



「もし、○○な仕様のサービスを立ち上げるなら、あなたはどんなアーキテクチャを組みますか?」著名企業のエンジニアに聞いた
システムのアーキテクチャを設計する際には、単に技術的な知識だけがあればよいわけではありません。企業の事業戦略や開発組織の規模、サービスのビジネス特性など、さまざまな制約や要件を考慮する必要があります。最適なアーキテクチャを構築することは、一筋縄ではいかないのです。
では、優れたスキルを持つエンジニアは、具体的に何を念頭に置いてアーキテクチャを構築するのでしょうか。今回は、架空のWebアプリの仕様をテーマとして掲げ「もし、そのアプリを立ち上げるならば、どのようなアーキテクチャを提案するのか」を、著名IT企業のアーキテクトの方々に伺いました。いうなれば、お題に沿ってアーキテクチャを回答する"アーキテクチャ大喜利"のような企画です。
今回ご協力いただいたのは、Sansan株式会社 技術本部 研究開発部 Data Directionグループ データエンジニアの中村崚さん・矢田結一郎さんと株式会社カケハシ 技術戦略室 チーフアーキテクトの木村彰宏さん。エンジニアのみなさんが何を考慮してどのようなアプローチを取るのかを、ぜひご覧ください。
架空のシステムのお題
「急成長中のBtoC ECサイト運営企業に、データ分析基盤をゼロから構築するなら」
あなたは、月間アクティブユーザー数10万人を突破した急成長中のECサイト運営企業に参画し、データ分析基盤の構築を担当することになりました。
これまでは非エンジニアがGoogle Analytics 4やスプレッドシートを駆使して手動で分析していましたが、事業の成長に伴い、以下のような課題が顕在化しています。
- 手動でのKPIレポーティングに、担当者が週10時間以上費やしており、意思決定のスピードが鈍化している。
- 広告費が増大しているが、LTVベースでの効果測定ができず、広告予算の最適な配分ができていない。
- ユーザーの行動履歴に基づいたパーソナライズ施策(レコメンドなど)を打ちたいが、そのためのデータが整備されていない。
これらの課題を解決し、マーケティングやプロダクト改善を加速させるため、データを蓄積・可視化する分析基盤を設計してください。
■制約条件・前提
- データソースは複数あります
- Webサイトのユーザー行動データ(Google Analytics 4などから出力されるイベントログ)
- Amazon RDSに格納されている業務データ(注文・顧客・商品など)
- 一部の外部SaaSから定期的にCSVなどでダウンロードされるデータ(広告レポート、CSツールのチケット情報など)
- データ基盤はまだ整備されていない状態です
- すでに稼働しているアプリケーション群はありますが、分析基盤に関してはゼロベースで構築する必要があります
- 社内のデータ活用ユースケースが複数パターンあります
- 経営層は週次でKPI(売上、UU、CPA、LTVなど)を自動で更新されるダッシュボードで見たいと考えています
- マーケチームは、広告のROASを最大化するため、LTVやキャンペーンの効果測定をしたいと考えています
- プロダクトチームは、ユーザー行動分析やABテスト結果の集計を高速化し、パーソナライズ施策に繋げたいと考えています
- 開発チームの構成
- 分析基盤の整備に当たるチームは、あなたを含めて3名程度
- あなた以外のメンバーはアプリケーション開発経験は豊富ですが、データパイプラインの構築や分散処理基盤の運用経験はありません
- リソース制約
- 人数的にもインフラ運用コスト的にも、あまりにも複雑な構成は維持できません
- 将来的な拡張性(データ量やデータ活用の高度化)はある程度見据えておく必要があります
- クラウド環境
- 現在、アプリケーションはAWSで稼働中です
- フルマネージドサービスは積極的に使って構いません(Amazon Redshift、AWS Glue、Amazon Athenaなど)
- フェーズ感
- 今は「スモールスタート」で良く、最初の3ヶ月で経営層向けのKPIダッシュボードをリリースすることが目標です
- 1年以内には数TB規模のデータ、10人以上の分析ユーザー(主に経営層やマーケチーム、プロダクトチーム)が想定されます
Sansan株式会社 技術本部 研究開発部 Data Directionグループ データエンジニア 中村崚さん・矢田結一郎さん
はじめに
データ基盤では、優先度をつけることが重要と考えています。そこで、以下の点を重視しました。
- 少数メンバーで開発やメンテナンス可能
- 経営層へ認められるまではコストセンターであるため、なるべく低コストでクイックにアウトプットができる
- ビジネス意思決定に必要なデータソースを網羅している
主要なシステム説明
アーキテクチャ概略図
本アーキテクチャの概略図となります。各項目については次に取り上げていきます。
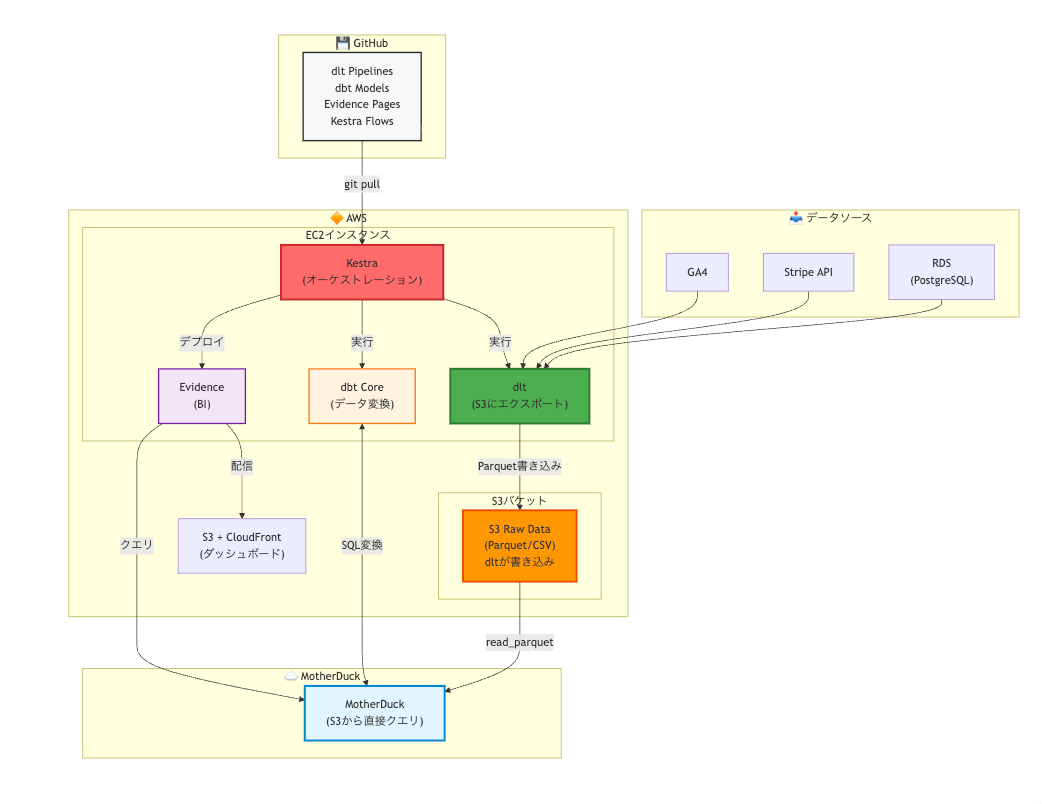
図1:アーキテクチャ概略図
それぞれのコンポーネント選定理由
データウェアハウス(MotherDuck)
DWH製品としては、AWS上であれば、Amazon RedshiftやSnowflakeが有力な候補となりました。
今回MotherDuckを採用した理由としては、小規模なデータセットから始める場合に、コストパフォーマンスが良く、複雑なウェアハウスやリソース管理が不要である点が魅力的だったためです。
今後、事業拡大した場合に大規模バッチ処理、リアルタイム処理が必要になった場合には別のDWHに移行する可能性もありますが、LakeとしてAmazon S3にデータを保存しておき、DWHを切り替えやすい構成にしています。
アナリティクス観点では、Notebook機能も備えており、分析ユーザーやBI開発者がSQLを直接実行・共有できる点も魅力でした(あと、ロゴがかわいいのもポイント高いです)。
執筆をしている2025年12月時点のプランでは、無料・クレジットカード登録不要で、最大5人まで利用できるため、今回は3人のデータチームメンバーで利用要件を満たし初期コストを抑えられる点も魅力です。
また、今後組織が拡大した場合でも、ビジネスプランで組織メンバー無制限で利用できるため、スケールしやすい点も良いと思います。
データローダー(dlt)
多くのデータコネクタを備えていて、今回の要件であるBtoC ECのビジネスで利用が発生しそうな、StripeやGoogle Analytics、各種RDBもあります。
また、現在もメンテされている数少ないPython製のOSS製品であることからdltを採用しました。Amazon S3へのエクスポートもサポートされているため、MotherDuckと組み合わせやすい点もポイントです。
ワークフロー(Kestra)
比較対象としては、AWSであればAmazon MWAAやAWS Step Functionsがあると思いますが、今回はアーキテクチャ大喜利企画ということもあり、あまりメジャーでないものを選んでみました。
UIが洗練されており、ワークフローがYAMLでシンプルに記述でき、GUIから作成したワークフローをExportすることもできる点も良いと思います。
ワークフロー設計においては初期段階でリアルタイム性を要件とすることは控え、冪等性を持ったバッチ処理を定期的に回し、運用するコストを下げる方針を取ろうと考えています。データ品質の監視やアラートについては、KestraからSlack通知などを行うような構成が良いと思います。
想定としてはAmazon EC2かAmazon EKSに構築することを考えていますが、現在pre-GAのフルマネージドのKestra Cloudもあるため、後述するPoCの手応えと価格次第では導入を検討しても良いかもしれません。
データ変換(dbt Core)
これはあまり議論の余地はないと思います。エコシステムとして成熟しつつあり、導入事例も多いことからdbt Coreを採用しました。
現状、ETLツールの現実的な選択肢として、Dataformやdbt、SQLMeshなどがあります。
今回は、データ処理量に応じてDWHを変更することも見据えベンダーロックインを避ける観点でDataformを採用できませんでした。
海外ではdbtと競合するほどSQLMeshの利用も広がっていると聞きますが、日本語の情報が少なく、コミュニティもまだ小さいため、今回はdbtを選定しました。
BI(Evidence)
BI as Codeのツールとして有名なEvidenceを採用しました。
最大の特徴は、ダッシュボードやレポート全体をGitで管理できる点です。バージョン管理、コードレビュー、変更履歴の追跡が可能になり、データアナリストは信頼性の高いレポートを提供できます。
MarkdownファイルにSQLクエリとビジュアライゼーション設定を直接記述できるため、データ分析とドキュメンテーションが一体化します。
特に全てテキストでBIが作成されるためClaude Codeなどの生成AIによるBI作成をGUIの操作なく迅速に行える点が魅力的です。将来的には問い合わせからBIレポートの自動生成までを自動化することも検討できます。
アーキテクチャの外の要素
提供までの戦略
今回本番稼働を見据えたアーキテクチャを設計しましたが、3ヶ月で本番提供するより前に短期的なPoCとして、ローカルでも開発・動作検証が可能なOSSを選定しています。
また、このアーキテクチャを全て作りきる必要もなく、ダッシュボードを提供することが可能であることもこの構成のメリットです。具体的には、Amazon S3にサンプルデータを保存し、dbtでモデリングを行い、Evidenceで可視化することが可能です。また、MotherDuckをローカルのDuckDBで代用するなどでも対応可能です。
そのため、小規模のサンプルデータを元に、ローカルでのモデリングとBIによる可視化を行い、開発着手2週間以内を目安に、経営層やステークホルダーに対して、デモを行い、フィードバックを得ることを想定しています。
この時点でのフィードバックを元に、必要に応じてデータモデリングや指標、アーキテクチャの見直しや追加要件の検討を行い、本番環境への展開を進めていくのが望ましいと考えています。
リポジトリ構成
今回のアーキテクチャはmonorepoで管理することを想定しています(Kestra、Terraform、dlt、dbt、Evidenceなど)
これにより、
- 生成AIにより、一貫した開発フローの自動化が行いやすい
- 上流データソースの変更時に、Kestraのワークフローやdbtモデル、Evidenceのレポートのコード修正を一括で行えるなど
- メタデータの一元管理やBIツールへのメタデータ連携が行いやすい
などのメリットがあります。
運用フェーズでのリスクマネジメント
データ基盤というものは利用してもらい続ける必要があります。
今回のようなBtoC EC事業の場合では、運用していく中で考えられる課題として、
- データソースの仕様が不明で、データエンジニアのモデリング工数が増大してしまう
- 経営指標が頻繁に変わり、データモデルの変更が追いつかない
- データアナリストがクエリを実行した際に、パフォーマンスに問題が発生し、分析が滞る
などがあげられます。
こういったリスクについては、事前に死亡前死因分析を行い、リスクマネジメントを行うことも重要であると考えています。
おわりに
本記事では、MotherDuck、Kestra、dlt、Evidenceを組み合わせたモダンデータスタックの構成案を紹介しました。
より詳細な検討項目は多くありますが、Findy Toolsのアーキテクチャ大喜利企画という趣旨を踏まえ、シンプルな構成と各プロダクトの選定理由に焦点を当てています。
株式会社カケハシ 技術戦略室 チーフアーキテクト 木村彰宏さん
1. 概要
最初の3ヶ月間で「経営層向けKPIダッシュボード(売上、UU、CPA、LTVなど)」を週次で自動更新できる仕組みを構築することを短期ゴールとしています。最小限の構成で価値提供を優先しつつも、データ活用ニーズや組織体制の変化・新たなユースケース発生に耐えうる「設計方針」(レイヤ分離、データ契約、メタデータ管理など)を明らかにします。
2. 短期(最初の3ヶ月)のアーキテクチャ
2.1 前提
- 経営層向けKPIの週次可視化が目的で、深い探索分析や複雑なユースケース横断は短期では要求されません。
- 必要なデータソースは少なく、GA4からUU、CPA、LTVなどのデータを取得し、Amazon RDSから注文・商品などの業務データを取得する程度で実現可能です。
2.2 設計方針
2.2.1 「KPIダッシュボードを確実に出す」ための最小構成を作る
3ヶ月で価値を出すため、コンポーネント数を抑え、プレゼンテーションの要求を満たすための最小限の構成を作ります。
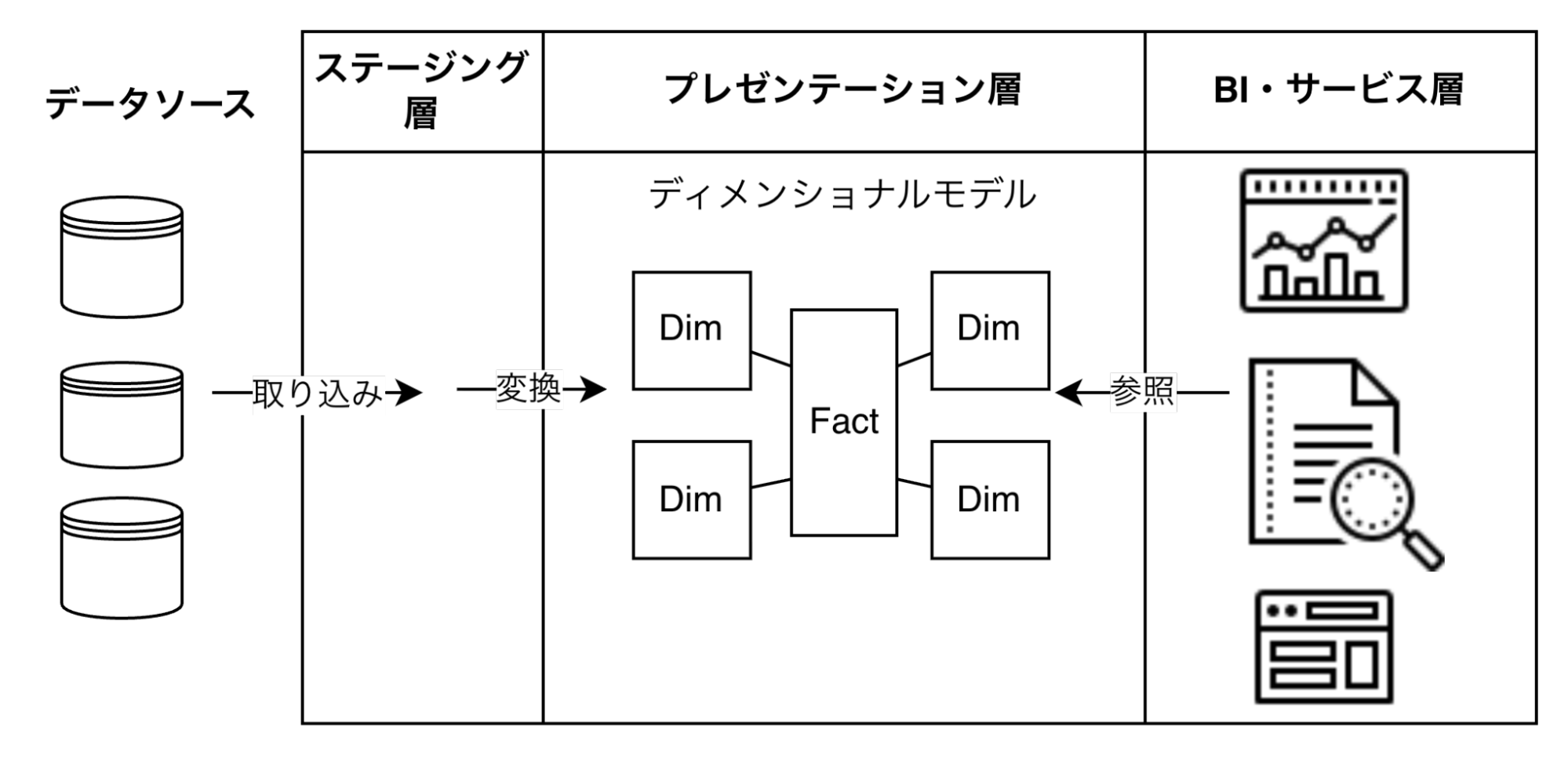
図2: Kimball Technical DW/BI System Architecture
- 取り込み (Ingestion): サーバレスサービスを利用してデータを取り込みます。
- 変換 (Transform): DWH内で変換処理を行います。
- 保存 (Save): Open Table Format (ex. Apache Iceberg、Delta Lake) での保存を検討します。
- 提供 (Serving): DWHとの連携が容易なBIツールでダッシュボードを作成します。
2.2.2 最小限のレイヤー分離をし、データの再利用性を高める
データソースから取り込んだデータをそのままプレゼンテーション層に提供するのではなく、ステージング層を仲介します。ステージング層のデータから変換し、プレゼンテーション層に提供します。必要最小限ですが、しっかりレイヤーを設けることで、各レイヤーにおけるデータの責任範囲が明確になり、関心の分離が行いやすい構成になります。
また、チームのスキル状況を鑑みて、プレゼンテーション層への書き込み時にはOpen Table Formatとして保存することで、プラットフォーム依存性を低くすることを検討します。
Open Table Formatとは、Apache Iceberg、Delta Lake、Apache Hudiなどに代表されるオープンソースのテーブルフォーマットの総称です。データレイク上のファイルをデータベースのテーブルとして扱うことを可能にし、ACIDトランザクション、スキーマ進化、タイムトラベル(履歴管理)などの機能を提供します。特定のベンダーやクエリエンジンに依存せず、複数のプラットフォームから同一データにアクセスできるため、データのポータビリティを確保できます。
2.3 構成図

図3: 短期インフラ構成図
2.3.1 データ取り込み (Ingestion)
GA4 → BigQuery
GA4のデータはBigQuery Exportを使います。GA4管理画面で設定するだけで日次でBigQueryへ同期でき、短期の“確実性”と“運用の少なさ”が両立します。ここは中期以降も高い確度で再利用されるコンポーネントです。
BigQuery以外に、GA4のコネクタを備えているDWHはありますが、大抵は一次取り込み先としてBigQueryにデータを流した後に、DWHにデータを取り込み(EL)することになります。
Amazon RDS → BigQuery
短期ゴールが週次KPIであるため、まずは日次バッチで十分です。RDSの取り込みは選択肢が複数あるため、短期は「実装スピード」「事故りにくさ」を優先します。
- 推奨(短期): スナップショット同期方式
- 手法: RDSスナップショットエクスポート → Amazon S3 → BigQuery Data Transfer Service
- 参考: Amazon RDSエクスポート、BigQuery Data Transfer Service
- 使い所: 更新頻度が低く、日次で十分な分析業務。
- 留意: スナップショットエクスポートの制約 (DBエンジン/設定) と、フルロード寄りである点は事前に確認すること。
- 次の一手: リアルタイム同期方式
- 手法: Datastream (CDC) → BigQueryへのリアルタイム同期。
- 目的: 差分取り込みによりデータ鮮度を上げ、データ量が増えてもワークロードを安定させること。
- 参考: CDC 用に Amazon RDS MySQL データベースを構成する
なお、BigQuery Omniを利用すれば、Amazon S3にエクスポートしたデータをBigQueryから直接クエリできますが、執筆時点では、日本国内リージョンでは利用できないため、マルチクラウド間でのデータの転送が必要になると想定します。
2.3.2 データ変換 (Transform)
BigQuery上でELT処理を行うことで、変換 (Transform) 用のコンポーネントを別途追加しない構成にします。
2.3.3 データ保存 (Save)
BigQueryでは
BigLake
を利用することで、Open Table Formatでのデータ保存が可能です。具体的には、
BigLake tables for Apache Iceberg
を使用することで、Apache Icebergフォーマットでテーブルを作成・管理できます。
この構成により、短期ではBigQueryの利便性を享受しつつ、中期以降に他のプラットフォームへの移行や並行利用が必要になった場合でも、データのポータビリティを確保できます。
2.3.4 データ提供 (Serving)
BigQueryはLooker Studioとの連携が容易で、即座にダッシュボードを作成できます。
3. 中期(1年後)のアーキテクチャ
短期の構成では、ユースケース増と変更頻度の上昇に対して次の理由で破綻しやすくなります。
- KPI/ユースケースが増えると、変換 (ETL/ELT) が肥大化し、変更影響が読めなくなる。
- ソーススキーマ変更が下流 (プレゼンテーション層/BI) に波及し、壊れやすくなる。
- 権限・監査・データリネージュが必要になり、属人運用が限界を迎える。
そこで中期は、ユースケース横断で再利用できる標準化データ (中間層) と データ契約 を導入し、変更容易性とガバナンスを向上させます。
3.1 設計方針
3.1.1 変更容易性のための中間層 (例: Data Vault) を導入する
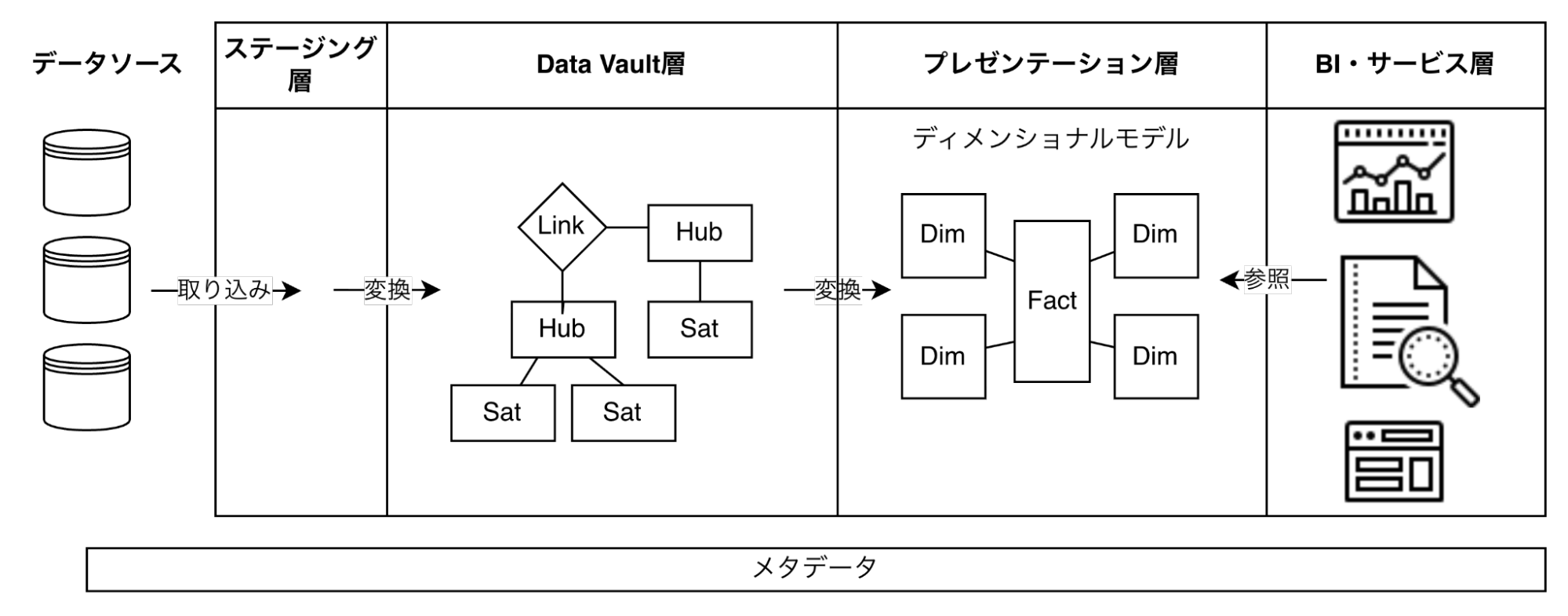
図4: Data Vaultを利用した中間層の設計
Data Vault(2.0)は、ステージング層とプレゼンテーション層の間に「履歴を保ちつつ統合しやすいモデル」を置くことで、ソース追加や変更に強い中間層を作る考え方です。
- 期待効果
- データソースの追加/変更時の影響を中間層で吸収しやすくなる。
- 複数のユースケースでデータを再利用しやすくなる。
3.1.2 データ契約 (Data Contract) で組織をスケールさせる
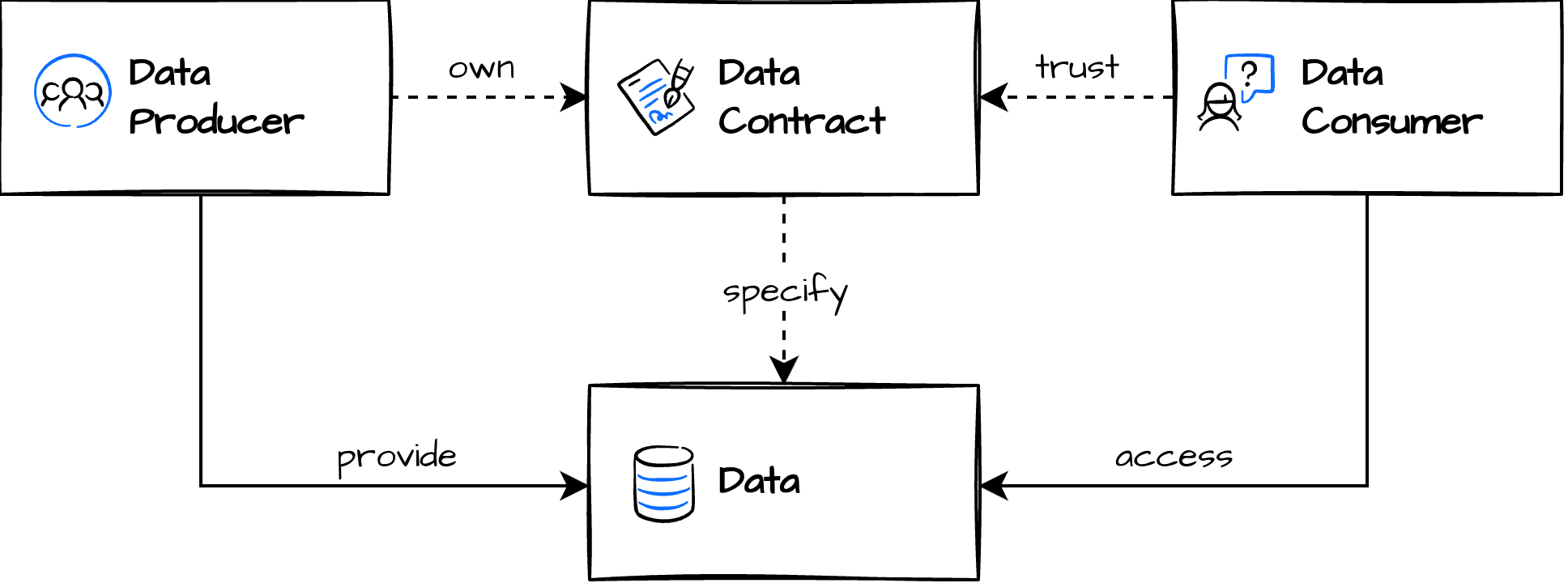
図5: データ契約
出典:Data Contract,https://datacontract.com
分析者が増えると「欲しいデータを都度作る」方式は破綻します。中期は、提供するデータ (Data Vault層/プレゼンテーション層) に対して契約を設け、責任境界を明確にします。
データ契約は単なる仕様書ではなく、チームの分割単位にもなります。契約ごとにオーナーシップを持つチームが明確になるため、組織がスケールしてもデータの提供責任と利用責任の所在が曖昧にならず、自律的なデータ運用が可能になります。
データ契約に含める内容は、Open Data Contract Standard
に基づいて定義します。以下はv3.1.0の項目です。
- Fundamentals(基本事項)
- Schema(スキーマ)
- References(参照情報)
- Data Quality(データ品質)
- Support & Communication Channels(サポート・連絡手段)
- Pricing(料金)
- Team(チーム)
- Roles(役割)
- Service-Level Agreement(サービスレベル合意/SLA)
- Infrastructures & Servers(インフラ・サーバー)
- Custom & Other Properties(カスタム・その他特性)
3.1.3 メタデータによるガバナンスの強化を図る
利用用途が拡大すると、影響範囲の把握と権限管理がボトルネックになります。中期では以下を段階的に導入します。
- データリネージュ
- 用語集 (指標/ディメンションの定義) とオーナーシップ
- 権限 (データセット/ビュー/行列レベル) と監査ログ
Data LakeやDWH、データマートがそれぞれ異なるツールやサービスで管理されている場合、横断的な検索や依存関係の把握が難しくなります。このため、各システムをつなぐメタデータ基盤やデータカタログ、権限管理の仕組みが必要となり、加えてデータ連携やジョブ管理のためのオーケストレーションにもコストがかかります。
こうした課題を解消するため、中期ではこれらを統合的に扱えるデータプラットフォームの導入を検討します。プラットフォームを一元化することで、データの発見性・ガバナンス・自動化運用が容易になり、分析者の利便性や提供者の運用負荷の削減を図ることができます。
3.1.4 アドホック分析 (仮説検証) の受け皿を分ける
現場では探索的な分析のニーズが必ず発生します。中期では、「本番環境」と「アドホック分析環境」を分離することで、統制とスピードの両立を図ります。
- 本番環境:契約および品質基準を満たしたデータのみを扱う環境
- アドホック分析環境:分析者が自由にクエリやNotebookを使える環境
分析要件が多様化・増加すると、データ供給側のキャパシティを超過したり、タイムリーな対応が難しくなることがあります。その結果、分析者がデータソースやステージング層 (未加工) に直接アクセスし、アドホック分析を行うケースが発生します。これらは本番環境の用途とは異なり、主に仮説検証など一時的・探索的な用途を想定しています。
こうした用途に対応するため、データをETLで移動させることなく、Federated Queryを用いて複数の異なるデータソースを単一クエリで横断できる基盤を構築します。これにより、柔軟かつ迅速なアドホック分析が可能となります。ただし、データソース側の品質やサポートなどの事情によりFederated Queryが困難な場合には、一時的にステージング層へデータをインジェスト(取り込み)して利用してもらう方針とします。この場合も、専用のデータインジェストツールを導入し、工数を最小限に抑えることで運用効率化を図ります。
3.1.5 周辺システム連携 (リアルタイム連携・機械学習基盤への拡張) を図る
ECサイトにおけるパーソナライズ施策としては、サイト内のレコメンド表示や、オーディエンスデータに基づいたマーケティング施策などが考えられます。たとえば「ECサイトの注文履歴データをデータ基盤でリアルタイム分析し、分析結果とユーザーのセッション情報を活用して、個々のユーザーごとに最適な商品をレコメンドする」といった活用シーンも想定されます。そのためには、アプリケーションとデータ基盤(DWH)が相互に、ニアリアルタイムでデータ連携できるストリーミング実行基盤への拡張性が中期における重要なポイントとなります。
さらに、パーソナライズの精度向上や施策の自動化を図るには、ML(機械学習)モデルの開発・運用基盤との連携も視野に入れる必要があります。具体的な中期の拡張ポイントとして、下記が挙げられます。
- CDC (Change Data Capture) やイベントストリーミングによるリアルタイムデータの取り込み(データ鮮度の向上、迅速な施策展開)
- Feature StoreやMLOpsなどMLモデル開発環境との接続(モデル開発・運用の生産性向上、継続的な精度改善)
3.2 選定プロセス
3.1で述べた設計方針は、Modern Data Stackを組み合わせることで実現可能です。しかし、以下の観点から中期の技術選定は慎重に進める必要があります。
まず、Modern Data Stackのサービスを個別に導入する場合、運用やコスト管理の観点で負荷が高くなりやすく、特に少人数のチーム体制では管理が煩雑になりがちです。次に、市場環境においてはSaaSサービスの企業買収や合併、標準化の進展により、プロダクトの選定や将来的な継続性の見極めが一層難しくなっています。
(参考:激動の2025年、Modern Data Stackの最新技術動向)
さらに、中期の実務では要件の変化が頻繁に発生するため、初期の段階から全てを固定するのではなく、PoC(概念実証)やプロトタイピングを通じて、柔軟にデータプラットフォームを選択・評価していくことが現実的です。
3.3 参考:Databricksを採用した場合の構成図
参考情報として、3.1で挙げた設計要件はDatabricksのエコシステムにより包括的に実現可能です。
3.3.1 Databricksのリファレンスアーキテクチャ
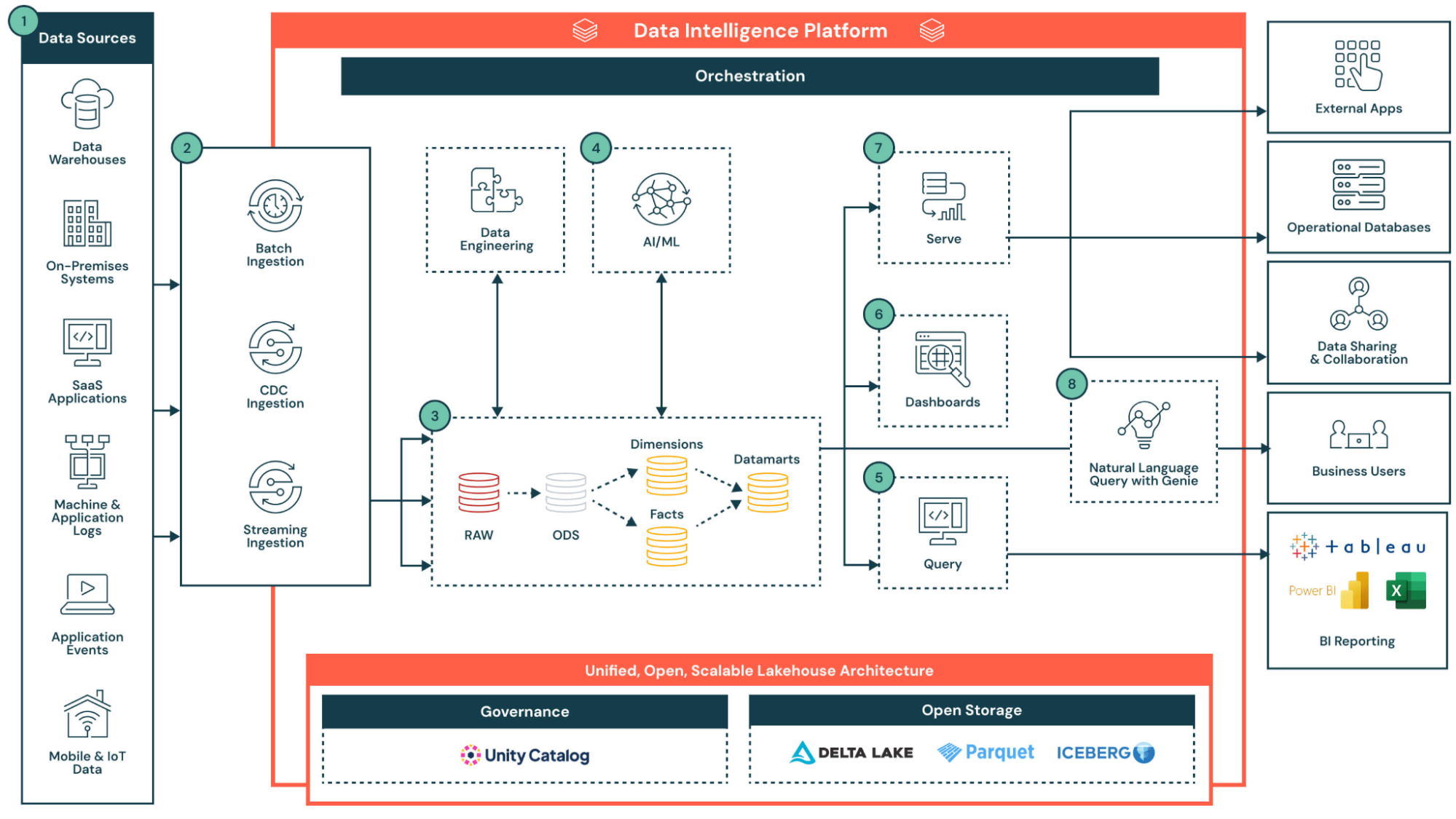
図6: Databricksのリファレンスアーキテクチャ
出典: Intelligent Data Warehousing on Databricks,https://www.databricks.com/resources/architectures/intelligent-data-warehousing-on-databricks
この図はDatabricksを用いた基盤構成の一例を示したものです。詳細な技術仕様やサービス解説は本稿の主旨を逸するため割愛しますが、3.1で挙げた設計原則(レイヤ分離・データ契約・メタデータ管理・アドホック分析・周辺システム連携など)を、Databricksプラットフォーム上でどのように体現・整理できるかをイメージする参考資料として位置づけています。
次のセクションでは、これらの設計要件とDatabricksのアーキテクチャとの具体的な対応関係を簡潔に整理します。
3.3.2 各設計方針との紐づけ
3.1.1 レイヤー分離と責任範囲の明確化 データレイクとDWHの特性を融合したマルチレイヤ構造でデータの品質や責任範囲を段階的に分離します。
このレイヤ設計によって、エンジニアリングチームと分析チームの役割分担も明確化されます。3.1.2 データ契約の導入の容易性
Databricksでは、データ契約(Data Contract)を定義することで各テーブルのスキーマや品質条件を明示的に担保できます。例えばHow to Build a Data Product with Databricks では、テーブルの定義・データ契約・品質テストを一体的に管理する方法が紹介されています。3.1.3 メタデータの一元管理によるガバナンス強化
Unity Catalogにより、データリネージュやガバナンス、権限制御、監査ログの一元管理が実現できます。各レイヤーのデータセットだけでなく、外部データソースに対する外部テーブル (External Table) の管理もカタログ化でき、分析用セマンティックレイヤーの定義 (ViewやModel等) も一元的に管理・分類できます。これにより、データ資産の可観測性・再利用性が高まり、データ管理全体のガバナンスが強化されます。3.1.4 ワークスペースの分離による柔軟性と統合ガバナンスの両立
Databricksでは、本番環境とアドホック分析環境をワークスペース単位で分離することで、各用途に応じたリソース制御や開発サイクルの柔軟性を確保します。これにより、各Workspaceでジョブやパイプライン、ジョブクラスタなどのアクセス制御を独立して設定でき、チーム内で最適な運用ポリシーを実現できます。一方で、3.1.3で述べたようにUnity Catalogを活用することで、分離されたワークスペースを跨いでデータアクセス権限やセキュリティルールを一元管理し、プラットフォーム全体で一貫したガバナンスを実現します。
加えて、Federated Queryにより、異なるクラウド環境のデータソースをデータ移動なしに単一クエリで横断できます。本番・アドホック分析環境いずれでも利用可能で、特にアドホック分析において柔軟性を発揮します。3.1.5 周辺システム・リアルタイム・ML基盤連携
Databricksの心臓部はApache Sparkであり、バッチ処理だけでなくストリーム処理にも強みを持っています。StreamingデータはAuto Loader、Structured Streamingでリアルタイムに処理され、ストリーミング処理特有の複雑性はLakeflow Spark Declarative Pipelines で吸収・簡素化されています。
また、MLflowやFeature Storeを活用することでML/MLOps基盤ともプラットフォーム上でシームレスに連携できます。
企画協力:兼平大資(アソビュー株式会社)、中山貴博(株式会社LayerX)
編集:中薗昴







