



【アーキテクチャConference 2025】「AIエージェント」のアーキテクチャ変遷〜技術黎明期の意思決定を振り返る〜
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に登壇した株式会社Algomatic ネオセールスカンパニー CPO兼CTOの菊池 琢弥さんは、営業AIエージェント「アポドリ」の開発を通して得た知見として「『なるべく作らない、なるべく後回し』が重要」だと語ります。本セッションでは、AIエージェント開発だからこそ直面する課題にフォーカスし、「アポドリ」の開発開始から現在に至るまでの技術的課題とその解決策についてご紹介いただきました。
■プロフィール※2025年11月時点
菊池 琢弥
株式会社Algomatic
ネオセールスカンパニー CPO兼CTO
電気通信大学在学中から、セキュリティソリューションを手がけるスタートアップでソフトウェアエンジニアとしてのキャリアをスタート。以降、複数のスタートアップで経験を重ね、FinTech系スタートアップにてVPoEを務める。その後、飲食店向けSaaSプロダクトを展開するShowcase Gigでは、VPoTとして技術統括および開発組織の運営をリード。2023年8月よりAlgomaticに参画し、営業AIエージェント「アポドリ」のCPO兼CTOとしてプロダクトと技術の両面から事業成長を牽引している。
「しんどい」を代行する営業AIエージェント「アポドリ」
「『AIエージェント』のアーキテクチャ変遷」をテーマにお話しいたします。私は2年以上、生成AIを使った事業創りに取り組んできました。それまでは10年以上、ソフトウェアエンジニアとしてプロダクト開発に携わってきました。
本題に入る前に、自社プロダクトである営業AIエージェント「アポドリ」についてご紹介します。
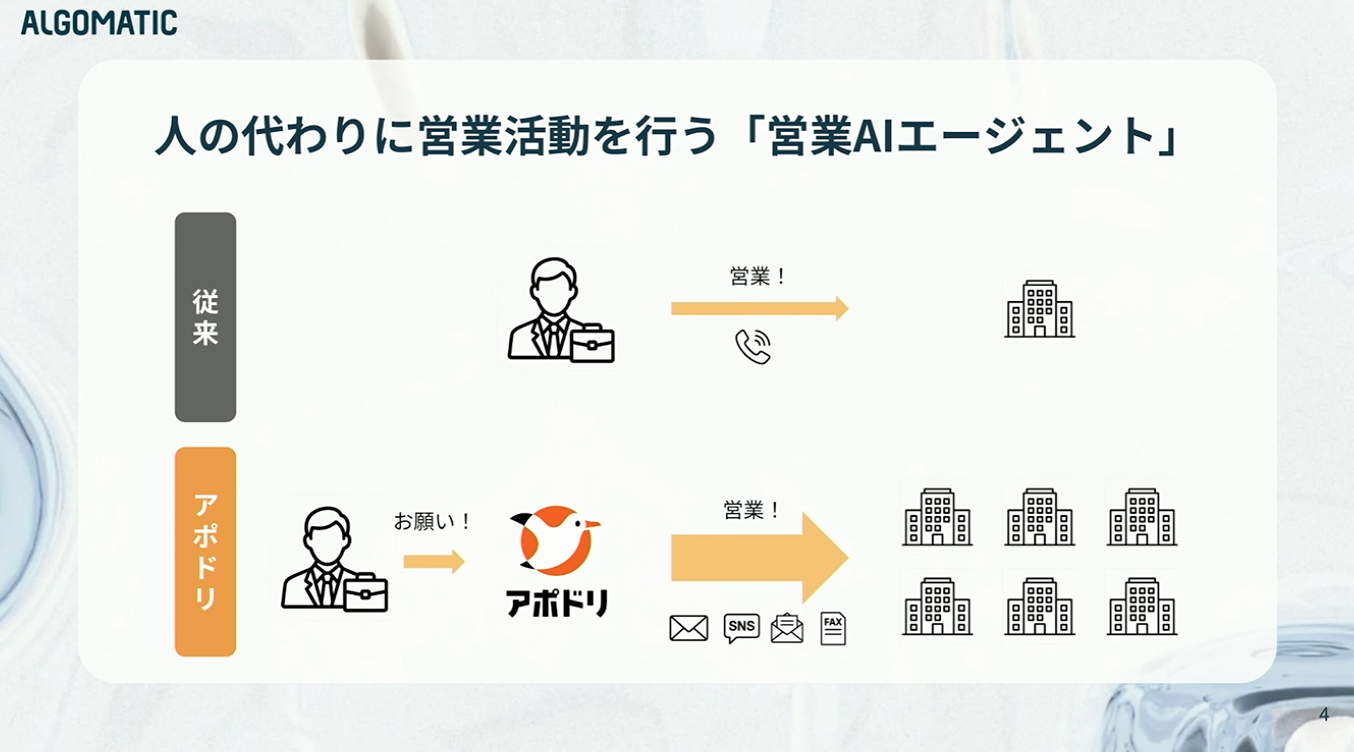
従来の営業では、接点のない企業に提案を行う際、担当者がインターネットで情報を調べ、電話番号を探し、業態を確認したうえで連絡を試みる、といった非常に労力のかかるアプローチが必要でした。それも対象は1社や10社ではなく、月に数百社に及びます。
もう少し具体的にお話しすると、営業組織として「アプローチしたい企業リスト」を1,000件ほど保有しているケースを想定してください。リストには企業名しか記載されていないことも多く、各社の連絡先をExcelやスプレッドシートに整理した上で、ひたすら電話やメールでアプローチしていきます。しかし、昨今は電話が繋がりにくく、メールも開封されているかすらわからない。お問い合わせフォームから連絡をしても、1,000件送って1件アポイントが取れればいい、というのが実情です。
アポドリは、こうした営業活動における「しんどい部分」をAIによって代行するサービスです。
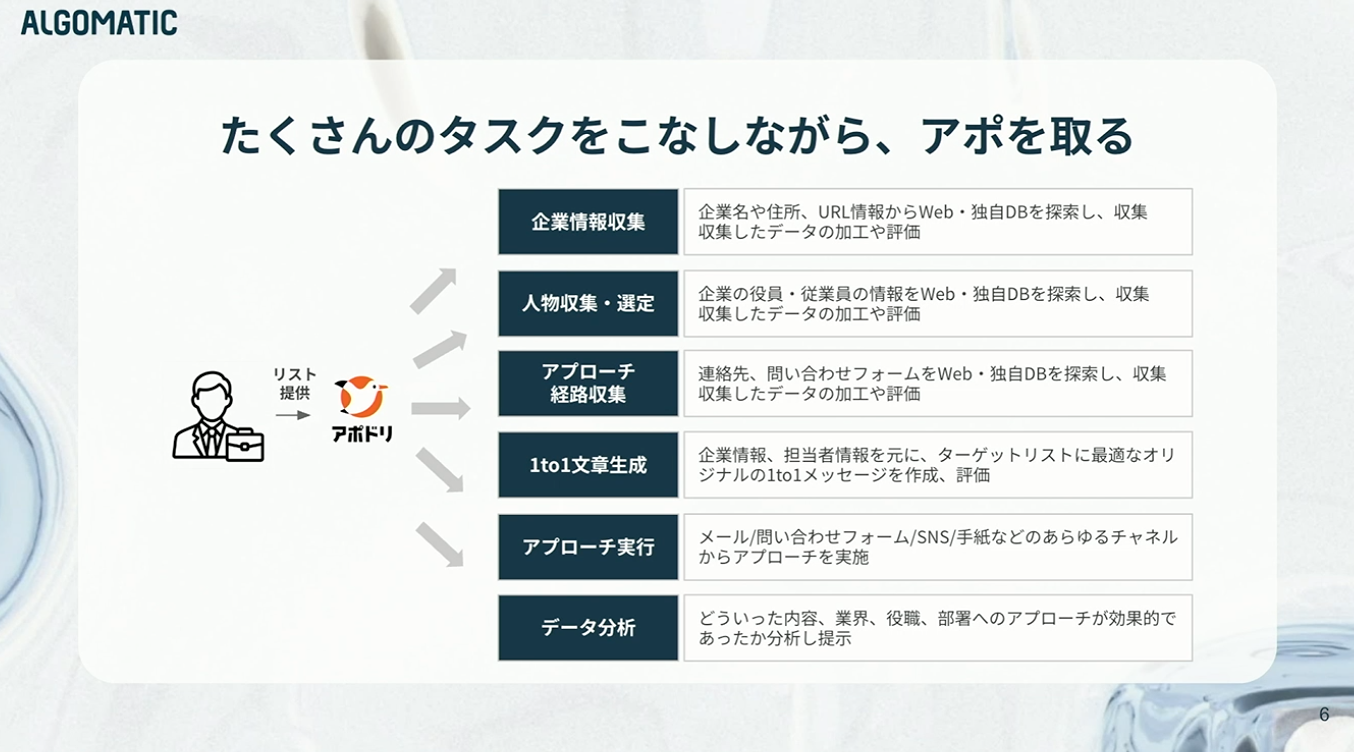
アポドリは営業リストを受領すると、企業情報に加え、その企業に在籍する人物情報までリサーチします。企業宛てではなく、関連部署の担当者をバイネームで特定してアプローチした方が、反響率が高いためです。
さらに、その人物に対してどのチャンネルで接触可能かを特定し、ターゲットに最適化されたメッセージをAIが作成・アプローチします。そして、その結果を分析し、次のアプローチへとつなげていきます。
これらのプロセスは、人間にも実行できないものではありません。ただし、膨大な件数を前提としたとき、「やりきること」が極めて困難になります。つまりアポドリは、トップセールスが実践している丁寧な営業アプローチを、より多くの対象に向けて、継続的に実行可能にするサービスです。
私たちは、かれこれ2年半以上にわたり、この営業AIエージェントを開発してきました。その中で得られた重要な知見のひとつが「なるべく作らない、なるべく後回しにする」というスタンスです。一見すると消極的に聞こえるかもしれませんが、この考え方こそが、AIエージェントを実用レベルまで引き上げるうえで極めて重要だと実感しています。
AIエージェント開発で直面する「判断をシステム化」する複雑さ
まず、AIエージェント開発の難しさについてお話しします。「AIエージェントの開発に設計は必要なのか」と疑問に思われる方もいらっしゃるかもしれませんが、これは大きな誤解です。インターネット上では「LLMに良いプロンプトを書き、適切なコンテキストを渡すことが重要だ」という議論をよく見かけますが、それだけで成立するものではありません。
そもそも、私たちの日常業務は、業務ルール、業務フロー、そして各プロセスにおける「判断」の積み重ねによって成り立っています。「この場合はどうすべきか」という意思決定を、人間が都度行っているわけです。これまで私たちは、業務システムを構築することでこうした負担を軽減してきましたが、その実装は決して容易ではありません。だからこそ、アーキテクチャや設計といった領域で試行錯誤を重ね、進化させてきました。それほどまでに複雑な対象です。
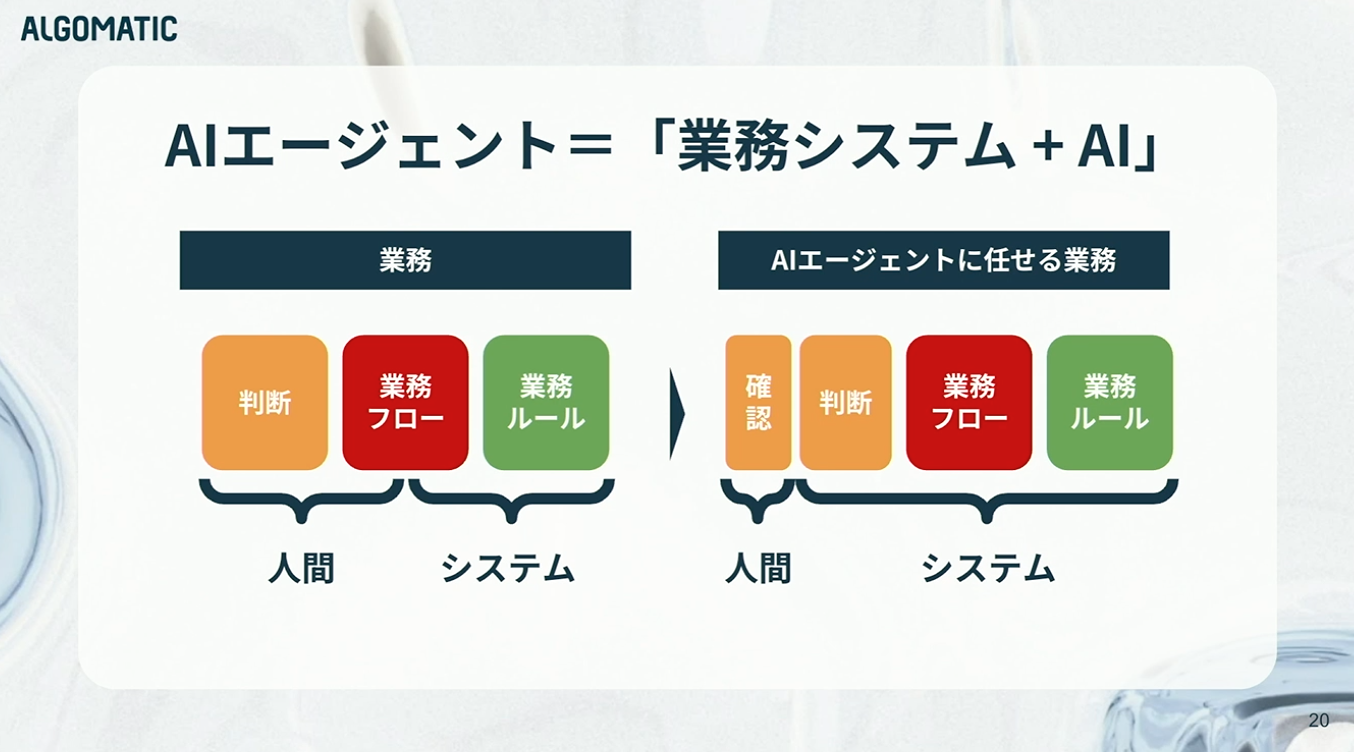
AIエージェントは、その複雑な業務システムに加えて、人間が担ってきた「判断」そのものまでシステムで代替しようとする試みです。この「判断のシステム化」にこそ、従来のシステム開発とは本質的に異なる難しさがあります。

LLMは、少し動かしてみると非常に「それっぽく」振る舞います。短期間で60~70点ほどのアウトプットには到達しますが、実業務で安定的に使える水準にはなかなか届きません。
では、どうすればよいのか。結論としては、改善ループを回し続けるしかありません。
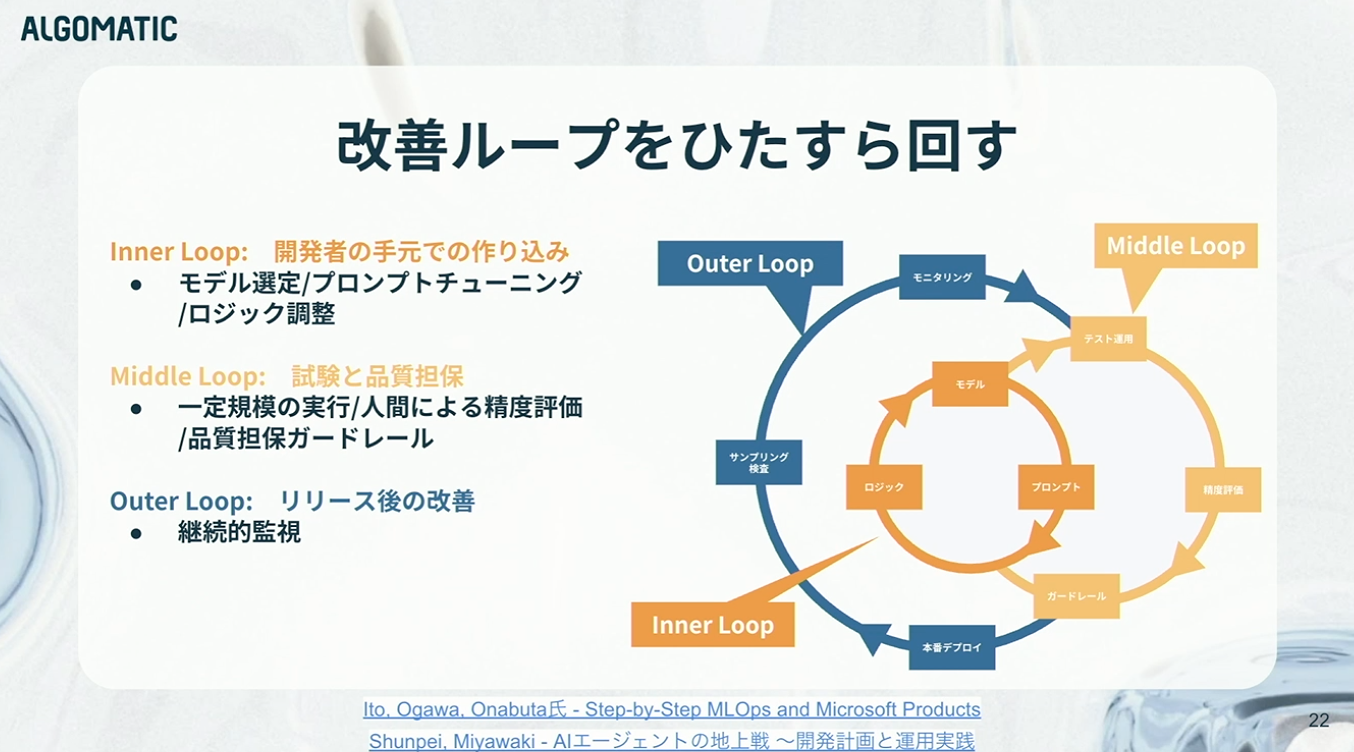
これは機械学習開発の考え方に近いのですが、まず手元でモデル選定やプロンプト設計、ロジック実装を行う「インナーループ」。次に、限定的な環境にデプロイし、一定規模で動かしながら人間によるチェックやガードレールを設ける「ミドルループ」。そして、本番データに基づいて継続的な改善を行う「アウターループ」。これら速度の異なるループを、いかに高速に回し続けられるかが極めて重要になります。
AIエージェント開発は、従来のシステム開発でも難易度が高かった「業務ルール」に加え、不確実性の高い「判断」まで開発対象に含みます。一言でいえば「超複雑」です。だからこそ、設計やアーキテクチャが重要になります。こうした領域に本気で向き合い、試行錯誤を楽しめるエンジニアと一緒に、挑戦を続けていきたいと考えています。

高速回転を支える「アポドリ」の疎結合なアーキテクチャとオーケストレーション
アポドリのアーキテクチャについてお話しする前に、まず機能を簡単におさらいします。
アポドリにアプローチしたい企業リストを渡すと、企業情報を収集し、在籍している人物情報を特定します。そのうえで適切な担当者を選定し、「いつ・誰に・何通送るか」を設計し、ターゲットに最適化された文面を作成して送信まで実行します。
こうした一連のプロセスをどのように開発しているかというと、現時点では各業務を疎結合な形で構築しています。

営業業務は頻繁に増減・変化するため、各処理を独立したジョブやAPIとして実装し、業務同士を直接結合させない構成を採用しています。これにより、特定の機能だけを差し替えたり改善することが容易になります。また、少人数のチームでも全員が横断的に開発に関われるように、ソースコードのリポジトリは共通化しています。

設計方針として特徴的なのは、「トランザクションスクリプト的なベタ書き」を意図的に多用している点です。LLMが関与する処理は「こういう入力がきたら、こう判断してこう動く」といった人間の思考プロセスに近いため、フローチャートのように直線的に記述する方が、理解しやすく改善もしやすいからです。さらに、AIモデルの進化に伴い、実装の前提自体が短期間で変わることも少なくありません。実際、画像生成を伴う処理などは、Nano Bananaのような新しいモデルの登場によって、今後も大きく変わっていく可能性があります。こうした前提を踏まえると、「作り込みすぎない」「いつでも作り直せる」構造にしておくことが重要になります。
一方で、LLMが関与しない静的な業務ロジックについては、オブジェクト指向をベースに堅牢に実装しています。こちらも十分に複雑な領域であるため、動的で不確実性の高いLLM領域と、安定性が求められる静的なロジック領域とで設計思想を切り分け、全体としてのバランスを保ちながら開発を進めています。
オーケストレータパターンの採用とトレードオフ
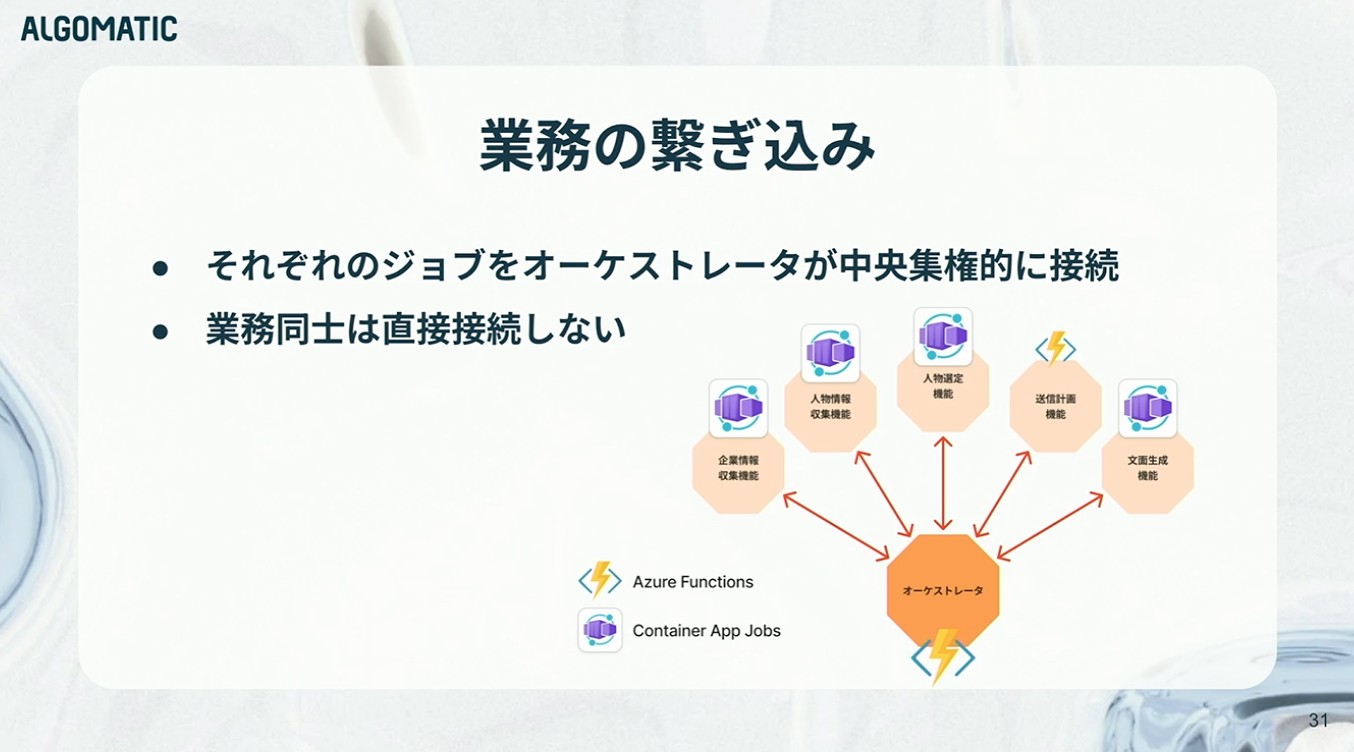
各業務の接続については、オーケストレータ的なモジュールを用意し、中央集権的に制御する構成を採っています。インフラにはAzureを採用しているおり、Container Apps JobsとAzure Functionsを組み合わせて構築しています。

なぜオーケストレータなのか。マイクロサービスの設計パターンにおける「オーケストレータ」と「コレオグラフィー」の対比は、本件においても有効なメタファーになります。
一般的に、オーケストレータのメリットは、ロジックを1箇所に集約できる点にあります。これにより、処理全体の可視性と制御性が高まり、「ジョブが失敗した場合にどう振る舞うか」といった例外処理の知識も一元管理できます。その結果、保守性や運用のしやすさが向上します。一方で、単一障害点(SPOF)になりやすい、あるいはスケーラビリティに制約が生じやすい、といったデメリットが指摘されることも多いです。
ただし、これはあくまで大規模マイクロサービスにおける一般論です。アポドリの現在のサービス特性を踏まえると、トラフィックが突発的にスパイクするような構造ではないため、これらのデメリットは現時点では本質的な問題にはなりません。また、オーケストレータが肥大化し、いわゆる「ゴッドサービス」化するリスクについても認識はしていますが、現段階では過度に先まわりして複雑性を持ち込むよりも、「問題が顕在化してから分割する」方が合理的だと判断しています。

現在の設計は、あくまで「高速に改善ループを回すこと」を最優先にしたものです。オーケストレータによって制御をシンプルに保つことで、各業務のインナーループやミドルループを素早く回せる状態をつくっています。これにより、業務の追加・変更や、「やはりこの処理が必要だった」といった方針転換にも柔軟に対応できる構成となっています。
「アポドリ」が生き残るために辿った進化の全貌
ここからは、現在のアーキテクチャに至るまでの道のりについてお話しします。決して最初から「オーケストレータで業務分離して設計しよう」といった形でスタートしたわけではありません。新規事業として試行錯誤を重ねる中で、とにかく生き抜くために手を動かし続けた結果、今の形に辿り着いた、というのが実態です。
アポドリは現在に至るまで、大きく3つのフェーズを経て進化してきました。フェーズ1は、ほぼ人力。フェーズ2は、人力オーケストレータ。そして、フェーズ3が、現在の構成です。
CLIツールと人間が支えたフェーズ1
アポドリの始まりは、営業代行の請負でした。営業領域で新規事業を立ち上げるにあたり、まずはアウトバウンド営業代行を通じてドメイン解像度を高めることからスタートしました。
そのうえで、せっかくならAIを活用し、人間では実行しきれない量と質の両立によって価値を出したいと考えました。具体的には、アプローチ先の1社1社を丁寧に調べ上げ、営業担当者の意図や温度感を反映した、受け取った方が嬉しくなるようなオリジナルの文章を届ける、という方針です。
当時、私たちにあったのは「案件(お客様)」と「人(営業エキスパート、エンジニア、運用メンバー)」だけで、それ以外は何もない状態からのスタートです。
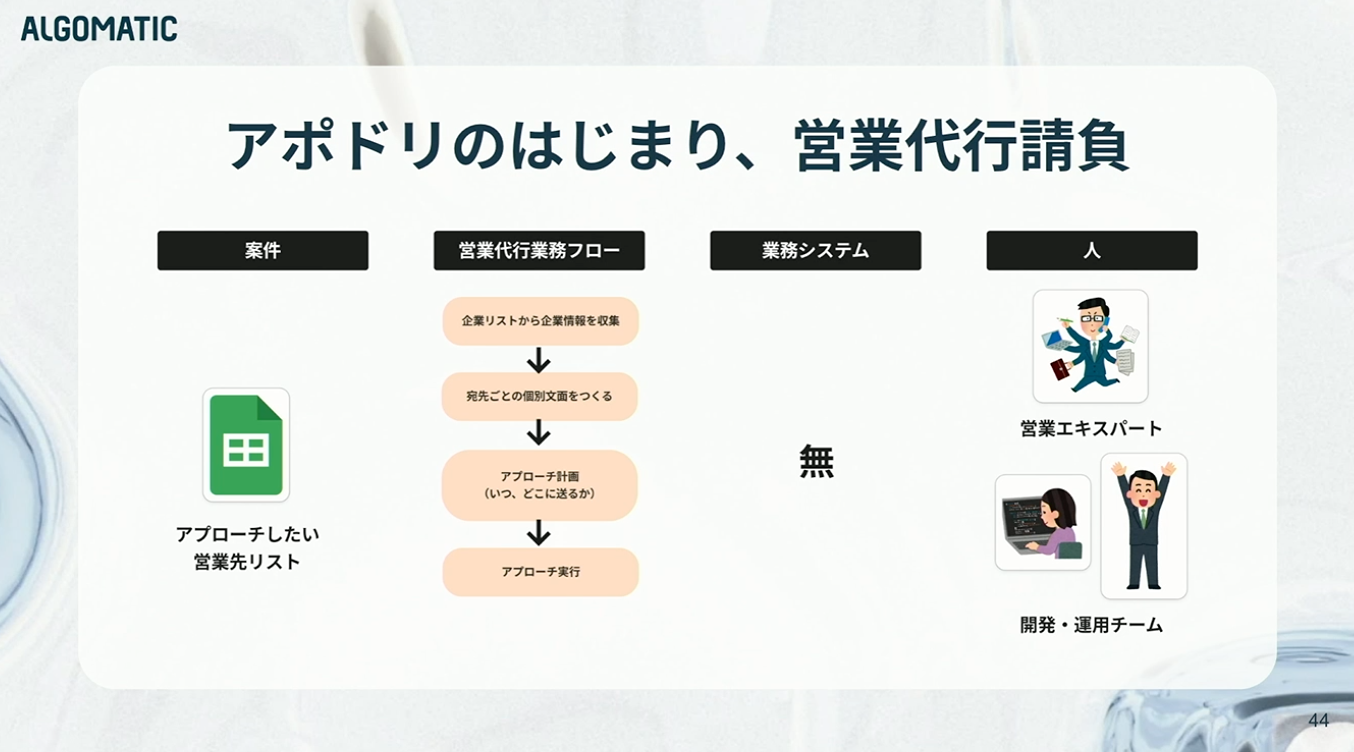
まずは営業代行の業務フローを作りました。リストをもとに情報を収集し、文面を作成し、送信計画を立てて実行する。この一連の流れです。
次に直面したのが、「何をシステム化し、何をあえて作らないか」という意思決定でした。
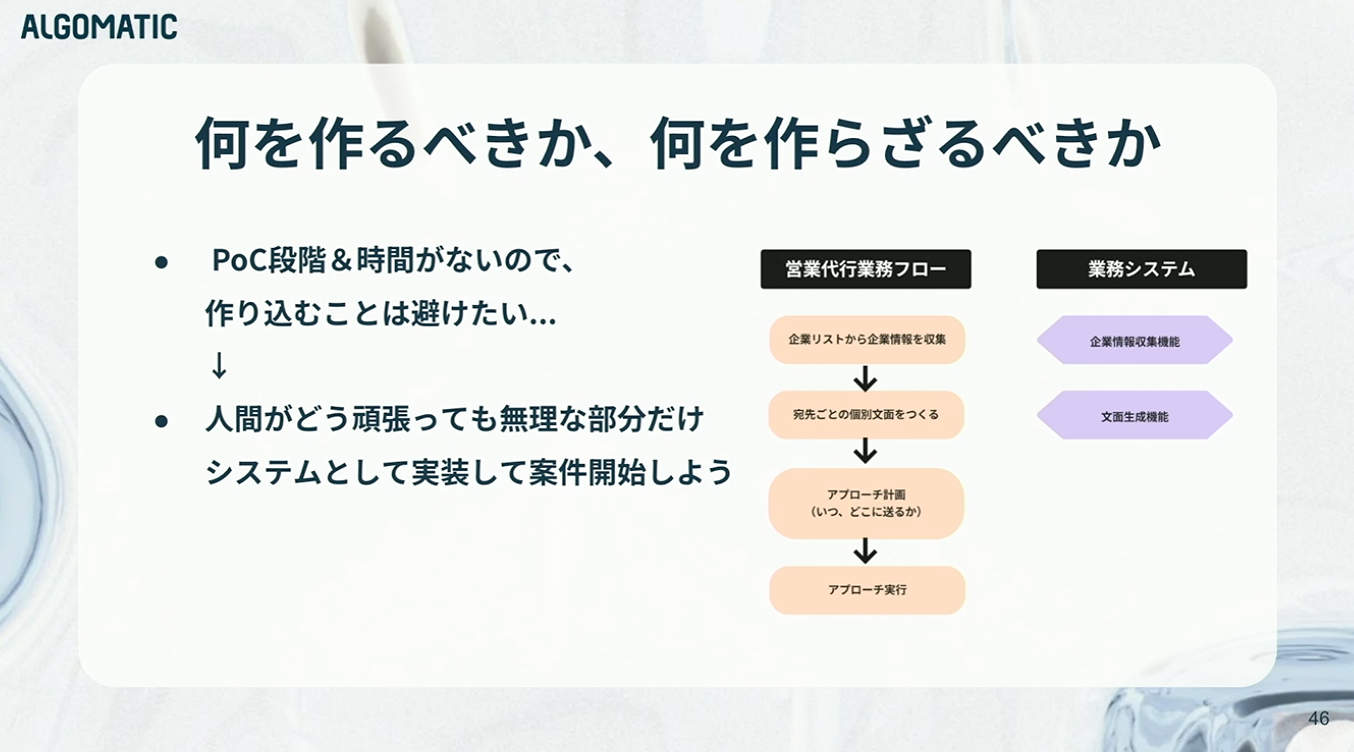
PoC段階で時間もリソースも限られている以上、作り込みは避ける必要があります。そこで、明らかに人間にとって負担が大きい「企業情報の収集」を優先的に実装しました。また、文面生成についても、エキスパートの知見を組み込みながらLLMをフル活用して実装する判断をしました。
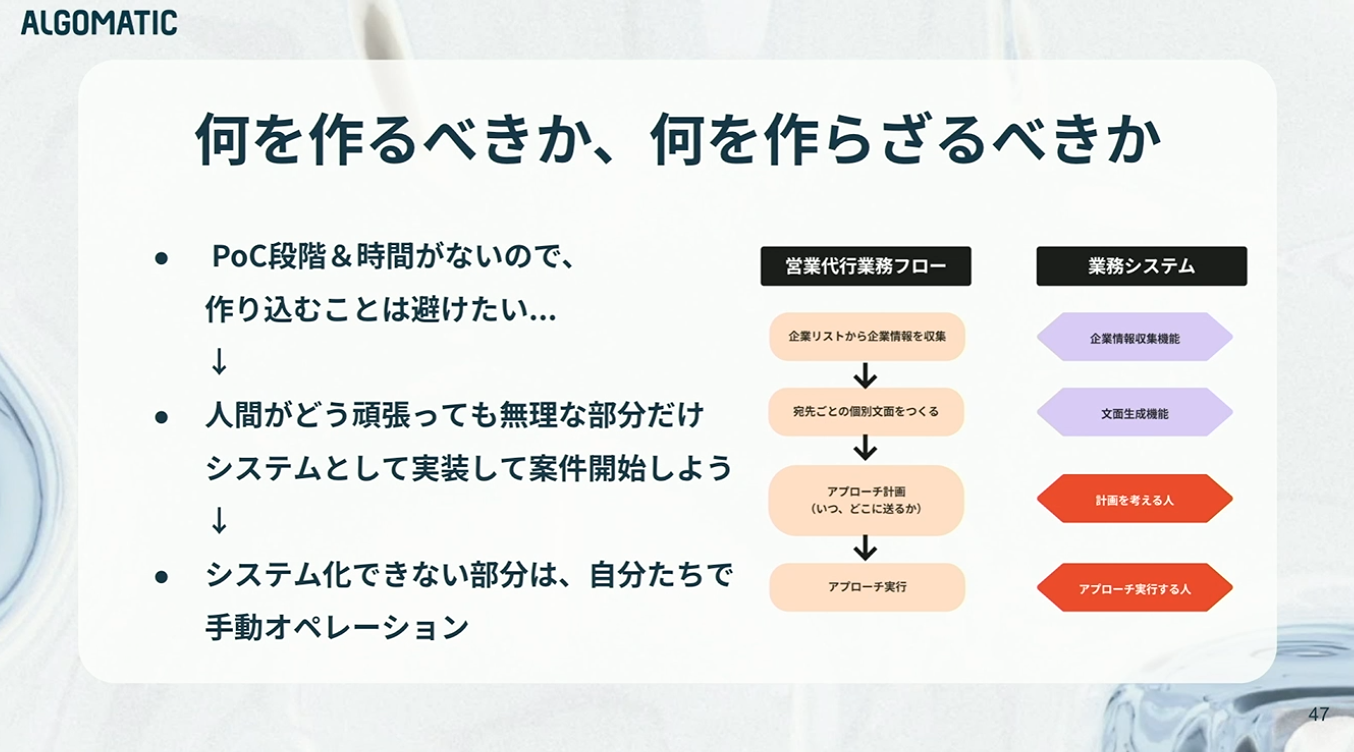
一方で、それ以外の部分はあえてシステム化せず、手動オペレーションとしました。いわゆる“Human as a System”ですね。
結果として、このフェーズで実装されたのは「企業情報収集」と「文面生成」のみ。しかも、システムといっても、CLIツールとしてエンジニアが実装して、ローカルで実行ボタンをポチっと動かして運用する形でした。
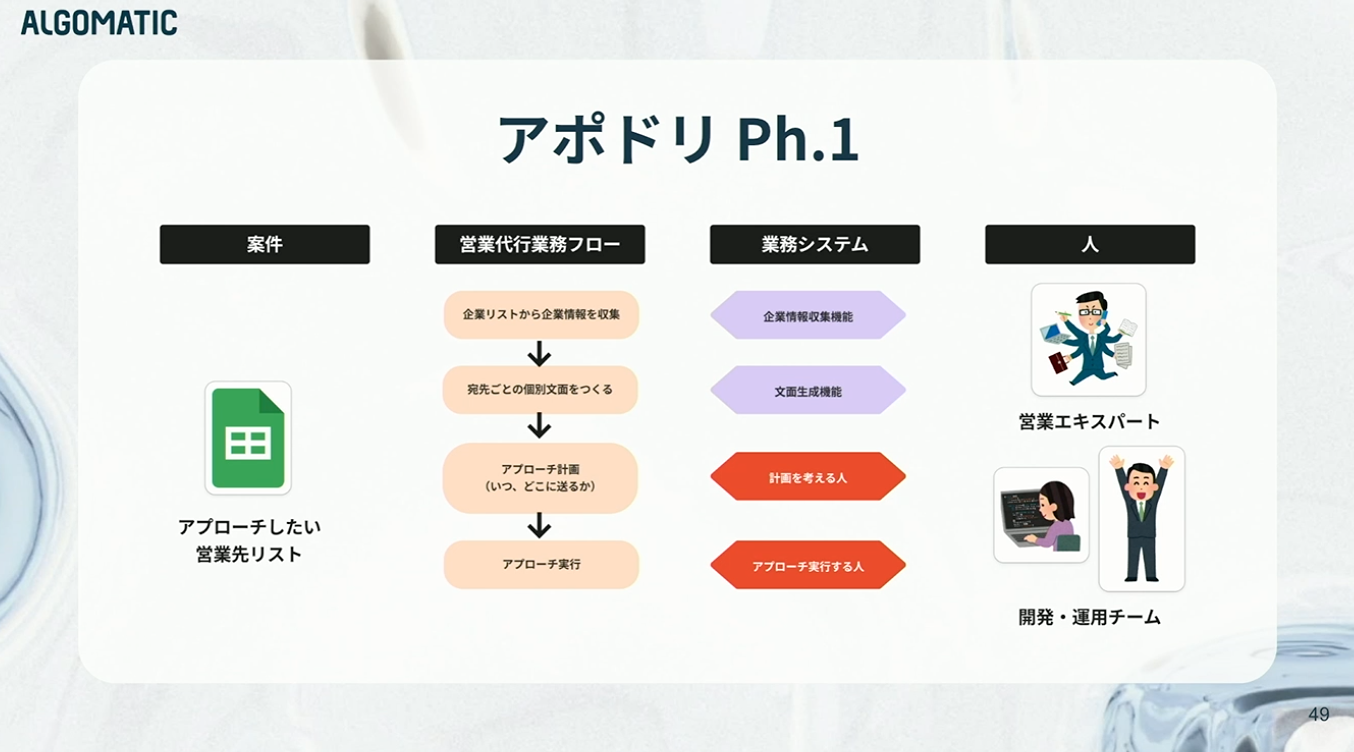
フェーズ1をまとめると、案件・業務フロー・システム・人が最低限揃い、実際に複数の案件を回せる状態になりました。
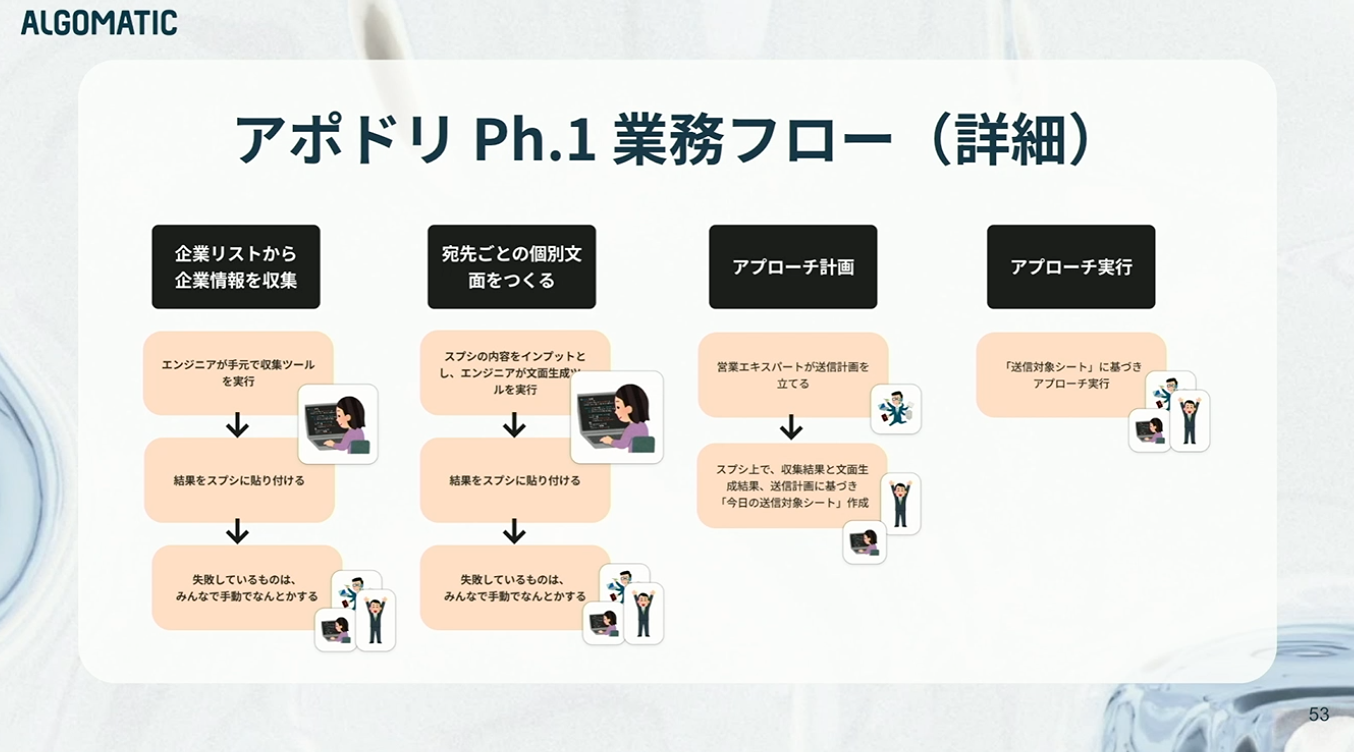
当時の具体的な運用はかなり泥臭いものです。企業情報収集は、エンジニアが手元でツールを実行し、結果をCSVで出力。それをスプレッドシートに貼り付けます。ただし、2~3割は失敗するため、チーム全員で手動リカバリーを行う。実態としては、人力に大きく依存した運用でした。
文面生成も同様です。スプレッドシートの情報をもとにエンジニアが生成処理を実行し、結果をシートに戻す。失敗した場合は手動で修正して、場合によっては一から自分で文章を考える、なんてこともありました。
アプローチ計画については、営業エキスパートが「このリストであれば、この頻度で、1日◯件ずつ送り、1ヶ月で送り切る」といった計画を立てます。その内容をスプレッドシートに落とし込み、関数で「今日の送信対象」を自動抽出。実際の送信は、そのリストをもとにメンバー全員で対応する、という流れです。
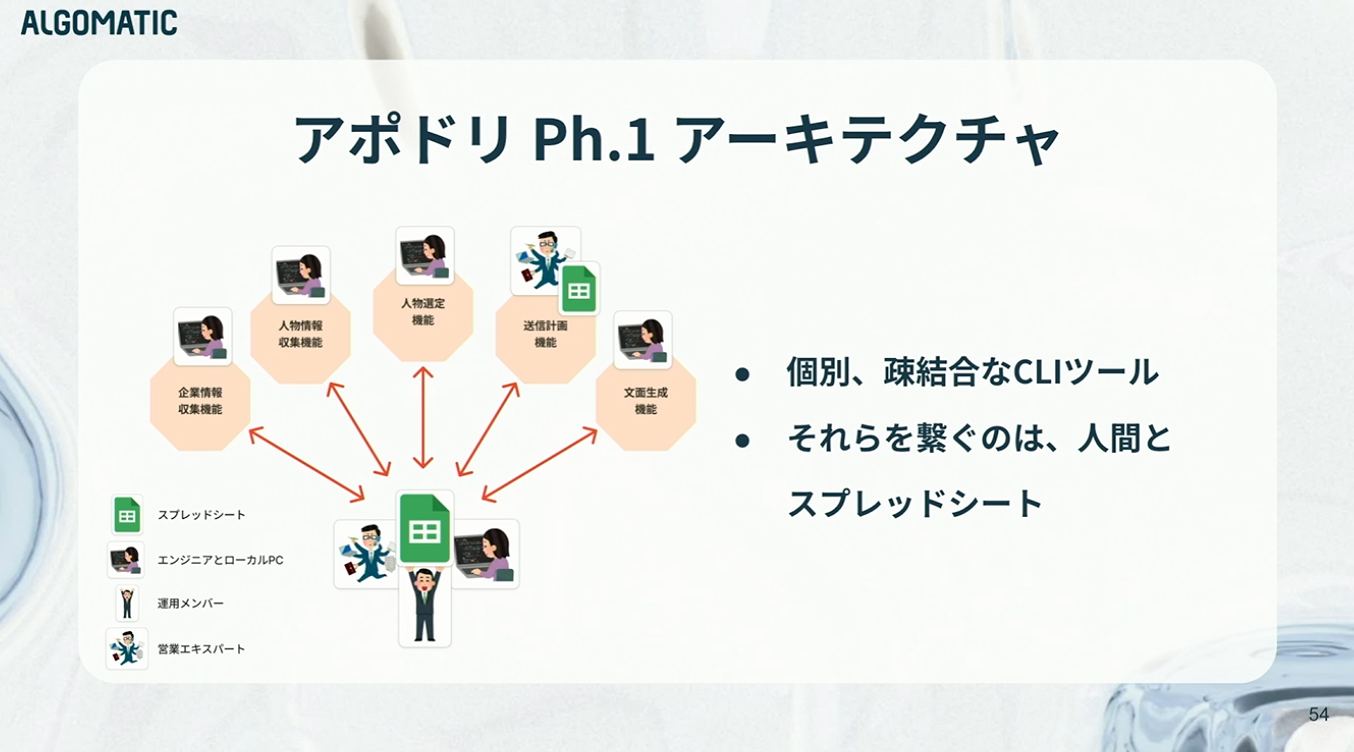
これがフェーズ1のアーキテクチャです。個別に存在する疎結合なCLIツールがあり、それらを繋ぐのは人間とスプレッドシート。トポロジー自体は現在と似ていますが、実態としては「ほぼ人」によって成立している構造でした。
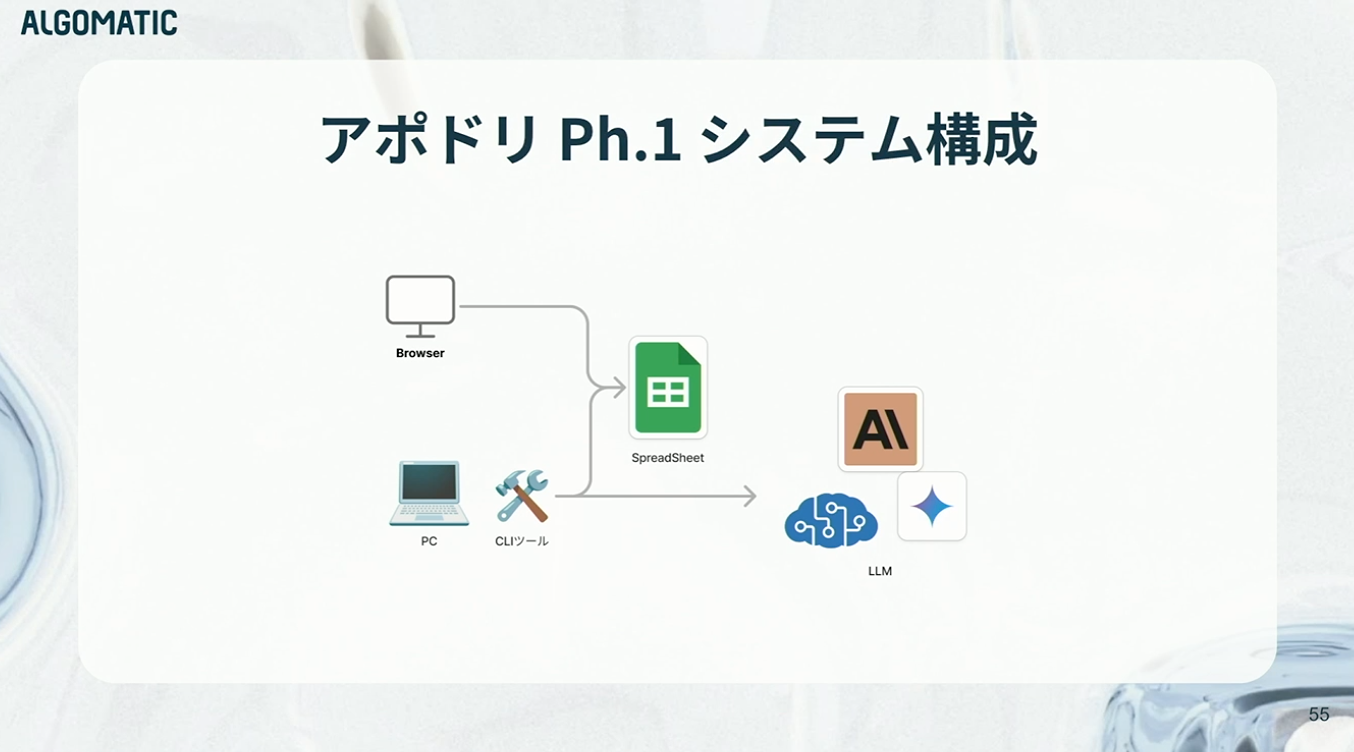
システム構成も極めてシンプルで、「ほぼ何もない」と言っていいくらいの状態です。
ただし、これは決して悪いものではありません。インフラもデプロイも不要で、圧倒的なスピードで試行錯誤を重ねることができます。0→1フェーズを経験したことがあるエンジニアであれば共感いただけると思いますが、「とりあえず作って動かし、すぐに改善する」というサイクルは、最も早く、そして最高に楽しく、学びが多い。AIエージェント開発の初期フェーズにおいて重要なインナーループを、爆速で回すことができます。
スプレッドシートの限界からクラウド移行に挑んだフェーズ2
フェーズ1は「意外と悪くない」とお話しましたが、当然ながら限界も見えてきます。まず、ローカルPCで本番業務を実行している状態はあまり健全とは言えません。すべての業務のバス係数が1に近く、誰か1人でも動けなくなると業務全体が止まってしまう構造でした。加えて、スプレッドシートにも限界があります。1シートあたりの上限が1,000万セルで、実運用を回していくと、この制約がボトルネックになっていきます。
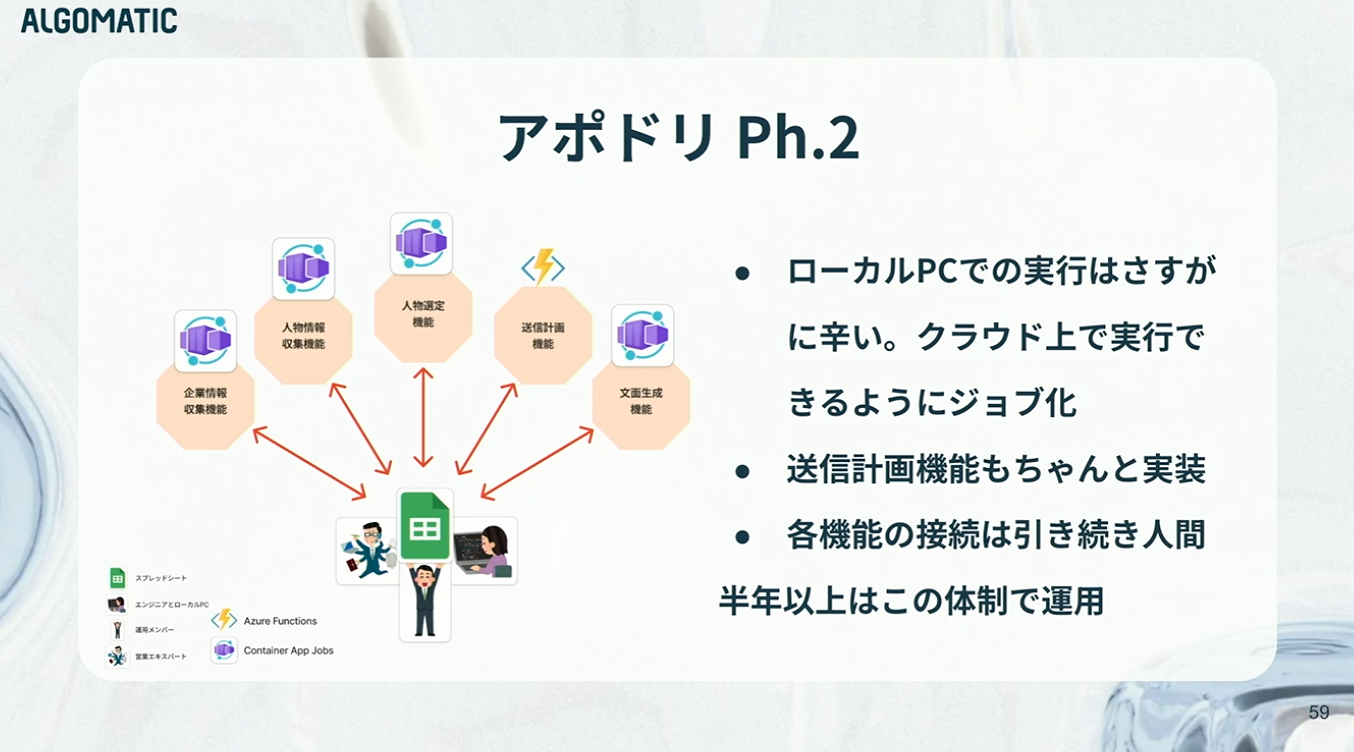
こうした背景から、フェーズ2ではクラウドへの移行に踏み切りました。各処理をジョブ化して切り出し、Azure上で実行できるようにしました。具体的には、Container Apps Jobsとして非同期実行する形に移行しました。
また、送信計画の機能についても、スプレッドシートでの管理には無理があったため、ここはしっかりとシステムとして実装しました。条件分岐や制約が複雑な領域であるため、オブジェクト指向をベースに設計し、堅牢に作り込んでいます。これは前段で触れた「静的なロジック領域」に該当します。
一方で、各機能同士の接続は引き続き人間が担っていました。この状態で、およそ半年間運用を続けていました。
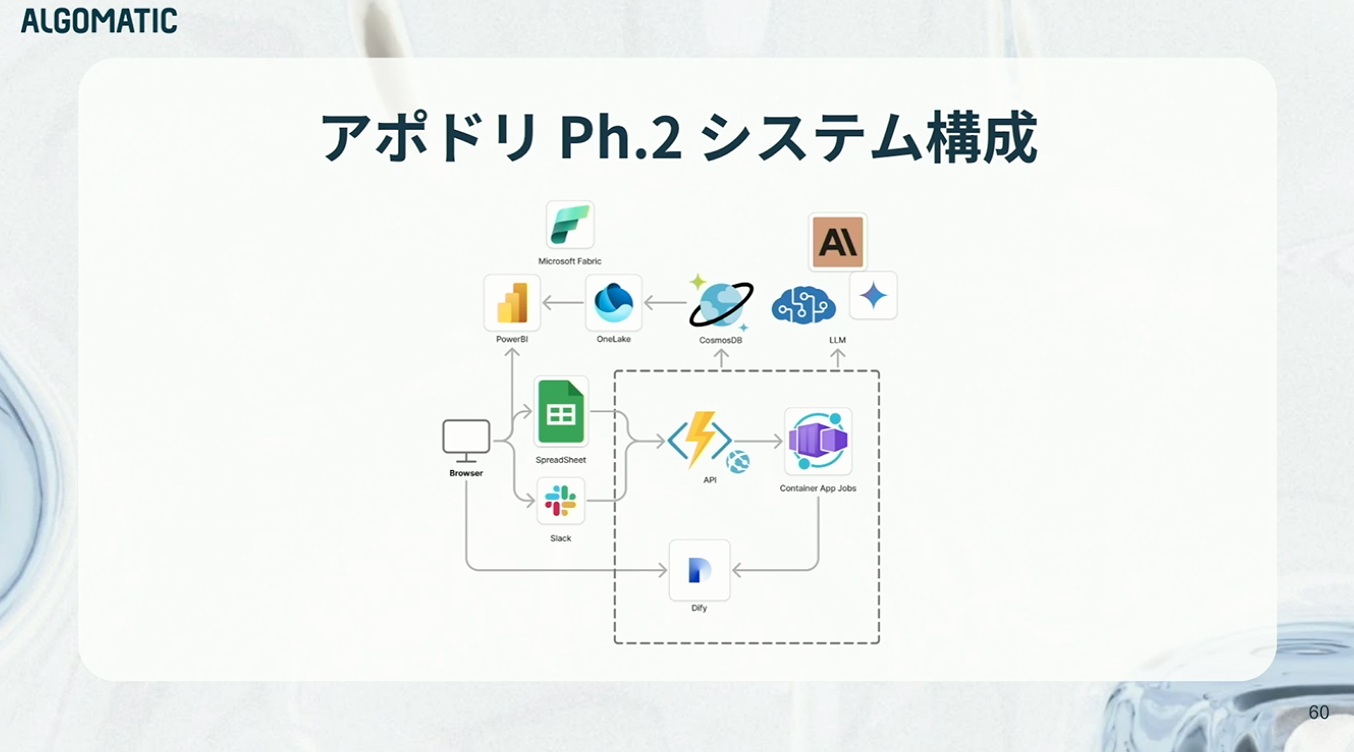
システム構成としては、Azure FunctionsとContainer Apps(非同期ジョブ処理)をコンポーネントとして使用しています。インターフェースとしては、スプレッドシートとSlackを利用しています。「できる限り作らない」という方針を維持したまま、データ分析ニーズに対応するためにFabricとの連携も実現しています。
ただし、この間にも業務フローは頻繁に変化していました。例えば、当初は収集結果の品質を担保するための仕組みを導入していましたが、運用を進める中でやはり想定外のデータが多く出現しました。その結果、別のロジックに基づいた収集結果の品質担保が必要だと判断し、人間によるチェック工程を新たに設けています。とはいえ、すべてを人間が1,000件ものフォームを確認するのは現実的ではありません。そこで、人間が確認すべき対象を絞り込むためのプレ検査機構も追加で開発しました。このように、実運用を通じて業務フロー自体が変化し、それに合わせてシステムも変化していきます。
さらに、このフェーズでは各業務のインプットとアウトプットが頻繁に変わる状況でした。「企業情報収集のインプットに業界情報を追加した方が良いのではないか」といった、試行錯誤が常に行われていたためです。この点において、人間がスプレッドシートを介してデータ連携していたことは、結果的にインターフェース変更に伴うコストを比較的小さく抑える要因となっていました。
この時期に重要視していたのは、複数の案件に並行して対応しつつも、AIエージェントが日業務で通用する高い精度で動けるかどうかという点でした。そのため、各業務の実装と改善に注力し、それ以外の要素については意図的に優先度を下げていました。
人間が担っていた部分が全てシステム化されたフェーズ3
フェーズ2を経て、人力でオーケストレーションしてきた業務は、かなり高度に洗練されていきました。業務フローの変化も徐々に落ち着き、「なぜこの工程をまだ人間が担っているのか」と、ふと立ち止まって見直せるタイミングが訪れました。この段階に至って、初めて本格的なシステム化に踏み切りました。
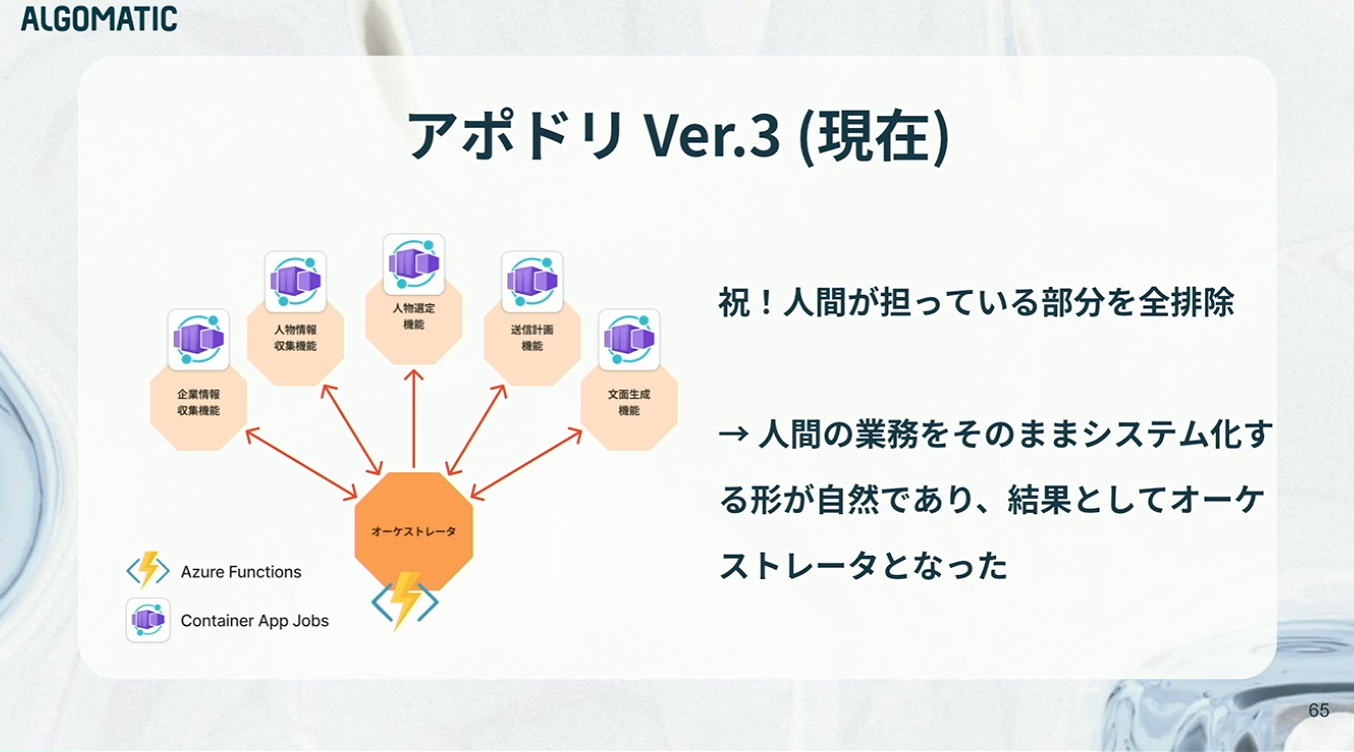
具体的には、人間が担っていた接続・判断の部分を削除し、そのままオーケストレータに置き換えています。ゼロから新しい仕組みを設計したというよりも、人間が実際に行っていた手順や判断を、そのままシステム化する方が自然だったため、結果として現在のオーケストレータ型の構成に収束したという感じですね。
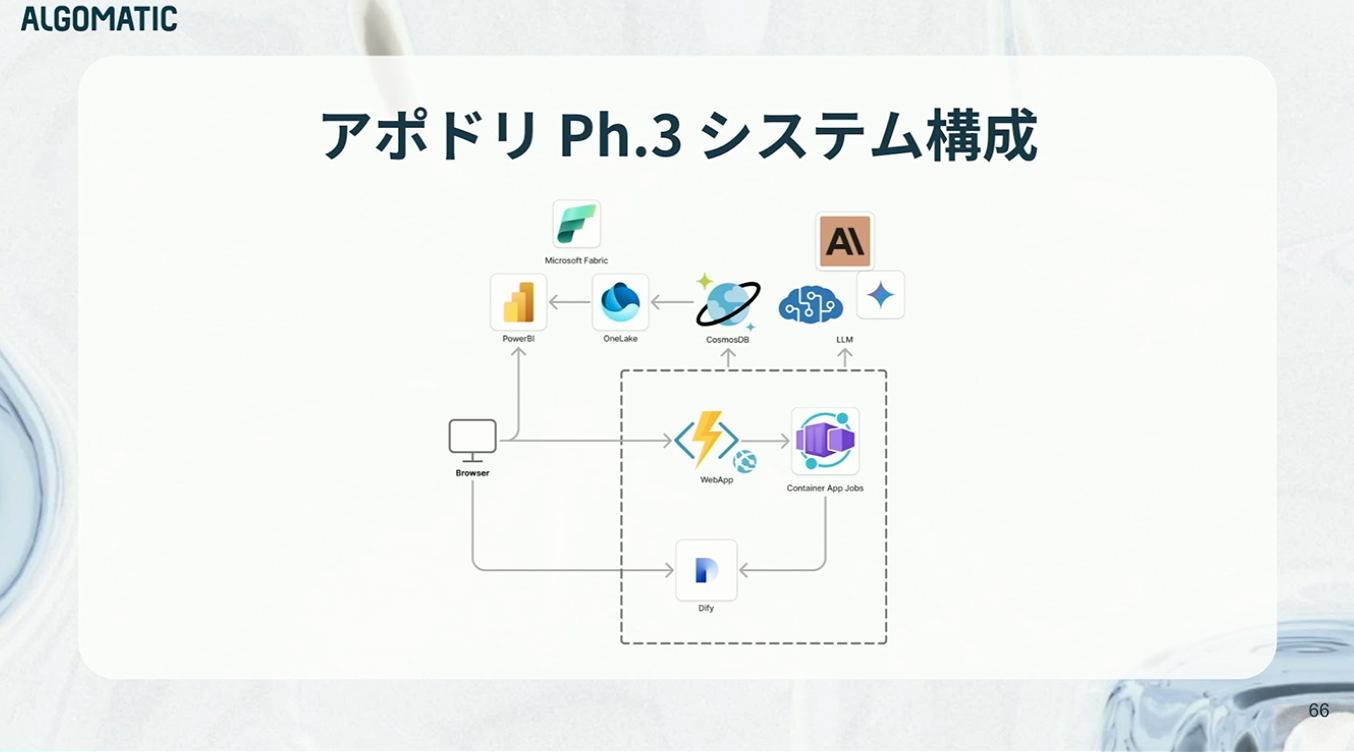
システム構成としても、人力操作を前提としたインターフェースは役割を終え、削ぎ落とされています。結果として、全体はよりシンプルで見通しの良い構成へと整理されました。
技術黎明期にエンジニアが持つべき「作らない勇気」
最後に、ここまでの振り返りとしてお話します。当時はリソースも限られており、事業がどこまで続くかもわからない、不確実性の高い状況でした。だからこそ、お客様に価値提供を行う上で「これを作らなければ明日を迎えられない」という最小限の部分だけを見極めて実装してきました。
システムとしては不十分な状態であっても、価値提供と事業仮説の検証を最優先に作り続けてきた結果、すべての工程がシステム化されたのは、開始から1年以上が経過してからのことです。
しかし、その頃にはエンジニアも含めたチーム全体の営業代行業務に対する解像度は大きく向上していました。業務フローも洗練・最適化され、非常にシステム化しやすい状態ができ上がっていたのです。
もし、当初から潤沢にリソースがあり、最初から全てを繋ぎ込んで実装していたとしたらどうなっていたか。業務の解像度が低く「LLMでどこまで可能なのか」「どこを人間が担保すべきか」も見えない状態で早期に開発しきってしまうと、むしろ後からの必要な変化を妨げていた可能性が高いと考えています。
実際に、オーケストレータを導入した現在は、人間が介在していた頃に比べて柔軟性は確実に下がっています。だからこそ、「まだまだ改善していくぞ」というフェーズにおいては、「あえて作り込まない」という選択が非常に大切なのだと思います。
グッとこらえて「なるべく作らない、なるべく後回し」を意識する

まとめます。現在のアポドリは、個別の業務ロジックとそれらを統括するオーケストレータによって構成されています。私たちは一貫して「本当に必要なものだけを作る」という意思決定を続けてきました。その結果として、今のアーキテクチャへと自然な流れで辿り着いたのです。
AIエージェント開発においては、各業務の実装は前提から頻繁に変化します。重要なのは、改善ループをいかに高速に回し続けられるかです。業務の実装は固定するものではなく、常に変わり続ける前提で設計すべきものです。ここで変化を妨げるような実装をしてしまうと、本来到達できたはずの精度に届かず、「やはりAIでは難しかった」という形でプロジェクトが終わってしまう可能性があります。
だからこそ、改善ループを阻害する要素はできる限り排除することが大切です。特に、システム同士の繋ぎ込みの実装は慎重であるべきです。業務フローや判断基準の解像度が十分に高まる前に固定してしまうと、その後の進化の余地を自ら狭めてしまいます。

繰り返しになりますが、お伝えしたいのは「なるべく作らない、なるべく後回しにする」ということです。作るべきものに注力して、それ以外のものは作らない。
エンジニアはどうしても作りたくなる生き物です。私自身も、システム同士を綺麗に繋ぎ込みたくて代表と議論になったことがあったぐらいですが、今振り返ると、あの時作らなくて良かったなと。作りたい気持ちをグッとこらえて、「今、本当に作るべきか」を問い続ける。その積み重ねが、プロダクトと事業の進化速度を最大化するのだと考えています。
最後に、Algomaticは生成AIを活用したサービス開発を行っている会社です。営業AIエージェント「アポドリ」に加えて、採用活動を支援する「リクルタAI」や、ゲーム向け翻訳サービス「AlgoGames 翻訳」などを展開しています。自社プロダクトを開発するAIプロダクト事業と、大企業向けのAI導入支援や研修を行うAIソリューション事業の両輪で、生成AI領域にフルベットしています。エンジニア職も募集しておりますので、ぜひご興味のある方はぜひお声がけください。
本日は、ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





