



【AI Engineering Summit Tokyo 2025】マルチモーダルAIサービス「Papago」開発事例及び最新AIトレンド紹介
2025年12月26日、ファインディ株式会社が主催するイベント「AI Engineering Summit Tokyo 2025」が開催されました。
株式会社APTOの狩野 洋一さんとNAVERクラウドのチョン・クワン・ウーさんによるセッション「マルチモーダルAIサービス『Papago』開発事例及び最新AIトレンド紹介」の内容をお届けします。
本セッションでは、韓国における医療や公共、農業分野での具体的なAI活用事例から、次世代翻訳サービス「Papago」が目指すマルチモーダルな「オムニモデル」の開発の裏側までを詳説しています。

■プロフィール
狩野 洋一
株式会社APTO COO
株式会社APTOについて
事業概要
チョン・クワン・ウー(Jung Kweon Woo)
NAVER Cloud Text LLM leader/Papago Tech leader
AI開発のボトルネックを解消する両社の役割
狩野:本日はお集まりいただきましてありがとうございます。本セッションではマルチモーダルAIサービス「Papago」の開発事例とAIトレンド紹介について、株式会社APTOとNAVER Cloudが共同開発している事例をメインにご紹介いたします。
まずは、株式会社APTOについて簡単にご説明します。
当社はデータセントリックなAI開発を掲げ、AIの精度を上げるためにデータを作ったり集めたりすることで精度に貢献する事業を行っています。2020年に創業し、現在は高品質なデータ提供で国内外から認知を得ており、NVIDIAさんをはじめ様々なプログラムに採択いただいています。私たちのメイン事業は、AI開発の最初のステップであるデータの収集やアノテーションです。ここは組織として非常に負荷が高い部分ですので、当社でご支援をしています。
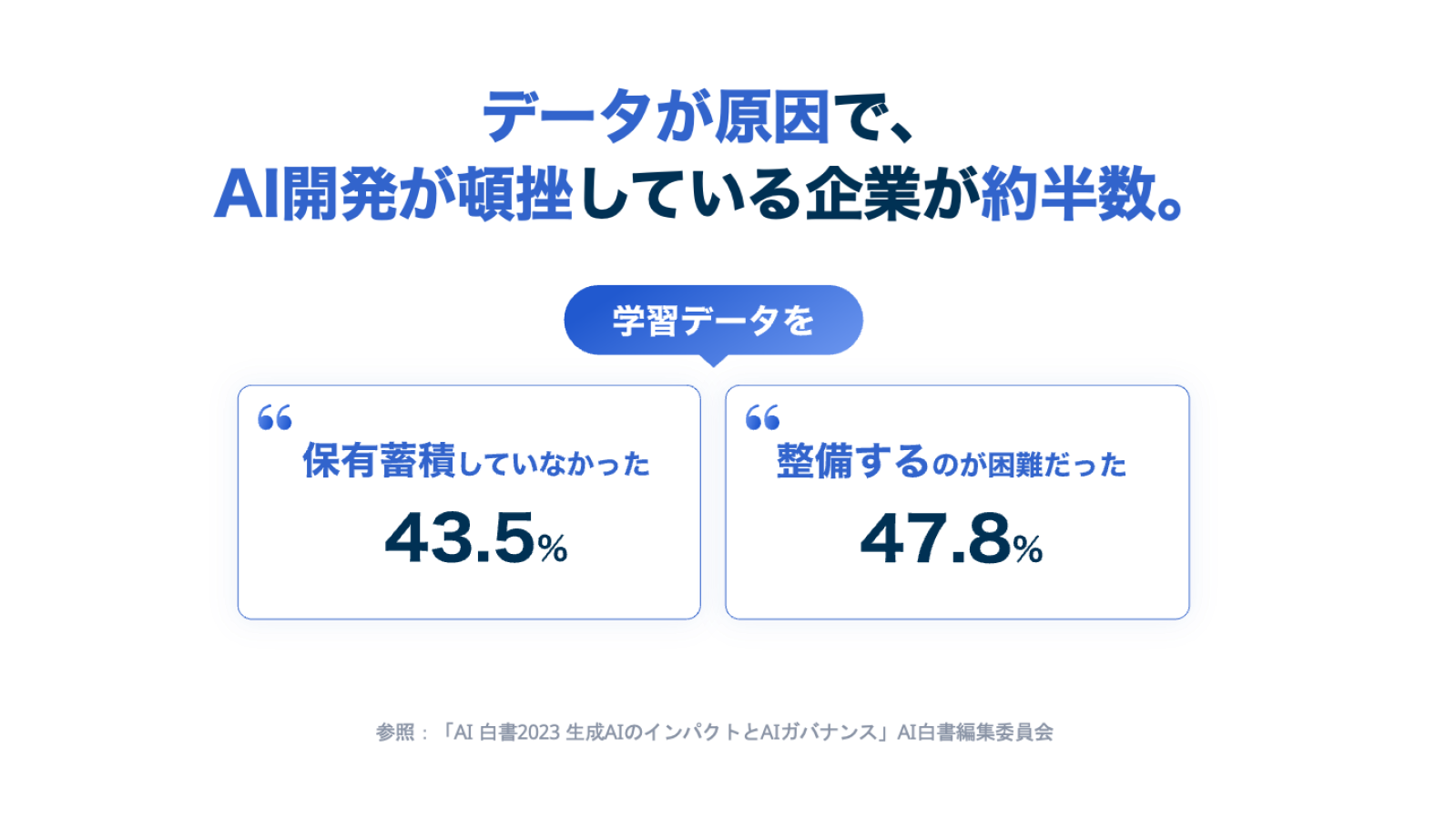
国内では、データを持っていてもAI開発のために整理するのが難しい企業が多いため、その点をサポートしています。具体的には、医療系の画像、自動運転用のライダーデータ、異常検知に関わるランドマークやキーポイントのデータセットのほか、そして自然言語に関わるデータセットなども提供しています。また、一般の方や海外から専門的な分野のデータを収集できる複数のソリューションもございます。
続いてNAVER Cloudのチョン・クワン・ウーさん、お願いします。
クワン・ウー:NAVER CloudのText LLMチームでリーダーを務めるチョン・クワン・ウーです。よろしくお願いします。
NAVER CloudはNAVERの100%子会社であり、親会社にAIモデルやGPUインフラを提供しています。NAVERは1999年に韓国で検索エンジン事業を開始し、現在は自国の検索エンジンが最も利用されています。2008年のモバイルやクラウドへの技術転換期にも素早く対応し、2022年以降のAI時代においても、サービスやアプリケーションに人工知能を取り入れようと努めています。

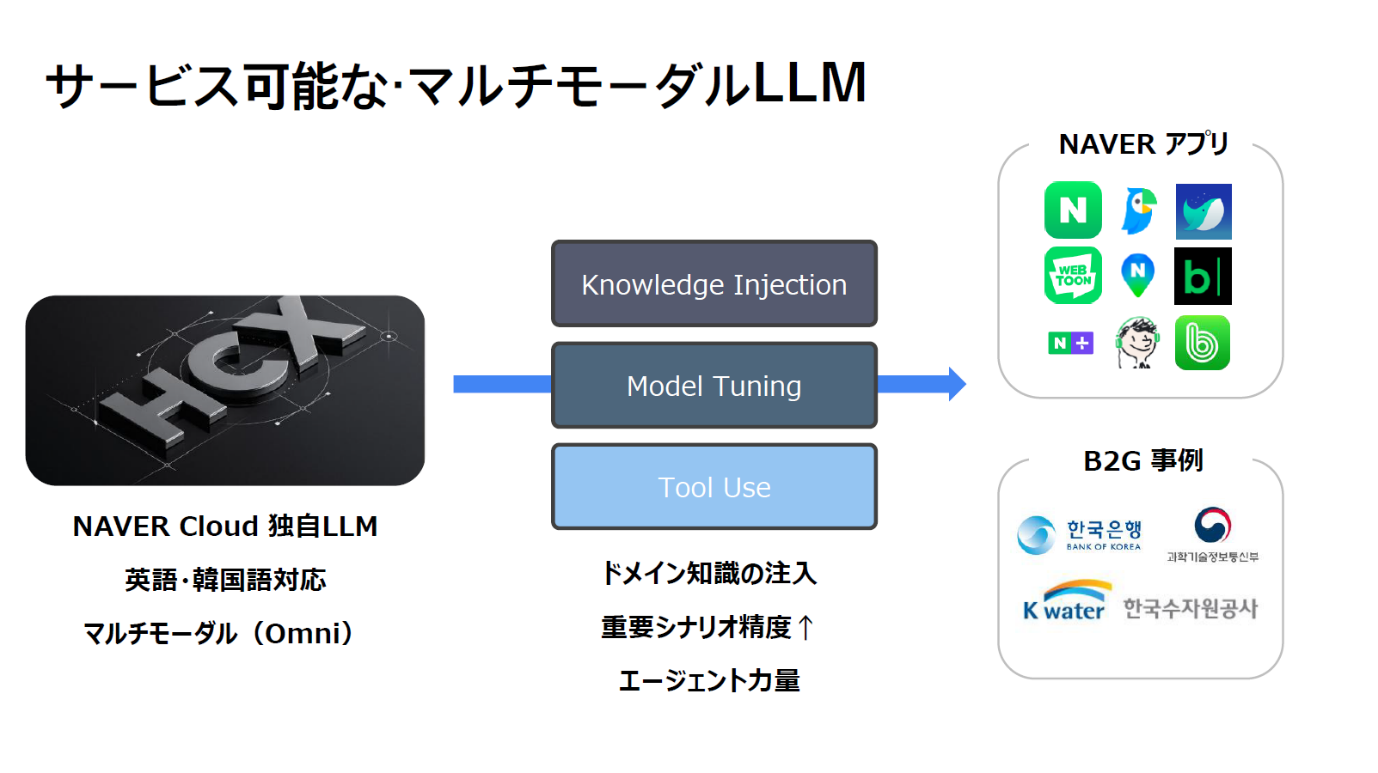
クワン・ウー:弊社では独自のLLMを持っており、英語と韓国語に対応したマルチモーダルな入力と出力が可能です。検索エンジンや地図、ショッピングなどの既存アプリに独自のLLMやオープンソース、外部APIを導入する際、そのままでは精度が出ないことが多いため、弊社がそれらをチューニングしてアプリケーションに合った精度を保つ役割を担っています。そして韓国政府にもソリューションを提供しています。
韓国の最新AIトレンドと戦略
独自LLMのチューニング
クワン・ウー:特化モデルを開発する際、特定のタスクの精度は上がりますが、既存モデルが持つ汎用的な精度が失われてしまうことがあります。それに対して弊社では2025年、アプリ向けの精度を上げつつ、既存モデルの能力を維持するチューニング技術を確保することができました。
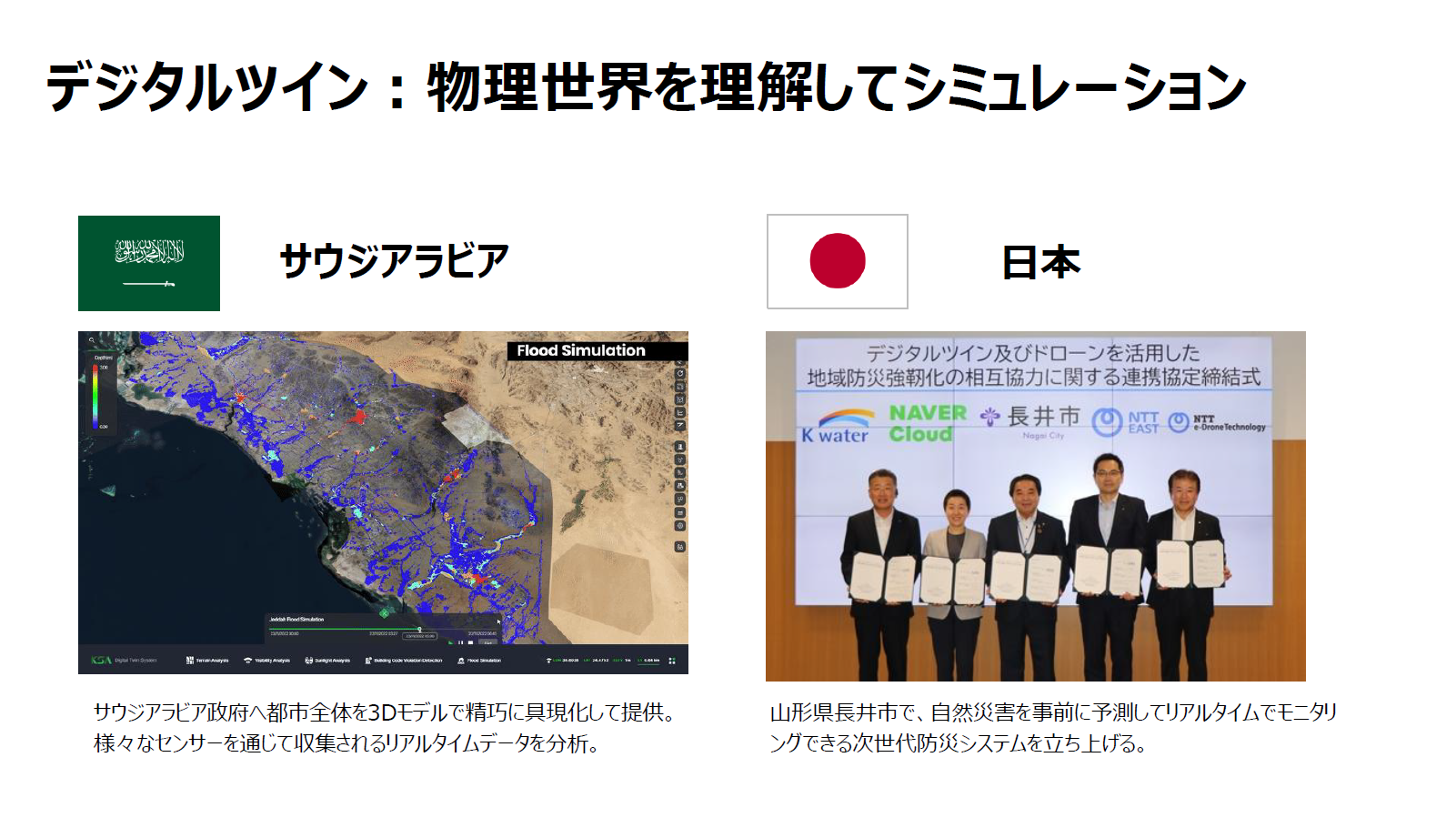
またテキストや画像だけでなく、3D情報をデジタル空間にマッピングしてシミュレーションを行う「デジタルツイン」のソリューションも展開しています。サウジアラビアでは洪水対策のシミュレーションに活用され、被害の軽減に貢献しました。日本では山形県長井市で、山崩れのモニタリングのためにデジタルツインの立ち上げを共同で行っています。
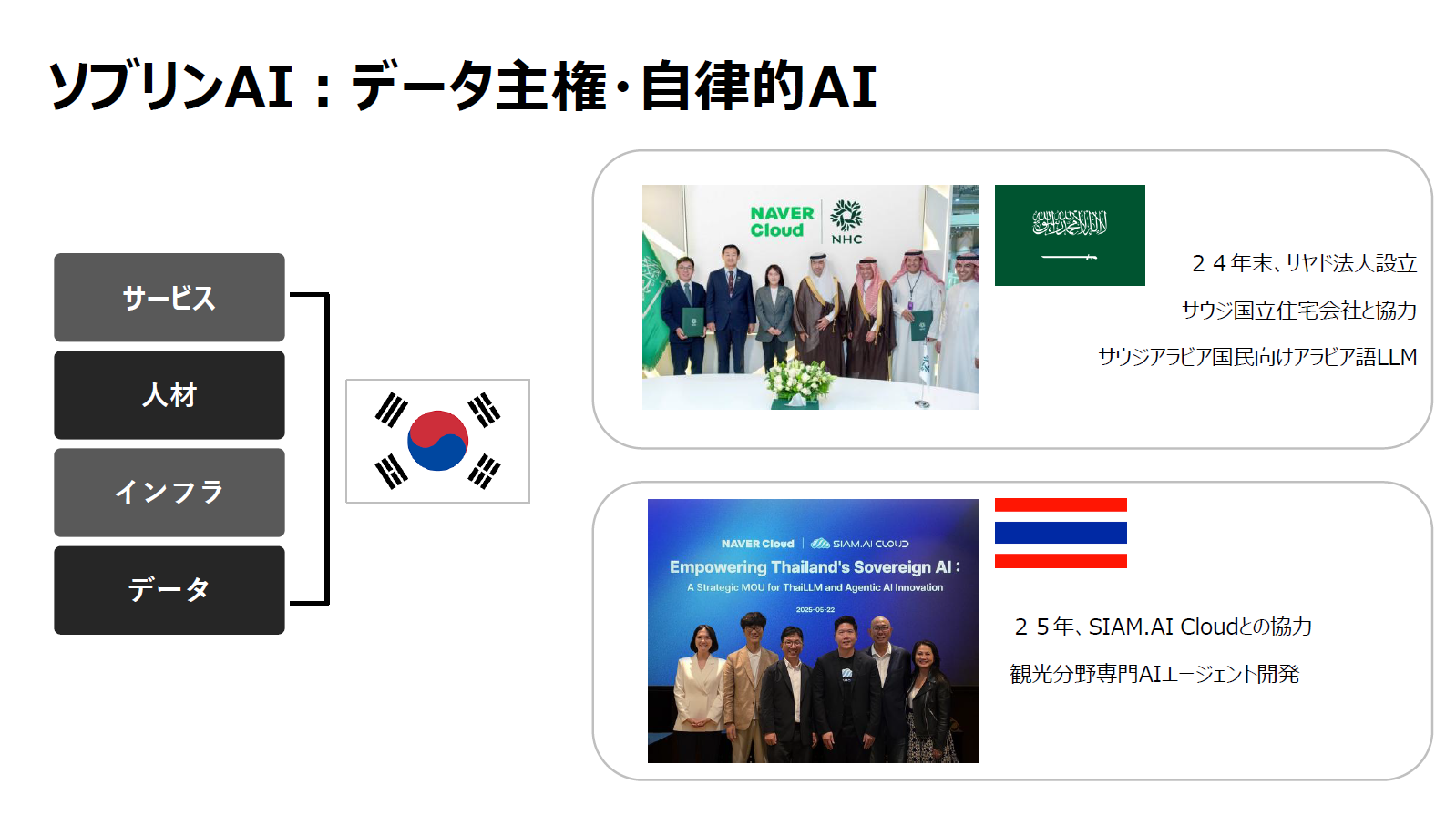
データ主権・自律的AIを目指す「ソブリンAI」
さらに弊社では「ソブリンAI(AI主権)」というメッセージを発信しています。学習データ、GPUインフラ、人材、サービスといったレイヤーが現在アメリカや中国に依存しています。しかし長期的に見て自国のデータやインフラでサービスを作ることは、主権を守るうえで非常に重要です。韓国だけでなく、サウジアラビアでのアラビア語LLMの共同開発や、タイでの観光分野のエージェント開発など、海外のソブリンAIイニシアティブにも貢献しています。
ショッピングアプリのエージェントも開発
今年注力したのはショッピングアプリへのエージェント機能の導入です。ユーザーの検索履歴や文脈をもとに、その人に合った商品を推薦する機能を開発しました。これは独自のLLMを用い、検索やブログなどのサービスにある個人の情報を文脈として活用することで、同じクエリでもユーザーの意図に合わせた推薦を可能にしています。
ショッピングエージェント向けの能力向上自体は、データを作ってモデルをチューニングすれば難易度はそれほど高くありません。しかしベースモデルが持つ言語理解能力や指示遂行能力を維持、向上することが技術的に非常に難しいです。
高品質なデータや合成データを作成することで、これらの技術的成果を得ることができました。
オープンソースや既存のAPIは精度が高いですが、実際のサービスに組み込もうとすると、フォーマットが合わない、あるいは精度が90%前後で頭打ちになるケースも少なくありません。そこを99%以上へ上げていくには、やはり特化モデルを作る必要があると個人的に考えています。
現場実装から見る韓国のAIトレンド
医療・公共・農業へ積極的に活用
狩野:ここからは韓国の最新AIトレンドについてお話しします。
クワン・ウー:チャットツールの中で言語の壁を越えるソリューションは、韓国では一般的になっています。NAVERクラウドでも、日本やアメリカ、フランスなど様々な国の方々と仕事をする際、Slackなどで翻訳機能がデフォルトで使われています。
狩野:医療系では、患者と医師の対話を自動で記録・要約し、カルテを作成するサービスも開発されていますね。
クワン・ウー:はい。音声を認識して記録するだけでなく、会話の意味合いを理解し、過去のデータからどの情報を採用すべきかを抽出するポイントが医師から求められています。
狩野:また、街中で迷子や認知症の方をカメラとAIを使って発見する事例もありますね。

クワン・ウー:はい。CCTV映像から人が何人いるかを検知し、動きのスピードや路線を基に、一般的な動きなのか認知症や迷子なのかを分類できます。現在は個人を特定するレベルまでは難しいですが、人であるか、動きがあるかを判別する精度は持っています。
狩野:農業分野では、農業機器メーカーのデドンと協働で、AIを通じて生産性を上げる取り組みを行っています。
クワン・ウー:畑やビニールハウス自体はまだロボットフレンドリーではありません。しかし従事者に高齢者が多いため、農業機器にチャットや電話機能を入れてAIがサポートしています。例えば、雨が降る予定を知らせたり、一日の活動記録から日記を自動作成して翌日の活動を推薦したりというサポートです。韓国も日本と同様に若者が減り、お年寄りが多い現状があります。

狩野:また、NAVER Cloudの本社ではロボットがコーヒーを運ぶ光景が見られました。日本でもレストランでオーダーや配膳を行うロボットが普及し始めていますが、オフィスで動いているのはまだあまり見かけませんね。
クワン・ウー:環境面でまだまだ導入が難しい部分もあります。しかし弊社のように、オフィス自体が階段や段差のないロボットフレンドリーなデザインであれば可能になってきています。
開発事例1:10年目の「Papago」
オムニモデルによるマルチモーダル翻訳の未来
狩野:続いて、株式会社APTOとNAVER Cloudの協業内容をご紹介します。まずは翻訳サービスの「Papago」についてです。
クワン・ウー:「Papago」は2016年に始まり、2025年で10年目を迎えました。当初はGoogle翻訳などの既存サービスがある中で疑問の声もありましたが、翻訳精度が高かったためサービスを開始しました。2017年末にはトランスフォーマーを機械翻訳エンジンとして採用しました。トランスフォーマーの最初のアプリケーションが機械翻訳だったこともあり、早期に取り入れたことでクオリティが大幅に向上し、サービスも成長しました。
その後、画像翻訳や音声翻訳、対応言語の拡大など利便性を重視してきました。2022年にChatGPTが登場した際、翻訳精度の高さから「Papago」が危ういのではないかという懸念もありましたが、実際には利用者がさらに増えたのです。翻訳の精度が高ければ、ユーザーは戻ってきてくれることを確認できました。
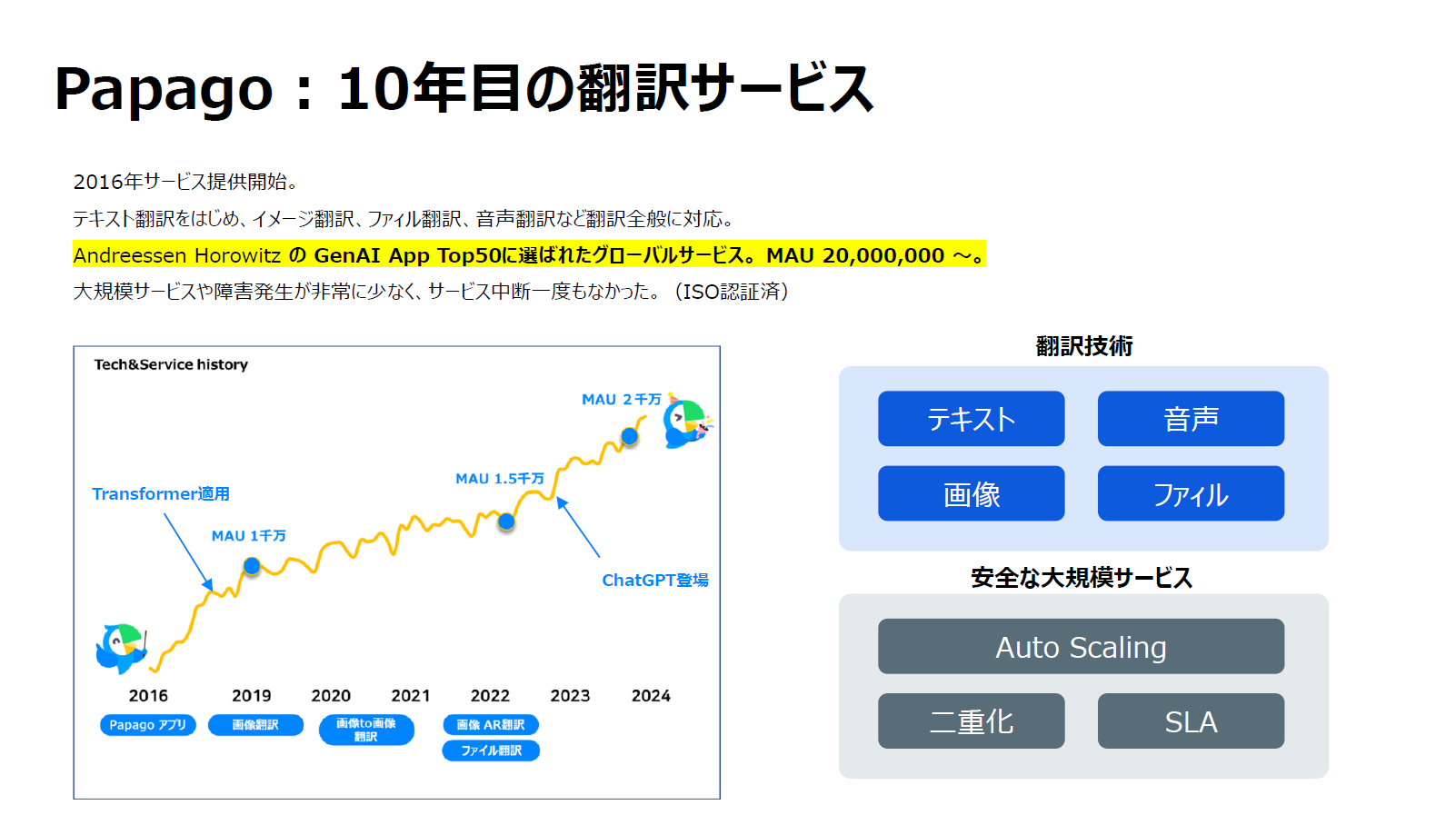
技術面では、画像翻訳でコンペティション一位を獲得し、2025年には、一つのモデルで完結するエンドツーエンドの音声翻訳モデルを開発しました。またビジネス環境で需要の高いファイル翻訳において、独自のファイルパーサーを開発し、精度の向上を図っています。現在、月間利用者は約2,000万人で、韓国以外からの利用も30%ほどを占めています。
「Papago」はもともと日常生活向けの翻訳として始まり、SNSなどの崩れた文字の翻訳に強みがありますが、現在はビジネス向けの精度向上も進めています。
狩野:開発における課題はありますか。
クワン・ウー:あります。現在は各モダリティごとにモデルを開発していますが、今後は一つのマルチモーダルな翻訳モデルで進める方向性が正しいのではないか、と実験を通して確認しています。内部では「オムニモデル」と呼んでいます。
ファイル翻訳の場合、テキストだけでなく位置や色合いといったビジュアル面も重要です。ビジョンランゲージモデルなどでファイルを画像として認識し、ファイルレベルでの文脈を得ることは、マルチモーダルモデルでないと解決できない課題です。
狩野:そうですね。弊社が創業した2020年頃は画像がメインでしたが、徐々に専門的なデータが必要になり、モデルがマルチモーダルに集約していくのはグローバルなトレンドだと感じます。
クワン・ウー:ユーザーからのフィードバックは非常に重要で、音声モデルのアップデート後に精度について指摘をいただくこともあり、責任を持って開発しています。
開発事例2:「CareCall」
高品質データによる方言・訛りへの対応とマルチモーダル化
狩野:続いて、弊社のデータで一緒に開発している、AIと電話を活用した高齢者支援ソリューション「CareCall」をご紹介します。
クワン・ウー:「CareCall」は韓国の自治体で、一人暮らしの高齢者の安否確認を職員が行うのが物理的に難しくなったことから始まりました。現在は韓国の自治体の半分ほどで使われており、2025年の初めには日本でも出雲市でPoCを実施しました。
高齢者の話し方は方言や訛りがあり、若者とは言葉の使い方も異なりますが、高品質なデータを組み込むことで精度を上げています。今後は、より「人と話しているような感覚」を与えるために、音声認識やテキスト処理を一つのマルチモーダルモデルに統合していく必要があると考えています。
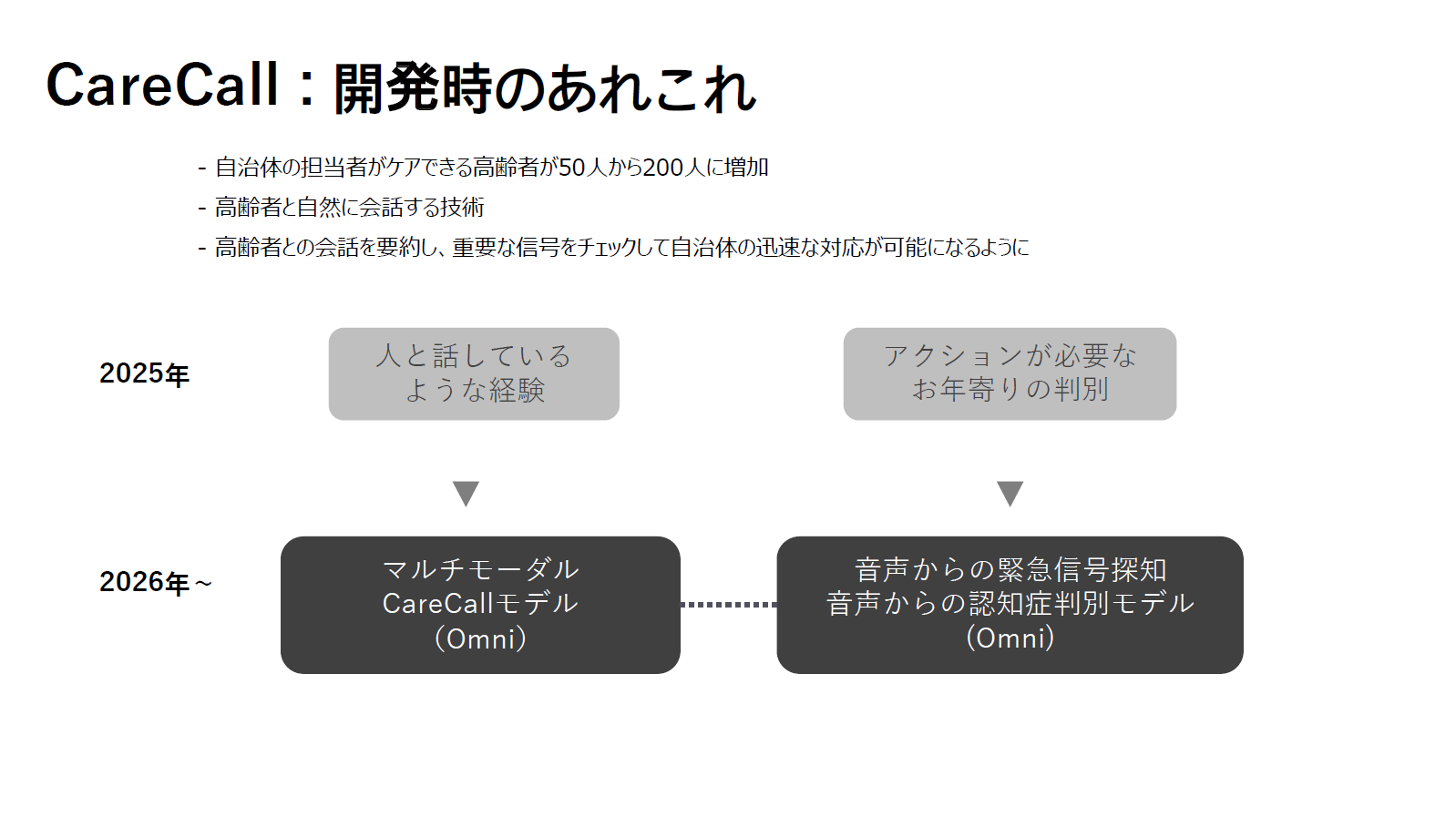
また、電話後の内容を要約し、アクションが必要な場合に自治体職員へアラートを上げる機能や、音声から緊急信号や認知症の兆候を検知するモデルの必要性も高まっています。
LLM精度向上のための専門的データ戦略- 「harBest Expert」の展望
狩野:最後に、株式会社APTOの「harBest Expert」についてご紹介します。

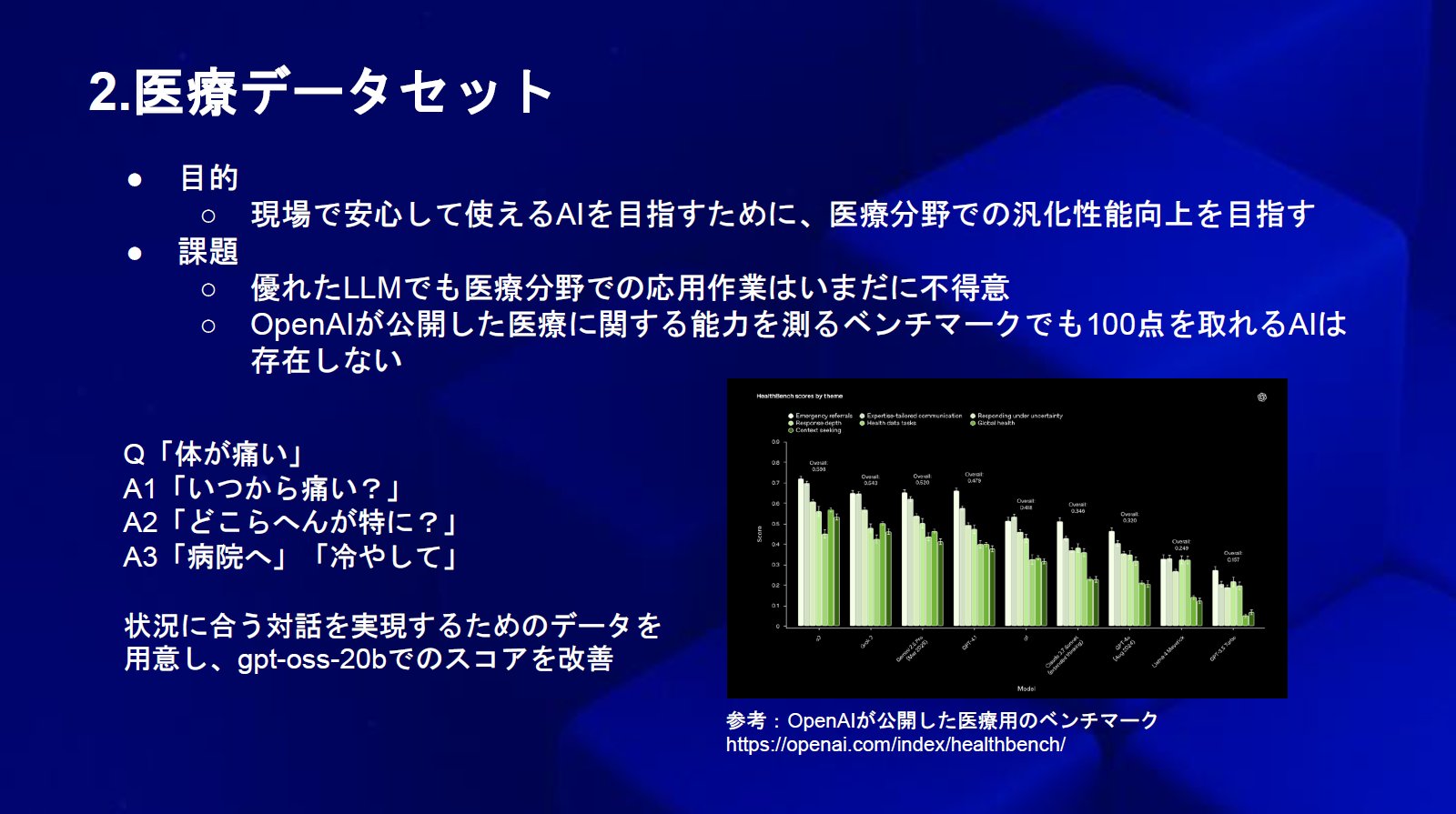
こちらは国内初の、専門家や有識者からのデータ収集、データ評価のプロジェクトマッチング型のデータプラットフォームです。弊社は基礎研究にも力を入れており、Qwen-3に対してファインチューニングを行い、メジャーなベンチマークで精度が向上した実証実験を多数行っています。本日はその中から、特に注目されている安全性のデータセットと医療系のデータセットについてお話しします。
専門領域に特化したデータセットの重要性
安全性のデータセットでは、悪意のあるプロンプトや誤情報に対してLLMが安全な回答を出すための学習・評価用データを提供しています。当社のデータで学習させることで、例えば「弟の妄想が激しい」という相談に対し、単に追加の質問をするだけでなく、状況を理解し、まずは受け止めることを示唆するような適切な回答が可能になります。

医療系のデータセットでは、医師国家試験における「禁忌肢」の対策を重視しています。現在、グローバルなLLMでも禁忌肢を選んでしまうことがあり、100点を取れるAIはまだ存在しません。カルテ作成や患者との対話モデルの開発が進む中で、安全性と医療の面で貢献できるようデータセットを作成しています。
狩野:最後に、2026年はマルチモーダルAIのモデル開発にさらに力を入れていく予定ですか。
クワン・ウー:その通りです。MoE(Mixture of Expert)モデルやマルチモーダルモデルが基本となっており、NAVERクラウドでもその方向で開発を進めています。
狩野:一方で、北米のビッグテックとは開発規模などの面で、対抗するのが難しい気もするのですが。
クワン・ウー:確かに業界内で話を聞くと、北米のビッグテックとは、GPUインフラの規模で大きな差がある印象です。しかしビッグテックのイノベーションによって公開されたモデルを活用し、高品質なデータを組み合わせて追いかけることで、私たち日本や韓国の企業にも十分チャンスがあると考えています。
狩野:発表は以上です。本日はありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
AI Engineering Summit Tokyo 2025
※動画の視聴にはFindyへのログインが必要です。





