



【Data Engineering Summit】生成AI時代の業務改革:DeNAのAI Workspaceと実践的データ基盤
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」がオンラインで開催されました。
本記事では、株式会社ディー・エヌ・エー IT本部 AI・データ戦略統括部 データ基盤部、深瀬 充範さんによるセッション「生成AI時代の業務改革:DeNAのAI Workspaceと実践的データ基盤」の内容をお届けします。
セッションでは、全社的なAIワークスペース構想の推進と、個別事業で直面したデータ品質の課題、そしてそれを乗り越えるための実践的なデータ基盤の取り組みについて語られました。
■プロフィール
深瀬 充範
株式会社ディー・エヌ・エー
IT本部 AI・データ戦略統括部 データ基盤部
DeNAのAI戦略とデータ基盤の役割

DeNAの深瀬と申します。本日はよろしくお願いいたします。私は2020年にDeNAにデータエンジニアとして中途入社し、現在はデータエンジニアやMLOpsエンジニアを抱えるデータ基盤部の部門長を務めています。私の主な役回りとしては、プレイヤーとしてプラットフォームの調整なども行いつつ、基本的なマネジメントとしてDeNAグループ全体でのデータガバナンスの推進を担当しています。
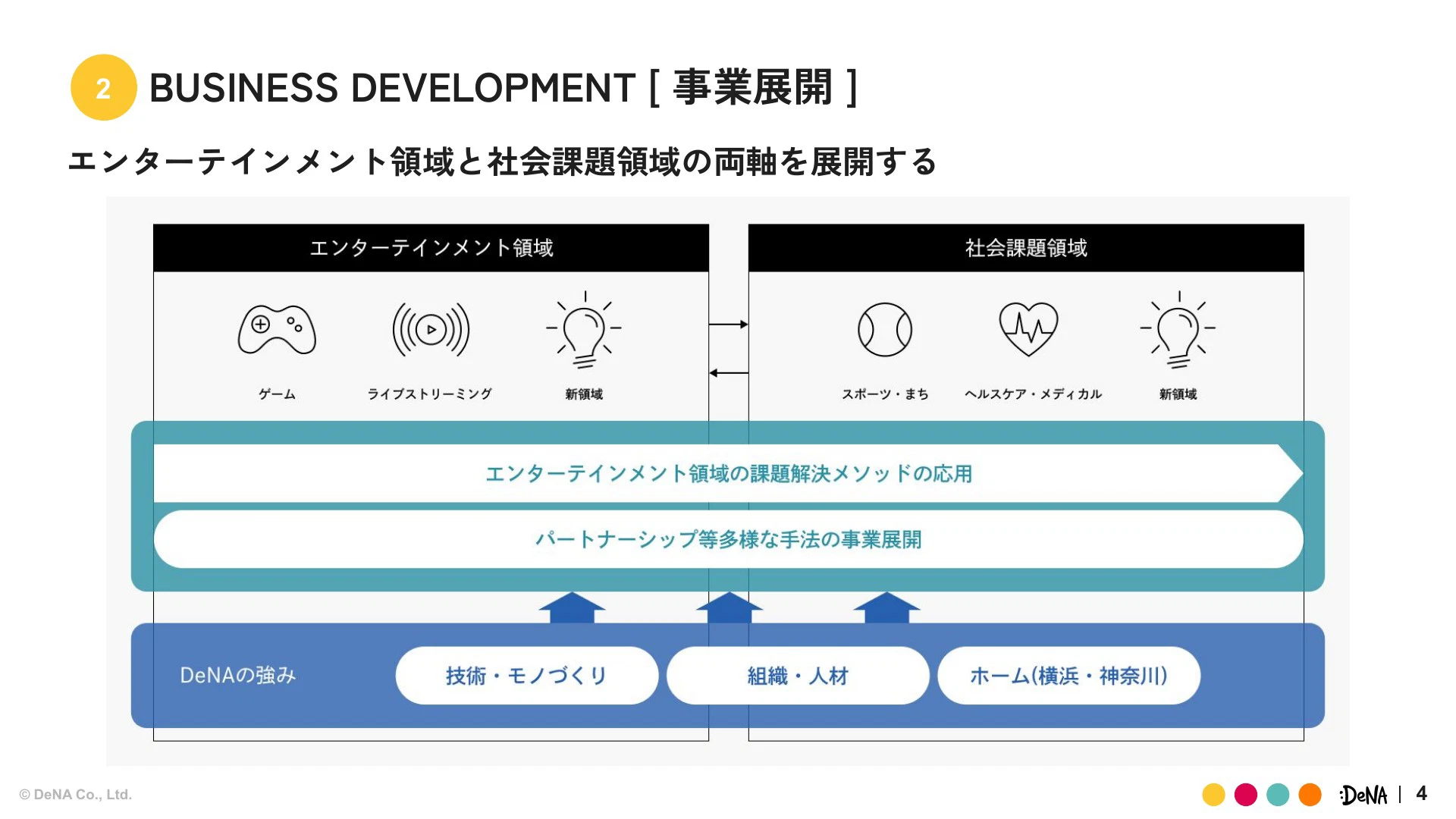
DeNAはゲーム、ライブ、スポーツといったエンターテイメント領域から、ヘルスケア、メディカルといった社会課題領域まで、多岐にわたる事業を手掛けるコングロマリット企業です。多様な事業を抱える中で、弊社のIT本部は、CoE(Center of Excellence)としてモノづくりのケイパビリティを全社横断で提供する組織として位置づけられています。
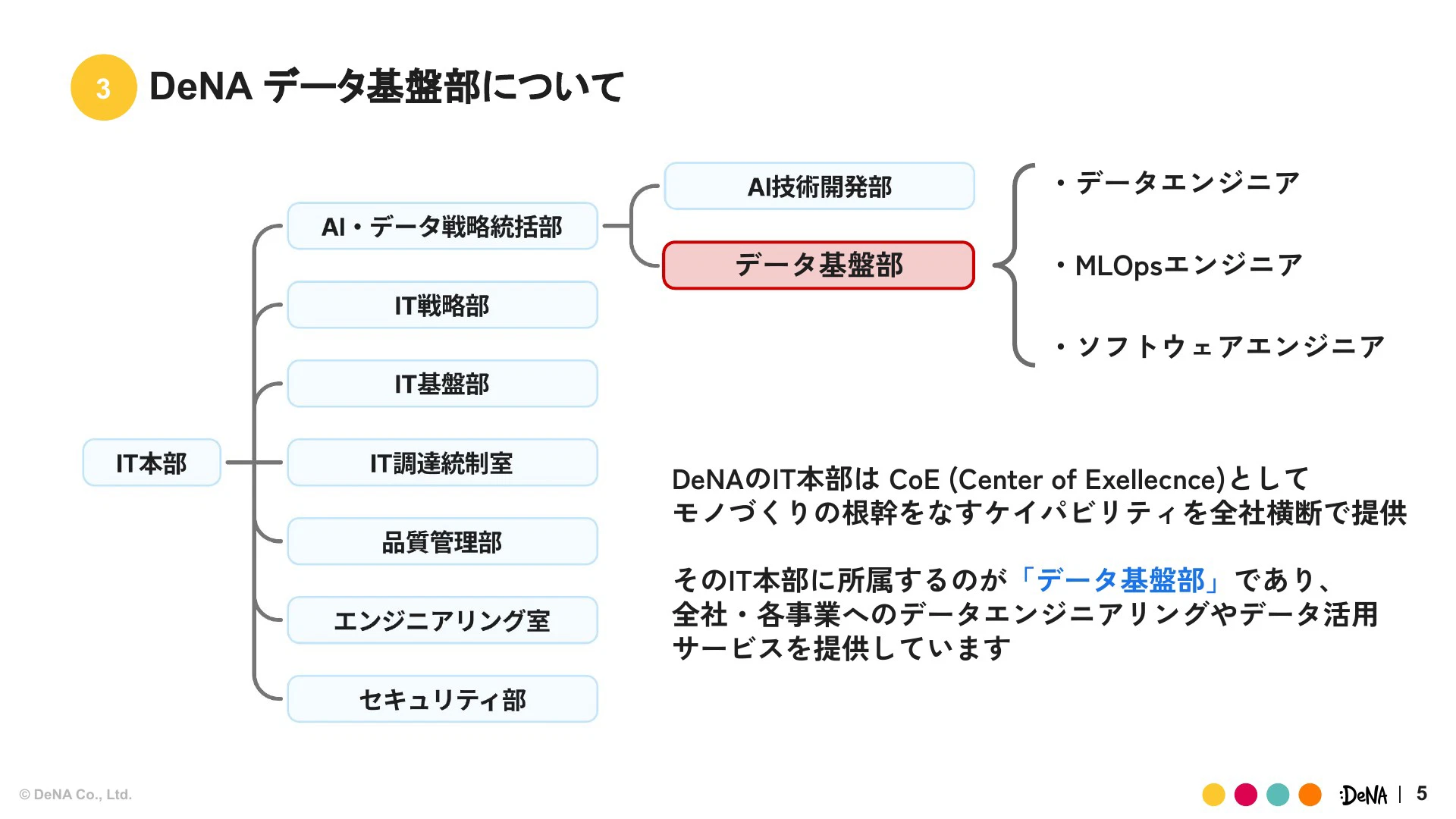
そのIT本部の中に我々データ基盤部が所属し、幅広く事業に対する技術・サービスの提供を行っています。
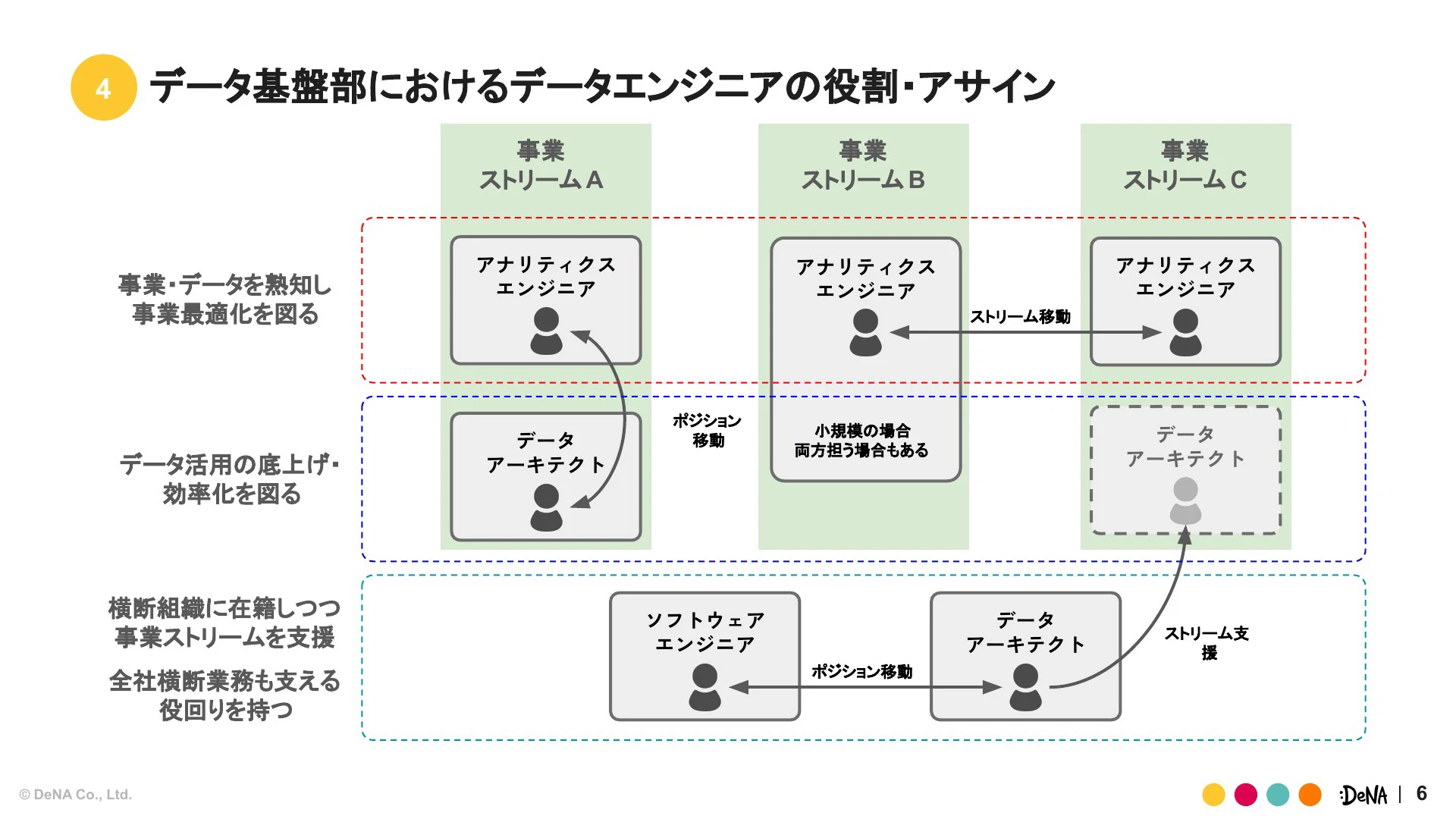
データエンジニアは各事業領域に点在していますが、深く事業の最適化を図る「アナリティクスエンジニア」と、横断的なインフラ・プラットフォーム寄りの業務を担当する「データアーキテクト」に役割を二分化しています。

データ基盤部が全社に提供しているBIツールは二本柱です。1つは10年以上利用されている内製の「Argus(アーガス)」、もう1つはGoogle社が提供する「Looker」です。それぞれデータ基盤部が主導となって、事業や案件に対し適切なソリューションを提供しデータ利活用を進めています。
本日のテーマではBIツールを前提とした事例があるため、Googleの「Looker」に加えて「Argus」という言葉も覚えていただけると幸いです。
「AIオールイン」戦略とデータ基盤の2つの役割
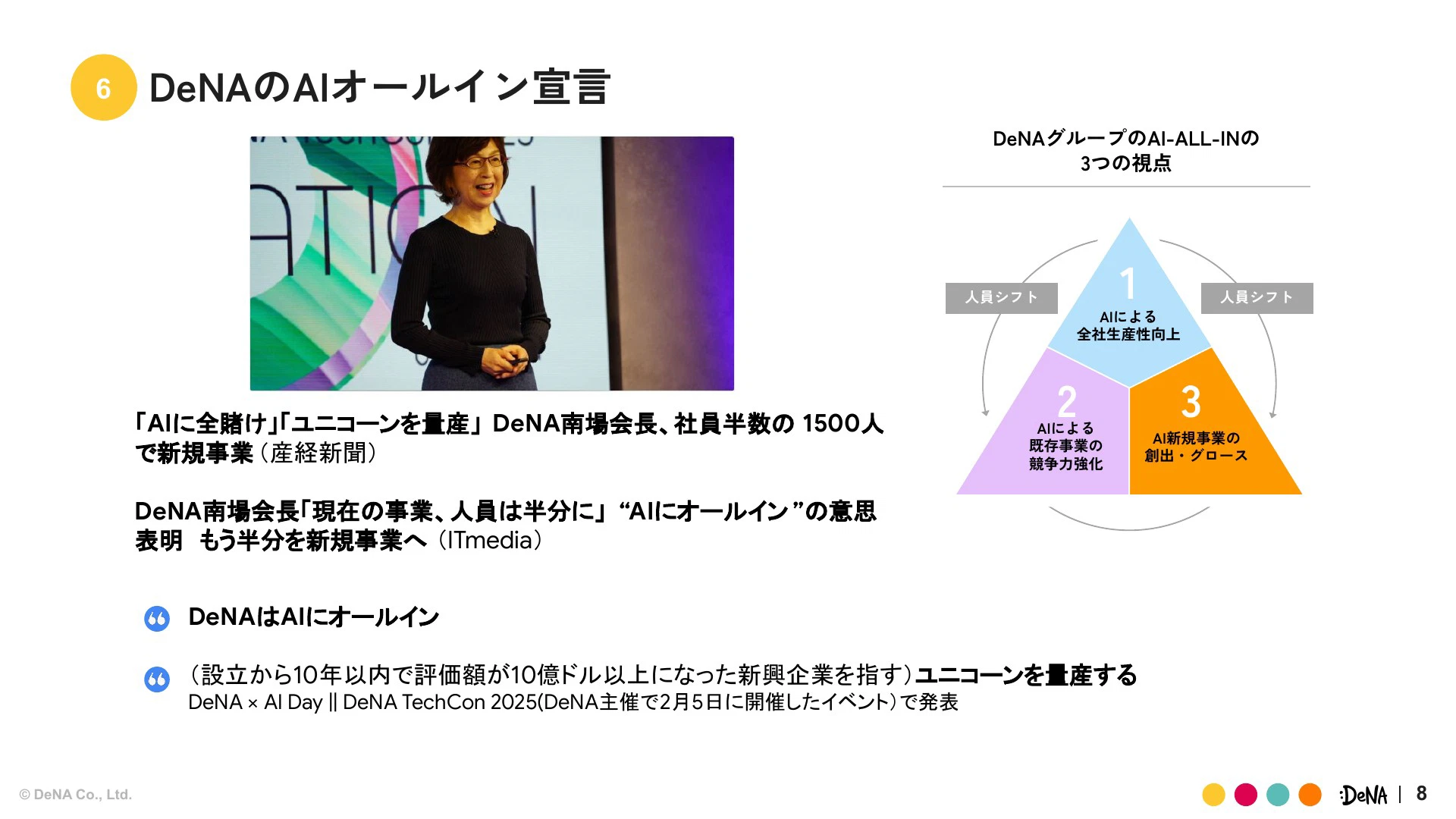
弊社の会長である南場より、2025年は「AIにオールインする」という非常に強力なメッセージが発信されました。この戦略には3つの視点があります。1つ目はAIによる全社生産性向上、2つ目はAIによる既存事業の競争力強化、そして3つ目はAIを活用した新しいサービスの創出です。
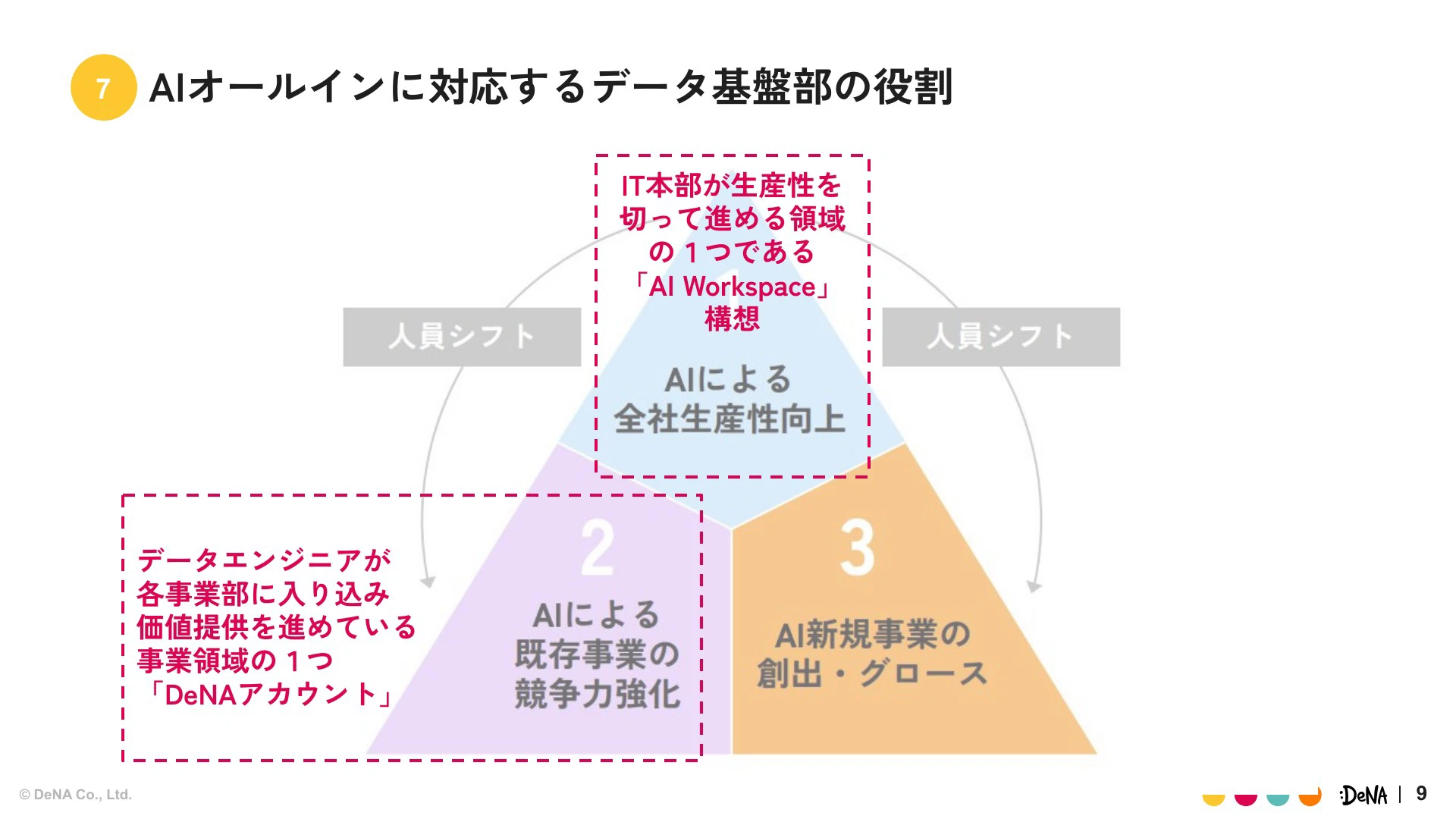
我々データ基盤部は、このうち特に「全社生産性向上」に当たるIT本部主導の「AIワークスペース構想」と、「既存事業の競争力強化」の事例として「DeNAアカウント」事業の支援に取り組んでいます。
AIワークスペース構想:ガバナンスを効かせたプラットフォーム整備
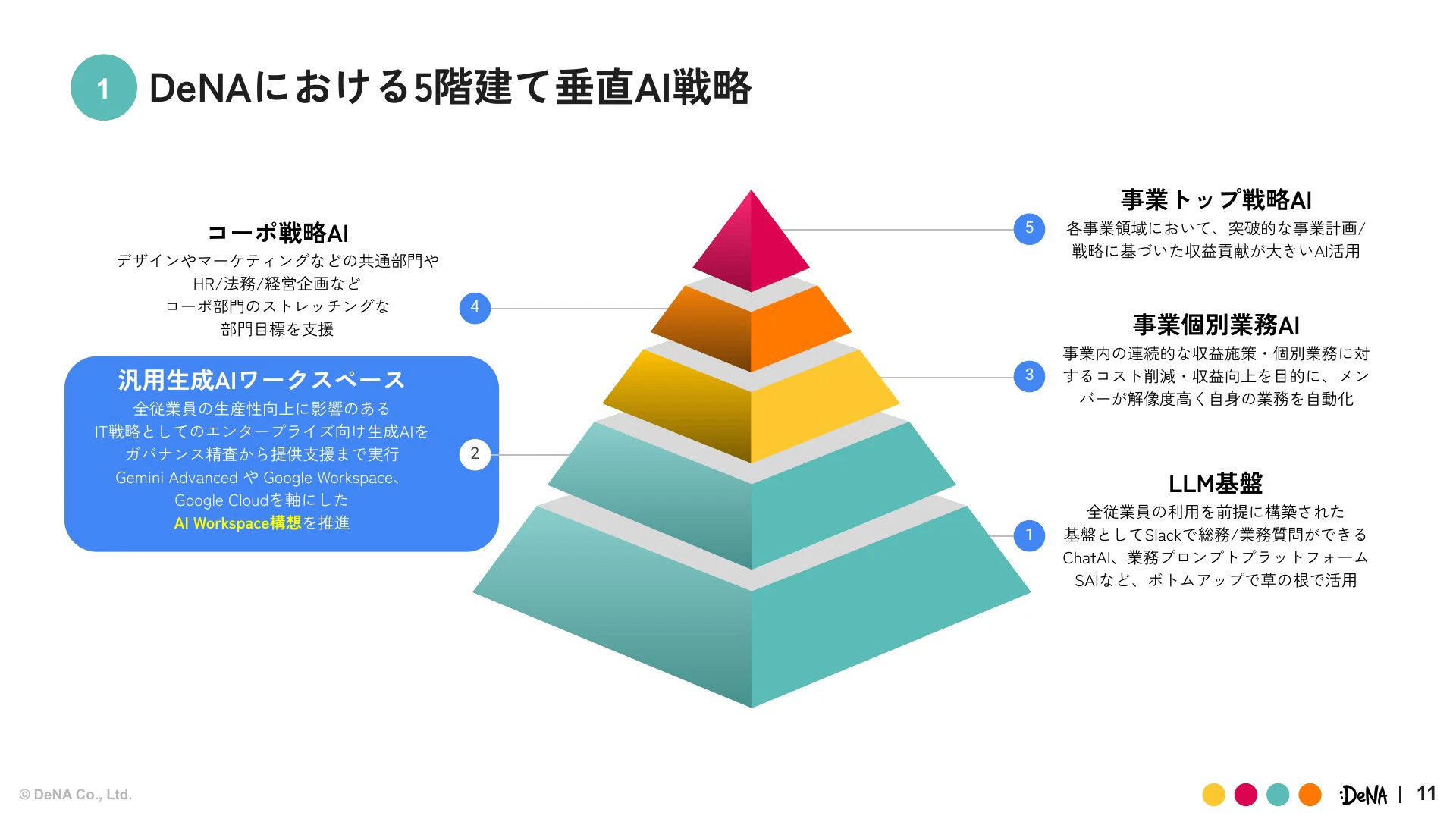
まずは「AIワークスペース構想」についてご紹介させていただきます。弊社には5階建て垂直AI戦略があります。AIワークスペース構想は「汎用生成AIワークスペース」としてレベル2に位置づけられ、全従業員の生産性向上を目的としたIT戦略です。
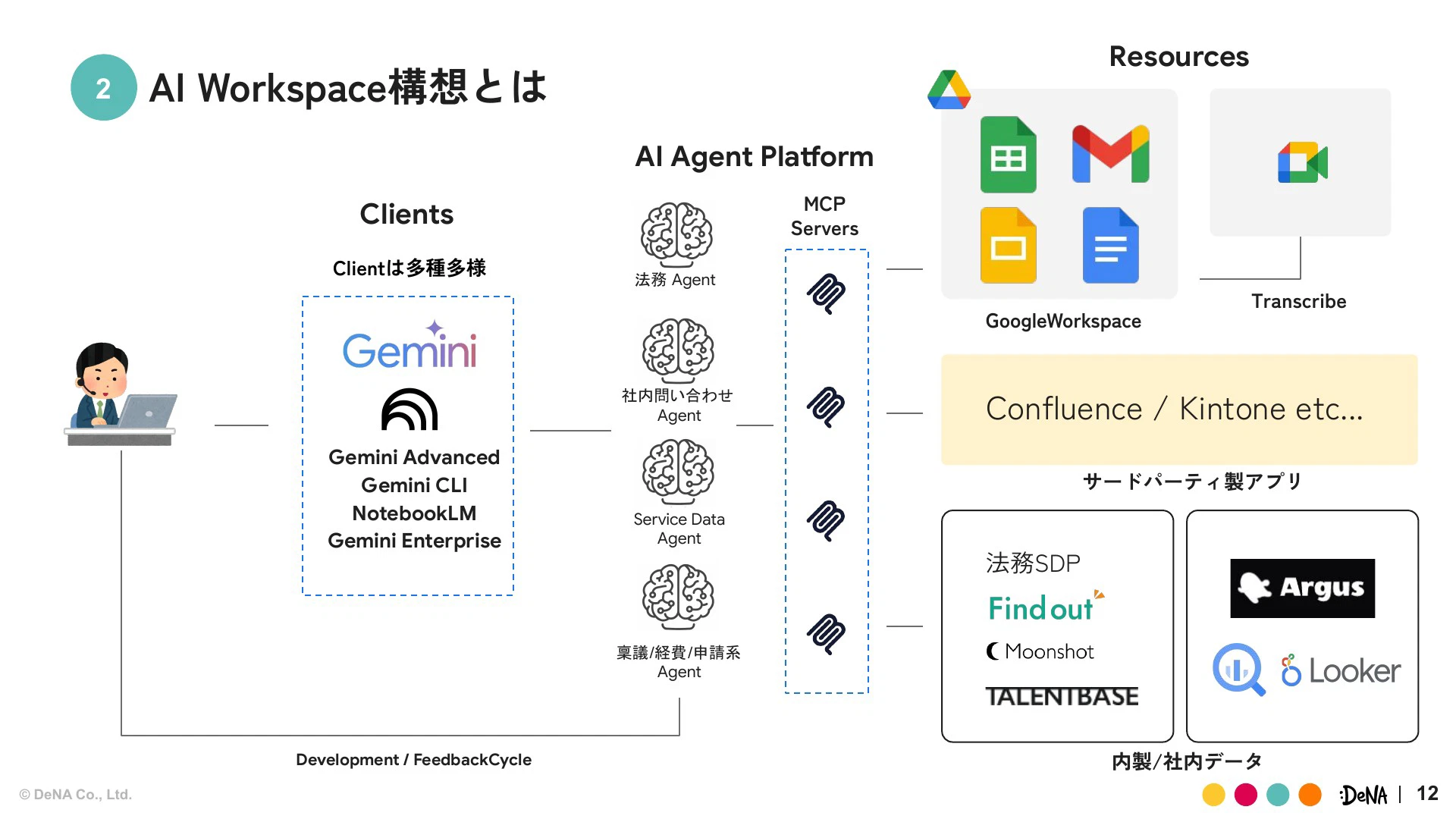
AIワークスペース構想の全体像は、Gemini Advancedなどのクライアントと、Google Workspace、社内データ(Argus、Looker、BigQueryなど)といったリソースの間を、AIエージェントプラットフォームが繋ぐ形です。

DeNAのように多様な事業を持つコングロマリット企業では、事業単位でしっかりセキュリティのガバナンスを持ちながらも、データ活用の柔軟性を保つことが求められます。
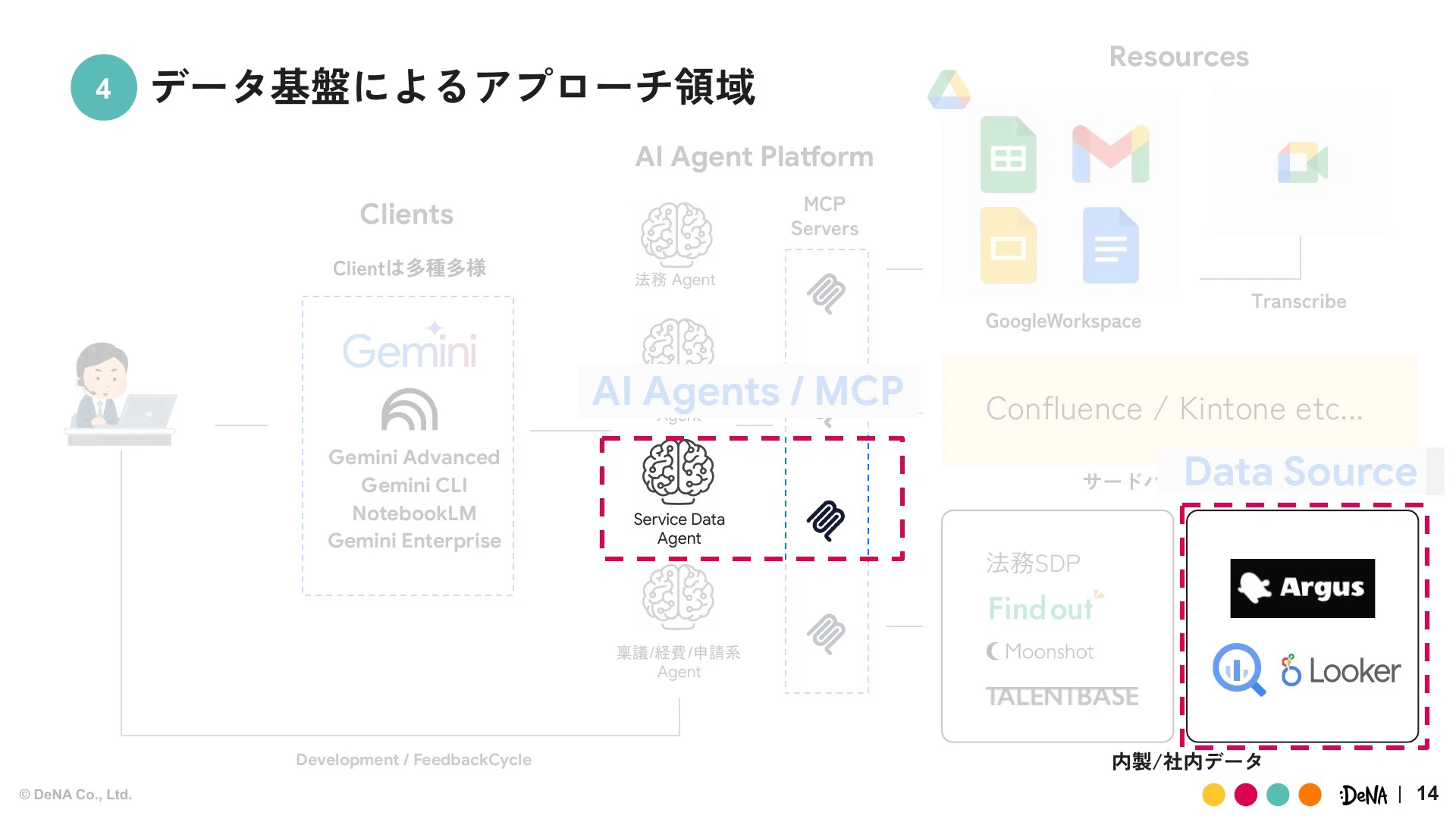
データ基盤部としては、データ活用(攻め)とデータガバナンス(守り)の両方の軸を持っており、このAIワークスペース構想においても、AIエージェントプラットフォームの一部であるAI Agents/MCPと、社内データソースの機能開発という2つの領域を担当しています。
優先したのは「まず動かす」ための要素技術開発

我々が最初に取り組んだのは非常にシンプルで、AIからクライアントがデータ参照を可能にし、使える状態をつくることから始めました。Lookerについては公式のMCPツールボックスを活用しましたが、内製のArgusについては独自にMCPサーバーの開発に着手しました。
なぜここから始めたのかというと、初期の段階では具体的なロードマップが明確に固まっておらず、要件がはっきりしていないという課題があったためです。そこで我々が重視したのは、「まずはつくる、動かす」ということです。
AI特有の不確実性に対応するため、トライ&エラーが非常に重要だと考えました。最初から「こういうエージェントが良い」と深くつくり込むウォーターフォール的なアプローチは避け、ミニマムのサイクルを回して早期にフィードバックを得る体制を目指しました。これは、方向性が変わったとしても迅速に対応できる「要素技術」としての機能開発を優先するという判断でした。

AIワークスペース構想においては、セマンティックレイヤーの拡充は後回しにしています。これは、まずプラットフォームとしてガバナンスを効かせ、AIがデータ参照できる状況の確立を優先したためです。
データ基盤まで含めてAIモデルの改善やコンテキストをどうするかという話は、個別事業でのデータ活用事例からフィードバックを得て判断する必要があると考えました。
認証基盤連携の課題とIdPへのアプローチ

プラットフォーム整備において避けて通れないのが、認証認可のガバナンスです。弊社では長年Oktaを使っていましたが、最近は独自のIdP(アイデンティティプロバイダー)への移行が進んでいました。初期のMCP構築ではスピードを重視したため、APIキーを使った簡易認証でしたが、次のステップとして認証基盤連携をスコープにしました。

我々は独自IdPの開発チームと連携し、MCP仕様に沿った認可機能(OAuth 2.1)の実装などを共同で推進しました。
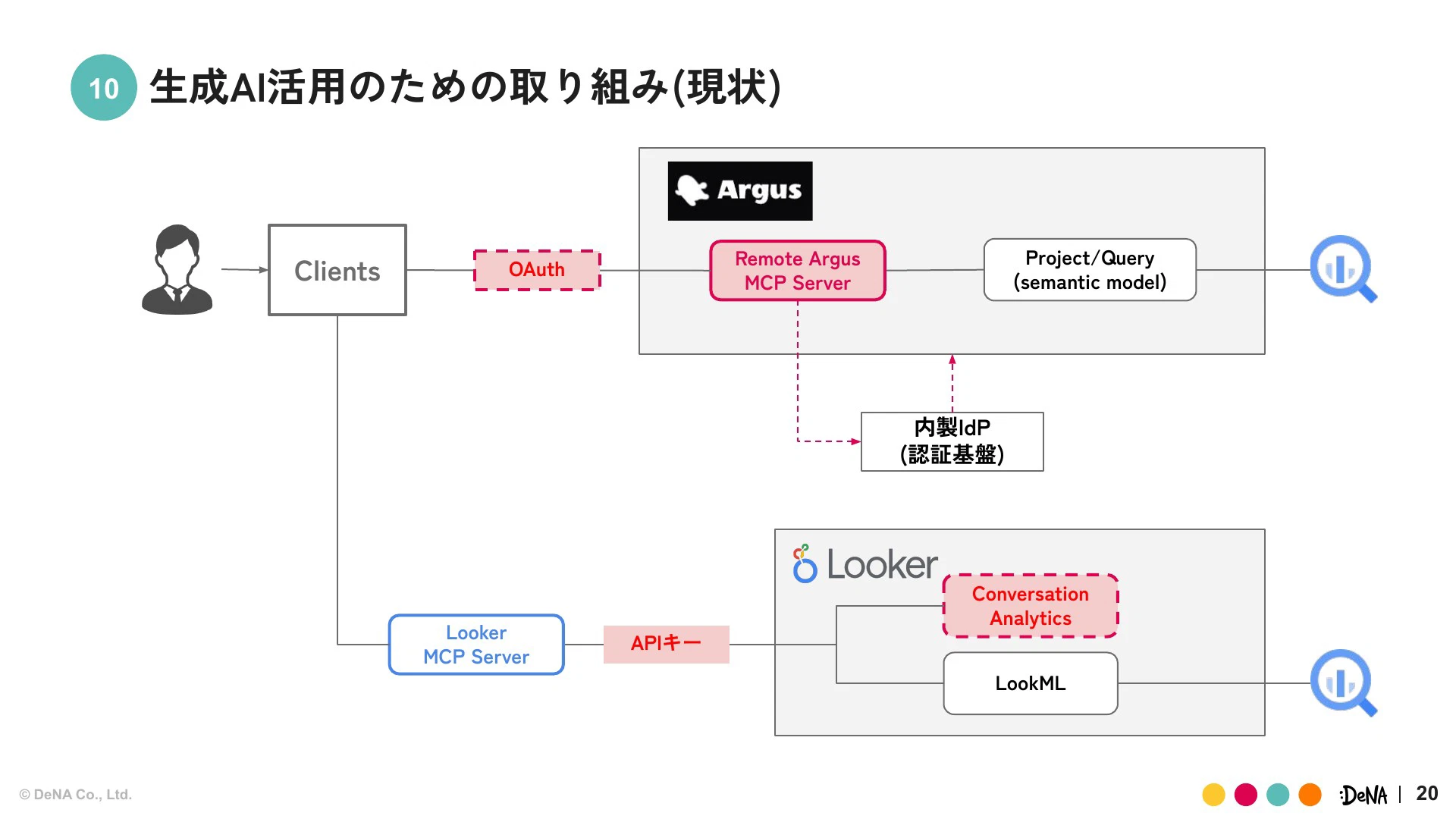
現在、ArgusはリモートMCPサーバーと内製IdPがOAuth連携する形を試しています。Lookerに関しても、技術検証を通じてプラットフォームとして認証を含めてどう提供できるのかを考慮している最中です。
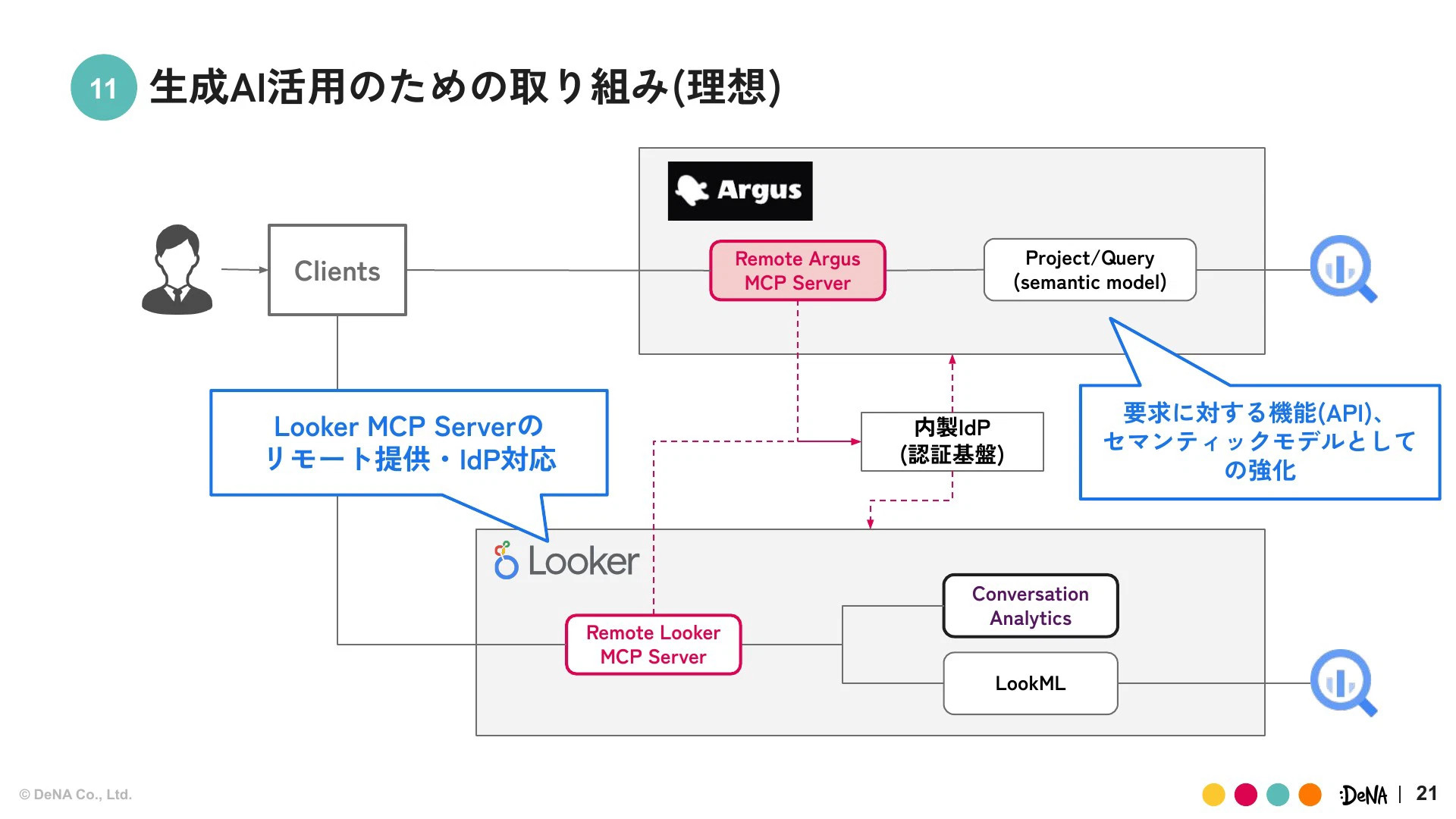
理想については具体的なロードマップが見えていないものの、LookerのAPIキーの部分をIdP対応させていくほか、Argusはセマンティックモデルとしてメタデータを抱えられる状況をつくっていく方向性で開発を進めていきたいと考えています。

権限管理やMCPエコシステムはまだ未熟だと感じています。認証認可や権限周りなど、ワークスペースとして完璧であるべき領域はまだ追いついていません。そのため、現状は共通APIキーを使うことによるデータ閲覧範囲のリスクに対し、アプリケーションレイヤーでユーザー情報から制御するなど、個別対応が避けられない状況です。
我々は、今後MCPの仕様が成熟し、ビッグテックカンパニーからソリューションが出てくる可能性ももちろんあると考えていますが、そこをただ待つのではなく、その間に何ができるかを見極めて推進していくことが、現状のモチベーションです。
個別事業の活用事例:DeNAアカウントでのデータ品質改善
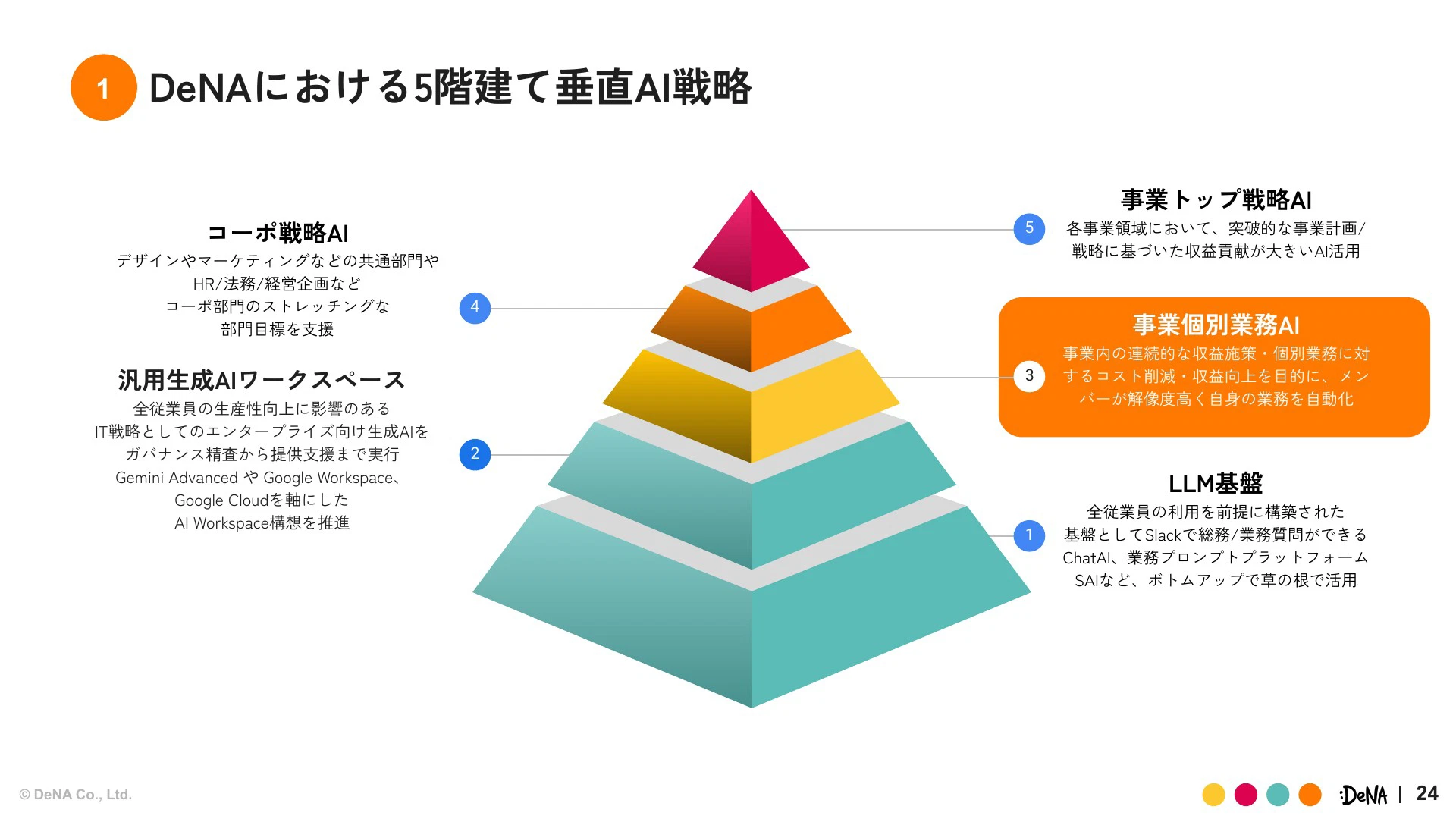
AI戦略のもう1つの柱である「事業個別業務AI」の事例として、「DeNAアカウント」という共通基盤サービスの取り組みをご紹介します。
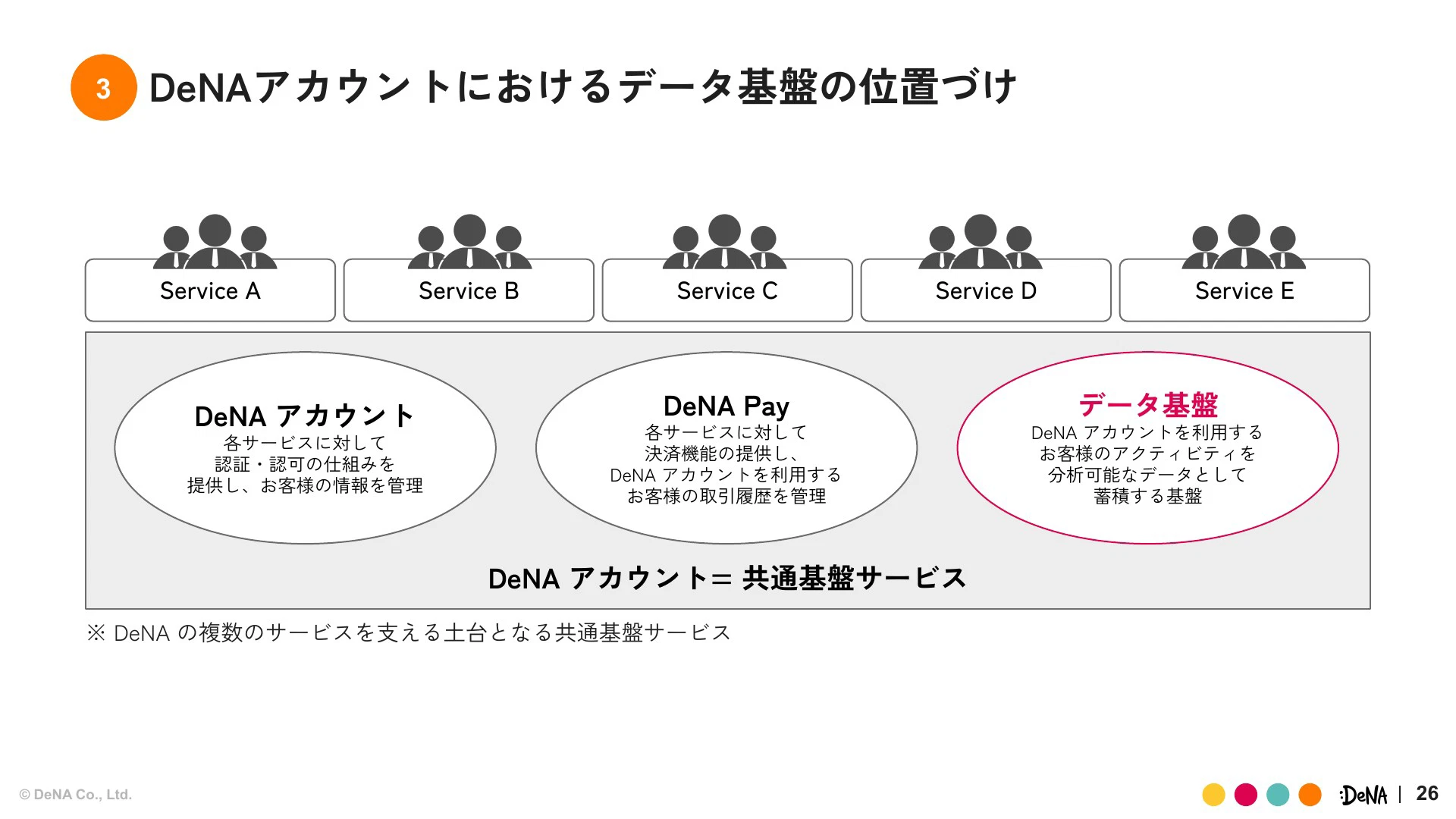
DeNAアカウントは2024年12月にリリースされたばかりのアカウントサービスで、顧客基盤としてのサービス(DeNAアカウント)、決済機能であるDeNA Pay、そしてデータ基盤という3本柱で構成されています。
プロジェクト初期に直面したデータ品質の危機と生成AIを活用した改善プロセス

プロジェクト初期はデリバリー優先で進めた結果、データパイプライン構築とデータ品質の両面で深刻な課題に直面しました。
具体的には、BIツールであるLookerのLookMLモデル上でSQLを直接定義する派生テーブルが乱立し、KPIの統一ができなくなってしまいました。さらに、LookML周辺のエコシステムが未熟だったため、派生テーブルの実装が原因で、フォーマッターを適用しただけでモデルが破壊されるという問題も発生しました。データエンジニアリング固有の、データ品質に直結した問題に陥っていたわけです。

この課題に対し、我々はまず「データ品質担保」を最重要ミッションとして、半年間集中して改善に取り組みました。
我々はBigQuery環境でLookML上にSQLを直接書くのをやめ、dbtパイプラインにデータ処理を完全に集約しました。並行してKPIの要件整理や、dbt test、Elementaryの導入による品質担保とモニタリング強化も実施しました。
さらに、このデータ品質改善プロセスに生成AIを積極的に組み込みました。エージェントを使ってデータモデリングのコンテキストを整備したり、dbtテストケースの自動生成を行ったりしました。また、プルリクエストのレビューにもエージェントを導入し、開発全体の効率化を図りました。結果として、KPIの乱立やデータ欠損の検知ができない状況は解決し、生成AIのための基盤が整ってきました。
品質向上で浮上した新たな工数課題と生成AIでの対応

データ品質の課題が解決し、事業部門でのデータ活用が進み始めると、今度はデータエンジニアやアナリストへの要求が膨大になるという新たな問題が浮上しました。細かいデータ可視化や連携要求が多発し、工数が増大しました。
そこで、これらの細かいニーズを生成AIで解決できないかというアプローチに着手しました。
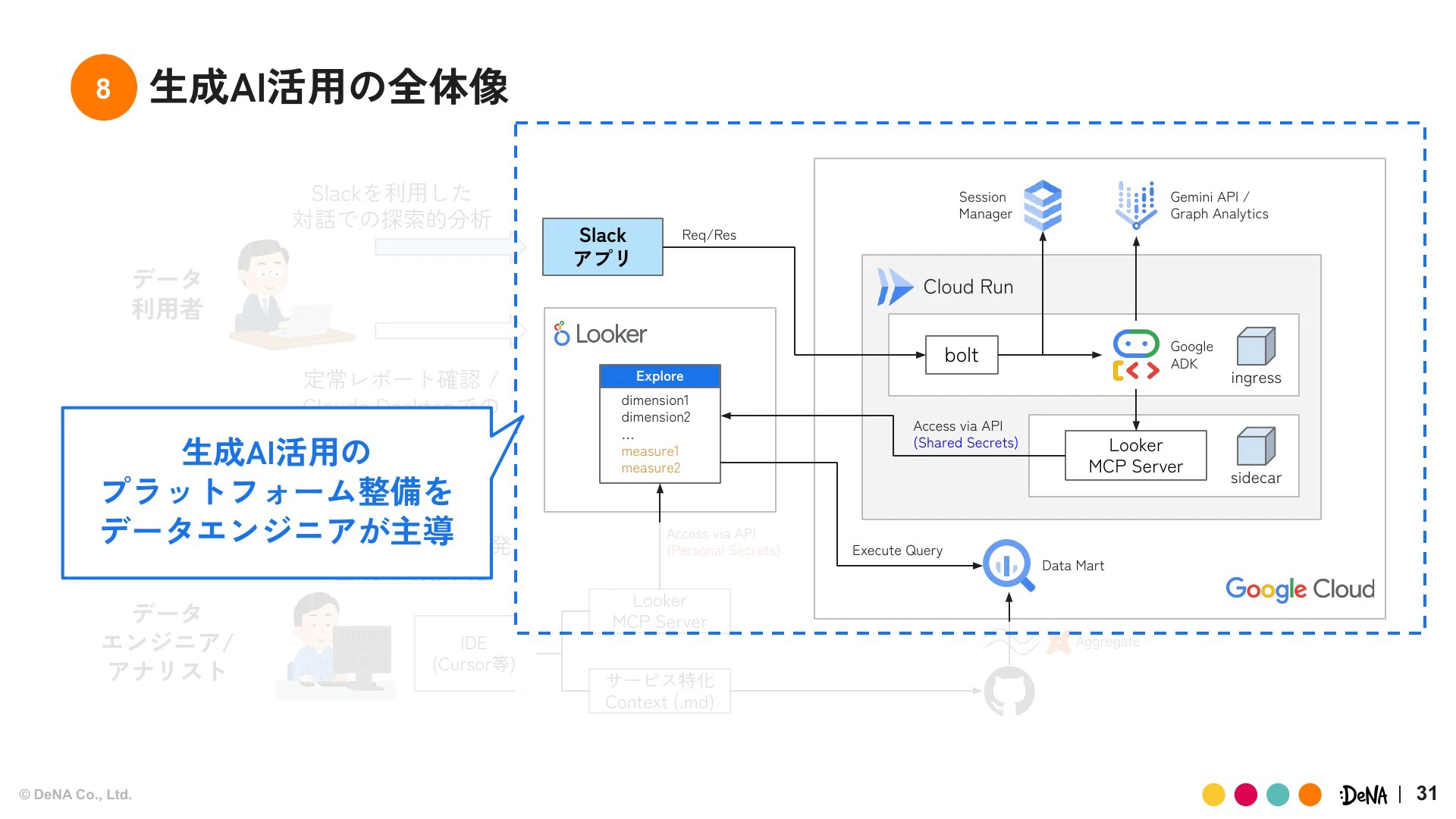
我々は、Google Cloudを実行基盤とし、AIワークスペース構想と同じくLooker MCPサーバーを組み込んだAIエージェントを開発しました。LookMLを参照してセマンティックモデルを拡充し、分析活用できる状況をつくりました。
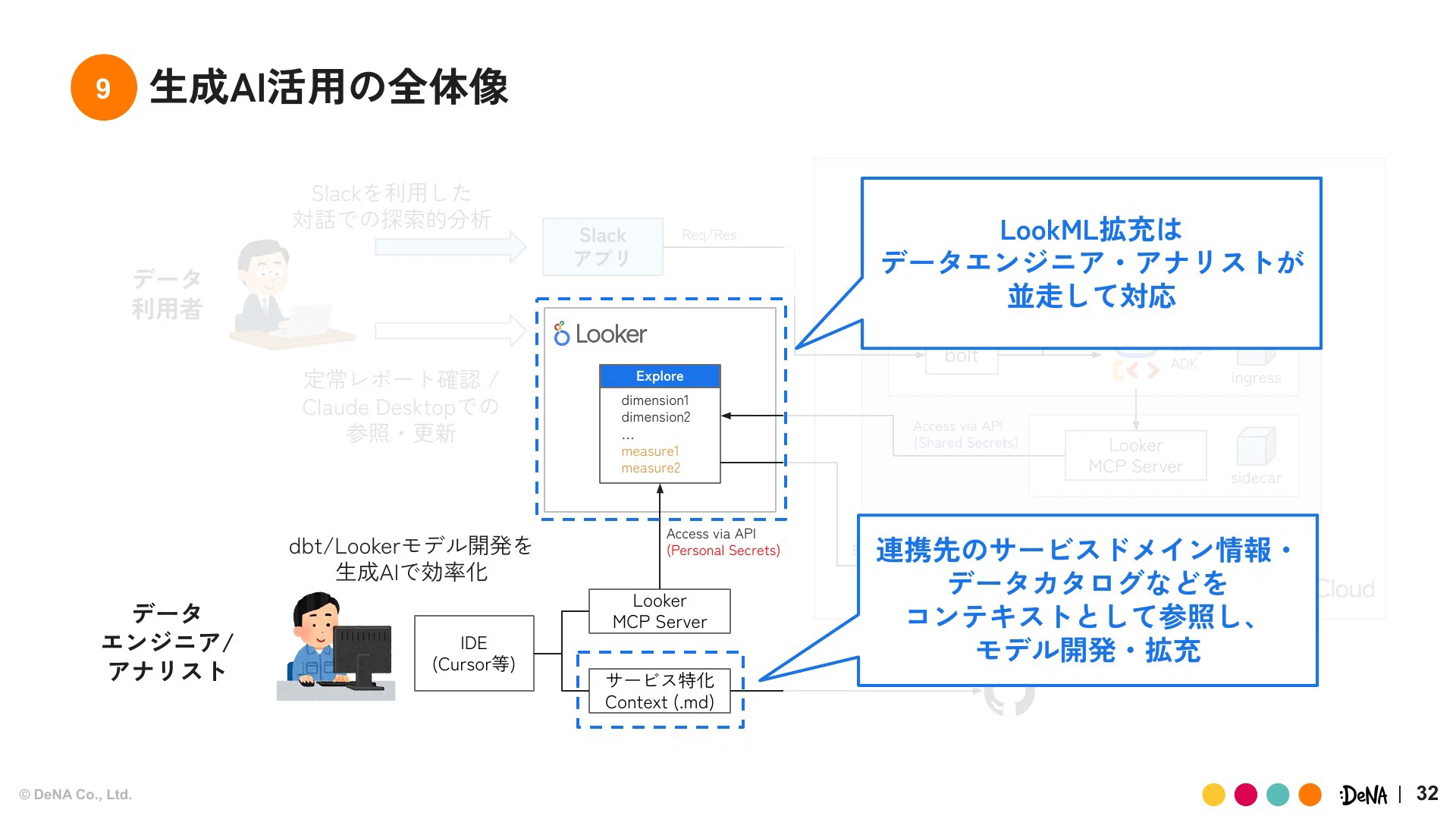
これと同時に、データエンジニアやアナリストの業務効率化についても環境整備を行いました。連携サービスのドメイン情報やデータカタログなどをコンテキストとして整備しモデル開発の効率化を図ってきました。
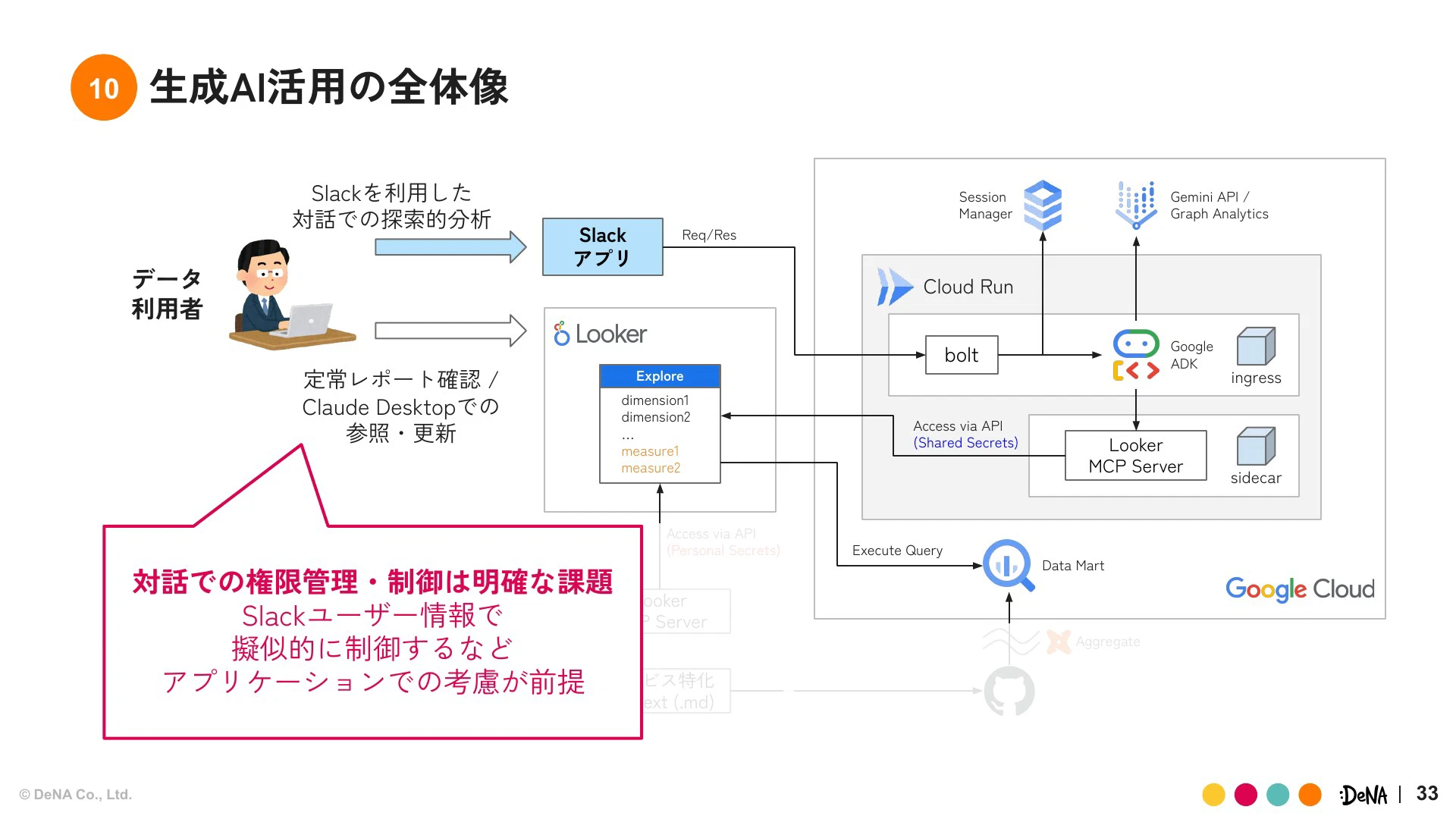
さらに、全ユーザーにLookerライセンスを配るコストを避けるため、Slackアプリとしてインターフェースを提供し、全社員が生成AIをクライアントとして利用できるようにしました。ユーザーはSlackで自然言語で問い合わせをすると、裏側でAIエージェントがLookerのAPI認証を使いデータを参照し、レポートの要約や解釈を出力してくれます。
これにより、細かいニーズや小さな要求は、ある程度の対話で吸収できる状況をつくりつつあります。
コンテキスト整理はセキュリティのガードレールにもなる
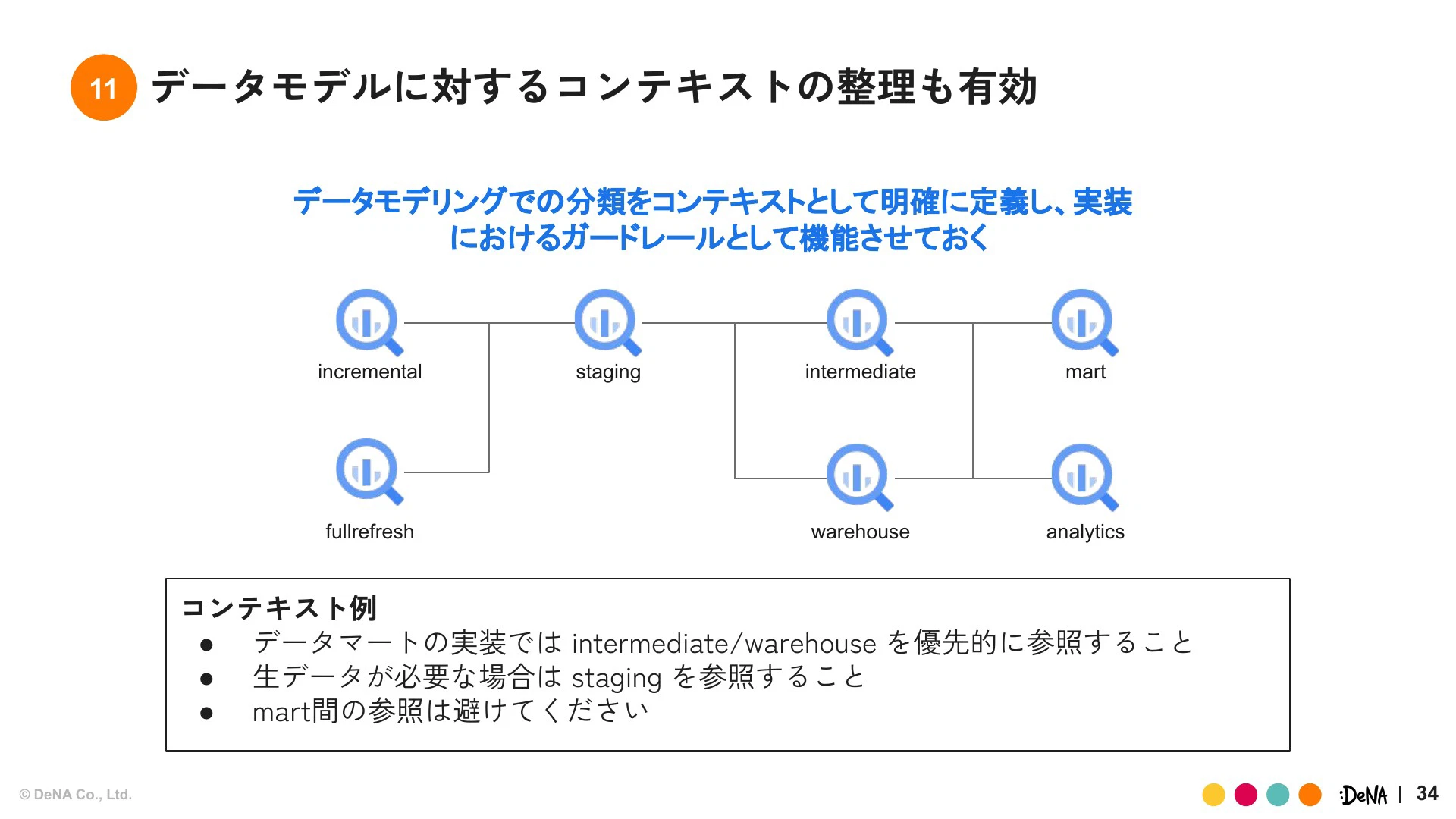
データモデリングにおけるコンテキストの整理は、非常に有効でした。例えば、「データマートの実装ではintermediate/warehouseを優先的に参照すること」「生データが必要な場合はstagingを参照すること」「mart間の参照は避けること」といったルールを明確に定義し、それを生成AIに学習させました。
これにより、効率化が進むだけでなく、セキュリティ的なガードレールとしても機能しました。モデルが不十分だと、加工されきっていない個人情報に抵触する可能性があるステージングを参照してしまうリスクがあるため、参照を制限するコンテキストはガバナンス的に有効です。
生成AI時代のデータエンジニアの仕事

開発効率化からデータ活用まで、生成AIをフル活用している状況ですが、結果として工数削減や業務効率化にしっかり寄与しています。
しかし、データエンジニアの仕事は決して減ったわけではありません。むしろ、データ品質担保やメタデータ整備といった「人間向け」の業務に加え、「生成AI向け」にも仕事をしないといけない状況になっており、業務のスコープが別のベクトル、つまり生成AIの面倒を見るという方向にも向かっています。
不確実な時代を乗り越えるマインドセット

最後に総括として私が一番お伝えしたいことは、「生成AI時代において、データ基盤とデータエンジニアリングの重要性はますます高まっている」ということです。AIがデータを参照するという意味では、従来のメタデータやデータカタログの拡充は、これまで以上に精度高く、徹底してやっていかなければなりません。
ただし、これを全てデータエンジニアが担うのではなく、AIと向き合って共存し、技術の多様性を受け入れながら、うまく役割を分離して効率化していくことが、今後生き残る上での重要なポイントだと考えています。
不確実性のある状況においては、組織として「トライしていく」というマインドを持ち、本質的な課題解決が価値提供に繋がる状態へ向かわせていくことが非常に重要だと思っています。
私からのお話は以上です。ご静聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





