



【アーキテクチャConference 2025】空調ソリューションの未来を支える基盤 ─ダイキン工業のKubernetes活用とAIセキュリティ強化
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に行われた本セッションでは、Sysdig Japan合同会社の清水孝郎氏とダイキン工業株式会社の寺西翔汰氏が登壇。ダイキン工業がソリューションビジネスへの事業変革を目指す中で、空調IoTシステムを横断して故障予知や省エネなどの分析アルゴリズムを展開するためのプラットフォーム開発について紹介されました。
グローバルに展開する製造業がどのようにクラウドネイティブ技術を活用し、開発スピードと統制のバランスを取っているのか。その実践的な知見が詰まったセッションをレポートします。
■プロフィール
清水 孝郎
Sysdig Japan合同会社
日本地域担当技術責任者/プリンシパルSE
2018年よりSysdig日本法人立ち上げに参画。日本地域担当技術責任者/プリンシパルSEとして日本のお客様を支援し、クラウドネイティブ環境のセキュリティ設計・可観測性・脅威検知を専門に活動している。
寺西 翔汰
ダイキン工業株式会社
テクノロジーイノベーションセンター(TIC) 情報通信グループ チームリーダー
2018年にダイキン工業に新卒入社。ダイキン情報技術大学でAI/IoTやシステム開発の基礎を学習。2020年からTIC 情報通信G所属。海外の開発拠点と連携し、仮想チームを構成して社内の空調IoTシステムのデータを収集し、アプリケーション開発に利用するデータ基盤の研究開発に携わる。
空調ソリューションのアプリケーション開発と現在のサービスアーキテクチャ
寺西:本日はダイキン工業のKubernetes活用と、ソリューションのアプリケーション開発についてお話しさせていただきます。
ダイキン工業は昨年100周年を迎えた大阪の企業で、グループの売上としては8割以上が海外というグローバルな会社になっています。拠点も各地域にありまして、「市場最寄化生産」をベースに、世界28カ国90カ所以上に生産拠点を構築しています。また、それぞれの地域において研究開発の拠点を持っています。
ダイキン工業がこれまで注力していたのは、「川上」と呼ばれる領域で、空調機をパッケージとして販売するところと、システムを販売する機器売り・物売りの世界でした。
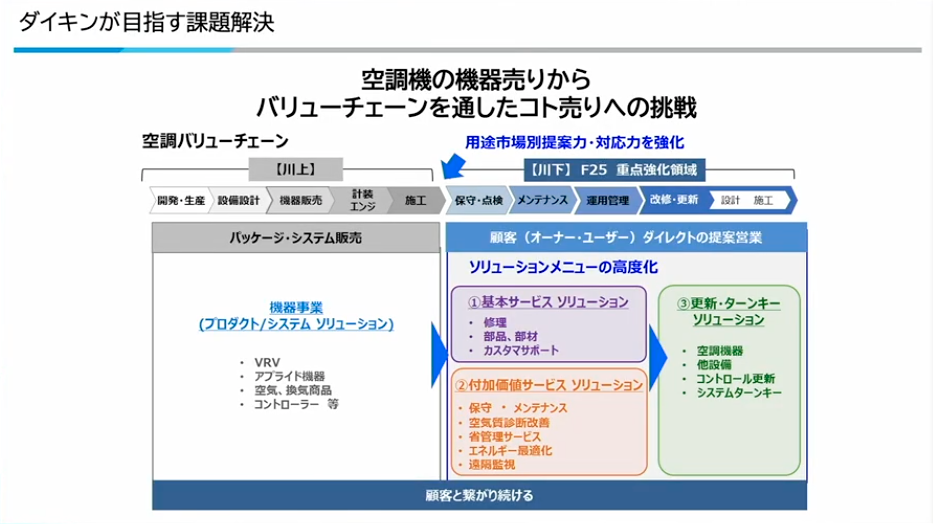
寺西:現在、ダイキンの経営戦略である「FUSION25」においては、お客様へのダイレクト営業につなげるようなソリューションのアプリケーション開発を重点強化しています。お客様へ納入された後から保守運転、最後の機器の更新といったところまで担うような開発です。
基本のサービスソリューションでは、修理、部品・部材、カスタマーサポートはもちろんのこと、付加価値サービスとして保守・メンテナンス、施工管理、エネルギー最適化といったところを提供しています。また、最終的な更新・ターンキーと呼んでいる部分では、空調設備の更新の最適化を図っています。
空調バリューチェーンの中で、それぞれお客様の困りごとや課題がありますので、既存の空調機をクラウドにつないで、データを使って課題解決に取り組んでいます。
次に、運用や保守メンテの領域での具体例を紹介させていただきます。
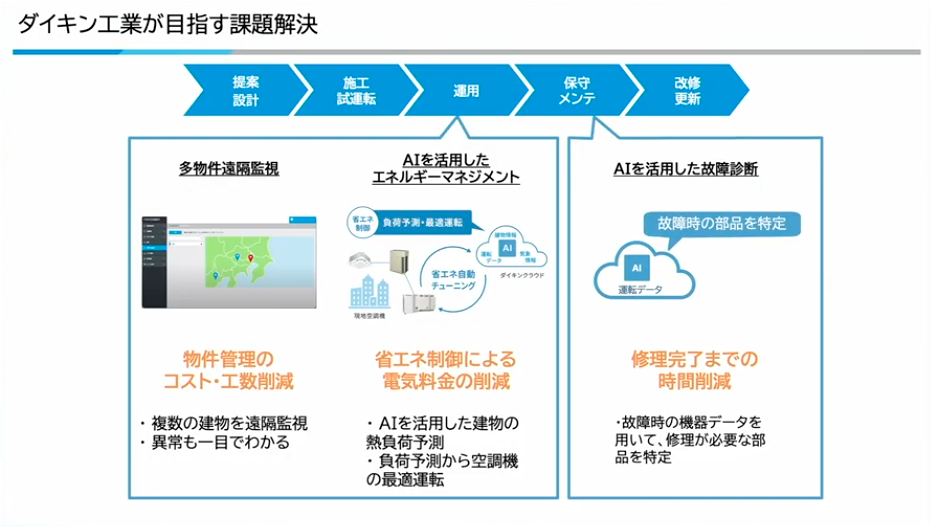
寺西:まず多物件遠隔監視のアプリケーションです。ターゲットとなるお客様は、施設内に複数の施設があるような工場、大学キャンパス、地域に複数の店があるようなチェーン店などを想定しています。複数の物件を遠隔で監視して、異常を一目で分かるようにすることで、物件管理のコスト・工数削減を目標にしています。
次がAIを活用したエネルギーマネジメントです。省エネ制御によって電気料金の削減や、さらなる環境負荷の低減を目指しています。AIを活用して、空調機器の運転データ、物件の静的情報(例:南向き、緯度経度など)、気象情報を組み合わせて建物の熱負荷を予測します。その熱負荷をもとに空調機のパラメータをあらかじめ事前に先回りしてチューニングすることで、お客様の物件の快適性を維持しながら、エネルギー消費量を削減します。これまでと比べて20%削減するような効果も出ています。
最後はAIを活用した故障診断です。実際に故障は起きてしまうもので、故障が起きた時にサービスエンジニアが駆けつけます。その時にお客様への影響を最小限にするために、故障時の部品をあらかじめ特定する診断技術になっています。故障前30分ぐらいの運転データを使って、修理が必要な部品をあらかじめ特定してサービスエンジニアが駆けつけることで、修理完了までの時間削減を実現しています。

空調IoTサービスの現状と課題
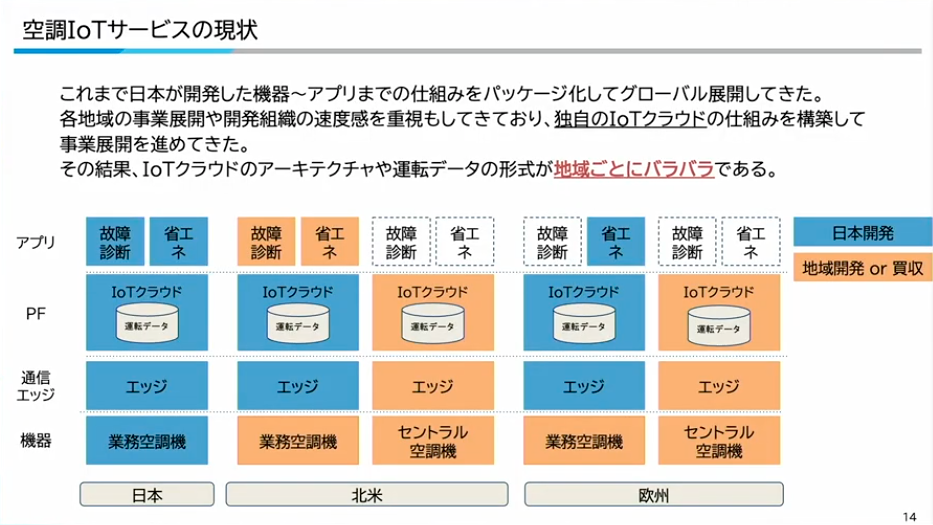
寺西:当社の空調製品のラインナップとしては、家庭用の住宅用エアコン、空気清浄機から、一般的なオフィスビルに入っているようなビル用マルチエアコン、さらに海外や大型施設(羽田空港など)に入っているようなセントラル空調機、ルーフトップと呼ばれるような機器まで存在します。ダイキン工業はそれらをすべてラインナップとして持っていて、お客様のニーズに応えようとしています。
これまで、ダイキン工業は開発した機器からアプリまでの仕組みをパッケージ化してグローバル展開してきました。ただ、各地域の事業展開や買収、開発組織の速度感なども重視してきており、独自のIoTクラウドの仕組みを構築して事業展開を進めてきました。
その結果、現状ではIoTクラウドのアーキテクチャや、そもそもの運転データの形式・保存といったところが、地域ごとにバラバラになっているという課題があります。
寺西:新たな空調機のデータを活用したアプリケーションを開発するケースでの課題についてお話しします。
研究開発のTICが、故障診断や省エネロジックなどを内部データを活用して開発します。開発が終わると、実際に北米に存在する開発拠点に仕様を提供します。開発拠点においては、その仕様に応じてIoTデータの変換を検討して、実際に地域の持つIoTクラウドのプラットフォームにデータ変換やロジック実装をしていきます。
一つの地域であれば問題になりませんが、ダイキン工業のケースだと、ヨーロッパ、アジア、インドなど複数の拠点があります。そういったケースにおいては、TICがそもそも複数の拠点向けのデータ変換が必要になったり、開発拠点の開発優先度によってはロジック実装が後回しにされてしまうようなケースもあったりします。
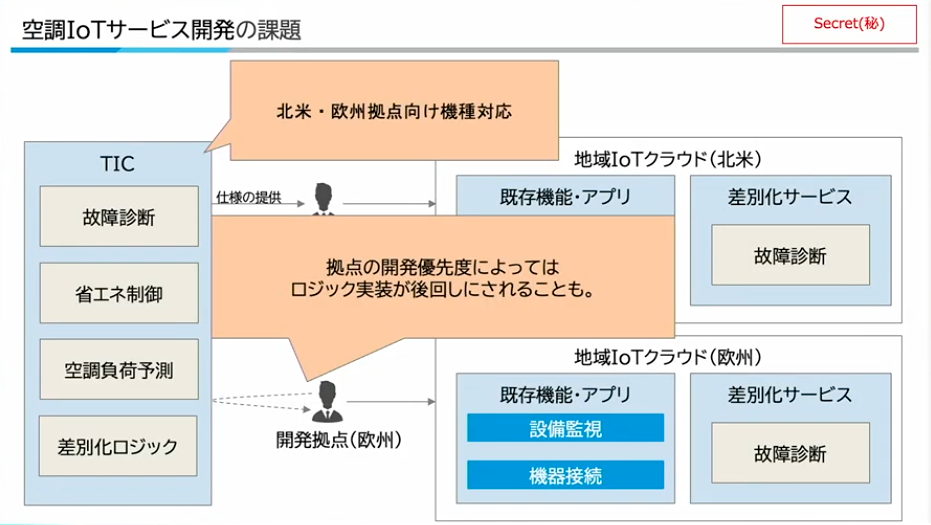
寺西:地域拠点は直近のビジネス課題の解決がやはり最優先の取り組みになっているので、TICが研究開発として生み出したロジックの実際の実装にバラツキがあったり、市場展開までの速度が遅いという課題があります。また、データ変換の部分は共通して仕様が決まっていて、共通して変換が必要なものについても、ロジックごとに検討や実装をしています。そのような背景があって、ロジック展開がそもそも遅いという課題があります。
ロジック展開促進のためのプラットフォーム開発
寺西:それを解決するために、現在新しいプラットフォームを構築しています。日本と地域間で役割を分担して効率化の仕組みを構築しようとしています。
あくまでも基本のポリシーは、お客様に近いアプリケーションは地域の法令やデザインの好みなどそれぞれありますので、そこはやはり地域開発に委ねます。
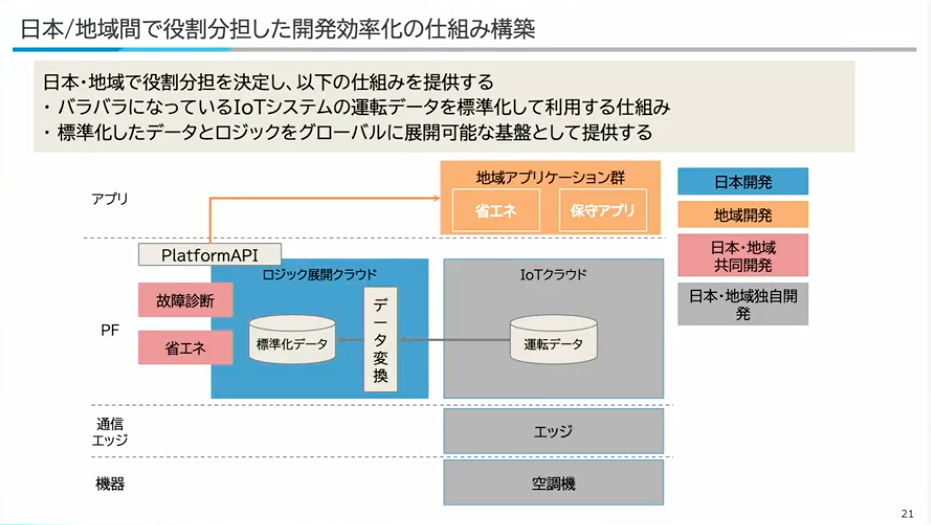
寺西:既存のIoTクラウドの仕組みを最大限に有効活用し、一つのクラウドにまとめるようなことはせず、日本側がこの「ロジック展開クラウド」と呼んでいるものを提供します。バラバラになっているIoTシステムの運転データをまず標準化して、利用する仕組みを提供するんです。日本と地域など開発拠点がそれぞれロジックなどをグローバルに開発して、それを展開する。それを実現するような基盤として提供しています。
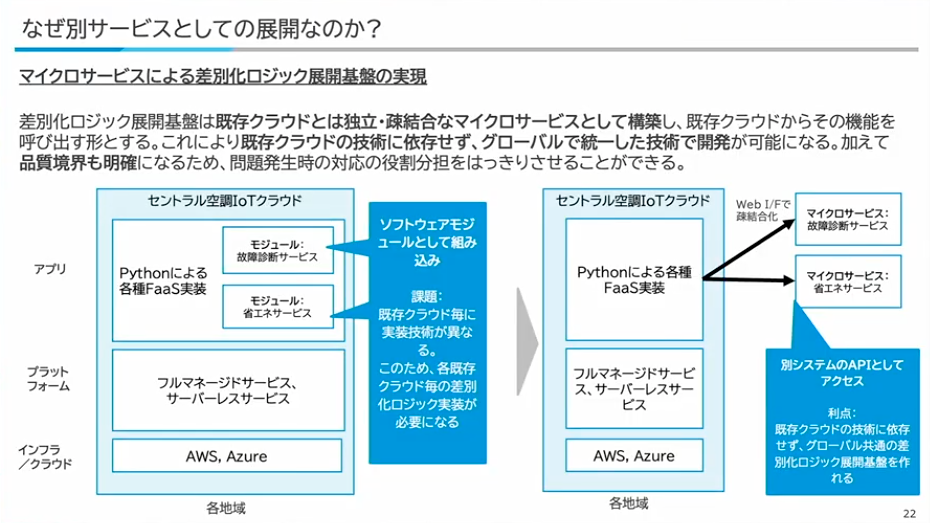
別サービスとしての展開についてお話しします。グローバルに複数のIoTクラウドがあると言いましたが、そもそも実現しているテクノロジースタックやクラウド基盤が違うケースがあったり、他社のOEMを使っているようなケースもあったりします。ソフトウェアモジュールとして制御などを組み込んでしまうと、既存クラウド特有の実装が必要になるという課題があるのです。
そのため、今回はグローバルで統一した技術スタックで開発するというところや、品質境界を明確にするという目的で、WebインターフェースでAPIとして疎結合にさせて、別システムのAPIとしてアクセスするようにしています。
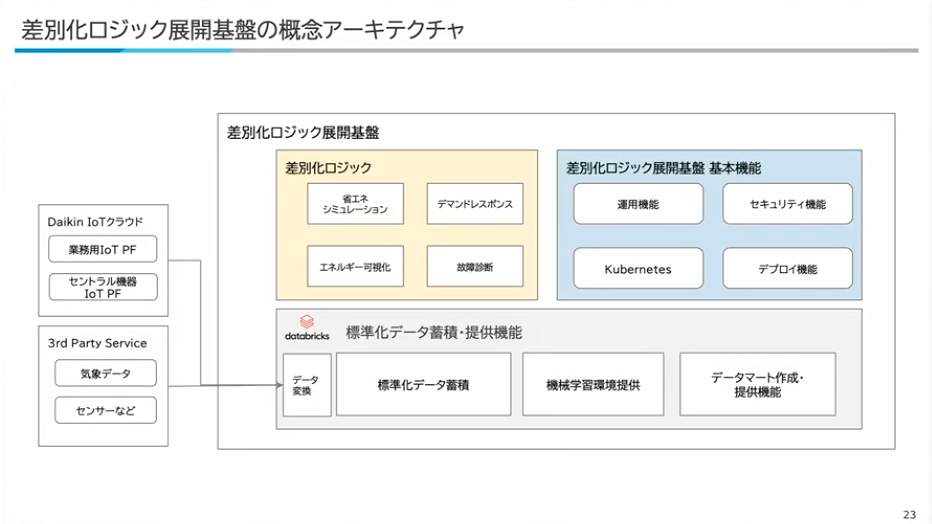
寺西:構築している差別化ロジックの概念アーキテクチャについてお話しします。左側にダイキンのIoTクラウドがあり、他にも気象データやセンサーデータなども使いますので、それらを一つの標準データという形で蓄積・提供します。基本的にはDatabricksを使っています。
その上で差別化ロジックの展開基盤として、Kubernetesとそれに付随した運用機能、セキュリティ、デプロイを提供して、その上に差別化ロジックを載せています。具体的には、デマンドレスポンス(お客様の電気料金を下げるもの)、省エネのシミュレーション、エネルギーの可視化、故障診断のようなロジックを構築しています。
現状は来年にかけて、このプラットフォームの基本機能や、省エネのシミュレーションを実際にして、お客様へ提案資料として出すようなアプリケーションを現在開発しています。
寺西:全体構成について、基本的なデータ基盤としてはDatabricksを、その上に乗るコンテナ基盤としてはEKSを用いています。Fargateの中でKarpenterを動作させてEC2のオートスケーリングを実現しながら、中のコンテナはIstioなどを使って、ネットワークの認可のレイヤーやリトライなどの仕組みをIstioに寄せつつ、ロジックに必要な機能は本当にロジックだけに寄せる。そのような機能を実現しています。
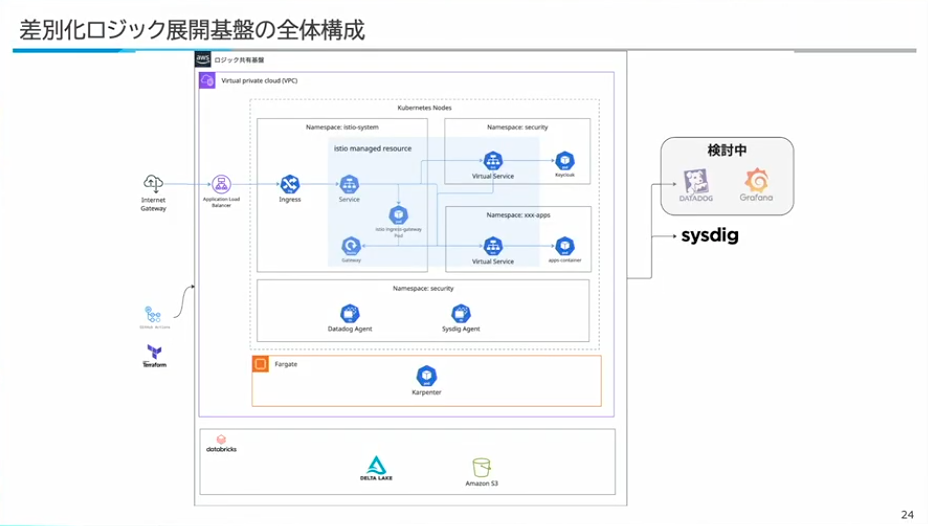
また、エージェントとしてDatadogやGrafana Cloudのようなオブザーバビリティの監視ツールのエージェント、セキュリティ関連ではSysdigのツールなどを導入しています。
次に、なぜダイキン工業がKubernetesを採用したのか、理由は大きくは2つあります。
1つ目は、ダイキン工業特有の課題として、グローバルのクラウド構成がすごく複雑で、クラウドベンダーニュートラルなコンテナ技術が不可欠だったというところがあります。アジアと欧州ではAWS主体なんですけれども、北米ではAzureとAWSの両方を使っています。さらに中国ではHuawei Cloudなどを使うことで、そもそもロジックコンテナの基盤を提供しようとすると、クラウドベンダーニュートラルが必須だったという背景があります。
2つ目は、グローバルで開発拠点があったので、それらもロジック開発に最終的には入ってほしいので、それらのプラットフォームを構築する必要があったからです。さまざまなOSSが存在して、開発者の認知負荷を下げる仕組みなどがあるので、それを支えるKubernetesを選定しました。開発者が本来価値創造に集中できる環境を実現したい、ロジック開発の自由度を実現しながらセキュリティ上守るべきガードレールの設定などが可能になるという点も理由として挙げられます。

寺西:Databricksを採用した理由については、大きく3つあります。
1つ目に、ダイキングローバルでそもそもDatabricksが広がっていました。たまたまDatabricksを用いてグローバルにデータ基盤を構築していたので、Databricksやデータに関するノウハウを各拠点に共有する土壌がありました。
2つ目は、Databricksが提供するサービスについても、データの特性が異なるアプリケーションの利用基盤として有望だったというところもありました。故障分析をはじめとするビッグデータには、Delta TableやMLflowなどが提供されていますし、省エネやデマンドレスポンスなど、ある程度ニアリアルタイム(5分程度)のリアルタイム性が求められる分析ロジック作成では、Databricksの「Zero Bus」と呼ばれるサービスやパイプラインなどがあります。
そして3つ目、Databricksそのものがオブジェクトストレージを主軸とした構成でコストが安価に済むということ、データからAIまで単一の基盤で提供されているので開発者の認知負荷が低いということ、Delta Sharingによって地域や環境間でのデータ利用が実現できるということが選定の理由になっています。

プラットフォームのアーキテクチャの変遷
寺西:ダイキン工業は、これまで既存のプラットフォームの開発をしてきました。その変遷についてもお話しさせていただきます。
2024年ぐらいまでは完全にセルフホストのOSS基盤で、現在から来年にかけてマネージドサービス・SaaSの徹底活用というところで、開発の変遷がありました。
完全セルフホストのOSS基盤というと、TIC傘下のシリコンバレーの拠点がKubernetesそのものからアプリケーションコンテナに至るまで、すべての領域でOSSを利用してホストする基盤を作成しています。

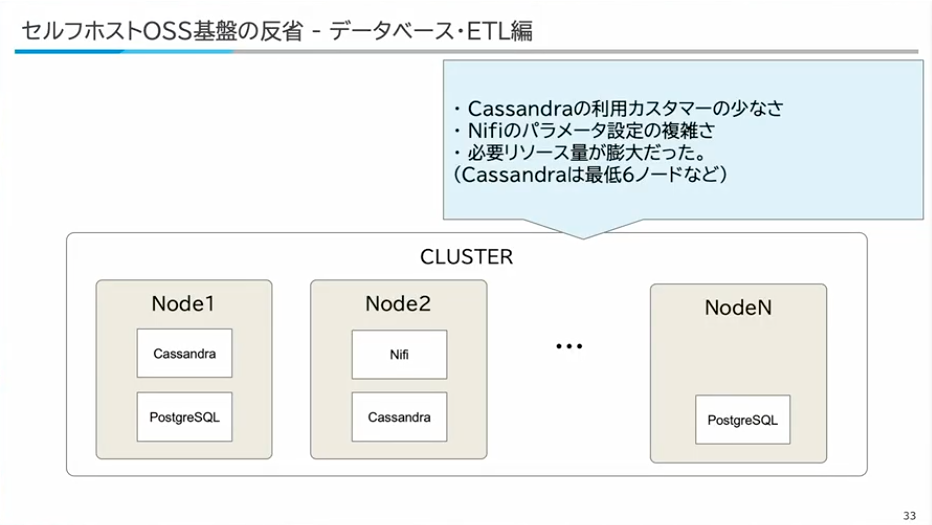
寺西:そもそものKubernetesもIaaSレイヤーを用いてkOpsを使って構築する、データベースの時系列データにはCassandra、セキュリティにはFalcoなどを使って実現していました。また、データのコストが高いCassandraからParquetファイルに移す処理では、Apache AirflowやNiFiなどを使って、Databricksで実現できるような機能を自前で構築していました。同様にオブザーバビリティについても自前で管理・構築していました。
その結果ですが、実際に2〜3年ほど日本環境に適応してアプリケーションの展開をやってきたんですけれども、やはり現在のダイキン工業の開発者の数や利用規模ではToo Muchなところもありまして、そもそもバージョンアップの工数が通常の開発業務を圧迫する、OSSエコシステムのそもそもの使いこなしで精一杯でした。
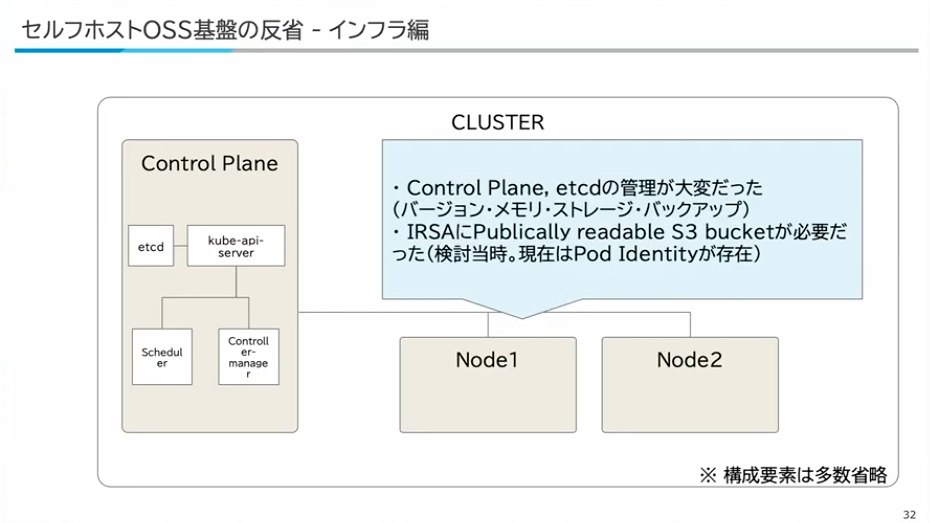
寺西:それぞれのレイヤーでいろいろな反省はあるのですが、そもそもKubernetesを自前で構築することは、コントロールプレーンの管理、可用性を担保することで非常に精一杯でした。バージョンアップもそうですし、メモリ・ストレージといったところも大変でした。
データベースについては、時系列データの保存にCassandraを採用していましたが、日本語での利用事例が少なくベストプラクティスの情報が入手しにくいという課題がありました。また、データパイプラインにはApache NiFiを使っていましたが、パラメータ設定が複雑で、必要なCPUリソースも大きくコストが高い構造になっていました。
寺西:オブザーバビリティについては、ログ収集にFluent Bit、トレーシングにJaeger、メトリクスにPrometheusと、目的ごとに異なるツールを使っていました。これにより3つの課題が生じました。
1つ目は、運用エンジニアが複数のツールを習得する必要があり学習コストが高かったこと。2つ目は、これらをすべてデーモンセットで展開していたため運用管理の負荷が大きかったこと。3つ目は、ログとメトリクスの紐付けが自動化されないため、障害発生時のデバッグに時間がかかり、調査ノウハウも属人化してしまったことです。
セキュリティについては、ランタイム脅威検知のOSSであるFalcoを導入していました。しかし、すべての検知ルールを有効にしてしまったため、大量のアラートが発生して「アラート疲れ」を招いてしまいました。また、検知されたすべての結果について内容を理解し、リスクを分析するというフローが本来必要なのですが、専門知識が求められるためチームとして対応しきれなかったという課題がありました。

寺西:これらの運用経験から得た教訓は大きく2つあります。
1つ目は、自社が本当に内製で構築・提供すべき箇所はどこか?を見極めることです。現在のダイキン工業においてという前提ですが、OSSをすべてセルフホストする基盤は、それ自体に価値があるわけではありません。ロジックと一緒になって、初めてお客様への価値が生まれます。加えて、データベースやセキュリティの専門エンジニアの採用はダイキン工業にとって容易ではないという事情もあり、そういった領域は積極的にSaaSやマネージドサービスを活用すべきだと学びました。
2つ目は、OSSエコシステムの採用判断基準を明確にし、履歴を残すべきということです。OSSのエコシステムはHelm Applyなどで簡単に導入できてしまいます。しかし、導入が簡単だからこそ、ツールが増えて学習コストが膨らみやすい。また、設定不備がそのままサービスの不具合や性能劣化、コスト増につながるリスクもあります。振り返ると、導入事例やベストプラクティスの入手しやすさ、エコシステムの成熟度といった観点をもっと重視すべきでした。そして、なぜそのツールを選んだのかを記録し、担当者が変わっても判断の経緯が分かるようにしておくべきだったと考えています。
続いて、今回採用したサービスとそのメリットを3つの領域に分けてご紹介します。

寺西:1つ目はインフラ・データ基盤です。AWSのマネージドサービス群(EKS、Aurora)やDatabricks(SaaS)を採用して自前で管理すべき構成要素を減らしています。
2つ目はオブザーバビリティです。DatadogまたはGrafana Cloud(現在検討中)の検討を進めています。ログやメトリクスが自動的に相関付けられるため、障害時の原因分析が効率化されます。また、以前は複数のエージェントで機能実現しておりましたが、、単一のエージェントに集約されるため認知・運用負荷も軽減されます。
3つ目はセキュリティです。Sysdigを採用することで、検知ポリシーの策定が簡略化され、コンプライアンスチェックも自動化できます。さらに、脆弱性を分類して優先順位をつけられるため対応すべき項目が明確になる機能も存在します。これらの機能を活用することで開発段階からセキュリティ対応を行うシフトレフトが実現できると考えています。
実際のSaaSの活用例を一部紹介させていただきます。
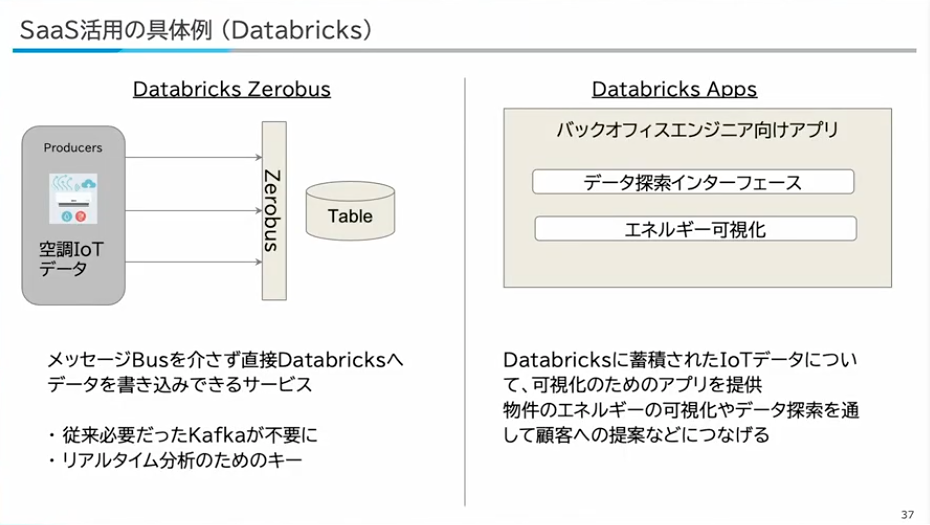
DatabricksのZerobusと呼ばれるサービスを使っています。これはメッセージバスを介さず、直接Databricksへデータを書き込みできるようなサービスです。従来はリアルタイムのインジェクションで必要だったKafka、Kinesisのようなメッセージバスが不要になっています。これを用いることでコストが安く、さらにリアルタイム性を担保できます。
また、Databricks Appsについても、蓄積されたIoTデータについて、可視化のためのアプリや生成AIのインターフェースを簡単に構築できるようになっています。これを使うことで、エンジニアではないバックオフィスのメンバーが自らデータ探索し、お客様へのエネルギーの提案などにつなげていきたいと思っています。
寺西:Sysdigの利用例を2つご紹介します。
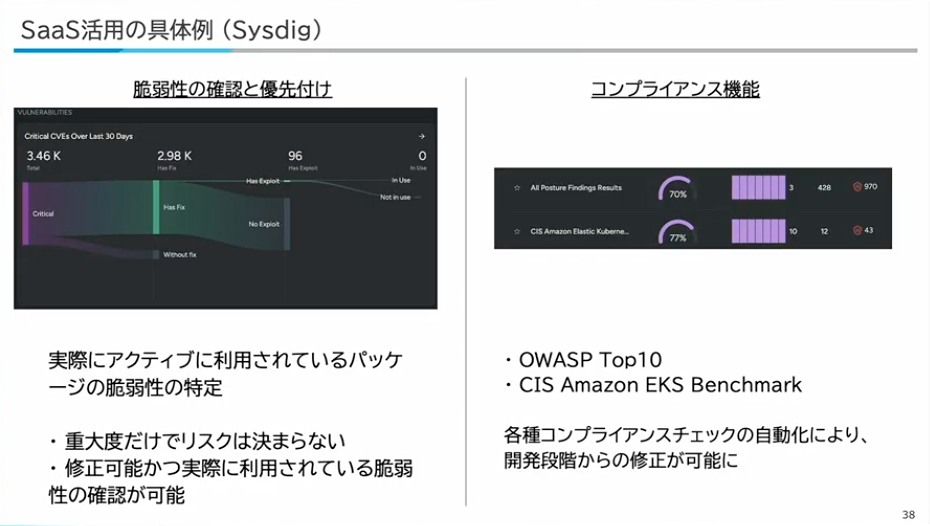
1つ目は脆弱性の優先順位付けです。コンテナ環境では膨大な数の脆弱性が検出されますが、重大度や件数だけでは本当のリスクは判断できません。Sysdigでは、修正可能かつ実際に利用されている脆弱性を確認できるので、どの脆弱性から対応すべきかの判断基準として活用しています。
2つ目はコンプライアンスチェックの自動化です。OWASP Top 10やCIS EKS Benchmarkといったセキュリティ基準への準拠状況を自動でチェックできます。これにより、開発段階からセキュリティの問題を修正でき、シフトレフトが実現できると考えています。
これからの展望
寺西:最後に、このロジック基盤を中心として、日本・地域で目指す姿についてお話しします。チームトポロジーの考え方を参考にしています。
まず、プラットフォームチームは日本で開発し、基盤として提供します。次に、ストリームアラインドチームが各地域の拠点側にいて、お客様に近いところでアプリケーションを開発します。そして、そこを支えるイネーブリングチームが日本と地域の連合で構成され、技術支援を行っていく。この3つのチーム構成を目指しています。
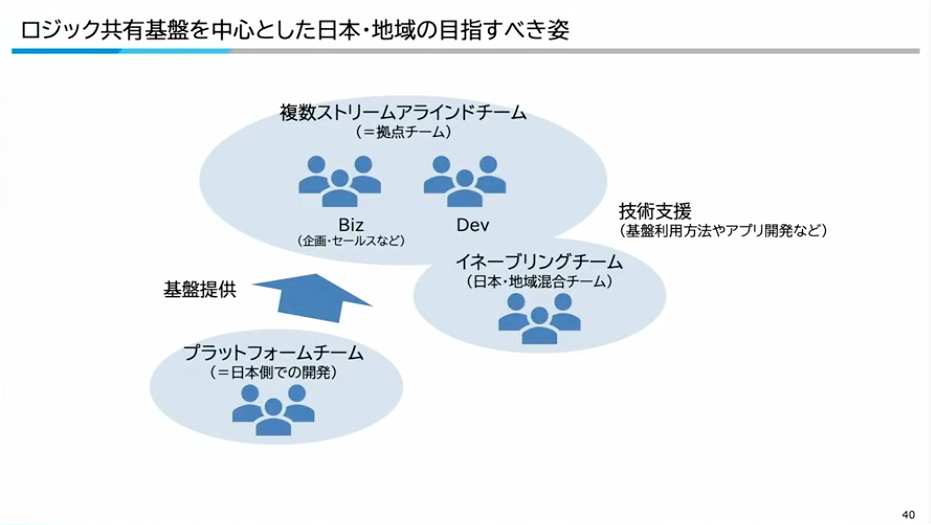
寺西:今回、基盤として提供するのはコンテナ基盤だけではなく、ロジックも含めた全体像になります。具体的には、SaaSやマネージドサービスを活用して、まずデータのプラットフォームとロジック実行のプラットフォームを構築します。その上に、省エネ用のドメインAPIプラットフォームや、故障診断・保守領域のAPIプラットフォームを構築して地域に提供していきます。そして、ストリームアラインドチームがそれらを使ってお客様向けのアプリを開発していく、という構造を目指しています。
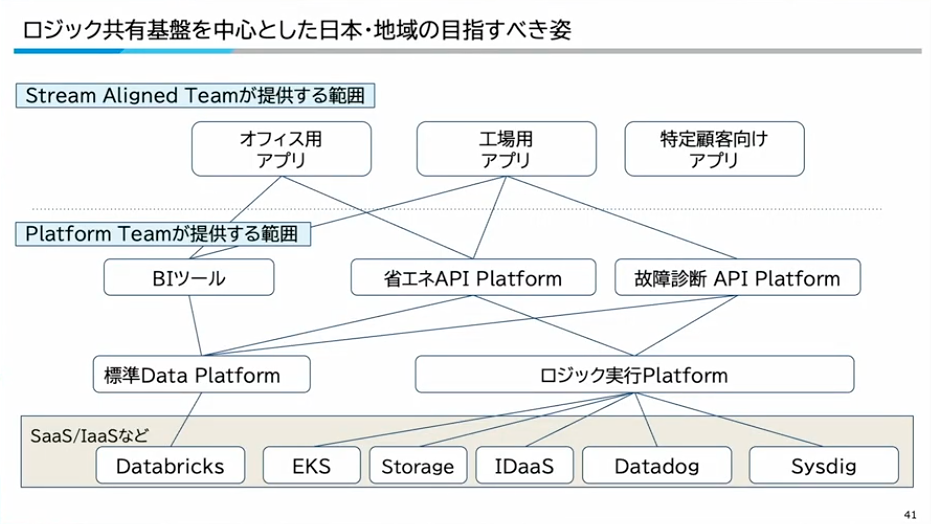
寺西:ただ、まだまだ道半ばなので、「実行可能な最小機能のプラットフォームから始める」という方針で進めています。最小限のコンテナ実行環境を用意し、地域でバラバラになっているIoTデータの標準化、ロジックの開発環境の提供、Pub/SubやJobなどの仕組みを抽象化して様々なクラウドに適用できる形で提供していきます。
また、開発者の認知負荷を下げるために、入門ドキュメントの整備、リファレンス実装によるソフトウェアライフサイクルの道のりの提示、リポジトリテンプレートなど各種テンプレートの提供を通じて、実装の標準化と知見の共有を加速させていきたいと考えています。

寺西:本日のまとめとしては、ダイキン工業がソリューションのお客様への空調バリューチェーンの課題を解決するためのアプリケーションを開発しているということ。また、日本と地域それぞれの開発スピードと統制のバランスを取るプラットフォームの開発。また、最後にそのアーキテクチャについてお話しさせていただきました。ご清聴ありがとうございました。

SysdigのAIセキュリティ ─ エージェンティックな仕組み
清水:私からは、Sysdigのアーキテクチャと今後の方向性についてお話しします。
SYSDIG SECUREのリリースが始まったのが2018年で、それから7年ほど経ちました。2018年当時はCNAPPという言葉すらなく、いつの間にかSysdigがCNAPPというカテゴリのツールの一部になっていました。
そして今、生成AIが登場したことで、従来のCNAPPの仕組みと生成AIをどう統合するかという課題が出てきています。これは結構複雑な問題です。
そこで我々のCTOであるLoris Degioanni(ロリス・デジワーニ)が、この問題に取り組みました。彼はもともとWiresharkを作った人物です。彼が考えたのは、「生成AIを中心としてCNAPPをゼロから設計したらどうなるか」ということでした。その結果、現在エージェンティックな仕組みでCNAPPを再構築するという取り組みを進めています。
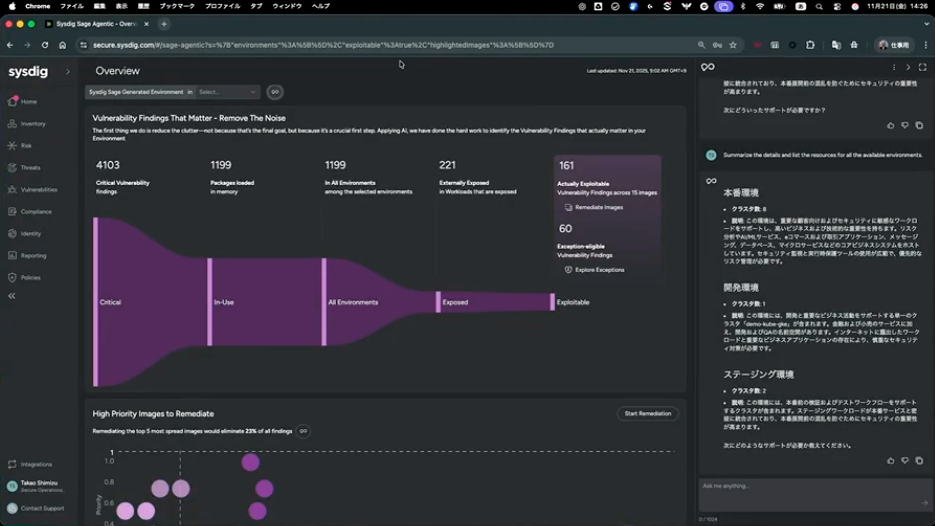
清水:今ご覧いただいている画面は、脆弱性管理がエージェンティックな仕組みになるとどうなるか、というデモです。
画面の一番上に、環境のグルーピングが表示されています。Development、Production、Stagingと出ていますが、これは実はあらかじめ設定したものではありません。Sysdigの仕組みが、Kubernetesの中のクラスター、ネームスペース、デーモンセット、デプロイメントなどを自動的に調査して、「これはDevelopment環境」「これはProduction環境」「これはStaging環境」と推論してグルーピングしているんです。
これを人間が手作業でやろうとすると、結構大変ですよね。例えばKubernetesのクラスターが100以上、ネームスペースが数百、デプロイメントに至っては数え切れないほどある環境で、それぞれを分類していくわけですから。それを自動的にやってくれるというのが、まず最初のポイントです。
問題は、みなさんも取り組まれているかもしれませんが、脆弱性がやはり多すぎるんですよね。クリティカルなものだけを洗い出しても、ここで出ているのは4,100件ぐらいあります。これを全部直すのは現実的ではないと思います。
じゃあ、どうやって優先順位をつけていくか。これはかなりチャレンジングな話なんですけども、エージェンティックな仕組みを使うと段階的に絞り込んでいけます。
まず、実際にパッケージにロードされてKubernetesでデプロイされている、つまり実際に使われているパッケージかどうかで絞ると、4,100件から約1,200件になります。次に環境を絞ります。今はオールエンバイロメントになっていますが、例えばProductionだけに絞るとさらに減ります。やはり優先順位が高いのはProductionですよね。さらに、その脆弱性が世の中で攻撃の手口が公開されているものかどうかで絞ると221件になります。加えて、外からのアクセスが可能な状態になっているかで絞ると161件になります。
このように、4,100件から161件まで絞り込めます。
でも161件でもまだ多いですよね。ここでさらにエージェンティックな仕組みが役に立ちます。すべての脆弱性はコンテナイメージで作られていると思いますが、どのイメージがより幅広く影響があって、より優先順位が高いかをバブルチャートで表示しています。
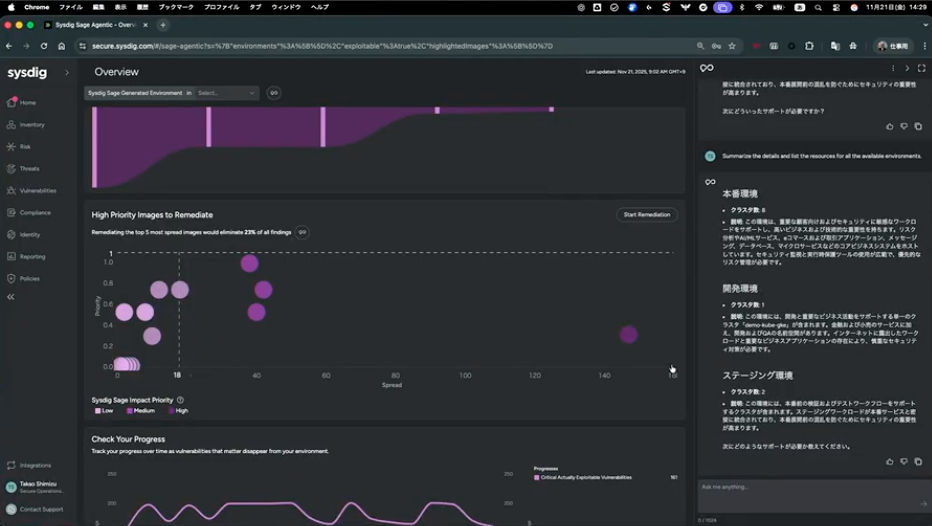
清水:このチャートの見方としては、右に行くほど幅広い環境に脆弱性が関係している、上に行くほどクリティカルで優先順位が高い、ということを示しています。例えば今出ているパッケージの脆弱性を直すだけで、全体の12%の脆弱性を削減できる可能性があると、エージェンティックな仕組みが自動的に見つけてくれています。
さらに、ここでクリックして「Fix Image」を選ぶと、どうやってそのイメージを修復すればいいかの手順を自動的に出してくれます。この手順を自分でWebで調べると大体3日間ぐらい費やして、実際に試すと1週間ぐらいかかってしまうと思いますが、それが自動で提供されます。
まとめると、エージェンティックな仕組みを活用することで以下のワークフローが実現できます。
- 直すべき脆弱性を素早く特定できる
- 修復手順が自動で提供される
- JIRAのチケットを作って、コンテキストをそのままチケットにして社内連携し、誰かのタスクに割り当てることもできる
こういったワークフローがこれから提供されるようになっています。
もう一つの取り組みとして、脅威検知の領域でもAIの活用が始まっています。
例えば、オープンソースのFalcoでランタイム脅威検知を行うと、いろんなイベントが上がってきます。SYSDIG SECUREでも同じようにFalco Ruleを使っていろんなイベントが上がってきます。
ただ、一つのイベントだけを見ても、それが一連の攻撃の一部なのかどうかを識別するのは難しいんですよね。複数のイベントを見て「どんな攻撃が発生しているか」を推論することは人間にはできますが、それには時間と専門知識が必要です。この推論をAIにやらせるという取り組みを進めています。
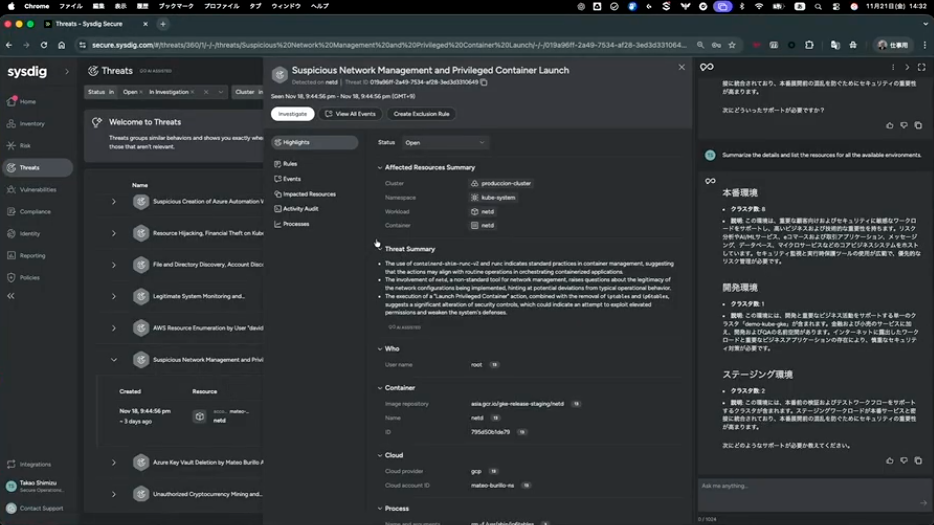
清水:具体的には、画面に「脅威のサマリー」というところがあります。これは複数のイベントからAIが自動生成したもので、「こういった状況の攻撃が今始まっています」ということを示唆しています。Falcoでトリガーされた一連のイベントは結構な数になるんですが、AIがそれらを分析してサマリーを作り、何が発生しているのか、あるいはこれは誤検知の可能性があるのか、といったところまで判断してくれます。
このようにSysdigでは、脆弱性管理から始まり、脅威検知へと、エージェンティックな仕組みの適用領域を広げているところです。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





