



【アーキテクチャConference 2025】 DMMプラットフォームのAI推進を支える情報アーキテクチャ
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に登壇した合同会社DMM.comの玉澤 裕貴さんは、プラットフォーム開発本部のメンバーとして、同社のAXを推進しています。「AI活用の本質はツールの導入ではなく、情報設計にある」と語る玉澤さん。AIを活用するために必要な情報設計とは何なのか? 本セッションでは、同社の取り組み事例をもとに、AXのグランドデザインと実践についてお話しいただきました。
■プロフィール
玉澤 裕貴
合同会社DMM.com
プラットフォーム開発本部 第1開発部
2020年より合同会社DMM.comにiOSアプリエンジニアとして入社。プラットフォーム開発本部にて、DMMポイントを貯めたり管理ができるサービス「DMMポイントクラブ」の開発に携わるほか、自社アプリ向けに認証と本人確認用SDKの開発および運用を担当。現在は、AIを活用した業務生産性の向上にも取り組んでいる。
DMMが目指すAXへの転換
本日はよろしくお願いします。DMM.comの玉澤と申します。「DMMプラットフォームのAI推進を支える情報アーキテクチャ」と題して、AIリーダブルな情報設計をどう実現するかについてご紹介します。AI推進における成功事例ではなく、直面した現実とそのアプローチについてお話しします。
私はプラットフォーム開発本部で、DMMポイントを扱うDMMポイントクラブと、自社で提供するアプリ向けの認証SDKの開発を担当しています。
本日は、AI活用で直面した情報負債について深掘りしたあと、負債に対するアプローチの現状と今後の課題についてお話しします。
初めに「AX」という言葉について触れておきます。AXとは「AI Transformation」を意味しています。AIを活用し、企業の業務プロセスやビジネスモデルを根本的に変え、新たな価値を創造する取り組みを指します。データ分析や予測、自動化などを通じて競争力を高めることを目的としています。
私が所属するプラットフォーム開発本部は数多くの事業と関わる組織であるため、AI活用においても中心となってベストプラクティスを生み出し、会社全体に対して推進できる状態を目指しています。
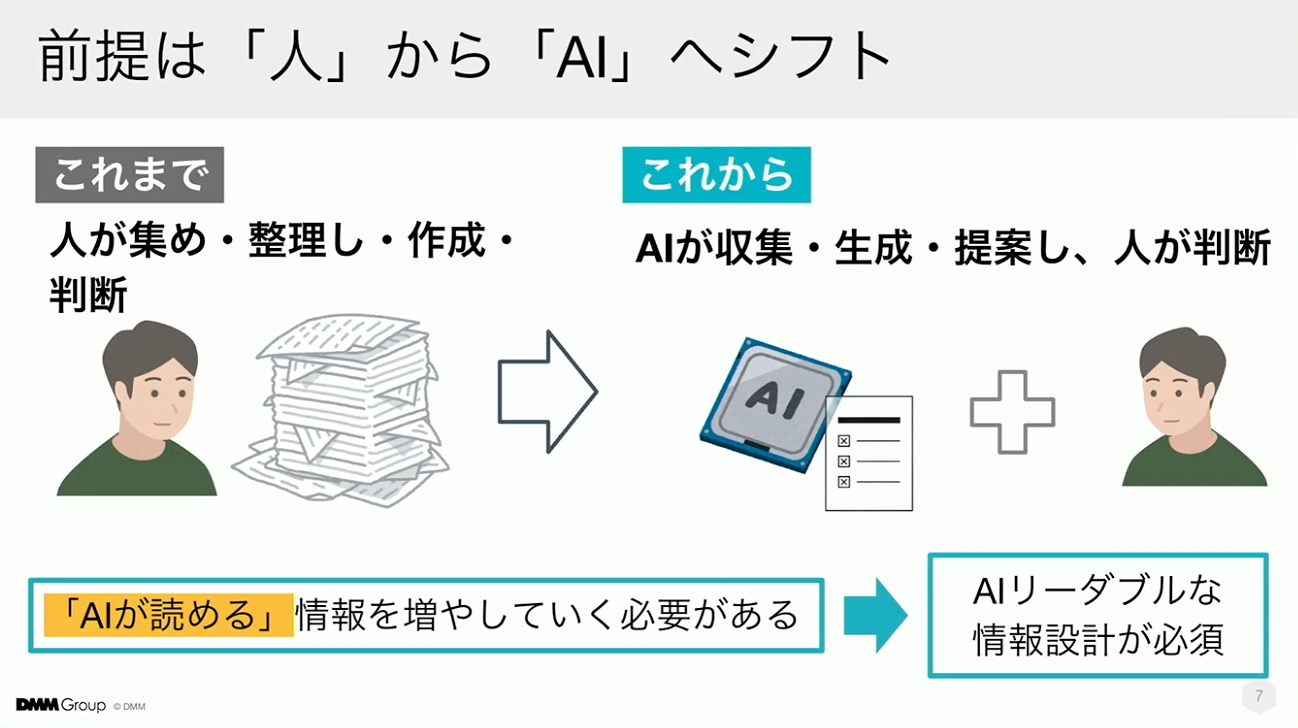
こちらは、AIの進化に伴う前提の変化を表しています。これまでのドキュメントは、人が読むことを前提に作られ、情報収集から判断まで手作業に強く依存していました。しかし、これからはAIが情報を収集・生成・提案し、タスクを前に進める。人は、結果を評価して意思決定する側へ移っていく。構造への転換が現実になりつつあります。
この変化を支えるために不足しているのが、AIが扱える形で情報を整備することです。AIがアクセスできる場所に情報を移動させるだけでは不十分であり、情報の単位や関係性、その意図といった要素もAIが理解できるように、情報構造そのものを再設計する必要があります。
AI活用を阻む3つの情報負債
AI活用を目指す上で壁として現れた3つの情報負債(分散、形骸化、属人化)についてお話しします。AIをうまく活用できない原因は、AIツールではなく、自分たちが保持している情報や設計に問題がありました。
どこにあるかわからない…「分散」の負債

1つ目の問題は、分散です。現場では「AIが期待通りの回答をしてくれない」という問題が発生していました。原因はAIの性能ではなく、情報が分散管理されていた点にありました。具体的には、要件はConfluence、設計はGitHub、運用ルールはSlackといったように、同じ内容の情報が複数の場所に存在したり、片方だけが更新されて情報が食い違ったりしていました。その結果、AIが矛盾した情報を拾ってしまうことで、正確に回答できないケースが生まれていました。
つまり、AIがつまずいていた理由は、人にとっても探しづらく維持しづらい情報構造にあったのです。AIが登場したことで、抱えていた情報負債が表面化したというのが最初の学びでした。

情報が分散していたのは、単なる運用ミスではありません。背景には、いくつかの構造的な要因がありました。まず、ドキュメントを誰が保守し、どこまで責任を持つのかが曖昧でした。担当者が変わった瞬間に所在が分からなくなる、というのは典型的な例です。
さらに、スピードを優先して「とりあえず置いた場所」がそのまま定着し、運用変更やツール移行のたびに格納先が増えていくという積み重なった負債もありました。
そして、最も根本的な原因は、情報をどんな構造で持つべきかという設計思想がなかったという点にあります。構造の設計思想がない状態では、情報が分散するのは必然です。つまり問題は、人の注意不足ではなく、分散を生み出す仕組みになっていた点にあったのです。

分散を解消するために有効なのが「AIナレッジベース」という考え方です。これは、AI専用の辞書を新しく作るといったものではありません。具体的には、事業の目的やKPI、分析クエリ、AIプロンプト、ガードレールなど、事業運営に不可欠な形式知を一元的に管理します。このように情報を人とAIの双方がアクセスできる形で構造化しておくことで、人は必要な根拠や文脈にすぐたどり着けるようになり、AIも同じ前提で業務を進めることが可能になります。
つまり、AIナレッジベースとは、情報を溜め込む場所ではなく、前提と文脈を揃えて、人とAIが同じ知識をもとに判断・行動できるようにする基盤なのです。
AIの不信感につながる原因でもある「形骸化」の負債

2つ目の問題は、形骸化です。ドキュメントが更新されず、複数バージョンが存在し、どれが最新なのか誰も判断できなくなる。この状態では、AIが参照する情報も当然ながら古くなり、誤った回答につながります。AIは情報の鮮度を見極めることができないからです。
例としては、古い運用手順書に基づいて作業し、手戻りが発生する、あるいは更新されていない分析クエリを使い続けた結果、誤った集計値をもとにAIが不適切な提案をしてしまう、といったケースがあります。
さらに、担当者の退職・異動によって、情報が保守されなくなり、放置されてしまうという問題も起こりがちです。結局のところ、AIが誤った判断をするのは、情報を更新し続ける仕組みを設計していなかったことが原因でした。
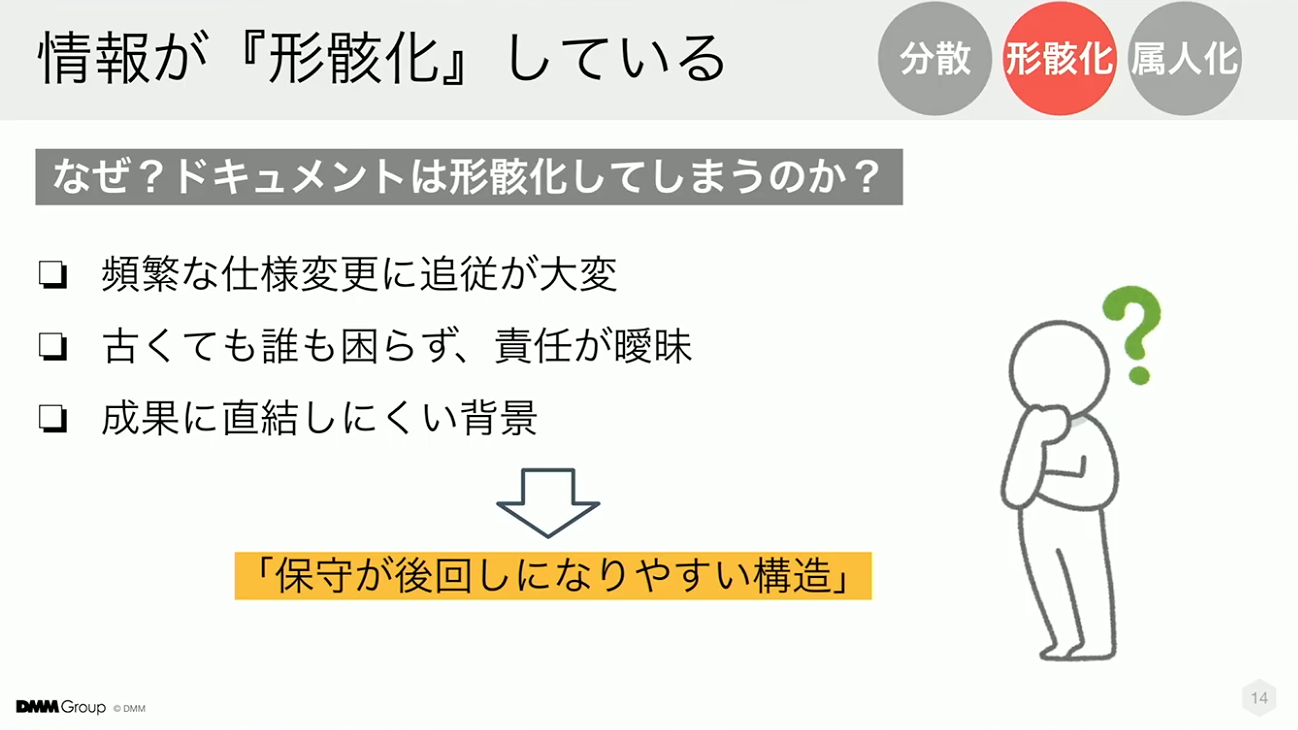
なぜドキュメントは形骸化するのか。理由は、3つの構造的な要因に整理できます。1つ目は、頻繁な仕様変更に追従できない運用設計です。変更のたびにドキュメントと同期を取る仕組みがなく、放置されるほど鮮度が下がる構造でした。
2つ目は、古くても当面は困らないため、責任が曖昧になることです。「そのうち誰かが直すだろう」という考えで、誰も更新しないまま時間が経ってしまいます。
3つ目は、ドキュメント更新が評価につながりにくいこと。コードは成果が見えますが、ドキュメントを更新しても成果が目に見えるわけではないため、どうしても優先度が下がってしまいます。
こうした構造が重なることで、情報は徐々に鮮度を失い、AIが参照しても間違った前提を返すようになる。つまり、形骸化は個人の怠慢ではなく、更新されない仕組みが生み出す構造的な問題です。

形骸化への対策として有効なのが「Docs as Code」です。ドキュメントをコードと同じようにリポジトリで管理し、Pull Request(以下、PR)でレビューし、CIで自動チェックする。こうすることで、更新忘れや表記揺れの検出など、運用の一部を自動化できます。さらに、レビューをAIエージェントに行わせれば、観点漏れや不整合を自動で検出し、品質も判定してくれます。
APIドキュメントでOpenAPI Specificationを必須化し、コードから自動生成することで、手動での作成作業を最小限に抑えられます。こうした仕組みを取り入れると、ヒューマンエラーを削減するだけでなく、「ドキュメントもプロダクトの一部である」という文化を組織に定着させることができます。
重要なのは、ドキュメントの更新を個人の努力に依存せず、形骸化しない構造を確立することです。
暗黙知が活用できない「属人化」の負債

最後の問題は、属人化です。重要な判断基準やトラブル対応のノウハウが特定の個人の頭の中やSlackのDMにしか存在しない。実は重要な知識ほど、人に紐づいています。こうした情報は、AIにとっては見えない領域です。形式知になっていなければ読み取れず、その人がいなければ再現もできない。結果として、AIだけでなく人間にとっても使えない情報構造になってしまう。
知識が属人化している組織でAIが活用できないのは、ある意味当然です。AIを活かすには、まず人が共有できる形へ知識を変換し、再現可能な構造に載せなくてはいけません。

属人化が起きる背景には、大きく2つの要因があります。1つ目は「あの人しか知らない」という状態が放置されても業務が回ってしまうことです。周囲もそれを個人の得意領域として扱い、問題として扱わない。これはありがちだと思いますが、AIを活用する上では大きなリスクになると考えています。
2つ目は「誰がどんな知識を持っているのかが可視化されていない」です。属人化が進んでいても組織としてその状況を捉えられず、問題が起きるまで気がつかない。この「見えない」「放置される」という構造こそが、属人化を慢性的に生み出す原因だと考えています。

属人化への対策として検討しているのが、AI前提の業務プロセスを再設計するアプローチです。既存の業務をそのままAIに置き換えるのではなく、業務プロセス自体を見直し、各プロセスの結果として自然にドキュメントや形式知が生成される構造を作れないかという考え方です。
例えば、会議なら会話をAIが自動で文字起こしし、要約やアクションを生成して、そのままナレッジベースに連携する。こうした業務全体を線で動かすための仕組みを検証しようとしています。この動きが実現すれば、知識を人の頭やDMに閉じ込めたままにしない構造を作れます。つまり、属人化の原因そのものを業務設計の段階で取り除くことができます。
目指しているのは、人の努力ではなく業務プロセスそのものが形式知を生み出す環境への転換です。
複数のアプローチで情報の質の担保に繋げる
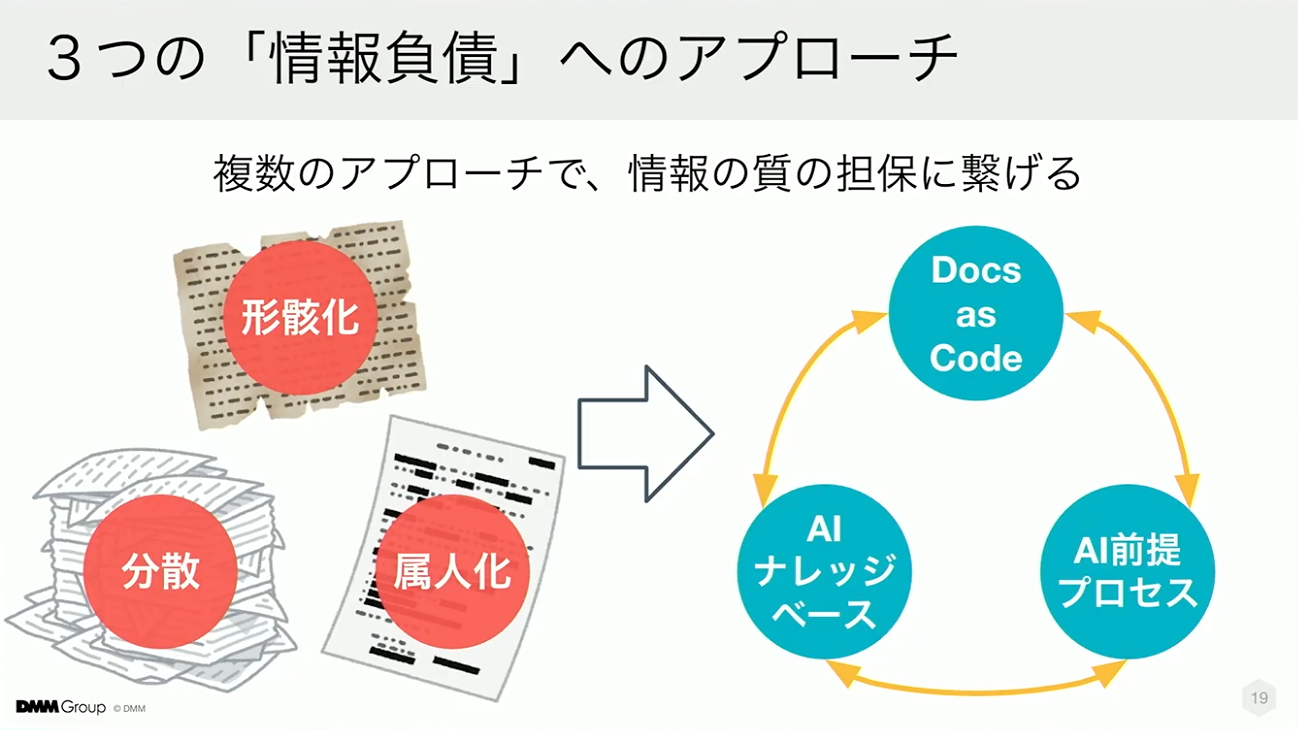
ここまでご紹介した3つの課題は、見た目は異なりますが、根本には同じ構造があります。それは「情報が分散し、古くなり、個人に閉じたまま蓄積されてきた情報負債」です。
対策として挙げた3つのアプローチは、それぞれが独立しているわけではありません。分散を防ぎ、鮮度を保ち、属人化を抑える。この組み合わせによって情報の質が安定し、AIが正しく機能する環境が整うのです。

DMMポイントクラブが取り組む「第二の脳作り」

ここからは、私たちが実践しているアプローチについてご紹介します。
DMMポイントクラブでは、価値提供のスピードを向上するために、認知負荷の高い業務をAIで効率化して浮いた時間をユーザーの価値創造に投資する構造の実現を目指しています。
現在、組織はフルサイクルエンジニアリングで、施策検討から開発・運用までを一気通貫で担っており、日々のコンテキストスイッチが多く、先ほど挙げた3つの情報負債が生産性を下げていました。
そこで進めているのが「人とAIが協働する第二の脳作り」です。情報負債を減らし、プロセス全体で人とAIが同じ知識を使って動ける環境を作ることで、チームの打席数と打率の最大化を狙います。
GitHubを活用したAIナレッジベースの構築
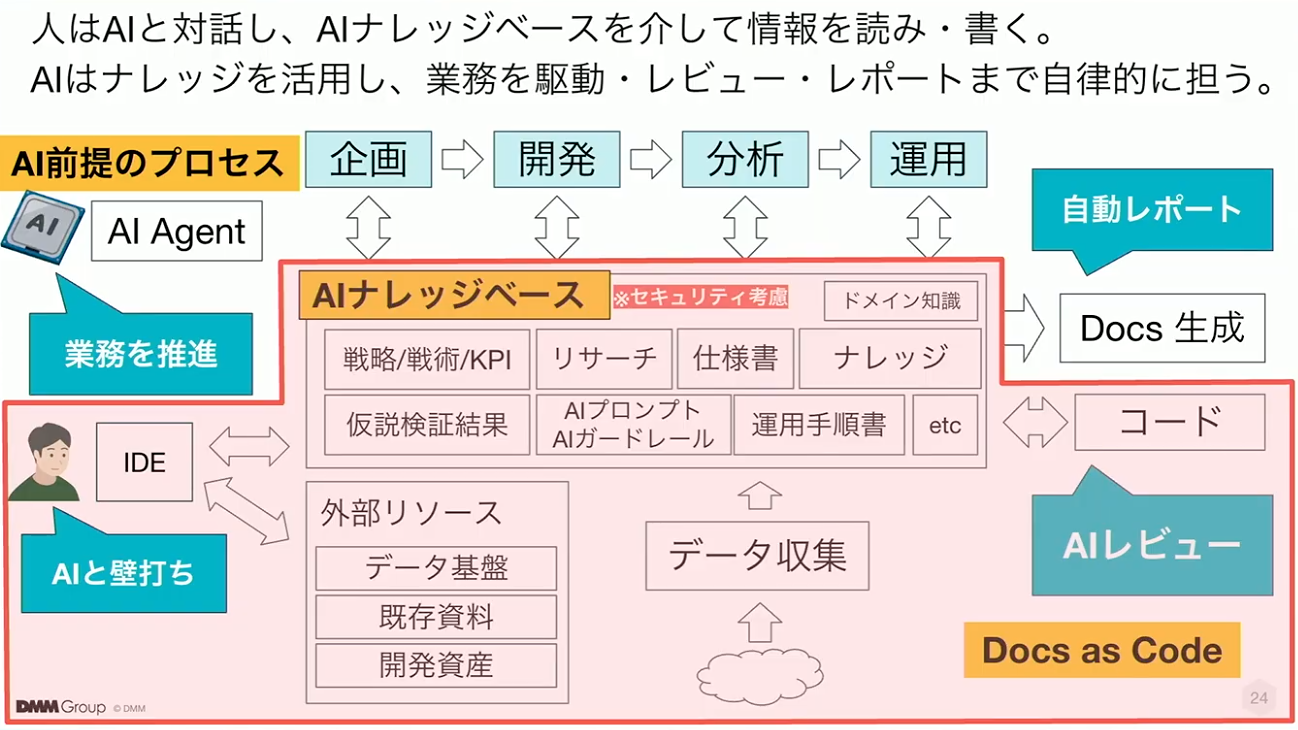
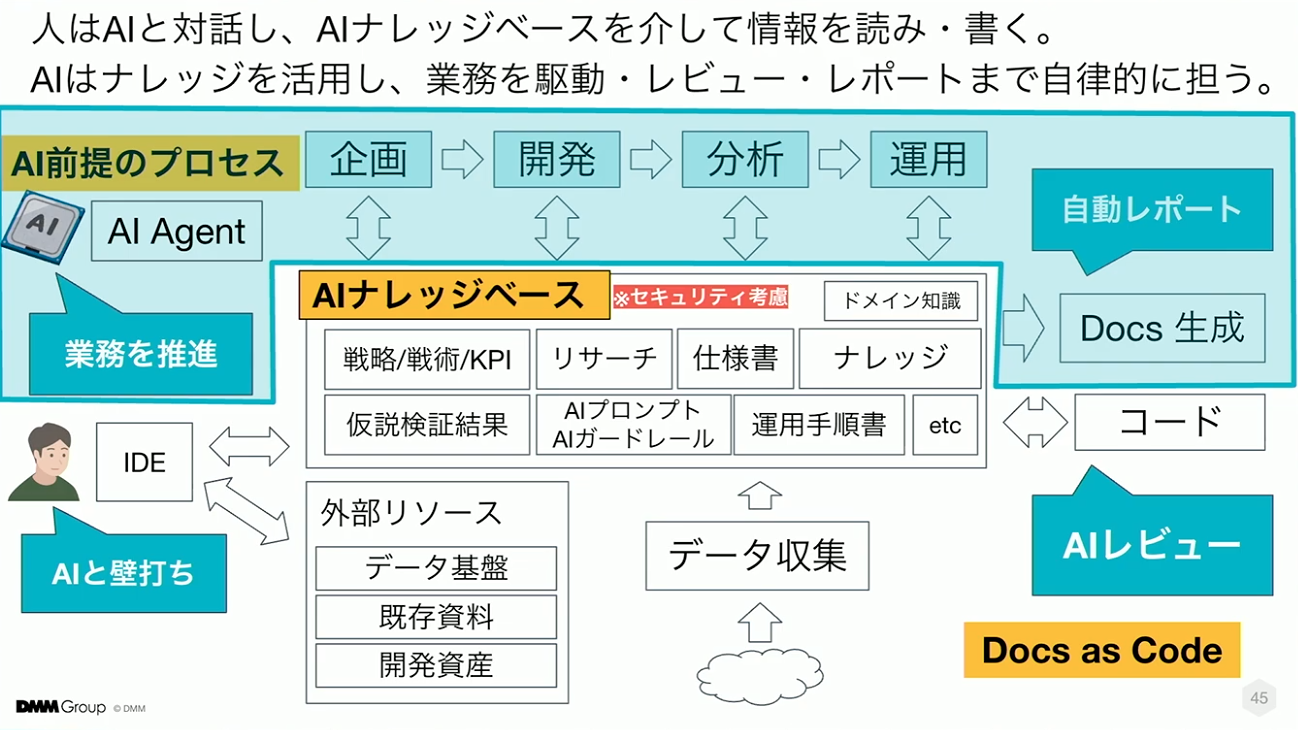
こちらは現在取り組んでいる「AIリーダブルな情報アーキテクチャ」の全体像です。この図は、分散、形骸化、属人化という3つの情報負債に対し、3つのアプローチを連動させることで解決を図るものです。
中心にはAIナレッジベースがあり、Docs as CodeやAI前提の業務プロセスといったアプローチを組み合わせることで、業務の流れや意思決定のプロセスが、人とAIの両方にとって扱いやすい形に整備されます。
これはAIを導入するためのものではなく、AIを適切に機能させるために必要な情報設計を示したグランドデザインです。人とAIが共通の情報構造に基づいて動作するという全体像だと捉えていただければ幸いです。
なお、現時点で、グランドデザインの活用が進んでいるのは赤枠の部分です。
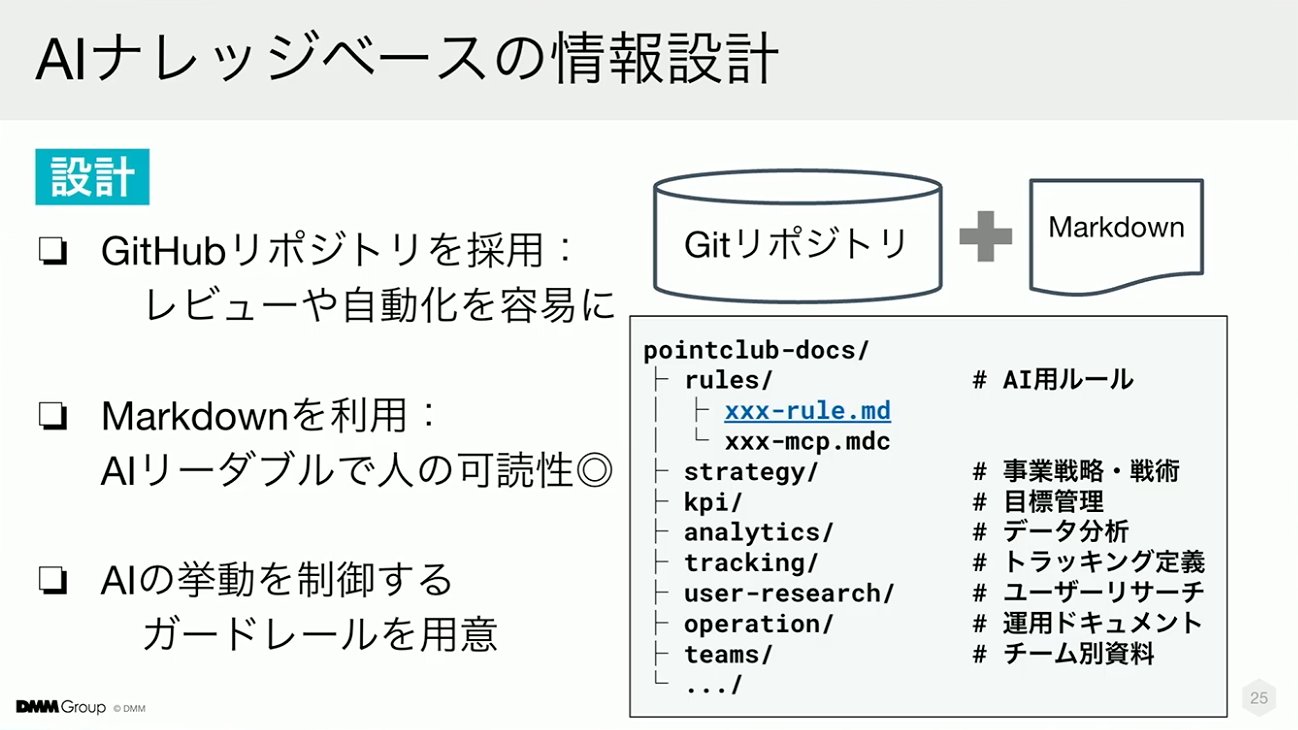
こちらがAIナレッジベースの情報設計です。基盤にはGitHubリポジトリを使用しています。コードと同様に管理することで、レビュープロセスや自動化を取り入れることが可能です。情報形式をMarkdownにすることで、AIが理解しやすく、人にとっても扱いやすいテキスト中心の構造にしています。情報は、事業戦略、KPI、分析、運用、チーム資料といったディレクトリで階層化し、AIが情報を適切に理解できるよう、情報と情報の文脈をルールとして明記。これにより、人とAIの両方が情報の意味や流れを追えるようにしています。AIの挙動を安定させるため、共通のプロンプトやガードレールを定義し、情報の読み込みに再現性を持たせています。
この設計において、特別な技術は使用していません。既存のGit運用に、AIが読み取れるフォーマットとルール設計を組み合わせることで実現しています。
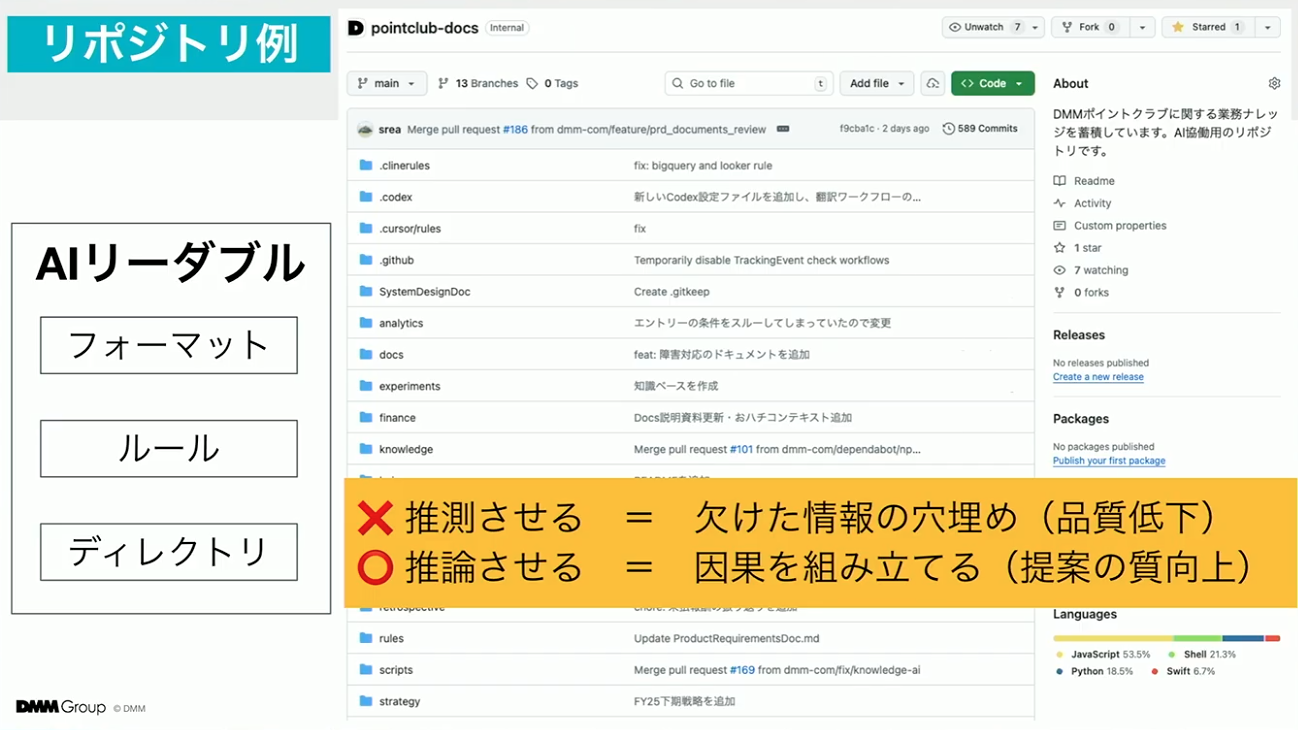
こちらは実際のリポジトリの様子です。現在取り組んでいるAIリーダブルな情報設計は、フォーマット、ルール、ディレクトリ構造に基づいています。この設計の目的は、AIが文脈を推測する余地を最小限に抑え、推論の精度を最大化することです。この3つの設計要素を通じて、人とAIが共通の文脈を共有できる基盤を確立しています。
AIガードレールによる挙動の安定化
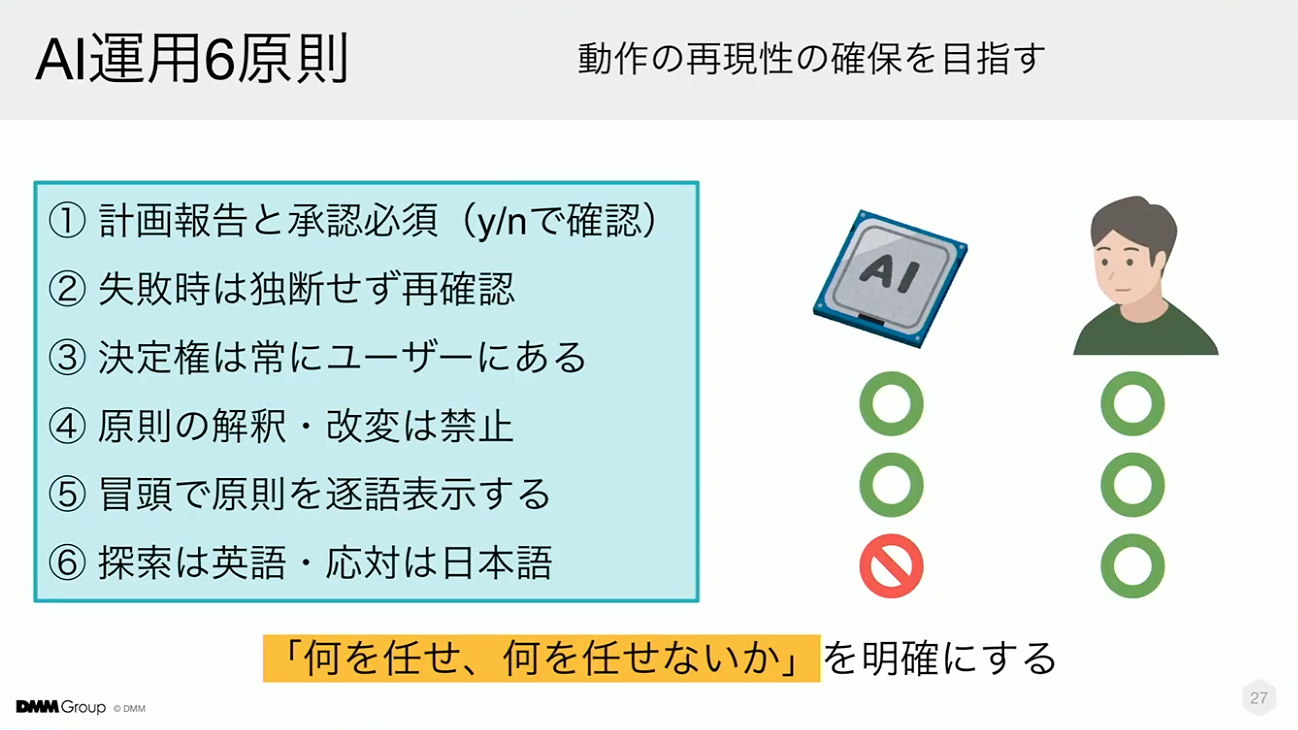
先ほど触れたAIガードレールについてもご紹介します。これは、AIと協働する際の動作をコントロールするために、プロンプト側に明記している原則です。ここに書かれている内容は、AIの暴走を止めるためのものではなく、人が安心してAIに任せられるように境界線を設計するためのものです。そのラインを明確にすることで、AIを共同者として安定的に活用できるようになります。

こちらは、実際にチームで使っている画面です。現在は、Cursorを活用してAIナレッジベースをローカルにチェックアウトし、日々の業務にAIを取り入れています。先ほどご紹介したガードレールが自動で適用されるため、対話時に毎回詳細なプロンプトを書かずとも、AIが一定のルールに基づいた対応をしてくれます。
企画・開発・分析の各工程でAIが自走!
レビュー負荷とリードタイムをまとめて短縮
実際の活用ユースケースについてもご紹介します。従来、企画書や要件定義などのドキュメントレビューにおいては、日程調整の難しさから、内容確認までにリードタイムが発生していました。
この時間を節約するため、企画フェーズでAIを活用し、レビュー前の壁打ちや下書きの精度を向上する取り組みを進めています。

事前にレビュー観点とその根拠となる情報をナレッジベースとして言語化しておくことで、壁打ちだけでなく、一定の品質を満たした草案までAIが作成してくれるようになります。
その結果、人がレビューする際の手戻りが減り、全体としてのレビュー負荷とリードタイムをまとめて圧縮できました。
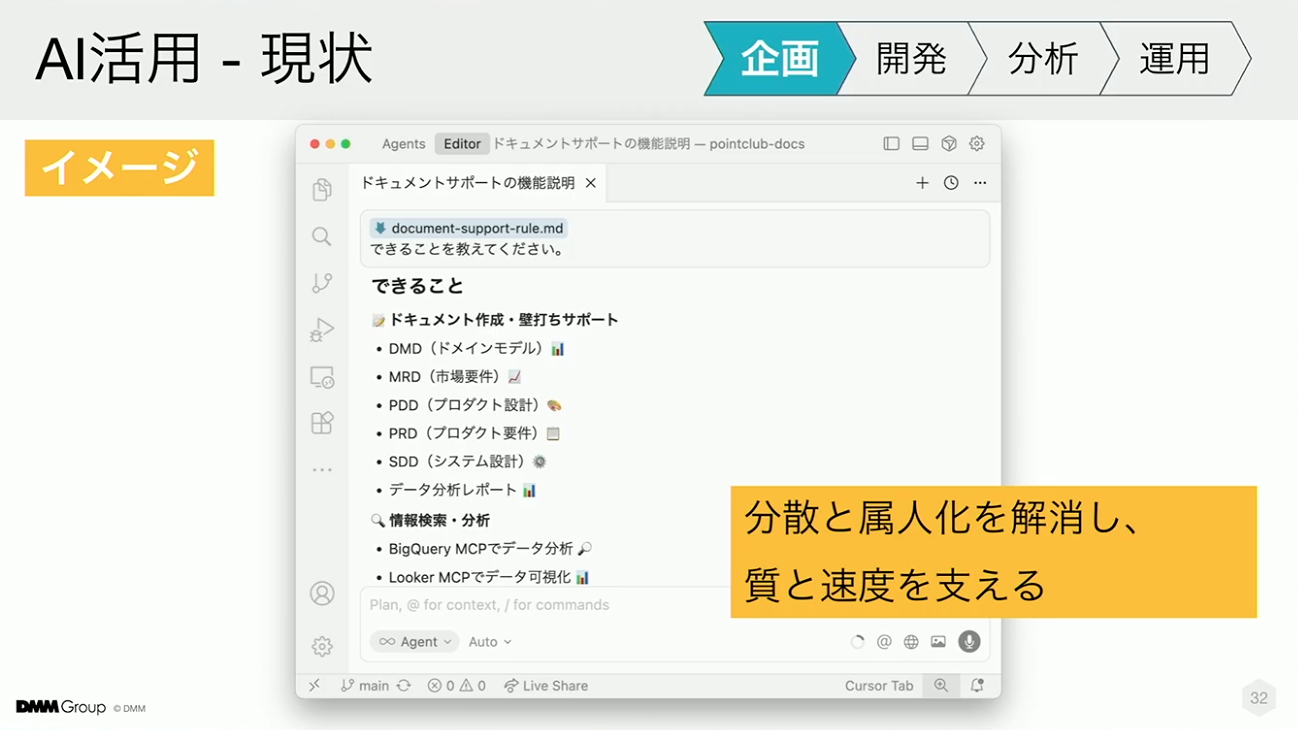
弊社では、ドキュメントをConfluenceなど別のツールで作成するケースもあるため、社内で開発されたMCPサーバーを使い、URLを指定するだけで壁打ちできる環境を整備しています。
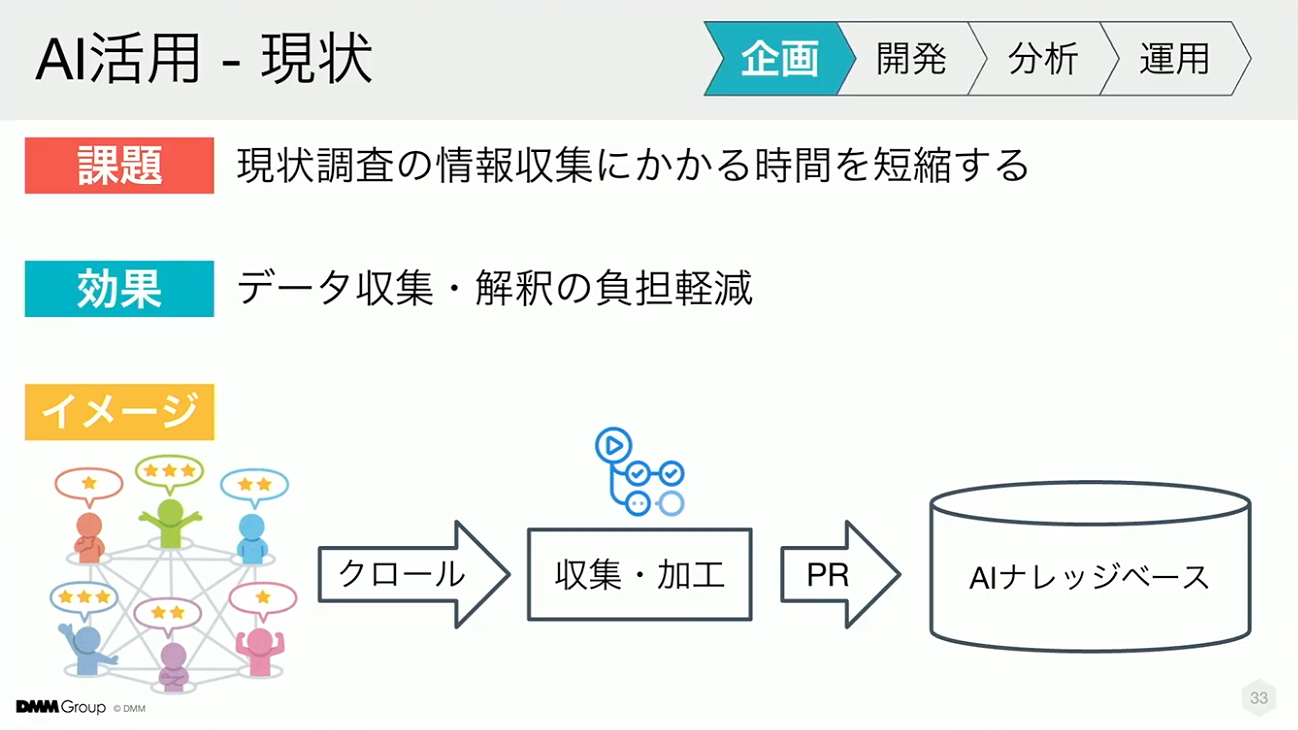
また、調査にかかる手間を削減するため、情報収集はcronなどで自動化しています。定期的にデータをクロールし、必要な加工をした上でAIナレッジベースに蓄積する仕組みです。これにより、調査時間を削減するだけでなく、データから見える問題を把握しやすくなります。
情報量が増えていくとコンテキストウィンドウの制約などが出てきますが、現時点ではクリティカルではなく、まずはナレッジベースの活用を優先しています。
自動レビューで手戻りを削減し、全体の品質を底上げ
続いて開発での活用です。 仕様通りに実装されているかを確認する際、通常であれば人がPRに記載された仕様やリンクを読み取り、コードと照らし合わせてレビューします。

しかし、仕様書をAIナレッジベースに蓄積することで、AIが仕様を理解し、PRの内容をチェックできるようになります。これにより、人のレビューを待たずにセルフレビューのような感覚で改善点を洗い出し、一定の品質に速やかに到達することが可能です。最終的な人のレビュー工程は維持しますが、手戻りを減らし、全体の品質を底上げする効果的な仕組みとして機能します。

AI前提で考えると、実装についてはすでにGitHub CopilotやCursor、Devin、Claude Codeなど多くの支援ツールがあります。そこにAIリーダブルな仕様書を渡すことで、仕様理解から実装までを一貫してAIに任せられます。
つまり、仕様が整っていれば、AIをレビューだけでなく実装そのもので使えるようになります。このあたりは「仕様駆動開発」と呼ばれています。
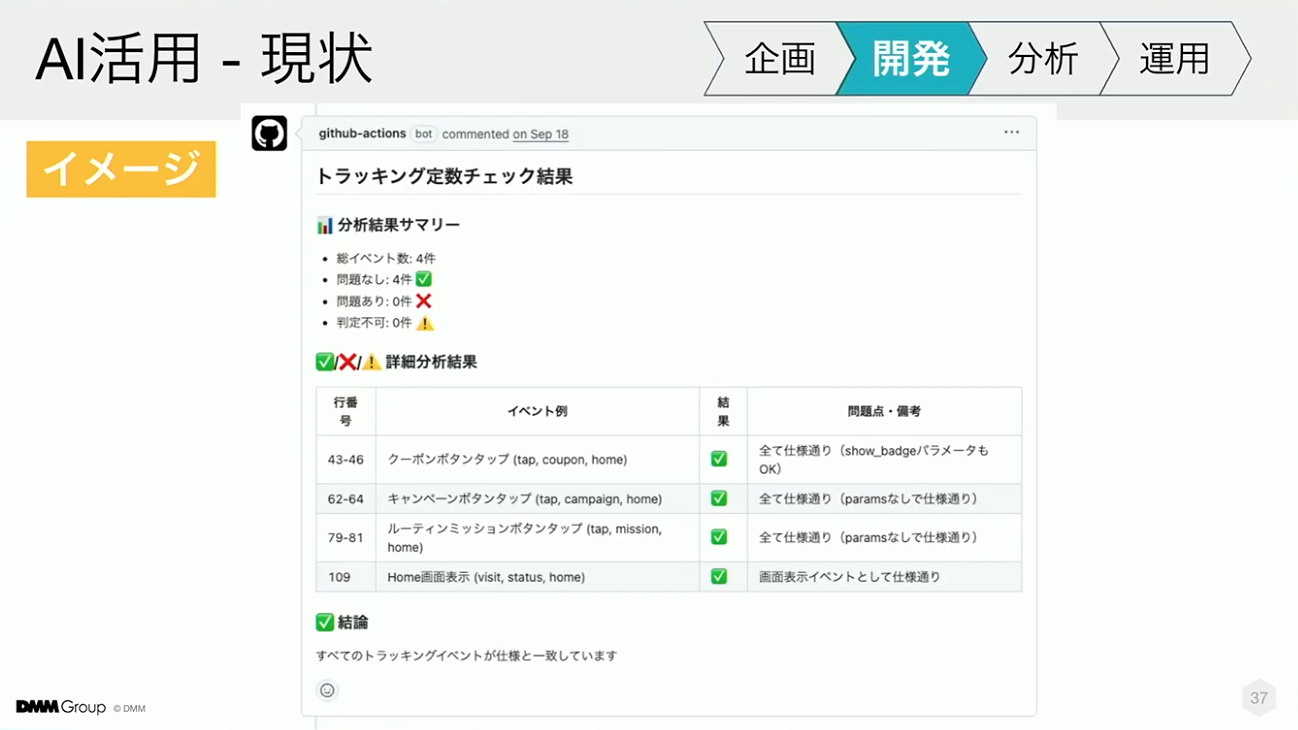
こちらは、実際の動作イメージの一例として、アプリの分析用トラッキングイベントが仕様通りに実装されているかをチェックしている様子です。PRが発行されたタイミングで、AIリーダブルなトラッキング定義を参照し、実装コードと仕様が一致しているかを自動でレビューします。
AIが仕様に基づいたコメントを生成することで、ドメイン知識を持つ人が確認していた作業が自動化され、レビュー工程における手戻りを削減することができています。
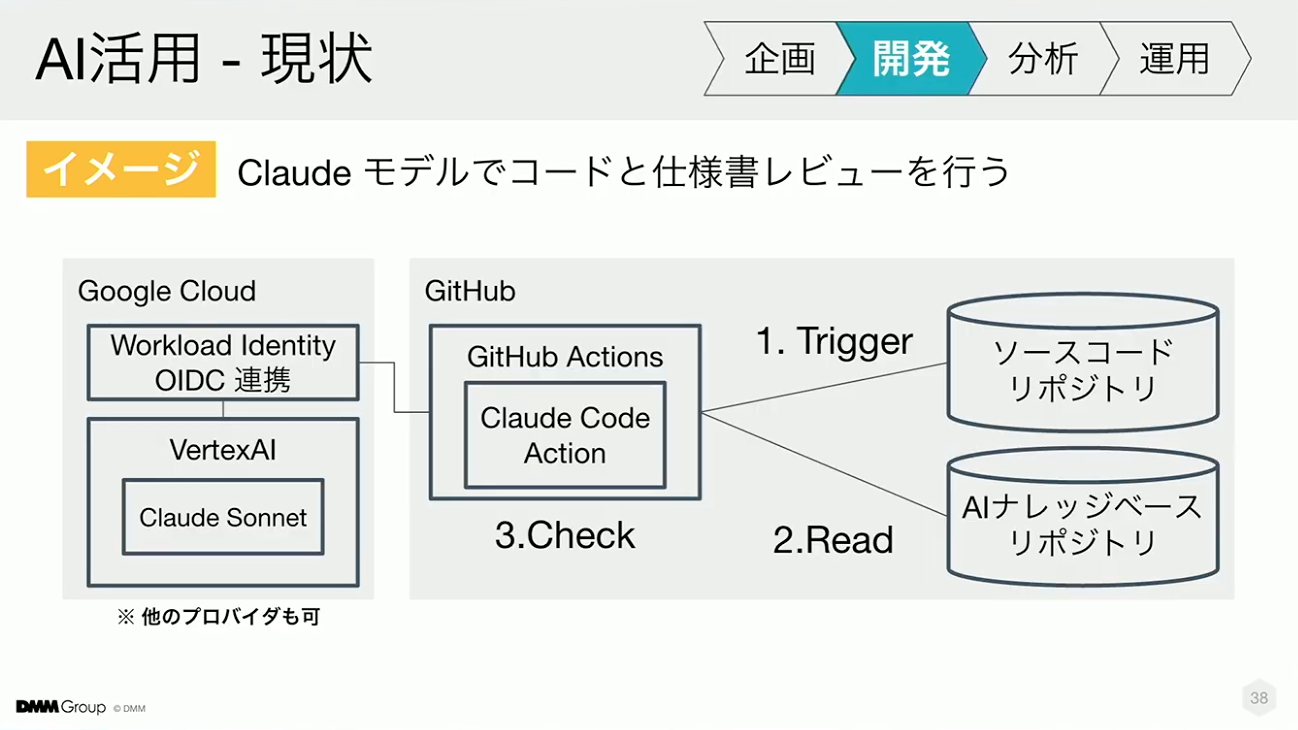
システム構成はシンプルで、PRのオープンをトリガーにGitHub Actionsが起動します。そこでAIナレッジベースに格納されている仕様書を参照してコードと突き合わせてチェックし、その結果をコメントとしてフィードバックする仕組みです。
ポイントクラブではVertex AI を利用していますが、Amazon BedrockやClaudeなど、モデルの種類を問わず同じ構成で運用することが可能です。
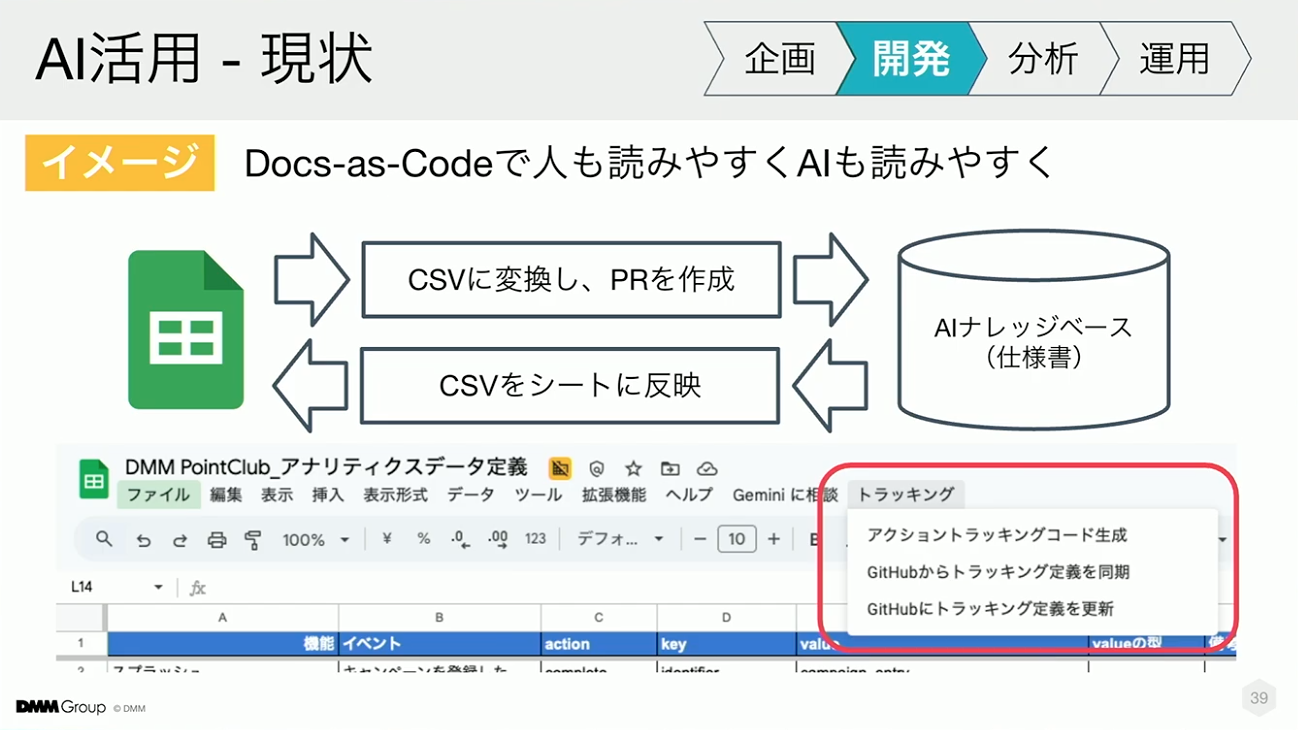
先ほど例に挙げた分析トラッキングの仕様は、これまでスプレッドシートで管理されていたため、Cloud RunやGoogle Apps Scriptを活用してAIナレッジベースと同期させています。
これは、人が読むドキュメントとAIが利用するドキュメントを完全に一致させると視認性を損なう懸念があったためです。この例では、現状の運用を尊重しつつ、AIに必要な情報のみを同期する設計を採用しました。
業務の負担を軽減し、分析サイクルが加速
続いて分析のケースです。単発で分析したいケースでは、その都度SQLを作成する必要があり、テーブルの仕様を忘れてしまったり、現状調査のためにドキュメントを探したり、人に聞いたりするなど、時間がかかるケースがよくありました。
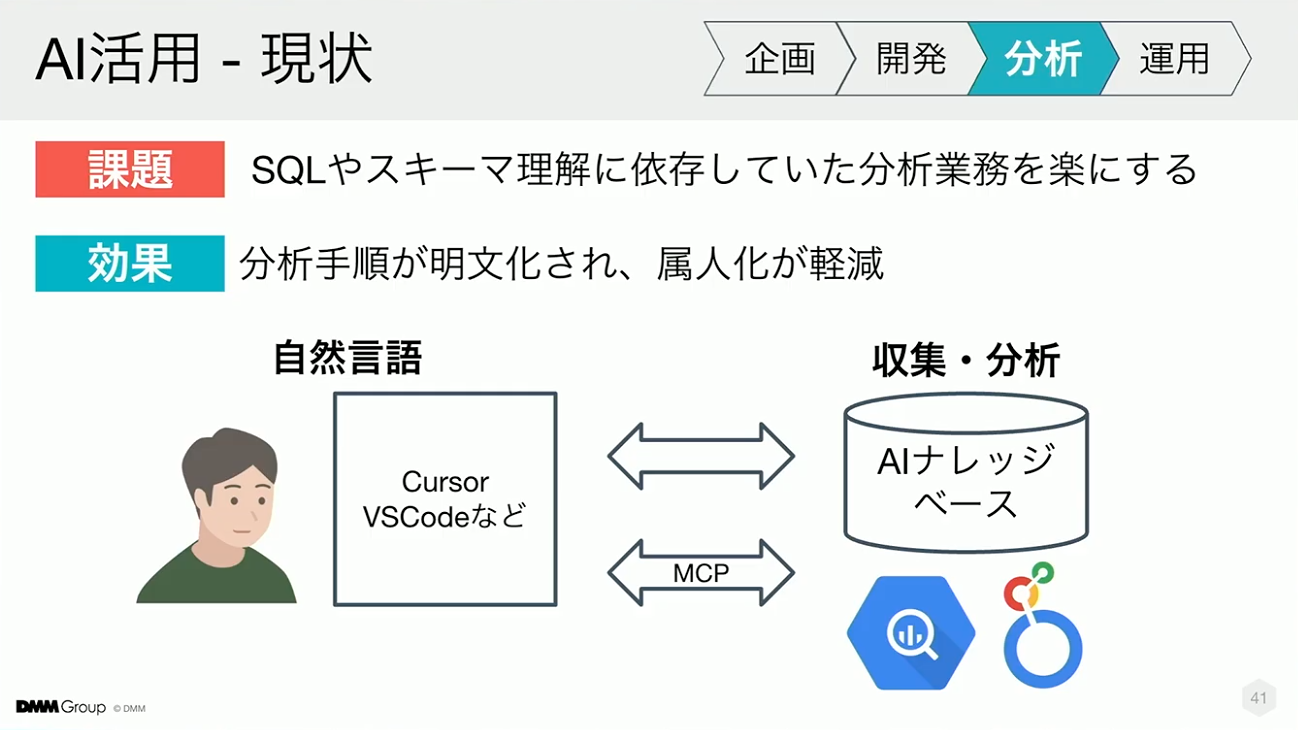
そこでドメイン知識をAIナレッジベースに集約し、自然言語でのクエリ作成やデータ抽出、簡易的な分析まで行えるようにしました。仕様理解やテーブル構造の確認をAIが代替するため、分析業務の負担を大幅に軽減できています。

例えば、自然言語で質問をするだけで、意図に沿ったクエリが自動生成され、集計結果の作成までサポートしてくれます。SQLを書く手間が省け、定期レポート作成や単発の調査にかかる負担が削減されたことで、分析サイクルが加速した事例も報告されています。
DMMがこれから取り組むべき、情報構造の拡張
ここまでの成果と課題について、前者としては、情報負債を構造的に可視化し、Docs as CodeやAIナレッジベースによってAIリーダブルな情報構造の原型を作るところまで実現できました。ただし、これはまだ全体の一部にすぎません。今後は、AIの特性を生かしたエージェントによる業務推進の仕組み作りや効果の定量化、運用の定着、そしてエンジニア以外でも活用できる情報構造への拡張が課題です。
AIエージェントの自律化に向けた「状態」の構造化
今後の取り組みについてお話しします。ここからはまだ概念レベルですので、小さく試しながら柔軟にアップデートしていきたいと考えています。
先ほどのグランドデザインで言うところの青枠の部分、AI前提の業務プロセスの設計アプローチです。
今後は、複数のAIエージェントが業務を推進する体制を目指します。業務推進におけるタスクの提案やアクションの提示、ドキュメントの品質維持管理や報告用定期レポート作成といった運用業務を、AIがAIナレッジベースを参照しながら自律的に実行し、必要なタイミングで人に報告する。そういった、AIが業務を自動で前に進める構造を作りたいと考えています。

その具体的な設計については、「状態」をメタデータとしてAIナレッジベースに保持するスタイルを考えています。
重要なのは、高性能なAIに丸投げすることではありません。AIが自律的に動くための鍵は、知能の高さそのものではなく、情報と状態が正しく構造化されていることだと考えています。
もしメタデータの中に進捗や担当者、レビュー状況、依存関係が明示されていれば、AIは推測ではなく「状態」を正確に読み取れます。さらには、そこに状態遷移ルールを定義しておくと、AIは次に打つべき手や不足要素を機械的に判断できるようになります。
今はまだ構想段階ですが、このように情報と状態を軸に置いたAIエージェントによって、業務推進の自動化がどこまで実現できるか、挑戦したいと考えています。
推論・推測・機械的処理の役割分担
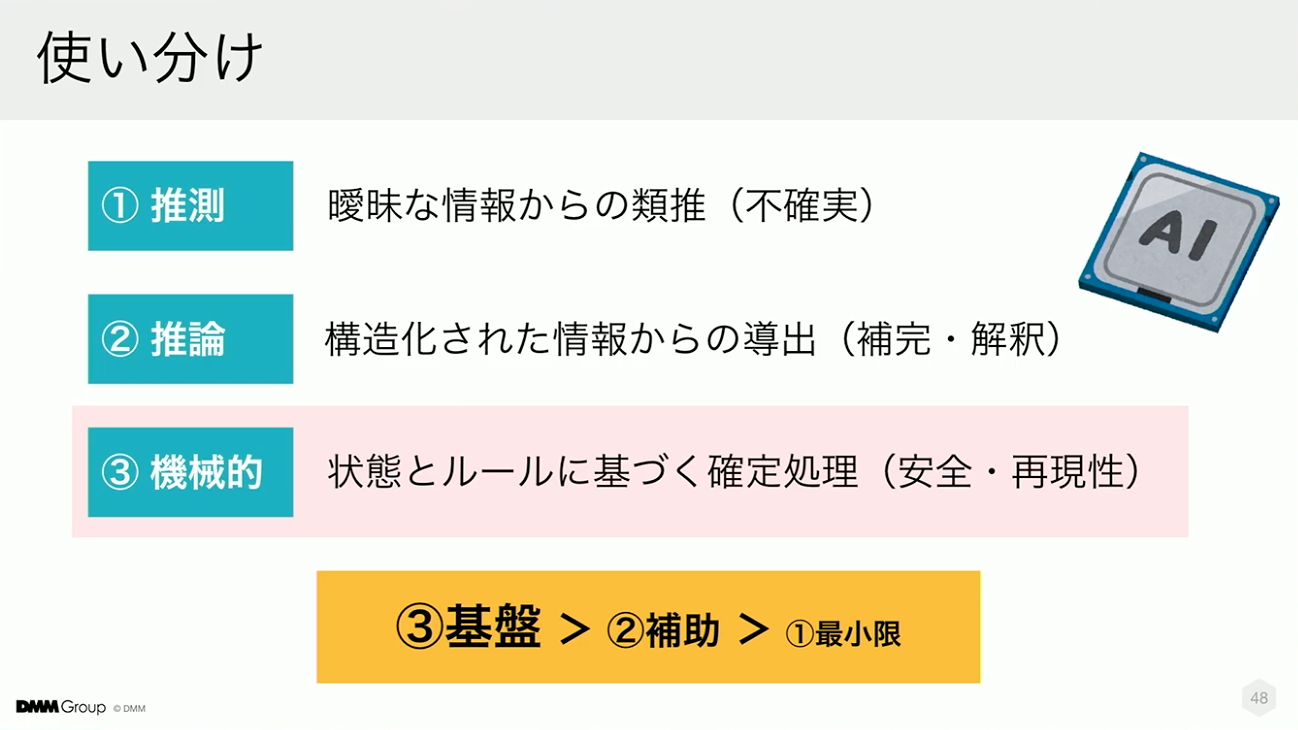
この構想を実現するために、AIを活用する上で重要な視点となるのがこの3つです。1つ目が曖昧さから判断する「推測」、2つ目が情報を整理して導く「推論」、3つ目がルール通りに確実に実行する「機械的な動き」です。
AIを前提としたプロセスでは、機械的な動きの領域を綿密に設計し、推論は補助的な役割に留め、推測を最小限に抑えることが重要です。これにより、AIが安定的に業務を推進できるようになると考えています。
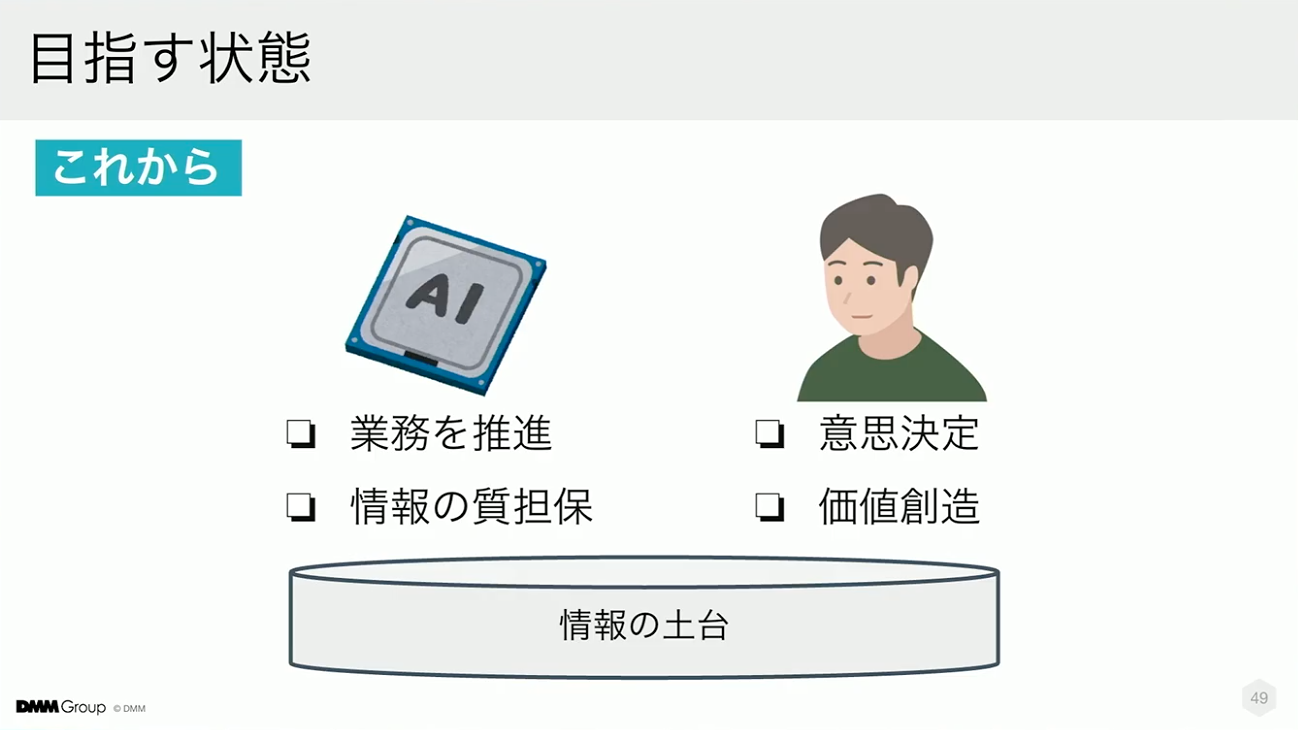
AI前提のプロセスで私たちが目指すのは、情報の土台の上でそれぞれが強みを発揮し、連携できる状態です。
AIは業務推進や情報品質の担保といったプロセスを確実に実行する役割を担い、人は意思決定や価値創造といった判断と創造の領域に集中できるようにする。こうした役割分担が確立されることで、組織全体の生産性が向上し、事業へのインパクトも高まると考えています。
AI活用を前進させる鍵は「情報設計」にあり

まとめます。AI活用の本質はツールの導入ではなく、情報設計にあります。蓄積された情報負債を仕組みによって解決し、AIが正しく読み取れる構造を維持し続けることで、AI活用を前進させることができます。本日の内容が、皆様の組織における取り組みにて、1つでも参考になれば幸いです。
ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





