



【Data Engineering Summit】Data Engineering Guide 2025
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」がオンラインで開催されました。
本記事では、株式会社風音屋 代表取締役の横山 翔さんによるセッション「Data Engineering Guide 2025」の内容をお届けします。
近年注目度が高まっている生成AIやデータ活用を踏まえ、データエンジニアリング分野の全体像を振り返りつつ、各種テクノロジーの進化と普及を踏まえたうえで実践的なアクションに繋がる道筋が紹介されました。
■プロフィール
横山 翔
株式会社風音屋
代表取締役
AIネイティブ時代、データ基盤人材への注目度は高まっている

はじめに、本日のセッションにあたりいくつか注意事項を記載しておりますので、お仕事などで資料をお読みいただく際にはご注意をお願いします。
本日は「Data Engineering Guide 2025」というテーマで、生成AIによって劇的に変化しているデータエンジニアリングの世界を、全体感から具体的な技術要素まで振り返ってみたいと思っています。
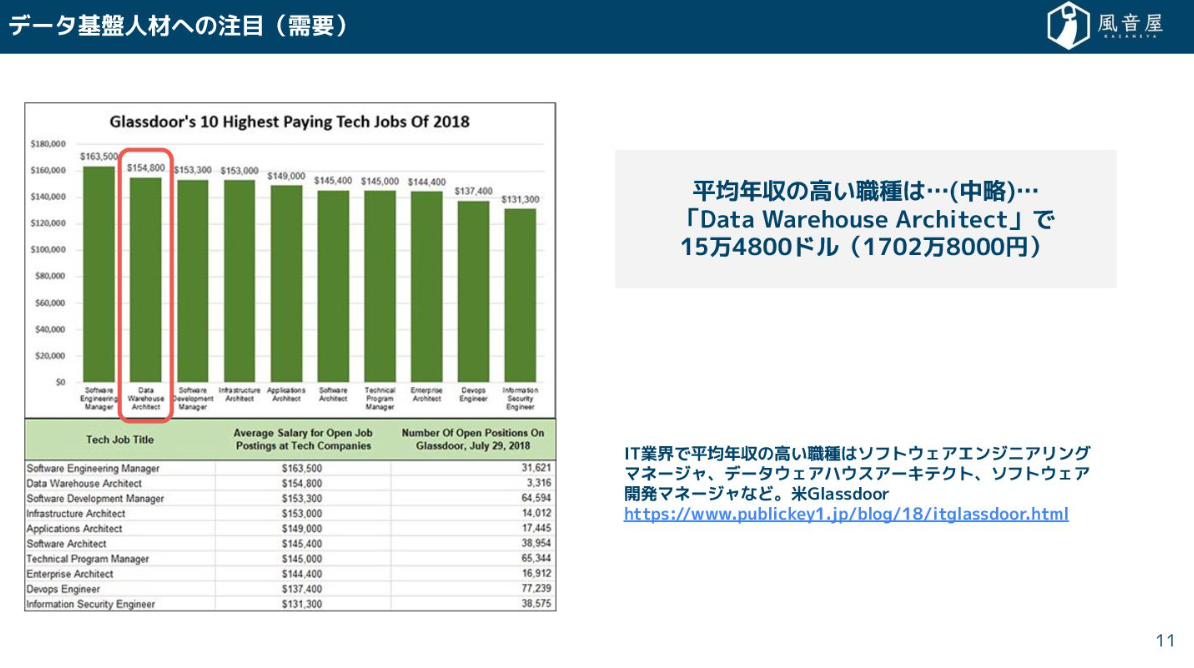
まず、データ基盤人材への注目度が非常に高まっています。少し前の記事ですが、アメリカでは「Data Warehouse Architect」がIT業界で平均年収の高い職種の2番目に入っているというデータがありました。

そして、最近のレポートを見ても、生成AIを「期待以上」に活用できる要因の2位に、日米ともに「データ品質」が挙げられています。データの整備が、AI活用という最先端の領域において、根幹を担っているということです。
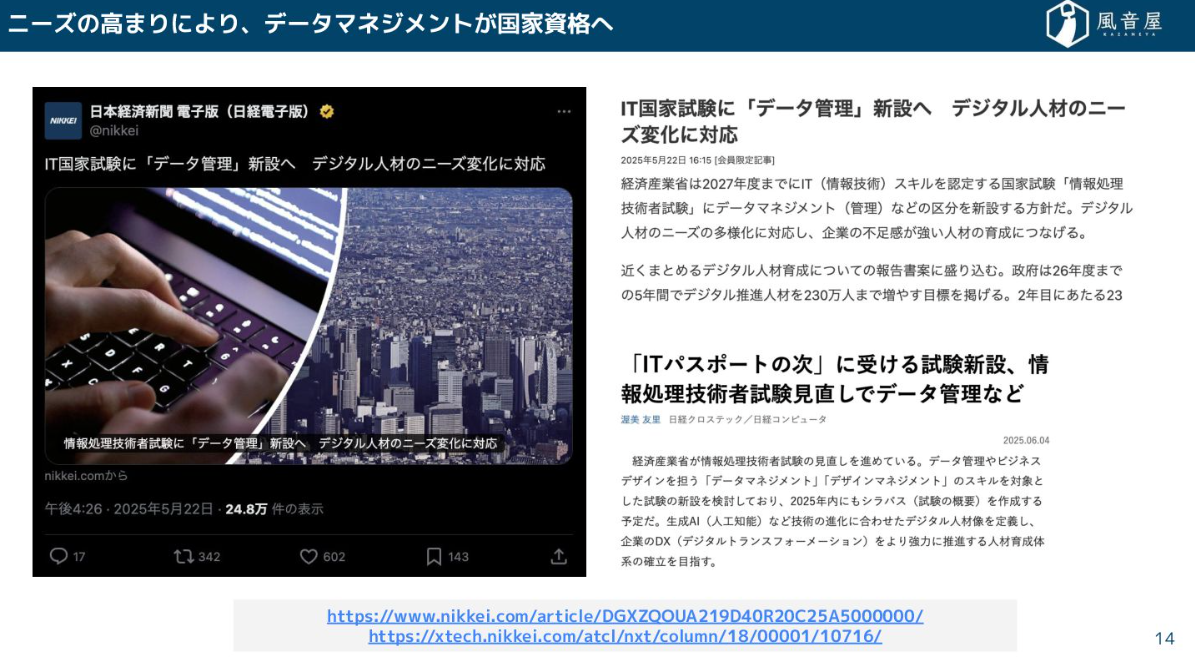
こうしたニーズの高まりを受けて、データ管理に関する国家資格の動きまで出ているという状況です。

あらためまして、ここで自己紹介をさせていただきます。私は「ゆずたそ(@yuzutas0)」というアカウントで活動しており、データマネジメントの本なども執筆してきました。

私たち風音屋は、データエンジニアたちが技術相談やノウハウを共有し合う副業ギルドとして始まり、そこから法人化して成長してきた会社です。現在はデータ基盤の構築や分析支援を行っています。データエンジニアは孤独になりがちなので、もしよければぜひ風音屋への転職を検討してください。未経験者の方々向けにも、260ページ、18万文字という豪華な教材を用いたデータ基盤構築のハンズオンオンライン講座を提供しています。
なぜデータ基盤が必要なのか?
私たちデータエンジニアは、なんのためにデータ基盤をつくるのでしょうか。もちろん、データ活用がしたいからですよね。
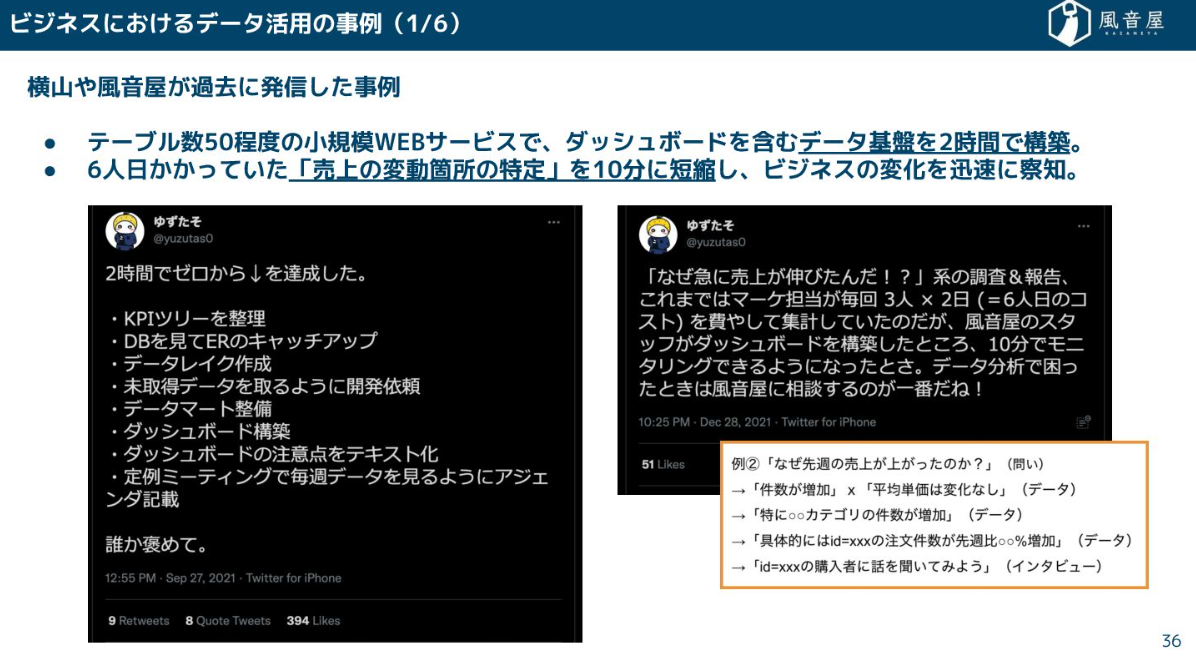
データ活用を進めたい時、例えば「売上の変動箇所の特定に1週間かかっていた作業を10分に短縮したい」といったニーズが出てきます。
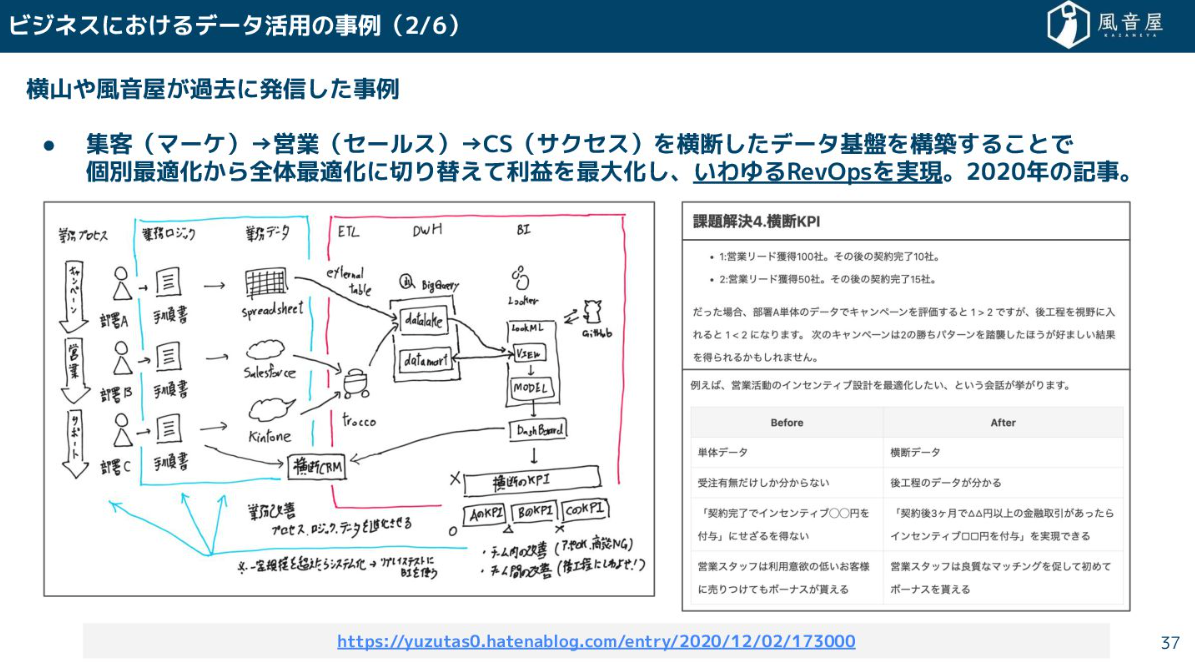
あるいは、マーケティング、営業、カスタマーサクセスといった一連の流れを横断してデータを分析し、利益を最大化する「RevOps(レベニューオペレーション)」を実現するためにも、データ基盤は大事になります。

私生活や非営利活動でも、データ基盤の活用事例は広がっています。例えば、私がつくった「古文書データ基盤」は、非構造化データ(古文書の画像)をAIで解読してデータベース化し、歴史空間にマッピングするといったものです。

最近の大きなトレンドとして、従来はテーブル形式の構造化データでしか管理できなかったものが、AI技術の発展に伴って、画像やPDFファイルといった非構造化データも扱いやすくなってきたという変化があります。
データ基盤のネックはデータ整備の課題

しかし、データ活用を進めようとすると、必ずデータ整備の課題が浮上します。国内の調査でも「質・量を備えたデータの取得」が課題の2位に挙がっています。

グローバルな調査でも、回答者の73%がデータのサイロ化によって必要なデータを提供できず、目標達成できていないと回答しています。

だからこそ必要になるのが、SSoT(Single Source of Trust=信頼できる単一の情報源)の担保です。分析者が「ここを見れば必要なデータがそろう」と信頼できる「寄る辺」が必要なのです。
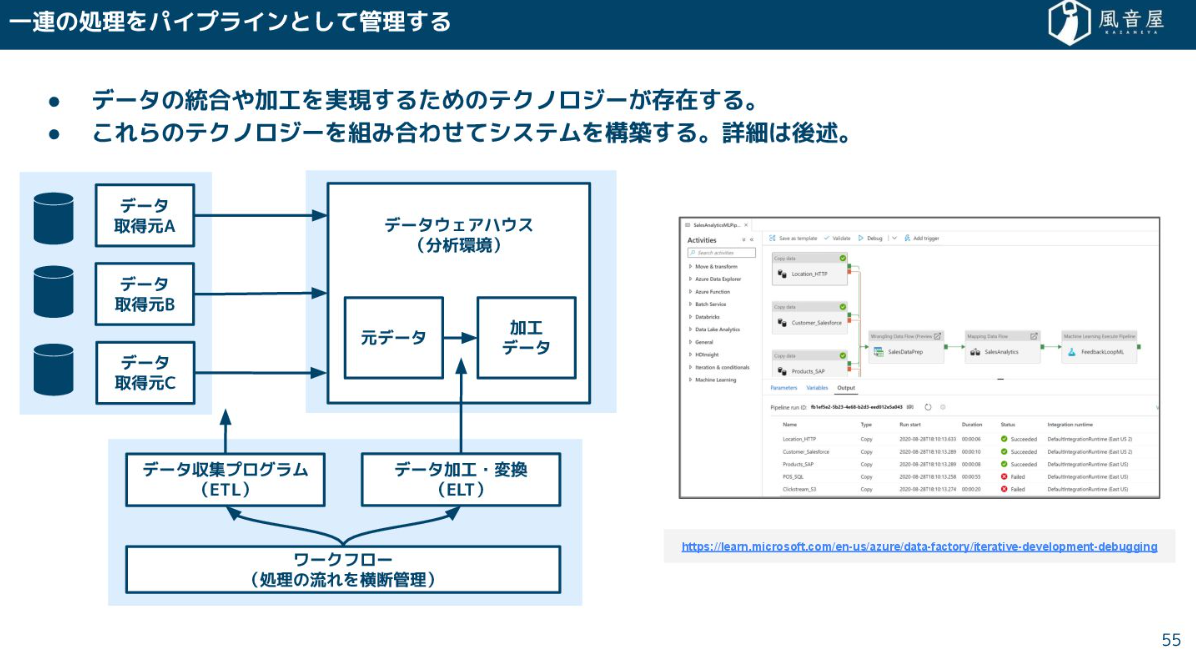
現在のデータ基盤では、社内外のデータをDWH(データウェアハウス)に集約し、統合や加工をパイプラインとして管理する実現方法が主流です。一般に、複数のテクノロジーを組み合わせて構築されます。
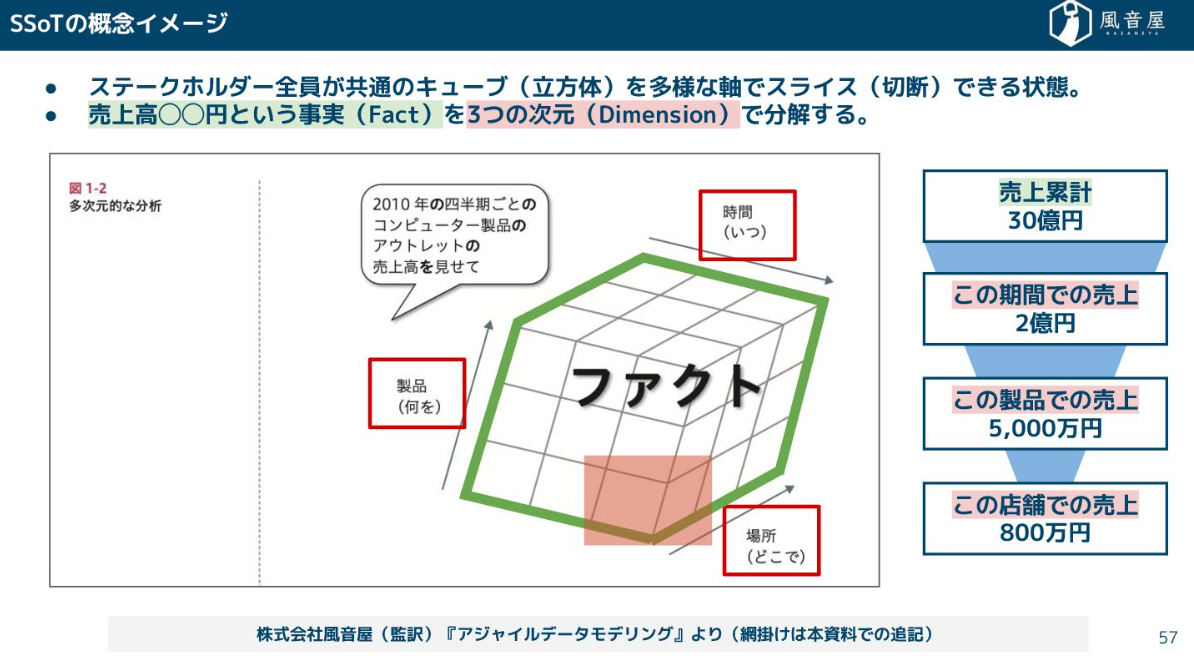
目指すのは、売上高という「Fact(事実)」を、期間、製品、店舗といった「Dimension(次元)」で柔軟にスライスできる状態です。これにより、「営業組織別で見ていた数字を、市場環境の変化に応じて業種別で見てみよう」といった柔軟な分析が可能になり、根拠のある意思決定と変化への適応が進みます。
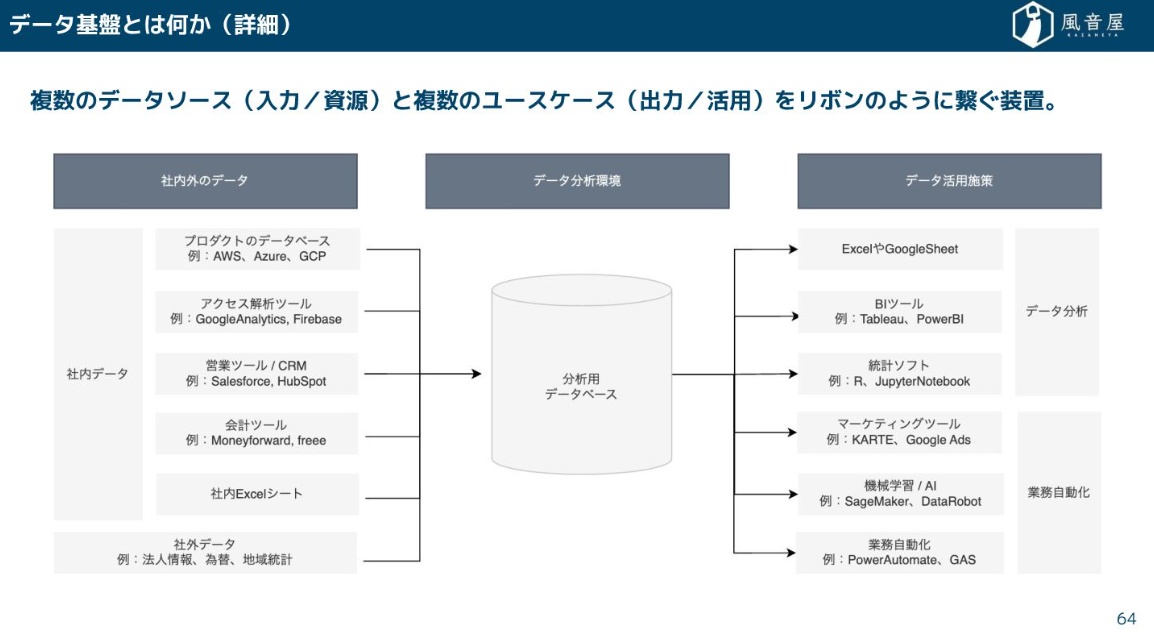
データの活用を行うためには、複数のデータソースとユースケースをリボンのようにつなぐ装置が必要です。これがデータ基盤です。
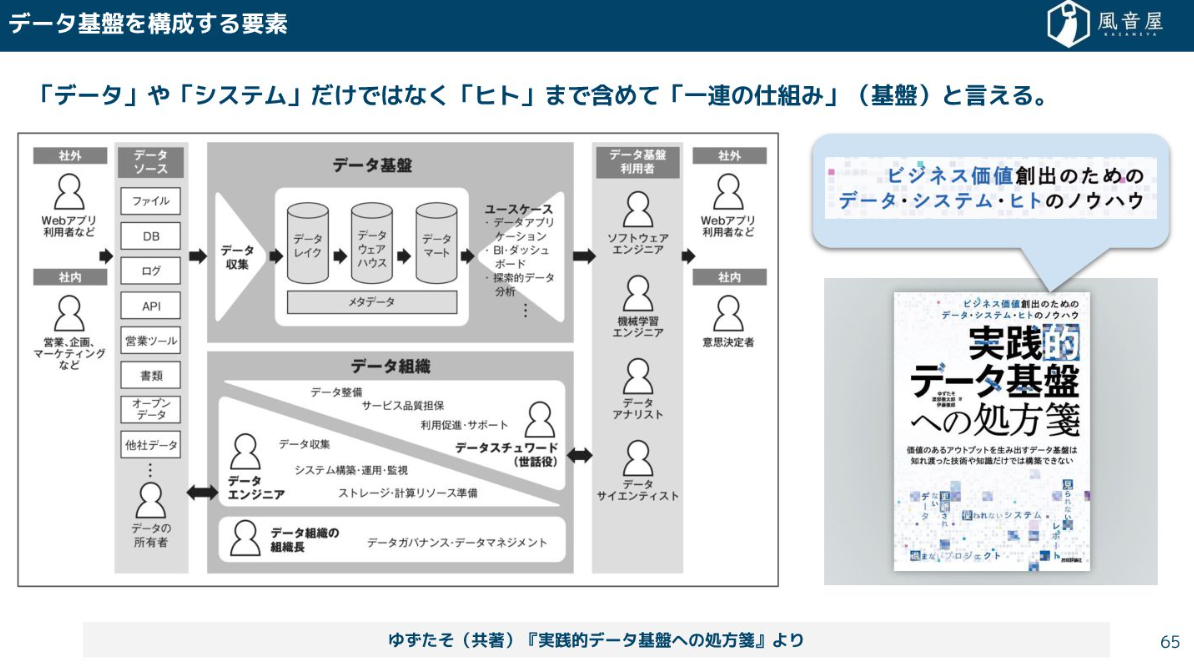
このデータ基盤は、「データ」や「システム」だけでなく、データを入力する人の業務フローや組織のカルチャーまで含めた「一連の仕組み」と言えます。
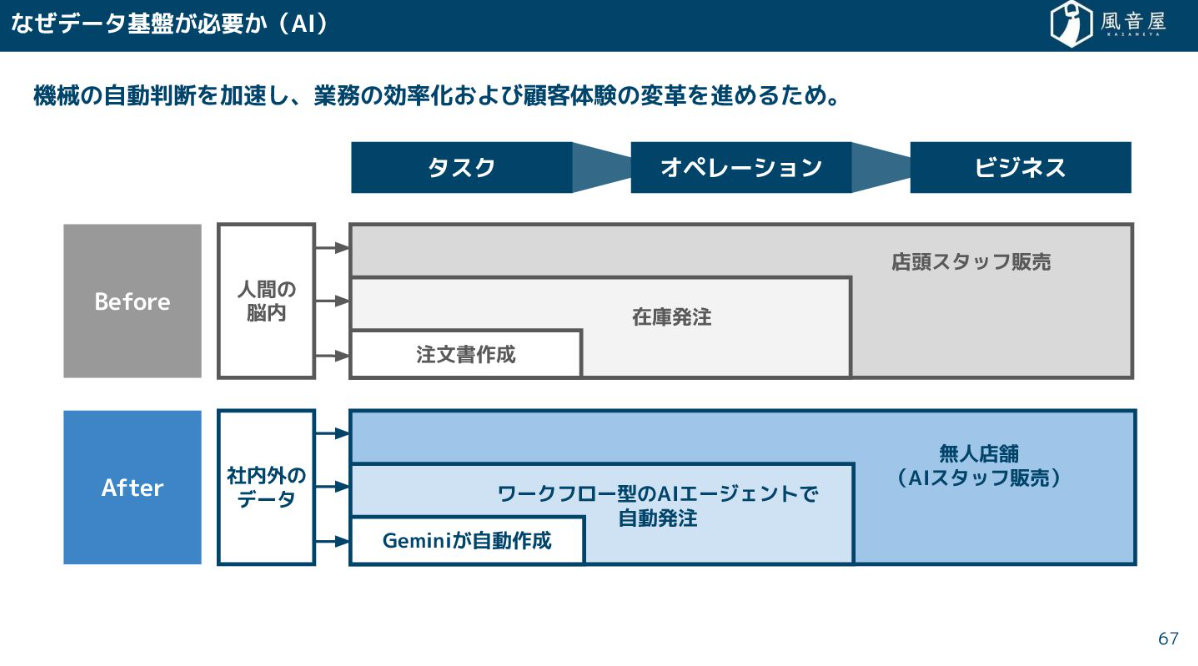
そして、データ基盤は、人間によるPDCAサイクルを加速するBI(Business Intelligence)のためだけでなく、AIエージェントによる自動判断を加速し、業務の効率化や顧客体験の変革を進めるためにも不可欠になっています。
データ基盤システムの構成要素
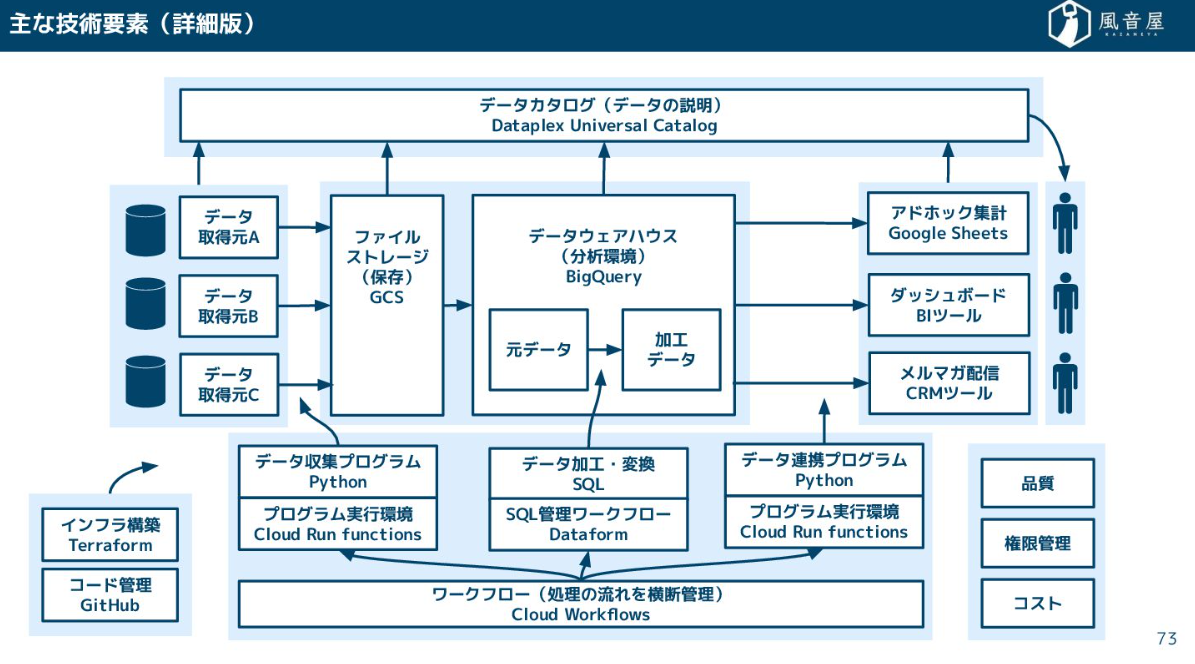
現在、データ基盤を支えるテクノロジーの全体像は、DWH(データウェアハウス)を中心に、BIツール、ETL/ELT、ワークフロー、データカタログなどが周囲を固める構成が主流になっております。
重要なのは、データだけではなく、システム、そしてそれを扱う「ヒト」まで含めた一連の仕組みとして捉えることです。
なお、今回は無料Googleアカウントさえあれば無料で使えるGoogle Cloudを前提に解説していきます。
BIツール
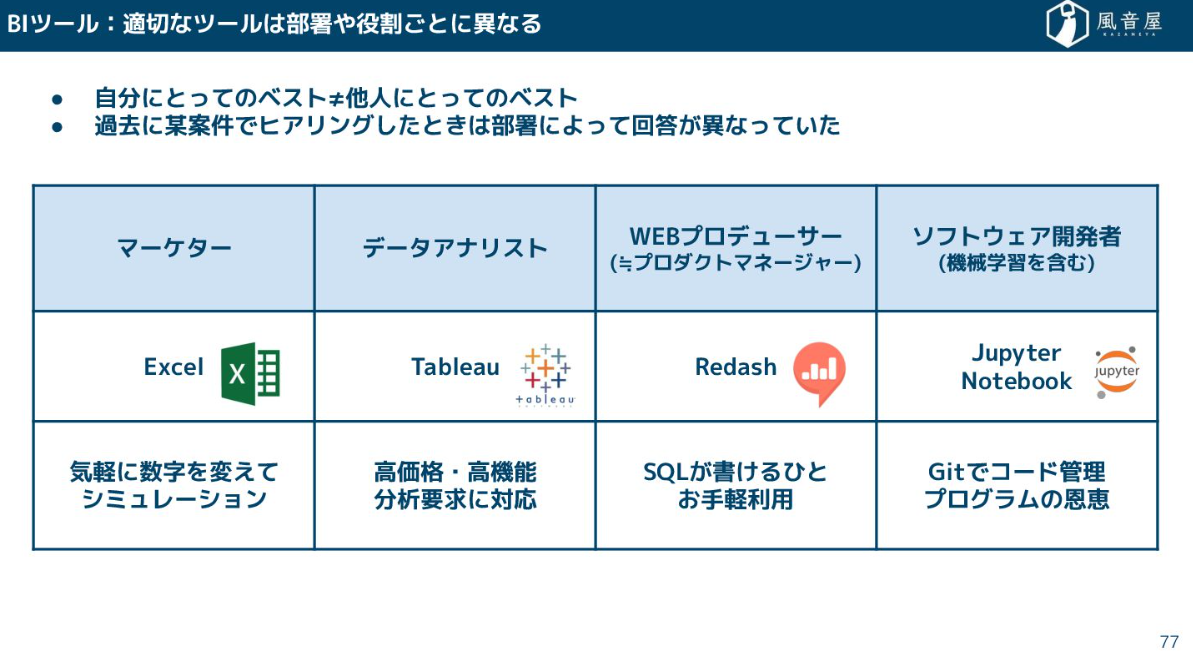
BIツールはデータの可視化やダッシュボード構築に特化しているツールです。部署や役割によって使いやすいツールが違ってくるため柔軟に対応していく必要があります。
DWH(データウェアハウス)
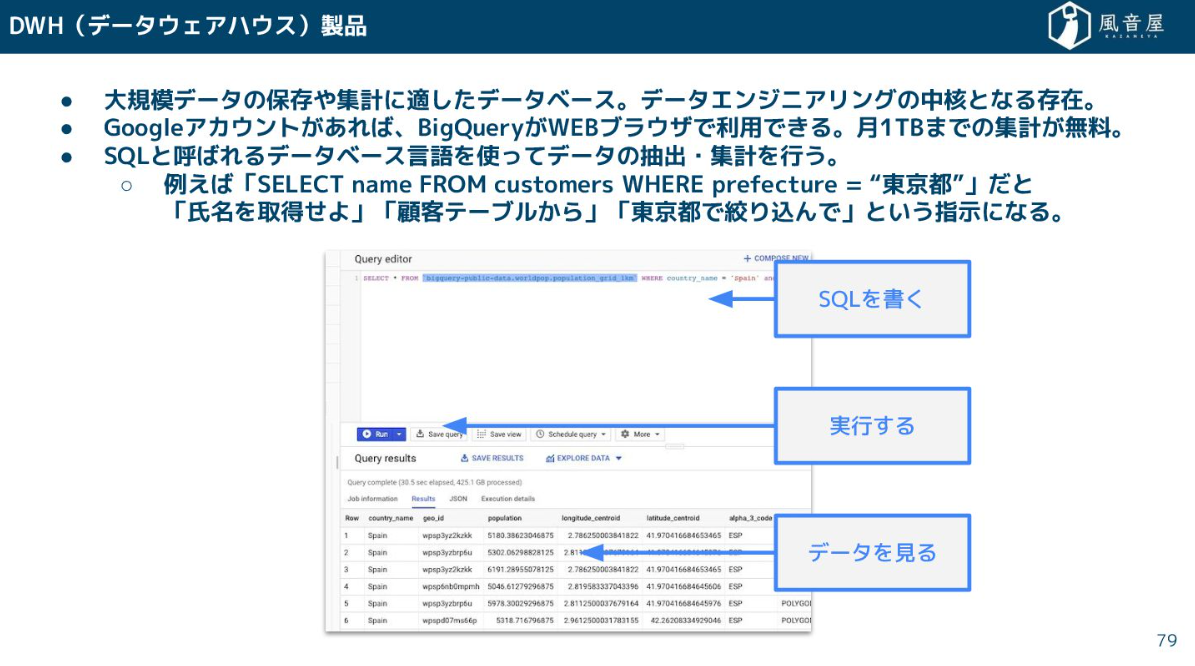
データの蓄積・集計を行うDWH(データウェアハウス)ですが、これは大規模データを扱うのに特化したデータベースです。分析や集計はSQLというデータベース言語で行います。例えば、「東京都に住んでいる顧客の名前を引っ張ってきて」といった指示をSQLで書くわけです。BIツールがDWHに接続する際、裏側ではこういったSQLが発行されています。
ファイルストレージ・クラウドストレージ
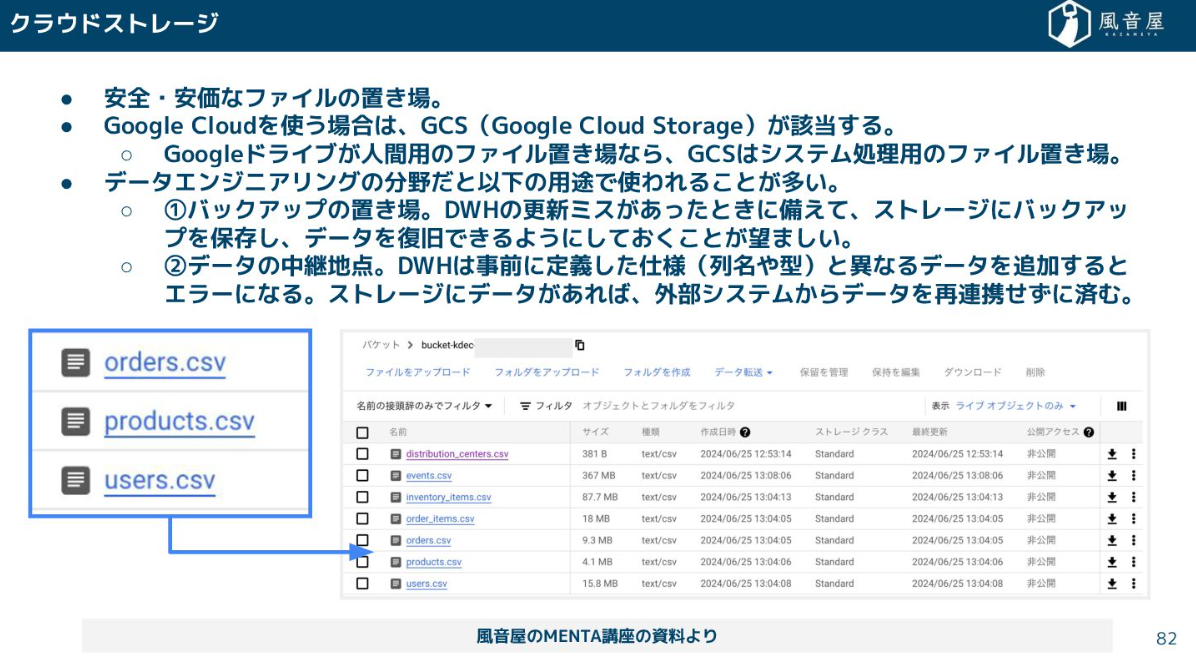
ファイルの一時保管場所としてクラウドストレージも重要です。DWHの更新ミスに備えたバックアップの置き場として使ったり、外部システムからデータを取り込む際の中継地点として一時的に保存したりするのに使われます。
プログラム実行環境
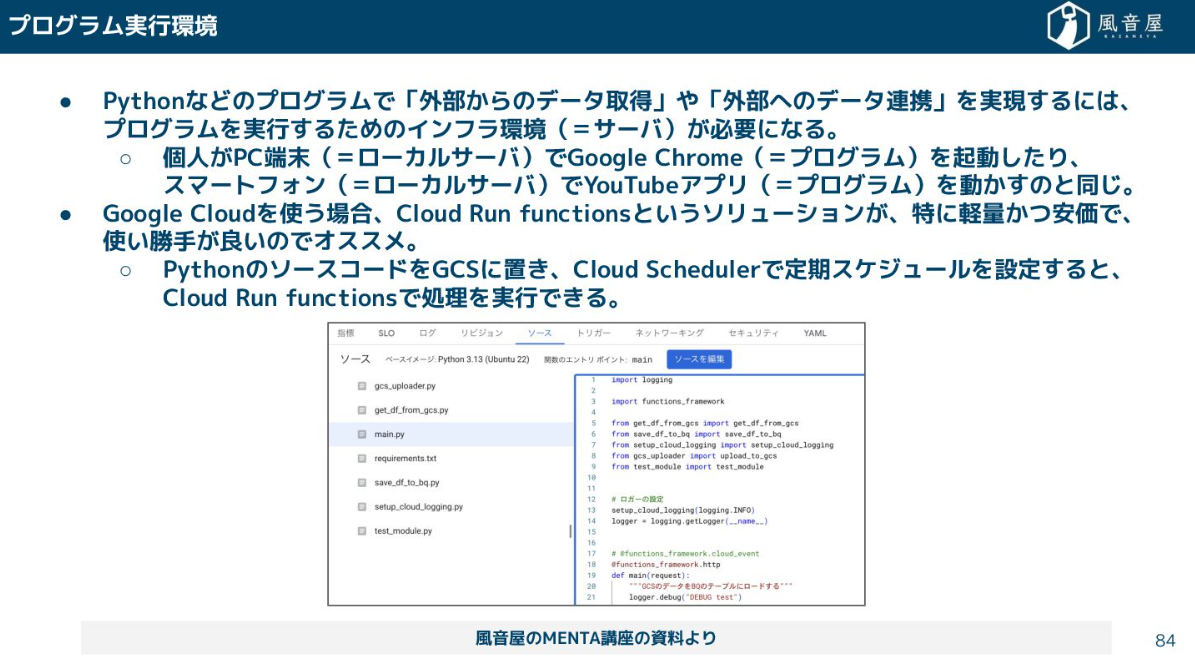
外部からデータを引っ張ってきたり、逆にほかのシステムにデータを提供したりする際には、Pythonなどのプログラムを実行するためのプログラム実行環境が必要です。個人のPCがGoogle Chromeを動かすのと同じように、プログラムを動かすにはサーバーが必要になるので、Cloud Run functionsのようなサーバーレスなマネージドな実行環境環境を使うことが多いです。
ETL/ELT

データの移動と変換を担うのがETL/ELTです。
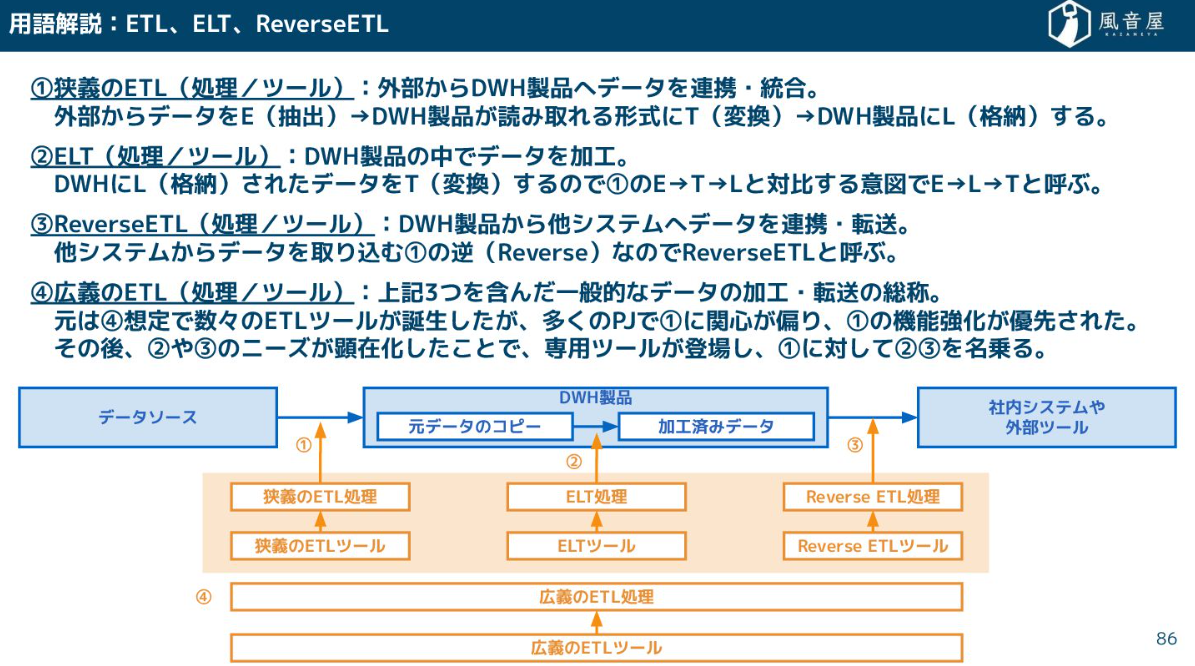
ETL(Extract, Transform, Load)は、外部システムからデータを抽出(E)し、DWHに読み込める形式に変換(T)して、格納(L)するツールです。
ELT(Extract, Load, Transform)は、DWHに格納(L)されたデータを、DWHの機能を使って加工・変換(T)する処理を指します。BigQueryの環境内でSQLを使ってデータを加工するイメージです。
Reverse ETLは、DWHで加工されたデータを、CRMツールや広告媒体といった外部システムへ連携・転送する処理です。
ワークフローエンジン
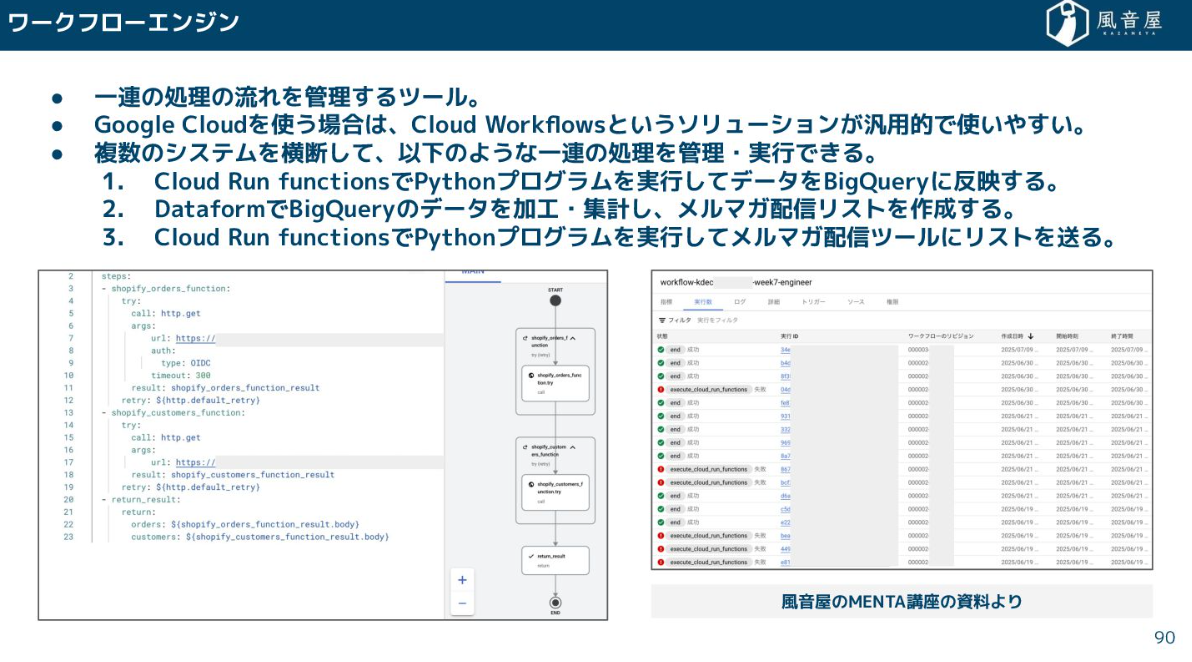
これらのデータ収集、加工、連携といった一連の流れを管理するのがワークフローエンジンです。ELTツールであるDataformは、SQLの依存関係をパイプラインとして管理できますし、より汎用的なCloud Workflowsなどを使えば、Pythonプログラムの実行からDWHでの加工、メルマガ配信ツールへの連携まで、複数のシステムを横断して一連の処理を管理・実行できます。
データカタログ
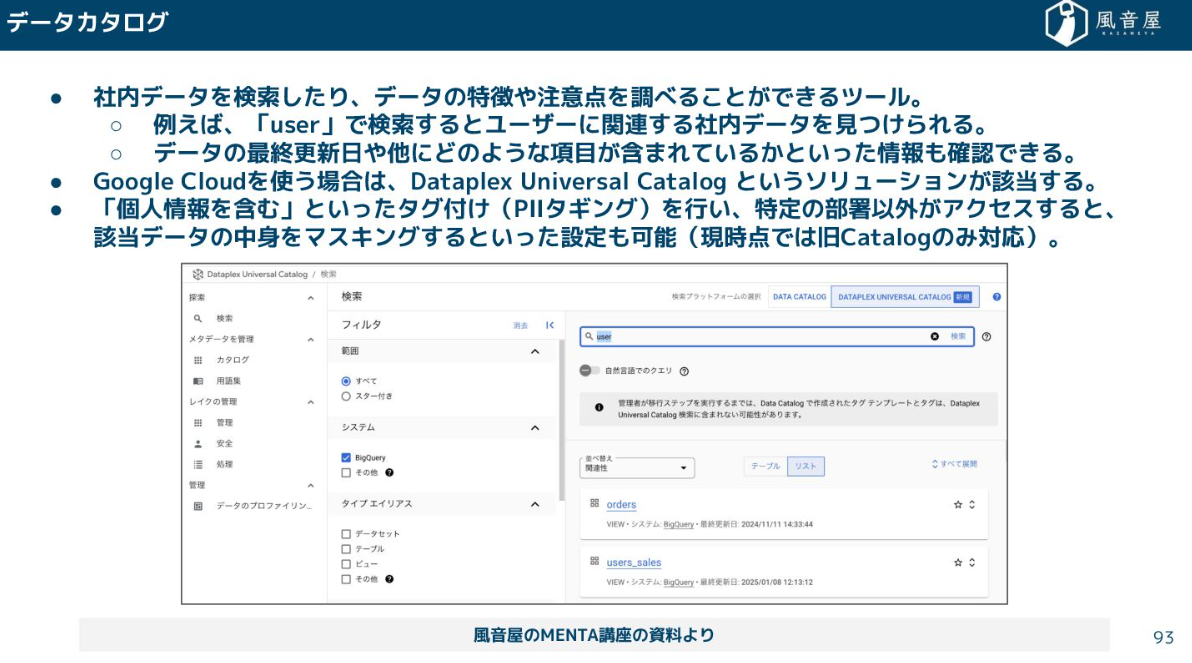
データカタログは辞書のようなものです。社内のデータを検索したり、データの特徴を調べたりする際に使用されるツールです。例えば、「user」と検索すればユーザーに関連する社内データを見つけられます。
権限管理
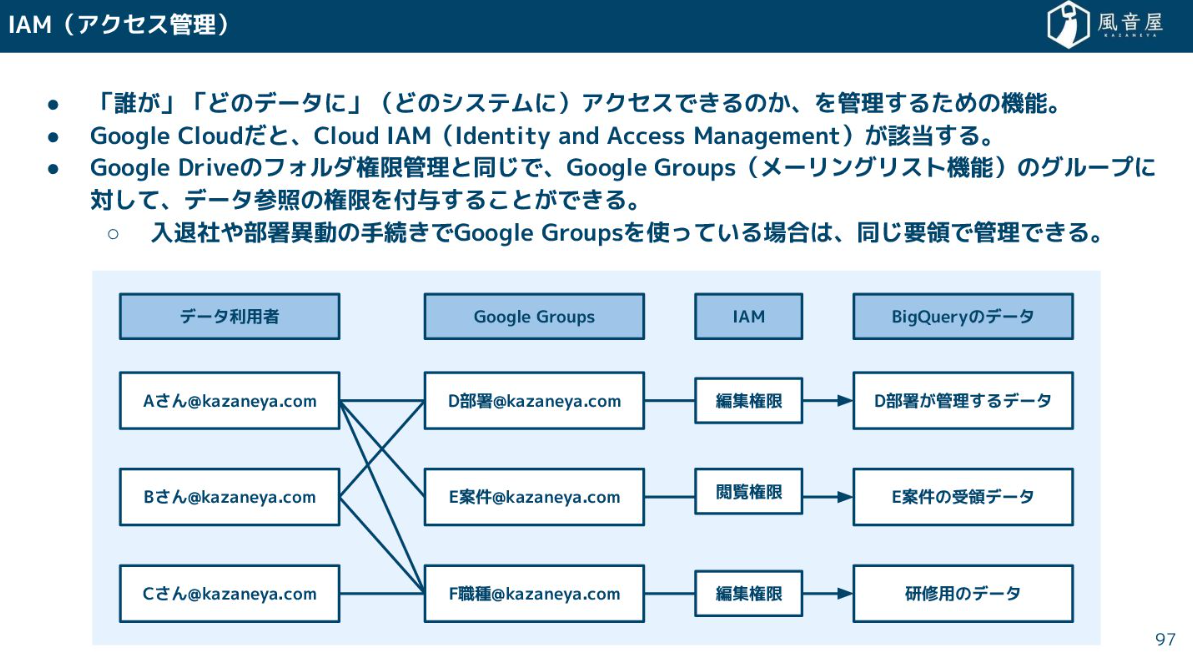
クラウド系のサービスを利用する場合、権限管理ではIAM(アクセス管理)を利用するケースが多いと思います。誰がどのデータにアクセスできるのかを設定するツールです。
監査ログ
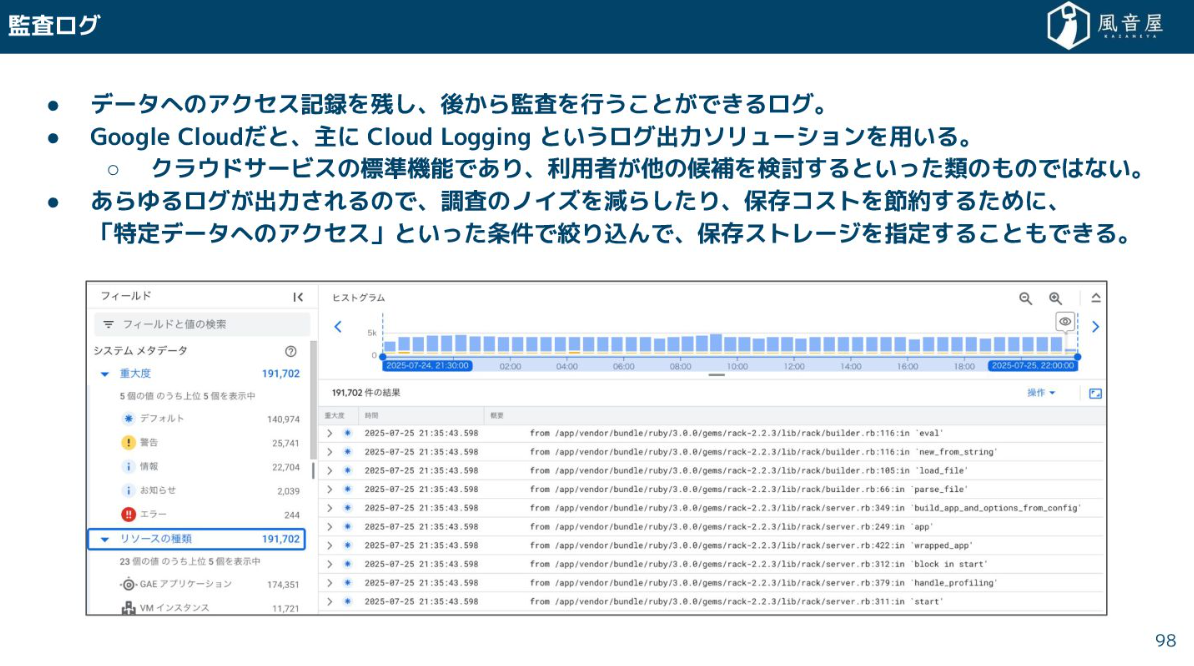
また、これと合わせてデータへのアクセスを記録し残しておける監査ログも不可欠です。
こういった様々な機能・ツールを組み合わせながらデータ基盤のシステムは構成されています。
データ基盤システムの実装方法
ここからは、データ基盤システムの実装方法についてご紹介します。
データ収集
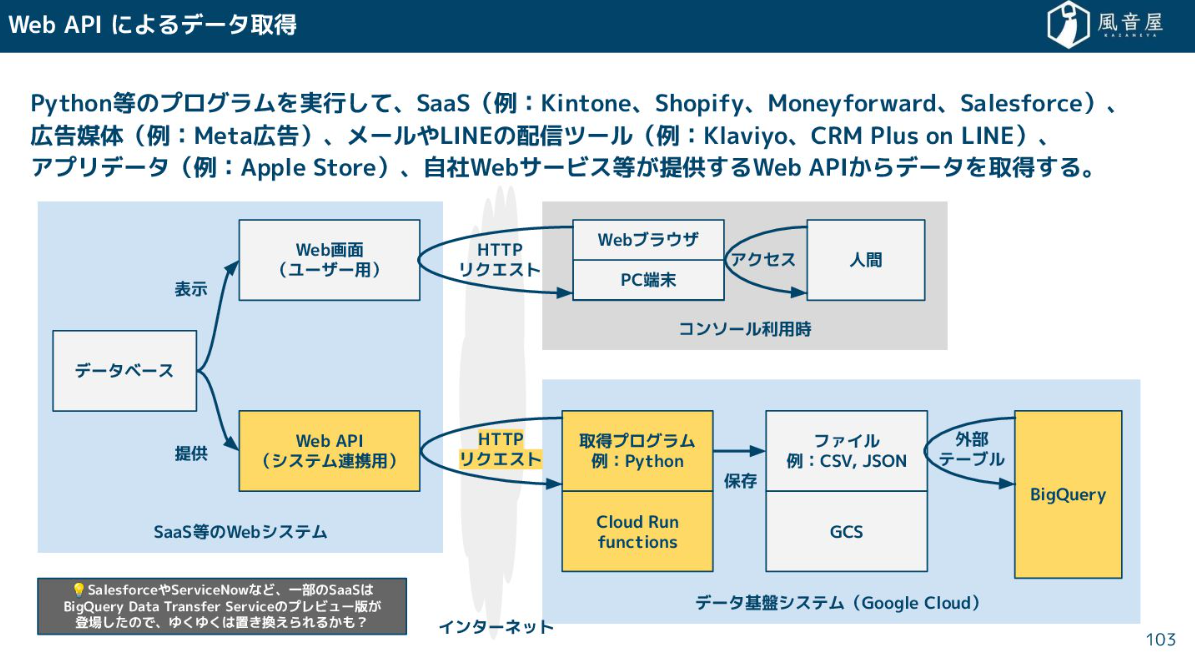
データ収集の実装は、データの取得元によって方法が変わってきます。 SaaSやWebサービスからデータを取得する際は、基本的にはPythonなどのプログラムを書いて、システムが提供しているWeb APIを叩いてデータを引っ張ってきます。
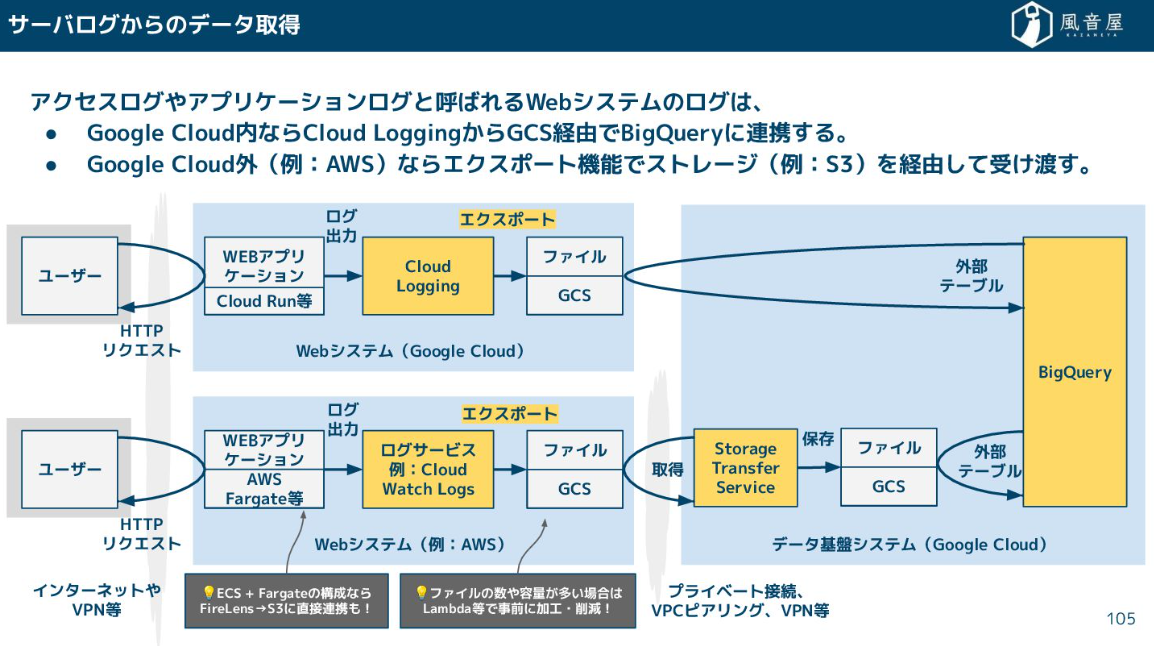
アクセスログやアプリケーションログについては、クラウドストレージのエクスポート機能を利用しデータを受け渡します。
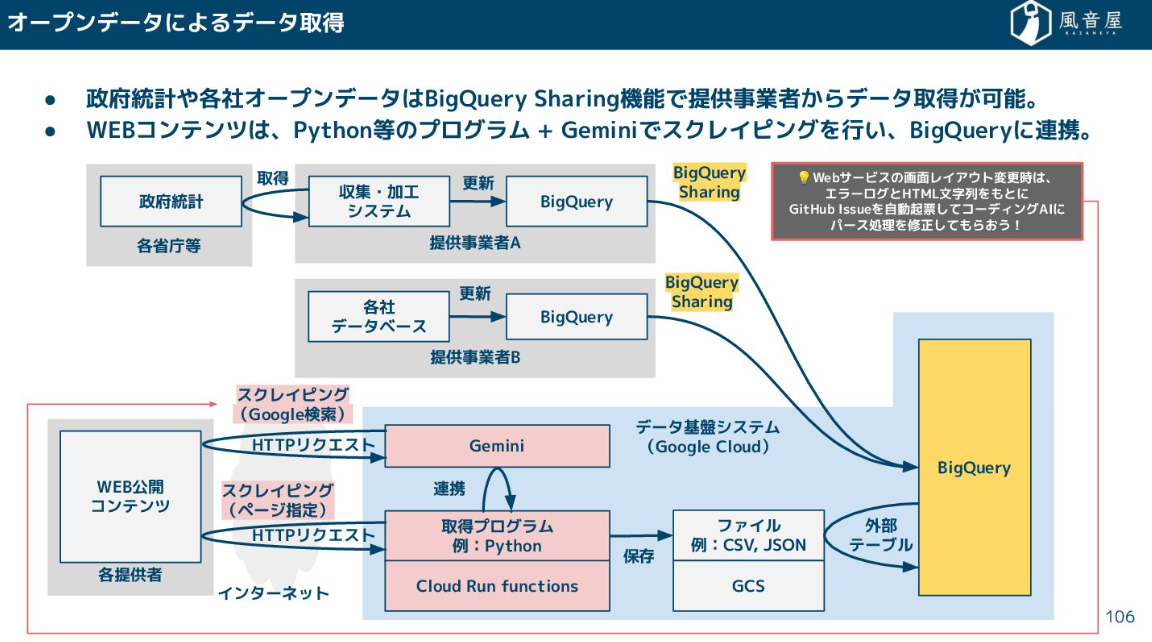
統計調査などで公開されているオープンデータは、Pythonなどでプログラムを書いてスクレイピングを行い、BigQueryに連携します。
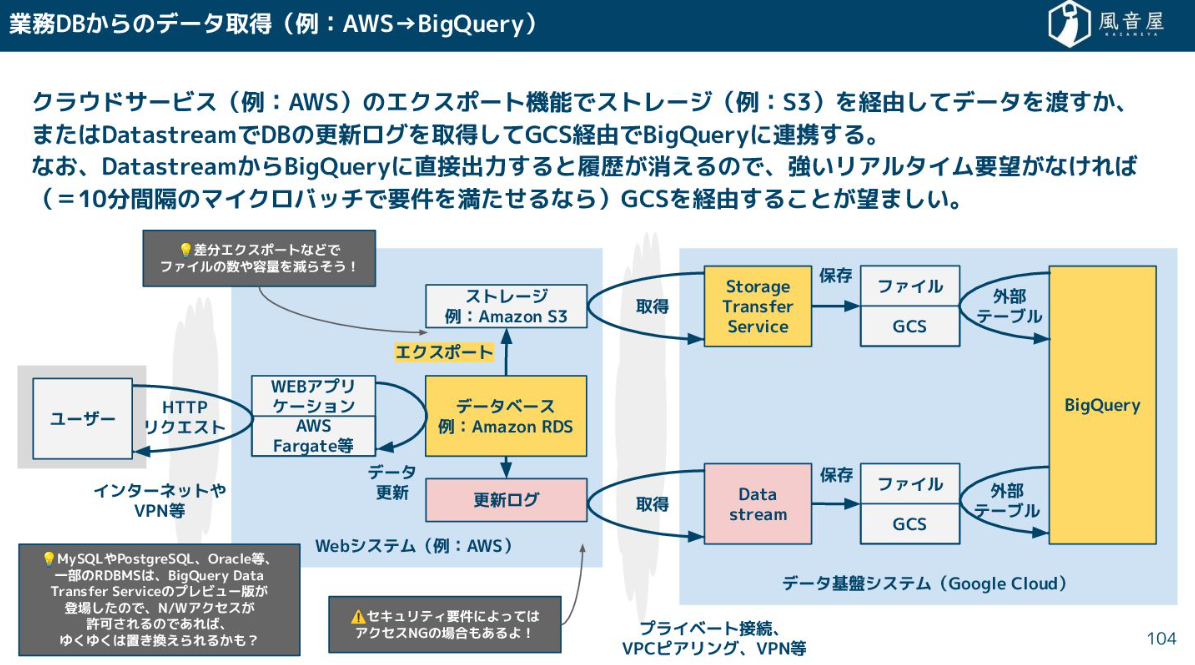
一方、業務データベースからデータを取得する場合は、ファイルにエクスポートしてから引っ張ってくるか、DatastreamのようなツールでDBの更新ログを取得し、クラウドストレージを経由してDWHに連携します。
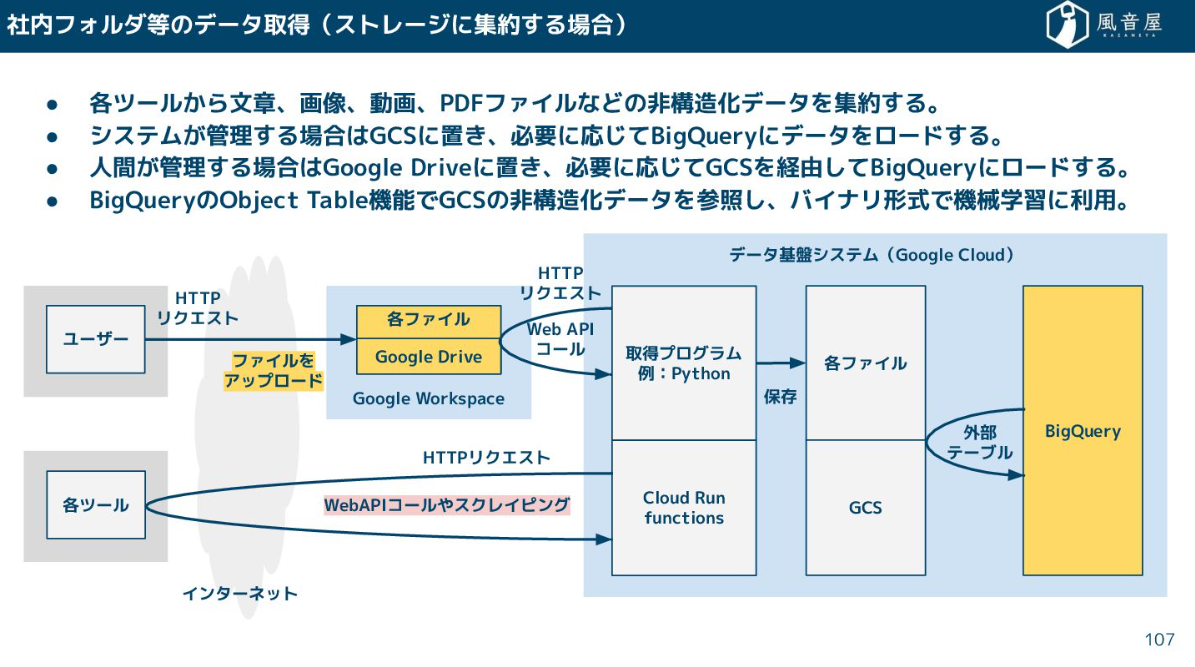
また、非構造化データ(文書、画像、PDF)を扱う場合、人間が特定のフォルダにファイルを上げておけば、それをCloud Run functionsなどのプログラムが参照し、クラウドストレージを経由してBigQueryにロードする、という流れになります。
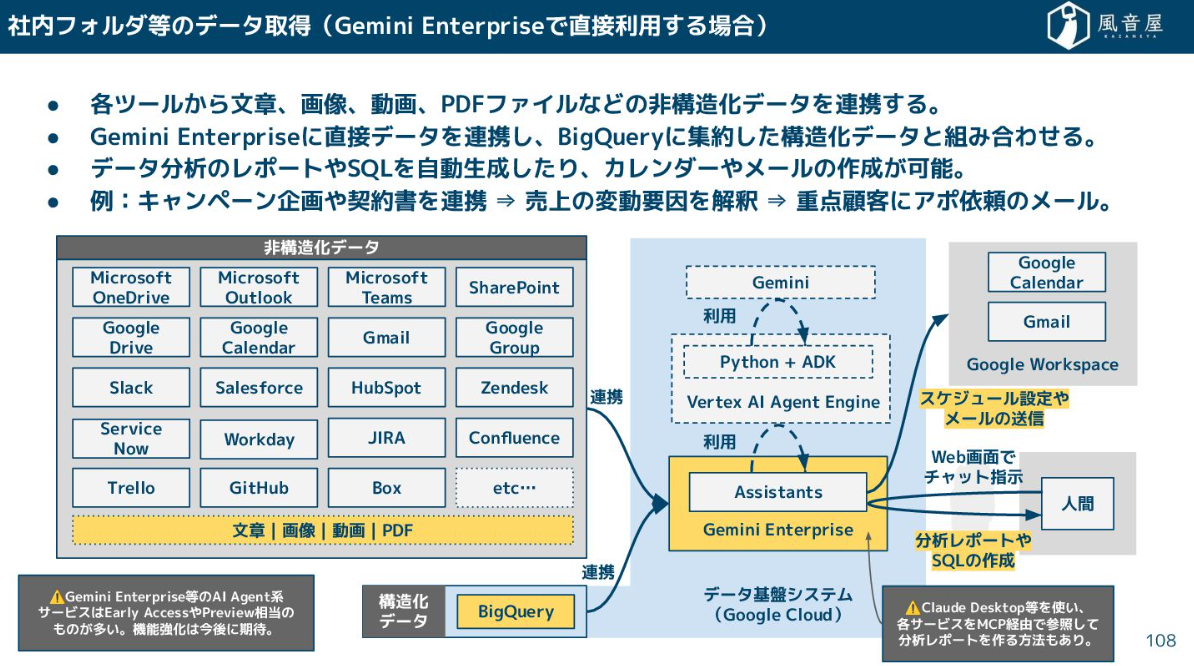
最近はAI側が進化しており、AIエージェントに直接データを連携して、構造化データと組み合わせて分析レポートやSQLを自動生成させる、というアプローチも出てきています。
データ加工
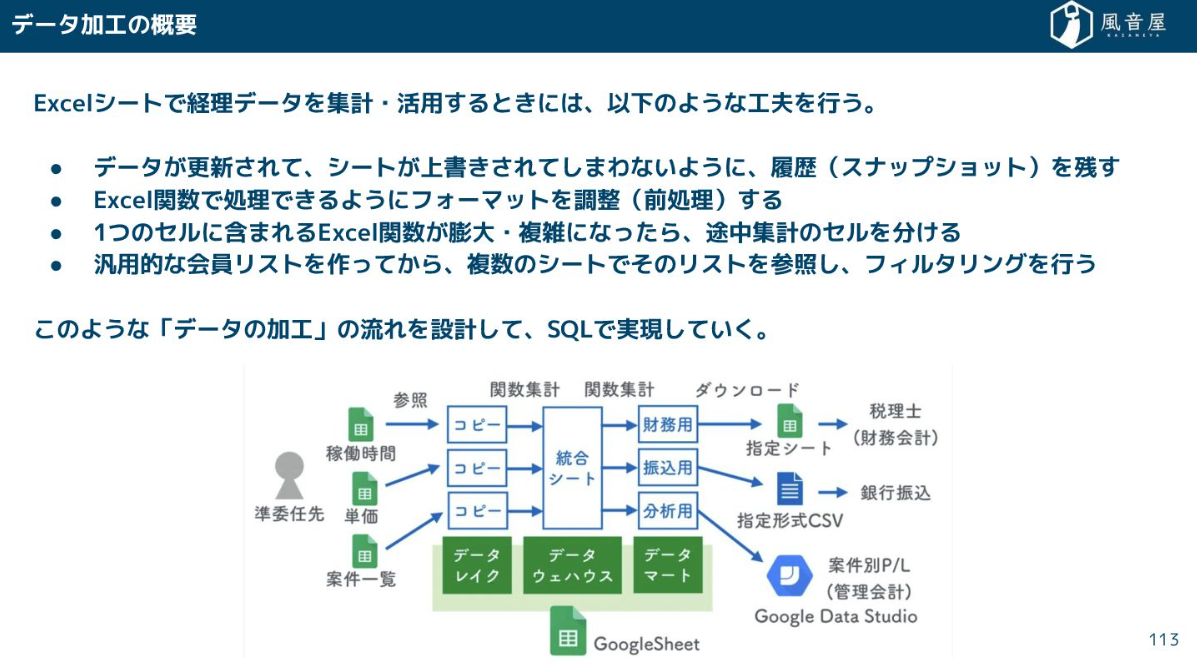
データ加工は、Excelで複数のシートを使って途中集計を行うのと同じように、SQLやPythonを使ってデータの加工の流れを設計・実装していきます。
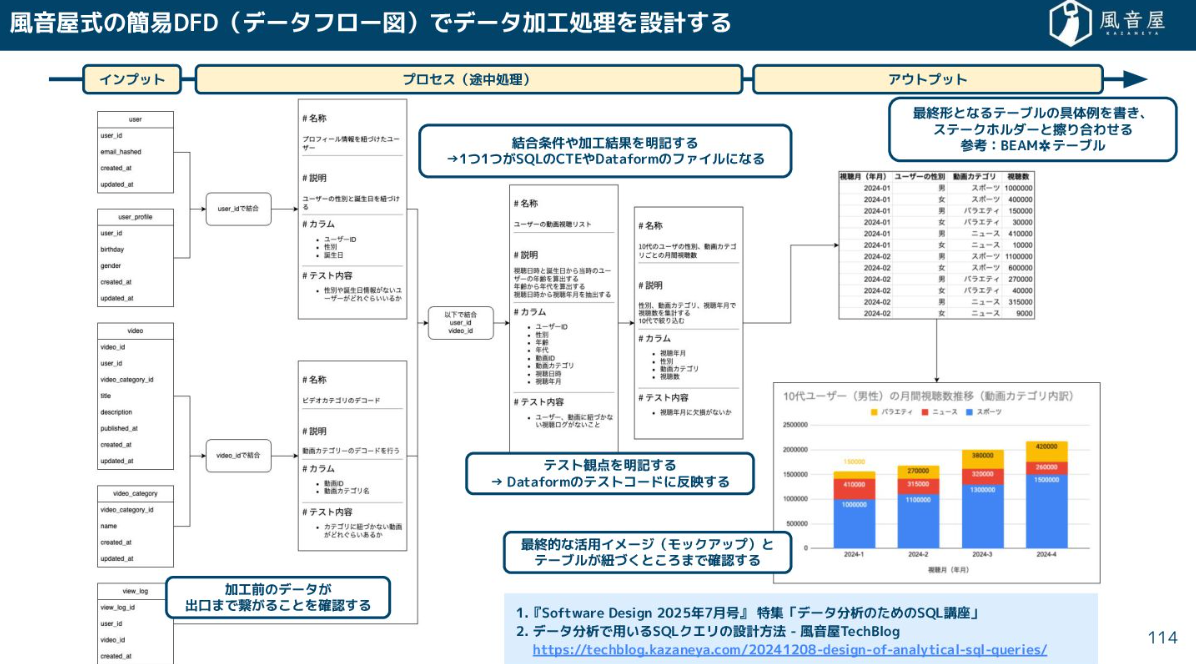
設計を安定させるために、弊社では風音屋式の簡易DFD(データフロー図)を作成して、インプットのデータソースから最終的なアウトプット(BIツールや利用者が欲しい形)まで繋がることを確認しています。
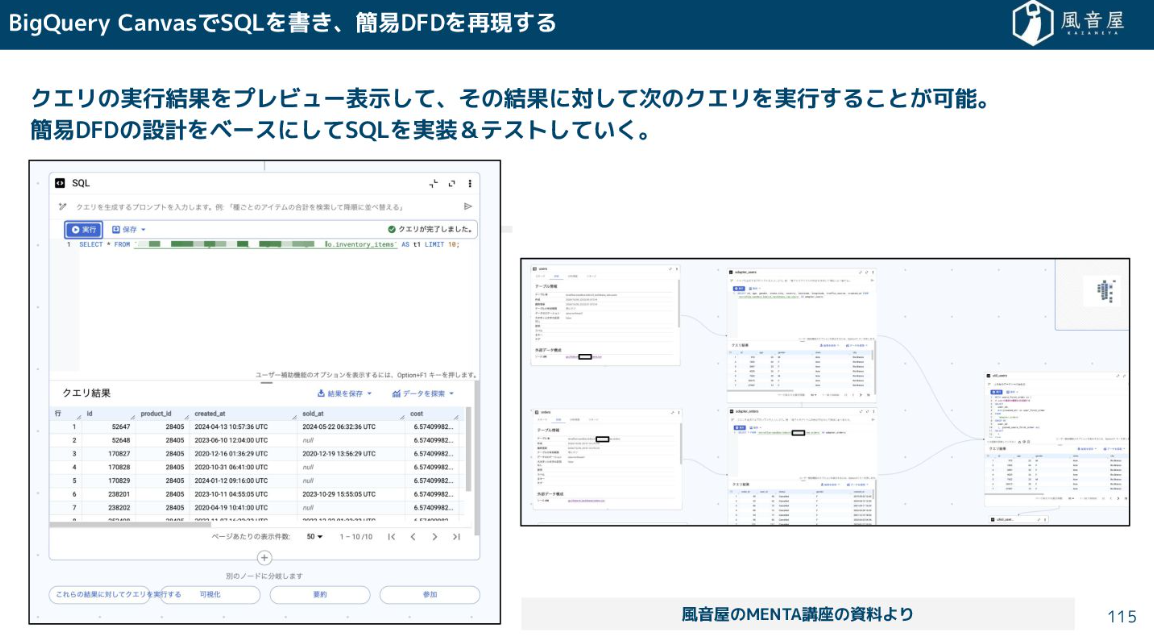
現在では画面上でクエリの実行結果をプレビューしながら実装・テストができます。こういったキャンバス機能も使いながらクエリの確認も可能です。
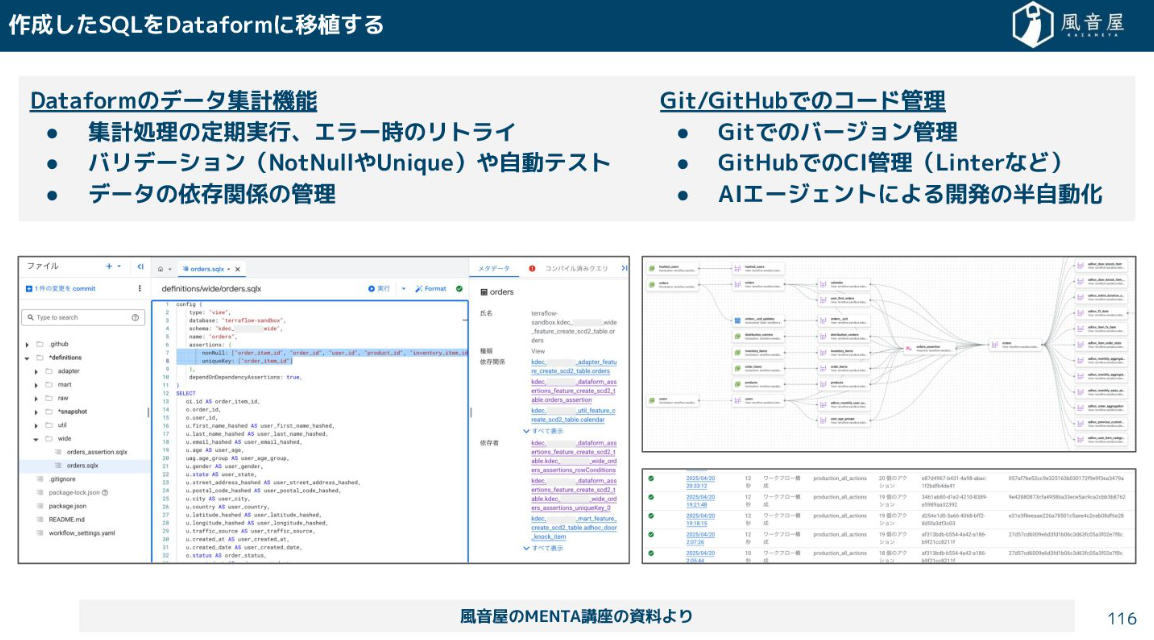
作ったクエリはELTツールへ移し実行していきます。
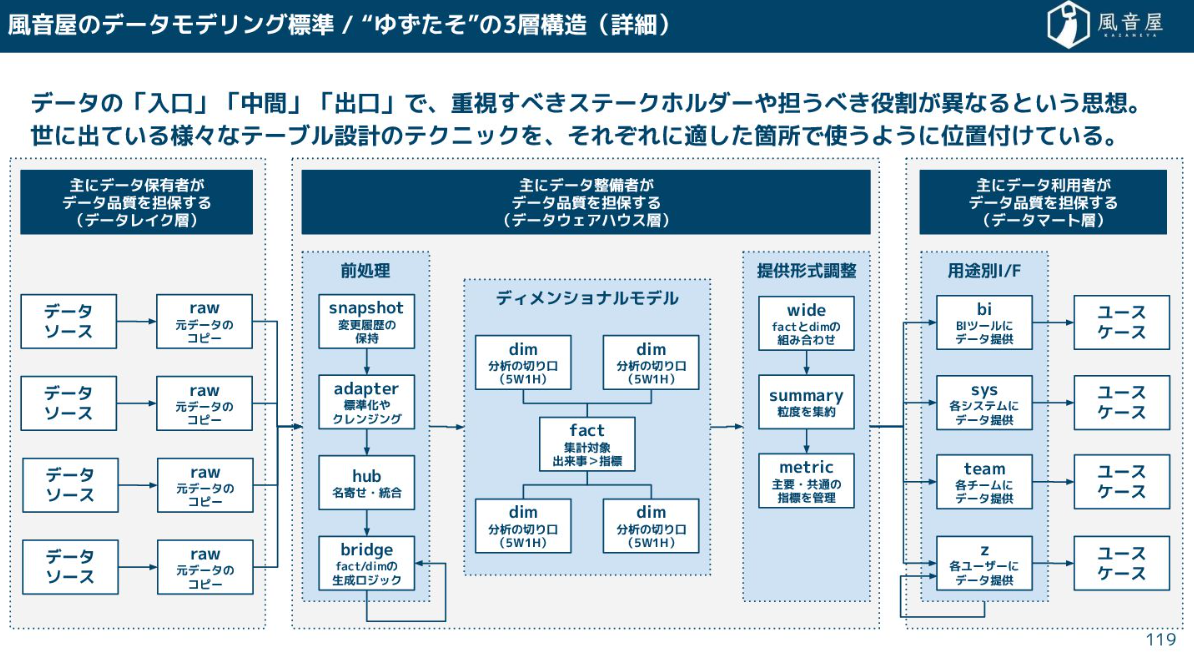
この時、適当にテーブルをつくっていくとすぐに管理不能になるので、レイヤリングという設計思想が重要です。弊社では「“ゆずたそ”の3層構造」として、様々なテーブル設計のテクニックを組み合わせています。
- データレイク層:外部から引っ張ってきた元データのコピーを格納するテーブル
- データウェアハウス層:分析の切り口となるテーブル(顧客属性や商品カテゴリなど)、集計対象となるテーブル(売上金額や注文数など)
- データマート層:BIツールへの提供など、特定の用途に合わせて整形するテーブル
この「入口」「中間」「出口」で層を分けて、それぞれ責任範囲(データ保有者、データ整備者、データ利用者)を明確にするという考え方が風音屋式データモデリングの標準となっています。
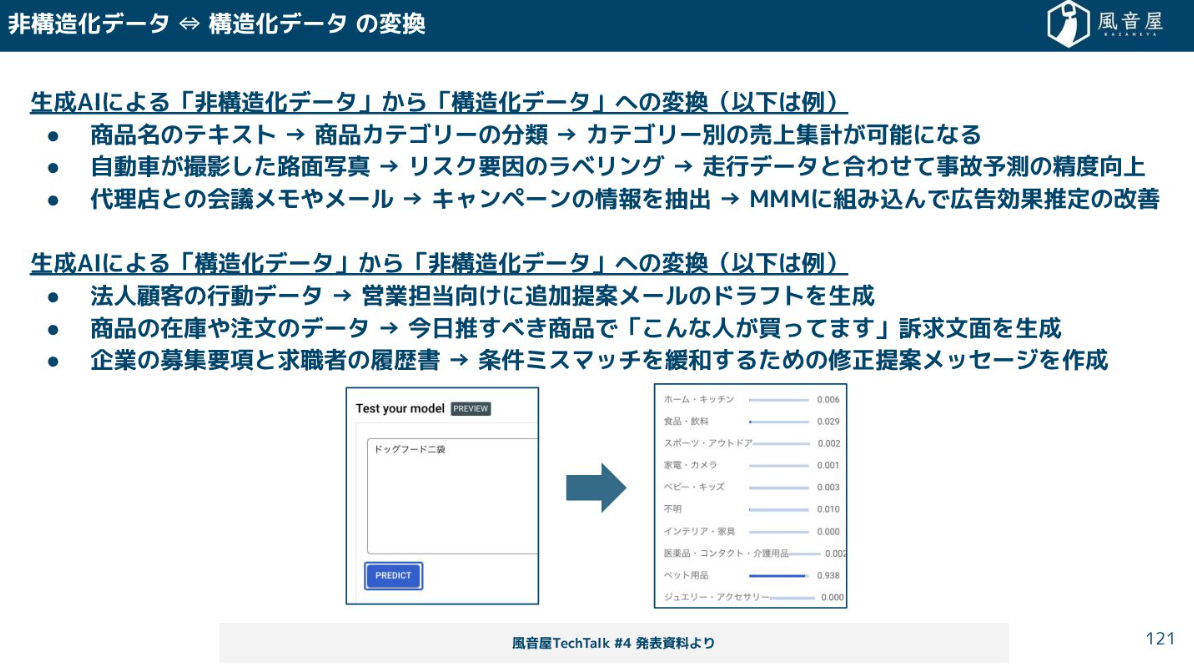
そして、AI時代において革命的なのが、SQLで非構造化データを扱えるようになったことです。例えば、商品名テキストから商品カテゴリーを分類したり、請求書のPDFから必要なデータを抽出したりといった処理を、SQLクエリに組み込めるようになりました。これにより、機械学習チームに依頼しなくても、通常のパイプライン上で高度な変換処理が可能になりました。
データ提供
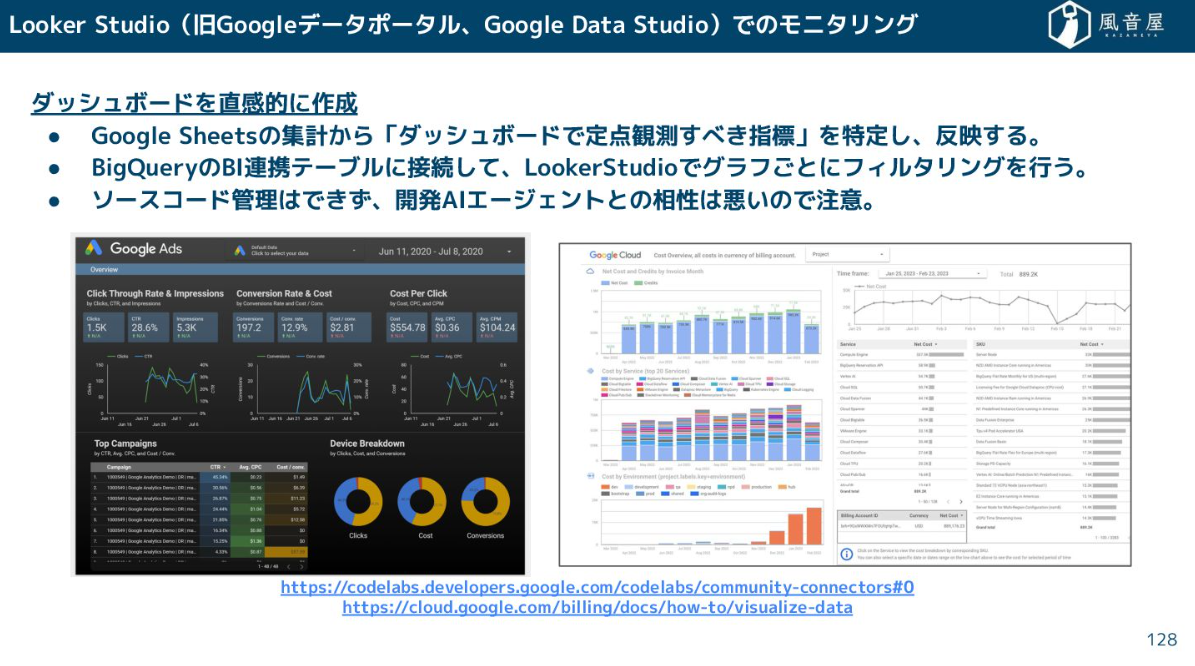
ここからは、DWHに集めたデータをどうやって使っていくかというお話になります。
Excelやスプレッドシートなどを利用するのはもちろんですが、BIツールを使ってグラフごとにフィルタリングをするのも1つの方法でしょう。

また、現在では生成AIによるアドホック分析も可能です。実際に生成AIでデータ分析レポートを出力する事例も増えています。
メタデータ管理

メタデータとは、データを説明するためのデータです。例えば、価格が「100」という数値だった場合、それが「100円」なのか「100ドル」なのかを説明するのがメタデータです。

テーブルの用途、カラムの型、データの更新頻度、既知のエラーケース、機密情報に該当するかどうか、誰がいつ使っているかといった情報が揃っていることで、データ利用者はそのデータが「信頼できるか」「どう使えばいいか」を理解できるようになります。
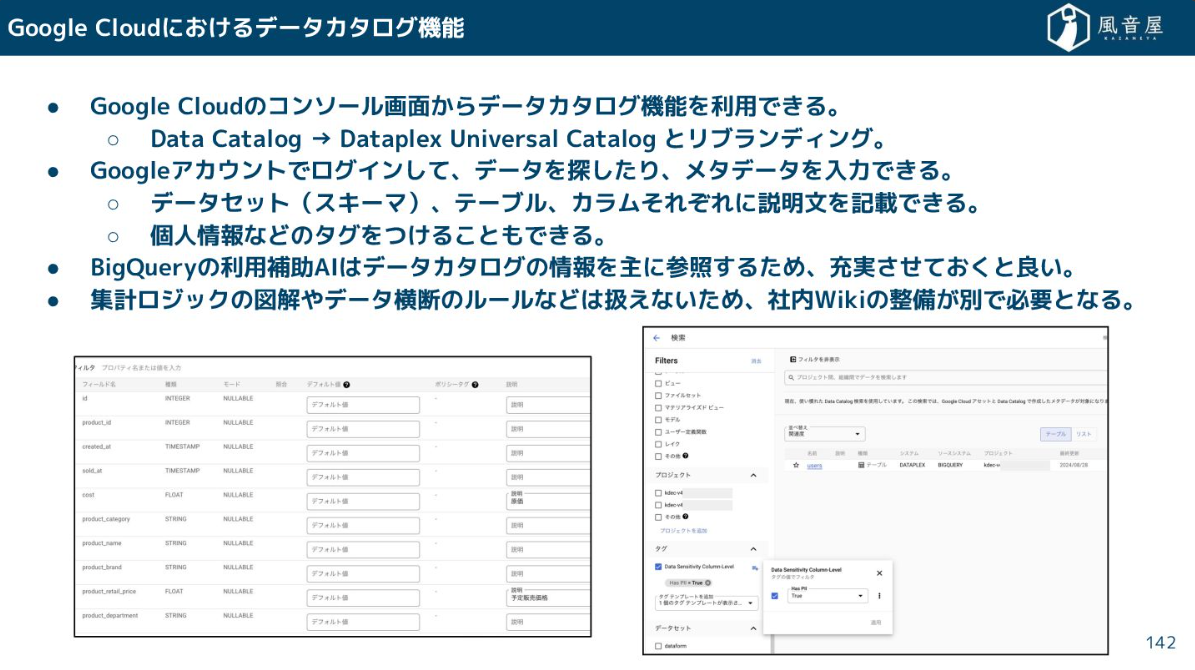
クラウドサービスでは、Dataplex Universal Catalogのようなツールが、wこのデータカタログ機能を提供しています。
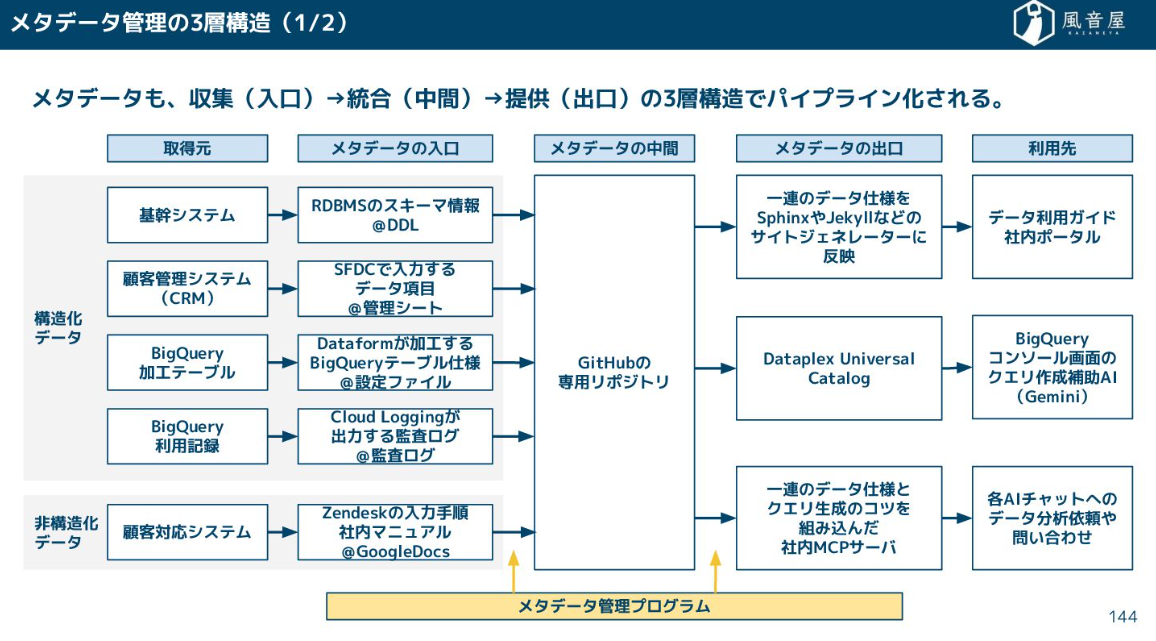
メタデータの管理も、データパイプラインと同様に三層構造で考えるべきです。システムによって収集するデータは異なるほか、提供されるデータは利用先によっても異なるためです。
生成AIを使うにはメタデータが必須なので、データを生成する箇所でメタデータを管理する必要があります。

ちなみに、メタデータの管理にあたっては自動生成されたデータにはラベルをつけるなどの工夫も必要です。
データ品質
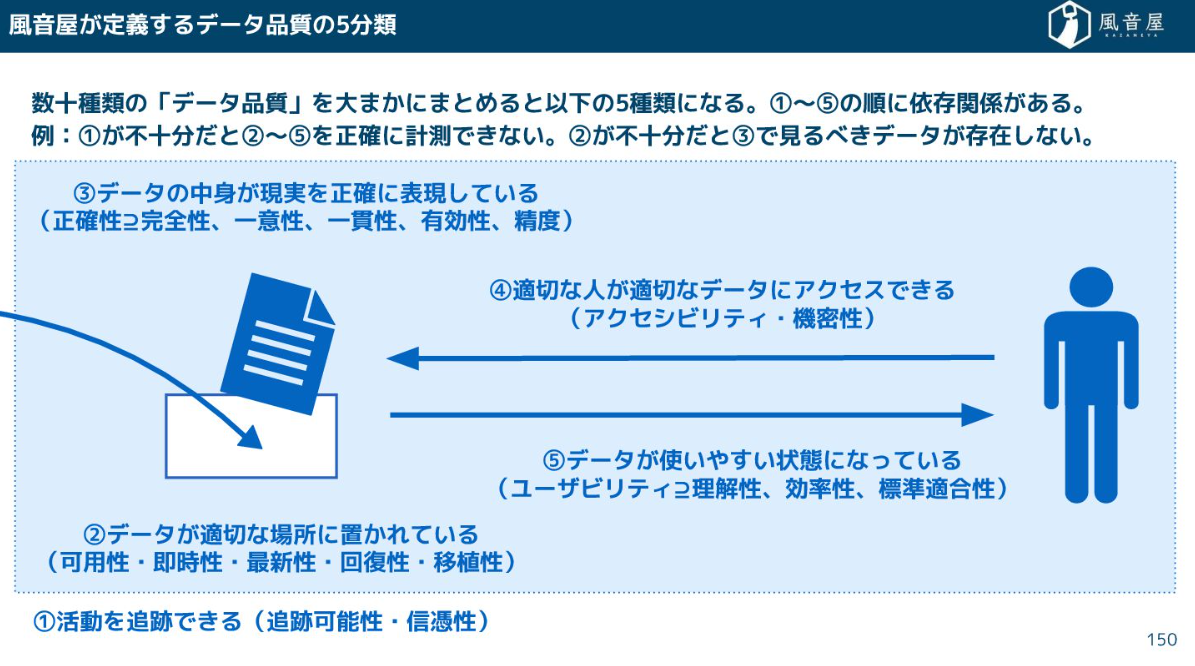
データ品質の定義は文献によっても様々です。弊社では以下の5つに分類しております。
- 活動を追跡できる
- データが適切な場所に置かれている
- データの中身が現実を正確に表現している
- 適切な人が適切なデータにアクセスできる
- データが使いやすい状態になっている

サービスレベルを明文化したうえでステークホルダーと合意し、テスト・監視をしながら運用しています。また、目標と現状のギャップが大きいボトルネックがあればそれを特定し、チューニング施策を実施しながら改善アクションを繰り返しています。
継続的開発を支える技術
ここからは、システムの継続的開発を支える技術について触れていきます。

開発環境についてはGitやGitHubなどのツール活用はもちろんですが、GitHub Actions、CI(継続的インテグレーション)、CD(継続的デリバリー)なども不可欠です。

また、弊社ではAIエージェントも積極的に活用しながら、データ基盤システムを最短工数で利用できる仕組みを構築しています。
データ利活用の推進
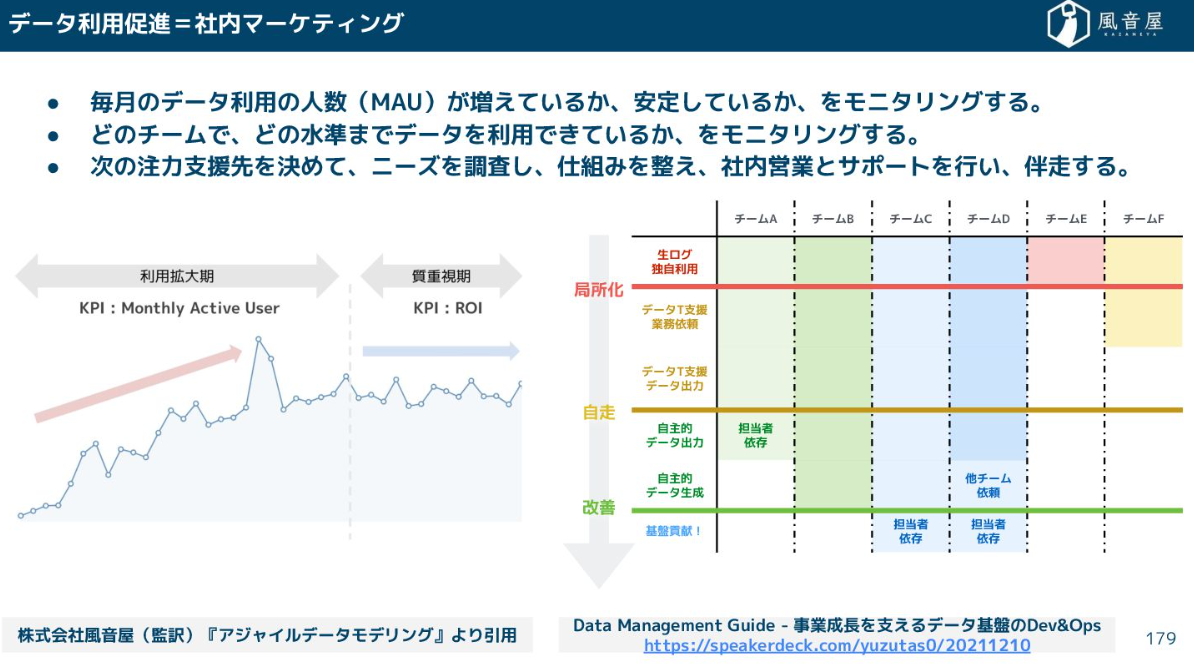
データの利活用推進とは社内マーケティングだと思っています。
データ利用状況をモニタリングし、ニーズを調査し仕組みを整え、サポートを行いながら伴奏していくことが重要です。
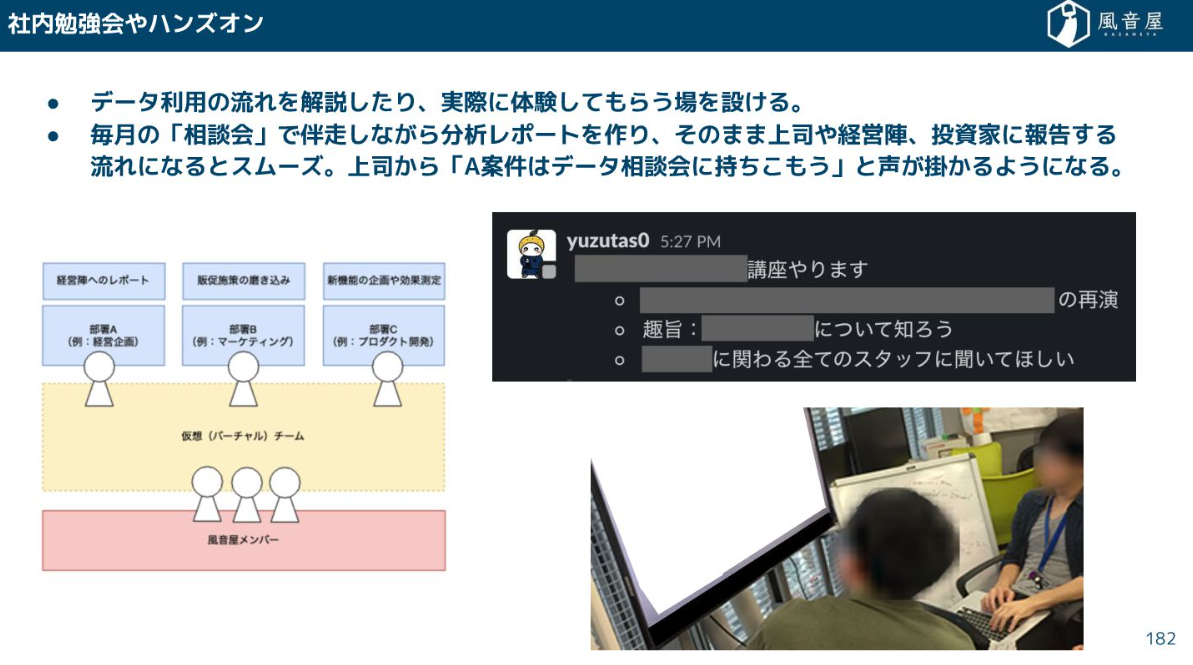
具体的には、「ここで全体像がわかる」という社内Wikiを整備したり、社内勉強会やハンズオンといった取り組みが挙げられます。

問い合わせ対応については、よくある問い合わせなどはドキュメントに残し社内Wikiに反映したり、チャットツールなどの相談場所を設け、チャットボットなどで回答する仕組みを構築する事例も増えてきています。
生成AIによるデータエンジニアリングの5つの変化

ここからは、生成AIの台頭によってデータエンジニアリング分野で起きている大きな変化を5つに分けて見ていきたいと思います。
データ収集の変化

オープンデータ取得やWEBスクレイピングの難易度が大きく下がりました。従来はWeb APIやデータベースからの取得が主流で、スクレイピングは専門チームがないと持続不可能でしたが、今ではAIエージェントやAIコーディングの進化によって、WEBコンテンツから情報を抽出したり、WEB画面のレイアウト変更時の修正もAIが自動起票したりできるようになっています。

この結果、外部データ収集用のETL SaaS(ETLツール)が不要になる、あるいはAI連携機能を強化しなければならなくなる、という過渡期に入っていくと思っています。
データ加工の変化
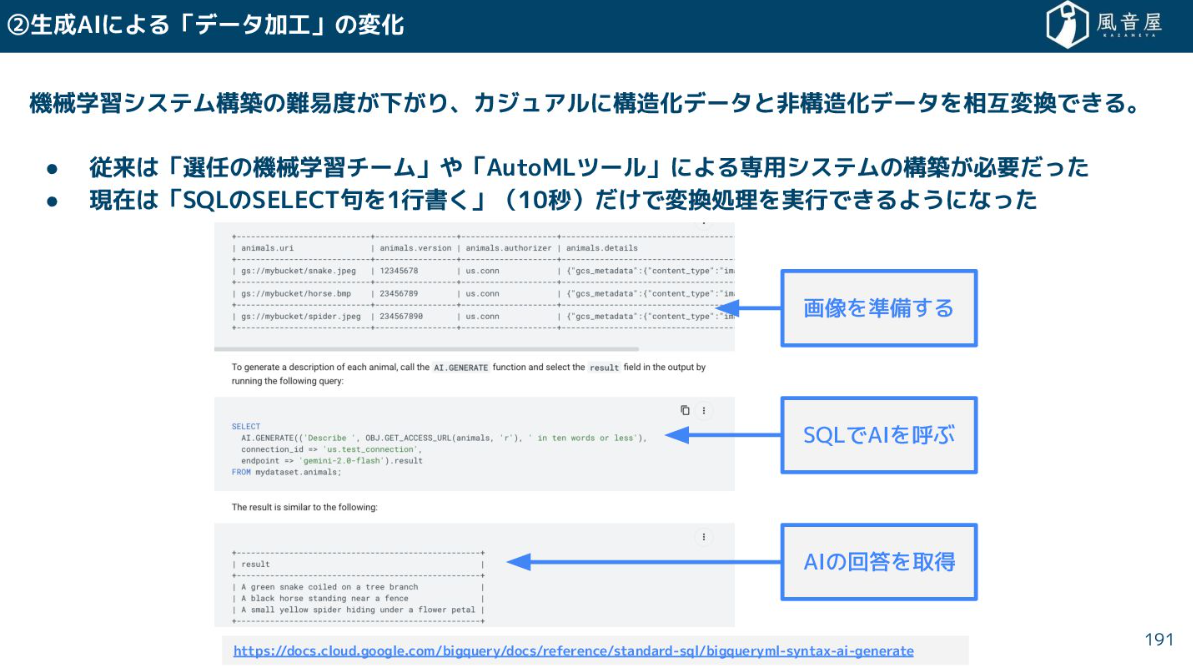
特に破壊的なイノベーションは、SQLのSELECT句を1行書くだけで、構造化データと非構造化データをカジュアルに相互変換できるようになったことです。
これまで、機械学習チームや高価なAutoMLツールが必要だった非構造化データ処理が、わずか10秒で、費用対効果を考えるまでもなく簡単に実装できてしまうのは本当にすごいことだと思います。
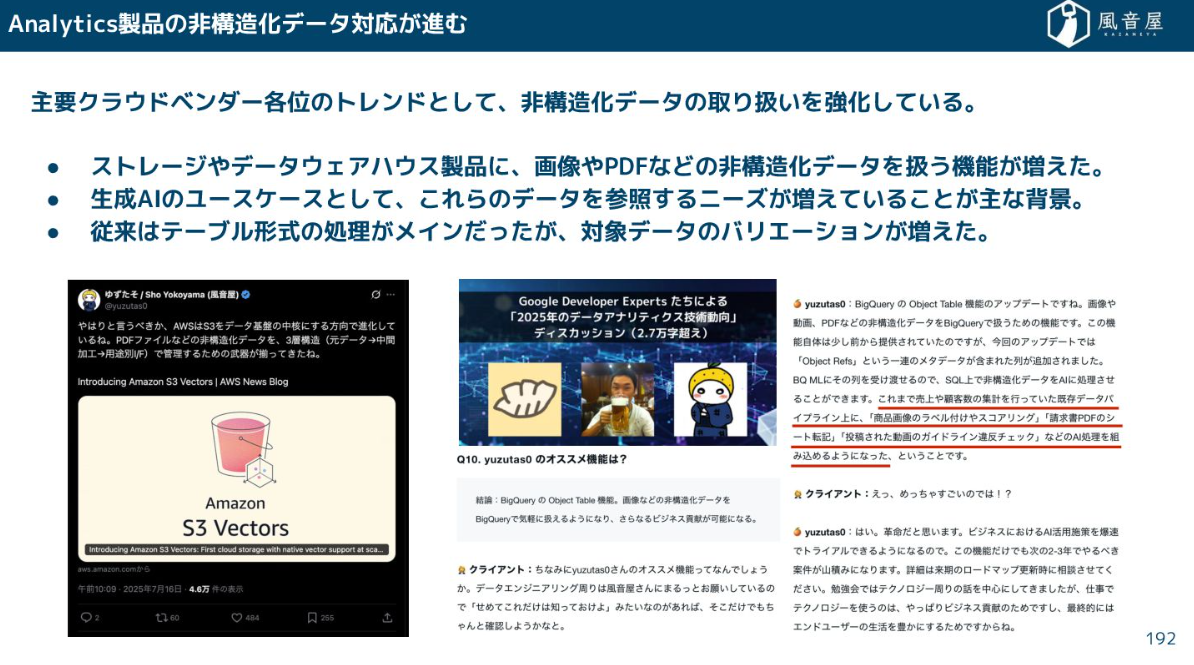
これにより、売上集計パイプライン上に、請求書PDFからのデータ抽出や、動画の違反チェック、商品画像のラベリングといった処理を簡単に組み込めるようになりました。

ただし、注意点があります。非構造化データもノイズや品質の低い情報が多いため、構造化データと同じように「入口」「中間」「出口」の三層構造で整理する必要があります。
現在、非構造化データの管理に関するリファレンスアーキテクチャはまだ定まっていません。そのため、今は既存のアーキテクチャを踏襲しつつ、後から修正できるように、元データを全てクラウドストレージに置いておくという方針が重要になります。

これは、DWH製品に寄せていた2010年代のトレンドから、AWSが提唱するデータレイク本来のコンセプトに揺り戻しが起きているタイミングかもしれません。
メタデータ整備の変化

生成AIは、メタデータの整備を容易にしました。従来は人間が入力・編集していたメタデータの一部を、AIが自動で処理・拡充できるようになりました。
一方で、生成AIを正しく使うためには、メタデータの整備が必須です。AIに「どんなデータか」というコンテキストを与えなければ、AIは正確な判断ができません。この需要の高まりを受けて、各クラウドベンダーはAIエージェントの機能提供とセットで、データカタログ機能を強化しています。

メタデータも三層構造で管理すべきですが、現状、中間層を満たすツールが市場にはまだ少なく、多くの企業が自前で仕組みをつくっている状況にあります。
DataDevOpsの改善
生成AIは、データエンジニアリングにおける一連の業務プロセスを効率化し、サイクルタイムを短縮しています。
システム開発ではコーディングの自動化、レビューの自動化。特に、シニアエンジニアのように振る舞うAIによるコードレビュー自動化は、レビュー負担を9割減らすといった効果を生んでいます。
システム運用ではリリース作業や監視、アラート対応の自動化、サービス運用では問い合わせ対応や権限管理、コスト管理を自動で実行できる時代になりつつあります。

ただし、これらのAIエージェントを正しく機能させるには、やはりデータの整備が必須です。例えば、社内に50個の「売上テーブル」が乱立していたら、AIはどれを分析に使えばいいか判断できません。
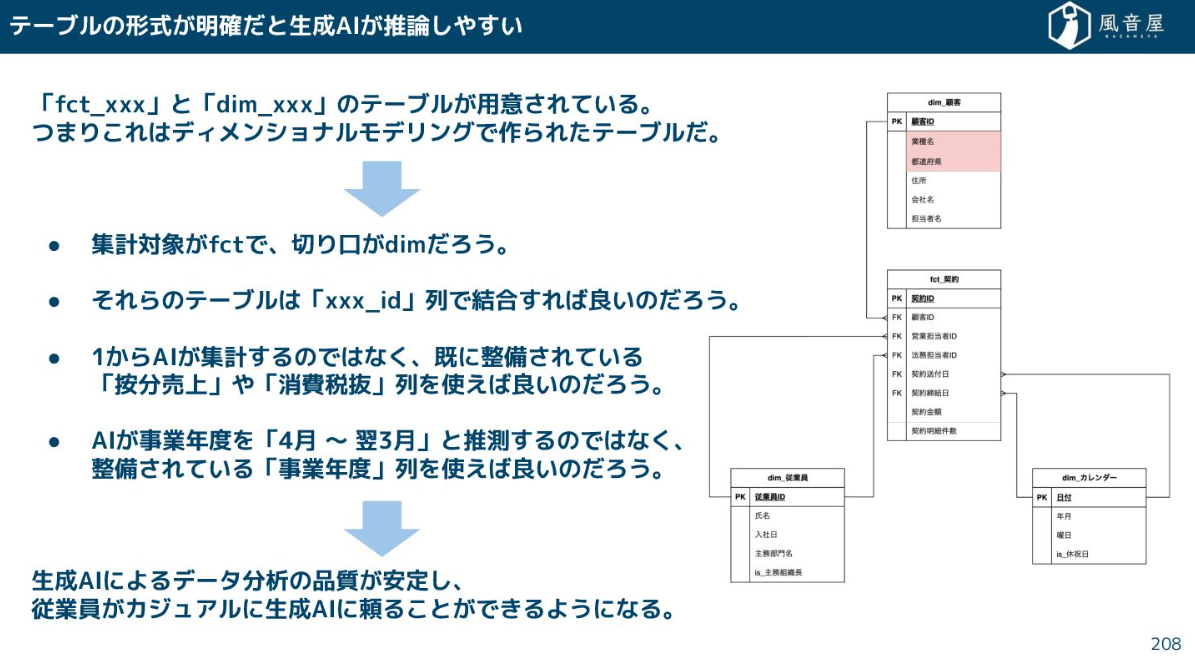
ひと目でわかるテーブルになっていたり、あるいはデータカタログが充実していれば、AIは正しく推論しやすくなりレポートの品質が安定します。
BizDevOpsの改善
AIエージェントの導入によって、「データ基盤」と「業務フロー」と「経営」が一体化しつつあります。
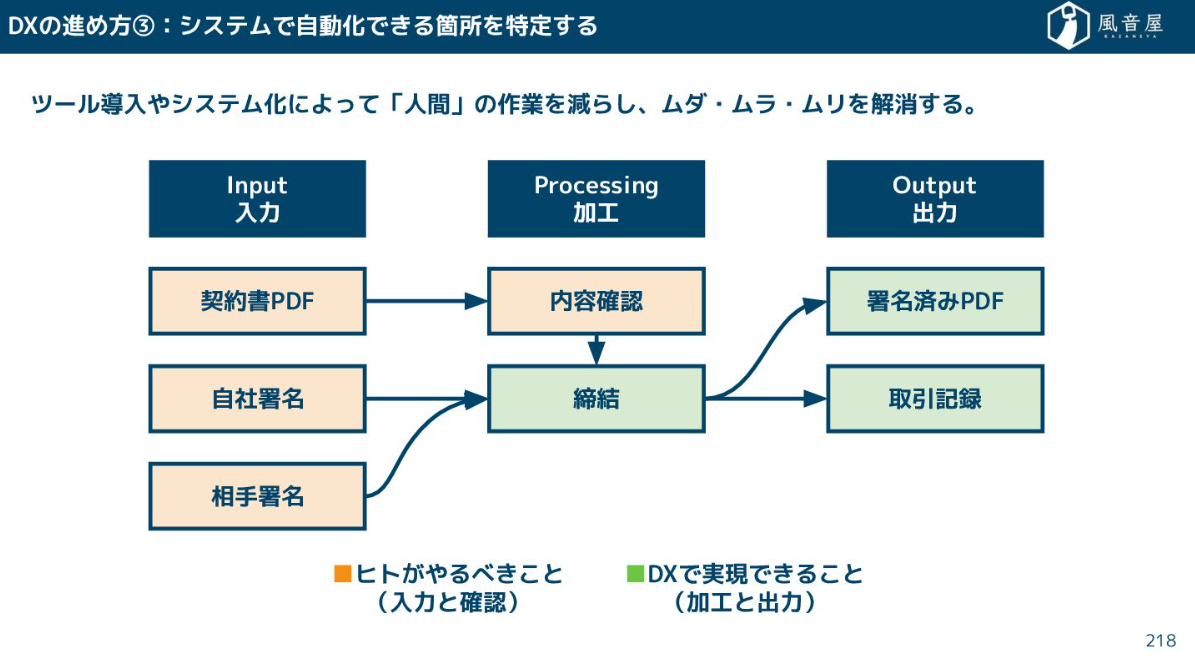
これまでのDXは、契約書の締結プロセスのように、アナログな業務をシステムで置き換え、人間の作業を減らすことが中心でした。AIエージェントの導入は、人間の作業だけでなく、契約書の叩き台作成やリスク指摘といった判断の一部までをAIに担わせ、業務フロー全体に組み込むことを可能にします。

AIネイティブな時代では、情報・データが担う部分が極限まで拡大します。結果として、特にオフィスワークに関わるあらゆるビジネスやオペレーションが「データエンジニアリング」化していくことになります。情報の流れを制御するデータ基盤、AIエージェント、業務定義、経営活動はもはや一体化し、切り離せなくなるでしょう。
目指すのは5000年後を見据えたデータ基盤
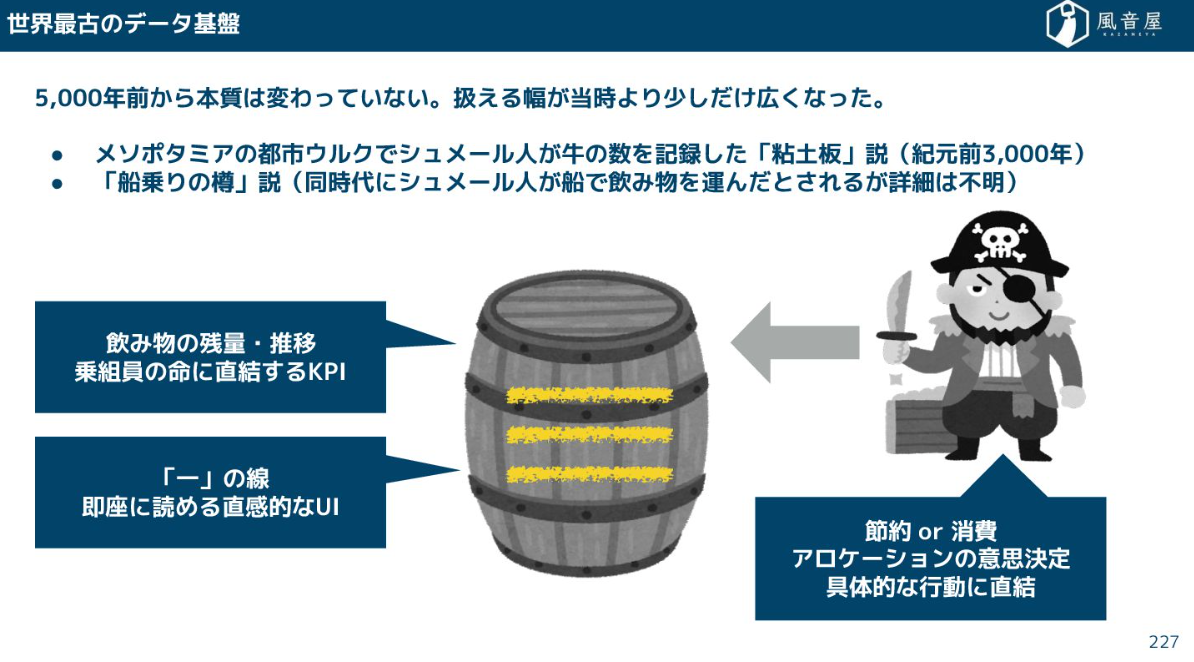
データ基盤の本質は、5000年前から変わっていません。古代メソポタミア文明があった遺跡からはシュメール人が牛の数を記録したものと思われる「粘土板」が出土されており、これこそが世界最古のデータ基盤なのではないかと思っています。

その後人類は、穀物の収穫高、工場の生産量、通販サイトの販売高といった普遍的な課題に対し、常にデータと対峙し続けてきました。

私たちが今いるのは、AIを活用するための「AI Readyなデータ基盤」をつくるフェーズです。これが進化し、15年後には「Robot Readyなデータ基盤」、さらに500年後には気候変動に対応する「Energy Readyなデータ基盤」、そして5000年後には宇宙進出に対応する「Space Readyなデータ基盤」が必要になるかもしれません。
私たちが開拓しているデータエンジニアリングのノウハウは、5000年後、あるいは5億年後の人類の試練にも役立つ、普遍的な知見に繋がる何かだと思います。データエンジニアリングは多くの要素を含む総合格闘技であり、ベストプラクティスが定まっていない未開の荒野に道を切り開く、非常にやりがいのある分野です。
この激動の時代を楽しみ、テクノロジーで遊び尽くす気概を持って、5000年後まで自分の爪痕を残していきましょう。
私からは以上です。ご静聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





