



【アーキテクチャConference 2025】コード分割から始める複雑さの解消に向けたkintoneのアーキテクチャ改善
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションでは、サイボウズ株式会社 開発本部 プロダクトエンジニアの前田 浩邦さんが登壇。10年以上にわたり進化を続けるノーコード・ローコードツール「kintone」のアーキテクチャ改善について紹介しました。長年の開発で肥大化・複雑化したコードに対し、プロダクトマネージャーのメンタルモデルを軸に「機能に沿ったパッケージへのコード分割」と「機能とwebの分離」という2つのアプローチで改善を進めた取り組みについてお話しいただきました。
■プロフィール
前田 浩邦
サイボウズ株式会社
開発本部 プロダクトエンジニア
2014年にサイボウズへ入社。以後、kintoneの開発に従事し、フロントエンドからサーバーサイドまでを経験。最近はサーバーサイドの改善に注力している。
kintoneとは
前田:まず、サイボウズが開発している「kintone」という製品について簡単に紹介させてください。kintoneは現場の人たちが業務システムを簡単に作成することができる、いわゆるノーコード・ローコードツールです。kintone上で業務システムを作ることで、仕事に必要なデータを管理し、チームで共有することができるようになっています。
作成できる業務システムとしては、案件管理や顧客管理システムなどが挙げられます。また、データを管理する以外にも、アクセス権の設定や業務プロセスの設定が可能です。外部システムとも連携でき、kintoneに閉じないような業務の改善も進めることができるようになっています。
機能に沿ったパッケージへのコード分割
前田:コード分割の背景となったのは、長年開発を続ける中で、kintoneのコードが肥大化・複雑化してしまったことでした。kintoneのサーバーサイドはJavaで書かれており、src/main/javaディレクトリ下にすべてのコードが収まっています。そしてそのコードの総行数は35万行を超えていました。
コードが大きいだけでなく、クラスの役割も曖昧でした。一つのクラスを理解しようとするときに、その呼び出し元や依存先のクラスを理解していく必要があり、周辺のクラスもすべて把握しないと元のクラスが理解できないという状況になっていました。
そのような状態だったので、開発が非効率になっていました。クラスの役割が曖昧なので、何か修正を加えるときに妥当な修正箇所を探しづらいです。頑張って探したとしても、結局探しきることができなくて、想定外の箇所に影響が出てしまうといったことも起きていました。また、新しいメンバーがキャッチアップしづらいという問題も起きていました。

前田:このような状態になってしまった要因としては、2つあると考えています。まず、kintoneそのものがローコード・ノーコードツールという柔軟性を持っており、そもそも複雑化しやすい性質を持っていたこと。にもかかわらず、kintoneの構造自体は初期のモノリシックでシンプルなWebアプリケーションとしての構造がずっと続いていて、これまで見直されてきませんでした。
ボトムアップな改善活動もされてはいたのですが、限界を感じていました。機能開発のたびに目についたコードをリファクタリングするようなことはしていたのですが、例えば100行リファクタリングしたとして、残りのコードは34万9千行ぐらいあるわけなので、「あと何回やればいいんだろう」という形で途方に暮れてしまうような状態になっていました。
そこで抜本的な改善として、コード分割という取り組みを始めました。コード分割はコードを以下のような状態にすることであると私たちは定義しています。
- 機能ごとに、その機能のためのコードを専用パッケージに分割
- 機能間で関わらないなら、コード間でも独立
- 機能間で関わりがある場合は、専用のインターフェースを公開して依存
前田:コード分割の実例を紹介していく前に、機能について紹介します。kintoneのアプリは、データを管理・共有するための簡単なデータベースのようなものになっています。このアプリを使って業務システムをつくっていきます。案件管理には案件管理アプリ、顧客管理には顧客管理アプリといった使い方をしています。
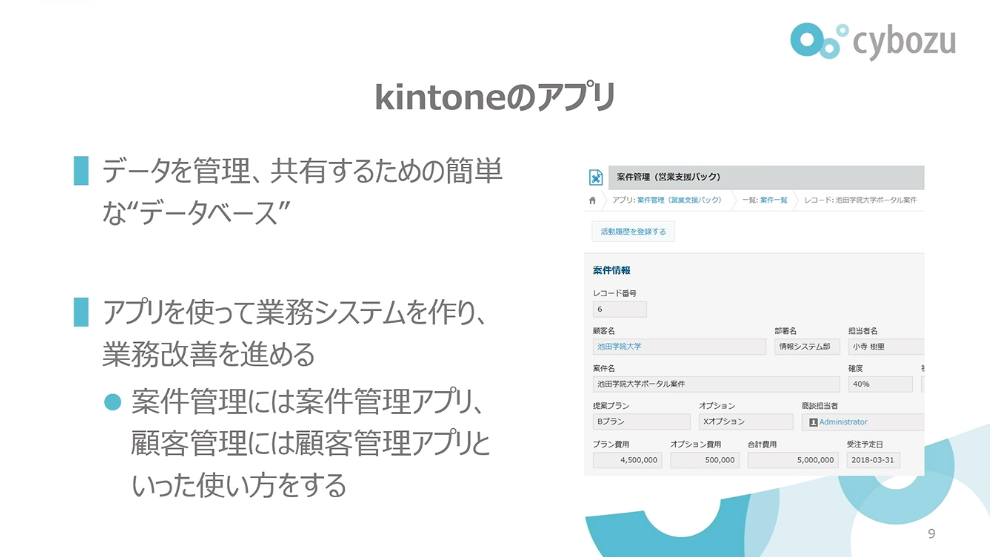
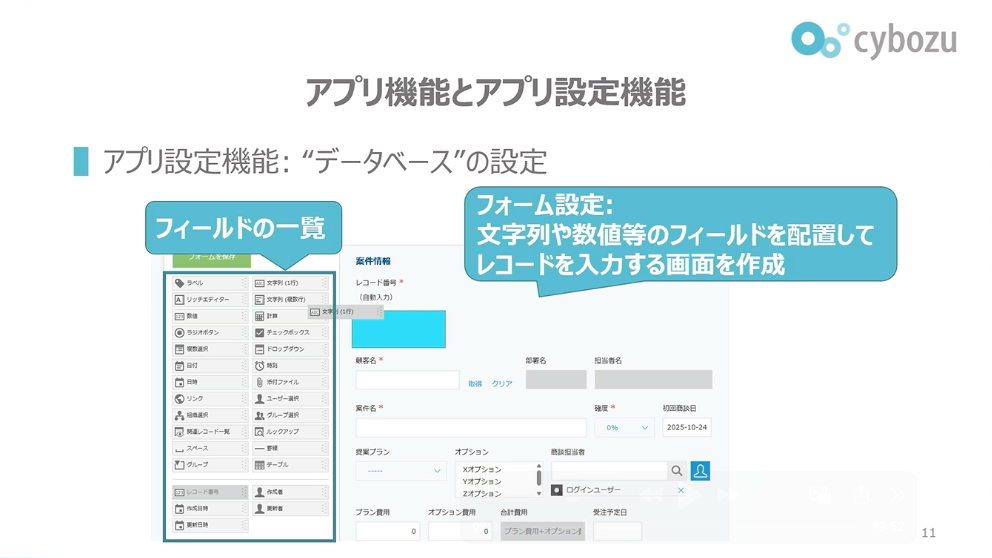
前田:kintoneには「アプリ機能」と「アプリ設定機能」があります。アプリ機能は、データベースにあるデータ(kintoneではこれをレコードと呼んでいます)の入力や表示を担当する部分です。アプリ設定機能は、データベースの設定をする部分です。フォーム設定と呼ばれる機能では、文字列や数値等のフィールドを配置してレコードを入力する画面を作成することができます。
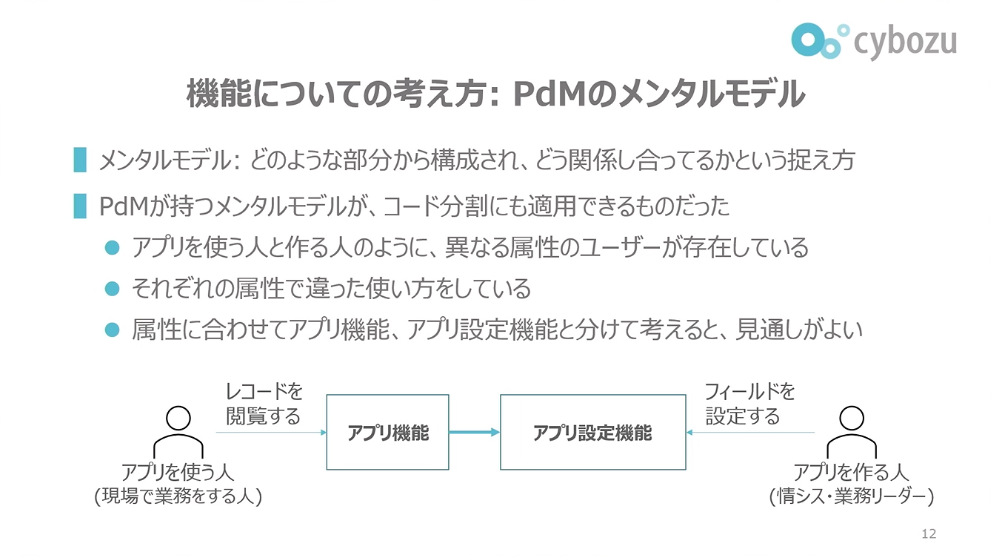
前田:このような機能の捉え方はプロダクトマネージャーのメンタルモデルから来たものになります。メンタルモデルとは、kintoneという大きなものがどのような部分から構成されていて、それら部分同士はどう関係し合っているのか、もしくはまったく関係しないのか、といった捉え方です。
同じkintoneのユーザーでも、「アプリを使う人」「アプリを作る人」のように、異なる属性のユーザーがいることがわかっています。アプリを作る人というのは、ユーザーの中でも情シスや業務リーダーに相当する人で、システムや現場の業務に詳しい人です。一方で、アプリを使う人というのは、現場で業務をする人になります。
ユーザーの属性が異なれば、利用するkintoneの機能も異なります。このようにユーザー属性に応じて機能を分けて捉えることで、プロダクト全体の見通しが良くなります。プロダクトマネージャーはこの考え方でkintoneを整理しており、コード分割ではこのメンタルモデルをそのままコード構造に反映させることを目指しています。
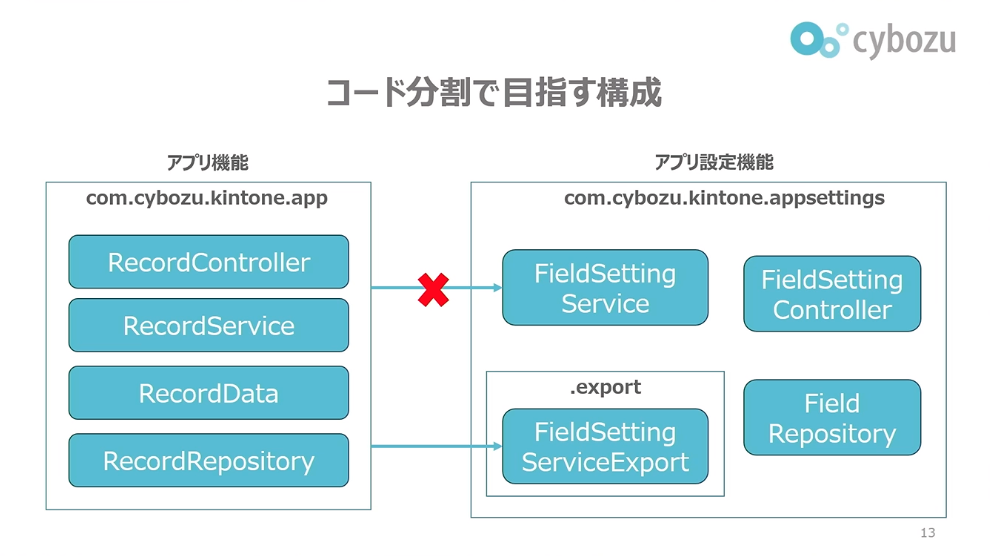
前田:次に、コード分割で目指す構成について話していきます。先ほどアプリ機能、アプリ設定機能について紹介しましたが、それに合わせる形でappパッケージやappsettingsパッケージをつくっています。機能に対応するパッケージをつくり、その機能に属するコードはすべてそのパッケージ内に収めるという状態にします。kintoneのコードはコントローラー、サービス、データ、リポジトリといったコードから成るのですが、そういったコードをすべて対応するパッケージに収めます。
そして、必要なら専用インターフェースも公開します。アプリ機能からアプリ設定機能への依存があります。アプリ設定で設定したレコード入力画面をアプリ機能で出すので、機能として依存関係があるのです。そのためにインターフェースを切って、そこにのみ依存を許可する形になっています。
前田:専用インターフェースは次のような形になっています。これはフィールド設定を返すインターフェースで、getというメソッドがあって、アプリのIDを引数に取ると、そのアプリのフィールドの設定が返ってくるというものです。アプリ機能側はここにある情報だけを使って、レコード入力画面等をつくるという形になっています。

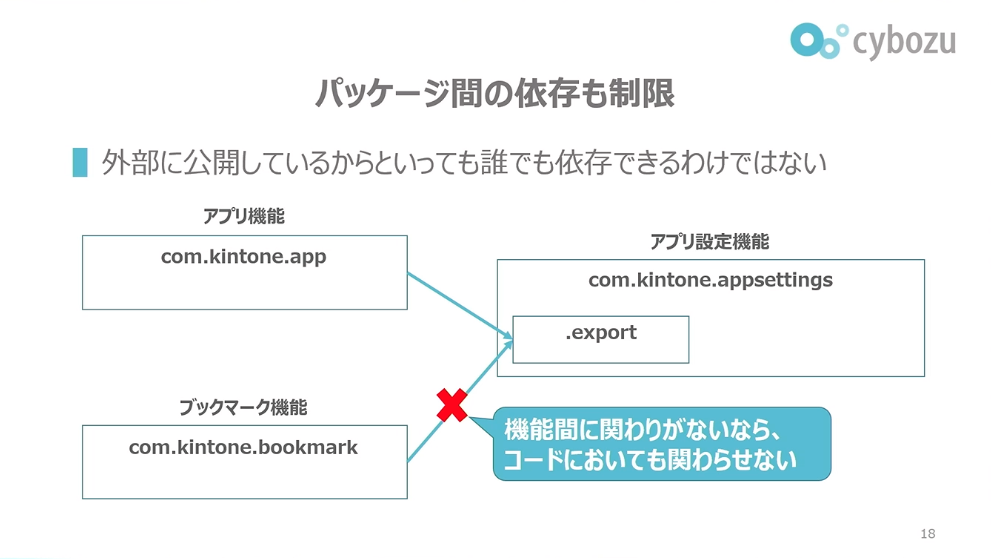
前田:パッケージ間の依存も制限しています。エクスポートにして外部に公開してあるからといって、誰でもそのエクスポートに依存できるというわけではありません。アプリ機能からアプリ設定機能は機能間に依存があるので問題ないのですが、例えばブックマーク機能からアプリ設定機能への依存は禁止しています。機能間で依存がないから、対応するコード間でも依存させないという状態にしています。
前田:このような依存の管理なのですが、kintoneではArchUnitを使って依存を定義し、ルール化しています。具体的には、内部実装に依存していないかとか、エクスポートにちゃんと依存しているかをチェックしますし、パッケージ間の依存についてもArchUnitを使ってルール化しています。この定義したルールはJUnitと組み合わせて利用し、単体テストとしてCIに組み込んでいます。これによって意図しない依存が入り込んだとしてもテストが失敗するので、それに気づけて修正でき、意図した依存を保つことができます。

前田:kintoneのコード分割では、機能の特徴を捉えた上で分割することを重視しています。既存のコードだけを根拠に分割しても、当初の目的である複雑さの解消にはつながらないと考えているからです。
例えば、複数のgetメソッドが同じクラスを返しているコードがあったとします。コードの見た目だけで判断すると、これらのgetメソッドを共通処理として切り出したくなるかもしれません。しかし、それらのメソッドが同じクラスを返しているのは、たまたま動作したからそうなっただけという可能性もあります。このような「偶然の一致」を根拠に分割してしまうと、論理的な裏付けのない構造になってしまいます。偶然をもとにした分割では複雑性を抑制できないため、私たちはコードの見た目だけに基づく分割を避けるようにしています。
一方、機能に沿った分割であれば、複雑さの解消が期待できます。コードは本来、機能を実現するために存在するものです。したがって、コードと機能の間には自然な対応関係があります。機能の分類に沿って分割することで、コードを独立したパッケージに整理でき、各パッケージ内に実装の複雑さを隠蔽できます。つまり、kintone全体の複雑さを個々の機能単位の複雑さに分解できるため、全体としての複雑さの解消が見込めると考えています。

前田:コード分割の現在の状況ですが、アプリ設定機能の分割が完了しています。これは2022年11月から2024年8月にかけて、約2年かけて分割していました。他の機能も現在分割が進行中です。また、新しい機能は最初から分割された状態で開発が進んでいます。
コード分割をしてみてどうなったかという話をします。まず、機能ごとの開発が容易になりました。分割前だとコードを延々と追わなければいけないという問題があったのですが、機能ごとにパッケージ分割されることによって、コードを把握する際にも、機能に対応するパッケージだけ読めばいいので、読む範囲が明確になりました。また、影響範囲も分かりやすくなりました。基本的にパッケージで影響が閉じますし、何らか影響が出るとしてもエクスポートを通して影響が出るので、エクスポートを見ればどういうことをすればいいかわかるようになっています。

また、複雑さの要因が一つ見つかりました。複数のアクター、つまりアプリを使う人や作る人のための処理が一つのクラスで書かれていたことによって、そのクラスの中が肥大化して、ロジックの見分けがつきにくくなっていたということです。コード分割によって、このアクターに対応する形でコードが分かれていったので、複雑さは解消されました。これについて詳しくは、「複雑性に立ち向かうためのサーバーサイドコード分割」というブログ記事ですでに発表していますので、興味ある方はご参照ください。
パッケージ内での機能とwebの分離
前田:大きな機能をパッケージ分割するという話をしたので、次はそのパッケージ内での改善、機能とwebの分離という話をしていきます。
まず、kintoneのwebアプリケーションとしての設計について簡単に紹介します。kintoneは基本的にService、Data、Controllerという3つの登場人物から成り立っています。Serviceはビジネスロジックを担当するクラスで、永続化やkintoneの仕様としての振る舞いを実現するレイヤーです。Dataはその機能内の主要な情報を表現するクラスです。ControllerはSpringのControllerで、リクエストを受け取ってServiceを呼び出し、返ってきたDataをレスポンスに変換してフロントエンドに返すという処理を担当しています。

前田:今回の分離に取り組んだ背景には、Controllerにおけるデータからレスポンスへの変換処理が曖昧だったという課題がありました。本来、この変換処理は単純なプロパティのマッピングにとどめるのが理想です。サービスレイヤーからコントローラーレイヤーへ値を受け渡すだけで、機能に関する知識は必要としないという方針でした。
しかし実際には、単純なマッピングを超えた機能寄りの処理が変換処理の中に混在していました。具体的には、DBを参照してアプリIDからアプリ名を取得する処理や、アクセス権をチェックして権限がなければ項目を除外する処理などが、変換処理として書かれていたのです。
このため、機能寄りの処理をどこまでControllerに残し、どこからServiceに切り出すべきかの判断基準が曖昧になっていました。この曖昧さを抱えたまま開発が続いた結果、開発効率が低下していました。処理の配置先をControllerにするかServiceにするか、開発者が都度迷いながら実装することになり、最終的には書き手の裁量で決まってしまう状況でした。その結果、コードの可読性も損なわれていました。
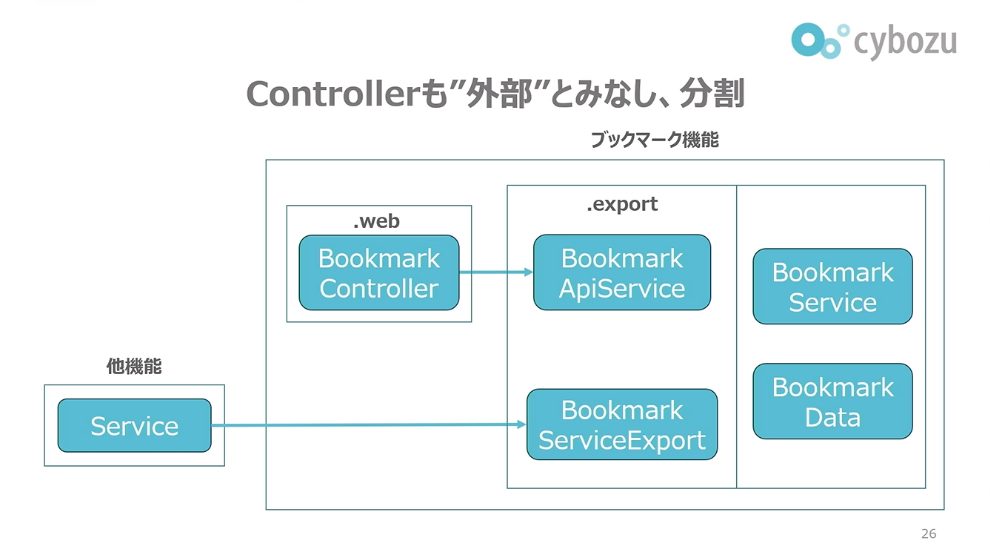
この課題に対する解決策として、Controllerも外部とみなして分割するというアプローチを採用しました。従来、他機能からブックマーク機能にアクセスする際は、エクスポート層にある専用のBookmarkServiceExportにのみ依存を許可していました。この考え方をControllerにも適用します。具体的には、BookmarkControllerから機能にアクセスする際は、BookmarkApiServiceにのみ依存を許可するという設計です。
他機能からServiceExportへの依存によって内部実装を隠蔽できていたのと同様に、webコントローラーからも内部実装を隠蔽できると考えました。この設計により、同じ機能内であっても、Controllerが属するwebレイヤーは他機能と同等の立ち位置になります。私たちはこれを「機能とwebの分離」と呼んでいます。
前田:ApiServiceの具体的な構造について説明します。Controllerが要求する機能の振る舞いは、すべてこのApiServiceに集約されています。例えば、listメソッドはユーザーIDを引数に取り、ListResponseを返します。ListResponseにはブックマークされたアプリのリストが含まれており、各アプリにはnameとしてアプリ名が格納されています。これにより、Controller側でDBを参照してアプリ名を取得する必要がなくなり、ApiServiceから返された値をそのままレスポンスとして返すだけで済みます。

前田:機能の振る舞いはすべてこのレイヤーに集約する必要があるため、addのようなメソッドもApiServiceに定義されています。この設計により、ControllerはApiServiceを呼び出すだけの役割になりました。Controller側から機能に関する処理は完全に排除されています。
ApiServiceの導入によって得られた効果について説明します。まず、曖昧だったControllerの役割が明確になりました。従来は機能寄りの処理をどこまでControllerに書いてよいかが課題でしたが、ApiServiceの導入により「機能に関する処理は書かない」という方針で決着しました。Controllerに許可されるのは、ApiServiceを呼び出すことのみです。
ただし、必要に応じてSpringやHTTPリクエストなどのwebフレームワークを使用し、webレイヤーから情報を取得することは認められています。例えば、getUserIdはControllerで呼び出しています。ユーザーIDの取得はブックマーク機能固有の処理ではなく、webレイヤーから取得する情報であるため、Controllerで処理するのが適切です。このように、Controllerの役割は「機能についての知識を持たず、webフレームワークを介してフロントエンドと機能をつなぐこと」に明確化されました。

前田:さらに、次のような効果も得られました。第一に、DataクラスとServiceクラスの肥大化が抑制されたこと。第二に、Javaのインターフェースで機能を定義できるようになったことです。
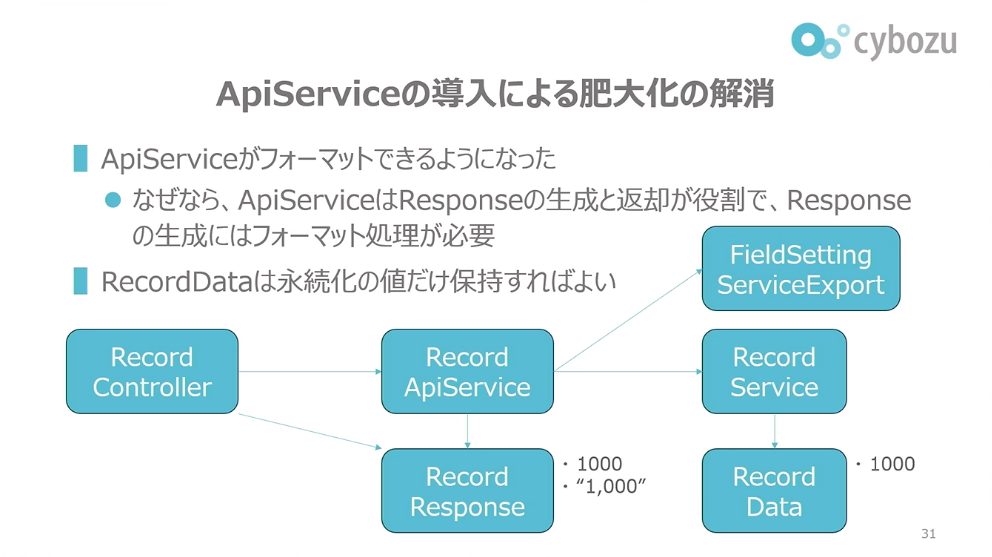
以前はControllerの役割が曖昧になっていただけでなく、Dataクラスが肥大化していました。例えばRecordDataクラスというのは、アプリのレコードを表現するDataクラスで、各アプリにあるフィールドの値をレコードごとに保持します。
数値フィールドの場合、例えば1000という値をRecordDataが保持していて、これがフロントエンドに返されることで画面に見えるようになります。ただ、画面では「1,000」のようにカンマ区切りで見えています。数値を具体的にどう見せるかはアプリ設定側で決まっています。そのまま1000と見せる場合もありますし、「1,000」という文字列で見せる場合もあります。
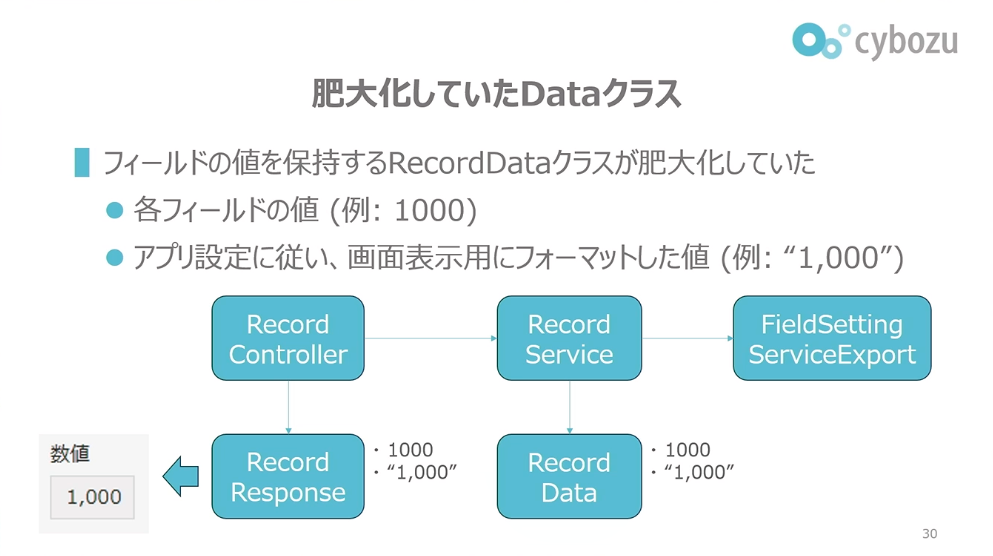
前田:従来は、設定に従ってフォーマットされた値もRecordDataに格納されていました。Serviceがアプリ設定側のインターフェースを参照してフォーマット済みの値を生成し、Controllerに返す構造です。この設計ではControllerの変換処理は単純で済みましたが、RecordDataは永続化すべき値に加えて画面表示用の値も保持することになり、クラスの肥大化を招いていました。
ApiServiceの導入により、この構造は改善されました。まず、フォーマット処理を担うレイヤーが明確になりました。ApiServiceでフォーマットを行う設計です。この設計が適切である理由は、ApiServiceの役割がレスポンスの生成と返却であり、レスポンスのメンバ変数としてフォーマット済みの値が必要だからです。したがって、フォーマット処理はApiServiceがRecordResponseを生成する際の一環として実行するのが自然です。具体的には、ApiServiceがアプリ設定のエクスポートを呼び出してフォーマット済みの値を生成します。この結果、RecordDataは永続化の値のみを保持すればよくなり、肥大化が抑制されました。
前田:続いて、ApiServiceの導入によって判明した複雑さについて説明します。今回問題になっていたアプリ名やフォーマットされた値は、レスポンスのJSONにのみ必要な情報です。これはview modelに近い概念と捉えています。返却されるJSONをviewと解釈した場合、そのviewを生成するためのmodelがview modelに該当します。
このview modelの観点で従来の設計を分析すると、view modelの生成箇所が不適切であり、これが複雑化の原因になっていたことがわかります。Controllerでアプリ名を取得する処理は、view modelをControllerで生成することに相当します。この設計では、Controllerにおいてどこまでが変換処理なのかが曖昧になっていました。一方、Dataにフォーマット済みの値を格納する処理は、Serviceでview modelを生成することに相当します。この設計ではDataクラスが肥大化し、さらにDataクラスを生成するServiceクラスも肥大化してしまいます。
ApiServiceの役割についても考えてみます。ApiServiceは次のような特徴を持つことから、ユースケースを実装する役割を持っていると現在は考えています。
- 常に機能の外から利用され、機能内での再利用は想定されない
- 外部からの入力と出力(view model)を定義している
- したがって、外部が期待する振る舞いを実現する責任を持つ
ユースケースの考えを導入して既存実装を見直すことによって、複雑さの解消も見込めると思います。外部が期待する振る舞いを分析して責務を割り出し、適切にクラスに定義する、いわゆるモデリングをすることによって、複雑さの解消を見込めると考えています。

前田:次に、Javaのインターフェースで機能を定義できるようになったことについて紹介します。.exportを中心として図示すると、他機能部分や.webパッケージ下には、ブックマーク機能に関するコードは存在しなくなっています。他機能部分はそもそも存在していません。機能に沿ったパッケージへのコード分割を行ったので、ブックマークのコードはブックマークパッケージ下に必ず置かれるようになりました。そして今回、機能とwebを分離しようとしてwebから機能的な処理を排除したので、web下にもブックマークに関する知識やコードはなくなっています。
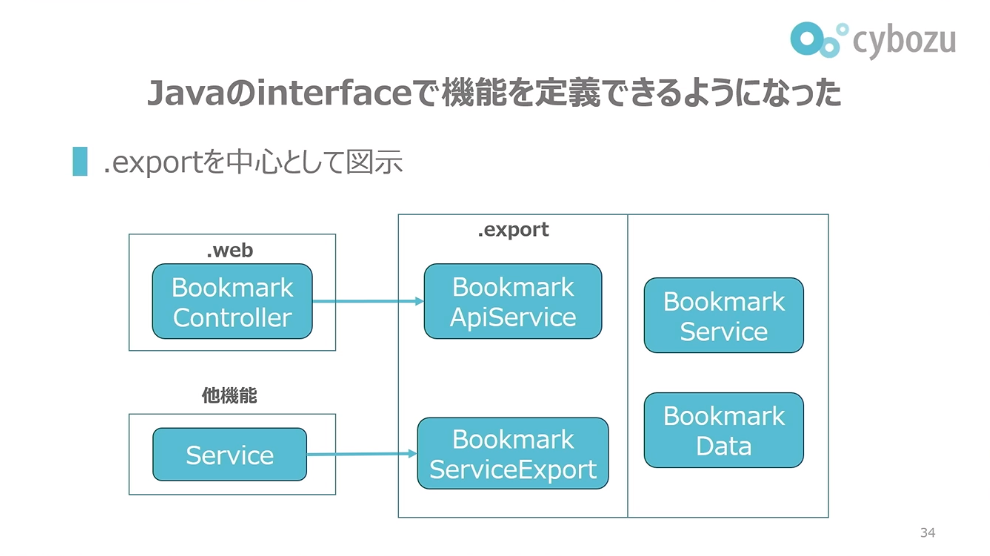
前田:ということは、機能に関するコードは.exportと内部実装に残っています。そして外部から機能を使いたいとなった場合、外部から機能として認識できているコードは.export部分のみになっています。依存を制限したからです。ServiceやDataはここらへんに存在はしているのですが、外部からは認識できていません。代わりに、そういったものはエクスポートされるメソッドの振る舞いに表れていると考えることができます。
ということは、外部が例えばブックマーク機能として本当に依存しているのは、.exportにあるインターフェースおよびそのインターフェースのメソッドが期待どおりに、いわゆる契約通りに振る舞うことのみになっています。ServiceやDataの特定のあり方には依存していないということになっています。逆に言うと、あり方が何であっても、これらの契約が期待どおりに振る舞うならば、それは機能として正しい実装になっているという形になっています。
ここまでを考えると、.exportのインターフェースが機能の定義になっていると考えてもいいと思っています。ServiceやDataは存在するのですが、それは機能を実現するための内部実装であって、その詳細や複雑さはこの中に隠蔽されます。最初に機能をコード分割して複雑さを隠蔽していくという話をしたのですが、まさにこのインターフェースの導入によって隠蔽されたといえると考えています。これはいわゆる抽象データ型で機能を定義していると考えています。
この応用としては、結合テストの対象にできたりとか、あとは修正を考える起点になるというものが挙げられます。
まず、結合テストの対象は簡単で、機能をテストしたいとなったら、エクスポートのテストをすればいいわけです。これより外に機能はありませんし、これより内側は特定のあり方のテストになってしまうので、ここで正しく機能をテストできると考えられます。このテストは内部実装に依存しませんし、機能を一番外側から観測できているので、テストとしてもすごく堅牢になっていると考えています。

前田:機能を修正する場合どうなるのかというと、機能が変わるということは機能の定義が変わるということになるので、基本的には.exportのレイヤーに手が加わるはずです。逆にこれが加わらないならリファクタリングになると考えられます。
なので、機能が変わる際に、その対応するエクスポートがどう変わるのか、それを変えるためにServiceやDataはどう変わるのかというような形で、トップダウンに考えることができるようになりました。機能の一番外側から全体を俯瞰した検討ができるようになったのです。
対して今まではどう考えていたのかというと、ServiceやDataをどう書くのかというボトムアップな考え方がほとんどでした。この方針ですと、ServiceやDataに詳しくないと修正箇所が見つけられませんし、ServiceやDataも役割が曖昧だったので、結局考慮漏れが起きてしまうというような問題がありました。

前田:実際にkintoneでこれを試した例を紹介します。性能カスタマイズオプションと呼ばれる新しい機能です。これはアプリの用途に適したレコード実装を提供したいというものです。今あるレコード実装は一つしかなくて、それは後からでもフィールドをドラッグアンドドロップで追加できるような柔軟なレコード実装になっています。これが既存実装です。
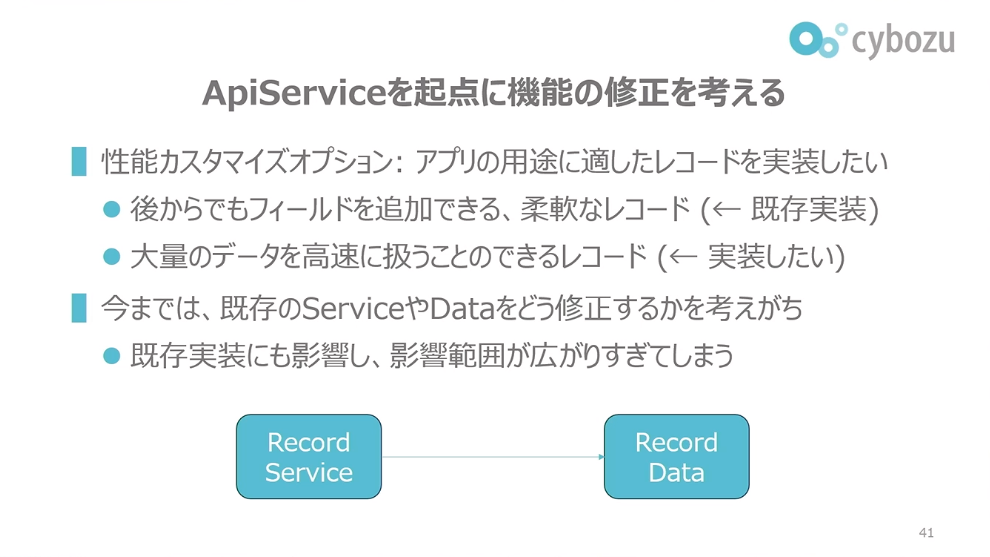
前田:一方で、その柔軟性をなくしてもいいので、大量のデータを高速で扱うことができたら、よりアプリの適用範囲が広がって、より広く業務改善もできるだろうということで、このような機能の検討が進んでいます。
今までの発想だと、既存のServiceやDataをどう修正するかを考えがちでした。Controllerがあって、RecordServiceがあって、RecordDataがあって、これをどう変えようかという発想です。これだと既存実装にも影響してしまって、影響範囲が広がりすぎてしまうといったことが起きていました。
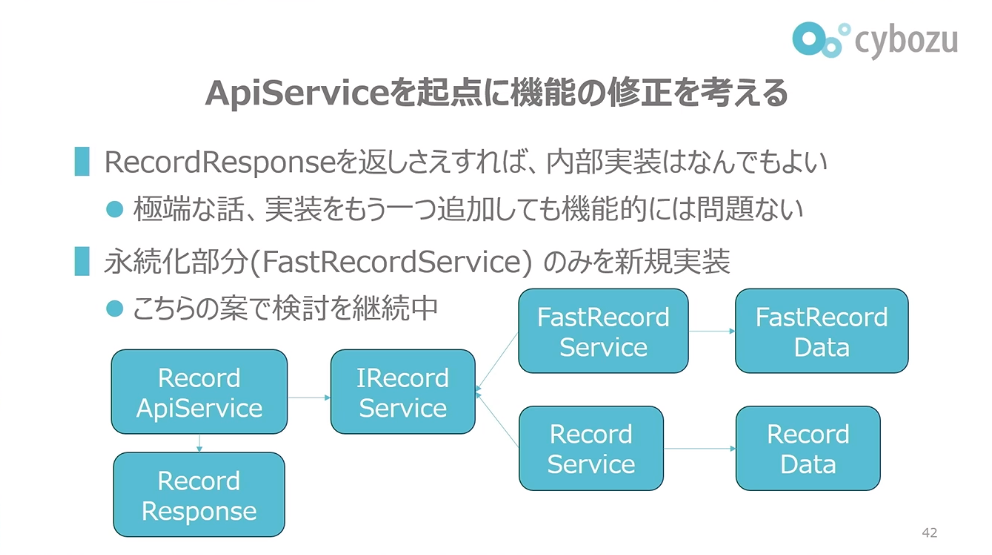
ApiServiceを起点にするとどう変わるかといいますと、極端な話、ApiServiceがRecordResponseを返しさえすれば、内部実装は何でもいいと割り切れるはずです。極端な話、もう一つの高速な実装をまるっきり実装しても何も問題ないわけです。機能としてはエクスポートによる振る舞いこそが大事で、内部実装は見えていないので、極端な話もう一つ高速実装をやっても機能的には問題ありません。
ただし、機能的に問題なくても、非機能的な、例えばメンテナンス性には問題が出てきます。二重実装になってしまうからです。なので、今回本当に変えたかった「永続化部分だけ新規実装すればいいよね」という発想になります。共通部分をインターフェースに切り出して分けていくという形です。こちらは実際にこの案で開発が進んでいる、検討しているものになっています。
前田:このようにControllerから機能を除くというシンプルなことだったのですが、広く応用ができてよかったと思っています。

AIによる支援
前田:最後にAIによる支援について話したいと思います。今まで紹介した分割やwebとの分離をするためには、公開インターフェースが必要になります。kintoneではこの公開インターフェースの生成が重量級になりがちで、用意が大変でした。
実際に定義した公開インターフェースがあるのですが、CALCというのは計算フィールドのこと、Categoryというのはカテゴリフィールドです。このようにフィールドごとにクラスが必要になってきます。このフィールドが10個以上あるので、これを手で生成するのはとても大変で、2、3個で断念してしまうと思います。

前田:しかし、生成AIでこの重量級なインターフェイスの自動生成が可能になりました。インターフェースは結局実装を隠蔽するためにあるので、既存実装と似たような構成になります。最初にやったのはCALCという計算フィールドなのですが、「既存の実装からこのインターフェースを抜き出して、同じことをやってください」という風にAIに入力することによって、カテゴリなど全部を自動で生成することができて、インターフェースの生成もすごく楽にできました。
もっと良かったのが、よりフィットするインターフェースの探索も可能になったことです。インターフェースも一つ試すのではなくて、いろんなパターンを試してみて、フィットするものを選びたいと考えています。ファクトリーがいいのか、プロバイダーがいいのか、または別のインターフェースがいいのかといろんなパターンを試してみて、既存のコードの中でしっくりくるものを選びたいという形です。

前田:生成AIによってこれも可能でした。実際何パターンか試してみて、あとよろしくという形でAIに生成することができました。一つはまだしも、何パターンも10個以上あるクラスを人で生成するのはちょっと難しいと思うので、ここはAIが活用できてよかった部分です。
このように開発がある程度進んでしまうと、分割するにしても、それに伴うインターフェースの整備というのがかなり負担となってしまって、実質進められないということになりがちですが、AIの活用によってここは挑戦できると思っています。
まとめ
前田:本発表では、プロダクトマネージャーのメンタルモデルを基にして、コードを外側から分割していくアプローチについて紹介しました。最初は機能に沿ったパッケージへのコード分割で、その次がそのパッケージ内での機能とwebの分離というものです。
このようなアプローチは、肥大化・複雑化したコードを改善するアプローチとして有効だったと考えています。また、開発が進んでしまうと、このような分割や分離をするにも大きな負担を伴ってしまうのですが、昨今のAIの活用によって十分に挑戦可能になったのではないでしょうか。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





