



SRE 30分クッキング「SLOベースのアラートを設定してみよう」
まえがき
ENECHANGE株式会社の岩本(iwamot)です。VPoTを務めるかたわら、全社的な技術方針をリードする役割のCTO室にて、インフラ・SREチームのマネージャーも務めています。個人としては、AWS Community Builder(Cloud Operation)としても活動中です。
この記事を読むと「SLOベースのアラート」の導入ステップが、料理のレシピのようにわかりやすく学べます。
具体的には、最終的な完成イメージや必要な材料・ツールを示しつつ、工程を順に説明していく内容です。学習時間として、およそ30分を想定しています。
SLOの策定・運用は、とても重要です。信頼性の低いサービスからはユーザーが離れてしまいます。一方で、100%の信頼性を目指すのも高コストで非現実的です。つまり適切なサービスレベル目標を定め、信頼性の低下をアラートで知らせる運用が最適解となります。
ぜひ一緒に「SLOベースのアラート」の導入ステップを学んでいきましょう。
完成イメージ
- 「複数ウィンドウ、複数バーンレートのアラート」を導入し、Webサービスの可用性を監視している状態
この記事で目指すゴールは、上記の状態です。
「複数ウィンドウ、複数バーンレートのアラート」とは、たとえば、下記の条件式が「真」になる場合にアラートする手法を指します。
expr: ( job:slo_errors_per_request:ratio_rate1h{job="myjob"} > (14.4*0.001) and job:slo_errors_per_request:ratio_rate5m{job="myjob"} > (14.4*0.001) ) or ( job:slo_errors_per_request:ratio_rate6h{job="myjob"} > (6*0.001) and job:slo_errors_per_request:ratio_rate30m{job="myjob"} > (6*0.001) )引用元:https://sre.google/workbook/alerting-on-slos/
文章で書くなら、下記のいずれかを満たす場合にアラートする手法です。
- 「直近1時間のエラー率が
14.4*0.001を超えている」かつ「直近5分間のエラー率が14.4*0.001を超えている」 - 「直近6時間のエラー率が
6*0.001を超えている」かつ「直近30分間のエラー率が6*0.001を超えている」
ここで、 14.4 や 6 などの係数は、警戒すべきバーンレート(エラーバジェットの消費速度)を表します。これらは、この手法を提唱している『サイトリライアビリティワークブック』の著者の経験則に基づく値です。
1時間や6時間といった複数のウィンドウ(時間軸)と、 14.4 や 6 といった複数のバーンレートを条件式に含めることにより、誤報が少なくなるメリットがあるとされています。詳しくは同書をご参照ください。
必要な材料
- 可用性を監視したいWebサービスのアクセスログ
この記事では、Webサービスのアクセスログを材料として工程を説明します。
ただし、イベントの成功/失敗が明確にわかるログであれば、なんでも構いません。たとえばフロントエンドのサービスレベルを監視したい場合は、フロントエンドのイベントログを材料にできます。
必要なツール
- メトリクス集計機
- メトリクス保存器
- アラート発報機
メトリクス集計機は、特定期間のログをスキャンし、全イベント数と失敗イベント数を集計する機械です。 これがなければ、肝心のエラー率が計算できません。
ひとつ飛ばして アラート発報機は、特定の条件を満たした場合にアラートを発報する機械です。 エラー率が計算できても、目視し続けるのは当然ながら非効率なので、バーンレートが高いときのみアラートするよう設定します。
残った メトリクス保存器は、集計したイベント数を保存する器です。 保存された値を、2つの機械から下記のように参照します。
- アラート発報機から、条件式が真となるか判定するために参照する
- メトリクス集計機から、無駄な再スキャンを抑えるために参照する
このように3つのツールをうまく使うことで「SLOベースのアラート」が効率的に実現できます。
AWSでのツール構成
AWSをお使いであれば、下記の構成で始めるのがシンプルかつ低コストです。
- メトリクス集計機:AWS Lambda + Amazon Athena
- メトリクス保存器:Amazon CloudWatchメトリクス + Amazon RDS
- 前者はアラート発報機から参照、後者はメトリクス集計機から参照
- アラート発報機:Amazon CloudWatchアラーム
メトリクス保存器をCloudWatchメトリクスだけにすると、特に長期間のデータを繰り返し集計する際、APIコストがかさみやすくなります。そこで、冗長にはなりますが、RDSなどのデータベースにも集計値を保存して再利用するのが効率的です。
工程
- 工程1:可用性のSLOを決める
- 工程2:5分間ごとのメトリクスを集計して保存する
- 工程3:30分間・1時間・6時間ごとのメトリクスを集計して保存する
- 工程4:集計結果に応じてアラートを発報するよう設定する
工程1:可用性のSLOを決める
まず、可用性のSLOを決めます。目標が決まらなければ、エラーバジェットも決まらず、適切な監視ができません。運用を始めてから変えるのも普通のことなので、気軽に決めてしまいましょう。
下記がSLOの例です。
POST https://example.com/critical-path の直近30日間の可用性が99.5%
特に浮かばない場合は、 運用しているWebサービスのうち、もっともPOSTリクエストの多そうなエンドポイントを選んで「直近30日間の可用性が99.5%であること」をSLOとします 。
なお、ここで可用性とは、イベントの成功率を指します。Webサービスの場合は「HTTPレスポンスのステータスコードが2xx・3xx・4xxのいずれかであること」を成功と見なすイメージです。ただし、意図しない「429 Too Many Requests」は、失敗と見なすことをお勧めします。
工程2:5分間ごとのメトリクスを集計して保存する
続いて、 5分間ごとの全イベント数と失敗イベント数をメトリクス集計機で集計し、メトリクス保存器に保存するようにします 。単位時間が5分なのは、前述の条件式において最短のウィンドウが5分だからです。
メトリクスの保存イメージは下記となります(※レシピに登場する時刻は、すべてUTCです)。
| 処理対象ウィンドウ | 全イベント数 | 失敗イベント数 |
|---|---|---|
| 2024-11-01 15:55~16:00 | 1,053 | 18 |
| 2024-11-01 16:00~16:05 | ... | ... |
| ... | ... | ... |
たとえば、AWSのApplication Load Balancer(ALB)でWebサービスを運用している場合は、下記が実装の一例です。
- 5分ごとに、下記の処理を実行するLambda関数を呼び出す
- ALBのアクセスログをAthenaでクエリし、処理対象ウィンドウの各イベント数を集計する
- 集計結果をCloudWatchにカスタムメトリクスとして保存する
- また、集計結果をRDSにも保存する
ALBのアクセスログをAthenaでクエリできるようにする方法は「パーティション射影を使用して Athena で ALB アクセスログ用テーブルを作成する」をご参照ください。
Athenaのクエリ例は下記の通りです。「パラメータ化されたクエリ」を使っています。
WITH params AS (
SELECT
-- 処理対象ウィンドウ(5分間)の終了時刻。例:"2024-11-01 16:00:00"
? param_data_point_time,
-- 監視対象とするHTTPメソッド。例:"POST"
? param_http_method,
-- 監視対象とするURLのパス。例:"/critical-path"
? param_path
)
SELECT
-- 全イベント数
count(*),
-- 失敗イベント数
count_if(is_bad_for_availability)
FROM (
SELECT
-- 「429 Too Many Requests」も失敗と見なす
(elb_status_code >= 500 OR elb_status_code = 429) is_bad_for_availability
FROM
-- ALBアクセスログ用テーブル
alb_access_logs,
params
WHERE
-- スキャン範囲を狭めるためのパーティションキー。例:"2024/11/01"
day >= ?
AND request_verb = param_http_method
AND url_extract_path(request_url) = param_path
-- 処理ウィンドウ内のログだけを集計する
AND date_format(
from_unixtime(
(FLOOR(to_unixtime(from_iso8601_timestamp(time)) / 300) * 300) + 300
),
'%Y-%m-%d %H:%i:%s'
) = param_data_point_time
) t, params;
また、CloudWatchメトリクスへの保存例は下記のようになります。
import boto3
import time
# 処理対象ウィンドウの終了時刻
timestamp = time.strptime("2024-11-01 16:00:00", "%Y-%m-%d %H:%M:%S")
# 全イベント数
total_count = 1053
# 失敗イベント数
bad_count = 18
metric_data = [
{
"MetricName": "TotalCount",
"Dimensions": [
{"Name": "TimeWindow", "Value": "5m"}
],
"Timestamp": timestamp,
"Value": total_count,
"Unit": "Count",
},
{
"MetricName": "BadCount",
"Dimensions": [
{"Name": "TimeWindow", "Value": "5m"}
],
"Timestamp": timestamp,
"Value": bad_count,
"Unit": "Count",
}
]
cloudwatch = boto3.client("cloudwatch")
cloudwatch.put_metric_data(
Namespace="SLO",
MetricData=metric_data,
)
あとは、RDSにも同様に保存すればOKです。
CREATE TABLE IF NOT EXISTS slo_metrics (
-- 処理対象ウィンドウ(5分間)の終了時刻。例:"2024-11-01 16:00:00"
data_point_time TIMESTAMP WITHOUT TIME ZONE,
-- 全イベント数
total_count INTEGER NOT NULL,
-- 失敗イベント数
bad_count INTEGER NOT NULL,
PRIMARY KEY (data_point_time)
);
INSERT INTO slo_metrics (data_point_time, total_count, bad_count)
VALUES ('2024-11-01 16:00:00', 1053, 18)
ON CONFLICT DO NOTHING;
AWSでの例が続きましたが、AWS以外のクラウドやオンプレミスでも、このような集計や保存は難しくないでしょう。
工程3:30分間・1時間・6時間ごとのメトリクスを集計して保存する
次に、 30分間・1時間・6時間ごとの全イベント数と失敗イベント数をメトリクス集計機で集計し、メトリクス保存器に保存するようにします 。前述の条件式において、30分間・1時間・6時間のエラー率が条件に含まれているためです。
メトリクスの保存イメージは下記となります。
| 処理対象ウィンドウ | 全イベント数 | 失敗イベント数 |
|---|---|---|
| 2024-11-01 15:30~16:00(30分間) | 6,352 | 80 |
| 2024-11-01 15:00~16:00(1時間) | 16,756 | 143 |
| 2024-11-01 10:00~16:00(6時間) | 139,302 | 984 |
| 2024-11-01 15:35~16:05(30分間) | ... | ... |
| 2024-11-01 15:05~16:05(1時間) | ... | ... |
| 2024-11-01 10:05~16:05(6時間) | ... | ... |
| ... | ... | ... |
集計の際には、工程2で保存した5分単位のメトリクスを参照するのが効率的です。たとえば「10:00~16:00」のイベント数を集計するなら、「10:00~10:05」「10:05~10:10」...「15:55~16:00」のメトリクスを合計します。期間内のログを再スキャンするより低コストです。
RDSだと、下記のようなSELECT文を実行するだけで集計できます。
SELECT SUM(total_count) AS total_count, SUM(bad_count) AS bad_count
FROM slo_metrics
WHERE data_point_time > '2024-11-01 10:00:00'
AND data_point_time <= '2024-11-01 16:00:00';
CloudWatchメトリクスへの保存時には、ディメンションを 30m 、 1h 、 6h のようにすればOKです。
以上のような集計や保存も、工程2と同じく、クラウドとオンプレミスのどちらでも難しくないでしょう。
工程4:集計結果に応じてアラートを発報するよう設定する
最後に、 完成イメージで示した条件式をアラート発報機に設定します 。条件式は下記の通りです。
expr: ( job:slo_errors_per_request:ratio_rate1h{job="myjob"} > (14.4*0.001) and job:slo_errors_per_request:ratio_rate5m{job="myjob"} > (14.4*0.001) ) or ( job:slo_errors_per_request:ratio_rate6h{job="myjob"} > (6*0.001) and job:slo_errors_per_request:ratio_rate30m{job="myjob"} > (6*0.001) )
AWSであれば、4つのCloudWatchアラームと、1つのCloudWatch複合アラームで、条件式が簡単に実装できます。複合アラームを使えば、複数の条件を組み合わせたアラートが可能です。他のクラウドやオンプレミスでも似た設定ができるでしょう。
工程2と3で例示した値の場合、2024-11-01 16:00時点でどのような結果になるか、実際に計算してみます。
expr: (
(143/16756) > (14.4*0.001) # 0.0085 > 0.0144 -> 偽
and
(18/1053) > (14.4*0.001) # 0.0171 > 0.0144 -> 真
) -> 偽
or
(
(984/139302) > (6*0.001) # 0.007 > 0.006 -> 真
and
(80/6352) > (6*0.001) # 0.013 > 0.006 -> 真
) -> 真
「偽 or 真」なので、結果は「真」で、アラートが発報されるのが正しい挙動です。
ただし、この条件式は「直近30日間の可用性が99.9%であること」のSLOを前提としています。SLOが「直近30日間の可用性が99.5%であること」の場合は、右辺の 0.001 を 0.005 としなければなりません。正しく設定しないと誤報につながるのでご注意ください。
expr: (
(143/16756) > (14.4*0.005) # 0.009 > 0.072 -> 偽
and
(18/1053) > (14.4*0.005) # 0.017 > 0.072 -> 偽
) -> 偽
or
(
(984/139302) > (6*0.005) # 0.01 > 0.03 -> 偽
and
(80/6352) > (6*0.005) # 0.01 > 0.03 -> 偽
) -> 偽
以上で「SLOベースのアラート」の完成です。「複数ウィンドウ、複数バーンレートのアラート」を導入し、Webサービスの可用性を監視している状態になりました。
アレンジレシピ:ダッシュボード添え
余裕のある方は、 サービスレベルの実測値(例:30日間で99.974%)を集計して保存し、ダッシュボードに表示してみましょう。
下図は、筆者が勤務先のENECHANGEで運用しているCloudWatchダッシュボードの例です。サービスレベルの実測値と推移、アラートの発報状況、エラー数の推移を表示しています。
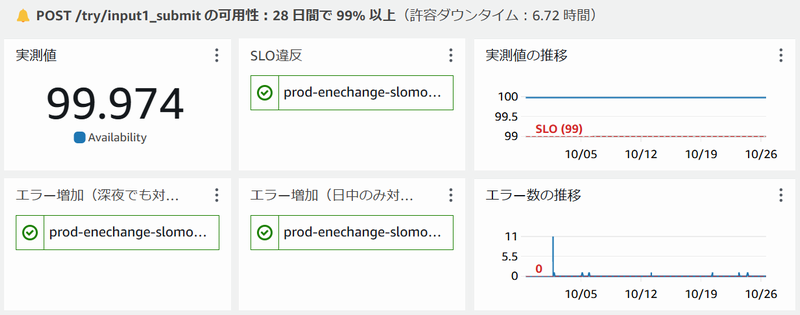
AWSに限らず、ダッシュボードをお使いの場合は、ぜひお試しください。
あとがき
この記事では「SLOベースのアラート」の導入ステップを、料理のレシピになぞらえてご紹介しました。 ぜひ手を動かして、この手法の便利さを味わっていただければ幸いです。
なお、ENECHANGEでの運用例は、Findy Toolsの「Amazon CloudWatchによるSLOエラーバジェットのバーンレート監視」にも投稿しております。AWSをお使いの方は、あわせてご参照ください。





