



【アーキテクチャConference 2025】Voicyが挑んだ大規模DB移行!AuroraからTiDBへ──障害とコストの壁をどう越えたのか
2025年11月20日・21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
PingCAP株式会社のスポンサーセッションとして20日に行われた本講演では、音声プラットフォーム「Voicy」を運営する株式会社VoicyのVPoE・山元亮典氏が登壇。メインデータベースをAWS AuroraからTiDB Cloudへ移行した約1年間の取り組みについて語りました。
コスト削減やスケーラビリティといった技術的なメリットだけでなく、移行中に発生した障害とその克服プロセス、そしてPingCAP社のサポート体制まで、リアルな現場の声が共有されました。
◾️プロフィール
山元 亮典
株式会社Voicy VPoE
早稲田大学でマルチメディアと機械学習を研究し、修士号を取得。その後ヤフー株式会社に入社し、ヤフー検索のバックエンドをフルスクラッチで開発。2019年にVoicyにジョイン。サーバサイド開発に加え、インフラやデータ基盤を構築し、データ部門の立ち上げを主導。その後、開発組織全体の責任者となり、技術・組織戦略の策定、開発プロセス適正化、コスト適正化、エンジニア組織の強化に携わる。2025年にVPoEに就任。
Voicyの概要説明
山元:私たちVoicyは、スマートフォン1台で音声発信や聴取を楽しめる音声プラットフォームです。ポッドキャストやラジオ、YouTubeの音声版のようなイメージが近いと思います。大きな特徴として、発信するためのアプリと聞くためのアプリを分けてリリースしています。発信者は3,000チャンネルを超えており、会員登録者数は250万人を超えています。

山元:Voicyの最も大きな特徴は、誰でも発信できるプラットフォームではなく審査制をとっている点です。音声メディアでは「話を聞いてほしい人」が発信しがちですが、Voicyは「この人の話を聞きたい」と思われる方々に発信してほしいと考えています。Voicyで発信することがブランドになる、Voicyで発信したいから今ポッドキャストを頑張っていますという方々も生まれています。そういったブランディングを含めて、戦略としてこのようなプロダクト作りをしています。
次に、今回の移行の対象となるデータベースについてご説明します。AWS Auroraで動いていたVoicyの主要なデータがすべて入っているデータベースです。YouTubeで例えると、チャンネルの名前やメタ情報、各放送のタイトル、チャプターのタイトルなど、すべてが入っている基幹のデータベースが移行対象でした。
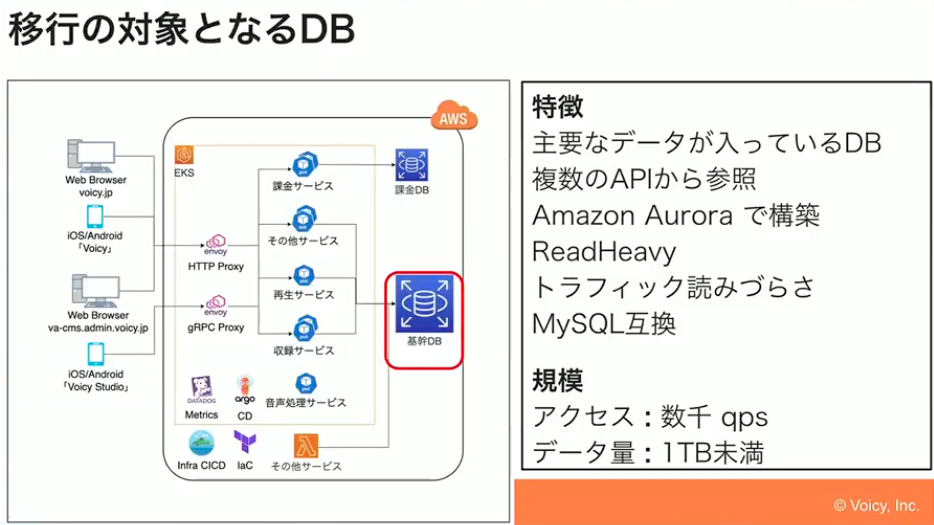
山元:このデータベースは、再生用や収録用など複数のAPIから参照されています。いずれもGoで実装しています。特徴としてはRead Heavyであること、つまり読み込みクエリが書き込みよりもはるかに多い点が挙げられます。これはメディアサービスではよくある傾向です。Voicyの場合、発信者よりもリスナーのほうが圧倒的に多く、リスナーは主にデータを取得して音声を聴くという使い方をするため、必然的に読み込みの比率が高くなります。
また、メディアサービスなので、ライブ配信が突発的に始まったりすると、影響力の大きい発信者さんの場合は急にユーザーさんが増えたりします。つまり、トラフィックが読みづらいというところもVoicyの特徴です。
移行前はMySQL互換のAuroraを使っていました。規模感でいうと数千qpsで、データ量は1TB未満という形になっています。

AWS AuroraからTiDB Cloud移行の1年の変遷
山元:では、AWS AuroraからTiDB Cloud移行の1年の変遷についてお話しします。移行に至るまでの変遷のタイムラインをご紹介します。
- 2023年1月 初回打ち合わせ
- 2023年3月 PoC開始
- 2023年6月 移行意思決定
- 2024年4月 移行完了・運用開始
PoCを開始したのが2023年3月、もう2年前になります。そこから約1年で移行を完了し、現在は安定して運用している状態です。
PoC──TiDBを検討した背景
山元:まずPoCについてお話しします。TiDBをPoC検討することにした背景ですが、結論から言うとコスト削減と副次的な効果を見込んでのことでした。せっかくなのでTiDBの特徴も含めて紹介します。
TiDB自体はNewSQLと言われているもので、特徴としてはライターのサーバーを分散させることができます。MySQLクラスタを組んだことがある方はわかると思いますが、masterとslaveで書き込みが基本一つのサーバーになり、それを広げていく場合はクラスタの設計を気にしなければなりませんでした。TiDBの場合は基本的にライターを横に並べることができて、Readと同じようにライターも分散してスケールアウトできるというところが大きな特徴です。

山元:以前だとCloud Spannerで達成できていた部分もありましたが、もう一つ大きな特徴としてMySQL互換になっているという点があります。MySQL互換でライターがスケールするというところが大きな特徴です。
もう1点、HTAPという特徴もTiDBの大きなものの一つです。MySQLでCOUNTやSUMといった集計関数を使うと重くなるという話はよく聞くと思います。TiDBでは裏側であらかじめ集計の関数を別で計算しておいて、そこからReadしてくるという特徴があります。クエリ計画によって変わりますが、サーバー上のアルゴリズムでそちらのほうが速いと判断した場合だけ、この集計関数を使う形になっています。
Voicyのようなメディアサービスの特徴を考えると、HTAPとは相性がいいのではないかとPoCの時点では考えていました。YouTubeを想像していただくと、再生回数がありますよね。あれも集計される関数です。Voicyでは取ってきたいエンティティがチャンネル、放送、音声と決まっていて、そこに対していろいろな集計をまとめて出したいというニーズがあったので、相性がいいのではないかと考えました。
DBのコスト削減についてですが、正直これはAuroraからTiDB Cloudに移行してコストが削減できるかは会社によります。私たちの場合はAuroraの使い方があまりイケてなかったこともあり、コストがかさんでいました。チューニングするには知識も工数も必要で、かつチューニングはかなりカリカリにやっていたので、やれる幅も少なくなってきていました。思い切ってワークロードを変えることでコスト削減につながるのであれば、経営課題を大きく打開できると考えました。
書き込み負荷がスケールしていくというところで、Voicyはこれからユーザーさんを増やしていきたいという中で、そこがボトルネックになる可能性がAuroraにはありました。運用が楽になるという点もあります。バージョンアップがとても楽で、サーバーがスケールしているので、バージョンを1台ずつ上げていくことが可能です。基本的にノーダウンタイムでバージョンアップもできます。
業界の事例としてブランディングをしていくことも大事だと思っていました。NewSQLは私自身すごく良い技術だと思っていて、Spannerが出たとき感動していたのですが、MySQL互換ではなかったので試せなかった経緯があります。今回こういった形で登壇もさせていただいていますが、Voicyがモダンな技術を積極的に取り入れているという姿勢を見せていくことも重要だと考え、思い切ってPoCに取り組み始めました。
次に、PoCをどのように設計して、どのようなことを考えていたかをご説明します。私たちはスタートアップでエンジニアの数は今15人くらい、全社員だと30人くらいという規模です。工数を絞ってリソースを絞って最低限を確認するしかないと考えていました。
大きく考え方としては2つあります。まずMust要件、これは評価において最も重要視する項目で、コストがしっかり達成できそうか、パフォーマンスがAuroraよりも下がらないか、ポータビリティつまり移行がしやすいかというところを重要視しました。

山元:コストやパフォーマンスは、正直PoCの段階ですべてわからないとも思っていましたが、開発2人月くらいでちょっとだけチューニングしたらうまくいくのであれば、丸をつけていいのではないかという形で評価しました。
Should要件は運用や機能面で必要な項目です。満たさない場合でも、代わりの案としてどうやってカバーできるかを考えました。具体的には監査ログが取れるか、DataDogと連携できるか、Terraformが使えるか、Nodeが落ちたときの復旧時間はどうかといった項目です。サポートの方に問い合わせたり、こちらで検証したりしていました。
山元:結果的にはコストとパフォーマンスの部分は、最初はしっかり出なかった側面もありますが、チューニングをしていくことで達成できると見込みました。ポータビリティは非常に高かったです。私たちのアプリケーションがMySQLの本当に基本的な構文しか使っていなかったので、PostgreSQLにしてもそんなに変わらないくらいの構文の使い方でした。そういった点でも移行は簡単にできたというところはポジティブに考えています。Should要件のチェック項目もいろいろやっていましたが、概ね問題なしという形になりました。
PoCで移行を意思決定するフェーズになって、実際に背中を押した点についてお話しします。今回スポンサーとして出していただいているPingCAPさんのサポートの手厚さ、ここの本気度が伝わったというところが大きかったです。
TiDBのパフォーマンスが出ないたびにPingCAPさんに相談をさせていただきながらチューニングしていただいたのですが、そのチューニング方法の透明性が高かったです。透明性が高いと何ができて何ができないのかがよくわかります。TiDB、NewSQLで何でも解決するということは実際にはなくて、結構泥臭くアーキテクチャに沿ったチューニング方法をやらないといけません。そういった中身のアーキテクチャに沿った形で、理路整然と一つひとつチューニングしていただいたことで、Voicyで起こるパフォーマンスの問題もこれで乗り越えられるのではないかと感じました。

山元:もう一つ、PingCAPさんのコミット度が本当にすごくて、信じられない時間にSlackが返ってくるんです。具体的には深夜に返ってくるとか。この人たちいつ仕事しているんだろう、ずっと仕事しているなという感じでした。チューニングの専門チームがサポートの協力のおかげでできたと錯覚するくらいコミットしていただきました。チームができてくると社内の関心度も上がっていって、どんどんチューニングのナレッジやデータベースのナレッジも蓄えられていきました。
これは正直Auroraのところでチューニングをやりたかったところでもあったのですが、PoCをやっていく中で、こういう形でチームとして貢献していただければ一緒にバリューを出せるかもしれないと感じたことが、移行の意思決定の判断として大きかったと思っています。
本番移行──設計
山元:移行を意思決定しましたので、次は実際に移行していく作業になります。移行のスケジュールですが、2023年8月に移行の設計を開始して、10月に移行作業を開始、そして2024年2月に障害を起こしてしまいました。その後、4月に移行完了という形になっています。
- 2023年8月 移行設計開始
- 2023年10月 移行作業開始
- 2024年2月 障害
- 2024年4月 移行完了
山元:実際には、VoicyのインフラのSREエンジニア1.5人くらいと、PingCAPさんのサポートという体制でやっていました。一人がずっと付きっきりというよりは、いろいろ意思決定しながら進めるという形で、ずっと作業しているわけではありませんでした。
どういう形で移行していたかをご説明します。もともとのサービスの概要図として、各APIからデータベースをWriteやReadしている状況がありました。TiDB Cloudにはいろいろなエコシステムのツールがありますので、TiDB Data Migrationを使ってAuroraからTiDBに書き込みを行う形です。レプリケーションの遅延時間はだいたい数十ミリ秒くらいでマイグレーションが完了します。
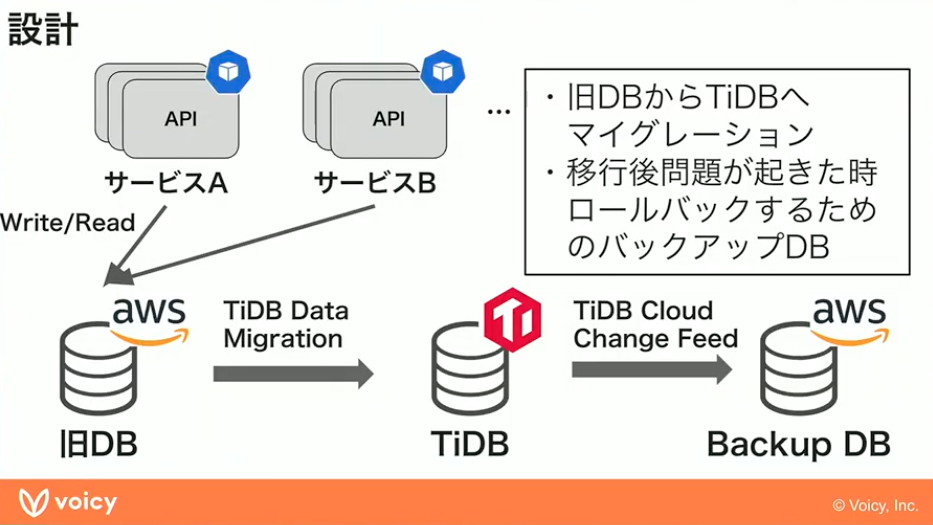
山元:実際ここからReadを切り替えていったり、WriteをTiDB側に切り替えていったりするのですが、仮にWriteを完全にAWSからTiDBに切り替え終わった後に何か障害が起こると、戻すことができません。その対策として、TiDB Cloud Change Feedを使ってAuroraにバックアップのデータベースを用意し、何かあったときはそちらにトラフィックを向け直すという想定で作りました。
実際の移行時には、Readの処理を少しずつTiDBに向けていきながら、DBをチューニングしていくという方針をとりました。最後にメンテナンスタイムを設けて、WriteとReadの処理をすべて移行するという設計です。
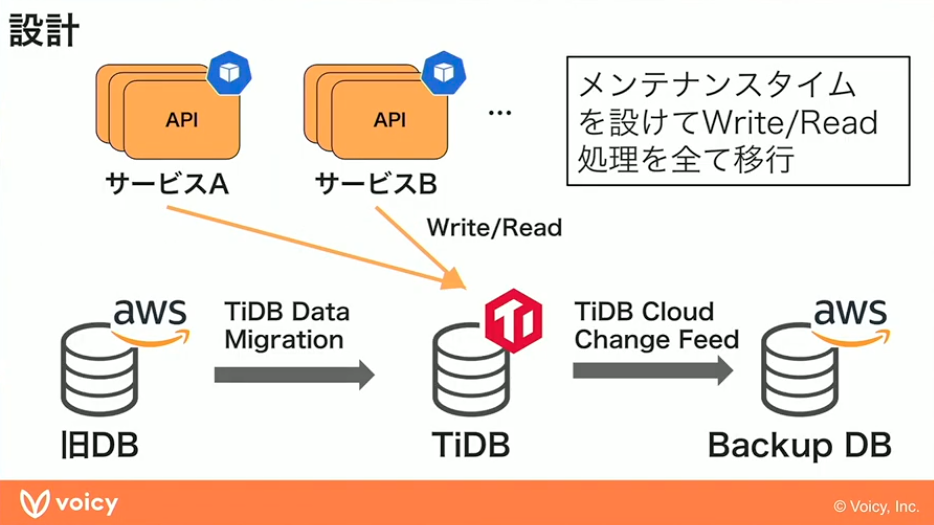
山元:設計のポイントですが、移行時のリードタイムをとても重要視しました。メンテナンスタイムを許容しています。実際ダウンタイムなしで移行するというやり方もサポートさんといろいろ相談しながらあったのですが、それを実現するにはとても工数がかかるという状況でした。
先ほど言ったように私たちもリソースが少ないので、メンテナンスタイムを設けることでそれがとても速くなるという判断になるなら、深夜止めることは問題ないだろうと経営チームとも話して意思決定しました。
本番ワークロードを再現した負荷試験は実施しませんでした。本来だったら本番のトラフィックミラーリングをしたり、本番のワークロードを再現するためにいろいろ実装したりというところは必要だったと思っていますが、それを再現するための工数がかかると考えました。もともとVoicyではKubernetesを採用していてカナリアリリースがやりやすい状況でしたので、Readを少しずつ本番環境から向けていくことで、多少のエラーが出てもすぐ戻してチューニングするという形でコントロールしながら、本番で負荷試験をしていくという手段を取りました。
作業を満を持して開始したのですが、Readのところでサービスが止まってしまうという障害がありました。少しずつカナリアリリースでトラフィックを向けていって、サービスとして処理はできていたのですが、CPUが高くなっていき負荷が高くなっていった中で、ピークタイムの時にTiDBが潰れてしまい、大きな障害につながってしまいました。
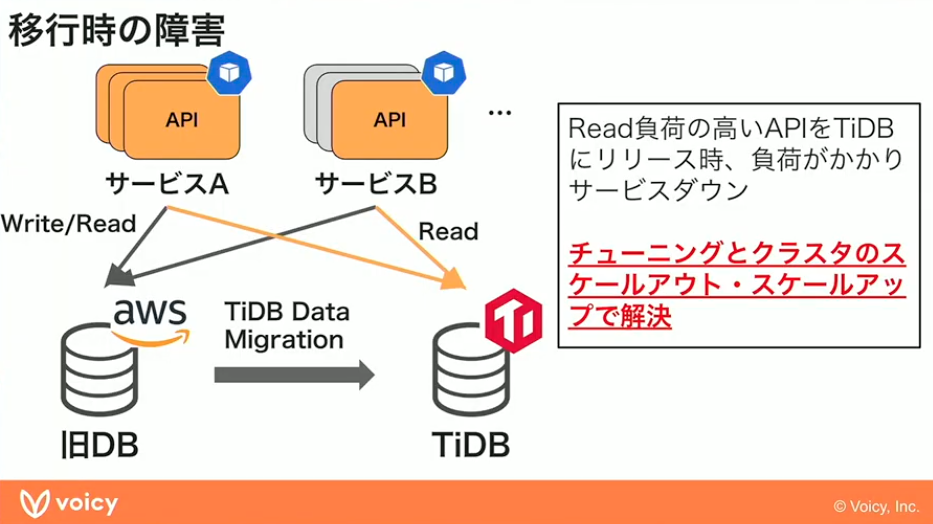
山元:もともとコストのところはとても気にしながら進めていたのですが、チューニングも間に合わないというところもあったので、一旦コストの部分の予算を増やして、スケールアウトとスケールアップで解決するという、言ってしまえば札束で殴っていくような解決をとりました。
もう一つ、Data Migrationのジョブの稼働中にレプリケーション遅延が発生するという事故も起きました。端的に言うと、書き込んだものがすぐReadに反映されないという形になるので、サービスを使う側からすると不整合が起きてしまっている状態でした。
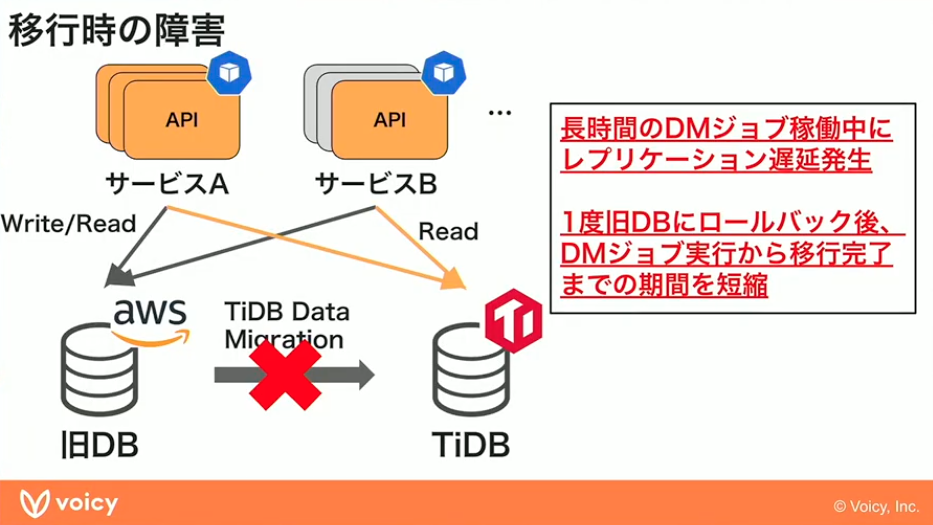
山元:こういったところが、TiDB Cloudを利用する上でのミスにつながる要素の一つだと感じました。エコシステムのツールもTiDB Cloud側で作っているものだったりするので、そこのエラーを考えながら移行を進めないといけないというところが注意のポイントになります。
このレプリケーション遅延の詳しい原因は正直わかりませんでした。その中でも移行を何とかやらないといけないという意思決定はしないといけなくて、この状態で1か月とか2か月とかずっと運用を続けていたというところが原因として大きかったと思っています。この段階ではReadをさばき切れるチューニングは完了していたので、一旦Readに切り替えて、その後すぐメンテナンスタイムを設けてWriteを最後に切り替えきるというのを短時間で行うことで、マイグレーションのエラーを回避していくという選択肢を取りました。
完全にそれで大丈夫と言い切れない形ではありましたが、サポートの方もとても注視して見てくれて、その間はとても協力的に動いていただいたという形で、なんとか移行を完了させたという経緯になっています。
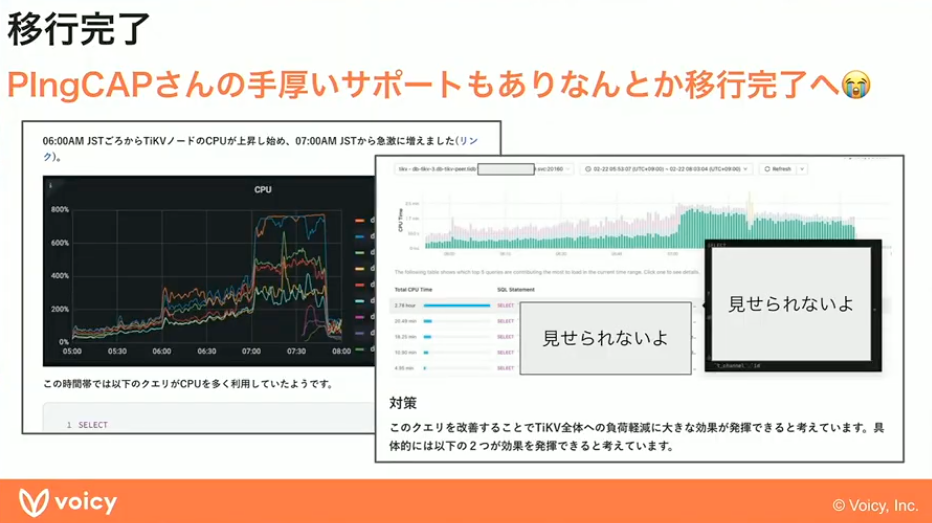
いろいろと障害もあったのですが、ベースにはPingCAPさんの手厚いサポートがありました。CPUの障害が発生した際には、どのデータベースサーバーでどのようにCPUが使われているかを細かく分析したレポートを毎回出していただきました。そのレポートをもとに、負荷の状況を確認しながらチューニングを進めることができました。移行完了をなんとかやり遂げられたのは、このサポートのおかげです。
本番運用──コスト・運用・ブランディング
山元:移行完了後、チューニングもしてコストが安定してきて、いろいろなメリットが得られるようになりました。最初は想定のコストよりも高い状態でリリースしたのですが、そこからパフォーマンスチューニングやクラスタ構成の最適化をして、目標コストを達成することができました。
AWSからTiDB Cloudに変更して困ることは、今のところないです。メリットのほうが多いと思っています。
ブランディングのところですが、モダンな技術を取り入れると一定の注目があると思っていますので、こういったところでも採用に効いてくるなどのメリットを出すことができたと思っています。
コスト最適化で私たちが工夫している点として、負荷を考慮しながらスケールイン・スケールアウトを毎日実行しています。Voicyは通勤で使われることが多く、トラフィックは朝が一番多いです。そのトラフィックのピークタイムが来る前にTiDBとTiKVというサーバーをそれぞれスケールイン・アウトすることでコストを最適化しています。

山元:TiKVはデータを保存するキーバリューストアです。スケールイン・アウトは3台単位で行うため、3台・6台・9台という形で増減します。そのためコストへの影響が大きい部分です。一方、TiDBはクエリの構文解析や実行計画の作成を担当し、どのTiKVに接続するかを判断する、いわばTiDBの脳みそに当たる部分です。こちらは1台単位でスケールできます。私たちはTiDBのスケールを細かくコントロールしつつ、TiKVのスケールは必要最小限に抑えるという工夫でコストを最適化しました。
TiKVをスケールアウトすると結構遅いです。私たちの場合はデータ量が少ないこともあり、だいたい1時間くらいかかります。データ量が多いと3時間とか4時間とかかかる場合もあるので、このあたりはサポートの方にいろいろと仕組みを聞いてリスクをコントロールできるといいと思います。
また、ゼロダウンタイムのおかげで最適化の検証がしやすかったです。先ほどのスケールイン・スケールアウトもそうですし、スケールアップ・スケールダウンも、ボタン一つで基本的にサービスがダウンしないような形で動かしてくれます。キャパシティの増減をカジュアルに試せるため、最適な構成を探る検証がとてもしやすかったです。

山元:バージョンアップのやりやすさもあります。基本的には1台ずつバージョンアップしていくので、ゼロダウンタイムでバージョンが上がっていきます。ただ、運用上の注意として、コネクションを接続しているところでサーバーのダウンが起こるとコネクションの切断が起こることもあります。一時的にその一部のトラフィックがコネクションエラーになることはあるので、検証環境やステージング、開発環境での動作確認は前提になるでしょう。
クエリチューニングもやりやすかったです。TiDB Cloudにはパフォーマンスインサイトのダッシュボードが付属しており、MySQLのSQLベースで確認できます。実行計画ごとの処理時間もデータとして蓄積されているため、ボトルネックになっているクエリを特定しやすく、チューニングを効率的に進められました。
ブランディングの部分についてです。TiDB自体は今まさに開拓フェーズにあります。ちょうどメルカリさんが社内のデータベースをほとんどTiDBに移行している最中かと思いますが、どんどん年ごとに事例が出てきています。まだ開拓フェーズなので、今入っていくことはとても効果が高いと思っています。
山元:ファインディさんにお声がけいただいたり、Findy ToolsでTiDBの話を書かせていただいたりして、Voicyさんはモダンなところを頑張っているよねと見られるのは、非常に良い効果だったと思っています。
余談ですが、HTAPは期待していたのですが、一切Voicyのサーバーでは動きませんでした。TiDBのアナリティクスをまだうまく活用できていない点は課題として残ります。TiDBを導入している企業さんのそれぞれの活用方法は、TiDBのイベントや事例として出ているので、ぜひブースなどで聞いていただければと思います。
まとめ
山元:最後にまとめです。2023年にTiDB移行を決めた時にTiDBのイベントで話した内容なのですが、100点満点のデータベースは存在しません。みなさんのアプリケーションのワークロードに沿って最適なデータベースは変わっていきますし、データベースごとにクエリのプランニングも違えば、中身のアーキテクチャもまったく違うので、そこに合ったものをしっかり選択していくことがとても大事です。
抽象的な概念ではなく物理的な部分が絡んでくるシステムなので、100点満点をすべてに出すということはないです。ただ、最初60点や80点だったとしても、100点に近づけることはできると思っています。
TiDB Cloudには、そのポテンシャルとサポートの両方があります。Writeのスケーラビリティを気にしなくて済む点は大きなメリットです。正直なところ、Voicyの現在のデータ規模ではまだ恩恵を十分に受けられていない部分もあるかもしれません。しかし、より大きなデータ規模になった時には、クラスタ運用の手間がなくなる、データをただ入れて出すだけという抽象的な概念として扱える、といった恩恵が得られます。運用しながら、非常にポテンシャルが高いものだと感じています。
そしてサポートについてです。PingCAPさんは本気で日本にTiDBを浸透させたいという姿勢で活動されています。Voicyに対しても深く入り込んで、今でもチューニングのサポートを継続していただいています。
銀の弾丸に頼るのではなく、一つひとつの課題を地道に乗り越えながら、データベースをより良いものにしていく。そういった姿勢が大切だと思っています。今日の話を通じて、TiDB Cloudがみなさんの選択肢の一つになれば幸いです。一緒に未来を切り開いていきましょう。ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





