



【AI Engineering Summit Tokyo 2025】コンテキスト情報を活用し個社最適化されたAI Agentを実現する4つのポイント
2025年12月16日、ファインディ株式会社が主催するイベント「AI Engineering Summit Tokyo 2025」が浜松町コンベンションホールで開催されました。
本記事では、株式会社ナレッジワーク CAIO(Chief AI Officer)の山崎はずむさんと、Product Div AIエンジニアの河東宗祐さんによるセッション「コンテキスト情報を活用し個社最適化されたAI Agentを実現する4つのポイント」の内容をお届けします。
生成AIの社会実装が加速する中、多くの企業が直面している課題が「いかにして自社固有の業務に合わせた AIエージェントを構築するか」という点です。講演では、商談解析AIの開発を通じて得られた知見をもとに、テキスト情報を活用してAIエージェントを個社ごとに最適化するための4つの技術的ポイントが詳しく語られました。
■プロフィール
山崎はずむ
株式会社ナレッジワーク CAIO(Chief AI Officer)
河東 宗祐
株式会社ナレッジワーク Product Div AIエンジニア
ソフトウェアの「再個別化」が始まる。エージェントが人に合わせる時代のデータ整備

株式会社ナレッジワークで CAIOを務めている山崎はずむと申します。本日は弊社のAIエンジニアの河東と一緒に、「コンテキスト情報を活用し個社最適化されたAI Agentを実現する4つのポイント」というテーマでお話しさせていただきます。
まず簡単に、私たち二人のバックグラウンドをお話しさせてください。私たちはもともとPoeticsというスタートアップの出身です。今年の5月にM&Aを通じてナレッジワークに参画しました。
Poeticsは商談記録ツール「JamRoll」を通じて、音声認識、話者分離、自然言語処理をモデルから自社開発してきました。AWSのグローバルプログラムにも日本で数社のみ採択され、論文発表などアカデミックな活動も行ってきました。

ナレッジワークCEO の麻野はリンクアンドモチベーションの出身、CTO の川中は Google で Chrome 開発に携わっていた人間で、現在は 200 名ほどの規模で大手企業様を中心にセールスイネーブルメントの支援を行っています。
ナレッジワークという会社は、「みんなが売れる営業になる」というビジョンを掲げ、営業担当者を支援するプロダクト群を提供しています。
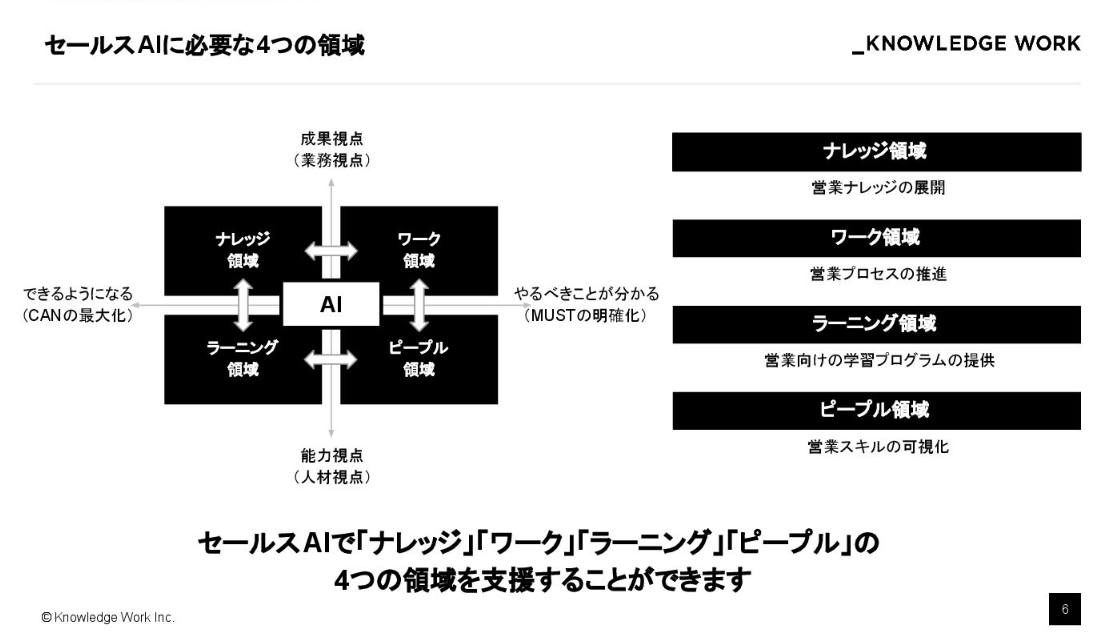
具体的には、ナレッジ領域、ワーク領域、ラーニング領域、ピープル領域といったように概念的に4つのマトリクスに分けて、それぞれに対応するプロダクトが存在します。
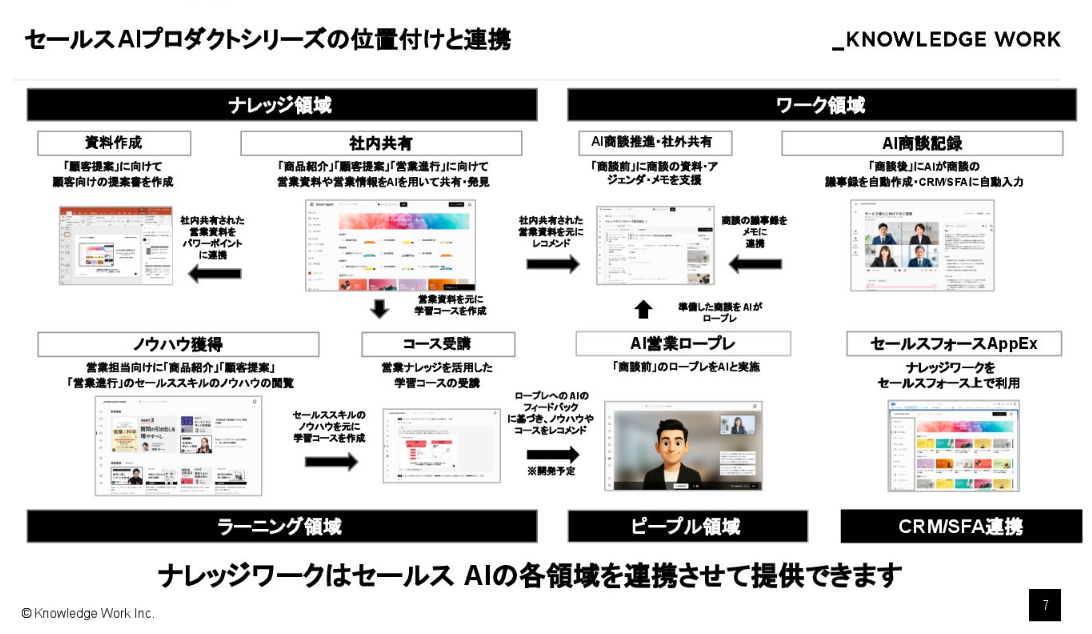
中でも創業期から展開しているのがナレッジ領域の「社内共有」というプロダクトで、営業資料などを統合し、高い検索性で必要な情報をすぐに見つけられるようにしています。
本日メインで紹介するのはワーク領域の「AI商談記録」です。商談内容を自動で文字起こし・要約・分析し、Salesforce に連携するプロダクトで、元々Poeticsで開発していました。
最近では AIアバターとロールプレイができる営業ロープレも提供していて、実際の商談データや営業情報を埋め込んだエージェントと対話できます。複数のプロダクトがモジュールとして連結しているのが特徴で、セールステックとしても珍しいラインナップだと思っています。
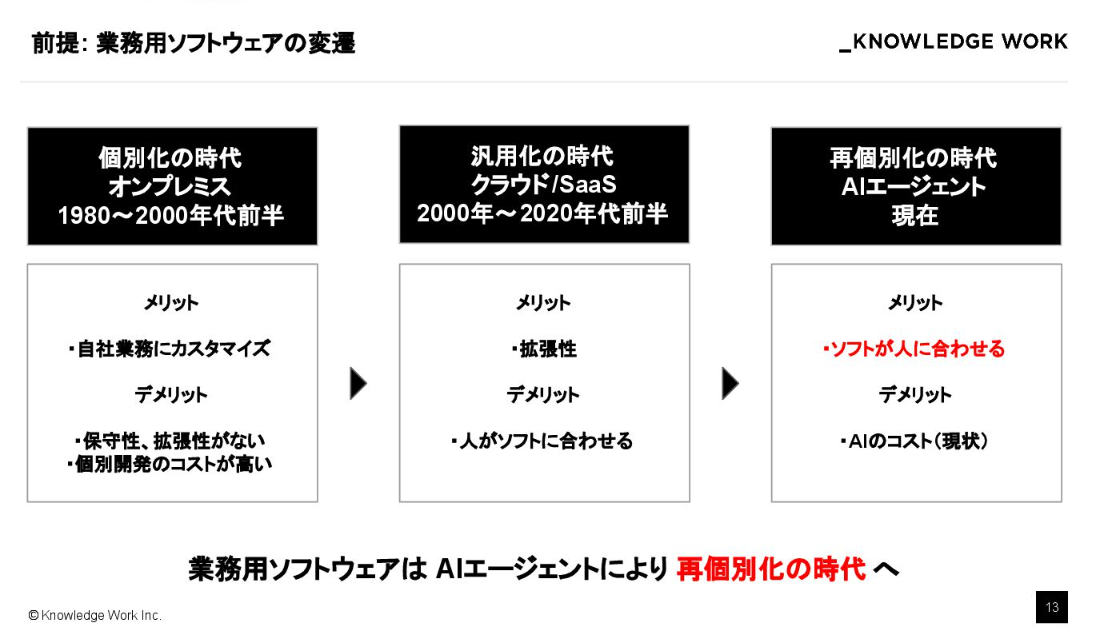
さて、今日の本題であるコンテキストの話に入る前に、なぜ今これが重要なのかという背景に触れたいと思います。私は、LLMの登場によって業務用ソフトウェアの歴史は「再個別化の時代」に入ったと考えています。
かつてのオンプレミスの時代は、各社の業務に合わせてシステムを個別につくり込む「個別化」が当たり前でした。それがクラウドやSaaSの時代になり、人がソフトウェアの仕様に合わせて使う「汎用化」が進みました。
しかし今、AIエージェントが登場したことで、再びソフトウェアが人や個別の業務に合わせていく「再個別化の時代」に入っています。

この変化の中で、SaaS のあり方も変わらざるを得ません。単にツールを提供するだけでなく、お客さまの深い業務理解に基づいたコンサルティングが重要になりますし、カスタマーサクセスを通じた業務把握も不可欠になっています。
そして何より、AIエージェントが動きやすいようにデータを整備する「エージェントレディ」な状態をつくることが必須になっています。

米国のVCが発表した「Big Ideas 2026」でも、非構造化データを整備してエージェントレディにすること、そしてエージェントのためのソフトウェア設計が大きなトレンドとして挙げられていました。
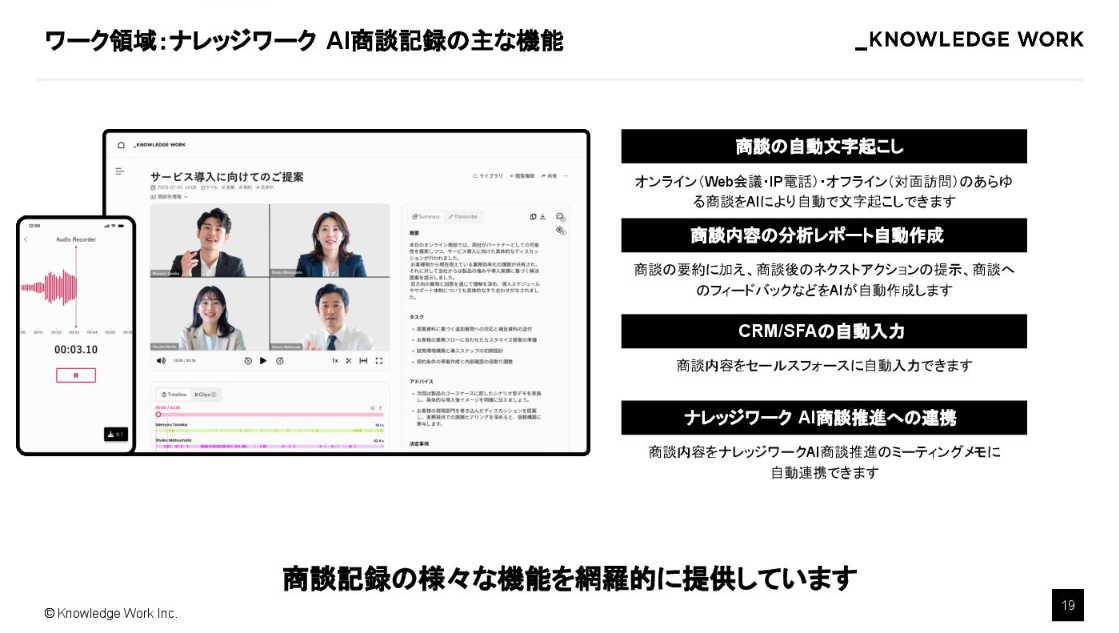
私たちが注力している「AI商談記録」というプロダクトは、まさにこの思想を体現しています。オンラインや対面での商談を自動で記録し、要約や分析を行ってSalesforceなどのCRMに連携することができますが、本日は実際のデモを通じてイメージしていただきます。
特徴的なのは、単に「何が話されたか」を要約するだけでなく、その企業の特定の業務ルールに即した分析ができる点です。
例えば現在ご覧いただいている銀行の融資提案のケースでは、「関連子会社の商材を直接提案してはいけない」といった非常にマニアックなルールがあったのですが、私たちのAIはそうしたコンテキストを理解して適合性をチェックすることができます。汎用的な要約ではなく、業務プロセスに即した分析を組み込める点が特徴です。
これを実現するためには、日本語の音声認識エンジンから話者分離、そして自然言語処理に至るまで、自社で一貫して開発している強みが活きています。今お聞きいただいたデモでは、3人以上の話し分けに対応しているほか、関西弁も適切に認識し極めて高い精度でテキスト化を行っています。
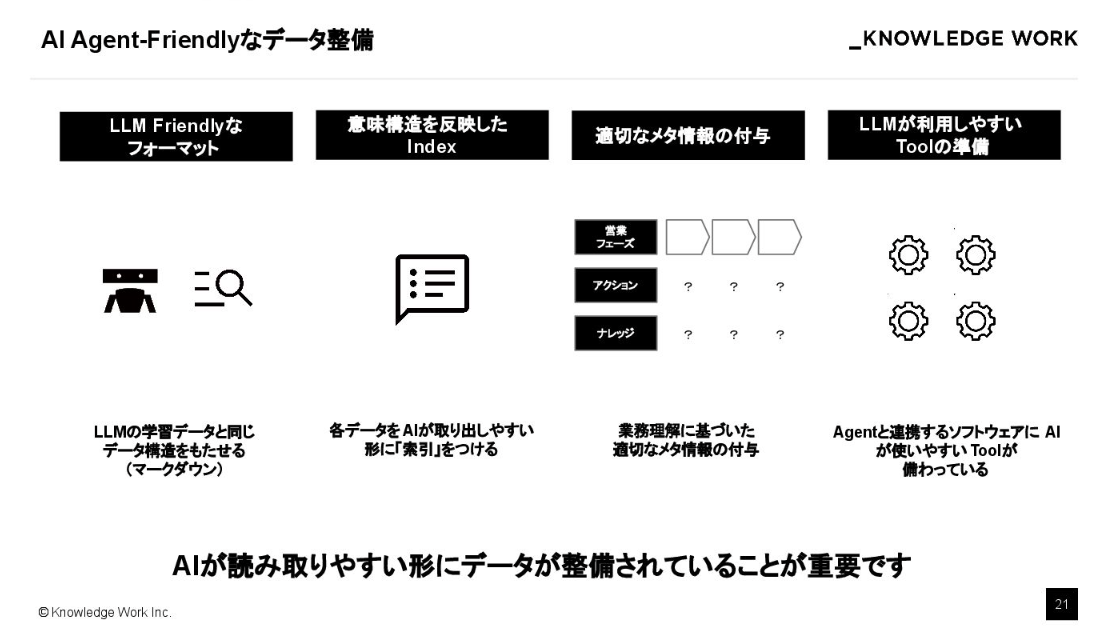
その上で、LLM が扱いやすいように構造化データやメタデータを付与していく。こうしたコンテキストエンジニアリングが、これからの AI 開発の肝になると確信しています。
実務に即したAIエージェント開発を実現するための4つの技術的ポイント
ここからは、実際に AI エージェントを開発する上で私たちが重要だと考えている4つのポイントについて、エンジニアの河東から具体的にお話しします。
ナレッジワークの河東です。私からは、「AI商談記録」のエージェント開発を例に、具体的な話をさせていただきます。
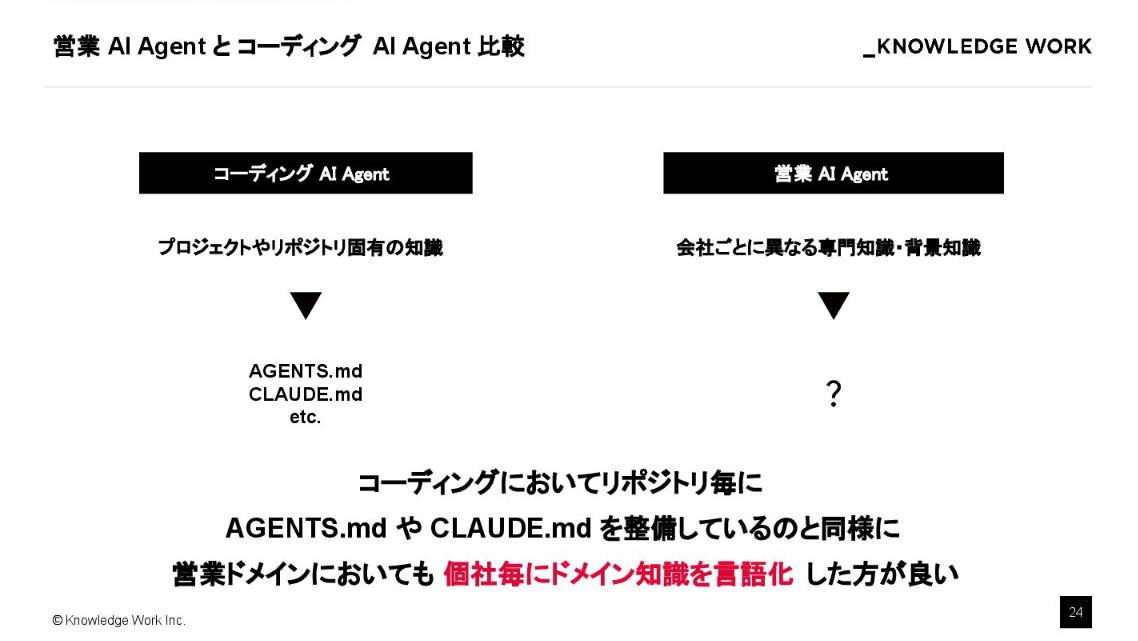
まず前提として、コーディングの世界でAGENTS.mdやCLAUDE.mdといったファイルにプロジェクト固有のルールを記述して AI に教えるのと同じように、営業領域でも個社ごとの方針やドメイン知識を言語化し、AIエージェントが扱いやすい形に落とし込むことが不可欠だと考えています。
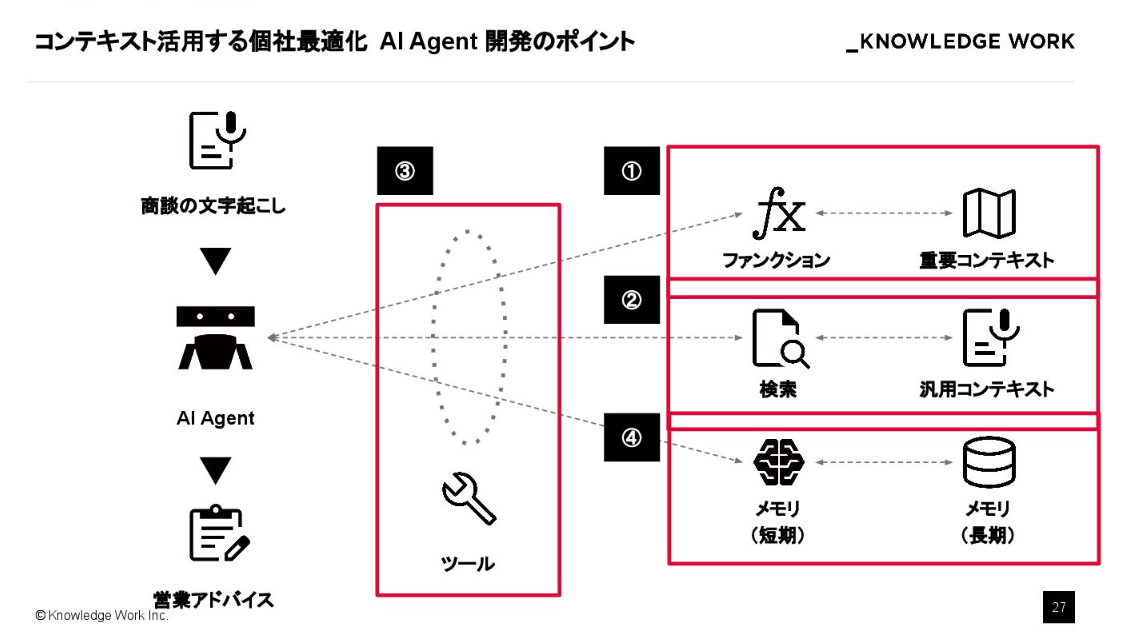
そこでここからは、コンテキストを活用した個社最適化エージェント開発の4つのポイントを説明します。
1.重要コンテキストのデータ整備
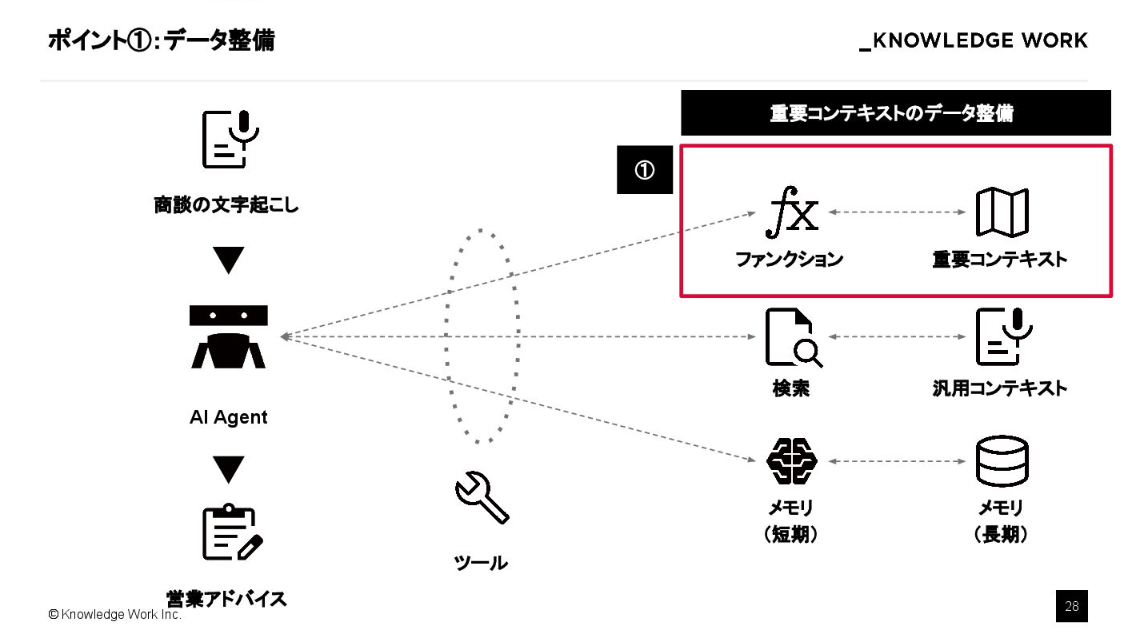
ポイントの1つ目は、重要コンテキストのデータ整備です。
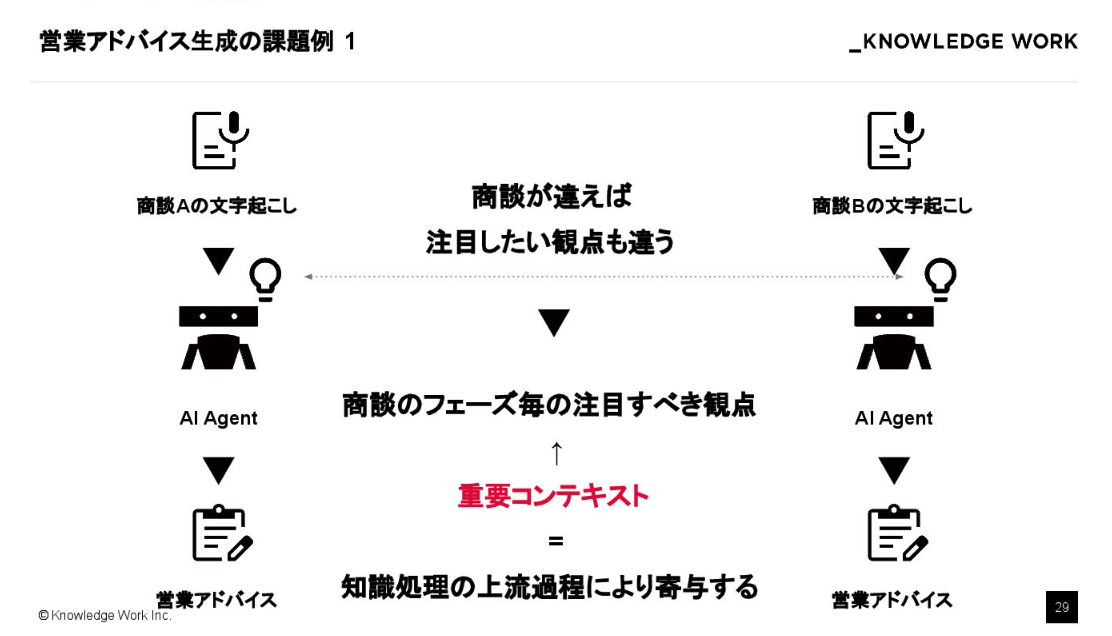
商談には「ヒアリング」や「クロージング」といったフェーズがありますが、フェーズが違えば注目すべき観点も当然変わります。こうした「今、何に注目して分析すべきか」という指針を重要コンテキストとして定義し、AIのプランニングといった上流の工程で動的に切り替える仕組みが必要です。

これには、検索結果をもとにタスクを分解するRaDA(Retrieval-augmented Web Agent Planning with LLMs)のような手法が非常に有効で、私たちの開発でも参考にしています。
2.汎用コンテキスト
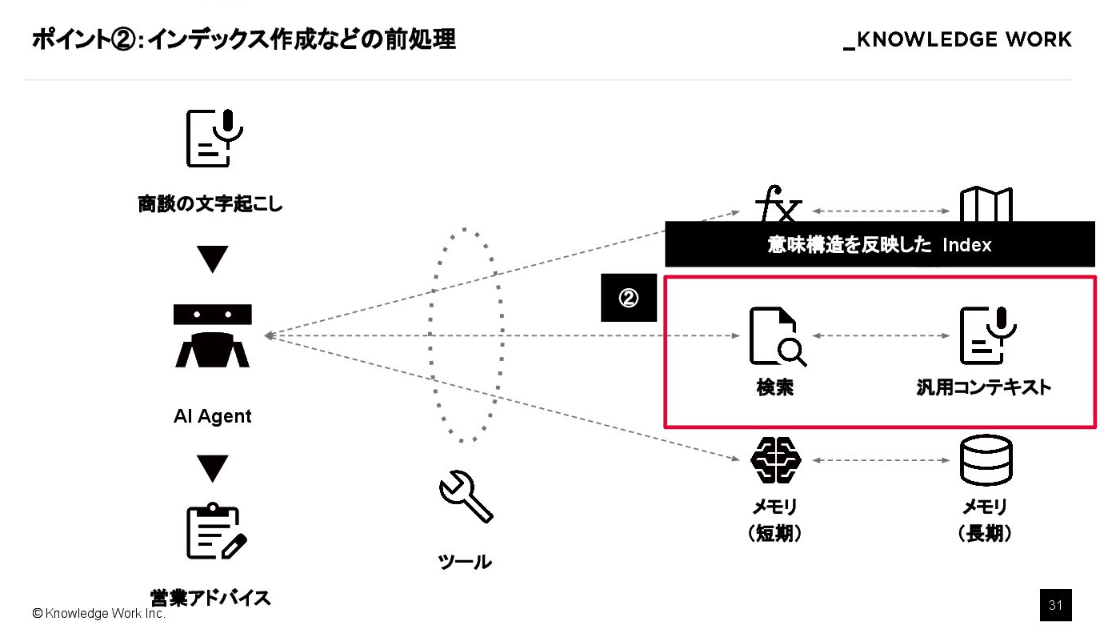
ポイントの2つ目は、汎用的なデータの検索性を向上させるための前処理です。
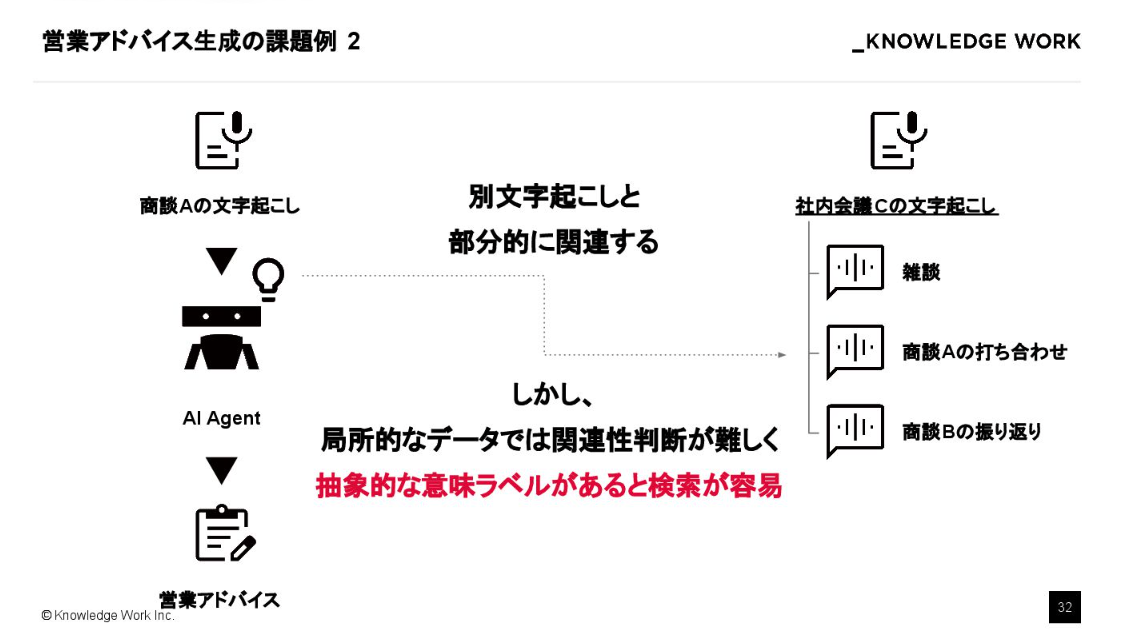
例えば、ある商談の解析をする際に、別の社内会議で話された一部の内容を参照したいとします。しかし、単なる発言単位の局所的なデータでは、AIが関連性を判断するのは困難です。
そこで、「この発言はどの商談に関するものか」といった抽象的な意味構造を反映した、階層的なインデックスを構築する必要があります。

RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)という、木構造で階層的な要約を生成する手法がありますが、こうした多層的なアプローチを非構造化データに適用することで、検索精度を劇的に高めることができます。
3.ツール設計
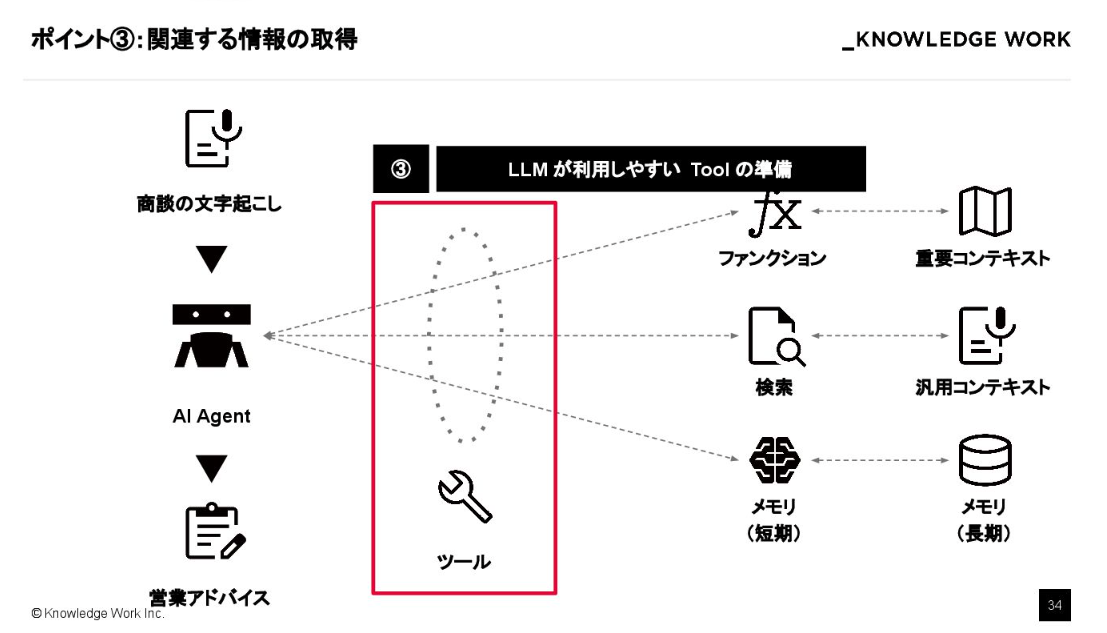
ポイントの3つ目は、LLM が利用しやすいツールの準備です。

基本的には、何でもできる汎用的なツールを一つ用意するのが前提となりますが、ドメイン知識をあらかじめ内包した「特化型ツール」を準備しておくこともAIの誤動作を防ぐ鍵になります。

ただし、ツールを増やしすぎるとLLM のコンテキストウィンドウを圧迫するというトレードオフが発生します。

そこで、クエリの内容に応じて最適なツールをリランキングしてフィルタリングするToolRerank(Adaptive and Hierarchy-Aware Reranking for Tool Retrieval)のような手法を取り入れ、LLM の思考を簡略化させる工夫をしています。
4.メモリマネジメント
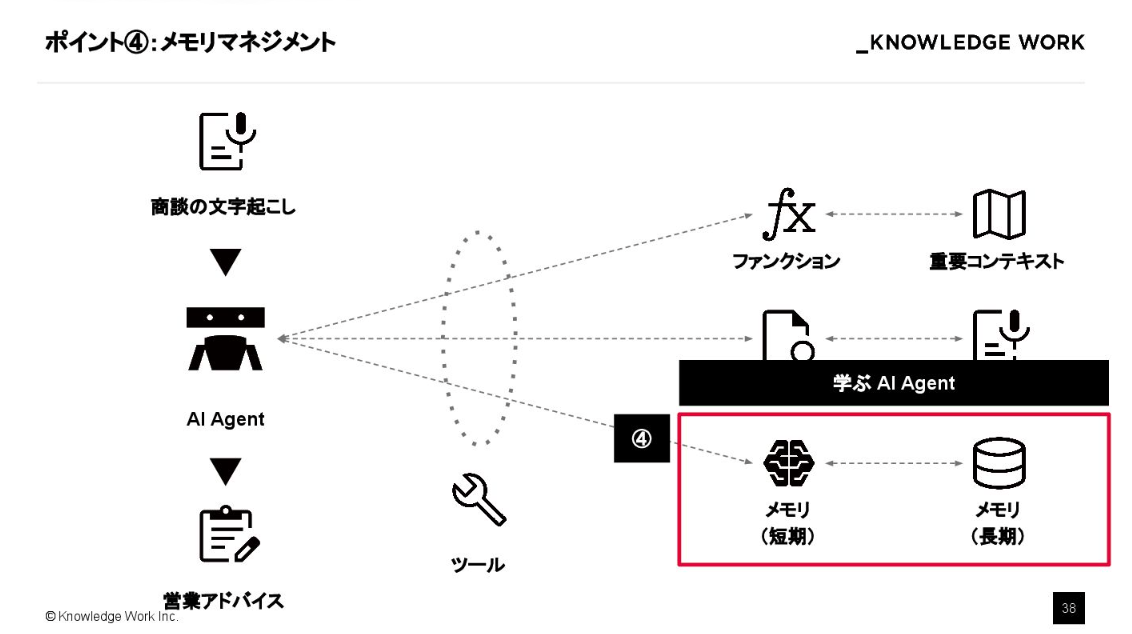
そして4つ目が、メモリマネジメントです。

対話履歴から情報を抽出して引き継ぐ「個人レベルの最適化」は手法が見えてきていますが、私たちが今チャレンジしているのは「個社(コミュニティ)レベル」での長期記憶です。会話の中から重要なファクトを抽出し、それをグラフ構造などで保持して継承していく。

学ぶ AI エージェントを実現するためには、このようなコミュニティレベルでの最適化が今後の大きなテーマになると考えています。
現在、個人レベルではFlexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Frameworkといった手法がありますが、これをコミュニティレベルに引き上げることができればメモリの個社最適化が実現できると思います。

ここまでの要点を整理すると、個社最適化されたAIエージェントを構築するためには、
- 業務理解とデータ整備が重要
- 重要コンテキストをAIエージェントの知識処理よりも上流で利用できるよう整備すること
- 非構造化データの検索性向上には抽象的な意味構造を反映するindexを構築すること
- ドメイン知識を内包したツールを利用しながら、フィルタリングする仕組みも求められる
という4点が特に重要なポイントとなります。
ナレッジワークAIチームが向き合う技術領域と採用背景

最後に少し採用のお話をさせていただきます。我々は ASR、TTS、音声信号処理、RAG、コンテキスト設計、データラベリングなど幅広い領域を扱っています。LLMとルールベース、従来の機械学習を組み合わせた研究開発も行っています。
検索に関してはリアルタイム性と正確性の両立が求められるため、メタデータ設計を含めた高度な情報検索に取り組んでいます。弊社のAIチームは少数精鋭で多くのプロジェクトを担当しているため、音声・NLP・検索に興味のある方とぜひお話ししたいと考えています。
ブースでは我々が扱っている要素技術やデータ、実際に動くプロダクトなども紹介しています。この後スピーカースタンドにもいますので、カジュアルにお話させていただければと思います。気になることがあればぜひお声掛けください。
本日はご静聴ありがとうございました。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
AI Engineering Summit Tokyo 2025
※動画の視聴にはFindyへのログインが必要です。





