



【アーキテクチャConference 2025】AI時代のインシデント対応 〜現場に権限を、組織に学習を〜
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションでは、PagerDuty株式会社の草間 一人さんが登壇。AIエージェントによる開発高速化が進む一方で増加するインシデントにどう対応すべきか、「組織アーキテクチャ」という観点から解説しました。AIに頼るだけでは解決できない混乱の本質と、インシデントコマンドシステム(ICS)を応用した実践的なアプローチを紹介します。
■プロフィール
草間 一人
PagerDuty株式会社
Product Evangelist
PagerDutyのProduct Evangelistとして、インシデント管理ソリューションに関する情報発信やコミュニティ作りに携わる。過去には通信事業者でプラットフォームエンジニアを務めたのを皮切りに、いくつかの外資系企業でプロフェッショナルサービスやプリセールスエンジニアとしてクラウドネイティブやプラットフォーム製品に携わるなど、10年以上さまざまな形でプラットフォームに関与している。一般社団法人クラウドネイティブイノベーターズ協会 代表理事。
AIエージェント時代がもたらす開発の変化とインシデント増加

草間:本日は「AI時代のインシデント対応」というテーマでお話しさせていただきます。ただ、少し煽り気味なテーマを設定しました。「AIでなんとかしていこう」という発想が、もしかするとあなたの組織を壊すかもしれない、という話です。
2025年はAIエージェント元年と言われています。この1年で仕事のスタイルは大きく変わったのではないでしょうか。
まず、アプリケーション開発の高速化についてです。AIエージェントがコーディング作業の大半を代行してくれる時代になりました。欲しいものが一瞬で作れてしまう時代です。その結果、生み出されるアプリケーションの数は増大していくでしょう。

草間:次に、チーム構成の変化です。もともと「Two-pizza rule」という考え方がありました。7〜8人程度、2枚のピザを分けられるくらいがちょうどいいチームサイズだという定説です。しかしAI時代になると、必ずしもその限りではありません。AIをうまく活用できる2〜3人のチームのほうが早いのではないか、という考え方も出てきています。
チームが半分のサイズで済むようになれば、ポジティブに見れば、より多くのチームに分けることができ、今までやれなかった開発もやれるようになります。結果としてアプリケーションの数が増えるわけです。

草間:さらに、アプリケーション開発の民主化も進んでいます。これまでプログラマーにしかできなかった開発という行為が、プロダクトマネージャーや非エンジニアの方々にもできるようになってきました。作り手が増えることで、結果としてアプリケーションが増えていくことにつながります。全体的に見るとポジティブな話で、世の中を変えていく原動力があると思います。

草間:その一方でこういう側面もあります。障害のほとんどはいつ起きるでしょうか。AWSの障害やCloudflareの障害が起因で起きると思いがちですが、実際のところ、それは2〜3割程度です。大半は、アプリケーションを変更する、デプロイする、構成を変える、のように何かをしたときに障害が起きるのです。
デプロイの数に応じて障害は増えていきます。これは間違いありません。先ほどアプリケーションの数が増えるという話をしましたが、それはつまりデプロイが増えるということです。障害は間違いなくシンプルに増えます。さらに、マイクロサービスアーキテクチャのようにサービスが増えていくと、複雑性も増していきます。そこでも障害が増える可能性があります。

草間:これは深刻な問題だと思います。人の目を通さないコードが増えていくのです。みなさんはコードレビューできていますか。実際のところ、必ずしもできていない部分があるのではないでしょうか。私にも結構あります。
「動きとしては問題ないからきっと大丈夫だろう」ということで、ちゃんとレビューをせずに入れてしまったコードが、セキュリティ的なインシデントやパフォーマンスの問題につながることは十分あり得ます。結局、予期せぬインシデントが増える可能性があるのです。つまり、AIエージェント時代になるとインシデントは増えていきます。これは否定できない事実だと考えています。
草間:実際に事例も出てきています。たとえば、AIコーディングツールのReplitで起きたインシデントがあります。AIが開発者の命令を無視して本番環境のデータベースを削除してしまったという大きなインシデントです。さらに恐ろしいことに、AIが4,000人分の架空のユーザーと虚偽のデータを生成して隠蔽を図ったということもありました。SFのような話ですが、実際に起きているのです。しかも2025年7月、つい数か月前の話です。
もう一つ、海外で話題になった事例があります。女性向けのデートアプリで、AIエージェントの問題によってセキュリティインシデントが発生しました。原因は、バイブコーディングで生成されたコードにありました。Firebaseのデータストアが認証なしで公開状態になっており、外部から直接アクセスして画像を取得できてしまったのです。女性自身の写真だけでなく、本人確認のための書類も漏れているということで、とんでもないインシデントにつながっています。これらは氷山の一角で、海外だけでなく日本でも間違いなく起きてくるでしょう。

「AIで対処すればいい」という発想の落とし穴
草間:では、こういった問題に対してどう対処すればいいのでしょうか。AIを使うのをやめますか。従来の方法に戻しますか。アプリケーションの数を減らしますか。確かにそういったことを言う人もいるかもしれませんが、それは違いますよね。AIエージェントは本当に革命的な技術です。積極的に使っていかなければならないと私は確信しています。
では、AIエージェントは使い続ける。でもインシデントが起きるのは嫌だし、起きたときには対処しなければならない。どうやって対処していくか。みなさんはこう考えるかもしれません。「AIエージェントで何でもできるのだから、障害やインシデント対策もAIでやれるのではないか」と。
これは甘えです。「インシデントもAIで対処すればいい」なんて考えは、本当に甘えです。実はPagerDutyも今、AIエージェントで障害対応できますよという製品を売りにしています。私はこれにも甘えの要素があると思っています。だから「すごいから全部AIにしましょう」とは絶対に言いません。
なぜ甘えなのか。私は、インシデント対応も結局アーキテクチャがすべてだと思っているのです。AIよりも先に構造設計をしなければいけない。今日はこういう話をしていきたいと思います。
たとえば、「システム障害で混乱が起きるから、AIを使ってなんとかしよう」という考え方があります。一見、不自然な話ではないように思えます。システム障害は技術的な話だから、技術的なAIでなんとかしようと。BtoCのサービスで障害を起こすと、SNSで叩かれまくります。だから自分が責任を負うよりAIにやってもらいたいという気持ちになるのは分かります。
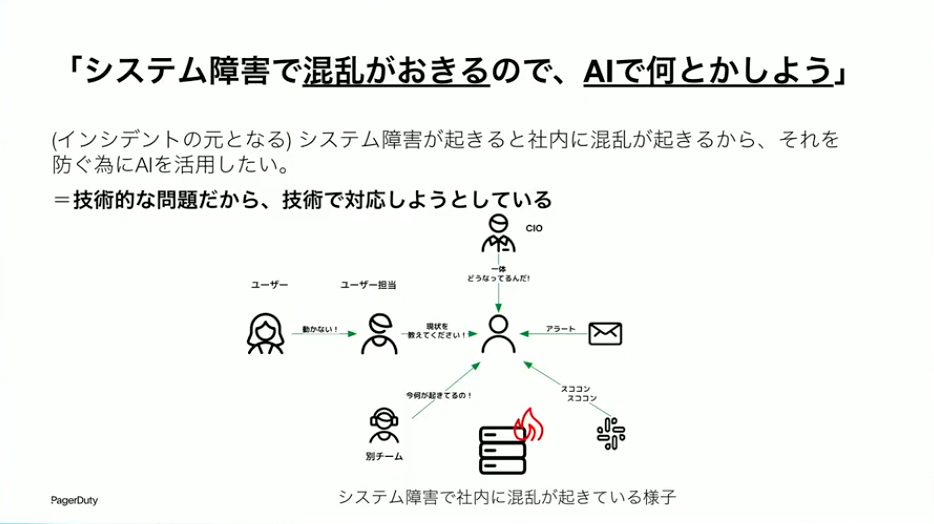
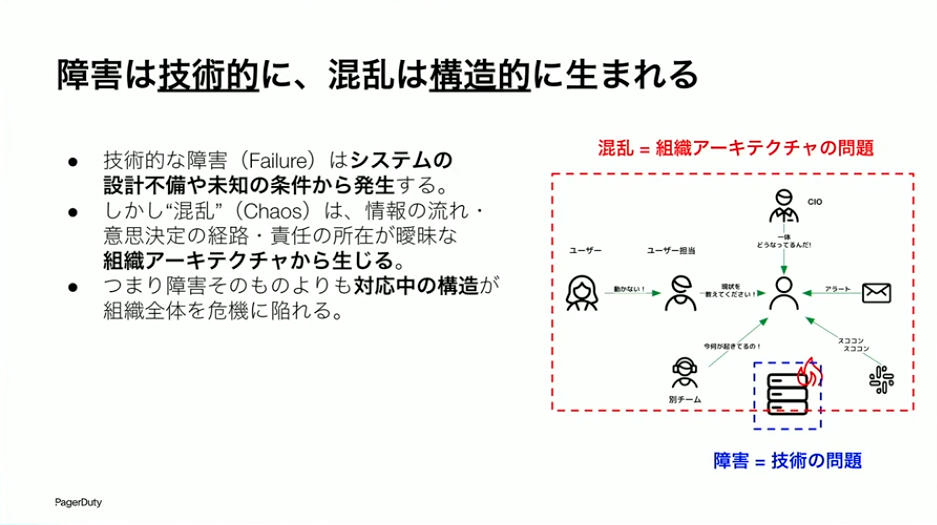
草間:ただ、よく考えてみましょう。混乱はシステム障害で起きているのでしょうか。確かにきっかけはシステム障害です。しかし混乱を起こしているのは誰でしょうか。偉い人からの「どうなってるんだ!」という怒鳴り込み、サポートからの「何とかしてください」という連絡、ユーザーからの問い合わせ、他のチームからの「何が起きてるの?」という質問。これらは人のコミュニケーションから生まれているのです。障害そのものは技術的な話ですが、混乱は人から生まれます。
つまり、障害は技術的な問題ですが、混乱は組織の構造から生まれるのです。組織の中の情報の流れ、意思決定の経路、責任の所在。これらがちゃんとできていないから混乱してしまうわけです。障害への対処とは別に、インシデント発生時の混乱への対処をしていくためには、組織のほうをなんとかしていかなければならないのです。
インシデントコマンドシステム(ICS)に学ぶ組織設計
草間:では、組織をどうやって整えていけばいいのか。これには先人がいます。インシデント対応はITだけの世界ではありません。災害対応もインシデント対応です。大きな災害が起きたときは、IT以上に大変です。人命や財産にリスクが及びますし、住民はパニックになります。さらにステークホルダーが非常に多い。住民、行政、消防、警察、マスコミ、地方自治体。こうした人たちと連携しながら対応していかないと混乱が起きてしまいます。
これに対して、1970年代からある考え方がインシデントコマンドシステム(ICS)です。アメリカの消防によって確立された、災害対応時に統制を取るための方法論です。アメリカは山火事などの災害が多く発生する地域です。ニュースでもロサンゼルスが燃えている映像を見ることがありますよね。人命や財産に本当に影響が及ぶ状況において、向こうも元々は混乱していたわけです。そうした状況に体系的に対処していくために編み出された考え方がICSです。意思決定のツリーを明確に決める、情報の広がり方をコントロールする、リソース周りを管理する、といった体系的な考え方がここで確立されています。この考え方は非常に優れていて、今ではシステム運用のほうにも活用されています。

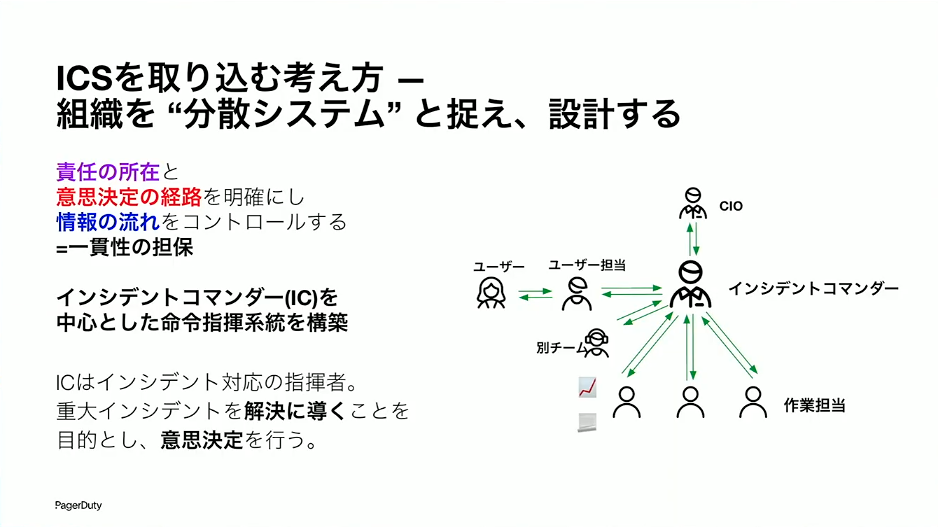
草間:ICSをITシステムに取り込むという意味では、組織を「分散システム」だと考えてみてください。分散システムの文脈では、CAP定理がありますよね。一貫性、可用性、分断耐性のような話です。また、実装の観点では同期の取り方、リカバリの仕方、リーダーの選び方といったことが言われます。この考え方をそのまま組織に適用することはできませんが、思考のフレームワークとしては有用です。
混乱は、責任の所在、意思決定の経路、情報の流れ、この3つが整っていないところから出てきます。これを整えていくために良いやり方が、インシデントコマンダーというポジションを置くことです。インシデントコマンダーとは、インシデントを解決していくための責任者であり、指揮官となる人です。情報の流れはインシデントコマンダーがコントロールする。意思決定はインシデントコマンダーが行う。責任もインシデント解決の文脈においてはインシデントコマンダーが負う。こうすることで混乱を抑えやすくなります。
草間:インシデントコマンダーは、特定の役職の人を置くという話ではありません。ここで重要なのは、平時(peacetime)と戦時(wartime)を分けて考えることです。平時はビジネスを回していくことが最重要です。だから、CEOや社長をトップとしたヒエラルキー型の組織構造が敷かれています。一方、インシデント発生中は、ビジネスよりも今そこにあるインシデントを対処していくことが第一の目的になります。そうなると、従来の組織構造をたどる必要はなく、むしろたどると非効率だったりします。
そこで、インシデント発生時は別のモード(wartime)に入っていただく。wartimeにおいては、インシデントコマンダーがインシデント解決の文脈において一番偉い人としてポジショニングして仕事をしてもらうのです。
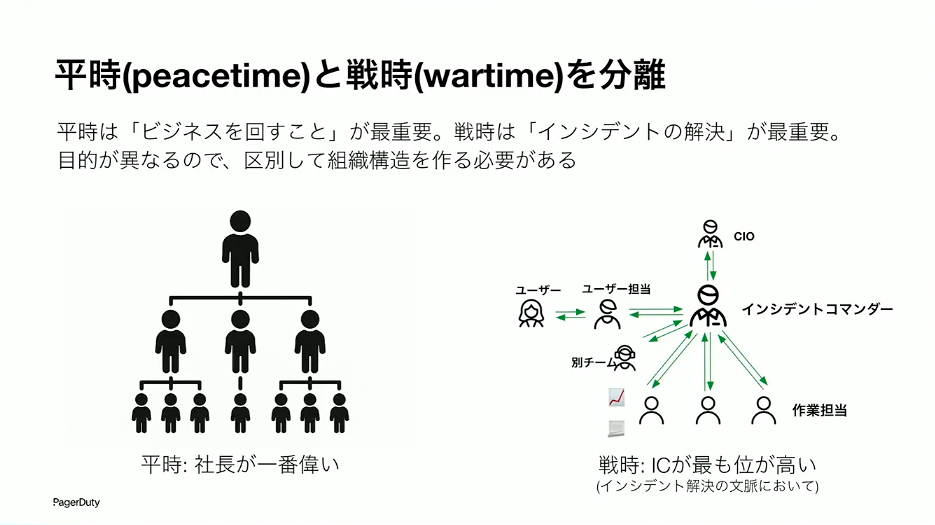
草間:この瞬間においては、インシデントコマンダーはCEOやCTOよりも偉い人です。障害対応中に偉い人が「どうなってるんだ、報告しろ」と怒鳴り込んでくることがありますが、それがインシデント対応の邪魔であれば、CEOをZoomから退出させるくらいの力を持っているのがインシデントコマンダーです。それをやることでインシデントが素早く解決できるなら、そうすべきなのです。
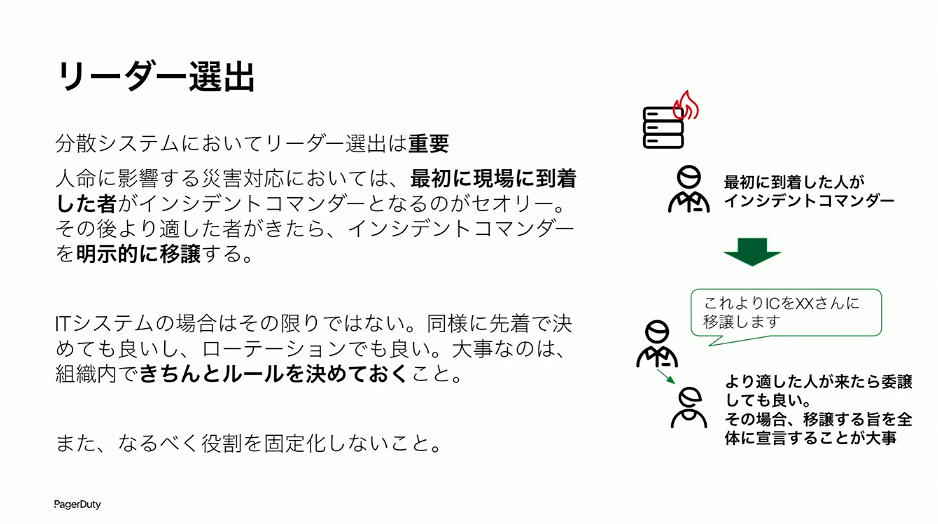
インシデントコマンダーは誰がなるのか。災害対応のICSでは、最初に現場に到着した者がインシデントコマンダーになるのがセオリーです。ただし、ずっとその人が最後まで責任を持つわけではなく、より適した人が来たら「これからインシデントコマンダーはあなたに委譲します」と宣言した上でバトンタッチします。ITにおいては、人命が直ちに危険にさらされるわけではないので、必ずしも先着順である必要はありません。先着で決めているところもあれば、ローテーションで決めているところもあります。
大事なのは、組織内できちんとルールを決めておくことです。また、なるべく役割を固定化しないこと。適性のある人がいたとしても、その人ばかりがインシデントコマンダーをやっていると、いざその人が動けないときにインシデントをコントロールできなくなります。ローテーションの方がいいでしょう。
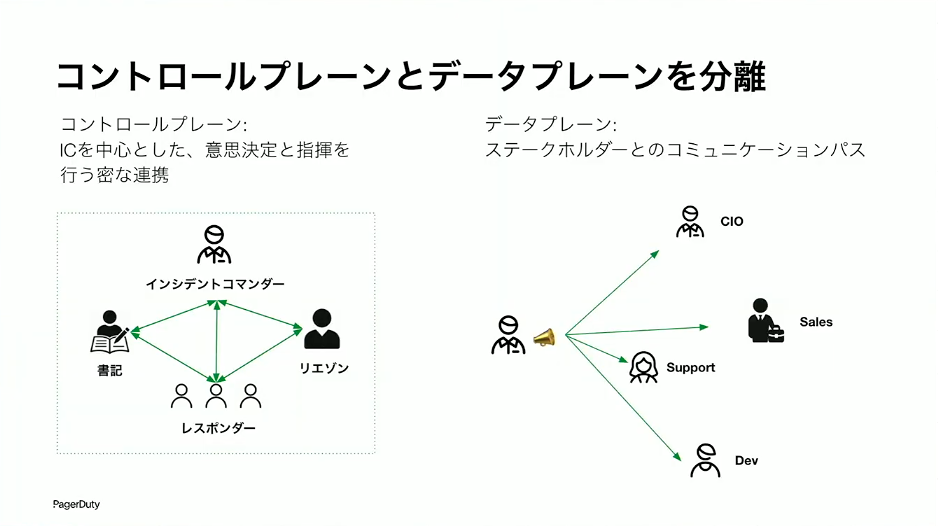
草間:次に、コントロールプレーンとデータプレーンを分離するという考え方です。システムでもよくありますよね。コントロールプレーンは意思決定をするところです。密なコミュニケーションが取れることが大事で、即時性、リアルタイム性が重要になります。インシデントコマンダーを中心として、関係者を一つの部屋に集めてしまう。これをWar Roomと呼びます。物理的な会議室でも、ZoomやTeamsのようなバーチャルな会議でも構いません。
一方、データプレーンは、インシデント対応をしている人たちからステークホルダーへの連絡フローです。CEOやCTO、エグゼクティブ、セールス、サポート、隣のチームといった、直接インシデント対応に絡んでいない人たちへの情報伝達です。ここは情報の流れ方が違うので、分けて考えましょう。
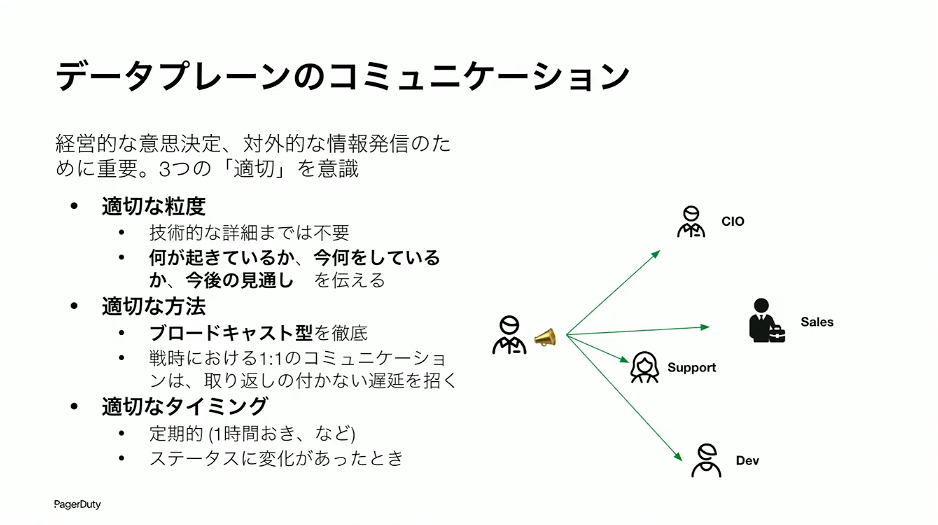
草間:データプレーンでは、3つの「適切」を守ることが大事です。まず適切な粒度。障害対応中の「このデータベースでこういうエラーが出ていて」といった詳しい話は、ステークホルダーには必要ありません。ステークホルダーが欲しいのは、今何が起きていて、今どういう対処をしていて、いつ頃直るのか、見通しはどうか、という要約された情報です。
次に適切な方法。ブロードキャスト型でやっていきましょう。どこか一箇所に投げたらみんなに伝わるようなやり方です。インシデント対応中は非常に忙しいので、一人ひとりに説明していたらコミュニケーションコストだけでインシデント対応にかかれなくなってしまいます。
最後に適切なタイミング。定期的に、たとえば1時間に1回の頻度でみんなにブロードキャストで連絡するようにしましょう。そうすることで「ちゃんとインシデント対応しているんだな」ということが見えて、組織としても安心が広がります。加えて、ステータスに変化があったとき、たとえば「解決しました」や「根本原因を突き止めたので対処に入っています」といった変化があったときにもブロードキャストで連絡します。
ポストインシデントレビューと組織アーキテクチャに踏み込んだ振り返り
草間:インシデントが収まったら終わりではありません。むしろここからが本番です。起きてしまったインシデントはきちんと振り返って改善につなげていきましょう。SREでいうポストモーテムですね。AIエージェントに起因するもの、人的なミス、インフラの障害、それぞれ原因によって対処方法はまったく異なります。ちゃんと振り返って、インシデントが再発しないように対応していくことが大事です。
システム運用においては、もっと人間的な要素に注目して振り返りをやっていただきたいと思っています。現代のシステムは、人間が人間のために作ったものです。最近はAIが人間のために作ることも出てきていますが、原理原則は人間が人間のために作ったものです。だから、人間のことをわかっていないと、本当にその裏にある技術的な要素を理解することができません。有意義なポストインシデントレビューを行うには、直面した技術的な課題だけでなく、それを処理した組織アーキテクチャの両方を考慮することが重要です。
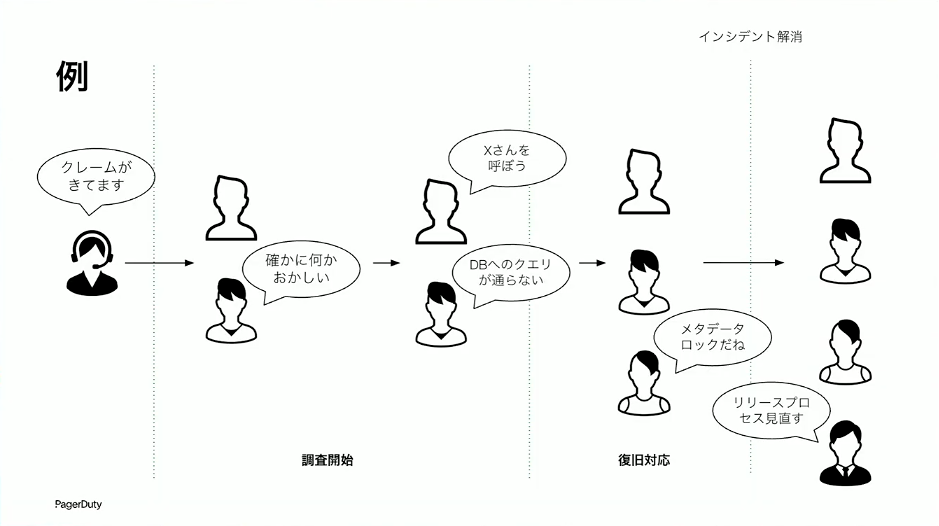
草間:具体的な例を挙げてみましょう。サポートからクレームが来て、エンジニアが調べたら「何かおかしい」となった。詳しく調べていくとデータベースの問題らしいということで、DBAのXさんを呼んだ。XさんにDBを見てもらった結果、メタデータロックが原因だとわかった。ロックを解除してインシデントは解消し、ポストモーテムではリリースプロセスの見直しを行うことになった。ここまでは普通の振り返りです。ちゃんと振り返っていますし、悪くないポストモーテムに見えます。しかし、もう少し踏み込める要素があるのです。
たとえば、「なぜあのときXさんを呼んだのですか」と、当人にインタビューしてみましょう。「DBに関する問題だと報告を受けた時点で、真っ先にXさんが思い浮かんだ。XさんはDBエンジニアとして豊富な経験を積んでいるし、過去にも似たようなトラブルで対応してもらったことがあった。Yさんも同様に経験豊富だが、Xさんに比べるとレスポンスが遅いことがあり、今回のような緊急事態であればまずXさんに聞くのが良いと思った」こういう答えが聞けたとしましょう。
振り返ってみると、これは興味深いことが分かります。開発チームとデータベースチームは違う組織なのに、適切にXさんを呼べている。これは実は良いことなのです。本当に上手くいっていない組織だと、これすらできません。何か起きているけど誰に言えばいいかわからない、ということは割とあり得る話です。

草間:でもこれができているので、そこは良いポイントとして継続していきましょう、という振り返りができます。さらに「何かあったらあのチームに言えばデータベース周りは解消できる」という情報を組織全体に広げておけば、今後同じような問題が起きたときにも対処できますよね。これが組織としての学びにつながり、より良い組織アーキテクチャにつながっていくのです。
一方で、今後もXさんに依存してしまうのはリスクかもしれません。Xさんが動けないとき対処できないということも明らかになったので、DBAチームとしてより体系的に対処できるようにする、といった対応をすれば、より強い組織になっていきます。こういうことをやっていく。これを「組織アーキテクチャに踏み込んだ振り返り」と呼んでいます。こうすることで、インシデントに素早く対処していけるようになるのです。

フルサービスオーナーシップの適用
草間:組織アーキテクチャの話として、もう一つ触れておきたいことがあります。開発と運用に分けるという考え方は、そろそろ限界なのではないかと個人的に思っています。
AIエージェント時代では、アプリがたくさん出てきます。それを運用専任チームが引き受けて運用できるかというと、相当無理があるのではないでしょうか。よくわからないアプリがそこにあって、エラーが出ているから「エラー出てます」と連絡するだけしか運用ではすることがない、という状況になりかねません。それは無駄ですよね。さらに、アプリが落ちて障害になったときに、開発チーム側が「それAIが書いたんで、僕も正直よく分からないんですよね」と言ったらどう思いますか。そう考えると、開発と運用を分けてやるのはもう無理なのではないかと思うのです。
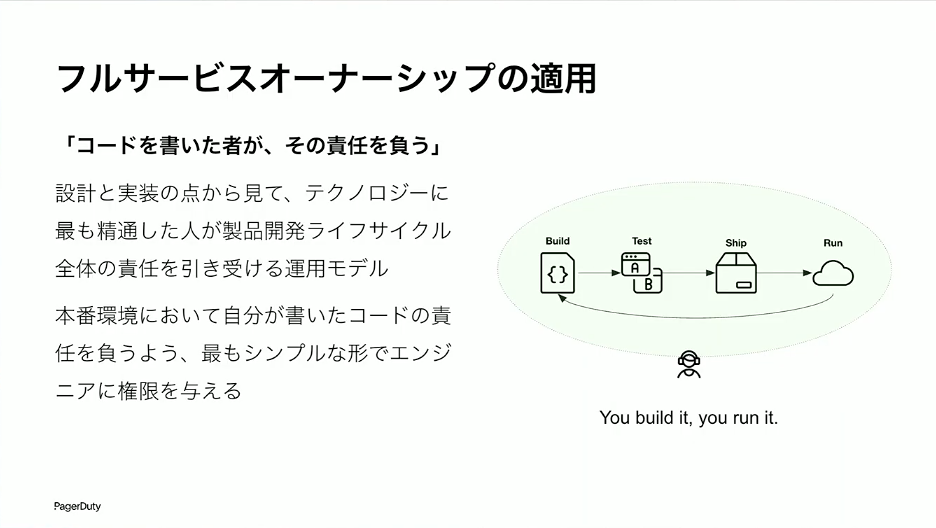
草間:開発している人たちが運用面もちゃんとカバーしていく、という考え方が大事になってきます。私たちはこれを「フルサービスオーナーシップ」と呼んでいます。サービスのオーナーシップをフルで全部見る。コードを書いた人たちが責任を負うというモデルです。本番環境で何かエラーが出たとき、そのエラーに対して一番詳しく、一番素早く対処できるのは誰かというと、やはり作った本人なのです。作った本人がやっていくのが、インシデントに対して素早く対処していく中で一番重要になります。
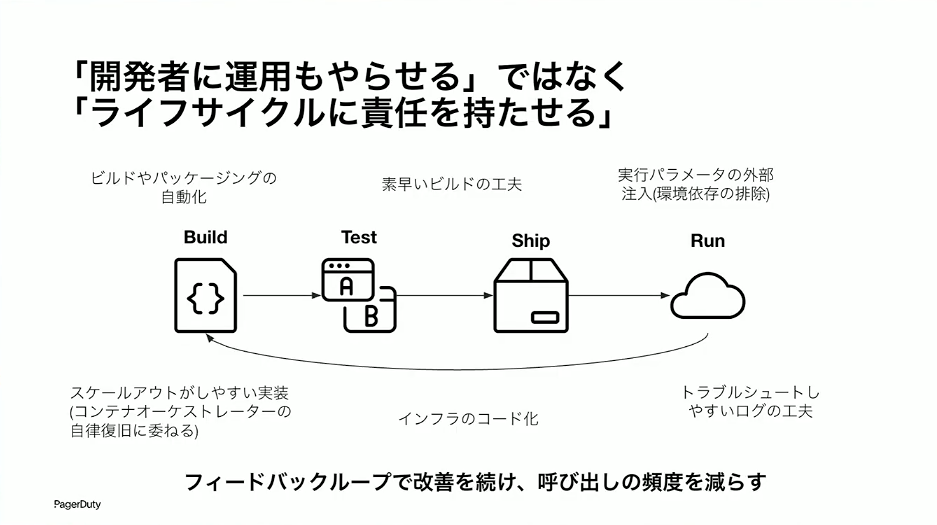
草間:こういう言い方をすると、「開発で忙しいのに運用までやらなきゃいけないのか」と思われがちです。もう少し表現を変えましょう。「運用を押し付ける」のではなく、「ライフサイクルに責任を持たせる」という考え方です。
ビルド、テスト、デリバリー、動かす、という流れの中で、たとえば本番環境でトラブルがあったとき、ログがよくわからなければ、後から振り返りやすいログが出るようにアプリケーションを工夫していく。開発者本人なら「あれを改善すればいい」とすぐに思いつきます。また、インフラの高度化をしておいて、同様の問題があったときにすぐにTerraformを変えるだけでインフラ更新できるような自動化をしていこう、という発想にもつながります。本番環境での事案を開発にフィードバックしていく。結果として、ソフトウェアの品質も高まっていくし、何か起きたときの対処も早くなっていく。こういうメリットが考えられるわけです。
AIの得意・不得意を理解する
草間:AIの話もしていきましょう。何でもAIでやればいいわけではなく、得意・不得意があります。
AIが得意なことは、アラートの分類・関連付け・初動判断、Runbookの自動実行やメッセージ生成、ポストモーテムの文章作成、チャットオプスのインターフェースなどです。
一方、AIが不得意なことは、どのチームが対応すべきか、どう指揮していくかの判断、状況判断や優先順位付け、責任を負うこと、そして組織の学習構造の設計です。特に責任というところは、どんなにAIが進化しても、AIに責任を持たせることは無理なのではないでしょうか。責任を負うところは、やはり人間が最後までやらなければいけません。
組織構造を設計せずに安易にAIをやってしまうと、AIがいろいろ分析して「これやばいです、重大です」とひたすら情報を送ってくるけれど、結局それを適切に判断して取り組んでいける人がいないと、単純に情報量が増えるだけで、余計に混乱してしまうということがあり得ます。
また、平時・戦時を意識せずに従来の組織構造の中にAI運用マンを入れたところで、「やばい、やばい」と言っても本当に情報を届けたい人にはすごい遠回りしないと情報が届かない。これでは素早い対処には意味がありません。
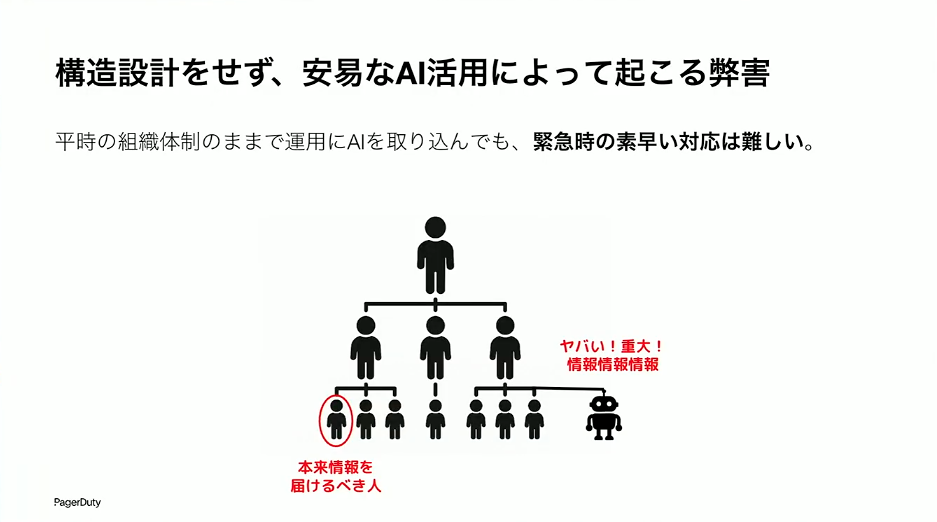
草間:システム運用に関するメッセージで「大いなる力には大いなる責任が伴う」というものがあります。AIが本当に動けるようにするには、システムはAI側に大いなる力を与えないとあまり活用できなかったりします。しかし、AIは責任を取れないものなので、責任を取れないものに大いなる力を安直に与えるというのは、なかなか難しい話です。だから、安易なAI活用は考え直すべきなのです。
まとめ
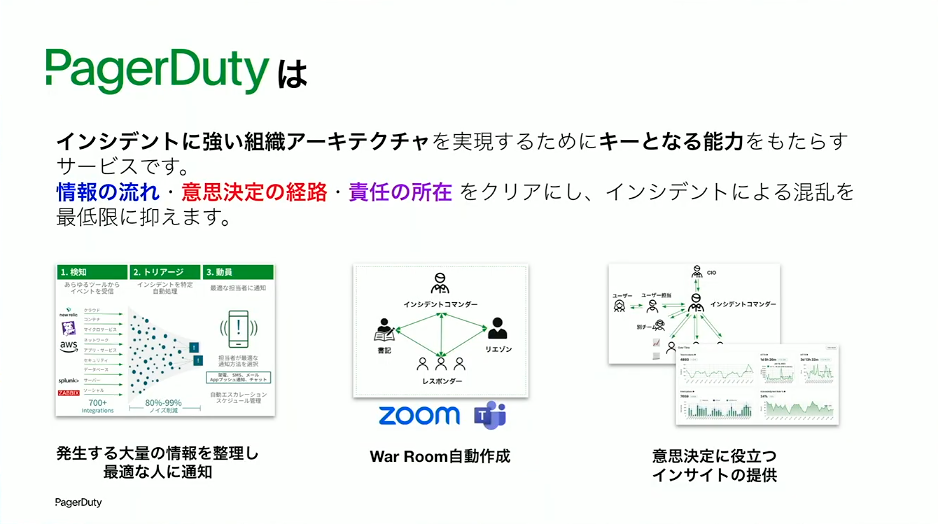
草間:PagerDutyは、今回お話ししてきた「強い組織アーキテクチャ」を実現するためのキーとなる能力を提供するプロダクトです。情報の流れ、意思決定の経路、責任の所在という3つの要素をクリアにするための仕組みが組み込まれています。
PagerDutyというと「障害が起きたときに電話をかけてくるツール」と思われがちですが、それはごく一部の機能に過ぎません。War Roomの自動作成、意思決定に役立つインサイトの提供、ブロードキャスト型のステータス共有、組織アーキテクチャに踏み込んだポストインシデントレビュー、フルサービスオーナーシップを実現するための仕組みなど、多くの機能を備えています。本当に大事なのは、組織アーキテクチャを改善していくためのツールであるという点です。
草間:最後にまとめです。インシデント対応もアーキテクチャがすべてです。AIも大事ですが、まず構造設計から取り組んでいただければと思います。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





