



【Data Engineering Summit】少人数で支える日本最大級商業用不動産データベース:アーキテクチャーとチーム戦略
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」が、オンラインにて開催されました。
本記事では、株式会社estie データマネジメント事業部 エンジニアリングマネージャー 万代 悠作さんによるセッション「少人数で支える日本最大級商業用不動産データベース:アーキテクチャーとチーム戦略」の内容をお届けします。
膨大かつ多様な商業用不動産データを、限られた人数でどのように処理・運用しているのか。アーキテクチャと組織戦略の両面からご紹介いただきました。
■プロフィール
万代 悠作
株式会社estie データマネジメント事業部 エンジニアリングマネージャー
estieの事業領域と扱うデータの特徴
株式会社estie データマネジメント事業部でエンジニアリングマネージャーを務める万代 悠作が、「少人数で支える日本最大級商業用不動産データベース:アーキテクチャーとチーム戦略」というテーマでお話しします。
私は入社以来、データマネジメント事業部でデータモデリングやdbtによる移送処理、データ提供APIの設計・開発などを担当してきました。現在も引き続き、これらの領域を中心に業務に取り組んでいます。

estieの事業領域
株式会社estieは「商業用不動産」という領域でデジタルインフラを展開している会社で、創業してまもなく7年目を迎えます。
商業用不動産と聞くとあまり馴染みがないかもしれませんが、簡単にいうと投資の対象となるような不動産で、不動産のプロが扱う領域になります。
商業用不動産には、私たちが“アセットタイプ”と呼ぶオフィス、商業施設、物流施設、ホテル、住宅など、様々な種類があります。estieでは、こうした商業用不動産を幅広く網羅できるプロダクトの開発を進めています。

プロダクト概要とDaaSの特徴
現在、弊社では様々なプロダクトを開発しており、大きく分けるとDaaSとSaaSの2種類があります。
DaaSはData as a Serviceの略で、アセットタイプごとに不動産データを調査できるプロダクトを提供しています。このDaaSが現時点でestieの主力製品であり、私たちデータチームも深く関わっている領域です。今回の発表でも、このDaaSを中心に取り上げます。
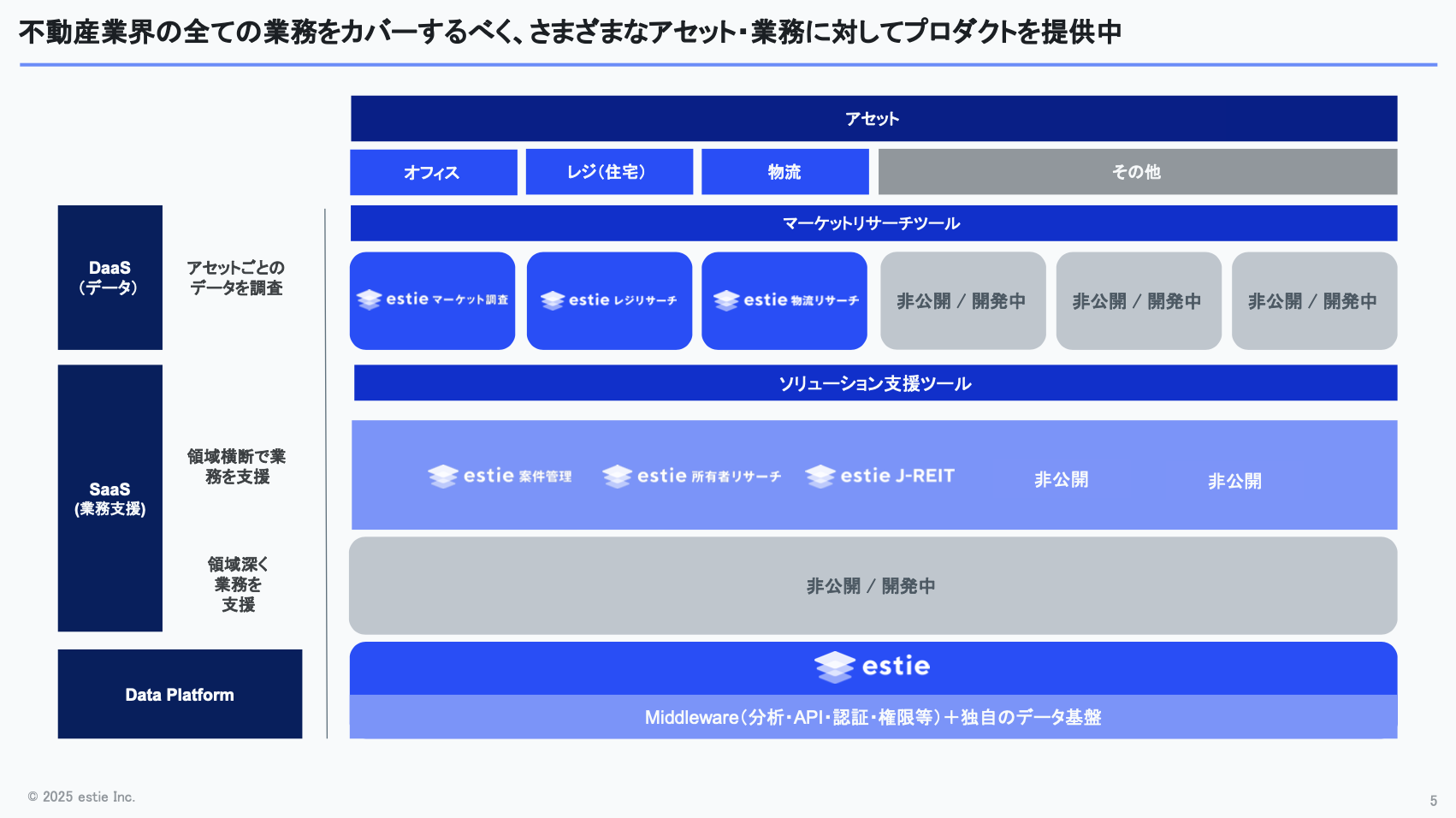
例として、弊社が提供しているDaaSのひとつ「マーケット調査(estie マーケット調査)」をご紹介します。
このプロダクトは、オフィスビルのマーケット状況を簡単に分析できるもので、不動産デベロッパーのお客さまや、オフィスビルを投資対象として扱っているお客さま、あるいはビルの賃貸契約管理をされているお客さまにご利用いただいています。
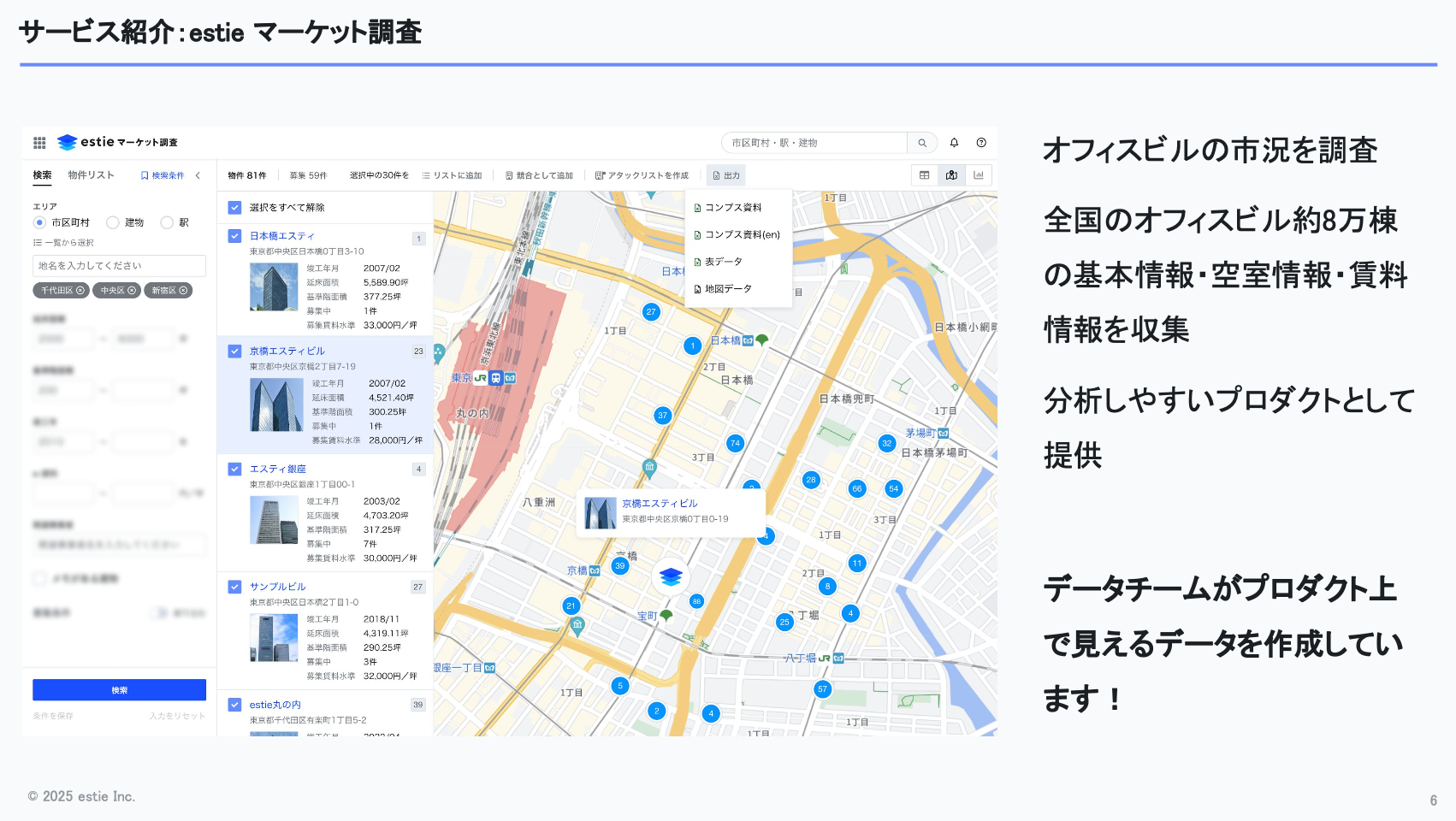
例えば不動産デベロッパーのお客さまであれば、周辺環境を分析することで、自社が保有するビルを貸し出す際に「いくらで貸すべきか」「賃料をどう設定すべきか」といった判断に役立てていただけます。
これまで「ビルをいくらで借りられるのか」という情報は、分析しやすい形でまとまっていませんでした。そのため、不動産業者の方々が様々な場所に電話をしたり、メールで届くPDFに載っている賃料情報を集め、それを蓄積して自分たちで分析する、という作業をしていました。
estieのサービスを使うことで、そういった情報をすぐに、しかも簡単に分析できるようになり、その点に価値を感じていただいているのではと思っています。
ビルの名称や住所といった基本情報、そして現在どんな空室があり、賃料がどの程度なのかといった募集情報を、私たちデータチームが様々な場所から集め、データとして提供しています。
今回は、このデータを「どうやって効率よく作るのか」についてお話しします。
estieの組織規模
組織の規模についても簡単に説明します。私たちデータチームは現在およそ10名ほどで構成されており、1名がPdM、残りはデータエンジニアやデータサイエンティストといったメンバーでチームが成り立っています。
estie全体では大体100名ほど社員がいて、そのうち約40名がエンジニアにあたります。その中の10名ほどがデータエンジニアやデータサイエンティストとして開発に携わっている状況です。
人数比で考えると、およそ10%がデータ領域に関わっていることになります。さらに実際には、estie マーケット調査を開発しているフロントエンドエンジニアやバックエンドエンジニアも、時にはデータ関連の開発に取り組むことがあります。
そういった点からも、estieがデータ領域に対してしっかりと人的投資をしている会社だということを感じていただけるかと思います。

データ需要の急増と少人数で支える必要性
なぜ少人数で支える必要があるのか
「なぜ少人数で支える必要があるのか」という点についても触れておきたいと思います。
estieでは建物に関する様々な情報を扱っており、建物そのものの情報や空室・募集の情報に加えて「どの企業がどの階にいつ入居して、いつ退去したのか」といった入居履歴、さらに「この建物は登記上、誰が保有しているのか」といった所有者情報まで幅広く管理しています。
これらの情報はアセットタイプごとに存在しているため、扱うデータは非常に多様で、ボリュームも相当なものになります。大小あわせておよそ1,000以上のテーブルを管理する必要があり、そこから各種プロダクトへデータを連携しています。
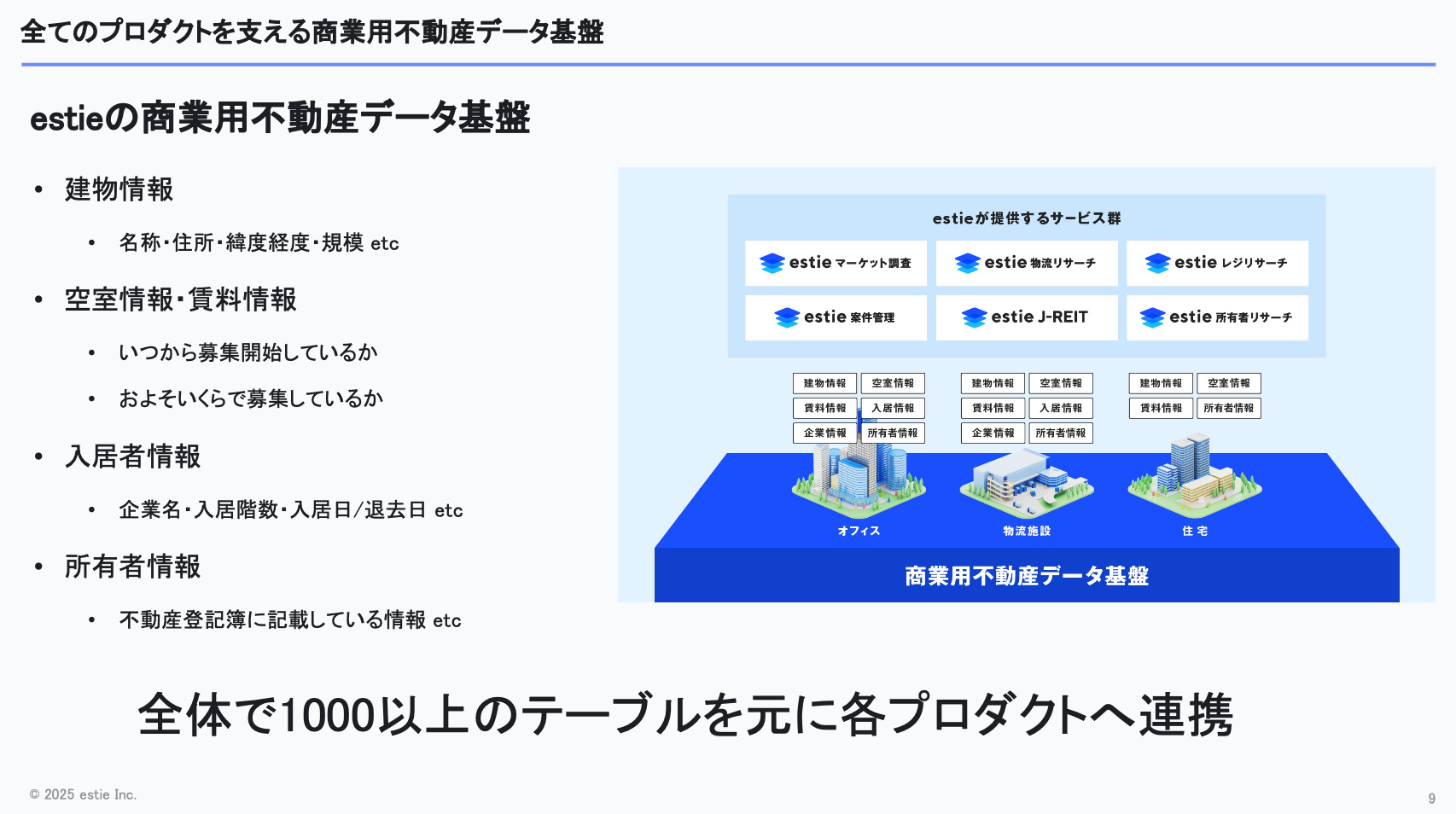
会社規模ではデータ領域に多くの人材投資をしていますが、それを上回るスピードでデータ関連の開発需要がどんどん増えています。
データそのものが価値のコアになっているプロダクトも多いですし、マルチアセットでドメインが異なるデータを生成するパイプラインを構築するとなると、さらに複雑さが増していきます。
加えて、今後はプロダクトや対応すべきアセットタイプもますます増えていく見込みです。さらに、社内データの整備に加えて、PDFや音声、画像といった非構造化データから構造化データを抽出する仕組みなど、これまで対応してこなかった業務がデータチームに寄せられるケースも増えてきました。
その結果、手が回り切らなくなってきているという課題があります。
さらに会社のフェーズ的にも、事業の収益性を高めていく時期に入っており、エンジニアリング面でも効率化を図る必要性が高まっています。
そのため、「少人数で多くのデータに効率よく対応できるようにしたい」という課題意識があります。
本セッションでは、こうした課題に対して私たちがどのように向き合ってきたのか、という点を中心にお話しします。
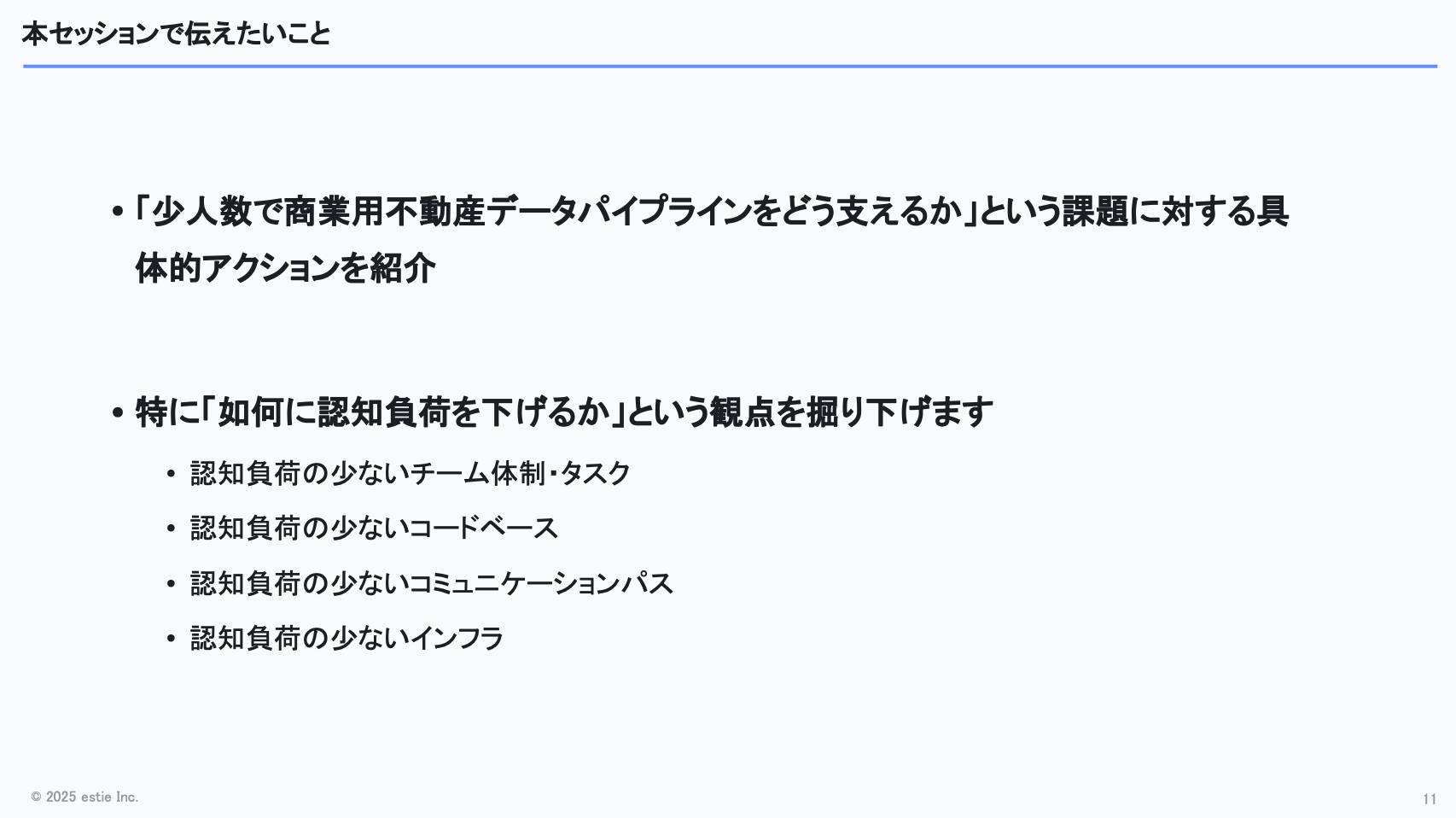
少しネタバレになりますが、今回のテーマは“いかに認知負荷を下げるか”というところに集約されます。
認知負荷の少ないチーム体制やタスクのあり方とは何か、コードベースやコミュニケーションパスをどう設計すべきか、インフラをどう整えるべきか──そんな観点で進めていければと思います。
少人数で支える工夫
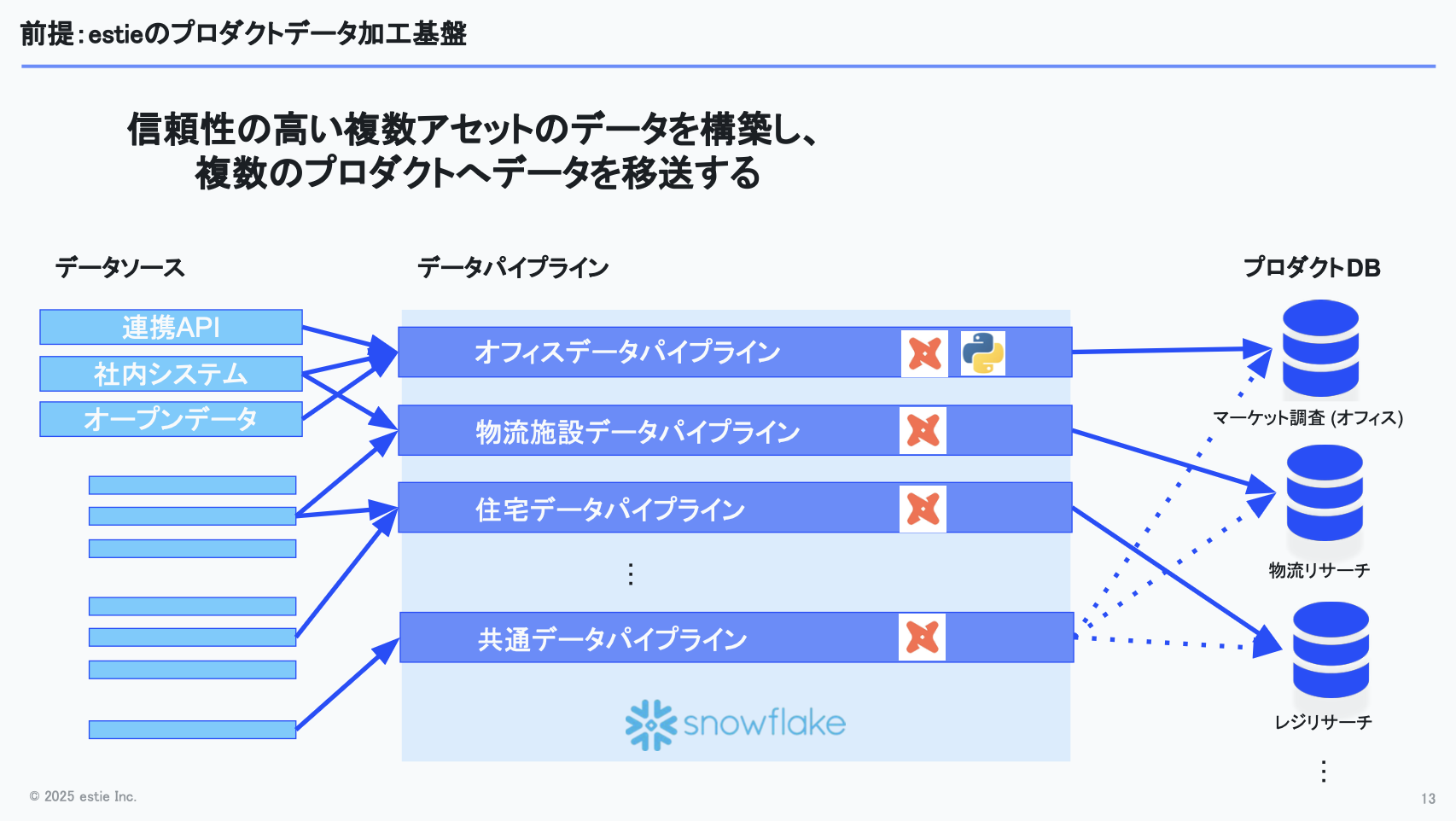
ここからは、実際に少人数で支えるためにどんな工夫をしているのかについてお話しします。まずは、私たちがサービス上で表示されるデータをどのように作っているのか、全体の流れを簡単に説明します。
大まかな流れとしては、データソースやデータパートナーからデータを受け取り、それをSnowflake上でdbtパイプラインで処理し、処理済みのデータを各サービスのRDBMSに移送する──このサイクルを回し続けています。
dbtパイプラインでは、複数のデータソースから来た情報を名寄せしたり、名称の表記ゆれを正規化したりしています。履歴管理しているデータから最新の情報を取得する処理もあります。
名寄せについては機械学習モデルを利用しているものもあり、そのぶんロジックが複雑になる場面もあります。
また、オフィスや物流施設、住宅といった複数のアセットタイプがあり、それぞれに対応するサービスが存在します。そのため、アセットごとにデータを生成する必要があり、ドメイン知識も異なってきます。開発を進めるには、それぞれの領域に対する一定の知識を学び、習熟していく必要がある、という状況です。
複雑性の増大と認知負荷の問題
データチームの担当についてですが、私たちの守備範囲はデータを移送するところまでで、下図にあるほぼすべての工程を担っています。
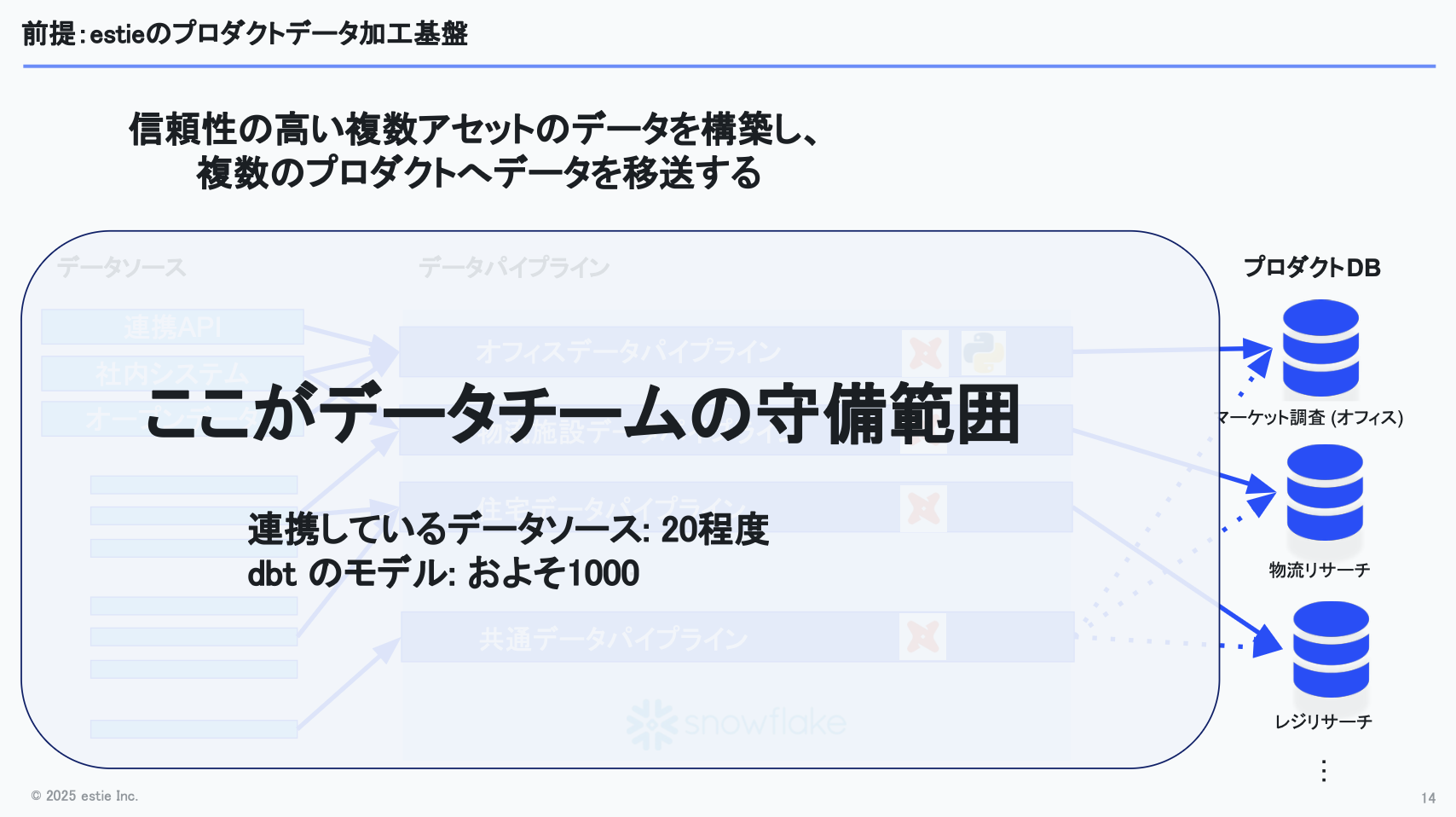
現在連携しているデータソースはおよそ20ほどあり、dbtのモデル数でいえば約1,000に達する規模になっています。そのため、管理がかなり大変な規模になってきている、というのが現状です。
ここまでの前提をまとめると、複数のアセットを扱う必要があり、アセットごとに異なるドメイン知識を習得しなければならず、さらに提供先となるプロダクトも複数存在します。一方で、人数は限られていて、アセットあたりに換算すると1〜2名ほどしかアサインできない状況です。
その中で達成したいのは、限られた人数でも必要なデータを生成するパイプラインを構築し、保守運用できるようにすることです。振り返ってみると、私たちがやってきたことは、いかに認知負荷を下げるかという工夫だったのではないかと感じています。

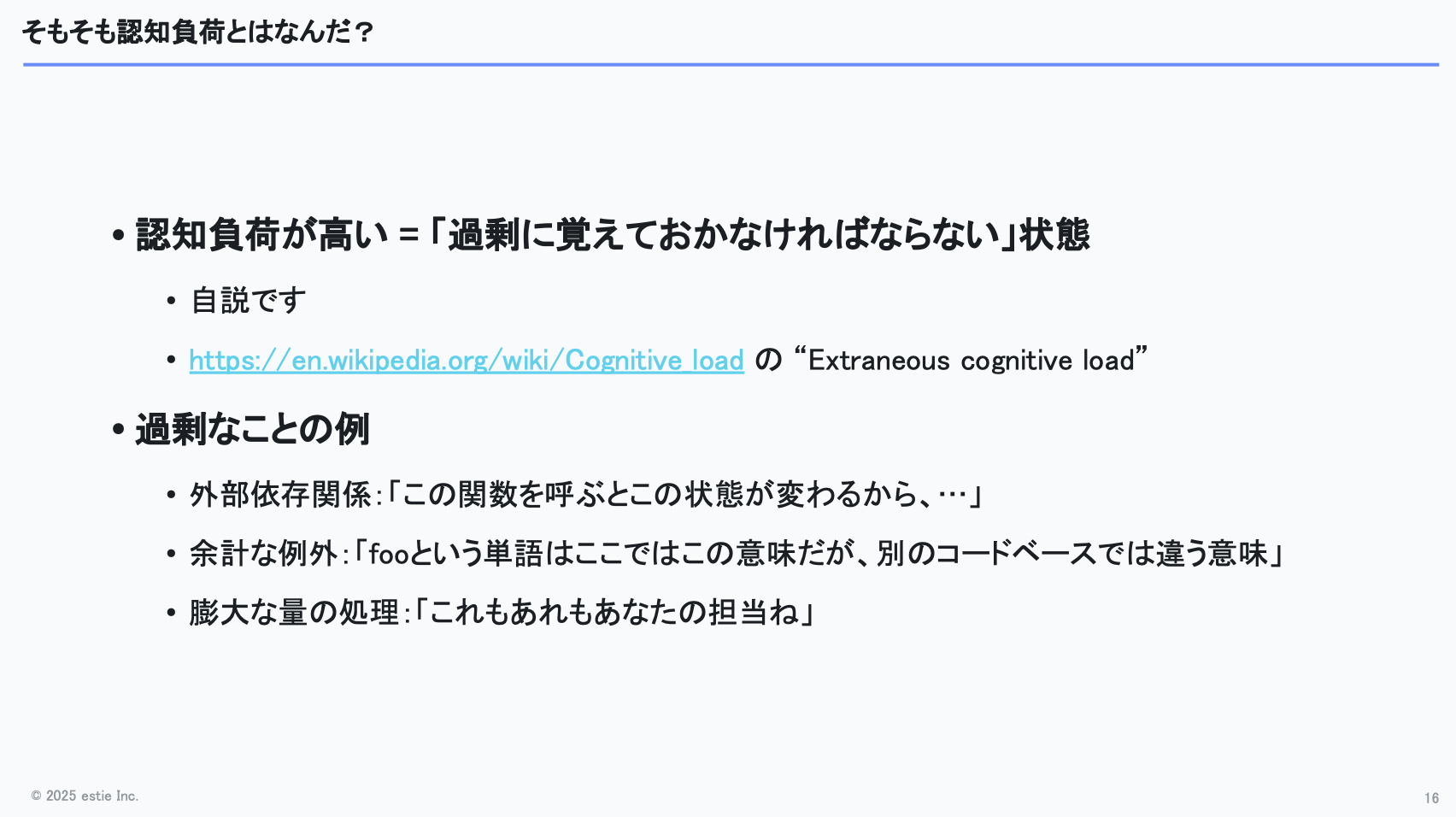
ここでいう「認知負荷が高い」とは、必要以上のことを覚えておかなければならない状態を指します。
もともとは教育理論・学習理論で使われる概念で、Wikipediaで“extraneous cognitive load(余剰負荷)”と説明される概念が、私たちが使っている「認知負荷」に近いニュアンスです。
エンジニアリングの現場では、外部依存が多い設計や、副作用を常に意識しなければならないコードなど、注意すべき点が多くあります。さらに、同じ単語がコードによって異なる意味で使われているケースもあり、文脈ごとに解釈を切り替える必要が生じます。加えて、多くのタスクを1人で抱えることでスイッチングコストが増大するなど、余計な認知負荷が発生しやすい状況が少なくありません。
そういった「過剰に覚えておかなければならないこと」を減らすために、今回のセッションでは次の4つの取り組みについてお話しします。
- 自分担当領域に集中できる環境を作る必要がある
- コードベース全体で意味論を揃える必要がある
- 他チームに任せられること任せる必要がある
- できるだけ構成をシンプルに保つ必要がある
取り組み①:自分担当領域に集中できる環境を作る
チーム再編が必要になった背景
1つ目の取り組みは「自分の担当領域に集中できる環境をつくる」ことです。
この方針を検討するきっかけとなったのは、昨年の夏ごろの状況です。当時のデータチームはフラットな体制で、各メンバーが様々な業務を横断的に担当していましたが、扱うデータの種類自体はまだ多くありませんでした。
ところが昨年、estieでは複数のプロダクトをリリースし、それに伴ってデータチームが担うべき責務が大きく広がりました。もともとはestie マーケット調査のデータのみを扱っていましたが、物流や住宅といったほかのアセットタイプのデータも取り扱う必要が出てきたのです。
この状況では、フラットな体制のままでは認知負荷が増大してしまいます。そのため、データチームの構成を見直すべきではないかという議論が生まれ、将来的な変化も踏まえて再編に踏み切りました。

Architect・Streamの2チーム体制への再構築
具体的にいうと、以下の2点を念頭に置き、チームを大きく2つに分ける決断をしました。
- 対応すべきアセットタイプは今後も増えていきそうである
- 中央集権的にパイプラインを構築するより、アセットごとにパイプラインを分けた方が各プロダクトとのやり取りがしやすくなる
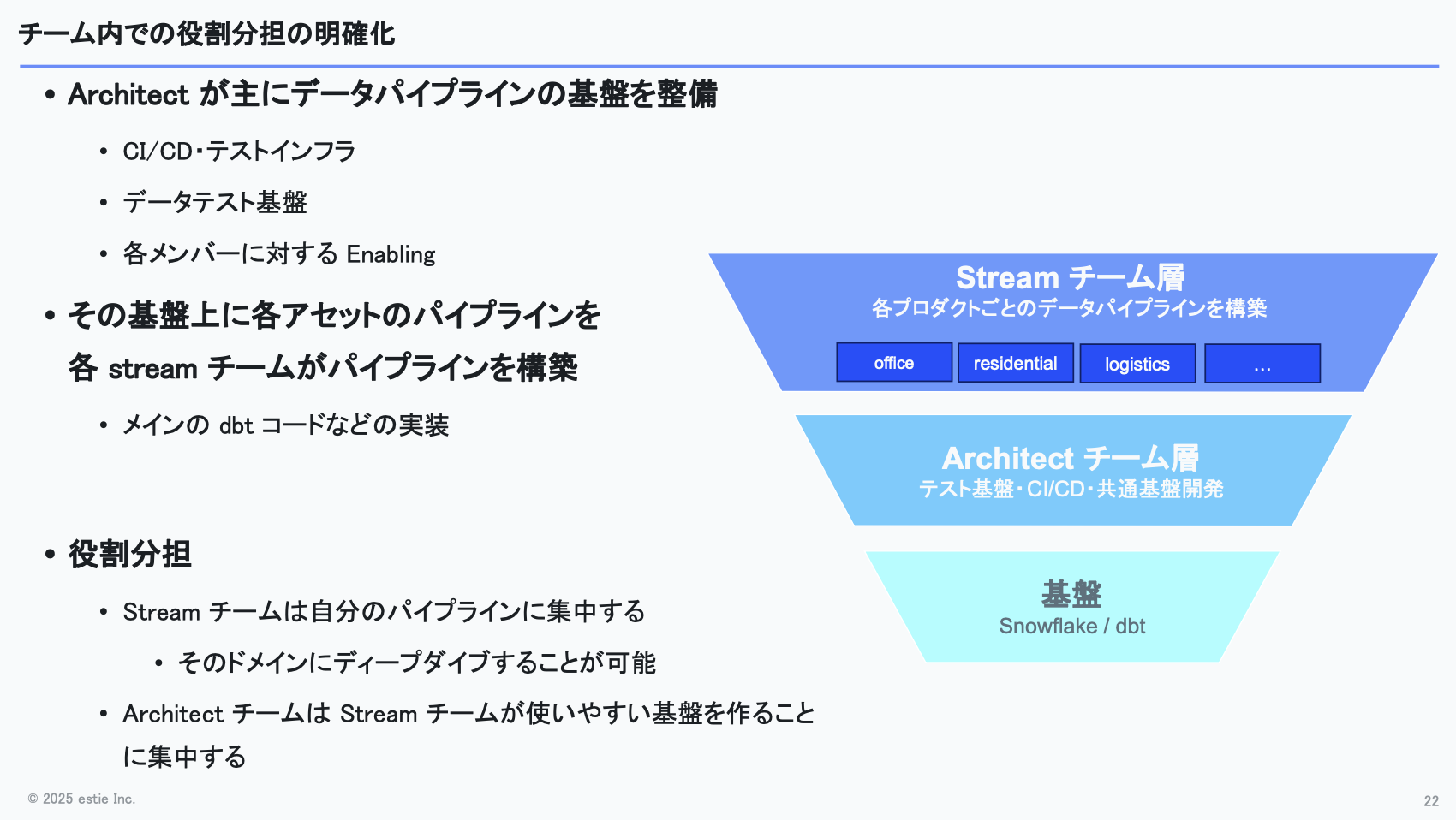
1つ目のチームは、データパイプラインの基盤整備やコード最適化、開発生産性の向上に責任を持つチームで、社内ではArchitectチームと呼んでいます。
2つ目は、オフィス・物流施設・住宅といった特定アセット向けのパイプライン開発の責任を持つStreamチームです。Streamチームはアセットの種類ごとに複数存在し、ひとつのアセットでの開発が一段落したら、別のアセットに移る場合もあります。

図にすると、まず土台としてSnowflakeやdbtの基盤があり、その上にArchitectチームが乗っていて、テスト基盤やCI/CD、共通モジュールの作成、開発ツールの整備といった領域を担っています。
そして、そのArchitectチームがつくった基盤の上で、複数のStreamチームがdbtのメインコードやPythonを使った処理を開発しています。
Architectチームは、dbtの便利な機能を伝えたり基盤を整えたりと、開発生産性を向上させることに集中します。その上でStreamチームが各アセットタイプの理解を深め、適切な実装を進められる構成です。
サイロ化問題とその対策
利点としては、何よりStreamチームが他アセットのことを気にせず、自分が担当するアセットのロジックに集中できる点が大きいと思っています。
一方で、気をつけないと各Streamチームがサイロ化しやすい、という課題があります。対策として、まだメンバーが10名程度ということもあり、定期的にデータチーム全体で知見共有のミーティングを行ったり、Architectチームのメンバーが全体的にコードレビューをするようにしており、彼らの横断的な視点によりサイロ化を防いでいます。
もうひとつの課題は、Architectチームに非常に多くの知識とスキルが求められる点です。
現状は人的なカバーに頼っている部分もありますが、そもそもArchitectチームに強いエンジニア、いわゆるスタッフエンジニアのような役割を持つ人材を配置するようにしています。
また、最近ではAIを活用してコードレビューを効率化できないかという取り組みも考えてはいますが、まだ本格的には取り組めていません。

取り組み②:コードベース全体で意味論を揃える
統一された意味論が必要になった背景
2つ目の取り組みは、「コードベース全体で意味論を揃える」という点です。
Streamチームがそれぞれのアセットに集中してパイプラインを作り、その数もどんどん増えていく状況になると、どうしてもコードの品質や作り方が各メンバーのやり方に寄ってしまいます。
そうなると、まったく異なるスタイルで書かれたパイプラインを少人数でメンテナンスするのは、かなり大変です。
そのため、データパイプライン全体で用語を統一したり、ある程度の作り方のルールを揃えたりといったことを、データチーム全体で進めています。
命名規則・パイプライン構築ルールの標準化
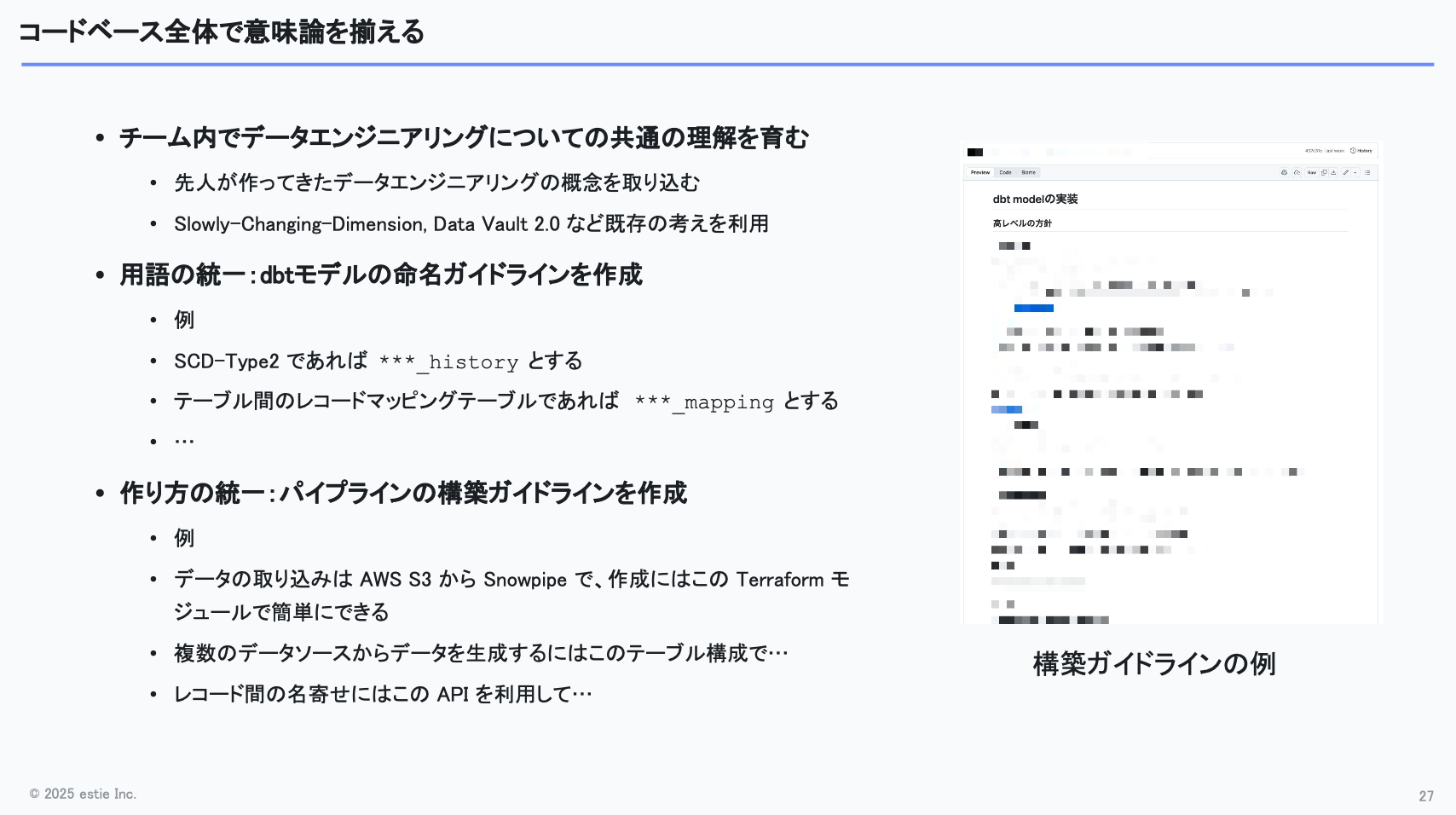
具体的な取り組みとしては、まずチーム内でデータエンジニアリングに関する共通の概念を育てるところから始めました。先人がつくってきた有用な概念や既存の手法、例えばslowly changing dimensionやData Vault 2.0といった考え方を学びました。
そのうえで、dbtのモデル名の命名ガイドラインを整備し、名前を見ればそのモデルが何をしているのか分かるようにする取り組みも進めました。例えば、CD-Type2に該当するモデルであれば「***_history」という名称に統一する形です。
また、不動産データという共通性がある以上、どのアセットでも似た処理が発生します。そこで、パイプライン構築のガイドラインを整備し、どのパイプラインも共通の方針で開発できるようにしました。
例えば、次のようにパイプラインの基本方針を統一しています。
- データの取り込みはAWS S3からSnowpipeを使う
- 名寄せが必要な場合はこのテーブル構成を使う
- 名寄せ処理は外部API化して、APIを呼ぶだけで完結するようにする
これらをガイドラインとして整備したことで、未経験のパイプラインでも処理の意図を読み取りやすくなり、別アセットを担当する際の習熟もスムーズになったと感じています。
効果と残る課題
課題は、すべてのコードがこのルールに完全に沿っているわけではない、という点です。
基礎的なコードやレガシーな部分も残っているため、どうしてもガイドラインが守られていない例外はいくつか存在します。また、ルールの統一を完全に強制するというのは、実際のところなかなか難しい部分でもあります。
Architectチームが全体を横断して見ているとはいえ、すべてを確実に実行するのはやはり容易ではありません。今後は、生成AIにコンテキストを渡し、コードレビュー時に設計ができるようにするなど、新たな仕組みの活用も検討しています。

取り組み③:他チームに任せられること任せる
データチームの集中領域を守るための発想
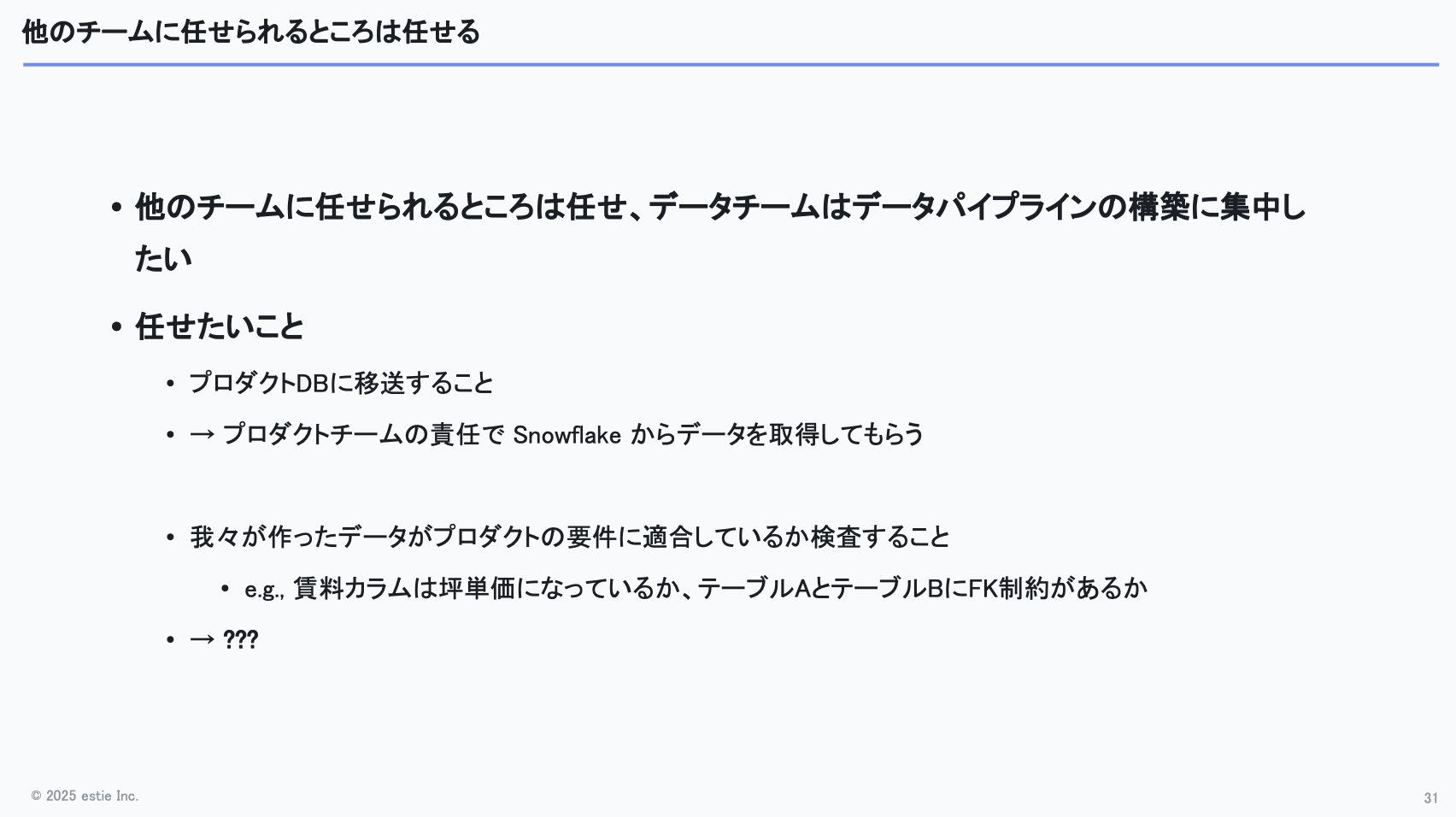
3つ目の取り組みは「ほかのチームに任せられることは任せる」という点です。
データチームとしては、データ生成までを担当し、その先の活用はプロダクト側に任せる形が理想です。こうすることで、プロダクトが増えても個別仕様を深く追う必要がなくなり、パイプライン構築に集中できると考えています。
任せたいことはいくつかありますが、その1つがデータ移送の工程です。
Snowflakeからプロダクト側データベースへの移送は、現在プロダクトチームが担当しています。これにより、データチームがプロダクトごとのデータベース仕様を細かく把握する必要がなくなり、認知負荷の軽減につながっています。
もう1つ任せたいのは、作ったデータがプロダクトの要件を満たしているかどうかのチェックです。
例えば、オフィス賃料を坪単価で表すといった業界標準の形式になっているかどうか。あるいは、テーブルAのカラム値がテーブルBにも正しく存在し、外部キー制約を満たしているかなどが確認ポイントとして挙げられます。
Snowflakeにおける外部キー制約の課題
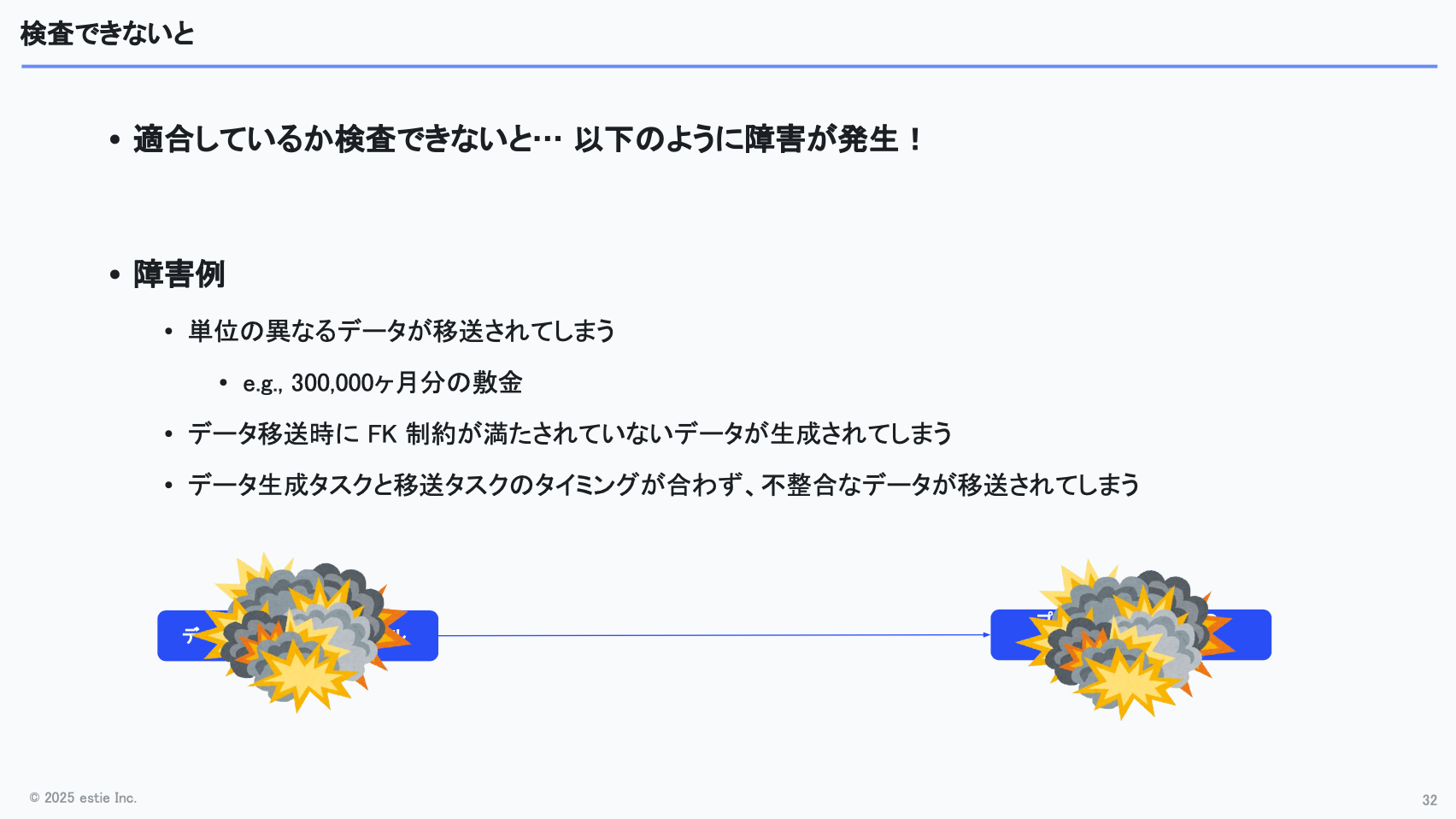
弊社ではSnowflake上で処理を行っていますが、Snowflakeは外部キー制約を自動で検証しないため、データベースに入れる前にチェックが必要です。
こうした検査ができていないと、例えば単位が守られていない状態のデータが移送されてしまうといった事故が起こりかねません。
実際の例でいうと、データチームは「月額の総額」を送っている想定だった一方、プロダクト側では「賃料の何カ月分か」という形式で敷金を受け取りたいケースがありました。このズレがあると、「300,000カ月分の敷金」といった異常値が生まれる可能性があります。
また、外部キー制約を満たさないデータを送ってしまえば、プロダクト側のデータベースで整合性エラーが発生する恐れもあります。
このように、データチームのテーブルからプロダクト側のテーブルへ移送する際に不備があると、そのまま不正なデータが反映され、影響が広範囲に波及してしまう可能性があります。
そのため、データチームが作成したデータが本当に正しい状態になっているかをプロダクトチームと一緒に確認していく取り組みを始めました。
データコントラクトの整備
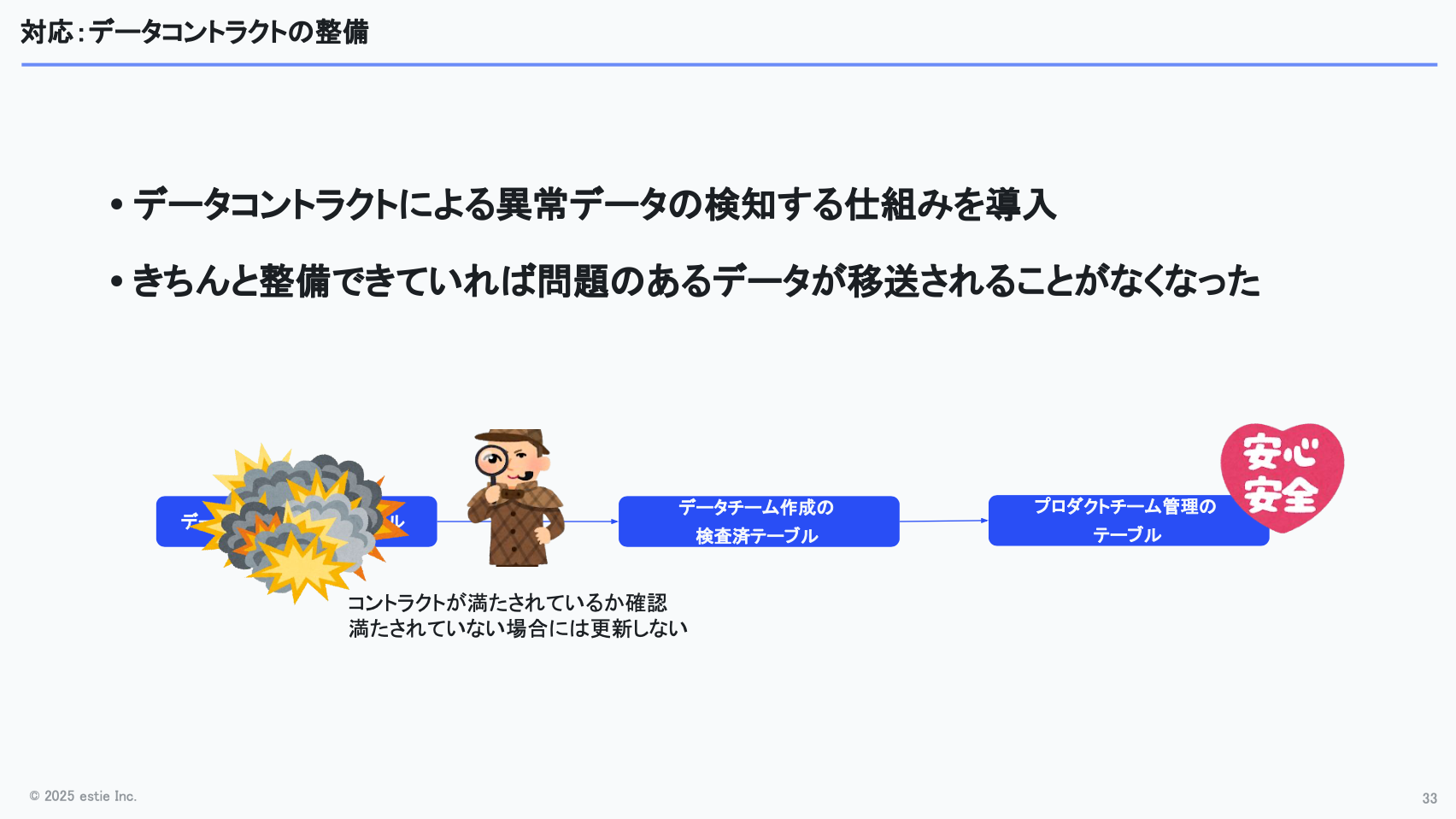
具体的には、dbtテストを整備し、データコントラクトを満たしているか検証できる仕組みを整えました。データチーム側で「検証済みテーブル」を用意し、プロダクト側にはそのテーブルからデータを取得してもらう運用にしています。
万が一、データチーム側で不正なデータが生成されていた場合でも、コントラクト違反を検知したら更新を止めることで、プロダクト側に影響が波及しないようにしています。
このあたりのデータコントラクトの整備については、プロダクトチームとも責務をきちんと合わせていて、「プロダクト仕様をデータチームだけで完全に把握するのは難しいので、一緒にデータテストを整えていきましょう」という形で進めています。
取り組み④:できるだけ構成をシンプルに保つ
最後の取り組みは「できるだけ構成をシンプルに保つ」という点です。
これまでお話ししたように、私たちはSnowflakeとdbt、AWSを利用してデータパイプラインを構築していますが、実は現時点ではあえてほかのツールをほとんど導入していません。
その理由は、様々なツールを追加することで得られるメリットよりも、ツールを管理するコストの方が上回ると判断しているためです。ツールを増やせば便利になる部分もありますが、人数が限られている状況で多数のツールを管理するのは現実的ではありません。

シンプルなアーキテクチャーの実例として、4つほど簡単に紹介します。

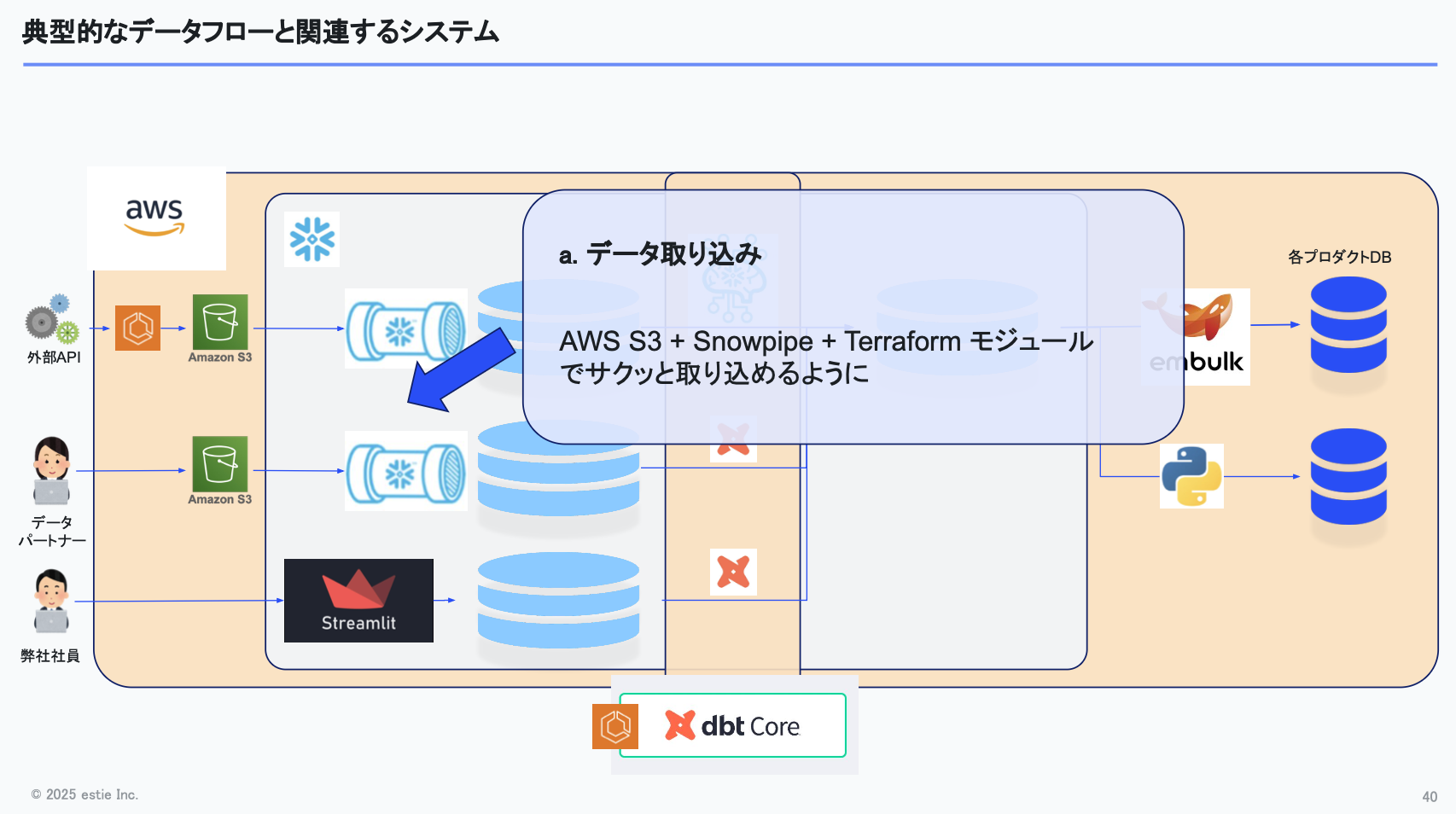
以下の図は、私たちが普段構築しているデータパイプラインの典型的なデータフローを表したものです。
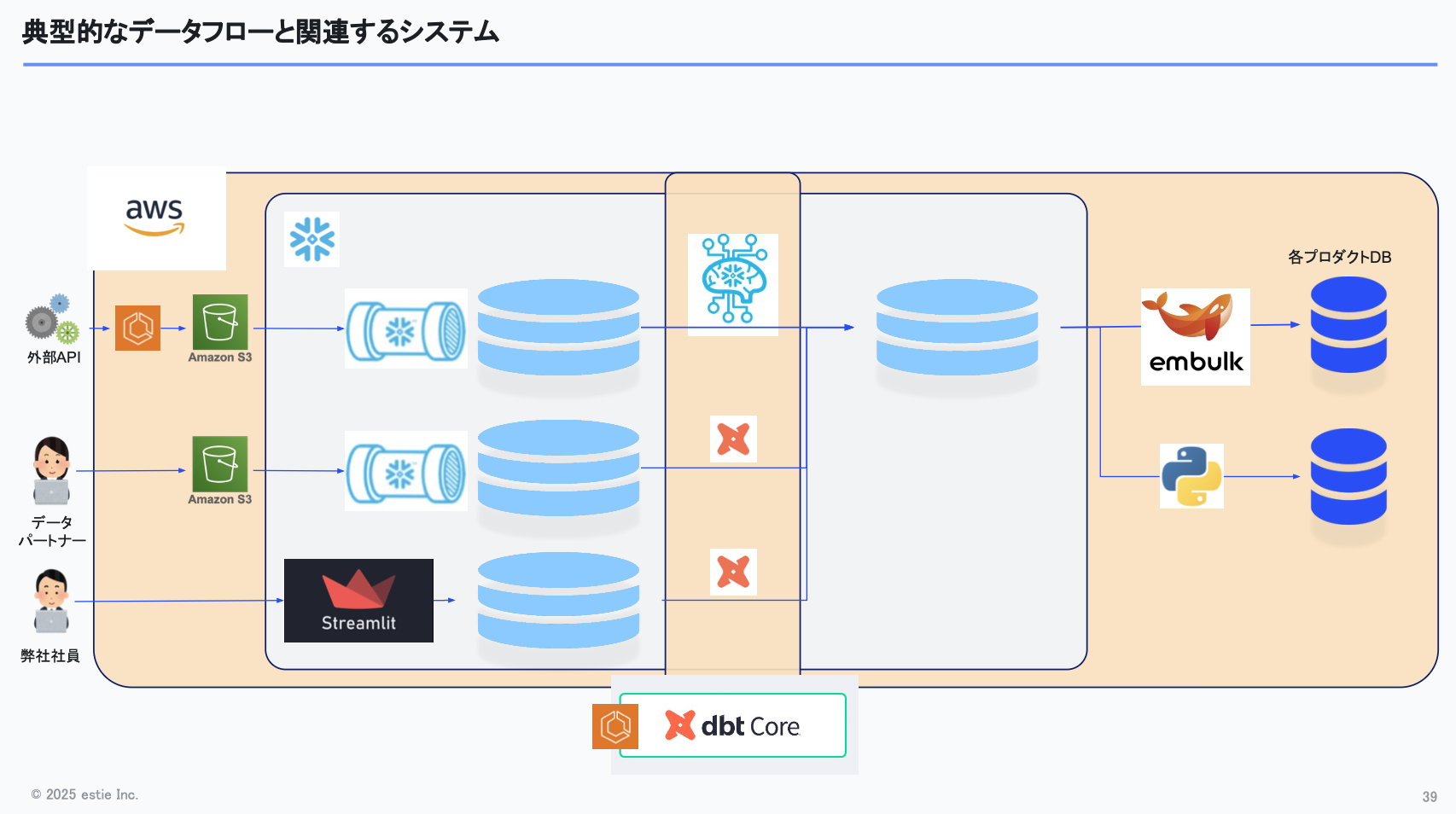
左から右へとデータが流れ、外部APIから取得したデータや、データパートナー・社内メンバーが入力したデータがSnowflakeに入り、dbtパイプラインで処理され、そこから各サービスへ移送される。そういった大まかな流れです。
シンプルさを保つため、データの取り込みは基本的にS3 と Snowpipeで完結させています。また、これらをすぐに利用できるようにTerraformでモジュール化し、すぐに取り込めるようにしています。
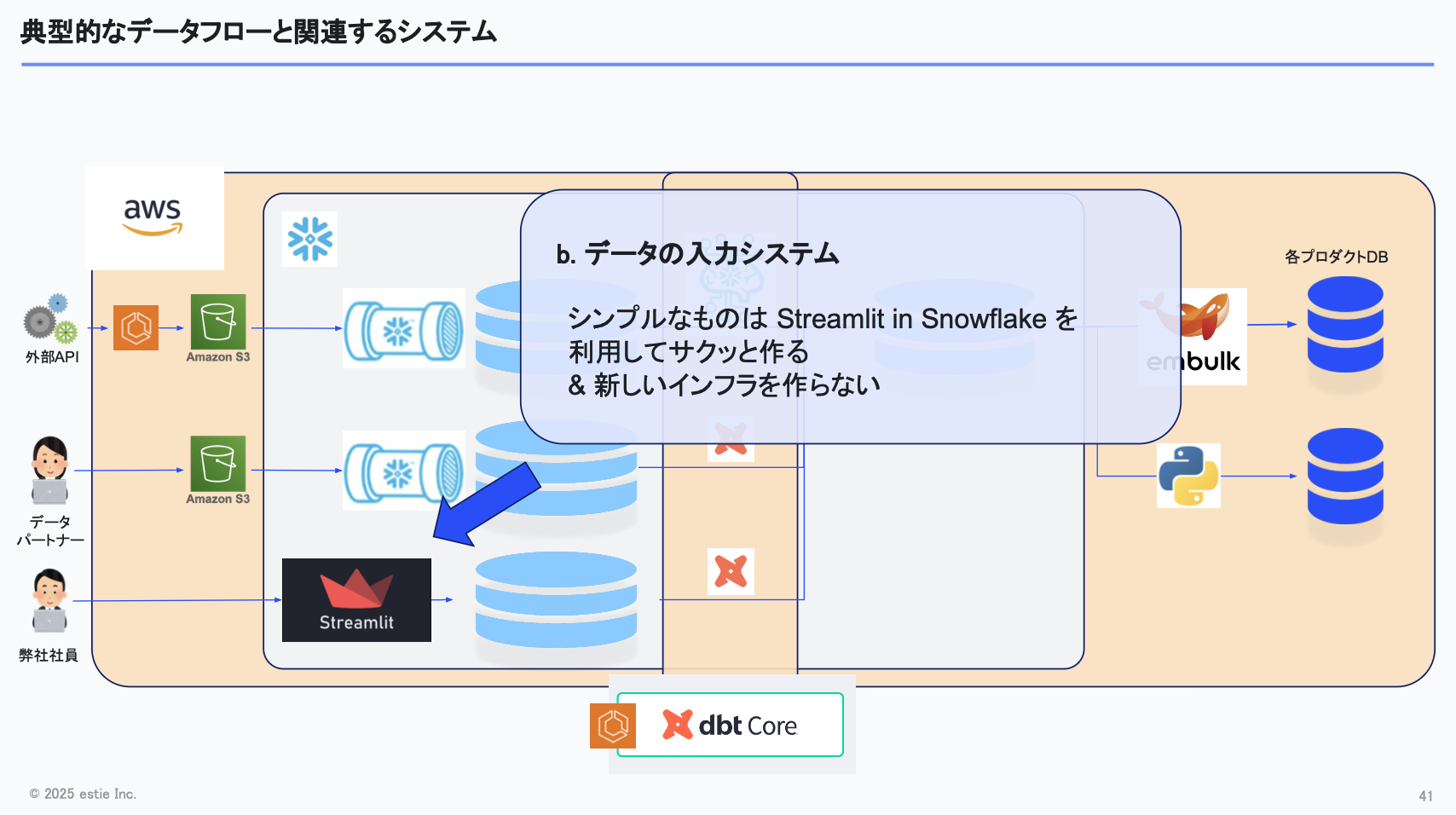
次に、社内メンバーが入力するデータについては、StreamlitというPythonで簡単にGUIを作れる仕組みを利用して入力システムを構築し、Streamlit経由でSnowflakeにデータを入れるようにしています。新たなインフラを増やすことなく、素早くできる点が利点です。
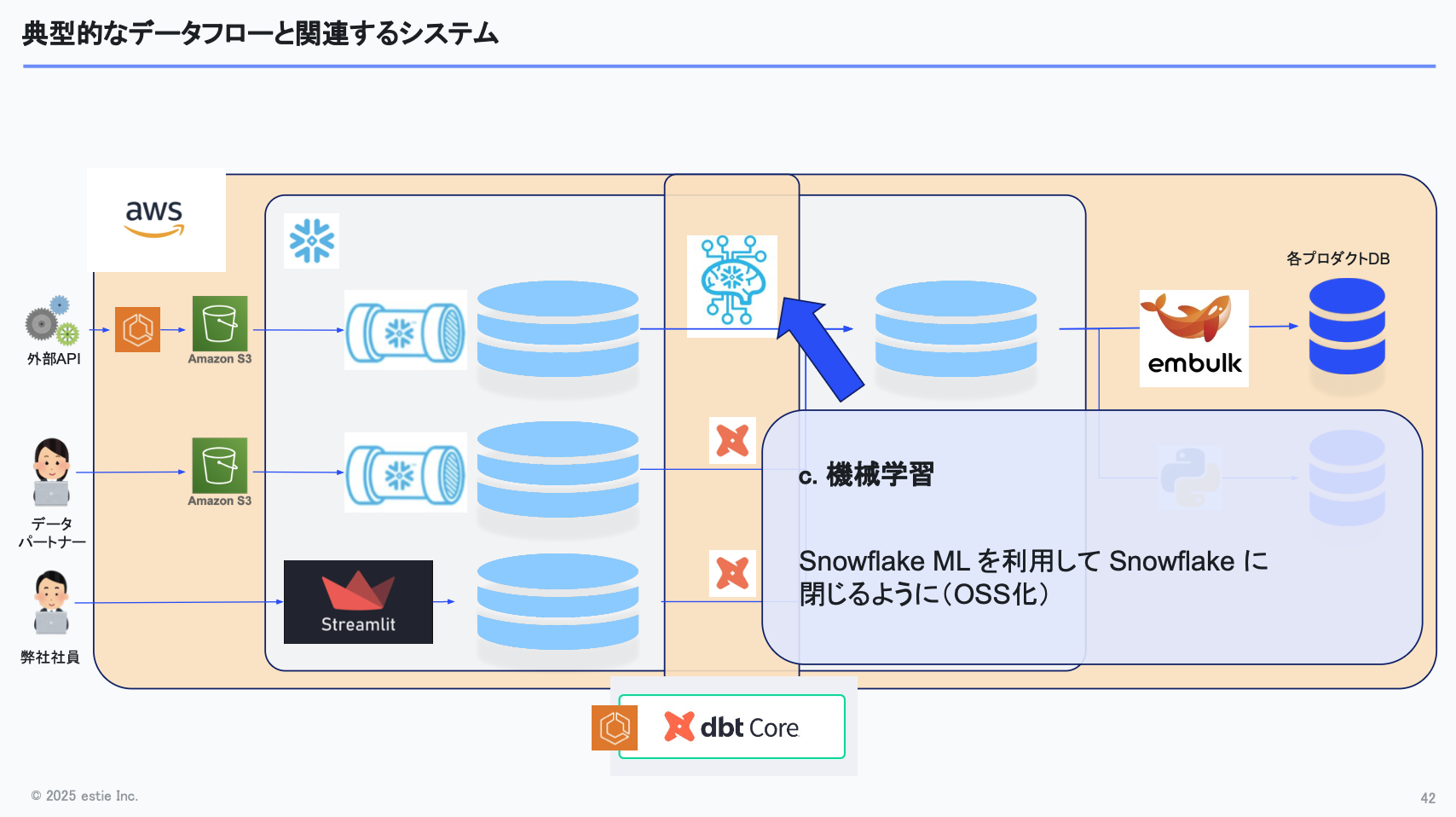
機械学習も一部利用しており、Snowflake MLを活用し、学習から推論までをSnowflake上で完結できるようにしています。
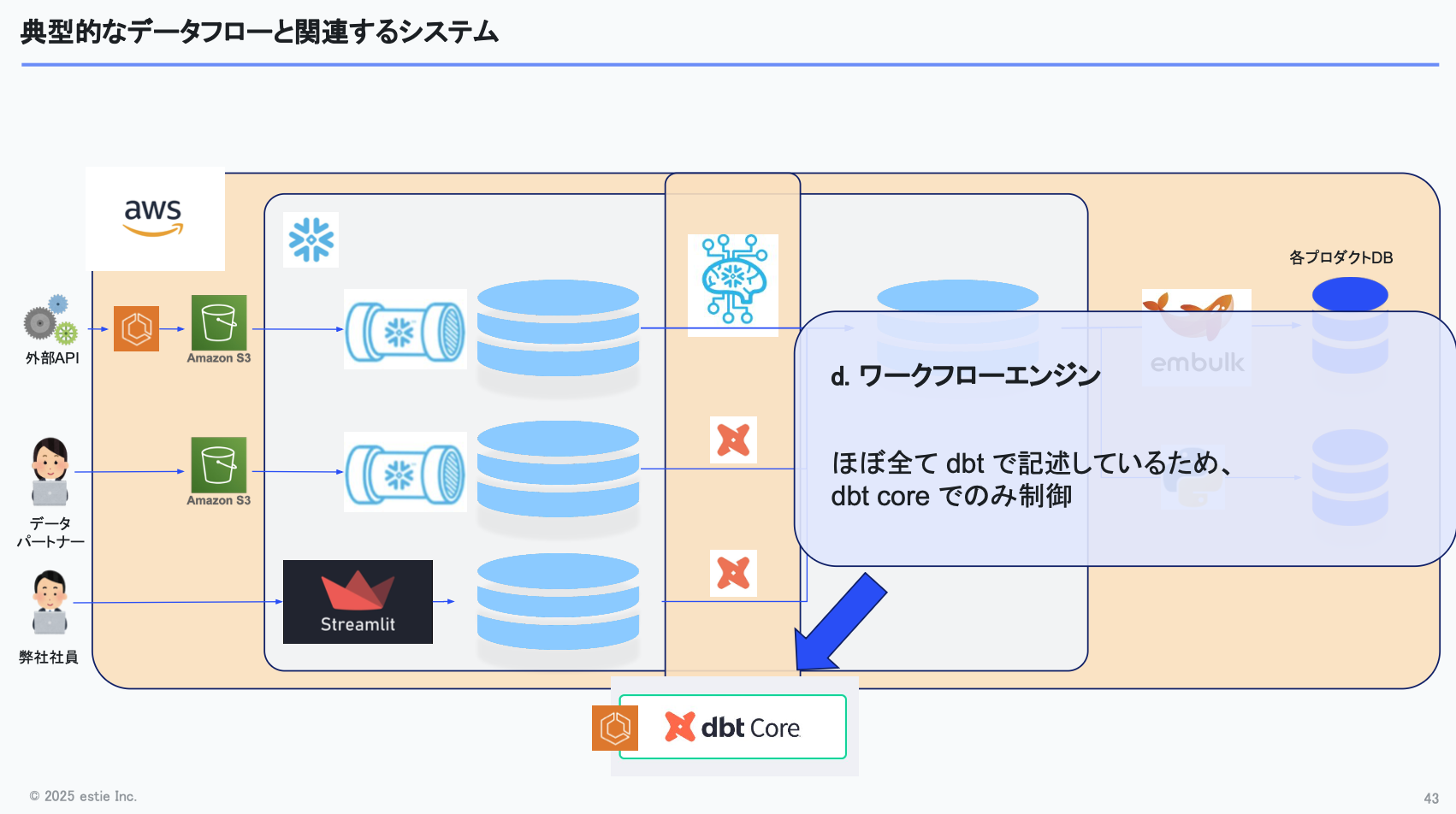
ワークフローエンジンについては、現状dbt Coreのみで管理しています。将来的にもっと複雑になれば別の選択肢を検討する可能性もありますが、今のところはdbt Coreで十分まわっており、AWS ECS上でdbtを動かしている状況です。
ここまでで「estieはdbtとSnowflakeが本当に好きなんだな」と感じていただけたかもしれません。実際、これらはデータチームだけでなく全社的に活用しており、一部の取り組みはOSSとしても公開しています。興味があればぜひご覧ください。
まとめ
このセッションでお伝えしたかったのは、認知負荷を下げるために様々な工夫をしてきたという点です。特別なことをしているわけではなく、「どうすれば認知負荷を下げられるか」をチームで考え、実践してきました。
質の高い、売り物になるデータを作るために、今後も改善を続けていければと思っています。

最後になりますが、estieではデータ領域の採用も積極的に進めています。興味のある方は、カジュアル面談も受け付けています。お気軽にご応募いただければと思います。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





