



【アーキテクチャConference 2025】 ドメイン駆動設計とマイクロサービスアーキテクチャ
2025年11月20日・21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に行われた本セッションは、「AWS Developer Live Show 出張編」として実施されたものです。アマゾンウェブサービスジャパン合同会社の宇賀神 みずき(しょぼちむ)さん、福井 厚さん、そして株式会社コドモンの成瀬 允宣さんが登壇しました。
セッションはパネルディスカッション形式で行われ、ドメイン駆動設計における境界の引き方、マイクロサービスとの組み合わせ方、生成AIを活用した開発ライフサイクルまで、実践的な知見が共有されました。
■プロフィール
アマゾンウェブサービスジャパン合同会社
アプリ開発コンサルタント
しょぼちむ(宇賀神みずき)
AWS Japan の公式 YouTube チャンネルにてドメイン駆動設計をテーマとした配信を実施。また、2022年にはエリック・エヴァンスのドメイン駆動設計の書籍を100日間毎日グラレコでのまとめをXにて発信した。現在は、アプリケーション開発コンサルタントとしてお客様にドメイン駆動設計の導入支援などを実施している。著書『いちばんやさしいGit&GitHubの教本』
アマゾンウェブ サービスジャパン合同会社
シニアソリューションアーキテクト
福井 厚
PCメーカーでサポートエンジニアとしてOS及び言語担当、ソフトウェアハウスでデベロッパー、SIベンダーで SE、アーキテクト、開発系コンサルティングファームでコンサルタントを経験後、2015年7月よりアマゾンウェブサービスジャパン合同会社でソリューション アーキテクトとして活動。現在は、デベロッパースペシャリストとして お客様のクラウドネイティブなモダンアプリケーション開発を支援する活動を行っている。
株式会社コドモン
成瀬 允宣
プログラマ。カンファレンス等でソフトウェア開発・設計を主軸に講演活動を行っている。著書『ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本』
このセッションの対象者とゴール
しょぼちむ:本セッションは「AWS Developer Live Show 出張編」としてお届けしています。
AWS Developer Live Show
は、プログラミングや開発の課題に特化したテーマの技術解説・ディスカッションを、AWSスペシャリストがAWS公式YouTubeチャンネルからライブセッションでお届けする番組です。
アーカイブ
も残っていますので、ぜひご覧ください。
本セッションの対象者は、次のような方々です。
- ドメイン駆動設計やマイクロサービスに興味がある
- 基本的な考え方は知っているが実践で悩んでいる
- ドメイン駆動設計の理論は知っているが「どこで境界を引くか」「どう関連させていくか」の判断に迷っている
そして目指すゴールは次のとおりです。
- ドメイン駆動設計における境界の引き方の判断基準がわかる
- ドメイン駆動設計とマイクロサービスアーキテクチャの各概念の関係性を理解する
- セッションを通じて実践的な知見を得る
パネルディスカッション形式のため、いろいろ脱線するかもしれませんが、楽しく進めていければと思います。
マイクロサービスを選択する前に考えるべきこと
しょぼちむ:ドメイン駆動設計とマイクロサービスアーキテクチャの話に入る前に、みなさんに確認しておきたいことがあります。
本当にマイクロサービスアーキテクチャで行きますか。
モノリスではダメですか。
モジュラモノリスではダメですか。
という3つの疑問をぜひ頭に入れておいてから、この話を聞いていただければと思います。
Martin Fowlerさん
の引用になりますが、「成功しているマイクロサービスの事例のほぼすべてが、大きくなりすぎたモノリスを分割することから始まっています。反対に、最初からマイクロサービスとして構築されたシステムのほぼすべてが、深刻な問題に直面しています。つまり、アプリケーションが将来大きくなることが確実だとしても、新しいプロジェクトをマイクロサービスで始めるべきではない」ということです。
昨日のSam Newmanさんのキーノートでも、「マイクロサービス自体を目的にしないように」という話がありました。マイクロサービスのメリット・デメリットを比較した上で、それでもマイクロサービスを選択した場合という前提で、今日の話を進めていきます。
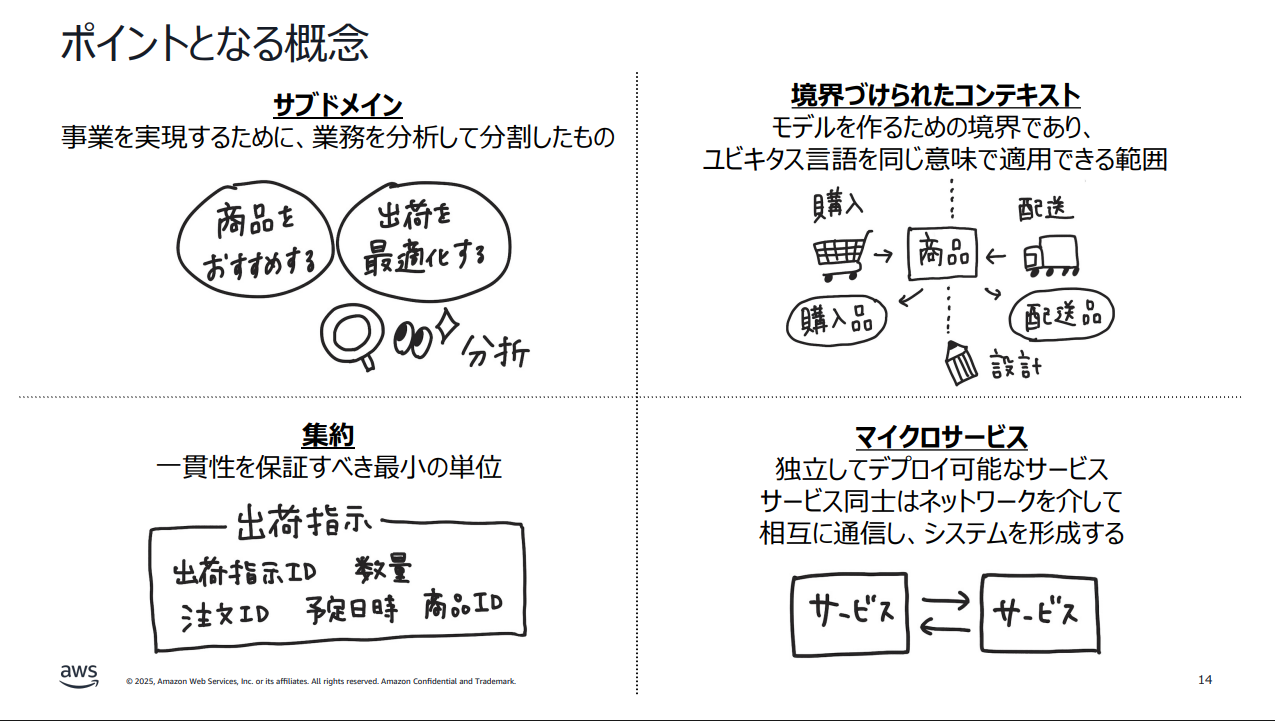
ポイントとなる4つの概念
しょぼちむ:みなさんの認識を揃えるために、今日は大きく4つの概念をテーマにお話ししていきます。
1つ目はサブドメインです。事業を実現するために、業務を分析して分割したものを指します。
2つ目は境界づけられたコンテキストです。モデルを作るための境界であり、ユビキタス言語を同じ意味で適用できる範囲を指します。例えば「商品」という言葉が、購入の文脈と配送の文脈では異なる属性を持つことがあります。どこで境界を引くかを決めるのは設計の作業です。
3つ目は集約です。データの一貫性を保証すべき最小の単位を指します。集約として管理される一貫性の範囲が正しくないと、業務として不正なデータが登録されてしまう可能性があります。
4つ目はマイクロサービスです。独立してデプロイ可能なサービスであり、サービス同士がネットワークを介して通信し、システム全体を形成します。
今日はこの4つの概念がどのように関係し合うのか、どこで境界を引くべきかをディスカッションしていきます。
サブドメインと境界づけられたコンテキストの関係性
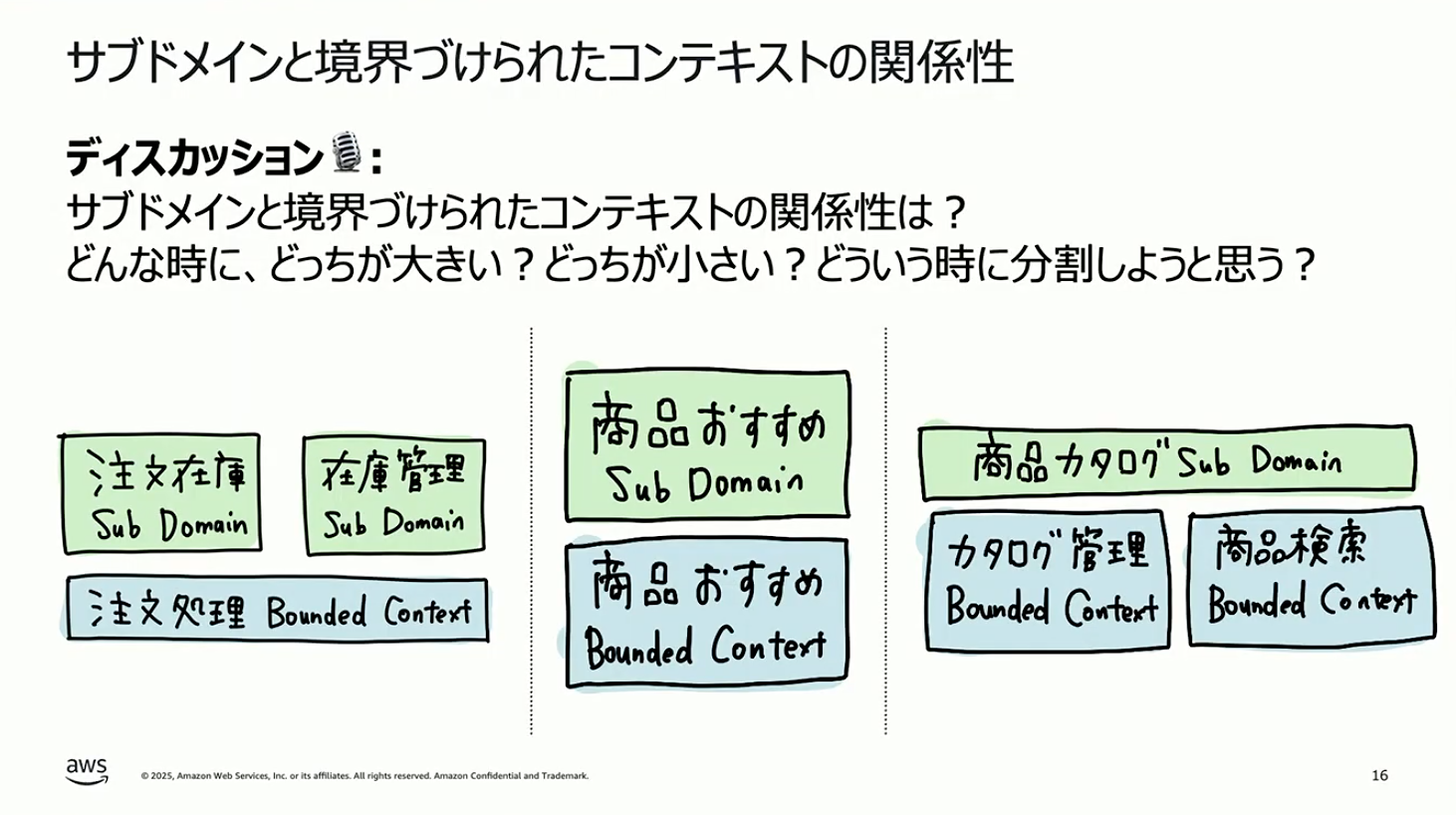
しょぼちむ:先ほど整理したとおり、サブドメインは分析から導き出すもの、境界づけられたコンテキストは設計で定義するものです。一方で、実務では両者の関係性について迷われることが多いと思います。サブドメインと境界づけられたコンテキストはどちらが大きいのか、どういう時に分割するのか、統合するのか、という判断基準に迷われることが多いと思います。
両者の関係性には、大きく3つのパターンがあります。
- 複数のサブドメインをまとめて、1つの境界づけられたコンテキストとする
- サブドメインと境界づけられたコンテキストが1対1で対応する
- 1つのサブドメインの中で、境界づけられたコンテキストを複数に分ける
これらのパターンについて、成瀬さんからお伺いしてもいいですか。
成瀬:理想はサブドメインと境界づけられたコンテキストが1対1の関係性になることだと思いますが、分かれるパターンも結構あります。例を挙げて説明します。
AIでファッションを提案して、それをECにつなげるシステムを考えてみてください。この事業で一番競争力があり、本業に関わる場所、つまりコアドメインはどこでしょうか。おそらく「AIで提案する」部分ですよね。
ところが、この「AIでファッション提案する」というコアドメインの中でも、テーマが2つに分かれます。1つはファッションのモデルを学習する側、もう1つはユーザーに提案する側です。
学習する側は機械学習やデータサイエンスの世界であり、提案する側はデータエンジニアの世界です。技術スタックがまったく異なりますよね。このように、同じサブドメインであっても、技術スタックの違いによって境界づけられたコンテキストが分かれるパターンがあります。
福井:おっしゃるとおり、1対1が理想ではあると思います。ただ、逆のパターンもあります。
成瀬さんの例は「1つのサブドメインが複数の境界づけられたコンテキストに分かれる」パターンでした。逆に、ユビキタス言語が通用する範囲、つまり境界づけられたコンテキストとしては1つであっても、ビジネス上の業務が分割されていれば、サブドメインが複数に分かれることもあります。
原則として、境界づけられたコンテキストの境界は、その中で保持すべきデータ属性を分類するためにあります。設計上は疎結合な境界線として機能するので、それで問題ありません。ただし、業務の観点では「この部署とこの部署がちゃんとコミュニケーションを取れているか」といった組織の実態も考慮する必要があります。
成瀬:組織図の話も関係してきますよね。担当者が変われば、サブドメインの区切り方も変わってくることがあります。
ここで、サブドメインと境界づけられたコンテキストの違いを整理しておきましょう。サブドメインは「問題空間」に属する概念で、ビジネスの領域そのものを指します。一方、境界づけられたコンテキストは「解決空間」に属する概念で、その問題を技術的にどう解決するかという設計上の境界を指します。
メタファーで説明すると、地図における地形がサブドメインに相当します。地形は客観的に存在するものですよね。それに対して、どこに国境を引くか、どこで市町村を区切るかは、我々の意思で決めるものです。その境界線が、境界づけられたコンテキストに相当します。
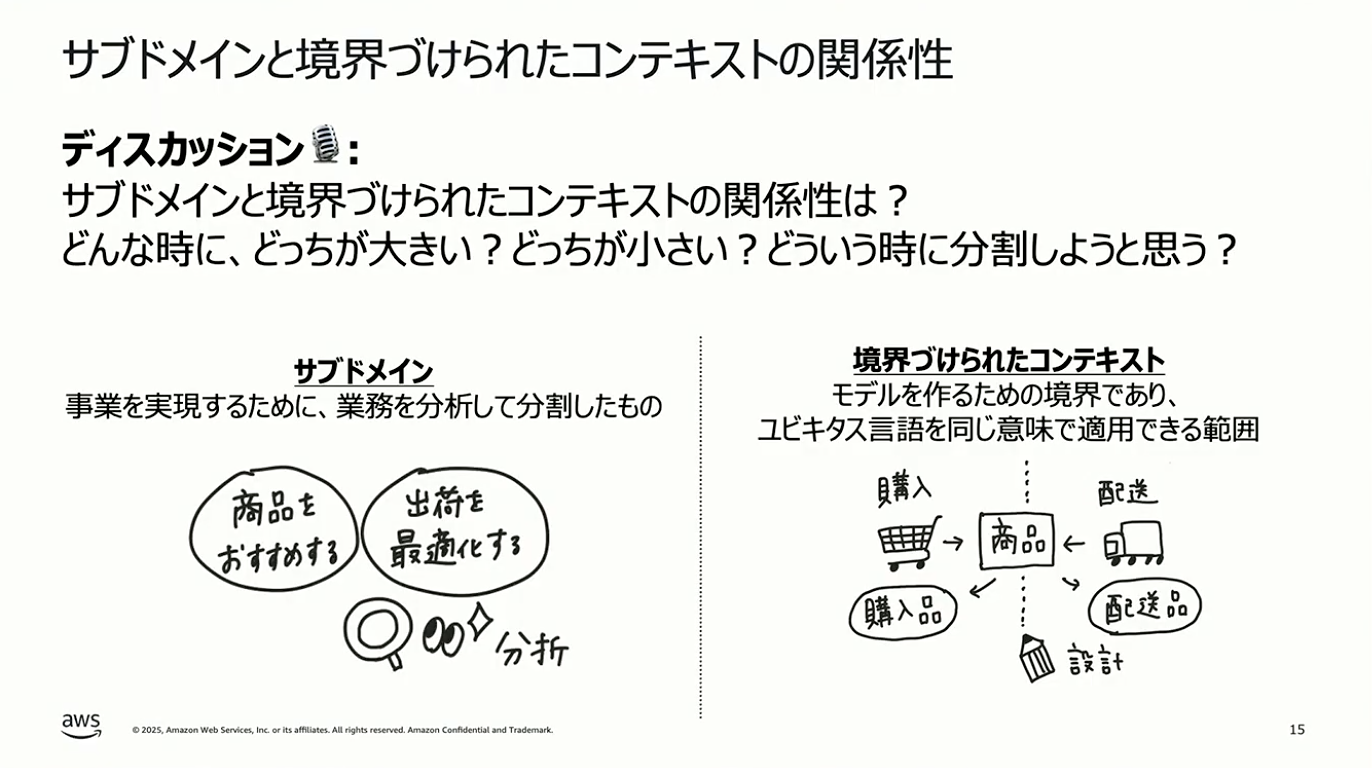
福井:すごくわかりやすい説明だと思います。
成瀬:一晩考えた甲斐がありました(笑)。
しょぼちむ:先ほど、技術と組織という観点で分割をしていくという話がありましたね。他にも、普段、分析や設計をされていて、「これは分けた方がいいな」と感じるのはどういうときでしょうか?
成瀬:サブドメインを分けたほうがいいと感じるのは、ミーティングする相手が変わった時でしょうか。
しょぼちむ:話している人たちが変わったな、この業務を一番知っている人が変わったな、という時ですね。
福井:組織は業務ごとに分かれていることが多いので、組織構造に従ってサブドメインを分けることが多いと思います。
しょぼちむ:では、お客様と「この部署のシステムを開発するぞ」となった時は、1つのサブドメイン内で境界づけられたコンテキストを引いていくことが多いのでしょうか。
成瀬:そうですね。最近は開発者がビジネス領域に深く入っていくケースが増えています。その結果、業務分析と設計を一体で進めることが多くなり、サブドメインと境界づけられたコンテキストが1対1になりやすい傾向があります。アジャイル開発の浸透も影響していると思います。特にスタートアップでは、イベントストーミングで業務を整理していくと、両者が自然と一致していくことが多いですね。
福井:イベントストーミングで言うと、最初のビッグピクチャーやプロセスモデリングが業務分析に相当します。そこから境界づけられたコンテキストを見出すところが設計フェーズになるので、その過程で見極めていく形ですね。
成瀬:ただ、サブドメインと境界づけられたコンテキストは、ずれることもあります。ビジネスの変化は速いですが、システムは物理的に存在するものなので、すぐには追従できません。ビジネス側でサブドメインの区切りが変わっても、システム側の境界づけられたコンテキストが追いつかないタイミングは必ず発生します。
しょぼちむ:ずれた時はどうするんでしょうか。
成瀬:ずれは修正していくのですが、ビジネスの変化が頻繁だと、システムの追従が追いつかなくなります。サブドメインの構造と、システム側の境界づけられたコンテキストの整合性をどう保つかは、永遠の課題ですね。
イベントストーミングで言うと、理想のコンテキストマップ(To-Be)を夢見て、現状のシステム構造(As-Is)と比較して、少しずつ近づけていくという進め方になります。
福井:極端な例なんですが、私のお客様でイベントストーミングをやった後のコンテキストマップを見て、逆コンウェイ戦略を採って組織を変えた方がいらっしゃいます。そういうのも極端ですけど、一つの選択肢だとは思います。
成瀬:逆コンウェイ戦略、僕も昔やったことあるんですよ。ですが大事なところで判断を誤って失敗したんです。反面教師としてお伝えすると、組織は分けたものの権限がなかったんです。
福井:それは一番やってはいけないパターンですね。
成瀬:やってはいけないパターンなんですね。みなさん気をつけてください(笑)。
しょぼちむ:『チームトポロジー』にも書かれていますが、まずはビジネスドメインで境界づけられたコンテキストを分けることが基本です。その上で、開発組織の違い、技術スタックの違い、変更頻度やパフォーマンスレベルの違いといった観点でも分け方は変わってきます。それぞれの境界を1つのチームがオーナーシップを持ち、ビジネス側と協議しながら進めていくのが目指したい姿ですね。先ほど福井さんがおっしゃった逆コンウェイ戦略のように、システムの境界に合わせて組織を変えるという意思決定ができるのは素晴らしいことだと思います。
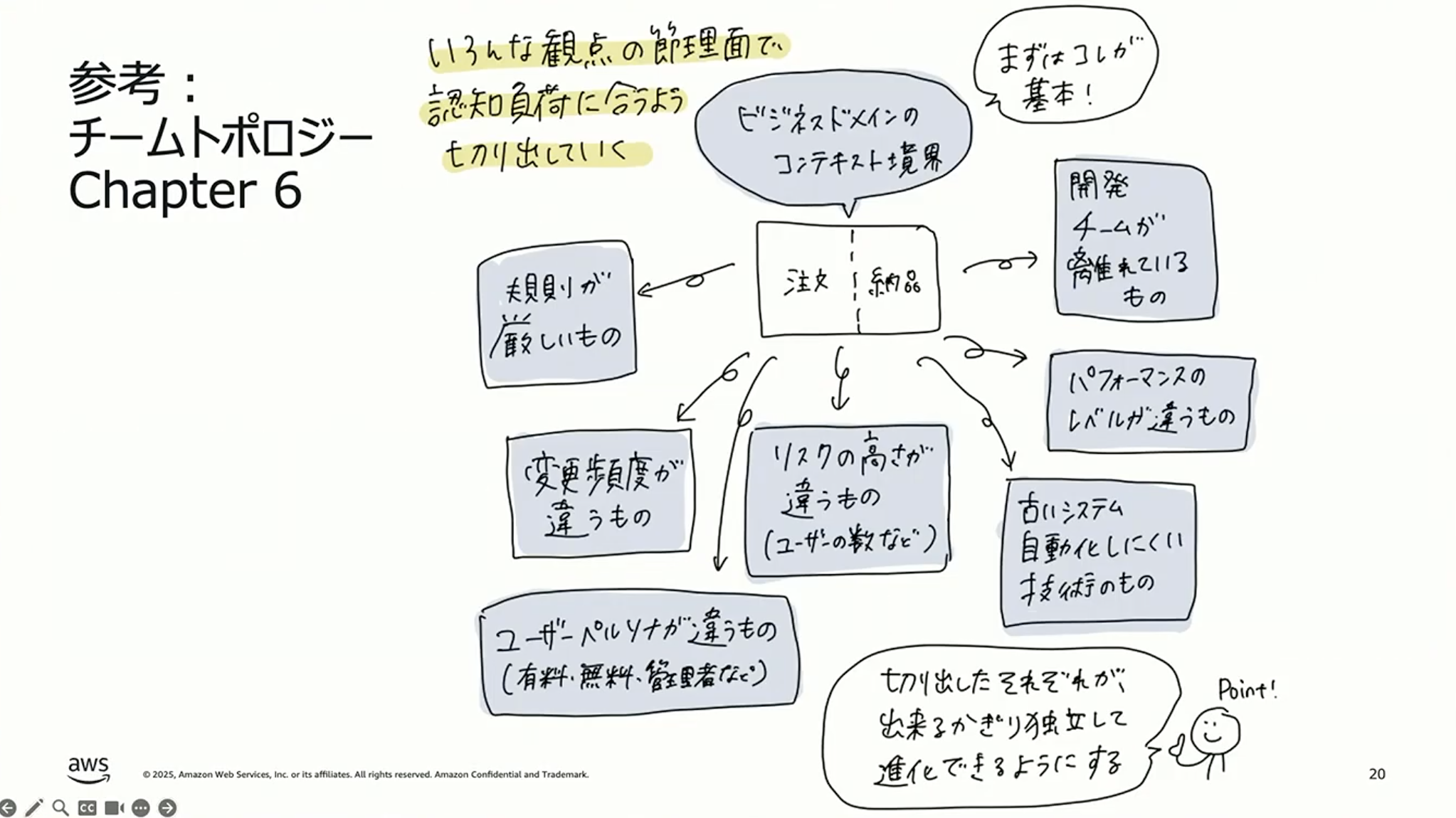
成瀬:ただ、組織を変えるというのは、文化を変えるという話に近いんですよね。私が以前メンバーレベルだった時に逆コンウェイ戦略を試みたことがあるのですが、権限がなくてやりづらかったです。結局、トップの理解を得ることに尽力した記憶があります。
しょぼちむ:組織を変えるとなると、それくらいの覚悟と根回しが必要になりますよね。
境界づけられたコンテキストとマイクロサービスの関係性
しょぼちむ:次のテーマに移ります。境界づけられたコンテキストとマイクロサービスの関係性を考えていきたいと思います。境界づけられたコンテキストとサービスは1対1になるのか、そうではない時があるのかをお伺いしたいです。
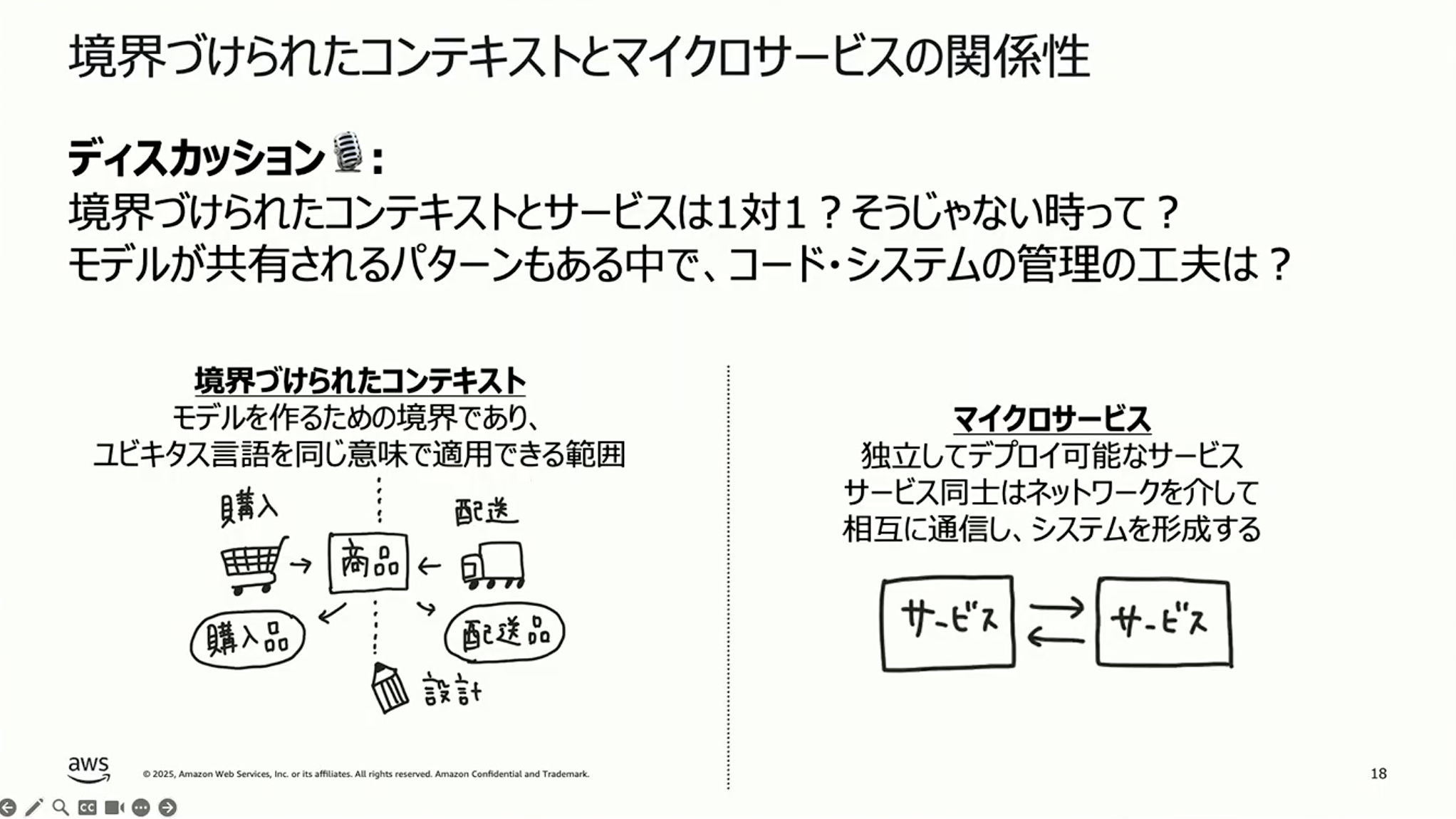
成瀬:僕は基本的に1対1にならないパターンが多いという印象です。以前、境界づけられたコンテキストごとにAmazon VPC (以下 VPC)まで分けたことがあるのですが、VPC間の接続で苦労した経験があります。その経験から、VPCを分けるかどうかは慎重に考えた方がいいと思っています。仮に分けない場合でも、同じVPC内でプロセスは一つにまとめておくことが多いですね。分散させると管理が大変になるからです。
福井:みなさんご存知のとおり、マイクロサービスは実態のあるアーキテクチャです。その目的としては、昨日Sam Newmanさんもおっしゃっていましたが、その単位でデプロイできて、その単位でスケーラビリティが取れるということが一番のメリットになります。
理想を言えば、境界づけられたコンテキストの単位と1対1でスケールするのが望ましいので、一致したほうがいいと思います。ただ逆に言うと、業務の中で一部の機能だけが高いスケーラビリティを求められるということであれば、そこだけ分けてもいいんじゃないかということですね。
もう一点押さえておきたいのは、基本的にマイクロサービスはデータソースも1対1で持っているという点です。境界づけられたコンテキスト単位のデータソースに対して、複数のマイクロサービスが存在するというのはあり得ます。これはいわゆる「分散モノリス」とは違う構造です。
成瀬:おっしゃるとおりですね。分けたいなと思う時はいつかというと、今のようにパフォーマンスが求められて、1つのプロセス全てにおいて一気にパフォーマンスを上げると無駄が出てしまう場合です。そういう時は、高いパフォーマンスが求められる部分だけを分離して、その部分の処理能力を上げたり、並列数を増やしたりします。
しょぼちむ:それから、「サーバレスアーキテクチャだったら分散されてマイクロサービスだよね」という誤解がよくあります。そのあたりをぜひ福井さんにお話しいただきたいなと思っています。
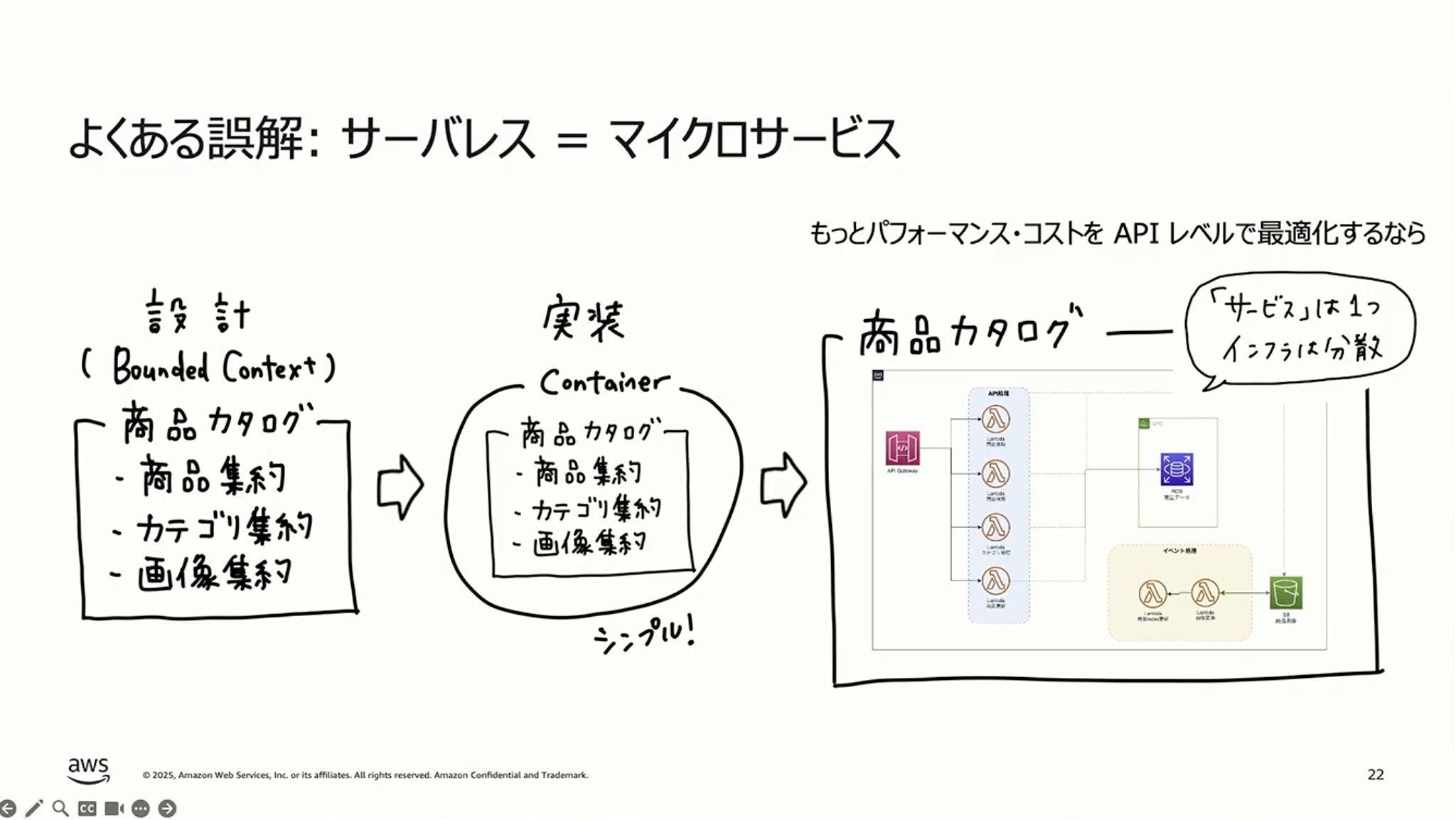
福井:ご存知の方も多いと思いますが、AWS Lambda(以下 Lambda)はいわゆるFunction as a Serviceに相当するものです。関数単位でイベントによって起動され、実行が終わったらすぐ終了します。その間しか課金されないというのがサービスのメリットです。そうすると、ファンクションを早く終わるようにしたほうがコスト的にもメリットがありますし、並列化もしやすくなります。また、Lambdaの場合、インスタンスが1回実行終了してもしばらく残りますので、同じリクエストが来た時に再利用されて、リソース効率もいいんです。
一方で、サブドメインの単位やコンテキストの単位で、1つのLambdaの中に全部実装するパターンがあります。我々はこれを「Lambdalith(ラムダリス:Lambdaとモノリスをかけた言葉)」と呼んでいます。モノリスのLambda版ですね。これが悪くない場合もあるんですが、先ほど言ったリソース効率の観点からすると、リクエストが多い機能とそうでない機能は分けたほうがいいです。例えばWrite(書き込み)とRead(読み取り)を分けるなど、いろいろなやり方があります。
ポイントは、複数のLambda全体で1つのマイクロサービスを構成するという考え方です。この考え方であれば、先ほどの境界づけられたコンテキストとマイクロサービスの関係と変わりません。逆に言うと、Lambda1つをマイクロサービスと呼ぶのは避けたほうがいいと思います。
成瀬:僕はLambdaばかり使っていてあまりサービスを作ったことはないんですけど、DDD的なモジュールを切って、それをみんなで共有しながら、複数Lambdaのハンドラーで呼び出すようにしています。そうやってアプリケーションサービスのようなものを構成していくイメージでしょうか。
福井:すごく良いポイントですね。Lambdaにはレイヤーという機能があって、共通のライブラリを読み込むことができます。
もう1つの選択肢として、さきほどお話ししたLambdalithのように、1つのLambdaで全部実装する方法もあります。LambdaにはWeb Adapterというライブラリが提供されていて、それを使うとあたかもHTTPサーバーのように動かすことができるんです。そういうやり方もないことはないので、ケースバイケースで選択していただければと思います。
成瀬:Lambdalithの場合、ボディにアクションを渡すような形ではなく、通常のHTTPのパスやメソッドでルーティングできるということですか。
福井:おっしゃるとおりです。リクエストは勝手にルーティングしてくれます。
成瀬:なるほど、それなら手軽にできそうですね。
福井:ただし、あまり大きくなりすぎると、Lambdaのメリットがなくなってしまいます。それだったらコンテナでいいじゃん、と(笑)。
成瀬:はい、Lambdalithやめましょう(笑)。
しょぼちむ:やっぱり選択ですよね。さきほど集約についてもご紹介しましたが、集約ごとにLambdaを分けて、それぞれでパフォーマンスをコントロールできるようにするというイメージで大丈夫でしょうか。
福井:集約だけとは限らないですが、ビジネスロジックのどの部分をLambdaに実装するかという判断ですね。
しょぼちむ:細かく分けずに1つのサービスとしてスケールをコントロールしたいなら、コンテナにまるっとマッピングして動かせばいいという話ですよね。
成瀬:わかりやすい例で言うと、月次請求のような処理があります。月に一度だけ一気に処理が必要になるけど、それ以外の期間は使わない。そういう処理は別のサービスに切り出して、普段動いているサービスには含めないほうがいいという話ですね。
しょぼちむ:モデルが共有されるパターンもある中で、コードやシステムの管理をどう工夫しているかを伺ってもいいですか。
成瀬:いろんなパターンがありますね。例えばコドモンで言うと、モノレポを採用しています。モノレポの良いところは、マイクロサービス同士の依存関係が見やすいことです。同じコードベースを落として、IDEでCtrl+クリックやF12を押すと定義元に飛べるので、非常に開発しやすい。
一方で、変更の影響範囲が広がりやすかったり、GitHub Actionsが一つのリポジトリに集中してしまったりと、デプロイまわりが辛くなる面もあります。一長一短ですね。
逆に、リポジトリを全部分けたパターンもやったことがあります。個々のシステムの中は見えるんですが、システム同士のつながりが見えなくなるんですよね。そこで、トレーシングを導入したり、Kafkaを使って依存関係を可視化したり、イベントストーミングの図をメンテナンスしたりして対応しました。結局、どちらのパターンでも依存関係をどう把握するかがメインの課題になりますね。
福井:おっしゃるとおりだと思います。モノレポと個別のリポジトリ、どちらもメリット・デメリットがあって、チームの形態などによっても変わってきます。
例えば、今だとKiroやAmazon Q Developerといった我々が提供している生成AIツールでも、ルートのワークスペースを複数持てるようにしています。個別のリポジトリを管理する時と、全体を俯瞰して見る時の両方に対応できるようにするなど、ちょっとした工夫をしていますね。
成瀬:確かに、そういったツールで開く時も、単体のリポジトリだけ開く時と、全体を開く時とでパターンを使い分けています。依存関係を確認したい時は全体で開くし、特定の機能に集中したい時はそこだけ開いて狭い範囲で作業する方が効率的です。改めて聞かれると、いろいろ工夫しているんですね(笑)。
しょぼちむ:業務の中で自然とやっているということですよね。生成AIを使うとなると、共有されたモデルもちゃんと情報として得たほうが開発自体はしやすいから、生成AIが見える範囲の中に一箇所でいろんな情報がまとまっていたほうがいいということですね。
福井:おっしゃるとおりです。自然言語のほうがトークンを節約できるので、情報をMarkdownファイルで保存しておくということをよくやります。「この情報はここにあるよ」というインデックス的な情報もそうですし、モデル自体の情報も自然言語でドキュメントに書いておきます。加えて、Mermaid形式でクラス図を置いておくといったこともよくやりますね。
成瀬:あとコドモンで観測した事例ですが、メンバーがMCPサーバーを立てて、ローカルの検索を高速化し、依存関係をすぐに確認できるようにしています。
しょぼちむ:いいですね。共有モデルのコードの場所をMCPサーバー経由で参照できるようにしておくんですね。
成瀬:最近、MCPサーバーの活用にはまっているんですよ。
しょぼちむ:モノレポにするとしても、構造をしっかり定義して「ここにはこれがある」という形で整理整頓しながらリポジトリを育てていくことが大事ですよね。
境界の分割後、何から着手するか
しょぼちむ:境界線をちゃんと分割して、このサービスはこういうサービス単位で作っていこうという全体の地図が見えたとします。その後、「じゃあ何から着手しようか」というところも迷われるポイントだと思います。何を基準に作り始めるサービスを選んでいますか。他のサービスとの連携数なのか、サブドメインの種類からなのか、新規サービスの場合と既存システムを切り出している場合は違うのか。成瀬さんからお聞きしてもいいですか。
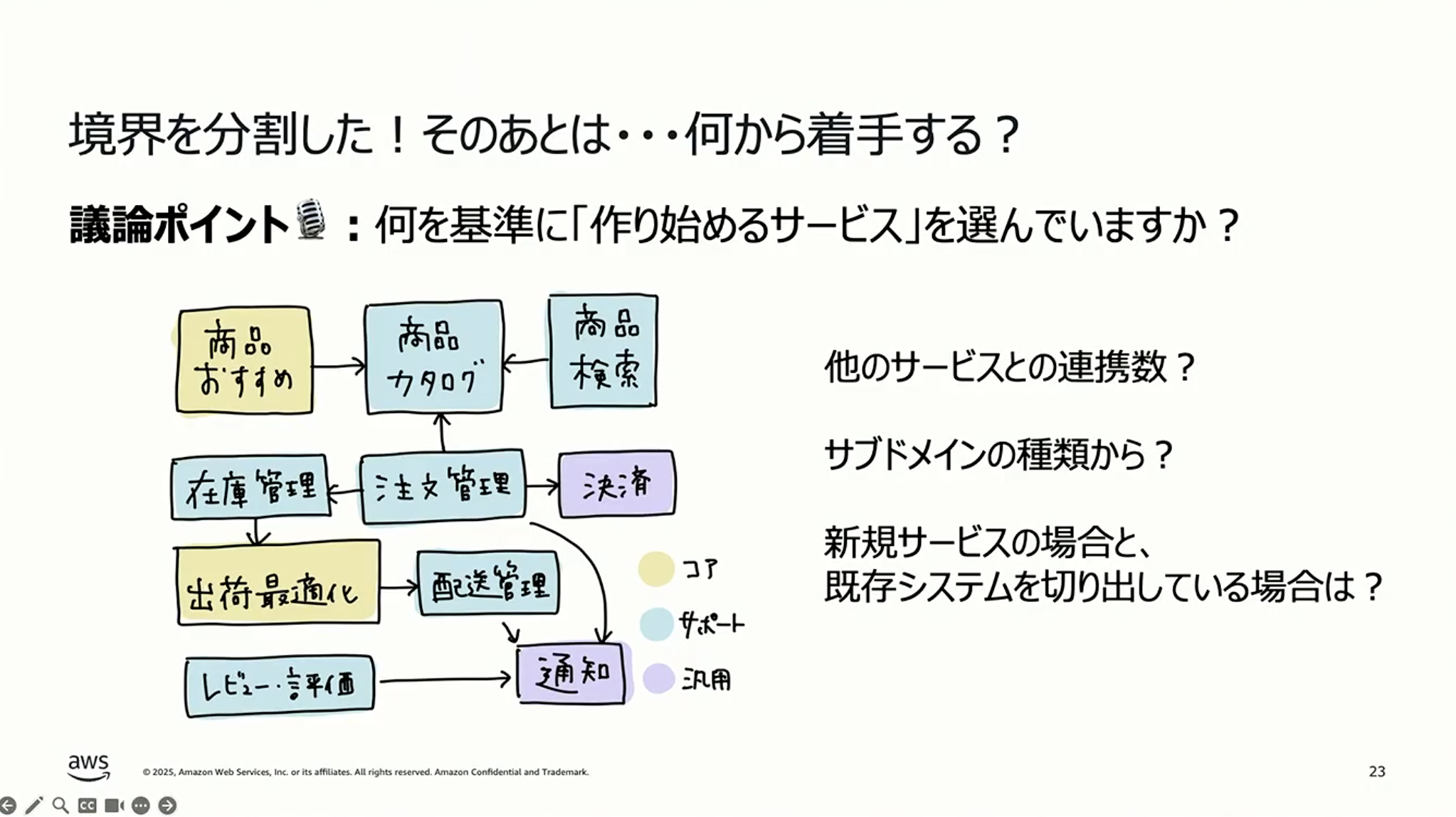
成瀬:どちらにしろ、コアドメインから着手したほうがいいと思っています。コアドメインとは、ビジネス上で自分たちの本業に関わる、差別化できる領域のことです。ここが理論どおりにやってみてうまくいかなかったら、他を作っても意味がないというのが、ビジネス上の観点です。
なので、まずコアドメインから始めて、実証実験ベースで検証していきます。そこがうまくいったら、次にサポートサブドメインに手をかけていって、汎用サブドメインはなるべくアダプターを作って外部サービスに任せるというパターンが多いですね。
福井:まさしくそのとおりだと思います。『ドメイン駆動設計をはじめよう』の中でも、コアドメインにDDDを適用するのはよいが、それ以外はサードパーティーの製品やパッケージでもいいんじゃないかと書かれていました。やはり、ビジネスの価値を生むコアドメインからまず始めるのが基本です。
新規と既存でやり方は違うと思いますが、全くの新規の場合は、我々はよく「一番難しいものから始めよう」と言っています。難しいものをクリアできれば、その後はどんどん簡単になりますし、やり方も理解できて、複雑性も解消できるからです。
一方、既存のシステムに対してストラングラーパターンで進める場合は、依存関係が最も少ないサービスから切り出していくことをお勧めしています。
成瀬:ちなみに私が既存のシステムに取り組む時は、コアドメインの中で一番依存関係が薄いものから始めます。具体的に言うと、システムの処理フローを考えた時に、一番後ろから着手するんです。後ろが一番依存関係が少ないからです。
後ろがうまくいかない場合は、次は一番前から着手します。前も依存関係は比較的少ないですが、真ん中が一番つらい。どうしても真ん中に手を付けなければならない場合は、まずその機能を後ろにずらす努力をして、それから分離していきます。これは『モノリスからマイクロサービスへ』という本に書いてあるやり方です。
なぜこういうことを意識するかというと、結局我々はビジネスをやっているので、バリューを出さないと「これは何の意味があるの。」と言われてしまうんですよね。例えば配送管理をマイクロサービス化しましたと言っても、「それで何が良くなったの。」と聞かれます。それに答えられるようにするためにも、やはりコアドメインから着手したいという気持ちがあります。
しょぼちむ:チームメンバーがまだドメイン駆動設計に慣れていない状態でスタートすることもあると思います。知見が少ないメンバーだと、気持ちの面で「簡単そうなところから始めたい」となりがちですが、そういう気持ちに惑わされることはないですか。私は惑わされてしまうかもしれません(笑)。
成瀬:実際そうなると思いますよ。実証実験レベルのものをしたいのであれば、サポートサブドメインで1回やるのはありです。ただ、本腰を入れるのはコアドメインだと、私はいつも主張しています。
しょぼちむ:いいですね。簡単なものだからすぐできるだろうと、いざ作り始めると結構長い期間かかってしまうということもあるので、PoCレベルでサクッとやってみるのはいいけれど、長期で考えたら、ちゃんとコアから取り組んでいきましょうということですね。そのタイミングで覚悟を決めなきゃなと思います。
成瀬:あとはEric Evansさんの本にも書いてありますが、コアドメインには優秀な人を当てろとよく言われています。「できる人がいない時はどうするんだ」と言われると難しいところですが、そういう時は福井さんを呼んでいただければ、きっとアドバイスしてくれると思います(笑)。
生成AIを活用した開発:AI-DLC
しょぼちむ:作るものが決まり、作る順序も決まったところで、次は実際の開発です。今の時代、生成AIの活用は切っても切れないものになっていますし、我々もお客様の支援の中で生成AIを積極的に活用しています。より効率的に良いものを開発していくにはどうすればよいのでしょうか。AWSでのさまざまなプラクティスを福井さんからご紹介いただけますか。
福井:今、AWSでは「AI-DLC(AI駆動開発ライフサイクル)」というものを推進しています。ポイントは、コーディングだけにAIを使うのではなく、要件定義から設計、実装、運用までの開発ライフサイクル全体でAIを活用しようという考え方です。従来の改善は少しずつ効率を上げていくステップアップ型でしたが、AI-DLCでは開発プロセス自体を根本から変えるパラダイムリープを目指しています。
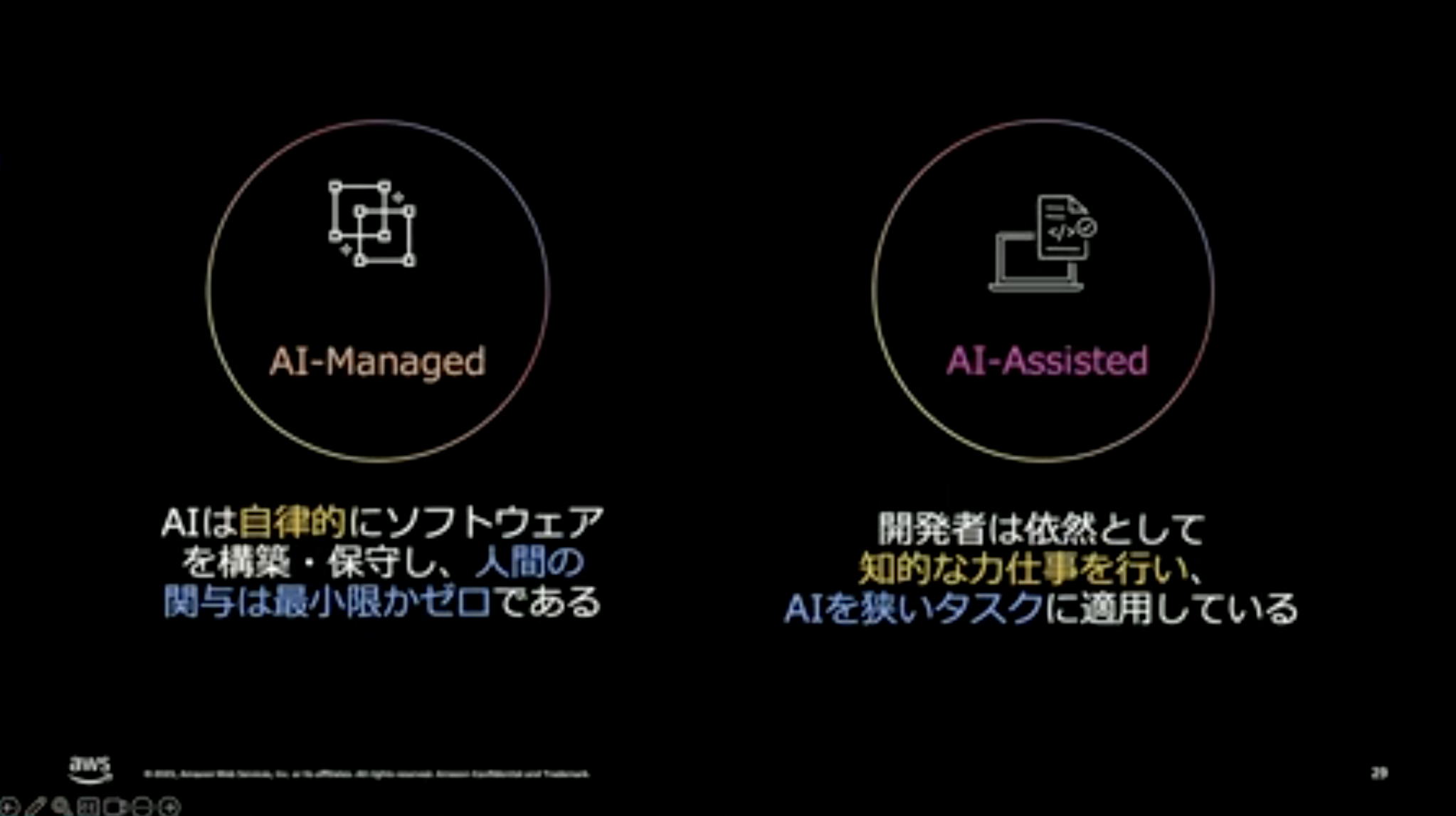
福井:現状、開発にAIを取り入れる際には、大体2つのアプローチが使われていますが、どちらにも課題があります。
1つ目は、いわゆるバイブコーディングです。AIにリクエストを投げて「あとはよろしく」というやり方ですね。簡単なテトリスのようなものなら作れますが、複雑なビジネスアプリケーションをこのやり方でうまく作れることはまずありません。
2つ目は、AIアシステッドな開発です。要件定義・設計・プランニングはすべてベテランのデベロッパーが行い、AIはコード生成の一部にだけ使うというやり方です。これはうまくいくのですが、AIの可能性を十分に引き出せているとは言えません。
ではどうすればうまくいくのか。我々が提案しているのがAI-DLC(AI Driven Development Lifecycle)です。ソフトウェア開発のライフサイクル全体にわたってAIの可能性を引き出しつつ、各フェーズで人間が意思決定をしていくというアプローチです。
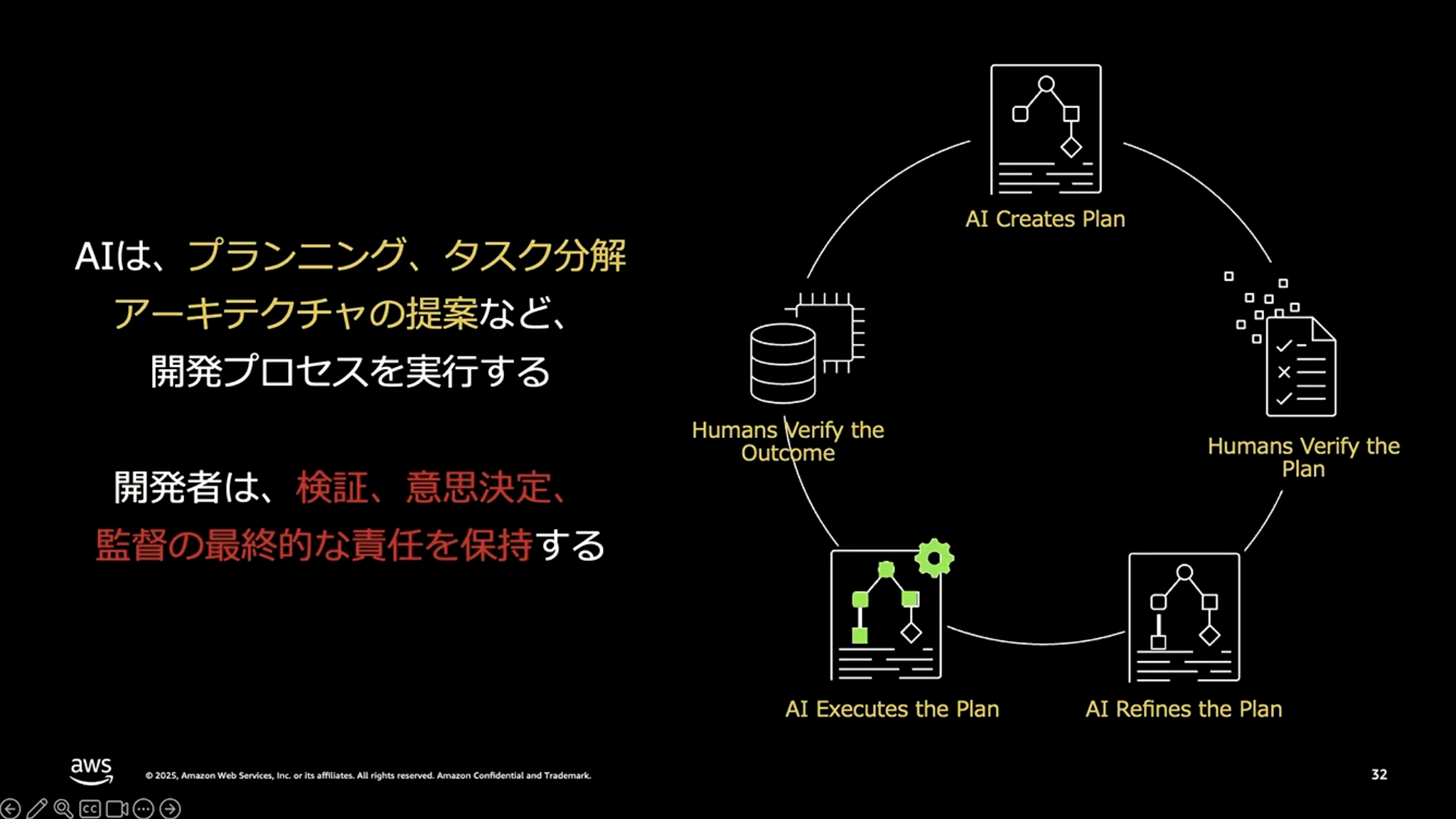
福井:具体的には、プランニングやタスクの分解、アーキテクチャの提案自体はAIが生成します。ただし、それをそのまま使うのではなく、各フェーズで人間がレビューし、方向修正をして意思決定をしていきます。
ポイントは、このサイクルをぐるぐる繰り返すことです。AIがプランを生成し、人間がレビューして補正を行い、AIがその補正を反映したものを再生成する。それでOKであれば、その計画に従って実際の成果物を生成させ、さらにそれもレビューする。このサイクルを回すことで、要件定義から実装・オペレーションまでを一気通貫で進めていきます。
これを実際にさまざまなお客様と一緒にやらせていただいて、かなりの効果を得ているというのが現状です。
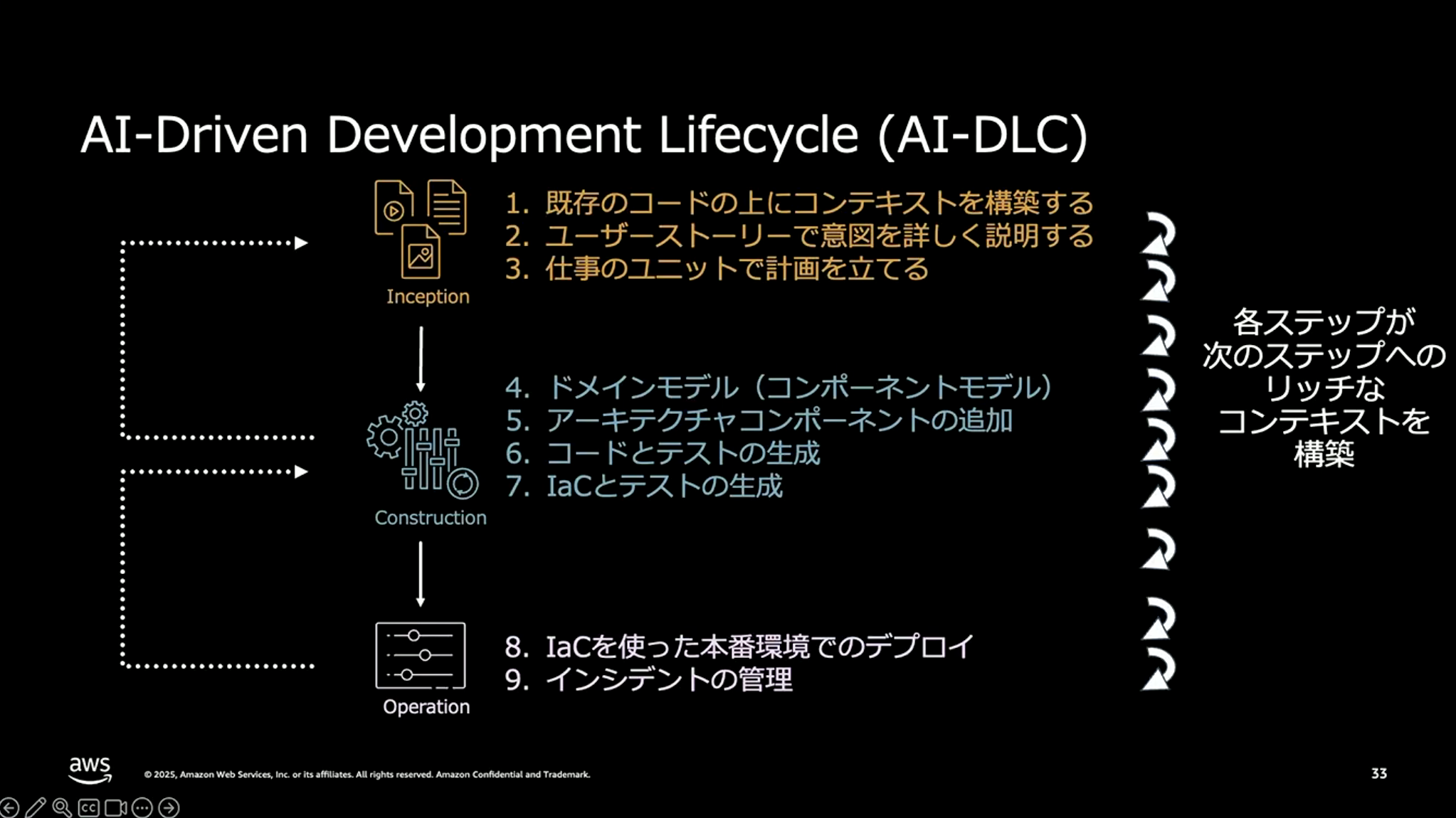
このやり方は大きく3つのフェーズに分かれています。
1つ目はインセプションフェーズです。既存のコードを読み取ったり、ユーザーストーリーやペルソナを作成したりする作業をAIにやらせて、要件が正しくストーリーとして定義できているかをレビューしていきます。レビュー結果がOKであれば、生成されたユーザーストーリーに対してユニット計画を立てるところまでがこのフェーズです。
2つ目はコンストラクションフェーズです。インセプションで分割したユニットに対して、それぞれ開発チームを割り当てて並列で開発します。ドメインモデルの生成、アーキテクチャコンポーネントの追加、コードとテストの生成、さらにIaCを生成して実際にインフラをデプロイし、CI/CDパイプラインでデプロイするところまでAIに生成させます。
3つ目はオペレーションフェーズです。IaCを使った環境でデプロイを行い、インシデント管理のためのアラート定義などを行います。
これらすべてのフェーズで、AIと人間が協働しながら進めていきます。
福井:インセプションフェーズの特徴について補足すると、「Mob Elaboration(モブエラボレーション)」というやり方を取っています。ビジネスサイドの方と開発者が1つの部屋に集まって、モブで要件定義を進めていく形です。従来のように、ビジネス側が要件ドキュメントを書き上げるのを待って、それを開発者が理解して、さらにディスカッションを行って、という流れだと1〜2か月かかることもあります。Mob Elaborationであれば、だいたい4〜8時間で完了します。全員が仕様を理解した状態でユニットを分割し、各ユニットに2〜3名ずつ割り当てる。そこからだいたい2〜3日でデプロイまで持っていくという流れですね。
従来のスクラムで2週間のスプリントだったものが、AI-DLCではだいたい3〜5日でリリースするというスピード感で回しているのが現状です。
ただ、肝心なのはレビューの部分です。ここが非常に負荷の高いところで、ビジネスをよく理解している人と、コード設計をよく理解している人が必要になります。レビューの質が成果物の品質に直結するので、そういう人材をどう育成するかは今後の課題ですね。
成瀬:インセプションあたりの話は僕もやったことがなかったので、今度教えてください。
まとめ
しょぼちむ:今日はサブドメイン、境界づけられたコンテキスト、集約、マイクロサービス、それぞれの概念についてディスカッションさせていただきました。最後に、生成AIも絡めながらどう開発していくかのお話もご紹介させていただきました。
ディスカッションは以上とさせていただきます。成瀬さん、福井さん、ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





