができます。
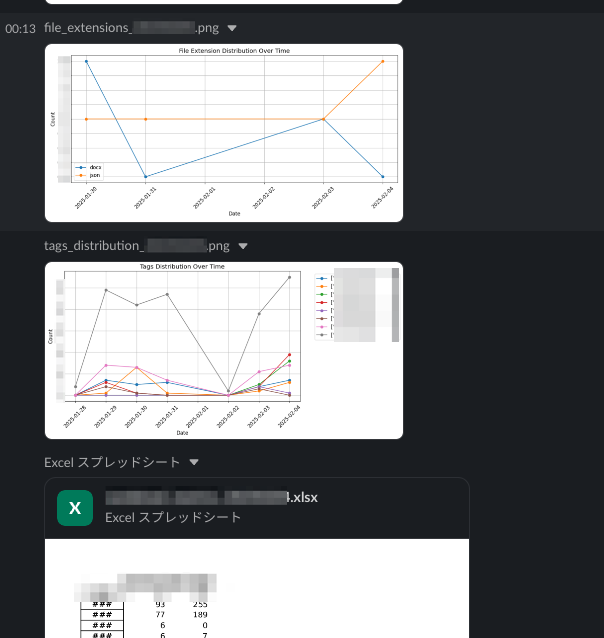
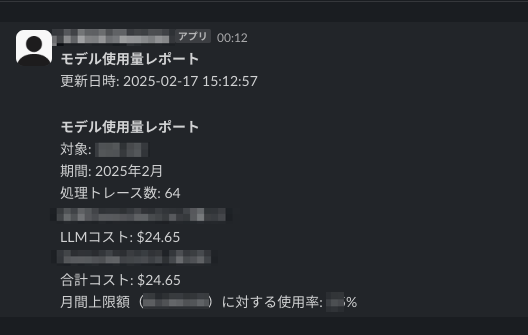
3. 機能ごとの利用状況とコストの通知
Langfuseのダッシュボードには、TraceやObservationの利用状況やコスト状況を確認する機能があります。
こちらも十分便利なのですが、あくまでもTraceの種別やLLMモデル別にコストが確認できるだけなので、例えば、細かなパラメータ(MetadataやTagsなど)ごとの分析には別途仕組みを作る必要がありました。
LangfuseのTrace APIをPythonスクリプトから実行・集計し、CI/CDパイプラインと組み合わせることで、利用状況やコストをさらに細かくSlackに通知する機能を実現しております。
ドメインエキスパートによる手動評価システム(Annotation Queue)
弊プロジェクトでは、開発者とは別にLLMの生成する内容を監修するドメインエキスパートがおります。
ドメインエキスパートはLangfuseに記録されたTraceを確認し、ユーザーに回答している内容が適切かどうかを判断する役割を担ってますが、多忙極めるドメインエキスパートにすべてのTraceを確認してもらうことが現実的に難しいという問題がありました。
Langfuseには、Annotation Queueという機能があり、ドメインエキスパートが確認すべきTraceをキューに溜めておき、ドメインエキスパートが空いたタイミングでキューに入った評価を確認することができる機能があります。
しかし、こちらの機能はLangfuseのPro版以上でしか利用できません。
そこで、LangfuseのDatasets機能をキューとして利用したうえで、LangfuseのDatasets API, LangfuseのScores API, LangfuseのMedia APIを利用して、Annotation Queueと評価システムを簡易的に自作しました。
このシステムを利用することで、ドメインエキスパートが確認すべきTraceを開発者が判断し、ドメインエキスパートが確認すべきTraceを選別する手間を省くことができます。
導入の背景・解決したかった問題
導入背景
ツール導入前の課題
1. LLMアプリケーション(サービス)の開発速度向上
AIエージェント開発の際、ユーザーの質問に対して思うような回答をしてない場合その原因がプロンプトにあるのか、中間で呼び出されるツールの結果によるのかがわからず、開発難易度が上がっていました。
特にLLMを多段で呼び出すようなアプリケーション開発だと、中間で呼び出されるLLMの回答内容が可視化できる必要がありますが、LLMOpsツールを使わないとその可視化が難しい現状があります。
2. プロンプト管理
運用上変更の多いプロンプトをLLMアプリケーションのソースコードから切り離す形で管理し、デプロイを伴わず迅速なデリバリーができる必要がありました。
3. フィードバックループを回す
ユーザーフィードバックやドメインエキスパートによる回答の評価をLLMの回答と紐づけながら格納し、分析することで今後の改善につなげる必要がありました。
4. コスト管理
サービスの機能ごとに生成にかかったコストを算出しにくく、予算を適切に設定する材料が不足してました。
どのような状態を目指していたか
上記を達成することでLLMアプリケーションの開発の細かな不満を取り除き開発速度を向上させることができることと、サービスの品質向上を期待しておりました。
比較検討したサービス
- Langsmith
- PromptLayer
比較した軸
- AIエージェントのLLMOpsが実施したかったため、LLMのINPUT/OUTPUTだけでなくツールのINPUT/OUTPUTも記録できること
- モデルの生成コストを可視化できること
- ユーザーフィードバック・ドメインエキスパートによる評価・LLM as a judgeができる基盤であること
- セキュリティ要件をクリアするためにセルフホステッドができること
- セルフホステッドを選択してもライセンス費が跳ね上がらないこと
- Langsmithなど主要なLLMOpsツールと比較して遜色ない機能であること(アップデートによる追従が頻繁であること)
選定理由
セルフホステッド
一番のポイントはセルフホステッドで運用できる点です。 もちろんLangsmithもセルフホステッド版はあるものの、エンタープライズライセンスからの提供のためOSS版が使えるLangfuseに軍配が上がりました。
セルフホステッドにすることで、構築の手間はありますがLLMアプリケーションと同一のクラウド環境にホストすることでセキュリティ要件の調整をスキップすることが可能という背景がございました。
可観測実装の容易さ
LangfuseSDKにはObserveデコレーターが用意されており、観測したい関数に対してデコレーターをつけることで比較的手軽に可視化を実施することができます。
from langfuse import observe
@observe() # INPUT: name, OUTPUT: "xxxxx"がLangfuseのSpanとして記録される
def hoge_output(name: str) -> str:
"""(LLMな処理...)"""
return "xxxxx"
ただし、Observeデコレータはあくまでも関数のIN/OUTを引数・戻りから記録し、可視化するのみなので中間イベントの記録、Generationの細かな記録(First Tokenのレイテンシーなど)、メタデータの記録をするにはLangfuseインスタンスから直接記録することをおすすめします。
@observe()
def complex_logic(tool_input: str) -> str:
langfuse.create_event(
name="external_tool_call",
metadata={
"tool_name": "SampleTool",
"input": xxxxxxxx,
}
)
例えばAmazon BedrockのConverse APIをBoto3から利用する場合、質問に対して 生成 -> Tool -> 生成とサンドイッチ構造になりますが、それぞれをLangfuseのGeneration(LLMの応答を管理する特別なObservation) -> Span(時間軸を持ったObservation) -> Generation(LLMの応答を管理する特別なObservation) と記録して、全体を親Observation or Trace(observeデコレーター)で紐づける、ということをするときれいに記録されます。
@observe
def use_tool():
# Langfuse SDKのセットアップ
langfuse = Langfuse()
trace = langfuse.trace(id=trace_id)
prompt_name = "hogehoge" # Langfuseに登録しているプロンプト名
prompt_version = 1 # Langfuseに登録しているプロンプトのバージョン
# 最初の生成処理のスパン作成
initial_generation = trace.generation(
name="invoke_converse_stream_use_tool_start",
input=message,
)
# Bedrock ConverseAPIの呼び出しを実施
messages = invoke_converse(messages, tool_config)
# 生成処理の結果を更新
initial_generation.end(
output=messages,
)
# (中略..)ツール呼び出し判定処理
# ツール使用のスパン作成
tool_span = trace.span(
name=tool_config["tools"][0]["toolSpec"]["name"],
input=tool["input"][tool_arg_key],
start_time=start_time
)
# ツールの実行
tool_output = tool_function(tool_arg)
# ツール使用のスパン終了
tool_span.end(output=tool_output, level="DEBUG")
message = invoke_converse(tool_output)
# ツール実行後の生成処理のスパン作成
final_generation = trace.generation(
name="invoke_converse_stream_use_tool_start",
input=message,
)
final_generation.end(
output=message,
metadata={
"tool_use": "end",
"context": tool_output,
"stop_reason": stop_reason,
"region": region,
"index_model": index_model
}
)
return message
キャプチャのように@observe単位で(赤と緑)括られ、その配下に子ObservationとしてGenerationやToolのSpanを保つ構造になってます。
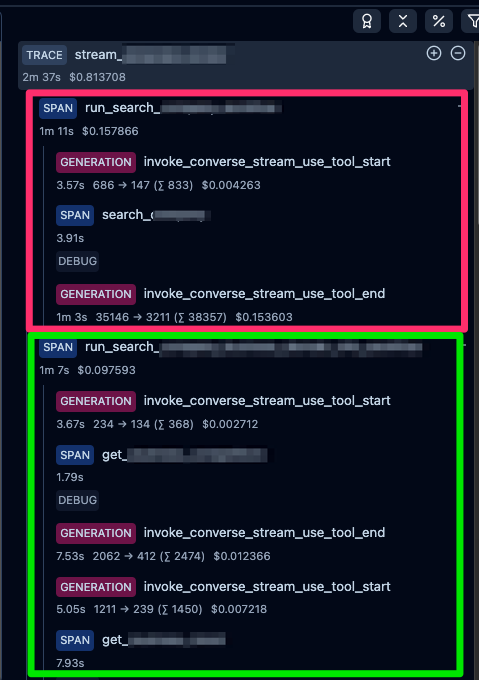
もし、LangChain、LangGraphをお使いでしたら専用のCallbackも提供されているためさらに実装が簡単になります。
# LangChainのCallbackを使う場合
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(
secret_key="sk-lf-...",
public_key="pk-lf-...",
host="https://xxx"
)
chain.invoke({"input": "<user_input>"}, config={"callbacks": [langfuse_handler]})
# LangGraphのCallbackを使う場合
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(
secret_key="sk-lf-...",
public_key="pk-lf-...",
host="https://xxx"
)
for s in graph.stream({"messages": [HumanMessage(content = "<user_input>")]}, config={"callbacks": [langfuse_handler]}):
コードを実行するとこんな感じで良しなに記録されます。
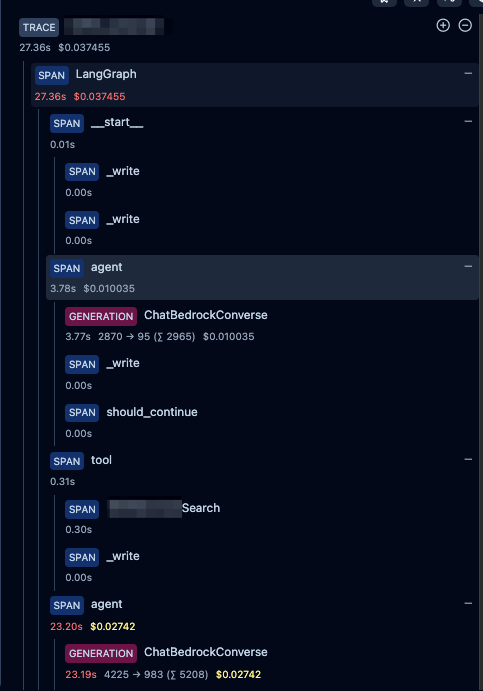
今更ですが、LangfuseのObservation種別については次のドキュメントを参照してください。
導入の成果
改善したかった課題はどれくらい解決されたか
すべて解決しています。
新機能開発でも利用しない日はないですし、本番運用の監視・分析用途でも毎日利用してます。
ただし、Langfuseのプランをあげないと使えない機能がいくつかあったのでその点はCI/CDと絡めて運用したり、自作で評価システムを作ることで対応しております。
どのような成果が得られたか
新機能開発時、AIエージェントのワークフローを構築する際のデバッグに利用したり、コスト含めモデルの挙動を細かく確認することができるようになったおかげで、開発速度があがったと思います。(プロジェクト初期から利用しているため、定量的な効果は出せませんが、肌感で工数が1/3〜2/3くらい減っていると思います。)
また、プロダクトオーナーやステークホルダーがアプリケーションの利用状況やレイテンシー、運用コストを確認する起点になっているため、サービスの提供機能のブラッシュアップ、予算・プライシング検討などに生かされております。
導入時の苦労・悩み
AWSによるコンテナアプリケーション構築の経験があれば、Langfuse v2の導入時はIaC化含めて苦労することはあまりないですが、Langfuseのバージョンをv3にする際に作成するコンポーネントが一気に増えるためインフラ構築の難易度が上がります。
また、本番・開発などの環境ごとにプロジェクトを切ってしまうと作成したプロンプトの引き継ぎができない(コピーできない)という細かいながら重要な課題がありました。
このあたりはアーキテクチャーにも記載しておりますが、CI/CDを活用してデプロイパイプラインとしてコピースクリプトを作成して解決しております。
導入に向けた社内への説明
上長・チームへの説明
プロジェクト発足時からLangfuseを導入していたため、LangfuseのようなLLMOpsツールを入れて当然という空気はそもそもチームにあったかと思います。
なのでLangfuse v2を導入するときは特に説明などは不要でした。
ただ、Langfuse v3化するにあたってはインフラコストが上がってしまうのでコスト増に対しての承認を貰う必要がありました。
ちょうど弊社開発のLLMアプリケーションの需要が増加される可能性があったため、V3化することによる基盤の安定性を押し出すことでV2 -> V3切り替えが実施できました。
加えて、少しでも基盤を安く運用するための工夫をAWSの様々なサービスを駆使することで実現してます。
活用方法
- チームでは開発でほぼ毎日利用
- プロダクトオーナー・ステークホルダーは週1回ほど、Langfuseで集計された利用状況・コストを確認
- 都度Langfuse上でLLMアプリケーションで処理したTraceを確認
よく使う機能
Trace/Observationの記録・確認
ツールの目的からすると当たり前といえば当たり前ですが、一番良く使うかと思います。
次のキャプチャは弊社プロジェクトのTraceを切り取ったものですが、最終回答(send_final_message)までに多くの生成・ツール処理が並列で走ってます。
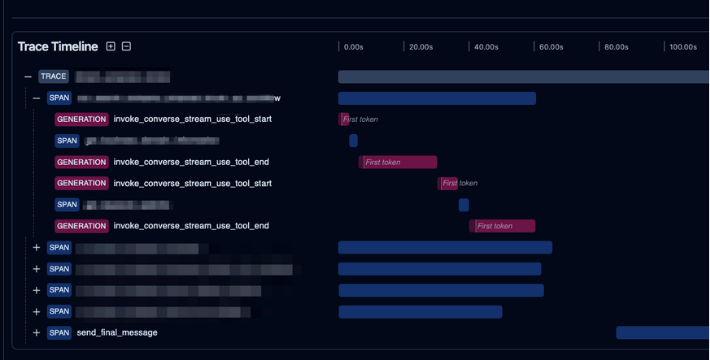
例えばアプリケーションの標準出力に中間の生成結果を吐き出した場合、並列で吐き出されるログから処理を追いかけるのは至難の業ですし、中間の結果一つ一つを確認せずに(勘だけで)最終出力を調整するのもまた至難の業、ということがわかるかと思います。
まだβ版ですが、LangChain + LangGraphで実装したLLMアプリケーションをTraceすると下のキャプチャのようにState Graphを図示することができます。
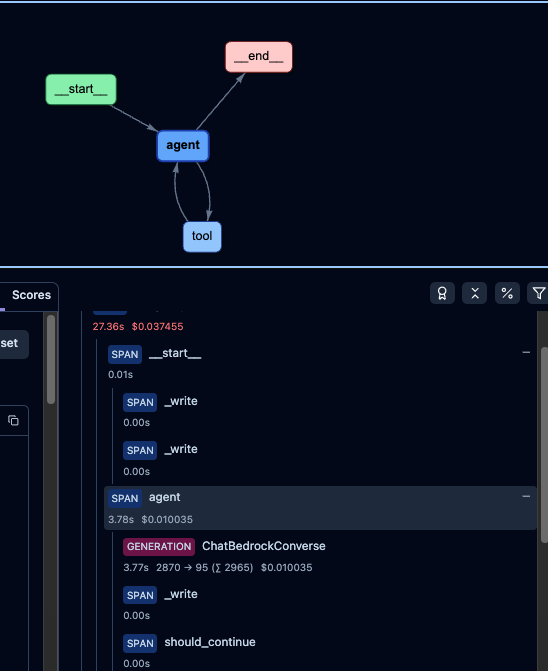
Conditional Edgesの条件ミスで想定しているNodesを通ってないことが視覚的ににわかるようになりました。
プロンプトマネジメント機能
次に利用が多いのがプロンプトマネジメント機能です。
開発時、プロンプトの変更はこちらで行う形を取ることでコードのデプロイを伴わず迅速にアプリケーションの動作を変更することができます。
また、バージョン管理機能、バージョンごとの差分を取得する機能もありますのでプロンプトのエディターとしても比較的高機能です。
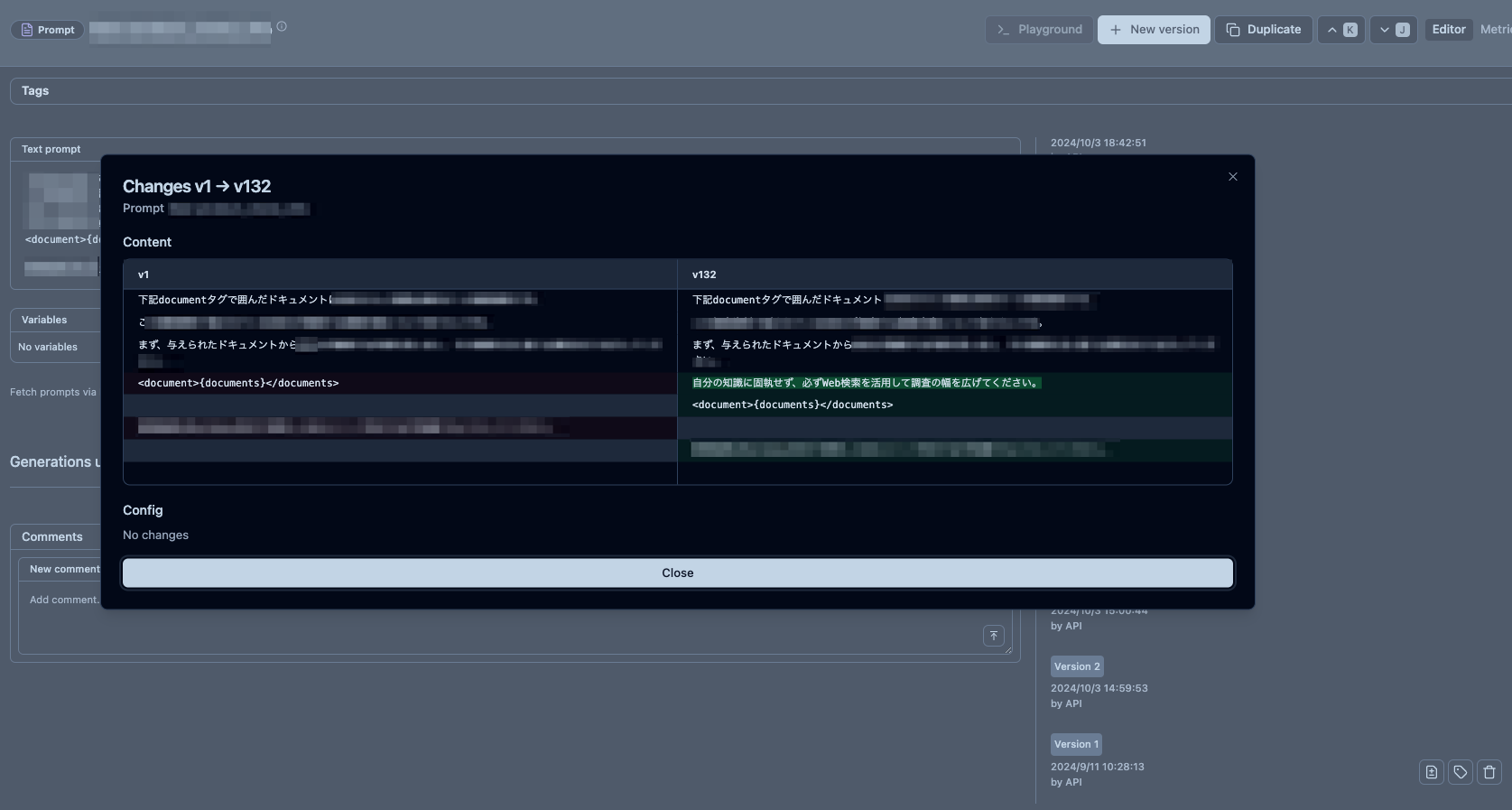
(キャプチャ、ほとんどモザイクですみません...)
ツールの良い点
LLMOpsツールとして一通りの機能が揃っているのでOSS版で満たされないことがあまりない点
- とはいえ100点ではないので、足りないところは別ツールと組み合わせて補うようにしてます。
機能リクエストや不具合、相談がGitHubのDiscussionで盛んであり、とても参考になる点
OSSなのでコードを読むことができ、利用する機能の仕様をコードから判断することができる点。
ツールの課題点
セルフホステッドでは下記の課題があります。
- v3にバージョンアップしてから必要となるコンポーネントの数が増えてしまったため、構築コスト・インフラ費用が上がってしまった点
- 特にインフラ構築力が高くないとマネージドサービスを組み合わせた最適な構築が難しいため、ある程度クラウドの知識が必要な点
ツールを検討されている方へ
LLMを用いたアプリケーション開発、特にAIエージェントなどツールや生成が入り交じるようなアプリケーションの開発においてはLangfuseのようなLLMOpsツールの導入をしないとかなり開発が困難です。
LangfuseはOSSかつセルフホステッドができるメリットを持ちつつ、他ツールと遜色ないレベルの機能が揃っている点がとても良いです。
昨年末(2024年末)からアップデートのスピードもかなり早くなっている印象があるので、新機能をほぼ毎週体験できるというワクワク感も魅力だと思います。
完全に余談なのですが、Langfuse開発者はかなりこまめにDiscussionを返信してくれるので、質問がある場合は気軽に聞いてみると良いかもしれません。
今後の展望
プロジェクトの垣根を超えて、弊社内全体でLangfuseを活用するにはまだ至っていないので、さらに普及させていきたいです。
またアーキテクチャ解説でもお話した通り、RagasとLangfuseを組み合わせた自働評価にもチャレンジしておりますが、まだ本格運用できてないのでこちらも活用に向けて検証進めていきたいと思います。
KDDIアジャイル開発センター株式会社 / tubone24
メンバー / フルスタックエンジニア・プロダクトエンジニア / 従業員規模: 101名〜300名 / エンジニア組織: 101名〜300名

KDDIアジャイル開発センター株式会社 / tubone24
メンバー / フルスタックエンジニア・プロダクトエンジニア / 従業員規模: 101名〜300名 / エンジニア組織: 101名〜300名
レビューしているツール
目次
- アーキテクチャ
- 導入の背景・解決したかった問題
- 活用方法