



【アーキテクチャConference 2025】 クラスタ統合リアーキテクチャ全貌~1,000万ユーザーのウェルネスSaaSを再設計~
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
21日に登壇した居石 峻寛さんが所属する株式会社hacomonoは、1,000万ユーザー超のウェルネス向けSaaS「hacomono」を開発しています。初代アーキテクチャではテナントグループごとにEC2を占有しており、事業スケールに伴い、運用コスト増大などの課題に直面していたのだそう。本セッションでは、そのような成長痛を解消するために実施された「ECS/Fargate移行とプールモデル刷新」や、現在進行中のリアーキテクチャプロジェクトについてお話しいただきました。
■プロフィール
居石 峻寛
株式会社hacomono
基盤本部 プラットフォーム部 プラットフォームエンジニア
2020年徳島大学大学院修了後、合同会社DMM.comにインフラエンジニアとして入社。全社を横断する検索エンジンの構築・運用に携わる。2025年に株式会社hacomonoに入社し、ウェルネス業界に携わる。プラットフォームエンジニアとして、導入店舗9500店、累計ユーザ数1000万人を超えるhacomonoを支えている。
全国1万施設を支えるウェルネスSaaS「hacomono」
BtoBtoC SaaSとIoT機器の提供を通し、新しい顧客体験を提供
「クラスタ統合リアーキテクチャ全貌~1,000万ユーザーのウェルネスSaaSを再設計~」と題して、発表させていただきます。
居石 峻寛と申します。株式会社hacomonoのプラットフォームグループにて、インフラの運用管理や基盤開発を担当しております。
会社とプロダクトについてご紹介させてください。株式会社hacomonoは「ウェルネス産業を、新次元へ。」をミッションとし、ウェルネス施設をトータルサポートするBtoBtoC SaaS「hacomono」を提供しています。
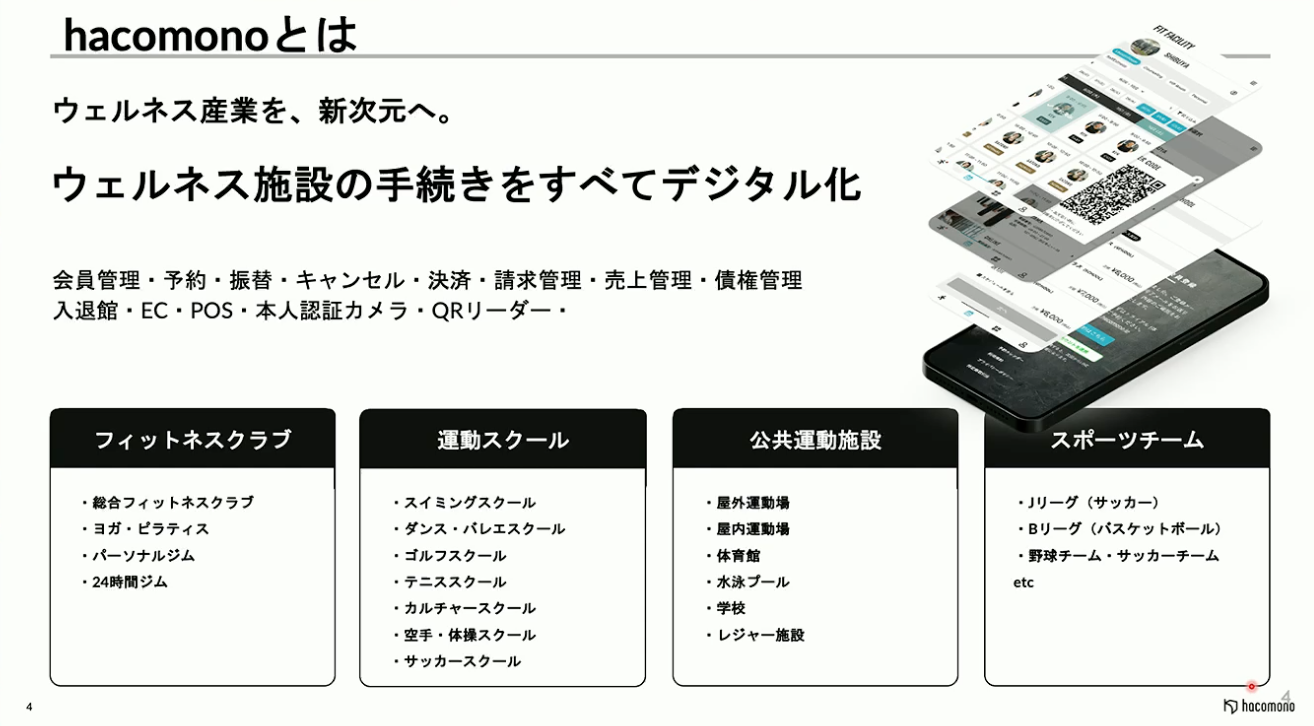
hacomonoは、予約管理や会員管理、決済等の手続きをDX化するサービスで、フィットネスクラブやスクール、公共施設、スポーツチームなど、幅広いお客様にご活用いただいています。
また、施設内部のIoT機器も提供しており、hacomonoの会員管理と統合した新しい顧客体験を提供しています。

例えば、スマートロックによる入退館管理、プロテインサーバーとの連携、 AIカメラなど、様々なプロダクトを用意しています。
おかげさまで、全国1万施設を超えるお客様にご利用いただいており、2026年には新たな取り組みとして、施設とユーザーをマッチングするBtoCサービス「FitFits」をローンチする予定です。
hacomonoを支える技術スタックと負荷特性
hacomonoの技術スタックについてご説明いたします。
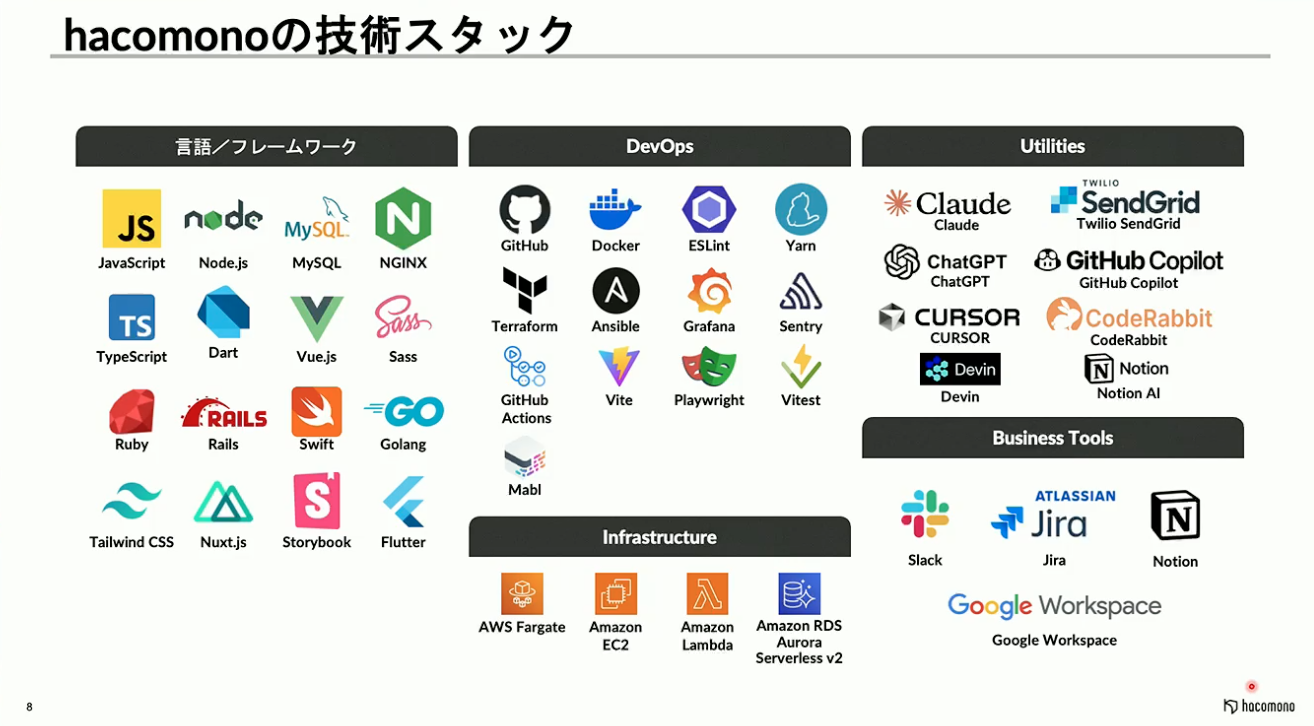
フロントエンドはVue.jsとNuxt.js、バックエンドはRubyとRailsのAPIモードを採用しています。インフラ面では、データ基盤の一部にGoogle Cloudを使用しているものの、基本的にはAWSをメインに活用しています。
続いて、hacomonoのサービス特性についてもお話しします。
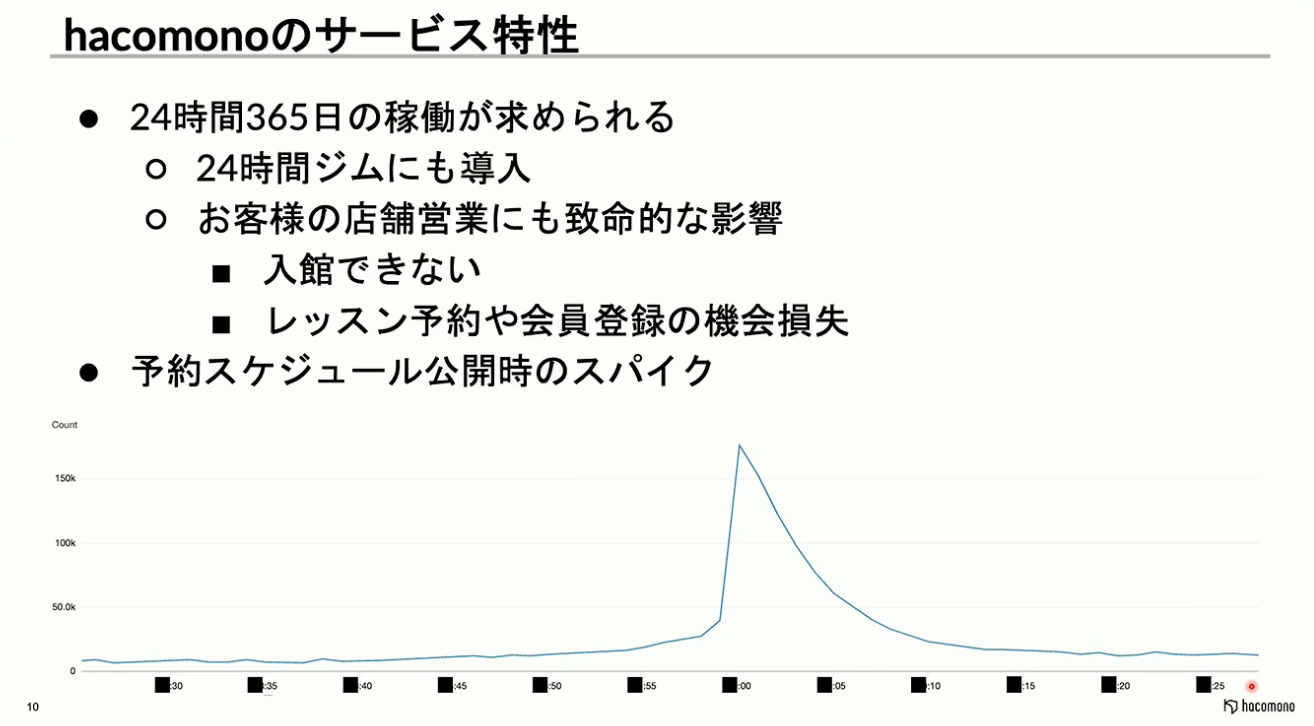
hacomonoは24時間営業のジムにも導入されているため、24時間365日の稼働が求められています。システムが停止すると、ジムの利用者がスマートロックを使った入退館ができなくなったり、レッスンの予約や会員登録ができなくなったりと、機会損失につながります。
負荷に関して、通常時のトラフィックはそれほど多くありません。しかし、一部のお客様が非常に多くの会員を抱えており、予約スケジュールの公開時などに急激なスパイクが発生するといった特徴があります。上のグラフを見ていただくと分かる通り、わずか1~2分という非常に短い時間で、テナントによっては数百倍という規模のスパイクが発生することもあります。
本日は、こういったhacomonoの負荷特性を念頭において、お聞きいただければ幸いです。

EC2占有による運用負荷とコスト非線形増大の苦悩
サイロモデルとプールモデルのトレードオフ
先ほど「テナント」という言葉を使用しましたが、ここで改めてご説明させてください。AWSのWell-Architectedフレームワークでは、SaaSの設計モデルとしてサイロモデルとプールモデルが提唱されています。
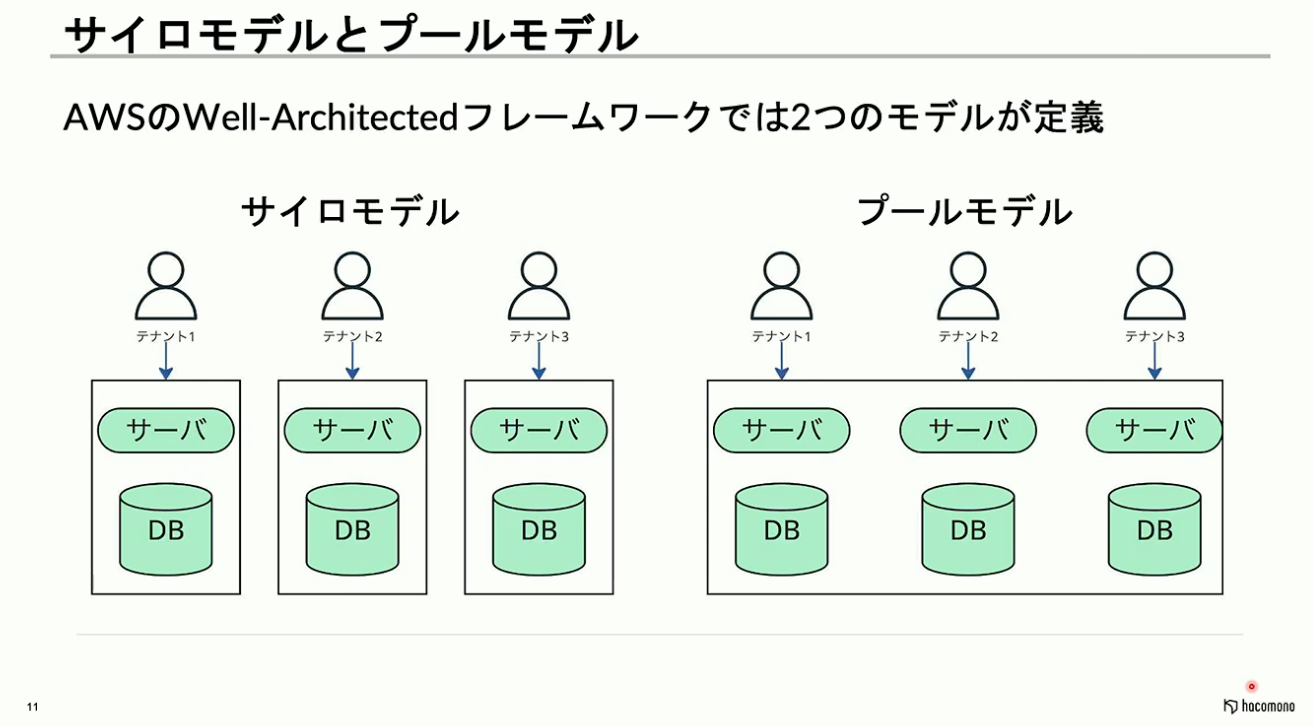
サイロモデルは、テナントごとに専用のクラスタを提供するモデルです。サイロモデルでは、テナント間のデータ分離やルーティングといった詳細な制御についてはあまり問題になりません。しかし、運用コストやランニングコストといったコスト面の負担が大きくなるという側面があります。
一方で、プールモデルはテナント間で同じクラスタを共有します。リソース効率が非常に良く、サービスがスケールした際にも、ランニングコストや運用コストの面でサイロモデルより優位性があります。ただ、データ分離やルーティング制御については、アプリケーションレイヤーなどの何らかの方法で保障する必要があります。また、一部のテナントの負荷が高まることで他のテナントに影響が及ぶ「ノイジーネイバー問題」への対応や、エラー発生時にどのテナントで問題が起きたのかを特定するためのトレーシング機構の実装も必要です。
計画的スケールアウトと運用上の限界
次に、hacomonoの開発初期におけるアーキテクチャについてご説明します。
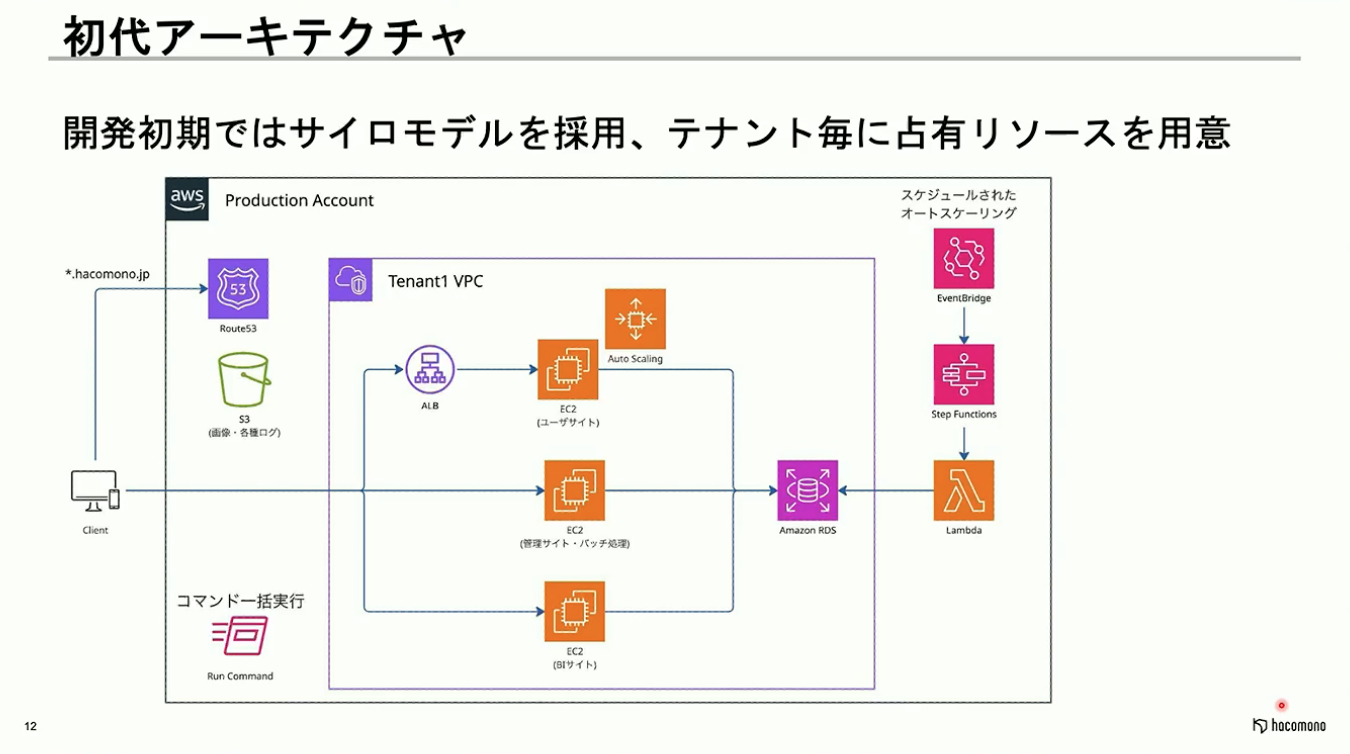
開発初期段階では、テナントごとにEC2ベースの環境を払い出すサイロモデルのアーキテクチャを採用しておりました。この環境下では、ジムに通っているお客様にご利用いただくユーザーサイト、ジムのスタッフやオーナーにご利用いただく管理サイト、そしてバッチ処理を実行するためのEC2を提供していました。加えて、一部のテナントに対しては、データ分析基盤としてのBIサイトも提供していました。
hacomonoで発生するスパイクは、メトリクス監視に基づく追従ではオートスケールが間に合わないため、計画的なスケールアウトを行っていました。EC2のAuto Scalingグループを活用し、あらかじめ指定した時間帯にリソースを増強し、スパイクが収束した後にリソースを縮小させるといった形です。
データベース(以下、DB)に関しては、EventBridgeによってスケジュールされたタイミングでLambdaを実行することでRDSのスケールアウトを行っています。また、VPCを含む一連のシステム構成がテナントの数だけ構築されており、全てのテナントにログインしてリリース作業などをしていたら時間が足りなくなるため、Run Commandを活用して複数のテナントに一括で作業を実行できる仕組みを導入しています。
ちなみに、一部の環境や作業においてはRun Command以外にJenkinsを活用しており、複数のリリースパイプラインが混在する中で、様々な問題が発生していました。
例えば、リリース先のサーバ自体のリソースがパンクしてリリースが失敗するといった事象や、Jenkins本体のリソース不足といった課題です。そのほか、ワークフローを変更した際に、暫定的な対応で実行せざるを得ない場面もあり、リリースの安定性に欠けていました。
事業拡大に伴うインフラ・運用コストの最適化に悩んだ開発初期
ここまでの話をまとめます。初期開発段階はサイロモデルを採用しており、インフラコストの最適化が難しく、事業のスケールに伴い運用コストが非線形的に上昇してしまいました。
インスタンスの数に比例してインスタンス障害が増加しただけでなく、各インスタンス間のライブラリやOSの状態に個別の差分が生じ、リリース作業が難航している面もありました。これらの要素が重なった結果、運用状態が不安定でした。
ECS/Fargateへの刷新とリリースの高速化
コンテナ化とテナントグループによる統合
そういった問題を解決するため、リアーキテクチャを進めることにしました。コンピュートインスタンスをEC2からECSへ移行してコンテナベースの運用に切り替え、サイロモデルからプールモデルへ移行することでコストの最適化も図っています。
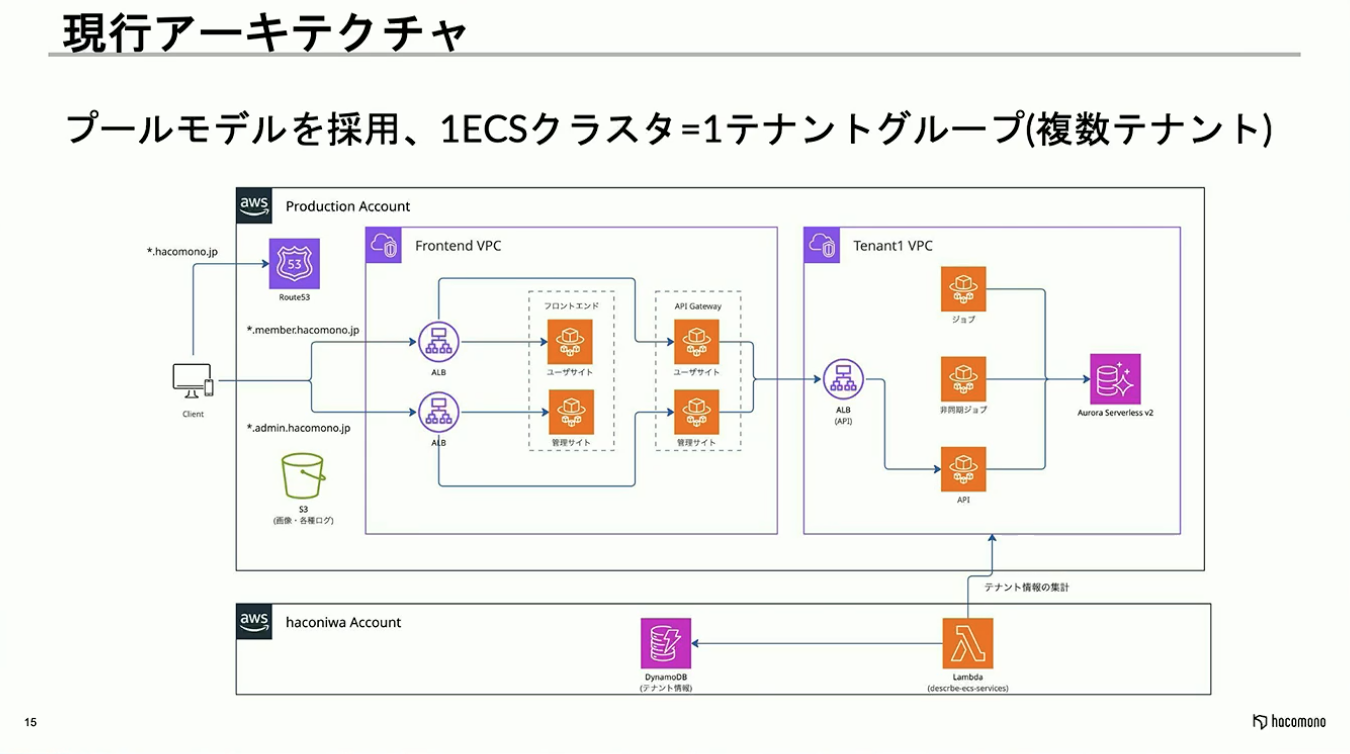
プールモデルへの移行については、全てのテナントを統合するのではなく、複数のテナントをまとめた「テナントグループ」を作成し、そのグループがいくつか存在する構成にしました。
フロントエンドのECSとAPI GatewayのECSは、全てのテナントで共通のものが利用されています。一方で、後ろに控えるAPIバックエンドのECSのみ、テナントグループごとに作成されています。リクエストが発生した際には、API Gatewayを通してどのテナントへのアクセスかを判断し、各テナントグループに対応するバックエンドのECSにリクエストを流して制御する形です。
apartmentライブラリによるマルチテナントの分離
プールモデルへの移行に際して、テナントの分離も必要でした。
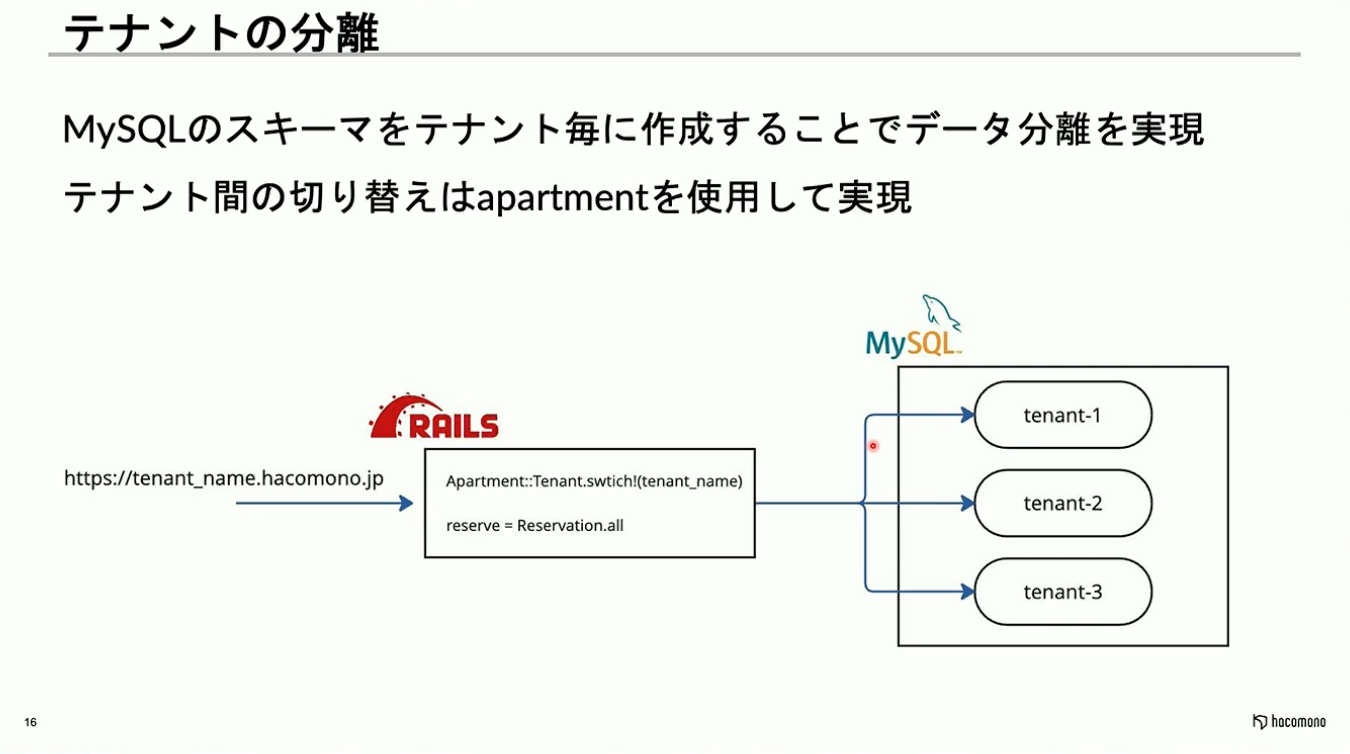
MySQLにはPostgreSQLのRow Level Securityのような機能がないため、アプリケーションレイヤーでの対応が求められました。hacomonoではRailsを採用しているため、ActiveRecordのライブラリであるapartmentを活用して、これを実現しています。
イメージとしてはhttps://tenant_name.hacomono.jp
というリクエストをRails上のapartmentが内部で検知し「Apartment::Tenant.switch!(tenant_name)」を実行することで接続先を切り替える構成です。このコードをRailsのミドルウェア層に隠すことで、アプリケーション開発側が接続先のテナントを意識することなく開発を進められるようにしています。
Run CommandやJenkins主体の運用から、コンテナベースに置き換えたことで、リリースフローも大幅に改善されました。
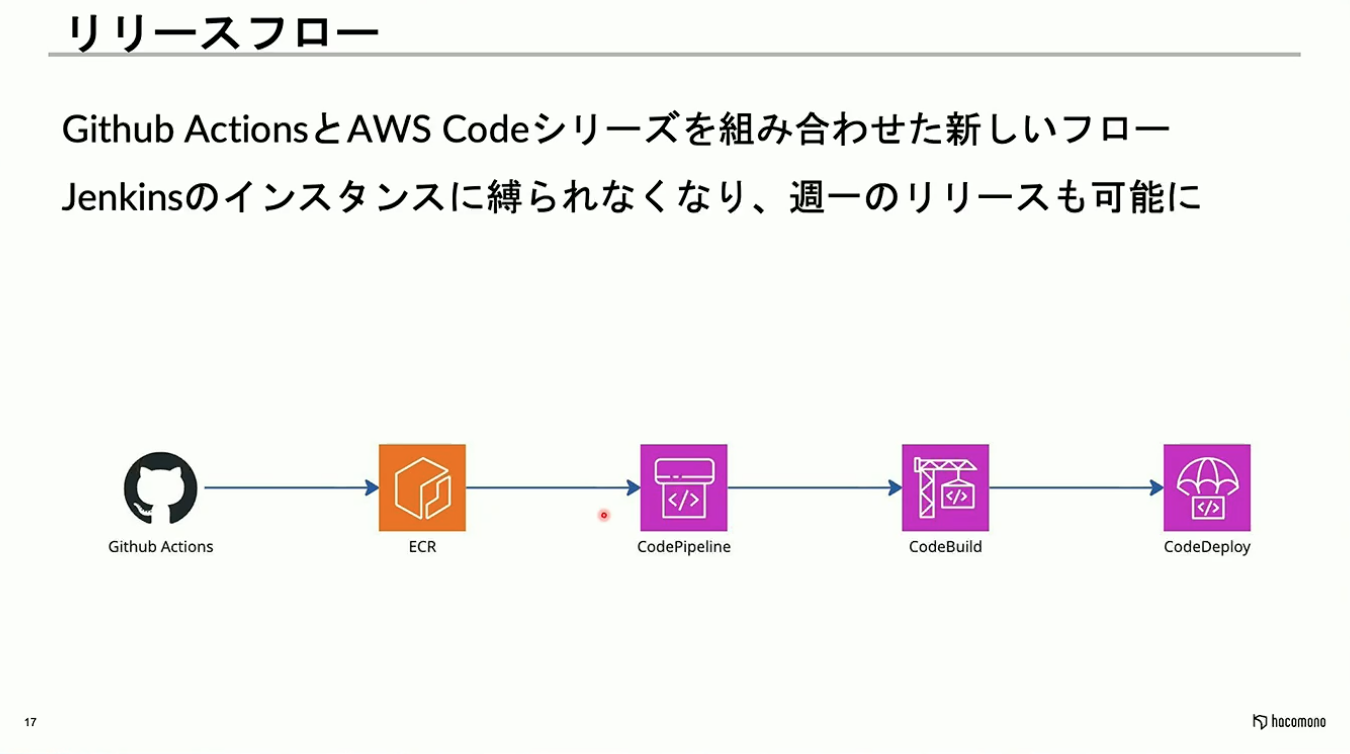
具体的には、GitHub Actionsをトリガーとし、AWS Codeシリーズを組み合わせたリリースフローを構築しています。これによりインスタンス固有の制約から解放され、安定したリリース作業が可能となり、現在では週1回の頻度でリリースを実施できています。
リスクを抑えるため、既存テナントの移行は段階的に実施
新規テナントをプールモデルのクラスタに追加する一方で、既存のサイロモデルのテナントも移行しなくてはいけません。
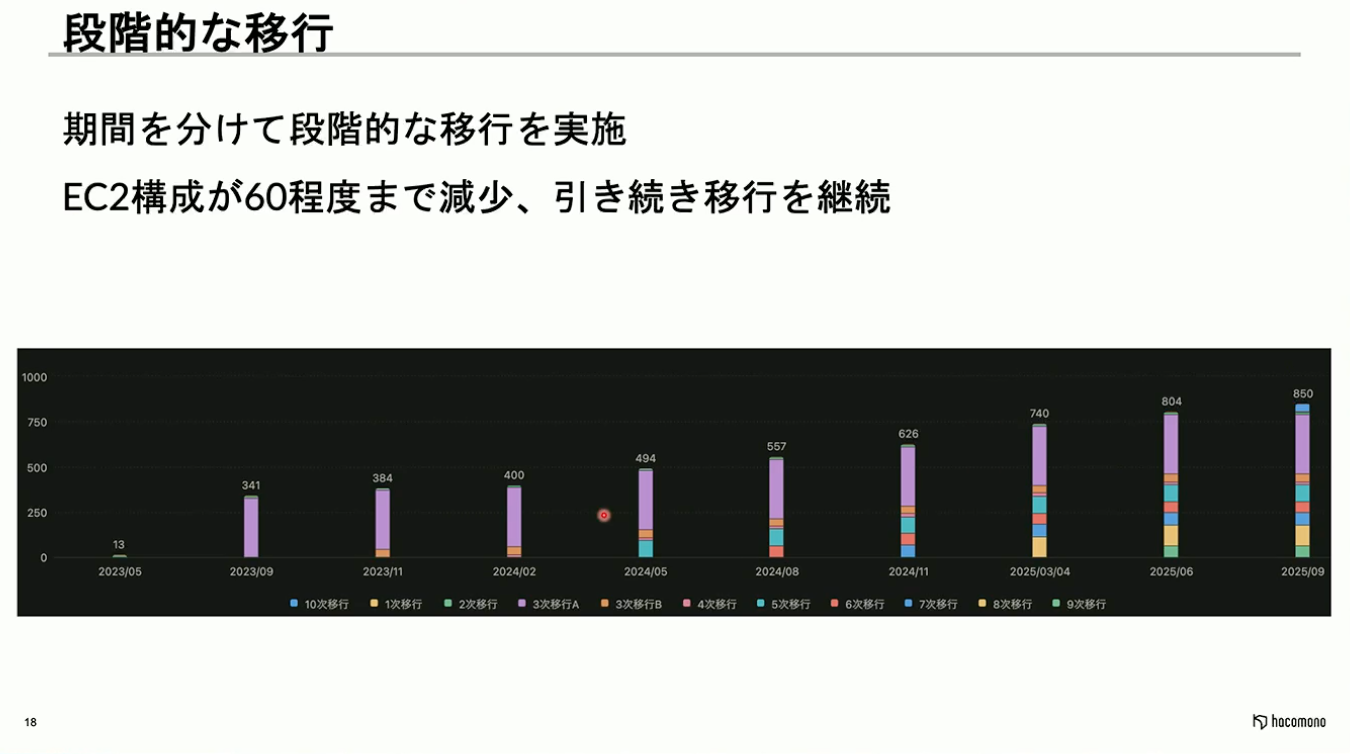
既存テナントの移行については、1次、2次、3次と分割することで、1回あたりの作業時間を短縮するとともにリスク制御を図っています。この移行作業は、2年以上の期間をかけて段階的に進めており、かつて多数存在したEC2構成は、現在60テナント程度に減少しています。
クラスタ数の変化についてもお話しします。現在hacomonoでは3,000以上のテナントを抱えています。これらを全てサイロモデルで運用した場合、3,000以上のクラスタと膨大な数のEC2を管理することになります。しかし、60のサイロモデルのクラスタと37のプールモデルのクラスタという規模に集約することで、コストの最適化や運用負荷の軽減、リリースやメンテナンス作業の効率化といった効果を得られました。

移行を阻む「データ統合」の壁
複雑化するハイブリッド構成の課題
続いて、現在進行中の「infra v2プロジェクト」について触れていきます。現在のhacomonoが抱える課題としては、サイロモデルとプールモデルの混在、およびプールモデル内でもバックエンドのECSクラスタが完全に統合できていないという点が挙げられます。
サイロモデルとプールモデルの混在に起因する問題は、監視ツールを統合しきれておらず、双方のアーキテクチャを考慮したアプリケーション設計が求められることです。両モデルを並列で本番稼働させる以上、常に双方が最新の状態である必要があり、どちらのクラスタ環境でも動作するようにアプリケーションを設計しなくてはいけません。
ここについては、内部的に環境変数を用意し、それをフラグとしてアプリケーションの挙動を切り替える対応が必要となっています。また、ライブラリのバージョンアップに関してもサイロモデル側の制約に影響を受けてしまうため、アプリケーション開発に大きな負荷がかかっています。
DB移行が困難な状況下でのクラスタ統一
ECSクラスタが統合しきれていない点について、インフラコストの最適化は進んだものの、デプロイ速度にはまだ改善の余地があり、これまでの運用で知見も蓄積されてきました。こうした背景から、ECSクラスタの統一とEC2の全撤廃を目指し、infra v2プロジェクトが発足しました。
ただし、このプロジェクトを推進する上で、DBの統合がボトルネックとなっています。パフォーマンスの観点では、全テナントを1インスタンスに集約すると規模が膨大になってしまいます。また、安全に移行するためにメンテナンス時間についてはお客様と相談の上で調整していますが、データ数が増大すると移行作業が長時間化してお客様の許容範囲を超えてしまう可能性がある。さらに、テナントごとに異なる可用性要件やスパイク時のスケールアウトの調整が難しいという問題もありました。
これらの状況を踏まえて、私たちは「DBを完全に統合するのではなく、現行のDBをそのまま流用すればいいのではないか」と考えるようになりました。
DBを動かさずクラスタを統合する逆転の発想
VPC EndpointによるセキュアなVPC跨ぎ接続
現行のDBを流用するためには、VPCを跨いだ通信経路の確保と、複数のDBを適切に切り分けるためのルーティング制御機構が必要となります。
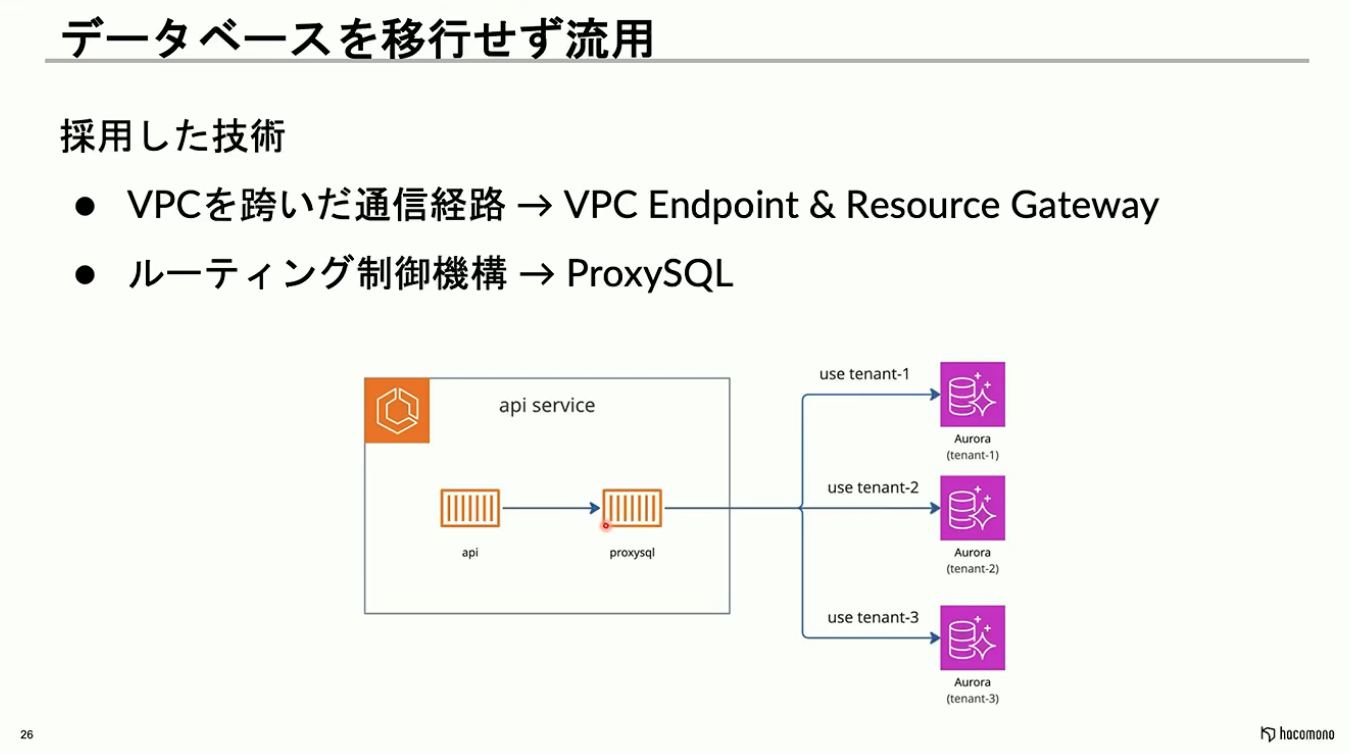
hacomonoでは、VPCを跨いだ通信経路にはVPC EndpointとResource Gatewayの2つを利用し、ルーティング制御機構にはProxySQLを活用しています。
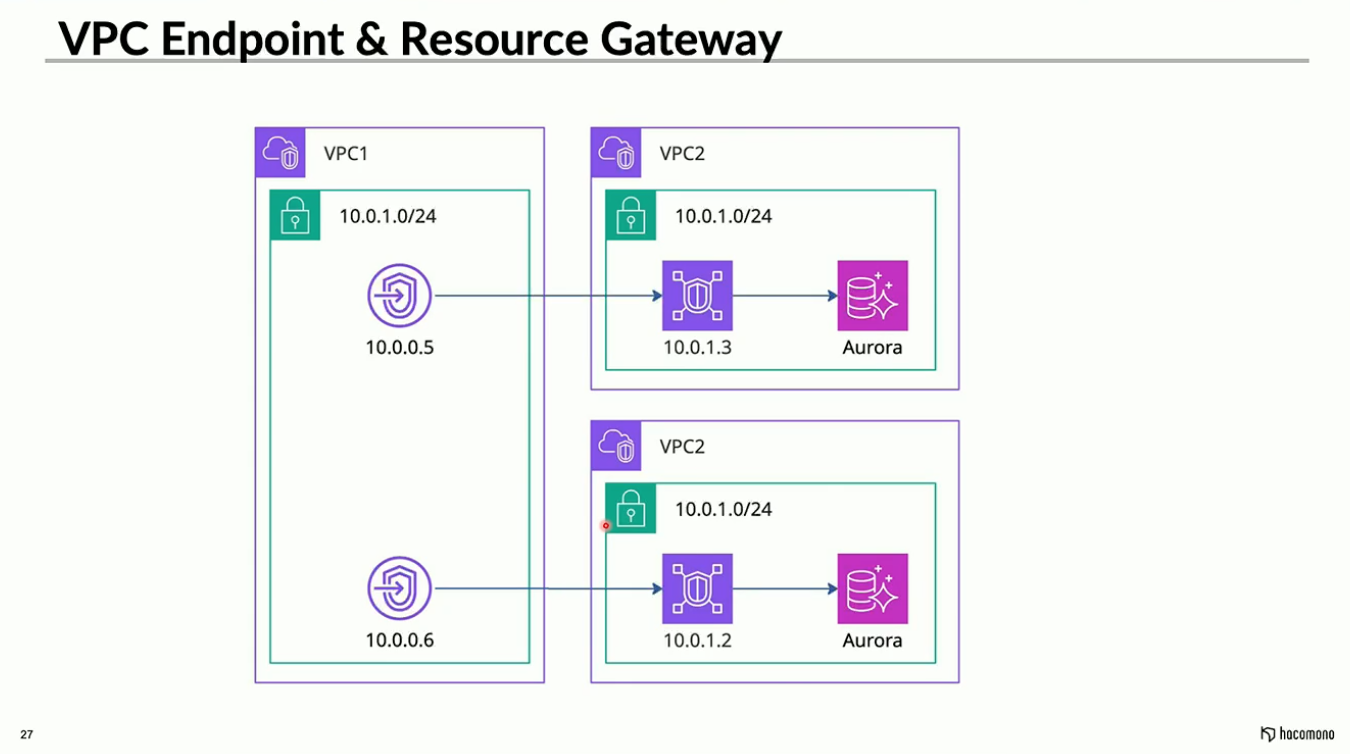
VPC EndpointとResource Gatewayは、VPC内部にネットワークインターフェースを設置し、外部サービスとの通信の接点とする仕組みです。VPC Endpointにはゲートウェイ型とインターフェース型が存在しますが、今回は後者を採用しています。
一般的にはS3やDynamoDB、ECRなどのマネージドサービスへインターネットを経由せずにアクセスする手段として活用されることが多いと思うのですが、ここでは複数のVPC間を接続する目的で利用しています。VPC間の接続について、Transit Gatewayなどの選択肢もありますが、hacomonoはTerraformを用いてクラスタをデプロイしており、異なる環境でCIDRが重複しているという課題があります。今から全てのCIDRを変更するのは大変であるため、重複の影響を受けずに接続できるVPC Endpointが最適な解決策だと判断しました。
ProxySQLによる動的なルーティング制御
先ほど、ライブラリのapartmentを用いてスキーマを切り替える手法についてお話ししましたが、このライブラリ自体にはインスタンスそのものを切り替える機能が備わっていません。
私たちとしては、プールモデルとサイロモデルの並列稼働がしばらく続くため、アプリケーション側に変更を加えることは避けたいという思いがありました。そこで、ルーティング制御機構としてミドルウェアを中間に配置することにして、いくつかの候補を検討した上でProxySQLを採用することにしました。

ProxySQLはDBとクライアントの間で動作するプロキシのOSSであり、MySQLとPostgreSQLをサポートしています。主な機能として、ルーティング機構とコネクションの保持を備えており、設定ファイルによって柔軟な制御が可能です。
具体的には、mysql_serversに接続するDBインスタンスを定義し、hostgroupという番号を割り振ることで、特定のルールに基づいたルーティング先をグループ化します。weightの値を調整すれば、インスタンスごとのリクエストの比重を制御することも可能です。さらに、mysql_usersで認証情報を管理し、mysql_query_rulesにより「どのルールにマッチした時に、どのホストグループへルーティングするか」を詳細に記述すると。
こうした設定により、アプリケーション側は接続先をProxySQLに向けるだけで、従来通り「use 」といったクエリを発行するのみで済みます。接続先のインスタンスがどこであるかをアプリケーション側が意識することなく、ProxySQL側で自動的に向き先を切り替えられるようになっています。
サイドカーによる設定自動反映(ProxySQL-Cron)
ProxySQLの設定変更には、設定ファイルを介する方法のほかに、MySQLのテーブル操作のようにクエリを発行して書き換える方法が存在します。
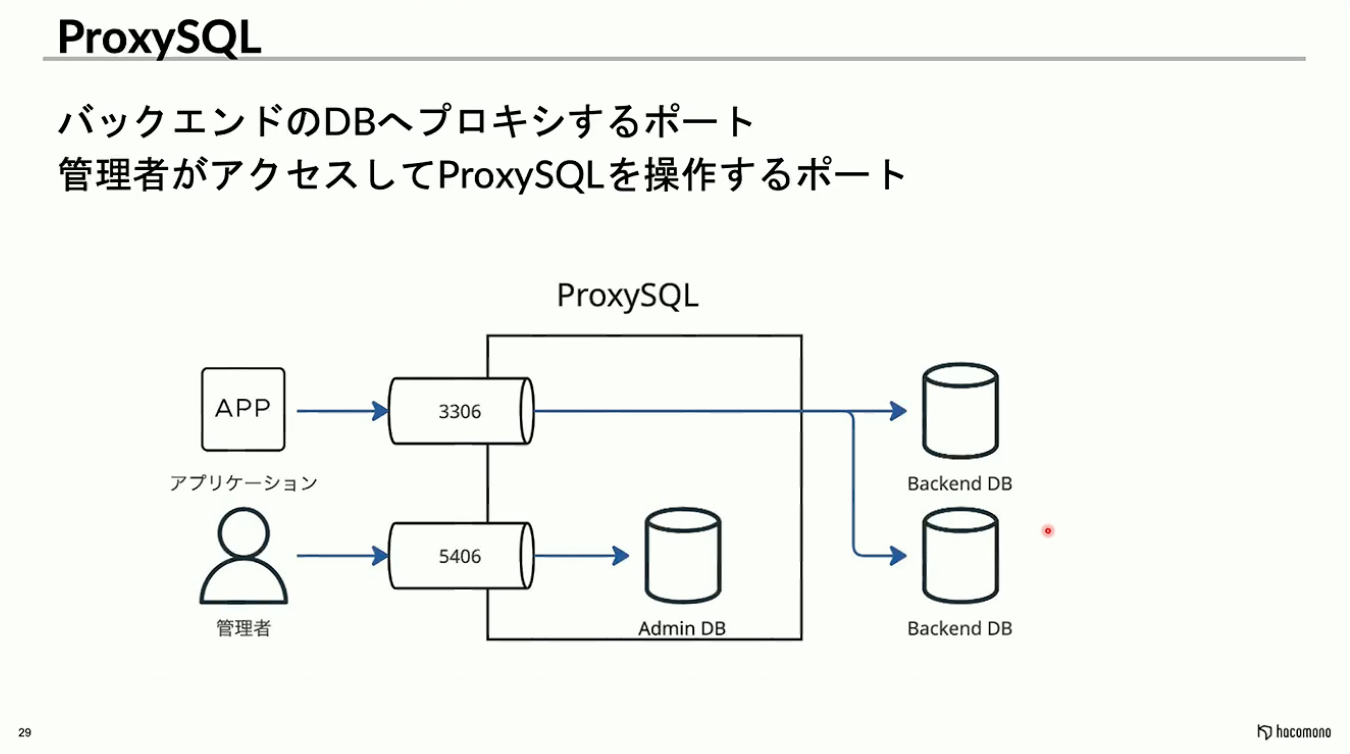
イメージで言うと、アプリケーションがDBへ接続するためのポートとは別に、管理者がAdmin DBにクエリを発行して設定を直接書き換えるためのポートがあります。
今回はステートレスな運用にしたかったため、設定ファイルを読み取る方式にしたいと考えました。しかし、テナントの増減に合わせてコンテナを再起動し、コネクションを張り直す運用はリスクが伴います。
実はProxySQLの設定は、設定ファイルとSQLの2つだけではありません。内部は三層構造になっており「Disk&Configuration File(設定ファイル)」「Memory(SQLで直接設定可能なレイヤー)」「Runtime(ProxySQLが参照するレイヤー)」の3つのレイヤーで管理されています。
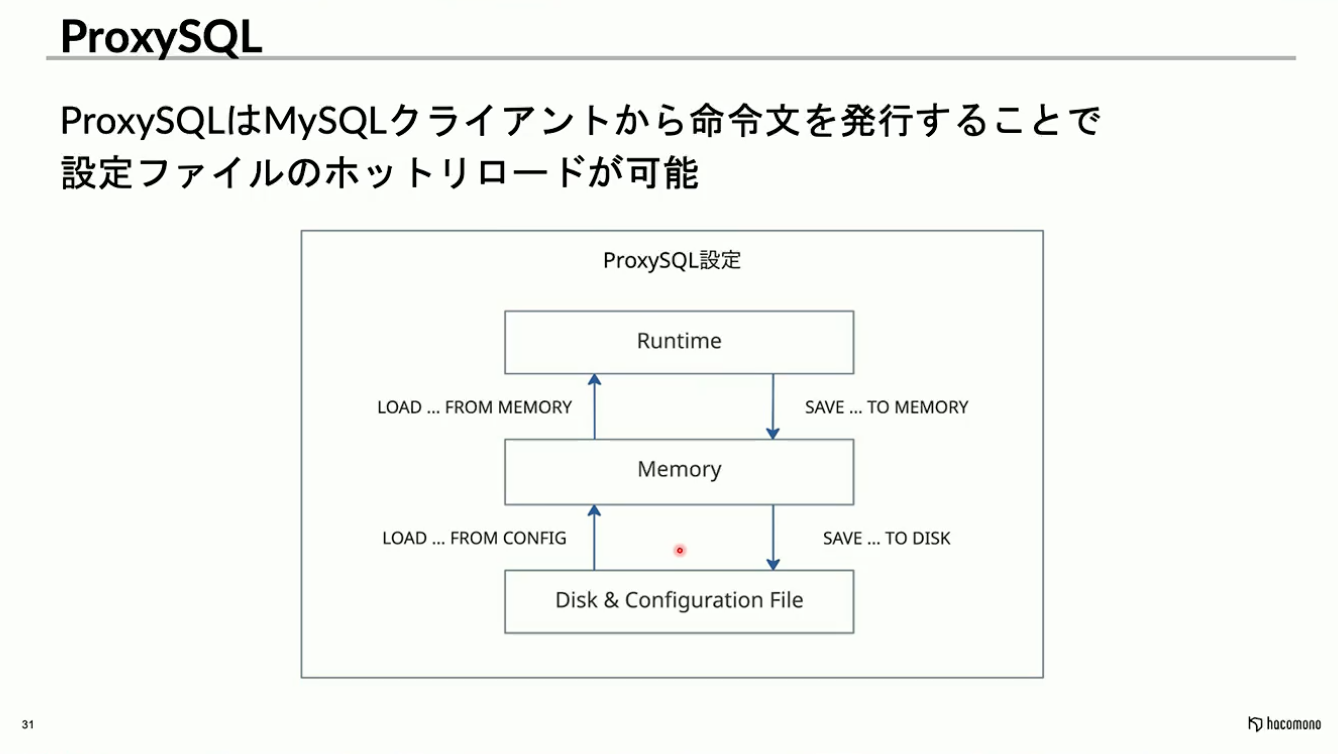
各レイヤー間は、管理用ポートから特定の命令を発行することで、コンテナを停止させることなく、ダウンタイムなしで設定を反映できます。
この仕組みを生かし、設定ファイルを書き換えた後にLOADで読み込めばいいのではないかと考えました。これを自動化するため、独自に実装したのが、サイドカーコンテナであるProxySQL-Cronです。
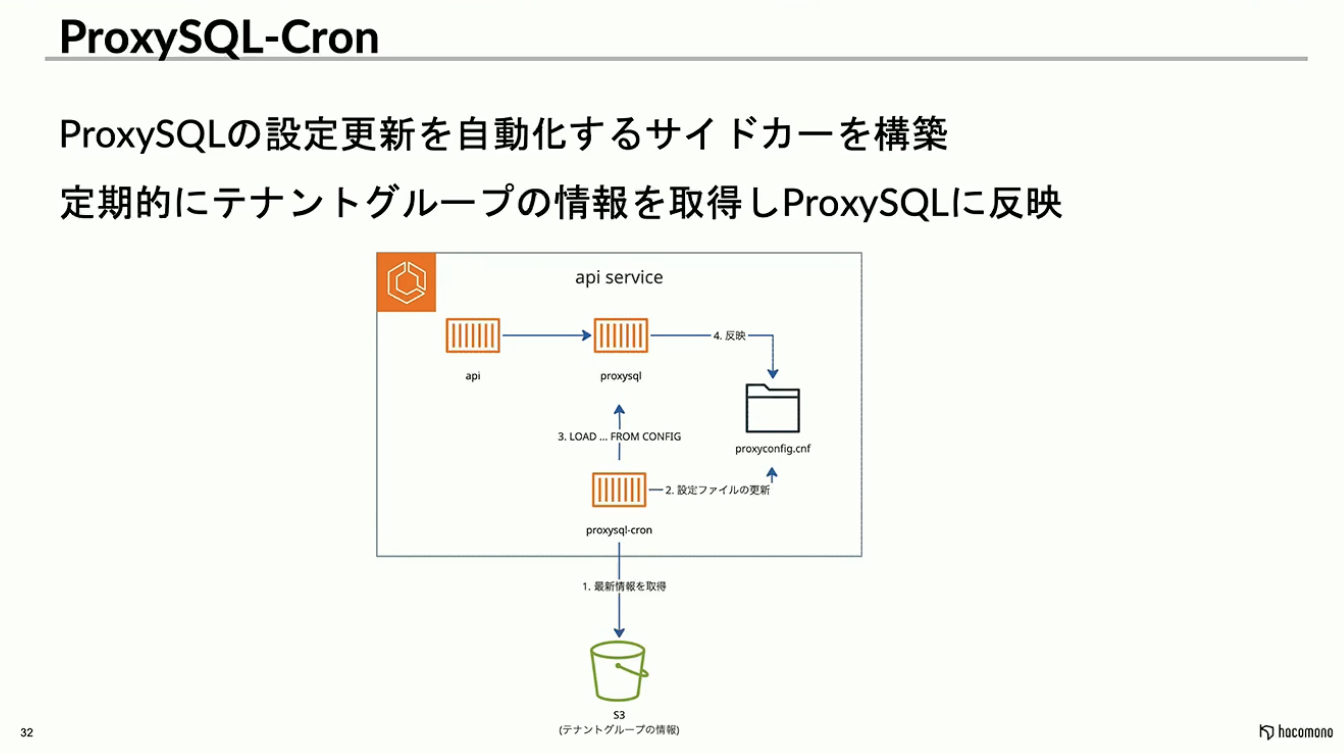
このサイドカーは、テナントとDBの紐付け情報が格納されたS3上のファイルを定期的にポーリングします。情報の更新を検知すると共有ボリューム上の設定ファイルを書き換え、ProxySQLに対してLOAD命令を発行することで、最新の設定を反映します。
統一された「infra v2」の最終構成
これらの技術要素を統合したinfra v2の最終的な構成は、非常に整理されたものとなりました。
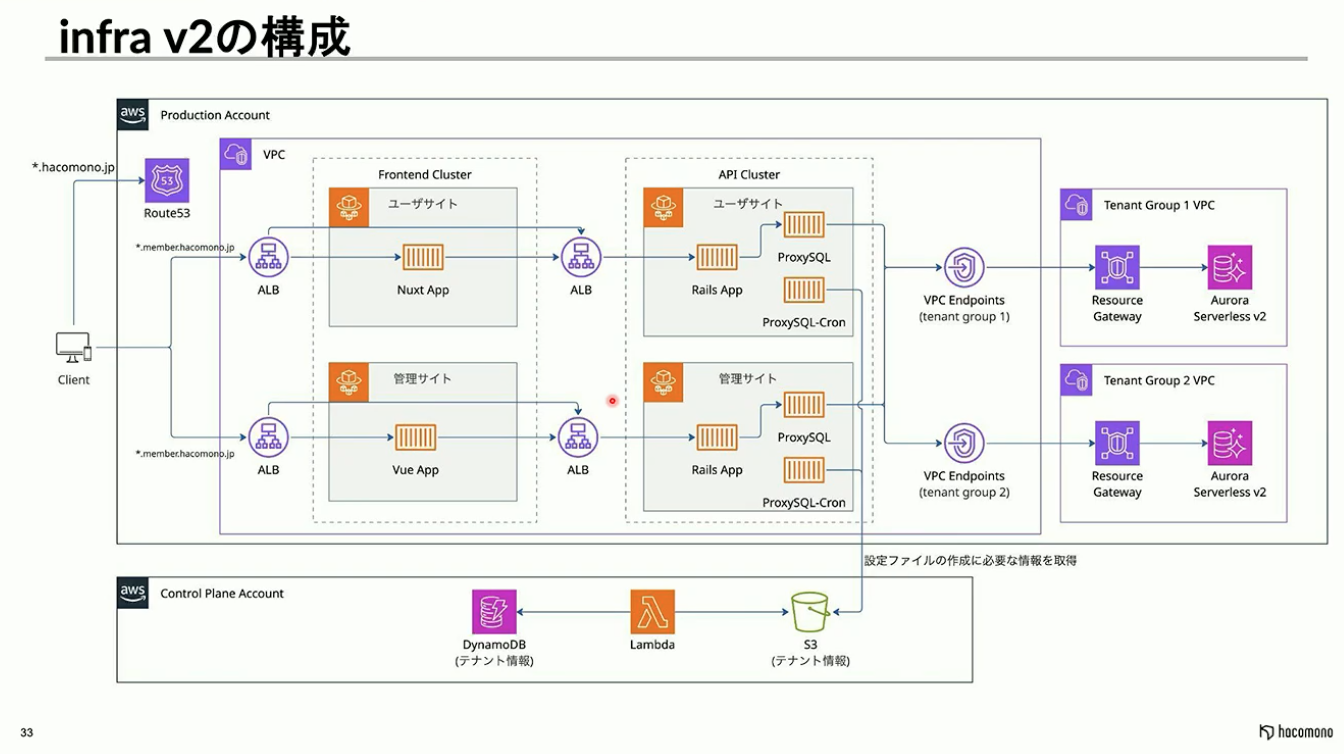
フロントエンドとAPIの2つのクラスタで全てのテナントを収容し、DBに関しては既存のものを流用してテナントグループごとに管理。サイロモデルのDBも、1テナントを1グループとして扱うことで、同一のアーキテクチャ内に統合して運用することが可能となりました。
可用性と効率を両立した次世代基盤への段階的移行
プロダクションレディーに向けた検証と改善
今後についてもお話します。これまでに実施してきたinfra v2の基本設計やProxySQLなどの技術検証の結果を踏まえ、現在は本番稼働に向けた具体的な検証フェーズに移行しています。具体的には、リリースパイプラインの検証として、ECSに新しく追加されたBlue/GreenデプロイやCanaryリリースの実装など、様々な技術を試している段階です。
今後は監視体制の構築や負荷試験の実施、移行手法についても考え直す必要があり、プロダクションレディまでの道のりはまだ長いと考えています。
成長し続けるSaaSを支えるインフラの進化

まとめます。hacomonoの開発初期ではサイロモデルを採用していましたが、事業成長に伴いコストが増大し、リリースの不安定さに直面していました。この課題を解決するためプールモデルへの移行を実施し、コンテナの最適化を行うことで、運用コストとインフラコストの大幅な削減を実現しました。この刷新により、リリースの高速化と安定化についてもあわせて達成することができました。
現在進行中のinfra v2プロジェクトでは、ECSクラスタの統合とEC2の廃止を目的としています。DBの統合は困難であるため、現行のものを流用する方針としています。その接続制御を実現するため、ProxySQLとVPC Endpoint、Resource Gatewayを組み合わせたルーティング機構を構築し、適切な接続先の管理を行っています。
最後に、hacomonoでは、ウェルネスを新次元へと押し上げるための新しい仲間を募集しています。まずはカジュアル面談からでも問題ございません。ご興味をお持ちいただけた方は、ぜひお声がけください。
本日は、ご清聴いただきありがとうございました。

※本登壇内容は2025年11月時点のものです。2026年4月現在、本登壇で触れたプロジェクトの一部は休止しています。
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





