



【Databricksで実践するAI Agent開発】デジタルネイティブ企業のユーザーボイス分析AIエージェント
はじめに
ECサイトやスマホアプリ、SNS、ゲームなど、多くのデジタルネイティブ企業が、ユーザーに直接サービスを届けています。そのほとんどが「ユーザーの声を聞き、サービス改善に活かしている」と謳っていますが、果たしてそれは本当でしょうか?サービスの利用者が増えるほど、寄せられるフィードバックのすべてに目を通すのは困難になります。「いつか対応しよう」と考えているうちに、宝の山であるはずのユーザーの声が、活用されないまま眠ってしまっているケースは少なくありません。
本記事では、これまで膨大な工数をかけてフィードバックを整理してきた方々へ向けて、DatabricksのAIがいかにその作業を効率化できるか、具体的な方法をご紹介します。
ユーザの声はどうやってAIで分析する?
ユーザーからのフィードバックは、主にアンケートなどの「テキストデータ」と、カスタマーセンターへの電話といった「音声データ」の2種類に大別されます。しかし、これらのデータを分析・活用する上では、それぞれに特有の課題がありました。
生成AI以前の課題:人手と精度のジレンマ
本記事では、特にテキストデータの分析に焦点を当てます。生成AIが登場する以前、主に分析方法は2つありました。
- 人力での分類・分析:柔軟性が高く精度を追求できる一方、担当者によって判断基準が異なるといった「属人化」の課題がありました。
- 従来のNLP(自然言語処理)による自動化:高度な技術力が求められる上、日本語特有の繊細なニュアンスを正確に読み取ることが困難でした。
LLMの登場で、すべては解決したのか?
LLMの登場は、データ分析の状況を一変させました。これまで多大な労力を要した分析作業の多くをLLMに任せられるようになり、自前でモデルを開発したり、担当者間で判断基準をすり合わせたりといった手間も不要になる──そう期待されています。
しかし、現実はそれほど単純なのでしょうか。
確かに、適切な指示(プロンプト)さえ与えれば、LLMは感情分析やキーワード抽出といったタスクを高い精度で実行します。ですが、実際の業務で活用する場面を想像してみてください。大量のデータを一つひとつLLMで処理し、その結果を元のデータと紐づけてシステムに格納する、といった一連のパイプラインを自前で構築し、運用し続けなければなりません。
さらに、精度向上のためのプロンプト調整や、複数のLLMモデルの性能比較といった作業も考慮に入れると、その手間は膨大なものになります。こうした実情を踏まえると、「LLMの登場でデータ分析は楽になる」と、一概に言えるでしょうか。
Databricksの解決策、それは魔法のような関数「ai_query」
Databricksであれば、自信を持って「YES」と言えます。 なぜなら、Databricksには<ai_query>という魔法のような関数があるからです。これを使えば、面倒なパイプライン構築や運用作業を驚くほど簡単に行えます。この<ai_query>の正体は、AIによるバッチ推論機能です。普段お使いのSQLと全く同じ感覚で、クエリの中から直接LLMを呼び出すことができます。
<SQL例>
SELECT
ai_query(
'利用したいLLMモデル',
'LLMへの指示プロンプト' || 入力したいテキストカラム)
FROM
テーブル名;
`<ai_query>`の最大の特長は、大量のデータに対する”バッチ処理”にあります 。100行でも10万行でも、レコード数に関わらず一度のクエリでLLMによる処理を一括実行できます 。ユーザーはクエリを実行した後は、ただ結果を待つだけで済みます 。さらに、利用できるLLMモデルの種類が非常に豊富である点もDatabricksの大きな強みです 。
- Databricksがホストする高性能オープンソースモデル
- OpenAI社やAnthropic社の最新商用モデル
- ユーザがファインチューニングした独自の高精度モデル
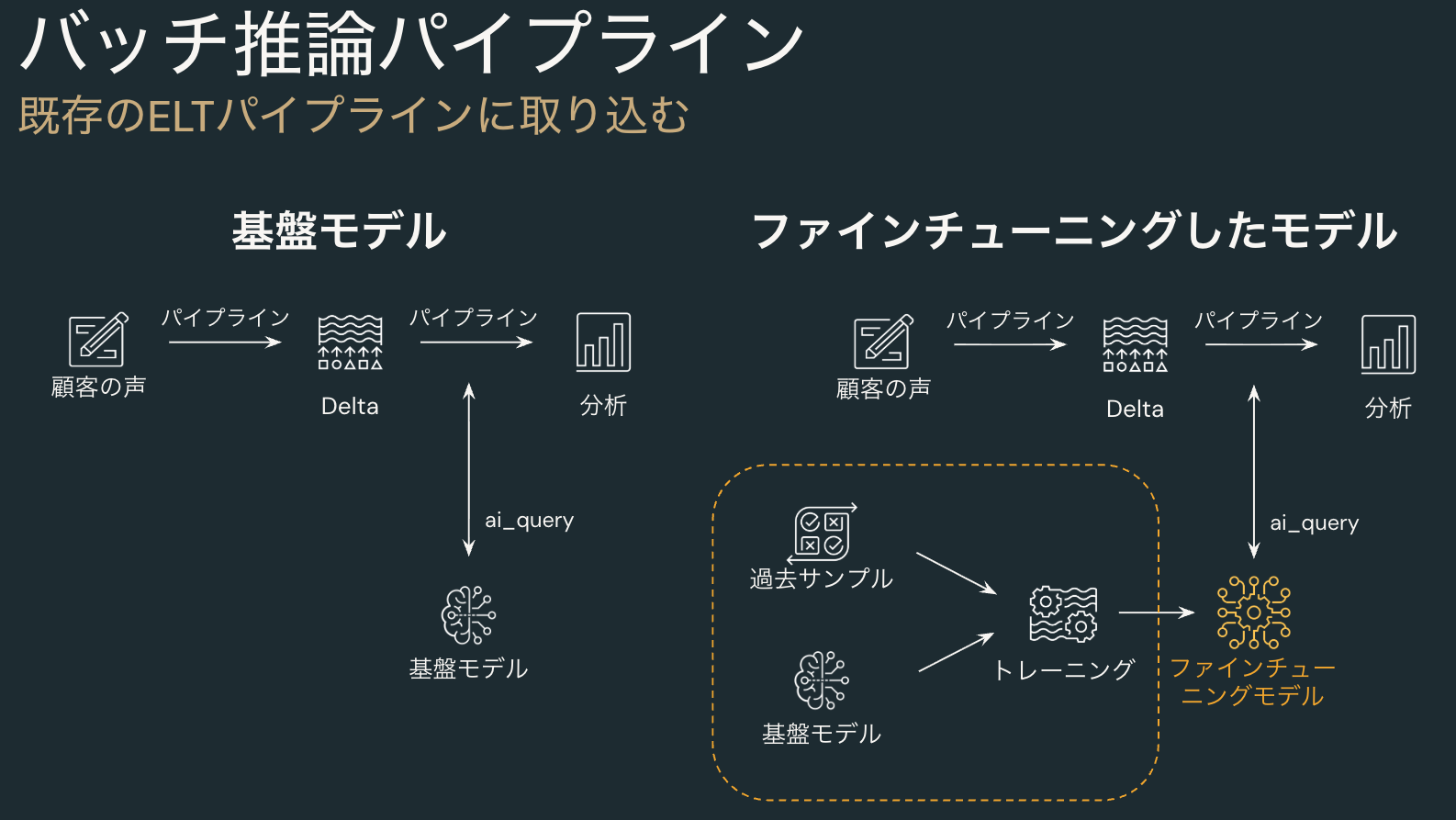
上の図が示しているように、すぐに使える既存モデルで素早く開発を進めることも、より高い精度を求めて独自モデルを活用することも、どちらも可能です。
あなたもDatabricksで「魔法使い」に
汎用的な<ai_query>以外にも、翻訳に特化した<ai_translate>やキーワード抽出用の<ai_extract>など、特定のタスクに特化した便利なAI関数が数多く用意されています 。現在、ユーザーの声の分析に課題を抱えているようでしたら、Databricksでこの”魔法”を試してみませんか 。
AIが分析した結果のもとにさらにAIが仮説を立てる?
さて、前節でご紹介した方法でユーザーコメントの分析などは実現できました 。では、さらに一歩進んで、データに隠された未知のインサイト(洞察)を発見するにはどうすればよいのでしょうか?
「仮説が当たらない…」データ分析の大きな壁
従来のデータ分析では、まずデータを探索して「仮説」を立てることから始まります 。そして、その仮説を証明するためにデータを深掘りし、インサイトを見つけ出すのが一般的なプロセスでした 。しかし、この最初の「仮説」が的を射ているとは限らず、むしろ見当違いであることの方が多いのではないでしょうか 。結果として、多大な工数を費やしたにもかかわらず、価値ある成果に結びつかないという課題がありました 。
その「仮説立案」、AIに任せてみませんか?
データ分析において最も困難で、かつ創造性が求められるこの「仮説立案」のプロセスも、AIに任せることができます 。その答えが、Databricksの年次イベント「Data + AI Summit」で発表された新機能、『Agent Bricks』です(現在はベータ版)。Agent Bricksは、複数のAIエージェントが協調して動作する「マルチエージェントシステム」です 。それぞれ異なる役割を持つエージェントを連携させることで、単体のAIでは実行不可能な、より高度なタスクを実現します 。
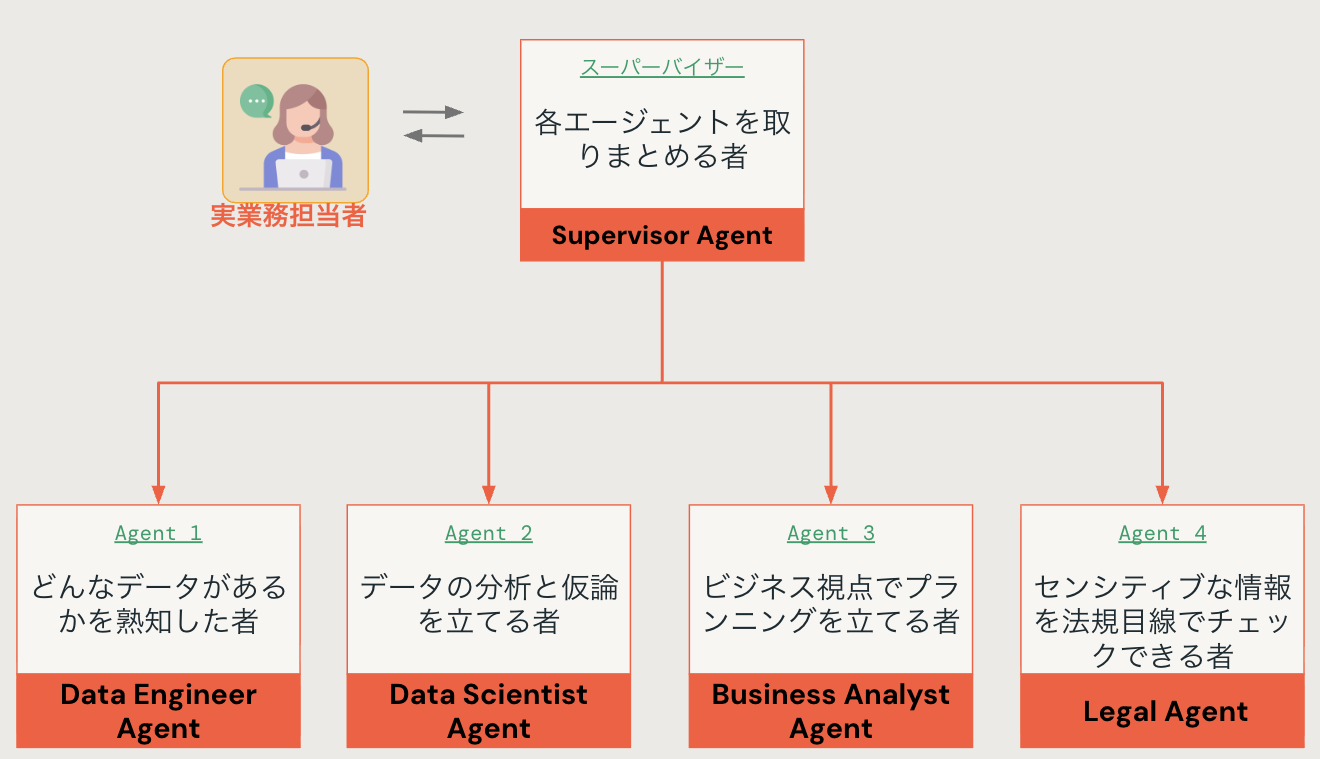
具体的には、次のような活用が可能です。まず、自社データを自然言語で分析できる「Genie」を『エージェント1』として設定します。次に、汎用LLMに「データサイエンティスト」の役割を与え、『エージェント2』として設定します。これにより、次のような一連のプロセスを自動化できるようになります。
- 【データ抽出】:エージェント1が指示に基づいて分析データから関連情報を抽出する
- 【仮説立案】:エージェント2が、そのデータを分析し、複数の有望な仮説を立てる
- 【深掘りと結論】:両エージェントが協力して各仮説を深掘りし、最終的な結論やインサイトを導き出す
専門家が多大な時間を費やしてきた仮説検証のプロセスをAIに任せることで、より短時間で質の高いインサイトを獲得できるようになります 。AIは単なる「分析ツール」から、自ら問いを立てて探求する「パートナー」へと進化するのです。
自社サービスを熟知したAIが改善意見まで出せる?
これまでご紹介してきたAIの活用法は、主に「汎用AI」の領域に属するものです 。そのため、「これでは、単にChatGPTに質問しているのと変わらないのでは?」と感じた方もいるでしょう 。その感覚はある意味で正しいです 。皆様の会社が提供する独自のサービス、その背景にあるコンセプト、そして届けたい価値。こうした企業固有の「文脈」を、汎用のLLMは理解できないからです 。
会社の「魂」を、AIはどう学ぶのか?
LLMが企業独自の「文脈」を理解するには、企画書や報告書、議事録といった、社内に蓄積された「非構造データ」の活用が不可欠です 。これらはWordやPDFなどのファイル形式、あるいはConfluenceやNotionのようなツール上で管理されているなど、その形式は多岐にわたります。
これらの多様な社内ドキュメントをLLMに参照させることで、「自社のことを最もよく知るAIエージェント」を育てられる可能性がありますが、その実現にはいくつかの疑問が浮かびます 。
- セキュリティ:機密性の高い社内データをLLMに学習させて、情報漏洩のリスクはないのか
- データ形式: フォーマットがバラバラなドキュメントを、AIはどうやって読み解くのか
- 開発コスト: そのような高度な仕組みを、一体誰がどうやって開発するのか
その答えは「RAG」にある
その課題を解決するのが「RAG(Retrieval-Augmented Generation)」です 。RAGとは、LLMが外部のナレッジベースをリアルタイムで検索し、そこから得た正確な情報に基づいて回答を生成する技術です 。これにより、LLMに直接機密情報を「学習」させることなく、社内のナレッジを安全に活用できるのです 。Databricksでは、このRAGを、驚くほど簡単かつ安全に構築することが可能です。特に前節でご紹介したAgent Bricksを活用すれば、そのプロセスはさらに加速します。
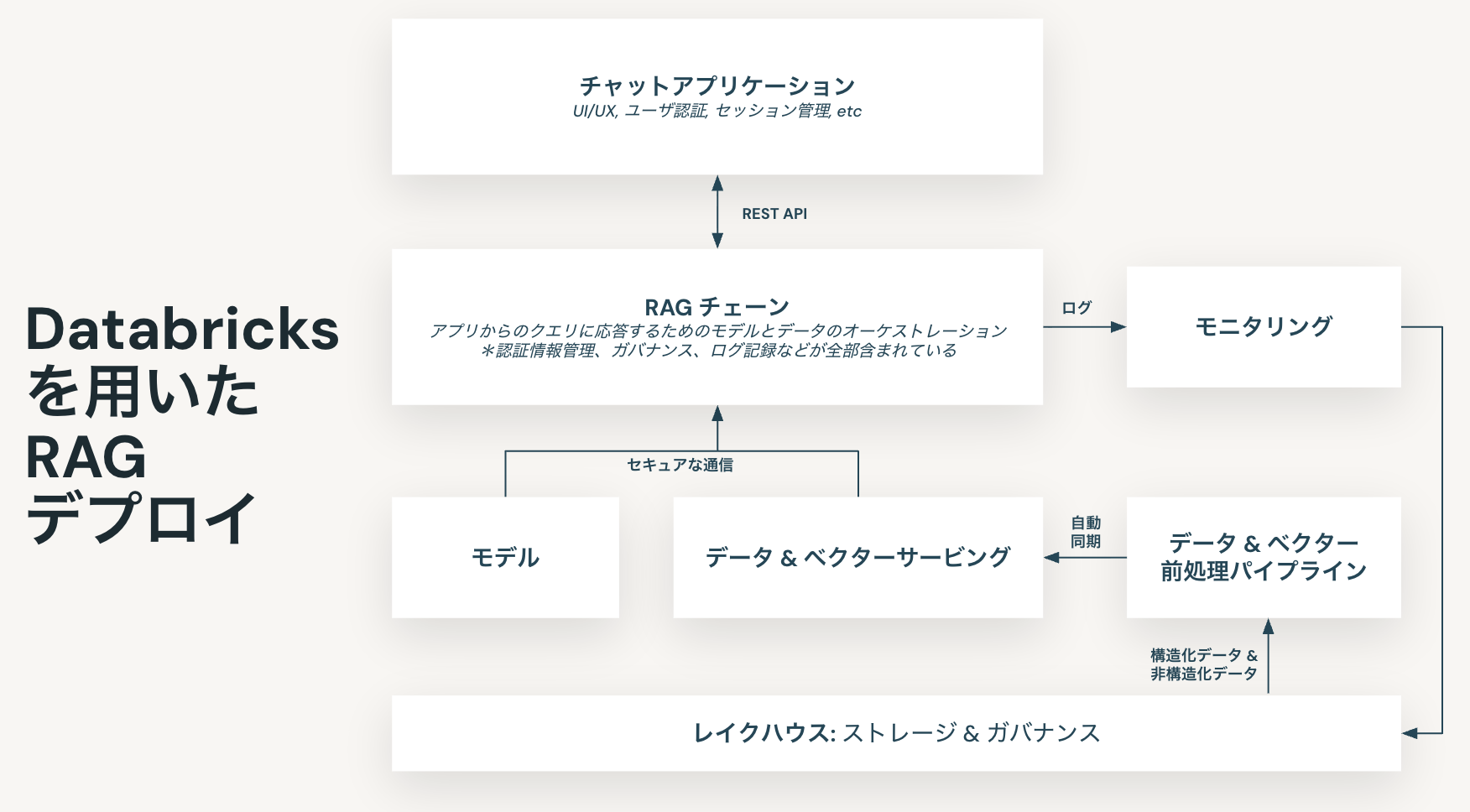
汎用のLLMにRAGを組み合わせることで、まるで経験豊富な社員のように頼もしい、貴社専用のAIが完成します 。この専用AIを前節で紹介したマルチエージェントの一員に加えることで、これまで一般的な回答しかできなかったAIエージェントが、貴社独自の「文脈」を深く理解し、的確な分析や具体的な改善提案まで行う、真に強力なパートナーへと進化するのです。
おわりに
本記事では、DatabricksのAI機能を活用し、埋もれがちなユーザーの声をビジネス価値に変える3つのステップをご紹介しました。
- AIによる効率的な分析:SQL関数一つで、膨大なユーザーの声を瞬時に分析する。
- マルチエージェントによる高度な分析自動化:複数のAIが協調し、仮説立案から検証、考察までを自律的に実行する。
- RAGによる「自社特化AI」の構築:社内ナレッジを安全に活用し、自社の文脈を深く理解したAIパートナーを育成する。
これらのアプローチを組み合わせることで、これまで人手・時間・精度に課題を抱えていた分析プロセスを、抜本的に改革できます。 本記事が、皆様のサービス改善、そしてその先にある顧客満足度の向上に繋がる一助となれば幸いです。
◆執筆:データブリックス・ジャパン株式会社・王 兆祺





