



【アーキテクチャConference 2025】AI時代の戦略的アーキテクチャ 〜Adaptable AIをアーキテクチャで実現する〜
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションには、株式会社ビットキー homehub開発部 部長の佐藤 拓人さんが登壇しました。AIによるコード生成・修正の自動化が現実的になる中、エンジニアはこのパラダイムシフトにどう向き合うべきか。佐藤さんは中長期的な視点から、アーキテクチャ設計の実践方法について紹介しました。AIを活用しながらも、人間が適切に検査・責任を果たせる仕組みづくりがわかる内容です。
■プロフィール
佐藤 拓人
株式会社ビットキー homehub開発部 部長
2015年4月、大学(建築学専攻)卒業後に株式会社ワークスアプリケーションズに入社。会計システムのソフトウェア開発を担当し、特に財務会計の仕訳関連に従事。2019年5月、ビットキーへ参画し、今のhomehub開発本部の前身となるチームで、法人向けスマートロック管理システムの管理画面やバックエンド、アプリの開発に従事。現在はhomehubの開発責任者。複雑な事象を読み解いて構造化し、抽象化 / 汎用化できるように設計し、低コストで多くの価値をだせる開発をすることを好んで日々開発しています。
株式会社ビットキーについて
佐藤:ビットキーは「つなげよう。人は、もっと自由になれる。」というミッション・ビジョンを掲げている会社です。「つなげよう」というのがキーワードで、デジタルの世界とリアルの世界をつなげ、滑らかにしようとしています。その一つとしてスマートロックを使っています。
例えば、賃貸マンションの入居体験を想像してみてください。最近は契約手続きがWebで完結するようになりましたが、申し込みと連動して、鍵もスマホに届くなら。鍵受け取りのための書面の提出も、わざわざ店舗まで鍵を取りに行く必要もありません。契約後スムーズに新居に引っ越すことが出来ます。こうした仕組みを社会に広げることで、人はもっと自由になれるのではないか、そういったことを目指している会社です。
現在は主に、住宅とオフィスの2領域で事業を展開しており、私はその中で、住宅向けのコネクトプラットフォーム「homehub」を日々開発しています。
佐藤:homehubの中には「スマートアクセス」という機能があります。これは、誰がいつどこに出入りできるかという権限と、そのために必要な処理を管理するものです。賃貸マンションの入り口一つとっても、実は非常に多くのユースケースが存在します。例えば、居住者は賃貸マンションに出入りする。宅配業者は置き配のために一時的にオートロックエントランスを通過する。仲介会社は内見の時だけ出入りするなど。こうした様々なユースケースに対して、利便性と安全性を向上するための機能拡張を日々行っています。
本発表では、AIをどう使うかという具体的なハウツーよりも、我々エンジニアがAIというパラダイムシフトに対してどう向き合うかという観点でお話ししたいと考えています。いかに優れたプロンプトを書くかといった短期的な実利というよりは、数年後を見据えてエンジニアとしてどう備えるか、中長期的な観点で話を進めていきます。
また、本発表では「責任」「信頼」「分割」「統治」といったキーワードをもとに発表していきたいと思います。
AIの進化と人間の新たな「役割」
佐藤:AI時代の生存戦略としてよく見かけるパターンがあります。AIが苦手な領域で勝負をする、AIをうまく活用する、AIを使って自身の能力を高める、といったものです。
例えば、すてぃおさんは「ポジショニング戦略が鍵です」という記事を出されています。t_wadaさんは「歴史から学んだ知見が重要で、能力向上への投資が必要です」とおっしゃっています。またフロントエンジニアのuhyoさんは「AIを超える技術力が必要で、創造的になる必要がある」とおっしゃっています。
これらの洞察を踏まえつつ、今回はもう少し先を見据えたお話をします。私のスタンスは、AIはいずれ人間を凌駕するものとして備えておくべき、というものです。
設計は人間にしかできないのか、AIには創造性はないのか、といった話はあるかもしれません。しかし、本当にそうでしょうか。私自身はAIがいずれ人間を凌駕すると考えていますし、それは段階的に行われるだろうと思っています。
そんな中、最後に何が残るのか。これは私の仮説なのですが、「責任」と「信頼」ではないかと思っています。
根拠は大きく2つあります。1つは、AIは本質的に責任を果たすことが難しいと考えているからです。AIは契約の当事者になれません。賠償能力もありません。なぜそうなったかをステークホルダーに説明することも難しいです。倫理的判断の主体にも、少なくとも現時点ではなりません。
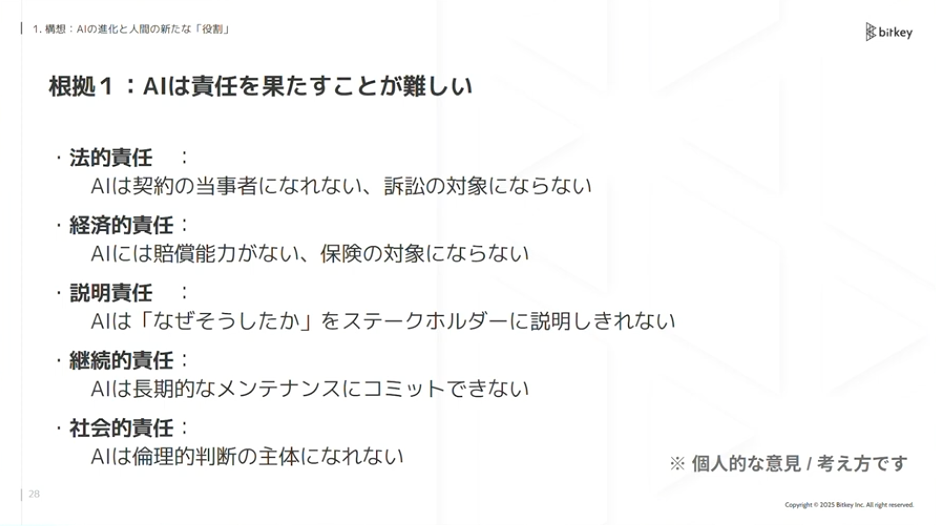
佐藤:もうひとつは、人間はAIを本当に信頼できるのか?という点です。プロダクトを本当に安心して使えるのか、リグレッションを起こさないか、セキュリティは大丈夫か。そういった不安を本質的に払拭することはかなり難しいのではないでしょうか。

佐藤:結果として、AIの責任・信頼という観点では、構造的・技術的には解決可能かもしれません。しかし、社会的・感情的には人間が受け入れられないのではないか。これが私の仮説です。AIが作ったものに対して責任を果たせないので、ステークホルダーはそれを信頼できないのではないかと考えています。
これを解決するために、間に人間が入ってAIの成果物を適切に検査する必要があります。それによって責任・説明責任などを果たし、利用者やステークホルダーが信頼してプロダクトを使える。そういった構造はしばらく続くのではないでしょうか。その結果、人間の役割は「コードを書く」ことではなくて、AIの成果物に対して適切に検査を行い、責任を果たしてステークホルダーからの信頼を勝ち取る。こういった未来になってくるのではないかと想像しています。
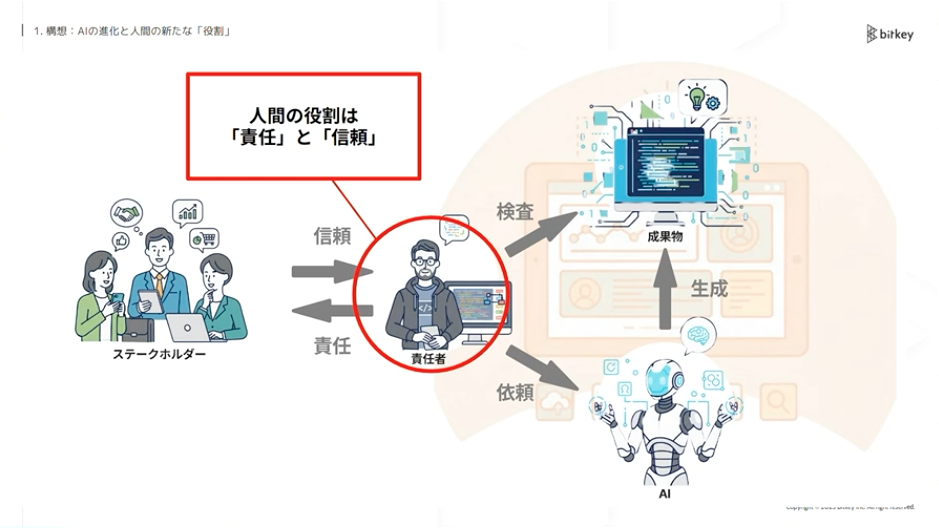
佐藤:もともとは人間が操縦してAIがサポートしていました。それが、AIが操縦して人間がサポートする時代に変わります。その後はAIが基本的に全部やり、人間は管理や制御をする時代になるでしょう。
さらにその先では、管理自体もAIがやるようになります。人間はポリシーを定め、それが守られているかを監査し、最終的に責任を取る。こういった未来になるのではないかと考えています。
「責任」を脅かすカオス
佐藤:このように、人間が最終的に責任を適切に負わなければいけないと考えている一方、その責任をちゃんと負えるかと考えたときに、なかなか課題があります。
Vibe CodingをはじめとするAIコーディングにはさまざまなリスクがあります。もちろん「動いているからよし」で済めばいいのですが、なかなかそうもいきません。

佐藤:AIが生成したコードにはセキュリティの脆弱性があったりします。軽微なバグの温床になりやすいこともあります。なぜ動いているか説明しづらいケースもあります。確率的な負債をどうしても積み上げてしまう特性もあります。このように、AIの成果物にはリスクがあります。
最終的に人間が責任を果たすためには、適切に検査を行うことが重要です。我々ソフトウェアエンジニアのミッションは、AIへの盲目的な信頼をやめて厳格な検査を行い、ステークホルダーからの信頼を獲得することではないでしょうか。
さらに、今後人間が負うべき責任というのは2つの観点でインフレするのではないかと考えています。量的な観点と質的な観点です。

佐藤:量的な観点について説明します。AIがいろいろやってくれる結果、実行はAIが担当します。その分、人間が責任を負う比率が高まります。1人の人間が負う責任の量が増えていくでしょう。
質的な観点についても説明します。求められる責任の水準やレベルも上がっていくと思います。まず、AIの成果物は信頼しづらいという漠然とした意識があります。それによって求める責任の水準が上がります。
また、AIによって非エンジニアのリテラシーが向上するでしょう。昨今のAIによって、非エンジニアでもソフトウェアを手軽に作れるようになっています。その結果、「不具合があるかないか」という世界から変わります。品質をどう測るのか、どう定量的に判断するのかという観点が重視されます。SLOなど定量的な信頼性や、適切な説明責任が今後より求められていくでしょう。

戦略的な「検査」
佐藤:では、エンジニアとしてこの責任にどう備えるか、どう検査するかという話をしていきたいと思います。
検査が大事ということで、レビューやBuild/Lintチェック、自動テストなどがあります。ただ、これだけでは足りないと思っています。今後はより専門的な知見を基にした検査方法の立案や、妥当性の説明が求められるようになるでしょう。
専門的な知見とは何か。私自身はアーキテクチャ、QA、SRE、データサイエンスあたりだと考えています。今回はこのアーキテクチャに限って話を進めます。
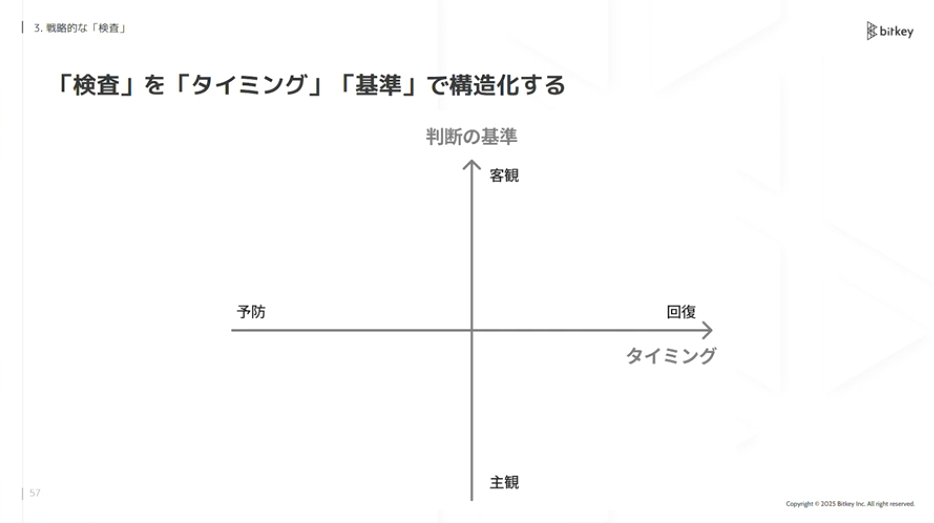
佐藤:検査を戦略的に行う際に、2つの軸で構造化して考えます。タイミングと判断の基準です。
横軸がタイミングです。「予防」と「回復」と書いてあります。「予防」はリリース前に検査して問題を防ぐこと。「回復」はリリース後に問題が起きた際、迅速に回復することです。
縦軸は判断の基準で、「主観」と「客観」です。主観は人間が属人的に判断します。客観は仕組みとして機械的に判断できます。この2軸で4つの象限に分けます。
いくつか手法をプロットします。Build/Lintは客観的・機械的に検査でき、リリース前にできるので「客観×予防」です。人間のレビューは主観的ですが事前にできるので「主観×予防」です。SLOの計測や自動ロールバックは仕組み的にできますがリリース後なので「客観×回復」です。問い合わせの傾向分析やポストモーテムは「主観×回復」です。
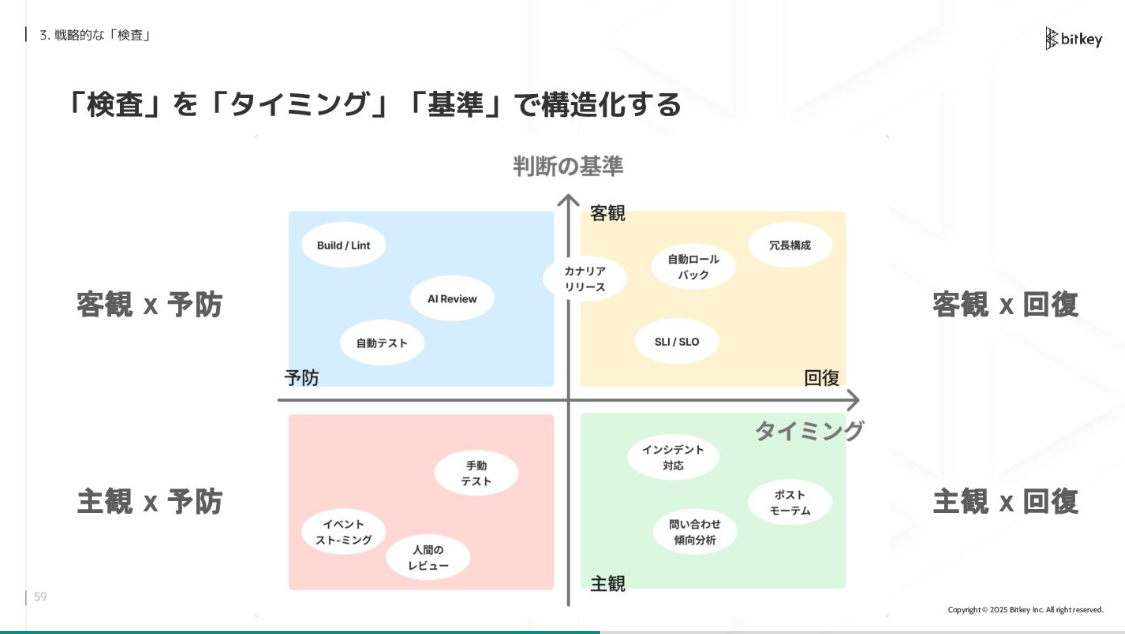
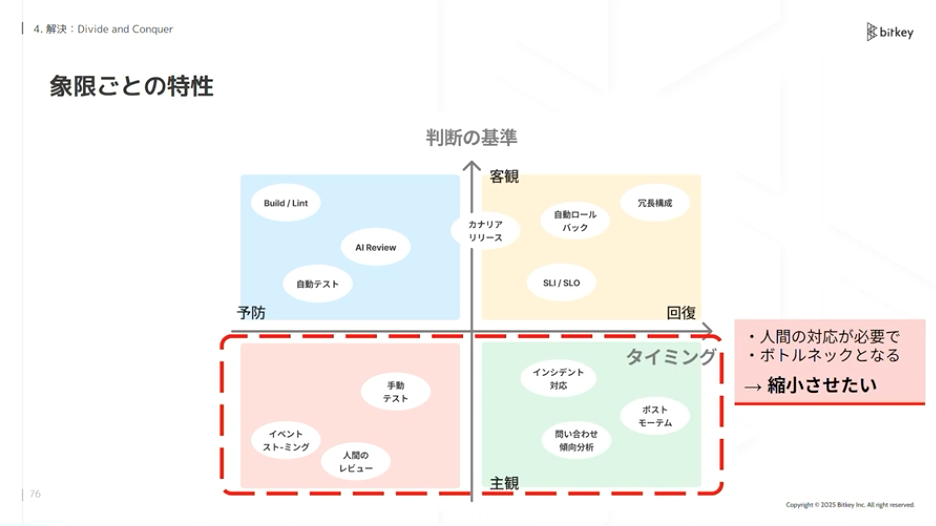
佐藤:この象限ごとに特性があります。下側の主観領域は人間の対応が必要でボトルネックになり得ます。ここはできるだけ縮小させたい。上側の客観領域はAIや仕組みで解決可能でスケールしやすいため、拡大させたい領域です。
左側の予防はリリース前に検査できます。市場で問題が発生する前に対処できるため、強化させたい。右側はリリース後の検査です。市場で発生するリスクを受容する必要があり、予防も合わせて必要です。
いくつかケーススタディを紹介します。プロトタイピングや社内ツールであれば、基本的にAIにガンガン委ねます。「客観×予防」のゾーンだけでやりきり、最後の合格だけ人間がやるという戦略が取れます。
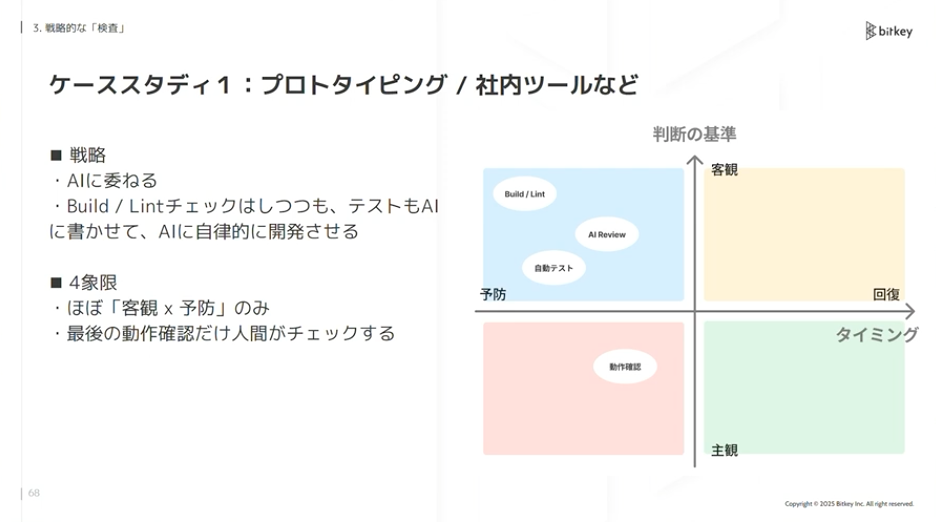
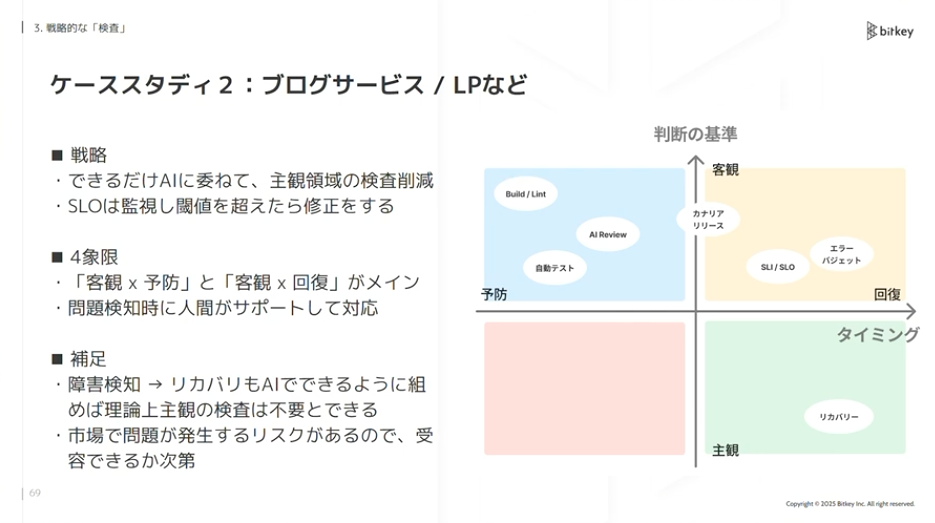
佐藤:ブログサービスやLP、toC向けであまり事業リスクがないサービスの場合はどうでしょうか。基本的にAIに委ねて人間の判断は最小限にします。レビューは基本せず、AIの中でレビューを回してリリースします。ただしSLOなどメトリクスで検査し、問題があれば即時リカバリーします。
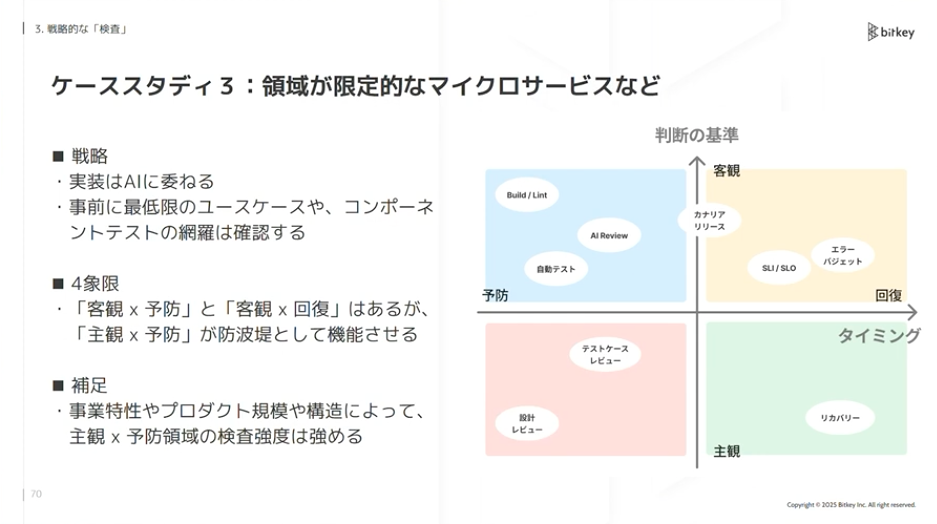
佐藤:逆にtoB向けのマイクロサービスなどでは、問題が起きるリスクは取れません。事前にテストケースだけレビューする、設計だけレビューする、特定のコードベースはしっかりレビューする、といったグラデーションが取れます。プロダクトや事業の特性によって、検査の戦略は変わってきます。
佐藤:余談ですが、今後SREは非常に重要になると思っています。AIが進化して精度が上がると、人間がチェック・検査をするコスト対効果は下がっていきます。
佐藤:そうなると、事業領域によってはある程度リスクを許容する選択もあり得ます。まずリリースして、メトリクスを計測し、問題があれば即時リカバリーする。そういう方針に切り替わっていく可能性があります。

Divide and Conquer(分割統治)による解決
佐藤:ここまで、責任がエンジニアにとって大事だという話をしました。そのために検査が大事で、戦略的にできると良いでしょう。ここからは実際どう解決するかという話です。
今回はDivide and Conquer、分割統治というキーワードでアーキテクチャが大事だという話をしていきます。
4つの特性の中で最も重要なのは、下側の「人間の対応が必要でボトルネックとなる部分」を縮小させることです。この領域のコストを下げるには何が重要か。本質的には認知負荷だと考えています。
佐藤:認知負荷を低減する有効な手段がアーキテクチャです。毛玉のようにいろいろ絡み合っていると、修正の影響範囲がわかりません。検査が大変です。一方、積み木のように構造化されていれば、影響範囲を限定しやすく検査しやすくなります。
毛玉から積み木の状態に強制的に分割し、その状態を維持する方法がアーキテクチャです。だからアーキテクチャが重要なのです。
なぜDivide and Conquerが重要かについて、2つ観点を挙げています。1つ目は「限られた範囲で検査可能とする」こと。影響範囲を限定させることで、人間が比較的簡単に検査できるようになります。
2つ目が「人間が認知しやすい状態を維持する」こと。認知しやすい単位で分割することで、全体の見通しが立ち、調整しやすくなります。
PRごとの行数が多いと精度が落ちると言われています。また、Vibe Codingだけでは難しく、コードの詳細を知っているからこそ効果的なAIコーディングができる、という声もあります。

佐藤:今の検査といえばコードレビューがメインです。しかし、今後もずっとコードレビューなのでしょうか。
私はコードレビューは局所的に残るかもしれませんが、だんだん移り変わると思っています。まず、コードではなくAIの思考プロセスを検査する段階があるでしょう。さらにその後は、人間がポリシーや倫理協定を作成し、AIがそれに則って活動しているかを監視・監査する世界になるのではないでしょうか。
このような世界線においても、プロダクトが構造的に整理されている状態を維持することは非常に有益であると考えています。
では実際アーキテクチャとして何をすればいいか。今日は具体的に6つの方法を紹介します。今回は特に「責任」と「信頼」のために検査しやすいアーキテクチャという観点で、これらの方法がどういう意義を果たすかを整理していきます。

佐藤:1つ目が境界づけられたコンテキストです。DDDで登場する概念で、システム的に独立して開発や運用がしやすい単位にしましょうというものです。イベントストーミングなどの手法で用いられることが多いです。

佐藤:この単位で分割することで、影響範囲が特定しやすく検査しやすくなります。さらに、コンテキストごとに検査戦略を分けられるのが今後非常に有益です。
例えば支払いの領域はミスがあると事業リスクが高いです。多少コストをかけても事前にチェックしましょうという戦略を取るでしょう。一方、アナウンスメントやお知らせの領域であれば、多少リスクを許容できます。AIに自律的にリリースさせ、人間のコストは他に割くという戦略が取れます。
2つ目はEvent-Driven Architectureです。特に境界づけられたコンテキスト間のやりとりを同期的ではなく、イベントをもとに非同期で行うような設計アプローチを意図しています。
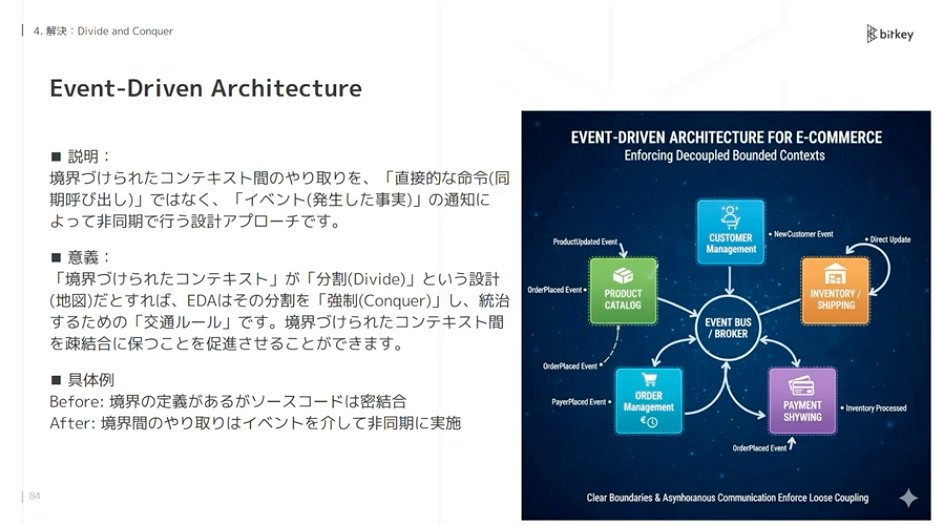
佐藤:境界づけられたコンテキストだけでは、定義はできてもソースコードが密結合になることがあります。Event-Driven Architectureを使うことで、境界を疎結合のまま維持するルールを強制できます。
3つ目はCQRSです。コマンドとクエリの責務を分離するという設計パターンです。コマンドはデータベースの登録や変更を伴うもので、クエリは登録されているデータをそのまま取ってきて画面に表示するような処理です。

佐藤:この観点で分割することで認知負荷が下がります。また、検査戦略にグラデーションをつけられます。コマンドは事業リスクを伴うことが多いので、しっかり検査します。クエリはリスクが低いので、AIに任せて人間は他にコストを割けます。
4つ目はAlways-Valid Domain Modelです。DDDの設計原則として語られることが多いです。常に有効な状態、整合性が取れている状態でなければインスタンスが存在しないという思想です。
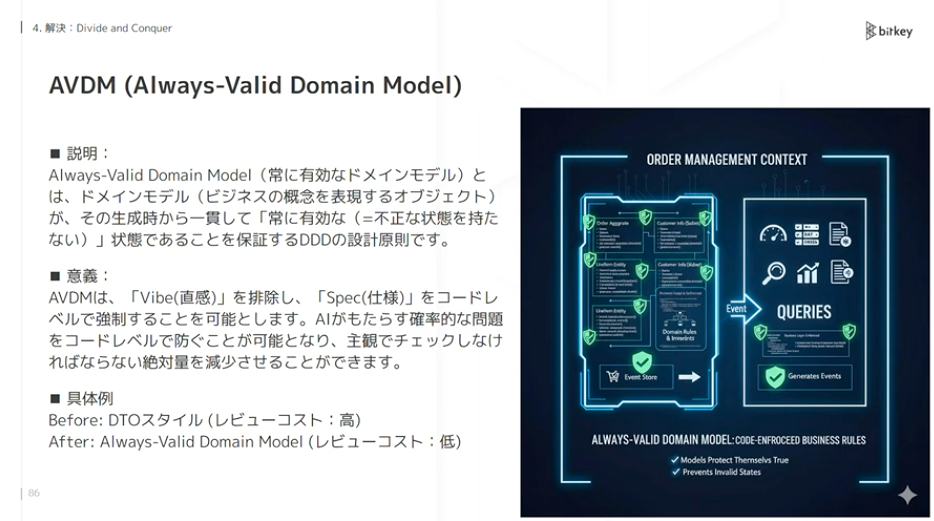
佐藤:モデルという単位でちゃんと整理・分割をしましょうという力学が働くので、そういった観点でも分割が進みます。また、モデル単位で制約・ルールをコードとして強制できます。AIが変なことをしようとしても、コードで守られていれば問題ありませんし、事前に弾けます。人間がチェックしなければいけない絶対量を減らせます。
5つ目はType Firstです。モデルの中の状態や制約ごとに型を決めて、その型で表現するという設計アプローチです。

佐藤:例えば注文には複数の状態があります。カートに入っている状態、決済が終わっている状態、配送待ちの状態、配送中の状態などです。状態ごとに型を定義して表現します。
これにより、例えば「注文の取り消しは決済前じゃないとできない」というルールを型で表現できます。実行時エラーではなくビルド時のチェックで、より早く防げます。AIのトライアンドエラーを速く回せるため、成果物の精度向上が期待できます。
最後、6つ目はEvent Sourcingです。システムの状態を管理するときに、スナップショットを保存するのではなく、それまで何が起きたかという事実を時系列で管理するような手法です。

佐藤:モデルからさらにイベント単位で細分化できます。最終的な結果だけでなく、そこに至る経緯も記録されます。調査やテストで「なぜそうなったのか」を検査でき、精度を上げられます。SLOなどのメトリクスも、経緯がすべてわかっているので精緻な計測が可能です。より高い水準の責任を人間が果たせます。
私の現在地
佐藤:私のチーム・プロダクトでは実際どうなのか。大変申し訳ないのですが、偉そうに話しながらまだまだ完璧ではありません。できないことはたくさんありますし、試験段階です。ただ、どうやっているか、どんな学びがあるかをお話しします。
私は新規プロダクトより既存プロダクトの機能強化がメインです。そのため、一気にやるのではなく段階的な導入が中心になります。
Event-Driven ArchitectureやCQRSなど、インフラにがっつり絡む部分は切り戻しが大変です。切り戻ししやすい程度に段階的に入れています。
さらに2つのアプローチで進めています。1つはプロダクト全体に対する施策。もう1つは「AI特区」と名付けた特定領域で試験的にガンガン試す施策です。

佐藤:境界づけられたコンテキストについては、イベントストーミングベースで整理しています。ただ、それが本当にいいかは引き続き洗練中です。コンテキストごとに検査戦略を分けることはまだできておらず、これからやっていきます。
Event-Driven ArchitectureとCQRSは部分的な適用にとどめています。CQRSでDBを分けるといったことはほぼやっていません。ただ、コマンドとクエリで責務を分け、ファイルやディレクトリで分けることはやっています。
Always-Valid Domain Modelは全面的に採用して推進しています。Type FirstとEvent Sourcingは、新規性があってイベントと親和性がある領域のみ採用しています。

佐藤:AI特区では、Event-Driven ArchitectureとCQRSも一部インフラまでやっています。ただ、そこまで積極的ではありません。検査を楽にするという観点で、分割を強制しやすい構造をベースにリファクタリングしています。
Always-Valid Domain Modelは全面的に採用しています。Type FirstとEvent Sourcingも全面的に採用しています。ただ、リファクタリングがメインなので、既存データの整合性には配慮しながら進めています。

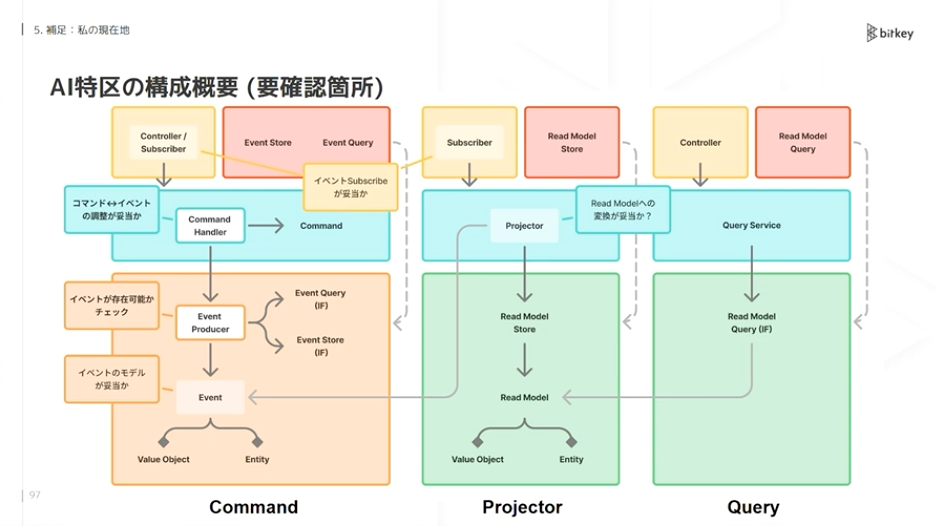
佐藤:実際どう分割しているかをお話しします。左側がコマンドの領域で、データを登録・変更します。右側がクエリの領域で、データを取得します。真ん中がプロジェクタで、イベントからリードモデルへ変換します。
ファイルごとに責務を分けて実装しています。これにより、人間がどこを検査すべきかをかなり限定できます。
私が特に念入りに確認するのは2箇所です。1つは、コマンドでイベントが存在可能か、バリデーション的に大丈夫かをチェックする領域。もう1つは、特定のコマンド実行時に適切なイベントが生成されるかを確認する領域です。
それ以外は、細かいソースコードまで確認するのではなく、ざっくり型が問題ないか、テストコードが妥当かという観点で確認します。比較的簡易なチェックで済む状態になっています。
佐藤:プロダクト全体の施策としては、AIに限らずコンテキストの整理が非常に重要だと感じています。今後もこの重要性は上がっていくでしょう。
Always-Valid Domain ModelやCQRSを入れた部分は、レビューが比較的簡易化されました。このファイルを優先的に見る、このファイルはテストコードを見れば大丈夫、といった見通しが立ちやすいです。
AI特区では、まだ試験的ですが、ファイル分割によってグラデーションをつけやすくなりました。どのファイルをしっかり検査すべきか、どれは簡易でいいかが明確になりました。これは非常に有益でした。さらに、ファイル分割によってAIに任せる実行ステップをルール化しやすくなりました。「まずこのファイルを作って」という基準を作りやすくなった点で、ファイル分割は非常に価値が高いと感じました。
まとめ
佐藤:人間の価値・役割は、コードを書くことから「責任を負う」ことへ移行するのではないか、という話をしました。Vibe CodingをはじめとするAIコーディングには脆弱性やリスクがあります。それを踏まえて人間は責任を遂行する必要があり、そのために検査が重要です。

佐藤:さらに、その検査を戦略的に行うために、タイミングと判断基準の2軸で4つの象限に分けて整理しました。この整理をもとに戦略的に検査を行えます。
またアーキテクチャによって、特に「主観」領域、つまり人間が判断しなければいけない領域を大きく改善できます。人間の介入が必要でボトルネックとなる部分を縮小できます。
その手段として、2つの方法を紹介しました。境界づけられたコンテキスト、Event-Driven Architecture、CQRS、Always-Valid Domain Model、Type First、Event Sourcingです。
最後に、AIを恐れるのではなく、AIを適用させるアーキテクチャをいかに設計するか。未来の信頼をいかに構築・獲得できるか。これが我々ソフトウェアエンジニアのミッションになるのではないでしょうか。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





