



【Data Engineering Summit】ジャパンダッシュボードを支えるデータ分析基盤sukuna〜特別でない設計の話〜
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」がオンラインで開催されました。
本記事では、デジタル庁 ファクトアンドデータユニット データエンジニアリードの長谷川 亮さんによるセッション「ジャパンダッシュボードを支えるデータ分析基盤sukuna〜特別でない設計の話〜」の内容をお届けします。
長谷川氏は、柔軟性と堅牢性のバランスをどう取るか、技術的負債をどう扱うかなど、データパイプライン全体を俯瞰した設計思想を解説。プロジェクト全体を管理するマネジメント層や、スキル領域を広げたいエンジニアにとって学びの多い内容となりました。
■プロフィール
長谷川 亮
デジタル庁 ファクトアンドデータユニット データエンジニアリード
「ジャパンダッシュボード」を支えるデータ分析基盤の設計哲学
ご紹介にあずかりましたデジタル庁の長谷川です。よろしくお願いいたします。本日は、「ジャパンダッシュボードを支えるデータ分析基盤sukuna」というテーマでお話しさせていただきます。

メインとなるのは、データ分析基盤の設計哲学についてです。デジタル庁でデータ分析基盤を実際につくる時、我々が何を考えたのか、そして技術的負債をどのように捉え、要求から仕様検討、開発、運用まで、データパイプライン全体をどう設計したのか、そのフルスタックな話をお届けします。
技術的に新しい挑戦などの話はあまりありません。メジャーな技術ばかりを組み合わせてつくっていますので、先端領域を攻めたい方には退屈かもしれません。しかし、長く持続可能な基盤をつくるための哲学について聞いてみたい方には、ご清聴いただけると嬉しいです。
政策可視化の要、「ジャパンダッシュボード」
まず、私が関わっている業務についてです。私はデジタル庁で、政策データダッシュボードと、それを支えるデータ分析基盤「sukuna」の開発・整備を担当しています。
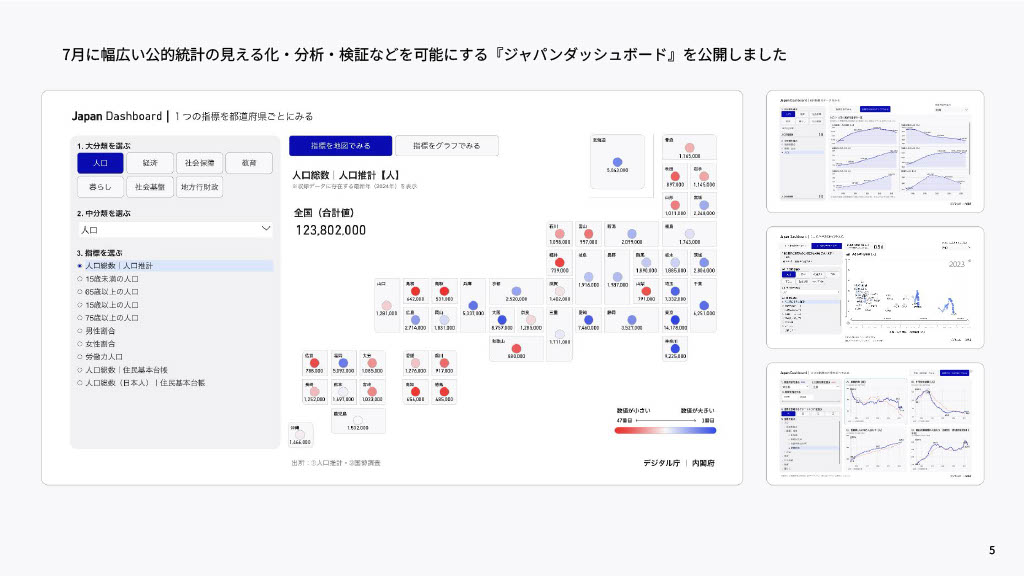
この「ジャパンダッシュボード」というのは、内閣府と共同で7月にリリースした、経済・財政・人口と暮らしに関するパブリックなデータダッシュボードです(2025年12月現在、GDPに関するジャパンダッシュボードも公開中)。パブリックですので、誰でも見ることができます。中身は、人口データや出生率、地方の財政データなど、いろいろな公的統計が入っています。もともと、公的統計は散らばっていましたが、それらを「見える化しましょう」という内閣府の取り組みに対し、デジタル庁が時系列表示やデザイン面の強化で協業させていただき、ダッシュボードで提供しています。
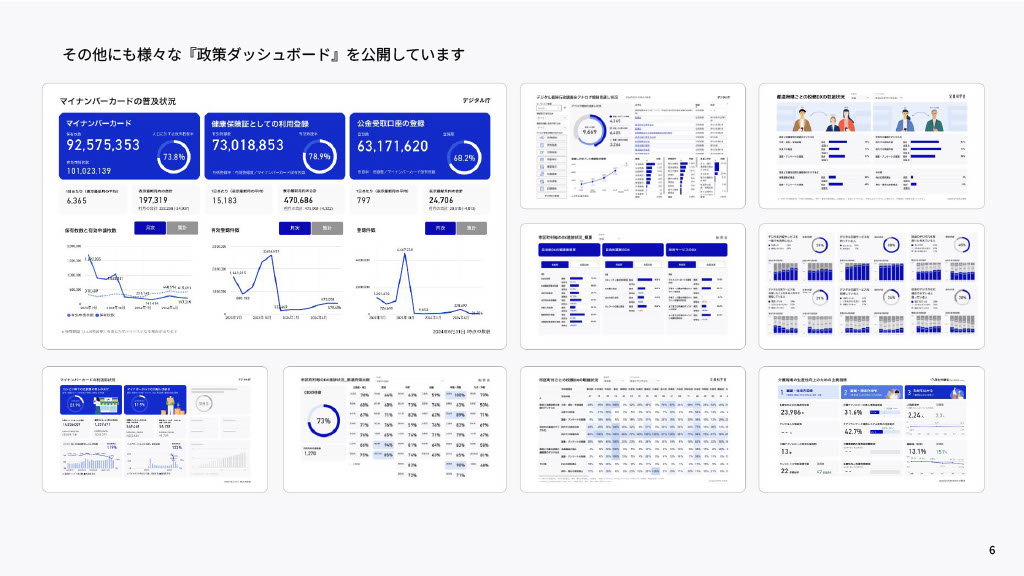
このジャパンダッシュボード以外にも、マイナンバーカードの利用状況や自治体のDX状況など、様々な政策ダッシュボードをデジタル庁のホームページで公開しています。これらのダッシュボードの裏側にあるのが、データ分析基盤「sukuna」です。名前は日本神話から取っています。政府内の様々なデータソースを取り込み、加工し、ダッシュボードで閲覧できるようにする一連のシステム群、これが「sukuna」です。
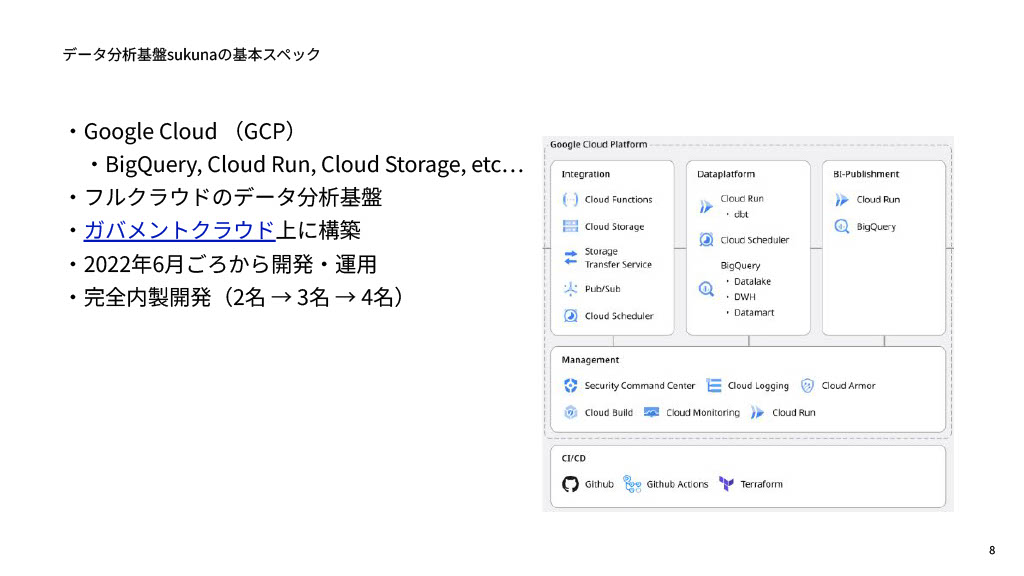
「sukuna」の基本スペックですが、政府だからといってオンプレミスでやっているわけではなく、フルクラウドでGoogle Cloud上に構築しています。BigQueryやCloud Run、Goolge Cloud Storageといったメジャーな技術を使っています。また、AWSやAzure、Google Cloud Platformなどと政府が契約した環境である「ガバメントクラウド」上に構築しています。開発運用は2022年6月頃から開始しており、すべて完全内製開発です。最初2名だったチームは、現在4名くらいで運用を行っています。

この「sukuna」は、ざっくり3つの層に分かれています。データソースから取り込むIntegration層、データを加工するDataplatform層、そして加工したものをBIツール向けにお出しするPublishment層です。この3層に分けて、順にご説明します。
Integration層:データの下ごしらえ

Integration層でやっていることは、データソースからデータを受け取り、なんとかしてBigQuery上にあるデータレイクにロードさせるところまでです。例えるなら、芋掘りで採れた芋を、まな板に乗せられる状態にまで下ごしらえするのと一緒です。不要な土を落とし、根っこを切り、不揃いな形や虫食いを切って、フォーマットを整える作業です。

我々が扱うデータソースは多岐にわたります。自治体や医療機関向けのアンケートデータ、政府システム上のRDBからエクスポートされたデータ、kintoneやSalesforceなどのSaaSからのAPIレスポンス(JSON)、ガバメントクラウド上のシステムから吐き出されるストリーミングログなど、案件によって様々なフォーマットがあります。そのため、案件ごとに柔軟に取得・加工方法を変える必要があります。

柔軟さが求められる最大の背景が、政府が持つデータのフォーマットの問題です。昔、データを紙で役所の掲示板などに貼り出すことを前提に工夫されたレイアウトを、そのままExcelに移し替えたものが多数存在します。そういったExcelを僕は「紙エクセル」と呼んでいます。そういったレイアウトのエクセルは、セル結合が複雑だったり、年度ごとに項目が異なったり、PDFでしか公開されていなかったりして、機械可読性やデータ活用という観点で問題を抱えています。デジタル庁としてもこの課題を認識しており、今年発表された政府文書(データ利活用制度の在り方に関する基本方針、2025年6月13日)の中にも「セル結合の回避」などデータ整備の必要性が言及されています。
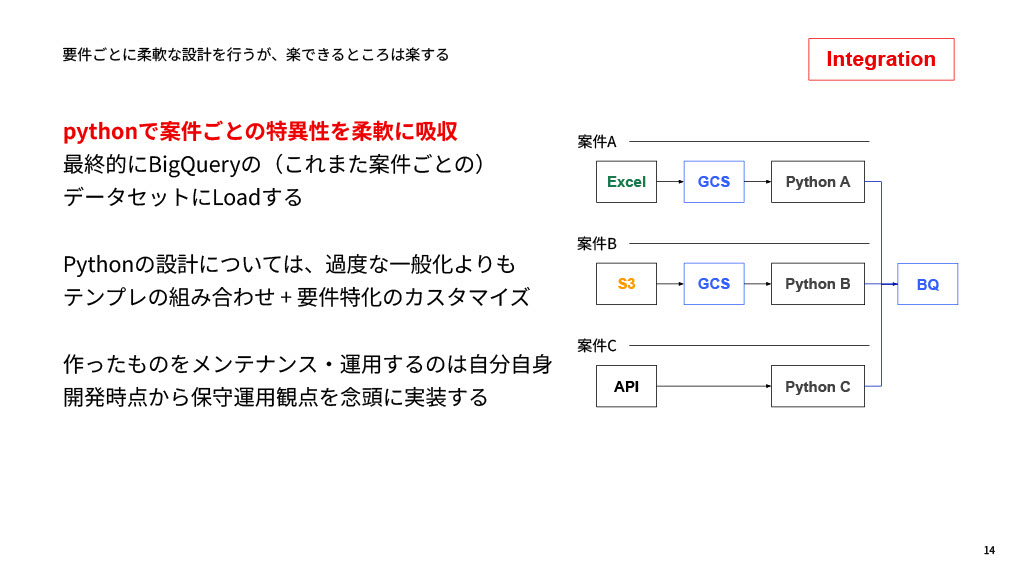
では、これらの柔軟なデータソースをどうBigQueryに入れるかというと、Pythonで案件ごとの特異性を柔軟に吸収しています。過度に一般化させたツールをつくるより、使い回せるテンプレートを組み合わせ、要件ごとに特化したカスタマイズを行って処理しています。我々には運用事業者が別に存在するわけではないので、つくったものを運用・メンテナンスするのは自分自身です。そのため、「将来運用するのは自分だから、自分が楽になるように」開発・実装することを心がけています。
ロードの際の方針として、Pythonで加工しすぎないことを意識しています。なぜなら、データソースと遜色ない状態、つまりExcelで開いた時に人間が受け取る情報と、BigQuery上のテーブルから得られる情報が大体同じになることを念頭に処理を行っています。レコード単位やカラムは極力変えません。

ここまでを「最低限の下ごしらえ」と定義しています。Pythonで読み込んでいるのであれば、自在に加工できるのではないかと考えがちですが、加工しすぎないのは、何か問題が発生した時にExcelまで戻らずBigQueryの上でSQLを使って調査を終わらせたいからです。SQLのほうが調査スピードは格段に早く、運用も楽になります。
Dataplatform層:データの加工

Integration層でBigQueryにデータをロードした後、いよいよデータモデリング、メインの加工をやっていくのがDataplatform層です。調理のメイン工程、つまりキッチンでやっていること全般ですね。この層では、ダッシュボードをつくる初期と、リリース後で調理の仕方を明確に分けています。
初期段階:技術的負債を積極的に借り入れるフェーズ

初期段階はデザインやデータソースの仕様、利用者の想定などが並行して進むため、BIの仕様は必ず二転三転します。ここでデータの仕様を早々にに設計し終えてしまうと、柔軟性やスピードが失われます。
そこで、この段階ではBigQuery上のデータももビュー形式で各人が柔軟につくって対応しています。

初期段階でもdbt(data build tool=SQLのデータ変換に用いられるツール)を使いますが、この目的はデータレイクのデータを「ちょうどいい塩梅」に加工するためです。分析目線やBIツール間での参照目線で使いやすいデータ構造を、データエンジニアの勘どころも交えてつくります。
もちろん、ダッシュボードに求められる背景やビジネス要件、データの仕様なども理解しておく必要もありますが、ここではあえて完璧を目指さずに、「多分こうなっていれば使いやすいだろう」というふんわりとした目標でモデリングを行っています。
リリース後:技術的負債を返済するフェーズ

一方で、リリース後は状況が一変します。政策のモニタリングや現場業務、行政・政府会議の委員等からの質問対応に使われるため、データの加工・モデリングには安定性、堅牢性、品質が求められます。公共性の高い部分なので、属人性や柔軟性は廃して、ガチガチにdbtで設計・加工を行います。
この段階で、初期に借り入れた技術的負債をどんどん返済していくフェーズに入ります。堅牢性、検証可能性、メンテナンス性を重視します。

最終的なモデリングでは、ビューなどで実装していたロジックもすべてdbtに移行し、最適なモデリングにつくり直します。処理の都合上、一番安く、早く動くような技術的なモデリング、そしてメンテナンスする観点を含めた最適な形を目指します。また、この段階でデータソースの取得元や制度の背景といったメタデータもdbtのソース情報としてしっかり記録しておきます。これは今後のAI時代や保守運用面で非常に重要になります。
データの逆流と混線を許さないガバナンスルール
モデリングを進める上で、いくつかのアンチパターンは考えられますが、例として以下の2つを定義し、排除しています。
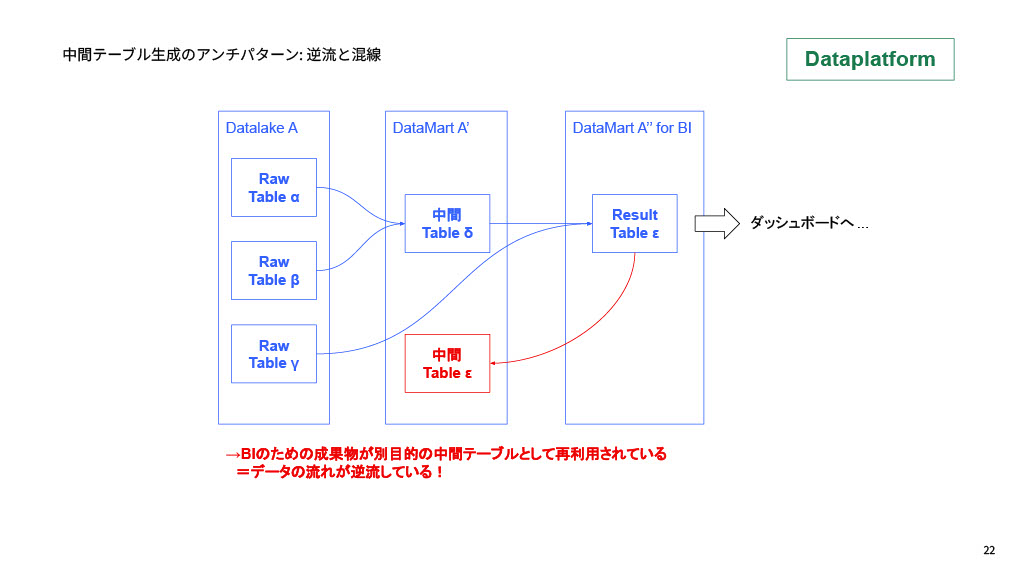
- データが逆流している:ダッシュボード参照用のデータマートを別目的のテーブルをつくるためのソースとして再利用(逆流)してしまうこと
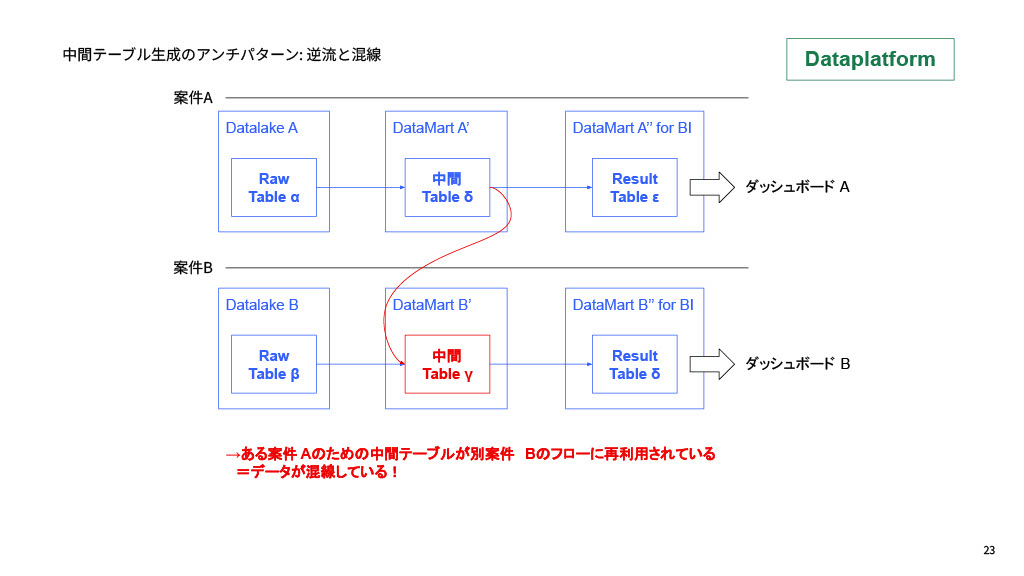
- データが混線している:ある案件Aのためのデータパイプラインの中間テーブルを、別の案件Bから参照(混線)してしまうこと
これらの不都合が起きないよう、開発時のルールを敷いています。例えば、データセット単位で必ずプレフィックス、サフィックスを指定し、何のためのデータセットなのかを明示するルールなどです。

具体的な例として「教員の働きやすさに関する校務DX」のパイプラインでは、データレイクの名称は「dl_school_dx」になっています。「dl」というのはデータレイクのことを指しており、ここではIntegration以外からのデータ作成禁止、dbtからは参照しかできないようになっています。その次の「dm_school_dx」はデータ分析基盤の三層構造におけるウェアハウスに近く、dbtでモデリングを行い、データレイクと中間テーブルのみ参照するようになっています。そして最後の「dm_school_dx_bi」はBI参照用のデータマートと定義しており、参照用に加工されたテーブルのみ配置しています。パフォーマンス効率化のために全て実体テーブルとして保存し、ビュー形式は禁止としています。

なぜこのように細かいルールを適用しているかというと、データ加工ロジックやモデリングの部分が最も絡まりやすく、頻繁に変更が起こりやすいからです。新しいデータソースへの対応、フォーマット変更、ビジネス要求によるKPI追加、テーブルの廃棄など、様々な要因による変更がある中で、絡まりを防ぐためにメンテナンス性重視のルールを適用し、それに従った開発をしていくべきという哲学を持っています。目指すのは、データエンジニアが「ここのモデリングは美しいね」と思えるようなモデリングです。最初から美しく完璧である必要はありませんが、最終的に美しいモデリングになることを諦めずに取り組み続けるのが大切です。

ダッシュボード開発の初期段階ではBigQueryのテーブルもビューで自由につくって柔軟に対応するとご説明しましたが、このアプローチを我々は「積極的な技術的負債の借り入れ」と表現しています。ダッシュボードのステークホルダーに「このデータの可視化には意味がある」と認識させ、取り組みを前進させるためにはスピードと品質が必要です。緩い仕様に対応できるような緩いモデリングで素早く結果を出すことが初期段階では重要です。
反対に、リリース後は堅牢性や検証可能性、継続性などを重視しなければならないため、厳格なルールのもとでモデリングを行います。このようなフェーズの移り変わりのことを、我々は「Agile & Fragile」から「Trust & Robust」と表現しています。
Publishment層:参照範囲の制御と自動化の徹底

Publishment層では、BIツールからデータが参照され、無事に可視化されるまでを担っています。つまり、加工が終わった料理をお皿に盛り付け、顧客に提供するところです。
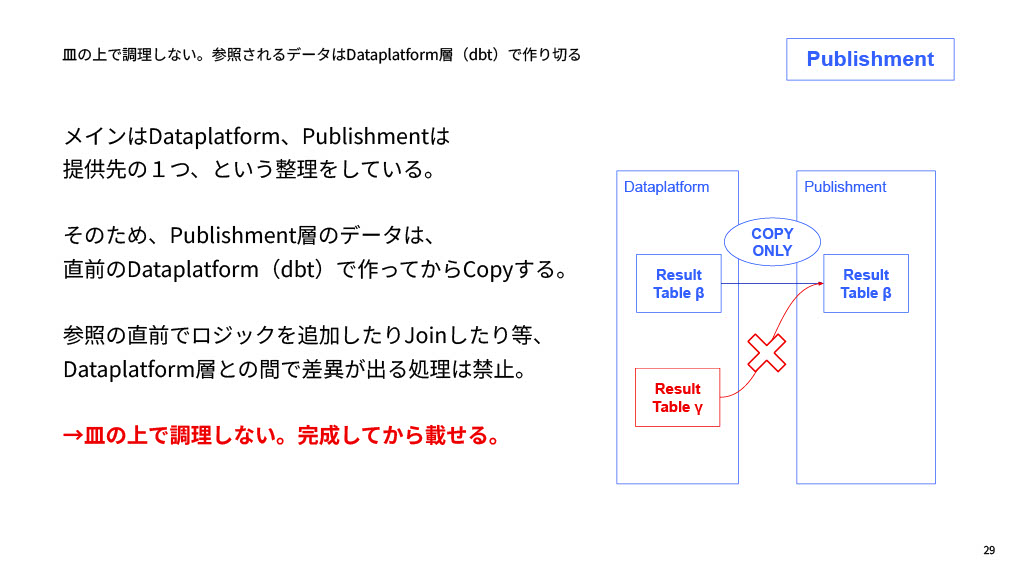
ここで徹底しているのが、「お皿に盛ってから料理はしてはいけない」という思想です。メインの加工モデリングはDataplatform層(厨房)でやり切ります。そのため、Publishment層では、ロジックの追加やテーブル結合などの処理は禁止しています。Dataplatform層でつくってから、Copy Onlyで提供します。
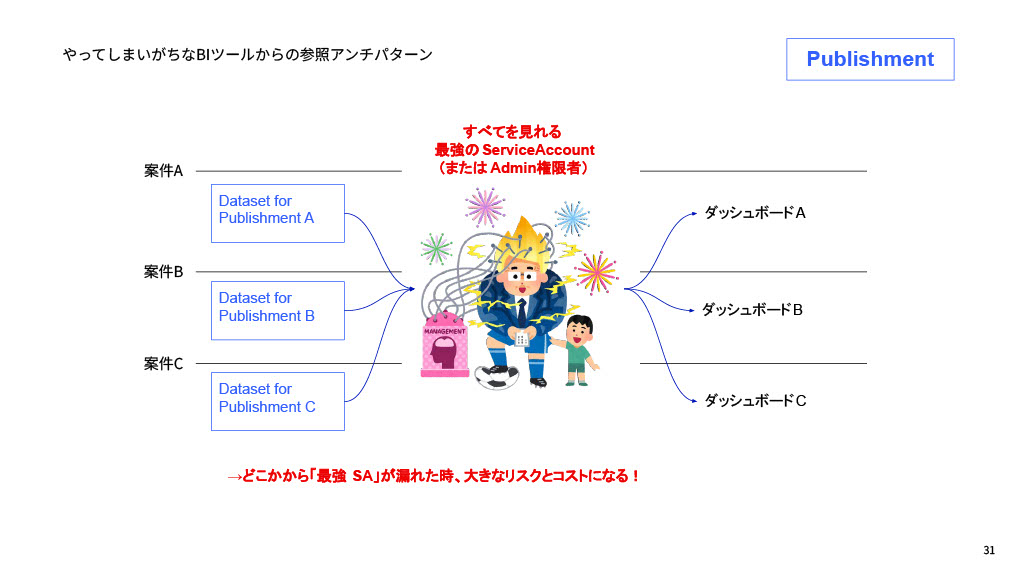
この層で特に重要になるのが、参照権限の管理です。現在、政策ダッシュボードは16〜20個前後を運用していますが、もし「すべてを見れる最強権限のSA(サービスアカウント)」を使っていると、SAが漏洩した時に大きなリスクとコストになります。

我々デジタル庁では、仮にどこかからSAが漏れても漏れるデータは一部でしかないことを担保するため、1つのダッシュボード案件に1つのデータセット、それに対応する1つのSAでデータを持っていく運用にしています。これにより影響範囲が限定的になりますし、ダッシュボードを改修する時に誤って別案件のデータを見てしまうリスクも統制できます。

そして、自動化できる部分はすべて自動化します。初期段階ではデータの取込みや加工に人力運用を許容しますが、リリース後はとにかく人力で動いている部分はなくしていく思想です。政策ダッシュボードの数は年度ごとに倍になるペースで増えており、人力運用ではそのうち破綻します。人間が動かしていることが一番のコストでリスクですので、基盤のコストとリスクを圧縮し続けるために、必ず機械化して人による運用をなくしていくという思想で自動化を進めております。
継続的な価値提供の哲学
最後に、みなさんのデータ分析基盤は「10年後も保ちますか?」という視点を持っていただけるといいなと思っています。特に我々行政の分野はタイムラインが長く、1つの政策に10年、20年かかることがあります。「最初の数年しか可視化できません」では不十分です。きちんと運用し続け、価値提供し続けられるバックエンドであるためにはどうあるべきか、と考えることが大事だと思います。

我々の場合、長く価値提供し続けるためには、「ちゃんとつくって、安くつくって、楽につくる」のが大事だと思っています。ちゃんとつくらないと壊れる、安くつくらないと金がなくなる、楽につくらないとしんどくなって続かなくなる。これらは相反するようで、実は相反しません。「ちゃんと安く楽につくる」のが、我々データエンジニアのプロフェッショナルとしての腕の見せどころかなと思っています。
そして、エンジニアがずっと価値提供し続けるためには、ルールやツール、プロセスに加えて、それをサポートするための人の体制や教育も必要です。幸せなエンジニア生活を送るためには、データやAIとコミュニケーションするだけでなく、周りのビジネスサイドの人たちとコミュニケーションし、ぜひ対人戦を進めていただければと思います。
私からのお話は以上となります。ご静聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





