



【Databricksで実践するAI Agent開発】データとAIを融合する次世代データ基盤の全貌
なぜDatabricksを活用するべきなのか
近年データの種類が急激に多様化し、構造化データだけでなく非構造データへの対応がより重要になりました。従来のDWHやデータレイクは構造化データと非構造化データを別々の場所で管理することになり、ETLの複雑化、データのサイロ化、コスト・管理負荷の増大などを招き、「全社的なデータ活用」のボトルネックとなってきています。
そこでDatabricksは「レイクハウス」を発明しました。レイクハウスはDWHの機能とデータレイクの利点を組み合わせたデータ基盤アーキテクチャです。これにより、構造化データ・非構造化データを一つのデータ基盤で扱うことが可能になります。また、単にデータをため込むだけではなく、統合されたデータガバナンス機能であるUnity Catalog、Databricks自らが開発した高い信頼性と処理性能を備えたDeltaLakeフォーマットを土台に、データエンジニアリング・AI/BIの機能も豊富に用意されています。
さらに、近年は急速にデータ利活用の機能を強化しており、データインテリジェンスプラットフォームとしてその姿を変えつつあります。データ基盤は単に企業のデータを集積・加工して分析する場所から、リアルタイムストリーミングを用いた顧客エンゲージメントや、業務やサービスを自動化するAI Agentの開発、自社データを活用した業務効率化アプリケーションを開発・展開できる基盤としてその守備範囲を広げています。
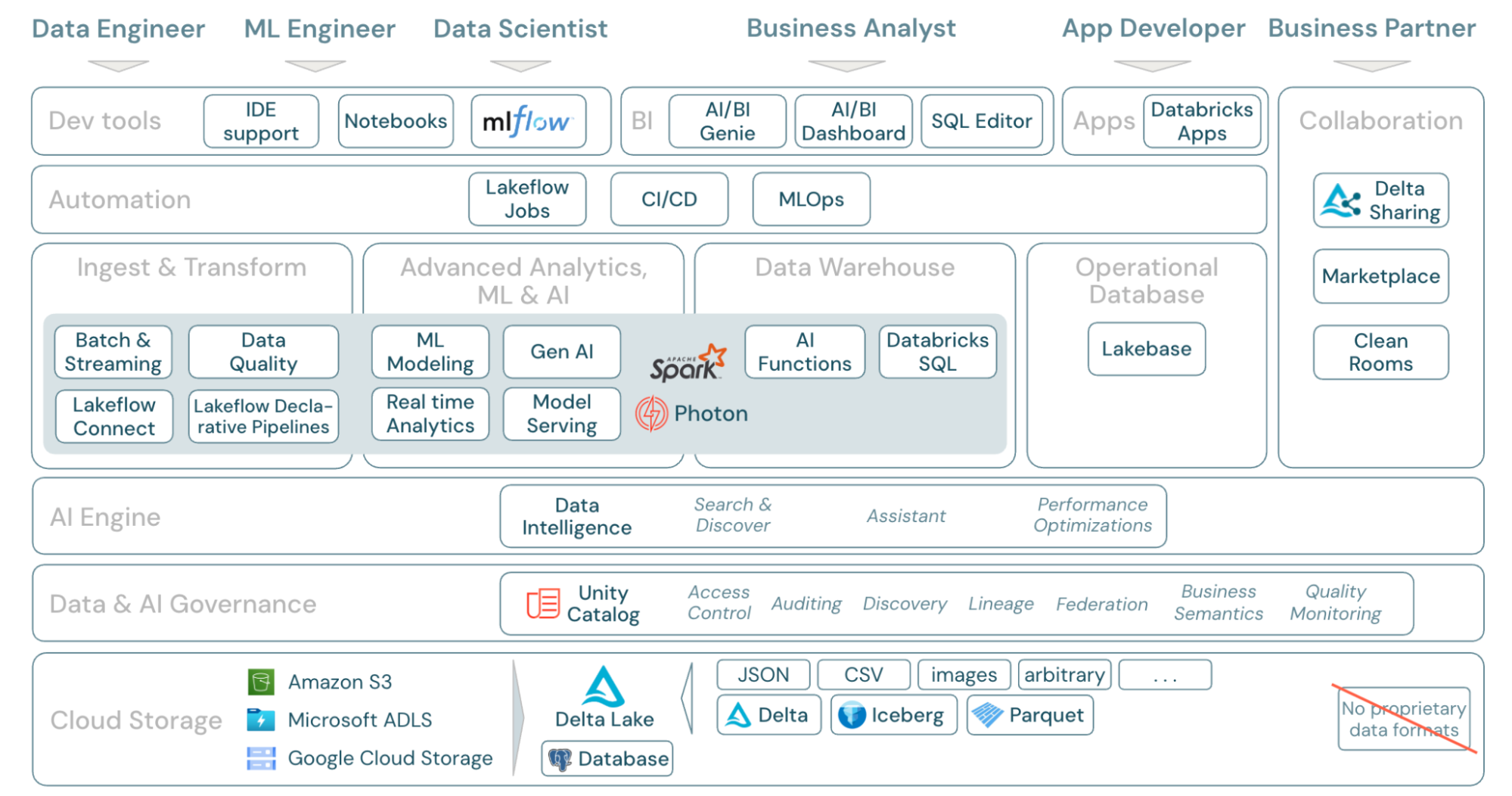
Databricksを活用することで得られるもの
構造化・非構造化を問わず一つの基盤で扱えるため、別製品間のデータ転送や重複管理が激減し、ETLやオーケストレーションの設計がシンプルになります。結果として、新しい分析やAIプロジェクトの立ち上げまでのリードタイムを短縮することができます。
Unity CatalogというDatabricks上のデータ/AI資産を一元管理できる機能を用いることにより、誰がどのデータにアクセスできるかを列・行レベルのきめ細かい粒度まで制御できる権限管理、データリネージ可視化、システムテーブルによる監査ログ取得、安全な外部共有(Delta Sharing/Clean Rooms)、AIモデルの管理までをカバーしておりデータガバナンスを実現することができます。プログラムだけでなく、データのバージョン管理・変更履歴の管理も可能であるため、誤った操作をしても安心です。
また、Databricksは分散処理フレームワークであるSparkの開発者が集まり起業されたという経緯があり、大規模データを高速に処理することに長けています。Databricksが開発したSQLクエリエンジンであるPhotonやOSS版からさらに高速化されたSpark、リキッドクラスタリングによりTB級のデータもスムーズに扱えます。
コストに関しても、Databricksでは使った分のみ料金を支払う従量課金の仕組みを採用しています。必要なときに必要なだけ使える仕組みで無駄なコストが発生しないようにしたいという思いで、各種機能開発も進めています。例えば、Auto LoaderやLakeflow宣言型パイプラインによる増分取り込みで無駄なIOの削減、サーバレスのコンピュートリソースを使うことによりオートスケール&自動停止で必要なときに必要な分だけコンピュートリソースを立ち上げることができたり、ChatGPTやClaudeなどの生成AIのモデルのサービング機能であるモデルサービング機能でも呼び出されたときだけ動く仕組みのため無駄な費用を削減できます。
また、ベンダーロックインの防止にも力を入れています。DatabricksはSpark、Delta Lake、MLflow、UnityCatalogなど中核技術をOSSとして公開し、Parquet/Delta Lakeといったオープンフォーマットを前提に設計することで、ベンダーロックインの防止と他サービスとの相互運用性を確保しています。ストレージと計算を疎結合にし、他エンジンからも読み書き可能なフォーマットを採用することで将来の拡張性を担保しています。コミュニティの改良提案を受け入れることで機能進化を加速し、透明性・再現性が求められる領域でも安心して使えるようにこだわっています。
主要機能の紹介
AI/BI Genie
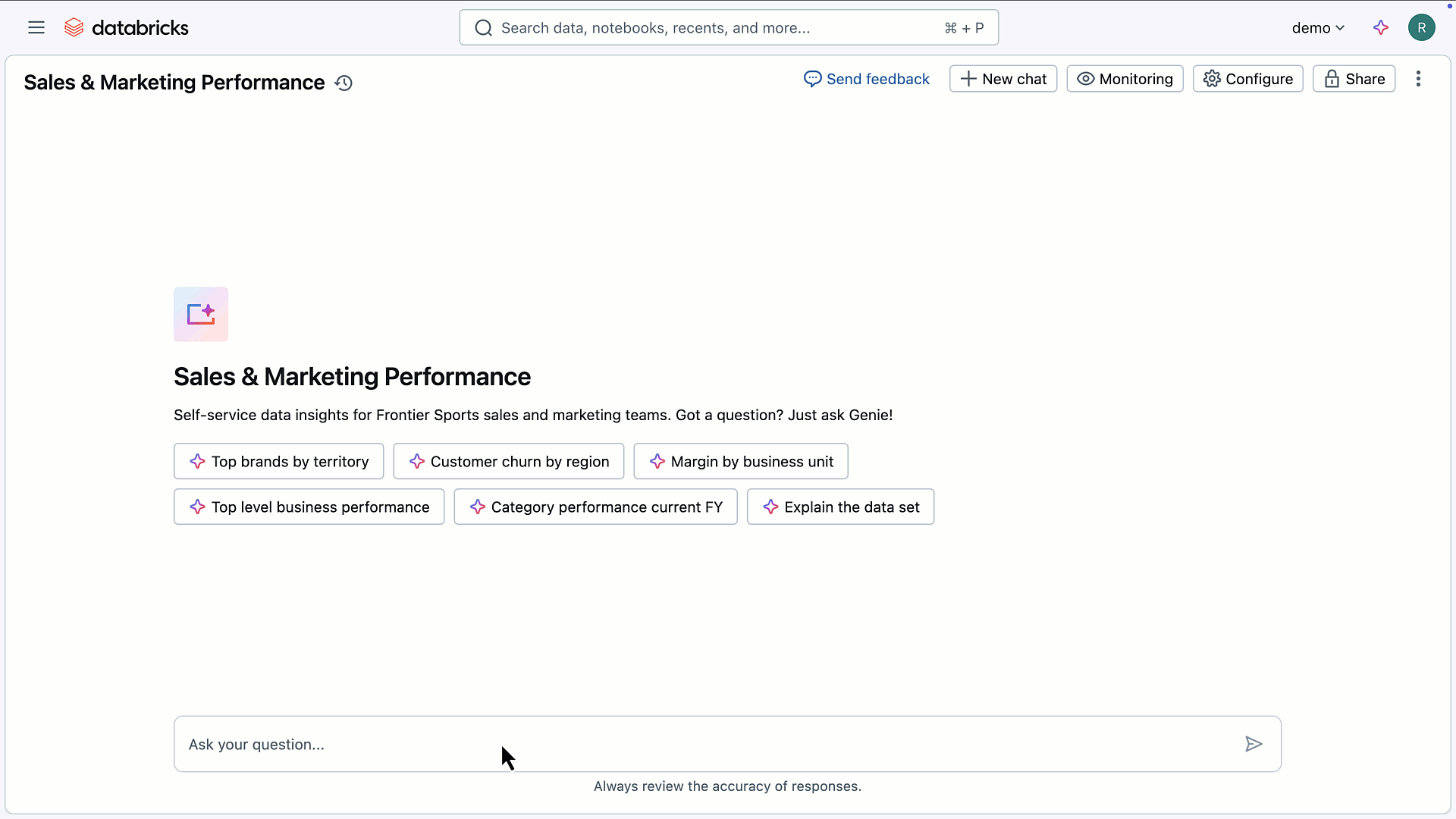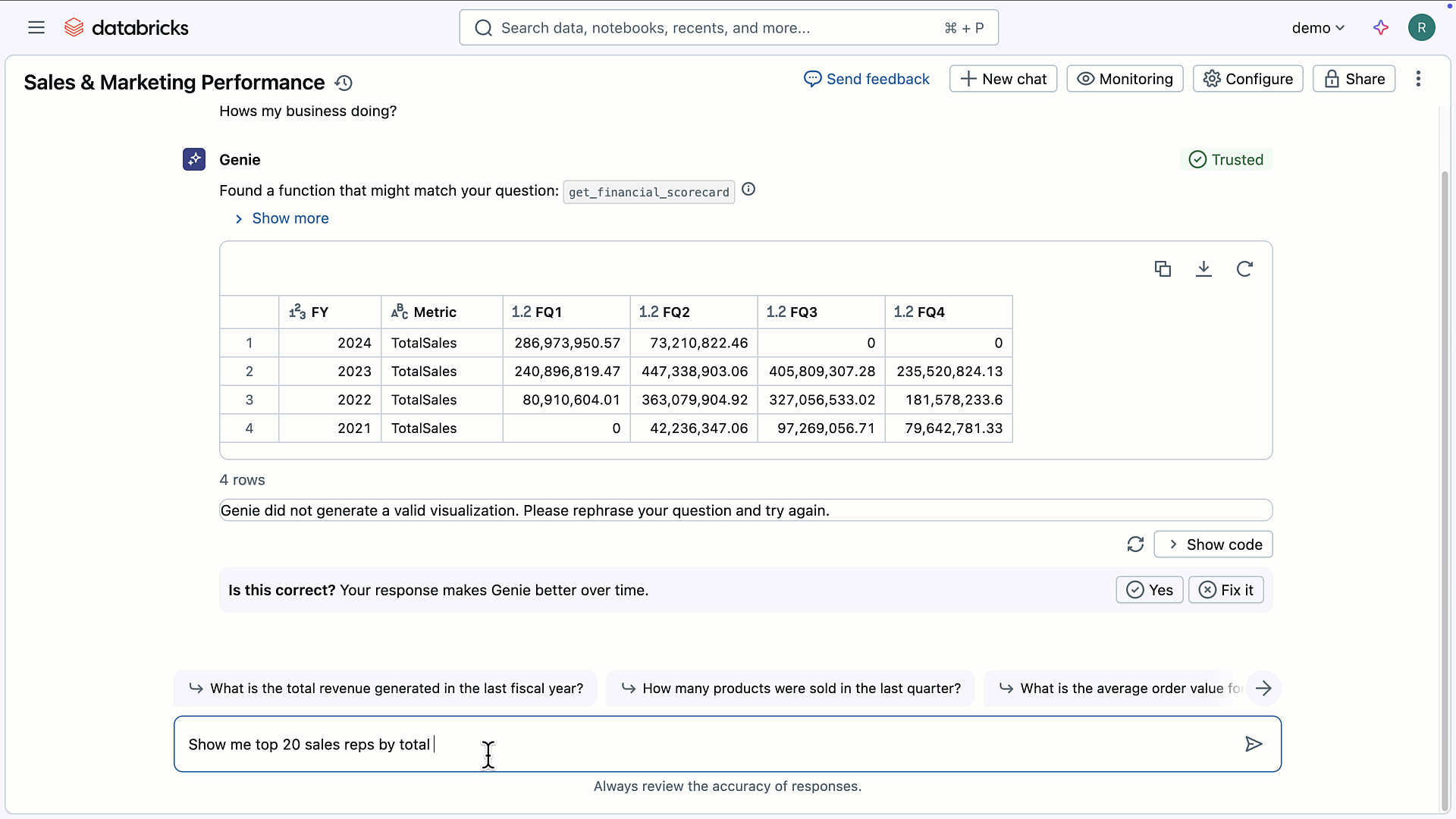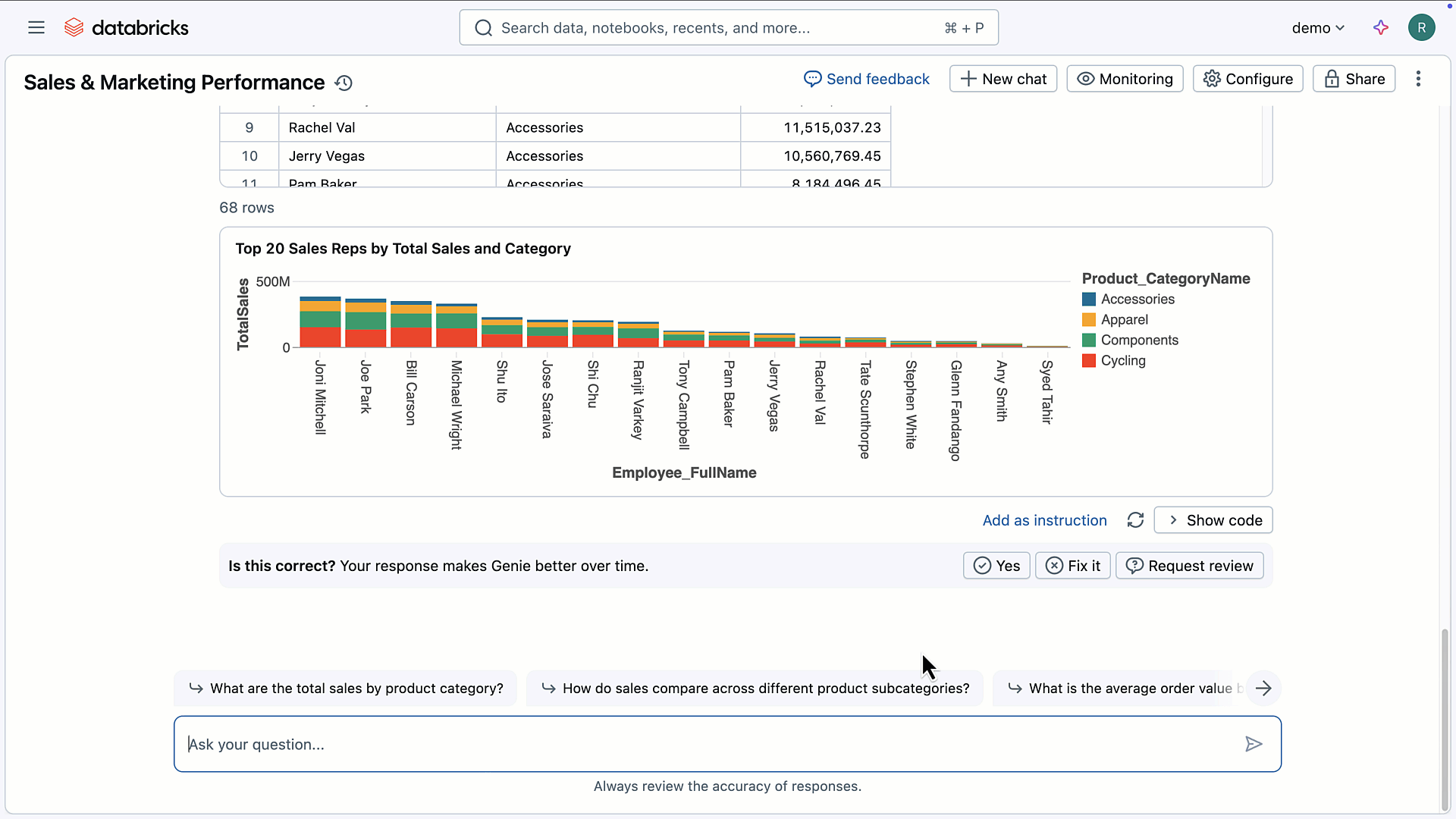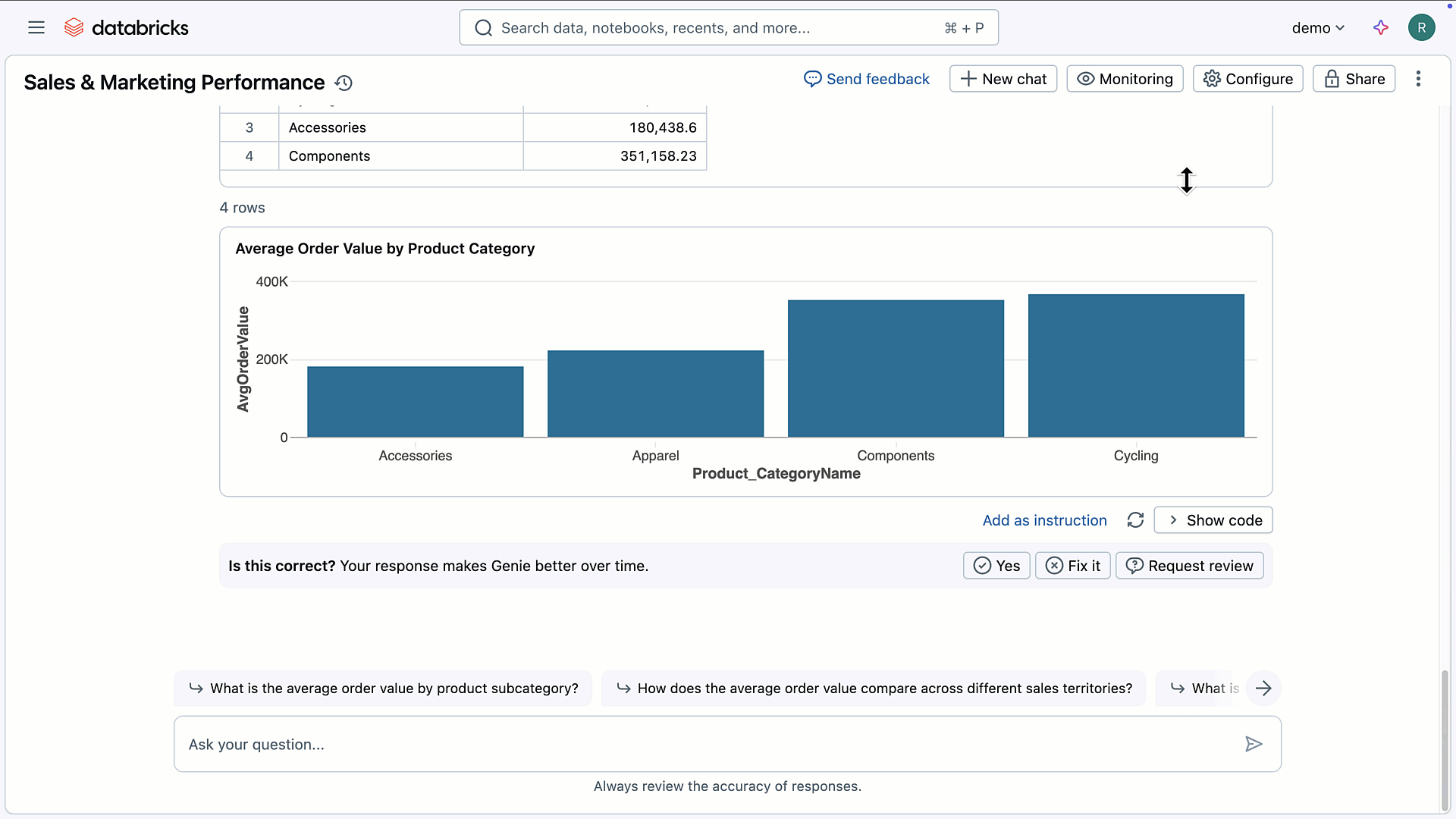
たとえば会社やお店で「今月の売上はどうなっている?」「特定の商品は先月より売れている?」といった疑問が出てきたとき、そのたびにエクセルを開いて自分で集計をしたり、専門のIT担当者に集計を頼まないといけない場面がよくあります。Genieでは「この商品の地域ごとの売れ行きを見たい」と入力するだけで、SQLを考えてデータベースにアクセスし、地域ごとに見やすいグラフを自動で作成します。さらに、Genieは事前に設定しておけば各企業に合わせた知識や業務用語も理解できるため、「自社独自のキャンペーンの効果を知りたい」といった質問にも、現場のルールや用語に合わせて答えてくれます。
ブラジル最大級の小売企業「Grupo Casas Bahia」では、全社の営業・在庫・売上データをGenieで統合しています。例えば「今週の店舗ごとの売上傾向は?」「不正注文の兆候をリアルタイムで検知」など、部門を超えた質問に現場スタッフ・経営層・IT担当含め誰もが即時アクセスでき、従来は数時間〜数日かかっていたデータ集計が、Genieだとほんの数分で完了します。導入前に多発していた「専門家に頼まないと分析ができない」「データ依頼がIT担当に集中してパンク」という課題が解消されました。
AI/BI Dashboard
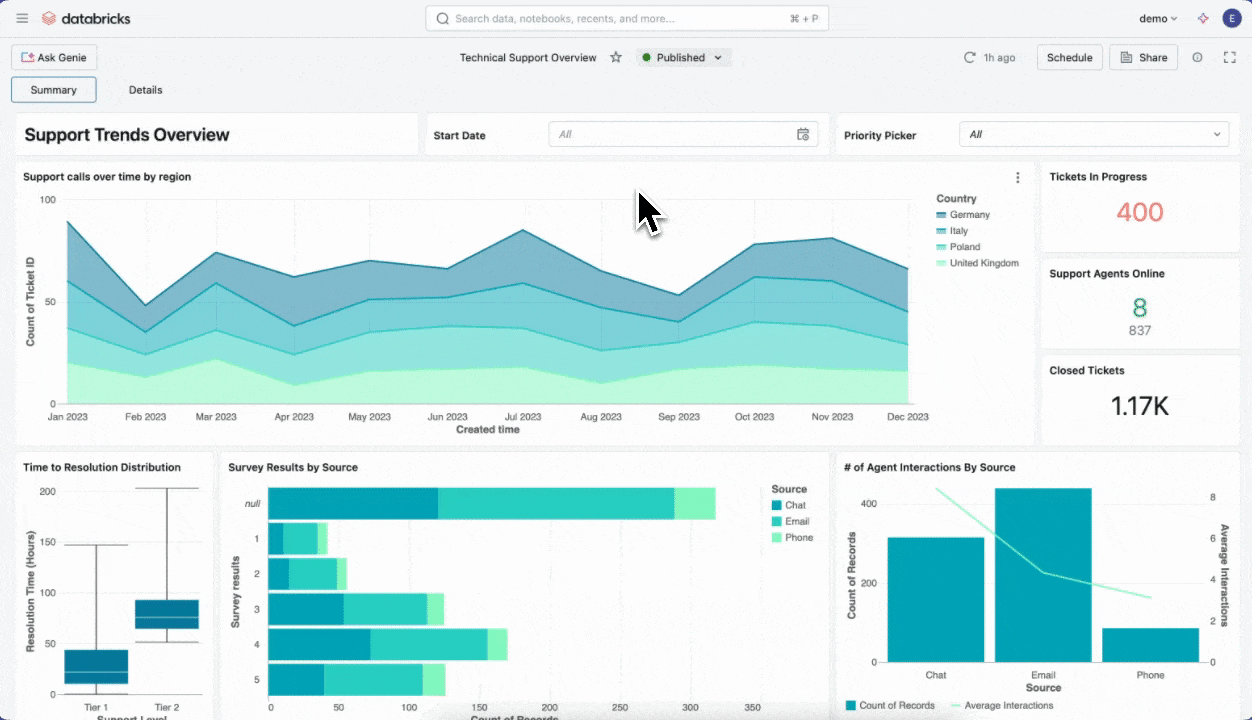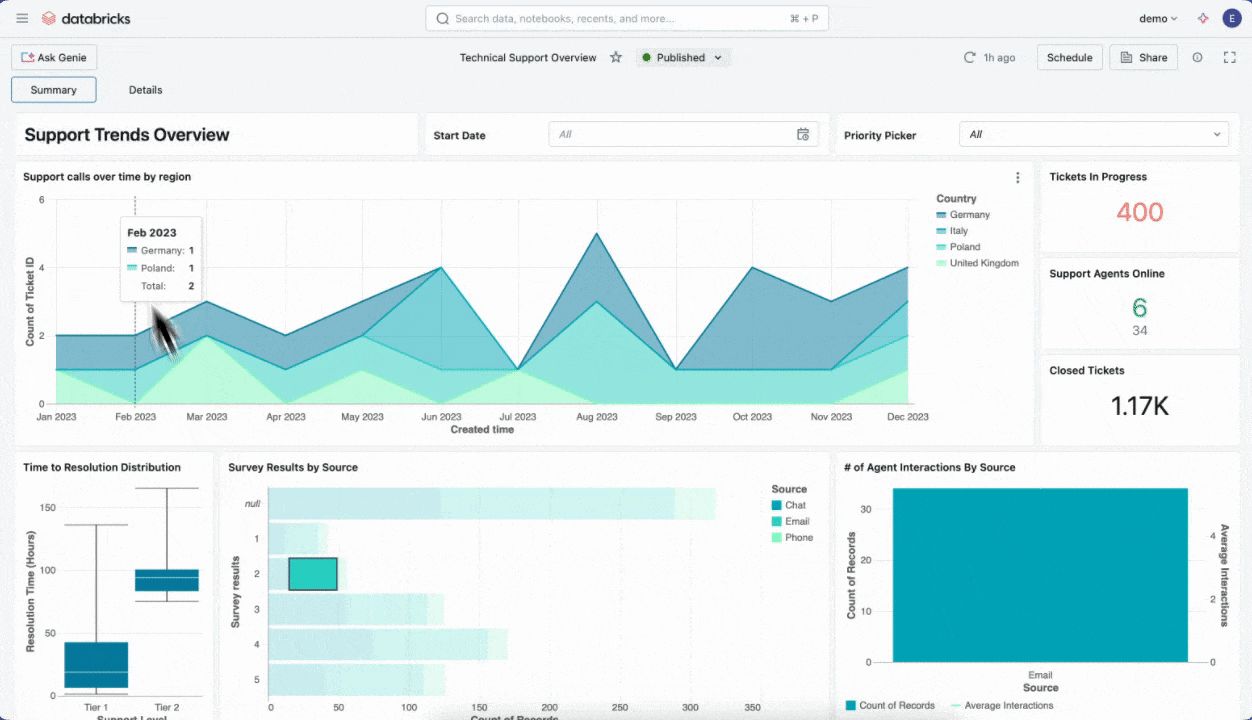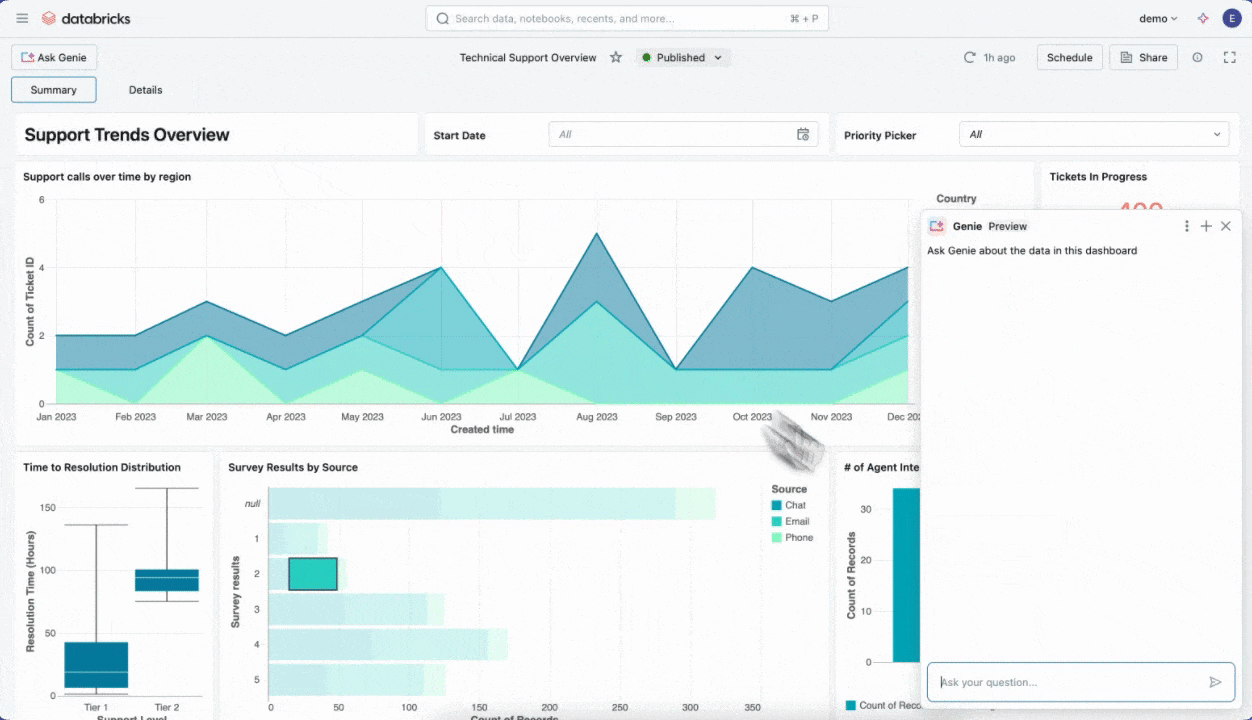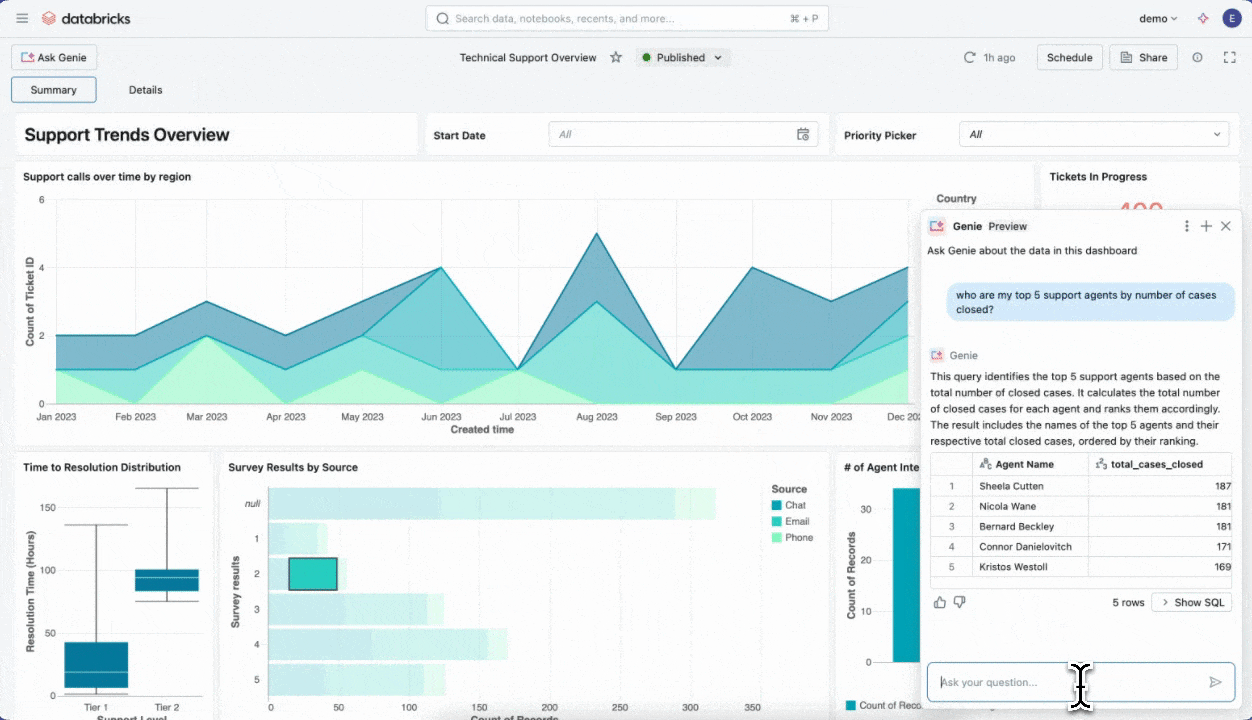
AI/BIダッシュボードは、「データ分析」や「業務レポート作成」といった少し難しそうな作業を、ITやデータに詳しくない方でもストレスなく使えるように工夫されたツールです。通常のBI(ビジネスインテリジェンス=グラフや表でデータをわかりやすく可視化)にAI技術が組み合わさることで、難しい設定や専門的な手順を気にせず業務の現場でデータ活用を進めることができます。
実際の現場では、例えば毎月の売上レポートや商品別の販売推移など、エクセルでグラフを作成して報告する作業がよく行われています。しかし、データが増えるたびにファイルをコピーしたり、集計ミスやグラフの修正などに時間を取られたりすることも少なくありません。AI/BIダッシュボードを使うと、大量のデータでもいつでも最新版が自動でグラフ化されるため、「次の会議までに最新の売上トレンドを見たい」「新商品の売れ行きをチームで共有したい」といったニーズに即座に応えられます。ダッシュボードの画面は直感的にドラッグ&ドロップで編集できるので、専門的なプログラミング知識は不要です。作り上げたレポートやグラフはPDFや画像として出力でき、そのまま会議資料に貼り付けることも簡単です。
例えばNTTドコモでは、多くの部署やグループ会社にわたる「生成AI活用の実績分析」にこのダッシュボードが使われています。もともとは利用状況や活用度合いの把握に手作業で長い時間がかかっていましたが、Databricks上にAI/BIダッシュボードを導入したことで、一連の分析・レポート作成作業の工数を削減できました。
Notebooks
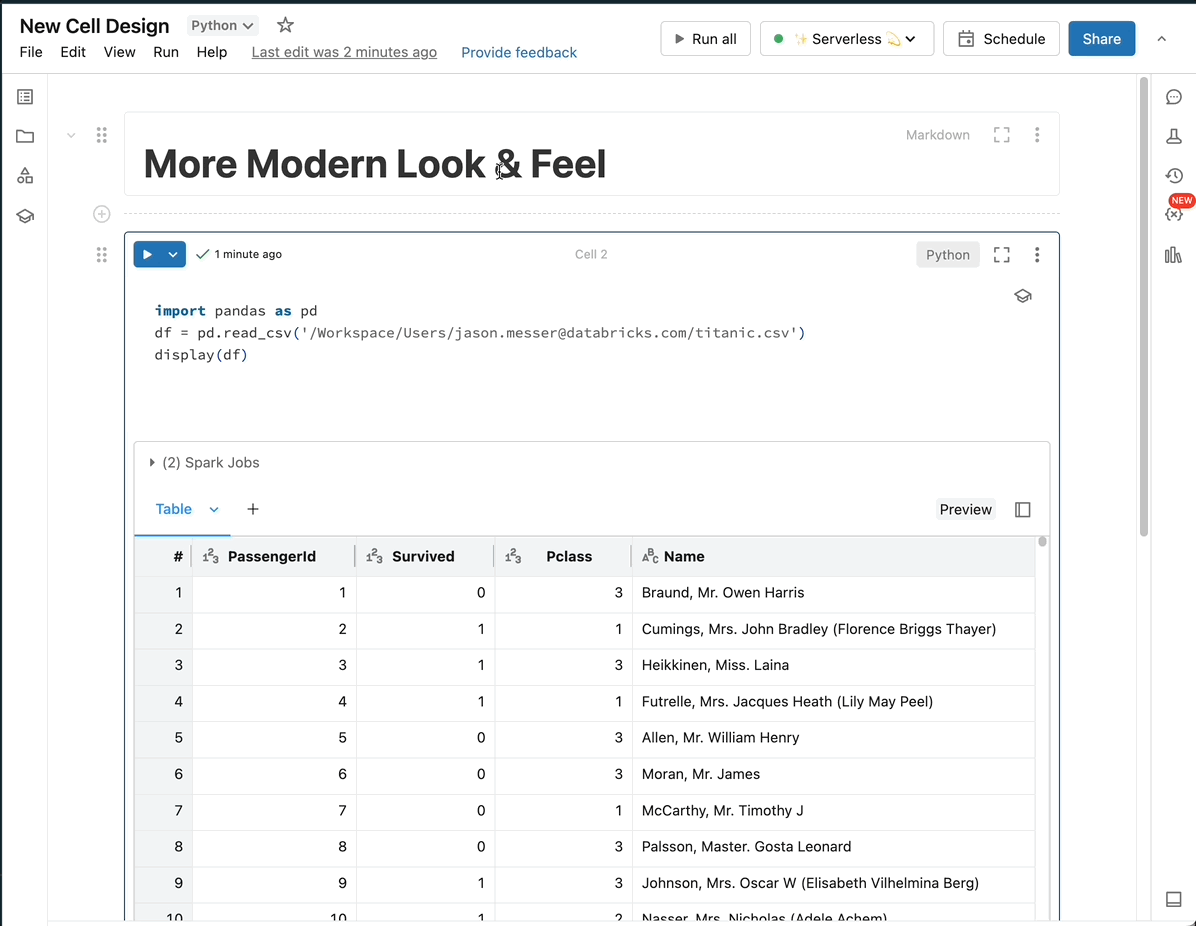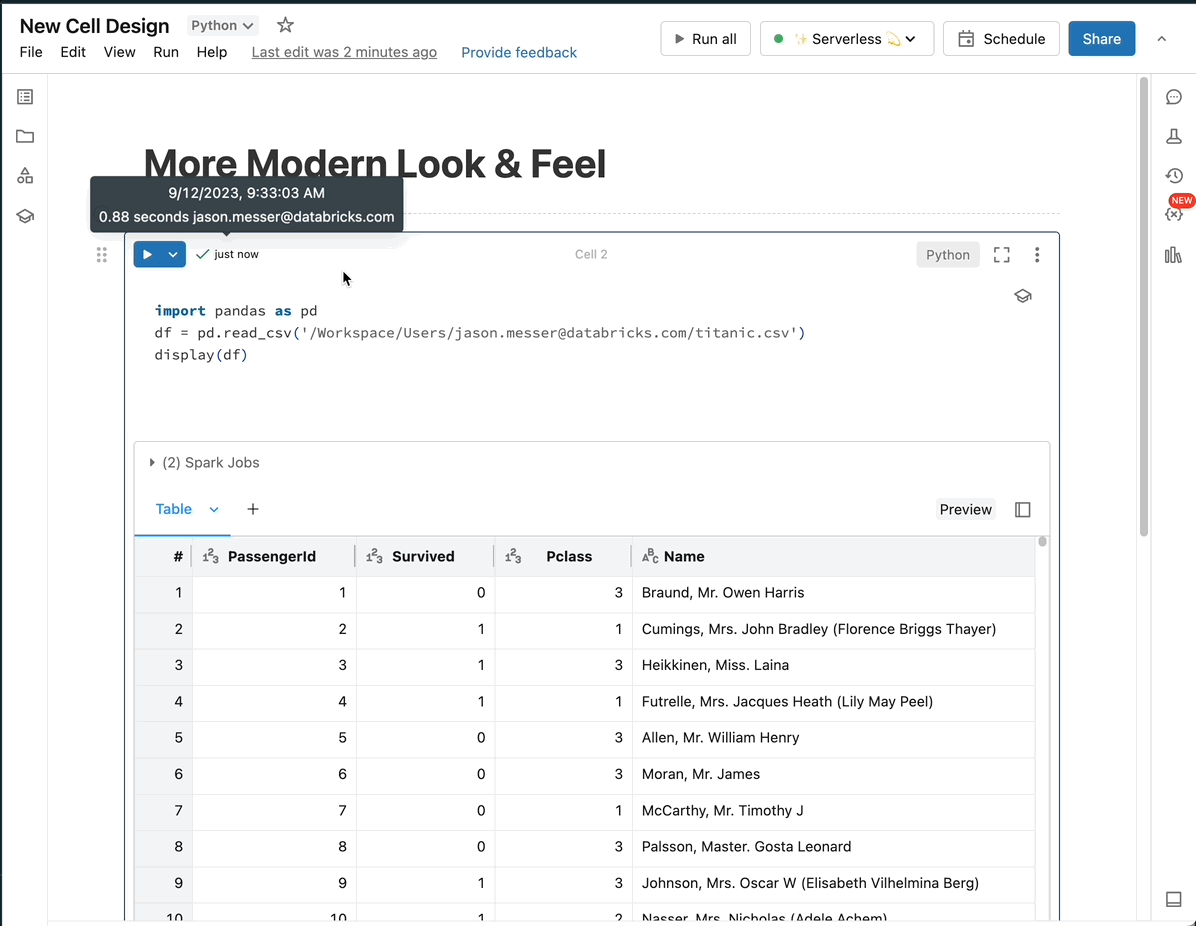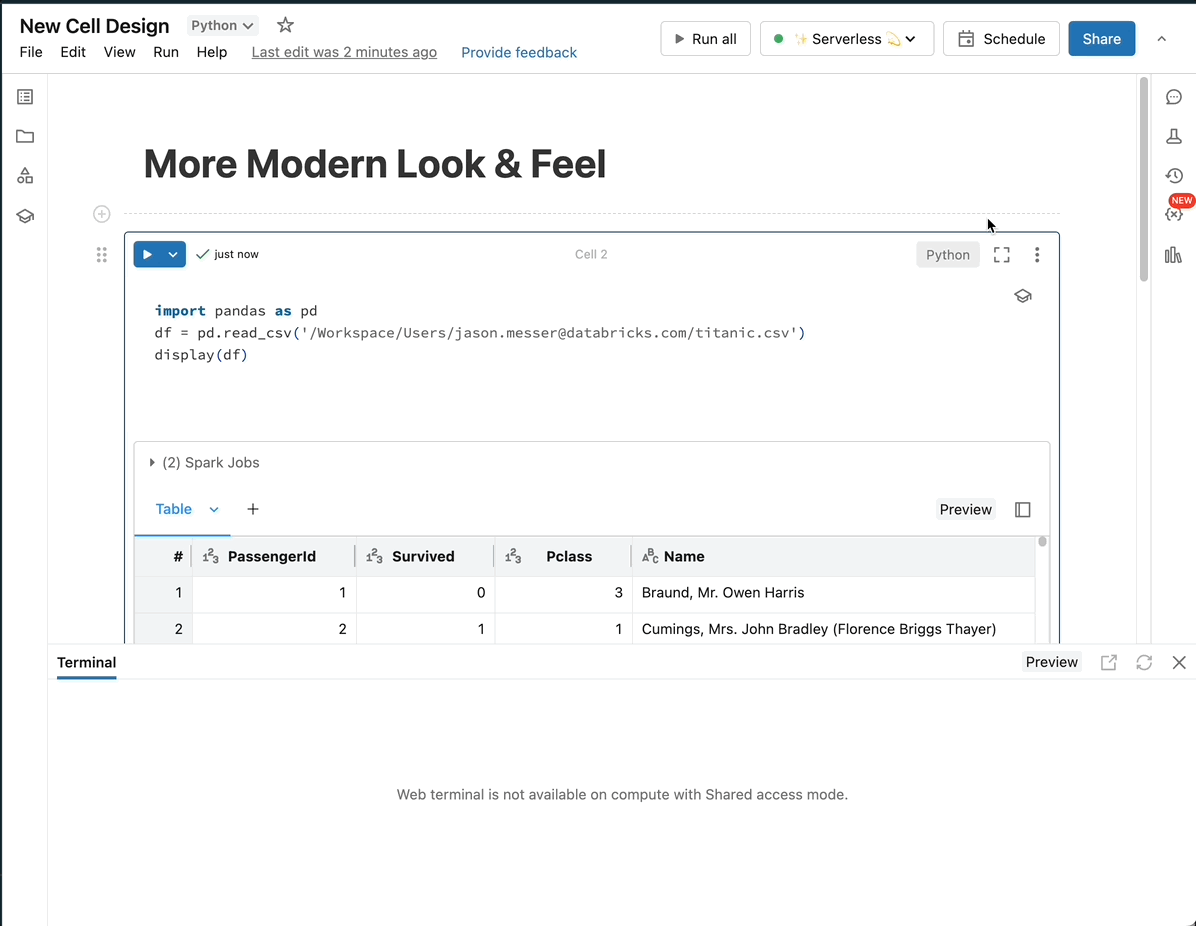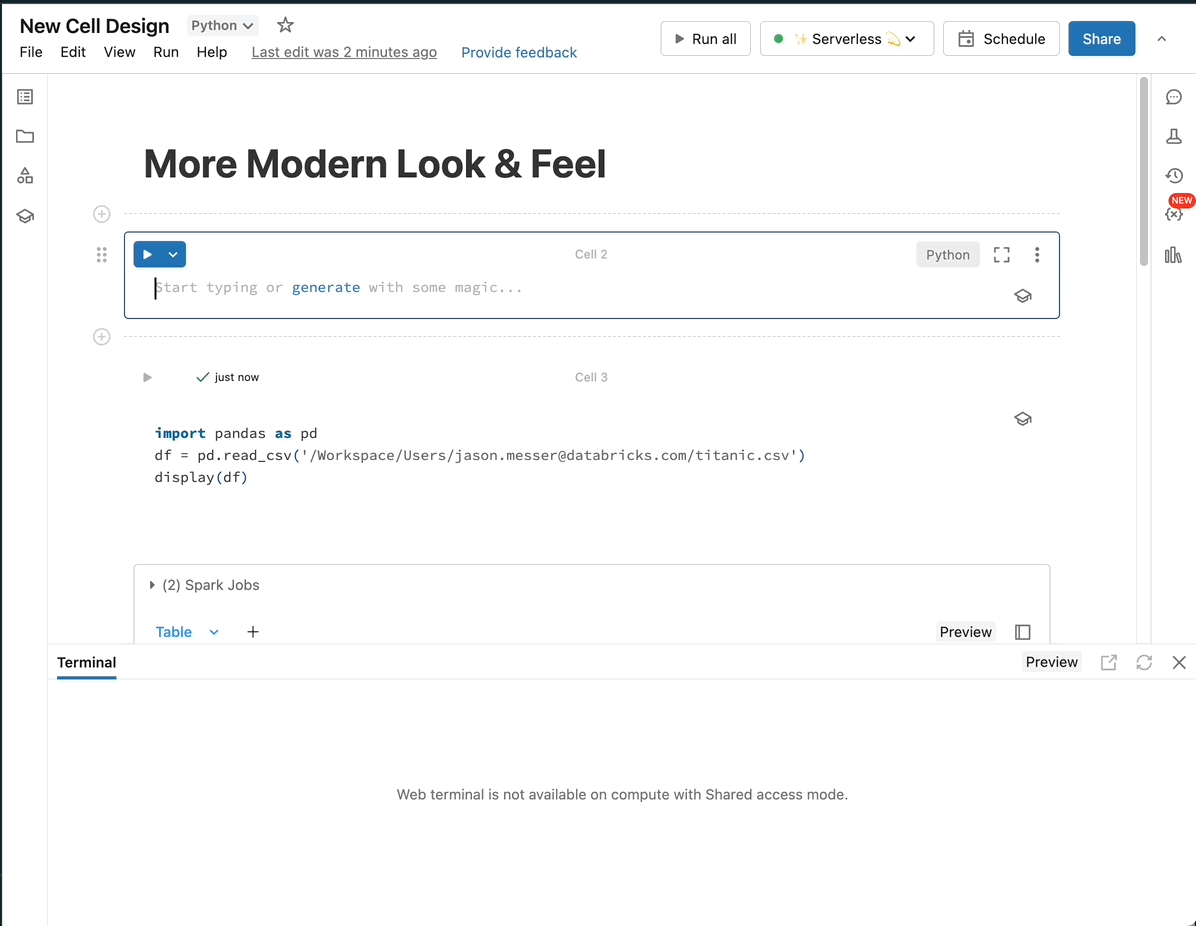
Databricks Notebooksは、Python、SQL、Scala、Rなど複数言語に対応したコードエディタです。セル単位で実行や可視化、Markdownによるドキュメント化、バージョン管理、Git連携、共同編集が行え、Jupyter Notebook以上にエンタープライズ向けのセキュリティやガバナンスを備えています。さらに、ローカルのVisual Studio Codeや他のIDEとの連携も公式にサポートされています。
VSCodeであれば、Databricks拡張機能をインストールし、DatabricksワークスペースとOAuth等で認証することでローカルPC上でノートブックやPythonコードを編集し、そのままクラウド上のDatabricksクラスターで実行・デバッグが可能です。Databricks上ではこのNotebooksをそのままLakeflowでジョブとして扱うことができ、本番環境用にバッチ処理を書き直す必要がなく開発のスピードを上げることができます。
Lakeflow
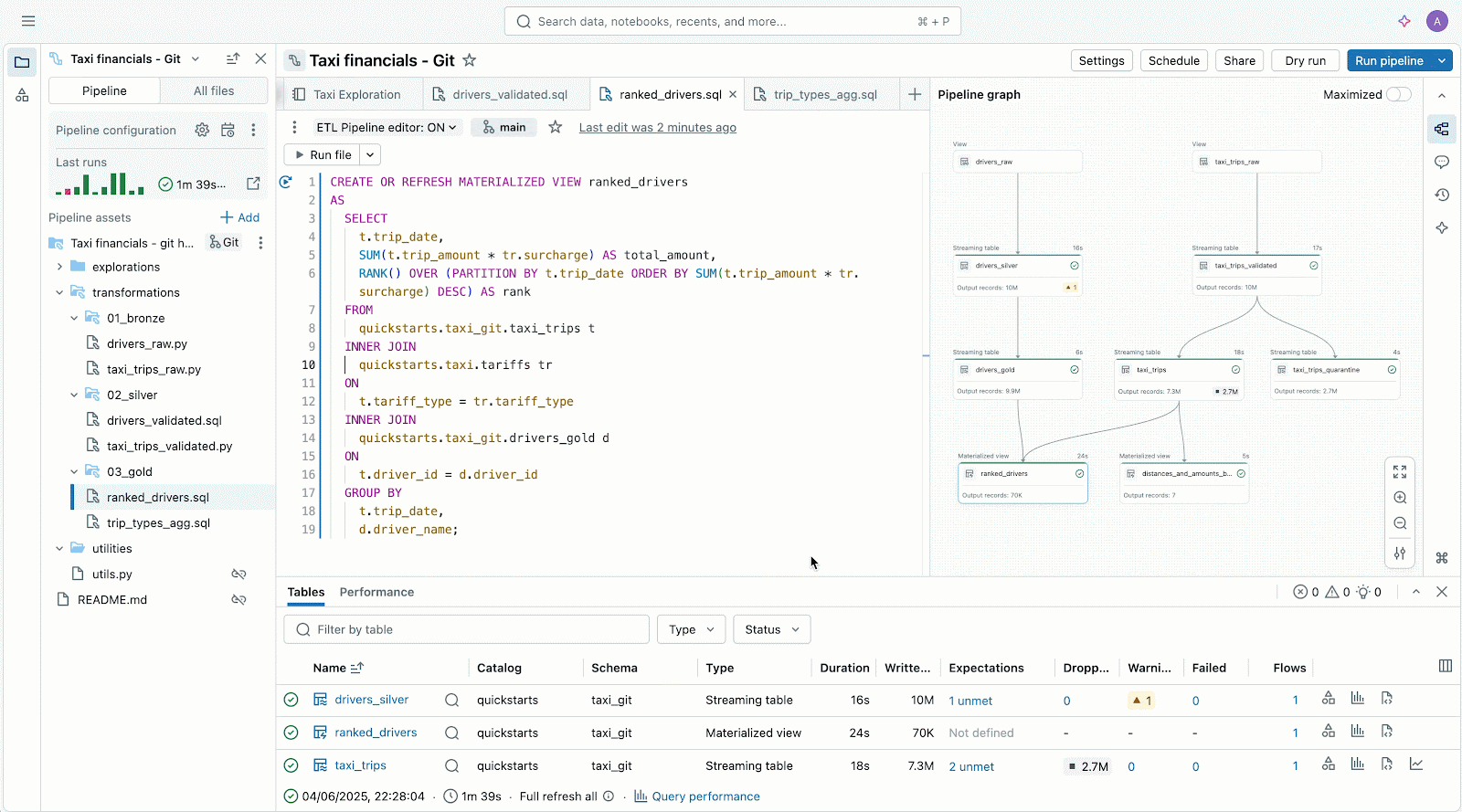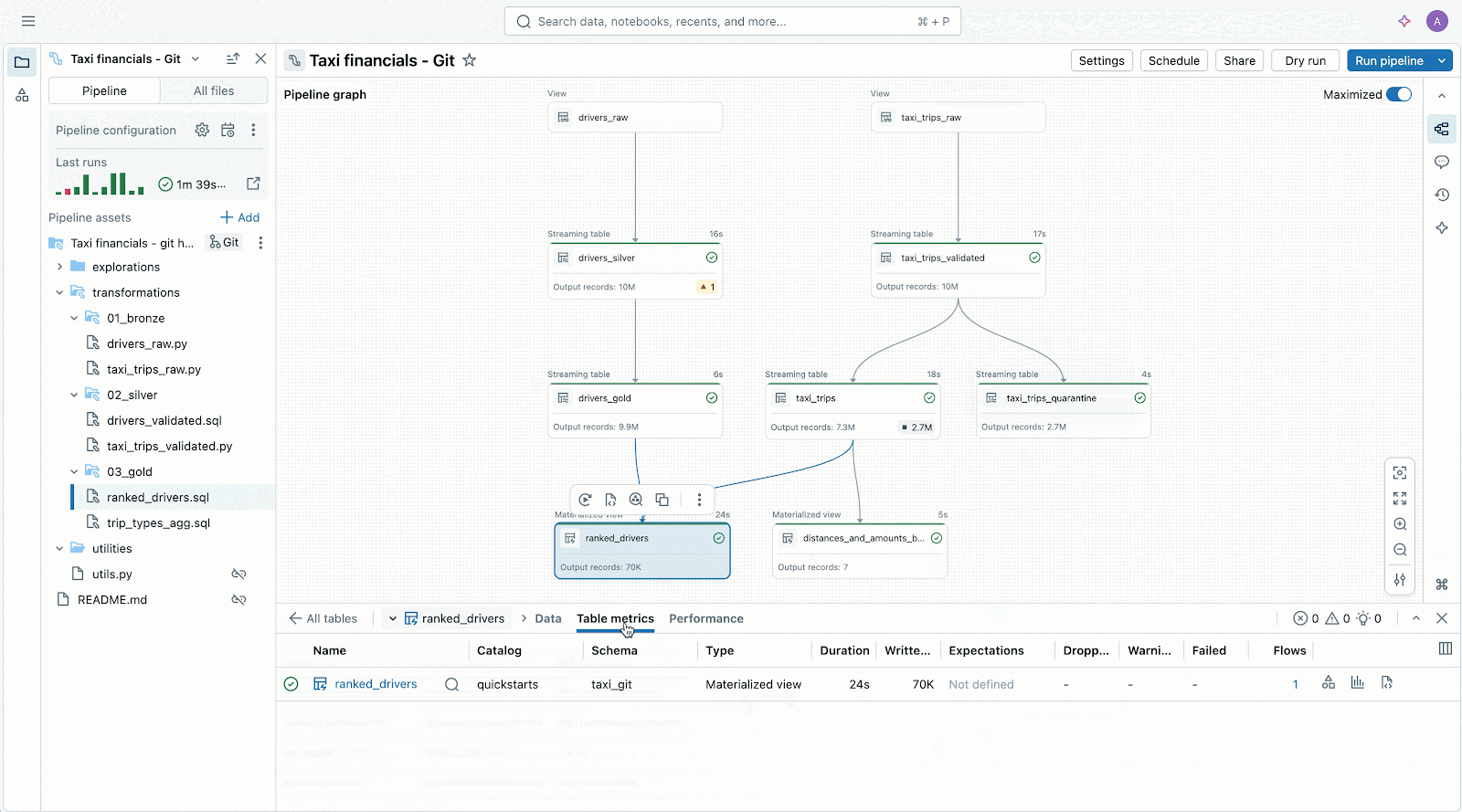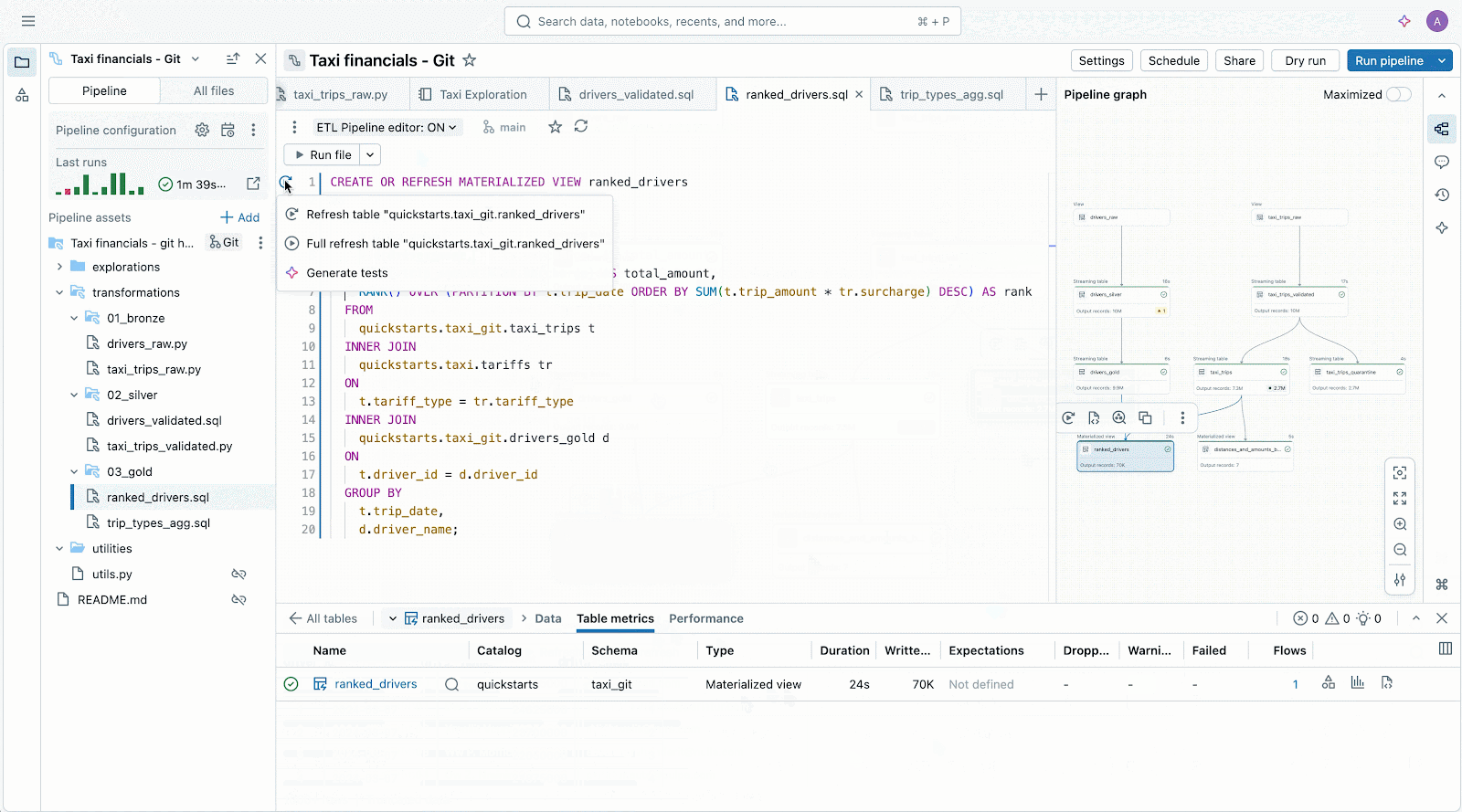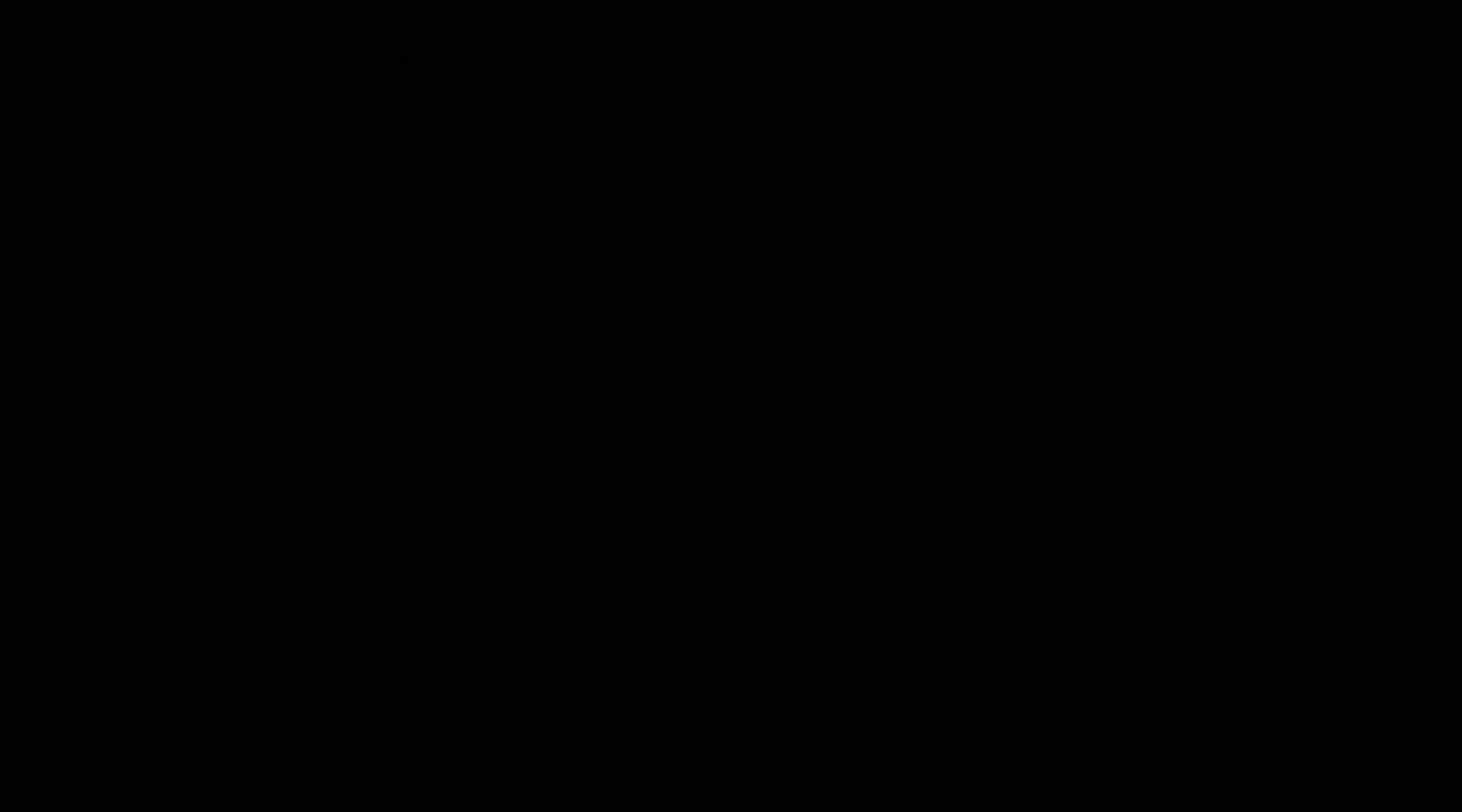
Lakeflowは、「データの取り込み・集計・加工」といった一連の作業をひとまとめにして、効率化できる新しいサービスです。例えば、社外の取引データや社内の売上記録を毎朝まとめる場合、従来はシステム担当者があちこちのデータを手作業で集め、それぞれ決められたルールで加工し、最終的に使いやすい形に整理していました。途中でデータのルールが変わったり、新たな計算が必要になった場合には、毎回作業フローの見直しや新しい手順書作成が必要で、現場の負担はとても大きいものでした。
Lakeflowを使うとバラバラになりがちな作業がすべて一つにまとめて管理されます。自動で「新しいデータだけを取り込む」といった処理をしてくれるので、「昨日の売上だけ抜き出して集計したい」「といったニーズにも簡単に対応できます。また、管理ルールや記録の履歴(リネージ)も自動で追跡できるため、「どのデータがいつどんな流れで使われたのか」もすぐ把握でき、安心してデータ連携やセキュリティ管理が行えます。
さらに、今後「Lakeflow Designer」という、マウス操作や画面選択だけで直感的にデータの加工処理・スケジュールを組めるツールも開発中です。これにより、IT部門とデータを使いたい現場の担当者が協力して「必要な情報をいつでも自動で手に入れられる仕組み」を簡単につくることが可能になります。
Porsche Holding Salzburgというヨーロッパ最大級の自動車販売会社では、顧客データがたくさんのシステムに散在しており、顧客一人ひとりの“統合プロフィール”を作るのが難しい状況でした。そこで、Lakeflow ConnectのSalesforceコネクタとパイプライン機能を活用し、SalesforceからのCRMデータを自動で集め、リアルタイムで加工することで、どの店舗・部署の接点も一元的に参照できる「顧客360度ビュー」を実現しました。
DatabricksApps
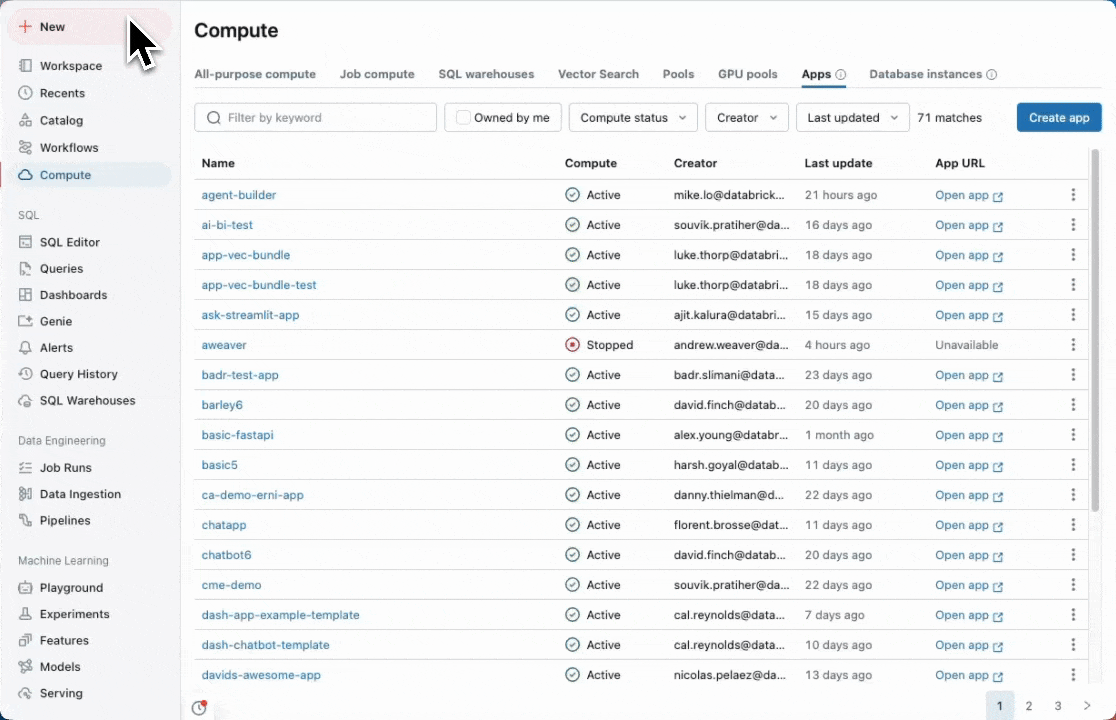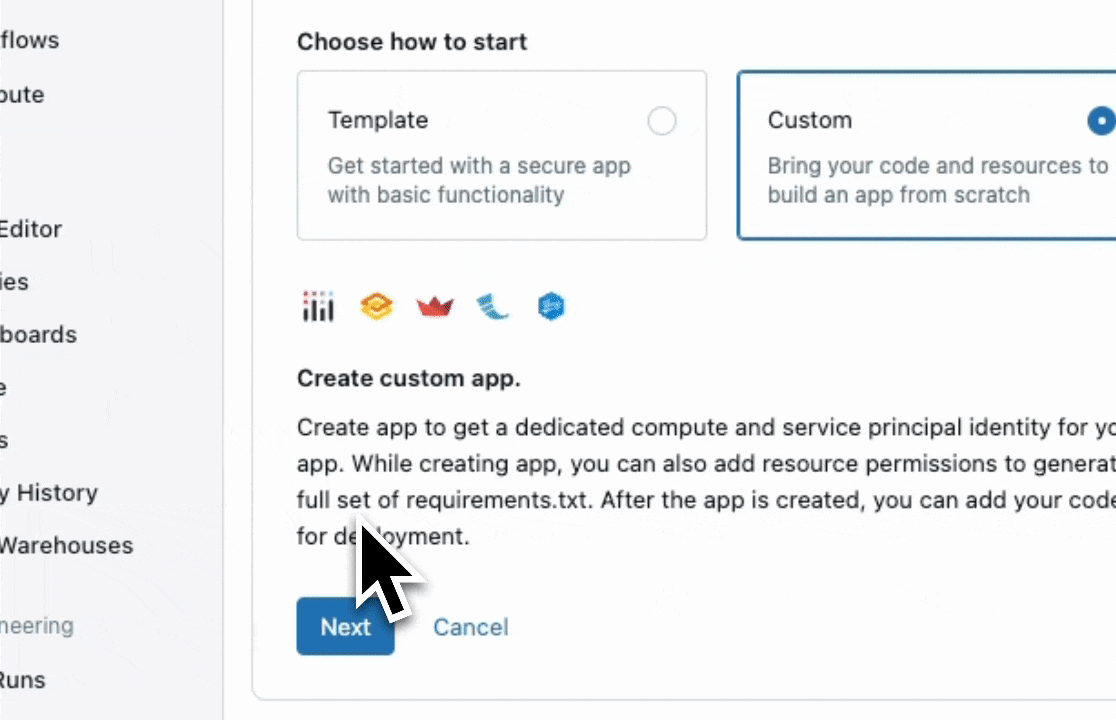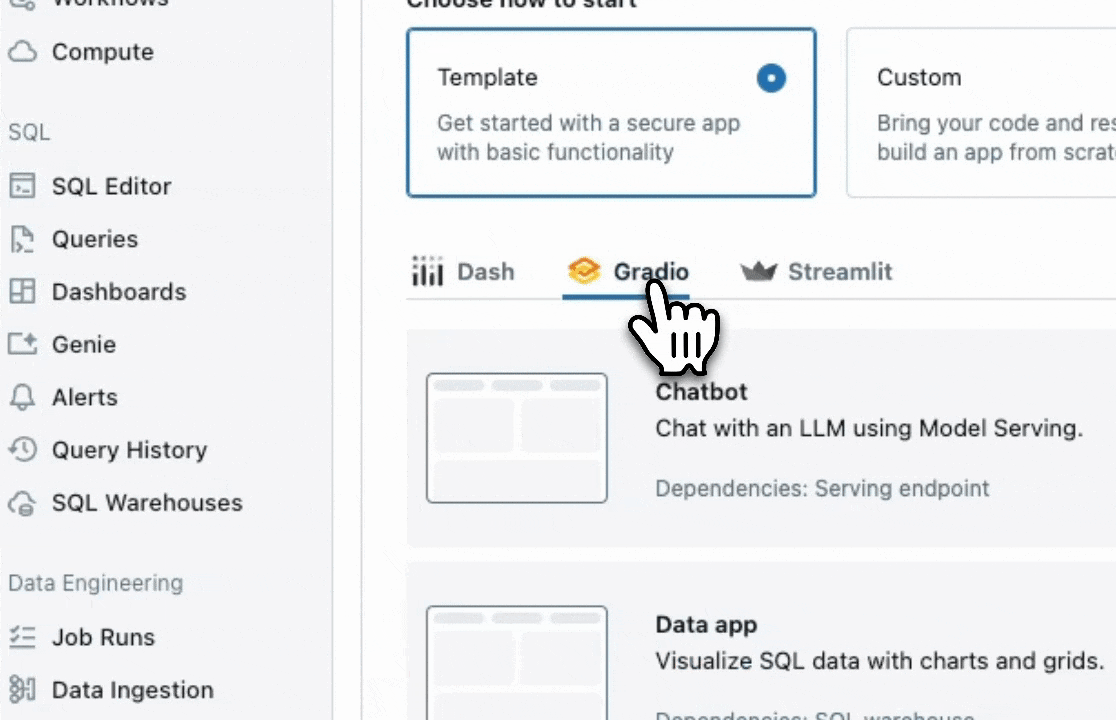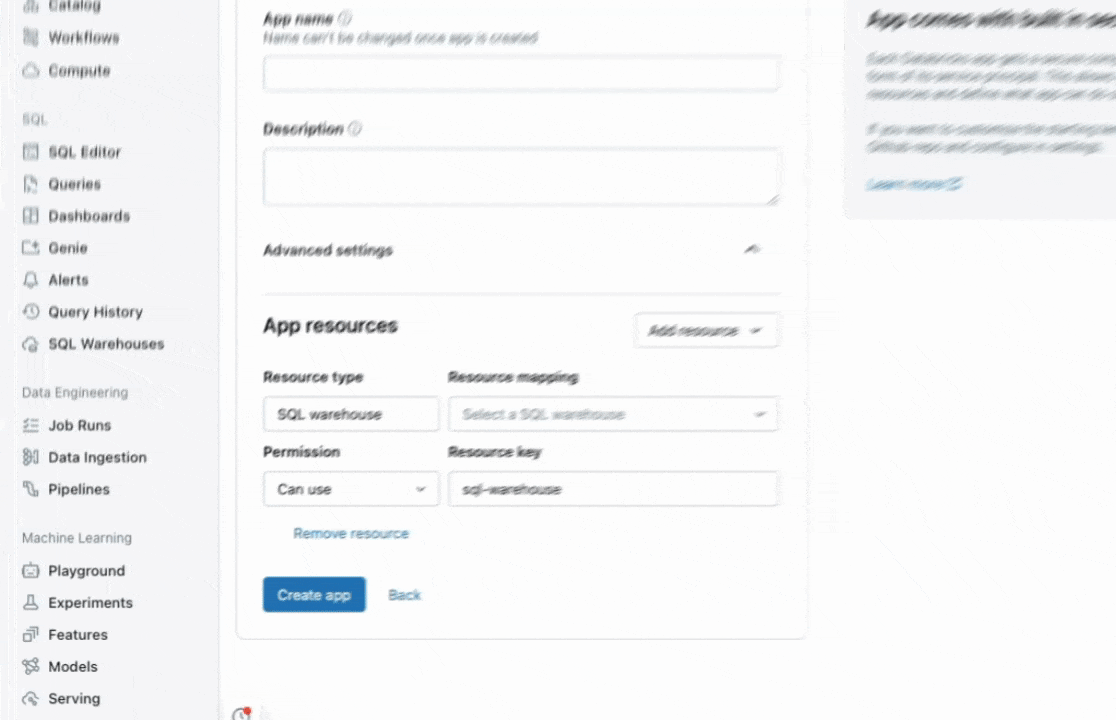
DatabricksAppsはセキュアでガバナンスを担保したアプリをDatabricks上で素早く開発・デプロイできる機能です。面倒な基盤構築が一切不要で、本質的なアプリケーションの構築・運用に集中できます。Unity Catalog連携やSSO対応によりきめ細やかなアクセス制御やワークスペースレベルのセキュリティも万全。GitやCI/CD連携も容易で、迅速にRAGチャット、ダッシュボード、業務効率化ツールなど多様なアプリを作成でき、業務ユーザー向けのツールを安全に社内に展開可能です。
E.ONというヨーロッパを代表する大手エネルギー企業では、Databricks Appsを使い電気自動車(EV)向けの契約管理や、作業員向けの安全管理BIダッシュボードなどを本番運用しています。GenAIを使った契約書データ抽出アプリや、現場作業員の安全監視ダッシュボードを迅速に開発・展開し、1,500人もの担当者がリアルタイムに業務データへアクセスしており、アプリの展開・分析・運用時間が数日→1〜2分に短縮されるなど、事業部門の生産性向上にもつながっています。
AgentBricks
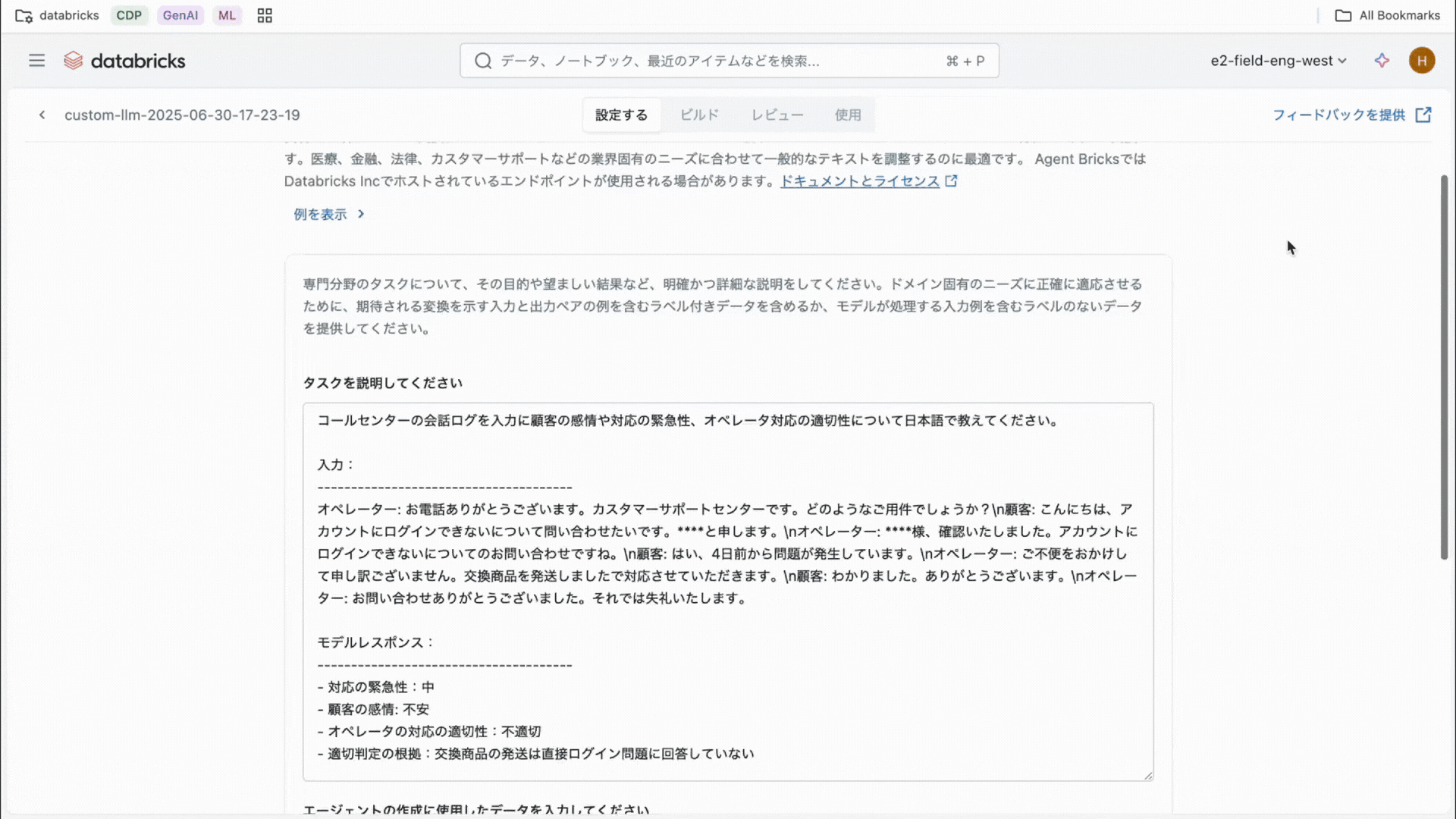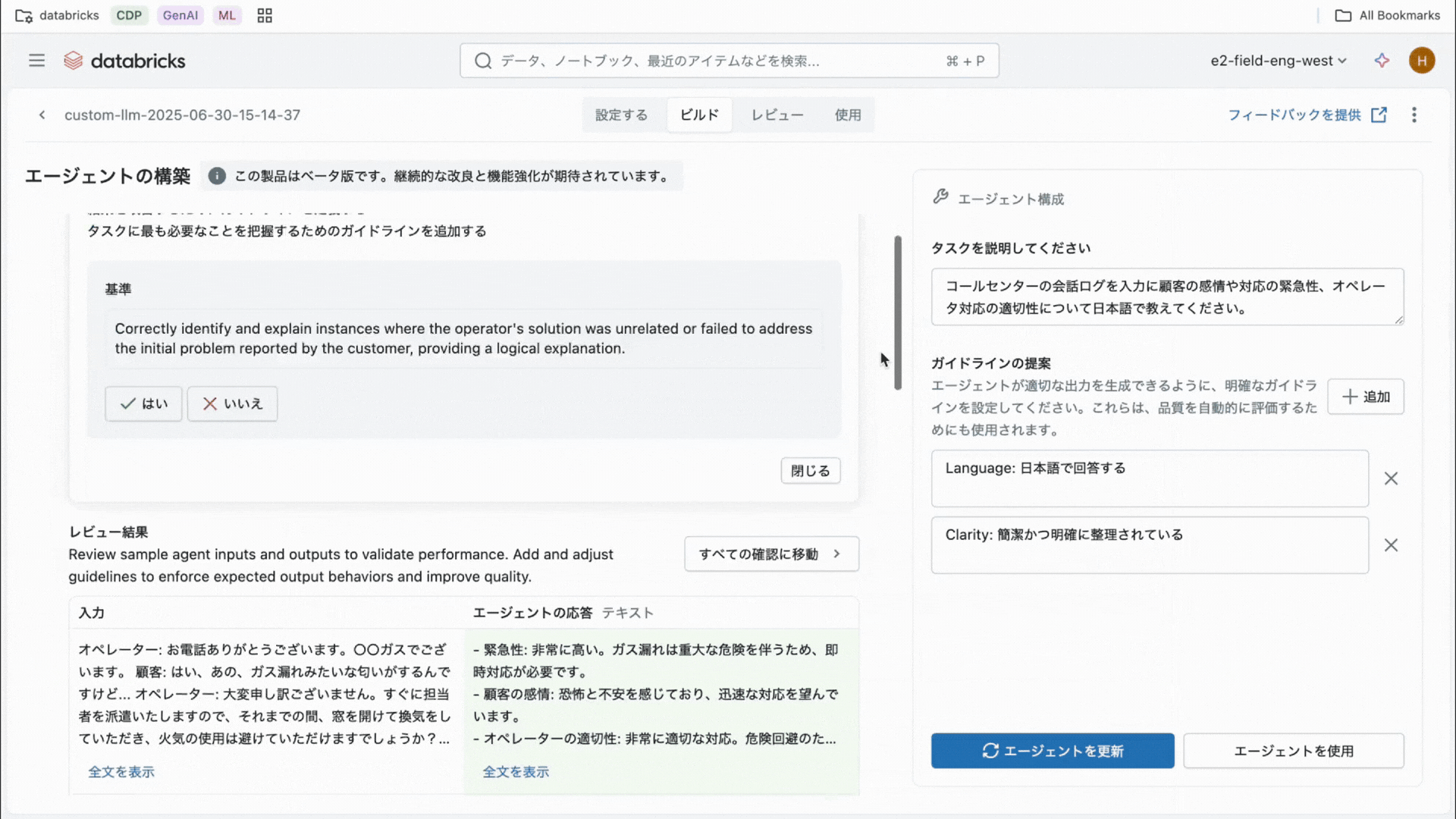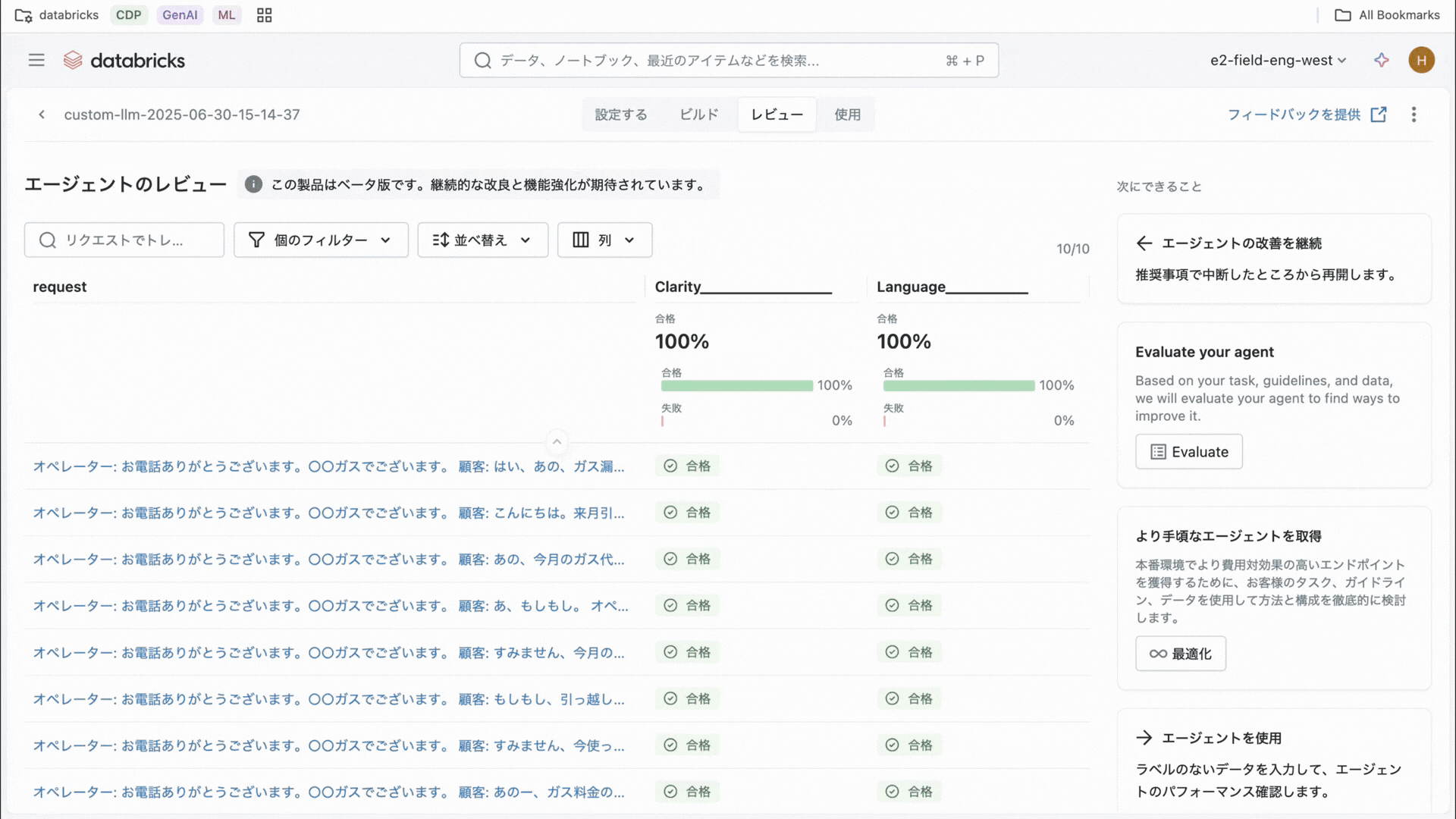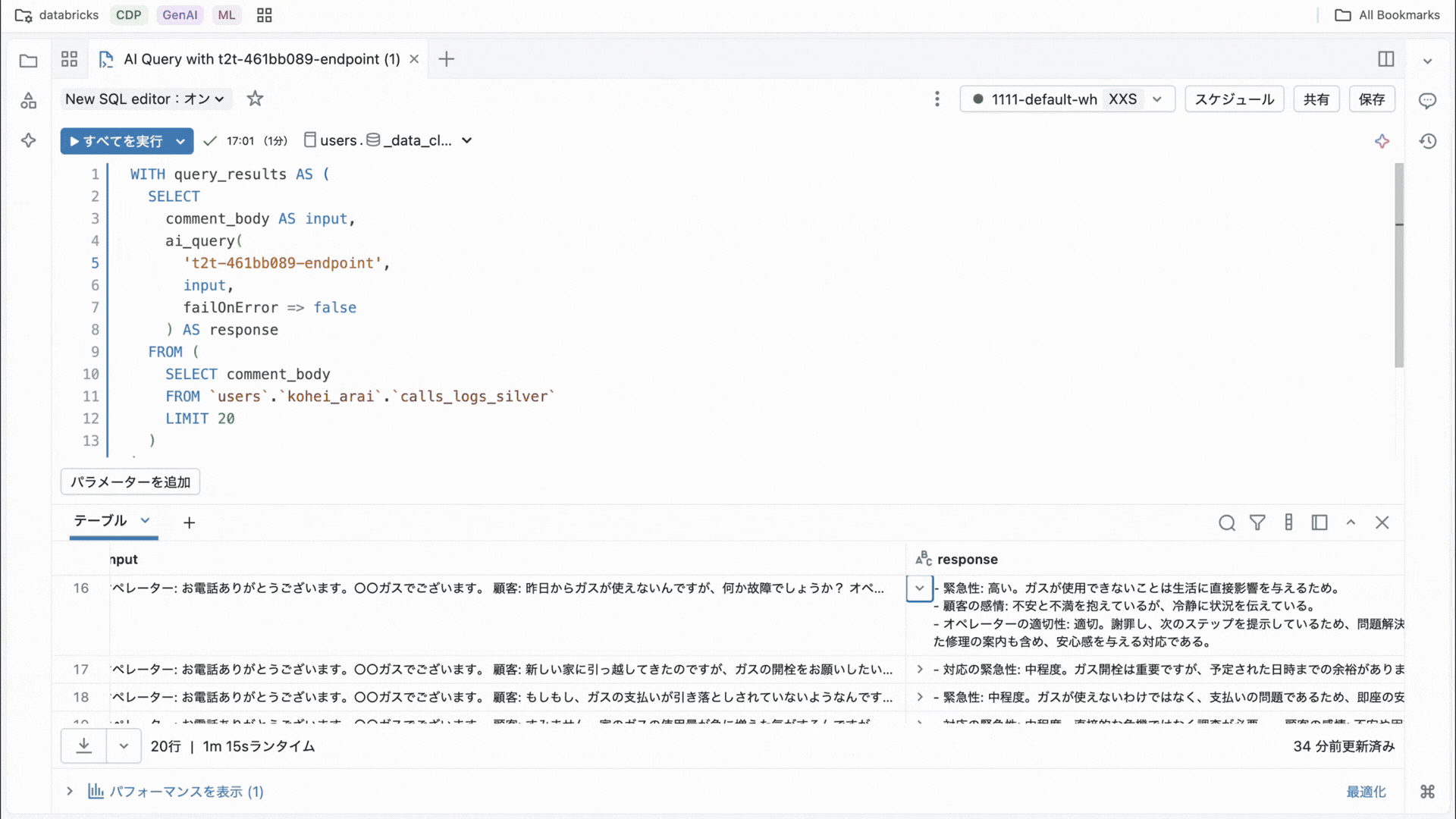
DatabricksはAI Agent開発において、生産性・品質を高める機能を複数提供しています。そのうちの一つがAgentBricksです。まだベータ版にもかかわらず、すでに世界中で400社〜500社以上の顧客に利用されています。Agent Bricksではプログラミングの知識がなくても画面操作だけでAI Agentを作ることができます。
Agent Bricksのガイダンスに沿って「どんな業務を自動化したいか」や「使うデータは何か」を入力し、案内のままに進めるだけでAIエージェントが完成します。新入社員のサポート用チャットボットや、毎月作成する定型レポート作成アシスタントなども、Agent Bricksで数分で作成が可能です。また、複数のエージェントを組み合わせて問い合わせ対応から資料作成まで一連の流れを自動化する、といったマルチエージェントの作成もマウス操作だけで実現できます。
実際に活用されている事例として、海外の大手監査法人ではAgent Bricksの「Knowledge Assistant」機能を用いて、複数のインタビュー記録や監査レポートからキーワードや重要なポイントを自動抽出しています。従来は担当者が時間をかけて整理していた内容もAIが質問に即答してくれるため、調査やレポート作成の負担を大幅に削減することができています。
UnityCatalog
日々の業務で「社内にたくさんのデータがあるものの、どれが最新で誰が管理しているか分からない」「他の部署とデータをやり取りしたいけれど、どんなデータがあるか、何に活用しているのか分からない」と感じたことはありませんか?Unity Catalogは、そうした“データにまつわるモヤモヤ”を解消し、ビジネス現場が安全かつスムーズにデータを使えるようにするためのDatabricksの仕組みです。
例えば、UnityCatalogを使うことで会社の色々な部署やプロジェクトのデータを一つのプラットフォームで管理し、今までシステムからダウンロードしてエクセルファイルで連携していたデータも最新かつ間違いの無い状態でURLひとつで連携することができてしまいます。しかし、そうすると問題になってくるのはセキュリティとガバナンスです。
Unity Catalogは、こうしたリスクを根本から解決します。たとえば「営業部の売上データはこの部署だけ」「顧客リストはこのプロジェクトのメンバーしか見られない」「個人情報は人事担当だけ編集可能」など、細かな利用権限を設定・管理できます。さらにUnity Catalogでは、すべての操作履歴(誰がどのデータをいつ参照・編集したか)が自動記録されます。もし誤った操作や不正なアクセスがあった場合も、履歴をたどってすぐ原因を発見できるため「透明性のあるデータ管理」が実現します。
また、「この売上データは誰が・どこから・いつ作ったもの?」「この集計に使われている元データは信用できる?」といった“データの履歴や出どころ”も、Unity Catalogなら自動で追跡される仕組みが組み込まれています。そのため毎回作った人にデータの出所を聞く必要がなくなります。
ネスレUSAでは、複数の部署やクラウド環境にまたがる大量のデータをUnity Catalogでまとめて一元管理しています。これにより1,000以上のデータテーブルが安全に横断的に利用できるようになり、社員による検索やセルフサービスでのデータ分析も簡単に行えるようになりました。サステナビリティやサプライチェーン分析の現場でも活用が進み、管理や運用にかかるコストは80%削減、年間で1万時間以上の工数が節約されています。
最後に
一部ではありますがDatabricksの概要を紹介させて頂きました。
しかし、実際に触ってみないと今ひとつ理解しづらいと思います。そこで興味がある方はぜひ無料で使用できるFreeEditionを触ってみてください。サーバレスで提供されており、ボタンひとつで起動でき、計算リソースは小規模に制限されているもののDatabricksの機能を簡単に利用することができます。
Databricksに実際に「触れて」みて初めてわかる発見がきっとあるはずです。まずはFree Editionで気軽に試し、Databricksが作るデータ基盤の未来と可能性に触れてみてください。
◆執筆:データブリックス・ジャパン株式会社・近藤拓三





