



【アーキテクチャConference 2025】手が足りない!兼業データエンジニアに必要だったアーキテクチャと立ち回り
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
11月21日に登壇した、ソーシャルデータバンク株式会社の技術本部エンジニアリング部プラットフォーム課課長の神 光佑さん。月間2.6億通のメッセージを配信する自社開発プロダクト「Liny」の膨大なデータを、最小限の人数・工数で運用し続けるために神さんが行き着いたのは、徹底して認知負荷を下げる工夫と、組織を巻き込むための取り組みだと話します。
「一人でデータ基盤を運用しており、手オペに追われている」「いつか来る仲間にスムーズに引き継げる自信がない」そんな悩みを抱えるエンジニアに向けた「運用を破綻させないための設計思想」をご紹介いただきました。
■プロフィール
神 光佑
ソーシャルデータバンク株式会社
技術本部エンジニアリング部プラットフォーム課 課長
SIerとSES企業を経てフリーランスエンジニアとして活躍し、データ基盤立ち上げにも参画する。その後、フリー株式会社でもデータ基盤チームへ。2023年よりソーシャルデータバンク株式会社にジョインし、SREに従事。
兼業エンジニアの時間を奪う「3つのボトルネック」
皆さんこんにちは。本日は「手が足りない兼業データエンジニアに必要だったアーキテクチャと立ち回り」と題して講演いたします。
「手が足りない」という課題において、なぜ手が足りなかったのかを具体的に言語化しながらお話を進めていきます。
個々に振り返ってみると、予想以上に時間を奪われる業務が3つ挙げられました。1つ目は「手オペ」が何かと発生しがちで、試行錯誤しているうちに時間がかかってしまう点です。2つ目はデータエンジニアのスキルセットが独特であるゆえに引き継ぎしづらく、運用の負担が上がり続ける点。そして3つ目は、兼業だとデータの民主化の優先度を上げにくいという点です。
これらの課題に対して、なるべく時間をかけずにうまくやっていくにはどうしたら良いかを解説していきます。
弊社のデータ基盤は小規模で、これからデータ活用していく段階にあります。これからデータ基盤を立ち上げる方や、人手が足りない中で何とかやっているみなさんに役立つ情報があればうれしいです。

月間2.6億通を支える「Liny」のシステム規模とデータ基盤
まずは弊社について簡単にご紹介します。
ソーシャルデータバンク株式会社は2017年に創業し、現在9期目を迎えています。従業員数は約70名です。
自社開発プロダクトの「Liny」は、LINE公式アカウントの配信や運用管理をサポートするツールです。月間2億6,000万通のLINEメッセージを配信しており、契約アカウントは2万を超え、総友だち数も約8,700万人を超えております。みなさんのLINE友だちのアカウントにも、弊社のサービスを介しているものがあるかもしれません。
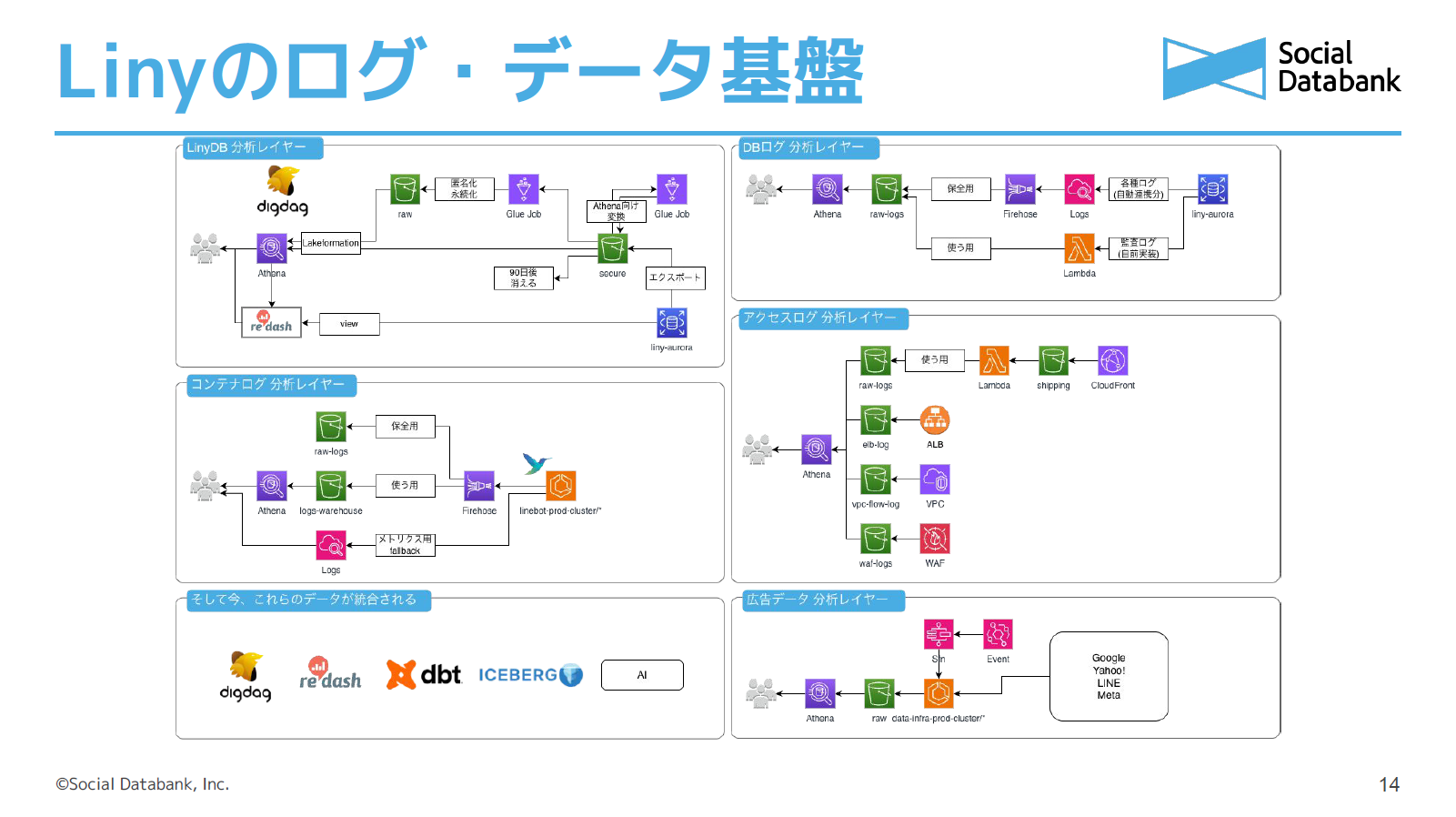
システム規模感として「Liny」はECSを中心に構成されており、常に500以上のコンテナが稼働し、毎日2TBほどのログが出力されています。メインのDBはAurora MySQLで、最大数百億レコードのテーブルがあります。他にもDynamoDBにテラバイト級のデータがあり、ElastiCacheもたくさん使用しています。これらのデータを統合して分析できるデータ基盤のアーキテクチャです。現在は、DBとログを統合して調査分析できるようなデータ基盤になっています。
DBのデータは、リアルタイムな調査向けに本番リーダーを直接見るルートと、分析向けに月1回S3エクスポートをしてAthenaで見るルートがあります。それ以外のログはSRE管轄で集約しており、ほぼ全てのログが何かしらのIDでジョインして参照できるようになっています。
なおログ基盤については、より詳細な記事をFindy Tools
で掲載していますので、ご興味あればぜひ合わせてご覧いただければと思います。
手オペの「効率化」を徹底。再処理に強いアーキテクチャーを
ここから本題に移ります。何かと手オペが多いデータ基盤の運用で、苦しまないためにできることは何かをお話します。
よくある手オペは、過去分の再集計やデータ欠損の対応依頼です。また過去のデータを大規模に扱う際に、「一部のデータが欠けている」「何かおかしい」といった問い合わせが稀に来ます。こういった場合はいったん時間をもらって、落ち着いて対応していきます。
事前に調査していても、過去のデータを扱うと想定外の事態が起きやすいものです。どんなに入念に設計・実装していても、手オペで解消せざるを得ないケースもあります。そのほか、問題がなくても「手動の方が早いので手オペしてしまう」というケースも多いでしょう。

こうした過去データ回りの手オペで苦しまないために、備えておくと良いものをご紹介します。決して特別なことではなく、基本的なことです。
手オペを「1タスク1業務」にする工夫
まずワークフローエンジンへの依存を極力減らし、1つのタスクで1つだけの業務を進めること。これが一番重要だと考えています。ワークフローエンジンからしか動かせなかったり、1つ動かすと他の副作用も動いてしまったりするつくりだと、特定の不具合の箇所だけを直すのが難しくなります。

この対策はシンプルで、ユースケースを切り離して実装することに尽きます。例えば弊社のAurora S3 exportタスクは、ポイントインタイムリカバリーでクローンを立て、そのデータをS3にエクスポートし、最後にクローンを掃除するという3段階に分かれています。これらを一気に行っても良いのですが、検証やトラブルシューティングで個別に動かしたいケースがあるため、独立したサブコマンドとして実装しています。
また入力では、環境変数ではなく引数を使用するように意識しています。ワークフローエンジンの定義とスクリプトを動かす時の見た目を同じにし、認知負荷を減らせるためです。この対応により、問題があった箇所のみを修正するのが容易になります。
手オペによるタイムロスを避ける仕組み
次は、スキップや上書きを柔軟に指定できる仕組みについてお話します。
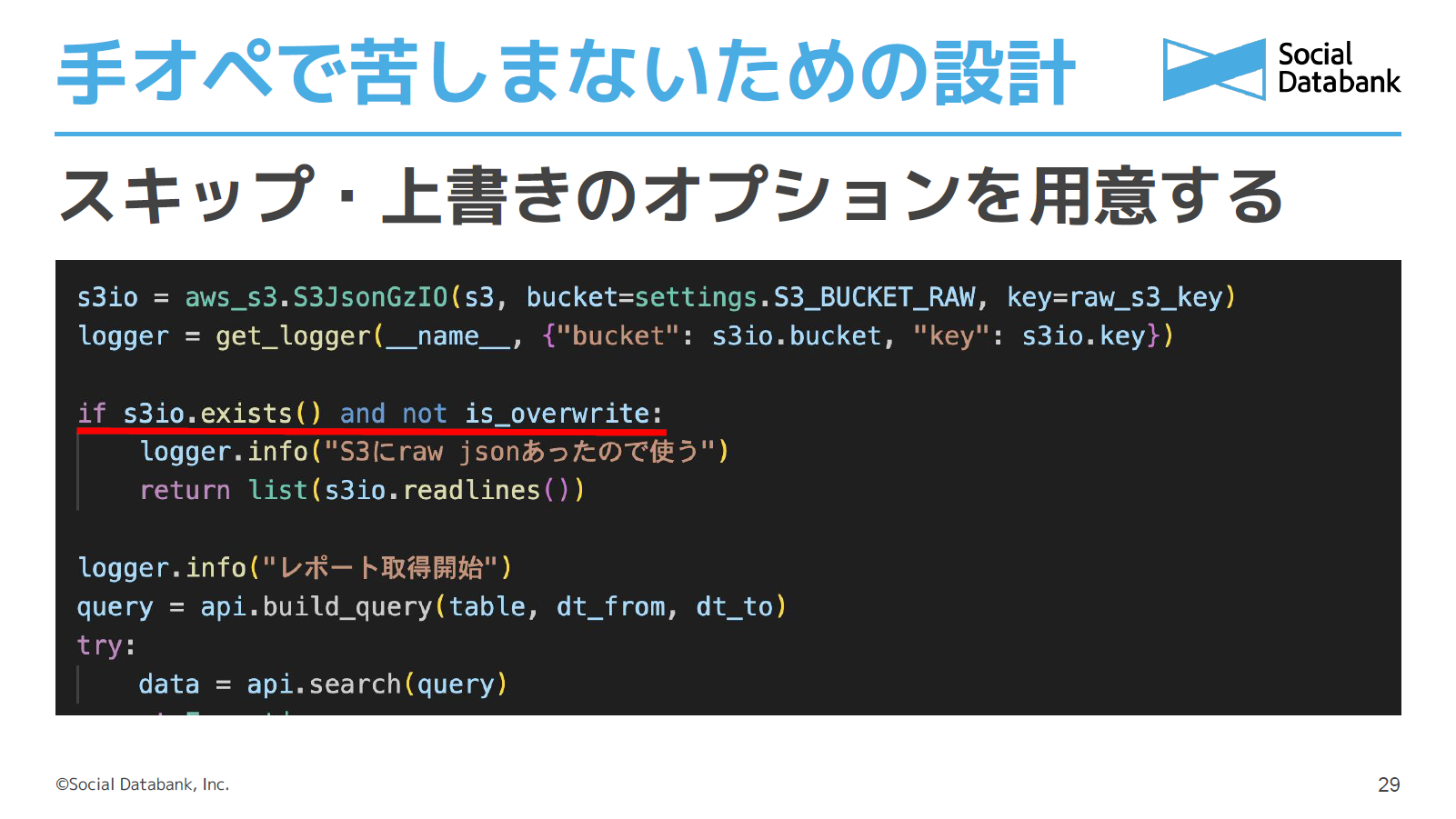
無駄な再計算を防ぐためにアウトプットが既にあればスキップし、更新したい時だけテーブル単位で上書きできるようにします。ただしRAWデータなどの取り直しがきかないものは、上書きできないように明示して実装しておくと安心です。たいていの場合は数行の簡単なコードで実現できるのでおすすめしています。
また、ログ集計のように日付をパラメータで受け取る場合は、特定の時間ではなく「From」と「To」の期間で受け取るようにします。
例えばスケジュール実行しているクエリだと10時の処理であれば10時からインターバル1時間で11時というふうに期間が固定されている場合をよく見かけます。そうすると、10時間分一気に再処理したい時に、そのままだと10発動かさないといけません。ですがこのように対応することで、10時間分を一気に再処理したい場合でも、一発のクエリで高速かつミスなく実行できるようになります。
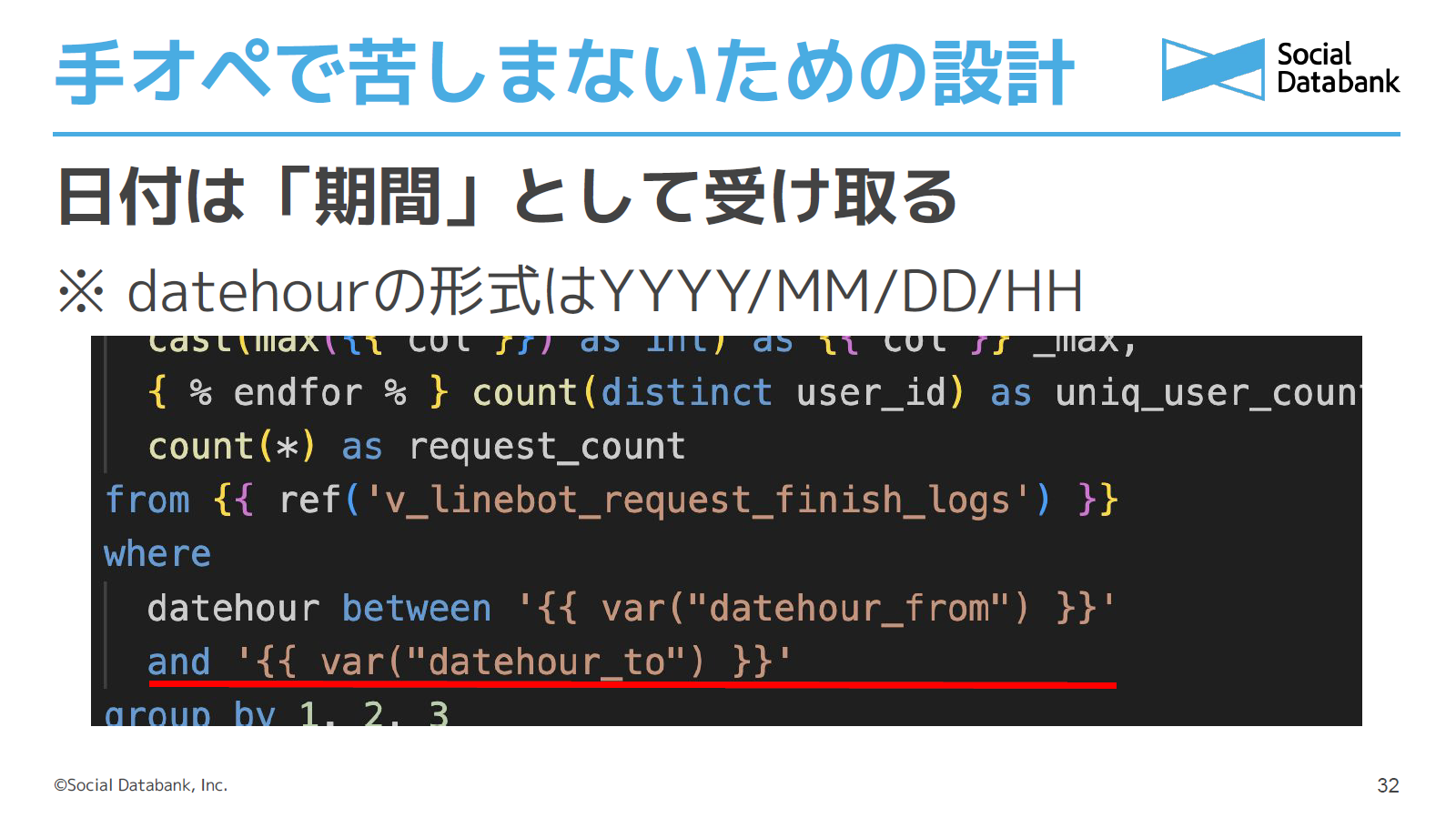
わずか数行でできるものですが、この期間指定クエリには何度も助けられているため、非常におすすめです。
手オペによる事故・ミスを防ぐ備え
手オペのミスのリスクには、最小権限の設定で備えるべきです。柔軟性とトレードオフで難しい部分もありますが、最低限余計なことはできないようにし、取り直しのきかないRAWデータはバケットを分離したうえで、バージョニングをセットで有効にしておくと良いです。
そして最後に、「手オペを手オペのままにしない」ということも重要です。頻繁に行う作業は見つかり次第、マニュアルのワークフローとして切り出して手オペを減らしていく活動も必要です。
手オペが発生する時点で、現場は何かしらの問題に困っている状況だと思います。その状況を悪化させないために、また問題を速やかに解決するために、日頃から備えておくことが大切です。
1人のうちから「引き継ぎ」に備える。認知負荷を下げるツール選定と開発環境
属人化と学習コストを抑えるためのツール選定
続いて、引き継ぎについてお話します。
データエンジニアは採用や社内勧誘が難しい分野であり、一人で担当すると属人化しがちです。しかし一人だからといって運用フローの整備を怠ると、いざ人が増えた時に引き継ぎで余計に忙しくなってしまいます。一人のうちから自信を持って関与できる体制をつくっておくことが大切です。
引き継ぎの準備として特に大事なのは、「覚えることをできるだけ減らしておくこと」です。データエンジニア初心者がジョインした際には特に重要かもしれません。
タスクを一つのコマンドとして切り離して実装していれば、ワークフローの全体像を気にせず、実装だけに集中できます。
ワークフローエンジンに関して弊社は、YAML定義である程度制限があり、画面の操作も比較的シンプルでとっつきやすいDigdagを採用しました。Python系は自由度が高い分、学習コストが高い傾向にあります。またStep Functionsも部分的に導入しましたが、数が増えると一覧しにくく、あまり向いていないと感じました。
上書き事故を防ぐ、Docker Composeのオーバーライド活用
そして、開発環境についてです。
データ基盤はAWSやGoogle Cloudをはじめ、クラウドの操作が非常に多くなっています。ローカルだけで完結させるのは難しいため、手元からクラウドを操作したくなりますが、チーム開発ではメンバーが環境の譲り合い、上書き事故も起きやすくなります。
こうした問題は人が増えると突然発生するため、引き継ぎに余計なコストがかかります。そのため、一人のうちにできるだけ予防策を打てると理想です。
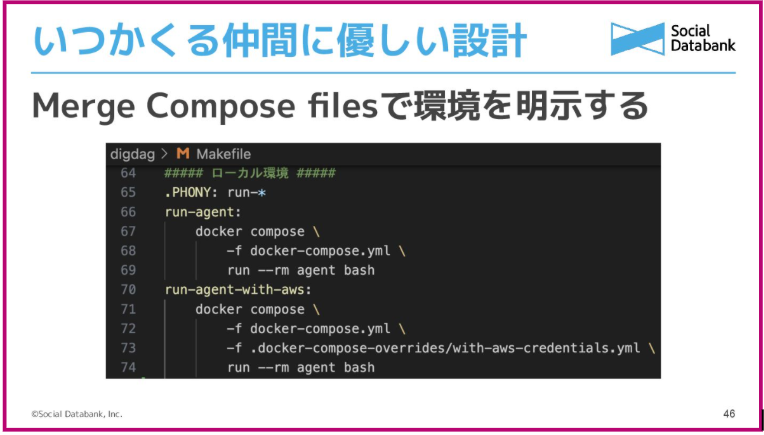
弊社ではDocker ComposeのオプションでYAMLを複数渡し、内容をオーバーライドしていく手法をとっています。ベースをユニットテスト用のコンテナにし、環境ごとのプロファイルに応じてAWS設定などをオーバーライドします。これにより、AWSの設定ファイルを誤ってコミットするミスを防ぎつつ、Makefile一発で環境を切り替えられるようになります。
本番用とは別の、実験用データベースを用意
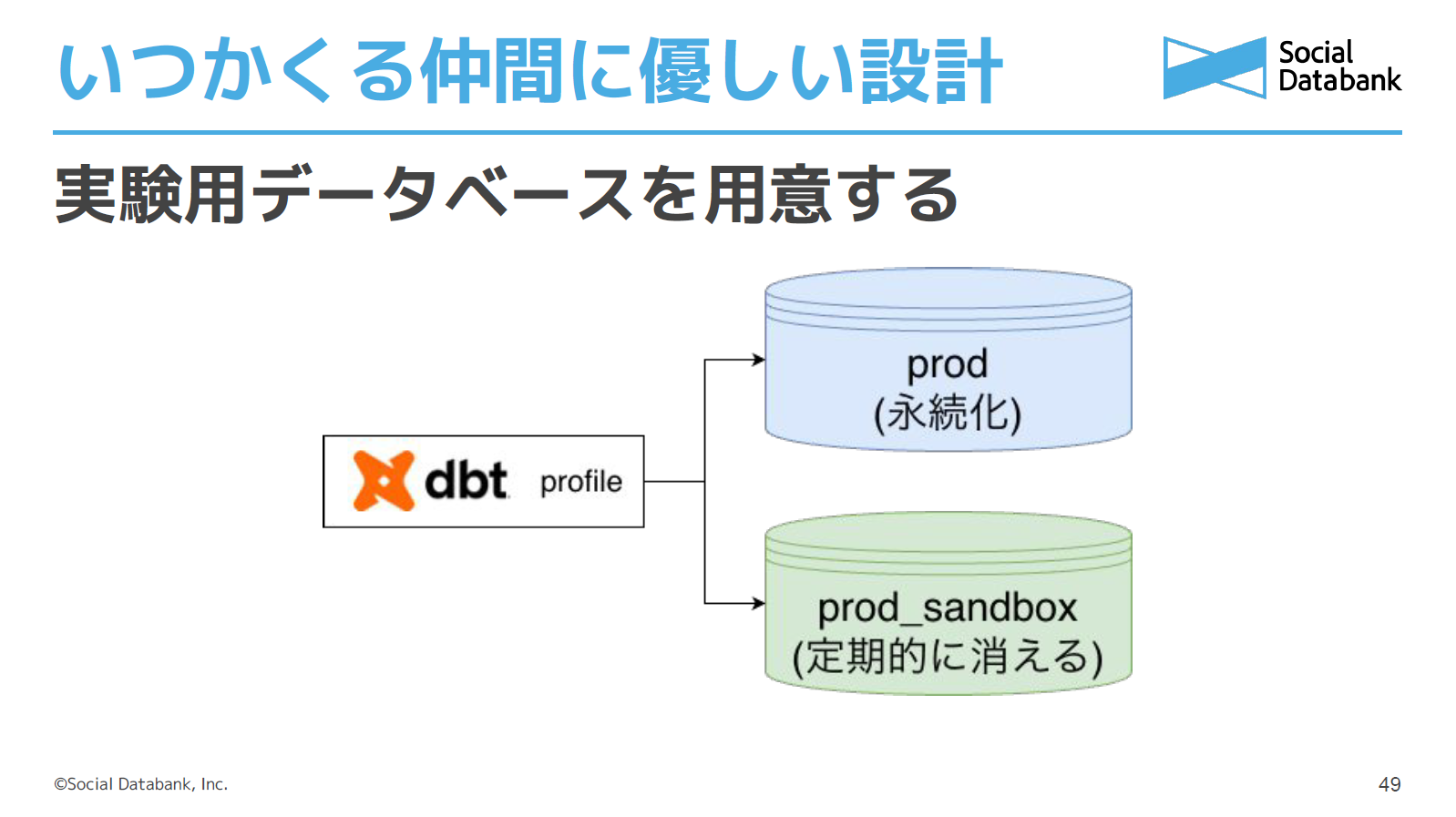
開発を進めやすくするという点では、実験用と本番用で最低二つのデータベースを用意することもおすすめです。実験用は書き込み権限を広めにして、定期的に掃除する仕組みもつくっておきます。
dbtを使う際は、環境変数などでターゲットやスキーマを切り替えてデータベースを使い分けられるようにしています。ここがあまり柔軟すぎると事故の元なので加減が必要ですが、さきほどのDocker ComposeのYAMLと組み合わせて使えば、たいていのミスは防げるのではないでしょうか。
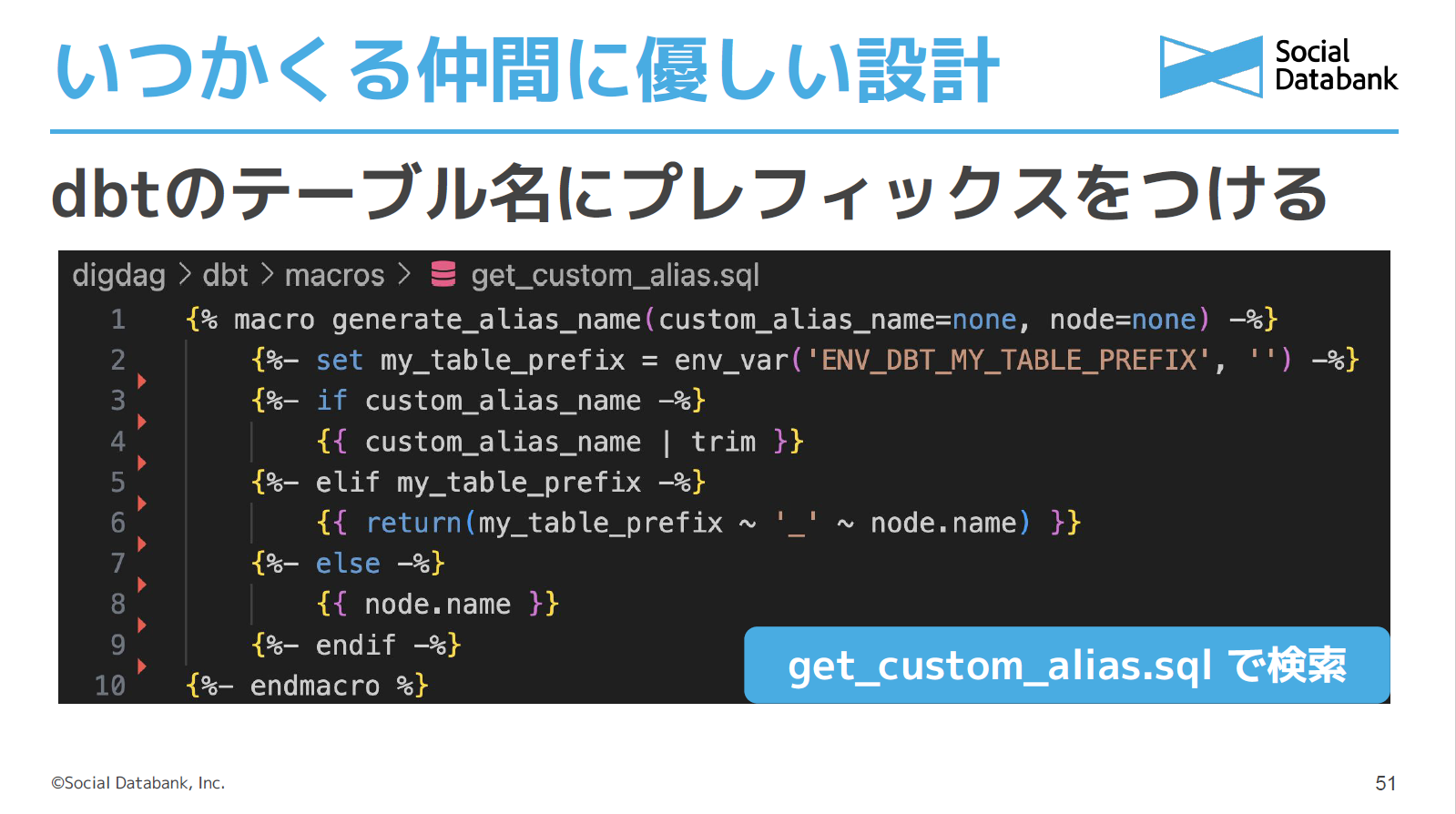
ただし、そのままでは複数人で開発した時にテーブル名がバッティングするため、テーブル名に自由にプレフィックスをつけることができるカスタムエイリアスの仕組みを入れています。環境変数で好きなプレフィックスを設定できるようにすることで、バッティングを防止できます。こうした準備によって、データ基盤やDockerに慣れていないメンバーが困りやすいポイントを事前に解消できると考えています。
データの民主化で、データ分析をセルフサービスに
社内講座と「草の根活動」でSQL文化を醸成する
最後に、データの民主化についてお話します。
データの民主化で目指すゴールは、データ分析をセルフサービスにすることです。
現実的には弊社でも手が足りておらず、アイデアの全てを実行することは難しいです。ですが、どんなに小さくとも実行できるものは継続しようと意識していました。そんな弊社の取り組みをいくつかご紹介します。
まず大切なのは、こまめに社内で宣伝し、基盤のアップデートや機能追加データソース追加などを盛大にアピールすることです。可能であれば社内講座を開くのも良いかもしれません。弊社では「Liny ファクトフルネス」と称し、「Liny」に関するクイズを出してSQLで解くデモを行いました。このように社員に興味を持ってもらう取り組みにも効果が見られました。

しかし講座の開催まではいかなくとも、社内向けのドキュメントなどを充実させることにも意味があると思います。また、Slack上で困っている社員を見つけた時はなるべくヘルプに入っていくような草の根活動もできると良いのではないでしょうか。つまり、「気になったらまずはSQLを書く」という文化を作っていくのが大切なのです。
セールスチームの声に応えたスプレッドシート連携
次は、データの出口を整える活動です。
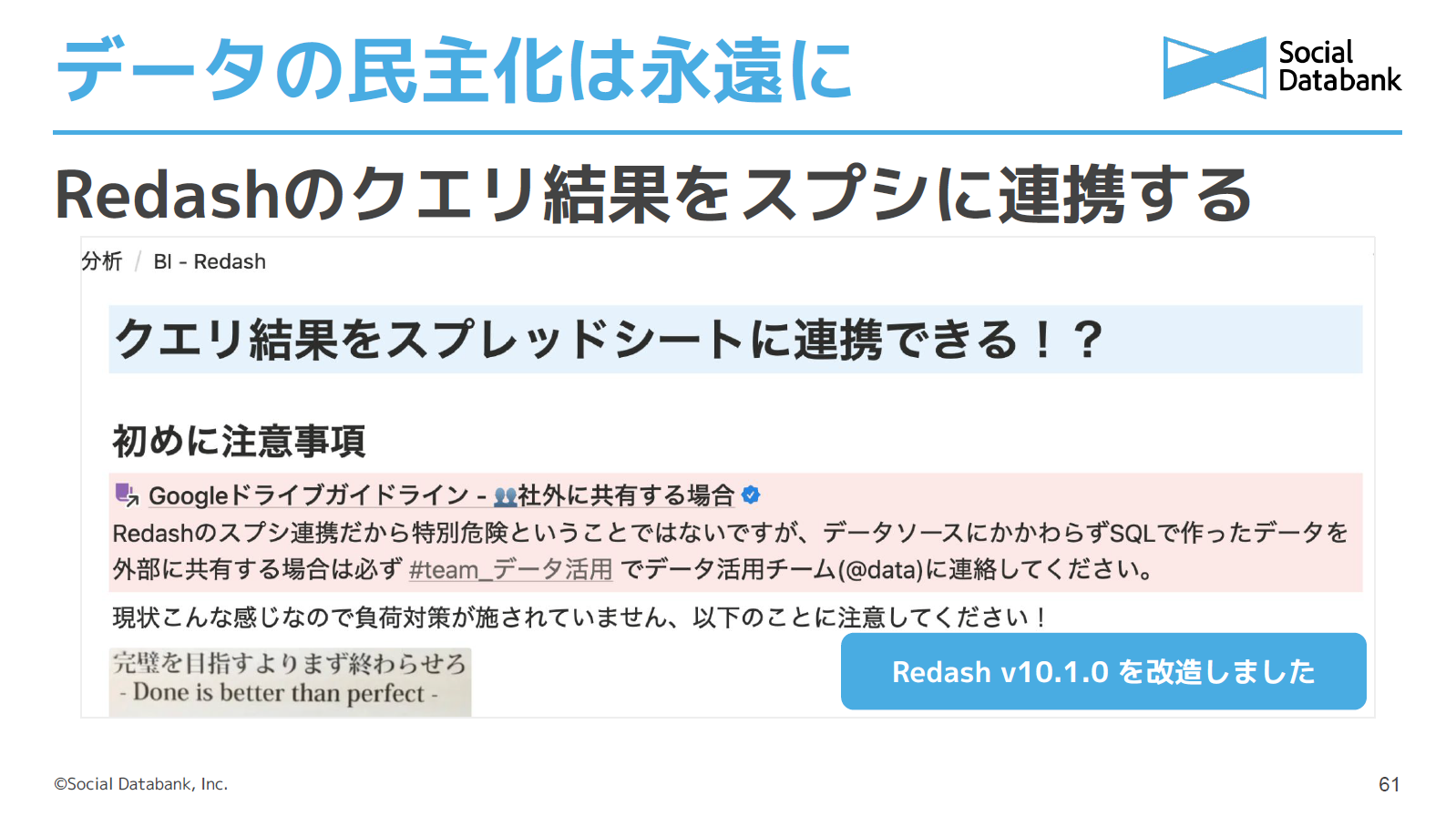
セールスチーム向けの取り組みとしては、Redashを改造してクエリ結果を直接スプレッドシートに書き出す仕組みを作りました。スプレッドシートのIDとシート名を渡すと同期されるようにし、スケジュール実行しておけば、毎週のデータ出し依頼を大きく減らすことができます。
BIツールに関しては、弊社も現在模索中です。QuickSightの導入は以前うまくいかなかったのですが、最近追加されたAI機能を含めて、もう一度チャレンジしたいと考えています。一方でGrafanaは、サポートチームのダッシュボードとしてうまく運用されています。
BIの活用促進は、ツールそのものより使い方の推進活動が重要です。そのため、自分が愛着を持って推進できるツールを選定していきたいです。
by
メタデータの拡充で、次世代の生成AI活用へ備える
BI選定と同等もしくはそれ以上に、メタデータの拡充も重要だと考えています。現在はカラムにコメントを追加していくだけでは不十分で、ドキュメントやコードベースもメタデータとして取り込んで使用する時代になってきました。現在弊社では、人間もAIも使いやすいメタデータ基盤を整えようと、メタデータを集約するハブを模索している段階です。
以上、手が足りない中でも円滑に開発運用を進めるための取り組みをご紹介しました。何か一つでも持ち帰っていただけるものがあれば嬉しいです。ぜひ、素敵なデータエンジニアライフをお送りください。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





