



【アーキテクチャConference 2025】 AI Native開発への挑戦 〜既存プロセスをどうAI化し、成果につなげたか〜
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に開催されたセッションでは、株式会社primeNumberの鈴木 健太さんと中根 直孝さんが登壇されました。同社では現在、AIが書くコードの割合が90%を占め、開発スピードは約1.5倍に向上しているといいます。なぜ、それほどの成果を出すことができたのか。本セッションでは、既存プロダクトと新規プロダクトという対照的な開発現場において、AIネイティブ化を推進するために行われた具体的な取り組みをご紹介いただきました。
■プロフィール
鈴木 健太
株式会社primeNumber
取締役執行役員CTO
東京大学工学部卒業後、株式会社リブセンスにてエンジニアとして同社WEBサイトの開発・企画・分析などに従事。primeNumberへは2017年に参画し、汎用型データエンジニアリングPaaS 「systemN ™」の開発を担う。データ統合自動化SaaS「TROCCO」リリース後は同プロダクトの開発をリードする。
中根 直孝
株式会社primeNumber
CTO室 室長
2017年より新卒でSWEのキャリアをスタート。2018年11月、当時社員数が一桁だったprimeNumberに入社。TROCCOの開発に黎明期から携わる。メイン機能の一つとなっている「ワークフロー機能」、新サービス「COMETA」のベースとなった「データカタログ機能」など、複数の0→1プロジェクトをリード。現在はCTO室を立ち上げ、組織横断的な課題や中長期的な開発戦略、技術的な壁打ち相手など幅広く従事。
誰もがAIでデータにアクセスできる世界の実現へ
鈴木:株式会社primeNumberのCTOを務める鈴木 健太と申します。昨年9月にCARTA HOLDINGSのCTOである鈴木健太さんとAI活用に関するポッドキャストを収録しました。記事にまとめておりますので、よろしければご一読ください。
本日は「AI Native開発への挑戦 〜既存プロセスをどうAI化し、成果につなげたか〜」と題して、既存プロダクトと新規プロダクト、それぞれをAIネイティブ化する取り組みについてお話しします。
primeNumberでは「TROCCO」と「COMETA」というデータエンジニアリング向けのプロダクトを開発しています。これらはRuby on RailsとReact、TypeScriptで構築されており、運用開始から約7年が経過しています。
私たちがプロダクト開発を通じて目指しているのは「誰もがAIでデータにアクセスできる世界」の実現です。例えば、インシデント発生時に影響を受けるお客様を調査するため、プロダクトのデータベース(以下、DB)にSQLを走らせるようなことがあると思います。しかし、そういった場面でSQLを書くのは大変です。もし、自然言語でAIに問いかけるだけで正確なデータが瞬時に返ってくるような世界が実現できたら、嬉しいですよね。
この理想を実現するためには、主に3つの要素が必要だと考えています。
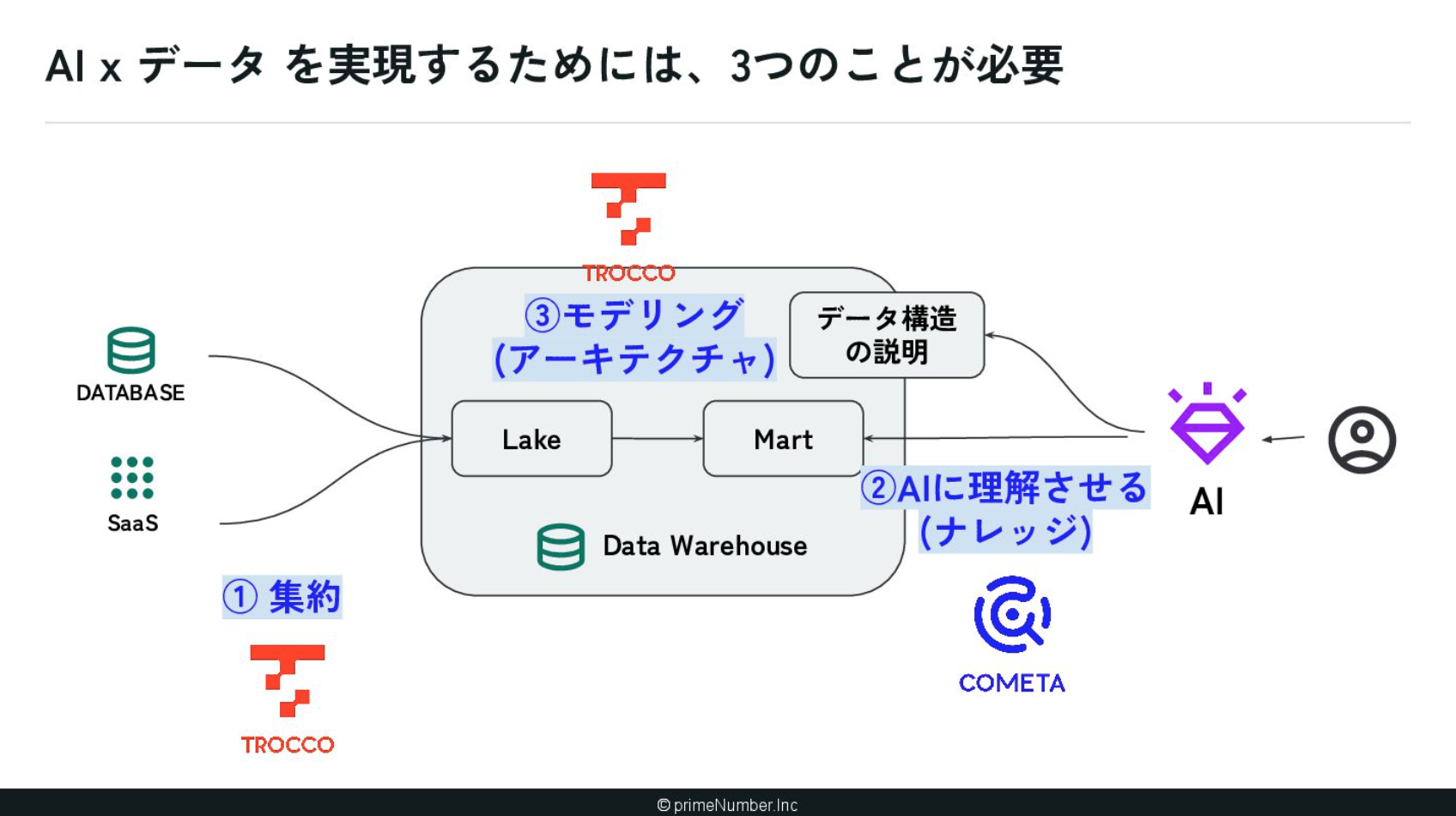
1つ目は「データの集約」です。AIが様々なデータソースを個別に参照するのは非効率であるため、最近はデータウェアハウスなどの分析用DBに情報を一元化し、シングルソースとして構築することが増えましたね。
2つ目は「AIにデータ構造を理解させるナレッジの付与」です。例えば、売上データがどこに格納されているのかといったメタ情報を、AIが正しく認識できる状態にする必要があります。
そして3つ目が「モデリング」です。AIが理解・処理しやすいように、データ構造そのものを最適化するアーキテクチャの設計を指しています。
我々が展開しているTROCCOおよびCOMETAは、これら3つを実現するためのプロダクトです。
既存プロダクトのAIネイティブ化に向けた取り組み
鈴木:ここからは、既存プロダクト開発におけるAIネイティブ化の取り組みについてお話しします。
既存プロダクト開発のAIネイティブ化は難しく、その理由には様々なものがあるかと思います。本日は弊社がそれらとどう向き合い、どのように取り組んできたのか、発表させていただきます。
まずは、弊社の状況をご紹介します。
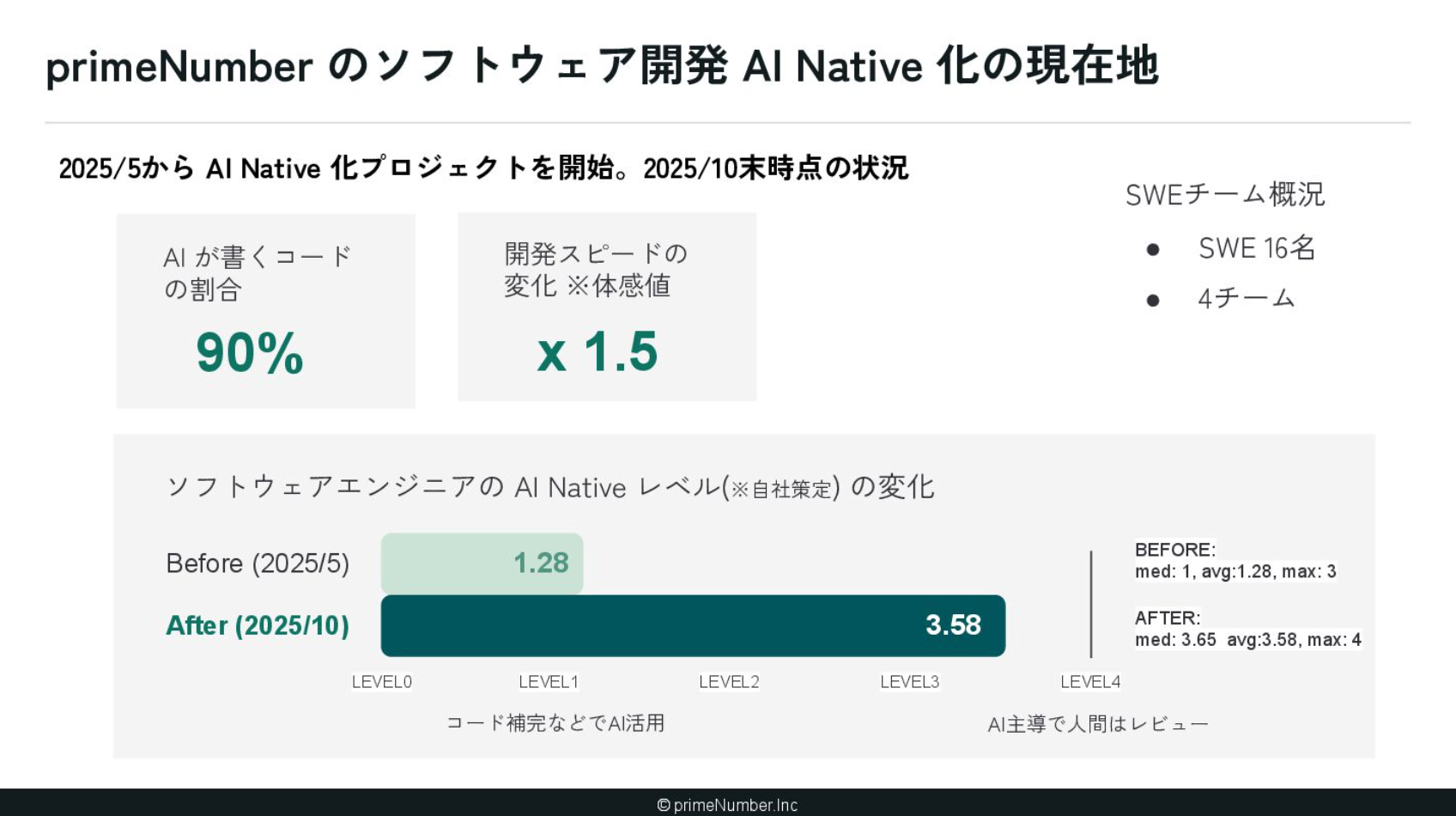
2025年5月にプロダクト開発チームで「AIネイティブを推進していく」という意思決定を行い、プロジェクトを始動させました。半年ほどが経過した段階で、開発におけるプルリクエスト(以下、PR)のうち、AIが書いたコードが90%を占めるまでになっています。定性的な数字ではありますが、開発者の体感値としても開発スピードが約1.5倍に向上しているという手応えを感じています。
プロジェクトの開始にあたり、独自の「AI Native レベル表」という指標を定義しました。こちらについては、後ほどまたご紹介します。ちなみに、プロジェクトを開始して半年ほどで、エンジニアそれぞれのレベルを引き上げることができています。
Claude Codeを活用したフィードバックループ
鈴木:既存プロダクト開発のAIネイティブ化が進まない背景には、4つの理由が関係していると思います。

1つ目は「暗黙知の存在」です。7年にわたり開発を続けてきた中で、「この実装なら〇〇を参考にして」といったエンジニア同士の会話に頼るような、多くの暗黙知を抱えていました。当然ながら、AIは暗黙知を理解できません。
じゃあどうすれば良いのかというと、解決策は非常にシンプルで、愚直にナレッジを増やしていくことにつきます。弊社はClaude Codeを使用しているため、AIにコードを書かせてみて、期待に沿わなければCLAUDE.mdを修正するという作業を繰り返しました。
とても地味なプロセスですが、ここを通らなければ前には進みません。初期段階で取り組んだ結果、現在ではナレッジを追加する頻度が大幅に減ってきています。

具体的な事例としては、Reactのコンポーネント実装など、細かなルールを次々とナレッジ化し、AIに試行させては改善するというサイクルを回してきました。
ここは正直なところ「気合い」で乗り切れば確実に成果が出る領域ですので、まずはやり抜くことが肝心だと思います。とはいえ、人間がすべてのナレッジを書くには時間がかかってしまうため、ナレッジの作成もAIに任せる方針を採りました。
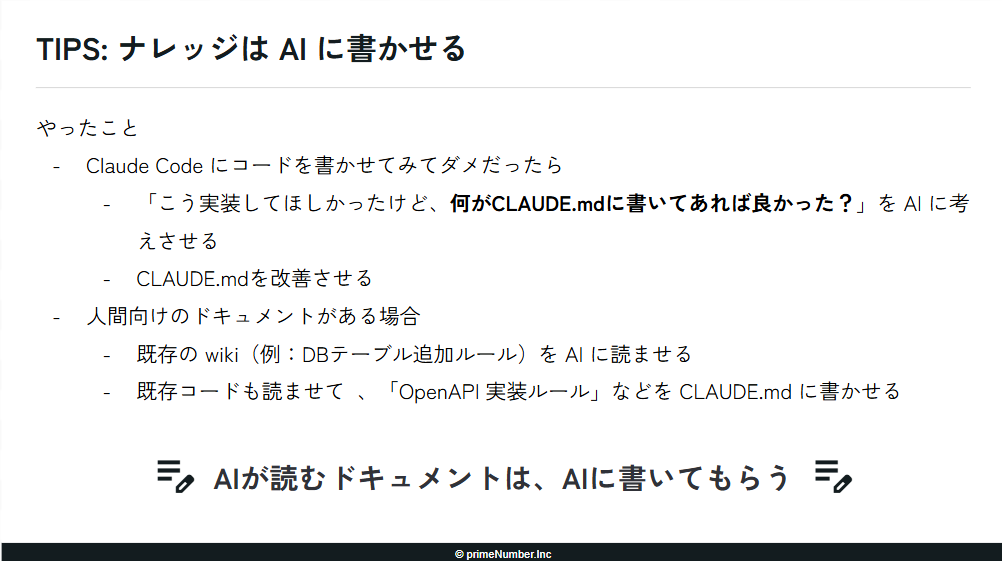
まずClaude Codeにコードを書かせて、期待通りに動かなかった場合に「どう実装して欲しかったか」を伝えて、AI自身に「どういうナレッジがあれば正解に辿り着けたか」を考えさせ、ドキュメントを生成させます。AIが読むドキュメントは、AIに書かせるのが効率的だと考えました。
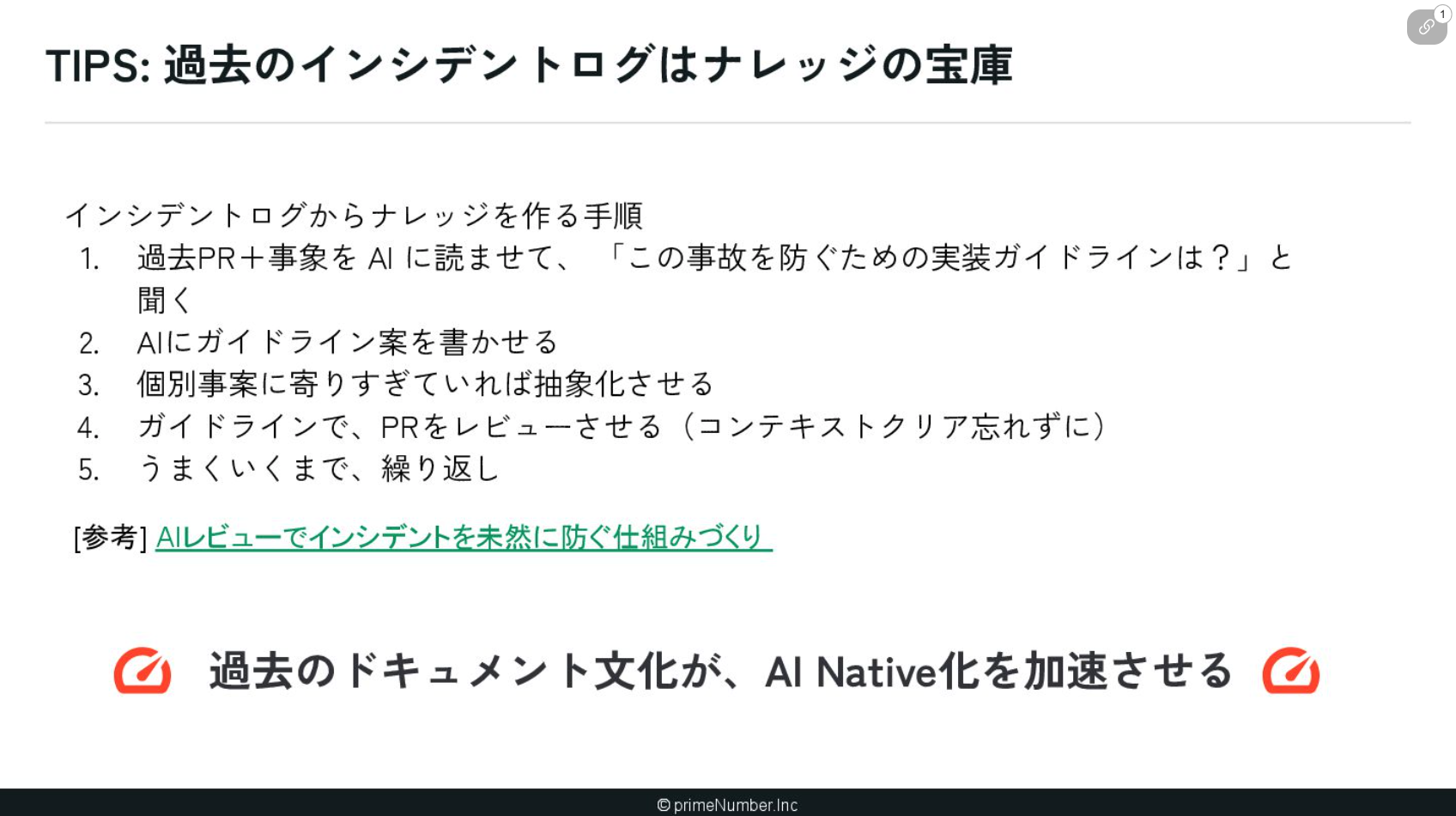
もう1つ具体例をあげると、弊社ではインシデント発生時にポストモーテムを開催しており、再発防止策をドキュメントとして蓄積しています。
これらをナレッジ化するため、原因となったPRと発生事象をClaude Codeに渡して「このインシデントを防ぐためにはどのようなガイドラインが必要か」を考えさせました。特定のインシデントに寄りすぎず、かつ抽象化しすぎて実用性を失わないよう、バランスを見ながら落とし込んでいきました。具体的な取り組み内容は「AIレビューでインシデントを未然に防ぐ仕組みづくり」でご確認いただけますと幸いです。
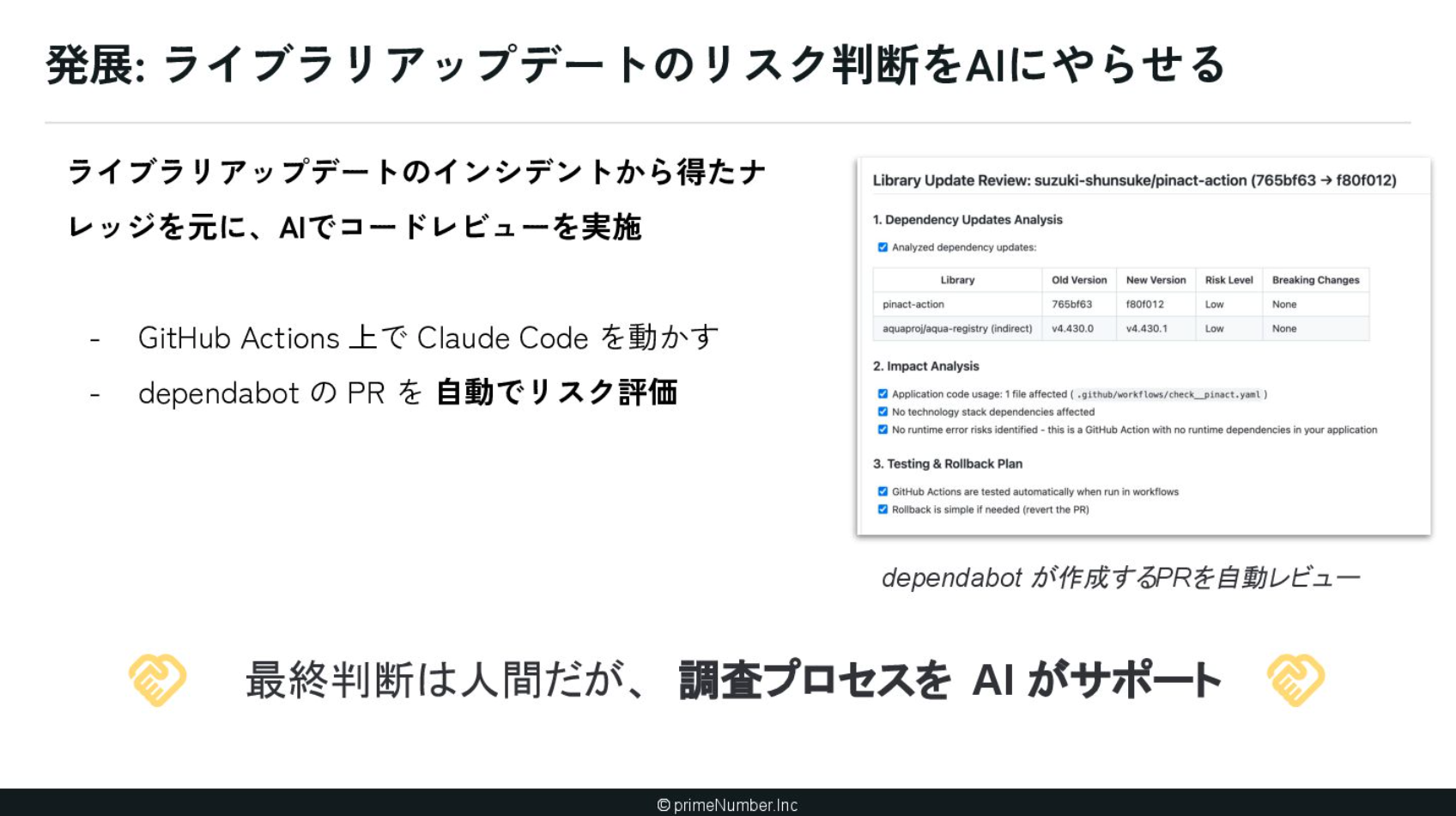
過去から積み上げてきたドキュメント文化が、AIネイティブ化において花開く、とてもいい事例だったと思います。現在では、このガイドラインに基づき、ライブラリのアップデートのリスク評価を自動化する取り組みも進めています。
AIへの「ガードレール」としての型定義
鈴木:2つ目の理由としては「コードベースの問題」が挙げられます。ナレッジを増やし続けていくと、ある段階で、AIがナレッジを十分に読み取ってくれないという壁にぶつかります。そこで、AIが理解しやすいようにコードベースそのものを変えていくという考え方が必要となります。

とはいえ、既存のコードベースを抜本的に変えるのは難しい。そのため、まずは「できるところから、できる範囲で取り組む」という姿勢が重要です。
弊社の場合は、型がある領域は変更しやすく、ここが大きなポイントになると感じました。型定義によってAIへのガードレールを引くことは、AI時代の技術選定における重要な要素であると、よく語られている通りです。
弊社はバックエンドにRubyを採用しており、この領域でも型の恩恵を享受したいと考え、TROCCOおよびCOMETAのコードベースに型を付与するプロジェクトを進めています。
認知負荷を下げるためのプロセス分解

鈴木:3つ目の理由は「プロセスの問題」です。具体的にどのプロセスからAI化を進めるべきかを検討する際、チームで集まって現在のフローを書き出し、付箋を貼りながら工程を可視化しました。その上で、時間と頻度に基づいた影響度マッピングを行い、優先順位を決めました。
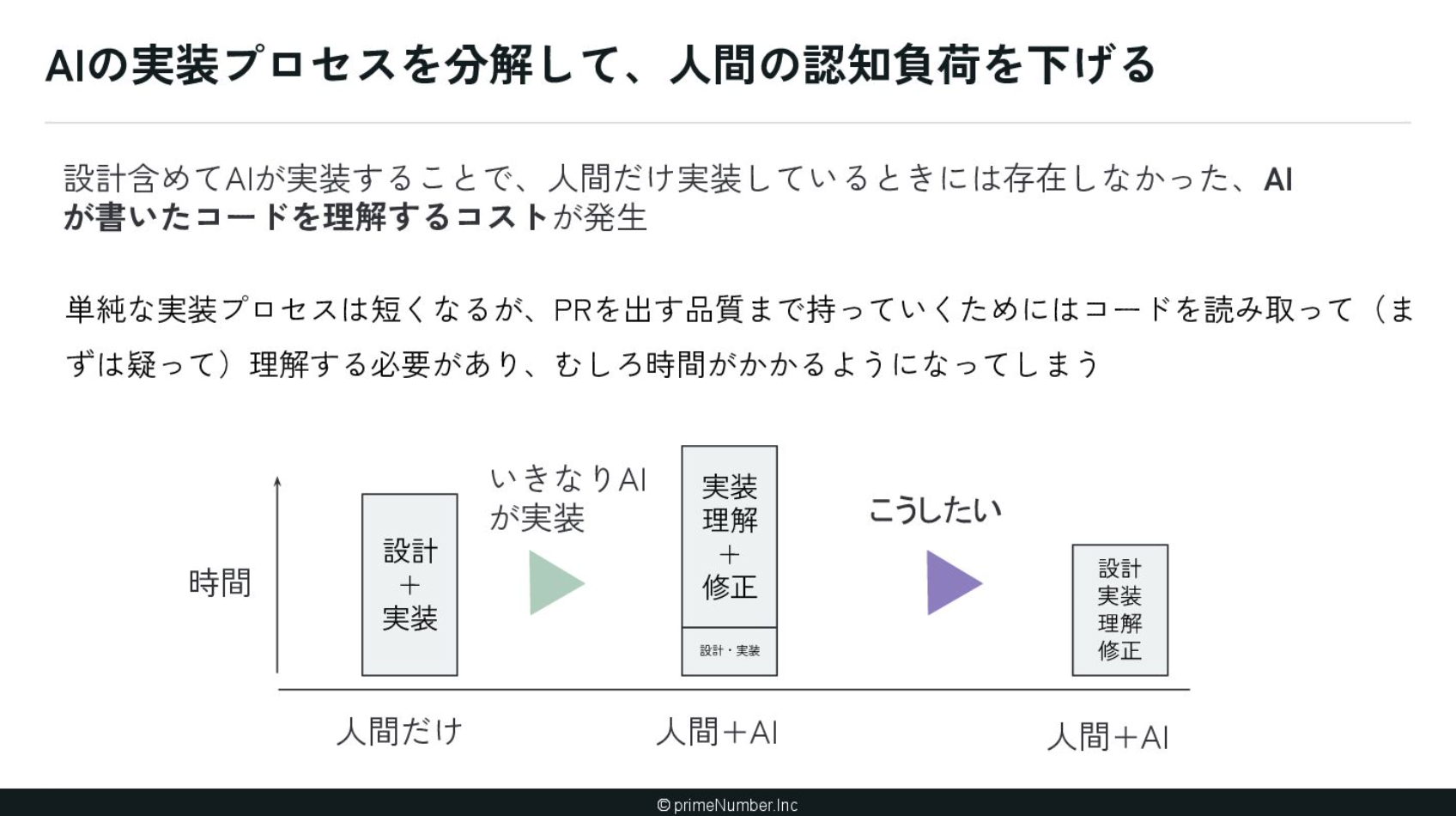
一方で、実装そのもののプロセスも分解し、いかにAI化するかを考える必要もあります。実際にAIにコードを書かせると、これまでにはなかった「AIが生成したコードを人間が読む」という時間が発生します。初見のコードをいきなり読み解くのには時間がかかるため、プロセスを分解して、どこをAI化するのか慎重に設計したいと考えています。
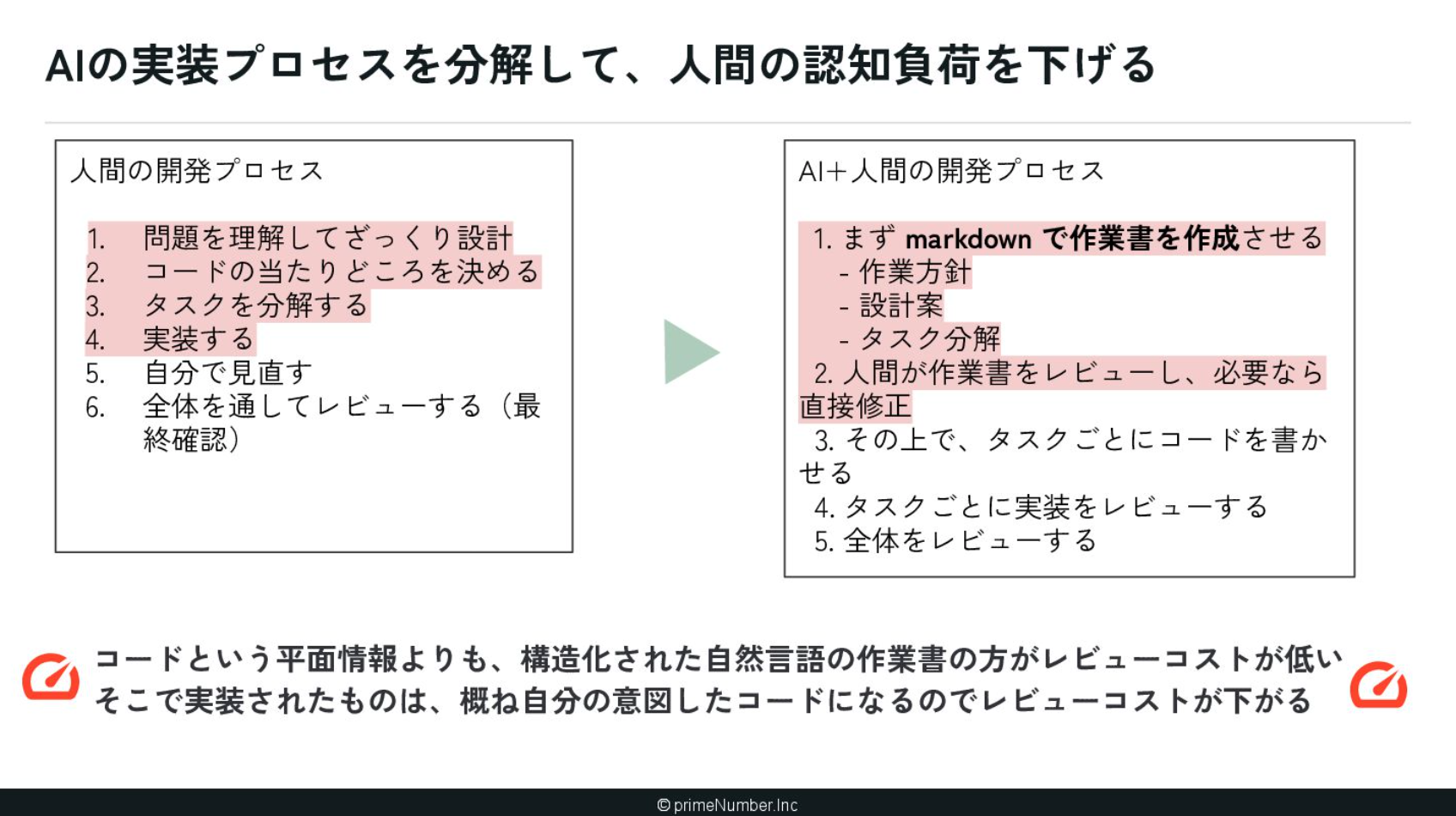
開発スタイルは様々ですが、私の場合はコードを書かせる前にAIに仕様書を書かせるようにしています。いきなり生成されたコードをレビューするよりも、自分の思考プロセスを自然言語ですり合わせながら、最終的なアウトプットを導き出す方が、結果として良いやり方だと感じています。最近は同じような手法を取る方が増えているのではないでしょうか。
ここでのポイントは、いかにAIに「いきなりコードを書かせないか」という点にあります。自分の想像するコードをAIに書かせるためのチューニングは、非常に重要になってくると考えています。
技術トップのコミットと「AI Champion」の役割
鈴木:ここまで3つの理由をご紹介してきましたが、最後は「AIネイティブ化を進める体制」が重要だと思います。よくある失敗として、AIツールを配布しただけで個人任せになってしまうケースがあると思いますが、既存プロダクトの開発においては、組織として着実に推進していく姿勢が重要です。
弊社でAIネイティブ化を進める上で、特に重要だった4つの取り組みをご紹介します。
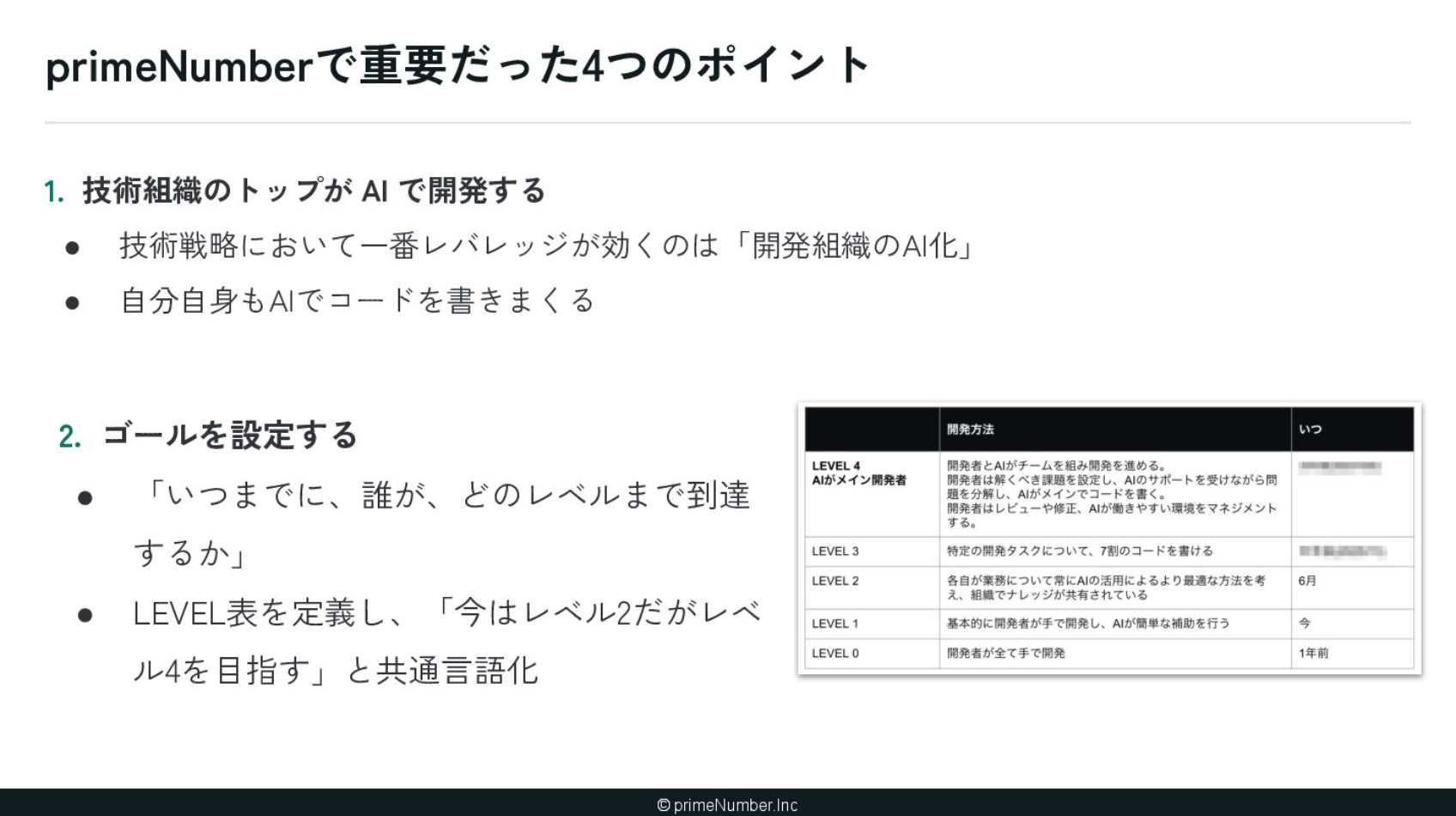
1つ目は、技術のトップ自身がAIで開発することです。これが何よりも重要だと考えています。現代の技術戦略において、最もレバレッジが効くのは開発組織のあり方やAIの組み込み方です。それを正しく判断するためには、技術組織のトップ自らがAIでコードを書きまくる必要があります。もし皆さんの上長がまだAIでコードを書いていないのであれば、ぜひ「書いてください」と伝えてみてください。
2つ目が、明確なゴール設定です。私たちは、いつまでに誰がどのレベルに達するのかを示すため、AI Native レベル表を定義しました。先ほども少し触れたものですね。「現在はレベル2だけど、半年後にはレベル4を目指しましょう」といった形で、共通言語化して目標を追いかけられるようになりました。
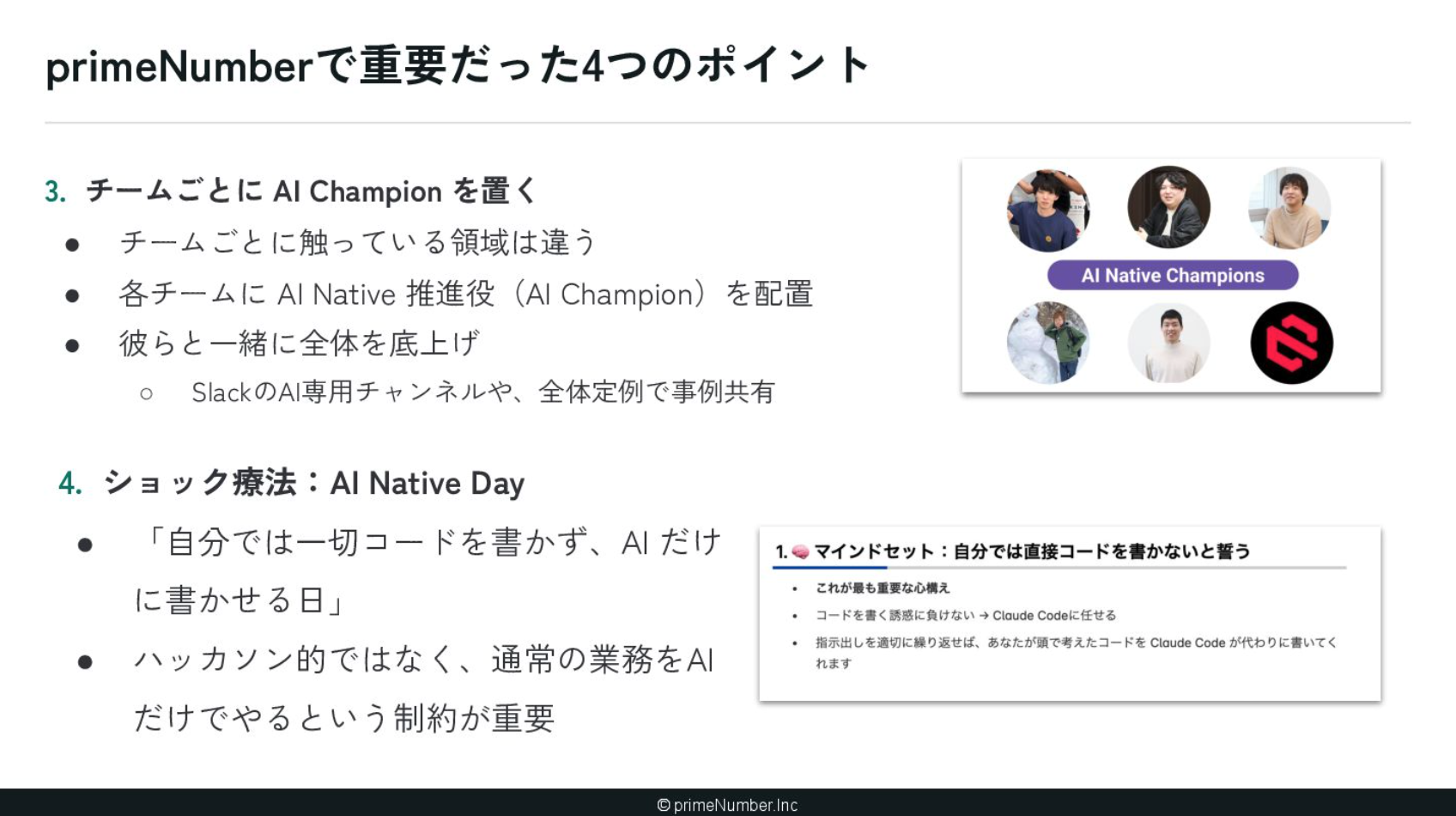
3つ目は、各チームへの「AI Champion」の配置です。弊社には4つのソフトウェア開発チームがあり、それぞれに触っている領域が異なります。そのため、各チームに推進役を置きました。彼らが各チームのAIネイティブ化を牽引し、全体で情報共有や成功事例を展開することで、組織全体の底上げを図りました。
4つ目は、あえて「ショック療法」と呼んでいる取り組みです。実際にAIに任せきったらどうなるのかを体感しない限り、前には進めません。そこで弊社では「AI Native Day」を開催して、自分ではコードを一切書かずAIだけに書かせる日を作りました。重要なのは、ハッカソンのような特別企画ではなく、通常の業務をAIだけで完遂させるという制約を設けた点です。これにより、AIをいかに実務に落とし込むかという視点を鍛えることができました。
課題と向き合い、組織一丸となってAIネイティブ化を進めていく

鈴木:まとめます。既存プロダクト開発においては、これら4つの課題をクリアしていくことが求められます。AIが理解しやすいようにコードベースやアーキテクチャを整え、ナレッジを整備し、その整備自体もAIに手伝ってもらいながら、組織一丸となって推進していくべきだと思います。

この「コードベースを整えてナレッジを整備する」というプロセスは、私たちが取り組んでいるデータエンジニアリングとAIの領域においても、全く同じ構造だと思っています。
AIのためにデータを整え、AIのためのナレッジを蓄積し、そのナレッジ拡充すらもAIに担わせていく。ソフトウェア開発のAIネイティブ化で培った知見やアイデアは、データ基盤の領域に留まらず、今後あらゆるAI系プロダクトの開発においても適用できるモデルになっていくだろうと、改めて思いました。

新規プロダクトのAIネイティブ化に向けた取り組み
中根:ここからは、新規プロダクト開発の視点でお話させていただきます。
改めまして、primeNumberのCTO室でソフトウェアエンジニアをしている中根と申します。私は7年ほど、TROCCOの開発に携わっており、「アーキテクチャConference 2024」でも登壇させていただきました。
そんな中で、2025年の夏より0→1のWebサービス開発に取り組むことになりました。内容の詳細は伏せますが、一般的なWebサービスを想像いただければと思います。
開発に着手する際、先ほど鈴木がご紹介した取り組みを間近で見ていたこともあり、当然ながら「0→1の技術選定やアーキテクチャ設計において、AI開発と親和性の高いものをどう選ぶか」という問いが浮かびました。

前半の発表から引用した4つのポイントのうち、組織やプロセスの話は、少人数の新規開発では影響が少ない一方、「ナレッジ」と「アーキテクチャ」は非常に重要だと感じています。
前者について、新規プロダクトには暗黙知がないと思われがちです。しかし、AIによるコード生成量が増えて開発が加速する世界では、数週間単位で「新しい書き方」と「古い書き方」が混在し始めます。こういったものが生まれないように、常に目を光らせながら仕組み化していく必要があります。
後者については、AIが書くコードは非決定的で、全面的に信用が置けるものではありません。手戻りを防いで開発速度をあげつつ、バグを抑えて信頼性を担保するためには、AIが自律的に動ける構造にするか、あるいはAIに頼らずに別の部分で信頼性を担保するような設計が必要だと考えています。
決定的なレイヤー「PostgreSQL RLS」の採用
中根:アーキテクチャの選定について考えてみます。

私が携わってきたTROCCOのアーキテクチャはこちらです。2018年にサービスが誕生した当時は、0→1で新規サービスを立ち上げる際にはRuby on Railsが一般的だったと思います。
しかし、携わる人数やコード規模が拡大するにつれ、バックエンドにも静的型付けが欲しいという声があがるようになりました。特にAIがコードを書くようになってから、その必要性はより顕著になりました。
また、これまではOpenAPIでYAMLを書いて、それをもとにTypeScriptのコードを生成してフロントエンドとバックエンドを繋いでいました。しかし、複雑な箇所でズレが生じたり、1画面に対して触るコード量が多くなったりと、AIに任せる上での課題も見えてきました。
これらを踏まえて、今回の新規開発ではフロントエンドにNext.jsを選択しました。他のフレームワークも検討しましたが、時間は有限です。AIの学習量が多いであろうデファクトスタンダードに則っておく方が賢明だと考え、あまり迷うことなく決断しました。
AIとシームレスに「対話」するための技術スタック
中根:問題はバックエンドの構成です。「RailsでAPIサーバーを立てる」「別の静的型付け言語を採用する」「Next.jsのAPIを使ってTypeScriptで書く」という、3つの選択肢を検討しました。

それぞれのメリットデメリットをあげていくと、Railsは慣れているとはいえ、型の問題があります。静的型付け言語については、社内の知見が十分ではありません。Next.jsについては「銀の弾丸」だと言われがちですが、バックエンドとフロントエンドをシームレスに記述できるため、AIにコードを書かせる際の恩恵が大きい。
また、弊社はフロントエンドとバックエンドのチームが分かれていないこともあり、馴染みのあるTypeScriptが使えるNext.jsでのフルスタック構成を採用することにしました。

DBについても、慣れ親しんだMySQLを使いがちでしたが、今回はPostgreSQLを採用しました。マルチテナントのサービスを開発する上で、ミドルウェアのレイヤーでテナント分離を担保する「Row Level Security(以下、RLS)」が非常に魅力的に映ったからです。AIがコードの大部分を書く時代において、セキュリティのようなクリティカルな部分は、AIが書くソースコードではなく、より低層の決定的なレイヤーで防ぐべきだと考えました。

ORMには、型の恩恵を最大限に得られるPrismaを選択しました。RLSの設定にはテーブルごとにDDLを書く手間がありますが、AIを活用して「自動生成するプラグイン」を一瞬で作成することができました。このように「目的が明確に閉じている」一方で「自分自身にはまだ十分な知見がない」という領域こそ、まさにAIの力が最大限に活きる場面だと強く実感しました。

Next.jsやRLS、Prismaについて、私自身は初めて触る技術スタックでしたが、AIと対話を重ねることで仕様を腹落ちさせながらスムーズに進めることができました。AIの価値はコード生成だけでなく、高度な壁打ちができる点にあります。これにより、初めて触る技術を選択するハードルが、以前よりも低くなっていると思います。
ただ、重要なアーキテクチャの意思決定や、開発の基礎となる初期作業は人間が行うべきです。初期構築のコマンド実行や設定ファイルの定義、ディレクトリ構造の決定といった「今後の開発を左右する土台」は適当にAIに任せるのではなく、自分で手を動かして整える。この辺りはコード量が多いわけではないため、自分でやるメリットの方が大きいと感じています。
AIの自由度を制約する仕組み
中根:ここからは、新規開発における「暗黙知の防止」について考えます。AIにコードの大部分を任せるからこそ、規約やルールを厳格に設けることが重要です。AIは放っておくと既存コードとの整合性を軽視しがちで、数日もすれば設計がバラバラになってしまうからです。
コーディング規約や命名、ディレクトリ設計など、初期開発でスピード感を求められる場面でも、人間にとっては少々鬱陶しいと感じるほどルールを固めておくことが、今の時代には有用だと考えています。
これらをドキュメントに起こしても、AIが全てを守り切れるわけではありません。しかし、AIの進歩は目覚ましく、ルールが存在していること自体が重要です。弊社では、余裕があればLintなどの静的解析ツールによる制約を設けるようにしています。例えば、ESLintの厳格なプラグインを初期段階から有効にすることで、AIの出力コードに一貫性が出てきたと実感しています。

ルールの詳細については簡単に触れるに留めますが、どのディレクトリから直接DBにアクセスしてよいか、あるいはレイヤー間の依存関係やインポートの可否、さらには各レイヤーにおける関数の引数の定義などを、初期段階から検討しておくことが重要です。
もちろん、こうした設計は実際に動かしてみないと分からない部分も多いため、しっくりこなければその都度AIと壁打ちをして再考すればよいと考えています。かつてはこうした広範囲の修正には膨大な時間がかかりましたが、修正方針さえ定まれば、AIを使って一気に書き換えることが可能となりました。まずは形にしてみて、AIの力を借りながら柔軟にブラッシュアップを繰り返していくのが、今の時代に合った進め方ではないでしょうか。
エンジニアが守り抜くべきソフトウェアプラクティス
中根:どのようなルールを設けるべきかという点については、まずはこれまでのエンジニアとしての経験に基づいたプラクティスを適用してみるのがいいと思います。その上で、AIと壁打ちしながら調整していくのを推奨します。
Claude Codeなどが登場した当初は「人間にとって読みやすいコード」と「AIにとって読みやすいコード」は別物ではないかという議論も目にしましたが、根拠は少ないように感じます。
そうした新説を重視するあまり、人類が築いてきた重要なプラクティスをないがしろにしてしまうのは非常にもったいないです。t_wadaさんが「AI時代のソフトウェア開発を考える」でおっしゃっていたように「両にらみ」という考え方が重要なのではないでしょうか。
ベースとなるアーキテクチャやルールを最初からしっかりと設計しておけば、簡単な機能追加などは、数秒で終わるようになっていきます。もちろん、既存プロダクト開発と比べて制約が少ないという面もありますが、AIのスピードを最大限に引き出せている実感があります。
人間によるレビューも行っているため、Vibe Codingのように、即座に設計が崩壊するようなことはありません。しかし、どれだけルールを定めていても、AIが書いたコードが積み重なると、目が滑るような感覚に陥ることがあります。2週間ほどでコードベースを追うのが辛くなってくるため、現在は2週間に一度、リファクタリングを行う人を設けています。
普遍的な価値への投資と、進化し続けるAIとの共生

中根:抽象的な話も多かったのですが、最後にまとめとさせていただきます。
この資料を作成している間にも、各社からAIの新機能が次々と登場しています。正直なところ、日々の業務の中で、その瞬間の最適な活用方法を常に追い求め続けるのは容易ではありません。
だからこそ、冒頭であげたような「ベースとなる部分」を日々整備しておくことが重要だと思います。どんなAIのパラダイムシフトが起きたとしても、基本となるデータ構造やナレッジ、アーキテクチャを整えておくことは、普遍的な価値を持ち続けます。そうして基礎を固めることで生まれた余裕を使い、新しい技術へディープダイブしていくのが良いと思います。
また、先ほどもお話ししたように、壁打ち相手としてのAIの価値は非常に大きいものです。何か新しい取り組みを始める際は、AIをパートナーとして活用し、積極的に挑戦していくのが良いのではないでしょうか。
最後に、primeNumberでは様々なポジションで募集をしております。興味を持っていただけたなら、ぜひ採用ページをご覧ください。
本日はご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





