



【Data Engineering Summit】Snowflakeとdbtで加速する「TVCMデータで価値を生む組織」への進化論
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」が、オンラインにて開催されました。
本記事では、株式会社CARTA HOLDINGSデータプランニングチーム チームリーダー 欧陽 江卉さんによるセッション「Snowflakeとdbtで加速する『TVCMデータで価値を生む組織』への進化論」の内容をお届けします。
本セッションでは、運用型テレビCMを支える「テレシーアナリティクス」で課題となっていた、AuroraのOLTPモデルに起因する分析コストの増大やSQLの複雑化を、Snowflakeとdbtの導入によるリモデリングでどのように解消したのかをご紹介いただきました。
■プロフィール
欧陽 江卉
株式会社CARTA HOLDINGS(株式会社テレシー)データプランニングチーム チームリーダー
CARTA HOLDINGSについて
株式会社CARTA HOLDINGS(株式会社テレシー)データプランニングチームのチームリーダーとして、社内データ分析基盤の構築・運用を担当している欧陽 江卉が、「Snowflakeとdbtで加速する『TVCMデータで価値を生む組織』への進化論」というテーマでお話しします。
私は新卒でCARTA HOLDINGSに入社し、広告配信ロジックの開発・運用に携わりました。その後、別企業への転職を経て、2022年にCARTA HOLDINGSへ再びジョインし、現在はテレシーに所属しています。
CARTA HOLDINGSは多様な領域で事業を展開しており、その数は全18にのぼります。
グループ内には8つのエンジニア組織があり、約180名のエンジニアが在籍しています。従業員数は2,000名を超え、テレシーを含むデジタルマーケティング領域のほか、エンジニア向けキャリア支援サービスやEC・コマースメディア関連事業など、幅広い分野でサービスを提供しています。

本日は、次の3つのテーマに分けてお話しします。
- テレシーが展開する事業概要とプロダクト「テレシーアナリティクス」について
- データセントリックな事業成長を加速させるための取り組み
- 「BEYONDテレシーアナリティクス」を見据えた今後のチャレンジ
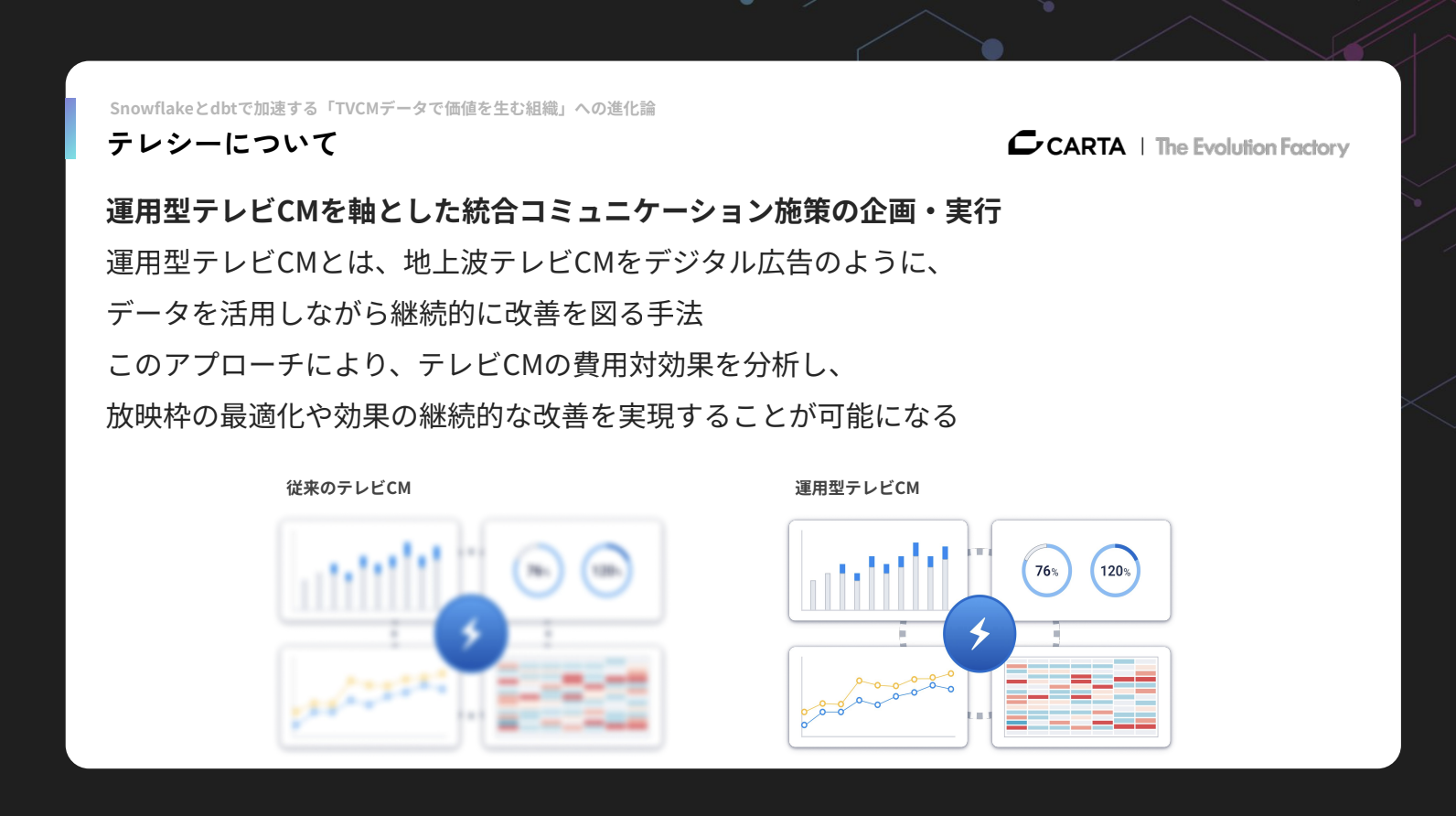
運用型テレビCMを支えるテレシーと「テレシーアナリティクス」
テレシーは、運用型テレビCMを軸にした統合コミュニケーション施策の企画と実施を行っている会社です。運用型テレビCMとは、地上波のテレビCMをデジタル広告のようにデータ活用しながら、放映枠に対して継続的に改善を図る手法のことを指します。
この手法によってテレビCMの費用対効果を分析できるようになり、放映枠の最適化や、効果の継続的な改善が可能になりました。
私たちは「テレシーアナリティクス」というサービスも提供しており、一言でいうと、テレビCMの効果分析とダッシュボードでの可視化を行うものです。
テレシーアナリティクスには独自開発の分析モデルが組み込まれており、従来は計測が困難だったテレビCMの効果を、統計学的手法を用いて推定できるようになりました。
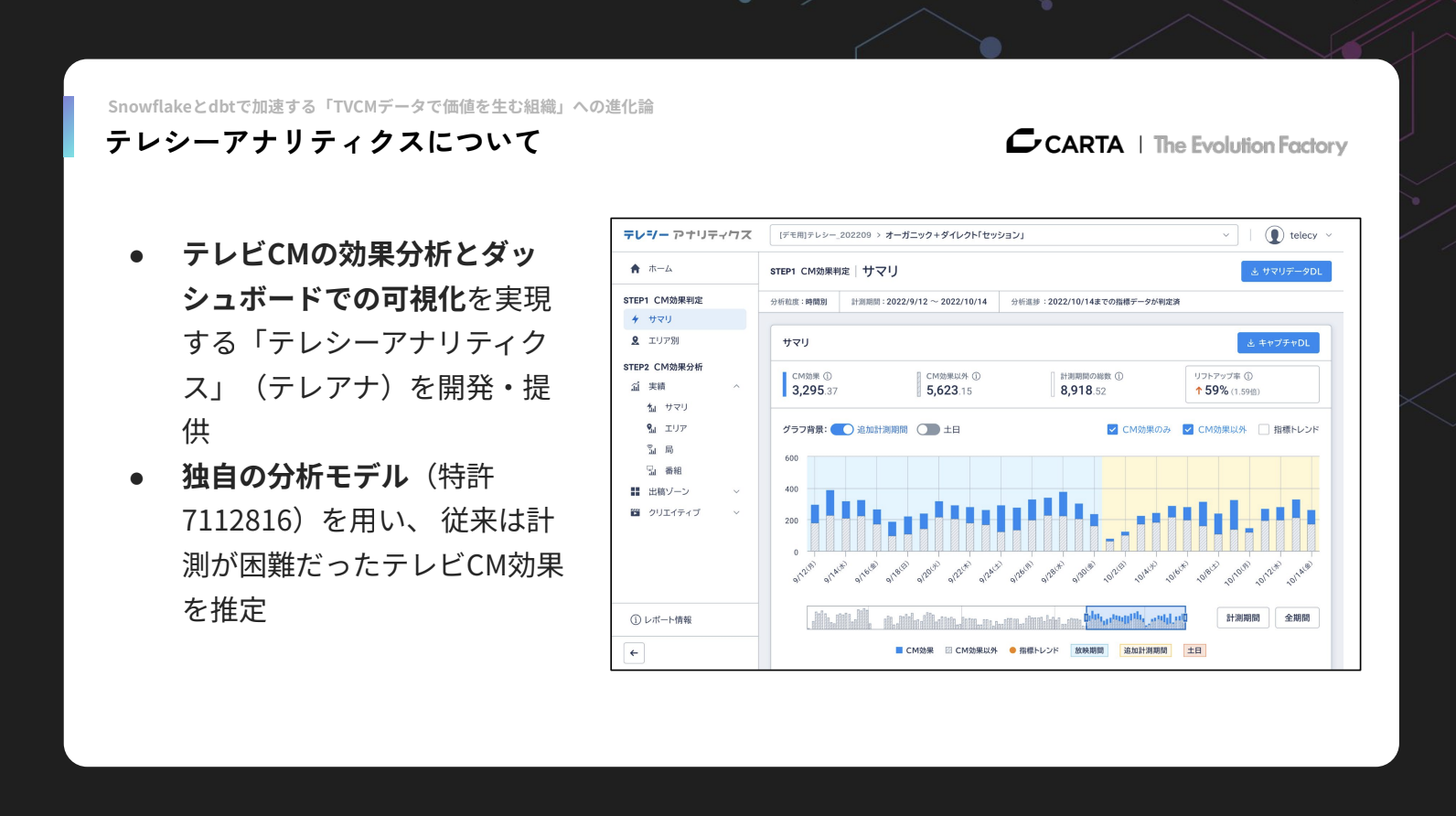
テレシーアナリティクスのナビゲーターにはステップ1とステップ2があります。
ステップ1の「CM効果」では、時系列でどれくらいのCM効果が発生しているかを可視化します。ステップ2の「CM効果分析」では、テレビCMがどの広告枠で放映され、どのクリエイティブによって効果が発生したのかを分析するダッシュボードを提供しています。
次に、テレシーアナリティクスが扱うデータについて説明すると、大きく分けて「消費者行動データ」と「テレビCM視聴率データ」の2種類を扱っています。

消費者行動データには様々なデータソースがあります。例えばWeb商材のクライアントに対しては、クライアントが提供するECサイトやメディアに紐づけたGoogle Analytics 4のAPIからWebサイトの訪問データや商品購入データを抽出して分析しています。
アプリ商材の案件では、Mobile Measurement Partners(通称MMP)のデータとして、アプリのインストールや起動ログなどを扱っています。また、Yahoo! DS.INSIGHTのデータを用いて、ユーザーの検索クエリボリュームなども利用することもあります。
そして、テレビCM視聴率データは自社で計測しているものではなく、視聴率データを提供している企業から取得しています。データ形式としては、テレビ局、番組、放映時間、リアルタイム視聴率、番組視聴率などが含まれています。
データセントリック事業を加速するための取り組み
次に、データセントリックな事業を加速するための取り組みについてお話しします。テレシーが提供している価値の核は、顧客ごとの課題に応じて質の高いサービスを実現することにあります。
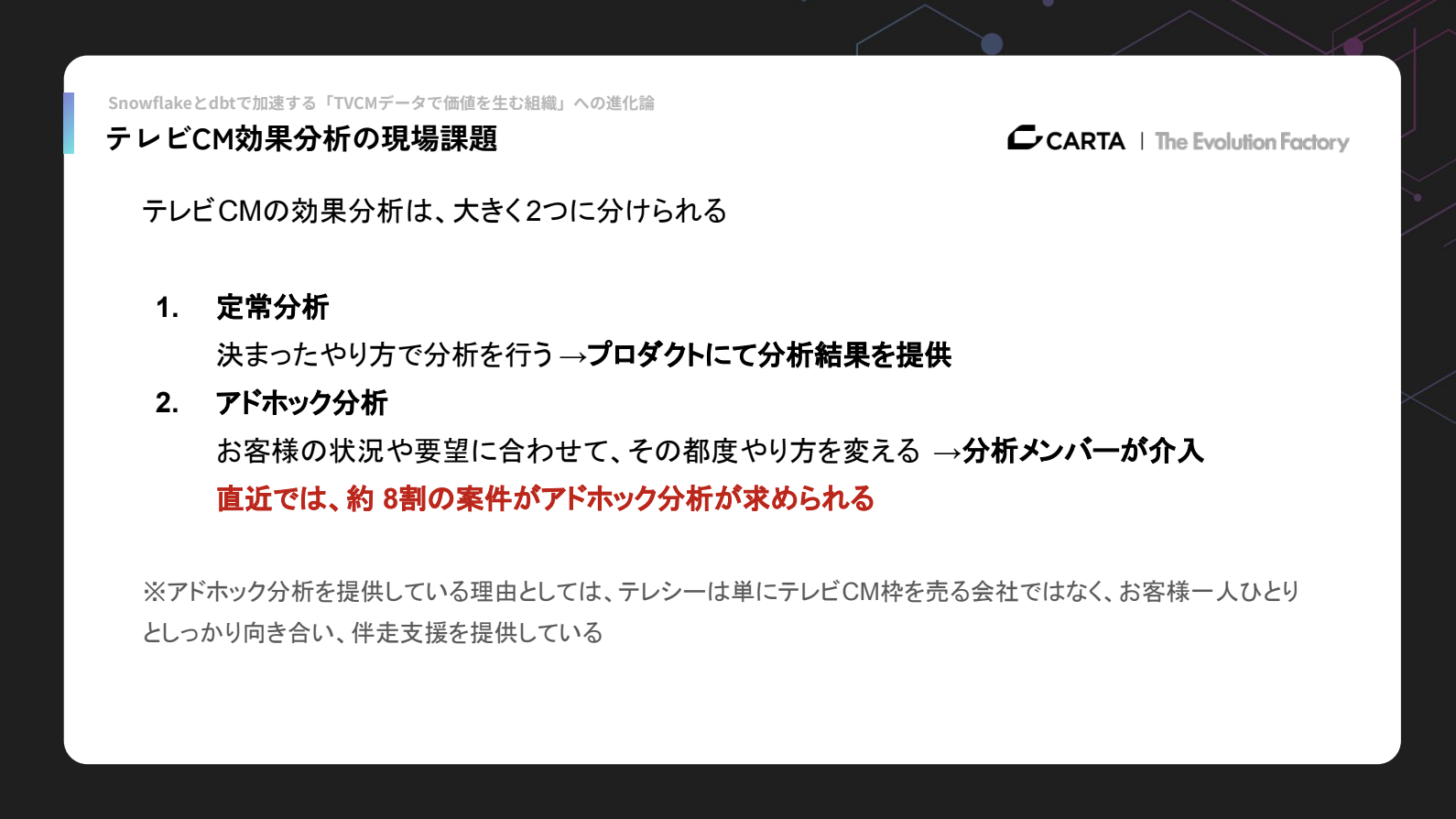
提供しているサービスは大きく2つに分かれており、プロダクトによる定常分析と、データサイエンスエンジニアによるアドホック分析を組み合わせてクライアントに届けています。
従来は分析に大きなコストが必要でしたが、プロダクト化によってその負担を大幅に削減し、さらにデータサイエンスエンジニアの知見を掛け合わせることで、より高品質なサービスを実現しています。

定常分析は、あらかじめ決まった手順と分析手法で行うもので、既にプロダクトを通じて分析結果をクライアントに提供できている領域です。
一方、アドホック分析は分析メンバー(データサイエンスエンジニア)の介入が必要で、直近では全案件の約8割がアドホック分析を求める状況になっています。
そもそも私たちがアドホック分析を提供しているのは、テレシーが単にテレビCMを販売する会社ではなく、クライアント一社一社に深く向き合い、成果創出まで伴走するパートナーでありたいと考えているからです。
しかし、アドホック分析は案件ごとに求められるものが変わるため、分析組織のリソース不足が大きな課題となっていました。
アドホック分析を通じてクライアントの課題解決を行う必要がある一方で、データサイエンスエンジニアは新規アルゴリズム開発に割くリソースが十分に確保できていませんでした。新規アルゴリズム開発によって獲得したクライアントに対しても、その後ある程度でのアドホック分析が必要となるため、この分析リソース不足が事業成長の大きなボトルネックとなっていました。
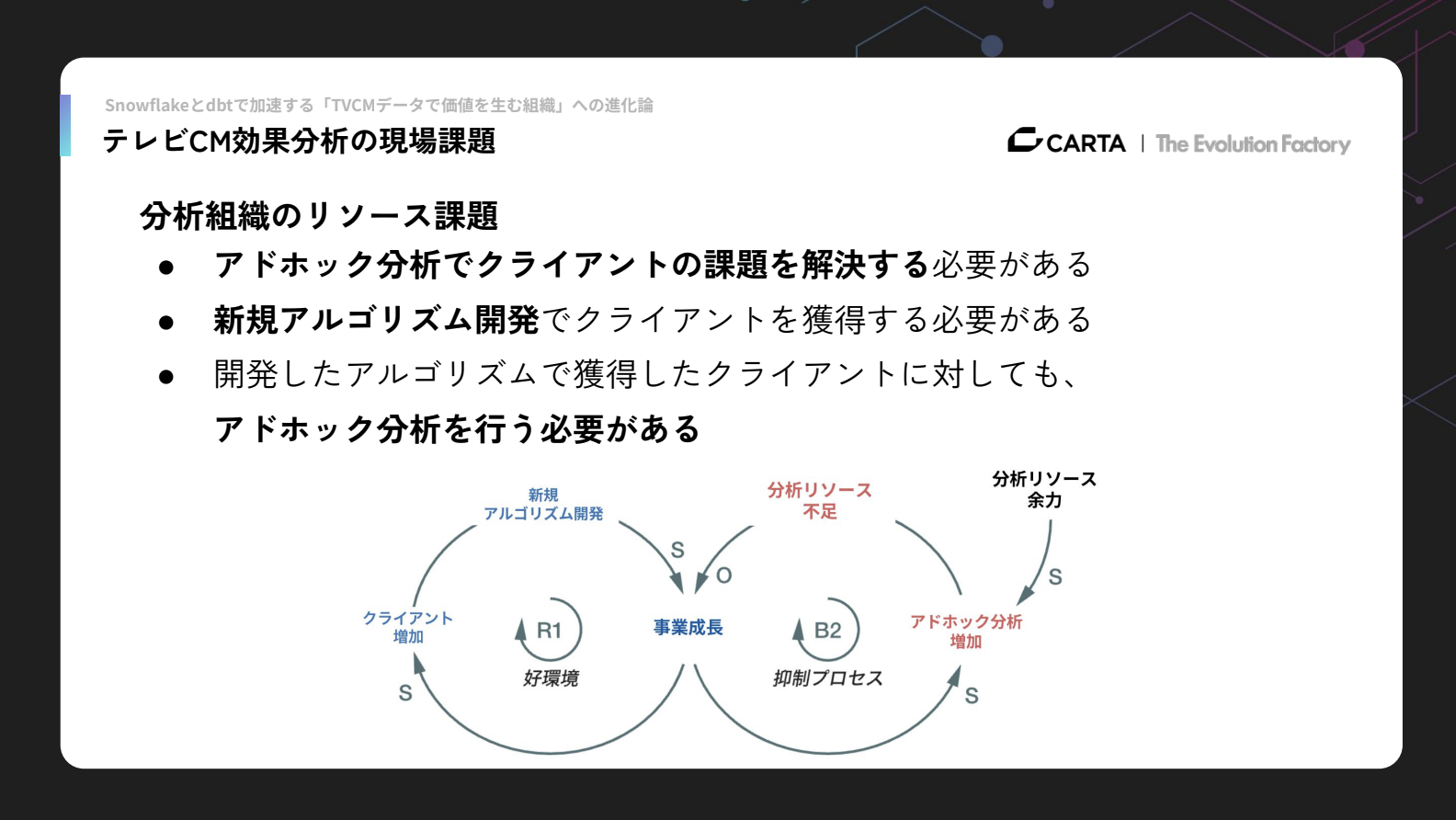
こうした分析組織の課題を解消するためには、分析メンバーの分析作業の効率化が最も重要だと考えています。そして、分析効率化のうえで最大のボトルネックになっていたのが、データ基盤の使いにくさでした。
データ基盤が使いにくい理由としては、大きく2つの要因があります。
1つ目は分析コストの増大です。これは、分析リードタイムの長期化や、複雑なSQLを作成するためのコスト増が背景にあります。
2つ目は、データ分析の品質を担保するためのコストの高さです。データの正確性・一貫性を保証するためには開発リソースが必要で、その負担が大きくなっていました。
今回の発表では、分析コストの増大という要因に着目して取り組みを紹介していきます。まずは、この分析コストがどのように増えていたのか、その状況についてご説明します。

Snowflakeとdbtで乗り越えた分析基盤のボトルネック
Aurora時代のOLTPモデルが抱えていた限界と解決策
これまで私たち分析メンバーは、AuroraのOLTPデータモデルを参照しながら様々な分析軸で集計処理を行っており、その都度集計クエリを作成して実行していました。
しかし、OLTPのデータモデルはそもそも分析処理には向いていません。トランザクションデータそのままの構造はシステム処理には最適化されている一方で、複雑な集計クエリをつくるには適しておらず、保守のコストもかかります。
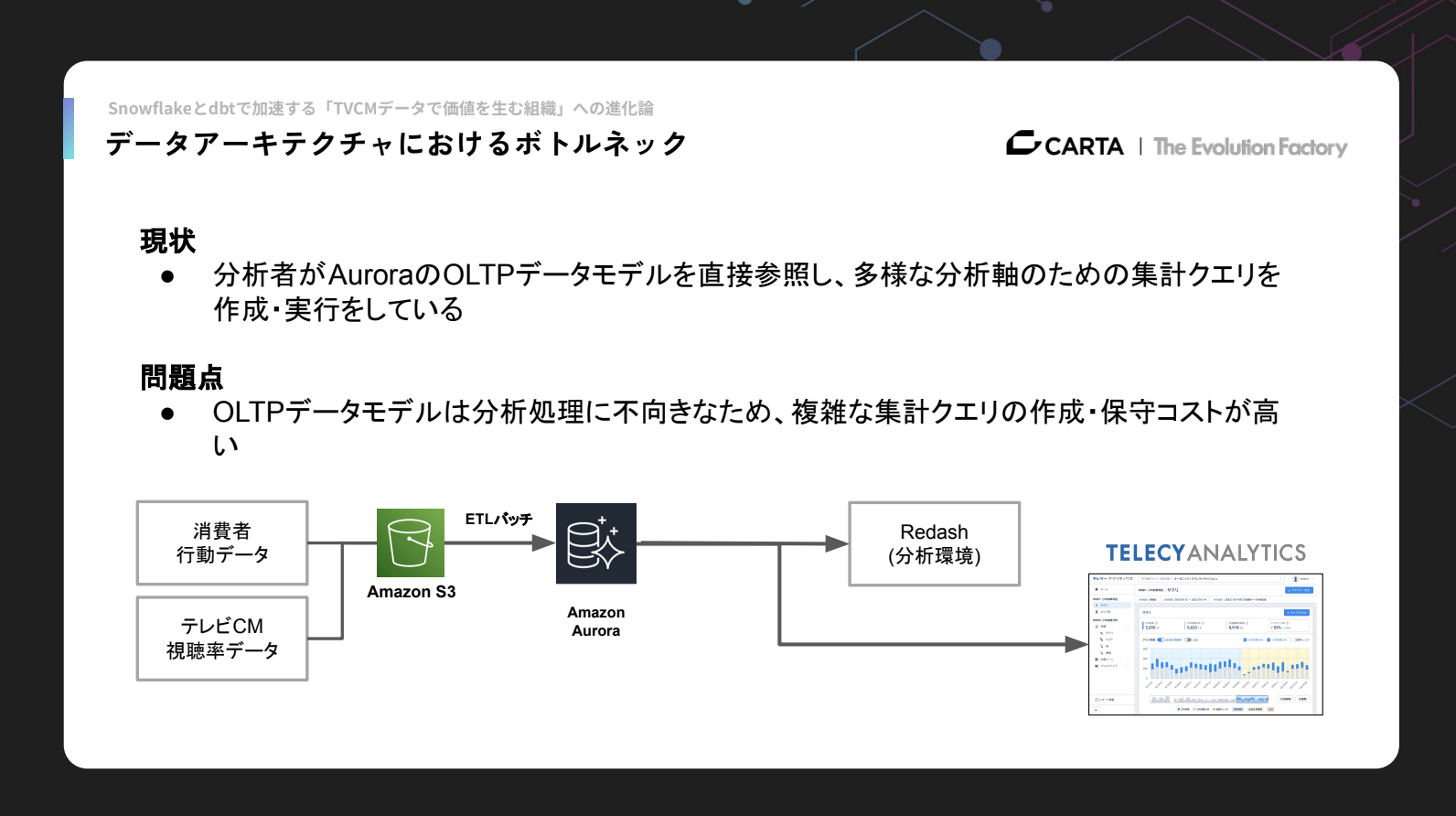
そこで、Snowflakeとdbtの導入を行いました。
Beforeの状態では、データがOLTPモデルで常に第三正規化されており、分析用のSQLは非常に複雑でした。データが複数のテーブルに分散していて情報を集約しづらく、ビジネスの観点から直感的にデータを抽出したり処理したりすることが難しい状況でした。
私たちが取り組んだことは、大きく2つあります。1つはSnowflakeの導入、もう1つはdbtを用いたデータモデルのリモデリングです。
Snowflakeを導入したことで、分析専用のデータウェアハウス(DWH)を構築でき、本番システムに負荷をかけず高速に分析処理を行えるようになりました。
さらにモデリングの部分では、元々のOLTPデータを基に、分析しやすい形へ再構築を進めました。

リモデリング後のパイプラインと効果
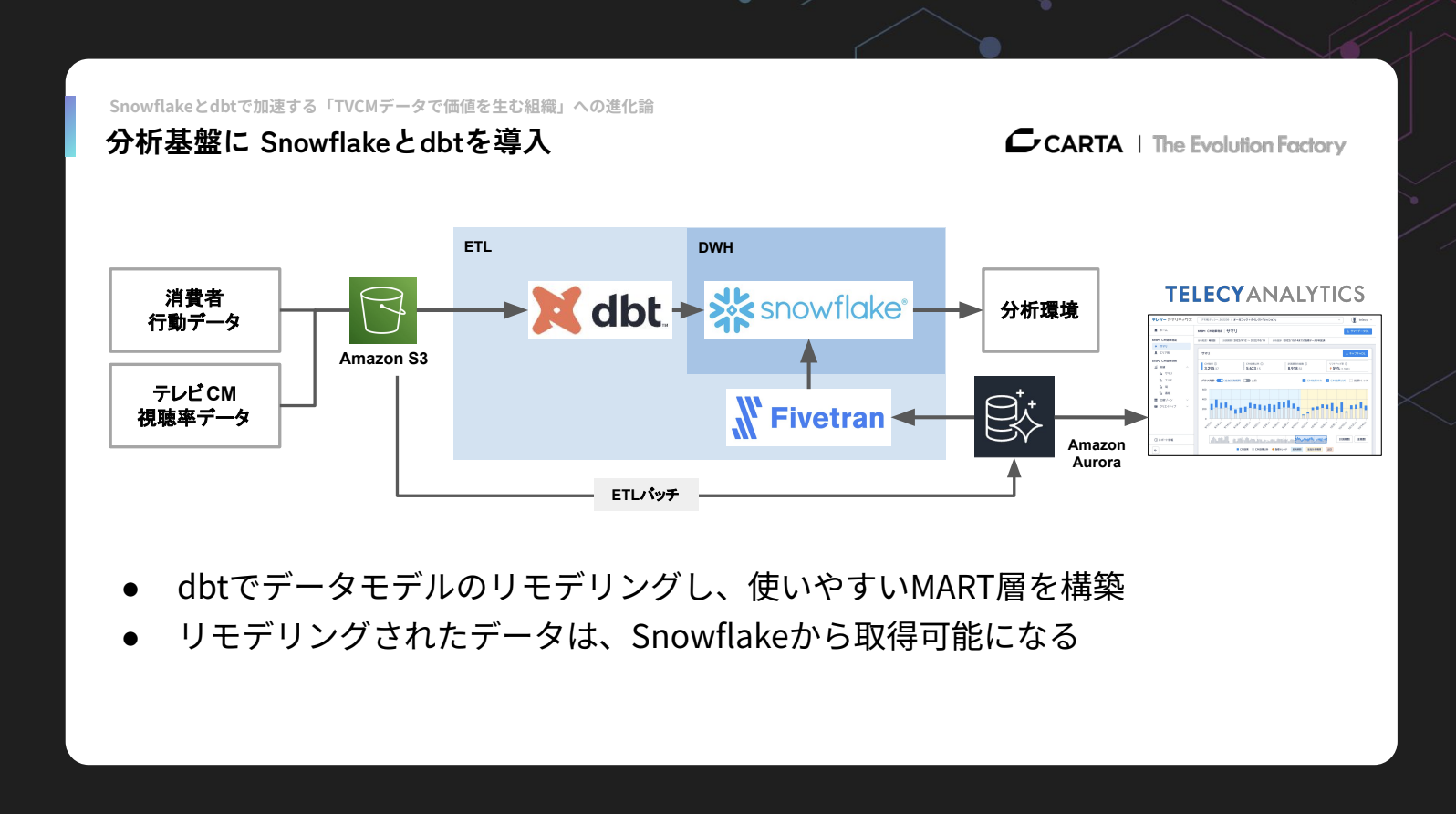
Afterのデータパイプラインでは、まず消費者行動データとテレビCM視聴率データをS3に配置し、ETLバッチ処理によってAuroraに取り込んでいます。Auroraのデータは、従来どおりテレシーアナリティクスのバックエンドDBとして利用されています。
分析環境においては、私たちはFivetranを用いてAurora内のデータをSnowflakeへローディングしています。Snowflakeの中のデータはdbtを使ってリモデリングを行い、分析作業はSnowflakeを直接参照する形にしています。
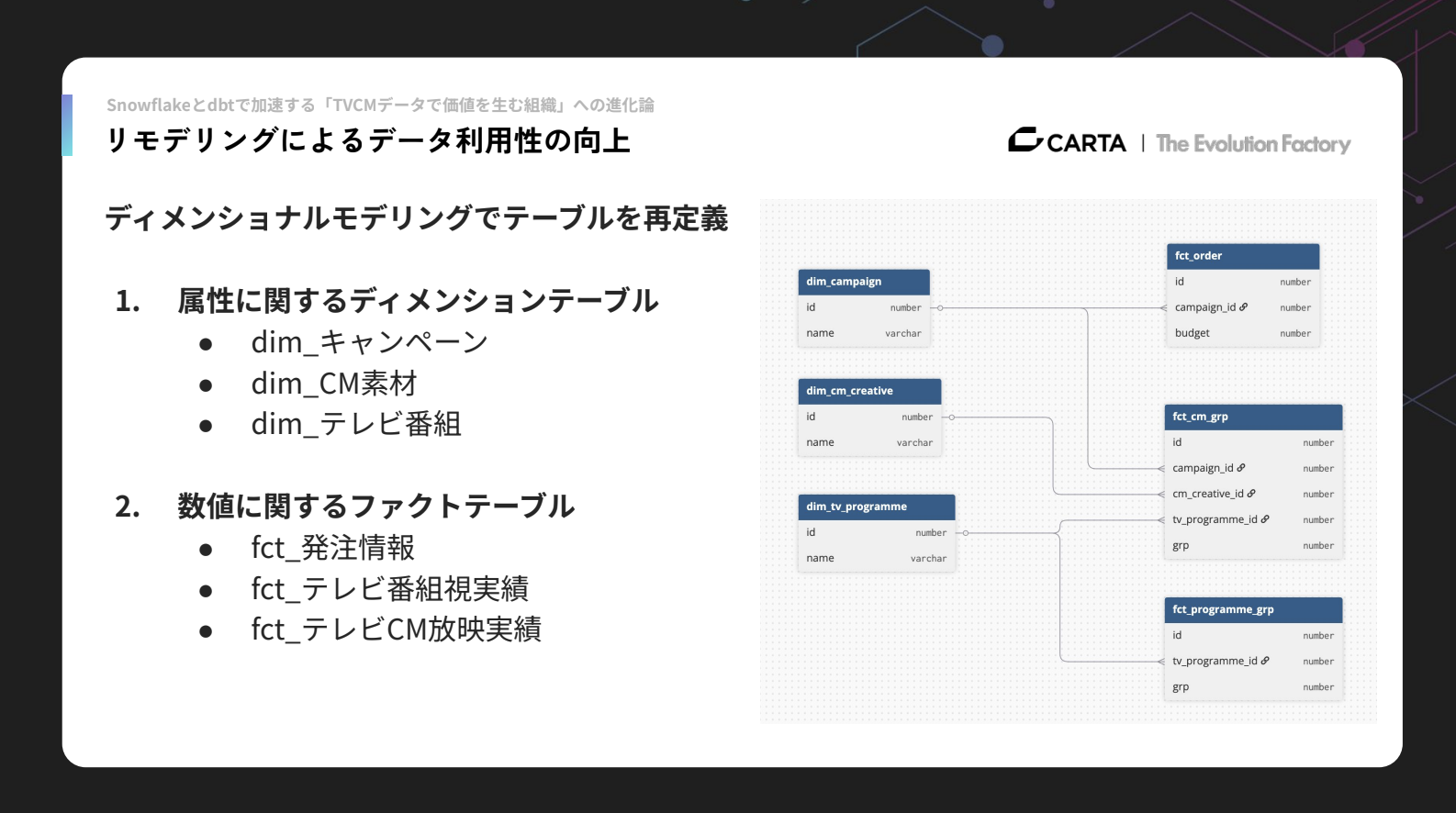
リモデリングでは、ディメンショナルモデリング手法を使ってテーブルの再定義を行いました。
まずはテーブルを、属性情報に関するディメンションテーブルと、数値に関するファクトテーブルに分けました。ディメンションには、キャンペーンやテレビCM素材、テレビ番組といった情報が含まれます。ファクトには、キャンペーンに紐づく発注情報、番組の放映実績、テレビCMの放映実績などを格納しています。
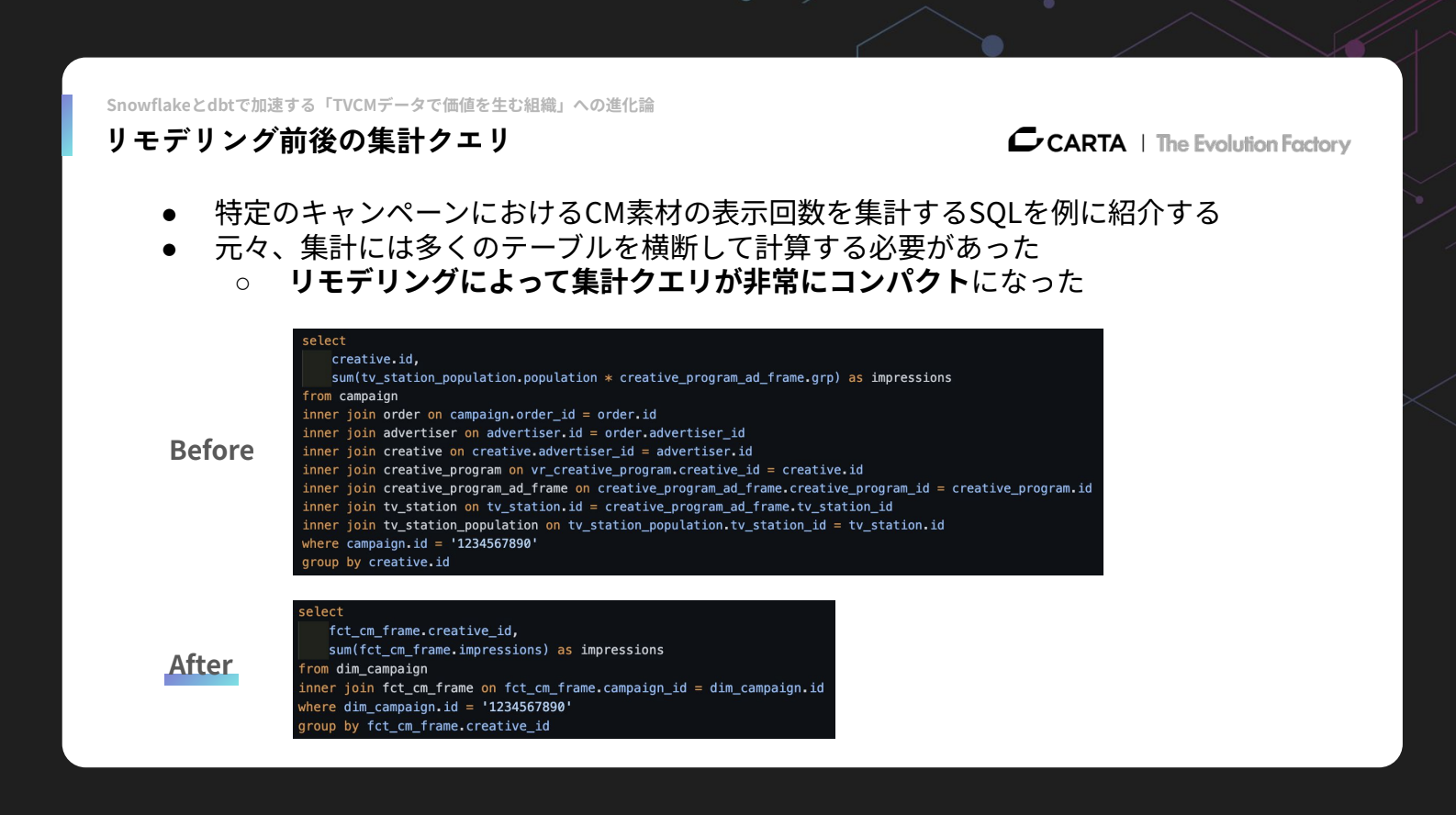
リモデリング前後の集計クエリの変化を一例として紹介します。これは、1つのキャンペーンの中の特定のクリエイティブの表示回数を集計しようとする際に使われるSQLです。
Beforeの状態では、キャンペーンから放映情報、さらに広告情報へと辿り、広告主に登録されているクリエイティブ情報を取得し、そのクリエイティブがどの番組で放映されたのかを追っていきます。そこから番組のテレビ枠情報へ進み、最終的にはその番組を持つ局の人口データと視聴率を突き合わせ、どれくらいの表示回数が発生していたかを集計する必要がありました。これらすべてを1つのSQLで書く必要があり、非常に複雑でした。
Afterの状態では、構造が大幅にシンプルになり、キャンペーンからテレビCM枠の実績テーブルに直接アクセスすることで、特定キャンペーンにおける各クリエイティブの実績を簡潔に取得できるようになりました。
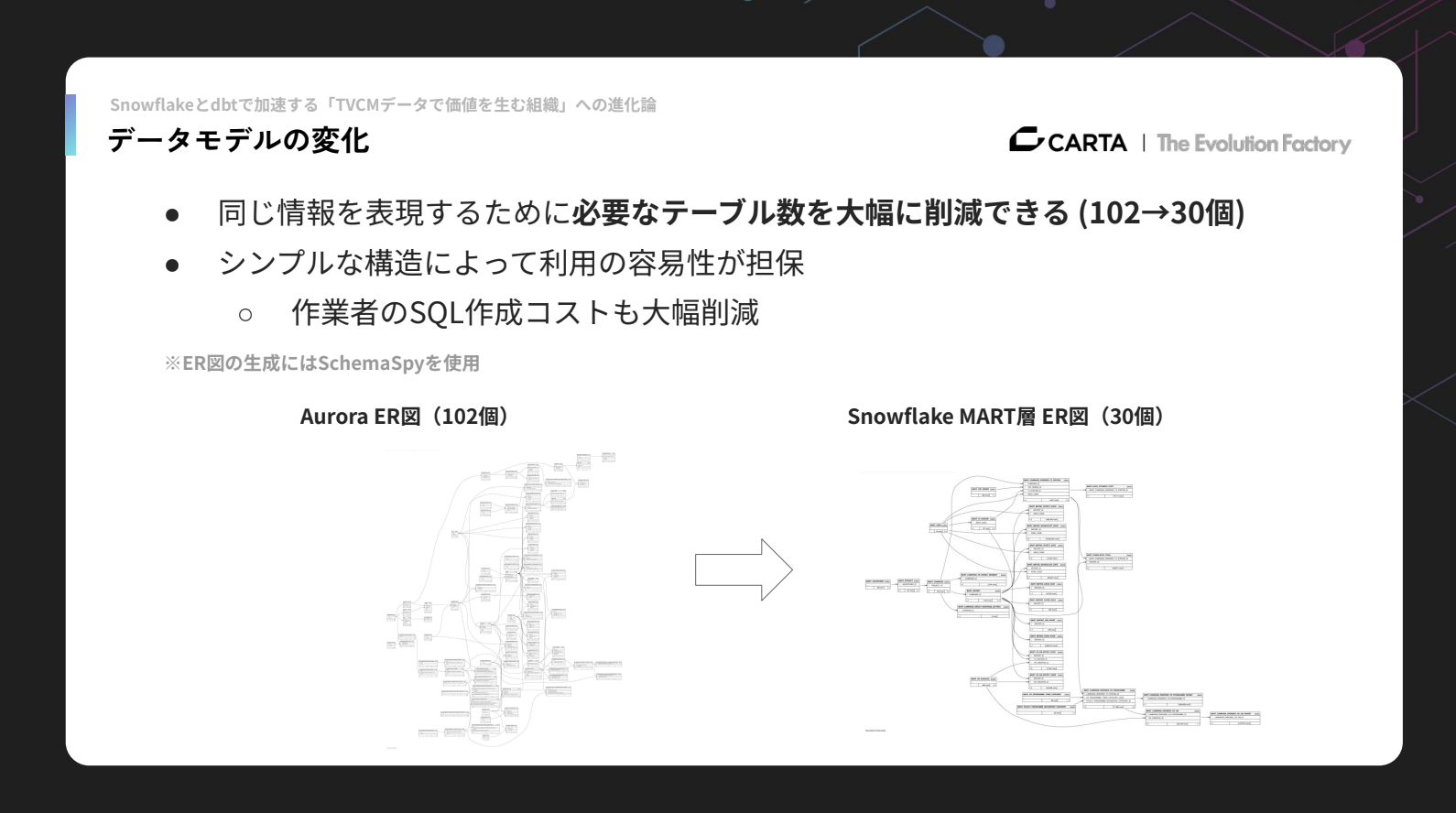
データモデルの面でも、Auroraには102個のテーブルが存在していましたが、リモデリングにより同じ情報をわずか30個のテーブルで表現できることがわかりました。
構造が整理されたことで利用しやすさが高まり、分析メンバーの作業コストも大幅に削減されています。
定量的に見ると、Snowflake導入前には1案件あたり5〜6時間かかっていた分析の前処理が、現在では1時間程度で対応可能になっています。単価などを踏まえると、年間で1,000万円以上のコスト削減につながったという結果になりました。

dbtを活用した実装プラクティス
具体的なプラクティスについても紹介したいと思います。複数のテーブルから必要な情報を集約する際には、dbt-utilsのgenerate_surrogate_keyマクロを使ってユニークキーを付与したり、dbtのgenericテストを用いてテーブルの品質担保を行っています。
さらに、dbtのconstraintsを使ってSnowflake上で制約を定義することで、テーブル間の依存関係を明確化できるようにしています。
また、SchemaSpyというデータベースの仕様書生成ツールも導入可能になっています。SchemaSpyは既にOLTPモデルで利用されているツールであり、私たちにとっても親和性が高いものです。

実装例としては、constraintsを使うことでプライマリーキーや外部キーの定義が可能になります。
例えばマートテーブルに対してcontract: {enforce: true}を設定すると、「このIDはプライマリーキー」「このIDは外部キー」といった形で定義できるようになります。

ただし、Snowflakeにおけるこれらの制約はあくまで強制力の弱いものです。そのため、外部キーやプライマリーキーが期待どおりに機能しているかどうかは、dbt testsと組み合わせて運用することをおすすめします。
「BEYONDテレシーアナリティクス」を見据えた今後のチャレンジ
次に、私たちが次のステージに進むうえで、どんなチャレンジに直面しているのかをご紹介します。テレシーは今後、中長期的に2つの方向性でデータ基盤を強化していきたいと考えています。
1つ目はマーケティング統合データ基盤、2つ目はデータドリブンな経営基盤(Revenue Operations: RevOps)です。
マーケティング統合データ基盤への挑戦
まず、マーケティング統合データ基盤について説明します。これまで私たちは運用型テレビCM領域に挑戦し、成果を出してきましたが、今後はテレビ以外の領域にもマーケティングデータを活かし、新たなソリューションをクライアントへ提案していきたいと考えています。

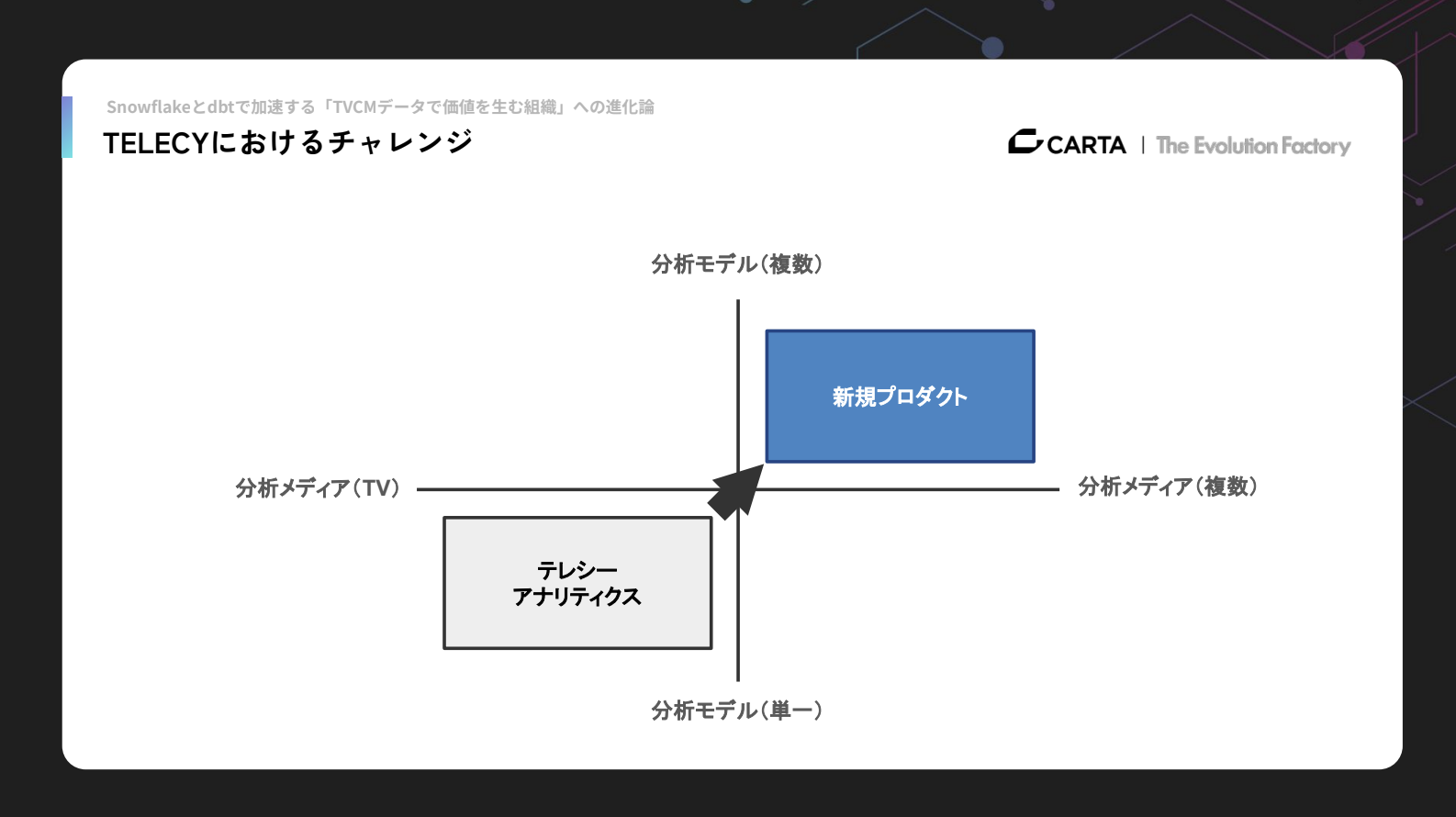
これまでのテレシーアナリティクスは、単一の分析モデルを提供し、扱っていたデータもテレビドメインが中心でした。
今後は新規プロダクトを開発し、デジタルマーケティングやほかのオフライン広告など、様々なメディアのデータを扱って、新規マーケティングソリューションの開発を進めています。
分析モデルについても単一モデルではなく、複数のソリューションの分析モデルを新規プロダクトの中でクライアントに提供しようと考えております。
データドリブン経営基盤(RevOps)の構築
2つ目の大きなテーマであるレベニューオペレーション(Revenue Operations:略称 RevOps)は、持続的な収益成長を実現するためにレベニュー組織(マーケティング、セールス、カスタマーサクセス等)の協業プロセスを強化し、戦略や戦術面で生産性向上を支援する方法論であり役割です。
現場が直面している課題としては、テレシーにおいて、前年同期比での売上・原価・売上総額がどう変動しているのか、その背景に何があるのかといった点が挙げられます。また、直接部門の一人あたり売上総額の推移や、顧客セグメントごとのパフォーマンスなど、把握すべきテーマも多く存在しています。
これらの課題を解決するには、データドリブンな経営基盤の構築が不可欠であり、このプロジェクトは先月から本格的に進めているところです。現在は、様々なデータを基盤に取り込む作業を進めています。
取り扱っているデータとしては、Salesforceで管理している顧客情報や商談履歴といったCRM(Customer Relationship Management: 顧客関係管理)データ、売上の実績が反映された会計・財務データ、さらに社員マスターや原価種目マスターなどのマスターデータがあります。各部門で個別に管理されているアドホックなデータについても、今後整備していく予定です。
ここで、このRevOpsにおけるチャレンジについて説明します。
1つ目は、Single Source of Truthの確立です。
データソースの単一化と定義の統一が必要であり、現在は複数のデータリソースが同じ情報を表しているにも関わらず複雑に管理されていたり、データの追従できていなかったりする点が課題となっています。Salesforceや請求書発行システムなどのデータを、すべて一箇所にまとめていくこと(Single Source of Truth)を目指しています。

2つ目のチャレンジは、ビジネス要件に基づくデータパイプラインの設計です。
現状、データは月次締めが終わるまで確定しないため、リアルタイムでのデータ活用ができず、経営層がスピーディーに意思決定したくてもできない状況があります。このため、ニアリアルタイムなデータフローの再設計と再実装を進めています。

3つ目はデータガバナンスです。経営基盤には多くのステークホルダーが関わるため、「誰がどのデータを管理するのか」「どこまでアクセス権を付与すべきか」といった点が不明瞭になりがちです。
データ品質の担保も難しく、実際に先月の作業では、2年前のSalesforceのオペレーションミスが発覚し、現在オペレーション担当に修正してもらっている状況です。今後は、このようなミスに気づくための仕組みづくりにも取り組んでいく必要があります。
データガバナンスの強化に向けては、ユーザーごとのアクセスコントロールの設計と実装、データ品質を担保するためのテストケースの整備なども進めています。

発表の総括:テレビCMから経営基盤まで広がるデータの挑戦
まとめになりますが、私たちはこれまでデータエンジニアリングを通じて、テレビCM領域における価値提供に様々な取り組みを行ってきました。そしてこれからは、先ほどお話しした通り、統合的なマーケティングプラットフォームへの挑戦を進めつつ、データドリブン経営基盤の構築にも全力で取り組んでいるところです。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





