



【Data Engineering Summit】NTT docomoにおけるデータ活用基盤の現在と未来
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」がオンラインで開催されました。
本記事では、株式会社NTTドコモ R&Dイノベーション本部 サービスイノベーション部ビッグデータ基盤 兼 ネットワーク本部 ネットワーク部技術企画部門のプリンシパルデータエンジニア、松原 侑哉さんによるセッション「NTT docomoにおけるデータ活用基盤の現在と未来」の内容をお届けします。
セッションでは、ビッグデータ基盤が直面する中央集権の限界、そしてそれを乗り越えるためのデータメッシュの具体的なアプローチ、さらに間もなく到来するAIが当たり前の世界に向けたデータ戦略が語られました。
■プロフィール
松原 侑哉
株式会社NTTドコモ R&Dイノベーション本部 サービスイノベーション部ビッグデータ基盤 兼 ネットワーク本部 ネットワーク部技術企画部門
Principal Data Engineer
NTTドコモのビッグデータ分析基盤の歩みと現状

NTTドコモの松原と申します。私はデータエンジニアとして、データ分析基盤やWeb3、LLMといったビジネスでデータを活用する基盤周りの開発・運用を担当しています。現在は社内のビッグデータ基盤の保守・開発・運用などを行っております。また、様々な技術コミュニティの運営にも参画しておりますので、どこかでお会いすることがありましたらよろしくお願いいたします。

※2025年1Q時点
まずは当社の事業とデータ基盤の現状についてご紹介させてください。当社は皆さんご存知の通り、通信事業を主軸としつつ、dポイントクラブなどのスマートライフ事業、法人事業を幅広く展開しています。特に通信事業は当社の源流であり、5G必須特許シェアが世界第3位、通信事業者の中では首位を誇るなど、技術的なリソースとバリューを保持しています。
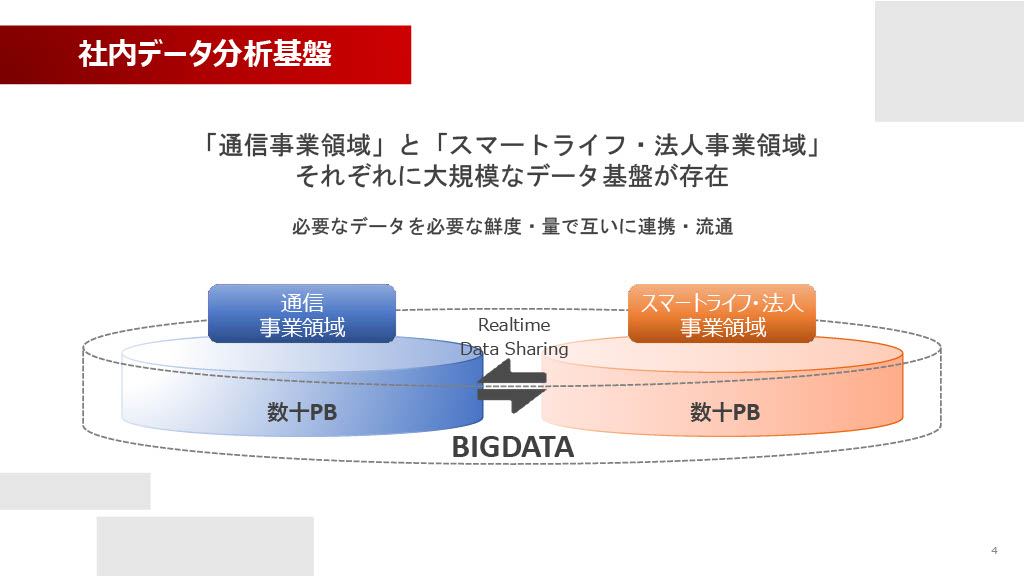
この大規模な事業を支える社内データ分析基盤は、大きく分けて「通信事業領域」と「スマートライフ・法人事業領域」の2つが存在しています。通信事業領域のデータは憲法で「通信の秘密」が定められていることもあり、非常にセンシティブな情報を取り扱います。このため、高いレベルのセキュリティとガバナンスが必要となり、明示的に基盤を分けて運用しています。もちろん、許容される範囲で相互のデータ連携は行っています。
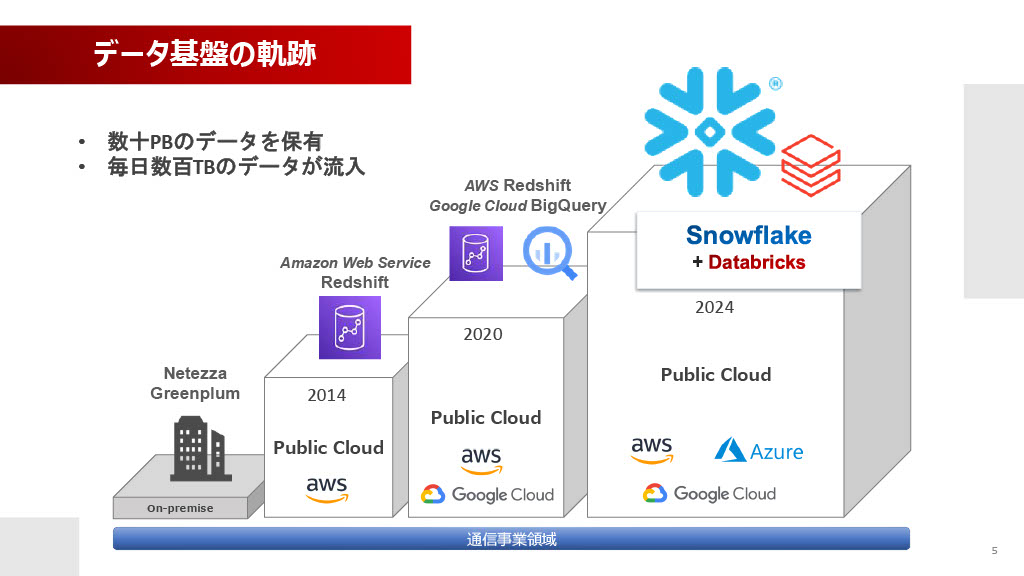
特に今回メインでお話しする通信事業領域のビッグデータ分析基盤は、およそ10年前、2014年頃のオンプレミス環境(NetezzaやGreenplum)からスタートしました。その後、クラウドへ移行し、AWS Redshift、Google Cloud BigQueryとの組み合わせを経て、現在はSnowflakeとDatabricksを組み合わせて運用しています。パブリッククラウドはAWS、Azure、Google Cloud Platformを利用しており、この基盤はすべて内製開発で構築・運用されています。
保有データ量は圧縮後で数十ペタバイト、毎日数百テラバイトのデータがバッチ/リアルタイムで流入しています。通信系のデータは数値が多く圧縮率が高いため、圧縮が解かれるとデータ量が10倍程度に跳ね上がることもあります。ビッグデータ基盤と言いつつ、保持期間が3日しかないデータもあるなど、データマネジメントには様々な側面があります。
AI-Readyな世界への視点と、中央集権の限界
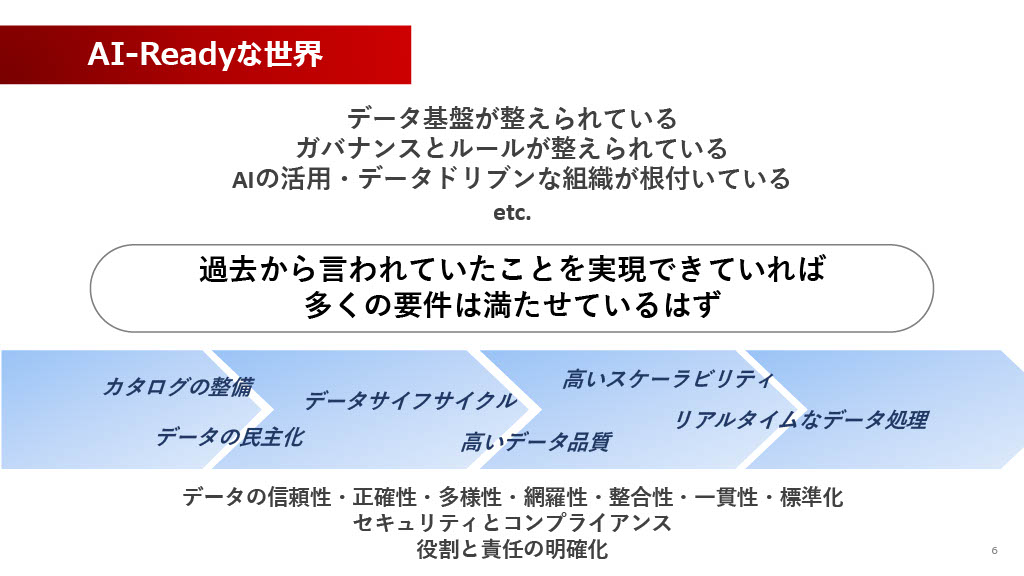
今回のサミットのキーワードは、やはりAI活用です。「AI-Ready」な世界とは、データ基盤が整い、ガバナンスとルールが整備され、データドリブンな組織が根付いていることだと考えられます。
私は個人的に、過去からデータ活用領域で言われてきたこと、例えば「データの民主化」「カタログの整備」「リアルタイムなデータ処理」「データ品質の向上」といった要件がきちんと実現できていれば、AI-Readyに必要な基盤の要件は最低限ほとんど満たされているのではないかと思っています。もちろん当社でも、完璧にできているかと言われれば「No」な部分もありますが、過去からの課題解決の積み重ねが重要だったという認識です。
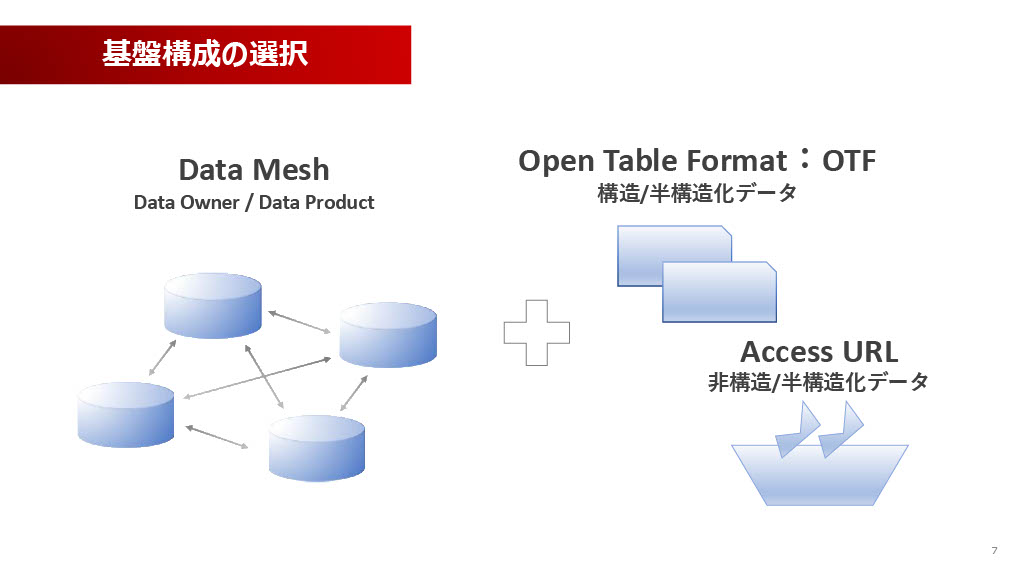
AIを活用していく未来に向けて、我々が今、発展させていこうと考えている、あるいは推進しているキーワードは主に3つあります。それが、Data Mesh、Open Table Format(OTF)、そしてAccess URLです。このうち、Data Meshについては後ほど詳しくご紹介させていただきます。Open Table FormatはApache Icebergなど、Access URLについてはAWSで言うならはS3のPresigned URLなどを想定していただくと良いと思います。
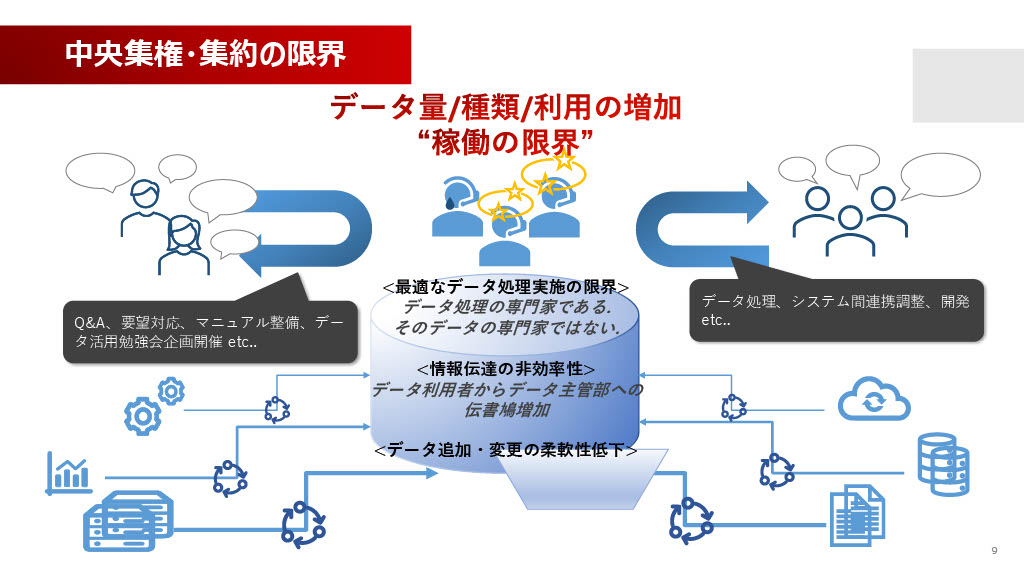
この方向性を推進するに至った背景には、従来の「中央集権・集約モデル」が限界に達したという明確な課題意識があります。
これまで、通信事業領域のビッグデータ分析基盤は、データウェアハウスやレイクと呼ばれる一つの大きな箱に、社内の様々なシステムからデータを集めていました。そして、その大きな箱を運用・開発するチームがデータの処理を行い、適切な権限をつけて利用者に公開するという、中央集権的な統括を行っていました。
しかし、当社のチームは全体で20名に満たず、ほかの基盤の運用も兼任しているため、集中して手を加えられるメンバーは10名以下という小規模体制です。データ量、種類、そしてAI活用による利用が爆発的に増加した結果、チームがデータを集めて処理し提供するという作業が限界に近づいています。
さらに深刻なのは、我々はデータ処理の専門家ではあっても、そのデータのビジネス的な意味や、利用しやすい形にするためのドメイン知識を持てていないことです。そのため、データの意味に関する質問や要望を、データ利用者とデータを生み出す主管部との間で、我々のチームが「伝書鳩」のように仲介する形となり、非常に非効率になっていました。この非効率性、すなわち対応スピードの低下は、昨今のAI活用スピードにまったく追いついていません。
中央集権から分散へ:「データはプロダクトである」
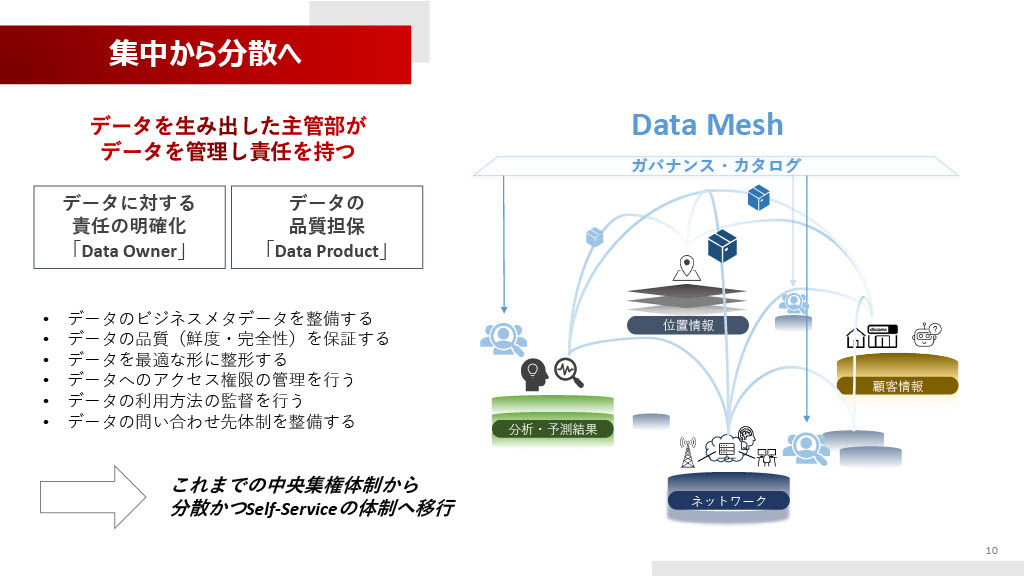
この非効率な中央集権体制を打破するために、我々は「Data Mesh」という概念を推進しています。
Data Meshでは、データを生み出すシステムを持つ主管部がデータオーナーとなり、そのデータに対して責任を持ち、適切な形に整形してユーザーに公開します。つまり、「データは商品(プロダクト)である」という認識を持っていただいています。
データオーナーには、データの品質(鮮度・完全性)の保証、ビジネスメタデータの整備、データへのアクセス権限の管理、問い合わせ先体制の整備など、多くの責任が明確化されます。
Data Meshの公開先は、いわばECサイトやフリーマーケットのような「カタログサイト」です。ユーザーはそのサイトでデータプロダクトを選択し、購入(サブスクライブ)の申請を行い、承認フローを経てデータを利用します。
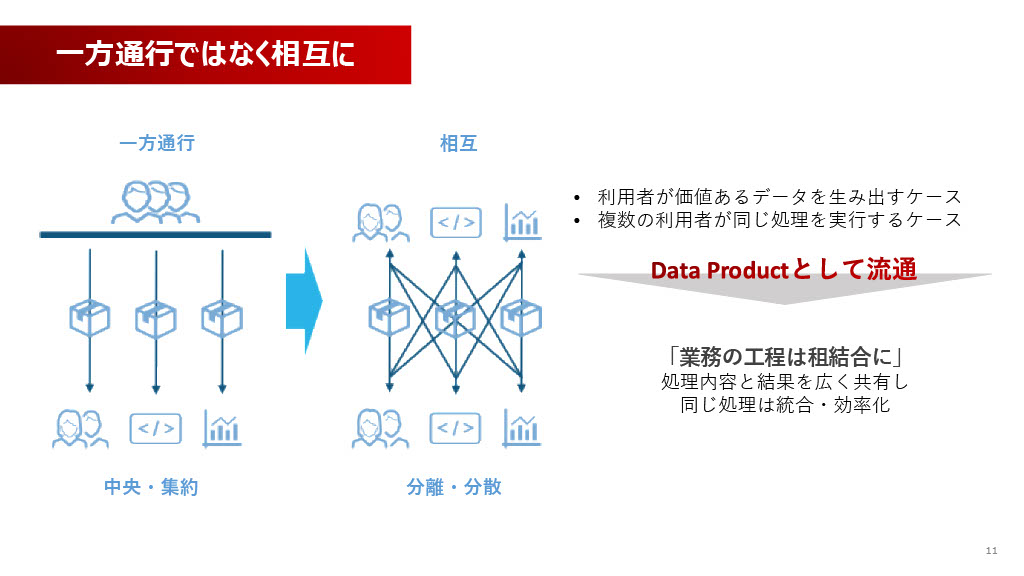
この転換により、中央集権の一方通行だったデータ流通が相互になります。これは、主管部だけでなく、今まで個人やプロジェクト単位でデータを利用していたユーザー自身が、分析を通じて新しい価値を生み出した結果のデータ(例えば分析結果や予測モデル)を、Data Productとして出品できるようになることを意味します。これにより、複数の分析者が共通の分析を重複して行わなくて済むなど、様々な効率化が期待できます。
もちろん、この分散かつセルフサービスの体制への移行は、データを生み出す主管部の負担を増やすことになります。また、出品するだけでは、その部署の評価が上がらない(実質的なメリットがない)という、組織的な課題も同時に発生します。これは後述するCoE活動で解決を図っている最中です。
処理性能と鮮度を両立する「アクセス権の流通」
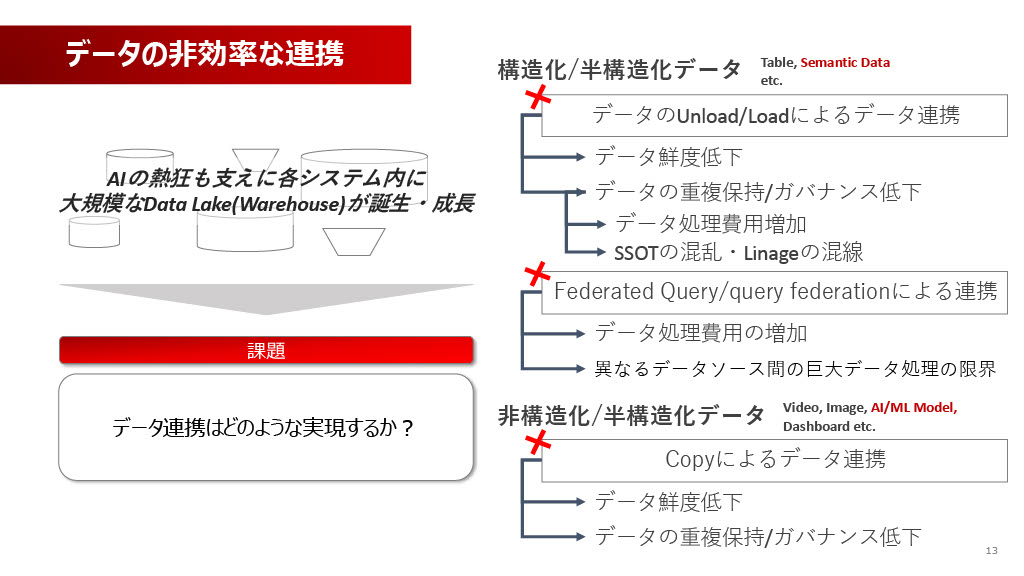
Data Meshの推進と並行して、もう一つ重要なのが、データ連携のあり方です。AI活用の熱狂を背景に、社内にはデータレイクやウェアハウスがリアルタイムで増えており、データ連携をどう実現するかが大きな課題になっています。
従来のデータのUnload/Load(コピー)による連携では、データ鮮度の低下、データの重複保持、ガバナンス低下といった問題が生じます。特に我々が扱う通信事業領域のテーブルは非常に大きく、数テラバイトで数兆レコードがあるテーブルもざらにあります。
このような巨大テーブルに対して、Federated Queryのような連携機能でジョインを含めた分析をさせようとすると、処理が回らずに爆発してしまうため、機能として使えません。非構造化データ(ビデオ、イメージ、AIモデルなど)のコピーも同様に、鮮度や重複の問題を招きます。
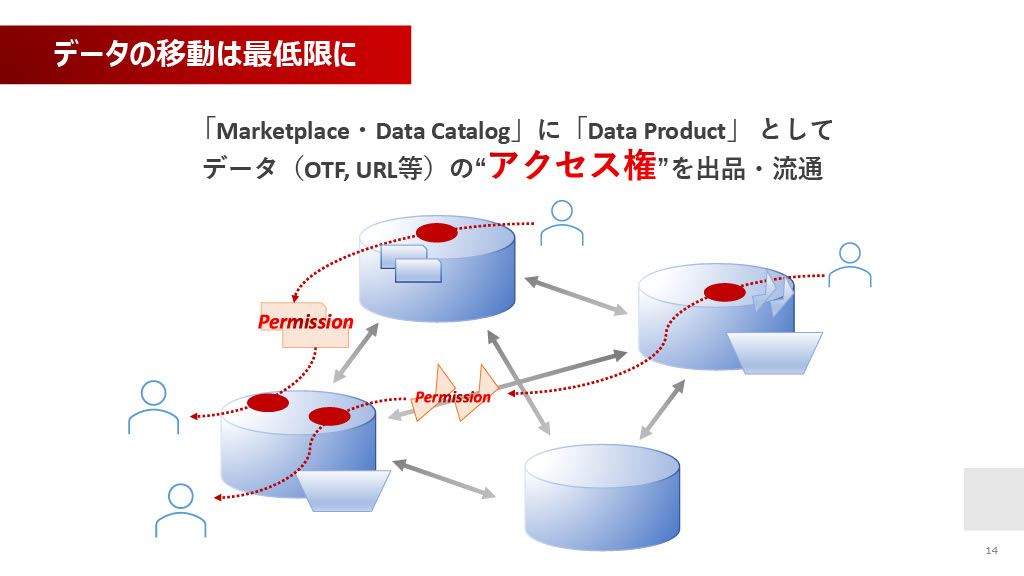
そこで、我々は「データの移動は最低限」という方針を採っています。
データの丸ごと移動ではなく、データ(OTFやURLなど)の「アクセス権」をMarketplace・Data Catalogに出品し、流通させます。Open Table Format(OTF、Apache Icebergなどを想定)やAccess URL(AWS S3のPresigned URLなどを想定)といった技術を用い、各レイクやウェアハウスにあるデータはそのままに、ほかのウェアハウス内からそのアクセス権を用いて組み合わせ分析を可能にします。
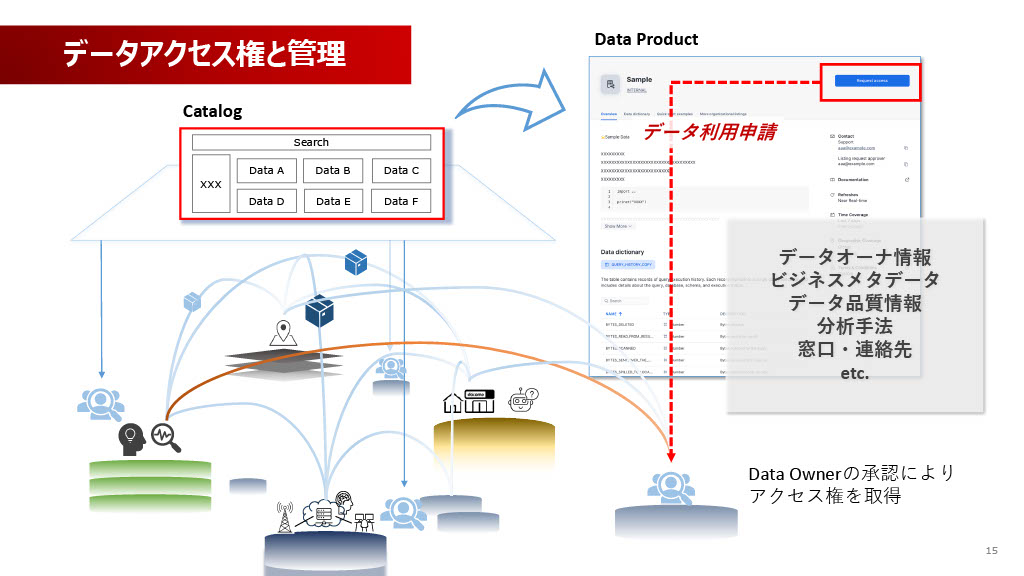
出品されるData Productには、データオーナー情報、ビジネスメタデータ、品質情報、分析手法、問い合わせ窓口など、一通りの情報が記載されます。利用者はこのカタログを見てデータ利用申請を行い、データオーナーの承認を経て、アクセス権を取得するという流れで進めています。
データ処理を担ってきたチームの新しい役割:育成とCoE活動
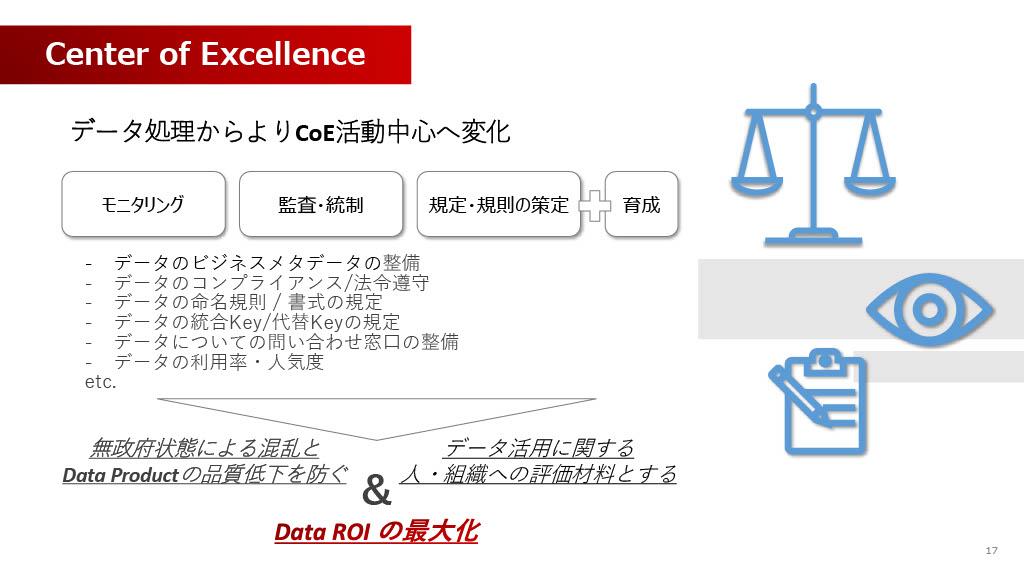
データメッシュによってデータ処理の役割が分散された結果、もともと中央集権でデータ処理を行っていたチームは何をするのかという疑問が残ります。もちろん、社内ニートになるわけではなく重要な新しい役割があります。それが「育成とCoE/コンサル活動」への変化です。
データメッシュを無条件に進めると、カタログに謎のデータ(意味のないゴミデータ)が出品され、リストが汚され、無政府状態になってしまうリスクがあります。
我々CoEは、この無法地帯化とData Productの品質低下を防ぐ役割を担います。具体的には、モニタリング、監査・統制、そして出品ルールや命名規則、コンプライアンス遵守といった規定・規則の策定を行います。また、データごとのルールを決めておかないとデータ同士の突合ができない可能性があるため、そういった統括も行います。
そして、最も重要な役割の一つが育成と評価体制の構築です。データ出品を行う方々への育成はもちろんのこと、データオーナーがデータを出品し、それが活用されることによって評価されるというインセンティブ評価体制をつくっていく必要があります。これにより、「データROIの最大化」を目指し、組織全体としてのデータ活用の価値を高めていく、といった形で活動を進めています。
AIが自己判断する未来を見据えたデータ基盤
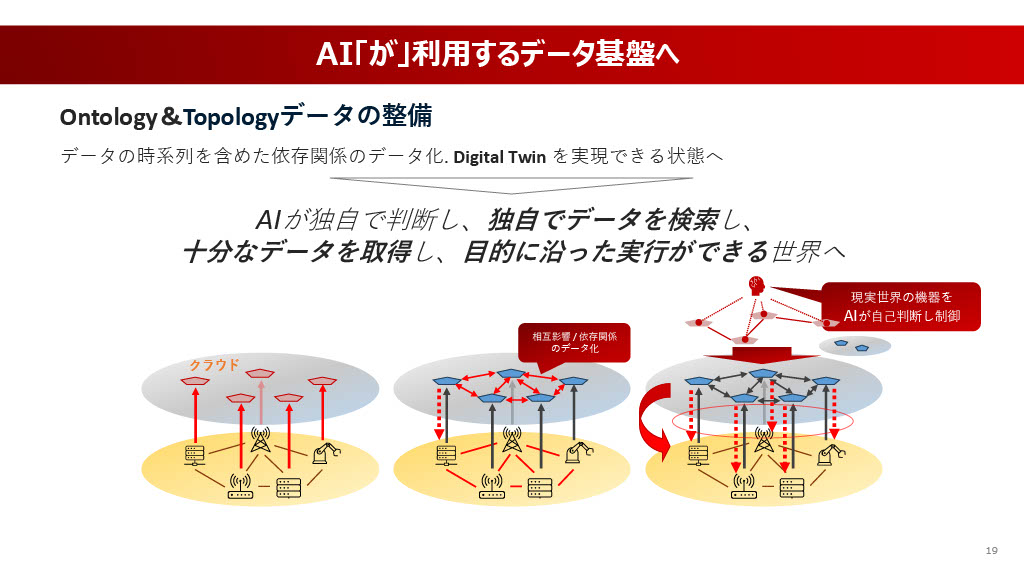
AIが当たり前の世界に向けて、我々がどのように次のステップを見据えているかをお話しします。
将来的に、AIは単に人間が用意したデータを利用するだけでなく、AIが独自で判断し、独自でデータを探し、取得し、目的に沿った実行を自己判断で行う世界が実現されるでしょう。もちろん、人間の承認が挟まるタイミングはあるかもしれませんが、AIが独自で動くことが基本になるはずです。
そうなると、今の断片的なデータではまったく足りなくなります。今後、Ontology(オントロジー)やTopology(トポロジー)といったデータ整備を本格的に進める必要があります。これは、「あるシステムがこういうパラメーターで動いたら、別のシステムや環境のパラメーターがどう変わり、出力データがどう変わるか」といった、時系列を含めた依存関係や相互影響、概念的な関係性をデータ化することに近いです。
この整備が進んだ先に見えてくるのが、デジタルツインのような世界です。AIが利用するデータ基盤として、データの断片性を解消していくことが次の大きな目標です。
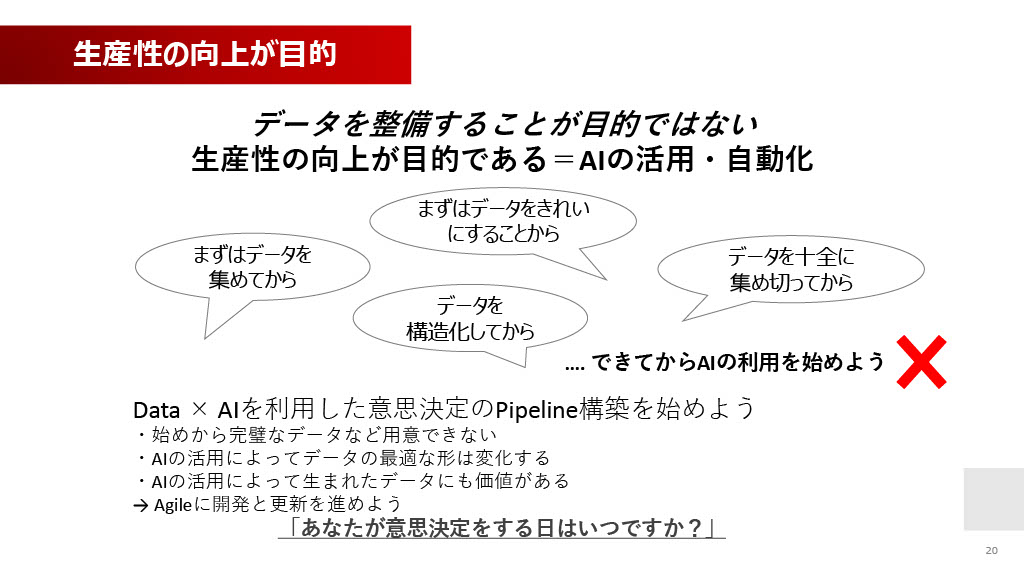
今回お伝えしたい重要なメッセージは、「データを整備すること自体が目的ではない」ということです。我々の目的は生産性の向上、すなわちAIの活用と自動化を通じて人々の生活を良くすることです。
よく「まずはデータを集めてから」「まずデータを綺麗にしてから」「データを構造化してから」AIの利用を始めようという、基盤整備を目標にしすぎるウォーターフォール的な考え方があります。しかし、これをやりすぎると、いつまで経ってもAI活用は進みません。
AIのパイプラインをまずつくり、いろんなデータから引っ張ってきて、その結果、本当に必要なデータだったとわかれば、そこで初めてデータの整備や出品を進める、というアジャイルな開発と更新を進めるべきだと考えています。
AIとデータを利用した意思決定を、より早めていくべきだと思います。最後に、「あなたが意思決定をする日はいつですか?」というメッセージをお送りし、私からのお話を終わらせていただきます。ご静聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





