



スタートアップのデータ分析基盤はじめの一歩 - AWSでデータパイプラインを爆速構築
はじめに
みなさん、こんにちは。アマゾンウェブサービスジャパン合同会社 ソリューションアーキテクトの冨山です。
スタートアップにとって、「データ駆動で意思決定する体制」を構築することは、事業を成功させるための重要な要素です。しかし、多くのスタートアップは限られた時間的・金銭的リソースの中で、データ分析基盤を構築することに苦労しています。本記事では、AWSサービスの構築例をまとめた公開レポジトリであるAWS Samplesをそのまま自社用に活用して、最小限の労力でクイックにコスト効率の良いデータ分析基盤を構築する方法を紹介します。
Amazon Simple Storage Service(以下、Amazon S3)、AWS Glue、Amazon Athena、Amazon QuickSightを組み合わせることで、データの収集から変換、分析、可視化までを自動化したエンドツーエンドのパイプラインを構築できます。このパイプラインは、AWS LambdaやAWS Step Functionsを用いてサーバレスで制御されるため、スケーラブルかつ運用負荷の少ない構成が可能です。
※ 本記事は、スタートアップ向けのデータ分析基盤の構築サンプル集 aws-samples/startup-data-pipeline-samples に含まれる、 aurora-athena-sample の構築手順を開発者向けにより詳細に解説したものです。バージョンの差異等の理由により不具合が生じた場合には、最新のレポジトリを参照されることを推奨いたします。
アーキテクチャ概要
パイプラインのアーキテクチャ
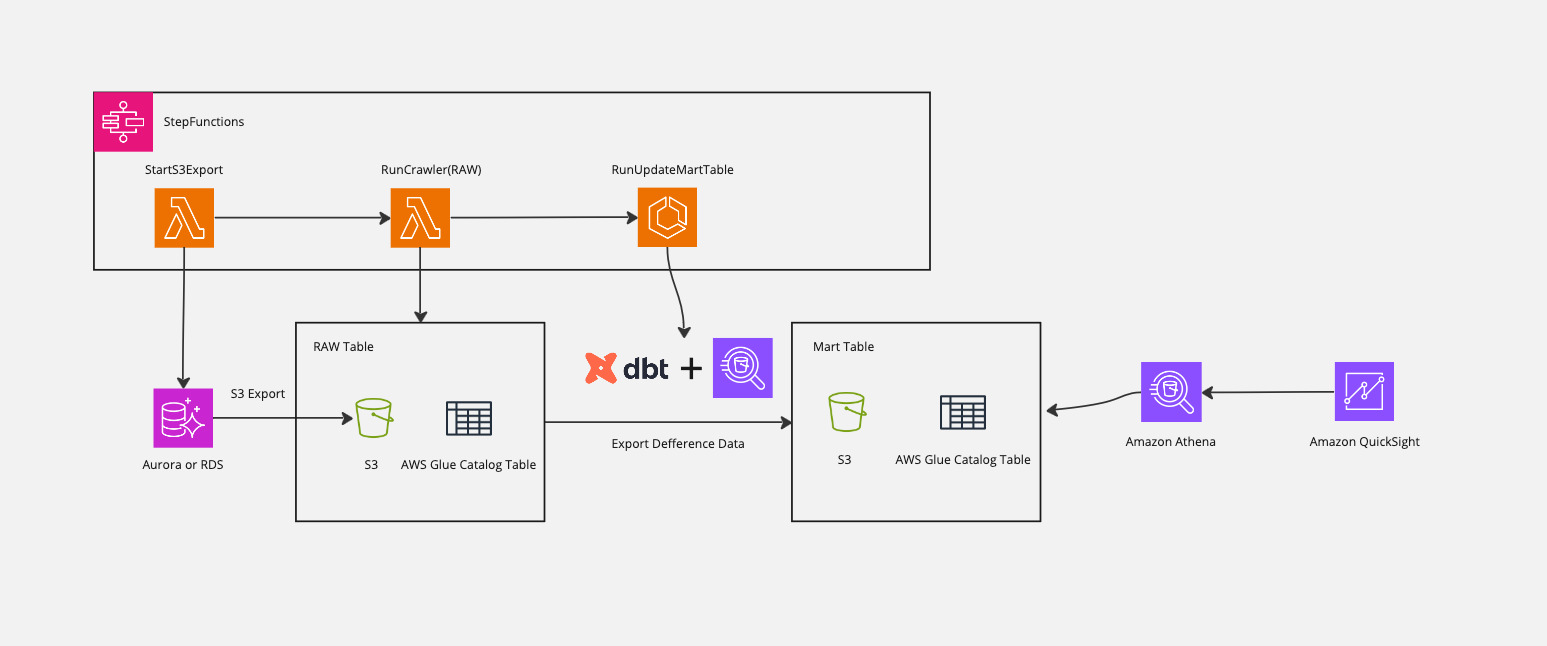
このデータパイプラインは以下のコンポーネントで構成されています。
- データソース: Amazon Auroraをデータソースとして使用します。既存のデータベースを利用することも、サンプル用に新規作成することも可能です。
- データ抽出: Cluster Exportを利用してAmazon AuroraのデータをAmazon S3にエクスポートします。Cluster Exportの仕様上、エクスポート対象は全データとなりますが、後続の処理で差分データのみを抽出します。
- メタデータ管理: AWS Glue Crawlerを利用して、S3に格納されたデータのスキーマを自動検出し、AWS Glue Data Catalogにメタデータを登録します。これにより、Amazon Athenaからデータを簡単にクエリできるようになります。
- データ変換: dbt(data build tool)とAmazon Athenaを利用して、モデルの定義に沿ってデータを変換し、データマートのテーブルを更新します。サンプルでは、タイムスタンプ情報を読み取り、差分データのみをインサートする実装になっています。
- データ分析・可視化: Amazon AthenaでSQLクエリを実行し、Amazon QuickSightでデータを可視化します。
上記の一連のプロセスを、AWS Step Functionsを使用してオーケストレーションしています。
本アーキテクチャはデータレイクにAmazon S3、データモデルの定義にdbtを使用しているため、すぐにデータウェアハウスをアーキテクチャに組み込むことができます。例えばクエリの実行時間が課題になった際、データウェアハウスにAmazon Redshiftを採用すると、Amazon S3のデータを直接クエリできます。Amazon S3からAmazon RedshiftにデータをCOPYすることも可能です。その場合、dbtにAmazon Redshiftの環境を追加することで、モデル定義を流用してデータパイプラインを展開できます。
料金試算
以下は、データ分析を始めようとするスタートアップでよくあるシンプルな利用ケースを想定した月額コストの目安です。この場合、月額の固定費はおよそ35USDとなります。
前提条件
- 分析対象のデータサイズ:10GB(Parquet圧縮後 約3GB)
- データ更新頻度:1日1回
- QuickSightの利用ユーザー:作成者1名、閲覧者(リーダー)2名
- Athenaの利用者:分析者3名が1日10回ずつクエリ実行
- 2025年7月時点のオレゴンリージョンでの価格をもとに試算
- VPCエンドポイント含むデータ転送料金は考慮外
| サービス | 費用 | 計算 |
|---|---|---|
| Amazon Aurora Cluster Export | 3 USD | 10GB × 0.01 (USD/GB) × 30(days) |
| AWS Glue Crawler | 2.2 USD | 0.44 (USD/h) × 10(min)/60(min) × 30(days) |
| Amazon QuickSight | 30 USD | 24 (USD/作成者) + 2 × 3 (USD/リーダー) |
また、3人の分析者が1日に10回ずつフルスキャンでクエリをする場合、月額の変動費はおよそ14USD。合計およそ月額49USDとなります(オレゴンリージョンでの試算)。
| サービス | 費用 | 計算 |
|---|---|---|
| AWS Glue Data Catalog | 0 USD | 3人 × 10(クエリ/day) × 30(days) < 100万回のため無料 |
| Amazon Athena | 13.5 USD | 0.003(TB) × 5(USD/TB) × 3(人) × 10(クエリ/day) × 30(days) |
このアーキテクチャは、サーバーレスのサービスを中心に構成されているため、インフラ管理の負担が少なく済みます。また、使用した分だけ従量課金されるため、コスト効率が良い特徴があります。
実装手順
Step1: 初期設定
まずは、必要な設定を行い、環境をセットアップします。
以下の手順は全てオレゴンリージョン(us-west-2)で行います。
1. リポジトリのクローン
$ git clone https://github.com/aws-samples/startup-data-pipeline-samples.git
$ cd startup-data-pipeline-samples/aurora-athena-sample
2. サンプルデータのアップロード
新規DBを作成してサンプルデータを使用する場合には、以下の手順を前もって行います。
- Amazon S3に任意のバケットを作成する。
- サンプルデータを解凍する。
# サンプルデータの解凍
$ tar -xzvf ../sampledata/sample.tar.gz -C /tmp/
- S3バケットにアップロードする。
# S3バケットにアップロード
$ aws s3 cp /tmp/sample/ s3://sample-ticket-data/ --recursive
3. 設定ファイルの編集
config/config.tsファイルを開き、以下のパラメータを環境に合わせて設定します。
export const config: Config = {
pipelineName: "sample-ticket-database", // パイプライン名
isExistDB: false, //既存DBを使う場合はtrue
dbClusterName: "sample-ticket-database", // Auroraクラスター名
dbName: 'demodb', // データベース名
schemaName: 'demodb', // スキーマ名
sampleDataBucketName: 'sample-ticket-data', // サンプルデータ用S3バケット名
snapshotS3BucketName: 'sample-snapshot-bucket', // スナップショット用S3バケット名
s3ExportPrefix: "s3export", // S3エクスポート先プレフィックス
enableBackupExportedData:true, // エクスポートデータのバックアップ有効化
loadSchedule: {minute:'30', hour:'3', weekDay:'MON-FRI', month:'*', year:'*'} // データロードスケジュール(毎日0時)
}
sampleDataBucketName には、先ほど作成したバケット名を記入します。
snapshotS3BucketName には、これからAWS CDKによって作成する予定のS3バケット名を記入します。このバケットを手動で作成する必要はありません。
4. CDKデプロイ
AWS CDKを使用して、必要なリソースをデプロイします。
$ npm install
$ npx cdk bootstrap
$ npx cdk deploy --all
デプロイが完了すると、以下のようなAWSリソースが作成されます。
- Amazon Aurora DBクラスター(
isExistDB: falseの場合) - S3バケット(スナップショット用)
- AWS Glue Crawler
- AWS Glue Database
- AWS Lambda関数(データ処理用)
- AWS Step Functions(パイプライン制御用)
- Amazon Elastic Container Serviceのクラスターとタスク定義(dbt実行用)
- AWS Identity & Access Managementロール(各サービスのアクセス権限用)
Step2: サンプルデータ取り込み
新規でデータベースを作成した場合(isExistDB: false)、データベースにサンプルデータを取り込む必要があります。
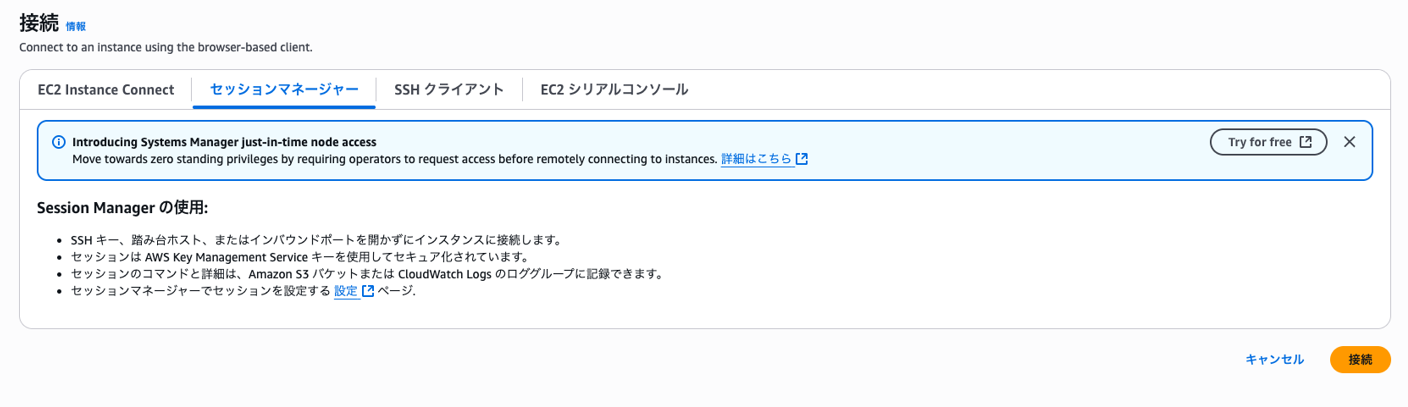
1. データベースへの接続
デプロイ時に作成されたEC2インスタンスを使用して、Auroraデータベースに接続します。
- AWS Management Consoleから、EC2サービスページを開きます。
SampleDataSourceStackから始まるインスタンス名を選択し、「接続」をクリックします。- Session Managerタブを選択し、「接続」を押します。ターミナルが開くので、一旦置いておきます。
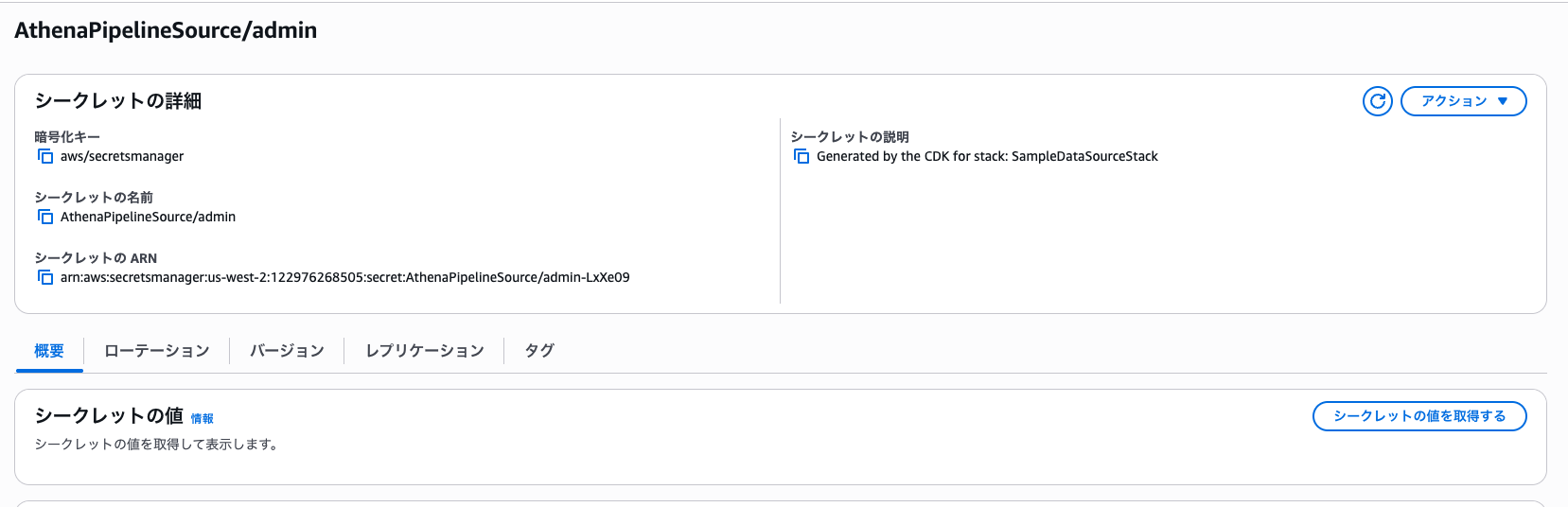
2. データベース認証情報の取得
- AWS Management ConsoleからAWS Secrets Managerサービスページにアクセスします。
AthenaPipelineSource/adminという名前のシークレットを選択します。- 「シークレットの値を取得する」をクリックして表示されるパスワードを、次のステップで使用します。
3. データベースへのログイン
- EC2インスタンスのターミナルで以下のコマンドを実行します。
mysql -h <host> -u admin -p
<host>には、先ほど取得しておいたシークレット内のhostを代入します。
- パスワードの入力を求められるはずです。その際は、先ほど取得した
passwordを入力します。

4. サンプルデータのインポート
sampledata/setupdata.sqlファイルを編集します。--- EDIT S3 BUCKET ---の行の下に登場するS3バケットの名前を、先ほど手動で作成したサンプルデータ用のバケット名に変更します。- 編集した
sampledata/setupdata.sqlの内容を、EC2上で開いているMySQLのシェルにコピー&ペーストして実行します。これにより、新規作成したデータベースにサンプルデータが挿入されます。
Step3: ETLパイプライン実行
パイプラインは、Amazon EventBridgeによって定期的に実行されるように設定されていますが、手動で実行することも可能です。
1. Step Functionsの実行
- AWS Management ConsoleでStep Functionsサービスを開きます。
SampleAthenaPipelineから始まるステートマシンを選択します。- 「Start Execution」をクリックし、以下のJSONを入力します。
{
"EnableBackup": "True"
}
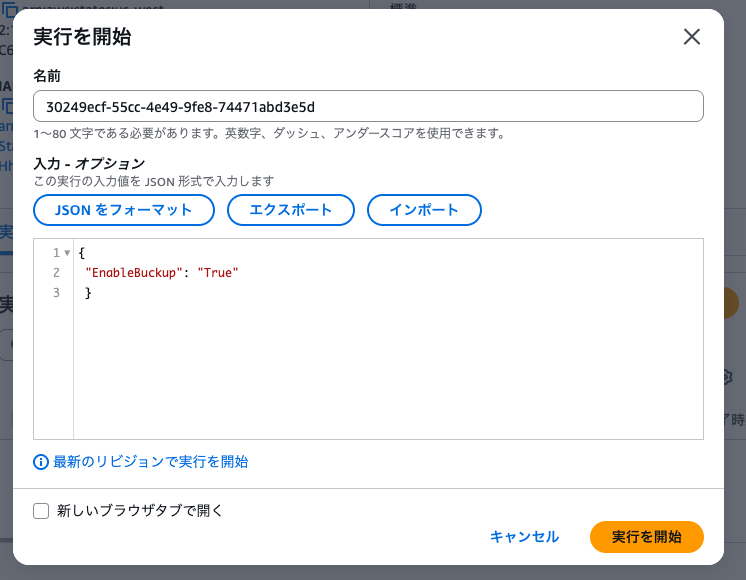
- 「実行を開始」ボタンをクリックして実行を開始します
2. 実行フローの確認
Step Functionsの実行フローは、以下のステップで構成されています。
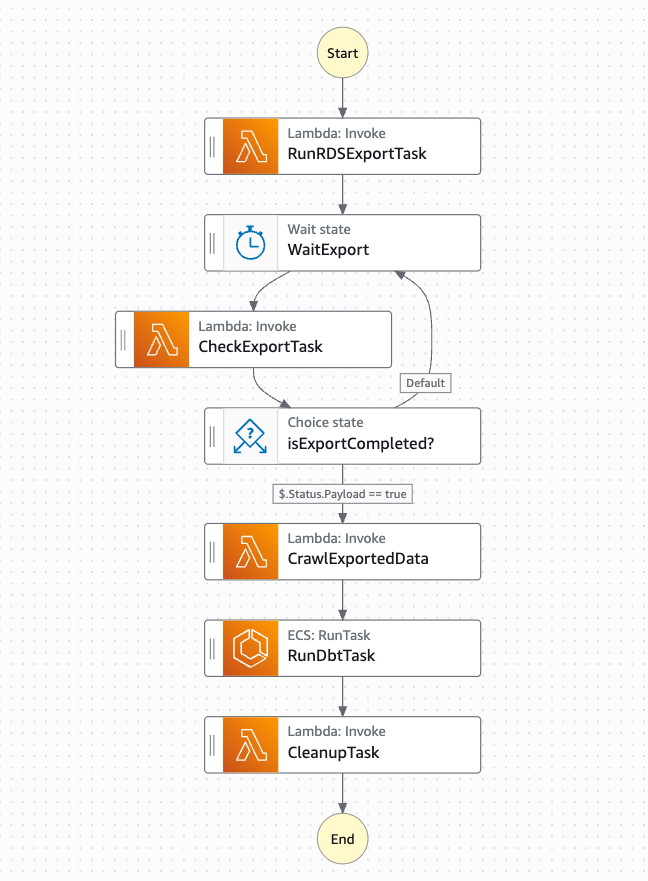
- RunRDSExportTask: AuroraからS3へのデータエクスポート
- CheckExportTask: エクスポートタスクの完了確認
- CrawlExportedData: AWS Glue Crawlerの起動
- Check Crawler Status: Crawlerの完了確認
- RunDbtTask: dbtによるデータ変換処理
- CleanupTask: 一時リソースのクリーンアップ
各ステップの実行状況はStep Functionsのビジュアルワークフローで確認できます。
3. Athenaでのクエリ確認
パイプラインの実行が完了したら、Athenaでデータをクエリできるようになります。
- AWS Management ConsoleでAthenaサービスを開きます。
- クエリエディタで、ワークグループ
athenaWorkGroupを選択し、作成されたデータベース(パイプライン名と同じ)を選択します。 - テーブル一覧から対象のテーブルを選択し、クエリを実行します。
SELECT * FROM "SampleAthenaPipeline"."event" LIMIT 10;
Step4: Amazon QuickSightを用いた可視化
最後に、Amazon QuickSightを使用してデータを可視化します。
1. QuickSightのセットアップ
Amazon QuickSightのアカウントをまだ作成していない場合は、公式ドキュメントを参照してアカウントを作成してください。
2. S3バケットへのアクセス権限設定
- QuickSightに管理者としてログインします。
- 右上の「QuickSightを管理」>「セキュリティとアクセスの許可」>「QuickSightのAWSのサービスへのアクセス」から、「管理」をクリックします。
- S3を選択し、対象のS3バケット(スナップショット用バケット)へのアクセス権限を付与します。
3. データセットの作成
- QuickSightのトップページに戻り、サイドバーの「データセット」をクリックします。
- 「データセットの作成」>「Athena」をクリックします。
- 対象のワークグループ、作成されたGlueデータベース(パイプライン名と同じ)、対象のテーブルを選択します。
- 「データセットの作成」をクリックします。
4. 分析とダッシュボードの作成
データセットが作成されたら、QuickSightの分析機能を使用してグラフやダッシュボードを作成できます。
- 作成したデータセットを選択し、「分析」をクリックします。
- ビジュアルタイプを選択し、フィールドをドラッグ&ドロップしてグラフを作成します。
- 複数のビジュアルを組み合わせてダッシュボードを作成します。
- 「公開」をクリックしてダッシュボードを共有します。
次のステップ
このサンプルパイプラインをベースに、以下のような拡張が考えられます。
1. データモデルの拡張
dbtを活用して、データマート用にオリジナルのデータには存在しないデータモデルを構築できます。サンプル内の soldnum.sql の例のように、既存のテーブルを統合して新たなテーブルを作成できます。
with sales as (
select * from {{source('raw','demodb_sales') }}
),
users as (
select * from {{source('raw','demodb_users') }}
),
rawdate as (
select * from {{source('raw','demodb_date') }}
),
sales_per_users as (
select
sellerid,
username,
city,
sum(qtysold) as qtysoldsum
from sales, rawdate, users
where sales.sellerid = users.userid
and sales.dateid = rawdate.dateid
group by sellerid, username, city
)
select * from sales_per_users
2. 差分更新ロジックのカスタマイズ
このサンプルでは、テーブルの差分更新を incremental materialization で行っています。サンプル内の event.sql の例では、 is_incremental 配下の WHERE 文が、差分を取るためのフィルタの役割をしています。こちらを変更することで、eventテーブルの更新ロジックをカスタマイズできます。
{{
config (
materialized = 'incremental',
unique_key = 'starttime'
)
}}
select
*
from {{ source('raw','demodb_event') }}
{%- if is_incremental() %}
where starttime > cast((select max(starttime) from {{ this }}) as timestamp)
{%- endif %}
まとめ
本記事では、AWS CDKを使用して、Amazon Aurora、Amazon S3、AWS Glue、Amazon Athena、Amazon QuickSightを組み合わせた、AWS Step Functionsによるミニマムなデータパイプラインの構成手順を紹介しました。このパイプラインにより、Amazon Auroraデータベース内に格納されたデータをダッシュボードで可視化することが可能になりました。
このように既存サンプルを有効活用すれば、初期投資を抑えながらスモールスタートでデータ分析基盤を構築できます。アジリティ・コスト削減・データに基づいた意思決定のいずれも重要なスタートアップの皆様には非常におすすめです。
◆執筆:アマゾンウェブサービスジャパン合同会社 ソリューションアーキテクト 冨山英佑





