


Databricksを活用してDELISH KITCHENのレシピレコメンドを開発した話

参考になった
12

株式会社エブリー / furu8
| ツールの利用開始時期 |
|---|
| 2018年4月 |
| ツールの利用開始時期 | 2018年4月 |
|---|
導入の背景・解決したかった問題
導入背景
データ基盤について
弊社ではメダリオンアーキテクチャを採用したデータ基盤を作っております。
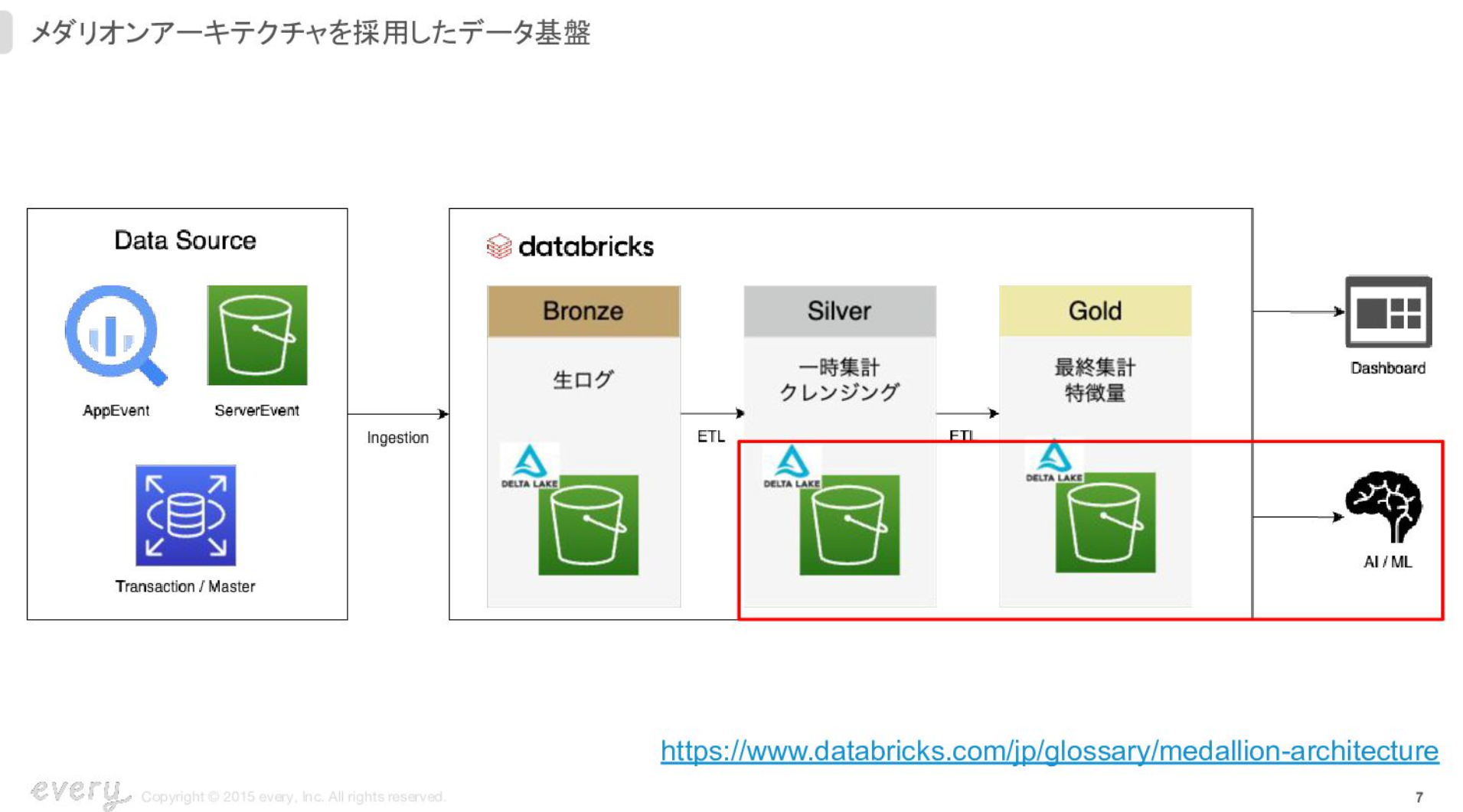
データソースとしてアプリやサーバーのイベントをDatabricksで読み込み、Bronze、Silver、GoldのレイヤーでETLを組んでいます。集計したデータはダッシュボードやAI/MLに活用しています。
DELISH KITCHENについて
エブリーでは三つの領域で、メディアの運営をしております。
その中でDELISH KITCHENは日本最大級のレシピ動画サービスになっております。専門家監修の5万本以上のレシピを動画とともに提供しているようなサービスです。
レシピレコメンド開発の背景
DELISH KITCHENのユーザー数とレシピ数の増加に伴い、ユーザーが好みのレシピを見つけるのが困難な状況でした。
そこで、DELISH KITCHENではユーザーの嗜好に寄り添ったアプリのパーソナライズに向けた開発を進めております。
レシピレコメンドについて
簡単にレシピレコメンドのご説明をします。
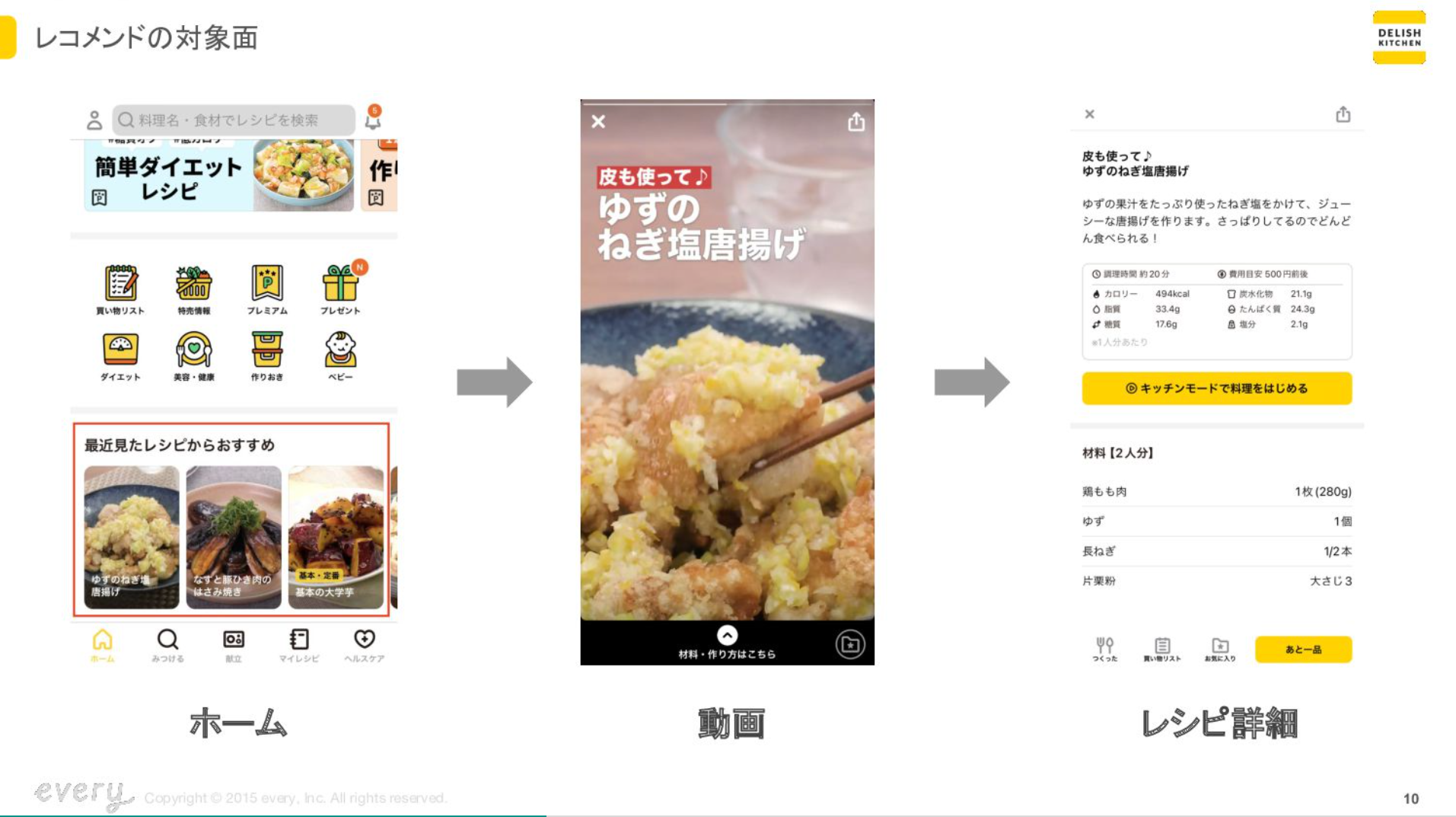
一番左がホーム画面になります。
ホーム画面をスクロールすると、最近見たレシピからおすすめというような、レシピの枠が出てきます。例えばここのから揚げをタップすると、全画面でレシピの動画が再生され始めますこの動画で実際に作る手順を確認ができます。また、レシピの詳細画面では栄養素や材料で作られているかなどを確認することができます。
今回のレコメンドはこの最近見たレシピがおすすめで、ここに出すレシピをどんなレシピにしたら良いかを考えます。
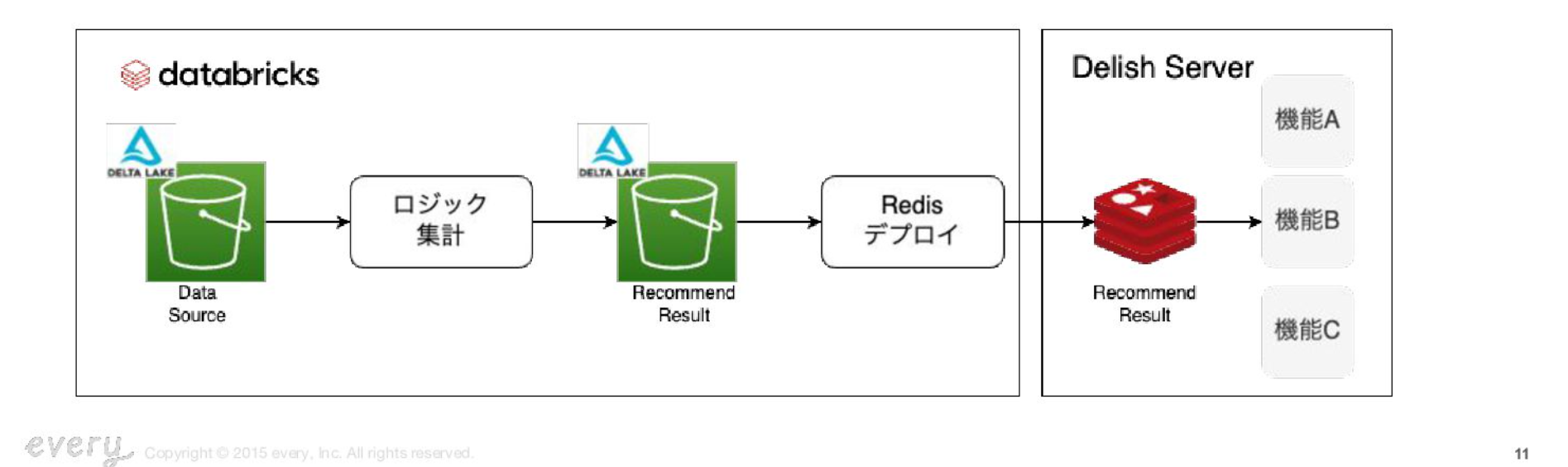
レシピレコメンドの全体構成
- delta lakeにあるイベントログをデータソースとして、レコメンドするためのロジックを集計する
- そのレコメンド結果をdelta lakeに保存
- レコメンド結果をDelish ServerのRedisにデプロイし、アプリのリクエストに対してServerがレシピを返す
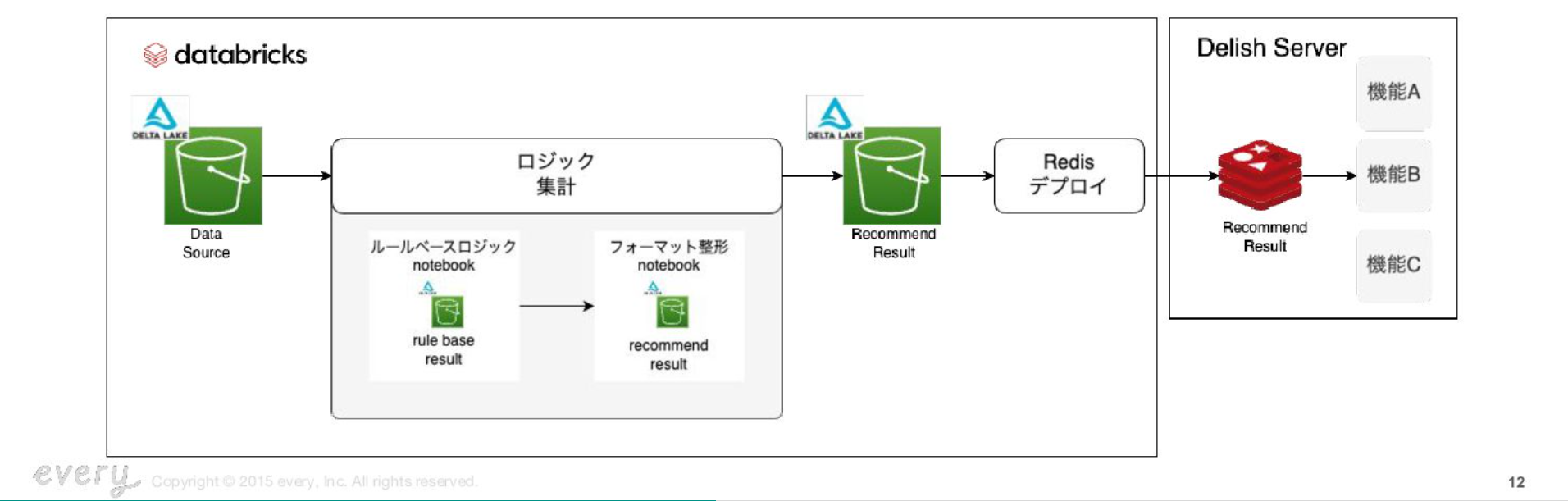
既存ロジックについて
既存のロジックは検索経由で視聴されたレシピのログをもとに集計しております。これはSQLでルールベースな集計しており、動画の視聴秒数が多いレシピ上位k件をレコメンドするといったようなロジックになっています。
既存ロジックの課題
- 視聴した動画が必ずしも興味があるレシピとは限らない
・動画を視聴しないユーザもいる
・ユーザの目的が動画の視聴をすることではなく、レシピを探しているため
・このようなユーザには材料などが見れるレシピ詳細の表示ログをもとにレコメンドしたい - 複数のイベントログを組み合わせるとルールが複雑化
・レコメンドの精度を上げるためにルールが複雑化していくのは目に見えている
・今回のケースでいえば、「検索経由の視聴ログ」と「レシピ詳細の表示ログ」を組み合わせたいなど
どのような状態を目指していたか
ユーザーの好みに寄り添ったパーソナライズされたレシピレコメンドの実現を目指しました。
導入の成果
改善したかった課題はどれくらい解決されたか
よりユーザの嗜好に寄り添ったレコメンドを実現するために、ルールベースから候補生成とリランキングによるレコメンドを実装・検証しました。
どのような成果が得られたか
A/Bテストをしたところ、クリック率の改善がみられました。

導入に向けた社内への説明
上長・チームへの説明
すでに使っているサービスのため、ありませんでした。
活用方法
アーキテクチャ図
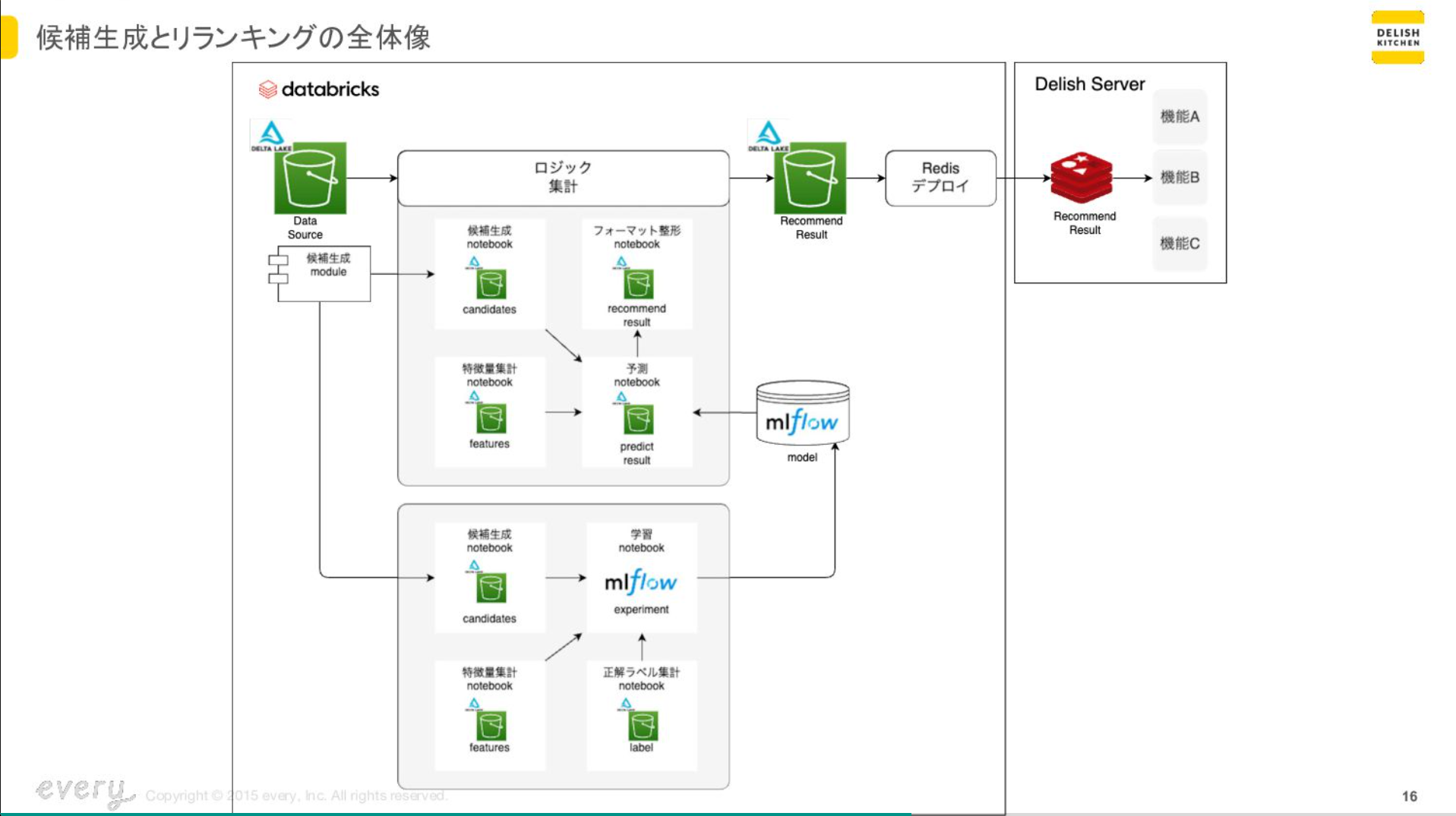
アーキテクチャの説明
候補生成とリランキングによるアプローチをしています。
これは大きく候補生成とリランキングという二つに分けてレコメンドする手法です。
- 候補生成
全てのユーザーxレシピの中からレコメンドするのではなく、このユーザーにはこのレシピの中からレコメンドするといったような候補を作ります。 - リランキング
作成した候補の中からユーザーの嗜好に合った順序にレシピを並び替えることでレコメンドします。
候補生成はspark.sqlで集計して、リランキングはMLでモデリングする実装で進めました。
よく使う機能
リランキングの学習部分について
学習する際の正解ラベルは翌日以降の動画の視聴有無を0 or 1で持って学習しています。学習にはLightGBMを使用し、二値分類問題を解くタスクとして学習させました。実験とモデルの管理はMLflowに任せており、新規ロジックと既存ロジックをオフライン評価指標で比較することが容易にできます。
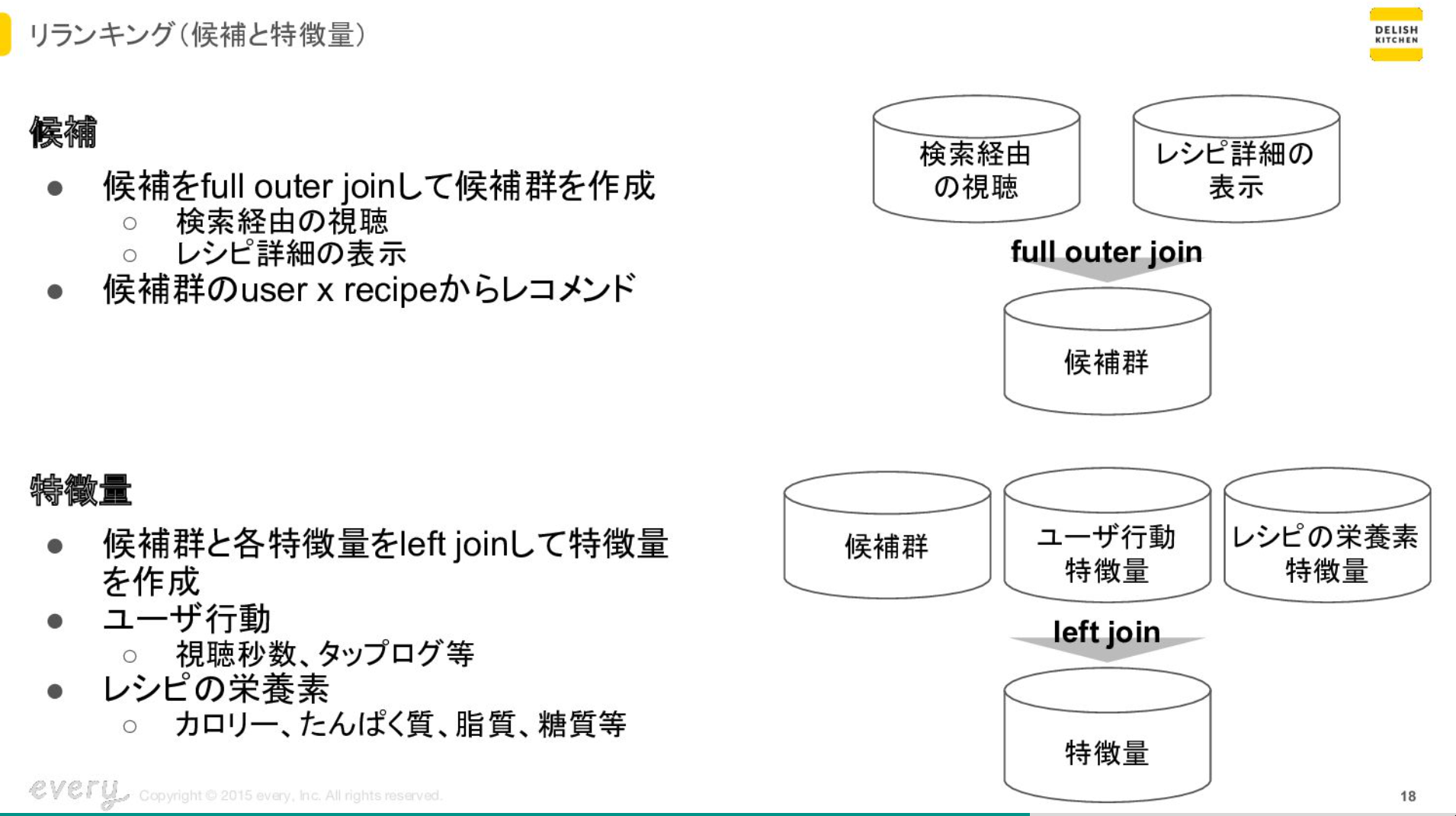
候補と特徴量について
候補は今回の場合は、検索経由の視聴とレシピ詳細の表示の二つのログを用います。このログをfull outer joinして候補群となるようなものを作ります。この候補群の中から、ユーザーにレコメンドしていくというような形になります。
リランキングしていく上でリランキングするモデルの特徴量を候補群に対してleft joinにして作っていきます。今回の場合はユーザーの行動の特徴量やレシピの栄養素の特徴をleft joinにして、学習のためのデータセットを作っています。
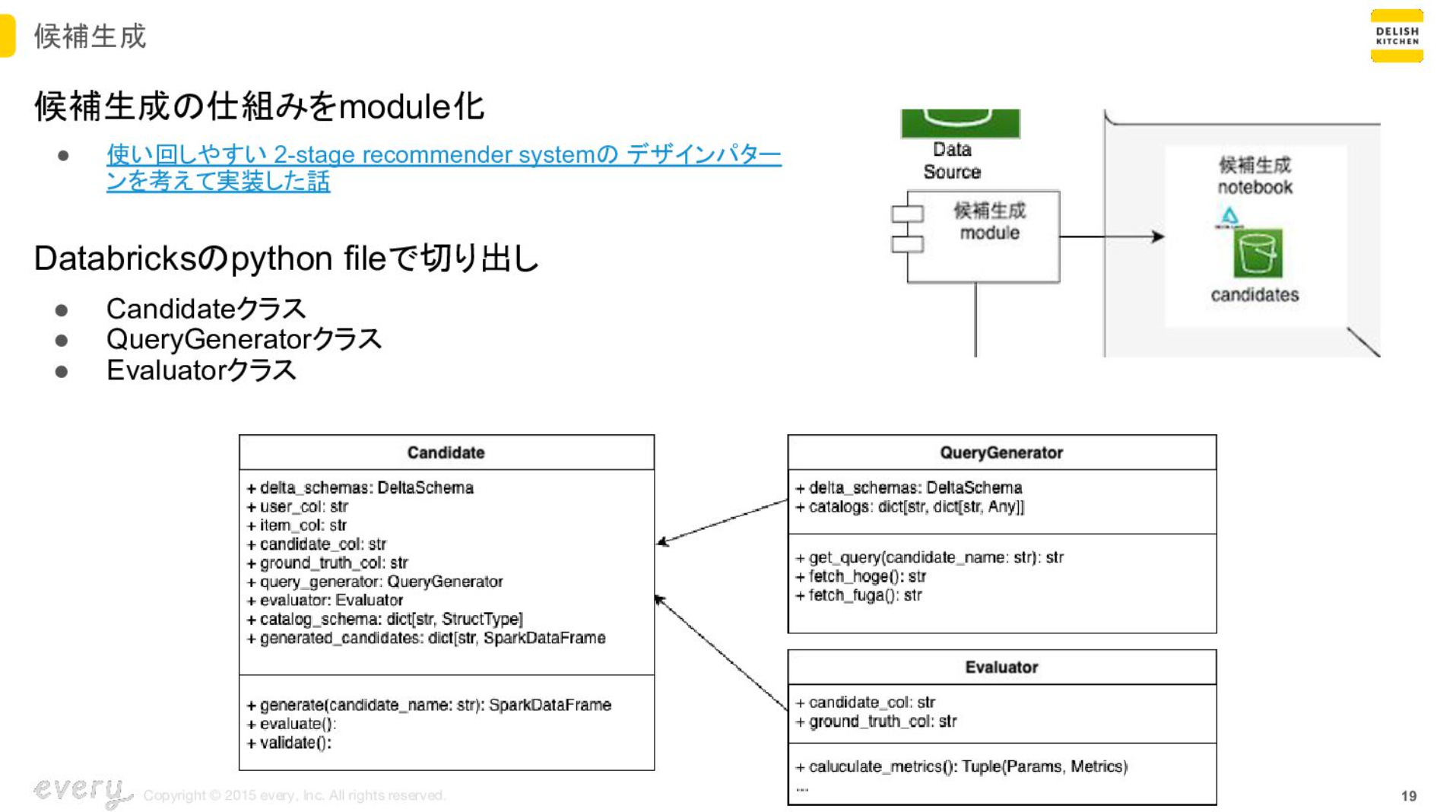
候補生成について
候補生成の仕組みで共通化できる部分があったためモジュール化しました。これはDatabricksでPythonのファイルとして切り出して大きく3つのクラスを作っています。メインで呼び出されるのはCandidateクラスで、候補生成を実行するNotebookからCandidateクラスを呼び出し、QueryGeneratorクラスで候補の集計するクエリを管理します。
リランキングについて
候補と特徴量から動画を視聴する確率を予測し、確率の高い上位k件をレコメンドするような仕組みになっています。
ツールの良い点
メダリオンアーキテクチャによりデータの抽象度に合った効率的なデータ基盤構築ができます。また、MLflowを始めとするML利活用のためのツールが整備されており、MLを始める導入コストが低いかなと思います。
ツールの課題点
特にありませんでした。
ツールを検討されている方へ
より詳細な話を弊社のテックブログでもまとめています。もしご興味がありましたら、ご一読お願いします。
株式会社エブリー / furu8

よく見られているレビュー



株式会社エブリー / furu8
レビューしているツール
目次
- 導入の背景・解決したかった問題
- 活用方法