


New Relic 導入レビュー:監視基盤の統合とAIエージェントの活用

参考になった
1

KINTOテクノロジーズ株式会社 / ryusuke.tesaki
メンバー / SRE / 従業員規模: 301名〜500名 / エンジニア組織: 301名〜500名
| 利用プラン | 利用機能 | ツールの利用規模 | ツールの利用開始時期 | 事業形態 |
|---|---|---|---|---|
Enterprise | APM, Logs, Browser, Alerts & AI, その他全般機能 | 301名〜500名 | 2024年6月 | B to B B to C D to C |
| 利用プラン | Enterprise |
|---|---|
| 利用機能 | APM, Logs, Browser, Alerts & AI, その他全般機能 |
| ツールの利用規模 | 301名〜500名 |
| ツールの利用開始時期 | 2024年6月 |
| 事業形態 | B to B B to C D to C |
アーキテクチャ
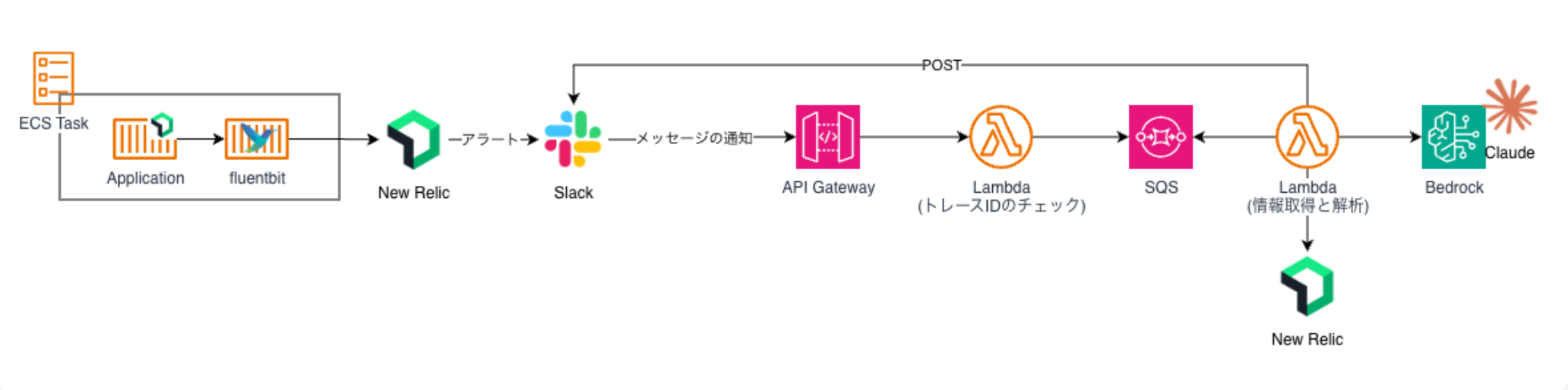
アーキテクチャの意図・工夫
インシデント対応時、運用者が普段触っているチャネルから観測データへ到達できるよう、Slack・AI エージェントを起点とした構成を採用しています。New Relic特有の課題であるNRQLの学習コストの壁をAIエージェントで軽減しています。
- Slack を入力起点に AI エージェントから New Relic を呼び出す構成
運用者が普段触っているチャネルから観測データへ直接アクセスできる - アカウント設計はプロダクト・環境はタグと app name で論理分離し要望に応じて個別アカウントへ分割可能な運用ルールを構築
- ログはアプリケーションログ / ALB / WAF / CloudFront / Lambda / RDS などを New Relic に集約
- アラート / ダッシュボードは Terraform でモジュール化し、複数プロダクト・複数環境に横展開
- New Relicのログは一定期間後削除しているため、ログを配信する際にS3へも同時配信しバックアップを取得
導入の背景・解決したかった問題
導入背景
当時はアプリケーションメトリクスをGrafana、トレースをX-Ray、ログをOpenSearch / CloudWatch、AWSインフラをCloudWatchと、4つの基盤に分散して利用しており、システム障害時の調査経路が複雑化していました。それを解消するために複数のモニタリングツールが分散している状況の見直しを開始しました。
比較対象の製品を実プロダクトで検証し、最終的にプラットフォーム共通の選択肢としてNew Relicの採用を決定。プロダクトに対しては「Grafana + α」か New Relic を選択できる形式でスタートし、オブザーバビリティを積極活用したいプロダクトからミニマムスタートを進めています。
ツール導入前の課題
監視ツールの分散と学習コストの高さが、運用上のボトルネックになっていました。
- 監視ダッシュボードが活用されておらず、ツールの種類が多く学習コストが高かった
- 監視の際に見る場所が分散していた
アプリケーションメトリクスは Grafana、トレースは X-Ray、ログは OpenSearch / CloudWatch、AWS インフラは CloudWatch - 情報が分散しているため、システム障害時の調査が困難で必要な情報にすぐたどり着けなかった
- 学習コストの高さから担当者が使えるようになるまでの時間が長く、有効活用できていないプロダクトが多かった
どのような状態を目指していたか
「まずここを見ればシステムの状況が分かる」という単一のエントリポイントを用意することをゴールに、以下の状態を目指しました。
- 見る場所を 1 か所に集約する
- 学習コストを削減し、担当者が素早く使いこなせるようにする
- 情報到達速度を上げ、システム障害からの復旧時間を短縮する
- 全てのプロダクトで監視ダッシュボードが有効活用されている状態を実現する
比較検討したサービス
- Datadog
- Grafana(+Prometheus / OpenSearch / Site24x7)
- New Relic
比較した軸
機能だけでなく、チームで継続して使えるかを重視しました。
- ダッシュボードを統合できるか(情報到達速度が向上するか)
- 既存機能(APM / ログ検索 / インフラメトリクスの確認 / アラート設定)を損なわず、かつプラスアルファの機能があるか
- コストに見合うか(利用費・運用コスト・移行コストを含む費用対効果)
- 使用感(UI/UX の快適さ・動作のスムーズさ)
- 権限管理(参照範囲の制御・ログのマスキング処理)
選定理由
最終的には、障害調査のしやすさと運用コストのバランスでNew Relicを選びました。
- APM・ログ・トレース・インフラを 1 プラットフォームに統合でき、障害時に情報をたどる場所が 1 か所に集約できると判断した
- 他製品と比較して、フルユーザを絞りつつ無料ユーザを活用することで費用対効果が高いと試算できた
- Agent をサイドカーとして追加するだけで既存アプリへの改修が最小限で済む(実装コストが低い)
- コストが都度見直し(3 か月ごと)の課金モデルのため、突発的なコスト増への対応がしやすい
- New Relic エンジニアによる定期的な勉強会・オンボーディングサポートの存在
導入の成果
改善したかった課題はどれくらい解決されたか
監視データをNew Relicに集約したことで、障害調査の動線が大きく改善しました。
- 監視データがNew Relicに集約され、障害時の調査経路が APM → ログ → ブラウザで1画面内に収まるようになった
- アラート・ダッシュボードをTerraform管理に移行し、PRレビュー上で差分追跡できるようになった
- Change Trackingの導入により、デプロイ前後のメトリクス変化を即座に確認できるようになった
どのような成果が得られたか
導入後は、障害調査だけでなく、アラートやログ調査の運用も見直しやすくなりました。
- アラート条件やダッシュボードを継続的に見直すサイクルを作りやすくなった
- 業務例外とシステム起因のエラーを分けて扱えるようになり、不要な通知を減らせた
- ログとトレースを同じ流れで確認でき、原因調査の手順をチーム内でそろえやすくなった
- UI だけでは難しい集計や過去ログ取得は、NRQLやNerdGraph APIを使って補完できるようになった
- New Relic MCP ServerをAIエージェントに接続し、日次ログレポートの自動投稿にも取り組み始めた
導入時の苦労・悩み
アカウント設計・権限・セキュリティ
1AWSアカウントに複数プロダクト・複数環境が同居している場合、New Relicの「1NRアカウント=1AWSアカウント」を前提とした思想と噛み合わず、設計面で時間を要しました。
- 単一アカウントへ統一するか、プロダクト別に新規アカウントを切るか判断に時間がかかった
- 子アカウントの分け方(システム単位 / グループ単位 / プロダクト集合単位)にそれぞれトレードオフがあった
- 横断的な可視化とセキュリティ境界の両立が難しかった
AWS インテグレーション
AWS連携では、ログ取得方式とサーバレスサービスの扱いに検討時間が必要でした。
- AWSログの取得方法(logstash 経由 / Lambda 経由 / Firehose 経由)の選定が必要だった
- OpenSearch をなくすためには、AWSログの取り込み方針を先に決める必要があった
- API GatewayなどLambda以外のサーバレスサービスのトレースをどう追うかが課題だった
- New Relicを採用しても、既存共通基盤のAWSコスト按分は別問題として残った
アプリケーション・コンテナ実装
ECS Sidecarの管理と、既存ロギング実装との接続も論点になりました。
- ECS Sidecarをどこで管理するか(ECR 登録運用の検討)を決める必要があった
- Spring Bootのlogback実装見直しが必要だった
- New Relic Agent経由のログ送信で、logbackで付与した情報を取得できるか確認が必要だった
導入に向けた社内への説明
上長・チームへの説明
導入推進時の説明内容
監視ツール分散による調査時間の長さと管理コストの増大を課題として提示し、New Relicに統合することで得られる効果と段階的な進め方を説明しました。
- APM (Grafana) / トレース (X-Ray) / ログ (OpenSearch・CloudWatch) / インフラ (CloudWatch) と監視ツールが分散しており、障害時の調査に時間がかかっている課題を提示
- New Relicに統合することで見る場所を 1 か所に集約でき、学習コストと障害調査コストを削減できると説明
- プラットフォーム側・アプリチーム双方の管理コスト削減効果を資料で提示
- まずは「選択肢として提供」から始め、オブザーバビリティを積極活用したいプロダクトへの限定導入でミニマムスタートを提案しました
フィードバック・懸念点
ユーザ課金モデルとAWSアカウント設計の前提に関する懸念が中心に寄せられました。
- ユーザ数課金のため、利用者全員にフルユーザを付与すると費用が高額になるためBasicユーザーで確認できる範囲も活用した
- Basic ユーザーでもダッシュボード・ログ・アラートの確認は可能で、既存の確認シナリオは簡易的には実施できた
- New Relicを採用しても既存共通基盤のコストは按分されてプロダクトに加算される(AWS 費用按分)
- 既存Grafanaを使い続けているプロダクトとの共存期間中の二重運用コスト
費用対効果についての説明
表面コストだけでなく、運用コスト・APM 実装コスト・学習コストを含めた総合費用対効果で説明しました。
- 既存のGrafana + Prometheus + OpenSearch + Site24x7の合計金額に対し、将来的なユーザ・データ量を想定したNew Relicの月額コストは高くなる
- ただし運用コスト・APMの実装コスト・学習コストまで含めた費用対効果ではNew Relicが優位と試算
- OpenSearch を単独のシステムとして運用するとインフラコストがNew Relic以上になるケースもあり、ログ基盤リプレースだけでもコスト削減効果がある
その他、必要要件や条件
強制移行ではなく、プロダクトが自分達に合うツールを選べるようにする方針としました。
- プロダクトが「Grafana + α」かNew Relicかを選択できる形式でスタート
- 「使いたい」ではなく「使うべきところ」に導入する方針。プロダクト単体ではなく関連プロダクトを含めた選択を推奨
- New Relicはライセンス費用が発生する一方、Agent のインストールのみで導入でき、実装にかける稼働を抑えられる
- 自由にカスタマイズしたい・コストを最小限に抑えたいプロダクトは、引き続き Grafana + Prometheus / OpenSearch / X-Ray を選択肢として残す
活用方法
障害調査・デプロイ前後の確認・AI エージェントによるレポート取得で活用しています。
- 障害発生時の調査:APM → ログ → ブラウザを横断して
trace.idで追跡 - デプロイ前後のメトリクス変化の確認
- AI エージェントから Slack 経由で日次のログサマリを自動取得
- アラート発報後、AI が状況を自動分析し影響範囲と対応方針を自動整理することで初動対応時間を 30〜60分→1分 に短縮しました
よく使う機能
- APM
- Logs
- Browser
- Alerts
- Dashboards
- Infrastructure
- Synthetic Monitoring
- Change Tracking
- Errors Inbox
- Workflow Automation
- Service Levels
- Serverless Functions
- AI Monitoring
- Trace
ツールの良い点
統合的な観測の網羅性と、IaC・APIによるカスタマイズ性を特に評価しています。
- NerdGraph APIやTerraform プロバイダにより、アラート・ダッシュボードの操作をUIに限定されずに管理できる
- 1アカウントで複数プロダクト・複数環境を論理分離でき、横断クエリが組める
- MCP Serverが公式に提供されており、AI エージェント連携の道筋が明確
- 自動生成されるダッシュボードを活用でき、初期導入のコストが低い
- SaaSのためインフラ環境のメンテナンス(バージョンアップ対応・EOL 対応)が不要
- サポート窓口・Slack 窓口があり、エンジニアへ直接連絡できる
- マルチクラウド対応が可能
- NRQLで複合データの組み合わせクエリが可能
- 生成AIを活用した分析機能が提供されている
- アラート・ダッシュボード・ログなどの設定変更がNew Relic上で完結する
ツールの課題点
導入・運用を進める中で、設計時点で気を付けるべきポイントがいくつかあります。
- New RelicアカウントとAWSアカウントの紐付けが1:1のため、マルチアカウント環境ではメトリクス取得方式に追加設計が必要になる
- CloudWatch Metric Streams方式は網羅性が高い反面、検証時点で月額相当のコストが発生する。取得対象を絞らないとデータ取り込みコストが膨らむ
- Agentのメジャー更新時に、フレームワーク側との組合せ次第でtrace属性が欠落することがある
- DashboardをTerraformで管理する際に差分が見づらく、レビュー性が落ちる
- NRQLやNerdGraph APIの学習コストがかかる
ツールを検討されている方へ
これからNew Relicを導入される方は、以下の観点を初期設計の段階で押さえておくと、運用に乗せやすくなります。現代のソフトウェアではオブザーバービリティツールの導入は必須と考えられます。
- アカウント設計(統一 / プロダクト別)の方針を最初に決めておく。後からアカウントを跨いだデータ集約は手間が大きい
- ログのマスキング/ドロップルールは導入時に設計する。PII を含む生ログを取り込んでしまうと後追いの整備が困難
- CloudWatchメトリクス取得方式(Pull / Metric Streams)は事前にコスト試算する。取得対象を絞り込まないと想定外の料金になる
- 最初からTerraformでIaC化することを推奨。後からIaC化するコストは高い
- 環境別のapp分離をローカル開発含めて初期に設計しておく
- 業務エラーと不具合を分けて通知設計する。Errors Inbox の信頼性は初期設計で決まる
今後の展望
監視データを集約した次のフェーズとして、AI エージェントによる運用自動化とSREプラクティスの充実化を見据えています。
- AIエージェントによる運用自動化の拡大(自律的なトリアージ・修正提案)
- SLOベースの監視への移行とエラー予算管理の運用化
- ビジネスメトリクスと技術メトリクスを1ダッシュボードで相関できる体制の構築
- Service Architecture Intelligence(Catalog / Maps / Teams / Scorecards)の活用:チーム・サービス単位の可視化と健全性スコアリング
KINTOテクノロジーズ株式会社 / ryusuke.tesaki
メンバー / SRE / 従業員規模: 301名〜500名 / エンジニア組織: 301名〜500名

よく見られているレビュー



KINTOテクノロジーズ株式会社 / ryusuke.tesaki
メンバー / SRE / 従業員規模: 301名〜500名 / エンジニア組織: 301名〜500名
レビューしているツール
目次
- アーキテクチャ
- 導入の背景・解決したかった問題
- 活用方法