



【アーキテクチャConference 2025】AI x Platform Engineeringでスケーラブルな組織を作るには
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に登壇した株式会社タイミー Platform Engineering 1G Group Managerの橋本 和宏さんは、「Platform Engineeringのチームは少数になりがちで、開発組織のボトルネックになりうる」と語ります。本セッションでは、成長フェーズにあるタイミーにおいて、AIを活用してPlatform Engineeringのスケーラビリティを担保する取り組みについて、現在進行形の試行錯誤を含めてご紹介いただきました。
■プロフィール
橋本 和宏
株式会社タイミー Platform Engineering 1G Group Manager
ネットワークエンジニアとしてキャリアをスタートした後、サーバインフラエンジニア、クラウドエンジニア(SRE)、Platform Engineering、セキュリティとキャリアを重ねる。2024年7月にタイミーに入社し、現在はPlatform EngineeringチームのGMとして活動中。
Platform Engineeringとは
橋本:本日は「AI x Platform Engineeringでスケーラブルな組織を作るには」という題名でお話しします。先にお断りしておくと、まだ取り組みの途中でして、完成形ではありません。現在進行形でこのようなことをやっていますという温度感で聞いていただければと思います。
アーキテクチャカンファレンスということで、開発者の方が多いカンファレンスだと思います。私は後ほどの自己紹介でも触れますが、インフラ寄りのキャリアを歩んできましたので、そういったところも交えてお話しします。
まずPlatform Engineeringについて説明させてください。これは弊社の組織構造を示した図になります。チームトポロジーという本(※1)をご存じの方も多いと思いますが、弊社では、この本の内容を参考に「実組織」と「仮想組織」にわけた開発体制を構築しています。左側の「会社組織としての組織」、いわゆる実組織と、右側の「価値創出を目的としたチーム」という仮想組織の、2つの異なる組織構造で運営しています。実組織は異動があまり頻繁ではない組織図で、仮想組織は比較的人の入れ替えを柔軟に行う構造です。
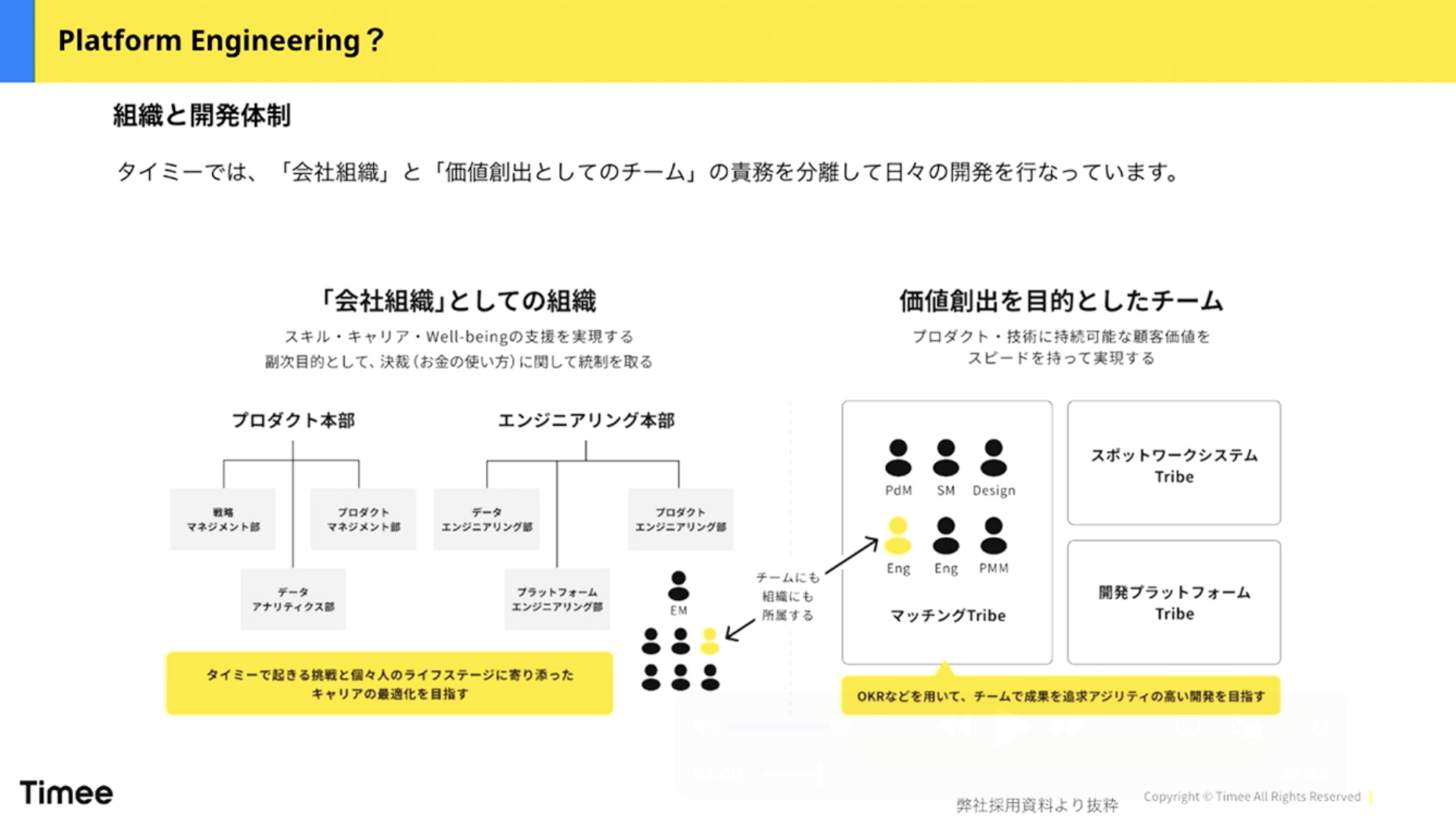
橋本:プロダクトを作るという観点で、私の立ち位置を説明します。プロダクト戦略があり、それにアラインする形でマッチングTribeやスポットワークシステムTribeといった開発組織があります。ここに開発者が所属しています。そして、これらの開発者のTribeを横断的に支援しているのが、私が所属する開発プラットフォームTribeです。Tribeというのは部のようなもので、複数のチームがぶら下がっている入れ物だと思っていただければと思います。開発プラットフォームTribeは多くの会社でも見られる、いわゆる共通基盤チームです。
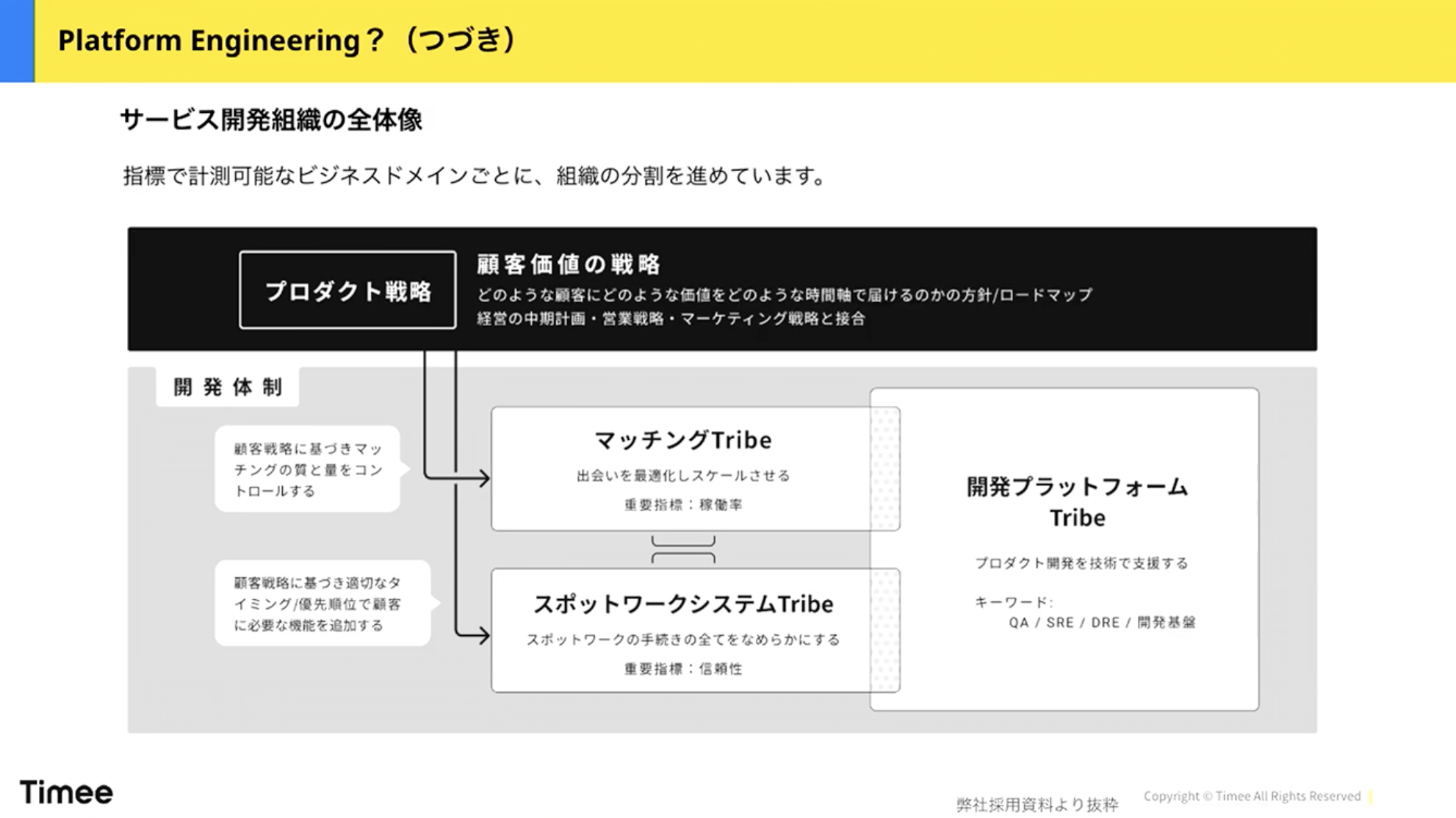
橋本:もう少し分解して、開発者の仮想組織について説明します。お客様にどのような価値を提供したいかという観点で、「Squad」と呼ばれる仮想組織を必要に応じて組み替えながら価値提供を行っています。PdMやスクラムマスター、EMがいて、メンバーとしてバックエンド・フロントエンド・モバイルなどの開発者で構成されます。左記の構成をフルセットとして、必要な職能(例えば、今回はPdMとフロントエンドエンジニアだけ等)が適宜離合集散しながら解くべき課題に合わせて組織が柔軟に変更されています。
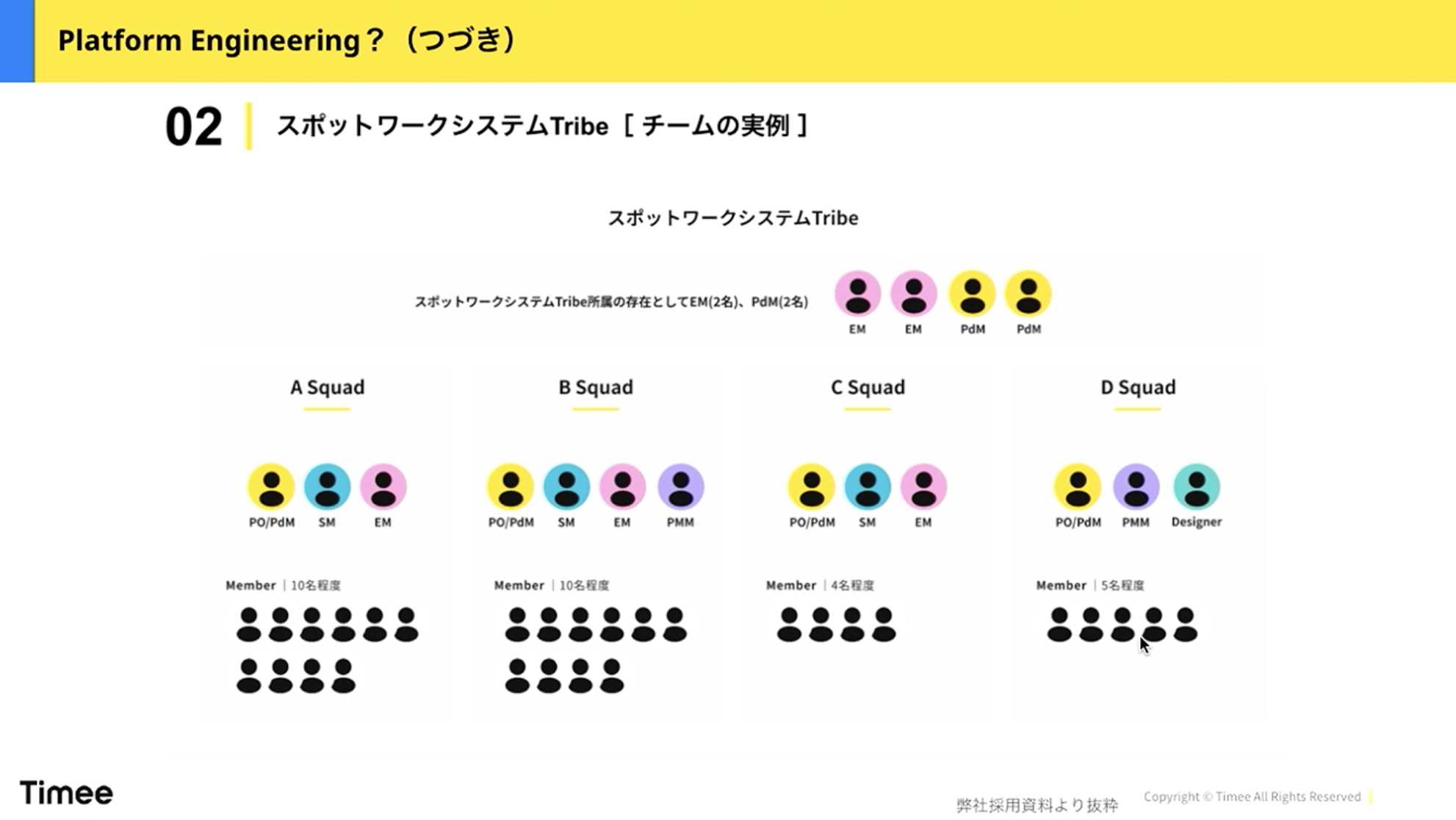
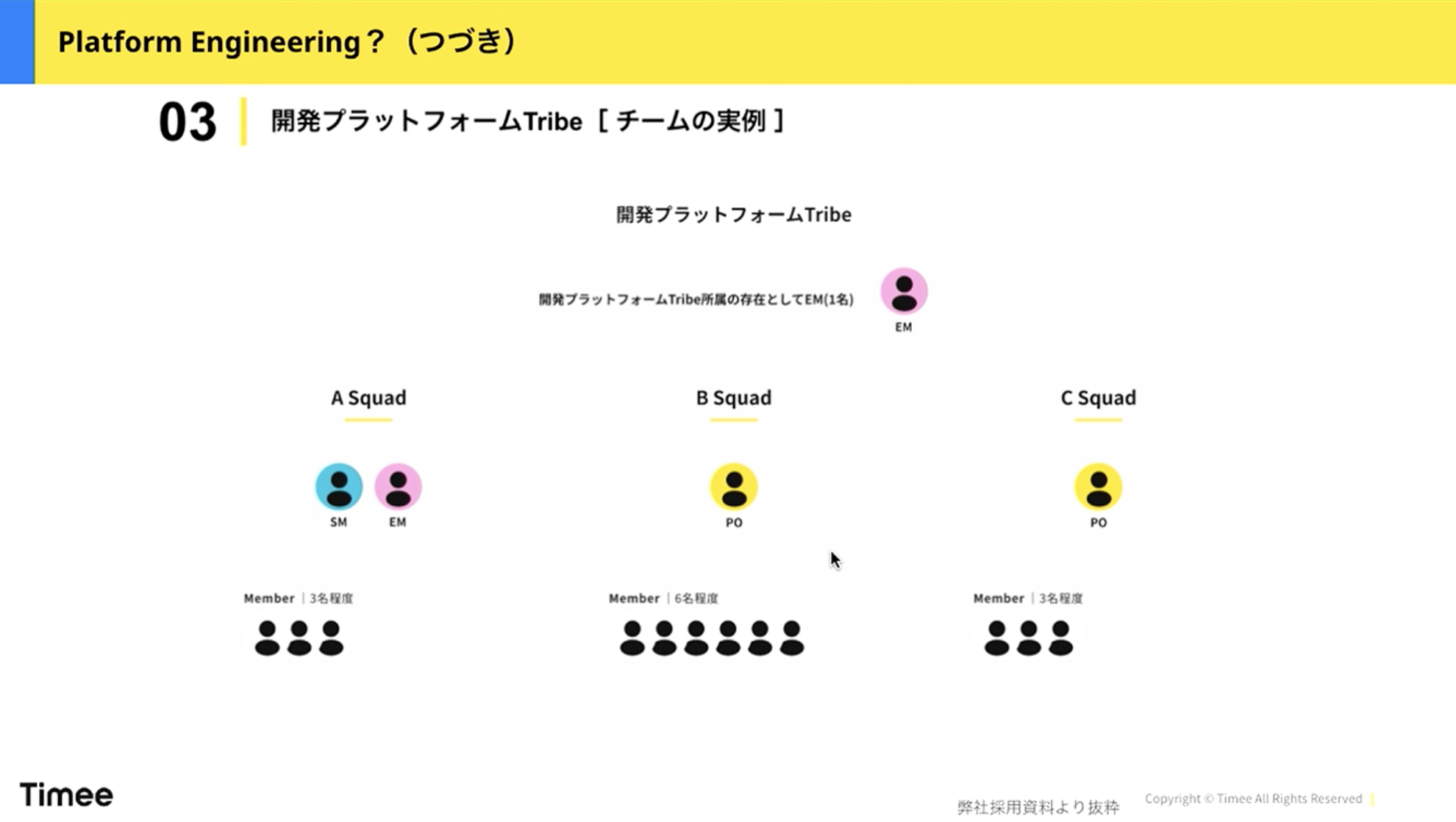
橋本:一方、私が管掌しているプラットフォームグループ1Gは、私がPO(プロダクトオーナー)として、6名のICメンバーと一緒にSREやクラウドプラットフォームといったインフラ領域を担当しています。このような組織構造でやっています。
橋本:そもそもPlatform Engineeringがなぜ必要なのか、なぜこういう組織が生まれたのかという話をします。私自身は1年4か月前に入社したばかりで、これは2〜3年前の話を伝え聞いた内容になります。
もともと開発者の人たちがいろいろなことを担当していました。弊社はRailsをメインで扱っていますが、「Railsのアップグレードは誰がやるのか」「クラウドコストが増加傾向になるので適正化したい。誰がやるか?」といった課題が出てきます。CI/CDワークフローのメンテナンスもそうですし、SRE的な運用もあります。これらは開発による価値提供とは少し軸が違う領域です。そこで、こうした領域を開発チームからオフローディングして、別の専門チームで担当しようという形でPlatform Enginering(PFE)部門が生まれました。
私が管掌している1Gのチームミッションは、SRE・インフラエンジニアの職能集団であり、開発チームの認知負荷を軽減し、スケーラブルなプラットフォームを提供することです。
具体的には、AWSとIaC(Terraform)、オブザーバビリティとしてのDatadog、そしてGitHub ActionsによるCI/CDパイプラインが主な領域で、通常業務の7〜8割はこれらに関わる仕事です。これは各社いろいろな切り口や組織構造があると思いますので、あくまで弊社タイミーにおけるPlatform Engineeringの一例としてご理解ください。
もう一つ重要な話として、Platform Enginering(PFE)の支援モデルがあります。これもチームトポロジーの本に書いてある内容をベースに、私なりの表現にしています。
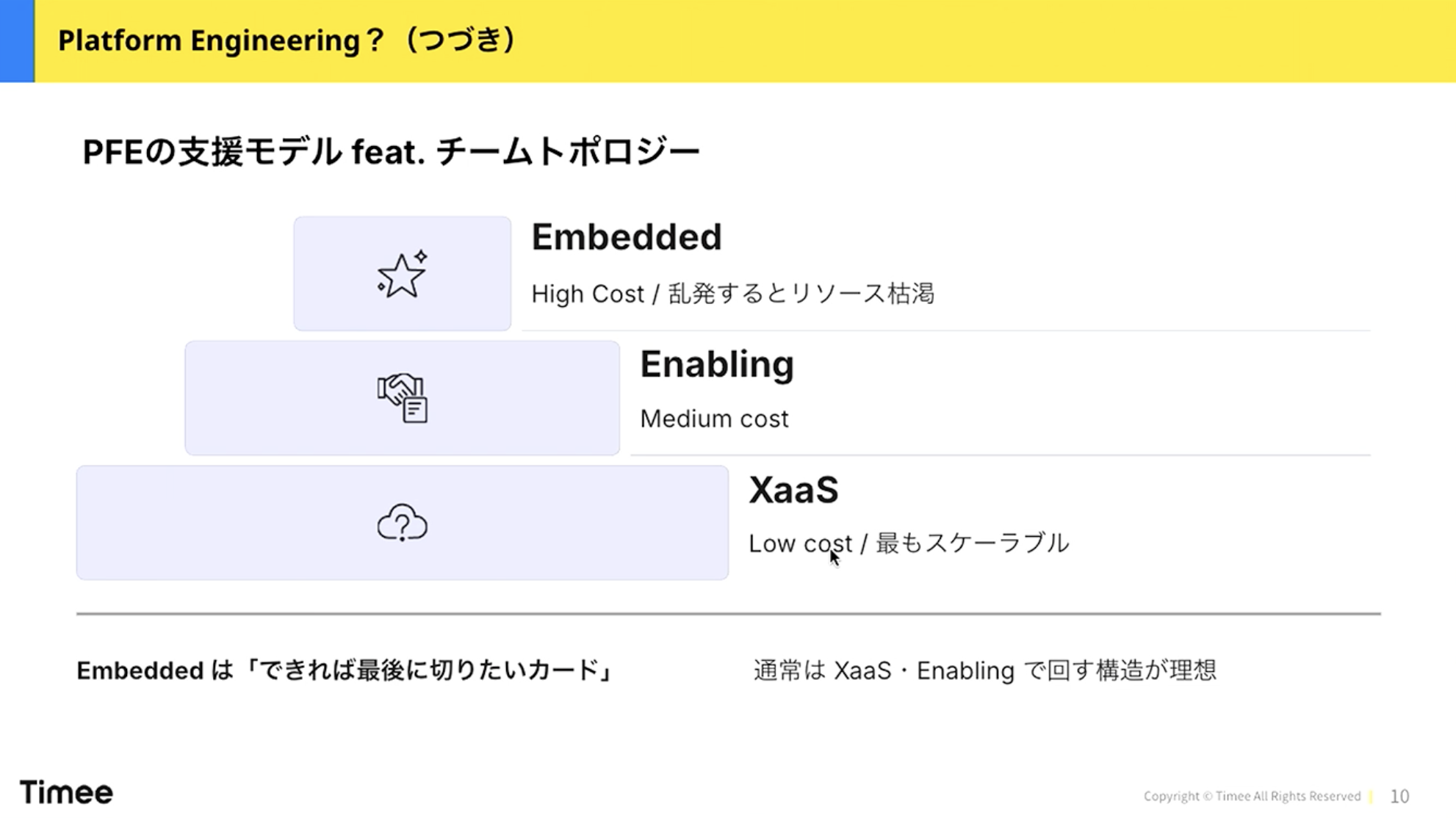
橋本:まずX as a Service(XaaS)、いわゆるセルフサービスです。開発者がAWS上に何かを置きたいときに、細かなところを意識せずに宣言的に仕組みを作れるようなものを提供します。次にEnablingで、開発者ができるようになるための支援です。そしてEmbeddedは、チームに入り込んでいろいろやるという形です。
リソース効率でいうと、できればXaaSを使いたいところです。Embeddedは乱発するとリソース枯渇を招くので、できれば最後に切りたいカードです。この3つの支援モデルをどう使い分けるか、どういうバランスでやるのかというのは、Platform Engineeringチームの重要な関心事の一つになっています。

株式会社タイミーについて
橋本:ここで弊社の紹介をさせてください。フルタイムで働いている方は、タイミーを使う機会はあまりないかもしれませんが、CMなどで認知していただいているかもしれません。
タイミーは、スキマバイトやスポットワークと呼ばれる領域でマッチングを扱っているサービスです。特徴として、面接や履歴書なしでお仕事ができて、報酬もその日に受け取ることができます。企業様からすると、人を集めたいときにマッチングプラットフォームを通じて人材を確保できます。
ありがたいことに多くの企業様、そしてワーカー様に使っていただいているサービスでして、会社としても拡大しているところです。そのため、組織として人を増やしたりシステムが複雑になったりという段階にあります。そこにPlatform Enginering(PFE)が関わってくるので、いかに会社の変化に対してPlatform Enginering(PFE)が対応するかというところに関心が向いています。これが「Platform Enginering(PFE)× スケーラブル」というテーマにつながります。
Platform Engineeringとスケーラビリティの課題
橋本:プロダクト・組織が成長すると、機能が増えたり、システム間の依存関係が複雑化したり、ガバナンスやセキュリティの要求が増加したりします。プロダクト組織はシンプルに保つべきだとは思いますが、複雑性は増していかざるを得ません。そうなると認知負荷も増えていきます。
会社やシステムが複雑になっていく一方で、Platform Engineeringのチームは少ないです。この辺りは実感のある方も多いのではないでしょうか。
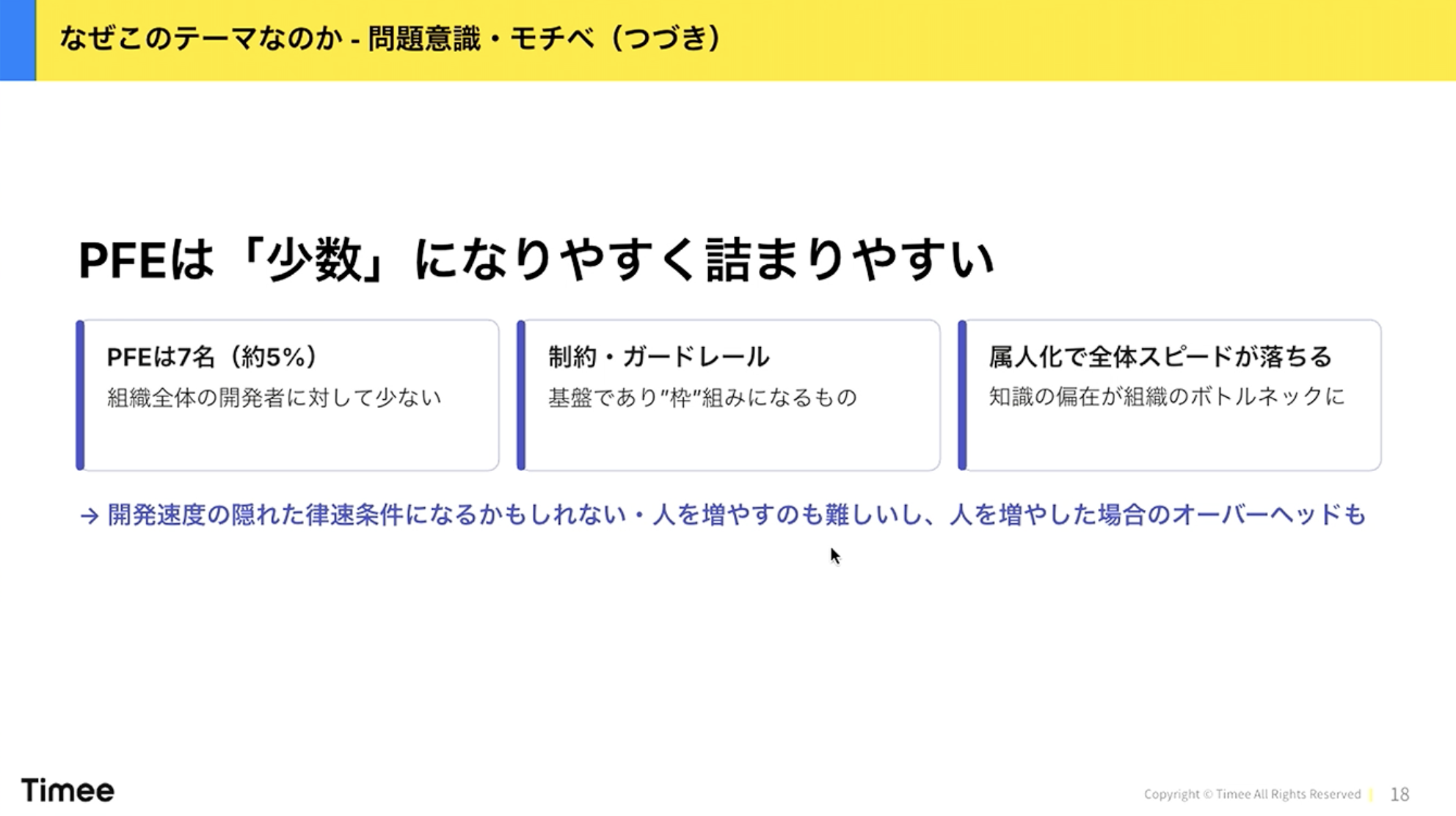
橋本:弊社の場合、私を入れて7名のチームで、開発者全体に対して約5%程度です。10%に達する組織は私もあまり見たことがありません。Platform Enginering(PFE)は開発における制約やガードレールを担っているため、インフラを作らないとそもそも始まらないし、デプロイする先がないと開発が進みません。そういった知識が組織の一部に偏在しやすく、それがボトルネックになる可能性があります。
また、採用市場でも少ない人材ですし、増員した後のオンボーディングにもオーバーヘッドがあります。つまり、Platform Enginering(PFE)はボトルネックになりがちだということです。
これは個人の感想ですが、組織規模によって分業の形態は異なります。私は副業でいくつかの会社と関わっていますが、小さい会社だと開発者が全部やりますし、大きい会社だと大規模な分業化が進みます。
小さいチームでは2〜3人で全部やる。大きい会社では、ものによってはCCoE(Cloud Center of Excellence)のように、知識やノウハウを中央集権的に持ちつつ周辺プロジェクトで活用する形もあります。弊社はその中間にいるような状況です。

橋本:今日聞いている方の中には「うちには関係ないのでは」と思われる方もいるかもしれませんが、小さな組織もいずれ大きくなりますし、大きな組織を細分化すると弊社のPlatform Enginering(PFE)チームに近いユニットが出てくると思います。そういう類似性を見ていただければと思います。
ここまでをまとめます。Platform Engineeringは開発者の認知負荷を軽減し、スケーラブルな基盤を提供します。しかし、比較的少数のPlatform Enginering(PFE)チームは開発組織のボトルネックになりうる。人がスケーラブルではないのです。
理想的なPlatform Enginering(PFE)支援モデルはXaaS化することですが、Embeddedが一周回って早いという場面もあります。手厚い支援を開発者が受けられる状態にしたいが、Platform Enginering(PFE)の人数は限られている。このジレンマをAIでなんとかできないかと考えました。
AIを活用したスケーラビリティの実現
橋本:早速本題に入ります。これが今まさに作ろうとしている仕組みの構成図です。試行錯誤に時間がかかり、まだ完全ではありませんが、おそらくこれでいけそうだという形になってきました。
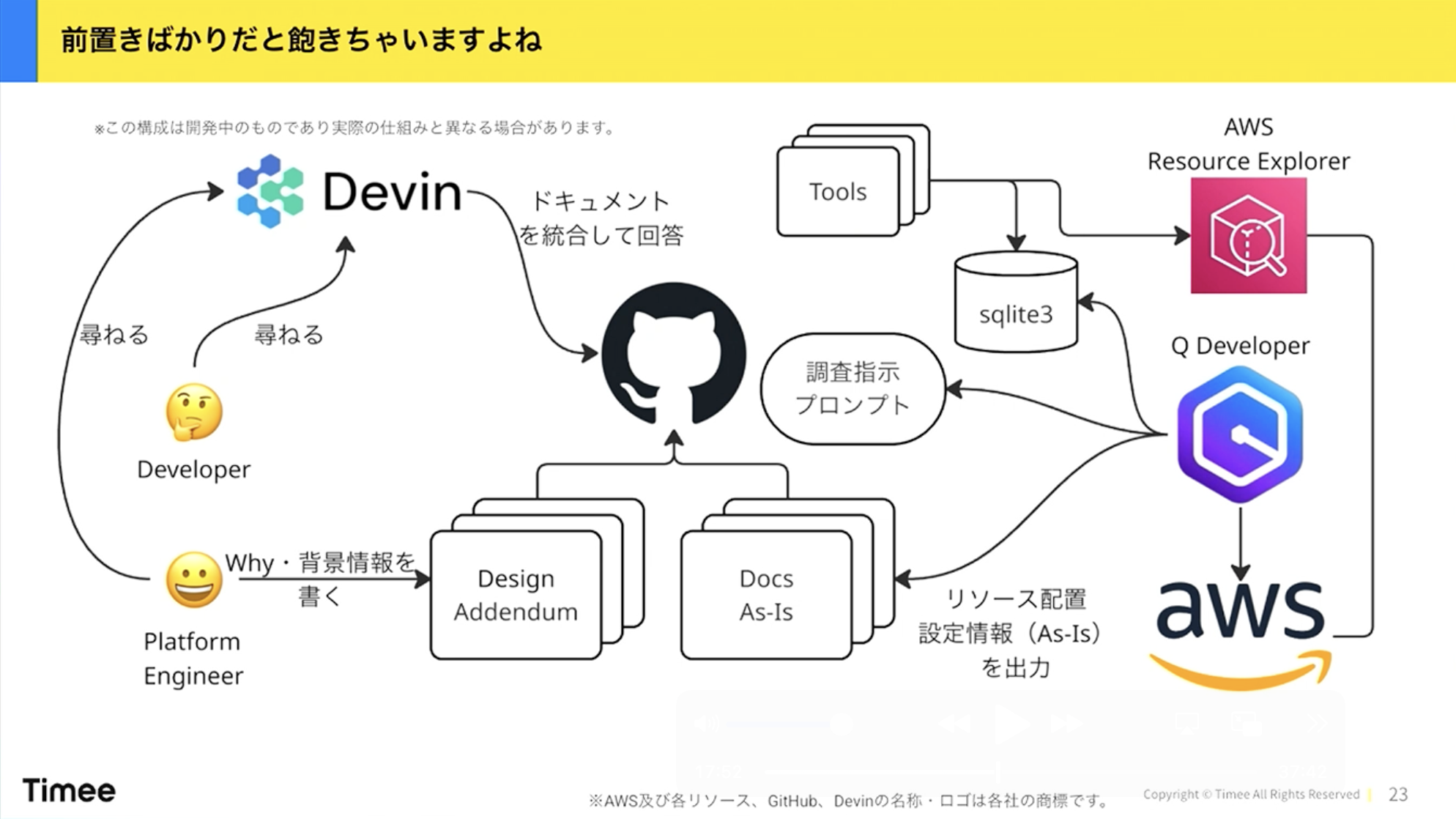
橋本:右側にAWSがあります。これはDatadogなどのオブザーバビリティ基盤の場合もありますが、こういった「知るべきもの・扱うべきもの」をいかにして「Docs As-Is」、つまり現状の設定としてドキュメント化するかという仕組みです。
まずQ Developerについて説明します。登壇の3日前にAWSの発表で「Kiroに統合します」というアナウンスがありましたが、Q DeveloperはいわゆるCLIのコーディングエージェントのようなものです。これにAWSのリソースを分析させて、ドキュメントに出力させます。
ここで一つポイントがあります。AWS Resource Explorerというサービスを使っています。最初はQ Developerに「このアカウントのリソースを全部引っ張り出して分析してドキュメントにしろ」と言ったのですが、全然ダメでした。
例えば、あるアカウントに30個くらいのS3バケットがあるとします。期待としては30個のバケットのリストがあって、設定がこうなっていますという表が出てくることでしたが、出てきたものには3つしかバケットがないという状態でした。AIあるあるですが、扱う情報が大きくなると途中でサボり始めます。これを防ぐためには、ある程度限定できるインターフェースにしてあげる必要があります。情報量をコントロールするイメージです。
そのためにAWS Resource Explorerを使っています。これは指定されたAWSにあるリソースをインデックス化して、どういうリソースがあるかを分かりやすい形で取り出せるサービスです。しかもsqlite3でインデックスしているので、コーディングエージェントが好むSQLで構造化的に引き出すことができます。ローカルキャッシュのようなものを使いながら情報を扱えるようにして、そこに調査指示のプロンプトを出します。
この形にすることで、AWSアカウントにどういうリソースがあるかを比較的高速に把握できます。30個くらいのAWSアカウントを使っている会社さんも多いと思いますが、そういった複数アカウントのドキュメントを次々と出していくことができます。
ドキュメント化においてもう一つ重要なポイントがあります。AIに調査とドキュメント化をさせる右側の部分と、人間がAIのドキュメントに補足する左側の部分です。
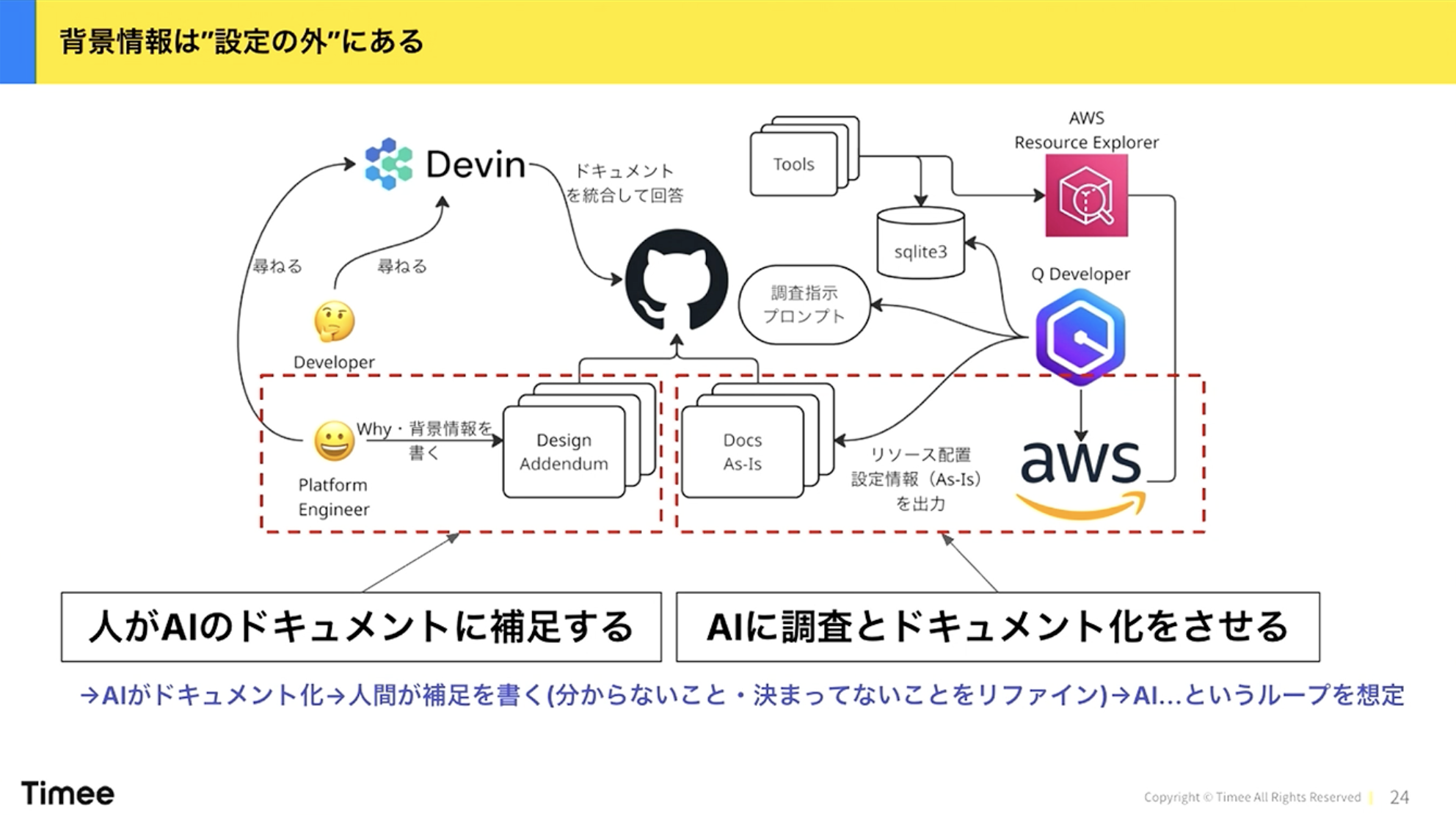
橋本:クラウドの状態を正確にドキュメントに反映し、かつ陳腐化させずに最新に保ち続けるのは不可能だと考えています。ここをAIで定型化するのが一つのキーポイントです。
ただし、背景情報は設定の外にあります。コードだけを見て仕様書を起こすのが難しいように、AWSの設定だけを見て「何のために、どういうビジネス要件でそうなっているのか」を逆算するのは困難です。何も補足せずにAIに書かせると、推論であらぬことを書き始めます。
そこで人間が「Design Addendum」として補足情報を書きます。AIがドキュメント化したものを人間が読んで、「これは決まっていなかった」「この設定はなぜこうなっているのか」といった点をリファインし、またAIにドキュメント生成させるというループを回すことで、鮮度を保ちながら考慮漏れを減らしていきます。
「Terraformのコードがあるのだから、コーディングエージェントとMCPでいいのでは」こう思った方もいらっしゃるのではないでしょうか。私も最初はそう思っていました。

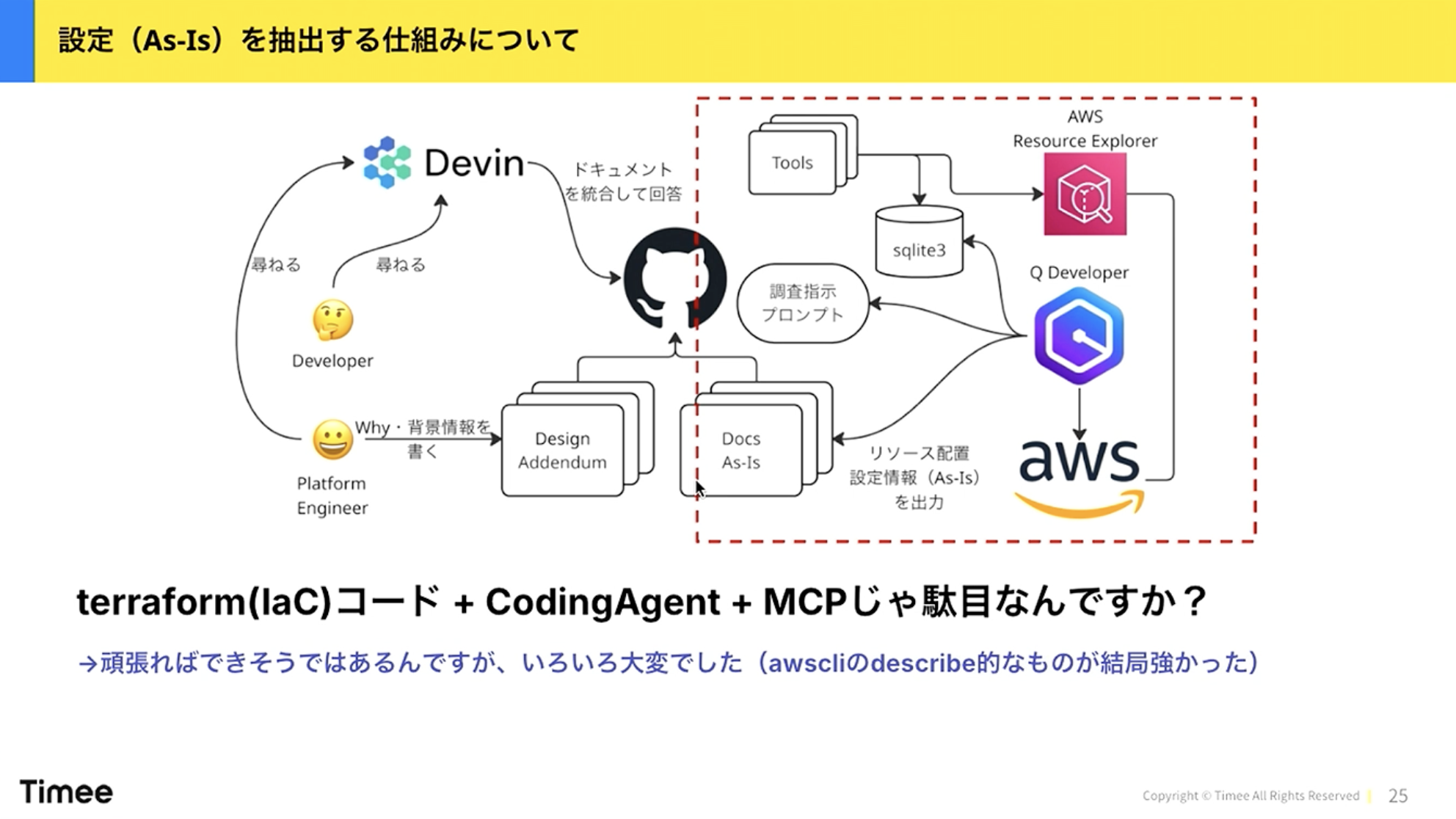
橋本:ただ、Q Developerの方が一周回って楽でした。なぜかというと、Q Developerは裏側でAWS CLIを叩いてdescribeやlistを行っており、どういうコマンドやAPIでリソースを引っ張ってこれるかをある程度知っているからです。
コーディングエージェントがいろいろな情報を集めてその場で推論するオーバーヘッドは大きく、AWS CLIが5回失敗してやっと取れましたということも起きます。また、TerraformですべてのリソースをIaC管理できていない場合、IaCに書かれていない情報が使えないと「As-Is」にならないという問題もあります。GCPでも同じことをしたいのですが、現時点では対応するサービスがないので、Googleさんにも期待しています。
最後に「聞くところ」です。図にはDevinと書いていますが、Claude Code、Cursor、GitHub Copilotなど、コーディングエージェントにローカルリポジトリを見に行かせて回答させることもできます。
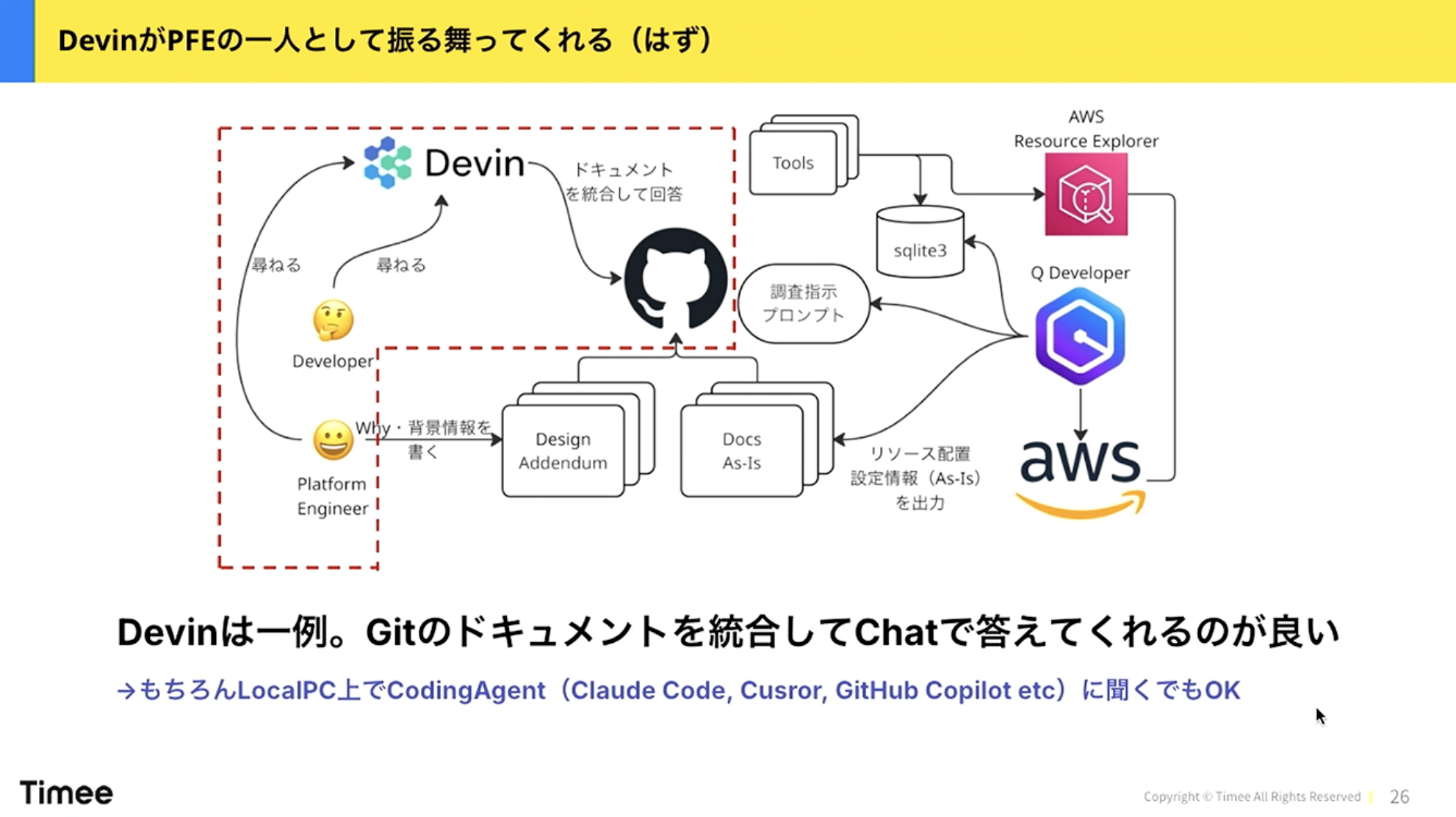
橋本:ただ、体験としてはSlackでChatOps的に使うのが良いと感じています。SlackでカジュアルにDevinに聞くと、裏側で複数のリポジトリやドキュメントを参照して答えてくれます。DevinがPlatform Enginering(PFE)の一人として振る舞うイメージで、24時間365日いつでも呼び出せて、Platform Enginering(PFE)の経験・知識に基づいた回答をしてくれる存在になります。
まだ遠い道のりではありますが、やりたい世界観は次のとおりです。
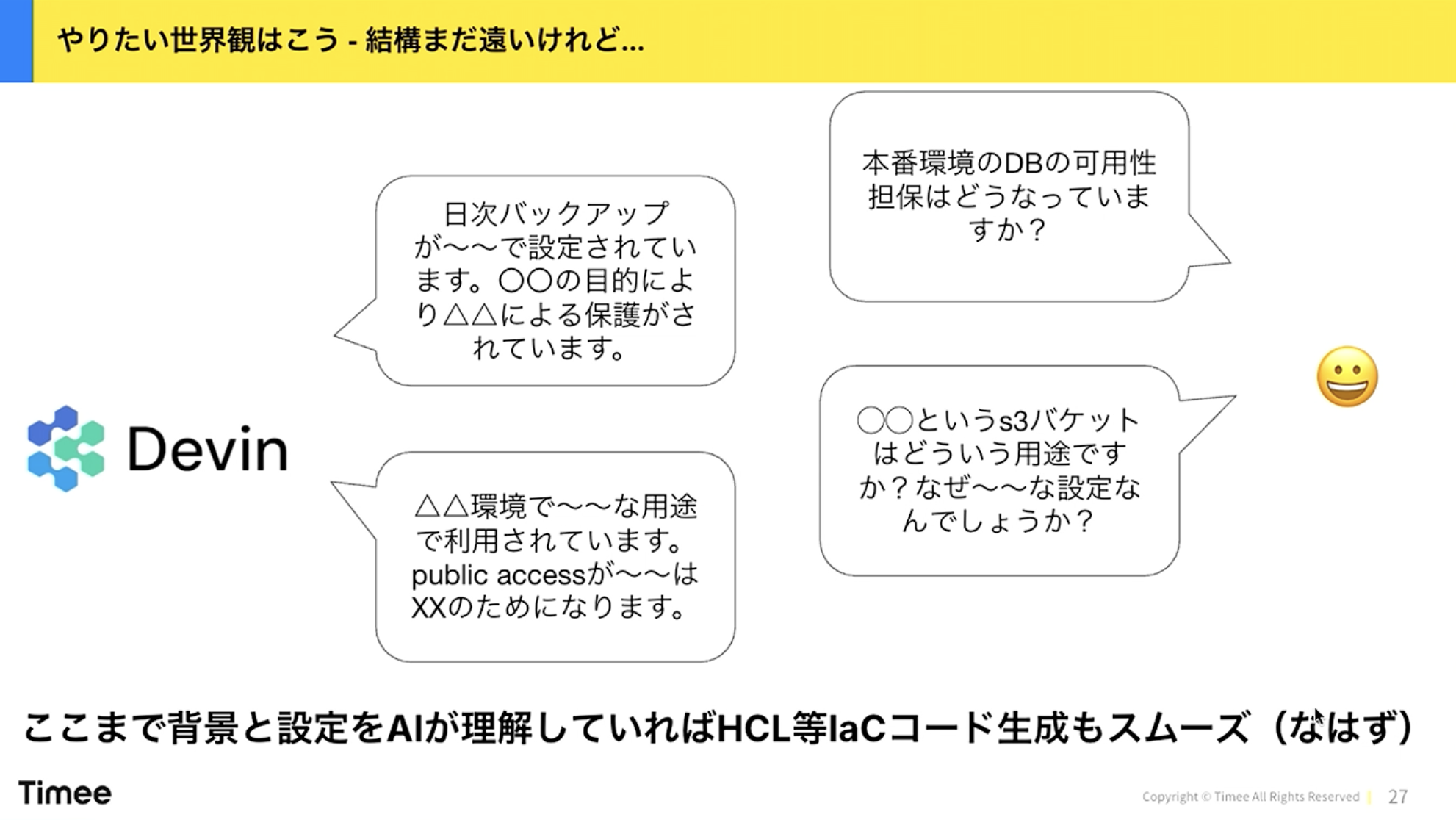
橋本:「本番環境のDBの可用性担保はどうなっていますか?」と聞くと、「日次バックアップが設定されています。◯◯の目的により△△による保護がされています」と答える。「◯◯というS3バケットはどういう用途ですか?なぜこういう設定なんですか?」と聞くと、「△△環境で◯◯な用途で利用されています。public accessの設定は××のためです」と答えてくれる。
ポイントは「本番環境」という雑な聞き方ができることです。何もコンテキストを与えないと、AWSアカウントのIDやアカウント名で識別しなければなりませんが、「タイミーにおける本番環境とは何か」という情報を与えることで、スムーズに情報を引き出せるようになります。
ここまで背景と設定をAIが理解していれば、HCL(Terraform)などのIaCコード生成もスムーズになるはずです。開発者が「◯◯の用途で、この環境で、こういうS3バケットが欲しい」と言えば、我々が作る必要もなく、AIがその場でライブで構成してくれるようになると期待しています。
この仕組みが効果を発揮するのは、XaaSよりも、EnablingやEmbeddedの部分だと考えています。開発者がSlackでDevinを使って気軽にリソースを作り、デプロイできるのであれば、わざわざ私たちが手厚くやらなくても、AIと開発者の協働で担保できるのではないか。これによってスケーラビリティが出せるのではないかと期待しています。

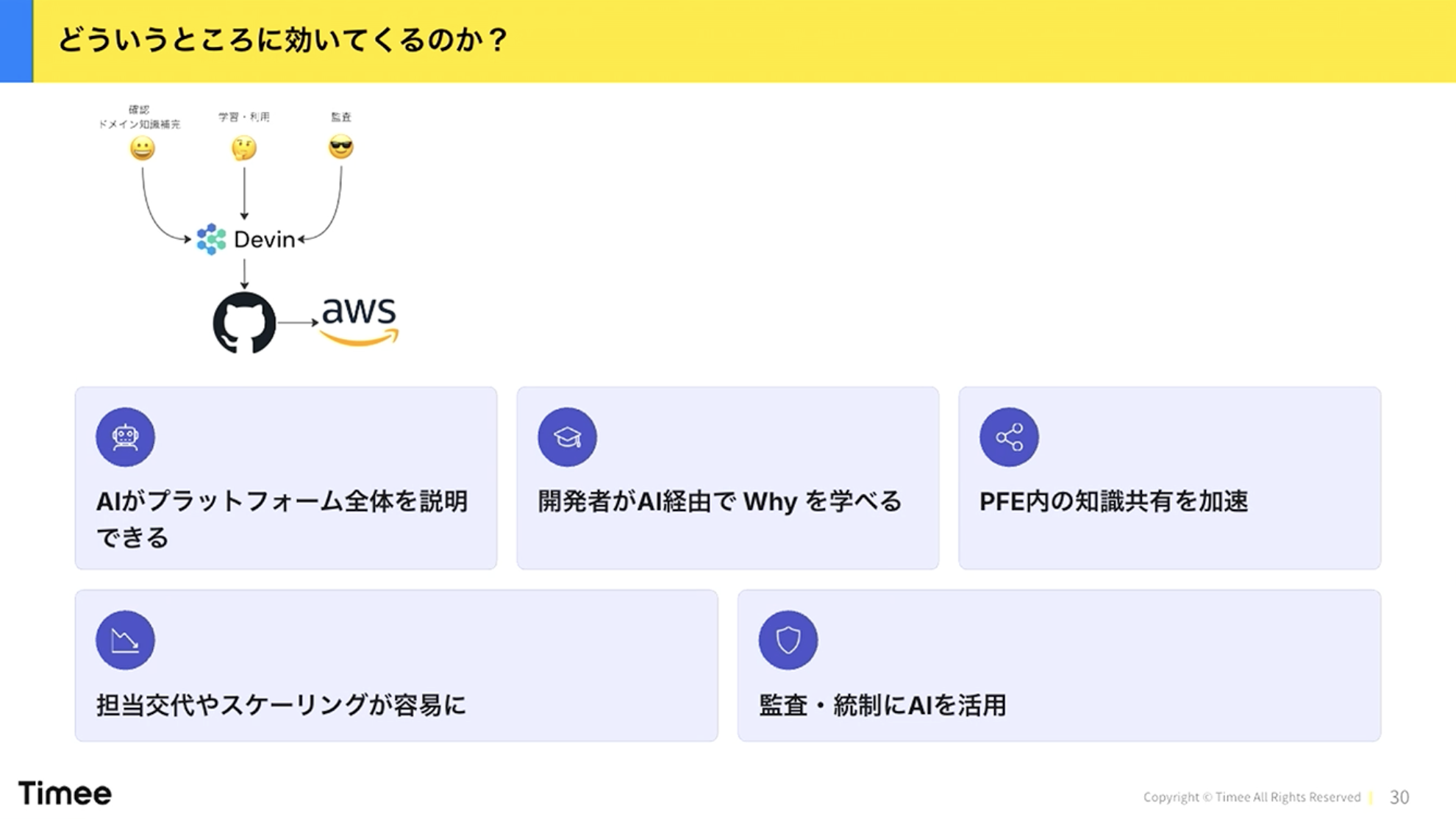
橋本:この仕組みがどう使われるかを少し俯瞰して見ると、主に3つのペルソナがあります。
まず開発者です。AWSに何かをデプロイしたい、S3バケットやDBを操作したいといった利用ニーズがあります。また、開発者の中でもPlatform Engineeringのドメイン知識を学びたいという人もいます。越境性を持ってインフラを触りたいけどよくわからないから学習したい、という場面でも使えます。
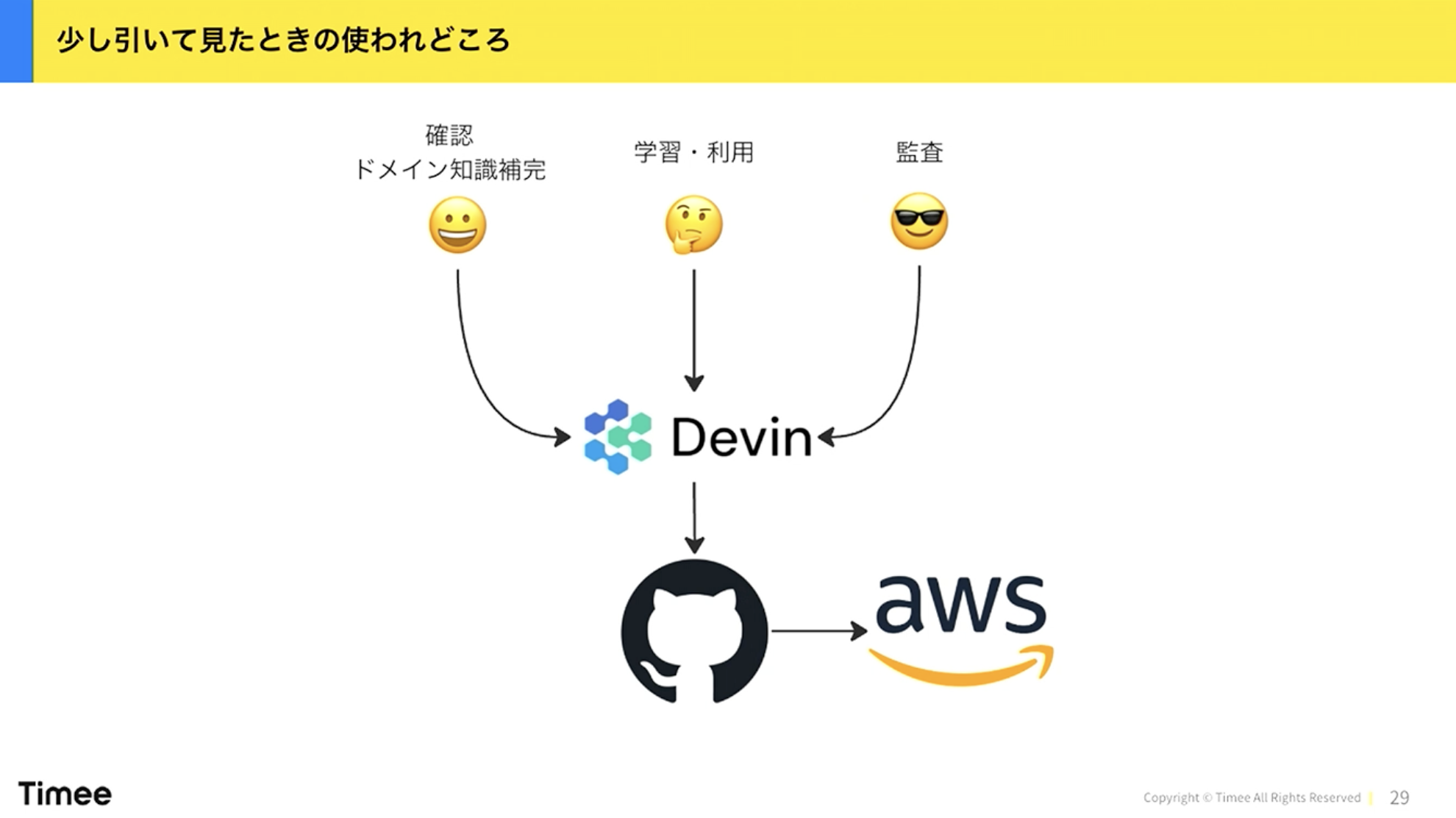
橋本:次にPlatform Engineering側です。チームが大きくなったり複数チーム化したりすると、隣のチームがやっていることのドメイン知識がわからなくなります。自分たちが使っていないAWSサービスの勘所を知りたいときや、経験の浅いプラットフォームエンジニアが学ぶときにも活用できます。
最後に監査目線です。私はセキュリティも担当していますし、マネージャーなので監査の視点もあります。「今の開発プラットフォームはどうなっているのか」を自然言語で聞けると便利です。
まとめると、AIが知識転写を通じてプラットフォーム全体を説明できるようになります。今回はAWSを例に取りましたが、同じアプローチでDatadogやGitHub Actionsなど他のSaaSサービスにも適用できます。
開発者がAI経由で「なぜそうなっているのか」を学べるようになり、Platform Enginering(PFE)内の知識共有も加速します。チームが2チーム、3チームに増えても、自分が知らないことをAIを通じて聞くことができます。担当交代やスケーリングが容易になり、監査・統制にも活用できます。いろいろなところにレバレッジが効いてくるのがポイントです。
まとめ
橋本:Platform Engineeringは開発者の認知負荷を軽減し、スケーラブルな基盤を提供します。しかし、比較的少数のPlatform Enginering(PFE)チームは開発組織のボトルネックになりうる。このPlatform Enginering(PFE)のスケーラビリティを、複数のドメイン知識の同期・キャッチアップも含めて、AI支援で担保しようとしています。
理想的なPlatform Enginering(PFE)支援モデルはXaaS化することですが、AIが開発者に対してEmbedded・Enablingをしてくれると、より良い開発体験になるのではないかと考えています。開発者がAI支援によりフルサイクル性を獲得することで、開発・価値提供速度が上がる可能性があります。
これはSDD(仕様駆動開発)と似ていますが、アプローチや扱うものが少し異なります。AI-DLC(AIによる開発ライフサイクル)は今後の開発のキーになると思いますので、これも一つのAI-DLCの形かもしれません。
AIの活用は知識共有を加速し、AIによってPlatform Enginering(PFE)をスケーラブルにしていく。これが本日お伝えしたかったことです。ご清聴ありがとうございました。
※1:原題書籍名: Team Topologies(邦訳書籍名: チームトポロジー 価値あるソフトウェアをすばやく届ける適応型組織設計)
アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





