



Google BigQueryからSnowflakeへ。バクラクのデータ基盤技術移管事例
はじめに
LayerXでは、「バクラク」という企業のバックオフィス業務を効率化するクラウドサービスを提供しています。稟議、経費精算、法人カード、請求書受取、請求書発行といった経理業務に加え、勤怠管理といった人事領域(HRM)の業務を効率化するサービスも展開しています。最新のAI技術を活用し、お客様の業務が、より「ラク」になる環境の実現を目指しています。導入実績は10,000社を超え、多くのお客様に選んでいただいております。
このようなサービスを支えるためには、ビジネスニーズに迅速に応えられる拡張性の高い効率的なデータ基盤が不可欠です。バクラクでは、サービスの成長と共に増大するデータ量や複雑化する分析ニーズに対応するため、データ基盤の見直しを行いました。その結果、これまで使用していたGoogle BigQueryから、Snowflakeへの移行を決断しました。
本記事では、この移行プロジェクトの紹介を通じて、バクラクがデータ基盤の主要技術をGoogle BigQueryからSnowflakeへ刷新した理由について詳しく述べます。
Disclaimer
本記事では、バクラクがデータ基盤の主要技術をGoogle BigQueryからSnowflakeへ刷新した話を書きます。しかし、すべての企業がデータ基盤の主要技術としてSnowflakeを採用すべきという意図は込めていません。Google BigQueryが最適解のケースもあれば、Amazon AthenaやDatabricksが最適解であるケースも多分に存在します。そのため、本記事は、あくまで一例として、データ基盤刷新における観点など、ソリューションそのものではない部分に着目して読んでいただけるとありがたいです。
Google BigQueryとSnowflakeの簡単な紹介
まず、本記事で登場するGoogle BigQueryとSnowflakeについて、簡単に紹介をします。
Google BigQuery
Google BigQuery(以下、BigQuery)は、Google Cloudが提供する、完全マネージド型のサーバーレスデータウェアハウスサービスです。最大の特徴はクエリエンジンとしてのパフォーマンスとスケーラビリティです。Dremelと呼ばれるクエリエンジン、Colossusと呼ばれる分散ストレージ、Jupyterと呼ばれる高速ネットワークなど、Google社によって開発された専用の分散システムによって、非常に大規模なデータセットに対しても、高速にクエリ結果を返すことが出来ます。BigQueryの利用者は、これらのGoogle内部のシステムを意識することなく、Slot(と呼ばれるコンピュートリソース量を表す単位)を管理するだけでよく、インフラストラクチャの管理も不要です。
BigQuery under the hood: Google's serverless cloud data warehouse | Google Cloud Blog
Snowflake
Snowflakeは、Snowflake社が提供する、クラウドに最適化されたデータウェアハウスプラットフォームです。BigQueryとの違いは、複数のクラウドプロバイダー上で動作する点です。Amazon Web Services、Google Cloud、Microsoft Azureから、使用したいクラウドプロバイダーを選択できます。さらに、Snowflakeの特徴として、データウェアハウス、データレイク、データ共有、データアプリケーション、AI/ML、データエンジニアリングなど、多様なワークロードを単一のプラットフォーム上でサポートできることも特徴として挙げられます。パフォーマンスに関してもBigQueryと遜色なく高速にクエリ結果を返すことができます。マイクロパーティションと呼ばれる専用のデータ保持形式で、データを細かくメタデータ付きで保持することで、クエリ実行時に走査するデータ量を極限まで減らす工夫が為されています。
Micro-partitions & Data Clustering | Snowflake Documentation
バクラクがBigQueryデータ基盤で抱えていた課題
バクラクでは2022年4月頃からBigQueryを使用したデータ基盤(以下、BigQueryデータ基盤)を構築・運用してきました。しかし、BigQueryデータ基盤を長期運用するにつれて、いくつかの課題が顕在化してきました。本記事では、主な課題である「コストコントロールの難化」「クラウドプロバイダーの不一致」「BigQueryで要求を満たし続ける費用対効果の悪化」について述べます。
コストコントロールの難化
バクラクのBigQueryデータ基盤は、構築当初からBigQueryのOn-Demand課金モデル、つまりスキャン量に基づく課金方式を採用してきました。この選択は、データ量が少ない初期段階においては非常にコスト効率が高く、適切な判断でした。
しかしながら、事業の成長に伴いデータ量が増加すると、新たな課題が浮上しました。意図せず大量のデータをスキャンしてしまうなど、管理者側でスキャン量の予測が困難になり、想定外の高額請求が発生するリスクが高まったのです。BigQueryの特徴である、インフラストラクチャをほとんど意識せずに利用できる利便性が、逆に「ついうっかり」大量のスキャンを引き起こす要因となっていました。
この問題は、Google Cloudプロジェクトの分離やQuotaによる利用制限などにより、一定程度コントロールが可能です。一方、同時に、こういった問題が多発し始めたら、より高い精度でのコストコントロールを可能にするため、BigQuery Editionsへの移行を検討する必要があります。
Understand BigQuery editions | Google Cloud
これは、スキャン量ベースの課金モデルから、Slot数(コンピューティングリソース)ベースの課金モデルへの変更を意味します。On-Demand課金モデルでは、必要に応じて最大2000Slot(バーストあり)まで即座に確保できましたが、BigQuery Editionsでは、ベースとなるSlotと、オートスケールによってSlotを確保する仕組みになります。しかし、この方式は、コストコントロールのために最大スケール数を抑えると、十分なクエリパフォーマンスが得られない可能性があります。また、Slot数の制御は管理者が設定を行う必要があるため、利用者側でワークロードに応じてSlot数を確保すると言ったことができず、柔軟性に欠ける側面があります。
BigQuery Editionsへの移行の必要性が、Snowflakeへの移行検討のきっかけとなりました。約半年から1年以内にBigQuery Editionsへの移行が避けられない状況下で、私たちは単純な金額比較にとどまらず、運用コストや将来的な拡張性など、総合的な観点からバクラクにとって最適な選択肢を模索し始めたのです。
クラウドプロバイダーの不一致
バクラクのインフラストラクチャは主にAmazon Web Services(以下、AWS)で構成されていました。一方、BigQueryデータ基盤だけがGoogle Cloudを使用している状況でした。この構成により、クラウドプロバイダー間でのデータ移動が必要となり、各プロバイダーが提供するエコシステムを十分に活用できないという課題が生じていました。
具体的には、AWSに存在するデータソースからBigQueryへデータを投入する際、マネージドサービスを利用できず、自前でデータパイプラインを構築する必要がありました。その結果、BigQueryへのデータ投入システムが、管理者の人数に比べて過度に複雑化していきました。そして、複雑であるがゆえに、トラブルシューティングにも多くの時間を要するようになっていました。
さらに、安全性、高速性、コスト効率を兼ね備えたデータ転送パイプラインを構築するには、AWS、Google Cloud双方のプラットフォームに精通している必要がありました。特に、認証やネットワークといった低レイヤーの領域に関する深い知識を持つ人材は希少であり、人材採用に関しても困難な状況に置かれていました。
これらの要因により、新規データパイプラインの追加に要する工数が増大し、既存システムの品質低下や運用コストの増加が予想される状況となっていました。また、異なるクラウドプロバイダー間でのデータ転送には追加のネットワーク費用がかかるため、コスト増加にもつながっていました。私たちは、LayerXというスタートアップの急成長を支えなければならない状況にあり、今後ますますデータの重要性が高まることが予想される中で、このような制約は看過できないものでした。この制約は、新しい技術やサービスの迅速な導入を妨げ、競合他社に対する競争力の低下につながる可能性があったためです。
BigQueryで要求を満たし続ける費用対効果の悪化
BigQueryにデータを保有していることで、データ利用に関しても問題が生じていました。BigQueryデータ基盤の利用者の半数以上がビジネスサイドの非エンジニアであったため、データを活用した施策を迅速に展開することができずにいました。例えば、アラートの設定やデータアプリケーションの作成といった施策を実施する場合、BigQueryはクエリの実行以外の機能を持たないため、必然的に追加のインフラ構築が必要でした。
この状況下では、AWSとGoogle Cloud、どちらの環境で構築する場合でも、インフラ構築の段階でデータエンジニアがボトルネックとなってしまいます。非エンジニアがセルフサービスで利用できる仕組みを構築するには多大な工数が必要となり、結果として多くの施策が実現できず、データエンジニアに負荷が集中する状況が続いていました。
また、BigQueryの利点であるGoogle Cloudのエコシステムを活用しようとしても、課題がありました。Google Cloudを使用する場合、当然ながらGoogle Cloudのセキュリティ要件も満たす必要があります。AWSをメインで使用しているバクラクには、Google Cloudのセキュリティ要件も満たす基礎的な運用が存在していませんでした。例えば、Security Command Center (SCC)やVPC Service Controlといったセキュリティサービスの運用が求められますが、データ基盤のためだけにこれらを導入・運用するのは過剰な負担でした。
つまり、バクラクにとってBigQueryを利用しつづける選択は、データの活用と運用の両面で様々な制約をもたらし、将来発生する要求に対して迅速に応答できなくなる可能性がありました。
課題解決の手段としてのSnowflake
ここまで述べたBigQueryデータ基盤の課題を解決するため、データ基盤の刷新を計画し、Snowflakeの導入を決めました。
データ基盤の理想像
バクラクのデータ基盤を刷新するにあたり、私たちは明確な理想像を描いていました。まず、データ基盤の利用者が自身で安全に、かつ容易に様々な操作を行える環境を構築することを目指しました。これは、エンジニアの介在なしに、ビジネス要件を持つ人自身が簡単かつ安全に施策を実行できる基盤を意味します。
次に、基盤運用者によるコストコントロールがしやすい状態を実現したいと考えました。ただし、単に運用者の視点からコストを抑えるのではなく、利用者の視点も考慮し、パフォーマンスを損なうことなくコストを最適化することを目標としました。
さらに、事業の成長を直接支援できる拡張性の高いデータ基盤を目指しました。つまり、ビジネスの発展に伴う新たな要求に迅速に対応できる、豊富な機能と拡張性を備えたプラットフォームを構築することを目標としました。
Snowflakeを選択した理由
これらの理想を実現するため、私たちはSnowflake、Databricks、BigQueryの中からSnowflakeを選択しました。Snowflakeを選んだ主な理由は以下の通りです。
まず、Snowflakeの単一プロダクトとしての完成度の高さです。以前、私がブログを書いたとおり、Snowflakeの単一プロダクトとしての完成度の高さは、その統合された機能性にあります。Data、Compute、AI、Security & Governance、そしてCollaborationの5つの要素が1つのプラットフォームでシームレスに統合されています。この統合により、データの移動や異なるシステム間の連携に伴う複雑さを大幅に削減しています。
特に、AIやデータプロダクトの開発において、この統合の利点が顕著です。大量のデータが存在する場所で直接処理やモデルの実行ができるため、データの移動に伴う通信コスト、セキュリティリスク、データ鮮度の問題を回避できます。また、一貫した開発環境を提供することで、環境構築の複雑さを軽減し、開発者・利用者の生産性を向上させることができます。
現地参加して良かった!Snowflake Data Cloud Summit 2024! - LayerX エンジニアブログ
次に、SnowflakeのインターフェースがSQL言語に統一されていることも決め手の1つです。既存のBigQueryデータ基盤の利用者はすでにSQLに精通しているため、新しいプラットフォームへの移行における学習コストを最小限に抑えることができます。SQLの文法さえ理解していれば、SQLを使ってSnowflakeの持つ様々な機能(例えば、アラートの設定など)を簡単に実行することができるため、データ分析以外のタスクも自発的に行うことが可能になります。
また、Snowflakeの機能はデータ利用のワークロードに特化して設計されており、多くの機能が抽象化されています。そのため、ユーザーのニーズに対して直接的に機能を提供できるケースが多く、加えて、その抽象化によってプラットフォームを操作するためのガードレールがSnowflake側で提供されていると言えます。これにより、管理者が大きな努力をすることなく、利用者が自由に安全に施策を実行できる環境を提供することが可能となりました。
Snowflakeのマーケットプレイスを通じた機能拡張性も、選択の決め手となりました。マーケットプレイスには多数のビジネスパートナーが参加し、追加機能やサービスを提供しています。通常、外部サービスの利用にはデータの移動が必要ですが、Snowflakeのマーケットプレイスでは、データを自社のSnowflake環境内に保持したまま、これらのサービスを利用できます。
最後に、SnowflakeはAWS上で構築可能であり、バクラクの既存インフラストラクチャとの相性が良かったことも選択の決め手となりました。例えば、同一リージョン内のAmazon S3とのデータ転送が無料であることや、AWS FirehoseがSnowflakeへのデータ転送用の専用ソリューションを提供していることなど、AWSとの親和性の高さが、私たちの要件に合致していました。
これらの理由により、Snowflakeが私達の理想とするデータ基盤を実現する最適なソリューションであると判断し、導入を決定しました。
Snowflakeを導入した結果
Snowflakeの導入により、バクラクのデータ基盤に大きな改善が見られました。まず、コストコントロールが格段に容易になりました。特に、スキャン量は多いものの抽出データ量が小さいワークロードにおいて、コストが大幅に削減されました。これにより、クエリ実行に対する心理的な障壁が大きく下がり、データ活用の促進につながりました。
さらに、データパイプライン追加の作業効率が向上し、従来の工数が7〜8割程度削減されました。この改善は、Snowflakeを AWS 上に構築できたことによるアーキテクチャの簡素化と、Snowflakeの豊富な機能および高い拡張性によるものです。データパイプライン追加の作業が大幅に効率化され、AWS との高い親和性により、データ転送や統合がより容易になりました。
最も顕著な変化は、ビジネスサイドのメンバーによるデータ活用の促進です。Streamlitやアラートといったツールをビジネスメンバーが主体的に利用し始め、日々の業務改善に役立てています。Snowflakeの洗練されたインターフェースは、必要最小限の機能を提供しつつ、高度な操作を可能にしています。さらに、AI技術との親和性が高いため、エンジニアの介在なしにビジネス要求を満たせる環境が整いつつあります。導入を推進した私自身も驚くスピードで、ビジネスメンバーの主体で利用が進んでいます。
これらの改善により、バクラクのデータ基盤は大きく進化しました。BigQueryからSnowflakeへの移行によって、コストコントロールが容易になり、データパイプライン追加の効率が向上し、さらにビジネスサイドのメンバーによるデータ活用が促進されました。結果として、各部門がより迅速かつ自律的にデータを活用し、効果的な意思決定を行える環境が整いました。この基盤刷新は、バクラクの事業成長を支援する、拡張性の高いデータ基盤の実現につながっていると信じています。
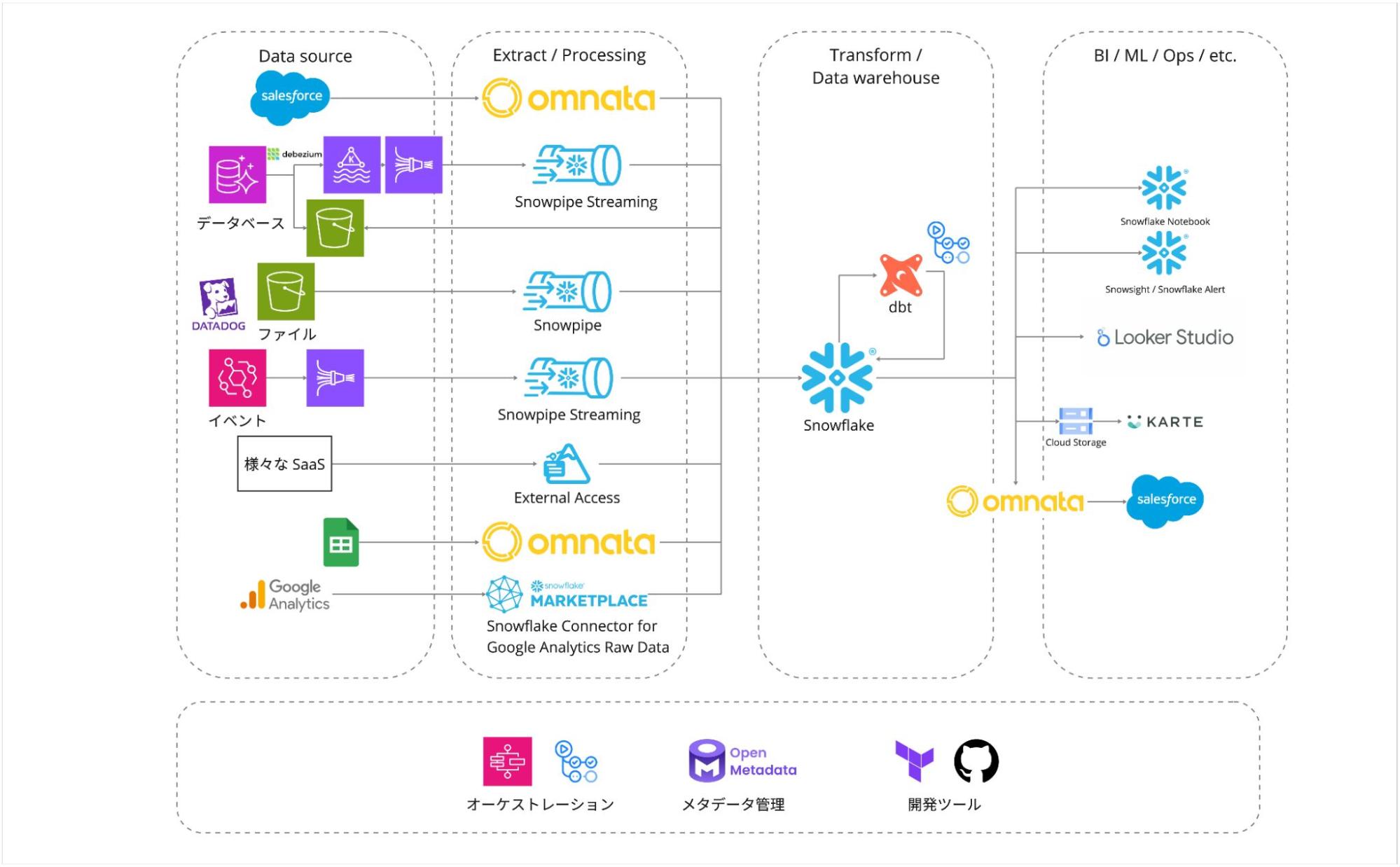
Snowflakeコミュニティ
ここまでの文章ではコミュニティの存在について触れていませんでした。Snowflakeを選択する上で、日本のSnowflakeコミュニティの存在も大きな影響を受けたので紹介させてください。日本には「SnowVillage」と呼ばれる活発なSnowflakeコミュニティが存在しています。このコミュニティでは、Snowflakeの機能や活用方法、ベストプラクティスについて学び合い、情報交換やディスカッションが活発に行われています。
特筆すべきは、Snowflake社自体がこうしたコミュニティ活動を大切にする姿勢を持っていることです。コミュニティ活動を通じて、Snowflakeというプロダクトが継続的に進化し、洗練されていくサイクルが見られました。これは、製品の将来性や長期的な支援体制を考える上で、非常に重要なポイントでした。
さいごに
本記事では、バクラクのデータ基盤をBigQueryからSnowflakeへ移行した経緯と、その過程で得られた知見を共有しました。コスト管理の難しさや、クラウドプロバイダーの不一致といった課題に直面し、Snowflakeへの移行を決断するに至った背景、そしてその結果もたらされた変化について詳しく説明しました。
データ基盤の基礎となる技術選択は、組織の未来を形作る重要な決断です。私たちがSnowflakeへの移行を選んだのは、単なる技術的な理由だけではありません。それは、データを通じて事業に具体的な価値をもたらす、という明確なビジョンに基づいた選択でした。今回の技術選定がバクラクにとって最良の選択だったかは、まだ答えが出ていませんが、最良の選択だったと言えるように努力していこうと思います。
最後に、このデータ基盤刷新を支えてくれた社内外の全ての方々に感謝申し上げます。そして、同じような課題に直面している方々に、この記事が少しでも参考になれば幸いです。
執筆

中山貴博 (@civitaspo)
X: https://x.com/civitaspo
GitHub: https://github.com/civitaspo
株式会社LayerX バクラク事業部
機械学習・データ部 DataOpsチーム 兼
Platform Engineering部 DevOpsチーム 所属
Snowflake Squad 2024
Snowflake 九州ユーザーグループ主宰


