



【Data Engineering Summit】音声解析におけるオーケストレーション処理のリアーキテクチャの話
2025年11月6日、ファインディ株式会社が主催するイベント「Data Engineering Summit」が、オンラインにて開催されました。
本記事では、株式会社RevComm エンジニアリングマネージャー 高橋 典生さんによるセッション「音声解析におけるオーケストレーション処理のリアーキテクチャの話」の内容をお届けします。
膨大な音声データと多様な解析処理を、どのように整理し直し、効率よく動かしているのか。モノリスの分解からオーケストレーション再構築まで、その取り組みをわかりやすくご紹介いただきました。
■プロフィール
高橋 典生
株式会社RevComm Technology Dept. AI Div. Research Group ASRIS Team Manager
RevCommの事業とサービス
株式会社RevCommでエンジニアリングマネージャーを務める高橋典生が、「音声解析におけるオーケストレーション処理のリアーキテクチャの話」というテーマでお話しします。
現在はエンジニアリングマネージャーというロールではありますが、実際にはプレイングマネージャーとして業務に関わっているため、肩書きとしてはソフトウェアエンジニアを名乗っています。担当領域は主にバックエンドやクラウドインフラで、DevOpsやMLOpsを中心に取り組んでいます。

RevCommは「MiiTel」シリーズを展開しており、インサイドセールス、フィールドセールス、カスタマーセールス、さらにはコールセンターのカスタマーサポート向けにクラウドIP電話を提供しながら、通話内容を解析するサービスです。

今回のテーマは、この通話解析の部分です。商談や社内会議といったビジネスミーティングをAIで解析し、生産性向上や営業トークの改善につなげる機能を開発・運用しています。
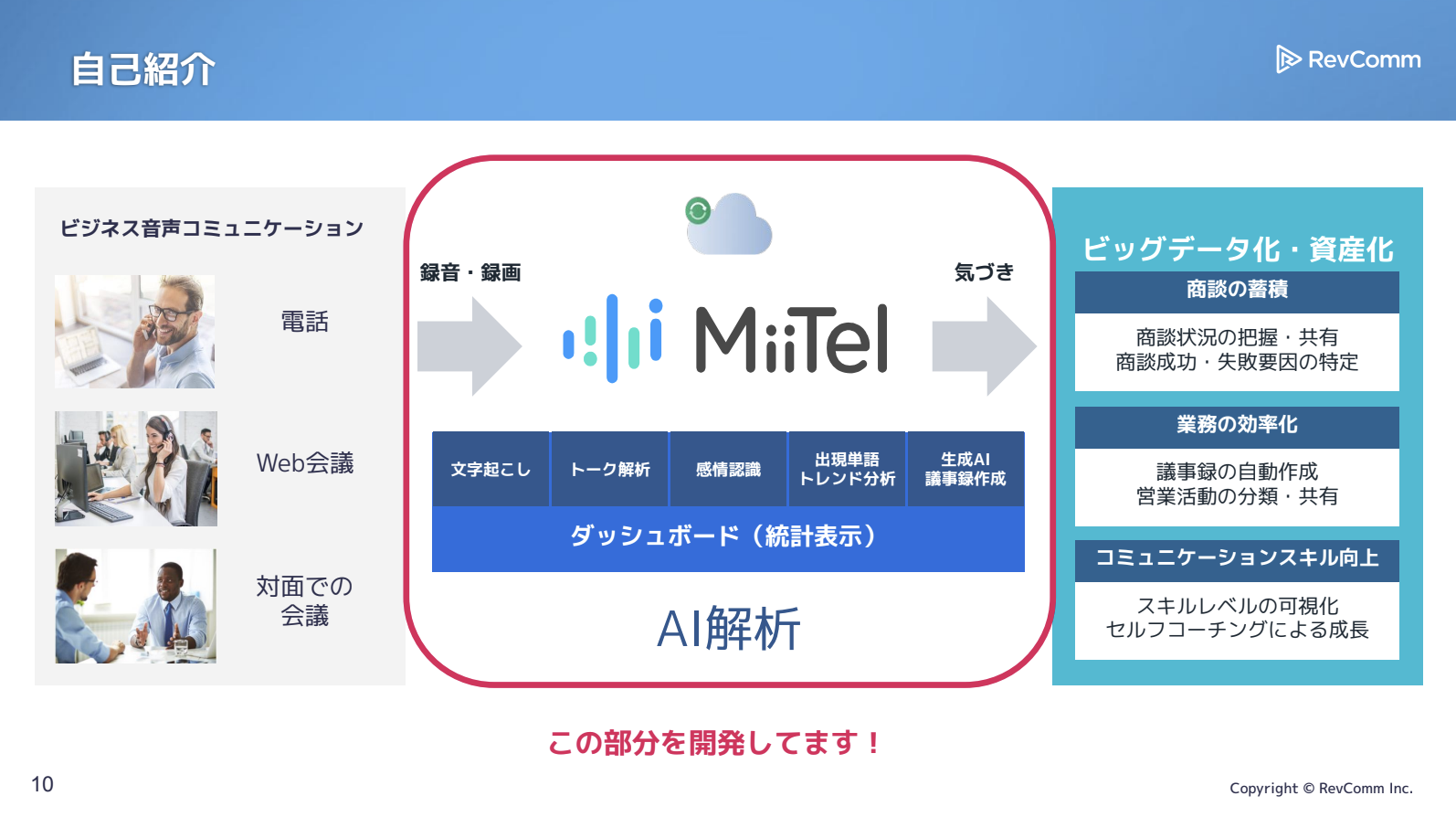
お話しする内容は、私たちがユーザーへ提供しているサービスの一部で行っている、オーケストレーションやデータパイプラインの取り組み、とくに「ビジネスのコミュニケーション解析」と位置づけている音声解析領域についてです。
巨大モノリスの限界
モノリス巨大化が起きた背景
まず、当時抱えていた課題の背景を紹介します。
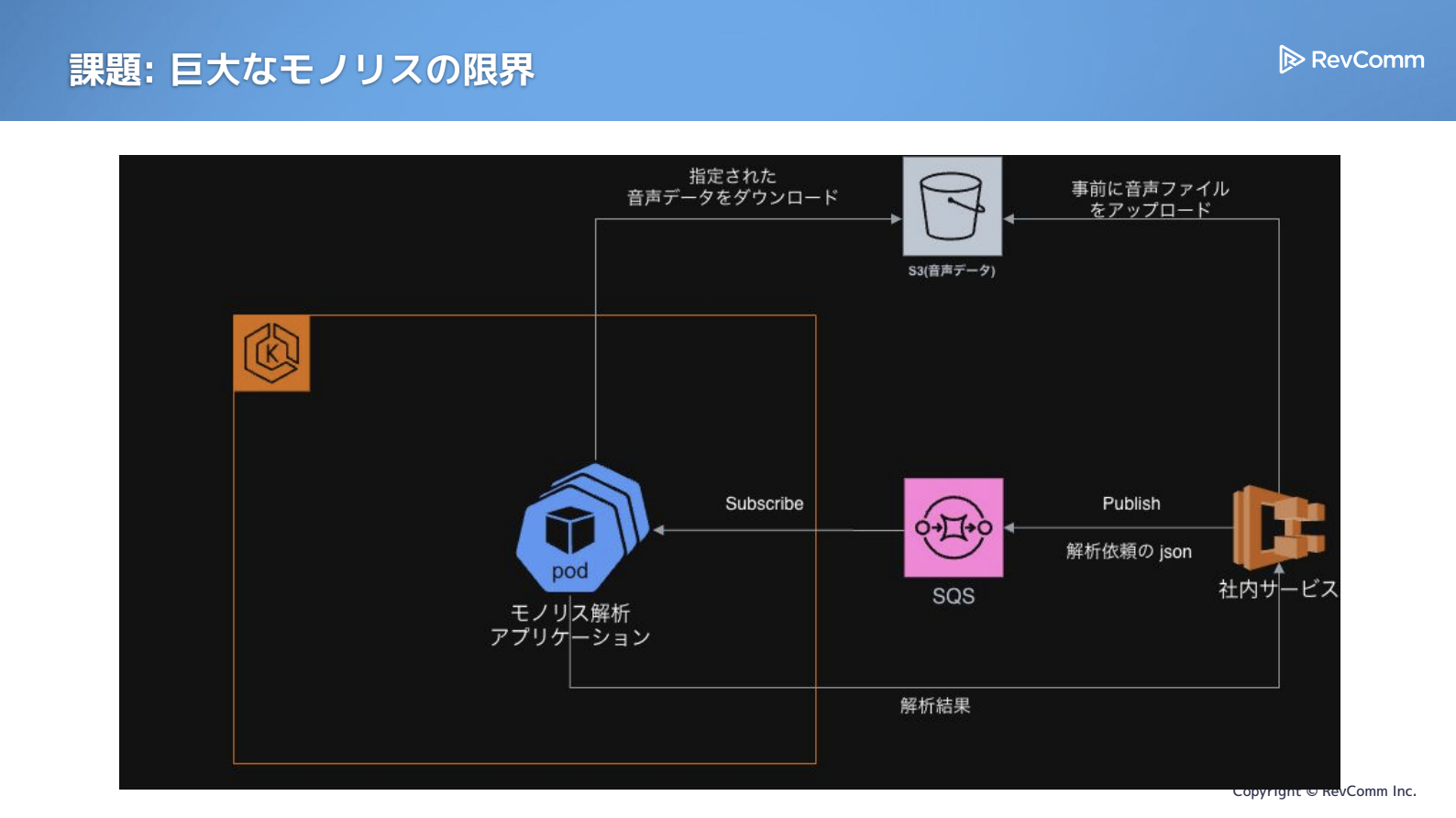
もともとは、図の右側にある社内サービスやMiiTelシリーズの各サービスから「解析したい」というリクエストがSQSに溜まり、それをサブスクライブして結果を返す。大きなデータはS3に置く。という、非常にシンプルな仕組みでした。
ところが、左側のモノリスアプリケーションが、気づけば大幅に巨大化していました。私がチームに加わった時点で、すでに「これはどうにかしよう」という動きがあり、元々EC2にそのまま置かれていたものが、すでにEKSへ移行されている状態でした。規模としては12xlarge相当のインスタンスが必要なほどでした。
私は途中からこのチームに参加したため、モノリスがここまで育つ過程をすべて把握しているわけではありません。ただ、創業当初から解析機能を磨き続けてきた結果、自然に積み上がっていったものだと考えています。
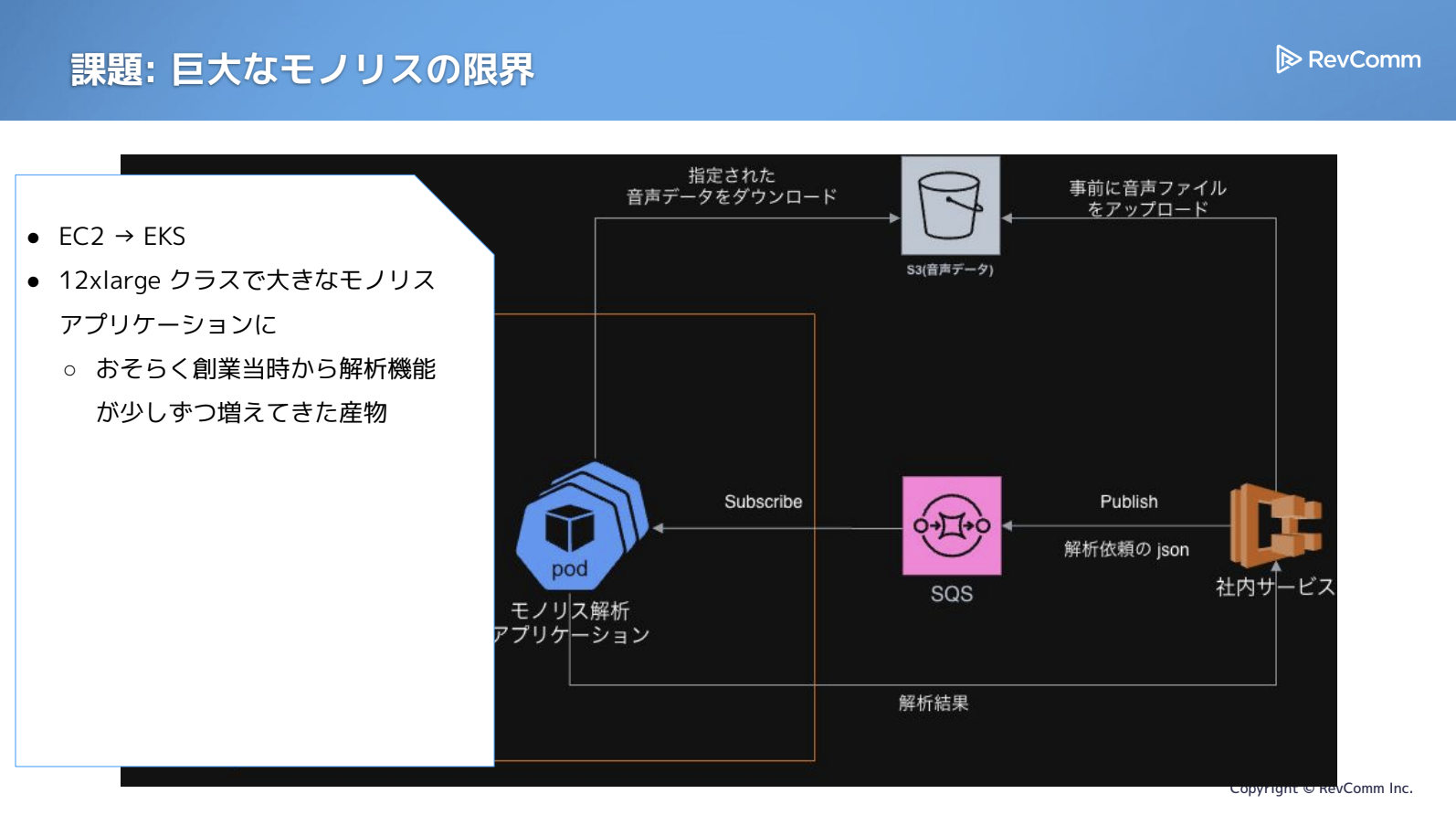
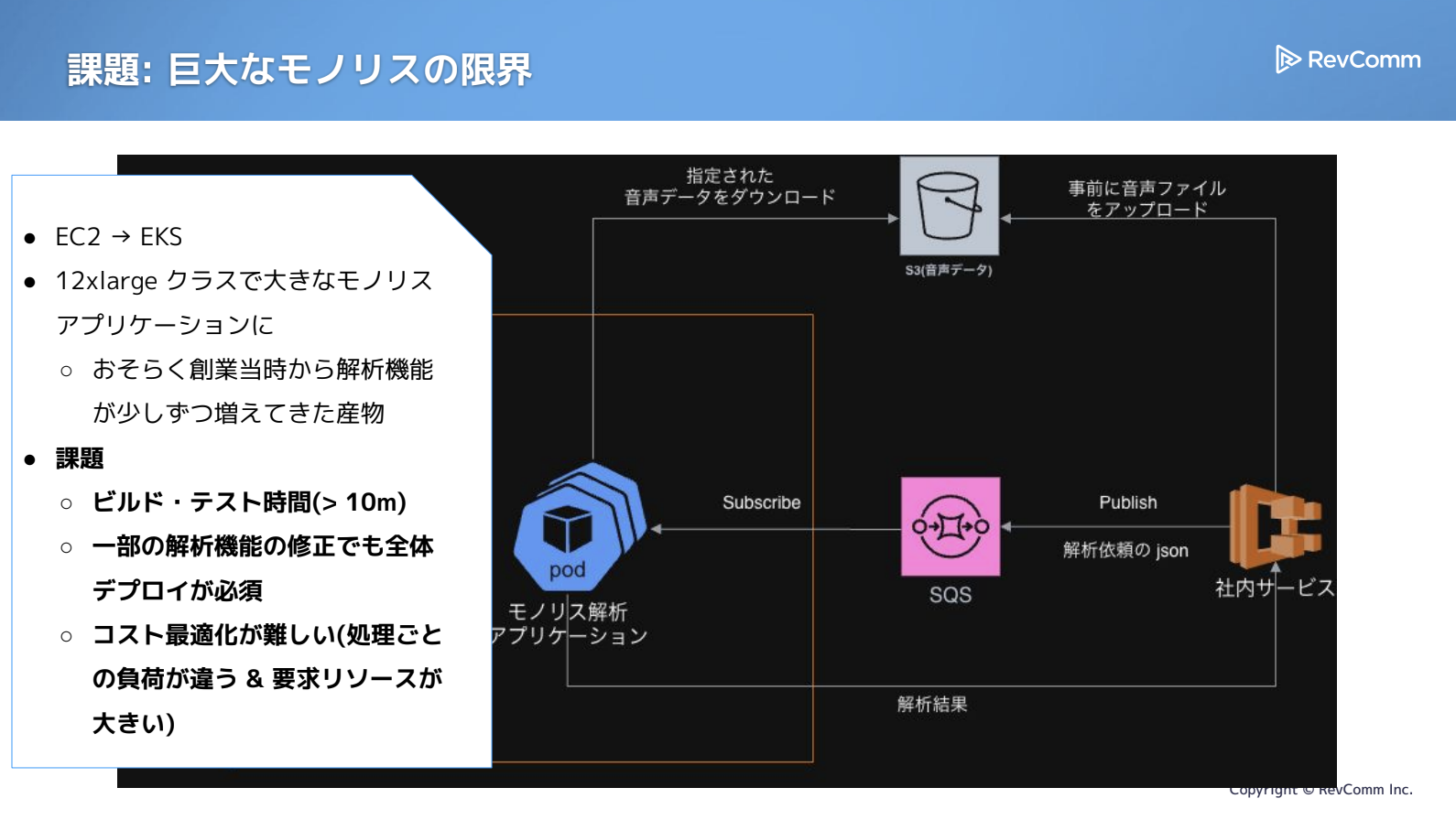
巨大モノリスが引き起こした主な課題
問題として、ビルドやテストにかかる時間が徐々に延び、最終的には約20分を要するようになっていました。解析機能のごく一部を修正しただけでもアプリケーション全体をデプロイし直す必要があり、その結果、解析処理の遅延や運用リスクの増大を招いていました。
また、モノリスであるがゆえに構造はシンプルなものの、コスト最適化が難しいという課題もありました。処理内容によって必要なリソース量は大きく異なるにもかかわらず、すべてを単一インスタンスでまとめて確保しているため、負荷に応じて柔軟にリソースを割り当てられず、稼働率を高めにくい状況でした。
こうした複数の課題が重なっていたことが、今回の取り組みの出発点となりました。私たちは、このモノリス構造を解消し、生産性と効率を両立できる運用体制を実現したいと考えていました。
ステップ1:処理特性による分割
モノリス分解の必要性と課題の洗い出し
ステップ1として、「モノリスを分解すれば本当に課題は解決するのか」をまず確かめる必要があると考えました。モノリスアプリケーションはアンチパターンとして語られがちですが、「分解すれば必ず良くなる」と短絡的に判断せず、現状の問題に対して本当に有効かどうかを慎重に見極める必要があります。
また、モノリスの分解といっても手法は1つではありません。コードベースを分割するアプローチもあれば、デプロイ単位で分割するアプローチもあります。後者は、デプロイされるアプリケーションをマイクロサービス的な単位に切り出していくイメージです。では、必要なのはどちらなのか。片方だけで十分なのか、それとも両方が必要なのか。この点を整理するため、まずは課題ごとに処理を切り離しながら状況を確認していきました。

ビルドとテストの観点から、どの分割が有効かを検討したところ、まずテストについてはコードベースの分解で十分に改善できることがわかってきました。いわゆるモジュラーモノリスの形で、同一リポジトリにまとまっていてもモジュールやパッケージ単位で整理されていれば、その範囲だけでテストを実行でき、独立性も確保しやすくなります。
解析機能は多岐にわたりますが、Speech-to-Text(文字起こし)、Topic Estimation(トピック推定)、Sentiment Analysis(感情認識)といった粒度で分かれていれば、モノリシックな構成でもテスト高速化の見込みがありました。
一方、ビルドに関しては事情が異なります。コードをどれだけ分割しても、最終的には1つの成果物に統合する必要があり、改善できる余地は限定的です。ある程度の工夫は可能ですが、「分けた単位ごとにコンテナを構築する」アプローチのほうが現実的で、より大きな効果が期待できると判断しました。
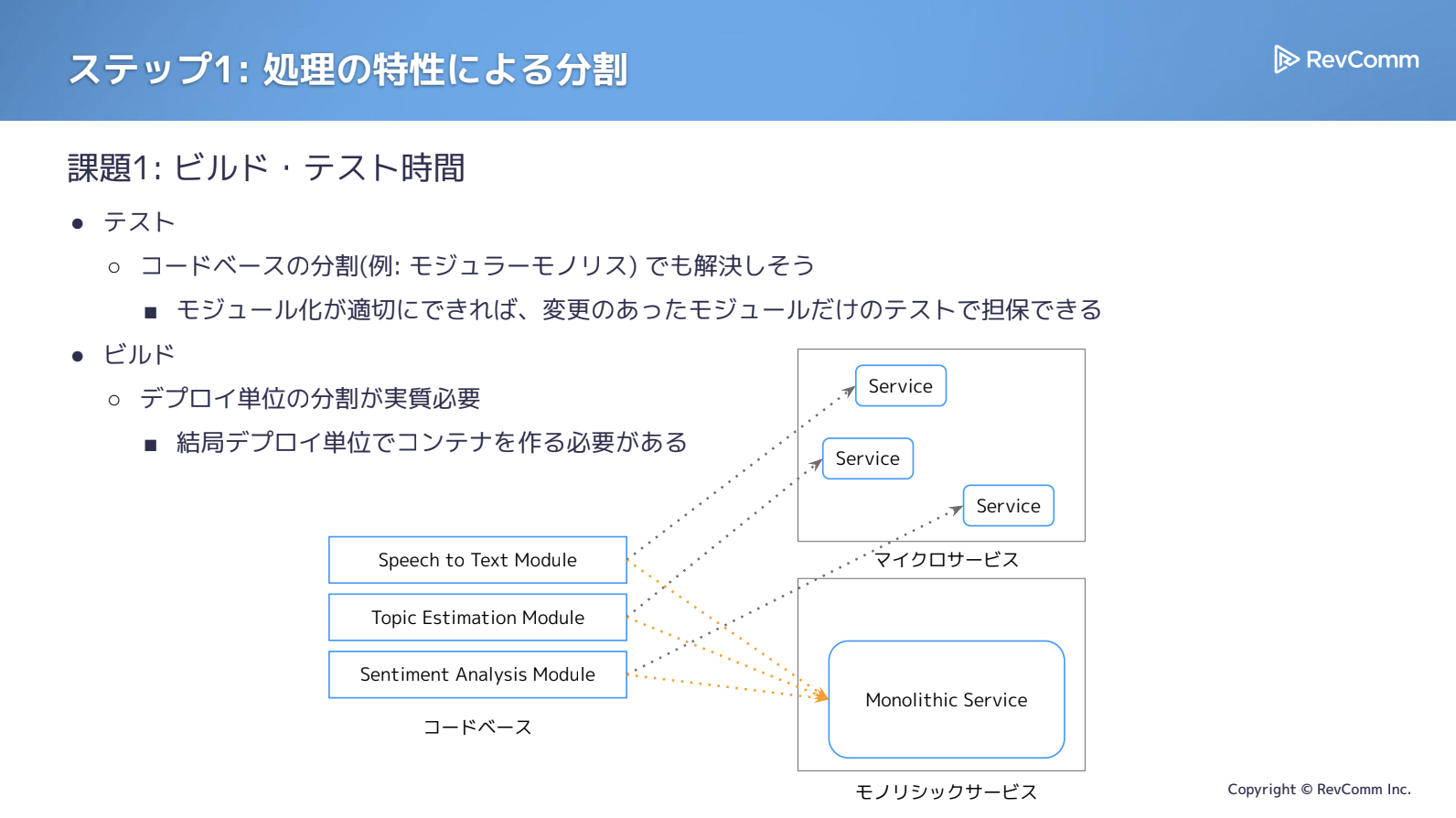
さらに、全体をまとめてデプロイしなければならないという構造上の問題は、アプリケーション自体を分割しない限り解決できません。
コスト最適化についても同様で、複数の処理が1つの大きなリソース上に載っている現状では、柔軟なリソース運用がどうしても難しくなります。
RevCommではEKSを利用していますが、大きな処理がひとつ存在するだけでリソースの敷き詰め効率が大きく低下し、稼働率が上がりません。一方で、処理の単位が小さければ、より柔軟に配置できるため稼働率を高めやすくなります。
例えば、12CPUのマシンに10CPUを必要とする処理が入ると、それだけでほぼ埋まってしまいます。ですが、処理を3CPU・4CPU・2CPUといった粒度に分割できれば、4・3・3・2と並べるような配置も可能になり、12CPUを無駄なく活用できます。
もちろん「小さくすれば良い」という単純な話ではなく注意も必要ですが、RevCommの場合は処理自体が非常に大きく、モジュールごとに必要リソースもまったく異なるため、分割する価値は十分にあると判断しました。

分割基準の検討:24種類の処理と「処理特性」という軸
分割が有効だという見通しは立ったものの、次に課題となったのは「どのように分割するか」です。
解析要素を細かく見ていくと、先ほど触れたトピック推定や文字起こしをはじめ、全部で24種類ほどの処理があります。
しかし、ここまで細分化してしまうと24個それぞれを管理する必要が生じ、運用負荷が極めて大きくなります。本番環境で動くシステムを大きく変えるのは避けたいという事情もあり、もう少し粗い粒度でグルーピングして分けたいと考えました。
では、何を基準に分割するべきか。Webソフトウェア開発ではドメイン単位で切るのが一般的ですが、今回求められているのは「汎用的に音声・自然言語処理の解析を実行できる基盤」です。インサイドセールス向け、コールセンター向けといった利用シーン別の分割は適していません。
そこで、ドメインに依存しない「処理特性」を基準に分割するほうが妥当だと判断し、処理特性に基づく構成へ整理していきました。
処理特性とは、ワークフロー上の各項目をどこに配置し、どのような依存関係を持たせるかという考え方です。「何を処理しているのか」「どう処理しているのか」「何に依存しているのか」といった観点から、処理内容ごとに最適なまとまりへと整理していきました。

処理特性に基づく7つの処理グルーピング
まず入力ベースで見ると、生の音声を扱う段階があります。WAVファイルを受け取り、VAD(話している部分だけを取り出す処理)や同一チャンネルで複数人が話しても情報劣化しないようにする話者分離など生データを解析可能な状態に整える工程で、これをpre-processingと位置づけました。
解析可能な音声を受け取った後の処理は大きく2つに分かれます。ひとつは、音の物理的特性に注目するsound-processingです。ピッチの高低判定、可視化用データへの変換、留守番電話検知といった処理が該当します。
一方、文字起こしや、クレジットカード番号など“文字にされると困る情報”をマスキングする処理をASR-processingであったり、フレーズ単位で扱う処理のためphrase-processingと呼んだりしています。
さらに、トピック推定や感情認識のように、文脈や話者全体の情報を踏まえて意味を解釈する処理はひとまとまりにし、conversation-processingとしてグルーピングしました。

こうした整理の結果、24個の処理をすべて細かく扱うのではなく、大きく7つの分類へまとめる形に落ち着きました。細かすぎず粗すぎない、適切な粒度で構成できたと考えています。

分割の効果:ビルド・デプロイ・コスト最適化へのインパクト
この分割によって、モノリスが抱えていた課題は大きく改善に向かいました。
まずビルド・テスト時間については、ビルドを分割したことで各処理をGitHub Actions上で並列実行できるようになりました。デプロイに関しても、たとえばトピック推定のみを更新したい場合はconversation-processingだけを更新すればよく、必要な領域に限定した適用が可能になりました。その結果、以前よりも積極的にリリースしやすい体制が整いました。
コスト面でも効果がありました。pre-processingが軽ければCPUを少なめに、負荷の大きい処理には多めに割り当てるなど、リソース調整が柔軟にできるようになり、全体としてリソース効率を高めやすい構成になりました。実際、2025年10月時点では運用サーバー費用を約10%削減するなど、具体的な成果も得られました。
今後もシステムの使用状況を見ながら継続的にチューニングを行い、さらなる最適化を進めていく予定です。

ステップ2:オーケストレーション
分割後に発生したオーケストレーションの新たな課題
ステップ2はオーケストレーションです。モノリスを分割しただけでは処理は動きません。分解された各サービスをどう繋ぎ、全体として動かすかが新たな課題になります。
これまでモノリシックなアプリケーションでは、処理の順序やフロー、どの状態で次の処理に進むかといった一連の管理はすべてメモリ上で完結していたため、あまり意識する必要がありませんでした。
しかしサービス単位へ分割した以上、その流れをどう管理するかを改めて設計し直す必要があります。ここでオーケストレーションをしっかり整備することが欠かせません。
なお、ここでの「オーケストレーション」は広義の概念として扱っており、コレオグラフィーのような仕組みも含め、処理をどのように繋いで動かすかを統合的に捉える枠組みとして用いています。
オーケストレーションについては、実は最初に大きな失敗を経験しました。Argo CDを利用していた流れもあり、まずArgo Workflowsを試したのですが、結果としてうまく機能しませんでした。当時の状況を振り返りながら説明します。
Argo Workflowsはジョブ型のワークフローエンジンで、リクエスト1件を受け取ると、それをジョブとして実行します。Kubernetesネイティブな仕組みで、各タスクは独立したPodとして動作します。
私たちのケースでは、音声解析のリクエストが1件届くと、ワークフロー全体を管理するPodがまず1つ立ち上がり、処理の順番に従ってタスクごとにPodを生成し、完了したら破棄し、また次のPodを生成する――といった流れで処理が進む構造でした。
ところが、この仕組みを本番環境で実際のトラフィックに乗せたところ、問題が一気に表面化しました。Argo Workflowsのコントローラーが再起動を繰り返し、さらにはKubernetesのコントロールプレーンまで不安定化。解析処理も大幅に遅延し、すぐに切り戻すことでようやく影響を最小限に抑えることができました。
なお、Argo Workflows自体に問題があったわけではありません。当時の私たちの利用方法がシステムの特性と合っていなかったことが、課題の本質でした。

Argo Workflows が適合しなかった理由と問題
では、どう使い方が悪かったのか、そしてどうすればよかったのかという点ですが、先ほどの問題を振り返ると、まず挙げられるのがワークフロー管理のコントローラーとKubernetesのコントロールプレーンが不安定化したことです。
背景には、私たちが元々内部で構築していた仕組みがあり、1つの通話につきSQSにメッセージが1件発行され、そのメッセージごとに1ワークフローを生成する構造でした。従来はSQSからメッセージを取得するとすぐに処理へ返す方式だったため、並列数を厳密に制御しなくても問題なく動いていました。
Argo Workflowsには並列実行数を制限する機能がありますが、強く制限すると処理全体が遅くなる懸念があり、実際にはほとんど制限をかけない運用にしていたことが問題の一因となりました。
必要な並列度を冷静に見積もると、MiiTel/RevCommの解析システムは1日あたり約100万件を処理しています。しかし、ビジネス系の電話であるため24時間均等に分散するわけではなく、ほぼ営業時間の8時間に集中します。
通話やミーティングを1件10分と仮定すると、1分あたり約2,000件のリクエストが到着します。これが10分続くケースを考えると、最大で2万件、つまり2万ワークフローを同時処理する必要があります。
Argo WorkflowsやKubernetesのチューニングで対応すること自体は不可能ではありませんが、現実的にはかなり難しいという見通しでした。

もうひとつの問題は、ワークフロー実行時の処理時間が増加した点です。3倍、4倍と極端に増えたわけではなく、実際には20%程度の増加でした。しかし当時は、もともとバッチ処理として提供していた頃と違い、「できるだけ早く届けたい」「遅くはしたくない」という要請が強くなっており、この20%の遅延も許容しづらい状況になっていました。この点も、実際に失敗して初めて気づいた課題です。
では、なぜ時間がかかるのか。処理によってはモデルサイズが大きく、起動そのものに時間がかかることが挙げられます。
例えば数GB規模のモデルであれば永続ボリュームを利用すれば多少は短縮できますが、モデルのロード自体に一定の時間が必要です。こうした起動オーバーヘッドがあるタスクはワークフローのステップごとに毎回発生するため、以前の処理方式と比べても遅くなりやすい構造でした。
さらに、GPUを利用する処理ではインスタンス確保が難しいケースもあり、こうした課題が次第に顕在化していきました。

ワーカープール型への転換と再構築後の効果
要求をあらためて整理すると、必要とされていたのはスループットを重視したバッチ処理というより、できる限り迅速に処理でき、かつ非同期で動作することでした。そのため、ある程度のコストは許容できる状況にありました。
GPUが必要な処理や起動オーバーヘッドが大きい処理も含まれており、10分の音声なら処理にもおおよそ10分かかるといったレベル感です。音声時間の分布も広く、数秒〜数分で終わる短い処理ばかりではない、という前提がありました。さらに、リクエストは8時間のあいだに集中して流れ込む状況でした。

こうした条件を踏まえると、当初導入していたジョブ型は要件と合わず、最終的にワーカープール型のほうが用途に適していると判断しました。
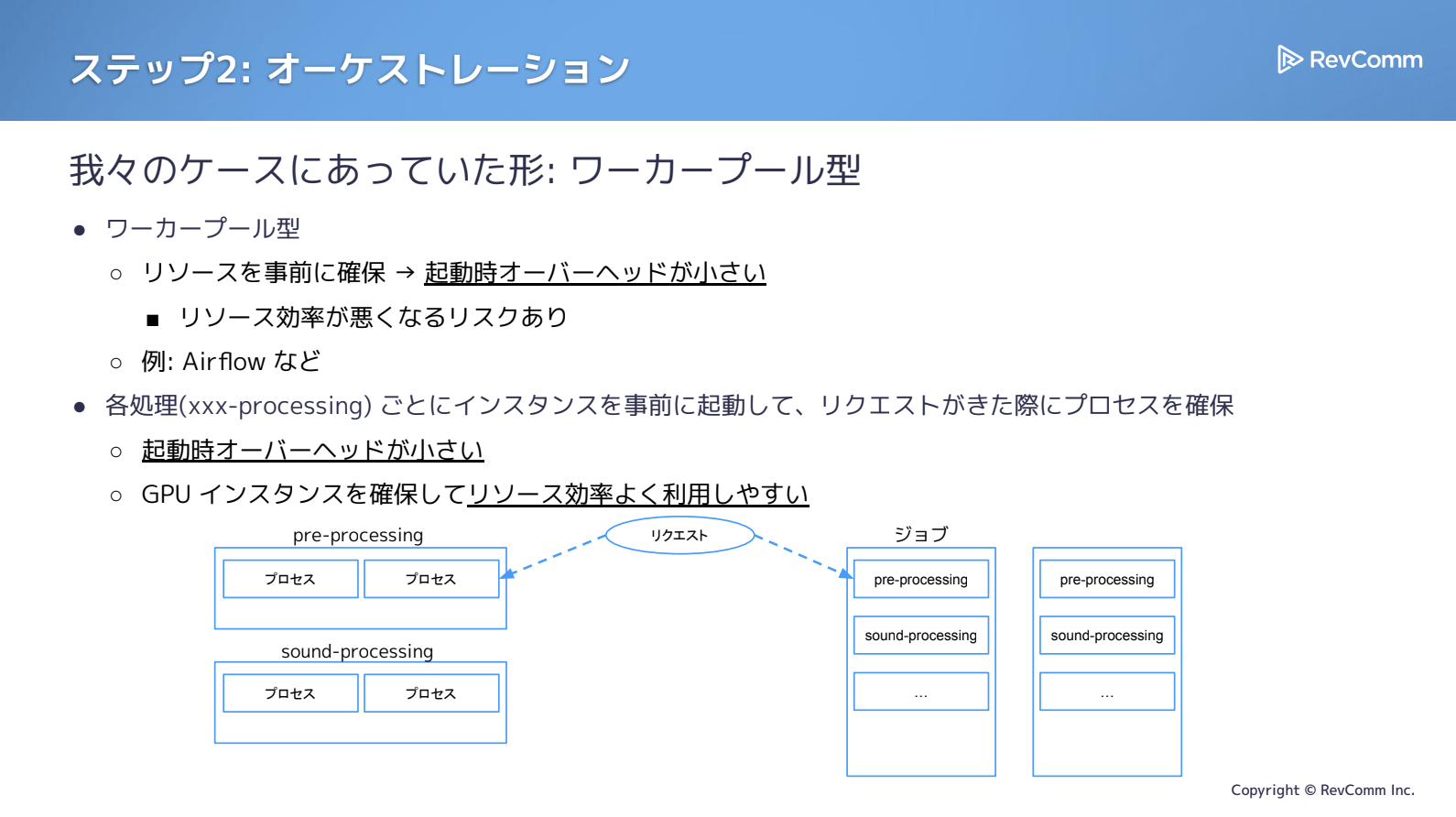
ワーカープール型は、インスタンスをあらかじめ立ち上げておき、リクエスト到着時にプロセスへ割り当てる方式です。ワーカーが余ればリソース効率は下がる可能性がありますが、あらかじめ起動済みであるためオーバーヘッドが小さいという特徴があります。実際のワークフローエンジンでいえば、AirflowやCeleryに近い思想といえるでしょう。
イメージとしては、下図の右側がジョブ型で、リクエストごとにジョブが生成され、各ステップでPodを立ち上げながら進めていく形式です。一方、左側のワーカープール型では、すでにワーカーが立っており、そこに処理を割り当てるため立ち上がりが早く、インスタンス確保も済んでいる分リソース効率を高められる余地があります。
以下は、簡略化した最終的な構成の図で、当初よりは複雑になっています。
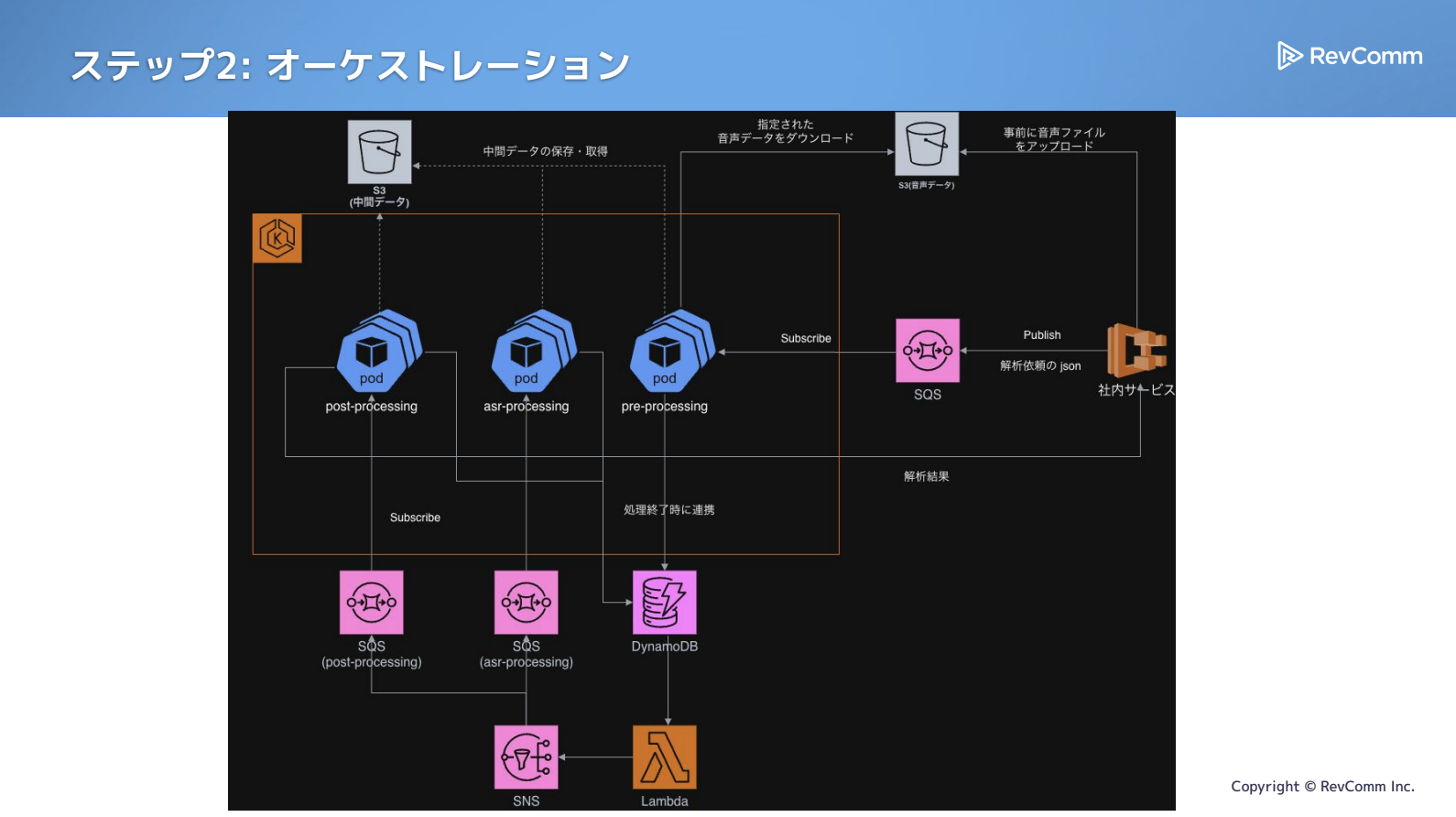
まず、モノリス時代と同様にSQSにサブスクライブし、処理を進めます。pre-processingを実行し、その後の処理はコレオグラフィー的にDynamoDB・SNS・SQSを組み合わせてつなげていく構成です。各処理ごとにSQSを1つ用意し、それを軸にDynamoDBやLambdaを使って次の処理へ渡していく形になっています。
スケーリングについてはSQSを使ったKEDAが使えているので、ここはSQS側でバッファを確保できており、バックプレッシャーも気にせずにスケールさせやすくなっていると思います。
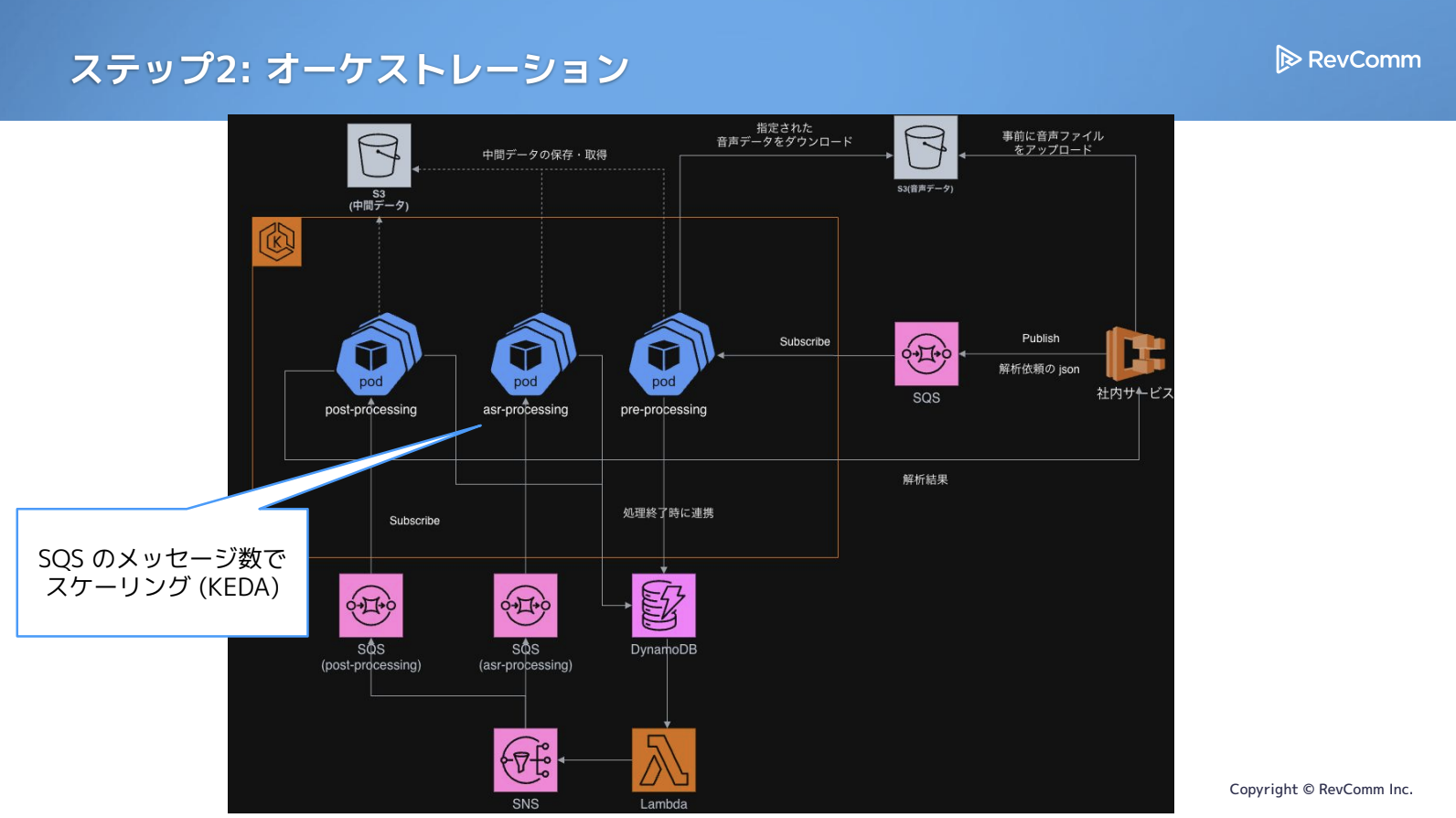
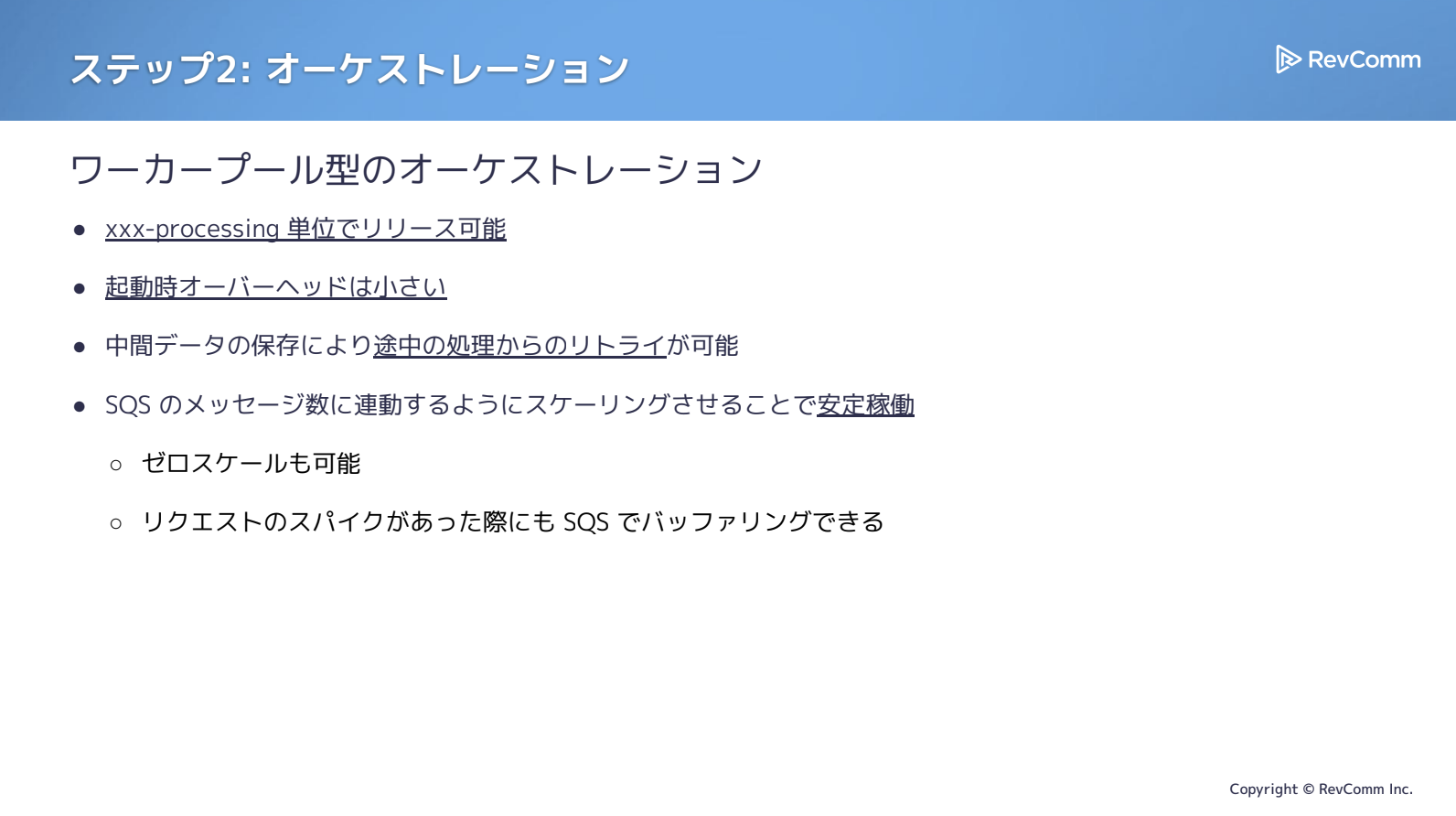
ワーカー型のオーケストレーションへ切り替えたことで、「◯◯-processing」といった単位ごとにリリースできるようになり、起動オーバーヘッドも小さく抑えられるようになりました。処理を分割したことで中間データを適切に保存でき、リトライもしやすくなっています。
また、先ほど示した構成のとおりSQSによるスケーリングも実現できており、ゼロスケールにも対応可能になりました。これによりコスト効率が向上し、リクエストスパイクが発生してもSQSがバッファとして機能するため、システム全体の安定性も大きく高まりました。
結果として、ビルド・テストは分割によってほぼ半減し、デプロイも7つの処理単位で行えるようになりました。処理を細かく分けたことでリソース最適化も進めやすくなり、実際にコスト削減の効果も現れています。さらに、オーケストレーションでは起動オーバーヘッドの課題がワーカープール型への転換によって解消され、大きな改善につながりました。

結果と今後の課題
分割と技術選定から得た主な学び
試行錯誤の中で多くの失敗も経験しましたが、その分得られた学びも大きいものでした。
まず、処理特性に基づいて分類・分割した点は有効でした。ドメインではなく処理特性で区切ることで、構造を整理しやすくなり、効率も追求しやすい状態がつくれたと感じています。
また、安易にArgo Workflowsに切り替えて失敗した経験からは、リクエスト量や処理の重さ、システムにとってどの指標が重要なのか(スループットか、レスポンス速度か)が状況によって変化すること、そしてそれらを正しく見極めて技術選定することの重要性を改めて認識しました。
ジョブ型とワーカープール型は、どちらか一方を100%採用するような関係ではないと考えています。起動オーバーヘッドが気になる部分だけワーカープール型で動かし、ジョブ型のワークフローから呼び出すといった構成も可能です。
現在のようにSQSを中心としたコレオグラフィー的なつなぎ方を採用している場合、ワークフロー全体を組み替えるのは簡単ではありません。そのため、ジョブ型のワークフローを基本としつつ、負荷の大きい箇所だけワーカープール型に寄せてAPI経由で利用する、といった選択肢も現実的ではないかと感じています。
今回のケースでは、特に起動オーバーヘッドが大きい処理について、ワーカープール型のアプローチが適していることが分かりました。

データ特性に起因する現在の課題と改善の方向性
まだいくつか課題が残っています。とくに、どのようなデータが流入するのか、その特性をより丁寧に分析する必要があると感じています。最近発生したトラブルの中にも、こうした分析を行っていれば防げた可能性があると気づく場面があり、その点を最後に共有したいと思います。
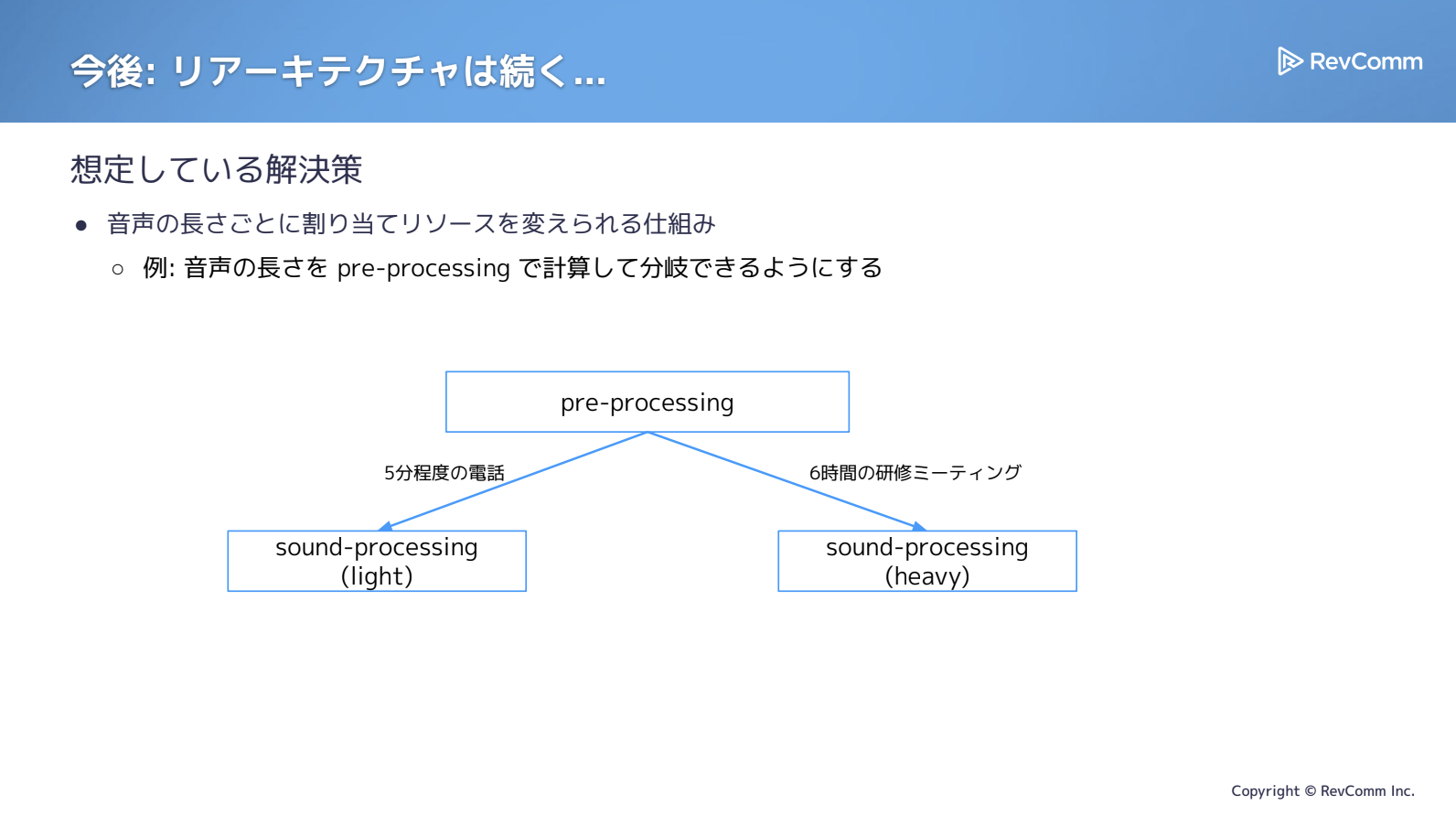
MiiTelに流れてくるデータには幅があり、インサイドセールスでの架電であれば、不在なら1〜2分で終わりますし、多少のやり取りがあっても5分程度で完了するものもあります。一方、ミーティングとなると状況は大きく異なります。たとえば3時間で参加者15名、あるいは4時間で参加者10名といったケースもあり、この規模になると40時間相当の処理量が一度に流れ込むことになります。つまり、同じ「1リクエスト」であっても、データによって処理の重さは大きく変動します。
短い通話を前提にリソースを用意すると不安定化やOOMが発生し、逆に長時間のミーティングを想定してリソースを確保すると、今度はリソース効率が大きく低下してしまいます。
全体を見なければならない処理、たとえばconversation-processingやpre-processingのような領域は、こうしたデータの長短差の影響を強く受けます。そのため、処理の重さに応じてリソースを割り当てられる仕組みが必要ではないかと感じています。

さらに、こうした要件が増えてくると、現在採用しているコレオグラフィー的な構成では対応が難しくなる可能性があります。ジョブ型に戻すかどうかは別として、もう少しフローを柔軟に組みやすい仕組みを導入することも検討すべきではないかと考えています。
まとめ
今回の取り組みでは、音声解析とNLPのシステムとして構築されていたモノリスを分解し、オーケストレーションの導入を進めてきました。
処理特性に基づく分類もうまく機能し、汎用的に解析したい、効率を高めたいといった要求に対して最適な分割だったと感じています。
オーケストレーションについても、起動オーバーヘッドを無視できない今回のケースでは、ワーカープール型が適しているという気づきを得られました。ハイブリッド構成など適材適所の選択肢はあるものの、もっとも重要な学びはまさにこの点にあるといえます。
データについても、特性を丁寧に分析していくことで、まだ多くの改善余地が残されています。最後に触れたとおり、長い音声にはリソースを多めに割り当て、短い音声にはレートを下げるといった分岐を設けることで、より効果的な処理が実現できるのではないかと考えています。
こうした取り組みは機械学習のパイプライン構築やサービス開発とも近く、データ処理という視点で見ても手を入れられる部分はまだ数多くあります。今回触れなかったところでは、機械学習モデルの改善やサービス改善に向け、各処理の間でデータを適切に蓄積する仕組みづくりなど、取り組むべき課題が残っています。そういった意味でも、一緒に取り組んでいただける仲間を募集しています。
MLOpsと呼んでいますが、実際にはMLサービス開発であり、今回紹介したようなパイプラインに加え、ストリーミング処理やMLプラットフォームの構築など、幅広い領域をカバーしています。データエンジニアリングのスキルを活かせる場面も多くありますので、ご興味があればぜひご覧ください。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
Data Engineering Summit
※動画の視聴にはFindyへのログインが必要です。





