



【AI Engineering Summit Tokyo 2025】CARTAのAI-CoEが挑む「事業を進化させるAIエンジニアリング」
2025年12月16日、ファインディ株式会社が主催するイベント「AI Engineering Summit Tokyo 2025」が浜松町コンベンションホールで開催されました。
本記事では、株式会社CARTA HOLDINGS Generative AI Lab リーダーの海老原 昂輔さんによるセッション「CARTAのAI-CoEが挑む『事業を進化させるAIエンジニアリング』」の内容をお届けします。
生成AIを単なるブームに終わらせず、いかにして実業務に浸透させ、事業を進化させる力へと変えていくのか。海老原さんは自らの組織が経験した手痛い失敗談を交えながら、AIエンジニアリングの本質と戦略的な推進体制について語りました。
■プロフィール
海老原 昂輔
株式会社CARTA HOLDINGS
Lighthouse Studio (CTO) / CTO 室 スタッフエンジニア / Generative AI Lab リーダー
AIアプリケーションの「予測不可能性」と向き合う

みなさん、こんにちは。株式会社CARTA HOLDINGSの海老原と申します。
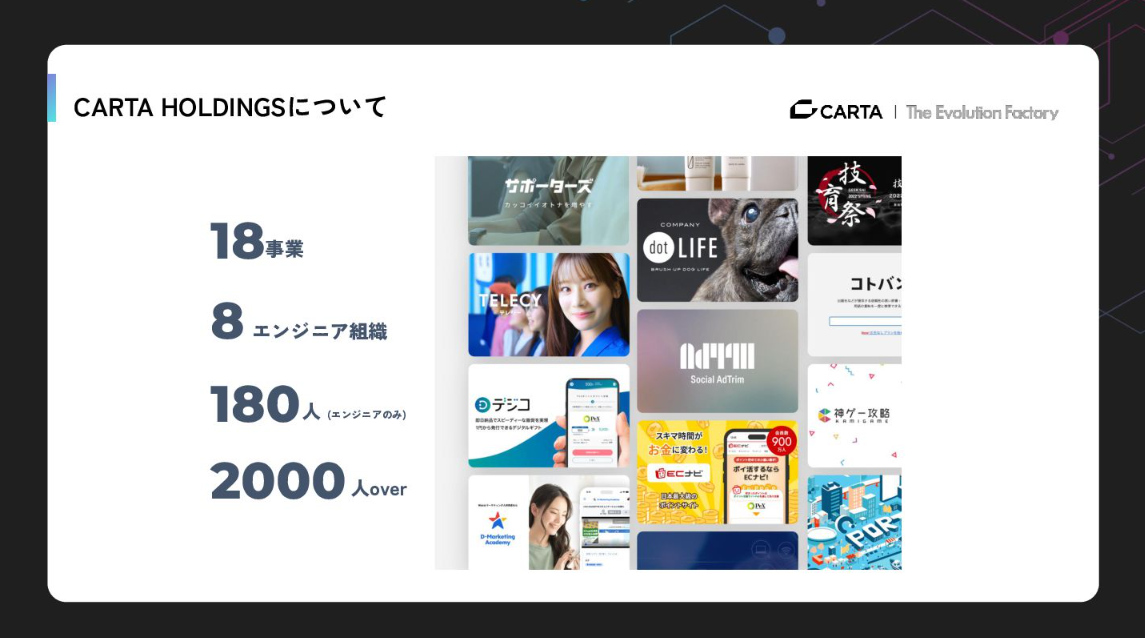
私たちCARTA HOLDINGSは、デジタルマーケティングやメディア運営、HRなど、多角的に18もの事業を展開し、約2,000名の従業員を抱える巨大な組織です。
今日お話しするのは「事業を進化させるAIエンジニアリング」というテーマですが、よくある成功事例の自慢大会にするつもりはありません。むしろ、私たちが経験した「失敗」こそが重要だと思っているので、そこから学んだことを率直にお伝えできればと考えています。
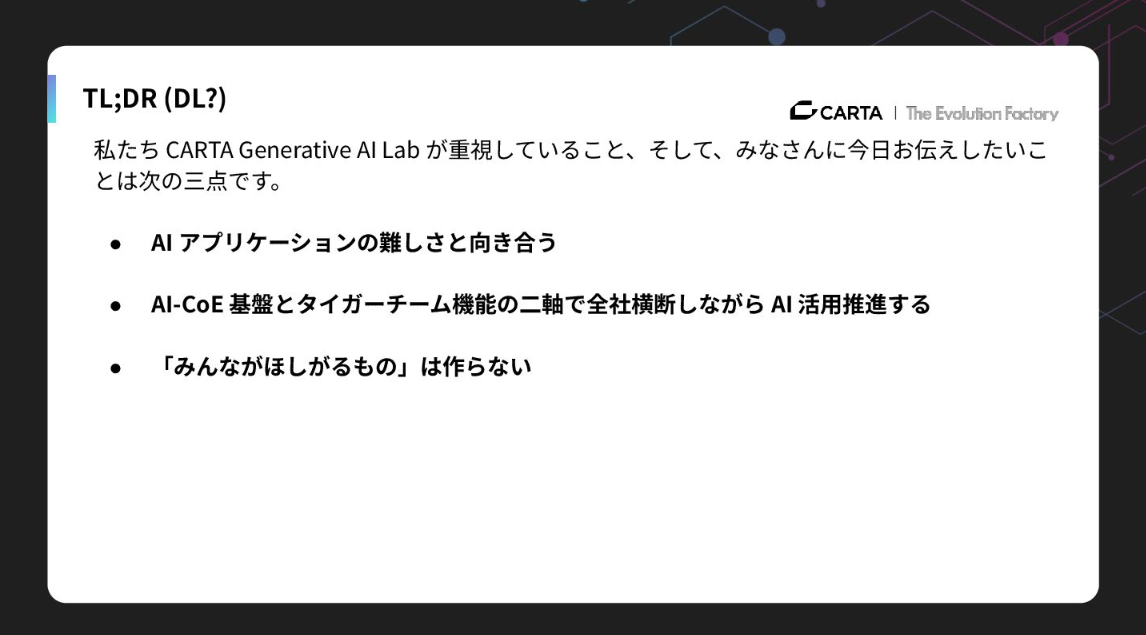
あらかじめ要点をお伝えしておくと、以下の3点です。
- AIアプリケーションの難しさと向き合う
- AI-CoE基盤とタイガーチーム機能の二軸で全社横断しながらAI活用推進する
- 「みんなが欲しがるもの」はつくらない
この3点を頭に入れながら、ぜひお聞きいただけると幸いです。
AIアプリケーションが陥りがちな罠
まずみなさんに問いかけたいのですが、こんなAIアプリケーションに心当たりはないでしょうか。
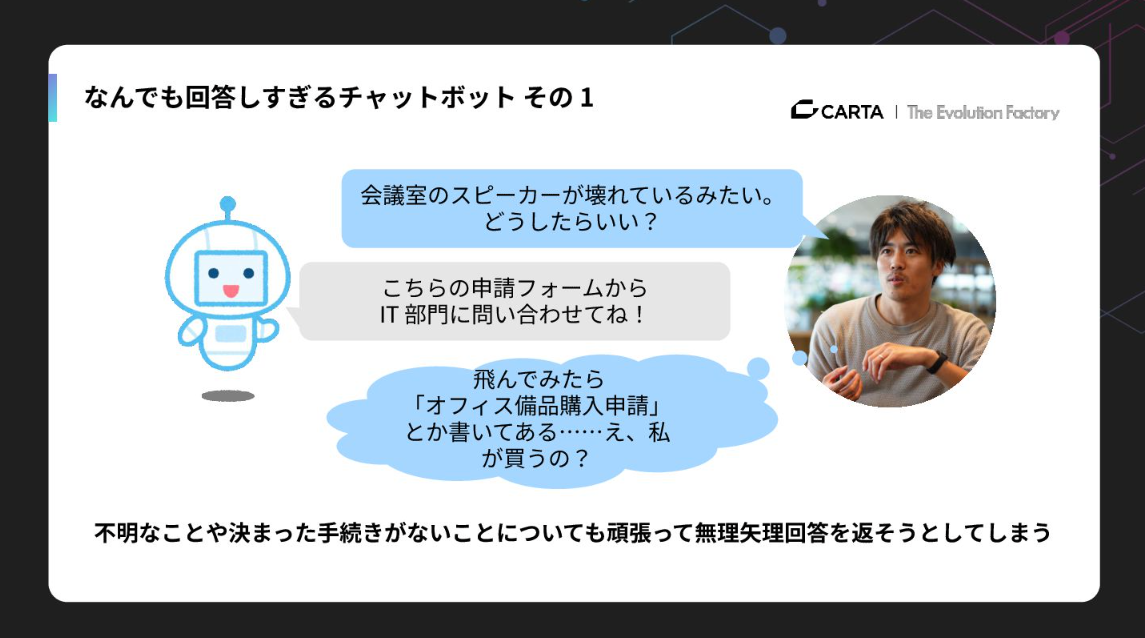
例えば、社内のチャットボットに「会議室のスピーカーが壊れているみたいなんだけど、どうしたらいい?」と素朴な疑問を投げかけたとします。するとボットが「この申請フォームから問い合わせてね」と返してくる。
リンクをクリックしてみると、そこには「オフィス備品購入申請」と書いてある。「いや、私は直してほしいだけで、買いたいわけじゃないんだけど…」という状況です。これは、LLMが決まった手続きや正解がないことに対しても、頑張って無理やり回答を生成した結果起こる「はた迷惑な頑張り」です。

ほかにも、Slackへ業務委託者を追加するための申請方法を聞いたときに「私の知識の範囲では回答できません」と突っぱねられたりするケースもあります。これは“マルチチャンネルゲストとして招待したい”という特定の文脈を汲み取れず、ファジーな問い合わせに対して「回答不能」になってしまう事例です。
これでは、知っている人には不要で、知らない人には使い物にならないツールになってしまいます。
「博多おせちラーメン問題」を通じて学んだLLMの本質
私たちがPoCの中で遭遇した象徴的な事例に、博多発のおせち通販のキャッチコピー生成アプリがあります。

開発時には、商品情報が詳細に載ったページを入力することを想定していましたが、実際の運用では情報量の少ないランディングページが入力されることがありました。すると、ページ内に「博多」という単語が1つあっただけで、おせちの紹介なのに関係のない「博多ラーメン」のコピーを延々と提案し続けるという、とんでもないアプリになってしまったのです。私たちはこれを「博多おせちラーメン問題」と呼んで反省しています。
なぜこうしたことが起こるのか。その本質は、私たちがこれまで扱ってきたプログラムというコンポーネントと、LLMの違いにあります。
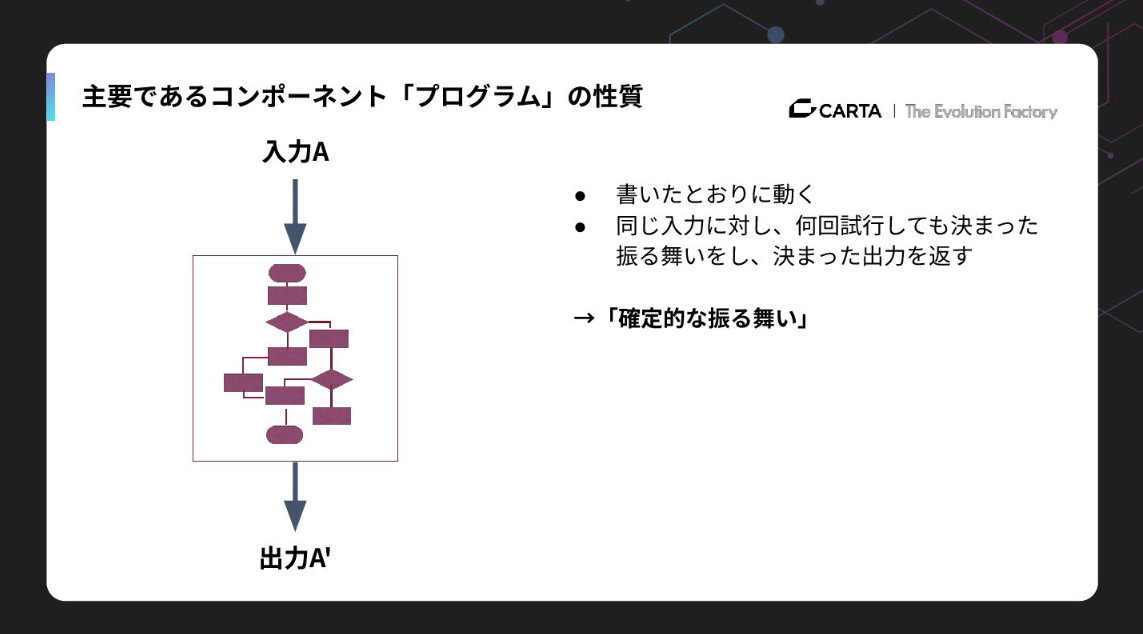
プログラムは「書いた通りに動く」もので、同じ入力には同じ出力を返す確定的な振る舞いをします。
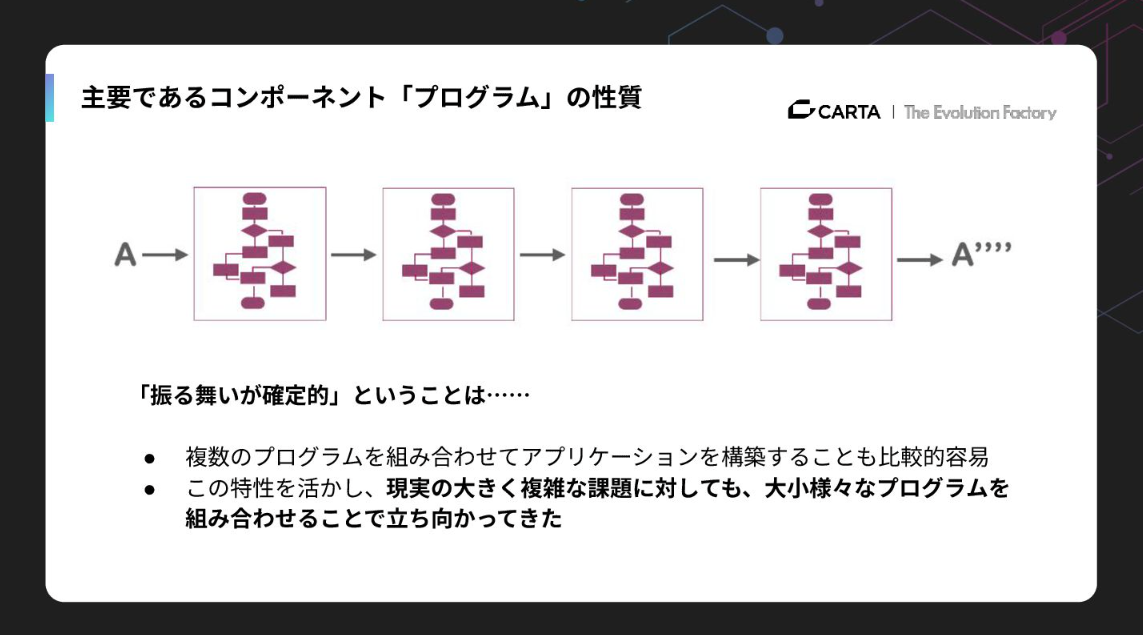
だからこそ、小さなプログラムを組み合わせて複雑な問題を解くことができました。
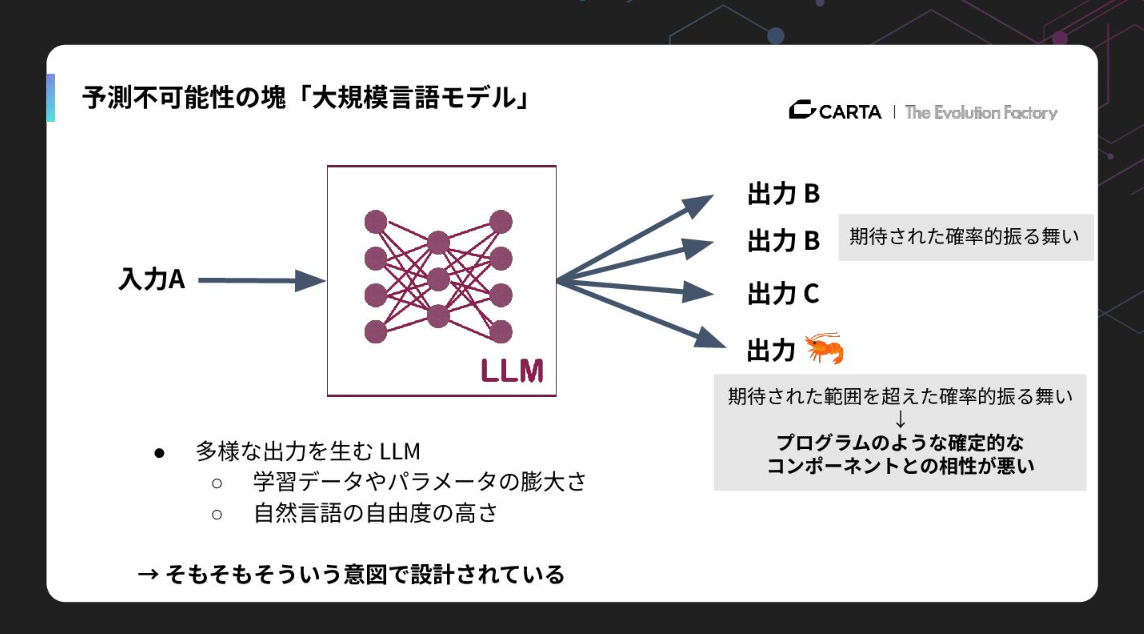
一方でLLMは、予測不可能性の塊です。確率的な振る舞いをするという点では従来の機械学習と同じですが、アウトプットの多様性が段違いなのです。学習データの膨大さや自然言語の自由度の高さゆえに、所々に「歪み」が出てきてしまいます。
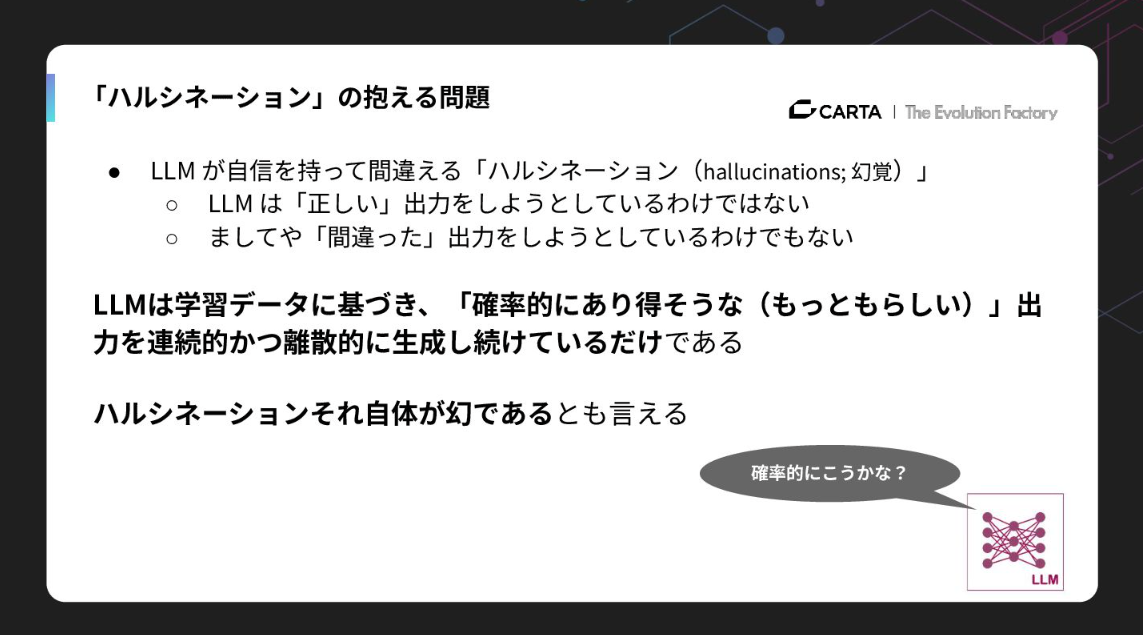
ここでよく言われるのがハルシネーションですが、私はこれは「LLMの特性」だと思っています。LLMは正しい出力をしようとしているわけでも、間違った出力をしようとしているわけでもなく、ただ確率的にありそうなものを生成しているだけなのです。

ハルシネーションはプロンプトエンジニアリングで軽減はできても、完全に回避することはできません。この現実を受け止め、「ハルシネーションは避けられない」という前提で設計しなければ、真のAIアプリケーションはつくれないと考えています。
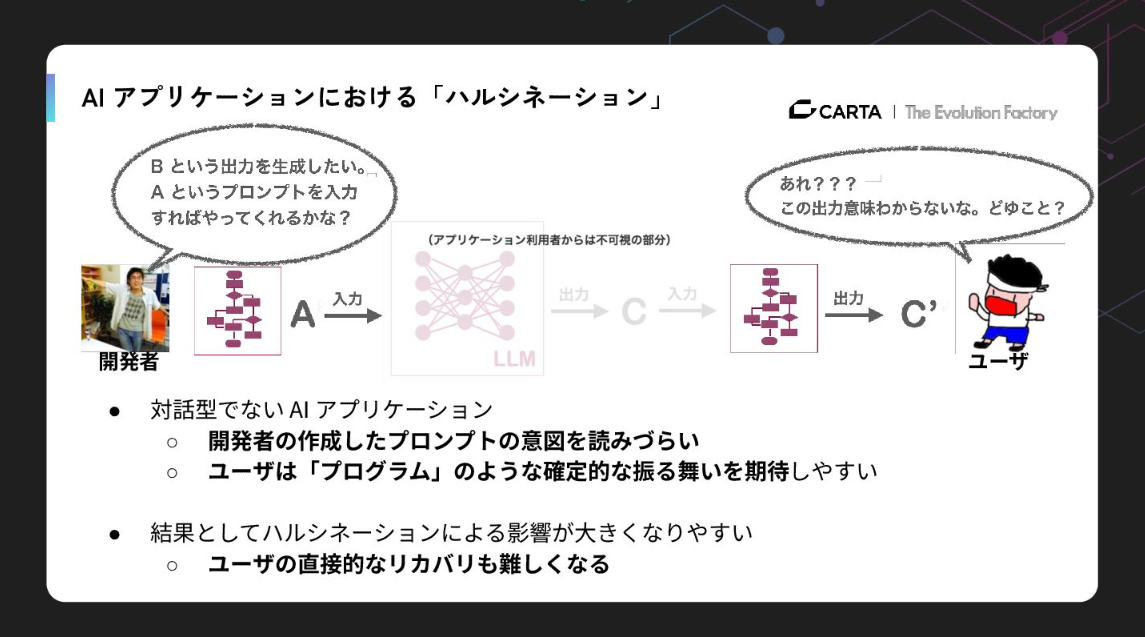
特にチャットUIであればユーザー自身がリカバリーできますが、対話型ではないアプリケーションに組み込むと、ユーザーは「確定的な振る舞い」を期待してしまい、意図しない結果が出た時の落胆が非常に大きくなります。
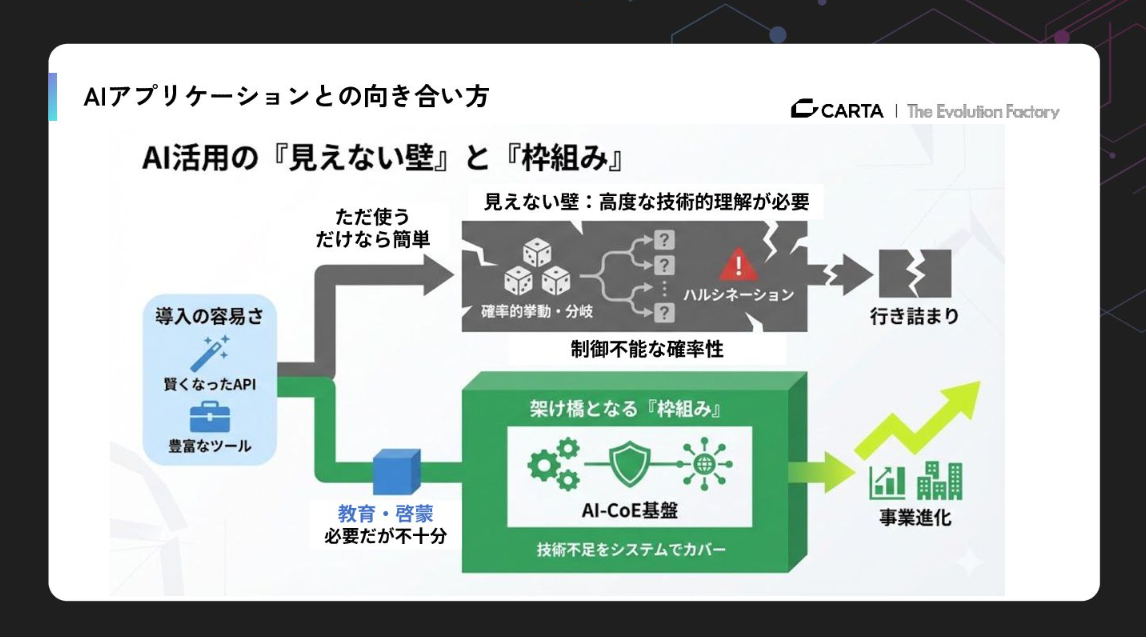
会社にはいろいろな属性の人がいますから、全員に技術的理解を求めるのは不可能です。だからこそ、技術理解が不足していても安全にAIを使える「枠組み」を提供する必要があるのです。
AI-CoE機能とタイガーチーム機能、二軸の組織戦略
こうした課題に立ち向かうために、私たちは「Generative AI Lab」という組織を立ち上げました。この組織は、大きく分けて2つの機能を持つ全社横断チームです。1つは「AI-CoE(AI Center of Excellence)機能」、もう1つは「タイガーチーム機能」です。
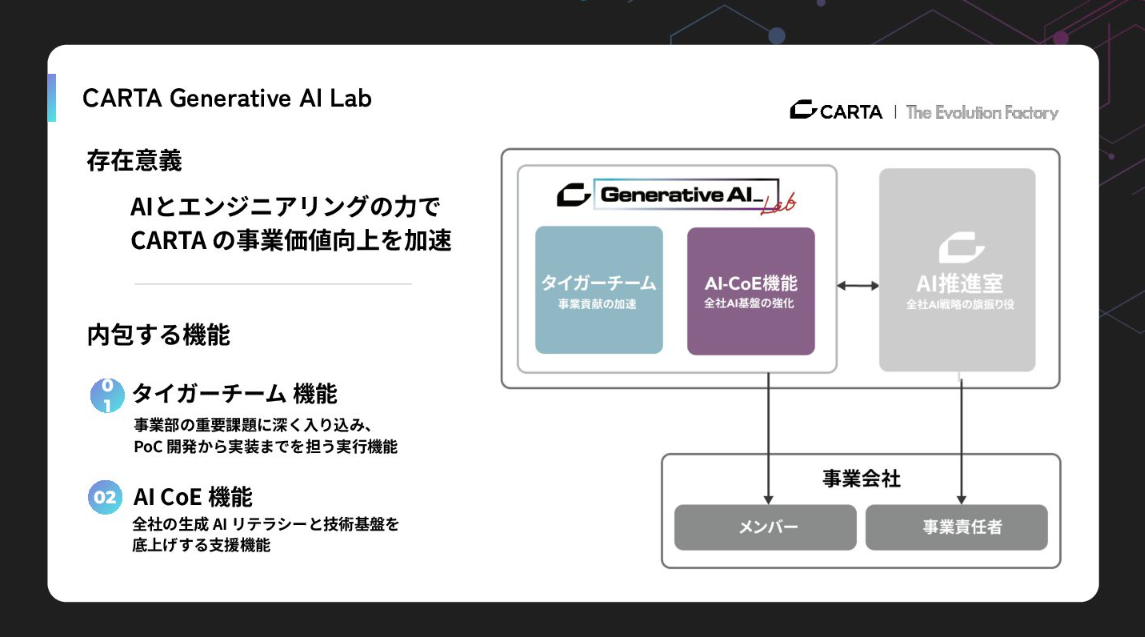

全社のリテラシーと技術の底上げを支援する「AI-CoE機能」
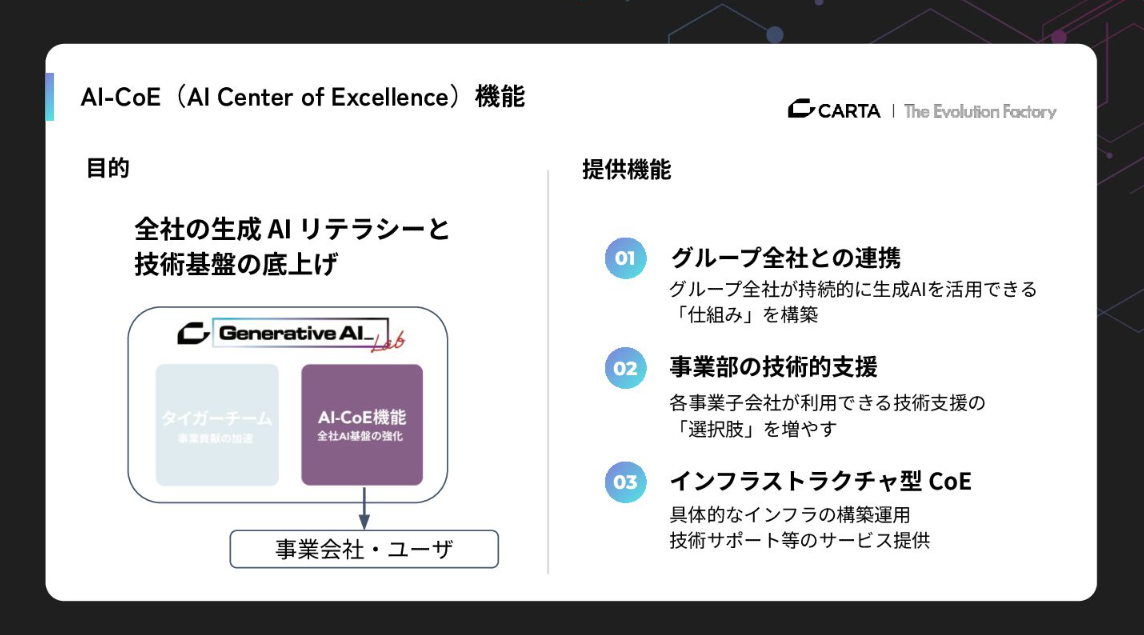
まずAI-CoE機能についてですが、これは全社の生成AIリテラシーと技術を底上げするための「支援機能」です。グループ全社が持続的にAIを活用できる仕組みを構築することを目的としています。単なるガイドライン策定だけでなく、AI実行環境のインフラそのものを提供することを重視しています。
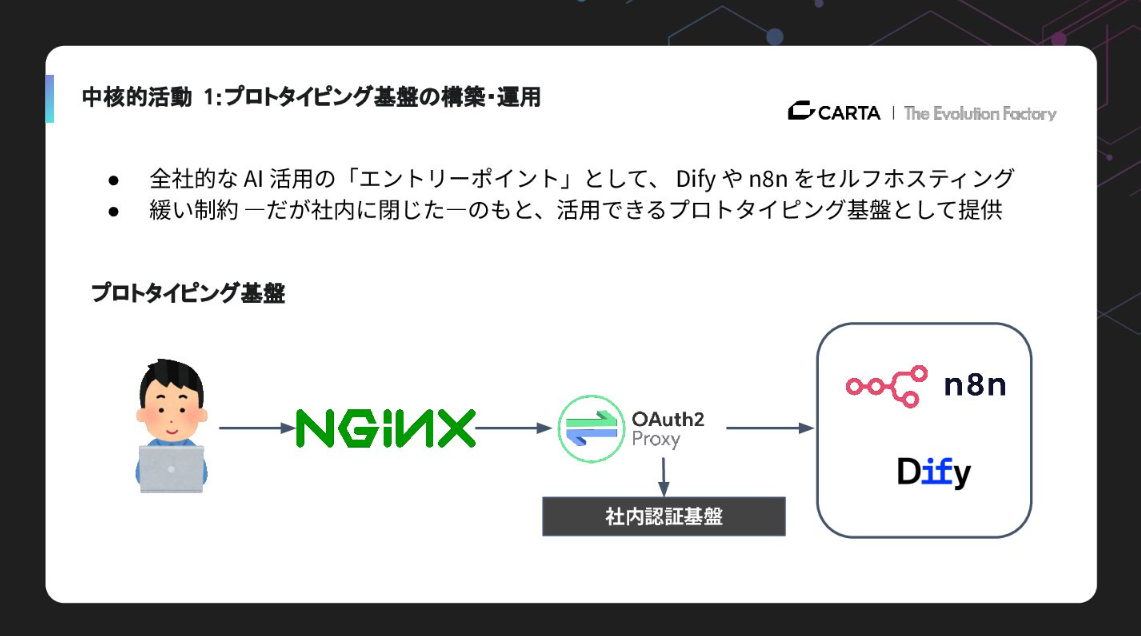
中核的な活動が、プロトタイピング基盤の構築と運用です。具体的には、Difyやn8nをセルフホスティングし、社内認証基盤と連携させて提供しています。最近、脆弱性が話題になったりもしましたが、社内に閉じた環境でインターネットに公開しない形をとることで、全従業員が「雑に、安心して」AI活用を試せるようにしています。これがいわばAIに対するエントリーポイントになっているわけです。
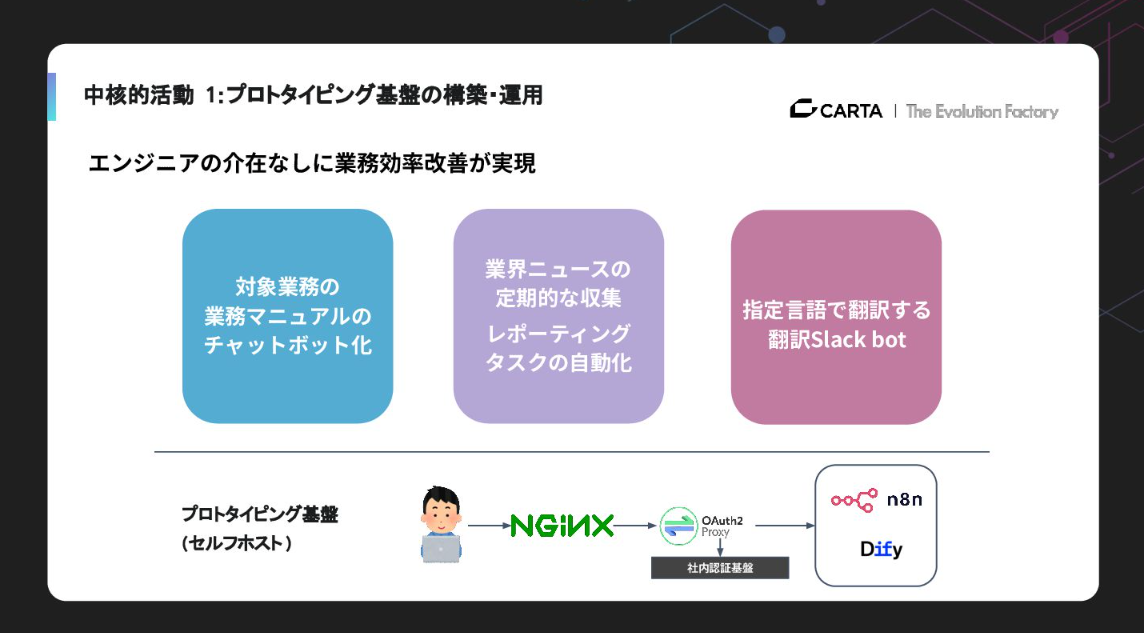
この基盤を提供したことで、私の知らないところでマニュアルのチャットボット化や情報収集の自動化、翻訳ボットなどが同時多発的に立ち上がりました。エンジニアが介在しなくても業務効率が改善されるという状態が実現できているのが非常に大きなポイントです。

また、LLMOpsツール Langfuseを活用し、ブラックボックスになりがちな入出力を可視化し、継続的に改善できる体制も整えています。
泥臭い実装作業で事業に貢献する「タイガーチーム機能」
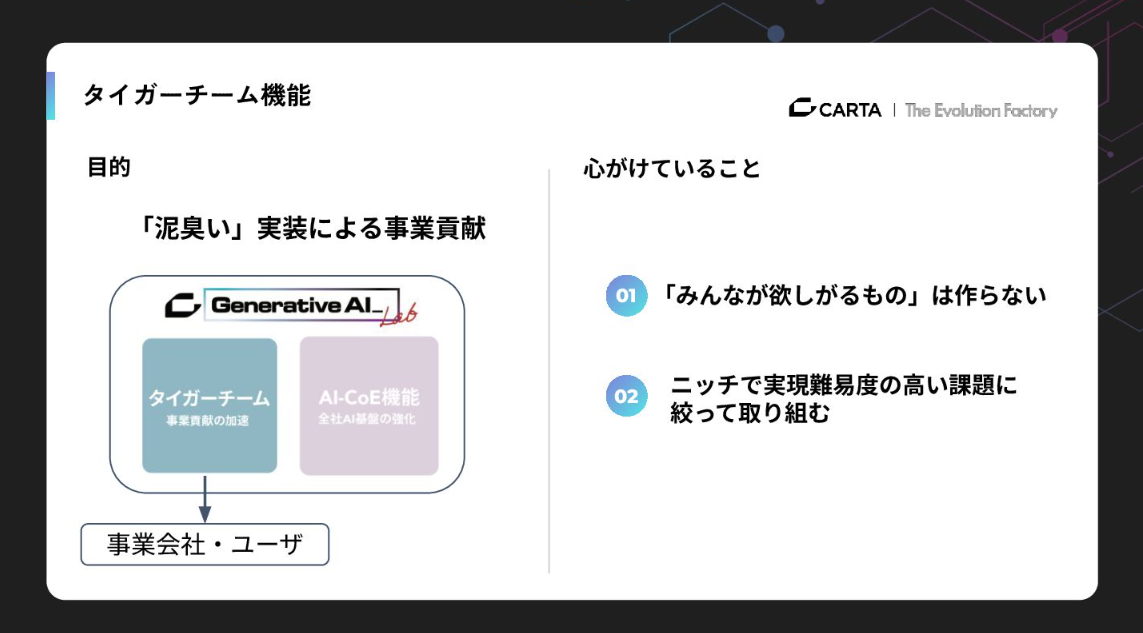
次に、タイガーチーム機能についてお話しします。こちらは単なる支援ではなく、実際に手を動かして泥臭い実装を行い、事業に貢献する「実行機能」です。PoCから本番実装までを一貫して担います。
ここで私たちが大切にしている思想が、冒頭でも触れた「みんなが欲しがるものはつくらない」ということと、ニッチで実現難易度の高い課題に絞って取り組むことです。
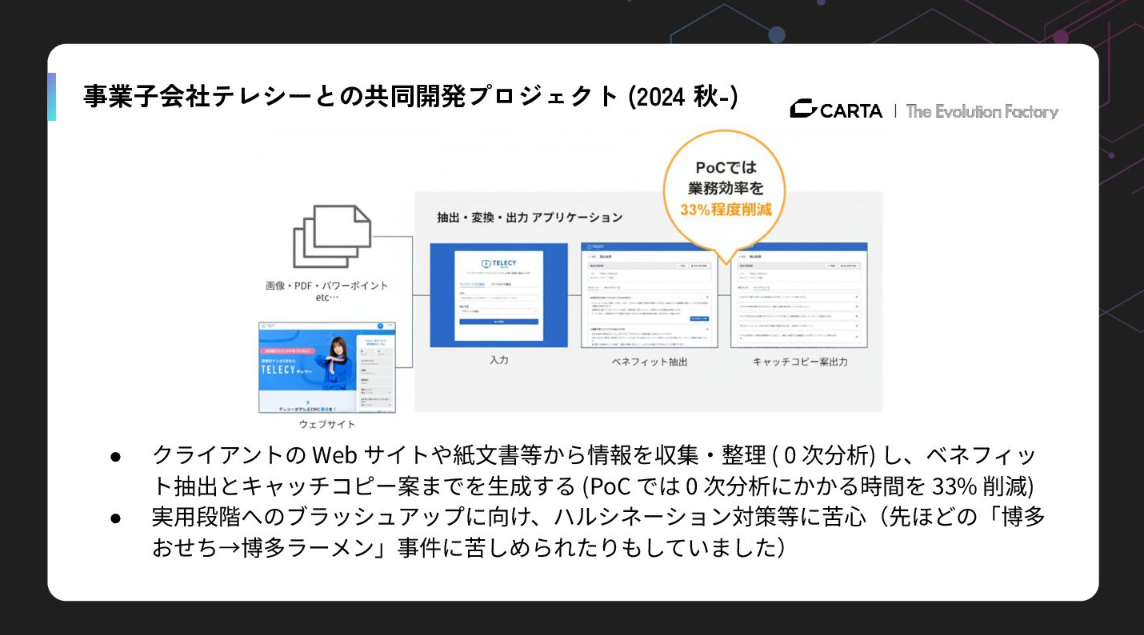
これには、事業子会社であるテレシーとの共同プロジェクトでの苦い教訓があります。Webサイトなどから情報を収集・整理する「0次分析」の効率化ツールをつくっていたのですが、開発の終盤にGemini Deep ResearchやNotebookLMといった、いわゆる「黒船」が襲来しました。

私たちのツールよりも精度が高く、汎用的なツールがビッグプレイヤーから次々と提供されるようになったのです。そこで太刀打ちできるビジョンが描けず、私たちは撤退を決めました。

ここから得た教訓は、一般的なニーズを満たすものはビッグプレイヤーがどんどん解いていくということです。今ちょうどいいものがなくても、すぐに出てくる。だからこそ、私たちはビッグプレイヤーとの安易な競争を避け、特定の事業にしかない「固有で難易度の高い課題」に集中すべきだと判断しました。つまり、「みんなが欲しがるものはつくらない」ということです。
事業固有の課題をエンジニアリングで解く
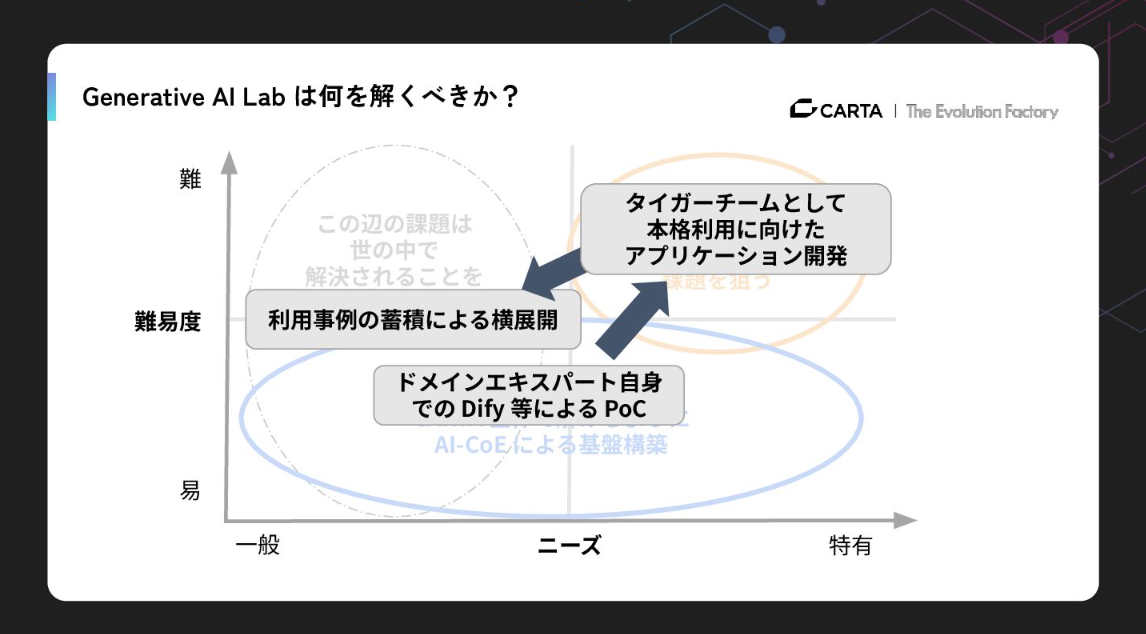
私たちが目指しているのは、AI-CoE機能とタイガーチーム機能を頻繁に行き来させるサイクルを描き、利用事例をもとに積極的に横展開していくことです。
AI-CoE機能で提供基盤を使ってドメインエキスパート自身が解いていく。一方で、本番データで動かない、スケールしない、精度が出ないといった壁にぶつかった時、エンジニアリングの力でそれを突破するのがタイガーチーム機能の役割です。つまり「現場がPoCしたものをProductionレベルに上げる実装への橋渡し」を担います。
概念的なお話をさせていただきましたが、ここからは具体的な事例をいくつかご紹介します。
事例1.広告クリエイティブ分類プロジェクト
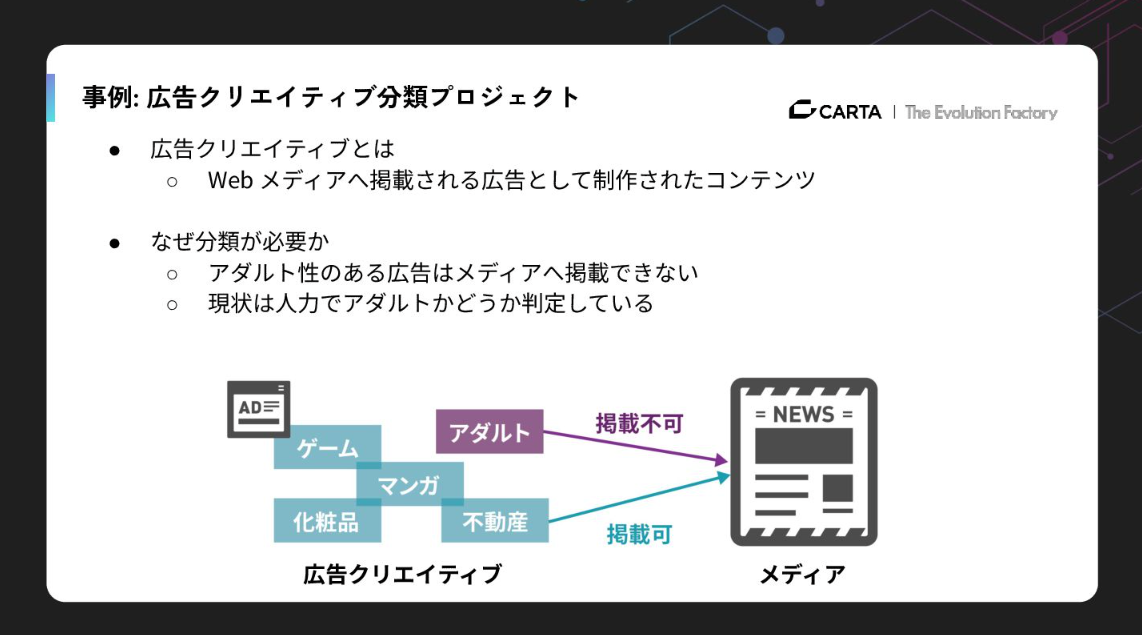
1つ目は「広告クリエイティブ分類プロジェクト」です。デジタル広告において、掲載メディアの規約に合わせたフィルタリングは不可欠です。特にアダルト表現の判定などは非常に難しく、これまでは人間が動画を1フレームずつ確認するような「苦業」が行われていました。
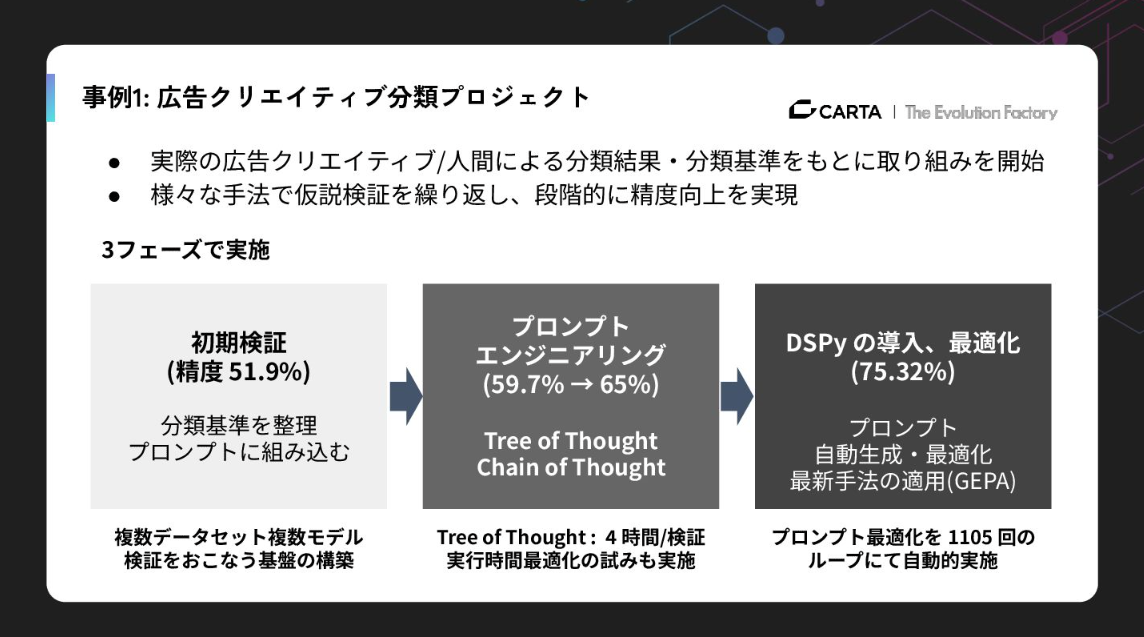
これを解決するために我々にご相談をいただいたのですが、当初、通常のプロンプトエンジニアリングでは精度が65%程度で頭打ちになっていました。そこで私たちはプロンプトエンジニアリングを自律的に行うDSPyというフレームワークを導入しました。
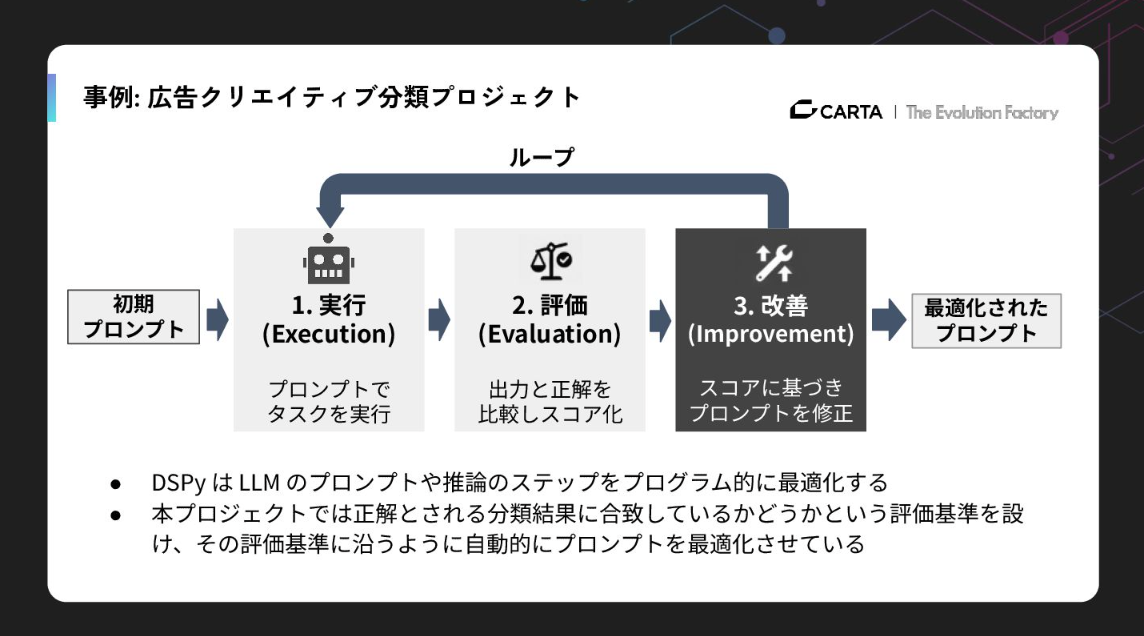
これはプログラム的にプロンプトを最適化するもので、1,105回のループを回してLLM自身に「反省と試行」を繰り返させました。これにより、精度を一気に75.32%まで引き上げることに成功。人間には思いつかないような微細なプロンプトの調整を、機械的な最適化によって実現したわけです。
事例2.ヘルプデスク問い合わせ効率化
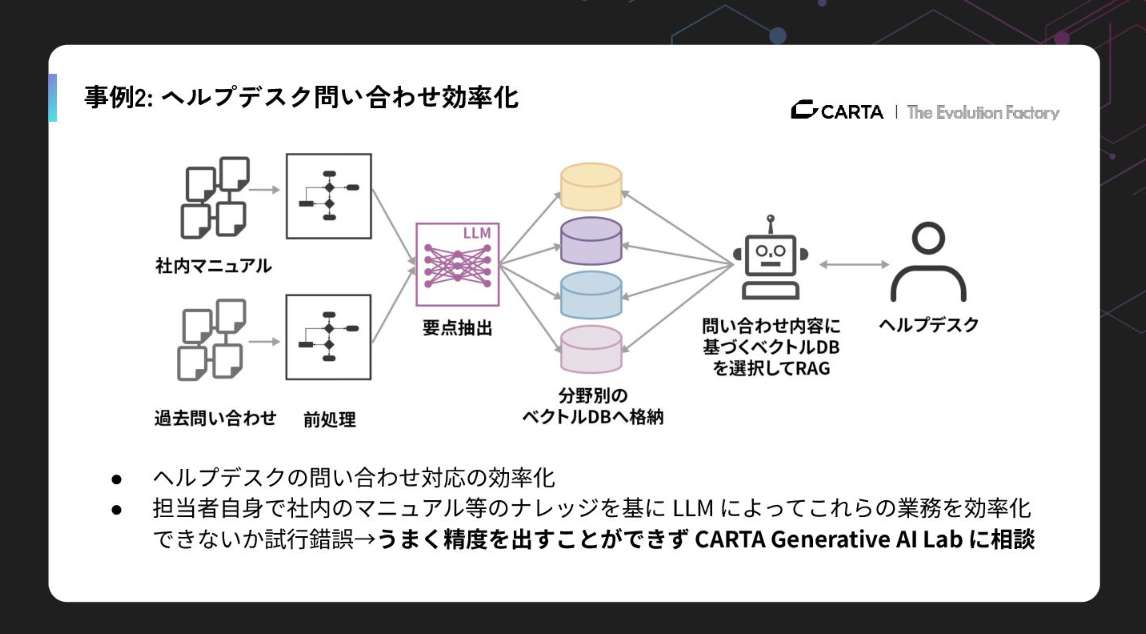
2つ目は、ITヘルプデスクの効率化です。RAGを構築してチャットボットをつくるというのは今や珍しくありませんが、実際に運用してみると精度が上がらないケースも多いものです。
例えば「Slackのアカウントをつくりたい」という質問に対し、マニュアルに直接の記述がないと関係のない手順を出してきたりするのは“あるある”だと思います。ここではデータの前処理や、問い合わせカテゴリーに応じたアーキテクチャの設計といった、丁寧なエンジニアリングが必要になります。これによってようやく実用的な精度を出すことができました。
事例3.セキュリティアラートのトリアージ
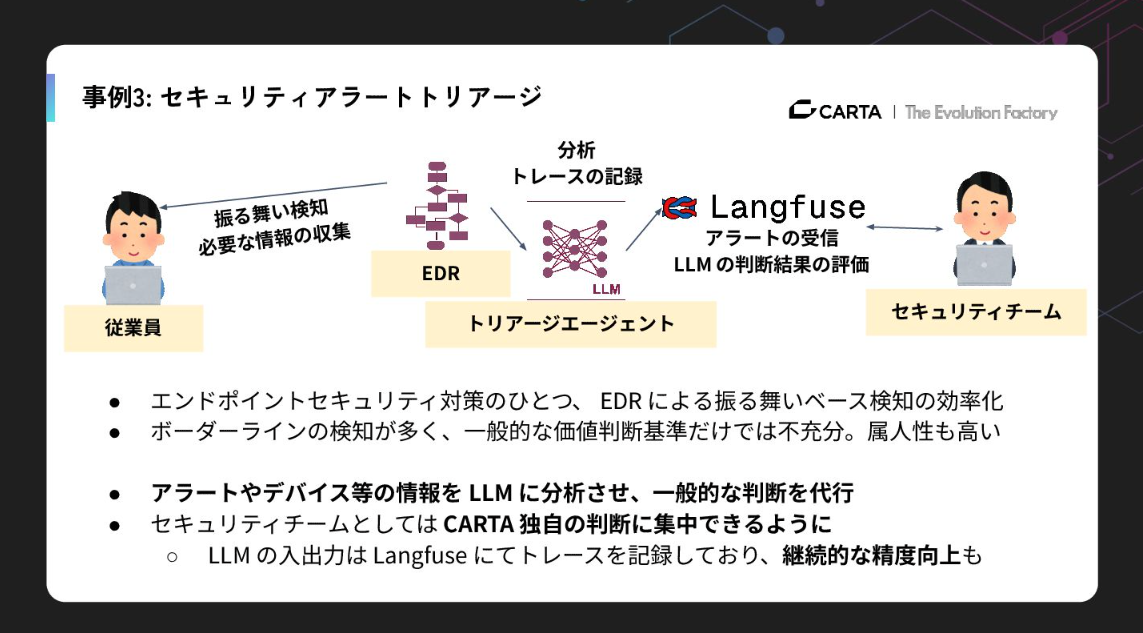
3つ目は、セキュリティアラートのトリアージです。毎日のように膨大なセキュリティアラートが届くと、オオカミ少年症候群のような状態に陥り現場は疲弊します。
そこで、アラートやデバイスなどの情報をLLMに分析させ、一般的な判断をAIに任せるトリアージを行っています。これはつまり「この人は普段からこういう挙動をするから大丈夫」といったCARTA独自のコンテキストを組み合わせて判断させる仕組みです。
LLMOpsツール Langfuseでトレースを記録し、継続的に「我々好みのトリアージ」に改善し続けることで、セキュリティチームがより高度な判断に集中できる環境をつくっています。
AI-CoE機能とタイガーチーム機能の二軸アプローチで事業価値向上に貢献

最後に、あらためて本日お伝えしたい内容をまとめさせていただきます。AIエンジニアリングにおいて重要なのは、LLMの予測不可能性という本質的な難しさから逃げず、ハルシネーションを前提とした設計をすることです。
そして、ビッグプレイヤーとの競争を避け、事業固有の難易度の高い課題に、深いエンジニアリングと泥臭い実装で立ち向かっていく。これからもAI-CoE機能とタイガーチーム機能の二軸アプローチで、事業価値の向上を加速させていきたいと考えています。
以上、ご清聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
AI Engineering Summit Tokyo 2025
※動画の視聴にはFindyへのログインが必要です。





