



【アーキテクチャConference 2025】進化するAIエージェント:未来を見据えた設計と運用戦略
2025年11月20日・21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションでは、グーグル・クラウド・ジャパン合同会社のAI/MLスペシャリスト 小野 友也さんが登壇。急速に進化するAIエージェントについて、その普遍的な設計思想と運用戦略を解説しました。シングルエージェントからマルチエージェントまでのアーキテクチャパターン、そしてPoCで終わらせず本番環境で安定稼働させるための「AgentOps」という運用思想まで、トレンドに左右されない開発の軸をご紹介します。
■プロフィール
小野 友也
グーグル・クラウド・ジャパン合同会社
AI/ML Specialist, Customer Engineer
Google Cloud にて AI/ML Specialist, Customer Engineer として活動中。学生時代に画像処理・パターン認識を専攻し、SIer でのアプリ開発、Private Cloud のサービス開発・インフラ運用を経験。2019 年より Google Cloud の Customer Engineer として数多くの AI 関連案件に携わり、お客様の課題に合わせた設計支援や製品紹介、イベント登壇などを担っている。
AIエージェントとは
小野:AIエージェントの話に入る前に、まず生成AIを取り巻く現状をおさらいしておきましょう。最近はどこを見てもAIというキーワードが溢れており、おそらくAIという言葉を目にしない日はないのではないでしょうか。チャット形式の対話型インターフェース、画像・動画の生成、文章の代筆、画像を使った検索など、5年前、10年前には実現が難しかったことが、今では当たり前のようにできる時代になりました。
AIエージェントの定義についてはさまざまな議論がありますが、私たちはKaggleを通じてホワイトペーパーを公開しています。同僚が日本語化したバージョンもありますので、ぜひダウンロードしてご覧ください。この領域は進化が非常に激しく、実は先週のKaggleイベントでも新しいホワイトペーパーが5本ほど発表されたばかりです。数か月経てばまた新たな知見が出てくるようなスピード感の世界だと認識しておいてください。

小野:今日お伝えするAIエージェントのイメージは、2つの要素で定義できます。1つ目は「何か目標を達成しようとするアプリケーション」であること。2つ目は「目標を達成するために自ら推論して考えることができる」こと。この2つを兼ね備えたものを、本セッションではAIエージェントと呼ぶことにします。
言い換えれば、AIエージェントとは人間の代わりに目標達成のためのタスクを実行してくれる存在です。ただ、よく考えてみると、これは広義にはITシステム全般に当てはまる定義ではないか?という問いかけもできるでしょう。
この後、LLMを中心にしたエージェントのアーキテクチャパターンをお伝えしていきますが、1つお願いがあります。ぜひ疑いの目を持って聞いていただきたい。すべてをLLMで実現するのが最適解とは限りません。従来のプログラムで十分なケースもあるため、適材適所で使い分けることを常に意識してください。
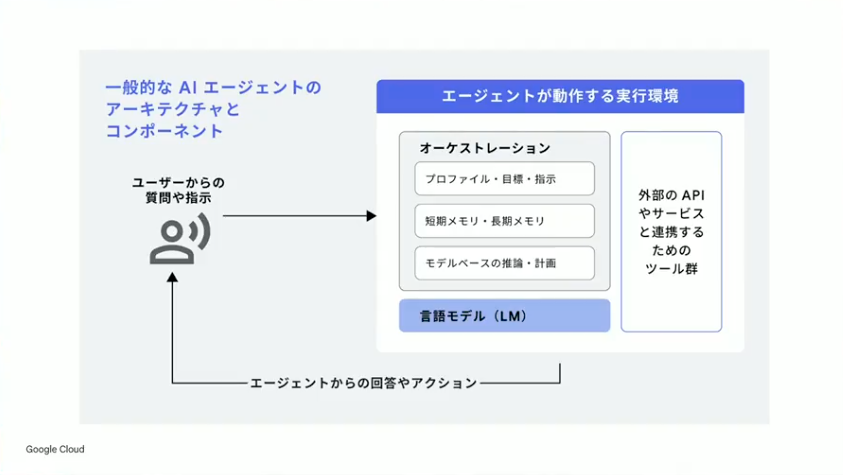
小野:AIエージェントの中身をおさらいすると、一般的には上記のような構成になります。ユーザーから質問や指示があった時に、エージェントがそれを理解して、必要があれば外部のツールを呼び出して実行し、その結果を見て内容をサマライズして回答する。つまりAIエージェントの中身としては、生成AIの言語モデル、外部APIとやり取りするためのツール、そしてそれらを有機的に動かすためのオーケストレーションレイヤーがあるということです。
AIエージェントのアーキテクチャ
小野:AIエージェントのアーキテクチャにはいろいろな種類があります。一番シンプルなシングルエージェント、そしてマルチエージェントシステムとして逐次パターン、並列パターン、ループパターンなどがあります。これらを基本的には組み合わせて、大きな複雑なエージェントを作っていくことになります。
まずシングルエージェント。文字どおり、1個のエージェントがタスクを実行して結果を返す、最も基本的なパターンです。複雑なことはあまりできないのですが、1つのタスクを確実にこなすときには向いています。メリットとしては、できることが限られるぶん、コアロジックの洗練に集中できるという点があります。

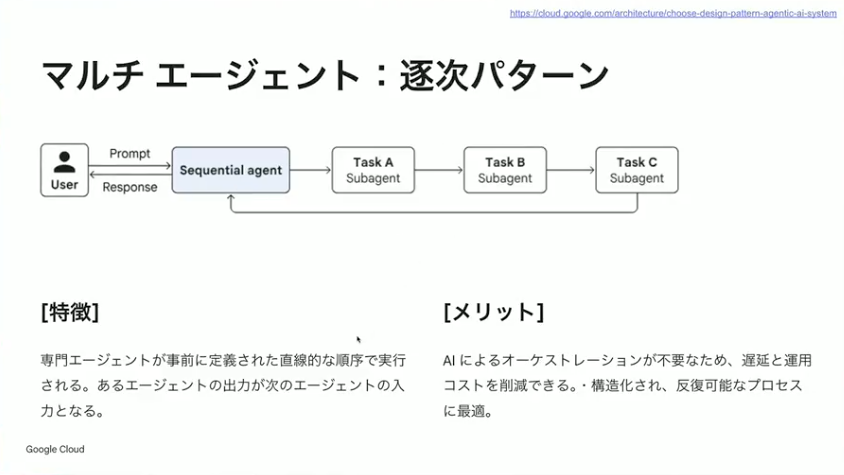
小野:次がマルチエージェントの逐次パターンです。タスクがA、B、Cと順番に実行していけば終わるようなパターンで、専門家のエージェントが事前定義されたタスクを順番に実行していきます。あるエージェントの出力が次のエージェントの入力になるイメージです。
AI自身にどのタスクをどの順番でやるか考えさせるのではなく、ワークフロー的にタスクAが終わったらタスクB、タスクBが終わったらタスクCと順次実行できます。確実にワークフローを守らせたいユースケースで特に効果があります。世の中的には意外とこのパターンが多いですね。
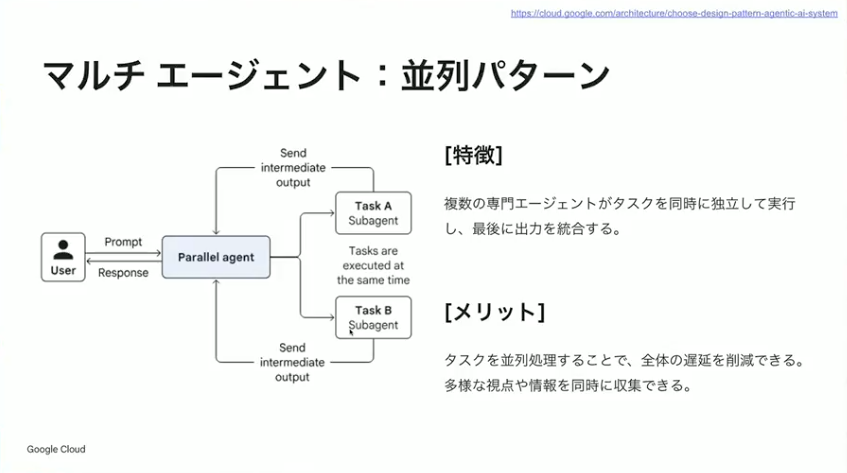
小野:続いて並列パターンです。複数のエージェントがタスクを同時に実行して、最後に結果をマージして出力するパターンです。調べものをするエージェントを作った時に、調べ先のソースが複数ある場合、それぞれのソースに対して調査を行って最終的に結果をマージしてユーザーに返すようなユースケースで使えます。逐次型の場合は1個ずつ順番にやっていくので時間がかかりますが、並列処理を行うことで全体の処理時間を削減できます。
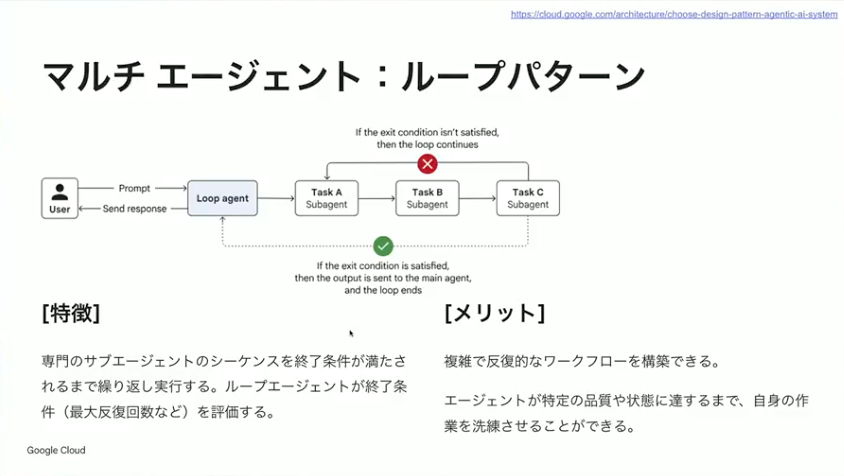
小野:続いてループパターンです。逐次型に近いところはありますが、終了条件が満たされるまで考えて再度実行し、結果が良くなるまで繰り返してくれます。複雑で反復的なワークフローを構築できるのがメリットです。エージェント自身に品質を判定させるためのプロンプトを書いてあげる必要はありますが、一定の品質になるまで自分で思考させて繰り返すことができます。デメリットとしては、処理時間が長くなりがちな点があります。
小野:マルチエージェントのパターンとして、レビューと批評パターンもあります。生成するエージェントと批判するエージェントが常にやり取りをして、一定の品質になるまで繰り返します。先ほどのループパターンのように順次処理をして最終結果を判定するというよりは、1つのアウトプットを繰り返し洗練していくパターンに強いです。
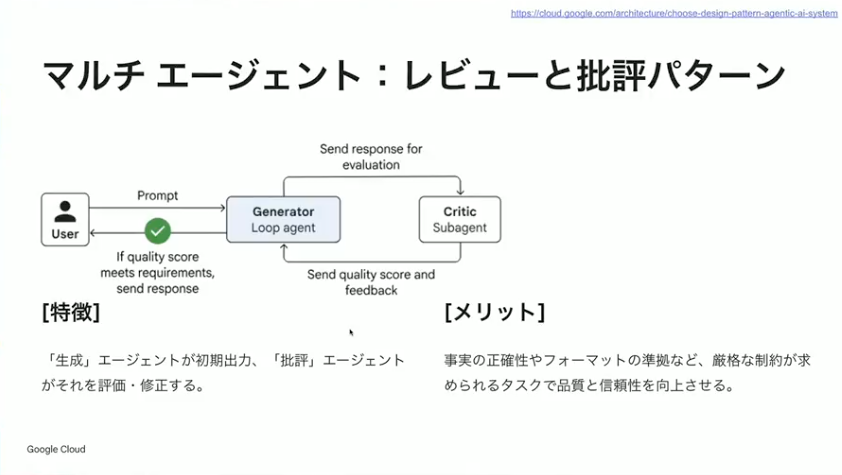
小野:そして協調型のパターンです。中央のコーディネーターエージェントがAIモデルを使ってリクエストを解釈し、自らタスクに分解して専門エージェントにタスクを割り振ります。ディスパッチャーのような役割をしてくれるので、より柔軟な対応が求められるユースケース、ユーザーの行動によって動きを変えなければいけないケースに向いています。
小野:これらが基本形になりますが、もう少し組み合わせていくと複雑なエージェントも作れます。最初にPoCなどで始められる時は、今挙げたような基本形のパターンに準じてスタートしていただくのがよい塩梅だと思います。
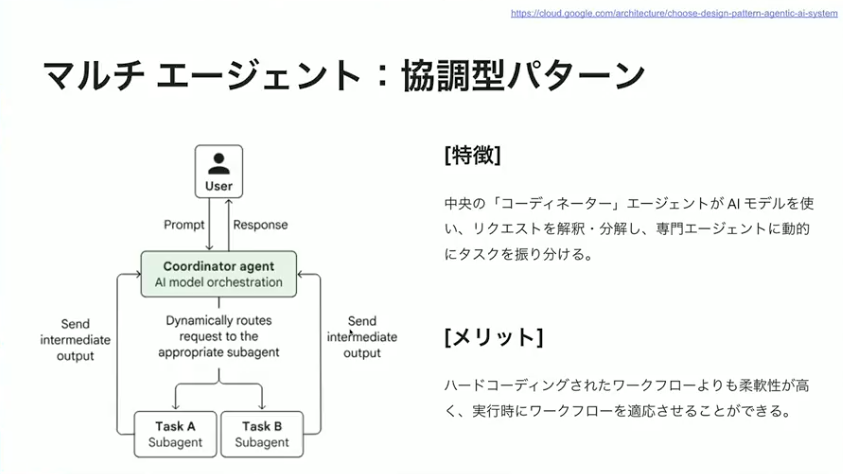
さまざまなパターンがあるのはわかったとして、ソフトウェア的にどうやって実現していくかという話があります。そこでご紹介したいのが、ADKと通称呼ばれているAgent Development Kitです。Google Cloud が出しているもので、先ほどご紹介したようなアーキテクチャを簡単に実現できるSDKになっています。
ADKはオープンソースとして公開されていますので、どなたでも自由に使っていただけます。シングルエージェントからマルチエージェントまで、割とシンプルなコードで実現できるのがメリットです。
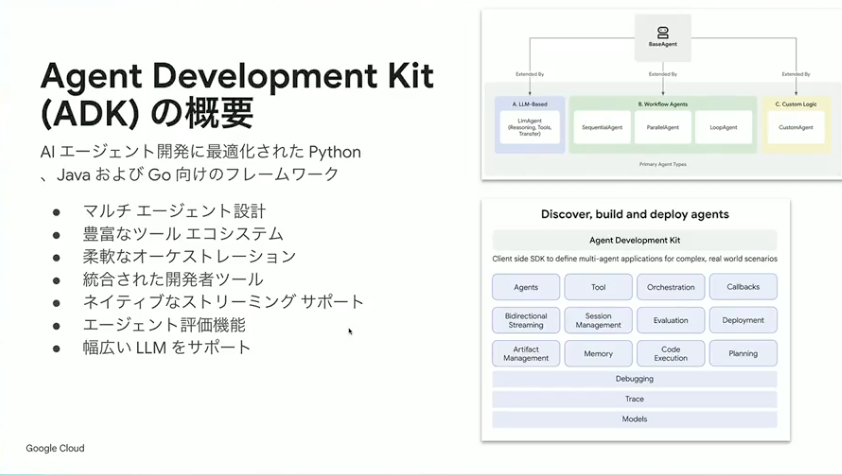
小野:今日時点でお伝えできるアップデートとしては、もともとPythonを対象としていたのですが、先日Go言語にも対応しました。アプリケーションをGo言語で書かれている方も多いと思いますので、ぜひ積極的に活用いただければと思います。
ADKで作ったエージェントのサンプルとして、Google Cloudのエージェントガーデンにサンプル動画があります。トラベルエージェントというもので、旅程の計画やフライトの予約ができるエージェントです。シンプルにコードが書けるとお伝えしましたが、実際のコードはこのぐらいシンプルに書けます。サブエージェントとしていろいろなエージェントが登録されていて、どういうツールを実行するエージェントなのか、どういう処理をするエージェントなのかという情報だけ与えてあげると動くようになっています。
ADKのいいところは、Webインターフェースが付属していて、ローカルの開発をする時にすぐに試すことができる点です。「東京からサニーベイルへ出張したいです」と書いてあげると、実際にどういう動きをするのかがその場でわかります。途中で動かしている過程もWebのインターフェースからわかるので、便利な機能になっています。
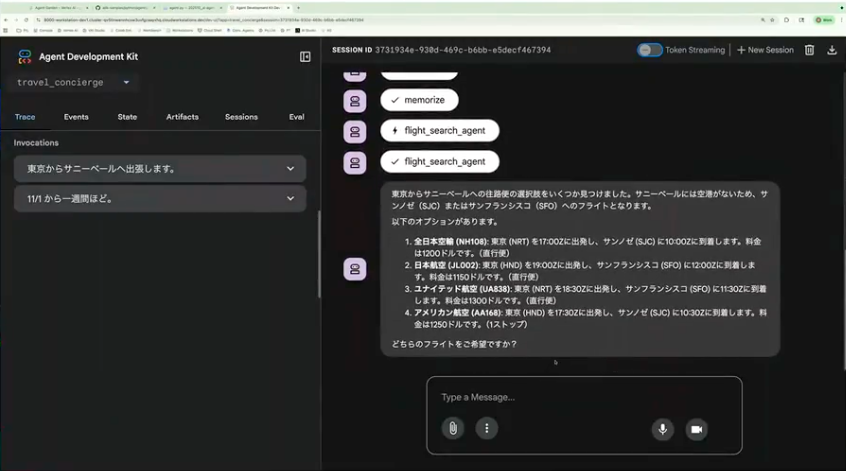
小野:例えば「11月1日から1週間ほど出張したい」と入力すると、エージェントがどこからどこへの出張なのか、いつの出発日・帰国日なのかを考えて実行してくれます。1週間というところから11月8日に帰ってこなきゃいけないという計算も自動でしてくれます。従来だとどこかで「1週間はプラス7日だから」という処理コードを書かなければならなかったのですが、生成AIらしく自分で考えて結果を出してくれるのが特徴です。
こういったエージェントをデプロイする環境として、Vertex AI Agent Engineがあります。ADKで作ったエージェントをデプロイして、外部のユーザーに公開できます。

小野:ADK以外も取り込むことができて、LangChainやLangGraphなど、エージェントを作るためのオープンソース系のフレームワークで開発されているエージェントもこの環境にデプロイできます。デプロイ環境としての機能のほか、評価の機能や、Gemini以外のモデルも裏側で呼び出せる機能など、いろいろな機能があります。
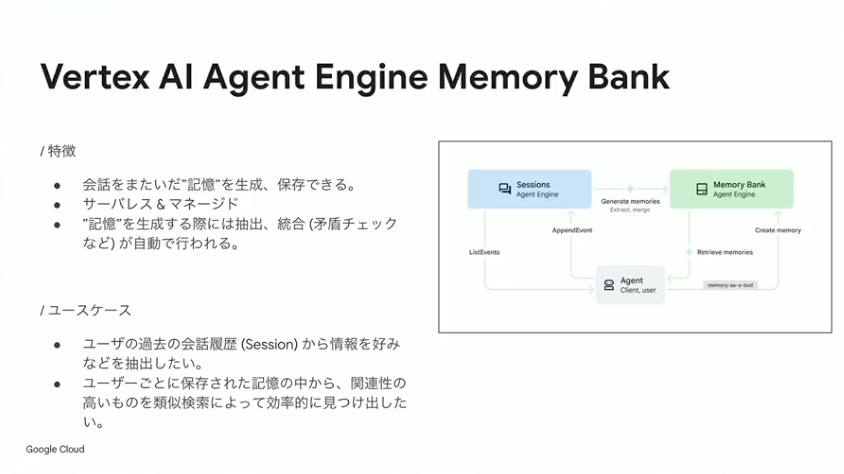
特にエージェントに必要なキーになる機能として、メモリーバンクと呼ばれる仕組みがあります。エージェントが過去の会話履歴を覚えておく必要があるユースケースのために用意されているものです。マネージド環境なので、セッション情報を保存するためのDBを自分で構築する必要がなく、Agent Engineとセットで使えます。過去の会話やユーザーのプリファレンスを覚えたエージェントを作りたい時には、この機能が役に立つでしょう。
AgentOps
小野:ここからは、作り方やアーキテクチャを理解したうえで、実際に運用していく際の注意点についてお話しします。キーワードはAgentOpsです。
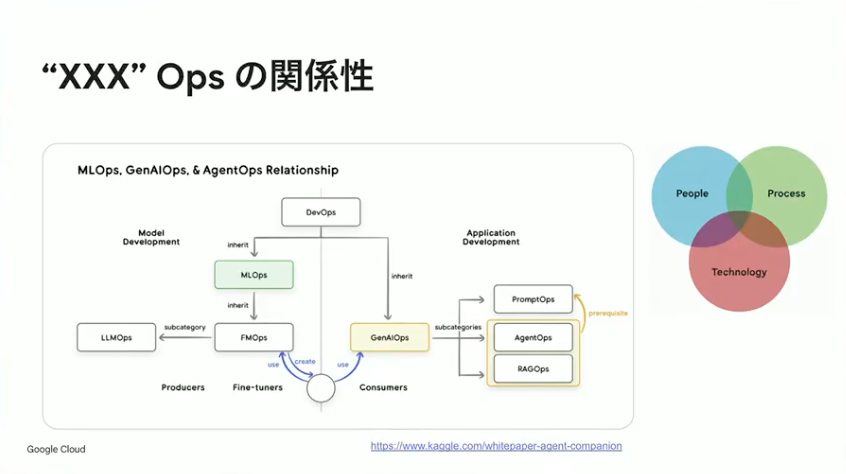
みなさんご存知のとおり、世の中には「なんとかOps」と呼ばれる概念がたくさん存在します。これらは無関係に乱立しているわけではなく、基本的にはDevOpsの発想を起点として生まれてきたものです。その系譜の中でGenAI Opsは、LLMのモデルそのものというよりも、LLMを活用するためのベストプラクティスを指す概念として位置づけられています。そしてAgentOpsは、このGenAI Opsの一部として、エージェント特有の運用課題に焦点を当てたカテゴリーという関係性になっています。
小野:もう1つ重要な点があります。Opsという言葉から、本番環境でのエラー対応といった狭義の「運用」をイメージしがちですが、AgentOpsの本質はそこにとどまりません。人・プロセス・テクノロジーの3つをどう組み合わせ、ビジネス効果を最大化するか。これがAgentOpsの目指すアプローチです。
その中で特にコアとなるのが、AIエージェントの成功指標の計測です。そもそもエージェントが本当にうまく機能しているのか、その価値を定量的に把握しなければ、改善の方向性も見えてきません。
ここで忘れがちなのが、ビジネスインパクトの計測です。PoCの段階では社内ユースケースから始まることが多く、「収益が上がったか」「ユーザー数が増えたか」といったメトリクスが後回しになりやすい。しかし、これこそが実は最も重要な指標であり、最初から意識して計測しておくべきポイントです。
もちろん、より細かいレベルのメトリクスも欠かせません。タスクの成功・失敗、実行回数と成功率、処理にかかった時間といったアプリケーションのテレメトリーを収集し、多角的な観点からエージェントが期待どおりに動作しているかを検証していくことが求められます。

小野:AIエージェントの評価には、大きく分けて「自動評価」と「人間による評価」の2つのアプローチがあります。ただし、これは従来型のソフトウェアテストとは性質が異なる点に注意が必要です。
従来型のソフトウェアであれば、決定論的なロジックに対して「正しく動く」状態を一意に定義できるため、テストコードで検証できました。しかしLLMの場合、計算結果だけでなく言語的な意味合いも考慮しなければならず、評価の難易度は一段上がります。
エージェントの評価となると、さらに複雑です。推論しながらツールを実行し、アウトプットを生成するという一連のプロセス全体を評価対象としなければなりません。加えて、エージェントの振る舞いは非決定論的かつ確率的であり、毎回同じ動きをする保証がない。こうした特性が、評価を一層困難なものにしています。

小野:一方、評価手法を分類してみると、実はそれほど種類は多くありません。まず大きな軸として「オフライン評価」と「オンライン評価」の2つに分かれます。オフライン評価は本番投入前に行うもので、静的なデータをゴールデンデータとして用意し、毎回同じ入力で評価を実行する方式です。オンライン評価はライブデータを用いて、実際のユーザーインタラクションの中で検証したり、ABテストを実施したりするアプローチになります。
測定方法についても整理しておきましょう。1つ目はGround Truthを用意するタイプで、正解データとの照合によって評価を行います。2つ目はLLM as a Judgeで、LLM自身に出力の品質を判定させる方式です。3つ目はHuman in the Loopで、人間が「これは良い」「これはダメ」とフィードバックを与えながらエージェントを改善していく手法になります。

小野:それぞれメリット・デメリットがあります。Ground Truthのパターンは、もともとデータセットがあるので高速で、みんなが納得感のあるテストデータができていれば信頼性も高いです。ただし、エージェントの挙動が変わった時、プロンプトを変えたりモデルを変えたりした時に、エージェントの出力のニュアンスを捉えきって評価していくのが難しいと言われています。
LLM as a Judgeのパターンは、データセットをあらかじめ作る必要がなく拡張性に優れています。判定基準を「こういう観点でジャッジして」と言語化できていれば、その指示どおりに判定してくれるのが特徴です。人間が複数人で判定すると評価者によってばらつきが発生しがちですが、LLMを使うことでそれを抑えられる可能性がある点もメリットと言えるでしょう。一方で、評価方法がモデルの訓練方法によって変わることや、人間の期待値と本当に一致した判定ができているかを確認する必要があるのは注意点です。モデルによって癖があるため、そこを意識して判定基準を設計することが求められます。
Human in the Loopは、人が介在するため「良い」「悪い」を確実に伝えられるのが強みです。専門性の高い評価者を集めることができれば、人間の期待値に合わせたゴールデンデータセットを時間をかけて構築できるでしょう。一方で、手動プロセスゆえに処理速度が遅くなりがちな点と、評価者を確保するコストがかかる点はデメリットと言えます。特に大規模な結果に対してフィードバックを返すのは現実的に困難になってくるため、スケーラビリティには課題が残ります。

小野:では、どの手法を組み合わせるのがベストか。理想を言えば、3つすべてを組み合わせることです。ただし現実的には、Ground Truthの整備、LLM as a Judgeの導入、Human in the Loopの仕組み構築を同時に実装するのは非常にハードルが高い。環境構築や運用にかかるコストも無視できません。
そこで現実解として提案したいのが、小さなループから始めるアプローチです。すべてを一度に揃えようとするのではなく、取り組みやすいところから段階的に評価の仕組みを育てていくことが重要になります。
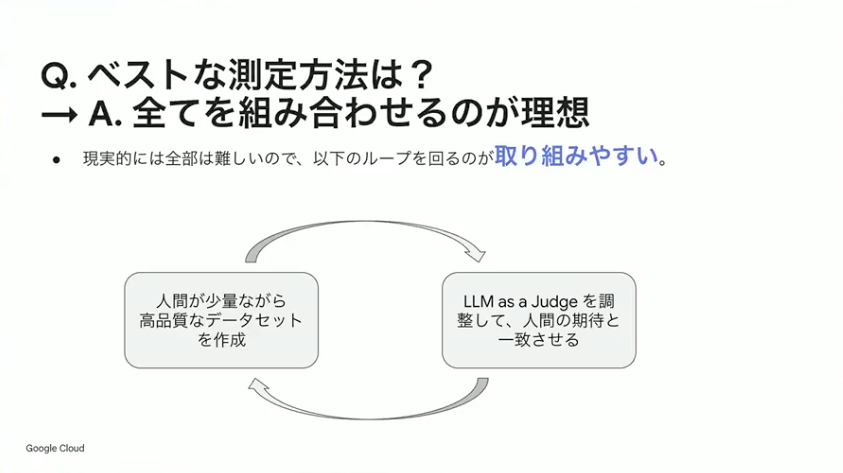
小野:LLMもAIエージェントも、人間が最終的に判断しなければならない部分が必ず出てきます。そのため、まずは5件や10件といった少量でも構わないので、人間が高品質なデータセットを作成することから始めてください。それを使って評価を行い、LLM as a Judgeを活用して人間の期待と一致させていく。データが足りなくなったら、また人間が追加するというサイクルを繰り返すのがポイントです。
このループを回していくことで、最初5件や10件だったデータセットも最終的には50件、100件へと成長し、エージェントを安定して評価できる仕組みが構築できるでしょう。
エージェントの評価方法として、機能的な観点からお話しすると、先ほどご紹介したADKのWebインターフェースであれば、簡単に対話型で評価する仕組みが提供されています。一方、もっと本格的にいろいろな観点で評価したい場合や、バッチ処理的に動かしたい、オンラインでやっていきたいといったスケールが重要になる場合は、Gen AI Evaluation Serviceという別のプロダクトを利用するのがよいでしょう。
ここでは、ADK Webを使った評価の流れを実際のデモでお見せします。
今回用意したのは、現在時刻を取得するツールを使って回答するシンプルなエージェントです。システムインストラクションとして、どういうエージェントなのかという概要を定義しており、「get_current_time」というツールを呼び出して時刻を返す仕組みになっています。
ADK Webのコマンドでこのエージェントを起動すると、先ほどお見せしたWebインターフェースが立ち上がり、その場でエージェントの動きを確認できます。「こんにちは」と入力すると「何かお手伝いできることはありますか」と返ってくるので、時刻を聞いてみる。「東京」と入力すると、エージェントが東京の時刻は午前10時30分ですと返してくれました。処理時間がどのぐらいかかったのかもインターフェース上で確認できるため、アプリケーションメトリクスの観点からも有用です。
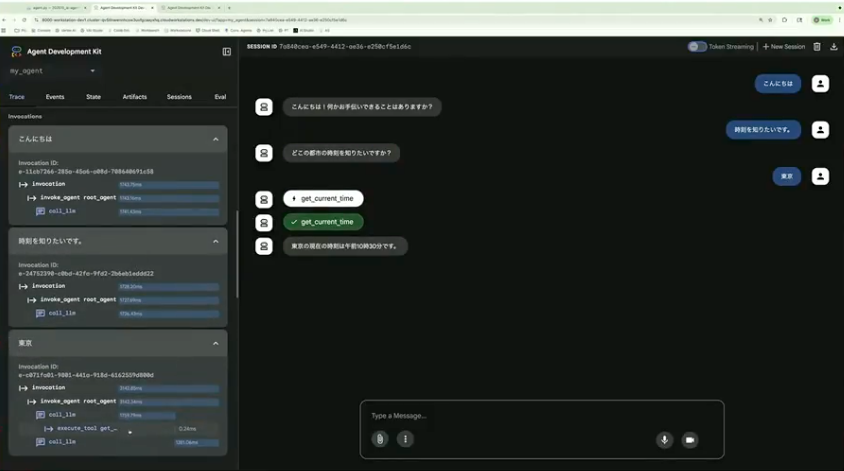
小野:ここからが評価のステップです。先ほどのやり取り、“「東京」と入力したら時刻を返す”をテストケースとして登録したいとします。インターフェース内の「Create Evaluation Set」をクリックし、現在のセッションを評価セットに追加します。このテストケースでは「ツールを確実に使ってほしい」「レスポンスは7割方合っていればOK」といった基準を設定して、評価を実行してみます。
すると、1回目の実行では失敗しました。結果を見ると「東京の時刻は午前10時30分です」と返しているのに、ツールを実行していないことがわかります。もう1回実行すると、今度は成功。ちゃんと「get_current_time」が呼ばれていて、当初の想定どおりのアウトプットが出ていることが確認できました。
このように、生成AIは確実に同じ動きをする保証がないため、こうした不安定さを検知できるよう評価セットを作っておくことが重要です。基本的な動きに問題がないかを継続的に確認できる仕組みを整えておくことで、エージェントの品質を担保しやすくなります。
ADK Webが提供しているのはほぼ文字列の一致を見る程度です。もっと意味的な解釈をしたい場合や、他のツールを実行した時の思考をたどるなどの複雑なことをやりたい場合は、Gen AI Evaluation Serviceが便利です。
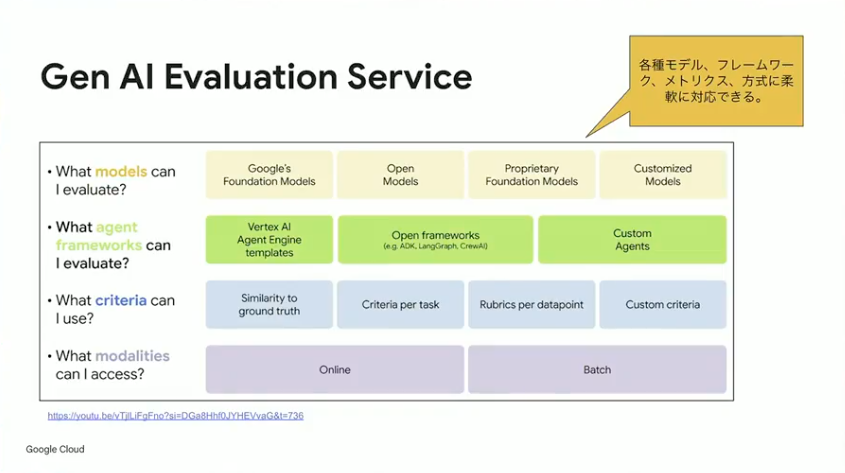
小野:Gen AI Evaluation Serviceは、使い方こそ複雑ですが、そのぶんできることの幅が広いのが特徴です。Gemini以外のモデルも評価対象にでき、豊富なテンプレートも用意されています。機械的に計算できるメトリクスの収集からLLM as a Judgeの実装まで対応可能で、独自のカスタムクライテリアを定義することもできます。
最近のアップデートでは、UIが一新されて使いやすくなったほか、データセットを与えると「この観点で評価してはどうですか」とサジェストしてくれる機能が追加されました。過去ログをもとに判定を行う機能も強化されています。
使い分けの目安としては、ローカルで開発しているPoCの段階であればADK Webで十分でしょう。一方、本番環境を意識したり、評価の仕組みをより成熟させたい場合は、Gen AI Evaluation Serviceの導入を検討してみてください。
まとめ
小野:本日のセッションでは、まず「AIエージェントとは何か」という定義の整理、次にシングルエージェントからマルチエージェントまでの基本的なアーキテクチャパターン、そして評価・運用の考え方であるAgentOpsについてお伝えしました。ADK Webを使った評価の流れも実際にお見せしました。
今日ご紹介した考え方の部分は、技術トレンドが変わっても大きくは変わりません。プロダクトや具体的な実装方法は進化していきますが、こうした設計思想を軸に持っておくことで、ブレのないエージェント開発ができるはずです。
一方、時間の都合でお話しできなかったテーマもあります。AIエージェントもシステム設計の一種であり、セキュリティ、リライアビリティ、オペレーション、コストオプティマイゼーション、パフォーマンスといった観点も本来は欠かせません。これらについては、また別の機会にお伝えできればと考えています。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





