


【内製開発フォーラム】~オブザーバビリティで育てる、強い内製開発組織~
2025年10月15日、ファインディ株式会社が主催するイベント「内製開発フォーラム」が、ベルサール汐留にて開催されました。
本記事では、New Relicの活用事例として、KINTOテクノロジーズ株式会社の粟田啓介さんによるセッション「オブザーバビリティで育てる、強い内製開発組織」の内容をお届けします。
内製開発を「やり切って終わり」にせず、継続的なデリバリーを実現する鍵として、オブザーバビリティをどう捉え、プロダクト開発から組織運営・人事評価まで広げていくのかが語られました。
■プロフィール
KINTOテクノロジーズ株式会社
DBRE / SRE Gr. Group Manager 兼 KINTO Innovation Lab. Principal Project Manager
粟田 啓介

トヨタグループ初のBtoC内製開発組織KINTOテクノロジーズとは
今日は「オブザーバビリティで育てる、強い内製開発組織」というテーマでお話しします。KINTOテクノロジーズ株式会社でDBRE、SREのマネージャー、またKINTO Innovation Lab.でプロジェクトマネージャーをさせていただいております。
本日の発表は、何でエンジニア組織にオブザーバビリティが必要不可欠なのか、New Relicを活用した実践事例と学び、オブザーバビリティを組織運営・人事評価に広げた経験をお話しさせていただきます。
まずは簡単に会社の紹介をいたします。
私が所属しているKINTOテクノロジーズ(以下、KTC)は、もともとは2019年に株式会社KINTOの開発編成部のような組織としてスタートしました。それが2021年に分社化し、トヨタグループ初となるBtoC・DtoC領域に特化した内製開発組織を担う、KINTOテクノロジーズという会社になりました。
KTCがどのようにトヨタグループのビジネスへ貢献していくのか。そのための今年のスローガンが『AIファースト』『ユーザーファースト』『リリースファースト』『組織インテンシティ』です。
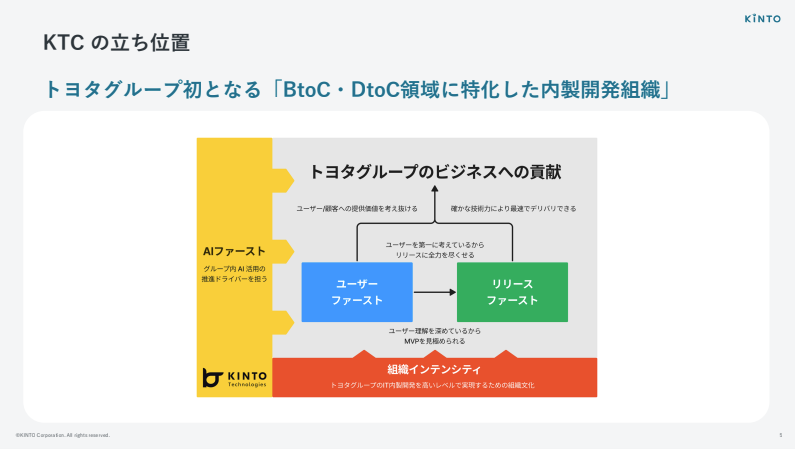
この4つのキーワードを掲げて、BtoC、DtoC領域に特化した内製開発組織を推し進めているというのが現状です。
DeliveryとQualityを両立させるオブザーバビリティとは?
Deliveryに偏っていると、じわじわ開発スピードが落ちていく理由
ここからは、「持続的にDeliveryを維持するために、オブザーバビリティとして何をやっているのか」という話をしていきます。
まず「内製開発で一番大事なことは何か?」という問いから入ります。
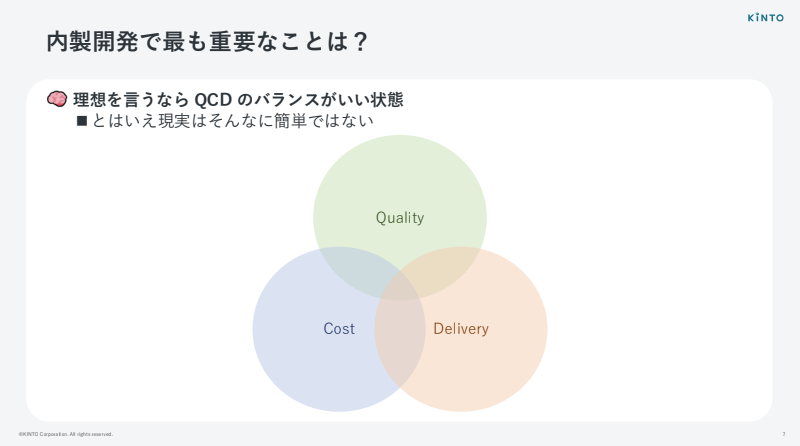
理想を言えば、QCD(Quality・Cost・Delivery)のバランスが取れている状態、図でいう真ん中あたりにいるのが良い、という話になると思います。
でも、実際の弊社はどうかというと、Deliveryに偏っていると正直感じています。
とはいえ、その状態でも内製開発を強力に推し進めていきたい。そのために、何をやると良いのか、というのが今日お話ししたいポイントです。
プロジェクトを進めていると、どうしてもDelivery優先になりがちです。一見するとそれでうまく回っているように見える。短期的には成果も出ますし、「きちんと進んでいる」となってしまいがちです。
ただ、時間が経つにつれて、そのしわ寄せの影響がボディブローのように効いてきます。Qualityが落ち、その影響でDeliveryも同時に落ちてくる。障害対応にリソースを取られ、メンバーも疲弊し、結果として開発自体のスピードが鈍化していきます。
本人たちは「走っているつもり」でも、気づいたらもう走れない状態になっている。そういうことが起こります。
なぜ内製開発は「Delivery偏重」になりがちなのか
なぜDelivery優先になってしまうのか。よくあるパターンの一つが、「限られたリソースと未整備の体制」です。
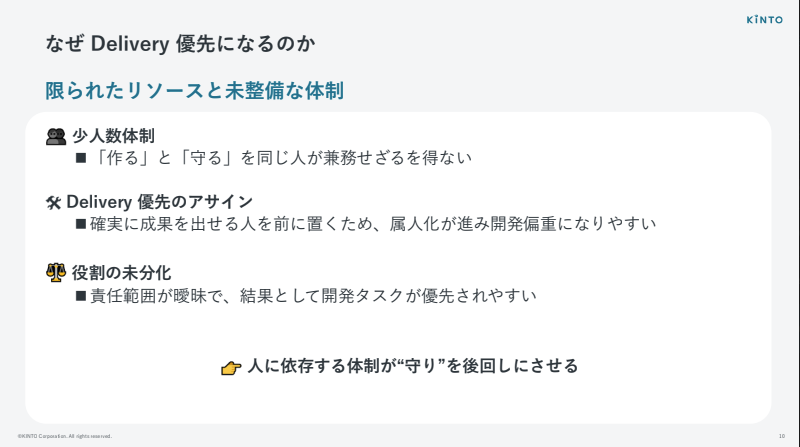
特にプロジェクトの立ち上げ期は、少人数体制だったり、「とにかくDeliveryできる人」を優先してアサインしたり、役割がきちんと分かれていなかったりします。結果として、人に依存した体制になり、守りの部分がどうしても後回しになりがちです。
ここで誤解してほしくないのは、僕はDeliveryを否定したいわけでは全くない、ということです。むしろ、ビジネスである以上、スピードと成果を出すことは当然に優先されるべきだと思っていますし、組織も会社もそれを求めて動くべきだと思っています。
ただ、その過程で忘れがちなのがQualityです。実はこのQualityこそ、Deliveryに直結する大事な要素だと考えています。だからこそ、DeliveryとQualityのバランスを「取り続ける」ことが重要です。
自然とそのバランスが取れる状態にしていくにはどうしたらいいのか。そこを考えることがポイントになります。
僕が目指しているのは、
- 開発を継続的に進められる基盤がある
- その上で改善サイクルを回し続けることができる
- 組織としても成長し続けられる
こういった状態です。ここまでたどり着くと、開発スタイルそのものが変わっていきます。
オブザーバビリティが「走り続けられる開発スタイル」の土台になる
では、開発スタイルそのものを進化させるために、何が絶対に欠かせないのか。
僕は、「Deliveryを続けるための基盤としてのオブザーバビリティ」だと考えています。

見えない問題に気づき、改善のサイクルを回していく。そのためには、まず「見えるようにする」ことが欠かせません。どれだけ頑張っても、見えないものは見えないままです。だから可観測性が必要になります。
問題が見えるようになれば、すぐに改善に着手できます。検知の仕組みを作れば、属人化も防げます。人の「気づき」に依存せず、自動で異常を捉えられる状態を作れる。
そうすると、チームとして動くときに重要な、「誰でも動ける状態」を作れます。特定の一人に依存して、その人がいなくなったら全て止まる、という状態から抜け出せる。みんなで問題を解決していけるようになります。
さらに、原因特定もシンプルに早くなります。障害復旧の際、「どこで障害が起きているのかわからない」という状態だと、最初から最後まで大量のログを眺めて、机上の空論のような議論を延々とやることになりかねません。
可観測性があると、「ここが怪しい」というポイントをすぐに絞り込めるので、障害対応にかかる時間はかなり短縮されます。その分、開発に集中できる時間が増え、結果としてDeliveryを維持できる開発スタイルに近づきます。
QualityとDelivery、その最低限の土台としての可観測性をきちんと押さえておくと、それ自体が「Deliveryを維持する強力な基盤」になる、というのが僕の考えです。
KTC SREが実際にやっている、オブザーバビリティ
KTC SREが目指す「ビジネスへの影響最小化」
この前提を踏まえたうえで、ここからはKTC SRE、つまり僕のチームの活動を少し紹介します。
まず、僕たちの立ち位置です。
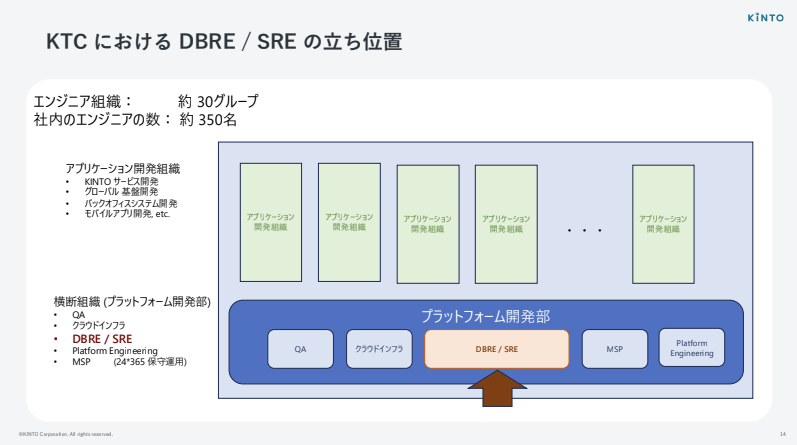
KTC全体では、エンジニア組織がだいたい30グループくらいあります。エンジニアは全社で約380名(2025年10月時点)。その中で、僕らDBRE/SREは横断組織の1つとして存在しています。
僕はメンバーに常に、「KTC SREが会社に良い影響を与えるための第一歩は何か?」という問いを投げ続けています。
その答えの一つが、「ビジネスへの影響を最小限に抑えること」です。

見えないものは当然、管理できません。だからこそ、システムの状態を可視化し、「正常な状態がわかっているからこそ、異常にも気づける」状態を作る。リアルタイムに影響を把握し、迅速に意思決定ができるようにする。
そのうえで、根拠のある改善と予防策を打てるようにする。そのための第一歩として、僕たちは「モニタリング」と「インシデントレスポンス」を重視し、その基盤としてNew Relicを採用しました。
New Relicを推進することにした背景と得られた効果
なぜNew Relicを推進したのか、という話をします。

実は、New Relicの前からオブザーバビリティ系のツールは社内にありました。OpenSearch、X-Ray、Prometheusなど、複数のツールを組み合わせた基盤を使っていたんです。
ただ、この構成だと学習コストが非常に高くなってしまう。1人のエンジニアがものすごく頑張って可視化しているチームもありましたが、そうなると、その人の目的がいつの間にか「可視化すること」になってしまう。
ログをオブザーバビリティツールに流すこと、メトリクスを集めること自体が目的化してしまい、本来やるべきプロダクトの改善にまで手が回らない、という状態です。
そこで僕たちは、「自分たちで状態を見られるようになること」を、できるだけ少ない学習時間で実現したかった。その観点から、New Relicを採用しました。
New Relicを使うことで、
- 事業KPIと開発の指標を1本でつなぎ、経営と現場の共通言語にする
- 仮説→実装→観測→学習のループを短くする
- 顧客体験の変化をしっかり見えるようにする
- それらを踏まえた優先順位づけで迷わなくなる
といったことがやりやすくなりました。そういう基盤としてNew Relicを採用しています。

副次的な効果として、SREなどをやっている他社でも、New RelicやDatadogを使っているケースは多いので、そういった経験を持つ方がKTCに入社してくれたときのオンボーディングが、ものすごく早くなりました。
結果的に、エンジニア採用にも良い影響が出ています。これからもっと効果を実感していけると思っています。
個人的には、「可視化を目的にしないで、その先の行動につなげる」ためには、こういったオブザーバビリティツールを入れることは、もうマストだと思っています。そこにかけたコストは十分ペイできるはずです。
極端な話、「迷わず導入しても良い」と感じるくらいには、僕は推しています。
「まずダッシュボードを作って毎日見る」だけで現場が変わり始める
とはいえ、最初からうまくいったわけではありません。
New Relicを導入したものの、「障害が起きたときだけ見るツール」になってしまっていた時期があります。本当にやりたかったのは、日常的なメトリクス監視や、プロアクティブな改善サイクルを回すことです。
でも、「トラブルが起きたときだけ見る」運用だと、組織はなかなか成長しません。
そこで僕らは、本当に泥臭いところから始めました。

具体的には、「日次の定例でNew Relicをどう活用するか」を、KINTOのバックエンドチームと一緒に、とにかく話し続けるところから始めました。
毎日ダッシュボードをみんなで見て、「ここはどうだ」「これはおかしくないか」と議論する時間を定例の中に組み込んだんです。
結果として、これがプロアクティブなパフォーマンス改善に大きく効いてきました。
プロダクトチームの“違和感”を拾い上げる日次レビューの回し方
ここで、現場じゃないとわからない感覚と、横断組織から見える世界の違い、という話も出てきます。
例えば、「いつも0.01秒で返っていたクエリが、今日は0.1秒かかっている」という状況があったとします。
僕たちDBRE/SREの立場からすると、「スロークエリにも出ていないし、DBの観点では特に異常じゃない」と判断して見逃してしまいがちです。
でも、プロダクトチームからすると「PKで1本釣りしているクエリなのに、なぜこんなに遅いのか」という違和感があります。そこに敏感になってくれます。
日次のダッシュボードレビューを通じて、そういう「現場の違和感」がどんどん可視化されていきました。僕らDBRE/SREは、その違和感を一緒に調査して、原因を突き止め、改善していく。
このサイクルのおかげで、かなり細かいレベルまで改善できるようになりました。
一番最初にやったことは、実はとてもシンプルです。「ダッシュボードを作る」「そしてちゃんと見る」。この2つだけです。でも、ここが一番重要なポイントだと思っています。
プロダクトのDeliveryを止めない強い内製開発組織
Slackから呼び出せる「リクエスト解析ツール」
続いて、「Deliveryを止めないための対応力を、仕組みでカバーする」という話に移ります。
僕たちは「リクエスト解析ツール」というものを社内に提供しています。

インシデントが発生したときに、New Relicのトレース情報やログ情報をもとに、「複数のAPIが連動しているこの一連の処理の中で、どこでエラーになっているのか」を逆算して見つけられるようにするツールです。
スライドだと1〜3本のAPIが連動している図を出しているのですが、その中のどこがボトルネックになっているのか、どこでエラーが起きているのかを、ログとトレースをつないでピンポイントで特定できるようにしています。
このツールはSlackから呼び出せるようにしていて、New Relicを使っているチームであれば、誰でも簡単に使えるようにしました。最近は、ここにAIも組み合わせて、よりスムーズに状況整理ができるようにしています。
まだ障害になっていない“兆候”を検知しプロアクティブな改善を実施
もう1つ、僕たちが今力を入れているのが「プロアクティブな改善サイクル」までを含めた仕組みづくりです。
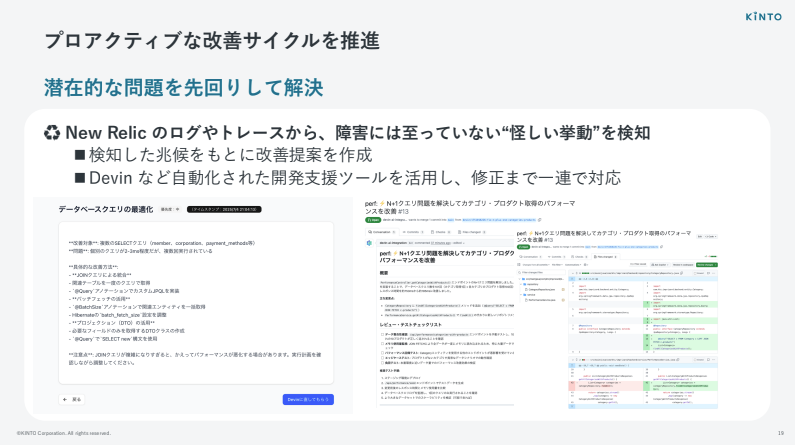
現在、ほぼ完成しつつあるところなのですが、New Relicのログやトレースを見ながら、「まだ障害には至っていないけれど、挙動として注意が必要な状態」を検知する仕組みを作っています。
それを検知したら、自動でDevinに渡して、Devinがプルリクエストを作ります。そのプルリクエストを見て、マージするかどうかはプロダクト側が判断します。
こういったツールを提供することで、オブザーバビリティ → インシデントレスポンス → プロアクティブな改善、という一連の流れを、みんなで回せるようにしようとしています。
横断組織である僕たちがこうした仕組みを用意することで、「プロダクトのDeliveryを止めない強い内製開発組織」を支えていく、というイメージです。
評価と組織運営にもオブザーバビリティを広げるとどうなるか
公平な評価の土台に「見える化」が欠かせない理由
ここまでは、オブザーバビリティをエンジニアリングの文脈で話してきましたが、「本当にそれだけなのか?」という問いがあります。
僕は、オブザーバビリティは組織運営にも広げられる、と考えています。
エンジニア組織における評価の難しさの一つは、「アウトプットを公平に評価すること」です。

そもそも「公平とは何か」「何をもって公平とするのか」は、人によって捉え方が違います。でも、そこに透明性がないと、メンバーのモチベーション低下や離職につながってしまいます。
評価がぶれると、組織文化そのものも歪んでいきます。
逆に、公平な評価ができれば、エンジニアの成長をしっかり支えられます。その結果として、組織としての持続的な開発にもつながっていく。
そこで僕がやっていることを、いくつか紹介します。
メンバー一人ひとりへの期待値を“見える化”する
1つ目は、「メンバー一人ひとりへの期待値を明確にする」ことです。

ある意味で、これも可観測性の話です。「何を期待しているのか」を曖昧にしたままにせず、きちんと言語化する。
僕は、メンバー一人ひとりに対して、「あなたに何を期待しているのか」を最初にちゃんと伝えるようにしています。後出しジャンケンにならないようにするためです。
同時に、「僕があなたに何を提供できるのか」もセットで伝えています。ここまでセットで見える化して、期待値を揃えることを大事にしています。
会社からのメッセージを自分たちの言葉に翻訳して伝える工夫
2つ目は、「会社からのメッセージを自分の組織の言葉に翻訳する」ことです。

さきほどの「AIファースト、ユーザーファースト、リリースファースト、組織インテンシティ」のようなキーワードも、そのままだと抽象度が高くて、正直よくわからないと思います。
そこで僕は、マインドマップのような形で、自分の組織の言葉に落とし込む、ということをやっています。
そうすると、矢印を会社ではなく自分に向けられるようになる。
これをやらずに、そのままの言葉でメンバーに伝えると、メンバーの不満の矢印が会社に向かいやすくなります。さらに厄介なのは、その不満を持った人が、横のグループを巻き込んで、上に向かって不満をぶつける構造が生まれることです。
僕はそれを避けたいので、まず自分がちゃんと咀嚼して、自分の言葉に変換し、そのうえでメンバーに伝えるようにしています。
メンバーの「やりたい」と会社の方向性をつなぐ目標設定
3つ目は「目標設定」です。

目標設定は、「上から降ってきたものをそのままやる」だけではダメだと思っています。
メンバーにしか見えない課題が必ずあります。それを各自に考えてもらい、「自分ごと」としてチームの目標に落とし込んでもらう。
僕の役割は、メンバーがやりたいことと、会社がやりたいことの方向性をつなぐことです。僕はこれを「メンバーの矢印を組織に向ける」と表現しています。
そのうえで、OKR形式で目標を分解し、みんなの目標を組み立てています。
定量的なアウトプットを読み解いて評価につなげる
4つ目は、「定量的なアウトプットをきちんと読む」ことです。

僕のチームでは、GitHub、Confluence、JIRA、Slackの4つを主に使っています。これらをちゃんと読み込むことで、より定量的な評価ができるようになります。
こうしたデータソースを、オブザーバビリティの視点でつなぎ合わせ、個人の行動や成果が見える状態をできるだけ統合して作っています。
正直に言うと、以前はこれを全部手作業でやっていました。
評価の時期になると、メンバー一人に8時間以上かけて、GitHub、Confluence、JIRA、Slackをひたすら眺め続けて、一人ひとりの活動を追いかける、ということをしていたんです。
さすがにこれを毎回やるのはつらくなってきたので、「自分が楽をするためだけの、自分のためのツール」を勝手に開発しました。

このツールでは、GitHub、Confluence、JIRA、Slackのデータを集約し、ある程度自動的に評価用のたたき台を作るようにしました。そこに僕の定性的なコメントを載せることで、「その人に本当に伝えたいメッセージ」を、今のAIの力も借りながら整形して出す、という形にしています。
オブザーバビリティがチームと組織にもたらすもの
最後にまとめです。

持続的にDeliveryを維持するためのオブザーバビリティという観点では、
- Deliveryとクオリティのバランスを保つことが重要
- 見えない問題を捉え、原因特定と対処のリードタイムを短縮できる
- 結果として、改善サイクルが回り、「開発を止めないスタイル」が作られる
という話をしました。
KTC SREとしては、そのための基盤としてNew Relicを推進し、「自律的なアクション」が各チームから自然に出てくる状態を目指しています。
そして、オブザーバビリティは、エンジニアリングやプロダクト開発だけの話ではなく、組織運営にも広げられる、という話もしました。
最後に問いかけです。
オブザーバビリティを文化として根付かせる準備はできていますか?
以上で僕の話を終わります。ありがとうございました。

アーカイブ動画&当日の発表資料も公開しております。あわせてご覧ください。
※動画の視聴にはFindy Toolsへのログインが必要です。






