



生成AI入門 - AWS社員が解説するAmazon Bedrock詳細ハンズオン
こんにちは。
今回は、アマゾンウェブサービスジャパンの菅原と北村が、Amazon Bedrockを用いたハンズオンを紹介させていただきます。
はじめに
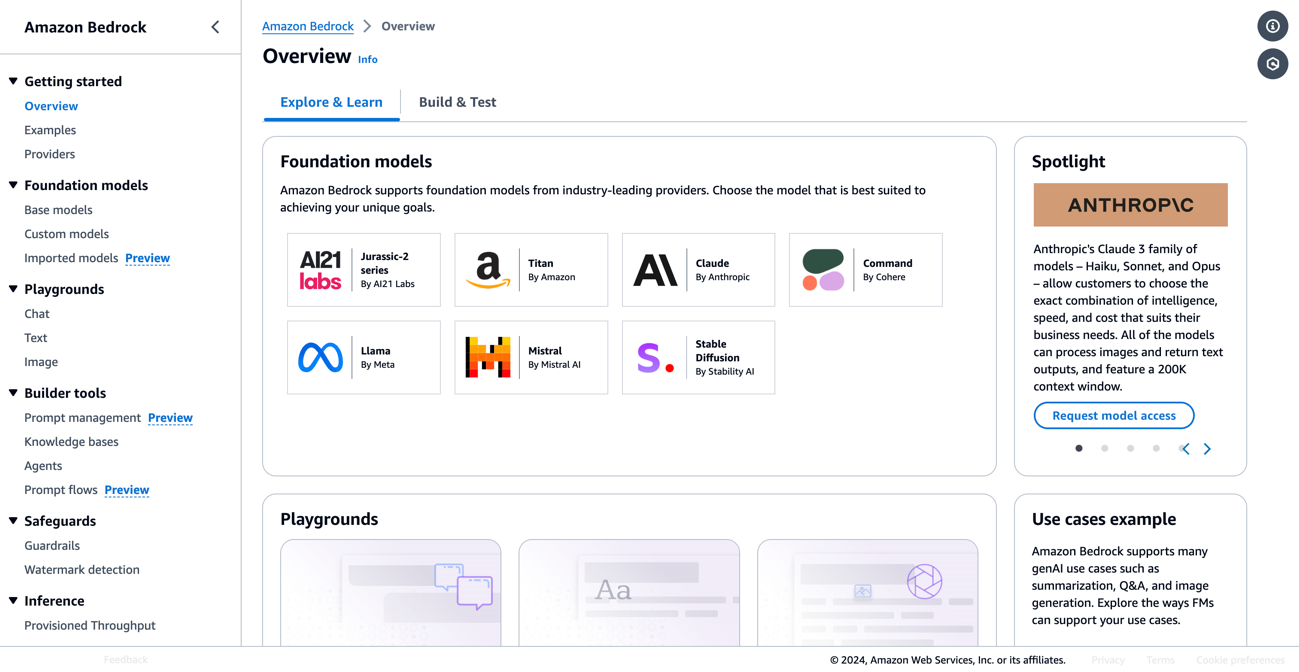
Amazon Bedrockは、業界をリードする種々の基盤モデル(Foundation Model・FM)を提供する、生成AIアプリケーションの構築に必要な幅広い機能を備えたフルマネージドサービスです。
生成AIを業務で導入するには、モデル選びやセキュリティなど、さまざまなことを考える必要があります。
Amazon Bedrockは、APIを通じて生成AIの基盤モデルを利用できるだけでなく、付随するサービスによってお客様が生成AIを簡単に導入できます。
Amazon BedrockはAWSマネジメントコンソール上でモデルを有効化し、API経由で入力を送信するだけで使用できます。コンソールでモデルを試したり、複数モデルを比較したりすることもできます。課金モデルは使用した分だけの従量課金制となっており、使わないときは料金が発生しません。本記事でご紹介するハンズオンでも使用しますので、ぜひ試してみてください。
Bedrockの良さ
Amazon Bedrockでサポートされている基盤モデルの一覧はこちらでご確認ください。Amazon TitanやAnthropic Claude、画像生成に特化したStable Diffusionなど、用途に応じて各社から提供される最適なモデルを選択できますただし、リージョンごとに利用可能なモデルが違うため注意が必要です。東京リージョンでは記事公開時点で最近のClaude 3.5 SonnetやClaude 3 Haikuを利用可能です。
これによりレスポンス速度が向上し、「海外にリクエストデータが行かないようにしたい」という企業ニーズにも応えられるようになりました。リージョンごとの利用可能なモデルはこちらでご確認ください。
Amazon Bedrockにより、さまざまな基板モデルに対してAPI経由で推論を行うことができます。基盤モデルの種類に関わらず、BedrockのAPIを呼び出すだけで利用できるため、後からモデルを変更することが容易になります。APIの呼び出し方は各モデルに対して一律のため、システムの実装後に基盤モデルを変更することも可能です。
昨今、生成AIの技術進歩は目まぐるしく、最新の生成AIモデルに追従する必要があります。APIの呼び出し方法が変わり、プログラムの修正が必要になることも度々あります。Amazon Bedrockでは、各社の生成AIモデルを提供しており、異なるモデルを使用したくなったら、呼び出す生成AIモデルを変更するだけなので簡単です。
セキュリティの観点から、Amazon Bedrockは入出力するデータを保存したり、再学習のために利用したりしません。また、各モデルはAWS基盤上に存在するため、サードパーティー企業に対して情報を送信することもありません。コンプライアンスの観点でも、お客様はAWSが取得している認証や監査をAmazon Artifact上で確認することができます。
上記に挙げた機能にも、生成AIをより便利に使うための機能がそろっています。後述するRAGの他、すでに存在するモデルを追加学習するためのFine Tuningや、生成AIに検索や操作をさせるためのエージェント機能も存在します。AWS Step FunctionsなどのAWSツールとの統合も可能なため、実装するアプリケーションの幅を広げることができます。
Claudeとは
今回は、Anthropic社のClaude 3を用いて実装を進めていきます。Claudeは、入力に文章と画像を用い、出力に文章を用いることができるマルチモーダルの生成AIモデルです。
Amazon Bedrockでは、Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, Claude 3.5 Sonnetを使用することができます。それぞれ回答速度や精度が異なりますが、Amazon Bedrockではモデルの切り替えが容易なため、さまざまなモデルを試行することができます。
独自データの活用とハルシネーション
生成AIを活用する上でよくある課題として、基盤モデルが学習データに含まれていない情報を回答できないということがあります。
学習された内容に基づいて、確からしい結果を推定するため、事実に基づかない情報を生成し、不正確な回答をしてしまうことがあります。
これを「ハルシネーション(幻覚)」といい、特に会話型AIサービスでは信頼性に関わる非常に重要な問題です。
以下にハルシネーションの例を示します。
質問「2023年に発表されたAWSの新しいサービスは?」
生成AIアプリの返答①「それはAmazon XXXです!」(現実に存在しないサービス名)
生成AIアプリの返答②「AWSは2023年に新しいサービスを発表していません。」(実際には発表している)
しかし、実際に生成AIを現場で活用しようとした際に、基盤モデルの学習データに含まれていない内容、つまり組織の情報や業界などの独自のデータを取り込みたいというユースケースは多く存在します。
その際、ハルシネーションを防ぎながら基盤モデルを拡張するというアプローチが必要になります。これを実現する方法を3つ紹介します。
1. プロンプトで解決
1つ目はプロンプトの中に独自のデータを取り込むという方法です。
基盤モデルに対して、何をしてほしいかの命令を自然言語で表現する必要があり、これをプロンプトと言います。プロンプトをどのように書くかは非常に重要であり、プロンプトの内容によって基盤モデルの性能が左右すると言っても過言ではありません。明確に、何をしてほしいのか、どういったステップで思考してほしいのかを指示する必要があります。
プロンプトの書き方はテクニックは、基盤モデルによって微調整が必要です。Claudeはプロンプトの作り方にも特徴があります。詳細についてはAnthropic社のプロンプトエンジニアリングの概要 - Anthropicをお読みください。
例えば、ある不動産の契約書の内容について正確に回答するチャットボットを作るとなったときに、プロンプト内に契約書のテキストをコピー&ペーストするという方法を取ることができます。
以下はそのプロンプトの一例です。プロンプトのタグの活用についてはこちらの記事を参考にしてください。
あなたは不動産の契約書の内容に関する質問対応ができるチャットボットです。
<contract>タグで実際の契約書のテキストを指定するので、その内容に基づいて正確に回答してください。
<contract>
(売買の目的物及び売買代金) 第1条 売主は、標記の物件(A)(以下「本物件」という。)を標記の代金(B1)をもって買主に売渡し、...
</contract>
この方法は簡単に独自のデータを取り込むことができますが、手動で都度プロンプトにデータを与える手間を考えると非効率的であり、システムとして構築する際には柔軟性や拡張性に欠けてしまいます。
独自データのサイズがそこまで大きくなく、簡単に試してみたいときなどに適しているでしょう。
2. RAG
RAGとは、Retrieval-Augumented Generation(検索拡張生成)の略で、独自のデータを追加で与えることで、LLMが学習済みの知識を拡張させるための手法です。与えられた入力に関連するデータを検索して、得られた情報を使用して自然言語の質問に答えます。
これにより、回答を生成する前に基盤モデルがトレーニングを行ったデータソース以外の信頼できるデータを参照することができます。
LLMの強力な機能を、モデルを再トレーニングすることなく特定の分野や組織の内部ナレッジベースに拡張することができるため、独自データを活用したいというユースケースで広く使われている手法です。
先ほど挙げた不動産の契約書の例で考えてみます。
不動産の契約書が数千枚にもわたるPDFファイルだったとして、それらの全てのテキストをプロンプトに埋め込むのは現実的ではありません。
そこで、PDFをRAGの検索対象データとすることによって、基盤モデルがPDFの情報をもとに回答できます。出力結果の根拠が明確になり回答の精度が増すこと以外にも、情報更新が容易になるというメリットもあります。
外部情報の文書やデータベース内の情報に変更があったとしても、最新の情報を即座に大規模言語モデルから出力結果に反映させることができます。
具体的な方法は、後半のハンズオンで説明します。
3. Fine Tuning
Fine Tuningは特定のタスクやデータセットに合わせて、LLMのモデルを再学習する手法です。
LLM以外でも深層学習の分野で長く使われている手法で、新たな知識をモデルに取り入れたい際に使われる一般的な手法となっています。
RAGは動的な(頻繁に最新版へと更新する必要のある)データを取り込むケースに適している一方で、Fine Tuningは静的な大規模データセットを利用するケースに適している場合が多いです。
Fine Tuningを行う際には、モデルの再学習に高品質な(ノイズの少ない)データセットを使用したり、学習の際に計算リソースが必要であったりと、作業コストがかかることに注意を要します。
ハンズオンの実施内容
今回の記事では、下記の内容を行います。
- 環境準備
- Bedrockの基本
- 画像生成
- RAG
1. 環境準備
1.1 Bedrockで利用する基盤モデルを有効化
① AWSコンソールから、Bedrockを開き、[使用を開始]ボタンをクリックします。
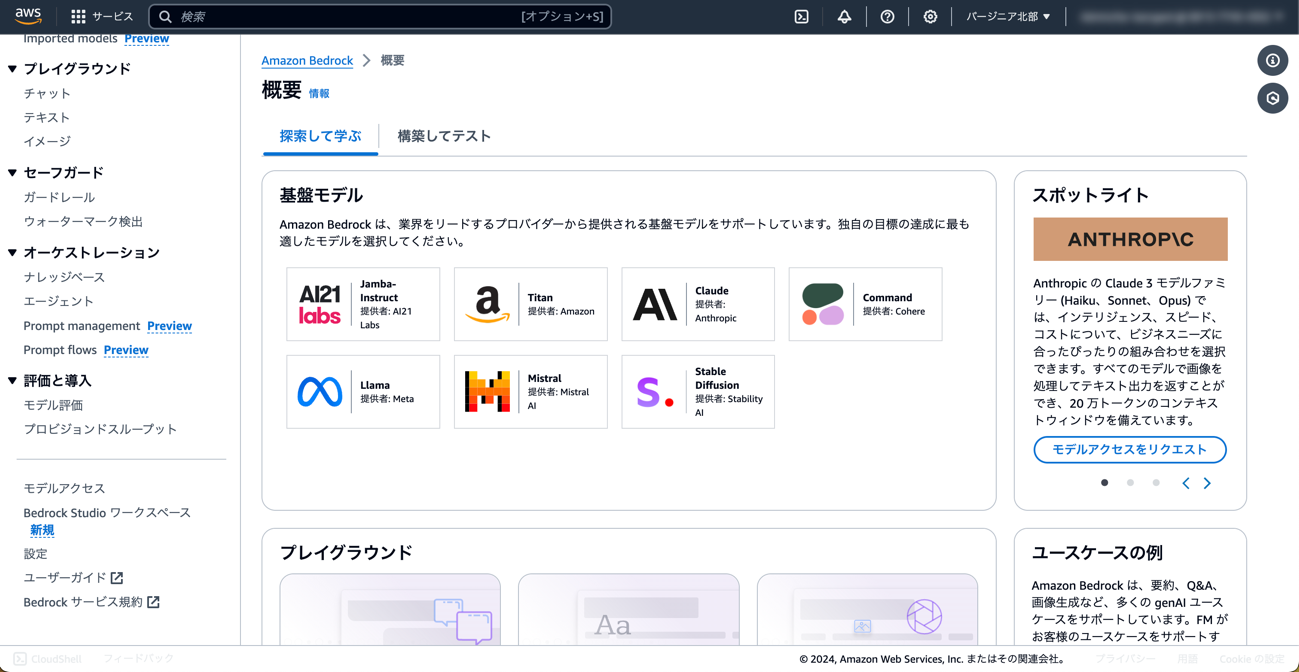
② 左側のメニューをスクロールし、「モデルアクセス」をクリックします。
③ [Enable specific models]ボタンをクリックします。
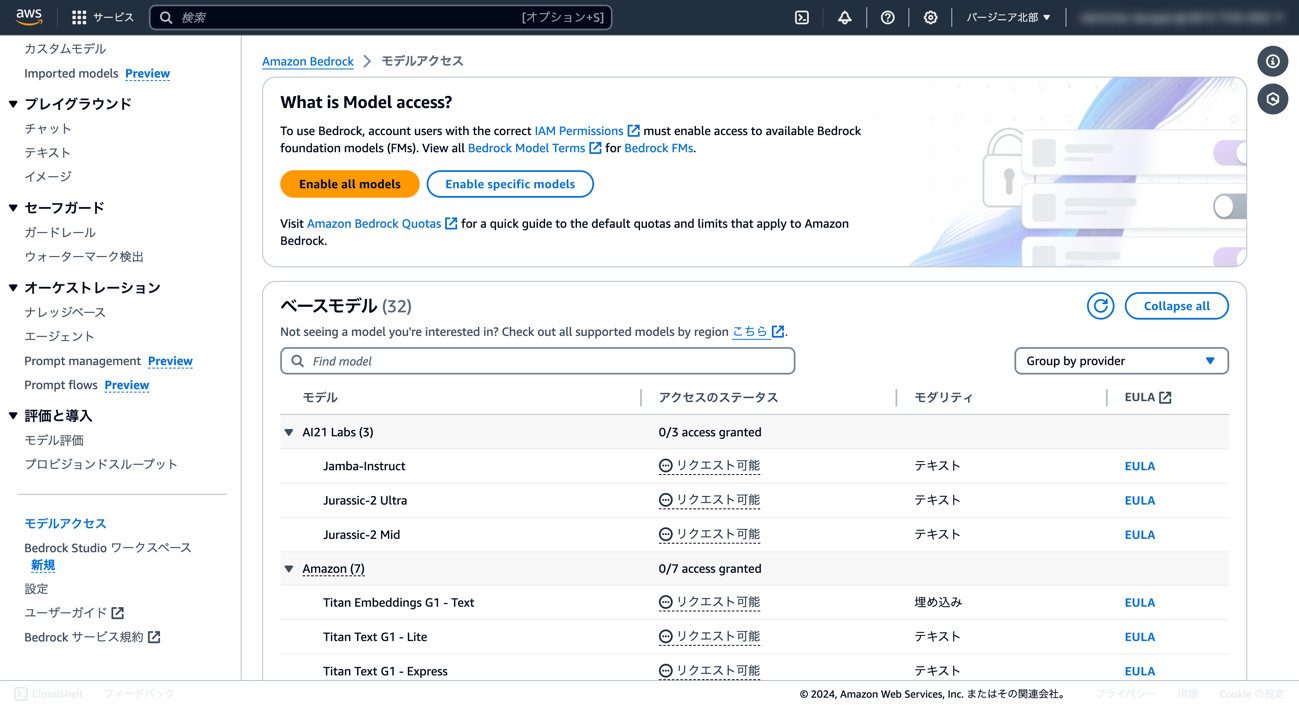
④ AnthropicのClaude 3 Sonnetにチェックを入れ、有効化します。
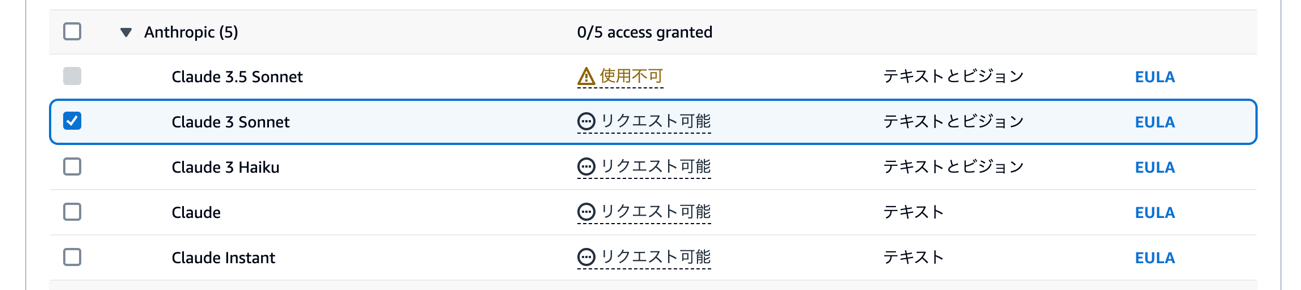
ここで他のモデルを選択して有効化することもできます。コンソール上で比較もできるので気になったモデルを有効化してみてください。本記事では、比較用としてClaude 3 Haikuを有効化しました。

⑤ 左側のメニューから「チャット」を開き、比較モードをオンにします。
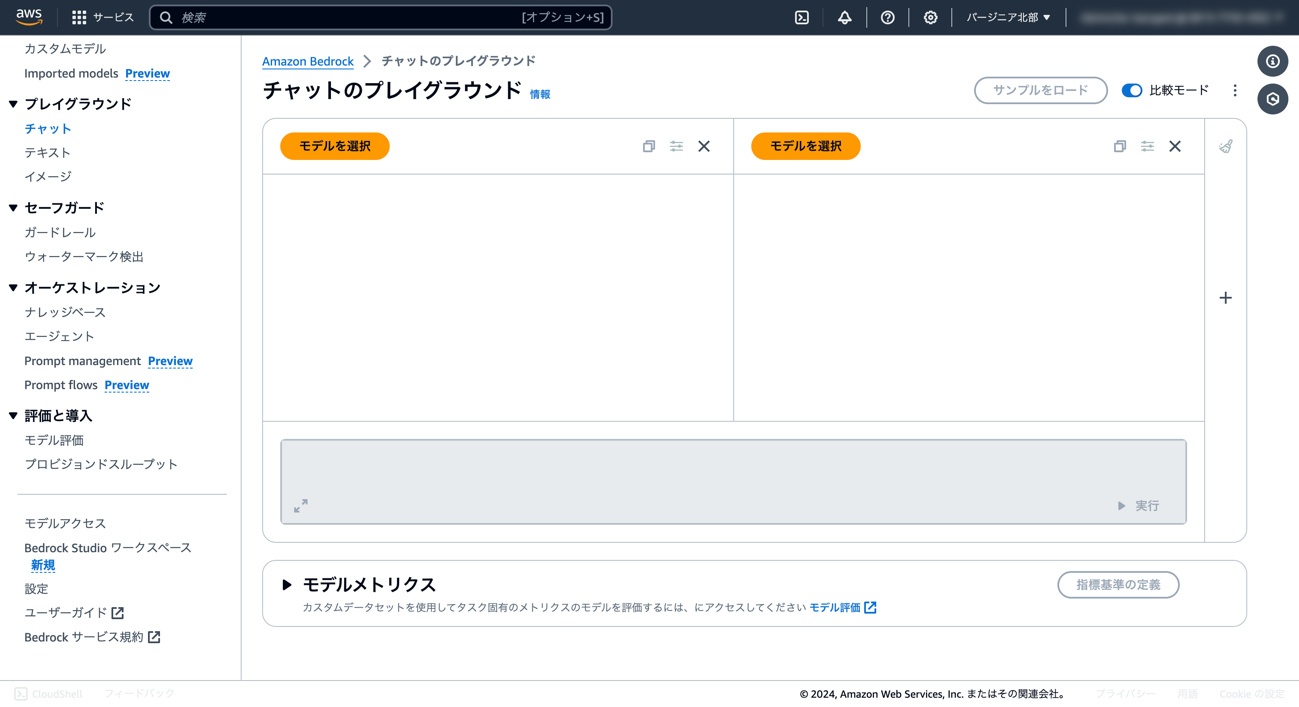
⑥ 「モデルを選択」から、左側にClaude 3 Sonnet、右側にClaude 3 Haikuを選択します。

⑦ テキストボックスに聞きたい内容を入力し、[実行]ボタンを押します。
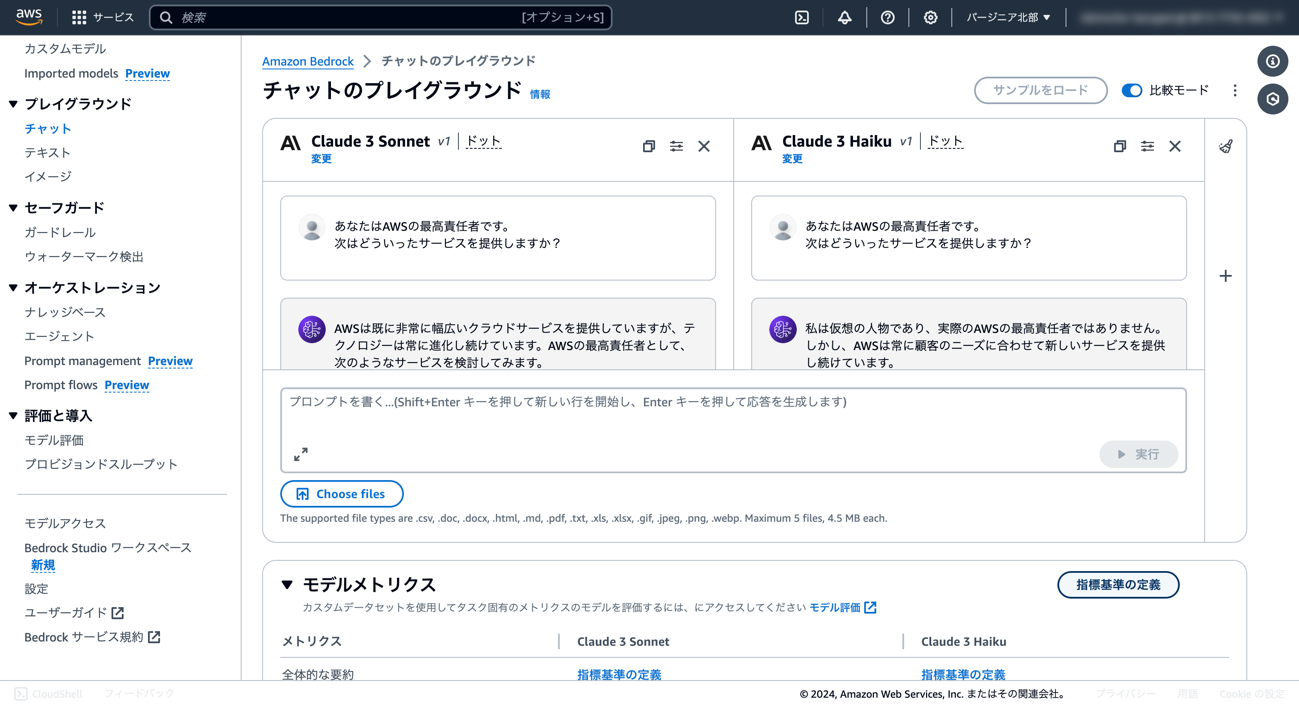
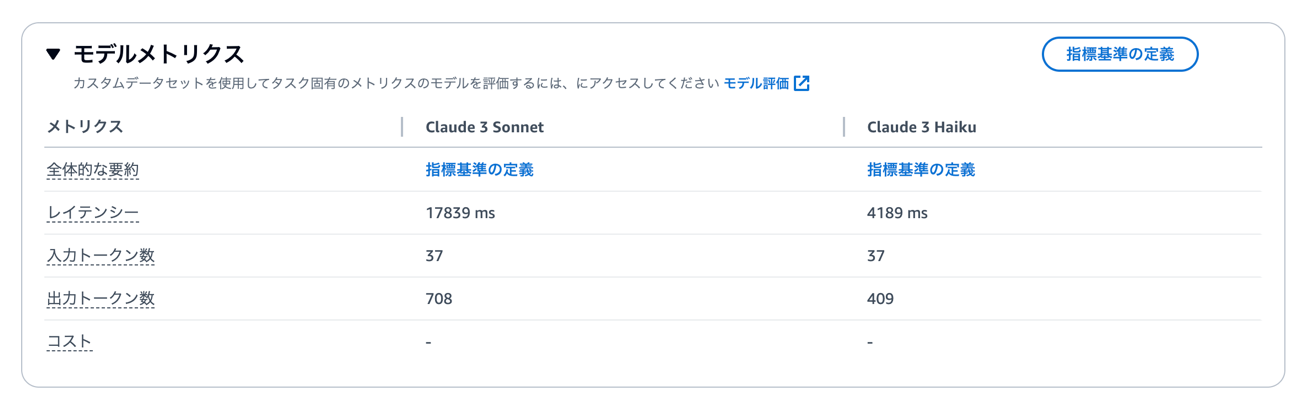
Bedrockコンソール上では、生成AIモデルが気軽に試せることに加えて、比較が可能です。精度のほかに速度も比較することができるので、さまざまなモデルを使ってみましょう。
1.2 SageMaker Notebookのセットアップ
① SageMakerをコンソールから開き、Notebooksから[ノートブックインスタンスの作成]ボタンをクリックします。
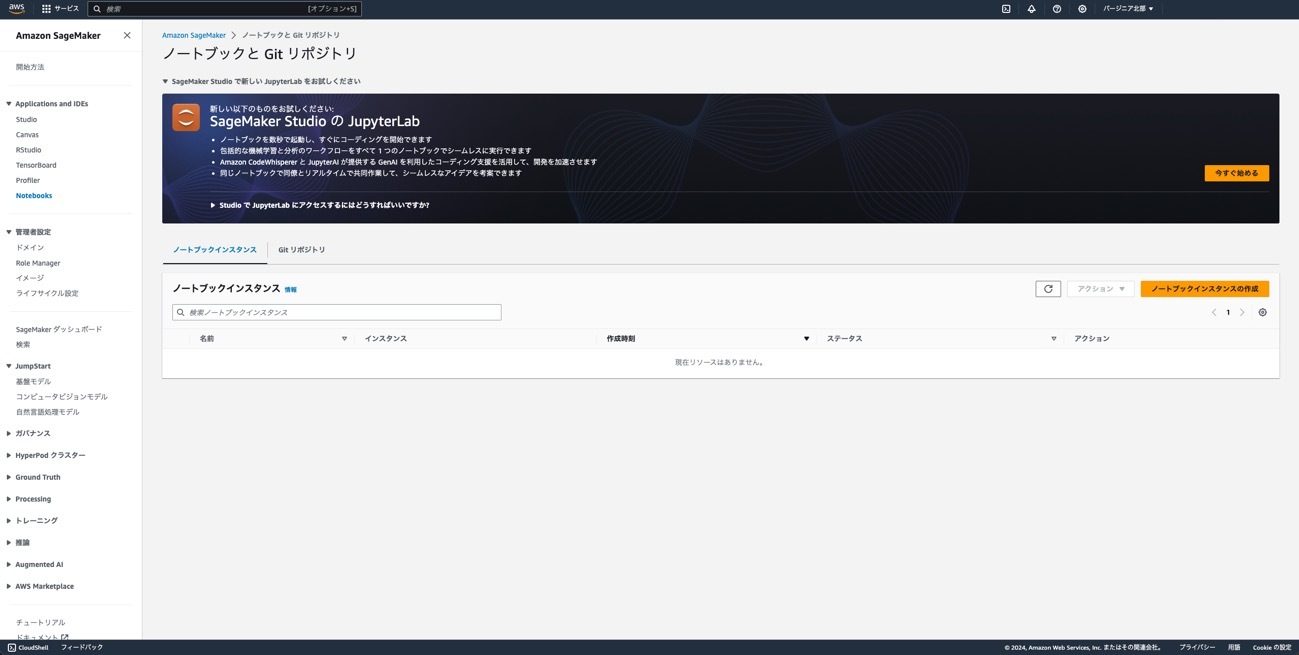
② ノートブックインスタンス名をhandson-bedrockとし、それ以外はデフォルトで[ノートブックインスタンスの作成]ボタンをクリックします。
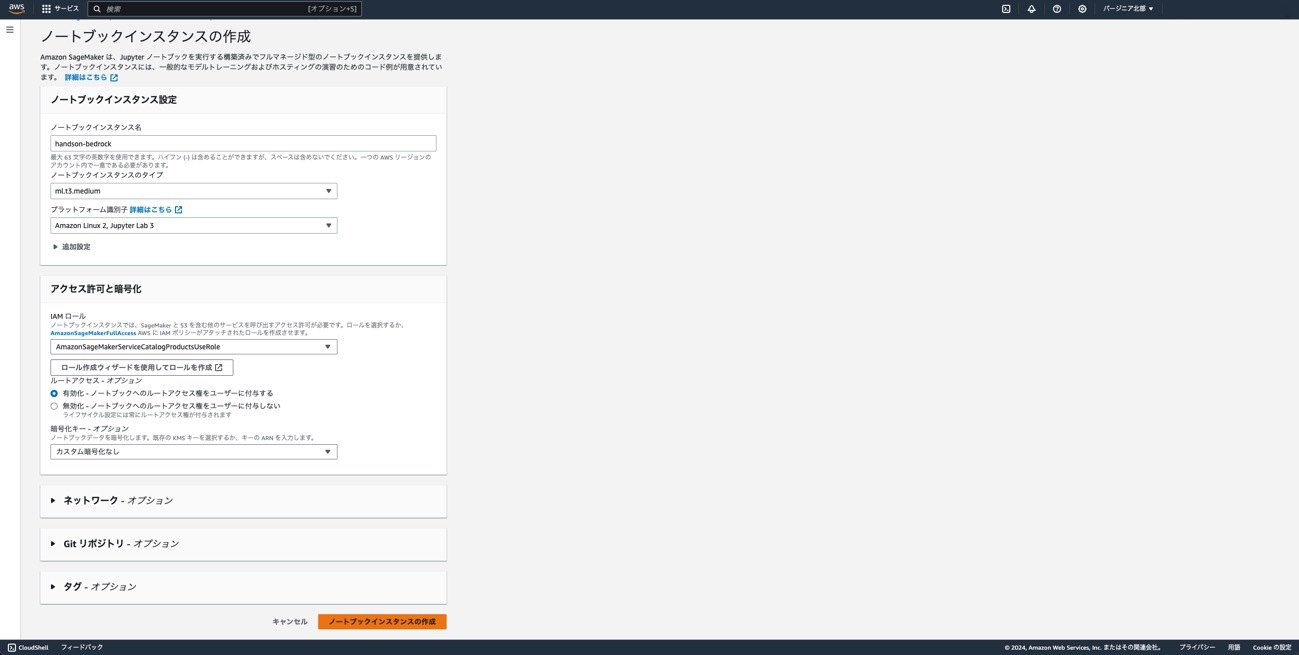
③ 「IAM ロールARN」をクリックし、「許可を追加」から[インラインポリシーを作成]ボタンをクリックします。下記のJSONを貼り付けます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
④ ポリシー名をbedrock-policyにして[ポリシーの作成]ボタンをクリックします。
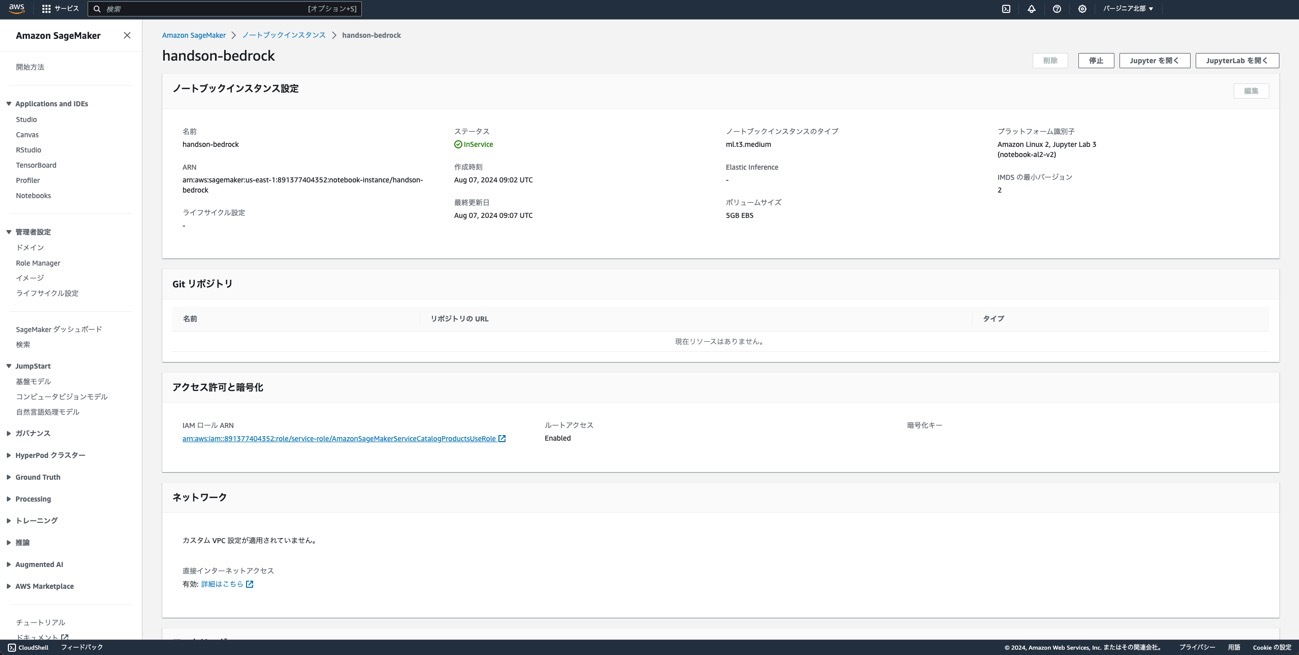
⑤ SageMakerの画面に戻り、ステータスがInServiceになったら、「Jupyter を開く」をクリックします。
⑥ 最初に作成したJupyter Notebookファイルをダウンロードし、アップロードを行います。
以上で準備完了です。
2. Bedrockの基本
2.1 ライブラリの準備
%pip install boto3 -U
import boto3
import json
import sys
# bedrock client
bedrock_client = boto3.client(service_name='bedrock')
bedrock_runtime_client = boto3.client(service_name='bedrock-runtime')
2.2 モデルの利用
Bedrockの提供するConverse APIは、一貫したリクエスト構文およびメッセージ構造のプロンプトを利用して、Bedrock経由でサポートしているLLMの呼び出しを簡略化するAPIです。
コードの変更なしに、モデル名のみ変更するだけで異なるモデルプロバイダーのモデルの間での切り替えが実現できます。
# 利用可能な基盤モデル一覧の表示
response_json = bedrock_client.list_foundation_models()
for models in response_json['modelSummaries']:
print(models['modelId'])
model_ids = [
"anthropic.claude-3-haiku-20240307-v1:0",
"mistral.mistral-7b-instruct-v0:2",
"cohere.command-r-plus-v1:0"
]
必要に応じて、全てのプロバイダーに共通ではない追加のモデル固有のリクエストフィールドを定義することもできます。詳細については、Bedrock Converse APIのドキュメントを参照してください。
https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference.html
def bedrock_converse(client, id, prompt, max_tokens=300, temperature=0, top_p=0.9):
response = ""
response = client.converse(
modelId=id,
messages=[
{
"role": "user",
"content": [
{
"text": prompt
}
],
}
],
inferenceConfig={
"temperature": temperature,
"maxTokens": max_tokens,
"topP": top_p
}
#additionalModelRequestFields={
#}
)
result = response['output']['message']['content'][0]['text'] \
+ '\n--- Latency: ' + str(response['metrics']['latencyMs']) \
+ 'ms - Input tokens:' + str(response['usage']['inputTokens']) \
+ ' - Output tokens:' + str(response['usage']['outputTokens']) + ' ---\n'
return result
prompt = ("日本で一番高い山はなんですか")
print(f'Prompt: {prompt}\n')
for i in model_ids:
response = bedrock_converse(bedrock_runtime_client, i, prompt)
print(f'Model: {i}\n{response}')
また、ConverseStream API を利用して出力のストリーミングも可能です。
def bedrock_converse_stream(client, id, prompt, max_tokens=500, temperature=0, top_p=0.9):
response = ""
response = client.converse_stream(
modelId=id,
messages=[
{
"role": "user",
"content": [
{
"text": prompt
}
]
}
],
inferenceConfig={
"temperature": temperature,
"maxTokens": max_tokens,
"topP": top_p
}
)
# Extract and print the response text in real-time.
for event in response['stream']:
if 'contentBlockDelta' in event:
chunk = event['contentBlockDelta']
sys.stdout.write(chunk['delta']['text'])
sys.stdout.flush()
return
prompt = ("いろは歌を教えて")
print(f'Prompt: {prompt}\n')
for i in model_ids:
print(f'\n\nModel: {i}')
bedrock_converse_stream(bedrock_runtime_client, i, prompt)
画像生成モデルの呼び出し
import base64
import io
from PIL import Image
from IPython.display import display
import botocore
# SDXLモデルのクライアントを定義します
bedrock_sdxl_client = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
prompt_data = "a fine image of an astronaut riding a horse on Mars"
body = json.dumps({
"text_prompts": [{"text": prompt_data}],
"cfg_scale": 10,
"seed": 20,
"steps": 50
})
modelId = "stability.stable-diffusion-xl-v1"
accept = "application/json"
contentType = "application/json"
try:
response = bedrock_sdxl_client.invoke_model(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
print(f'{response_body.get("artifacts")[0].get("base64")[0:80]}...')
except botocore.exceptions.ClientError as error:
if error.response['Error']['Code'] == 'AccessDeniedException':
print(f"\x1b[41m{error.response['Error']['Message']}\
\nTo troubleshoot this issue please refer to the following resources.\
\nhttps://docs.aws.amazon.com/IAM/latest/UserGuide/troubleshoot_access-denied.html\
\nhttps://docs.aws.amazon.com/bedrock/latest/userguide/security-iam.html\x1b[0m\n")
else:
raise error
出力結果はbase64でエンコードされているため、デコードしてから表示します。
base_64_img_str = response_body.get("artifacts")[0].get("base64")
image = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
display(image)
3. 画像生成
Bedrockでは、画像生成モデルを使用して画像の生成も行うことができます。
3.1 ライブラリの準備
%pip install boto3 -U
import boto3
import json
import sys
import base64
import io
from PIL import Image
from IPython.display import display
import botocore
# bedrock client
bedrock_client = boto3.client(service_name='bedrock')
bedrock_runtime_client = boto3.client(service_name='bedrock-runtime')
3.2 画像生成モデルの呼び出し
import base64
import io
from PIL import Image
from IPython.display import display
import botocore
# SDXLモデルのクライアントを定義します
bedrock_sdxl_client = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
prompt_data = "a fine image of an astronaut riding a horse on Mars"
body = json.dumps({
"text_prompts": [{"text": prompt_data}],
"cfg_scale": 10,
"seed": 20,
"steps": 50
})
modelId = "stability.stable-diffusion-xl-v1"
accept = "application/json"
contentType = "application/json"
try:
response = bedrock_sdxl_client.invoke_model(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
print(response_body["result"])
print(f'{response_body.get("artifacts")[0].get("base64")[0:80]}...')
except botocore.exceptions.ClientError as error:
if error.response['Error']['Code'] == 'AccessDeniedException':
print(f"\x1b[41m{error.response['Error']['Message']}\
\nTo troubeshoot this issue please refer to the following resources.\
\nhttps://docs.aws.amazon.com/IAM/latest/UserGuide/troubleshoot_access-denied.html\
\nhttps://docs.aws.amazon.com/bedrock/latest/userguide/security-iam.html\x1b[0m\n")
else:
raise error
出力結果はbase64でエンコードされているため、デコードしてから表示します。
base_64_img_str = response_body.get("artifacts")[0].get("base64")
image = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
display(image)
4. RAG
前章で解説したRAGを、Bedrock Knowledge baseを用いて実行するために、設定を行います。
今回は、Amazon Web Servicesの概要に関するホワイトペーパーを取り込んでみましょう。
https://docs.aws.amazon.com/ja_jp/whitepapers/latest/aws-overview/aws-overview.pdf
こちらのURLからPDFファイルをダウンロードしてください。
4.1 準備
① S3にバケットを作成し、バケット名を設定します。
バケット名は世界中で一意である必要があります。ユーザー名-日時-handsonなど、他とかぶらない名前にしましょう。
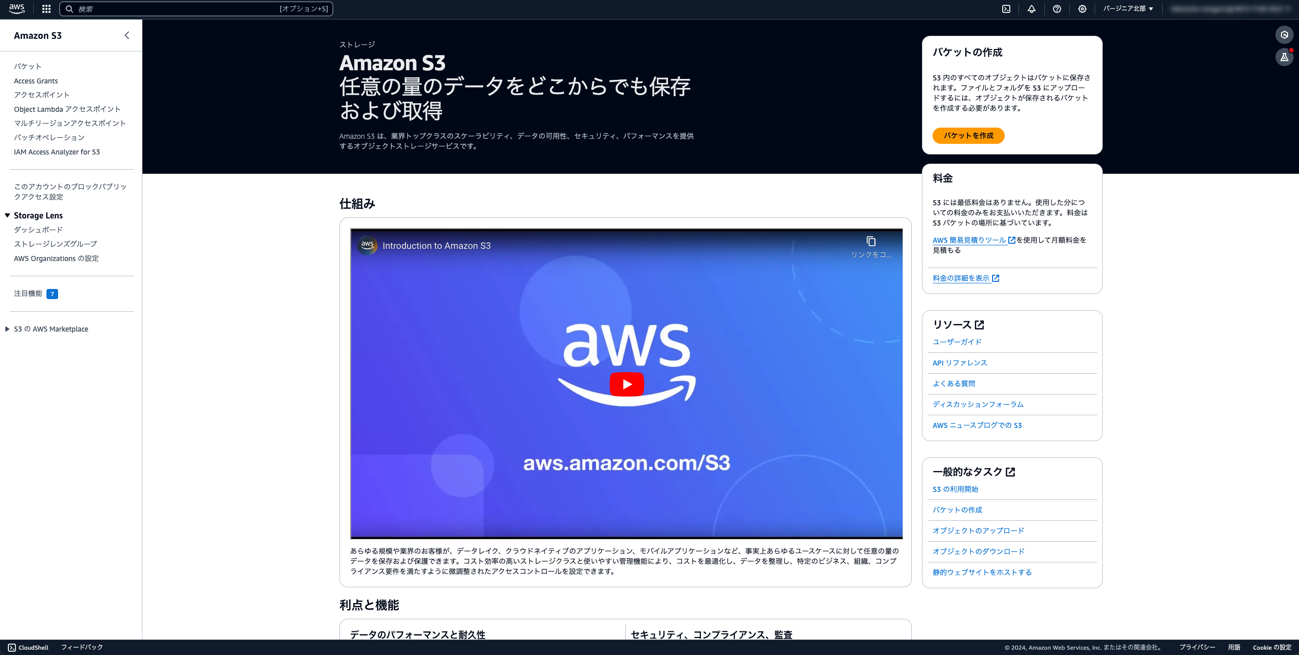
② 作ったバケットにダウンロードしたPDFファイルをアップロードします。
③ Bedrockのコンソールに移動し、ナレッジベースを選択します。
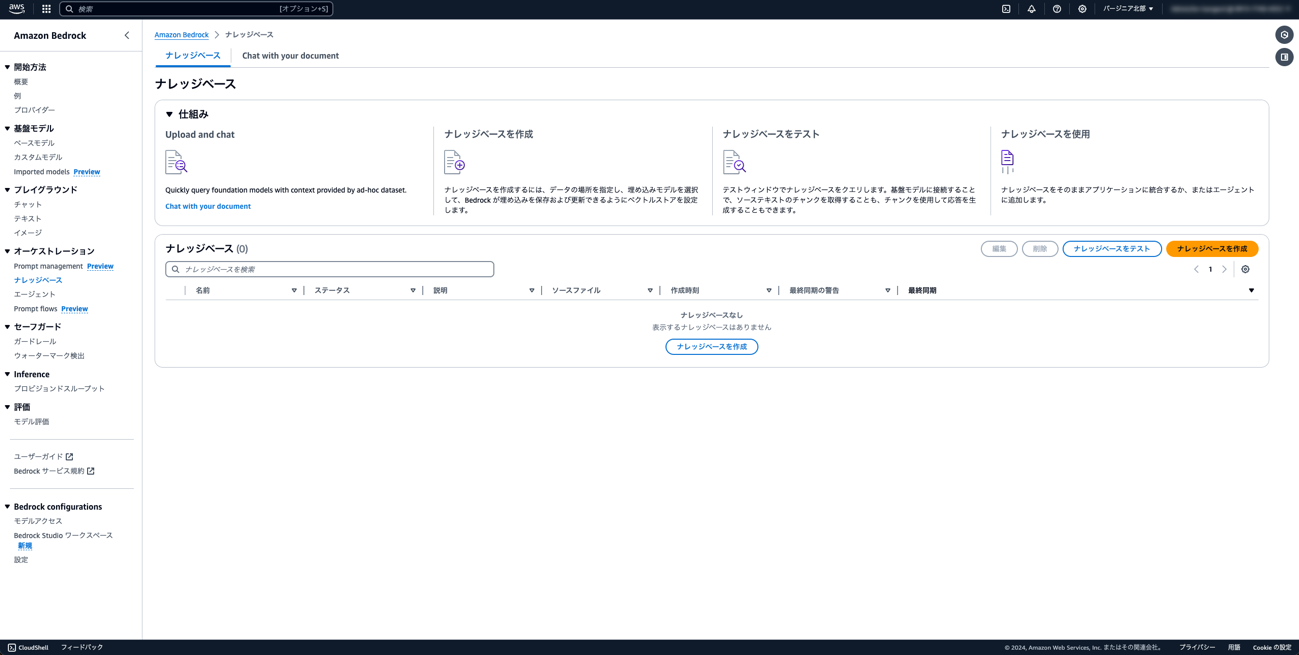
④ ナレッジベースの設定を行います。
ナレッジベース名: aws-whitepaper
S3のURI: 先ほど作成したS3を選択
埋め込みモデル: Titan Text Embeddings v2
その他は全てデフォルトで、[ナレッジベースを作成]ボタンをクリックします。
⑤ データソースの同期を行います。
データソースを選択し、[同期]ボタンをクリックします。

同期が終わったら、次の3つの値をメモします。
ナレッジベースID
データソースID
ジョブID
4.2 Knowledge baseの動作確認
import boto3
# RAG ハンズオンで作成した Knowledge base の情報。マネジメントコンソール上で確認できます。
knowledge_base_id = "XXXXXXX"
data_source_id = "YYYYYYYY"
# 推論用テキストモデルの情報
model_id = "anthropic.claude-3-haiku-20240307-v1:0"
region = "us-east-1"
4.3 データソースの同期
まずはデータソースを同期します。
start_ingestion_job のドキュメントはこちらです。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-agent/client/start_ingestion_job.html
client = boto3.client('bedrock-agent')
response = client.start_ingestion_job(
knowledgeBaseId=knowledge_base_id,
dataSourceId=data_source_id,
)
# 正常に同期が開始された場合、STARTING となります。
print(response['ingestionJob']['status'])
print(f"ingestionJobId: {response['ingestionJob']['ingestionJobId']}")
同期の状況を確認するには get_ingestion_job を利用します。
get_ingestion_job のドキュメントはこちらです。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-agent/client/get_ingestion_job.html
ingestionJobId の値は、直前のセルで同期を開始した際に出力したIDに置き換えてください。
response = client.get_ingestion_job(
knowledgeBaseId=knowledge_base_id,
dataSourceId=data_source_id,
ingestionJobId='XXXXXXXXXXX' # 同期開始時に出力した ID に置き換えてください。
)
print(response['ingestionJob']['status'])
COMPLETE と出力されたら同期完了です。
4.4 検索と生成
同期が完了したら、実際に質問をしてみます。
retrieve_and_generate のドキュメントはこちらです。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-agent-runtime/client/retrieve_and_generate.html
client_runtime = boto3.client('bedrock-agent-runtime')
response = client_runtime.retrieve_and_generate(
input={
'text': 'Amazon Bedrockとは?'
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': knowledge_base_id,
'modelArn': f'arn:aws:bedrock:{region}::foundation-model/{model_id}'
}
}
)
for i, citation in enumerate(response['citations']):
# 回答本文
print(citation['generatedResponsePart']['textResponsePart']['text'])
for ref in citation["retrievedReferences"]:
# reference の S3 URI
uri = ref["location"]["s3Location"]["uri"]
print(f'({uri.replace("s3://", "https://s3.console.aws.amazon.com/s3/buckets/")})')
いかがでしょうか。回答は正しく表示されましたか?
さまざまな質問をして正しい回答が得られるか試してみてください。
RAGを適用していない場合と比べ、精度やハルシネーションを確認してみてください。
まとめ
本記事では、Bedrockを通じて生成AIの基本的な使い方を解説しました。実際の業務にもお役に立てれば幸いです。
実際の業務に落とし込む場合、生成AIをより簡単に使うツールや、ユースケースを発掘するツールが便利です。AWSでは、Bedrockを使ったいくつかのツールを提供しています。
PartyRock
https://partyrock.aws/
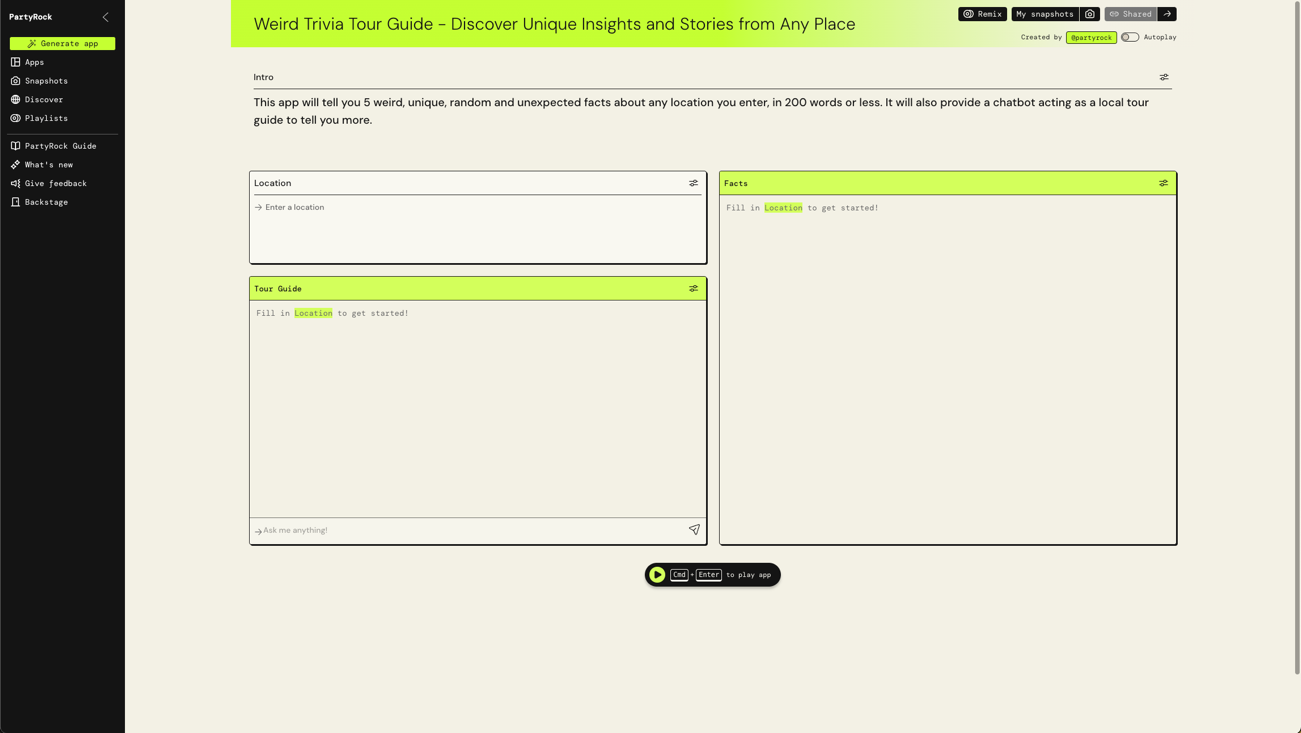
PartyRockは、ノーコードで生成AIアプリを簡単に作成・共有できるプレイグラウンドです。AWSアカウント不要で始められ、現時点では無料で使用することができます。
生成AIでどのようなことができるのかを発掘するのに役立ちます。ソースコードを書く前に、プロンプトを試してみてください。
Amazon Bedrock Prompt flow
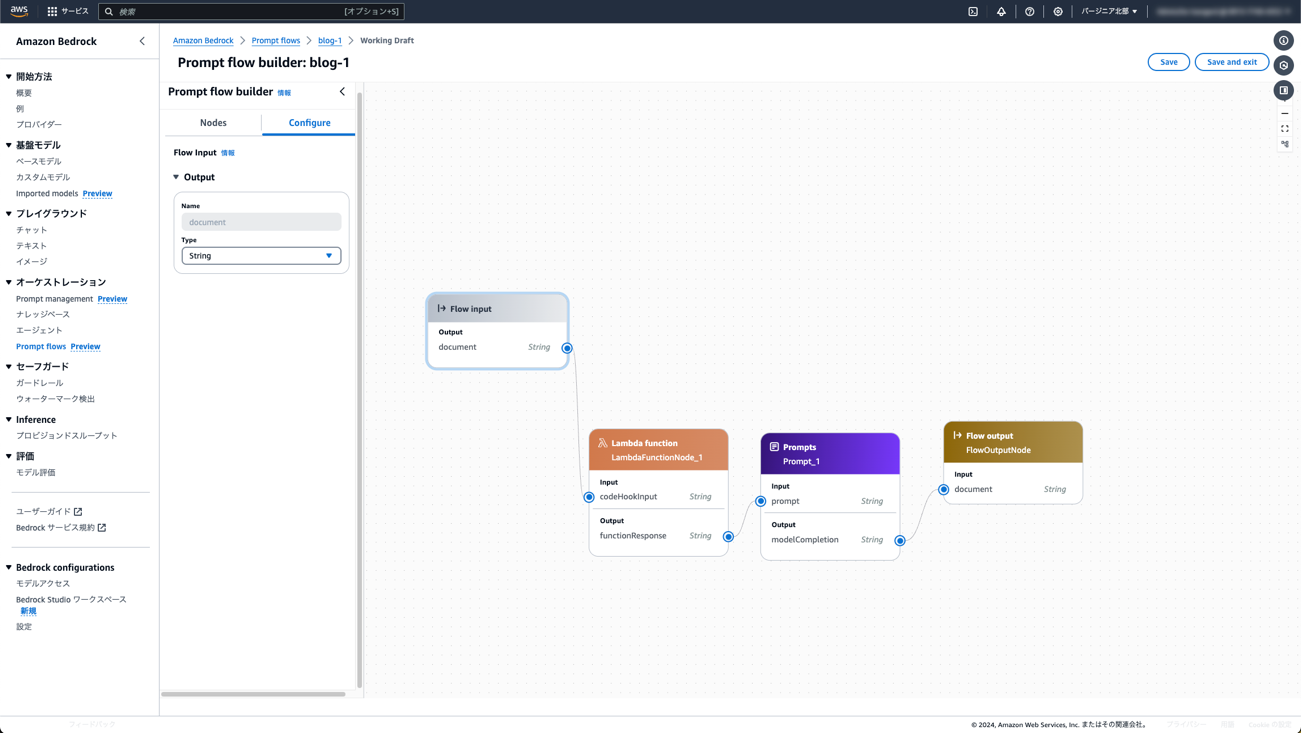
Amazon Bedrock Prompt flowでは、生成AIやその他のAWSサービスをGUIでつなげることにより、end-to-endのワークフローを構築できます。
基盤モデルやKnowledge baseとLambdaを簡単に統合・デプロイすることができるツールとなっています。ぜひ上のPartyRockで見つけたユースケースを本番環境に移してみてください。
Generative AI Use Cases JP
https://github.com/aws-samples/generative-ai-use-cases-jp
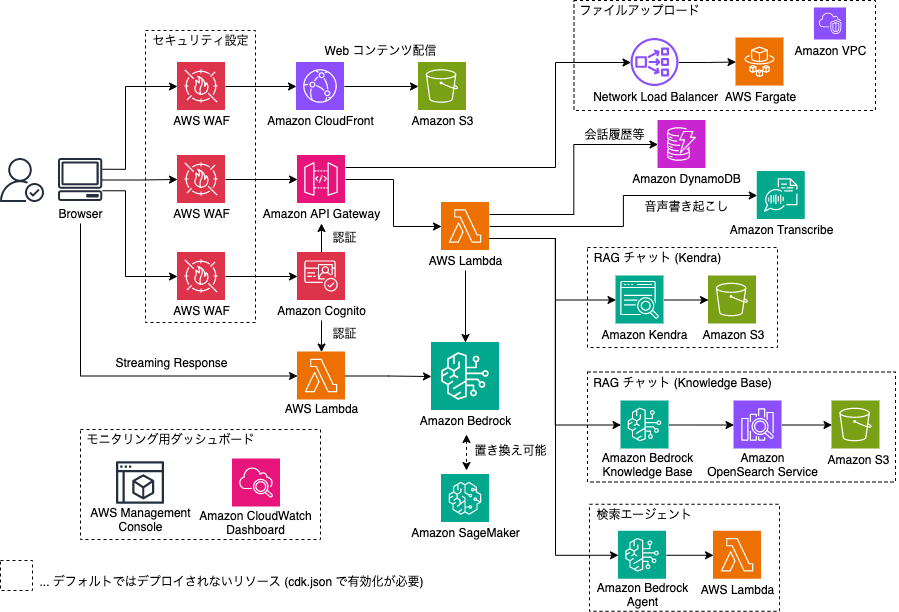
Generative AI Use Cases JP(略称:GenU)は、生成AIを安全に業務活用するための、ビジネスユースケース集になります。業務で使えるように実装がされているため、Bedrockを使った基本的なユースケースを簡単にデプロイすることができます。





