



【アーキテクチャConference 2025】ディップが挑む、20年超レガシー「バイトル」をAI駆動で再設計!事業成長を実現するリアーキ戦略
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションでは、ディップ株式会社 執行役員 CTOの長島 圭一朗さんが登壇。20年以上の歴史を持つ求人サービス「バイトル」のリアーキテクチャへの挑戦について紹介しました。「技術的負債」という表現では軽すぎる「技術的迷宮」とも言える状況から、いかにして脱出を図ったのか。AI駆動開発(AI DLC)の導入における成功と課題、そして組織変革のリアルを共有していただきました。
■プロフィール
長島 圭一朗
ディップ株式会社 執行役員 CTO (最高技術責任者)
20年以上に渡り、広告・メディア・EC・IoTなどの様々なWebサービスの企画・開発に従事し、2024年2月ディップ株式会社に入社。DX事業、『スポットバイトル』の立ち上げに従事し2024年7月にCTOに就任。現在はディップ全体のプロダクト開発や組織の改善に従事。
ディップ株式会社について
長島:インターネットの家庭普及率が18パーセント程度だった2000年、まだ紙媒体による求人情報が主流だった時に、ディップのサービスはスタートしました。すでに一般的だったコンビニ端末とインターネットを融合することで、すべての人が仕事を探せる社会を時代に先立って実現してきました。
その後もスマホ普及率がまだ4パーセントだった2010年、ガラケー全盛期の時代にバイトルの中に動画で仕事を探せる機能を実装し、時代の変化に合わせてユーザーのニーズを形にしてきました。技術的なハードルが高かったものの、早くからインターネットに特化してきたディップならではの技術でした。
そして2019年、労働市場における諸問題を解決すべく、AI・RPAを活用したDXサービス「コボット」をリリースし、昨年2024年からは日本初となる対話型バイト探しサービス「dipAI」をリリースして今に至っています。
ディップが実現したいことは、誰もが働く喜びと幸せを感じられる社会です。そういった社会を実現するために、仕事に出会えないというユーザーの課題を「バイトル」などの人材サービスで、職場環境やコミュニケーションの課題を「コボット」や「バイトルトーク」などのDXサービスで解決しています。
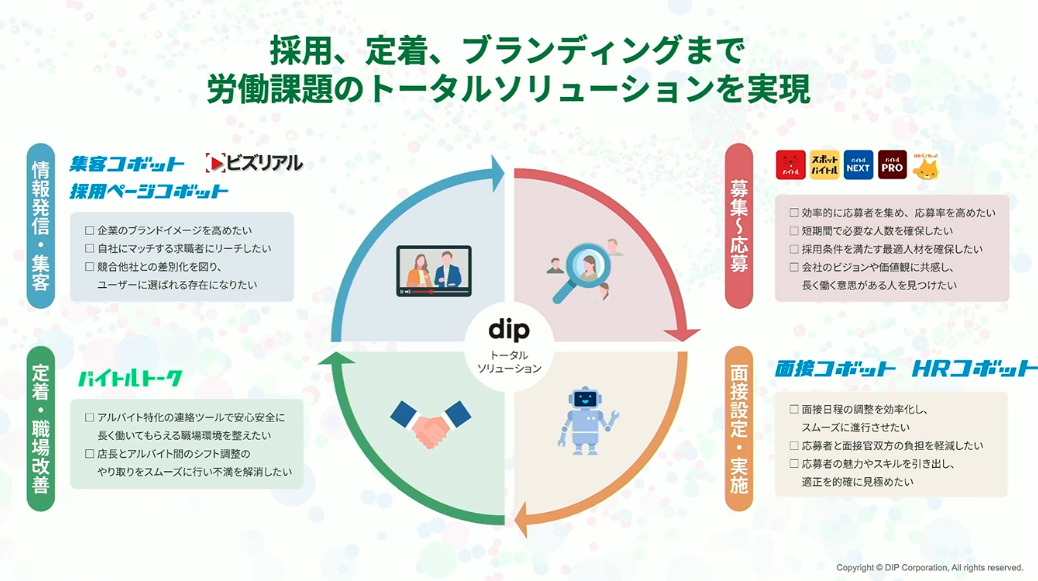
そしてAIネイティブな時代を迎えた2025年、「ユーザー・企業と繋がり続ける」を成長戦略に掲げ、採用・定着・ブランディングまで労働課題のトータルソリューションを提供しています。ディップのサービスを利用している1,000万人以上のユーザーと35万社以上の企業基盤を活かしたユーザーファーストなサービス展開を行っています。
蓄積されたデータを活用し、課題解決力を高めることで、ユーザー・顧客・企業の課題に対してのソリューション力を高め、結果、私たちのビジョンである“Labor force solution company”としての進化を遂げられると考えています。
導入:直面した現実と、共感──なぜ変える必要があったのか?
長島:そもそもなぜこれほどの基盤がありながら、大規模な変革を行う必要があったのか。私が入社して目にしたのは、技術的負債という表現では軽い、もはや「技術的迷宮」とも言えるような状況でした。
皆さんにお聞きします。技術的負債という言葉、少し聞き飽きていませんか?私たちは自分たちのシステムを「負債」という表現では軽いと感じていました。なぜなら、負債であれば返済すれば終わりだからです。でも、私たちが直面していたのはもっと複雑なものでした。
これはもはや技術的迷宮と呼べるものだと。20年という長い歴史の中で、増築に増築を重ねた巨大な城。そこには無数のビジネスロジックが隠されていますが、全体像を知る地図はもう失われていました。「ここを直すとどこが崩れるかわからない」。閉じ込められたというよりは、あまりに巨大すぎて現在地さえもわからなくなっていた、という状況でした。
20年前に生まれたバイトル。事業は素晴らしい成長を続けています。その成長を支えるために、システムは20年間改修を重ねながらも動き続けてきました。それは先輩たちが事業を守り抜いてきた巨大な城塞です。しかし、その裏でシステムは限界に達しており、事業戦略のスピードに全く追いつけなくなっていました。
成長の代償として、システムが抱えていた3つの構造的負債があります。

長島:1つ目は、脆さです。CI/CD自体は当然ありますが、複雑な密結合により改修の影響範囲を完全には見通せない状態でした。テストは通ったけど、本番で何か起きるかもしれない。そんな見えない負債への恐怖と戦いながら、デプロイボタンを押す重圧が現場にはありました。
2つ目は、調査コストの肥大化です。機能追加の時間のうちコードを書く時間はわずか。残りの大半は複雑怪奇な依存関係を解き明かす調査に消えていました。
3つ目は、組織のサイロ化です。ビジネスサイドとエンジニアが共通の言葉を失い、噛み合わない状態が続いていました。
事実、現場の開発チームからもこのような悲鳴が聞こえていました。密結合の恐怖により、一つの修正の影響範囲が誰にもわからない。テストの形骸化により、デグレを恐れるあまり不必要なほど慎重にならざるを得ない。そして、ブラックボックス領域が多数存在している。まさに属人化の極みです。
これらによる深刻な影響は、やはり開発スピードの低下です。これはエンジニアの能力不足ではなく、構造的な問題でした。水面上に見えるコーディング自体は一瞬で終わります。しかし、その水面下には巨大な調査コストが潜んでいました。「この一行を変えたらどこが壊れるかわからない」。その恐怖が膨大な調査・影響調査と手動テストを強要し、リードタイムの大部分を食い潰していました。
長島:ここで少しビジネスサイドの話もさせてください。今回のリアーキテクチャには事業戦略上の大きな目的があります。それは「売り方の転換」です。エンジニアの私たちには少しピンとこないかもしれませんので、身近なハンバーガー屋さんで例えさせてください。

長島:これまでの私たちのシステムは、ハンバーガー、ポテト、ドリンクをそれぞれ別のレジで会計し、別のカウンターで受け取らなければならない状態でした。これがクロスセル・単品併売の限界です。管理も大変ですし、お客様にとっても不便です。
私たちが目指すのは、これをバリューセットとして一つのレジで提供できるようにすることです。また、ポテトをLサイズにとか、ドリンクをシェイクにといった変更(アップセル)も、システムが裏側で統合されているからこそ、スムーズに実現できるものだと考えています。
このままでは事業成長を支えられない、ズレを解消できない。小手先の改善ではもはや限界でした。私たちに残された道は抜本的な再設計、リアーキテクチャしかありませんでした。しかし、ただ闇雲につくり直すだけでは、10年後に再び同じ迷宮を生み出すことになります。
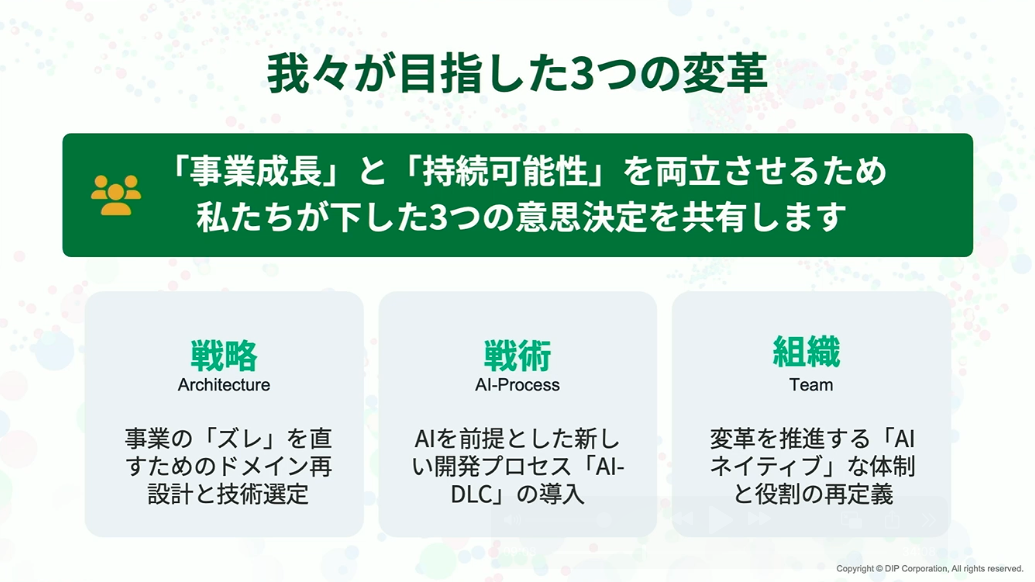
これが、この先にお伝えする3つの大きな意思決定を行うに至った理由です。その3つとは、戦略(アーキテクチャ)、戦術(AIプロセス)、組織(チーム変革)です。
戦略:アーキテクチャの意思決定──3つの重要な意思決定
長島:このセクションでは、私たちが下した3つの重要な意思決定のうち、まず「戦略」について、技術的な側面から解説します。
迷宮から脱出するために、私たちは奇をてらった技術は使わないように進めようと考えていました。選んだのは標準化とシンプルさです。
また、私たちの全体設計思想は、事業成長とAIネイティブの両立です。単に技術的負債を解消するだけでは、数年後にまたレガシー化してしまう可能性があります。奇をてらった技術は使わず、しかしAIによる開発プロセスを前提とすることで、事業とシステムのズレを解消し、5年後も10年後も戦えるシステムづくりを目指しました。
意思決定①:技術駆動からドメイン駆動へ
長島:アーキテクチャの1つ目の意思決定は、ドメインの再設計、すなわちDDD(ドメイン駆動設計)の採用です。これは全体構造の転換です。
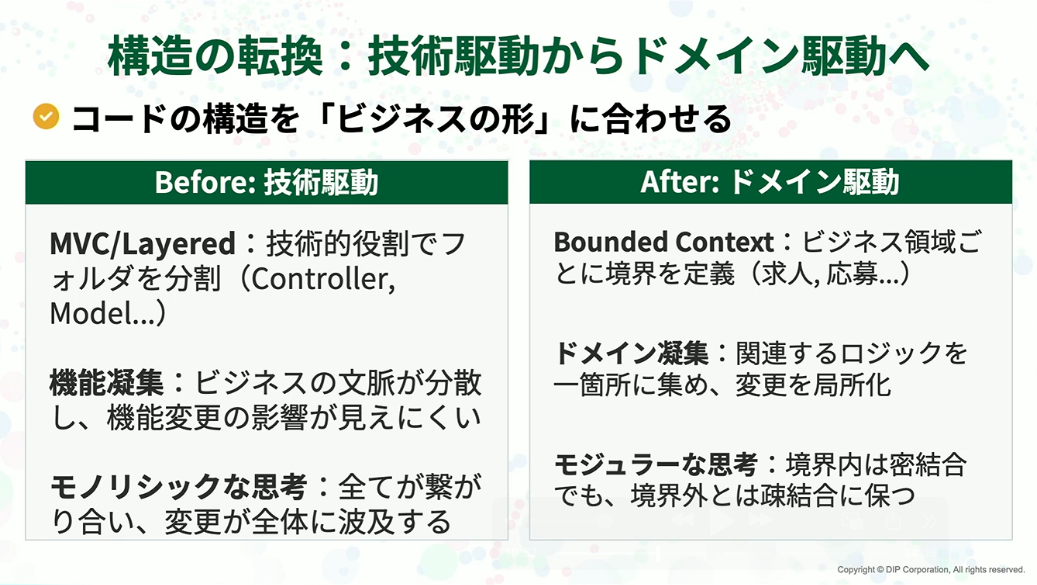
長島:これは単にモノリスかマイクロサービスかという話ではありません。思考の軸を技術駆動からドメイン駆動へ移すことです。これまではコントローラーやモデルといった技術的な役割で分割していました。しかし、これでは一つのビジネス変更が複数の場所に散らばってしまいます。
これを「求人」や「応募」といった私たちのビジネス領域(ドメイン)ごとに整理し直す。構造の主権をビジネス側に移すこと、これこそが今回の本質だと考えていたからです。
意思決定②:技術選定──RESTへの統一とBFF原則廃止
長島:ドメイン設計に続き、意思決定した技術選定の詳細です。私たちはRESTへの統一とBFFの原則廃止を決めました。

長島:tRPCやGraphQLといった技術も検討しましたが、最終的にはあえて採用しないと明示し、枯れた技術であるOpenAPIとRESTに統一しました。スキーマファーストで開発効率と品質を担保することを選択したかったからです。
また、既存システムの開発速度低下の原因の一つとなっていたBFFに近い機能を原則廃止とし、APIの責務を明確化し、フロントエンドの自立性を高める方針を取りました。スキーマからSDKを自動生成することで、各チームが疎結合にかつ高速に開発できる体制を目指しました。
BFFを原則廃止する方針について、皆さんが気になるのは、通信回数が増えるのではないか、パケット代はどうなるのか、という点かと思います。
これに対し、私たちはクライアントサイドでのアグリゲーション、つまりデータ収集に舵を切りました。通信回数の増加はHTTP/2の多重化で許容範囲とし、それよりもOpenAPIから自動生成されたSDKを使うことで、クライアント側で複数のAPIを型安全にかつ高速に叩けるメリットを優先しました。

長島:そして、クライアント側の集約ロジックが複雑になるのを防ぐための武器が次にお話しするKMPです。
技術選定の続きとして、UIとロジックの共通化も重要な決定でした。Webとモバイルで開発が分断しないようデザインシステムを構築し、UIコンポーネントをモノレポで一元管理することで、サービス全体で統一感のあるデザインシステムを整備・運用できることを目指しました。モノレポ内で共有UIコンポーネントを管理し、一貫したUXを提供します。
また、モバイル共通ロジックとしてKMP(Kotlin Multiplatform)を採用しました。OpenAPIスキーマからKMP SDKを自動生成し、iOS・Android間の開発分断を解消しました。
さて、この技術選定の過程には当然いくつかの論点がありました。ここで一つ、改めて先ほど触れたBFFの原則廃止について深掘りさせてください。

長島:当初はWebとモバイルアプリのフロントエンドごとに最適化されたAPIを提供するため、BFFの導入を検討していました。しかし、議論を進めるうちに「BFFいらない説」が台頭します。開発・保守コストの増加、新たなレイヤー追加によるレイテンシーへの懸念です。

長島:議論の分岐点となったのは、私たちのサービスにおいて、Webとアプリで本当にインターフェースを分離しなければならないほどの大きな差異があるのかという問いでした。深く議論した結果、必要なデータはほぼ共通でした。その前提であれば、APIはプロダクトから独立した汎用的なものにしたほうがよいという結論にたどり着きました。
ここまで長く語ってきたのですが、実はこれ、先週ひっくり返ってしまいました。きっかけの詳細はお伝えできないのですが、とあるビジネス要求でした。
その要求を汎用APIであるシステムにやらせようとすると、現場から猛反発が来てしまいました。「それをやると汎用APIが画面の都合を知りすぎて腐ってしまう」とか、「アプリからバラバラに叩くのにもパフォーマンス的に厳しい」など。
私たちはここで、純粋なデータAPIと、ごちゃごちゃした画面要求をつなぐ空白のレイヤーがあることに改めて気づかされました。

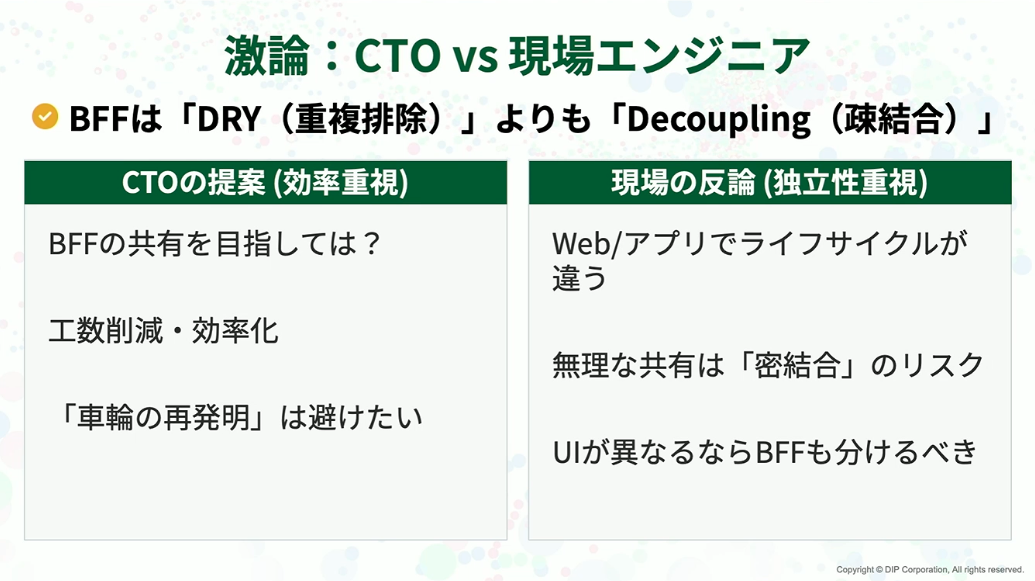
長島:BFFの必要性は再確認できたので、次は実装の話になる中で、私としてはやはりBFFの共有を検討してほしいと現場に伝えました。楽だし、車輪の再発明はしたくないからです。
ですが、Webとアプリのチームからは意見が出ました。「Webとアプリは更新頻度も体系も違います。無理に共有すれば将来お互いの足を引っ張る密結合になります」「UIが違うならやはりBFFも分けるべきです」と。
これは私が間違っていたと感じています。私の視点の効率よりも、やはり現場の保守性・独立性視点の方が長期的なアーキテクチャとしては正しいと思っています。
長島:こうして私たちは「BFF 2.0」という着地点に到達しました。かつてのようなロジック満載のBFFではありません。役割は3つです。1つ目はアグリゲーション、複数サービスの集約です。2つ目はオーセンティフィケーション、認証のゲートウェイとしての役割です。そして3つ目はトランスレーション、UIへの最小限の変換です。
さらに、アプリチームは技術スタックにKtorを採用し、クライアントと同じKotlinで記述することでコンテキストスイッチを減らすという調整も始めています。ドメインロジックを守るために薄いBFFをつくる。これが私たちの今の答えです。

長島:別の論点の話をさせてください。API設計についてです。フロントエンドからは必要なデータを柔軟に取得できるGraphQLを推す声が上がりました。一方で、バックエンドからは特に更新系処理のテストや管理が複雑になるのではないかという強い懸念が出されました。
私たちのユースケースで比較した結果、GraphQLはデータ取得効率では優位ですが、学習コストや更新系処理の複雑性がやはり懸念されました。一方、RESTはOpenAPIによるスキーマ定義とSDK自動生成のエコシステムが強力であり、我々のチームにとって学習コストが低いと判断しました。

長島:結論として、私たちはOpenAPIとRESTを採用しました。決め手はやはりスキーマ駆動開発による堅牢性の確保です。OpenAPIでスキーマを厳密に定義し、そこからサーバーコードとクライアントSDKを自動生成する。これによりインテグレーションテストにリソースを集中させる戦略です。当時のログにはTypeSpecを検討した形跡もあり、スキーマ定義の体験向上も追求していました。
最後の論点は認証基盤についてです。既存のレガシーシステムでは、認証基盤は完全に内製化されており、まさに「秘伝のタレ」状態でした。これはセキュリティリスクと保守コストの両面で大きな課題でした。
再設計にあたり、AWS Cognitoを最有力候補としてマネージドサービスの活用を検討しました。当時のインフラ議論のログを振り返ると、Cognito採用の決め手は、セキュリティとスケーラビリティの責務をAWSにオフロードできること、そして何より車輪の再発明を避け、貴重な開発リソースをコアビジネスに集中させることでした。
一連の議論を経て決定したインフラ全体のアーキテクチャでは、Fargate、Cognito、そしてOpenAPIを採用し、マネージドサービスとサーバーレスを積極的に推進することで、運用負荷を最小化する戦略を取りました。

長島:続いて、技術選定の意思決定としてモノレポの採用があります。既存の巨大なモノリスを稼働させたままで、どう安全に移行するか。私たちは新規開発領域にモノレポを導入し、モジュール間の依存関係を可視化・制御しました。さらにCI/CDを分離することで、既存システムと共存しながらも、秩序立った安全なリアーキテクチャを推進することが可能になりました。

意思決定③:「AIが前提」のアーキテクチャ
長島:そして3つ目の意思決定が最も重要で、私たちの戦略の核となる「AIが前提のアーキテクチャ」です。これは単なる負債解消ではありません。開発ガイドラインのゴールに「AIネイティブ」を明記しました。AIツールを前提に、設計からテストまでの全工程を支援すると。
そのためにAIがテストを書きやすいようにテストカバレッジ80%以上を義務化し、AI活用を組み込んだフロー、ドキュメントの自動更新などをルール化しました。

戦術:AI駆動開発プロセスのリアル──AI-DLCによる開発革命
長島:このセクションでは、戦略として立てた「AIが前提」という方針を、戦術としてどのように実践したのか。AI DLC(AI駆動開発ライフサイクル)の理想と現実、つまり「光と影」について解説します。
AI活用で悩まれている組織は多いと思います。どう使えばいいか、コストやROIは、品質はどうなんだろうといった悩みです。これは私たちも直面した課題です。そして、その悩みに対する私たちの解がAI-DLC、すなわちAI駆動開発ライフサイクルの導入でした。
AI-DLCは、単なるコーディング支援やCopilotの導入ではありません。開発の上流工程、すなわち要件定義からAIを組み込むアプローチです。ビジネスサイドから抽象的な要求をAIに入力すると、AIが詳細なユーザーストーリーと受け入れ基準を生成し、さらには開発チームがすぐに着手できるレベルのタスク分解までを支援します。
実際の事例です。従来はヒアリングからタスク分解まで、すべて手動で数日から数週間かかっていました。これがAI DLCでは、抽象的な要求をAI(我々のこの事例ではAmazon Q)に入力するだけで、ユーザーストーリー・受け入れ基準・タスク分解までをAIが支援します。

長島:このプロセスの光の部分、つまり効果は絶大でした。従来、ヒアリングからタスク分解まで数日から数週間かかっていた作業が、AI-DLCでは数時間で完了しました。
ポイントは2点あります。1つ目は、AIに役割とルールを厳格に定義していること。単に「つくって」ではなく、PMとしての振る舞いや出力形式をマークダウンで指示しています。2つ目は、インタラクティブな壁打ちを強制していること。大雑把な要求を渡しても、AIが勝手に捏造しないよう、不足情報は人間に質問するというフローを組み込んでいます。

長島:裏側のモデルにはコーディング性能に定評のあるClaude Sonnetを採用しており、このプロンプトを通じて要求の解像度を一気に引き上げています。最初は魔法のようでした。抽象的な要求を投げれば、AIが数時間でユーザーストーリーをつくり、テストケースをつくり、タスク分解までしてくれる。開発体験が劇的に向上し、速度は10倍になったかのように見えました。
しかし、本日のカンファレンスでお伝えしたいのは、この光の部分だけではありません。この成功体験の取り組みをスケールさせようとしたとき、私たちは3つの大きな壁に直面しました。

長島:第1の壁はドメイン知識の壁です。AIは一般的な知識は豊富ですが、私たちが20年かけて複雑化した独自ドメインは知りません。現場からは「ドメインが絡むとAIのパフォーマンスが著しく悪化する」という悲鳴が上がりました。
当時のAI-DLCに関するメンバーのアンケートにも、「既存の複雑なドメイン知識をどう効率よくAIにインプットすればいいか」という切実な悩みが寄せられていました。AI活用の前提として、ドメイン知識の整理がいかに重要かを痛感した瞬間です。
第2の壁はDDDの学習コストです。AIに正しい指示を出すためには、私たち自身がビジネスの本質、つまりドメインを深く理解していなければなりません。DDD(ドメイン駆動設計)の学習コストが重くのしかかりました。
AIは銀の弾丸ではありませんでした。むしろ、私たちの設計能力の欠如を残酷なまでに突きつけてきたのです。
第3の壁がレビューのボトルネック化です。これが特に深刻だと思います。AIは疲れを知りません。ものすごい速度でコードやドキュメントを生成します。しかし、その妥当性を判断するのは誰か?結局人間なんです。
気がつくと、AIが生成した大量のプルリクエストが積まれている。それを人間が必死に目で追う。AIの速度に人間が追いつかず、結果としてスループットが上がらない。「あれ、僕たちAIの下請けになってないか?」そんな空気すら流れていました。
AI-DLCの光と影を経験して得た学びは、AIは銀の弾丸ではなかったということです。体験してみて、やはりそれが当たり前であることに気づきます。AIは開発速度を劇的に上げますが、変革に伴う痛みやドメイン知識の整理といった泥臭いプロセスをなくしてくれるわけではありません。むしろその重要性を浮き彫りにしました。
少しフックとなる話ですが、私はこのAI-DLCというアプローチを開発プロセスにおけるマルチエージェントのようなものだと解釈しています。AIがアナリストとして要件定義を行い、アーキテクトとして設計を支援する。そして、人間はそれらをレビューし、最終的な意思決定を行う指導役となる。このような役割分担です。
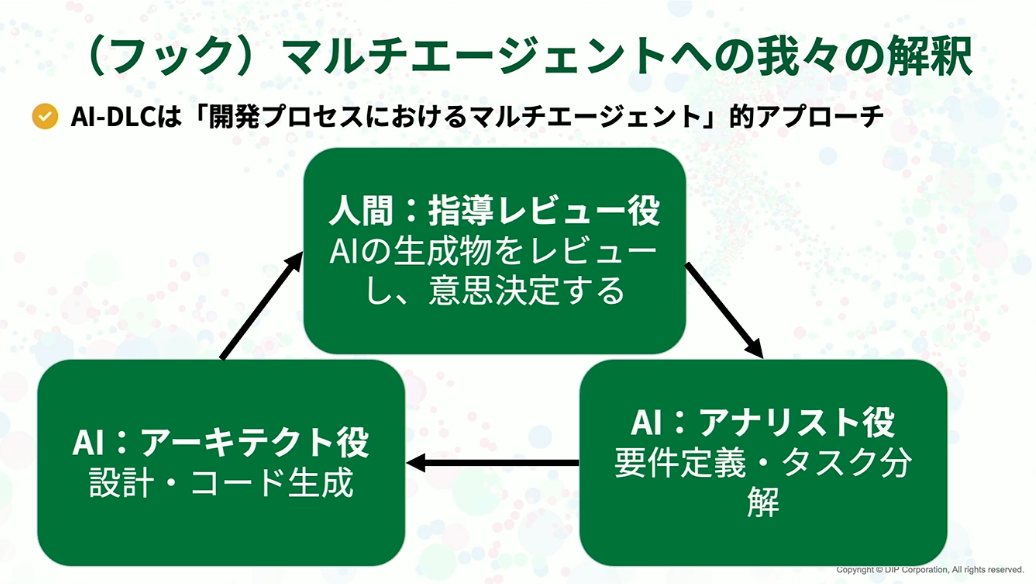
組織:変革を推進した体制──AIネイティブな組織づくり
長島:このセクションでは、戦略と戦術を実行するために必要だった組織変革について、AIネイティブな組織づくりの取り組みを解説します。
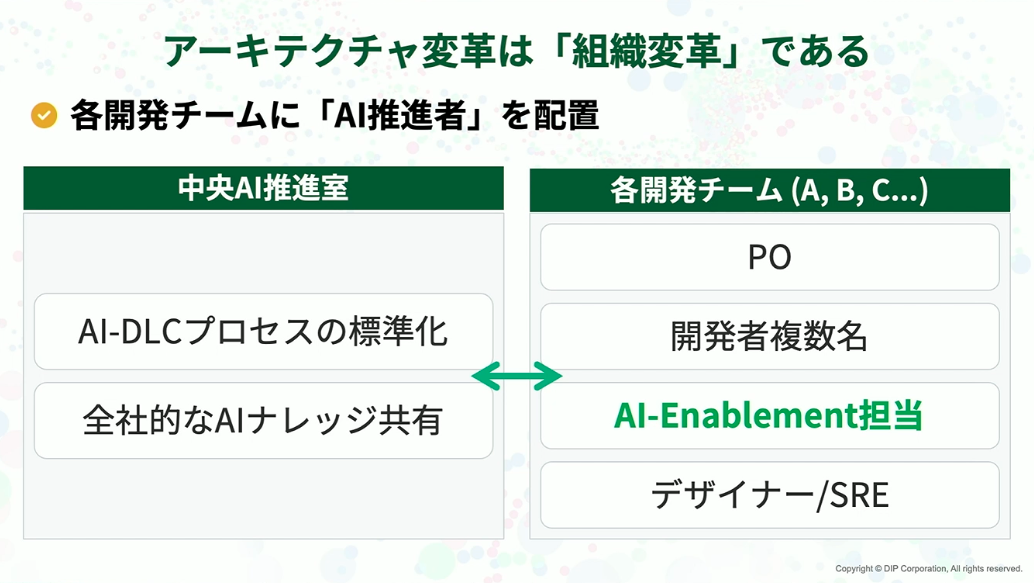
最高のアーキテクチャと最先端のAIプロセスを導入したとしても、それを使う組織が変わらなければ変革は失敗します。特に課題だったのは、既存のレガシー改修とAIを活用した新規開発をどう両立させるかでした。私たちは、組織構造そのものにAIを組み込む決断をしました。
私たちの解決策は、AIイネーブルメントチームの組成です。よく言われるように、組織構造とアーキテクチャは表裏一体です。中央集権的なAI推進室をつくるのだけではなく、既存の各開発チームの中にAI-DLCやDDDの導入を推進するAIイネーブルメント担当を配置しました。彼らが現場のドメイン知識と中央のAIナレッジをつなぐハブとなりました。
長島:AI-DLCは開発者の役割そのものを大きく変えました。単純なコーディング、つまり「How」の部分はAIが担う役割が増えました。その結果、開発者の役割は「何をつくるべきか」というドメインの定義や、AIの生成物をレビューし指導するという、より上流の意思決定へシフトしています。
AI-DLCを経て、私たち開発者の役割は明確に変化しました。これまでエンジニアの価値はコードを書く速さにありました。しかし、AI時代の今、その価値はAIを指導し、決定を下す力にシフトしました。コーディングという「How」はAIに任せ、私たちは「What(何をつくるべきなのか)」「Why(なぜつくるべきなのか)」という意思決定に全力を注ぐように変化したのです。

長島:もちろん、このような組織改革は1日にしてなりませんし、いまだに終わっていません。現場では日々、泥臭い試行錯誤が繰り返されています。
あるチームの最近のKPTでは、「AI-DLCが定着してきた」というKeepがある一方で、「レビュー負荷の集中」や「ドメイン知識の暗黙知」といったProblemが挙がっています。まさに先ほどの壁と現場が格闘している様子がわかります。

長島:別の施策として、ドメイン知識の暗黙知を乗り越えるために、私たちはすべての議論をAIの知識に変える仕組みを構築しました。会議の議事録、Slackの議論、設計ドキュメントなど、あらゆる情報をAIが検索・回答できるナレッジベースに格納していきました。
私たちが取り組んだのは、フロー情報のストック化です。これまでSlackでの熱い議論(フロー)とWikiに残るような無機質な結論(ストック)は分断されていました。結果、なぜその仕様になったのかという一番重要な背景情報が失われていました。
しかし、NotebookLMの導入で世界が変わりました。エンタープライズ版を活用し、個人情報等のマスキングを施した上で、例えばSlackの議論ログやFigmaの図をそのまま読み込ませる。たったそれだけでAIが文脈を理解し、組織の記憶として定着させることに成功したのです。
その結果はまさに劇的です。改善前の状態では仕様確認に数日かかっていました。「3年前の決定だから誰も知らない」と、迷宮入りすることもしばしばありました。改善後は、AIへの質問で仕様回答は30秒で終わります。

長島:象徴的だったのは、あるPOのメンバーによる「3年後に『なんでこんなアホな仕様にしたのか』と未来の仲間に言われたくないよね」という言葉です。実際にSlackの議論スレッドをそのままAIに読ませたところ、いつ、誰が、どんな懸念を持って、なぜその決定をしたかを完璧に回答してくれました。
ドキュメントを一生懸命書く時代は終わりました。日々の議論をAIに読み込ませる。これだけで組織の知識は資産に変わるのです。
このAIによる知識型ADRの実現フローを簡単に説明すると、会議はGeminiで自動文字起こししてPDFにしてNotebookLMに格納します。DesignDocやADRといったドキュメントも、最終的に合意されたらすべてNotebookLMに集約しています。
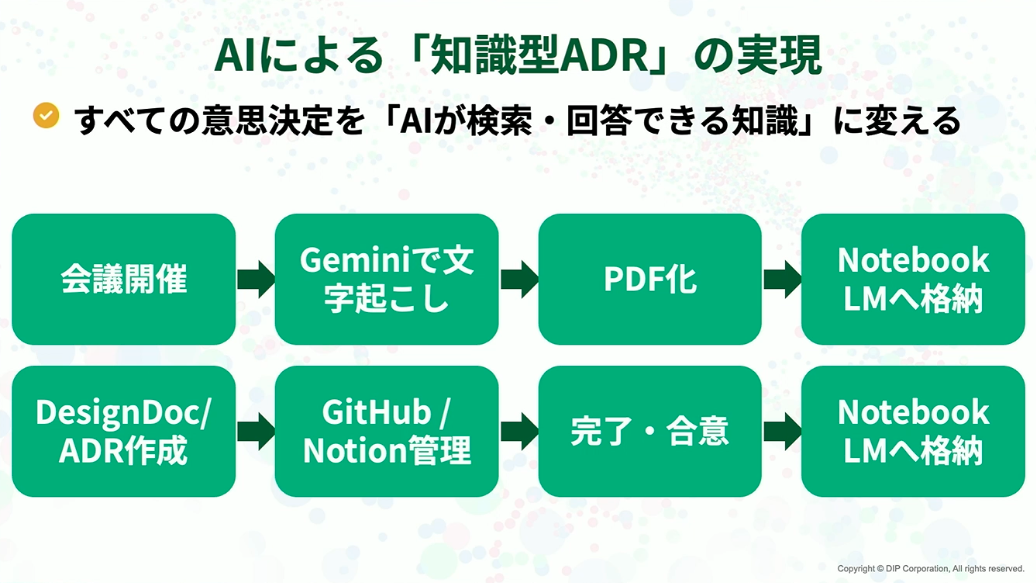
長島:これにより、「なぜこの技術を選んだのか」「この仕様変更の背景は?」といった問いに、人間がドキュメントを探す代わりに、AIが即座に答える体制を構築できました。ドキュメントは、人が探すものからAIが使えるものへと、その役割自体が変わったと思っています。
先ほどお話したBFF廃止からの復活劇やOpenAPI採用といったすべての泥臭い議論のプロセスは、「開発ガイドライン」として結実しました。これは単なる技術選定リストではなく、私たちの戦略と組織のあり方、アーキテクチャの意思決定と組織改革が結実したものです。つまり、なぜこの技術を選ぶのかを明文化し、組織全体の目線を合わせるための羅針盤となりました。
まとめ
長島:本日お話した3つの変革を振り返ります。戦略として泥臭い議論の末にアーキテクチャを決定しました。戦術として、AI-DLCの光と影を直視し、ドメイン知識の壁に向き合いました。そして、組織として開発者の役割を再定義し、議論を知識に変える文化を醸成してきました。
今日、会場にいらっしゃるみなさんの中にも、レガシーシステムと格闘されている方がいらっしゃるかもしれません。20年分のスパゲッティコード。それは私たちにとって確かに迷宮でした。しかし、見方を変えれば、そこには20年分のビジネスの成功法則、ドメイン知識、数え切れないほどの試行錯誤が詰まっているのです。それは、もはや負債ではありません。AIにとって最高の教師データであり、資産です。
また、多くのエンジニアのみなさんが「レガシーだから挑戦するのは難しい」と思われているかもしれません。しかし、私は逆だと思います。レガシーとAIの掛け算ほど、エンジニアとして面白く、社会に大きなインパクトを与えられる挑戦のフィールドはありません。
正直に申し上げまして、私たちの旅もまだ始まったばかりです。AI-DLCという戦略や地図は描けましたが、対象となるレガシーシステムはあまりに広大で、適用すべき課題は山積みです。AIがすべて魔法のように解決するわけではありません。AIに任せる領域と、人間が泥臭く解く領域を見極め推進できるエンジニアが、今最も必要とされています。
私たちはまだ完成された組織ではありません。だからこそ、技術で組織を変えていくこの過渡期を一番楽しめるのは今かもしれません。
ディップの取り組みについてご興味をお持ちの方は、ぜひテックブログもご覧ください。AI-DLCの挑戦や、今日お話ししたOpenAPIによるスキーマ駆動開発による詳細な技術Tipsを赤裸々に公開しています。綺麗な成功事例だけじゃなくて、そこに至るまでの泥臭い試行錯誤の記録も載せています。みなさんの開発のヒントになれば幸いです。
本日はご清聴いただきありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





