



大規模ワークフローを支える AWS Step Functions 活用ノウハウ ― Contract One Entry の事例に学ぶ
本記事は、Sansan株式会社 Contract One Entry チームの小山田征志さんによる寄稿です。AWS Step Functions の運用にフォーカスし、タイムアウト/ハートビート設計、リトライとフォールバック、冪等性・再実行、可観測性といった運用ノウハウを、大規模ワークフローの実例とともに解説します。複雑な業務プロセスを安定して稼働させるための設計・監視・改善の勘所を知りたいエンジニアにとって、実践的な指針となる内容です。
はじめに
「Contract One」は契約書を正確にデータ化し、クラウド上で一元管理できる契約データベースです。契約先名、契約書名、契約締結日・契約終了日といった主要項目を、自動化エンジンと人手による入力補正を組み合わせることで正確にデータ化し、検索性の高い契約書台帳を構築します。これにより、契約業務の効率化やコンプライアンス対応の強化が可能になります。
しかし、契約書は企業や契約形態によって形式が大きく異なります。紙のスキャンデータや電子契約の PDF など、多種多様なフォーマット・画質・構造の文書を扱う必要があります。また、契約情報は法的な裏付けを持つため、誤認識や欠損は許されず、精度と効率性を同時に追求する必要があります。
こうした背景の中、私たち Contract One Entry チームは、契約書をデータ化するための基盤システム「Contract One Entry」を開発・運用しています。このシステムは、複数の自動化処理と人手による入力を組み合わせ、柔軟かつ信頼性の高いワークフローを実現しています。そして、その中核に位置するのが AWS Step Functions です。
AWS Step Functions を採用したのは、単にワークフローを管理するためだけではありません。処理の可視化、並列実行、条件分岐、障害時の自動復旧といった複雑な要件を、安全かつ持続的に満たすための基盤とするためです。本記事では、Contract One Entry の概要と、その中での AWS Step Functions の活用方法についてご紹介します。
Contract One Entry の概要
Contract One Entry は、Contract One に取り込まれた契約書をデータ化する役割を担います。その特性上、以下のような要件が求められます。
- 多様なレイアウトに対応する柔軟な構造認識
契約書は発行元や契約種類によってフォーマットが大きく異なります。項目の位置や表現方法も統一されていないため、固定的なテンプレートでは対応が困難です。システム側で柔軟に構造を解析し、適切にデータを抽出する能力が必要です。 - 自動処理と人手入力のハイブリッド構成
自動化エンジンによる処理は効率的ですが、精度が不十分な場合には人手による入力が不可欠です。この二つをシームレスに組み合わせることで、精度とスループットを両立します。 - 処理進捗の可視化と監視性
大量の契約書が同時並行で処理されるため、現在どの段階にあるのか、どこでエラーや遅延が発生しているのかをリアルタイムに把握する仕組みが求められます。 - 将来的な拡張性
契約書の種類や処理内容は今後も増える可能性があります。ワークフローの変更や機能追加に柔軟に対応できる構成でなければなりません。 - 耐障害性と再実行性
外部サービスやネットワーク障害が発生しても、安全に途中から処理を再開できることが重要です。失敗時の影響範囲を局所化し、確実に復旧できる設計が必要です。
これらの要件をすべて満たすための中核技術として、私たちは AWS Step Functions を採用しました。
データ化フローの各ステップ
Contract One Entry のデータ化フローは、大きく分けて自動化プロセスと人手による入力の二つで構成されています。研究開発部で開発した複数の自動化エンジンが契約書の解析・データ抽出を行い、その後の判断や補完が必要な部分を専門のオペレーターが入力します。
自動化エンジンによる解析
複数のモデルやアルゴリズムを用いて、契約書から項目を抽出します。契約先、契約期間などの情報を構造化データとして取得します。信頼度評価とフィルタリング
抽出したデータには信頼度を表すスコアを付与し、一定基準を下回る項目は人手による入力に回します。これにより、全件入力に回すことはなくなるため、効率的なフローを構築することが可能になります。人手による補完・確定処理
専門オペレーターが入力画面を通じて契約情報を入力します。
入力に不備があった場合には、AWS Step Functions がその判定を受けて再度入力ステップに戻す制御を行います。これにより:- 自動化で足りない部分を人手で確実に補う
- 不備があれば再度入力に戻す
- 問題なければ次に進む
というループをワークフローの中で自然に実現しています。
こうした制御を AWS Step Functions に組み込むことで、オペレーターは迷わず入力作業に集中でき、システム全体としてもデータ品質を高く維持することが可能になります。
この一連のプロセスを統合的に制御し、状態遷移やエラー時のリカバリを担っているのが AWS Step Functions です。
アーキテクチャ全体像
Contract One Entry は AWS 上に構築されており、AWS Step Functions を中心に複数のサービスを連携させて柔軟な処理を実現しています。全体の構成は以下のようになっています。
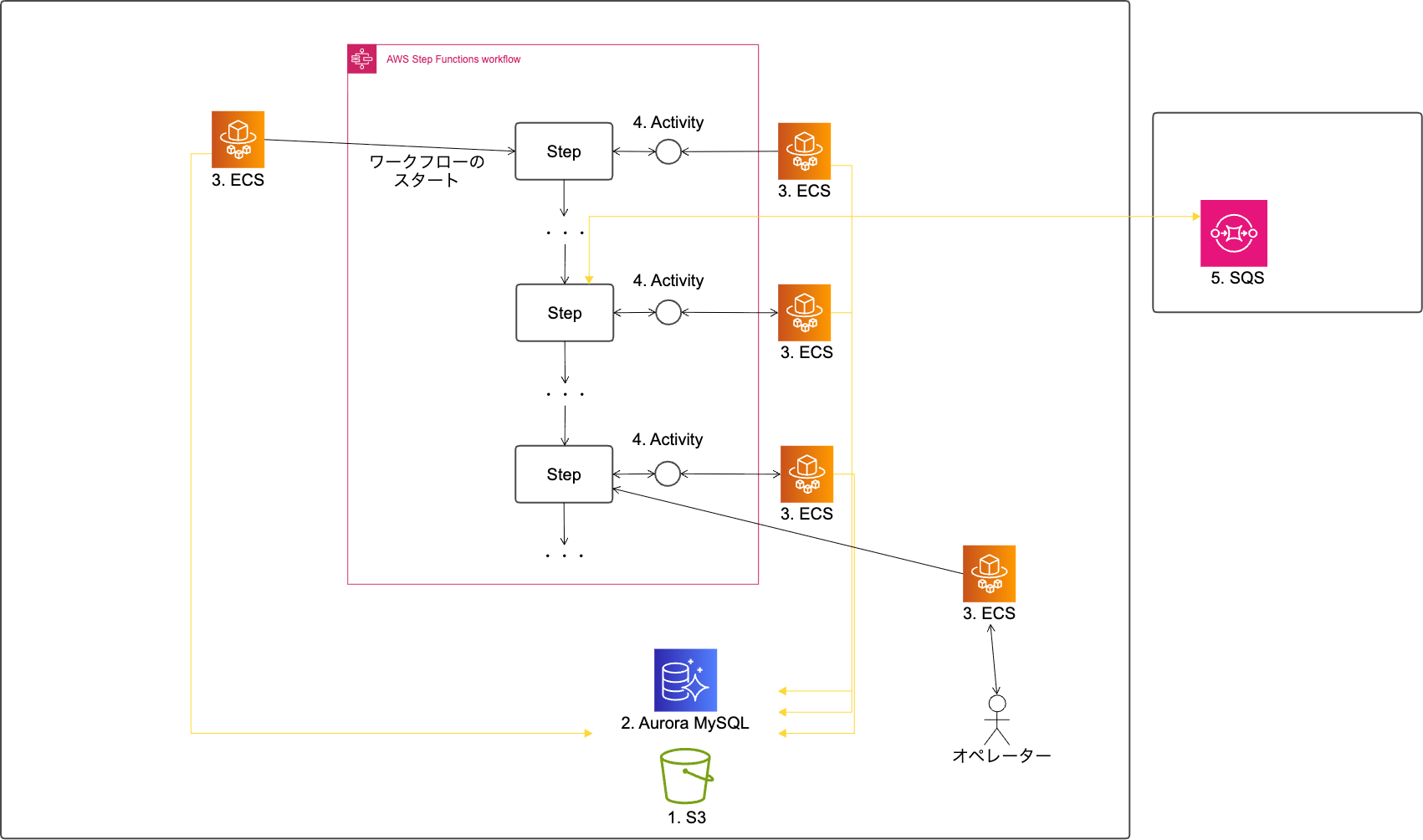
- 契約書の PDF データは Amazon S3 に保存
契約書ファイルはまず Amazon S3 に格納されます。スケーラブルでコスト効率の高いストレージに加え、ライフサイクル管理によってセキュリティも確保しています。 - データベースは Amazon Aurora
自動化エンジンの結果や人手入力で確定したデータは Amazon Aurora に保存されます。リレーショナルモデルで管理することで整合性と操作性を両立しています。 - アプリケーションは Ruby on Rails を Amazon ECS 上で運用
Rails アプリケーションは Amazon ECS で動作するコンテナにデプロイされており、AWS Step Functions と連携して処理を制御します。Amazon ECS の仕組みによりリソース管理やデプロイが容易になり、開発・運用の効率化につながっています。 - AWS Step Functions の Activity を利用したワークフロー制御
各処理ジョブは AWS Step Functions の Activity として定義され、ワーカーがポーリングしてタスクを実行します。これにより複数ワーカーによるスケールアウトが容易となり、ジョブの進捗や結果は自動的にステートマシンに反映されます。 - 自動化エンジンと Amazon SQS を介したプロジェクト間連携
自動化エンジンは、研究開発部が管理する別プロジェクトに切り出されています。Contract One Entry はこの自動化エンジンと直接結合するのではなく、Amazon SQS を介してメッセージをやり取りしています。
AWS Step Functions が自動化エンジン用プロジェクトの Amazon SQS に処理要求をエンキューし、エンジンが処理を行った後に結果を Amazon SQS 経由で返すことで、プロジェクトを跨いだ連携を実現しています。
この構成により、本番システム側は安定性を維持しながら、研究開発部は独自にエンジンの改良や実験を進められる柔軟性を確保しています。
AWS Step Functions の活用事例
AWS Step Functions の採用によって、私たちは複雑な処理フローを視覚的かつ柔軟に管理できるようになりました。
Contract One Entry のステートマシンは数十個のステートで構成されており、並列処理や条件分岐などを組み合わせた複雑な構成になっています。
このような大規模なワークフローでも、AWS Step Functions によって状態の可視化や分岐制御を直感的に扱える点が大きな利点となっています。
ここからは、具体的にどのような機能を活用しているか、ステートマシン定義のサンプルもお見せしつつ解説します。
状態遷移の可視化と柔軟な分岐
AWS Step Functions では、処理の各ステップが明示的に状態として定義されます。これにより、現在の処理位置や履歴を容易に把握できます。
また、各ステートは前のステートの出力を次のステートの入力として受け取り、その値に基づいて処理を分岐させます。
この仕組みによって、前段で得られた解析結果やフラグ値を参照しながら、最適な後続処理を動的に選択できます。
Choice ステートを用いることで、契約書の種類や属性に応じて異なる処理パスを動的に選択できます。
{
"ChoiceState": {
"Type": "Choice",
"Choices": [
{
"And": [
{
"Variable": "$.flag1",
"BooleanEquals": true
},
{
"Variable": "$.flag2",
"BooleanEquals": true
}
],
"Next": "NextAState"
}
],
"Default": "NextBState"
}
}
このような条件分岐により、異なる契約書フォーマットや処理要件に応じた最適なフローを実現しています。
エラーハンドリングと自動復旧
外部 API の一時的な応答遅延や処理タイムアウトは避けられません。AWS Step Functions では、Retry と Catch を組み合わせることで、こうした一時的な失敗に自動的に対応できます。これにより、障害時の手動対応を最小化し、運用負荷を軽減しています。
{
"TaskState": {
"Type": "Task",
"Resource": "xxxxx",
"Retry": [
{
"ErrorEquals": ["States.Timeout"],
"IntervalSeconds": 2,
"MaxAttempts": 3,
"BackoffRate": 2.0
}
],
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "HandleFailure"
}
],
"Next": "NextState"
}
}
並列処理による効率化
契約書の解析では、複数の自動化エンジンを同時に走らせて結果を統合します。Parallel ステートを活用することで、互いに依存しない処理を同時に実行でき、全体の処理時間を短縮できます。
"ParallelProcessing": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Engine1",
"States": { ... }
},
{
"StartAt": "Engine2",
"States": { ... }
},
{
"StartAt": "Engine3",
"States": { ... }
}
],
"Next": "AggregateResults"
}
結果は後続のステートで集約・比較され、最も信頼性の高いデータとして確定されます。
運用上の工夫
AWS Step Functions の活用を進める中で、運用の安定性・可観測性を高めるために、いくつかの工夫を積み上げています。代表的なものを以下に紹介します。
1. タイムアウトとハートビートの設計
- タイムアウトの適切な設定
AWS Step Functions 側の TimeoutSeconds とワーカー処理側のタイムアウトを組み合わせて設定し、異常があれば確実に検知できるようにしています。過剰に長く設定するのではなく、想定処理時間に合わせて適切な値を設定することで、異常を早期に把握できます。 - ハートビートの活用
長時間かかる処理では、定期的に AWS Step Functions に「まだ処理中です」というシグナル(ハートビート)を送ります。これにより、ワーカーが落ちていないことを検知でき、不要な失敗扱いを防げます。 - 処理時間のばらつき前提
入力に応じて処理時間が変動するため、タイムアウト値は「想定最大」に寄せすぎず、再実行の設計とセットで考えています。
2. リトライとフォールバックのポリシー
- エラーの粒度を分ける
失敗には種類があります。ネットワークや外部 API の一時的な不調など再試行で回復が見込めるものと、入力データの欠損や契約書の品質不良など再試行しても改善しないものです。前者はリトライを設定して自動回復を狙い、後者は速やかに人手による入力や別ルートに回します。 - フォールバックの明示化
最終的に失敗で終了させるのか、人手に引き渡すのか、別ワークフローに切り替えるのかといった方針をステート定義に書き込み、動作が一貫するようにしています。
3. 再実行と整合性管理
Contract One Entry の設計上、AWS Step Functions ではエラー時に処理を再実行することがあります。そのため、同じ処理が複数回走っても全体の整合性を保つ必要があります。
Contract One Entry では AWS Step Functions の状態管理に加えて、Amazon Aurora にもデータ化状況を適宜記録・更新し、DB 管理によって整合性を担保しています。これにより、処理が二重に実行されることを防ぎ、再実行を安全かつ効率的に行うことが可能になります。
仮に、処理中に一時的な障害が発生した場合でも、DB に保存された直前の状況を参照することで、同じ処理を安全に再試行できます。また、最初から実行し直す場合でも、DB に残っている進捗を基に「どこまで完了しているか」を判断し、不要な処理の繰り返しを避けながら再開できます。
こうした仕組みにより、リトライや再実行が発生しても処理の一貫性を維持しつつ、効率的で安定したワークフロー運用を実現しています。
4. 可観測性
構造化ログ
すべてのワーカーは JSON 形式で構造化ログを出力し、処理の入力・出力・実行時間などを記録しています。これを AWS Step Functions の実行履歴と突き合わせることで、問題が発生した際にどの処理で止まっているのかを迅速に特定できます。ワーカーのログやアプリケーションのログとも紐づけることで、システム全体を通じたトラブルシューティングが容易になります。処理遅延の検知
一定時間以上進捗がない実行を検知した場合にはアラートを発報し、担当者がすぐに状況を確認できるようにしています。これにより、処理の滞留やシステムの不具合を早期に発見し対応できます。
おわりに
Contract One Entry は、契約書の多様性と正確性要求という課題に対し、AWS Step Functions を中心としたワークフロー基盤で解決を図ってきました。
状態の可視化、柔軟な分岐、堅牢なエラーハンドリング、並列処理など、AWS Step Functions の特性がシステム要件に非常にマッチしています。
今後は、監視・分析の仕組みをさらに強化し、運用改善のサイクルを加速させたいと考えています。AWS Step Functions は、単なるオーケストレーションサービスではなく、信頼性・拡張性・可観測性を兼ね備えたプラットフォームです。本記事が、同様の課題を抱えるエンジニアの参考となれば幸いです。
著者プロフィール

小山田 征志
https://x.com/marcy_o
https://github.com/marcy
ソーシャルゲーム会社でバックエンド、フロントエンド開発を経験後、2014年にSansan株式会社に入社。名刺や請求書のデータ化サービスなどを手掛け、現在は契約書のデータ化システムを担当しています。
編集:中薗昴






